
TGLFusion: A Temperature-Guided Lightweight Fusion Method for Infrared and Visible Images



Abstract
1. Introduction
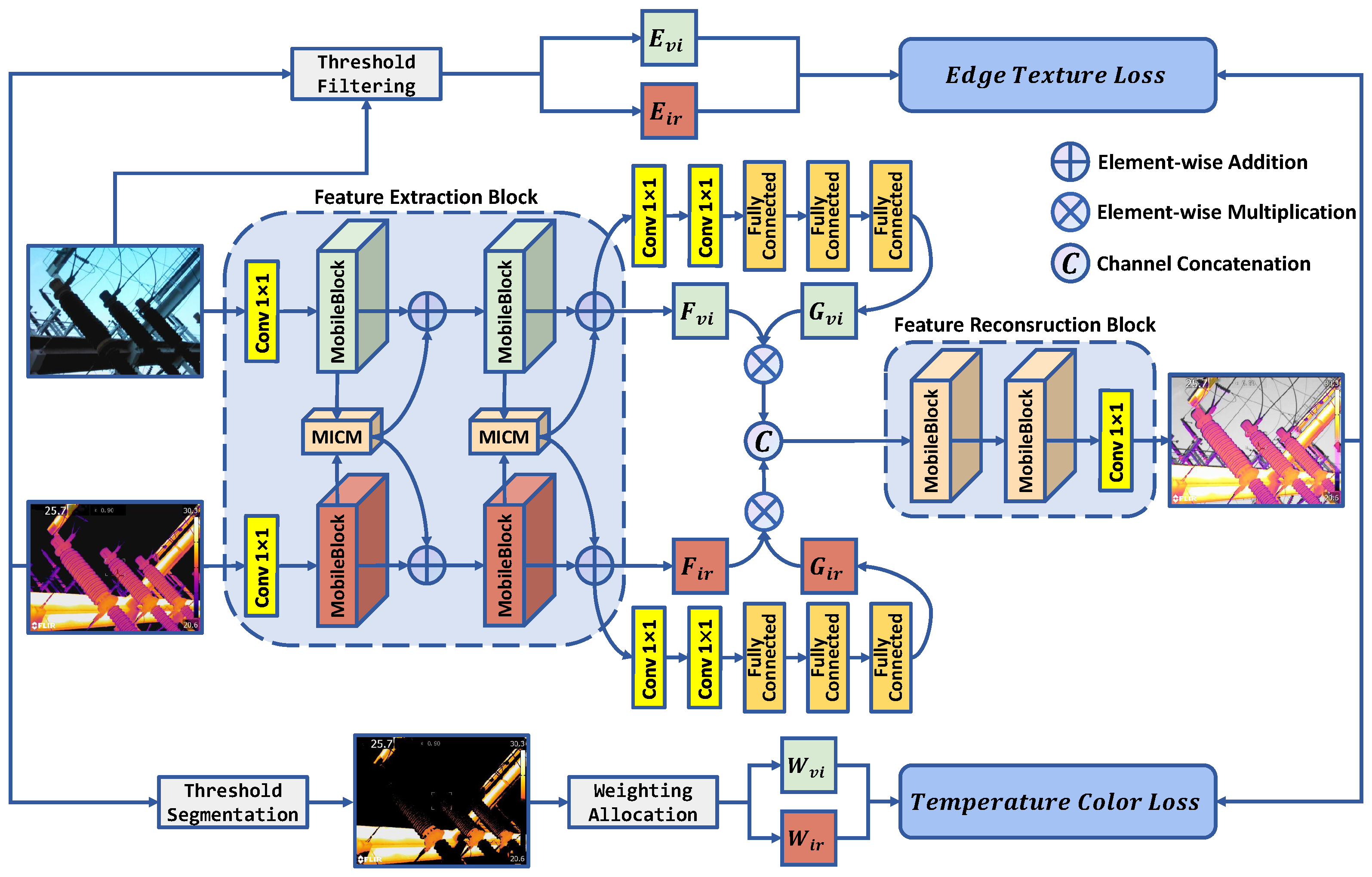
- Based on a comparative study focusing on power equipment and other heat-emitting scenarios, the pivotal role of temperature information in the fusion process of these scenes was confirmed. With this understanding, TGLFusion introduced a temperature-aware optimization weight allocation module tailored specifically for infrared images. This module calculates multispectral weights using a temperature distribution mechanism based on high-temperature ratios, aiming to represent the contributions of source images during the fusion process. Multispectral weights are adaptively assigned to more effectively fused image information. Guided by the temperature loss function, this model optimizes and integrates fusion images based on the thermal information from infrared images, significantly increasing the information content in the fused images.
