1. Introduction
The widespread availability of commodity wearables such as smartphones and smartwatches, has resulted in increased interest in their utilization for applications such as sports and fitness tracking [
1,
2,
3,
4,
5]. These devices benefit from onboard sensors, including Inertial Measurement Units (IMUs), which can track and measure human movements that are subsequently analyzed for understanding activities. The ubiquitous nature of the devices, coupled with their form factor, enables the collection of large-scale movement data without substantial impact on user experience, albeit without annotations.
Human activity recognition (HAR) is one such application of wearable sensing, wherein features are extracted for segmented windows of sensor data, for classification into specific activities (or the null class). The de facto approach for obtaining features is to compute them via statistical metrics [
6,
7] and the empirical cumulative distribution function [
8], or to learn them directly from the data itself (e.g., via end-to-end training [
9,
10,
11,
12,
13] or unsupervised learning [
14,
15,
16]). Either approach results in continuous-valued (or dense) features summarizing the movement present in the windows.
Alternatively, activity recognition has occasionally also been performed on discrete sensor data representations (e.g., [
17]). In those cases, short windows of sensor data are converted into
discrete symbols, where each symbol typically covers ranges of sensor values and a span of time. The motivation for such discretization efforts was to convert complex movements into a smaller, finite alphabet of discrete (symbolic) representations, thereby simplifying tasks such as spotting gestures [
17], and recognizing activities [
18,
19] via the use of efficient algorithms from string matching and bioinformatics, or even simple nearest neighbors in conjunction with Dynamic Time Warping (DTW). Some approaches for deriving the small collection of symbols include symbolic aggregate approximation (SAX) [
20] and the Sliding Window and BottomUp (SWAB) algorithm [
21,
22]. SAX in particular, is especially effective at discretizing even a long-duration time series efficiently [
17,
20].
Existing discretization methods are rather limited with regard to their expressive power—resulting in substantial loss of resolution, as movements and activities can only be expressed by a small alphabet of symbols, which often negatively impacts downstream recognition performance. It is also observed especially acutely in tasks where minute differences in movements are important for discriminating between activities, e.g., in fine-grained gesture recognition. Moreover, the discretization methods are more difficult to apply to multi-channel sensor data, requiring specialized handling and containing exploding alphabet sizes [
23]. The low recognition accuracy coupled with difficulty in handling multi-sensor setups especially has resulted in discretization methods falling behind their continuous representation counterparts and, thus, have been somewhat abandoned.
Yet, discrete representations—that are on par with contemporary continuous representations—can be crucial for tasks such as activity/routine discovery via characteristic actions [
24], discovering multi-variate motifs from sensor data [
25], dimensionality reduction [
20], and performing interpretable time-series classification [
26], since these techniques require time-series simplification as they would be produced by discretization. In recent years, the study and application of vector quantization (VQ) techniques to, for example, automatic speech recognition has resulted in the ability to learn mappings between the–continuous–audio and–discrete–codebooks of vectors, i.e., to map short durations of raw audio to discrete symbols [
27,
28]. In this paper, we propose to adopt and adapt such recent advancements of discrete representation learning for the HAR community, so that the symbolic representations of movement data can be derived in an unsupervised, data-driven manner, and be used for effective sensor-based human activity recognition tasks.
To this end, we apply
learned vector quantization (VQ) [
27,
29] to wearables applications, which enables us to directly
learn the mapping between short spans of sensor data and a codebook of vectors, where the index of the closest codebook vector comprises the discrete representation. In addition, we utilize self-supervised learning as a base (via the Enhanced CPC framework [
30]), thereby deriving the representations without the need for annotations. Sensor data are first encoded using convolutional blocks, which can handle multiple data channels (e.g.,
x-
y-
z axes of triaxial accelerometry) in a straightforward manner. This is followed by the vector quantization module which replaces the encoding with the nearest codebook vector. They are subsequently summarized using a causal convolutional encoder, which utilizes vectors from the previous timesteps in order to predict multiple future timesteps of data in a contrastive learning setup.
We present our method as a
proof of concept for discrete representation learning, and, as such, as a proposal for a return to discretized representations in HAR. We focus on recognizing human activities in order to demonstrate the efficacy of the representations using a standard classification backend, yet we also outline the potential the proposed return to discretized processing has for the field of sensor-based HAR. The representations are derived using wrist-based accelerometer data from Capture-24 [
31,
32,
33]—a large-scale dataset that was collected in-the-wild and, as such, is representative for real-world Ubicomp applications of HAR. The performance of our discrete representation learning is contrasted against other representations, including end-to-end training (where the features are learned for accurate prediction) and self-supervised learning (where unlabeled data are first used for representation learning), the latter recently having seen a substantial boost in the field. The evaluation is performed on six diverse benchmarks, containing a variety of activities including locomotion, daily living, and gym exercises, and comprising different numbers of participants and three sensor locations (as detailed in [
16]).
The conversion of continuous-valued sensor data to discrete representations often results in comparable activity recognition accuracy, which we show in our extensive experimental evaluation. In fact, in some cases, the change in representation actually leads to improved recognition accuracy. In addition to standard activity recognition, the return to now much-improved discretization of sensor data also bears great potential for a range of additional applications such as activity discovery, activity summarization and fingerprinting, which could be used for large-scale behavior assessments both longitudinally or population-wide (or both). Effective discretization also opens up the field to the potential of entirely different categories of subsequent processing techniques, for example, NLP-based pre-training such as RoBERTa [
34]—an optimized version of BERT [
35]—so as to further learn effective embeddings, improving the recognition accuracy.
The contributions of our work can be summarized as follows:
We combine learned vector quantization (VQ)—based on state-of-the-art self-supervised learning methods—with wearable-based human activity recognition in order to learn discrete representations of human movements.
