
Logistics Center Selection and Logistics Network Construction from the Perspective of Urban Geographic Information Fusion


Abstract
1. Introduction
1.1. Logistics Center Site Selection
1.2. Multi-Data Fusion
2. Modeling Multi-Objective Node Selection
2.1. Multi-Objective Node Selection Model
- Objective 1: Minimize Turnover Rate
- Objective 2: Maximize Node 3 km Coverage Rate
- Objective 3: Minimize Traffic Congestion Change Rate
- Objective 4: Minimize Distance Between Logistics Park and Nearest Primary Node
- Objective 5: Maximize Goods Transportation Efficiency
- Objective 6: Maximize Dispersion of Primary Nodes
- Objective 7: Maximize Aggregation of Secondary Nodes
2.2. Restrictive Condition
- Constraint One: Ensure Underground Goods Transportation Meets Actual Demand
- Constraint Two: Promote Traffic Flow
- Constraint Three: Control Ground Goods Volume Change
3. Preferred First-Level Node Identification Based on Cluster Analysis
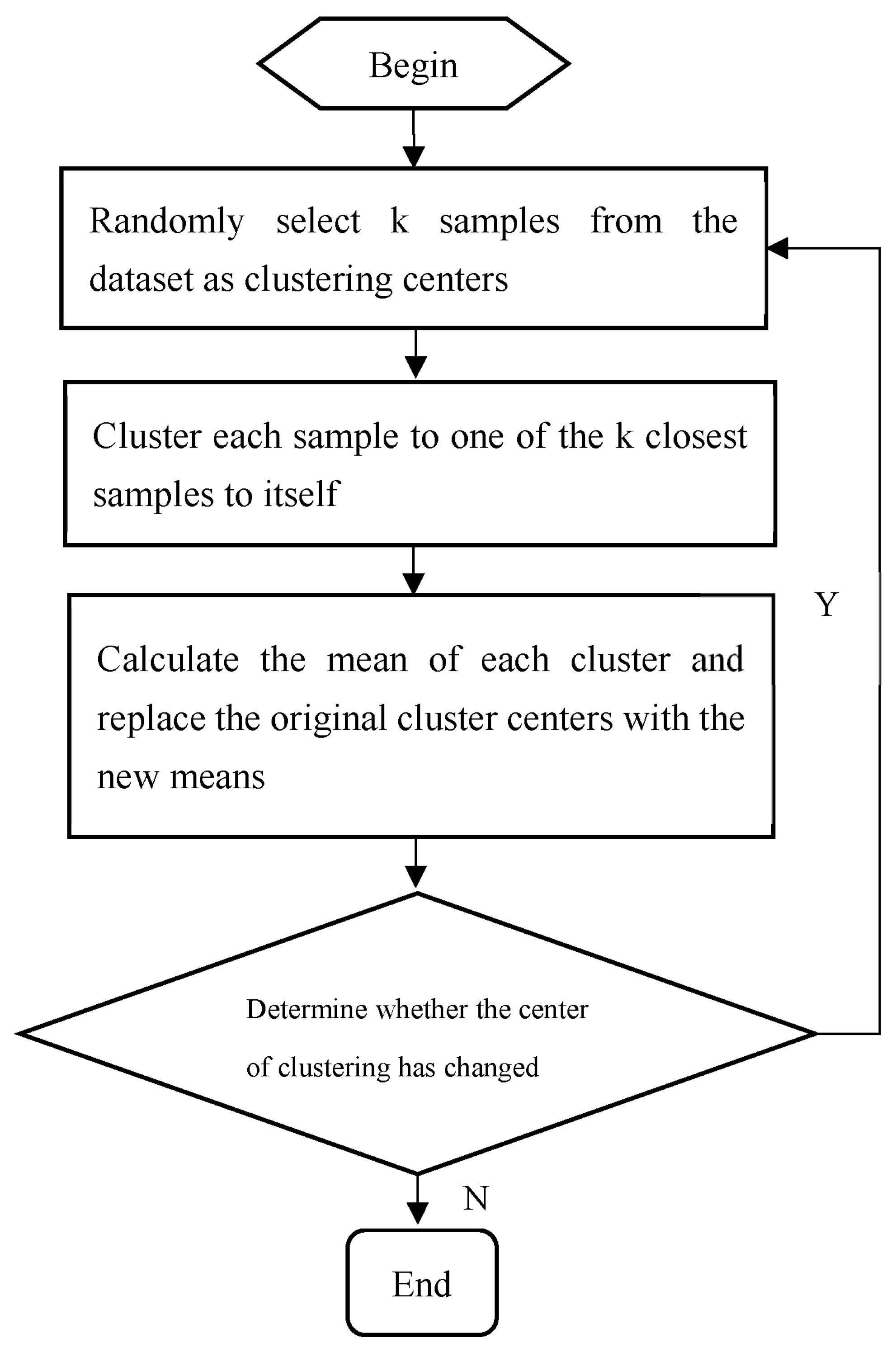
3.1. Cluster Analysis Algorithms
3.2. Cluster Analysis Results Test
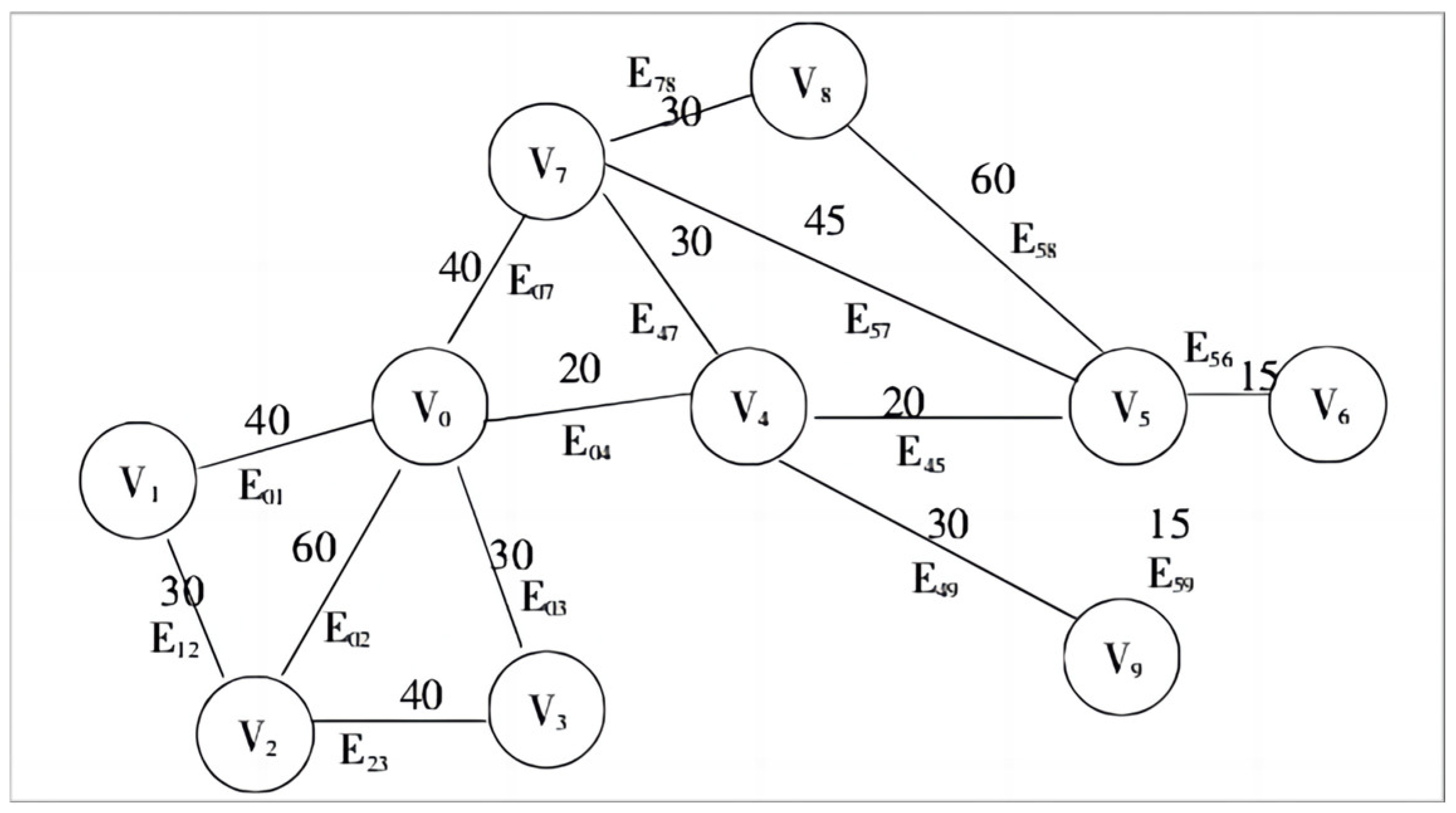
4. Selection of Secondary Node Identification Based on a Greedy Algorithm
5. Example and Result Analysis
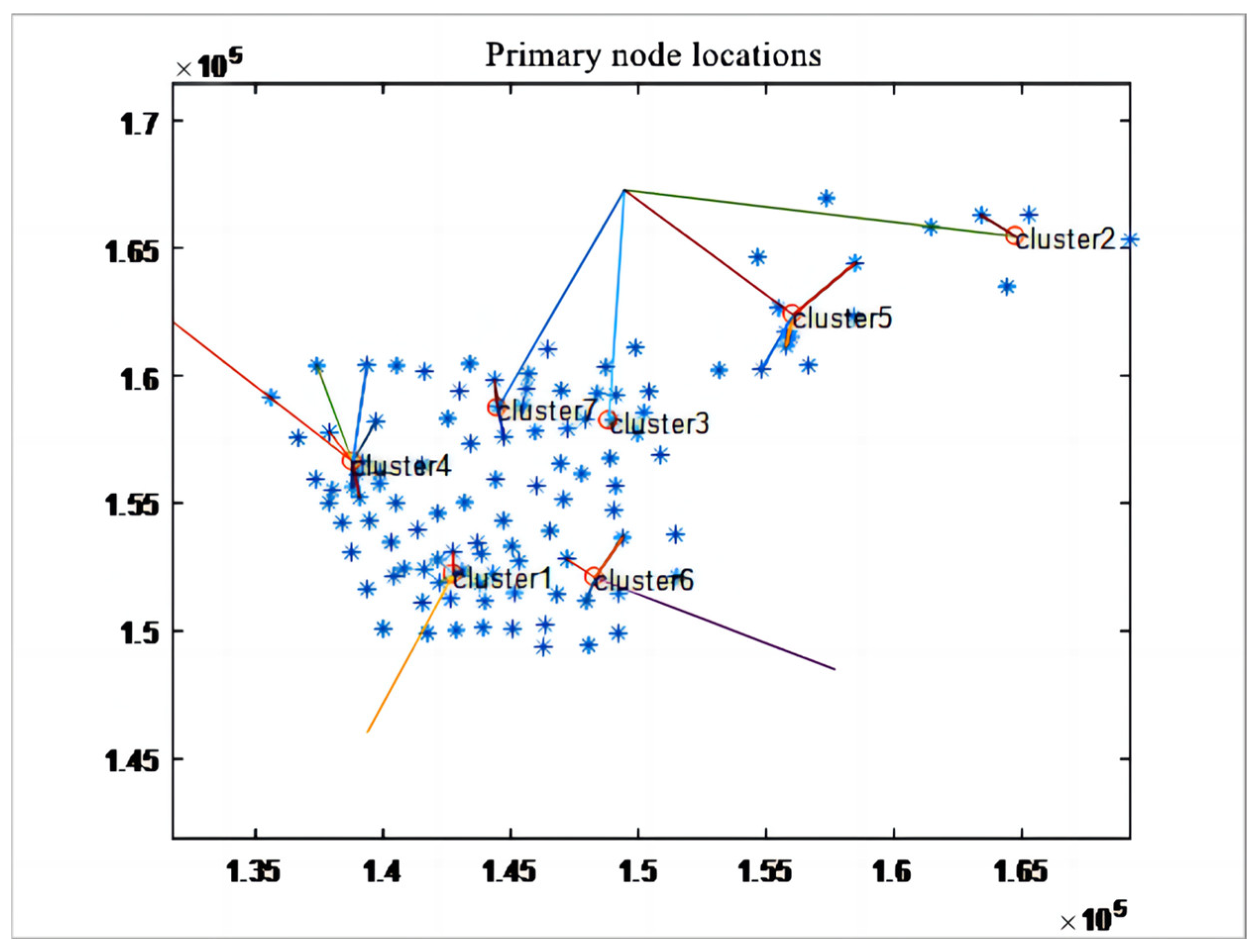
5.1. Selection of Underground Logistics Nodes
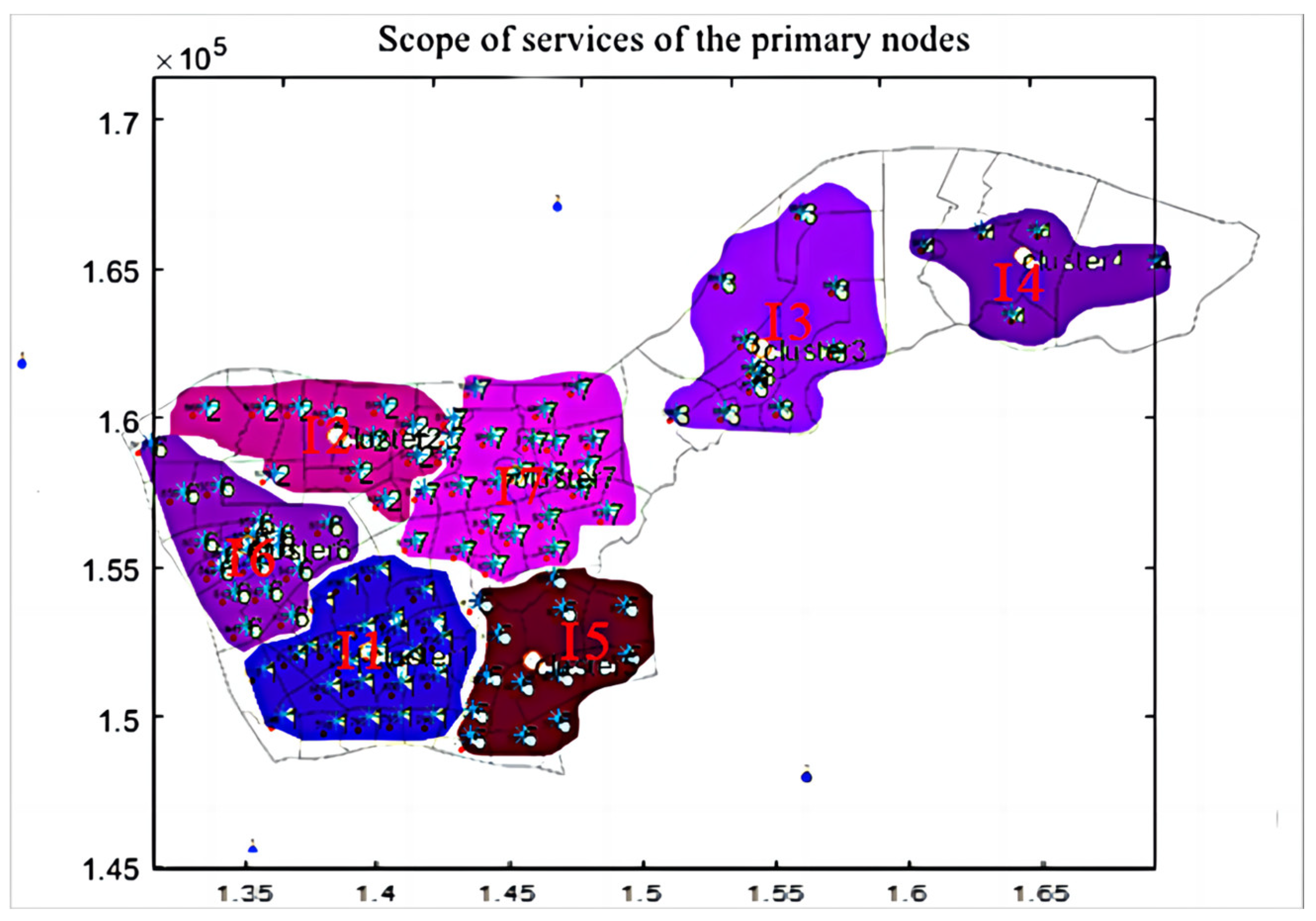
5.2. Scope of Nodal Services
5.3. Analysis of Results
5.4. Results Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Çakmak, E.; Önden, İ.; Acar, A.Z.; Eldemir, F. Analyzing the location of city logistics centers in Istanbul by integrating Geographic Information Systems with Binary Particle Swarm Optimization algorithm. Case Stud. Transp. Policy 2021, 9, 59–67. [Google Scholar] [CrossRef]
- Yazdani, M.; Chatterjee, P.; Pamucar, D.; Chakraborty, S. Development of an integrated decision making model for location selection of logistics centers in the Spanish autonomous communities. Expert Syst. Appl. 2020, 148, 113208. [Google Scholar] [CrossRef]
- Fernández, P.; Lančinskas, A.; Pelegrín, B.; Žilinskas, J. A Discrete Competitive Facility Location Model with Minimal Market Share Constraints and Equity-Based Ties Breaking Rule. Informatica 2020, 31, 205–224. [Google Scholar] [CrossRef]
