

Voice Synthesis Improvement by Machine Learning of Natural Prosody


Abstract
1. Introduction
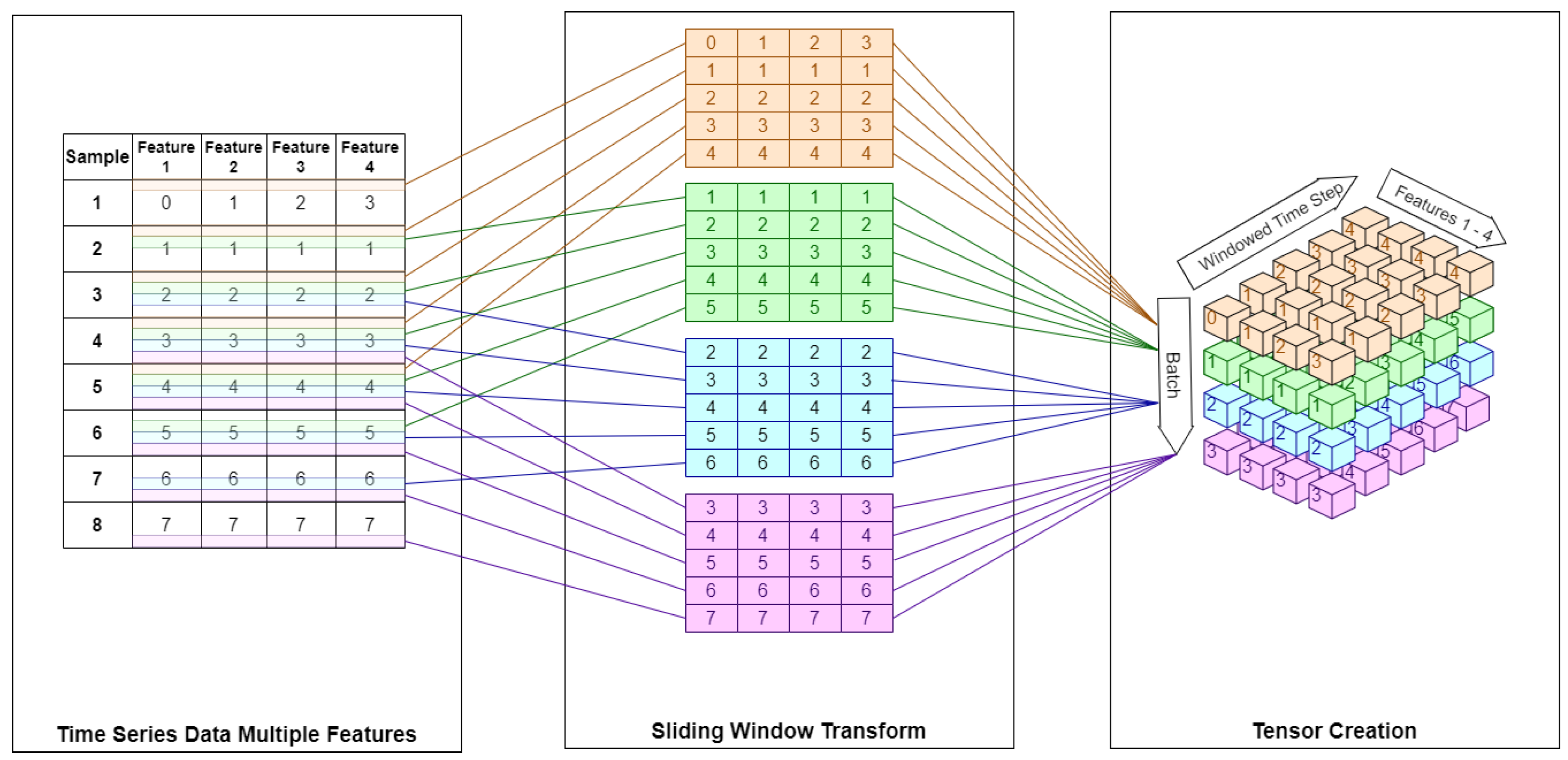
- We demonstrate the automated extraction of key prosodic elements for analysis, and train multivariate LSTMs on these interdependent variables.
- The LSTMs produce predictions of each feature variable, which are then input to the original audio sample. Utilization of the LSTM is critical in order to create predictions from multivariate time-series data.
- We demonstrate that the prosodic feature values can then be adjusted with the output from the trained LSTM. The updated values in the audio output creates a more natural prosody in the speech output. This is a novel approach as we are directly updating the prosodic information in an audio sample, which fills a research gap described in Section 3.
2. Background
3. Related Work
4. Materials and Methods
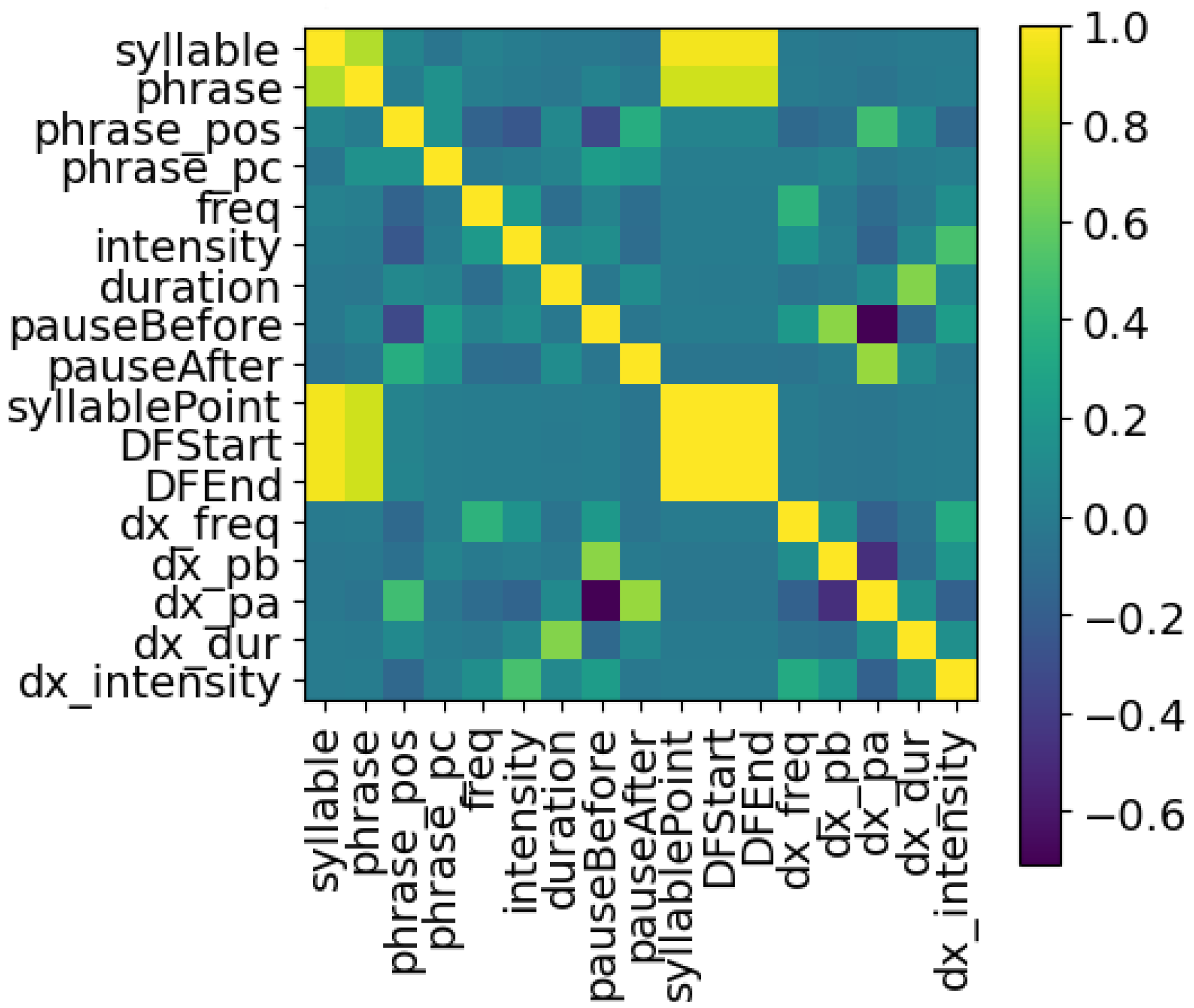
- —the fundamental frequency of each voiced syllable;
- the amplitude/intensity of each voiced syllable;
- the duration of each voiced syllable;
- the position of the voiced syllable in the spoken phrase;
- the duration of the syllable as a percentage of the spoken phrase;
- the length of the pause before and after each syllable.
