
FV-MViT: Mobile Vision Transformer for Finger Vein Recognition

Abstract
1. Introduction
- A lightweight finger vein recognition network, FV-MViT, based on CNN and Transformer, is proposed. It achieves competitive results when compared to the state-of-the-art (SOTA) in terms of parameter count, latency, and recognition accuracy.
- During the training of deep models, a combined loss function of soft target cross-entropy and center loss is employed. This loss function improves the model’s generalization, reduces intra-class distances, and increases inter-class distances, thereby enhancing the model’s recognition accuracy.
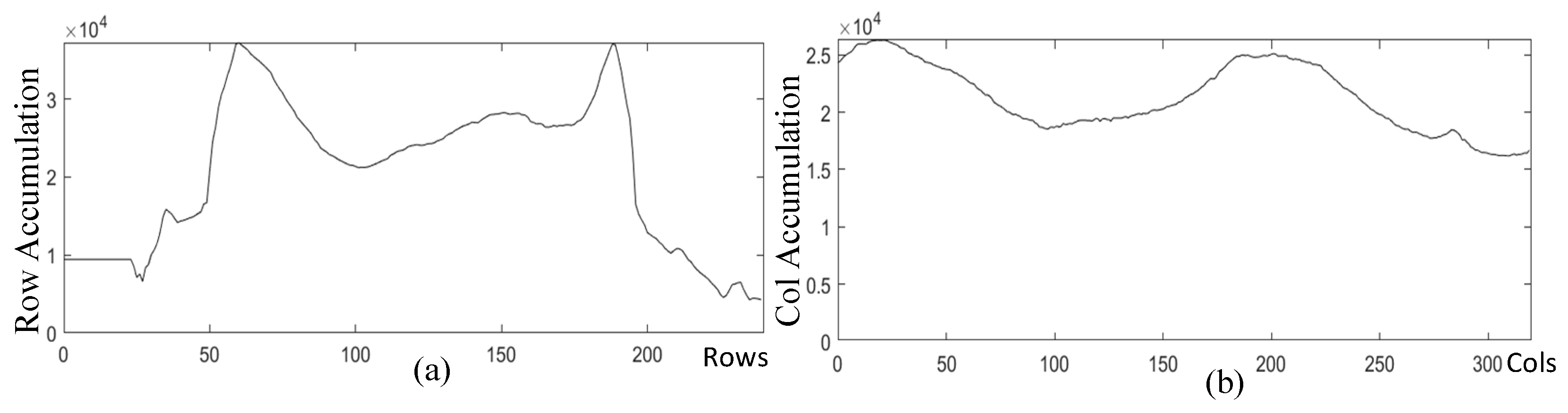
- We introduce a method for image preprocessing that utilizes adaptive histogram equalization with contrast limiting to enhance images. We locate the mini-regions of interest (Mini-ROI) area by using the coordinates corresponding to the peak value after the accumulation of grayscale values of row and column pixels. This algorithm effectively extracts the relevant region of finger veins, reducing the impact of redundant information on the accuracy of recognition.