- The backbone network of this model is composed of the MobileBlock framework and the MICM (Multispectral Information Complementary Module). During the feature extraction process, a feature-enhancement attention mechanism extracts and enhances unique features in various spectra. This approach effectively reduces redundant information while preserving complementary information.
- Through objective and subjective experiments, TGLFusion was compared with six mainstream fusion models, demonstrating significant advantages in the evaluation metrics for power equipment image fusion. This validates the importance of our model in the field of power equipment image fusion.
2. Related Work
2.1. CNN-Based Methods
2.2. Autoencoder-Based Methods
2.3. GAN-Based Methods
2.4. Transformer-Based Methods
3. Proposed Method
3.1. Temperature-Guided Mechanism Module
3.2. Model Structure
3.3. MobileBlock
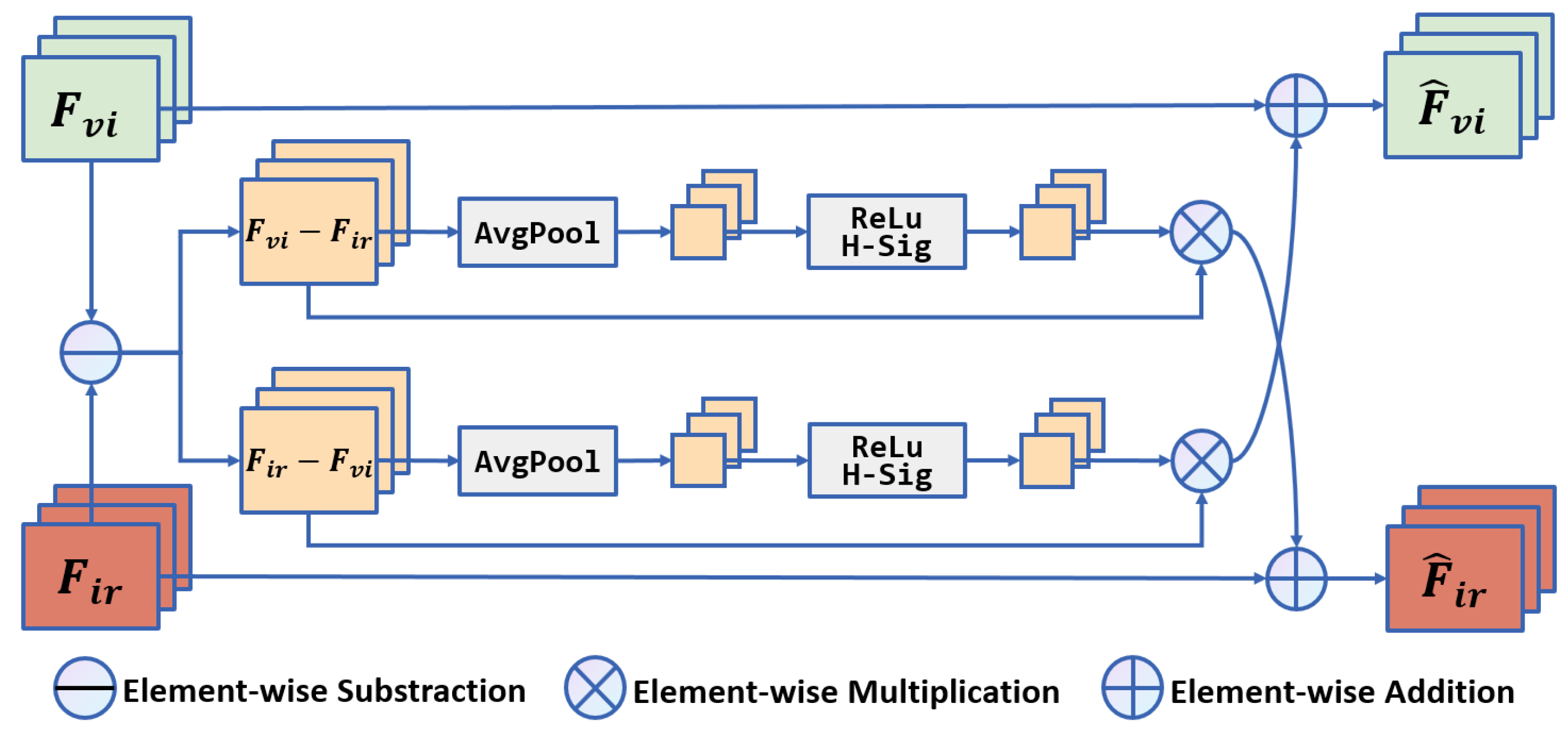
3.4. MICM
3.5. Loss Function
4. Experiment
4.1. Dataset Construction and Experimental Settings
4.2. Settings in Training and Testing Phase
4.3. Tuning of Hyperparameters
4.4. Analysis of the Public Dataset
4.4.1. Qualitative Comparison
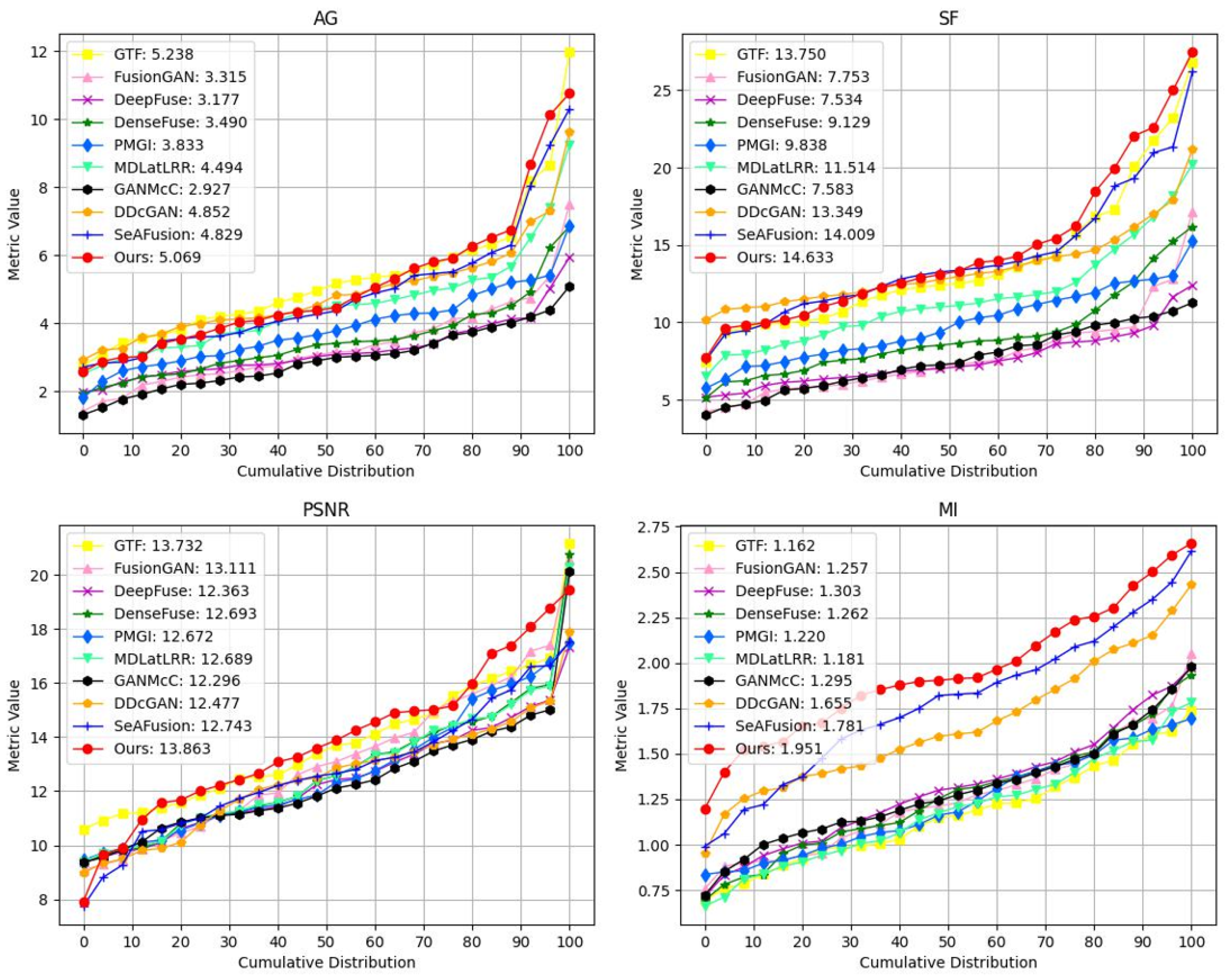
4.4.2. Quantitative Comparison
4.5. Analysis on the Electric Power Equipment Image Dataset
4.5.1. Qualitative Comparison
4.5.2. Quantitative Comparison
4.6. Ablation Experiment
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jain, D.K.; Zhao, X.; González-Almagro, G.; Gan, C.; Kotecha, K. Multimodal pedestrian detection using metaheuristics with deep convolutional neural network in crowded scenes. Inf. Fusion 2023, 95, 401–414. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, D.; Lu, H.; Yang, X. Learning Adaptive Attribute-Driven Representation for Real-Time RGB-T Tracking. Int. J. Comput. Vis. 2021, 129, 2714–2729. [Google Scholar] [CrossRef]
- Luo, Y.; Luo, Z. Infrared and Visible Image Fusion: Methods, Datasets, Applications, and Prospects. Appl. Sci. 2023, 13, 10891. [Google Scholar] [CrossRef]