4.1. Research Design
4.2. Laboratory and Experiments Design
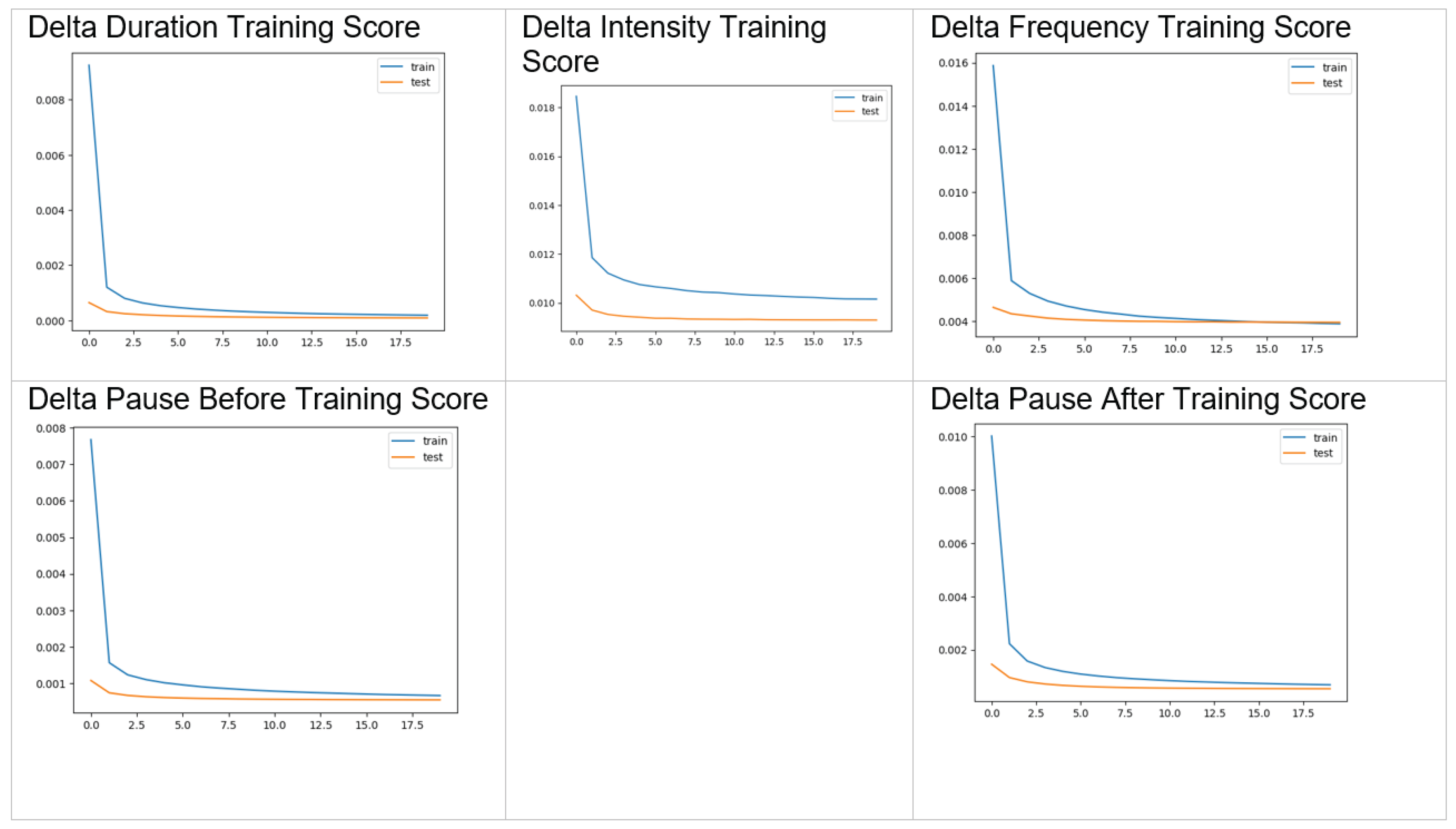
- Delta of the duration of spoken syllable, in seconds;
- Delta of the pause before syllable, in seconds;
- Delta of the pause after syllable, in seconds;
- Delta of fundamental frequency () of spoken syllable, in ;
