1. Introduction
As a key branch of computer vision, image segmentation aims to partition an image into distinct segments, each representing a specific category. There are three tasks in image segmentation. Semantic segmentation classifies each pixel by category, and instance segmentation identifies and segments objects within each instance mask. Panoptic segmentation combines both semantic and instance segmentation to provide a more comprehensive understanding of the visual scene.
One of the popular approaches for semantic segmentation is an encoder–decoder architecture. The encoder is to extract multi-scale features from images, and the decoder produces per-pixel-level predictions. Encoders based on the Convolutional Neural Network (CNN) [
1,
2,
3,
4] have been dominant in semantic segmentation with cascading convolutional layers. They use small convolutional kernels to balance computational efficiency with the need for a large receptive field. However, there is a limit to the number of layers, and over-stacking can lead to training saturation. To address this, transformers [
5] for Natural Language Processing (NLP) tasks have been introduced to computer vision. To process images, vision transformers divide them into fixed-size patches and flatten them into 1D arrays. Most importantly, they can offer superior representation learning than CNNs by extracting long-range dependencies in parallel.
In simpler terms, it was previously believed that mask classification was only apt for instance segmentation, while semantic segmentation required per-pixel-classification. However, MaskFormer [
6] demonstrated that mask classification can effectively handle both segmentation types with the same model structure and training process. As its successor, Mask2Former [
7] enhanced segmentation accuracy by incorporating mask attention to the transformer decoder. However, the improvement leads to the expense of higher computational costs and latency. While purporting to offer universal image segmentation, MaskFormer [
6] and Mask2Former [
7] necessitate separate training for distinct tasks. In contrast, OneFormer [
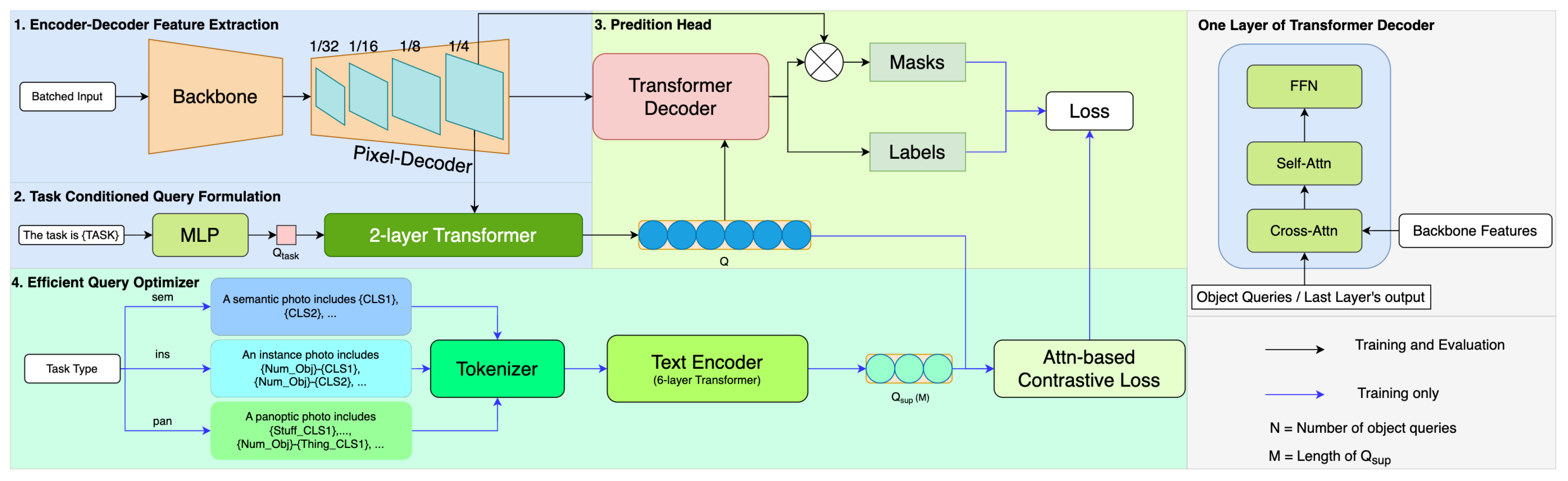
8] stands out as a genuinely universal framework. It achieves state-of-the-art performance across three image segmentation tasks through a single training cycle. This is made feasible by employing a joint training strategy coupled with a task-conditioned query formulation. These queries begin as task token repetitions and are subsequently refined by a two-layer transformer. With the involvement of the image features, the transformer decoder produces task-dependent and image-aware outputs. In the quest to refine segmentation accuracy, a specialized module is introduced during training for the optimization of queries. This module generates a group of text queries (denoted as
) to accentuate inter-class differences by guiding the object queries using a query-text contrastive loss. The text is derived from the training dataset, where each sentence corresponds to one object class present in an image. Due to the mismatch between the average count of objects per image and the number of object queries, the text lists are padded with a substantial number of duplicated sentences that carry limited supervisory information.