We establish the utility of learned discrete representations towards recognizing activities, where they perform comparably or better than state-of-the-art learned representations on three datasets, across sensor locations.
We also demonstrate the applicability of highly effective NLP-based pre-training (based on RoBERTa [
34]) on the discrete representations, which results in further performance improvements for all target scenarios.
3. Methodology
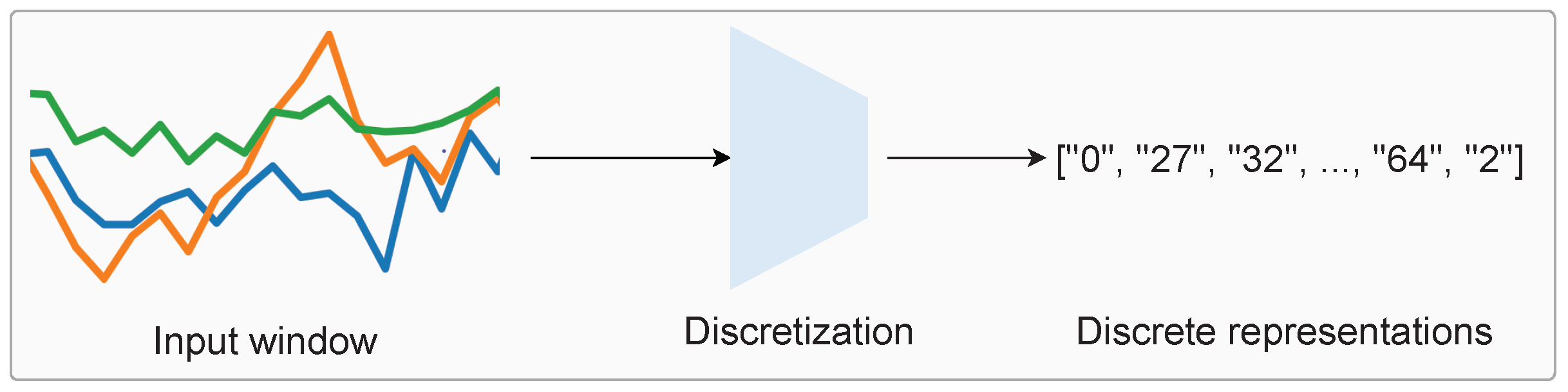
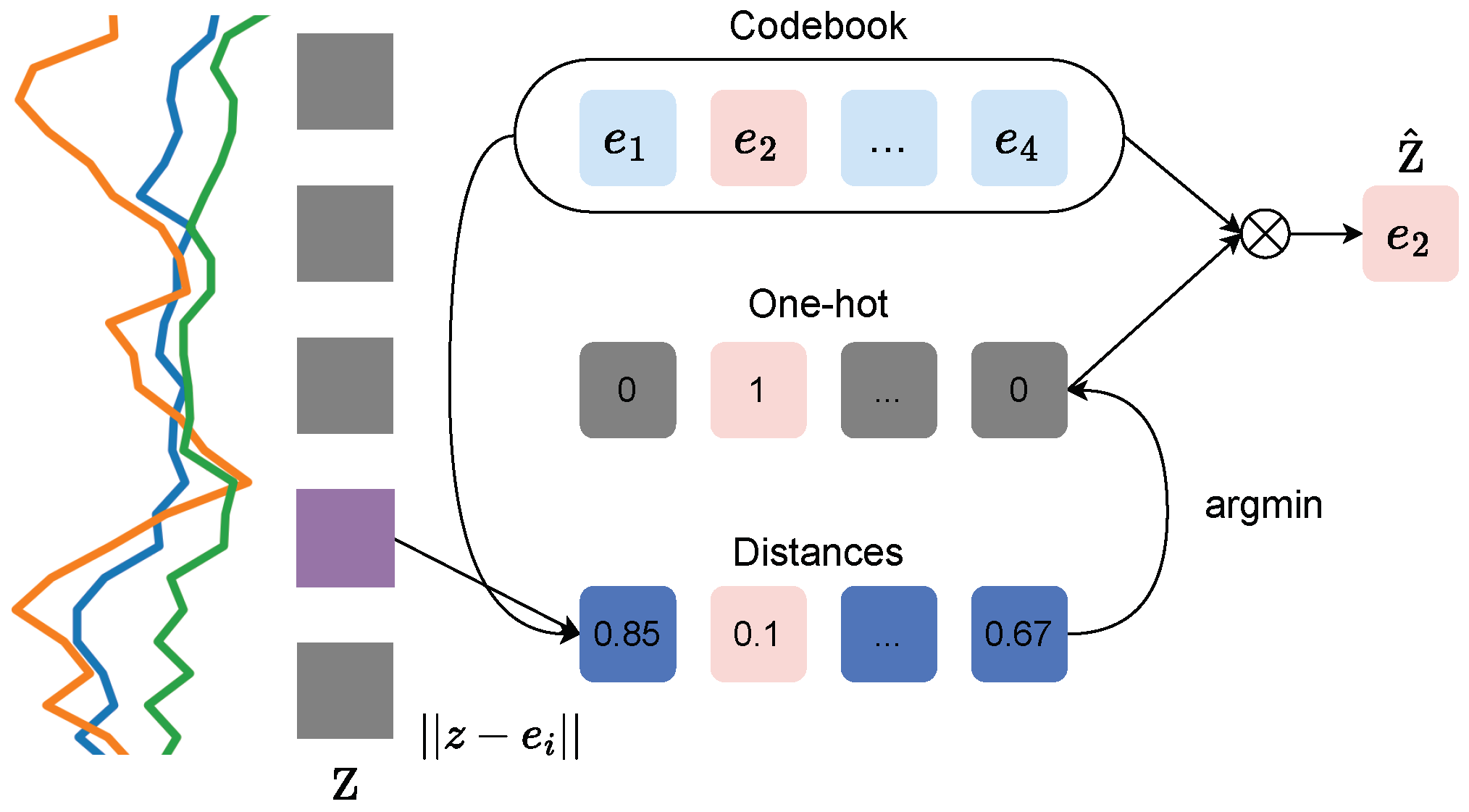
In this paper, we introduce the discrete representation learning framework for wearable sensor data, with the ultimate goal of improved activity recognition performance and better analysis of human movements. This paper represents the first step towards this goal, which effectively demonstrates the proof of concept for the effectiveness of learned discretization, which warrants the aforementioned “return to discretized representations”. Based on our framework, we explore the potential and next steps for discretized human activity recognition. An overview of discretization is shown in
Figure 1, which involves mapping windows of time-series accelerometer data to a collection of discrete ‘symbols’ (which are represented by strings of numbers).