- Delta of intensity (amplitude) of spoken syllable, in dB.
5. Results
- From the audio sample:
- –
- the syllable number;
- –
- the phrase number.
- Calculated the number of syllables in the phrase, and therefore:
- –
- the position in the phrase of the syllable (phrase_pos variable);
- –
- the percentage of the phrase (phrase_pc variable).
- Analyzed the voiced syllable frequency;
- Analyzed the voiced syllable intensity/amplitude;
- Calculated the pause before, the duration, and the pause after the voiced syllable.
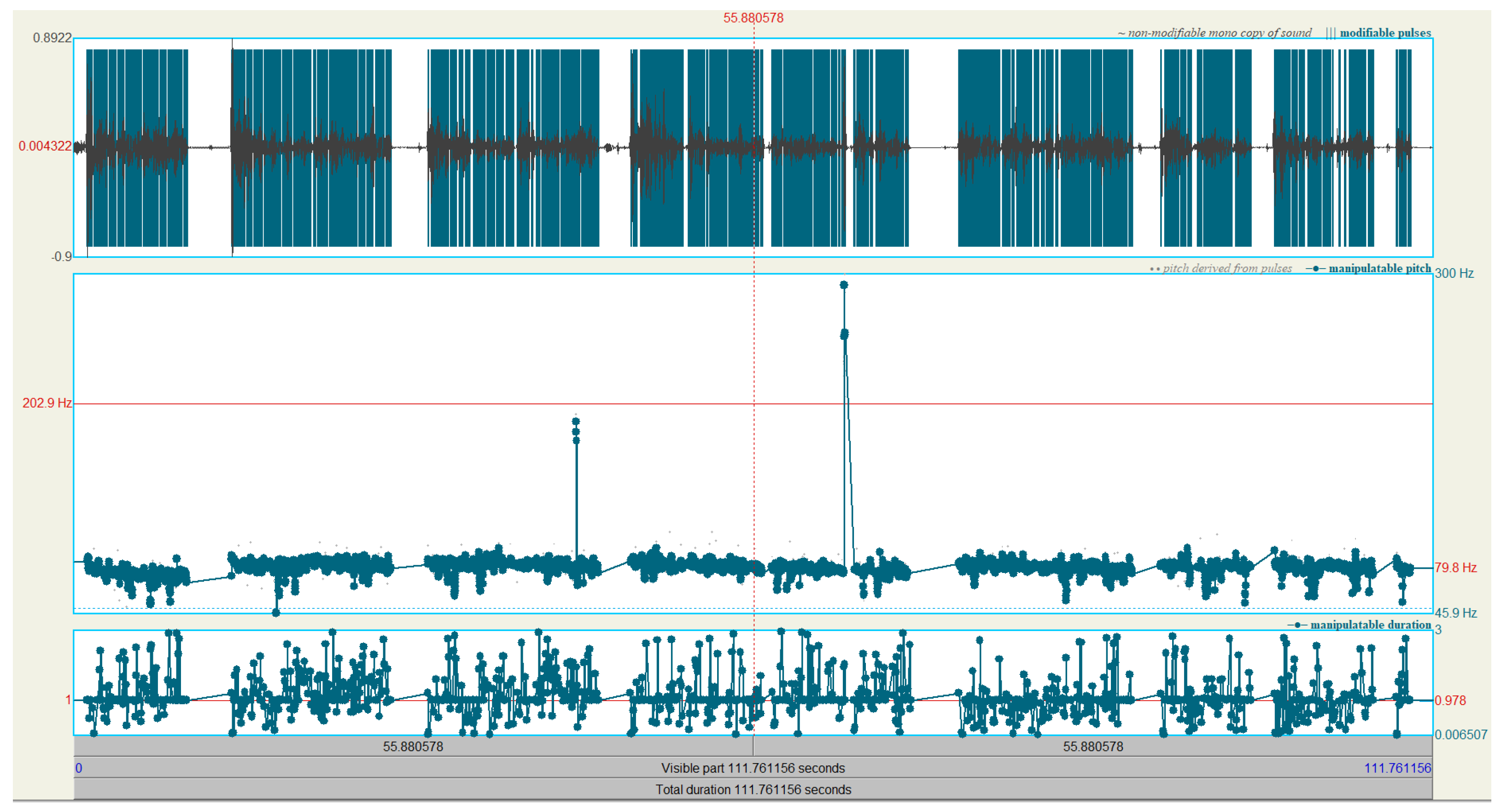
