
Utilizing Wearable Device Data for Syndromic Surveillance: A Fever Detection Approach

 , ,
, ,  , , and
, , and
Abstract
1. Introduction
2. Materials and Methods
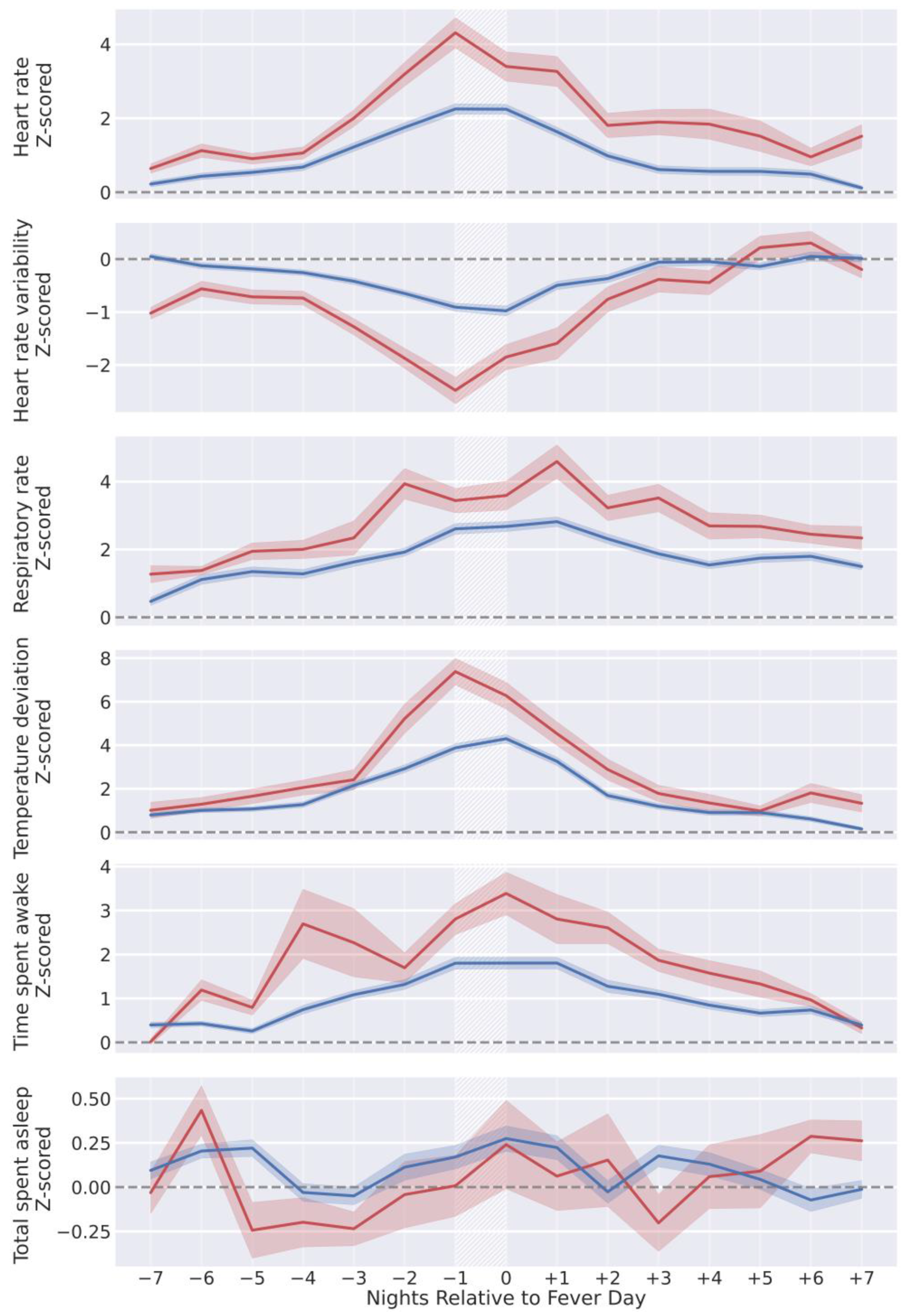
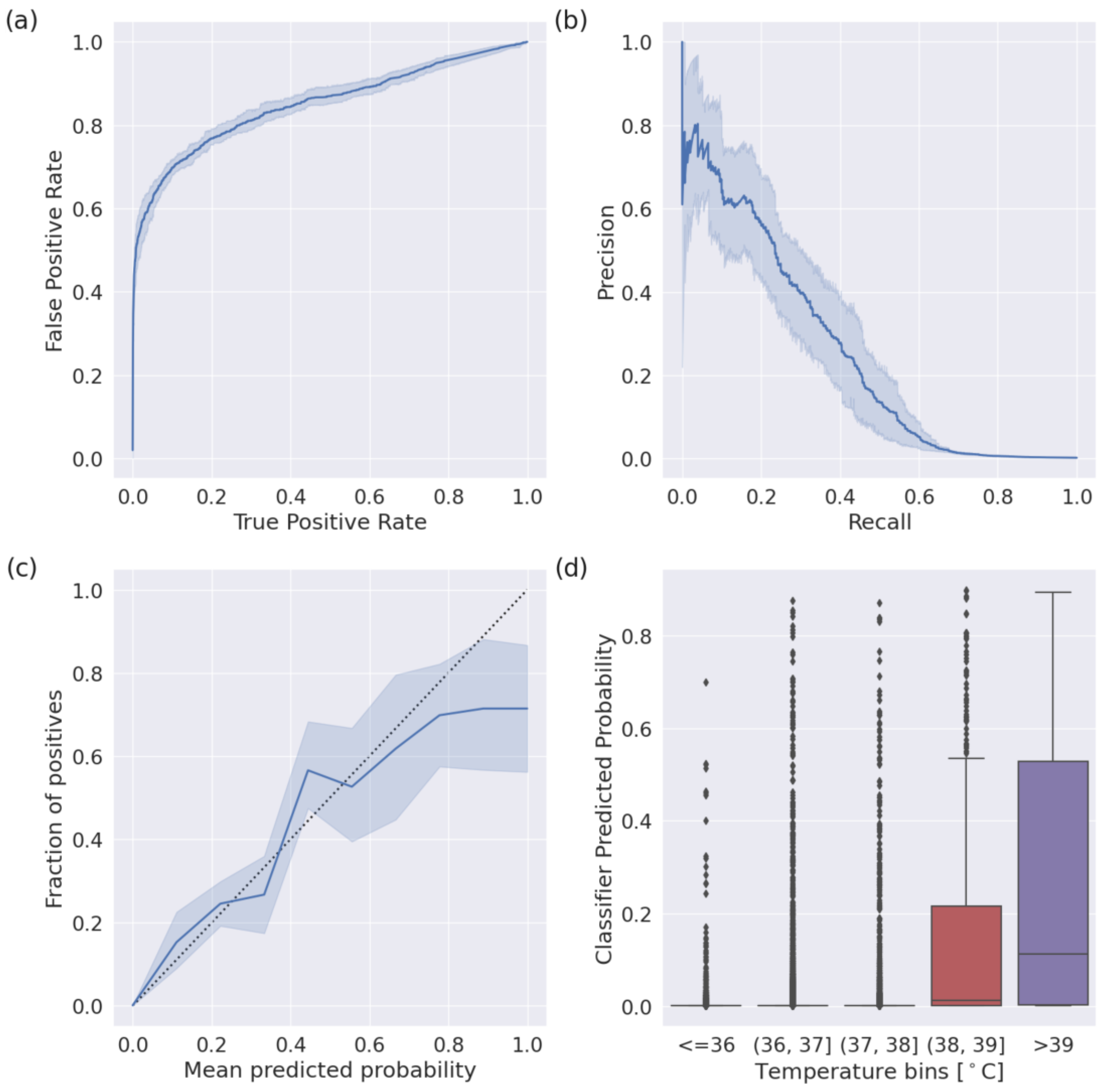
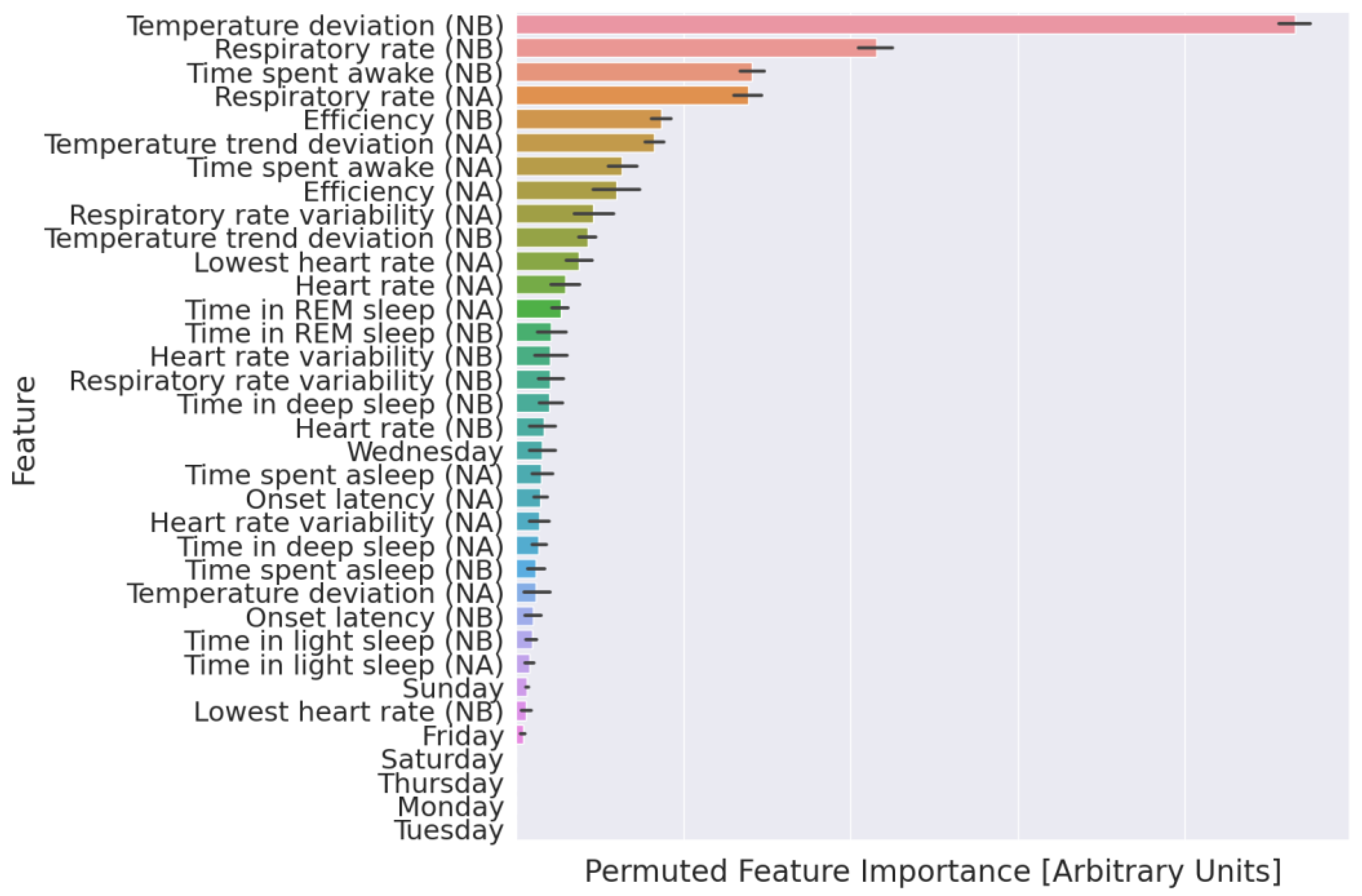
3. Results
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Correction Statement
Appendix A
Appendix A.1. Oura Ring Gen2 Sensor Specifications and Algorithm Descriptions
Appendix A.1.1. Sensors
Appendix A.1.2. Heart Rate, Heart Rate Variability, and Respiratory Rate