Following the self-supervised learning paradigm, our approach contains two stages:
(i) pre-training, where the network learns to map unlabeled data to a codebook of vectors, resulting in the discrete representations; and
(ii) fine-tuning/classification, which utilizes the discrete representations as input for recognizing activities. In order to enable the mapping, we apply vector quantization (VQ) to the Enhanced CPC framework [
30]. Therefore, the base of the discretization process is self-supervision, where the loss from the pretext task is added to the loss from the VQ module in order to update the network parameters as well as the codebook vectors.
To this end, we first detail the self-supervised pretext task, Enhanced CPC, and describe how the VQ module can be added to it. With the aim of quantitatively measuring the utility of the representations, we perform activity recognition using discrete representations derived from target-labeled datasets. Therefore, we also discuss the classifier network used for such evaluation, and clarify how the setup is different from state-of-the-art self-supervision for wearables.
3.1. Discrete Representation Learning Setup
The setup for learning discrete representations of human movements contains two parts:
(i) the self-supervised pretext task; and
(ii) the vector quantization (VQ) module. We utilize the Enhanced Contrastive Predictive Coding (CPC) framework [
30] as the self-supervised base, which comprises the prediction of multiple future timesteps in a contrastive learning setup. By predicting farther into the future, the network can capture the slowly varying features, or the long-term signal present in the sensor data while ignoring local noises, which is beneficial for representation learning [
79]. We borrow notation from [
27] for the method description below.
The aim of the Enhanced CPC [
30] framework is to investigate three modifications to the original wearable-based CPC framework:
