1. Introduction
Agriculture constitutes the lifeblood of a nation, and precise information regarding crop planting structure is imperative for assessing crop yields. With the evolution of computer-related technologies, remote sensing technology is pivotal in extracting crop planting structures due to its advantages, including wide coverage, high efficiency, and cost-effectiveness [
1]. Consequently, the adjustment of local crop planting structures, crop management, and the sustainable development of agriculture significantly benefit from utilizing remote sensing technologies to extract crop planting structure information [
2].
Currently, research by both domestic and foreign scholars aimed at identifying and extracting different crop planting areas predominantly relies on medium spatial resolution optical remote sensing images such as Landsat and MODIS [
3,
4]. However, the limitations of sensor performance render it challenging to ensure classification accuracy in areas with complex terrain [
5]. Sentinel-2 imagery offers a novel data source for crop identification, featuring advantages like high spatial resolution, multiple spectral bands, and dual-satellite synchronous operation. In a study by Han et al. [
6], the spectral characteristics and vegetation index information of Sentinel-2A images were employed to extract rapeseed planting areas, revealing that, in comparison with Landsat-8, Sentinel-2A images exhibit superior precision in extracting crop distribution information within complex planting areas. Similarly, Tian et al. [
7] utilized Sentinel-2A images to delineate extensive winter wheat planting areas, emphasizing the pivotal role of its red-edge band in extracting winter wheat planting information. While optical remote sensing technology is well established, its practical applications are susceptible to the effects of time and weather conditions [
8], leading to the diminished classification accuracy of ground objects. In contrast, radar images provided by the Sentinel-1 satellite operate continuously, overcoming temporal constraints and capturing ground feature information distinct from optical images [
9,
10]. The synergistic combination of optical and radar images maximizes their respective benefits, enhancing the ability to identify ground objects and improving information extraction accuracy. Notably, scholars [
11,
12,
13,
14] have validated that the integration of Sentinel-2 and Sentinel-1 images yields higher classification accuracy in surface information extraction, including wetland and agricultural land. Additionally, Zhang Hao et al. [
15] incorporated topographic data into the western region of the Loess Plateau to obtain relatively precise information about abandoned land, underscoring the importance of topographic data in classifying areas with complex topography.
In recent years, deep learning has emerged as a focal point in remote sensing image classification research. Its superior learning and generalization capabilities, particularly in intricate feature extraction, surpass traditional machine learning methods, leading to heightened classification accuracy [
16,
17]. Research indicates that the application of deep learning to fine crop classification has yielded promising results. For instance, Liu et al. [
18] employed the convolutional neural network method on Sentinel-2 remote sensing images to identify primary crops in Yuanyang County, Henan Province, achieving a classification accuracy of 96.39%. Similarly, Li et al. [
19] compared and analyzed the extraction effect of five deep learning models in fine crop distribution applications based on Sentinel-2 multi-temporal remote sensing images, revealing that all five models yielded accuracy rates exceeding 90%. Although deep learning methods have achieved high accuracy on a single data source, combining deep learning classification methods with multi-source data for crop information extraction has yet to be thoroughly investigated. Therefore, this paper aims to explore how to combine deep learning methods with multi-source data to improve the accuracy and reliability of crop information extraction.