Appendix A.1.3. Sleep Stages
References
- Mandl, K.D.; Overhage, J.M.; Wagner, M.M.; Lober, W.B.; Sebastiani, P.; Mostashari, F.; Pavlin, J.A.; Gesteland, P.H.; Treadwell, T.; Koski, E.; et al. Implementing Syndromic Surveillance: A Practical Guide Informed by the Early Experience. J. Am. Med. Inform. Assoc. 2004, 11, 141–150. [Google Scholar] [CrossRef]
- Smith, G.E.; Elliot, A.J.; Lake, I.; Edeghere, O.; Morbey, R.; Catchpole, M.; Heymann, D.L.; Hawker, J.; Ibbotson, S.; McCloskey, B.; et al. Syndromic Surveillance: Two Decades Experience of Sustainable Systems—Its People Not Just Data! Epidemiol. Infect. 2019, 147, e101. [Google Scholar] [CrossRef] [PubMed]
- Colón-González, F.J.; Lake, I.R.; Morbey, R.A.; Elliot, A.J.; Pebody, R.; Smith, G.E. A Methodological Framework for the Evaluation of Syndromic Surveillance Systems: A Case Study of England. BMC Public Health 2018, 18, 544. [Google Scholar] [CrossRef]
- Overview of Syndromic Surveillance What Is Syndromic Surveillance? Available online: https://www.cdc.gov/mmwr/preview/mmwrhtml/su5301a3.htm (accessed on 22 August 2023).