(i) the convolutional encoder network;
(ii) the Aggregator (or autoregressive network); and
(iii) the future timestep prediction task. First, the encoder from [
68] is replaced with a network with higher striding (details below), resulting in a reduction in the temporal resolution. In addition, a causal convolutional network is used to summarize previous latent representations into a context vector instead of the GRU-based autoregressive network. Finally, the future timestep prediction is performed at every context vector instead of utilizing a random timestep to make the prediction. These changes, put together, substantially improve the performance of the learned Enhanced CPC representations, compared to state-of-the-art methods. In what follows, we provide the architectural details and a detailed description of the technique.
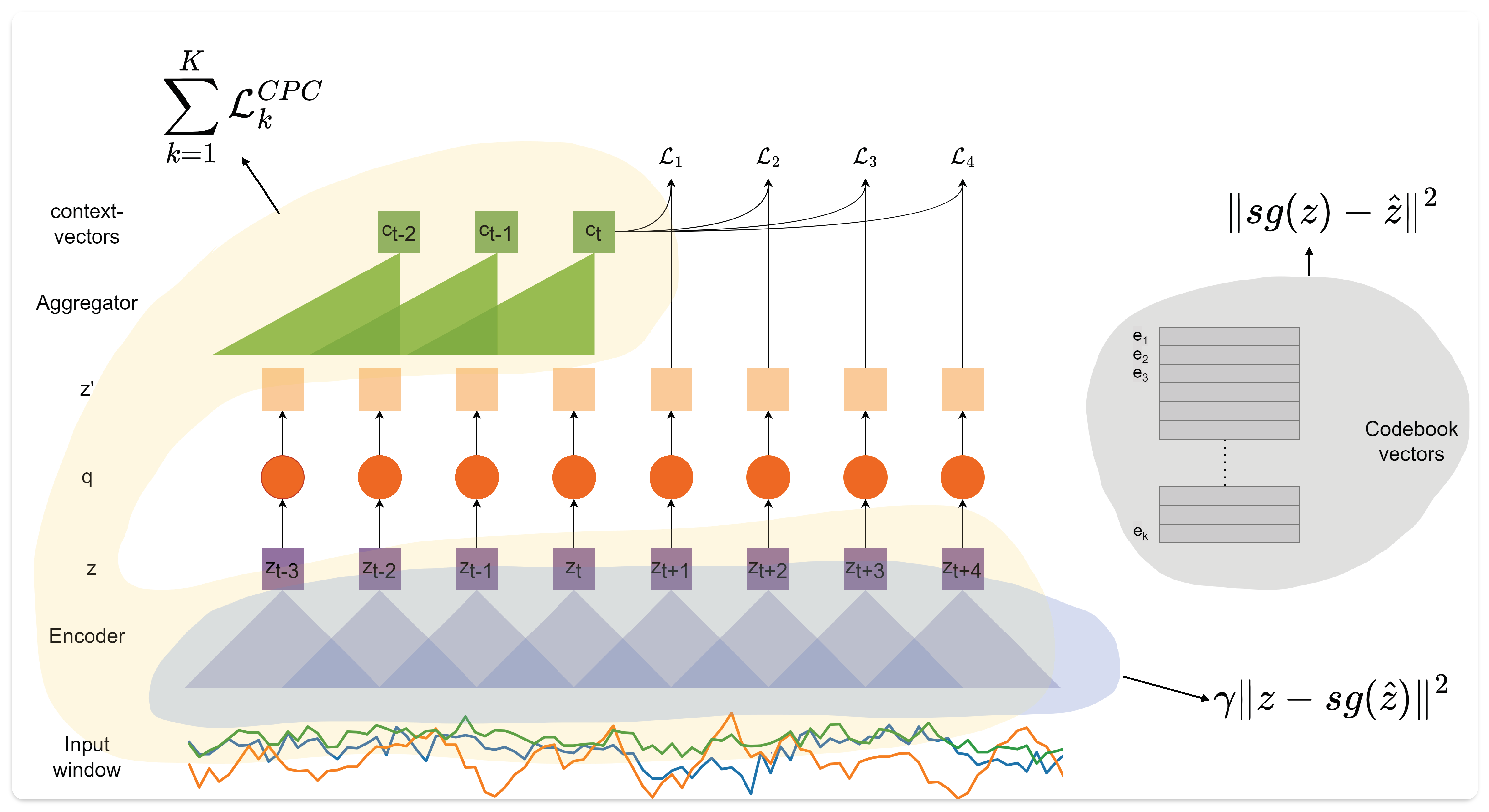
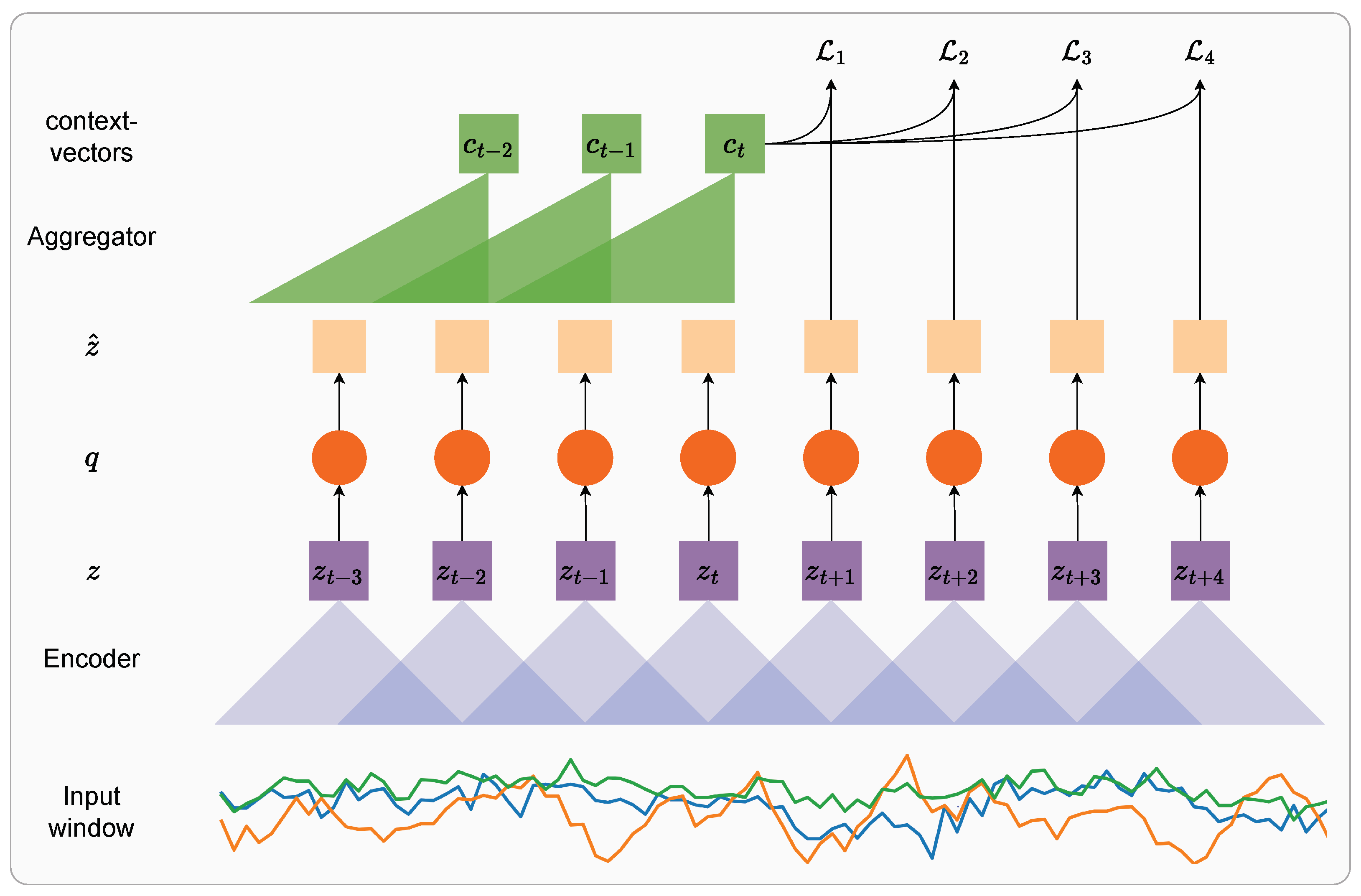
As shown in
Figure 2, we utilize a convolutional encoder to map windows of sensor data to latent representations
(called
z-vectors). It comprises four blocks, each containing a 1D convolutional network followed by the ReLU activation and dropout with
p = 0.2. The layers consist of (32, 64, 128, 256) channels, respectively, with a kernel size of (4, 1, 1, 1) and a stride of (2, 1, 1, 1). The encoder output frequency is 24.5 Hz, as we obtain 49
z-vectors for each window of 100 timesteps (i.e., two seconds of data at 50 Hz). Therefore, we obtain one
for approx. every
two timesteps of data. By adjusting the convolutional encoder architecture appropriately, the frequency can be adjusted to increase or reduce relative to the base setup detailed above (see
Section 5.4). In addition, the convolutional encoder can also be modified for training on data recorded at higher sampling rates (i.e., >50 Hz) in order to maintain an output frequency of
z-vectors at 24.5 Hz.