- Heine, O.F.C.; Demleitner, A.; Matuschke, J. Bifactor approximation for location routing with vehicle and facility capacities. Eur. J. Oper. Res. 2023, 304, 429–442. [Google Scholar] [CrossRef]
- Önden, I.; Eldemir, F. A multi-criteria spatial approach for determination of the logistics center locations in metropolitan areas. Res. Transp. Bus. Manag. 2022, 44, 100734. [Google Scholar] [CrossRef]
- Wu, J.; Liu, X.; Li, Y.; Yang, L.; Yuan, W.; Ba, Y. A Two-Stage Model with an Improved Clustering Algorithm for a Distribution Center Location Problem under Uncertainty. Mathematics 2022, 10, 2519. [Google Scholar] [CrossRef]
- Khairunissa, M.; Lee, H. Hybrid Metaheuristic-Based Spatial Modeling and Analysis of Logistics Distribution Center. ISPRS Int. J. Geo-Inf. 2021, 11, 5. [Google Scholar] [CrossRef]
- Ge, H.; Goetz, S.J.; Cleary, R.; Yi, J.; Gómez, M.I. Facility locations in the fresh produce supply chain: An integration of optimization and empirical methods. Int. J. Prod. Econ. 2022, 249, 108534. [Google Scholar] [CrossRef]
- Blanco, V.; Gázquez, R.; Saldanha-Da-Gama, F. Multi-type maximal covering location problems: Hybridizing discrete and continuous problems. Eur. J. Oper. Res. 2023, 307, 1040–1054. [Google Scholar] [CrossRef]
- Huang, Y.; Wang, X.; Chen, H. Location Selection for Regional Logistics Center Based on Particle Swarm Optimization. Sustainability 2022, 14, 16409. [Google Scholar] [CrossRef]
- Jalal, A.M.; Toso, E.A.; Tautenhain, C.P.; Nascimento, M.C. An integrated location–transportation problem under value-added tax issues in pharmaceutical distribution planning. Expert Syst. Appl. 2022, 206, 117780. [Google Scholar] [CrossRef]
- Regal, A.; Gonzalez-Feliu, J.; Rodriguez, M. A spatio-functional logistics profile clustering analysis method for metropolitan areas. Transp. Res. Part E Logist. Transp. Rev. 2023, 179, 103312. [Google Scholar] [CrossRef]
- Yan, L.; Grifoll, M.; Feng, H.; Zheng, P.; Zhou, C. Optimization of Urban Distribution Centres: A Multi-Stage Dynamic Location Approach. Sustainability 2022, 14, 4135. [Google Scholar] [CrossRef]