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Zhang, H.; Xu, H.; Xiao, Y.; Guo, X.; Ma, J. Rethinking the Image Fusion: A Fast Unified Image Fusion Network based on Proportional Maintenance of Gradient and Intensity. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12797–12804. [Google Scholar]
- Tang, L.; Yuan, J.; Zhang, H.; Jiang, X.; Ma, J. PIAFusion: A progressive infrared and visible image fusion network based on illumination aware. Inf. Fusion 2022, 83, 79–92. [Google Scholar] [CrossRef]
- Zhang, X.; Demiris, Y. Visible and Infrared Image Fusion Using Deep Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 10535–10554. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, X.; Cheng, J.; Peng, H.; Wang, Z. Infrared and visible image fusion with convolutional neural networks. Int. J. Wavelets Multiresolut. Inf. Process. 2018, 16, 1850018. [Google Scholar] [CrossRef]
- Liu, Y.; Dong, L.; Ji, Y.; Xu, W. Infrared and visible image fusion through details preservation. Sensors 2019, 19, 4556. [Google Scholar] [CrossRef]
- Hou, R.; Zhou, D.; Nie, R.; Liu, D.; Xiong, L.; Guo, Y.; Yu, C. VIF-Net: An unsupervised framework for infrared and visible image fusion. IEEE Trans. Comput. Imaging 2020, 6, 640–651. [Google Scholar] [CrossRef]
- Xu, H.; Gong, M.; Tian, X.; Huang, J.; Ma, J. CUFD: An encoder–decoder network for visible and infrared image fusion based on common and unique feature decomposition. Comput. Vis. Image Underst. 2022, 218, 103407. [Google Scholar] [CrossRef]
- Mustafa, H.T.; Yang, J.; Mustafa, H.; Zareapoor, M. Infrared and visible image fusion based on dilated residual attention network. Optik 2020, 224, 165409. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J.; Durrani, T.S. Infrared and visible image fusion with ResNet and zero-phase component analysis. Infrared Phys. Technol. 2019, 102, 103039. [Google Scholar] [CrossRef]
- Li, H.; Cen, Y.; Liu, Y.; Chen, X.; Yu, Z. Different input resolutions and arbitrary output resolution: A meta learning-based deep framework for infrared and visible image fusion. IEEE Trans. Image Process. 2021, 30, 4070–4083. [Google Scholar] [CrossRef]