The quantization module (
) replaces each
with
, which is the index of the closest codebook vector (also called the codeword), from a fixed size codebook
, containing
V representations of size
d (details in
Section 3.1.1). We utilize the online K-means-based quantization from [
28], which is similar to the vector quantized autoencoder [
29] detailed originally in [
29].
Following Enhanced CPC [
30], a causal convolutional network called the ‘Aggregator’ is used for summarizing previous timesteps of encoded representations
(
) into the context vectors
, which are used to predict multiple future timesteps. This enables improved parallelization due to the convolutions and results in faster training times. Each block in the Aggregator has 256 filters with dropout
p = 0.2, layer normalization, and residual connections between layers, as utilized in [
28]. For each causal convolution layer in successive blocks, the stride is set to 1, whereas the kernel sizes are consecutively increased from 2. The network is once again trained to identify the ground truth
, which is
k steps in the future from a collection of negatives sampled randomly from the batch for every
in the window. Such a setup was first introduced in VQ-Wav2vec [
28], where two quantization approaches—Gumbel softmax [
48] and K-means [
28,
29]—were studied for their effectiveness towards better speech recognition. In our work, however, preliminary explorations revealed the higher effectiveness of the online K-means-based quantization, described below.
3.1.1. K-Means Quantization
As detailed previously, the codebook has a size of
, where
V is the number of variables in the codebook, and
d is their dimensionality. The vector quantization procedure allows for a differentiable process to select codebook indices. As shown in
Figure 3, the nearest neighbor codebook vector to any
z-vector in terms of the Euclidean distance is chosen, yielding
. The
z-vector is replaced
, which is the codebook vector at the index
i. As mentioned in [
29], this process can be considered a non-linearity that maps latent representations to one of the codebook vectors.
As choosing the codebook indices does not have a gradient associated with it, the straight-through estimator [
80] is employed to simply copy gradients from the Aggregator input
to the encoder output
. Therefore, the forward pass comprises the selection of the closest codebook vector, whereas during the backward pass, the gradient becomes copied as-is to the encoder. The parameters are updated using the future timestep prediction loss as well as two additional terms:
where
,
is the stop gradient operator,
k is the future timestep, and
is a hyperparameter. Due to the straight-through estimation, the codebook does not obtain any gradients from
. However, the second term
moves the codebook vectors closer to the
z-vectors, whereas the third term
ensures that
z-vectors are close to a codeword. Therefore, the Aggregator network is updated via the first loss term, whereas the convolutional encoder is optimized by the first and third loss terms. The codebook vectors are initialized randomly and updated using the second loss term. This is visualized in
Figure A3 in
Appendix A. The weighting term
is set to
as utilized in [
27,
29], as we obtained good performance.
3.1.2. Preventing Mode Collapse
As discussed in [
28], replacing
z by a single entry
from the codebook is prone to mode collapse, where very few (or only one) codebook vectors are actually used. This leads to very poor outcomes due to a lack of diversity in the discrete representations. To mitigate this issue, ref. [
28] suggests independent quantization of partitions, such that
is organized into multiple groups
G using the form
. Each row is represented by an integer index, and the discrete representation is given by indices
, where
V is the number of codebook variables for the particular group and each element
is the index of a codebook vector. For each of the groups, the vector quantization is applied and the codebook weights are not shared between them. During pre-training, we utilize
(as per [
28]), and
, resulting in a possible
possible codewords. In practice, the number of unique discrete representations is generally significantly smaller than
.
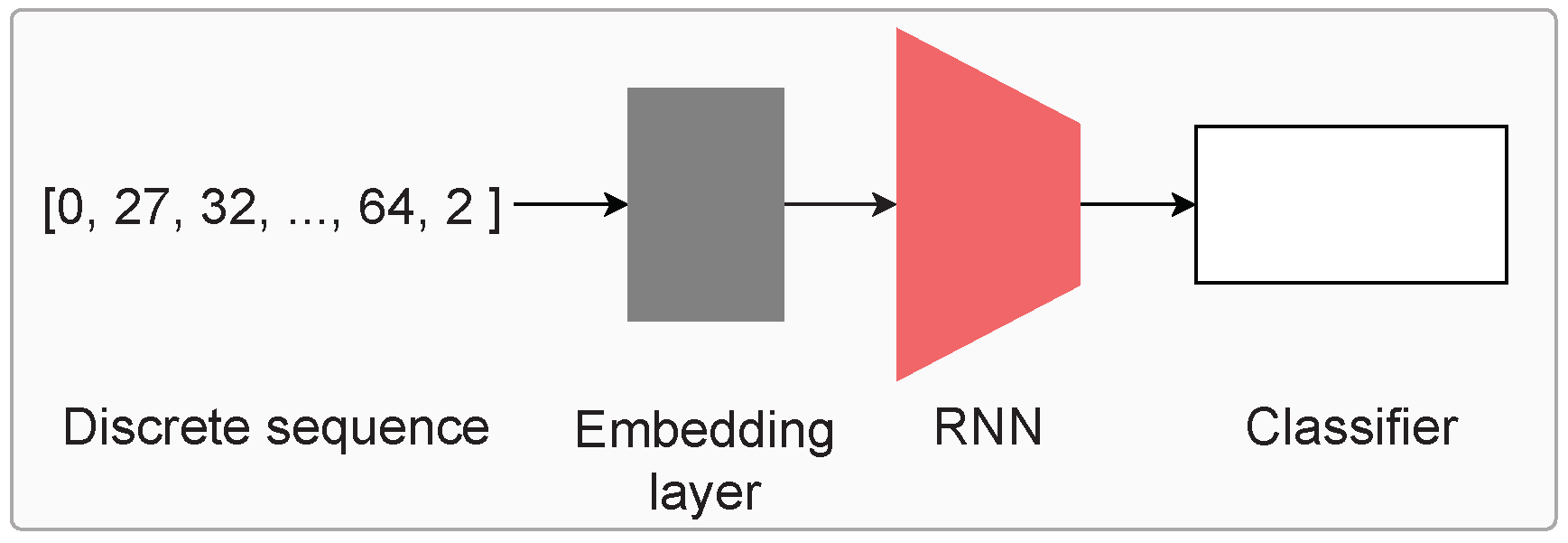
3.2. Classifier Network
As the obtained representations (or symbols) are discrete in nature, applying a classifier directly is not possible. Therefore, we utilize an established setup from the natural language processing domain (which also deals with discrete sequences) to perform activity recognition, shown in
Figure 4.