- Li, J.; Yang, Y.-H.; Lei, H.; Wang, G.-G. Solving Logistics Distribution Center Location with Improved Cuckoo Search Algorithm. Int. J. Comput. Intell. Syst. 2020, 14, 676–692. [Google Scholar] [CrossRef]
- Pan, J.S.; Fu, Z.; Hu, C.C.; Tsai, P.W.; Chu, S.C. Rafflesia Optimization Algorithm Applied in the Logistics Distribution Centers Location Problem. Internet Technol. J. 2022, 23, 1541–1555. [Google Scholar]
- Dupas, R.; Deschamps, J.-C.; Taniguchi, E.; Qureshi, A.G.; Hsu, T. Optimizing the location selection of urban consolidation centers with sustainability considerations in the city of Bordeaux. Res. Transp. Bus. Manag. 2023, 47, 100943. [Google Scholar] [CrossRef]
- Rao, C.; Goh, M.; Zhao, Y.; Zheng, J. Location selection of city logistics centers under sustainability. Transp. Res. Part D Transp. Environ. 2015, 36, 29–44. [Google Scholar] [CrossRef]
- Jiao, H.; Yang, F.; Xu, S.; Huang, S. Using Large-Scale Truck Trajectory Data to Explore the Location of Sustainable Urban Logistics Centres—The Case of Wuhan. ISPRS Int. J. Geo-Inf. 2023, 12, 88. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, N.; She, N.; Li, K. Location optimization of a competitive distribution center for urban cold chain logistics in terms of low-carbon emissions. Comput. Ind. Eng. 2021, 154, 107120. [Google Scholar] [CrossRef]
- Li, X.; Zhou, K. Multi-objective cold chain logistic distribution center location based on carbon emission. Environ. Sci. Pollut. Res. 2021, 28, 32396–32404. [Google Scholar] [CrossRef]
- Taouktsis, X.; Zikopoulos, C. A decision-making tool for the determination of the distribution center location in a humanitarian logistics network. Expert Syst. Appl. 2024, 238, 122010. [Google Scholar] [CrossRef]
- Chang, K.H.; Chiang, Y.C.; Chang, T.Y. Simultaneous Location and Vehicle Fleet Sizing of Relief Goods Distribution Centers and Vehicle Routing for Post-Disaster Logistics. Comput. Oper. Res. 2024, 161, 106404. [Google Scholar] [CrossRef]