- Cui, Y.; Du, H.; Mei, W. Infrared and visible image fusion using detail enhanced channel attention network. IEEE Access 2019, 7, 182185–182197. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, J.; Wu, Y.; Xu, J.; Zhang, X. UNFusion: A unified multi-scale densely connected network for infrared and visible image fusion. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 3360–3374. [Google Scholar] [CrossRef]
- Li, H.; Wu, X.J. DenseFuse: A fusion approach to infrared and visible images. IEEE Trans. Image Process. 2018, 28, 2614–2623. [Google Scholar] [CrossRef]
- Raza, A.; Huo, H.; Fang, T. PFAF-Net: Pyramid feature network for multimodal fusion. IEEE Sensors Lett. 2020, 4, 1–4. [Google Scholar] [CrossRef]
- Fu, Y.; Wu, X.J. A dual-branch network for infrared and visible image fusion. In Proceedings of the 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 10675–10680. [Google Scholar]
- Li, H.; Wu, X.J.; Durrani, T. NestFuse: An infrared and visible image fusion architecture based on nest connection and spatial/channel attention models. IEEE Trans. Instrum. Meas. 2020, 69, 9645–9656. [Google Scholar] [CrossRef]
- Patel, H.; Upla, K.P. DepthFuseNet: An approach for fusion of thermal and visible images using a convolutional neural network. Opt. Eng. 2021, 60, 013104. [Google Scholar] [CrossRef]
- Ma, J.; Yu, W.; Liang, P.; Li, C.; Jiang, J. FusionGAN: A generative adversarial network for infrared and visible image fusion. Inf. Fusion 2019, 48, 11–26. [Google Scholar] [CrossRef]
- Xu, J.; Shi, X.; Qin, S.; Lu, K.; Wang, H.; Ma, J. LBP-BEGAN: A generative adversarial network architecture for infrared and visible image fusion. Infrared Phys. Technol. 2020, 104, 103144. [Google Scholar] [CrossRef]
- Xu, D.; Wang, Y.; Xu, S.; Zhu, K.; Zhang, N.; Zhang, X. Infrared and visible image fusion with a generative adversarial network and a residual network. Appl. Sci. 2020, 10, 554. [Google Scholar] [CrossRef]
- Fu, Y.; Wu, X.J.; Durrani, T. Image fusion based on generative adversarial network consistent with perception. Inf. Fusion 2021, 72, 110–125. [Google Scholar] [CrossRef]