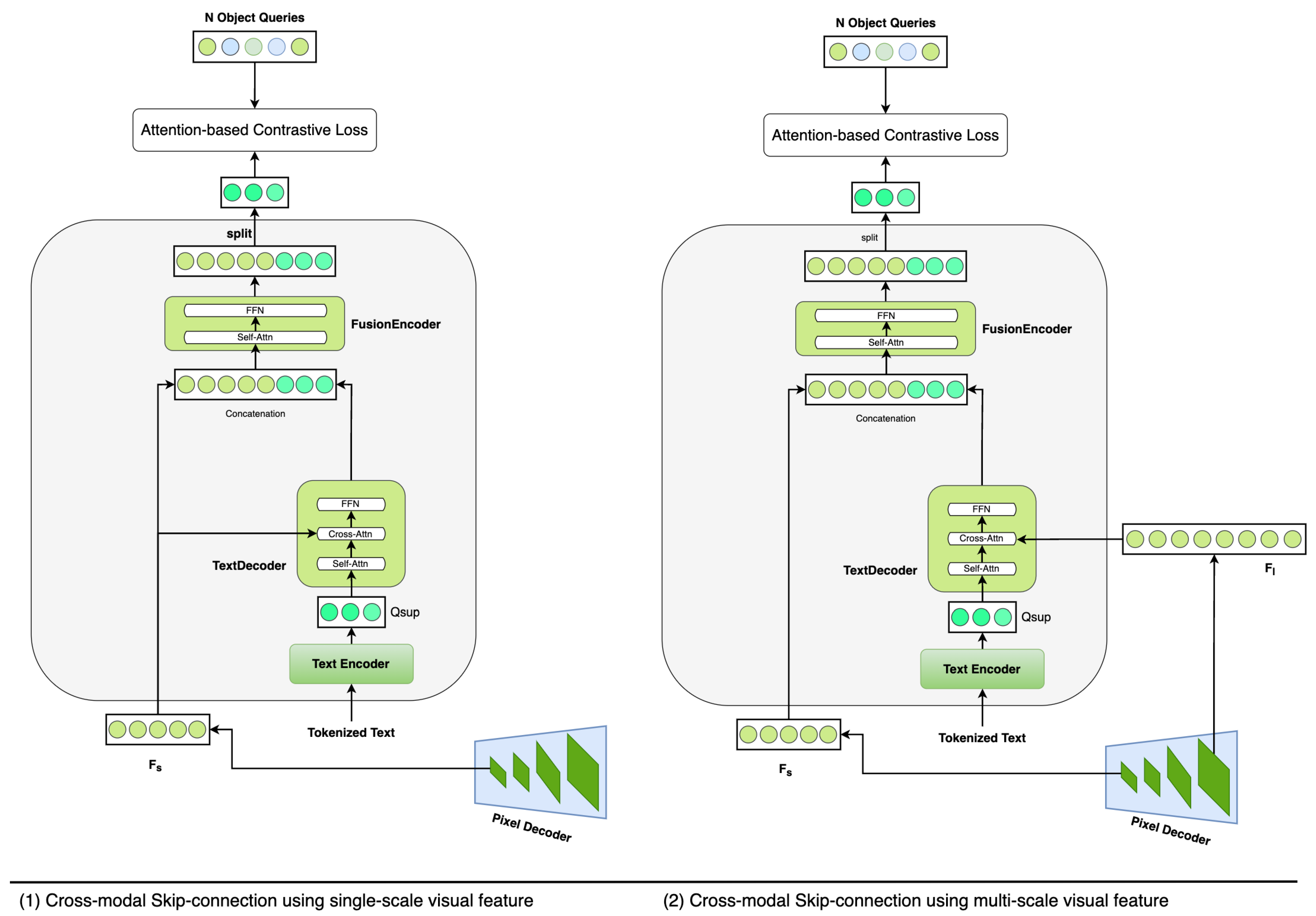
However, this universal segmentation method faces two primary issues that impede efficient query optimization during training. First, the generation of the text list entails a significant amount of redundant information. With the default number of object queries set to either 150 or 250 based on the choice of backbone, the majority of sentences contribute minimal supervisory information. This leads to excess parameters in the generation of
and increased computational costs during training. Second, the fixed one-to-one matching between
and
Q is not the most effective method for computing contrastive loss because it does not fully account for the multifaceted roles of
Q in image segmentation. The ablation studies of MaskFormer [
6] suggest that object queries, interpreted as region proposals, can capture objects from different categories. Moreover, the distribution of unique classes each query can recognize is not uniform. In contrast, each text query in
is linked to a specific class or object within an image, which differs fundamentally from object queries. Therefore, the one-to-one matching mechanism in contrastive loss computation restricts object queries’ capability to learn more robust representations. The experimental results in
Section 4.4.1 show that our attention-based contrastive loss boosts the model’s performance, independent of text formulation methods.
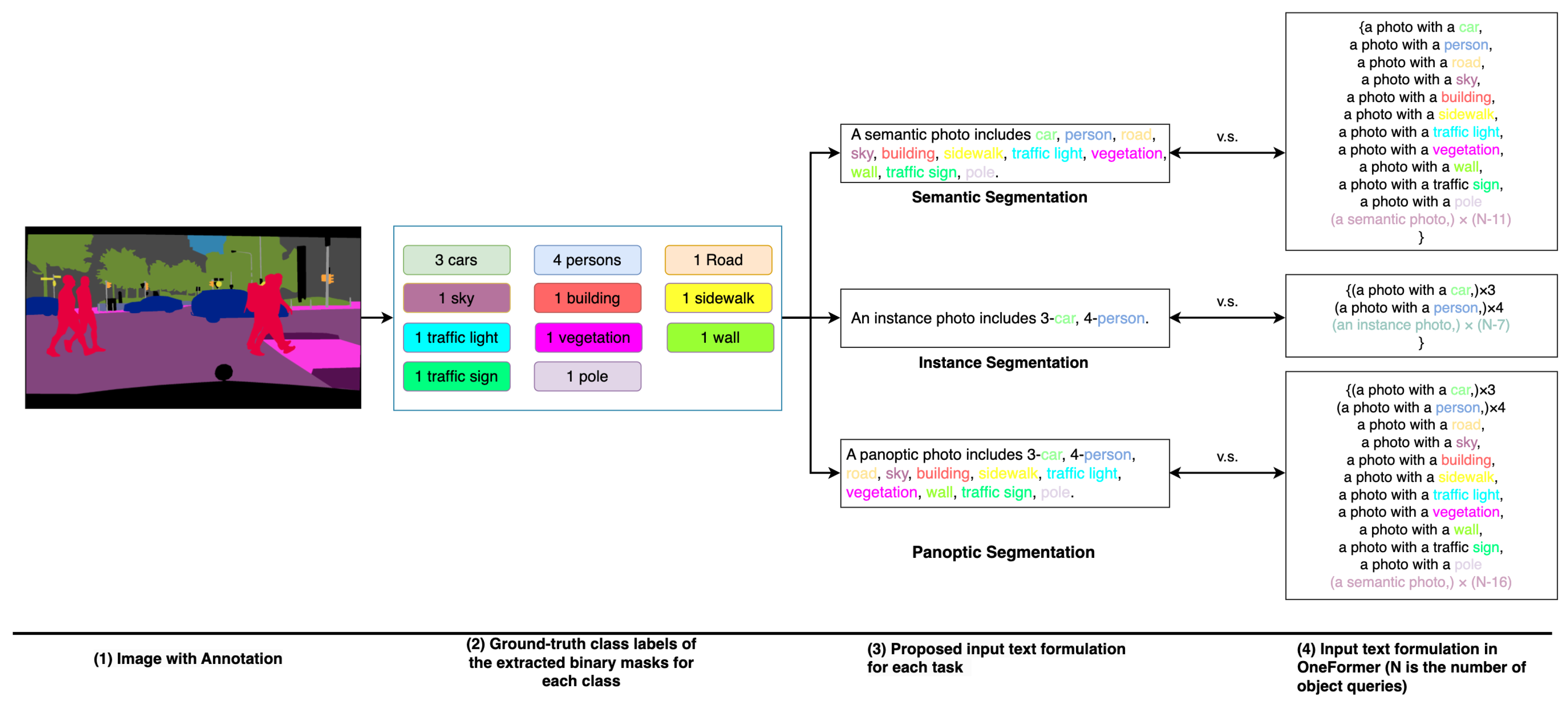
To overcome these limitations, we present an Efficient Query Optimizer (EQO) incorporating efficient text generation and attention-based contrastive loss. We streamline the text list by consolidating all semantic prompts into a single sentence per image. This strategy preserves essential inter-class and inter-task information only. Additionally, we employ an attention mechanism to establish a