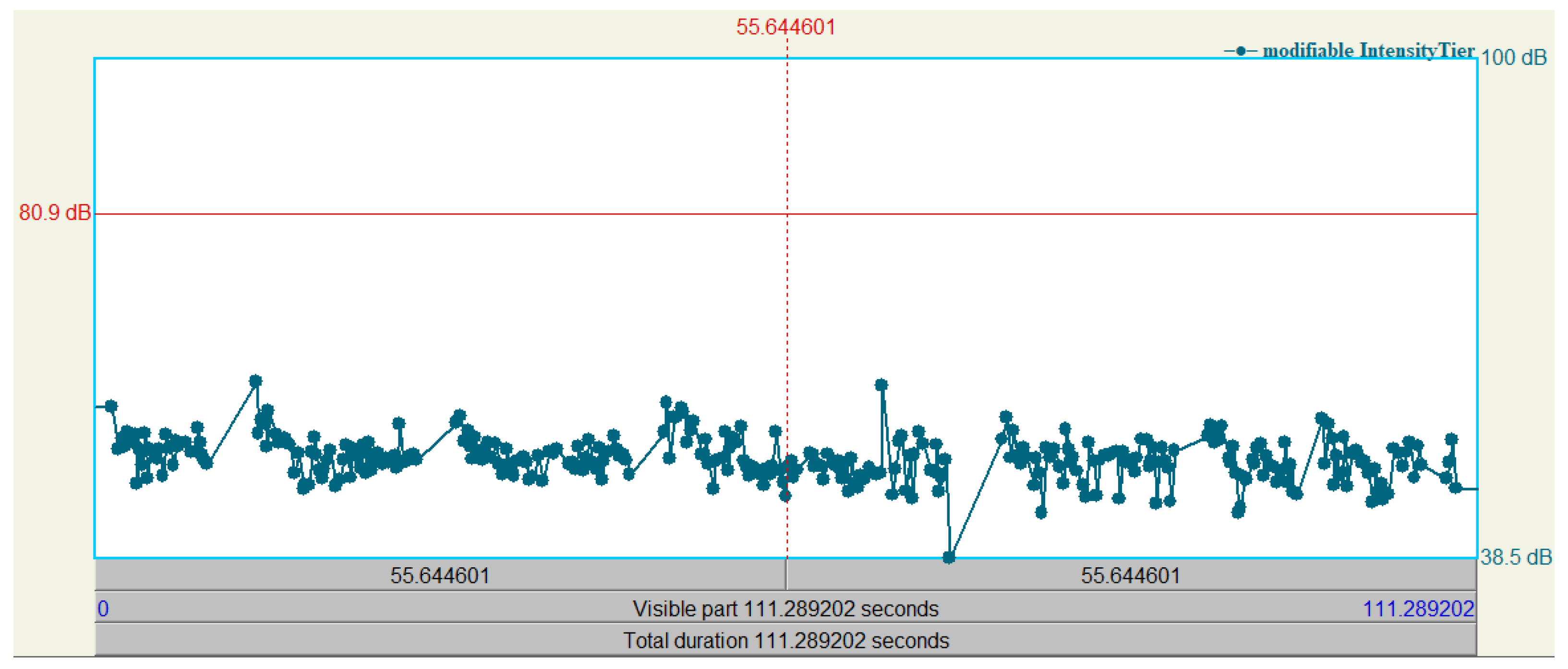
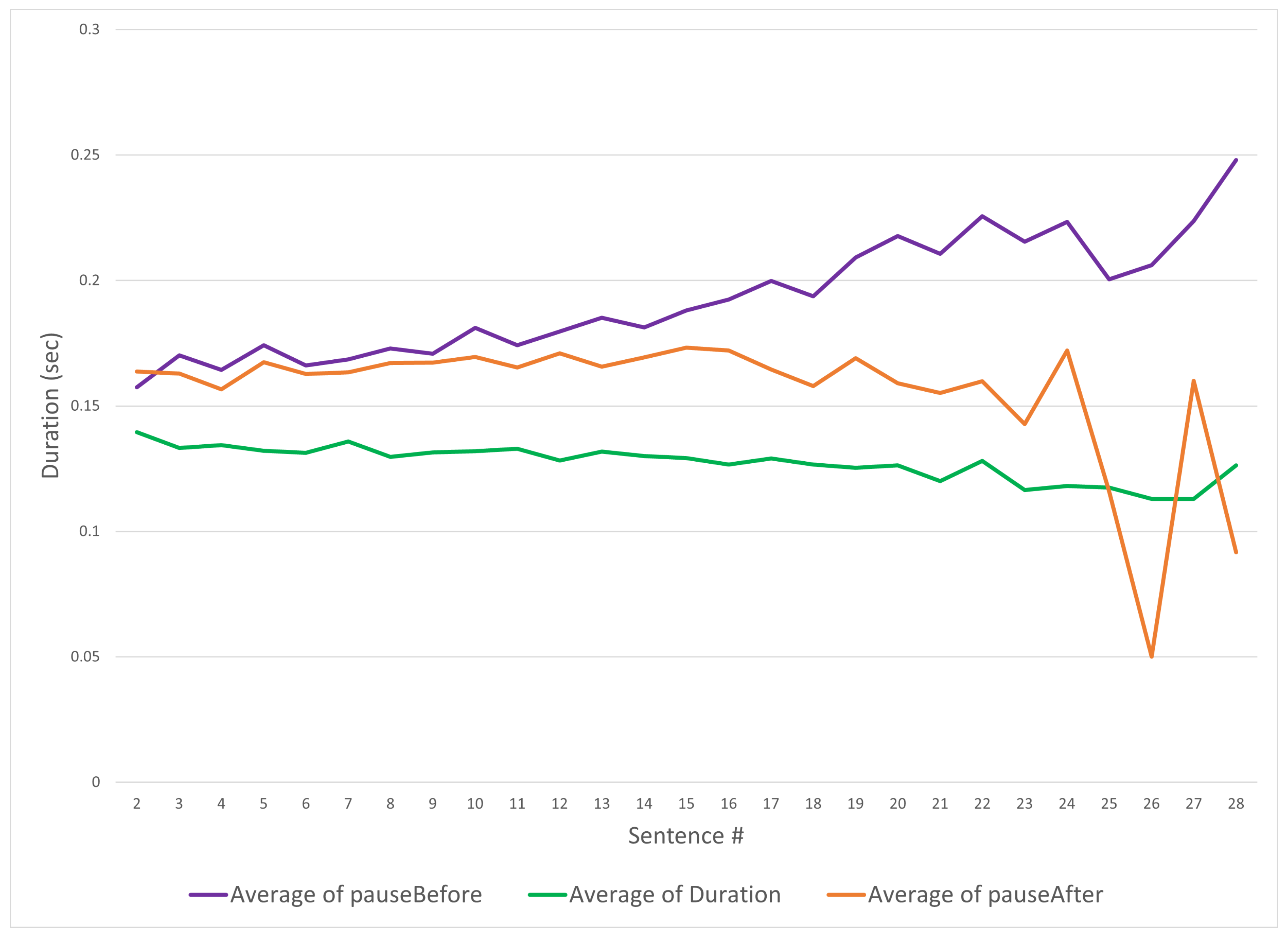
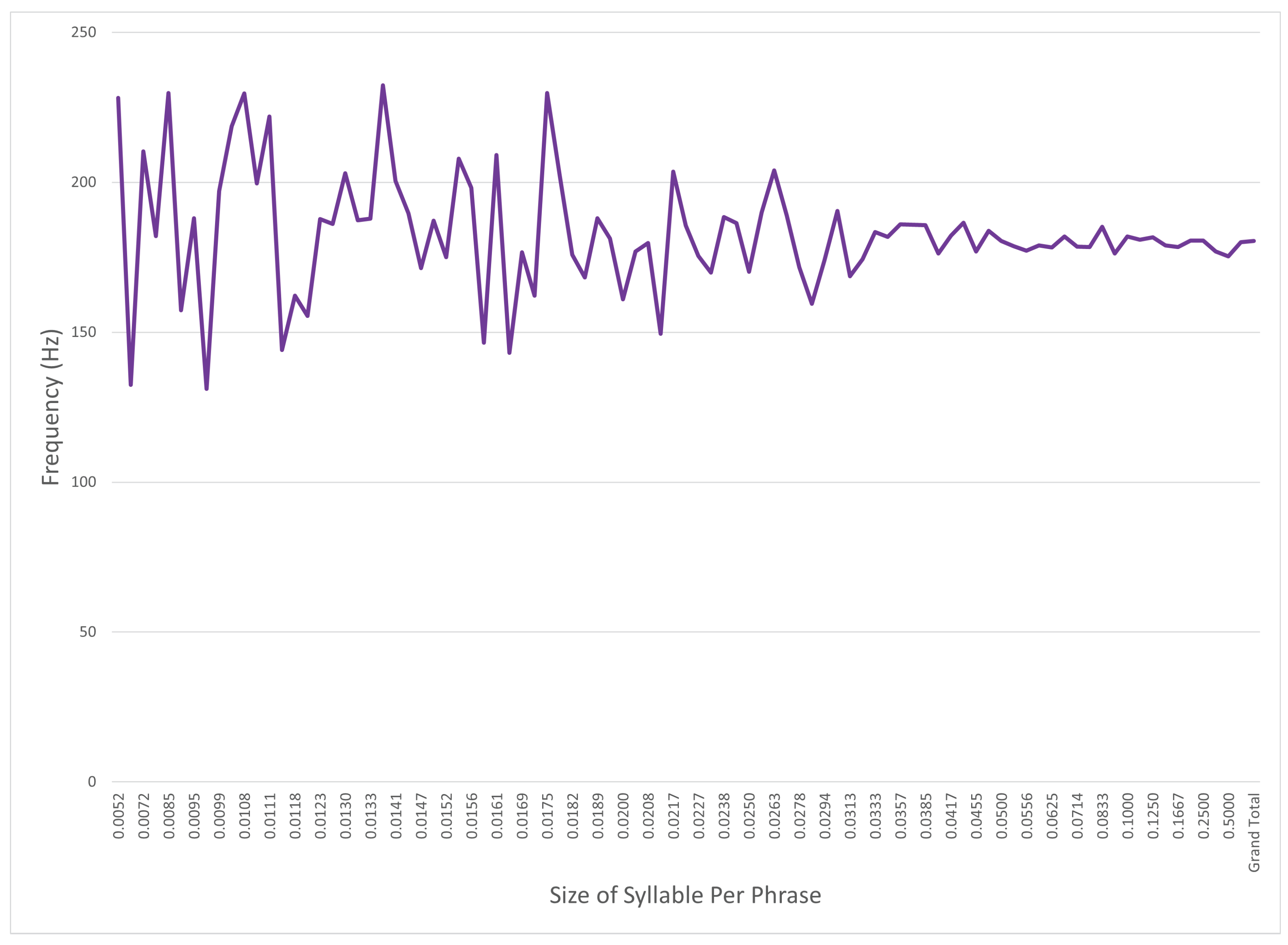
5.1. Analysis of Source Audio Data
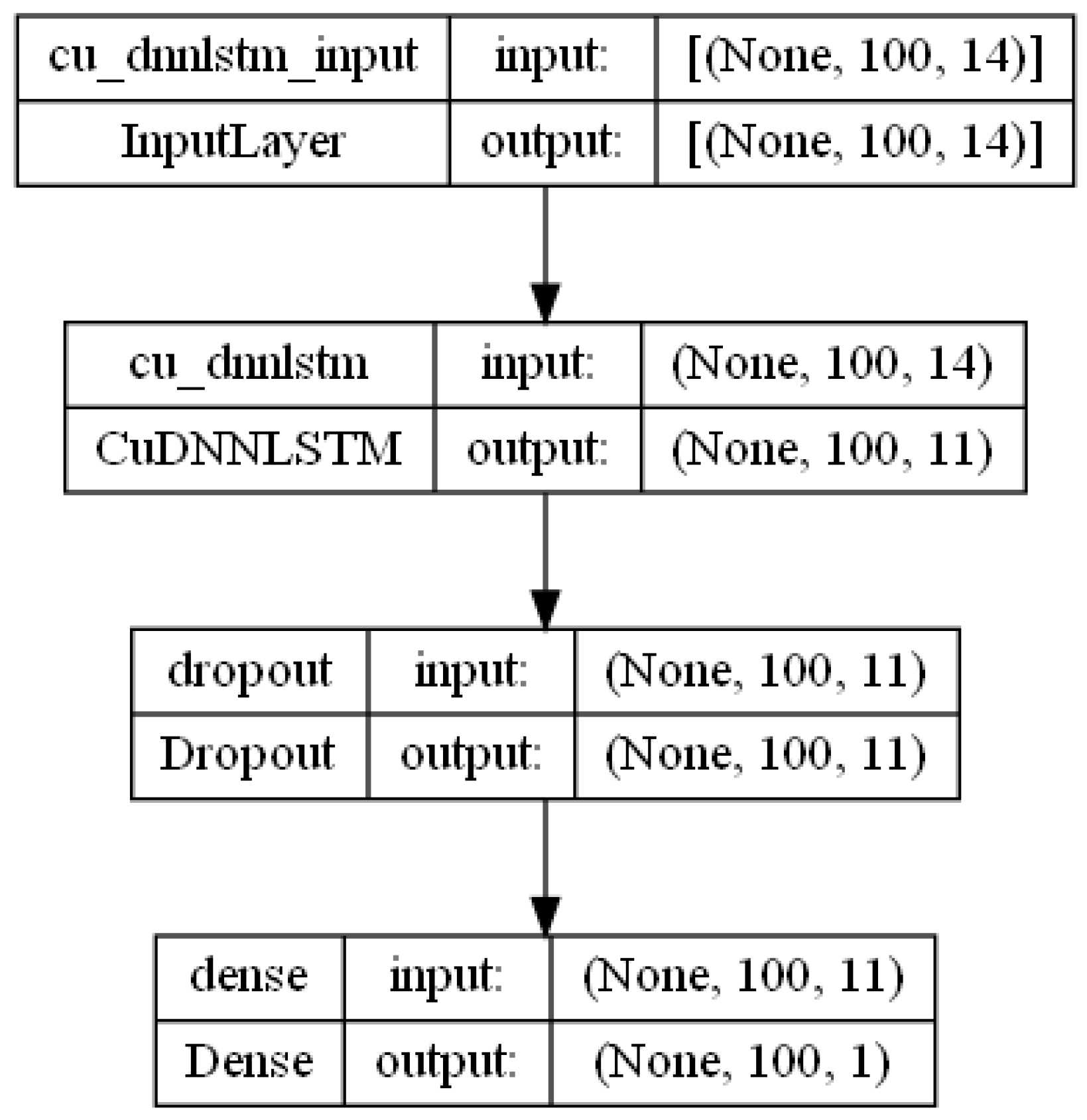
5.2. Training and Audio Processing
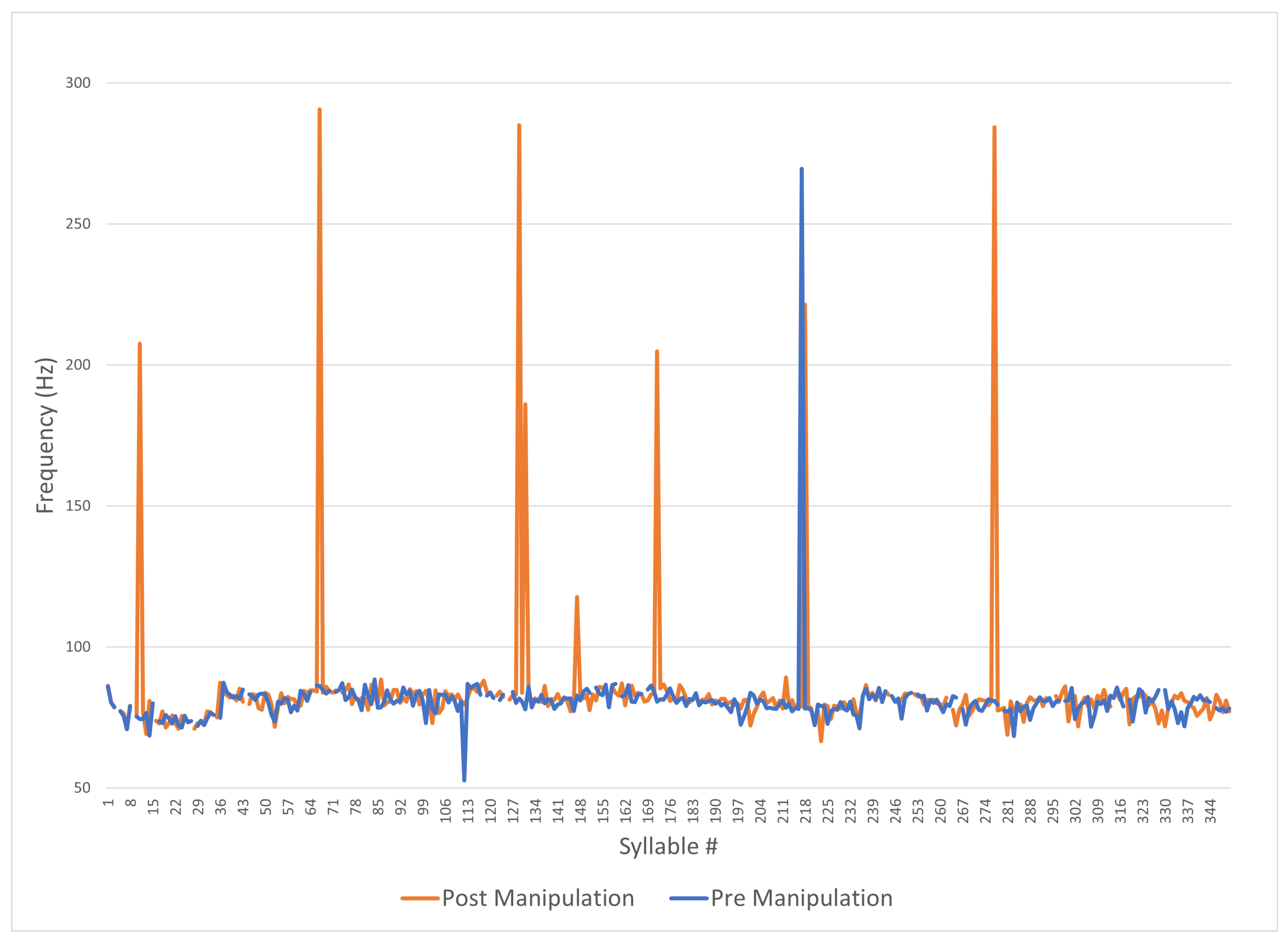