- Parragh, S.N.; Tricoire, F.; Gutjahr, W.J. A branch-and-Benders-cut algorithm for a bi-objective stochastic facility location problem. OR Spectr. 2022, 44, 419–459. [Google Scholar] [CrossRef] [PubMed]
- Feng, Z.; Li, G.; Wang, W.; Zhang, L.; Xiang, W.; He, X.; Zhang, M.; Wei, N. Emergency logistics centers site selection by multi-criteria decision-making and GIS. Int. J. Disaster Risk Reduct. 2023, 96, 103921. [Google Scholar] [CrossRef]
- Zhang, B.; Li, Z.; Song, F.; Zhou, Q.; Jin, G.; Raghavan, V.; Song, C.; Ling, C. Discrimination of black tea fermentation degree based on multi-data fusion of near-infrared spectroscopy and machine vision. J. Food Meas. Charact. 2023, 17, 4149–4160. [Google Scholar] [CrossRef]
- Wegayehu, E.B.; Muluneh, F.B. Super ensemble based streamflow simulation using multi-source remote sensing and ground gauged rainfall data fusion. Heliyon 2023, 9, e17982. [Google Scholar] [CrossRef]
- Chen, C.; Chen, Q.; Li, G.; He, M.; Dong, J.; Yan, H.; Wang, Z.; Duan, Z. A novel multi-source data fusion method based on Bayesian inference for accurate estimation of chlorophyll-a concentration over eutrophic lakes. Environ. Model. Softw. 2021, 141, 105057. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Chen, Y.; Qing, R.; Cao, X.; Chen, P.; Liu, W.; Wang, Y.; Zhou, G.; Xu, H.; et al. Fast deployable real-time bioelectric dissolved oxygen sensor based on a multi-source data fusion approach. Chem. Eng. J. 2023, 475, 146064. [Google Scholar] [CrossRef]
- Jiang, H.; Deng, J.; Chen, Q. Monitoring of simultaneous saccharification and fermentation of ethanol by multi-source data deep fusion strategy based on near-infrared spectra and electronic nose signals. Eng. Appl. Artif. Intell. 2024, 127, 107299. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, J.; Lin, H.; Chen, J.; Liu, S.; Luo, J. Voltage sag interactive platform of provincial power grid based on multi-source data fusion. Electr. Power Autom. Equip. 2023, 43, 196–203. [Google Scholar]