2. Related Work
2.1. Finger Vein Image Preprocessing Method
2.2. Lightweight Finger Vein Recognition Algorithm Based on Deep Learning
2.3. Loss Functions for Finger Vein Recognition
3. Proposed Method
3.1. Feature Extraction of Finger Vein Mini-ROI
3.1.1. Contrast-Limited Adaptive Histogram Equalization (CLAHE)
3.1.2. Mini-ROI Extraction
3.2. Lightweight Vein Recognition Neural Network FV-MViT Based on CNN and Transformers
3.2.1. Overall Architecture
3.2.2. MV2 Block and Mul_MV2 Block
3.2.3. Enhanced MobileViT Block
3.3. Training Algorithm
3.3.1. Data Augmentation
3.3.2. Soft Target Center Cross-Entropy Loss Function
4. Experiment and Results
4.1. Dataset Description
4.1.1. SDUMLA-HMT Database
4.1.2. FV-USM Database
4.2. Training Details
4.3. Results Evaluation and Comparison
4.3.1. Parameter Confirmation Experiment
4.3.2. Improved Component Experiment
4.3.3. Comparison against Mainstream Transformer-Related Frameworks
4.3.4. Comparison of Experimental Results for Various Vein Recognition Networks
4.3.5. Comparison of Experimental Results for Various Loss Functions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Phillips, P.J.; Moon, H.; Rizvi, S.A.; Rauss, P.J. The FERET evaluation methodology for face-recognition algorithms. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 1090–1104. [Google Scholar] [CrossRef]
- Jain, A.; Hong, L.; Bolle, R. On-line fingerprint verification. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 302–314. [Google Scholar] [CrossRef]
- Daugman, J.G. High confidence visual recognition of persons by a test of statistical independence. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1148–1161. [Google Scholar] [CrossRef]
- Wu, J.D.; Ye, S.H. Driver identification using finger-vein patterns with Radon transform and neural network. Expert Syst. Appl. 2009, 36, 5793–5799. [Google Scholar] [CrossRef]
- Kang, W.; Liu, H.; Luo, W.; Deng, F. Study of a Full-View 3D Finger Vein Verification Technique. IEEE Trans. Inf. Forensics Secur. 2019, 15, 1175–1189. [Google Scholar] [CrossRef]
- Syarif, M.A.; Ong, T.S.; Teoh, A.B.J.; Tee, C. Enhanced maximum curvature descriptors for finger vein verification. Multimed. Tools Appl. 2017, 76, 6859–6887. [Google Scholar] [CrossRef]
- Kumar, A.; Zhou, Y. Human Identification Using Finger Images. IEEE Trans. Image Process. 2012, 21, 2228–2244. [Google Scholar] [CrossRef]
- He, C.; Li, Z.; Chen, L.; Peng, J. Identification of Finger Vein using Neural Network Recognition Research Based on PCA. In Proceedings of the 2017 IEEE 16th International Conference on Cognitive Informatics & Cognitive Computing (ICCI*CC), Oxford, UK, 26–28 July 2017. [Google Scholar]
- Rosdi, B.A.; Shing, C.W.; Suandi, S.A. Finger Vein Recognition Using Local Line Binary Pattern. Sensors 2011, 11, 11357–11371. [Google Scholar] [CrossRef]
- Wang, J.; Wang, G. Quality-Specific Hand Vein Recognition System. IEEE Trans. Inf. Forensics Secur. 2017, 12, 2599–2610. [Google Scholar] [CrossRef]
- Garcia-Martin, R.; Sanchez-Reillo, R. Wrist Vascular Biometric Recognition Using a Portable Contactless System. Sensors 2020, 20, 1469. [Google Scholar] [CrossRef]
- Li, S.; Zhang, B.; Fei, L.; Zhao, S.; Zhou, Y. Learning sparse and discriminative multimodal feature codes for finger recognition. IEEE Trans. Multimed. 2023, 25, 805–815. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 27–30 June 2016. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the 9th International Conference on Learning Representations (ICLR 2021), Online, 3–7 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV 2021), Online, 11–17 October 2021. [Google Scholar]
- Mehta, S.; Rastegari, M. MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Fang, Y.; Wu, Q.; Kang, W. A novel finger vein verification system based on two-stream convolutional network learning. Neurocomputing 2018, 290, 100–107. [Google Scholar] [CrossRef]