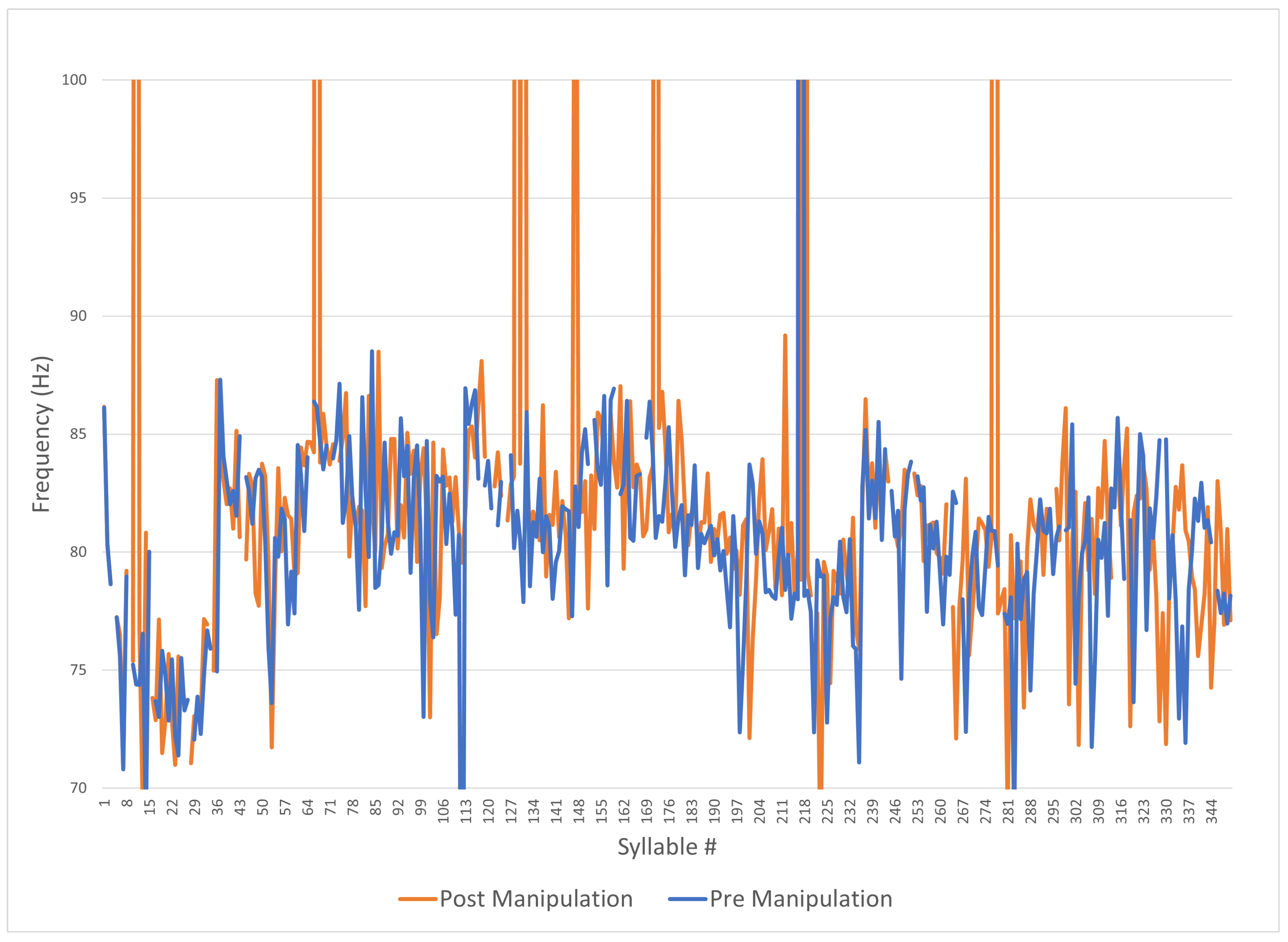
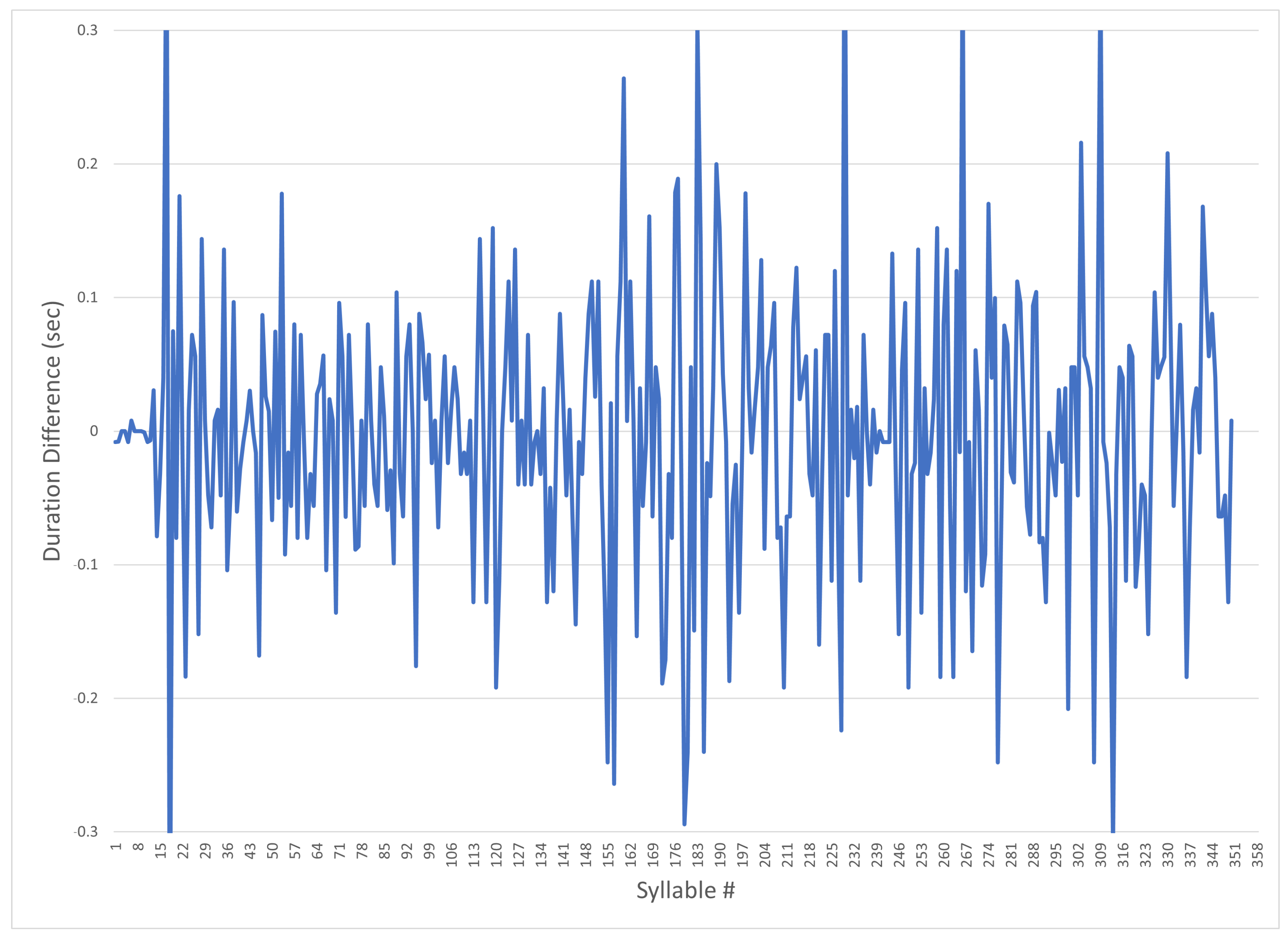
5.3. Analysis of Monotonous Non-Prosodic Audio Pre- and Post-Manipulation
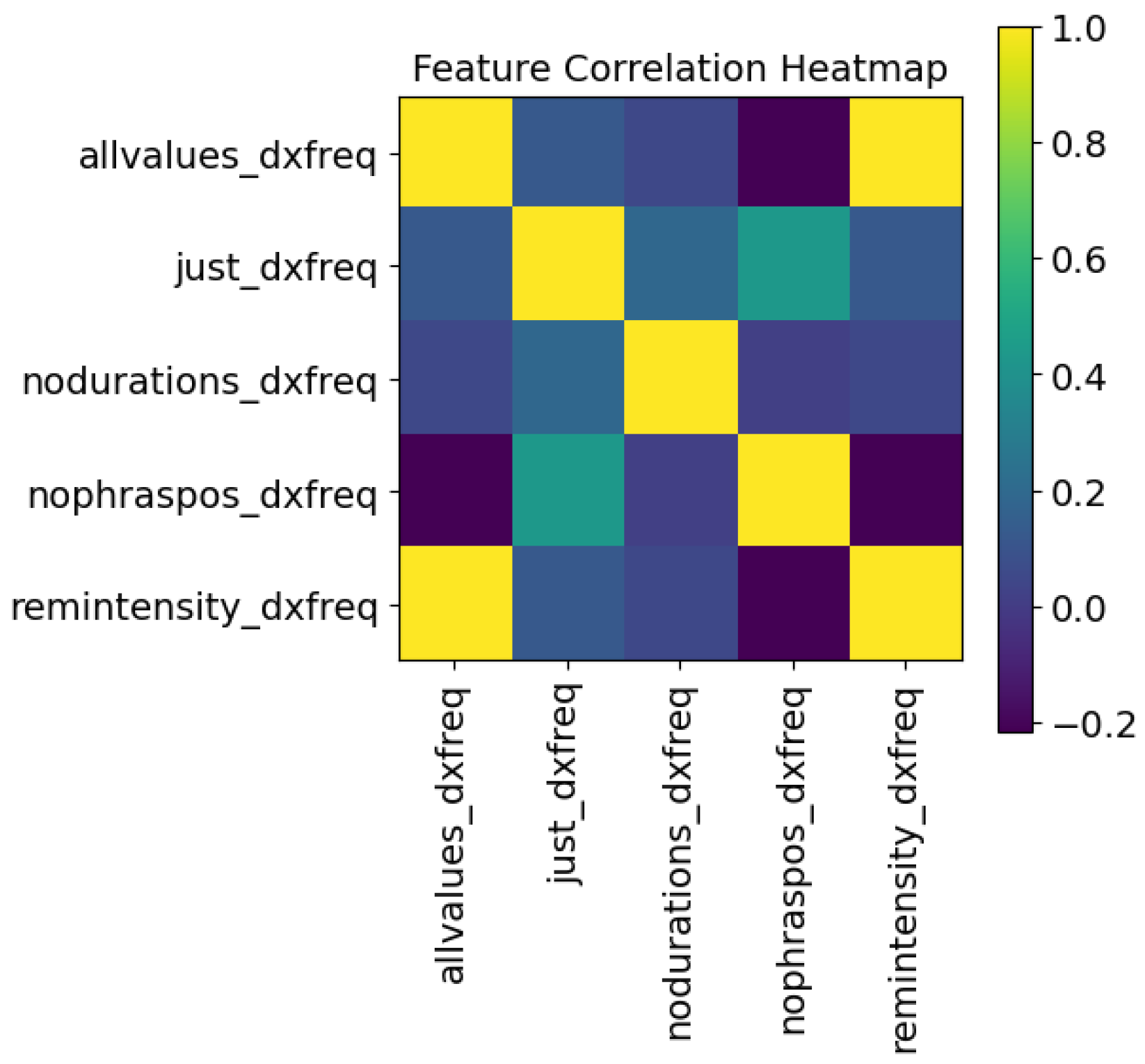
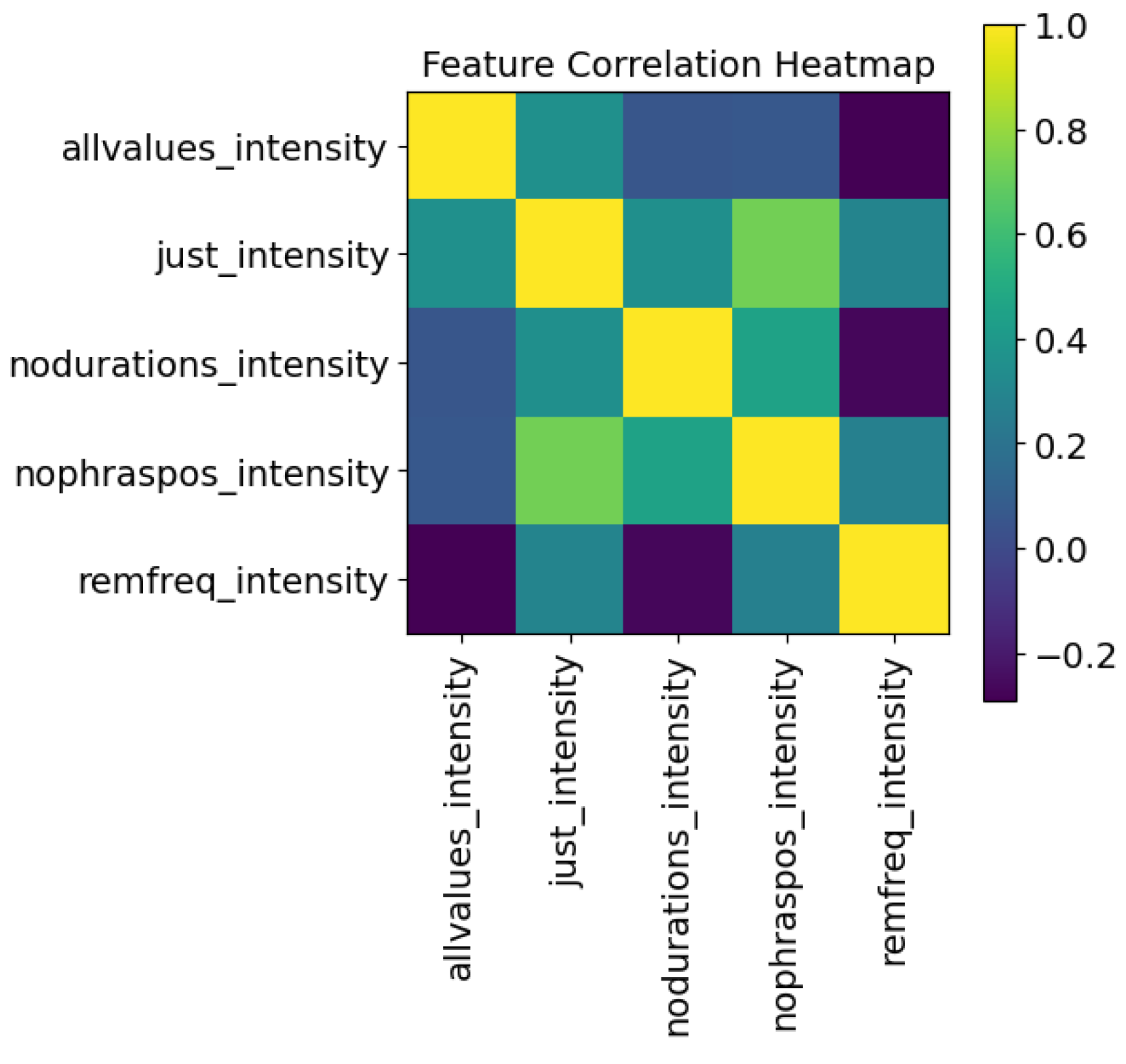
5.4. Ablation Study
- “allvalues”—All of the features.