one-to-many matching relationship for contrastive loss computation. In this way, more adaptive matching is feasible in the query optimization stage. In addition, the proposed method can be extended to scenarios involving multiple sensors such as multimodal scene understanding in autonomous driving. In order to achieve robust and accurate scene understanding in autonomous driving, autonomous vehicles are usually equipped with multimodal sensors, (e.g., cameras, LiDARs, and Radars), and different sensing modalities can be fused to exploit their complementary properties. For example, disparity maps, as derived from the depth maps captured by stereo cameras [
9], can be used as input to a Transformer to generate depth embeddings and used to learn a joint embedding space between images and disparity maps using similar approaches proposed in [
10]. Specifically, the image embeddings generated by our proposed model can be paired with the depth embeddings generated by a plug-in module for contrastive learning during training. Based on this approach, our proposed model can be extended into applications using multiple sensors without changing the base architecture.
Our major contributions are summarized as follows:
In this study, we introduce an Efficient Query Optimizer (EQO) designed for universal image segmentation. This optimizer is adept at directing object queries towards capturing task-dependent and object-centric information, which is extracted from input images.
Our research addresses the issue of redundant text formulation observed in the existing methods. The text paradigm we propose includes only the information of the objects present in the images. To maintain the capability of a single object query to recognize objects of multiple classes, we depart from the traditional contrastive loss with its fixed one-to-one matching mechanism. Instead, we implement an attention-based loss computation strategy, which inherently supports a one-to-many matching process during training.