- Liu, Q.; Dong, M.; Sun, P.; Yan, B.; Wang, J.; Zhu, L. All-parameter calibration method of the on-orbit multi-view dynamic photogrammetry system. Opt. Express 2023, 31, 11471–11489. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Yuan, H.; Xiong, C.; Zhang, Q.; Jia, S.; Liu, J.; Men, H. Improving performance: A collaborative strategy for the multi-data fusion of electronic nose and hyperspectral to track the quality difference of rice. Sens. Actuators B Chem. 2021, 333, 129546. [Google Scholar] [CrossRef]
- Zou, J.; Zheng, H.; Wang, F. Real-Time Target Detection System for Intelligent Vehicles Based on Multi-Source Data Fusion. Sensors 2023, 23, 1823. [Google Scholar] [CrossRef] [PubMed]
- Jiao, H.; Song, W.; Cao, P.; Jiao, D. Prediction method of coal mine gas occurrence law based on multi-source data fusion. Heliyon 2023, 9, e17117. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Ren, C.; Yan, Z.; Lai, J. Improving soil moisture retrieval from GNSS-interferometric reflectometry: Parameters optimization and data fusion via neural network. Int. J. Remote Sens. 2021, 42, 9085–9108. [Google Scholar] [CrossRef]
- Gawde, S.; Patil, S.; Kumar, S.; Kamat, P.; Kotecha, K. An explainable predictive maintenance strategy for multi-fault diagnosis of rotating machines using multi-sensor data fusion. Decis. Anal. J. 2024, 10, 100425. [Google Scholar] [CrossRef]
- Li, X.; Li, Z.; Qiu, H.; Chen, G.; Fan, P. Soil carbon content prediction using multi-source data feature fusion of deep learning based on spectral and hyperspectral images. Chemosphere 2023, 336, 139161. [Google Scholar] [CrossRef]
- Feng, J.; Qin, D.; Liu, Y.; You, Y. Real-time estimation of road slope based on multiple models and multiple data fusion. Measurement 2021, 181, 109609. [Google Scholar] [CrossRef]
- Xiao, Y.; Li, X.; Yin, J.; Liang, W.; Hu, Y. Adaptive multi-source data fusion vessel trajectory prediction model for intelligent maritime traffic. Knowl. Based Syst. 2023, 277, 110799. [Google Scholar] [CrossRef]
- Li, Y.; Jiang, W.; Shi, Z.; Yang, C. A Soft Sensor Model of Sintering Process Quality Index Based on Multi-Source Data Fusion. Sensors 2023, 23, 4954. [Google Scholar] [CrossRef]
- Jiang, Y.; Li, C.; Sun, L.; Guo, D.; Zhang, Y.; Wang, W. A deep learning algorithm for multi-source data fusion to predict water quality of urban sewer networks. J. Clean. Prod. 2021, 318, 128533. [Google Scholar] [CrossRef]