First, the discrete representations are indexed, i.e., assigned a number based on the total number of such symbols present in the data. For each window of symbols, we append the
and
tokens to the beginning and end of the window. The dictionary also contains the pad
and unknown
tokens, which represent padding (sequences of differing lengths can be padded to a common length) and unknown (symbols present during validation/test but not during training, for example). The indexed sequences are used as input to a learnable embedding layer (shown in grey in
Figure 4), followed by an LSTM or GRU network of 128 nodes and two layers with dropout (
p = 0.2). Subsequently, a MLP network identical to the classifier network from [
16] is applied. It contains three linear layers of 256, 128, and
units with batch normalization, ReLU activation, and dropout in between.
5. Results
Through the work presented in this paper, we aim to demonstrate the potential of learning discrete representations of human movements. For this, we first evaluate their effectiveness for HAR via a simple recurrent classifier. The performance is contrasted against established supervised baselines (such as DeepConvLSTM), as well as the state-of-the-art for representation learning, which is self-supervision. Subsequently, we contrast the impact of learning the discrete representations rather than computing via prior methods involving SAX. This is followed by an exploration into the discrete representation learning framework, where we study the impact of controlling the resulting alphabet size (i.e., the fidelity of the representations) and the effect of the duration of sensor data on each symbol’s representation. Finally, we apply self-supervised pre-training techniques designed for discrete sequences in order to study whether such tasks can further help improve recognition performance. Overall, these experiments are designed to not only study whether discrete representations can be useful but also to derive a deeper understanding of their working.
5.1. Activity Recognition with Discrete Representations
First, we evaluate the performance of the discrete representations for recognizing activities from windows of discrete sequential data. After the pre-training is complete, we perform inference to obtain the discrete representations and utilize the setup detailed in
Section 3.2 for classification. The performance is compared against diverse self-supervised learning techniques, which represent the state of the art of representation learning in HAR (as shown in [
16]), including:
(i) multi-task self-supervision, which utilizes transformation discrimination;
(ii) Autoencoder, reconstructing the original input through an additional decoder network;
(iii) SimCLR, contrasting two augmented versions of the same input window against negative pairs from the batch;
(iv) CPC, which uses multiple future timestep predicton for pre-training; and
(v) Enhanced CPC, as before but with improvements to the CPC framework on the encoder, aggregator, and future prediction tasks [
30]. Here, the encoder weights are frozen and only the MLP classifier is updated with annotations.
DeepConvLSTM, a Conv. classifier with the same architecture as the encoder for Multi-task, Autoencoder, and SimCLR, along with a GRU classifier function as the end-to-end training baselines. We perform five fold cross validation and report the performance for five randomized runs in
Table 2. The comparison is performed on six datasets across sensor locations (Capture-24 is collected at the wrist, whereas the target datasets are spread across the wrist, waist, and leg) and activities (which include locomotion, daily living, health exercises, and fine-grained gym exercises).
For the waist-based Mobiact, which covers locomotion-style activities along with transitionary classes such as stepping in and out of a car, the discrete representation learning performs comparably or better than all methods, obtaining a mean of 77.8%. However, for Motionsense, the performance is similar to the best performing model overall, which is Enhanced CPC, once again outperforming other self-supervised and supervised baselines. Considering the leg-based PAMAP2 dataset, VQ-CPC obtains lower performance and is similar to the GRU classifier. For MHEALTH as well, the performance drops significantly compared to Enhanced CPC, showing a reduction of around 4.8%, yet outperforming the Autoencoder, SimCLR, Multi-task, and CPC.
Finally, we consider wrist-based datasets such as HHAR and Myogym. HHAR comprises locomotion-style activities and the discrete representations improve the performance over Enhanced CPC by around 1.5%, thereby constituting the best option for wrist-based recognition of locomotion activities. Interestingly, the discretization results in poor features for classifying fine-grained gym activities, with the performance dropping significantly compared to other self-supervised methods. Enhanced CPC also sees substantially lower performance than SimCLR, likely due to the increased striding in the encoder, which results in a latent representation for approx. every second timestep, thereby negatively impacting the recognition of activities such as fine-grained curls and pulls. In addition, the discretization results in a smaller, finite codebook, which is a loss in temporal resolution compared to continuous-valued high-dimensional features. This is detrimental to Myogym, resulting in poor performance.