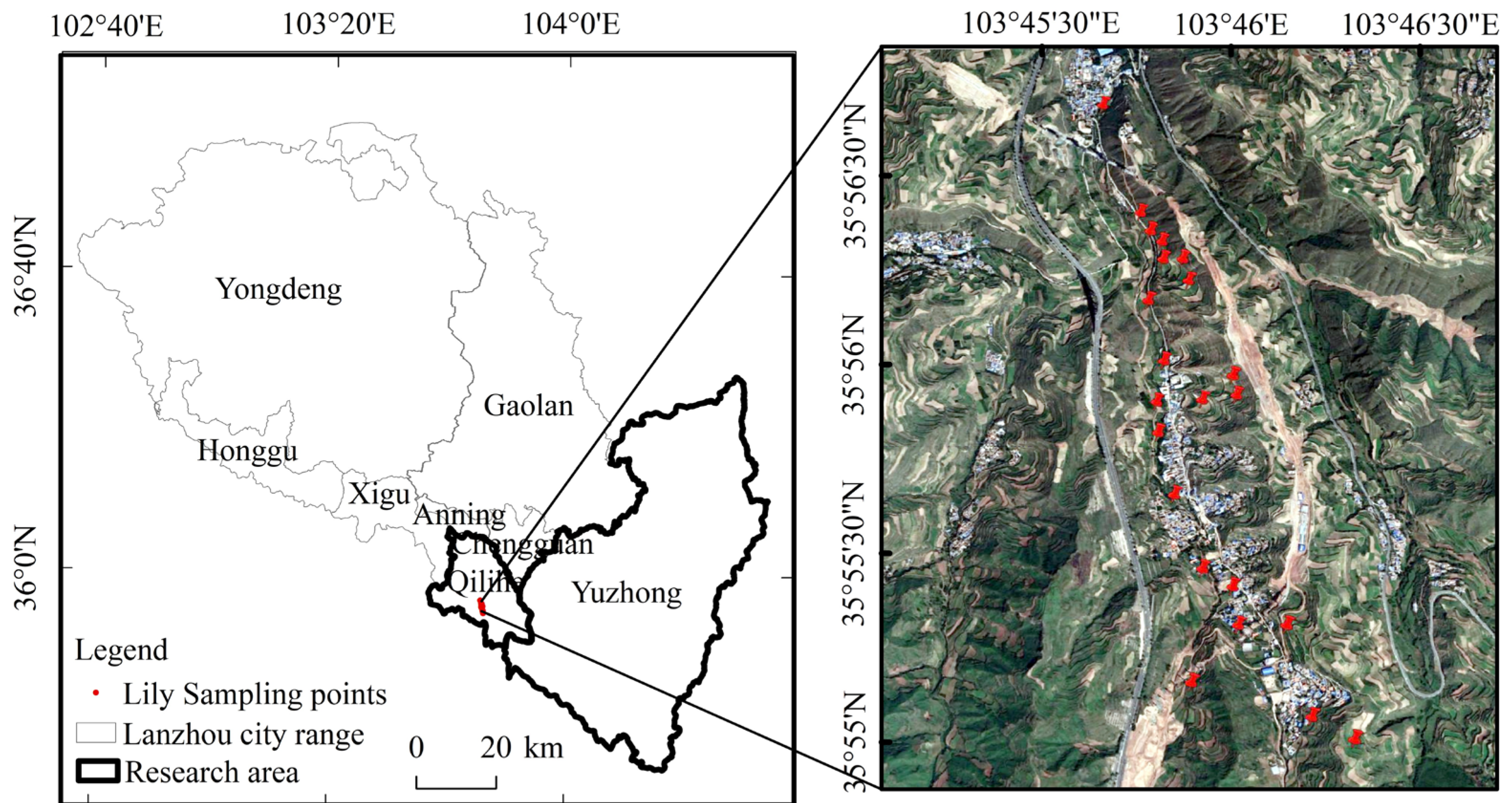
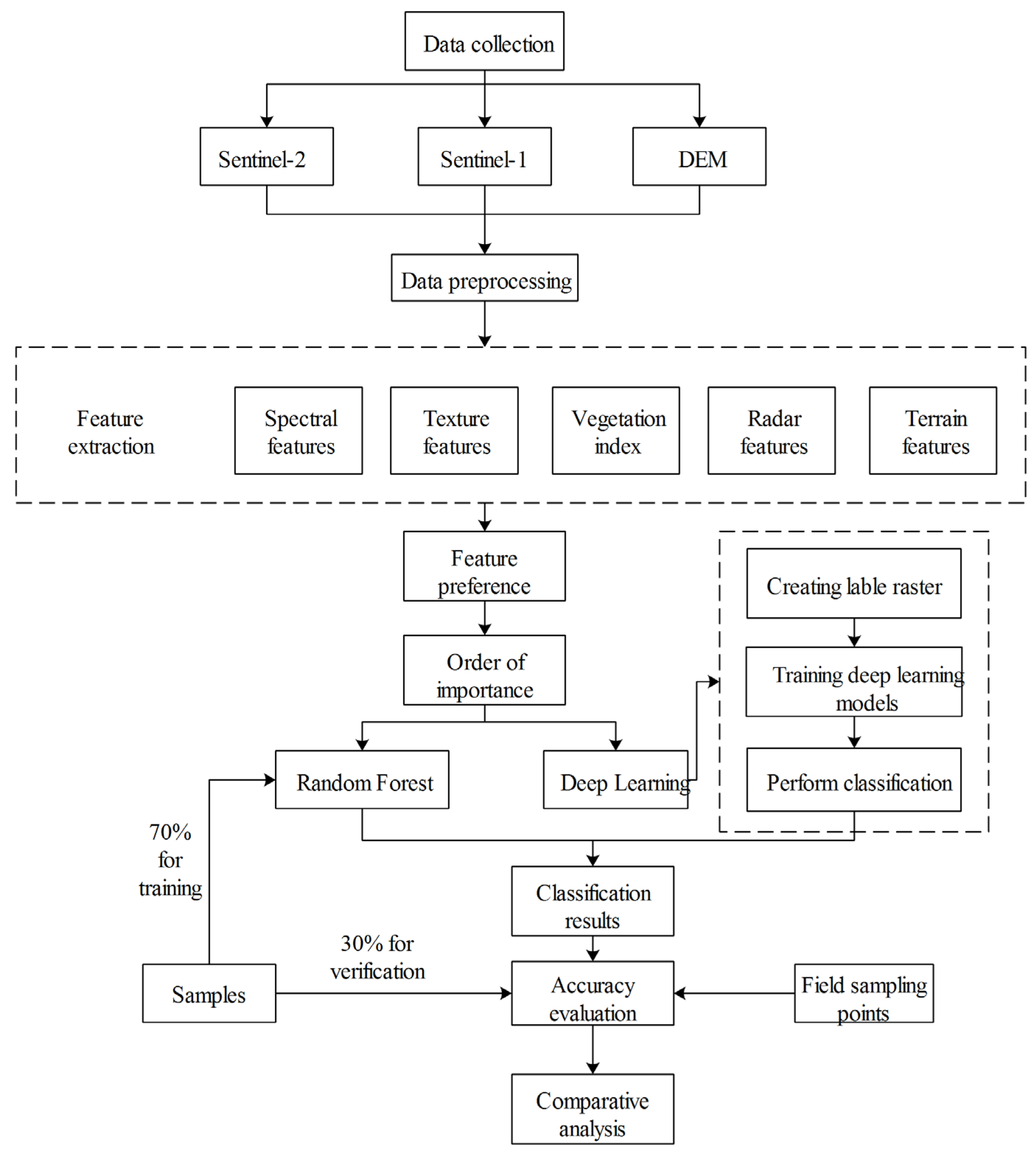
To address the above issues, we used the U-Net architecture in the deep learning method based on Sentinel-2A, Sentinel-1, and DEM multi-source image data, along with the best index, spectrum, texture, terrain, and radar feature dataset selected by the Relief-F algorithm, to identify lilies in Qilihe District and Yuzhong County of Lanzhou City, obtain their planting structure, and analyze their spatial distribution characteristics. In addition, a comparative analysis was conducted between the random forest classification method and the deep learning classification method. This study provides basic data support for planting structure adjustment, growth monitoring, yield estimation, and pest and disease monitoring of lilies, which helps to achieve sustainable agricultural development.