- Yuan, G.; Yang, W. Study on optimization of economic dispatching of electric power system based on Hybrid Intelligent Algorithms (PSO and AFSA). Energy 2019, 183, 926–935. [Google Scholar] [CrossRef]
- Wang, B.; Li, Z.; Xu, Z.; Sun, Z.; Tian, K. Digital twin modeling for structural strength monitoring via transfer learning-based multi-source data fusion. Mech. Syst. Signal Process. 2023, 200, 110625. [Google Scholar] [CrossRef]
- Wang, S.; Li, W. GeoAI in terrain analysis: Enabling multi-source deep learning and data fusion for natural feature detection. Comput. Environ. Urban Syst. 2021, 90, 101715. [Google Scholar] [CrossRef]
- Yang, N.; Yang, L.; Du, X.; Guo, X.; Meng, F.; Zhang, Y. Blockchain based Trusted Execution Environment Architecture Analysis for Multi-source Data Fusion Scenario. J. Cloud Comput. 2023, 12, 122. [Google Scholar] [CrossRef]
- Liang, H.; Yuan, G.; Han, J.; Sun, L. A multi-objective location and channel model for ULS network. Neural Comput. Appl. 2019, 31, 35–46. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level 1 Node Number | Freight Volume/t | Transit Rate | Position Coordinate | |
|---|---|---|---|---|
| X | Y | |||
| I-1 | 44,549.12 | 0.1949 | 142,746.9 | 152,213.7 |
| I-2 | 13,254.41 | 0.189 | 164,769.5 | 165,451.4 |
| I-3 | 31,508.57 | 0.1888 | 148,832.7 | 158,220.1 |
| I-4 | 31,094.69 | 0.1888 | 138,800.1 | 156,621.5 |
| I-5 | 28,393.75 | 0.1818 | 156,051.9 | 162,385.7 |
| I-6 | 29,472.58 | 0.1802 | 148,284.2 | 152,085.8 |
| I-7 | 19,674.26 | 0.1759 | 144,477.2 | 158,718.5 |
| Node Number | Approaching Node | Freight Volume/t | Position Coordinate | Node Number | Approaching Node | Freight Volume/t | Position Coordinate | ||
|---|---|---|---|---|---|---|---|---|---|
| X | Y | X | Y | ||||||
| II-1 | 811 | 500.95 | 143,105.67 | 152,346.13 | II-29 | 859 | 237.997 | 139,712.38 | 158,196.62 |
| II-2 | 811 | 499.3 | 143,005.54 | 152,357.19 | II-30 | 869 | 231.447 | 137,403.37 | 160,390.60 |
| II-3 | 819 | 478.205 | 142,735.81 | 153,102.05 | II-31 | 868 | 278.97 | 139,355.42 | 160,403.74 |