- Yang, L.; Yang, G.; Zhou, L.; Yin, Y. Superpixel based finger vein ROI extraction with sensor interoperability. In Proceedings of the 2015 International Conference on Biometrics, Phuket, Thailand, 19–22 May 2015. [Google Scholar]
- Yang, J.; Shi, Y. Finger-vein ROI localization and vein ridge enhancement. Pattern Recognit. Lett. 2012, 33, 1569–1579. [Google Scholar] [CrossRef]
- Yang, J.; Wei, J.; Shi, Y. Accurate ROI localization and hierarchical hyper-sphere model for finger-vein recognition. Neurocomputing 2019, 328, 171–181. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Shen, J.; Liu, N.; Xu, C.; Sun, H.; Xiao, Y.; Li, D.; Zhang, Y. Finger vein recognition algorithm based on lightweight deep convolutional neural network. IEEE Trans. Instrum. Meas. 2022, 71, 5000413. [Google Scholar] [CrossRef]
- Wang, K.; Chen, G.; Chu, H. Finger vein recognition based on multi-receptive field bilinear convolutional neural network. IEEE Signal Process. Lett. 2021, 28, 1590–1594. [Google Scholar] [CrossRef]
- Song, Y.; Zhao, P.; Yang, W.; Liao, Q.; Zhou, J. EIFNet: An explicit and implicit feature fusion network for finger vein verification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 2520–2532. [Google Scholar] [CrossRef]
- Huang, J.; Tu, M.; Yang, W.; Kang, W. Joint attention network for finger vein authentication. IEEE Trans. Instrum. Meas. 2021, 70, 2513911. [Google Scholar] [CrossRef]
- Huang, Y.; Ma, H.; Wang, M. Axially Enhanced Local Attention Network for Finger Vein Recognition. IEEE Trans. Instrum. Meas. 2023, 72, 1557–9662. [Google Scholar] [CrossRef]
- Huang, J.; Luo, W.; Yang, W.; Zheng, A.; Lian, F.; Kang, W. FVT: Finger vein transformer for authentication. IEEE Trans. Instrum. Meas. 2022, 71, 5011813. [Google Scholar] [CrossRef]
- Qin, H.; Hu, R.; El-Yacoubi, M.A.; Li, Y.; Gao, X. Local attention transformer-based full-view finger-vein identification. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 2767–2782. [Google Scholar] [CrossRef]
- Garcia-Martin, R.; Sanchez-Reillo, R. Vision transformers for vein biometric recognition. IEEE Access 2023, 11, 22060–22080. [Google Scholar] [CrossRef]
- Zhao, D.; Ma, H.; Yang, Z.; Li, J.; Tian, W. Finger vein recognition based on lightweight CNN combining center loss and dynamic regularization. Infrared Phys. Technol. 2020, 105, 103221. [Google Scholar] [CrossRef]
- Hou, B.; Yan, R. ArcVein-Arccosine center loss for finger vein verification. IEEE Trans. Instrum. Meas. 2021, 70, 5007411. [Google Scholar] [CrossRef]
- Zuiderveld, K. Contrast Limited Adaptive Histogram Equalization. Graph. Gems 1994, 474–485. [Google Scholar] [CrossRef]
- Mehta, S.; Rastegari, M. Separable self-attention for mobile vision transformers. arXiv 2022, arXiv:2206.02680. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2018, arXiv:1710.09412. [Google Scholar]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A discriminative feature learning approach for deep face recognition. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 499–515. [Google Scholar]
- Yin, Y.; Liu, L.; Sun, X. SDUMLA-HMT: A multimodal biometric database. In Proceedings of the Chinese Conference on Biometric Recognition, Beijing, China, 3–4 December 2011; pp. 260–268. [Google Scholar]
- Asaari, M.S.M.; Suandi, S.A.; Rosdi, B.A. Fusion of band limited phase only correlation and width centroid contour distance for finger based biometrics. Expert Syst. Appl. 2014, 41, 3367–3382. [Google Scholar] [CrossRef]
- GB/T 35676-2017; Public Safety—Finger Vein Recognition Application—Testing and Evaluation Methods for Algorithm Performance. Standards Press of China: Beijing, China, 2017.