Therefore, the discrete representations can result in effective recognition of locomotion-style and daily living activities, and overall perform the best (or similar to the best) on three benchmark datasets, at the wrist and waist. The loss in resolution due to mapping the continuous-valued sensor data to a finite collection of codebook vectors (and their indices) does not have a significant negative impact on locomotion-style activities but is detrimental for recognizing fine-grained movements (as present in Myogym for example). In addition, the effective performance across sensor locations indicates the capability of the discrete representation learning process and shows its promise for sensor-based HAR. This result presents practitioners with a new option for activity recognition, with comparable performance and potentially lowered data upload costs, as the discretized representations result in more compressed data than continuous-valued sensor readings.
5.2. Comparison to Established Discretization Methods
In this experiment, we compare the performance of SAX, which is an established method for discretizing uni-variate time-series data, and SAX-REPEAT [
37], which utilizes SAX for discretizing multi-channel time-series data. For appropriate comparison, SAX also results in one symbol for every second timestep of sensor data, with an alphabet size of 512. SAX-REPEAT separately applies SAX to each channel of accelerometer data, resulting in tuples of indices for every second timestep. As utilizing the tuples as-is results in a possible dictionary size of
, SAX-REPEAT performs K-Means clustering (with k = 512) on the tuples in order to maintain an alphabet size of 512, where the cluster indices function as the discrete representation. The same classifier setup (
Section 3.2) is utilized for activity recognition (including the parameter tuning for classification) and five random runs of the five fold validation F1-score is detailed in
Table 3. The comparison is drawn against the learned discrete representation method, which is VQ-CPC.
For all datasets, the SAX baseline performs poorly compared to the learned discrete representations, showing a reduction of over 10% for HHAR, Myogym, and Motionsense, and a smaller reduction for Mobiact, MHEALTH, and PAMAP2. This can be expected as SAX utilizes the magnitude of the accelerometer data as the input, thereby reducing three channels to one and losing information about the direction of movement. Considering SAX-REPEAT next, we see that it shows worsened performance to SAX on HHAR, MHEALTH, and PAMAP2. For Mobiact, the performance is only 6% lower than VQ-CPC + GRU classifier, whereas for the other datasets, the difference is greater. Only on Myogym, the performance is better than VQ-CPC, albeit substantially lower than the state-of-the-art self-supervised as well as end-to-end training methods. The lower performance for SAX and SAX-REPEAT for Myogym also indicates that discretization is not a good option for fine-grained activities. Our experiments clearly show that SAX and SAX-REPEAT are worse at recognizing activities compared to VQ-CPC. Further, the reduction in performance of SAX-REPEAT relative to SAX on HHAR, MHEALTH, and PAMAP2, indicates that modifying SAX to apply to multi-variate data is challenging. Overall,
Table 3 shows that the traditional methods are not effective for discretizing accelerometer data, and that learning a codebook in an unsupervised, data-driven way results in a better mapping of sensor data to discrete representations.
5.3. Effect of the Learned Alphabet Size
One of the advantages of discrete representation learning via vector quantization is the control over the size of the learned dictionary. It can be set depending on the required fidelity of the learned representations and the capacity of the computation power available for classification. For applications where the separation of activities requires a small dictionary (e.g., 8 or 16 symbols), we can accordingly set the dictionary size and thereby save computation power during classification. For our base setup (
Table 2), we utilize independent quantization of partitions of the vectors, resulting in a possible
dictionary size. Here, we explicitly control the dictionary size by setting the number of groups to 1 and varying the number of variables (i.e., the number of codebook vectors) between (32, 64, 128, 256, 512). We also note that the final dictionary size can be lower than the codebook size and depends on the underlying movements and sensor data. We perform activity recognition on the resulting discrete representations of windows of sensor data using the best performing models from
Table 2, albeit with increasing alphabet sizes. The results from this experiment are tabulated in
Table 4. A similar analysis was also performed in VQ-APC [
51].
First, we notice that having a max. alphabet size of 32 results in poor performance. Such a small dictionary size provides limited descriptive power for the representations and therefore leads to significant drops in performance relative to the base setup of utilizing multiple groups during quantization (see
Section 3.1.2). Along the same lines, having too large a dictionary size is also slightly detrimental (max dict size = 512), as it can lead to long-tailed distributions of the symbolic representations and the network starting to pay attention to noises instead.
We obtain the highest performance when the max dictionary sizes are 64, 128, or 256. For HHAR, the constraint on the dictionary size results in an increase of over 7% relative to the base setup (VQ CPC + GRU classifier). For Myogym and Mobiact, however, not constraining the resulting dictionary sizes is the best option, with clear increases over the constrained models. For Motionsense and PAMAP2, controlling the learned alphabet size results in modest performance improvements of 1%, whereas for MHEALTH, it is around 0.6%. Clearly, with reducing codebook sizes, the model is forced to choose what information to discard and what to encode [
51]. This process can result in higher performance as the network can more efficiently learn to ignore irrelevant information (such as noise) and picks up more discriminatory information.
Next, we consider the mean dictionary size across all folds obtained by utilizing groups = 2 (as in
Table 2; see
Section 3.1.2 for reference). For all target datasets, the size <160 symbols, emphasizing that effective recognition can be obtained using just around 130–160 symbols. This is encouraging, as downstream tasks such as gesture or activity spotting, can be performed more easily with a smaller dictionary size. The importance of creating groups during discretization is also visible, as it results in the highest performance for two target datasets, along with comparable performance for three datasets, without having to further tune the dictionary size as a hyperparameter.