- Chandrasekaran, R.; Katthula, V.; Moustakas, E. Patterns of Use and Key Predictors for the Use of Wearable Health Care Devices by US Adults: Insights from a National Survey. J. Med. Internet Res. 2020, 22, e22443. [Google Scholar] [CrossRef] [PubMed]
- Mason, A.E.; Hecht, F.M.; Davis, S.K.; Natale, J.L.; Hartogensis, W.; Damaso, N.; Claypool, K.T.; Dilchert, S.; Dasgupta, S.; Purawat, S.; et al. Detection of COVID-19 Using Multimodal Data from a Wearable Device: Results from the First TemPredict Study. Sci. Rep. 2022, 12, 3463. [Google Scholar] [CrossRef] [PubMed]
- Alavi, A.; Bogu, G.K.; Wang, M.; Rangan, E.S.; Brooks, A.W.; Wang, Q.; Higgs, E.; Celli, A.; Mishra, T.; Metwally, A.A.; et al. Real-Time Alerting System for COVID-19 and Other Stress Events Using Wearable Data. Nat. Med. 2022, 28, 175–184. [Google Scholar] [CrossRef]
- Gadaleta, M.; Radin, J.M.; Baca-Motes, K.; Ramos, E.; Kheterpal, V.; Topol, E.J.; Steinhubl, S.R.; Quer, G. Passive Detection of COVID-19 with Wearable Sensors and Explainable Machine Learning Algorithms. npj Digit. Med. 2021, 4, 166. [Google Scholar] [CrossRef]
- Richards, D.M.; Tweardy, M.J.; Steinhubl, S.R.; Chestek, D.W.; Hoek, T.L.V.; Larimer, K.A.; Wegerich, S.W. Wearable Sensor Derived Decompensation Index for Continuous Remote Monitoring of COVID-19 Diagnosed Patients. npj Digit. Med. 2021, 4, 155. [Google Scholar] [CrossRef]
- Miller, D.J.; Capodilupo, J.V.; Lastella, M.; Sargent, C.; Roach, G.D.; Lee, V.H.; Capodilupo, E.R. Analyzing Changes in Respiratory Rate to Predict the Risk of COVID-19 Infection. PLoS ONE 2020, 15, e0243693. [Google Scholar] [CrossRef]
- Grzesiak, E.; Bent, B.; McClain, M.T.; Woods, C.W.; Tsalik, E.L.; Nicholson, B.P.; Veldman, T.; Burke, T.W.; Gardener, Z.; Bergstrom, E.; et al. Assessment of the Feasibility of Using Noninvasive Wearable Biometric Monitoring Sensors to Detect Influenza and the Common Cold before Symptom Onset. JAMA Netw. Open 2021, 4, e2128534. [Google Scholar] [CrossRef]
- Chaudhury, S.; Yu, C.; Liu, R.; Kumar, K.; Hornby, S.; Duplessis, C.; Sklar, J.M.; Epstein, J.E.; Reifman, J. Wearables Detect Malaria Early in a Controlled Human-Infection Study. IEEE Trans. Biomed. Eng. 2022, 69, 2119–2129. [Google Scholar] [CrossRef] [PubMed]
- Mitratza, M.; Goodale, B.M.; Shagadatova, A.; Kovacevic, V.; van de Wijgert, J.; Brakenhoff, T.B.; Dobson, R.; Franks, B.; Veen, D.; Folarin, A.A.; et al. The Performance of Wearable Sensors in the Detection of SARS-CoV-2 Infection: A Systematic Review. Lancet Digit. Health 2022, 4, e370–e383. [Google Scholar] [CrossRef] [PubMed]
- Smarr, B.L.; Aschbacher, K.; Fisher, S.M.; Chowdhary, A.; Dilchert, S.; Puldon, K.; Rao, A.; Hecht, F.M.; Mason, A.E. Feasibility of Continuous Fever Monitoring Using Wearable Devices. Sci. Rep. 2020, 10, 21640. [Google Scholar] [CrossRef]