| II-4 | 819 | 412.385 | 142,734.58 | 153,100.82 | II-32 | 869 | 227.177 | 145,960.34 | 157,813.24 |
| II-5 | 819 | 392.17 | 142,733.35 | 153,099.59 | II-33 | 845 | 226.562 | 139,062.69 | 155,216.00 |
| II-6 | 819 | 337.825 | 142,730.59 | 153,096.83 | II-34 | 859 | 211.112 | 139,712.38 | 158,196.62 |
| II-7 | 819 | 336.925 | 142,727.83 | 153,094.07 | II-35 | 887 | 204.432 | 155,779.18 | 161,153.63 |
| II-8 | 817 | 328.8 | 142,147.44 | 152,788.09 | II-36 | 887 | 204.202 | 155,972.26 | 161,519.38 |
| II-9 | 817 | 311.925 | 143,839.80 | 153,020.83 | II-37 | 894 | 202.802 | 158,485.91 | 164,411.95 |
| II-10 | 807 | 299.115 | 142,199.94 | 151,897.77 | II-38 | 894 | 196.537 | 154,679.32 | 164,648.90 |
| II-11 | 817 | 286.42 | 142,733.35 | 153,099.59 | II-39 | 886 | 194.062 | 154,828.66 | 160,253.62 |
| II-12 | 811 | 279.64 | 143,106.67 | 152,356.13 | II-40 | 894 | 191.002 | 158,429.82 | 162,320.97 |
| II-13 | 811 | 272.69 | 143,146.67 | 151,356.13 | II-41 | 886 | 182.712 | 156,649.10 | 160,401.30 |
| II-14 | 899 | 265.59 | 165,295.96 | 166,307.48 | II-42 | 894 | 173.282 | 155,475.94 | 162,649.70 |
| II-15 | 899 | 262.93 | 157,354.70 | 166,956.66 | II-43 | 826 | 173.012 | 136,654.80 | 157,552.12 |
| II-16 | 899 | 258.065 | 163,428.02 | 166,293.35 | II-44 | 826 | 171.227 | 139,712.38 | 158,196.62 |
| II-17 | 872 | 256.29 | 145,961.77 | 157,814.67 | II-45 | 805 | 168.927 | 142,526.33 | 158,311.54 |
| II-18 | 872 | 243.59 | 147,221.06 | 157,904.41 | II-46 | 826 | 167.215 | 144,511.24 | 158,818.60 |
| II-19 | 872 | 263.135 | 149,007.88 | 158,255.23 | II-47 | 826 | 165.815 | 135,605.67 | 159,147.49 |
| II-20 | 872 | 250.325 | 147,900.64 | 158,283.67 | II-48 | 805 | 159.55 | 142,989.12 | 159,395.66 |
| II-21 | 872 | 237.63 | 150,211.94 | 158,547.64 | II-49 | 822 | 157.075 | 144,347.43 | 159,827.39 |
| II-22 | 872 | 230.85 | 145,488.59 | 158,833.25 | II-50 | 826 | 154.015 | 143,383.79 | 160,462.05 |
| II-23 | 872 | 223.9 | 148,375.72 | 159,294.26 | II-51 | 856 | 145.725 | 141,628.28 | 160,162.22 |
| II-24 | 872 | 216.8 | 149,100.78 | 159,241.67 | II-52 | 864 | 279.56 | 140,521.56 | 160,395.32 |