5. Discussions
In this paper, 48 features such as spectrum, texture, and red-edge index were chosen to extract lily planting information based on the planting conditions of lilies in the study area and using Sentinel-1, Sentinel-2, and DEM as data sources, avoiding the problem of the low classification accuracy of a single feature. However, too many characteristics are prone to data redundancy, which reduces the classification effect. As a result, the Relief-F algorithm is used to sort and group the importance of features, and the deep learning approach is utilized to select the ideal feature group, with a total of 36 features. Deep learning classification with only terrain and radar features is poor, with an overall accuracy of only 75.7%; the overall accuracy increases to 87.2% with the addition of partial vegetation indexes and red-edge indexes, and the overall accuracy increases to 90.5% with the addition of the more important texture features on top of the terrain, radar, and partial index features. As the number of features rises, so does the classification accuracy. When all features are classified, the accuracy falls, the most accurate feature group is chosen as the optimal feature dataset, and the 12 features with a lower-importance ranking are eliminated (ranked 37–48 in
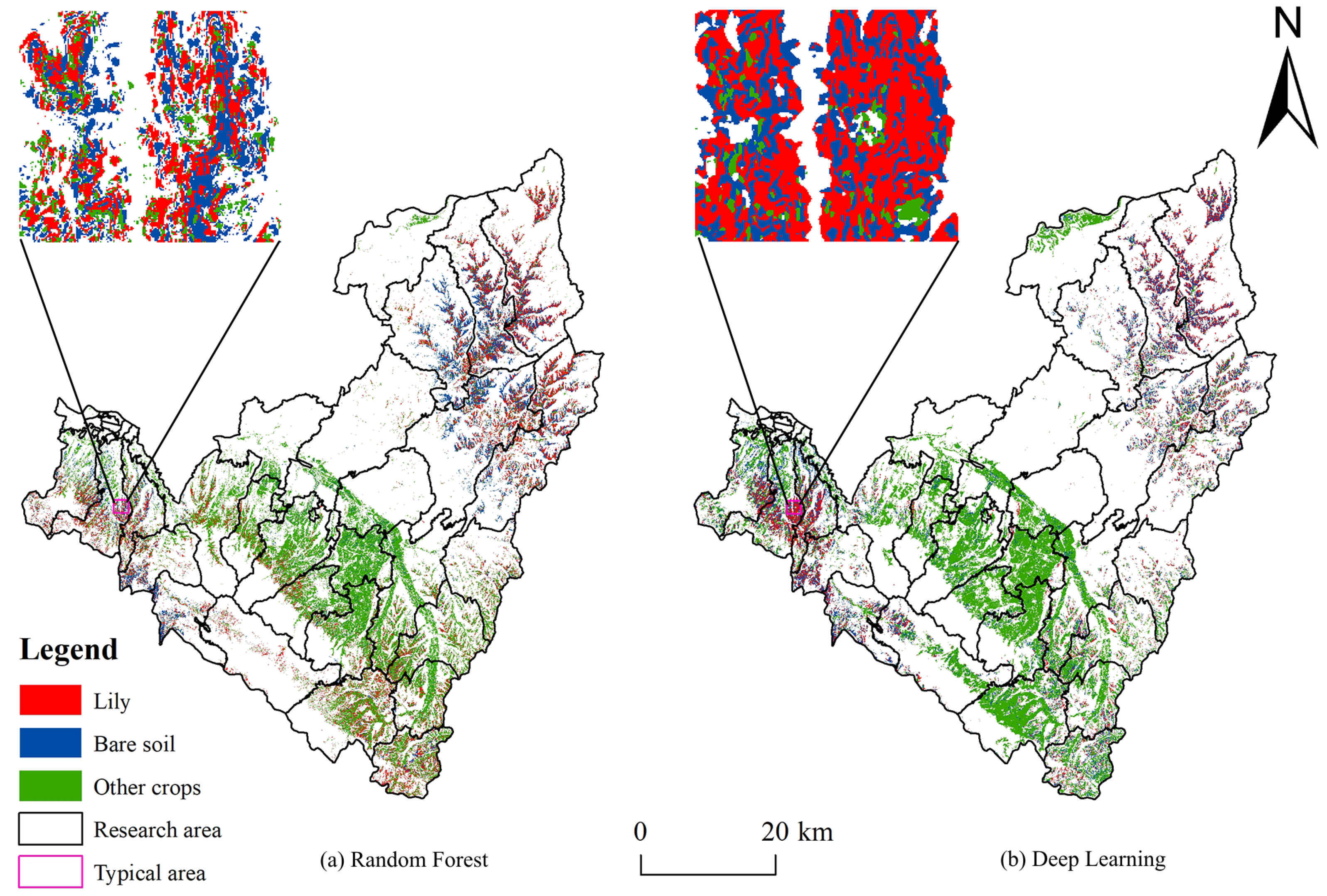
Table 4). The producer accuracy and user accuracy of diverse ground objects are both greater than 76%, according to the random forest and deep learning classification results based on the optimal feature dataset. Among them, the producer accuracy and user accuracy of lilies are relatively excellent, both exceeding 87%. The overall accuracy of the deep learning classification algorithm for the optimal feature dataset is 95.9%, with a kappa coefficient of 0.934. The overall accuracy and kappa coefficients have increased by 1.3% and 0.023, respectively, as compared to the random forest classification approach. This indicates that the combination of the Relief-F and deep learning classification methods performs well in extracting lily planting information in Lanzhou, which can meet the requirements of lily planting structure extraction and spatial distribution monitoring in Lanzhou.
The deep learning classification method based on multi-source data in this article produced satisfactory results. However, deep learning approaches necessitate a huge quantity of data to train the model, and parameter adjustments have a certain degree of subjectivity and exploratory nature. As a result, further research is needed in parameter adjustment and training techniques. Feature optimization can improve classification accuracy, but different feature optimization methods are based on different models and principles, and the results obtained by a single feature optimization method may be one-sided, so it is necessary to consider combining multiple feature optimization methods to obtain the best feature. In addition, this paper is based on single-phase remote sensing image information extraction. In most cases, the classification accuracy of multi-temporal is significantly higher than that of single-phase. In the subsequent research, images with obvious phenological differences in different periods are selected for classification as far as possible.