- Merrill, M.A.; Safranchik, E.; Kolbeinsson, A.; Gade, P.; Ramirez, E.; Schmidt, L.; Foschini, L.; Althoff, T. Homekit2020: A Benchmark for Time Series Classification on a Large Mobile Sensing Dataset with Laboratory Tested Ground Truth of Influenza Infections. In Proceedings of the Conference on Health, Inference, and Learning, Cambridge, MA, USA, 13 June 2023; pp. 207–228. [Google Scholar]
- Konty, K.J.; Bradshaw, B.; Ramirez, E.; Lee, W.-N.; Signorini, A.; Foschini, L. Influenza Surveillance Using Wearable Mobile Health Devices. Online J. Public Health Inform. 2019, 11, e249. [Google Scholar] [CrossRef]
- Mezlini, A.; Shapiro, A.; Daza, E.J.; Caddigan, E.; Ramirez, E.; Althoff, T.; Foschini, L. Estimating the Burden of Influenza-like Illness on Daily Activity at the Population Scale Using Commercial Wearable Sensors. JAMA Netw. Open 2022, 5, e2211958. [Google Scholar] [CrossRef]
- Surveillance Case Definitions for ILI and SARI. Available online: https://www.who.int/teams/global-influenza-programme/surveillance-and-monitoring/case-definitions-for-ili-and-sari (accessed on 25 August 2023).
- Shimoni, Z.; Rodrig, J.; Dusseldorp, N.; Niven, M.; Froom, P. Increased Emergency Department Chief Complaints of Fever Identified the Influenza (H1N1) Pandemic before Outpatient Symptom Surveillance. Environ. Health Prev. Med. 2012, 17, 69–72. [Google Scholar] [CrossRef]
- Shimoni, Z.; Niven, M.; Kama, N.; Dusseldorp, N.; Froom, P. Increased Complaints of Fever in the Emergency Room Can Identify Influenza Epidemics. Eur. J. Intern. Med. 2008, 19, 494–498. [Google Scholar] [CrossRef] [PubMed]
- Hiller, K.M.; Stoneking, L.; Min, A.; Rhodes, S.M. Syndromic Surveillance for Influenza in the Emergency Department–A Systematic Review. PLoS ONE 2013, 8, e73832. [Google Scholar] [CrossRef] [PubMed]
- Mason, A.E.; Kasl, P.; Soltani, S.; Green, A.; Hartogensis, W.; Dilchert, S.; Chowdhary, A.; Pandya, L.S.; Siwik, C.J.; Foster, S.L.; et al. Elevated Body Temperature Is Associated with Depressive Symptoms: Results from the TemPredict Study. Sci. Rep. 2024, 14, 1884. [Google Scholar] [CrossRef]
- Cao, R.; Azimi, I.; Sarhaddi, F.; Niela-Vilen, H.; Axelin, A.; Liljeberg, P.; Rahmani, A.M. Accuracy Assessment of Oura Ring Nocturnal Heart Rate and Heart Rate Variability in Comparison with Electrocardiography in Time and Frequency Domains: Comprehensive Analysis. J. Med. Internet Res. 2022, 24, e27487. [Google Scholar] [CrossRef] [PubMed]
- Kryder, C. How Accurate Is Oura’s Respiratory Rate? Available online: https://ouraring.com/blog/how-accurate-is-ouras-respiratory-rate/ (accessed on 28 August 2022).
- Kryder, C. How Accurate Is My Oura Temperature Data? Available online: https://ouraring.com/blog/temperature-validated-accurate/ (accessed on 28 August 2022).