| II-25 | 872 | 245.78 | 140,522.99 | 160,396.75 | II-53 | 864 | 338.67 | 137,403.37 | 160,390.60 |
| II-26 | 848 | 345.47 | 138,792.09 | 155,636.76 | II-54 | 864 | 217.89 | 139,355.42 | 160,403.74 |
| II-27 | 848 | 217.65 | 139,841.39 | 155,777.27 | II-55 | 856 | 457.32 | 145,960.34 | 157,813.24 |
| II-28 | 857 | 407.68 | 137,888.25 | 157,780.23 | |||||
| Primary Node | Contains Secondary Nodes | Includes Service Area Centers |
|---|---|---|
| I-1 | II-1~II-13 | 793, 795, 796, 797, 798, 800, 801, 802, 804, 806, 807, 809, 810, 811, 813, 814, 815, 816, 817, 818, 819, 820, 821, 823, 827, 828, 830, 833 |
| I-2 | II-14~II-16 | 892, 896, 897, 899, 900 |
| I-3 | II-17~II25 | 832, 836, 837, 838, 839, 840, 871, 872, 873, 874, 876, 877, 879, 880, 882, 884 |
| I-4 | II-25~II-32 | 841, 842, 843, 844, 845, 846, 847, 848, 849, 850, 851 852, 853, 854, 857, 858, 859, 862, 867, 868, 869 |
| I-5 | II-33~II-40 | 885, 886, 887, 888, 889, 890, 891, 893, 894, 895, 898 |
| I-6 | II-41~II-48 | 791, 792, 794, 799, 803, 805, 808, 812, 822, 824, 825, 826, 829, 831 |
| I-7 | II-48~II-55 | 834, 835, 855, 856, 860, 861, 863, 864, 865, 866, 870, 875, 878, 881, 883 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, Z.; Zheng, X.; Liang, H.; Luo, P. Logistics Center Selection and Logistics Network Construction from the Perspective of Urban Geographic Information Fusion. Sensors 2024, 24, 1878. https://doi.org/10.3390/s24061878
Ma Z, Zheng X, Liang H, Luo P. Logistics Center Selection and Logistics Network Construction from the Perspective of Urban Geographic Information Fusion. Sensors. 2024; 24(6):1878. https://doi.org/10.3390/s24061878
Chicago/Turabian StyleMa, Zhanxin, Xiyu Zheng, Hejun Liang, and Ping Luo. 2024. "Logistics Center Selection and Logistics Network Construction from the Perspective of Urban Geographic Information Fusion" Sensors 24, no. 6: 1878. https://doi.org/10.3390/s24061878
APA StyleMa, Z., Zheng, X., Liang, H., & Luo, P. (2024). Logistics Center Selection and Logistics Network Construction from the Perspective of Urban Geographic Information Fusion. Sensors, 24(6), 1878. https://doi.org/10.3390/s24061878