- Li, X.; Zhang, B.-B. FV-ViT: Vision transformer for finger vein recognition. IEEE Access 2023, 11, 75451–75461. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| λ | 0.01 | 0.001 | 0.0001 | 0.00001 | |
|---|---|---|---|---|---|
| α | |||||
| 0.001 | 98.74% | 99.21% | 99.37% | 99.53% | |
| 0.0001 | 99.05% | 99.21% | 99.37% | 99.53% | |
| 0.00001 | 99.05% | 99.21% | 99.53% | 99.53% | |
| 0.000001 | 99.05% | 99.37% | 99.53% | 99.53% | |
| λ | 0.01 | 0.001 | 0.0001 | 0.00001 | |
|---|---|---|---|---|---|
| α | |||||
| 0.001 | 98.17% | 98.98% | 99.79% | 100.00% | |
| 0.0001 | 98.37% | 99.39% | 99.79% | 100.00% | |
| 0.00001 | 98.37% | 99.79% | 100.00% | 100.00% | |
| 0.000001 | 98.98% | 99.79% | 100.00% | 100.00% | |
| Components | SDU-Acc | SDU-EER | USM-Acc | USM-EER |
|---|---|---|---|---|
| Original Image | 93.87% | 9.37% | 98.98% | 1.80% |
| Dynamic LR | 94.33% | 9.95% | 99.19% | 4.85% |
| Mini-ROI | 97.80% | 7.64% | 99.39% | 4.27% |
| Lightweight | 98.89% | 3.01% | 99.79% | 0.16% |
| Center Loss | 99.53% | 0.47% | 100.00% | 0.02% |
| Method | SDU-Acc | SDU-EER | USM-Acc | USM-EER | #Params. | FLOPS | Latency |
|---|---|---|---|---|---|---|---|
| VisionTransformer [17] | 83.96% | 9.30% | 87.40% | 4.51% | 37.98 M | 4.75 G | 6.99 ms |
| SwinTransformer [18] | 93.55% | 6.62% | 98.58% | 2.86% | 63.49 M | 15.03 G | 24.00 ms |
| MobileNetV2 [26] | 96.10% | 4.35% | 98.98% | 3.96% | 1.42 M | 0.06 G | 6.00 ms |
| MobileViT [19] | 98.11% | 5.84% | 99.39% | 4.27% | 5.09 M | 1.82 G | 11.00 ms |
| FV-MViT | 99.53% | 0.47% | 100.00% | 0.02% | 5.26 M | 1.84 G | 10.00 ms |
| Method | SDU-Acc | SDU-EER | USM-Acc | USM-EER | #Params. | FLOPS | Latency |
|---|---|---|---|---|---|---|---|
| Huang et al. [30] (2021) | 98.61% | 1.18% | 99.77% | 0.49% | - | - | - |
| Shen et al. [27] (2022) | 99.3% | 1.13% | - | - | - | - | 14.2 ms |
| Huang et al. [32] (2022) | 89.29% | 3.25% | 99.59% | 0.54% | 50 M | 1.7 G | - |
| Li et al. [44] (2023) | 92.21% | 1.022% | 99.73% | 0.116% | - | - | - |
| Ours | 99.53% | 0.47% | 100.00% | 0.02% | 5.26 M | 1.84 G | 10.0 ms |
| Method | SDU-Acc | SDU-EER | USM-Acc | USM-EER |
|---|---|---|---|---|
| SoftMax | 98.17% | 13.39% | 98.98% | 5.54% |
| SoftMax + center loss | 99.05% | 2.38% | 99.79% | 1.51% |
| Soft target cross-entropy | 98.89% | 3.01% | 99.79% | 0.16% |
| Soft target cross-entropy + center loss | 99.53% | 0.47% | 100.00% | 0.02% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Feng, J.; Cai, J.; Lin, G. FV-MViT: Mobile Vision Transformer for Finger Vein Recognition. Sensors 2024, 24, 1331. https://doi.org/10.3390/s24041331
Li X, Feng J, Cai J, Lin G. FV-MViT: Mobile Vision Transformer for Finger Vein Recognition. Sensors. 2024; 24(4):1331. https://doi.org/10.3390/s24041331
Chicago/Turabian StyleLi, Xiongjun, Jin Feng, Jilin Cai, and Guowen Lin. 2024. "FV-MViT: Mobile Vision Transformer for Finger Vein Recognition" Sensors 24, no. 4: 1331. https://doi.org/10.3390/s24041331
APA StyleLi, X., Feng, J., Cai, J., & Lin, G. (2024). FV-MViT: Mobile Vision Transformer for Finger Vein Recognition. Sensors, 24(4), 1331. https://doi.org/10.3390/s24041331