- “just_output”—Only the object of the LSTM, here frequency or intensity, and its delta values are utilized in training the model and prediction of the robotic sample.
- “nodurations”—All features related to duration (duration, pauses before and after) are removed.
- “nophraspos”—All features relates to the position of the syllable (phrase, phrase position, syllable#) are removed.
- “remobject”—In the two examples given, the intensity values are removed from the frequency LSTM, and the frequency values are removed from the intensity LSTM.
5.5. Qualitative Evaluation
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| ANN | Artificial neural network |
| DNN | Deep neural network |
| GAN | Generative adversarial neural network |
| HMM | Hidden Markov model |
| LSTM | Long short-term memory |
| MOS | Mean opinion score |
| PESQ | Perceptual evaluation of speech quality |
| RNN | Recurrent neural network |
| SAN | Storage area network |
| SVM | Support vector machine |
| TTS | Text-to-speech |
References
- Medeiros, J. How Intel Gave Stephen Hawking a Voice. 2015. Available online: https://www.wired.com/2015/01/intel-gave-stephen-hawking-voice/ (accessed on 10 April 2022).
- McCaffrey, M.; Wagner, J.; Hayes, P.; Hobbs, M. Consumer Intelligence SeriesPrepare for the Voice Revolution. 2018. Available online: https://www.pwc.com/us/en/advisory-services/publications/consumer-intelligence-series/voice-assistants.pdf (accessed on 10 April 2022).
- McAdams, D.P.; McLean, K.C. Narrative Identity. Curr. Dir. Psychol. Sci. 2013, 22, 233–238. [Google Scholar] [CrossRef]
- Yao, B.; Belin, P.; Scheepers, C. Brain ‘talks over’ boring quotes: Top-down activation of voice-selective areas while listening to monotonous direct speech quotations. NeuroImage 2012, 60, 1832–1842. [Google Scholar] [CrossRef] [PubMed]
- Arvaniti, A. The Phonetics of Prosody. In Oxford Research Encyclopedia of Linguistics; Aronoff, M., Ed.; Oxford University Press: Oxford, UK, 2020. [Google Scholar] [CrossRef]
- WHO. Blindness and Vision Impairment. 2021. Available online: https://www.who.int/news-room/fact-sheets/detail/blindness-and-visual-impairment (accessed on 10 April 2022).
- NIDCD. Quick Statistics About Voice, Speech, Language. 2016. Available online: https://www.nidcd.nih.gov/health/statistics/quick-statistics-voice-speech-language (accessed on 10 April 2022).
- McKay, C.; Masuda, F. Empirical studies of wireless VoIP speech quality in the presence of Bluetooth interference. In Proceedings of the 2003 IEEE Symposium on Electromagnetic Compatibility, Symposium Record (Cat. No.03CH37446), Boston, MA, USA, 18–22 August 2003; Volume 1, pp. 269–272. [Google Scholar] [CrossRef]
- Broom, S. VoIP Quality Assessment: Taking Account of the Edge-Device. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1977–1983. [Google Scholar] [CrossRef]
- Sanchez-Iborra, R.; Cano, M.D.; Garcia-Haro, J. On the effect of the physical layer on VoIP Quality of user Experience in wireless networks. In Proceedings of the 2013 IEEE International Conference on Communications Workshops (ICC), Budapest, Hungary, 9–13 June 2013; pp. 1036–1040. [Google Scholar] [CrossRef]
- Verma, R.; Mandal, S.; Kumar, A. Improved Voice Quality of GSM Network through Voice Enhancement Device. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2012, 2, 77–80. [Google Scholar]
- Ohala, J.J. Christian Gottlieb Kratzenstein: Pioneer in Speech Synthesis. In Proceedings of the International Congress of Phonetic Sciences 2011, Hong Kong, China, 17–21 August 2011. [Google Scholar]
- Umeda, N. Linguistic rules for text-to-speech synthesis. Proc. IEEE 1976, 64, 443–451. [Google Scholar] [CrossRef]
- Pollack, A. Technology; Audiotex: Data By Telephone. The New York Times, 5 January 1984; 2. [Google Scholar]
- DECTalk Software Help—Programmer’s Guide. Available online: https://dectalk.github.io/dectalk/how_it_works.htm (accessed on 23 February 2024).
- Siri Team. Deep Learning for Siri’s Voice: On-Device Deep Mixture Density Networks for Hybrid Unit Selection Synthesis. 2017. Available online: https://machinelearning.apple.com/research/siri-voices (accessed on 10 April 2022).
- Lei, Y.; Yang, S.; Wang, X.; Xie, L. MsEmoTTS: Multi-Scale Emotion Transfer, Prediction, and Control for Emotional Speech Synthesis. IEEE ACM Trans. Audio Speech Lang. Process. 2022, 30, 853–864. [Google Scholar] [CrossRef]
- Wang, C.; Chen, S.; Wu, Y.; Zhang, Z.; Zhou, L.; Liu, S.; Chen, Z.; Liu, Y.; Wang, H.; Li, J.; et al. Neural Codec Language Models are Zero-Shot Text to Speech Synthesizers. arXiv 2023, arXiv:cs.CL/2301.02111. [Google Scholar]
- Juvela, L.; Bollepalli, B.; Tsiaras, V.; Alku, P. GlotNet—A Raw Waveform Model for the Glottal Excitation in Statistical Parametric Speech Synthesis. IEEE ACM Trans. Audio Speech Lang. Process. 2019, 27, 1019–1030. [Google Scholar] [CrossRef]
- ITU, P. 800: Methods for Subjective Determination of Transmission Quality. 1996. Available online: https://www.itu.int/rec/T-REC-P.800-199608-I/en (accessed on 10 April 2022).