- Altini, M.; Kinnunen, H. The Promise of Sleep: A Multi-Sensor Approach for Accurate Sleep Stage Detection Using the Oura Ring. Sensors 2021, 21, 4302. [Google Scholar] [CrossRef]
- Nestor, B.; Hunter, J.; Kainkaryam, R.; Drysdale, E.; Inglis, J.B.; Shapiro, A.; Nagaraj, S.; Ghassemi, M.; Foschini, L.; Goldenberg, A. Machine Learning COVID-19 Detection from Wearables. Lancet Digit. Health 2023, 5, e182–e184. [Google Scholar] [CrossRef]
- Conroy, B.; Silva, I.; Mehraei, G.; Damiano, R.; Gross, B.; Salvati, E.; Feng, T.; Schneider, J.; Olson, N.; Rizzo, A.G.; et al. Real-Time Infection Prediction with Wearable Physiological Monitoring and AI to Aid Military Workforce Readiness during COVID-19. Sci. Rep. 2022, 12, 3797. [Google Scholar] [CrossRef]
- Vaicenavicius, J.; Widmann, D.; Andersson, C.; Lindsten, F.; Roll, J.; Schön, T. Evaluating Model Calibration in Classification. In Proceedings of the Twenty-Second International Conference on Artificial Intelligence and Statistics, Naha, Japan, 11 April 2019; pp. 3459–3467. [Google Scholar]
- Sahoo, R.; Zhao, S.; Chen, A.; Ermon, S. Reliable Decisions with Threshold Calibration. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2021; Volume 34, pp. 1831–1844. [Google Scholar]
- Roulston, M.S. Performance Targets and the Brier Score. Meteorol. Appl. 2007, 14, 185–194. [Google Scholar] [CrossRef]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Su, W.; Yuan, Y.; Zhu, M. A Relationship between the Average Precision and the Area Under the ROC Curve. In Proceedings of the 2015 International Conference on the Theory of Information Retrieval, Northampton, MA, USA, 27–30 September 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 349–352. [Google Scholar]
- Jagannath, B.; Lin, K.-C.; Pali, M.; Sankhala, D.; Muthukumar, S.; Prasad, S. Temporal Profiling of Cytokines in Passively Expressed Sweat for Detection of Infection Using Wearable Device. Bioeng. Transl. Med. 2021, 6, e10220. [Google Scholar] [CrossRef] [PubMed]
- Shih, C.-H.; Lin, Y.-J.; Lee, K.-F.; Chien, P.-Y.; Drake, P. Real-Time Electronic Nose Based Pathogen Detection for Respiratory Intensive Care Patients. Sens. Actuators B Chem. 2010, 148, 153–157. [Google Scholar] [CrossRef]
- Hirten, R.P.; Danieletto, M.; Tomalin, L.; Choi, K.H.; Zweig, M.; Golden, E.; Kaur, S.; Helmus, D.; Biello, A.; Pyzik, R.; et al. Use of Physiological Data From a Wearable Device to Identify SARS-CoV-2 Infection and Symptoms and Predict COVID-19 Diagnosis: Observational Study. J. Med. Internet Res. 2021, 23, e26107. [Google Scholar] [CrossRef]
- Shiba, S.K.; Temple, C.A.; Krasnoff, J.; Dilchert, S.; Smarr, B.L.; Robishaw, J.; Mason, A.E.; Shiba, S.K.; Temple, C.A.; Krasnoff, J.; et al. Assessing Adherence to Multi-Modal Oura Ring Wearables from COVID-19 Detection among Healthcare Workers. Cureus 2023, 15, e45362. [Google Scholar] [CrossRef] [PubMed]
- Chikwetu, L.; Miao, Y.; Woldetensae, M.K.; Bell, D.; Goldenholz, D.M.; Dunn, J. Does Deidentification of Data from Wearable Devices Give Us a False Sense of Security? A Systematic Review. Lancet Digit. Health 2023, 5, e239–e247. [Google Scholar] [CrossRef]
- Regulation-2016/679-EN-Gdpr-EUR-Lex. Available online: https://eur-lex.europa.eu/eli/reg/2016/679/oj (accessed on 21 February 2024).