- Ma, J.; Liang, P.; Yu, W.; Chen, C.; Guo, X.; Wu, J.; Jiang, J. Infrared and visible image fusion via detail preserving adversarial learning. Inf. Fusion 2020, 54, 85–98. [Google Scholar] [CrossRef]
- Ma, J.; Zhang, H.; Shao, Z.; Liang, P.; Xu, H. GANMcC: A generative adversarial network with multiclassification constraints for infrared and visible image fusion. IEEE Trans. Instrum. Meas. 2020, 70, 1–14. [Google Scholar] [CrossRef]
- Zhao, H.; Nie, R. Dndt: Infrared and visible image fusion via densenet and dual-transformer. In Proceedings of the International Conference on Information Technology and Biomedical Engineering (ICITBE), Nanchang, China, 24–26 December 2021; pp. 71–75. [Google Scholar]
- Vs, V.; Valanarasu, J.M.J.; Oza, P.; Patel, V.M. Image fusion transformer. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 3566–3570. [Google Scholar]
- Liu, X.; Gao, H.; Miao, Q.; Xi, Y.; Ai, Y.; Gao, D. MFST: Multi-modal feature self-adaptive transformer for infrared and visible image fusion. Remote. Sens. 2022, 14, 3233. [Google Scholar] [CrossRef]
- Rao, D.; Xu, T.; Wu, X.J. Tgfuse: An infrared and visible image fusion approach based on transformer and generative adversarial network. IEEE Trans. Image Process. 2023. early access. [Google Scholar] [CrossRef]
- Ma, J.; Tang, L.; Fan, F.; Huang, J.; Mei, X.; Ma, Y. SwinFusion: Cross-domain long-range learning for general image fusion via swin transformer. IEEE/CAA J. AutomgSin. 2022, 9, 1200–1217. [Google Scholar] [CrossRef]
- Jiamin, G.; Tao, G.; Yi, C.; Huabo, L.; Beibei, W. Correlativity analysis between image gray value and temperature based on infrared target. Infrared Laser Eng. 2016, 45, 0304006. [Google Scholar] [CrossRef]
- Zhu, J.; Wu, H.; Zhao, Q.; Zeng, H.; Zhu, X.; Huang, J.; Cai, C. Visible-infrared person re-identification using high utilization mismatch amending triplet loss. Image Vis. Comput. 2023, 138, 104797. [Google Scholar] [CrossRef]
- Toet, A. TNO Image Fusion Dataset. Figshare. 2014. Available online: https://figshare.com/articles/dataset/TNO_Image_Fusion_Dataset/1008029/2 (accessed on 30 July 2022).