- Juvela, L.; Bollepalli, B.; Yamagishi, J.; Alku, P. GELP: GAN-Excited Linear Prediction for Speech Synthesis from Mel-Spectrogram. In Proceedings of the Annual Conference of the International Speech Communication Association 2019, Graz, Austria, 15–19 September 2019; pp. 694–698. [Google Scholar] [CrossRef]
- Jin, Z.; Finkelstein, A.; Mysore, G.; Lu, J. FFTNet: A Real-Time Speaker-Dependent Neural Vocoder. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2251–2255. [Google Scholar] [CrossRef]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. In Proceedings of the 9th ISCA Speech Synthesis Workshop, Sunnyvale, CA, USA, 13–15 September 2016; p. 125. [Google Scholar]
- Li, H.; Xu, Y.; Ke, D.; Su, K. μ-law SGAN for generating spectra with more details in speech enhancement. Neural Netw. 2021, 136, 17–27. [Google Scholar] [CrossRef]
- Kons, Z.; Shechtman, S.; Sorin, A.; Hoory, R.; Rabinovitz, C.; Da Silva Morais, E. Neural TTS Voice Conversion. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018; pp. 290–296. [Google Scholar] [CrossRef]
- Hodari, Z.; Lai, C.; King, S. Perception of prosodic variation for speech synthesis using an unsupervised discrete representation of F0. In Proceedings of the Speech Prosody 2020, Tokyo, Japan, 25–28 May 2020; pp. 965–969. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Jorge, J.; Giménez, A.; Silvestre-Cerdà, J.A.; Civera, J.; Sanchis, A.; Juan, A. Live Streaming Speech Recognition Using Deep Bidirectional LSTM Acoustic Models and Interpolated Language Models. IEEE ACM Trans. Audio Speech Lang. Process. 2022, 30, 148–161. [Google Scholar] [CrossRef]
- Khandelwal, P.; Konar, J.; Brahma, B. Training RNN and it’s Variants Using Sliding Window Technique. In Proceedings of the 2020 IEEE International Students’ Conference on Electrical, Electronics and Computer Science (SCEECS), Bhopal, India, 22–23 February 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Atila, O.; Şengür, A. Attention guided 3D CNN-LSTM model for accurate speech based emotion recognition. Appl. Acoust. 2021, 182, 108260. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Łukasz, K.; Polosukhin, I. Attention is All you Need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Liu, X.; Chen, C.; He, Y. Temporal feature extraction based on CNN-BLSTM and temporal pooling for language identification. Appl. Acoust. 2022, 195, 108854. [Google Scholar] [CrossRef]
- Barbulescu, A.; Hueber, T.; Bailly, G.; Ronfard, R. Audio-Visual Speaker Conversion using Prosody Features. In Proceedings of the 12th International Conference on Auditory–Visual Speech Processing, Annecy, France, 23 August–1 September 2013; pp. 11–16. [Google Scholar]
- Karpagavalli, S.; Chandra, E. A Review on Automatic Speech Recognition Architecture and Approaches. Int. J. Signal Process. Image Process. Pattern Recognit. 2016, 9, 393–404. [Google Scholar]
- Mary, L.; Yegnanarayana, B. Extraction and representation of prosodic features for language and speaker recognition. Speech Commun. 2008, 50, 782–796. [Google Scholar] [CrossRef]
- Tan, X.; Qin, T.; Soong, F.; Liu, T.Y. A survey on neural speech synthesis. arXiv 2021, arXiv:2106.15561. [Google Scholar]
- Rehman, A.; Liu, Z.T.; Wu, M.; Cao, W.H.; Jiang, C.S. Speech emotion recognition based on syllable-level feature extraction. Appl. Acoust. 2023, 211, 109444. [Google Scholar] [CrossRef]
- Zhang, H.; Song, C. Some Issues in the Study of Chinese Poetic Prosody. In Breaking Down the Barriers: Interdisciplinary Studies in Chinese Linguistics and Beyond; Institute of Linguistics, Academia Sinica: Taipei, Taiwan, 2013; pp. 1149–1171. [Google Scholar]
- Ekpenyong, M.; Inyang, U.; Udoh, E. Unsupervised visualization of Under-resourced speech prosody. Speech Commun. 2018, 101, 45–56. [Google Scholar] [CrossRef]
- Al-Seady, M.J.B. English Phonetics and Phonology; University of Thi-Qar: Nasiriyah, Iraq, 2002. [Google Scholar]
- Wu, C.H.; Huang, Y.C.; Lee, C.H.; Guo, J.C. Synthesis of Spontaneous Speech With Syllable Contraction Using State-Based Context-Dependent Voice Transformation. IEEE ACM Trans. Audio Speech and Lang. Proc. 2014, 22, 585–595. [Google Scholar] [CrossRef]
- Kallay, J.E.; Mayr, U.; Redford, M.A. Characterizing the coordination of speech production and breathing. In Proceedings of the International Congress of Phonetic Sciences. International Congress of Phonetic Sciences, Melbourne, Australia, 5–9 August 2019; Volume 2019, p. 1412. [Google Scholar]
- Fuchs, S.; Petrone, C.; Krivokapić, J.; Hoole, P. Acoustic and respiratory evidence for utterance planning in German. J. Phon. 2013, 41, 29–47. [Google Scholar] [CrossRef]
- Prakash, J.J.; Murthy, H.A. Analysis of Inter-Pausal Units in Indian Languages and Its Application to Text-to-Speech Synthesis. IEEE ACM Trans. Audio Speech Lang. Proc. 2019, 27, 1616–1628. [Google Scholar] [CrossRef]
- Scott, B.A.; Johnstone, M.N.; Szewczyk, P.; Richardson, S. Matrix Profile data mining for BGP anomaly detection. Comput. Netw. 2024, 242, 110257. [Google Scholar] [CrossRef]
- Woodiss-Field, A.; Johnstone, M.N.; Haskell-Dowland, P. Examination of Traditional Botnet Detection on IoT-Based Bots. Sensors 2024, 24, 1027. [Google Scholar] [CrossRef]
- Yang, W.; Wang, S.; Hu, J.; Ibrahim, A.; Zheng, G.; Macedo, M.J.; Johnstone, M.N.; Valli, C. A Cancelable Iris- and Steganography-Based User Authentication System for the Internet of Things. Sensors 2019, 19, 2985. [Google Scholar] [CrossRef] [PubMed]
- Johnstone, M.; Peacock, M. Seven Pitfalls of Using Data Science in Cybersecurity. In Data Science in Cybersecurity and Cyberthreat Intelligence; Sikos, L.F., Choo, K.K.R., Eds.; Springer: Cham, Switzerland, 2020; Volume 177, pp. 115–129. [Google Scholar] [CrossRef]
- Biron, T.; Baum, D.; Freche, D.; Matalon, N.; Ehrmann, N.; Weinreb, E.; Biron, D.; Moses, E. Automatic detection of prosodic boundaries in spontaneous speech. PLoS ONE 2021, 16, e0250969. [Google Scholar] [CrossRef] [PubMed]
- Braunschweiler, N.; Chen, L. Automatic detection of inhalation breath pauses for improved pause modelling in HMM-TTS. In Proceedings of the 8th ISCA Speech Synthesis Workshop, Barcelona, Spain, 31 August–2 September 2013. [Google Scholar]
- Rahman, A.; Tomy, P. Voice Assistant as a Modern Contrivance to Acquire Oral Fluency: An Acoustical and Computational Analysis. World J. Engl. Lang. 2022, 13, 92. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Freq | Intensity | Duration | Pause Before | Pause After | |
|---|---|---|---|---|---|
| phrase | Y | Y | Y | Y | Y |
| phrase_pos | Y | Y | Y | Y | Y |
| phrase_% | Y | Y | Y | Y | Y |
| freq | target | Y | Y | Y | Y |
| intensity | Y | target | Y | Y | Y |
| duration | Y | Y | target | Y | Y |
| pauseBefore | Y | Y | Y | target | Y |
| pauseAfter | Y | Y | Y | Y | target |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kane, J.; Johnstone, M.N.; Szewczyk, P. Voice Synthesis Improvement by Machine Learning of Natural Prosody. Sensors 2024, 24, 1624. https://doi.org/10.3390/s24051624
Kane J, Johnstone MN, Szewczyk P. Voice Synthesis Improvement by Machine Learning of Natural Prosody. Sensors. 2024; 24(5):1624. https://doi.org/10.3390/s24051624
Chicago/Turabian StyleKane, Joseph, Michael N. Johnstone, and Patryk Szewczyk. 2024. "Voice Synthesis Improvement by Machine Learning of Natural Prosody" Sensors 24, no. 5: 1624. https://doi.org/10.3390/s24051624
APA StyleKane, J., Johnstone, M. N., & Szewczyk, P. (2024). Voice Synthesis Improvement by Machine Learning of Natural Prosody. Sensors, 24(5), 1624. https://doi.org/10.3390/s24051624