- 104th Congress Health Insurance Portability and Accountability Act of 1996. Available online: https://www.govinfo.gov/content/pkg/PLAW-104publ191/html/PLAW-104publ191.htm (accessed on 21 February 2024).
- Kinnunen, H.; Rantanen, A.; Kenttä, T.; Koskimäki, H. Feasible assessment of recovery and cardiovascular health: Accuracy of nocturnal HR and HRV assessed via ring PPG in comparison to medical grade ECG. Physiol. Meas. 2020, 41, 04NT01. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metric | Unit of Measurement | Description |
|---|---|---|
| Heart rate | Beats per minute | The average heart rate registered during the sleep period. |
| Lowest heart rate | Beats per minute | The lowest heart rate (5 min sliding average) registered during the sleep period. |
| Heart rate variability | Milliseconds | The average HRV calculated using the rMSSD method. |
| Respiratory rate | Breaths per minute | Average respiratory rate. |
| Respiratory rate variability | Breaths per minute | The average variability of respiratory rate (STD) in the sleep period. |
| Temperature deviation | Degrees Celsius | Skin temperature deviation from the user’s long-term temperature average. |
| Temperature trend deviation | Degrees Celsius | Skin temperature deviation from weighted three-day rolling temperature average. |
| Onset latency | Seconds | Detected latency from the time the user entered their bed to the beginning of the first five minutes of persistent sleep. |
| Time spent awake | Seconds | Total amount of awake time registered during the sleep period. |
| Time spent in REM sleep | Seconds | Total amount of REM sleep registered during the sleep period. |
| Time spent in light sleep | Seconds | Total amount of light (N1 or N2) sleep registered during the sleep period. |
| Time spent in deep sleep | Seconds | Total amount of deep (N3) sleep registered during the sleep period. |
| Time spent asleep | Seconds | Total amount of sleep registered during the sleep period. |
| Dataset Composition | ||
|---|---|---|
| N | 16,794 | |
| Sex, n (%) | Female | 7324 (43.6) |
| Male | 9455 (56.3) | |
| Other | 15 (0.1) | |
| Age, mean (SD) | 47.2 (12.3) | |
| Race, n (%) | African American/Black | 226 (1.4) |
| East Asian | 685 (4.2) | |
| Caucasian/White | 14,120 (86.3) | |
| Middle Eastern | 94 (0.6) | |
| Native American/Native Alaskan | 27 (0.2) | |
| Native Hawaiian or Other Pacific Islander | 28 (0.2) | |
| South Asian | 162 (1.0) | |
| Other | 429 (2.6) | |
| Prefer not to answer | 596 (3.6) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kasl, P.; Keeler Bruce, L.; Hartogensis, W.; Dasgupta, S.; Pandya, L.S.; Dilchert, S.; Hecht, F.M.; Gupta, A.; Altintas, I.; Mason, A.E.; et al. Utilizing Wearable Device Data for Syndromic Surveillance: A Fever Detection Approach. Sensors 2024, 24, 1818. https://doi.org/10.3390/s24061818
Kasl P, Keeler Bruce L, Hartogensis W, Dasgupta S, Pandya LS, Dilchert S, Hecht FM, Gupta A, Altintas I, Mason AE, et al. Utilizing Wearable Device Data for Syndromic Surveillance: A Fever Detection Approach. Sensors. 2024; 24(6):1818. https://doi.org/10.3390/s24061818
Chicago/Turabian StyleKasl, Patrick, Lauryn Keeler Bruce, Wendy Hartogensis, Subhasis Dasgupta, Leena S. Pandya, Stephan Dilchert, Frederick M. Hecht, Amarnath Gupta, Ilkay Altintas, Ashley E. Mason, and et al. 2024. "Utilizing Wearable Device Data for Syndromic Surveillance: A Fever Detection Approach" Sensors 24, no. 6: 1818. https://doi.org/10.3390/s24061818
APA StyleKasl, P., Keeler Bruce, L., Hartogensis, W., Dasgupta, S., Pandya, L. S., Dilchert, S., Hecht, F. M., Gupta, A., Altintas, I., Mason, A. E., & Smarr, B. L. (2024). Utilizing Wearable Device Data for Syndromic Surveillance: A Fever Detection Approach. Sensors, 24(6), 1818. https://doi.org/10.3390/s24061818