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A dual-discriminator conditional generative adversarial network for multi-resolution image fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Tang, L.; Yuan, J.; Ma, J. Image fusion in the loop of high-level vision tasks: A semantic-aware real-time infrared and visible image fusion network. Inf. Fusion 2022, 82, 28–42. [Google Scholar] [CrossRef]
- Ram Prabhakar, K.; Sai Srikar, V.; Venkatesh Babu, R. Deepfuse: A deep unsupervised approach for exposure fusion with extreme exposure image pairs. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4714–4722. [Google Scholar]
- Li, H.; Wu, X.J.; Kittler, J. MDLatLRR: A novel decomposition method for infrared and visible image fusion. IEEE Trans. Image Process. 2020, 29, 4733–4746. [Google Scholar] [CrossRef]
- Ma, J.; Chen, C.; Li, C.; Huang, J. Infrared and visible image fusion via gradient transfer and total variation minimization. Inf. Fusion 2016, 31, 100–109. [Google Scholar] [CrossRef]
- Jiang, Q.; Liu, Y.; Yan, Y.; Deng, J.; Fang, J.; Li, Z.; Jiang, X. A Contour Angle Orientation for Power Equipment Infrared and Visible Image Registration. IEEE Trans. Power Deliv. 2021, 36, 2559–2569. [Google Scholar] [CrossRef]
- Ma, W.; Wang, K.; Li, J.; Yang, S.X.; Li, J.; Song, L.; Li, Q. Infrared and Visible Image Fusion Technology and Application: A Review. Sensors 2023, 23, 599. [Google Scholar] [CrossRef]
- Kaur, H.; Koundal, D.; Kadyan, V. Image fusion techniques: A survey. Arch. Comput. Methods Eng. 2021, 28, 4425–4447. [Google Scholar] [CrossRef]
- Chen, J.; Chen, L.; Shabaz, M. Image fusion algorithm at pixel level based on edge detection. J. Healthc. Eng. 2021, 2021, 5760660. [Google Scholar] [CrossRef]
- Fu, L.; Gu, W.B.; Ai, Y.B.; Li, W.; Wang, D. Adaptive spatial pixel-level feature fusion network for multispectral pedestrian detection. Infrared Phys. Technol. 2021, 116, 103770. [Google Scholar] [CrossRef]
- Zhao, J.; Wang, H.; Zhou, Y.; Yao, R.; Zhang, L.; El Saddik, A. Context-aware and part alignment for visible-infrared person re-identification. Image Vis. Comput. 2023, 138, 104791. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature Extractor Block | Image Reconstructor Block | |||||
|---|---|---|---|---|---|---|
| Layer | Input Channels | Output Channels | Layer | Input Channels | Output Channels | |
| Layer1 | Conv 1 × 1 | 1 | 16 | MobileBlock | 128 | 64 |
| Layer2 | MobileBlock | 16 | 32 | MobileBlock | 64 | 32 |
| Layer3 | MobileBlock | 32 | 64 | Conv 1 × 1 | 32 | 1 |
| Input | Layer | Operator | Output |
|---|---|---|---|
| Expansion Conv | 1 × 1 conv2d, BN, H-swish | ||
| Depthwise Conv | 3 × 3 conv2d, BN, H-swish | ||
| Projection Conv | 1 × 1 conv2d, BN, H-swish |
| AG | SF | PSNR | MI | |
|---|---|---|---|---|
| 1 | 5.956 | 11.397 | 15.495 | 1.760 |