6. Conclusions
In this study, we extracted spectral, texture, vegetation index, red-edge index, topography, and radar features from Sentinel-1, Sentinel-2A, and DEM data to construct a multidimensional feature dataset, excluded irrelevant variables using the Relief-F algorithm, selected the optimal feature dataset, and extracted the lily planting structure in Qilihe District and Yuzhong County using a deep learning method and compared it with the random forest classification method for comparison. The main findings are as follows:
- (1)
Using the Relief-F algorithm for feature selection and feature importance ranking, deep learning classification revealed that accuracy increased initially and subsequently decreased, achieving the best accuracy when the number of features was 36. According to the importance ranking of features, it can be seen that, among the topographic features, elevation has the greatest contribution in feature classification, radar features are only followed by elevation and slope, texture features and spectral features have lower contributions, and the addition of red light bands to red-edge bands can effectively reflect the characteristics of each feature.
- (2)
Deep learning classification accuracy is higher than random forest classification accuracy under the same feature dimension, with overall accuracy of 95.9% and a kappa coefficient of 0.934, which can inhibit the generation of the “pepper and salt phenomenon” and more accurately extract the planting structure information of lilies in the study area.
- (3)
The lily planting area extracted based on multi-source data images is 137.24 km2, mainly concentrated in Xiguoyuan Township in Qilihe District and in Shanghuacha Township and Yuanzicha Township in Yuzhong County.
The deep learning method based on multi-source data exhibits promising performance in extracting structural information concerning lily cultivation. Looking ahead, future work could delve into optimizing the fusion of unmanned aerial vehicle (UAV) data with other data sources, improving algorithms for more accurate feature extraction and exploring the integration of advanced sensing technologies to extract more accurate crop areas. In addition, the method can be used not only for agricultural production management but also extended to other fields such as food security monitoring, land use planning, and environmental protection. As an effective means of digital agriculture, the method is expected to promote the development of agriculture in a more efficient and sustainable direction.




{kind=link}
{kind=link}
{kind=link}