We evaluate our model across three segmentation tasks (semantic-, instance-, and panoptic segmentation) on two datasets (ADE20K [
11] and Cityscapes [
12]) with the Swin-T Backbone. Our model outperforms its baseline [
8] and other Swin-T-based models on three image segmentation tasks; on the ADE20K dataset [
11], our model achieves
49.2 mIoU (single-scale),
29.3 AP, and
43.6 PQ using one universal architecture. On the Cityscapes dataset [
12], the presented architecture achieves
81 mIoU (single-scale),
41.9 AP, and
65.6 PQ.
6. Conclusions
In this paper, we introduce the Efficient Query Optimizer (EQO), an efficient approach to universal image segmentation. It efficiently employs multi-modal data to refine query optimization during training. Inside this module, attention-based contrastive loss is presented with one-to-many matching, which enhances the capability of object queries to capture multiple categories within images. To avoid redundancy in the text input, we redesign the text template for extracting semantic information from input images, which achieves a dual benefit of computational efficiency and improved performance. Notably, the components responsible for query optimization are not required during the inference stage, allowing for a more parameter-efficient learning process. Comprehensive experiments have been conducted to validate our model’s superior performance across all three segmentation tasks, compared to OneFormer and other universal segmentation models. We hope our work will stimulate further research interest in the area of query optimization for universal image segmentation, paving the way for advancements in this field.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}