| 2 | 6.194 | 13.210 | 16.833 | 1.925 |
| 3 | 6.151 | 12.185 | 18.821 | 2.054 |
| 4 | 6.118 | 12.173 | 18.743 | 2.091 |
| 5 | 6.205 | 12.324 | 19.357 | 2.137 |
| Method | AG | SF | PSNR | MI |
|---|---|---|---|---|
| GTF | 4.604 | 8.822 | 15.395 | 1.547 |
| FusionGAN | 3.029 | 5.755 | 16.624 | 1.435 |
| DeepFuse | 4.726 | 8.784 | 14.977 | 1.457 |
| DenseFuse | 2.667 | 5.373 | 16.937 | 1.248 |
| PMGI | 4.546 | 8.654 | 15.234 | 1.425 |
| MDLatLRR | 3.530 | 6.947 | 16.947 | 1.325 |
| GANMcC | 3.149 | 6.001 | 13.913 | 1.437 |
| DDcGAN | 6.919 | 9.955 | 13.413 | 1.104 |
| SeAFusion | 5.228 | 11.834 | 19.039 | 1.853 |
| Proposed model | 6.205 | 12.324 | 19.357 | 2.137 |
| Method | AG | SF | PSNR | MI |
|---|---|---|---|---|
| GTF | 5.238 | 13.750 | 13.732 | 1.162 |
| FusionGAN | 3.315 | 7.753 | 13.111 | 1.257 |
| DeepFuse | 3.177 | 7.534 | 12.363 | 1.303 |
| DenseFuse | 3.490 | 9.129 | 12.693 | 1.262 |
| PMGI | 3.833 | 9.838 | 12.672 | 1.220 |
| MDLatLRR | 4.494 | 11.514 | 12.689 | 1.181 |
| GANMcC | 2.927 | 7.583 | 12.296 | 1.295 |
| DDcGAN | 4.852 | 13.349 | 12.477 | 1.655 |
| SeAFusion | 4.829 | 14.009 | 12.743 | 1.781 |
| Proposed model | 5.069 | 14.633 | 13.863 | 1.951 |
| Model | Parameters | Model Size (MB) | FLOPs (G) |
|---|---|---|---|
| FusionGAN | 924,673 | 3.698 | 551.006 |
| DeepFuse | 114,497 | 0.457 | 70.257 |
| DenseFuse | 74,193 | 0.296 | 45.475 |
| GANMcC | 1,862,209 | 7.448 | 1109.800 |
| DDcGAN | 212,721 | 0.850 | 130.498 |
| SeAFusion | 166,657 | 0.667 | 101.931 |
| Proposed model | 57,313 | 0.229 | 34.573 |
| AG | SF | PSNR | MI | Parameters | Size (MB) | FLOPs (G) | |
|---|---|---|---|---|---|---|---|
| Proposed model | 5.029 | 12.805 | 65.020 | 2.770 | 57,313 | 0.229 | 34.573 |
| w/o | 4.863 | 12.644 | 64.841 | 2.507 | — | — | — |
| w/o MICM | 4.829 | 12.543 | 63.219 | 2.514 | — | — | — |
| w/o MobileBlock | 3.863 | 11.246 | 59.512 | 2.096 | 143,265 | 0.586 | 87.805 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yan, B.; Zhao, L.; Miao, K.; Wang, S.; Li, Q.; Luo, D. TGLFusion: A Temperature-Guided Lightweight Fusion Method for Infrared and Visible Images. Sensors 2024, 24, 1735. https://doi.org/10.3390/s24061735
Yan B, Zhao L, Miao K, Wang S, Li Q, Luo D. TGLFusion: A Temperature-Guided Lightweight Fusion Method for Infrared and Visible Images. Sensors. 2024; 24(6):1735. https://doi.org/10.3390/s24061735
Chicago/Turabian StyleYan, Bao, Longjie Zhao, Kehua Miao, Song Wang, Qinghua Li, and Delin Luo. 2024. "TGLFusion: A Temperature-Guided Lightweight Fusion Method for Infrared and Visible Images" Sensors 24, no. 6: 1735. https://doi.org/10.3390/s24061735
APA StyleYan, B., Zhao, L., Miao, K., Wang, S., Li, Q., & Luo, D. (2024). TGLFusion: A Temperature-Guided Lightweight Fusion Method for Infrared and Visible Images. Sensors, 24(6), 1735. https://doi.org/10.3390/s24061735