5.4. Impact of the Encoder’s Output Frequency
In
Section 3, we detailed the architecture for learning discrete representations of human movements. The convolutional encoder results in approximately one latent representation per two timesteps of sensor data. With appropriate architectural modifications, we can increase or reduce the output frequency of the encoder. Intuitively, a lower output frequency can be problematic as too much motion (and variations of motion) can be mapped to each symbol. When this occurs, nuances in movements are not captured well by the symbolic representations. In this experiment, we vary the output frequency and study the impact on performance. The convolutional encoder is modified accordingly:
(i) for an output frequency of 50 Hz (i.e., no downsampling relative to the input), we change the stride of the first block to 1 and for the second block, set the kernel size and stride = 1; and
(ii) for an output frequency of 11.5 Hz (i.e., further downsampling by two relative to the base setup), the second block also has a kernel size of 4 with stride = 2. We perform activity recognition on the six target datasets, and report the five fold cross validation performance across five randomized classification runs in
Table 5.
As expected, an encoder output frequency of 11.5 Hz (i.e., # timesteps/symbol ≈ 4) results in substantial reductions in performance relative to the base setup (where the output frequency is 24.5 Hz). For HHAR, the drop in performance is around 10%. However, for Myogym, MHEALTH, and PAMAP2, it is over 15%. The waist-based datasets see the highest impact on performance, experiencing a reduction of over 20% with the longer duration mapping. We can reasonably expect that a lower encoder output frequency, will result in further reduction in performance.
We also note that maintaining the same output frequency as the input also causes a drop, albeit smaller, in the test set performance. While this configuration can be utilized for obtaining discrete representations, the training times are considerably higher, while also not resulting in performance improvements. Therefore, an output frequency of 24.5 Hz (relative to an input of 50 Hz) is better, allowing for quicker training while also covering more of the underlying motion.
5.5. NLP-Based Pre-Training with RoBERTa
One of the advantages of converting the sensor data into discrete sequences is that it allows us to apply powerful NLP-based pre-training techniques such as BERT [
35], RoBERTa [
34], GPT [
89], etc., as learned embeddings for the RNN classifier. In addition, the release of new techniques for text-based self-supervision can be accompanied by corresponding updates to the classification of the discrete representations learned from movement data. Therefore, in this experiment, we investigate whether Robustly Optimized BERT Pretraining Approach (RoBERTa) [
34] based pre-training on the symbolic representations is useful for improving activity recognition performance. While RoBERTa can increase the computational footprint of the recognition system, it can be potentially replaced with recent advancements in distilling and pruning BERT models such as SNIP [
90], ALBERT [
91], and DistillBERT [
92] while maintaining similar performance.
First, we extract the symbolic representations on the large-scale Capture-24 dataset (utilizing 100% of the train split), and use it to pre-train two RoBERTa models, called ‘small’ and ‘medium’. The ‘small’ model contains an embedding size of 128 units, a feedforward size of 512 units, and two Transformer [
93] encoder layers with eight heads each. On the other hand, the ‘medium’ sized model comprises embeddings of size 256, with a feedforward dimension of 1024, and four Transformer encoder layers with eight heads each. The aim of training models with two different sizes is to investigate whether increased depth results in corresponding performance improvements or not. Following the protocol from
Table 2, the performance across five random runs is reported for five fold cross validation is reported in
Table 6. As shown in
Figure A1 (in
Appendix A), the randomly initialized learnable embedding layer is replaced with the learned RoBERTa models, which are frozen. Only the GRU classifier is updated with label information during the classifier training.
First, we observe that utilizing the learned RoBERTa embeddings (VQ CPC + RoBERTa small/medium in
Table 6) instead of the random learnable embeddings (VQ CPC in
Table 6) results in performance improvements for
all target datasets. This indicates the positive impact of pre-training with RoBERTa. For the small version, the HHAR and Myogym see increases of 2% and 2.8%, respectively. A similar trend is observed for the waist-based Mobiact and Motionsense as well, improving by 1.6% and 2.5%. Finally, the leg-based datasets also see improvements of around 2.5% each. Interestingly, the medium-sized model of RoBERTa shows a similar performance to the small version, except for the wrist-based HHAR and Myogym, where the increase over random embeddings is 3% and 3.5%, respectively. The similar performance demonstrated by the medium version indicates that the increase in model size did not result in corresponding performance improvements, likely because Capture-24 is not large enough to leverage the bigger architecture. Potentially, an even larger dataset (e.g., Biobank [
94]) can be utilized for the medium version (or even larger variants).
The advantage of performing an additional round of pre-training via RoBERTa is clearly observed in
Table 6, as VQ CPC + RoBERTa outperforms the state-of-the-art self-supervision on three datasets (HHAR, Mobiact, and Motionsense) by clear margins. For the leg-based datasets, the performance with the addition of RoBERTa is closer to the most effective methods through improved learning of embeddings. This result is promising for wearables applications, as it proves that the rapid advancements from NLP can be applied for improved activity recognition as well.
6. Discussion
In this paper, we propose a return to discrete representations as descriptors of human movements for wearable-based applications. Going beyond prior works such as SAX, we instead learn the mapping between short spans of sensor data and symbolic representations. In what follows, we will first visualize the distributions of the discrete representations for activities across the target datasets and examine the similarities and differences. The latter half of this section contains an introspection of the method itself, along with the lessons learned during our explorations.
6.1. Visualizing the Distributions of the Discrete Representations
We demonstrated that training GRU classifiers with randomly initialized embeddings (
Table 2) results in effective activity recognition on five of six benchmark datasets. In addition, deriving pre-training embeddings from the discrete representations via RoBERTa further pushes the performance, exceeding state-of-the-art self-supervision on three datasets. Given their recognition capabilities, we plot the distributions of the discrete representations for each activity, in order to visualize how the underlying movements may be different. This serves as a first check to visually examine whether similar activities such as walking and walking up/downstairs—which may have similar underlying movements—are actually represented in similar discrete representations.
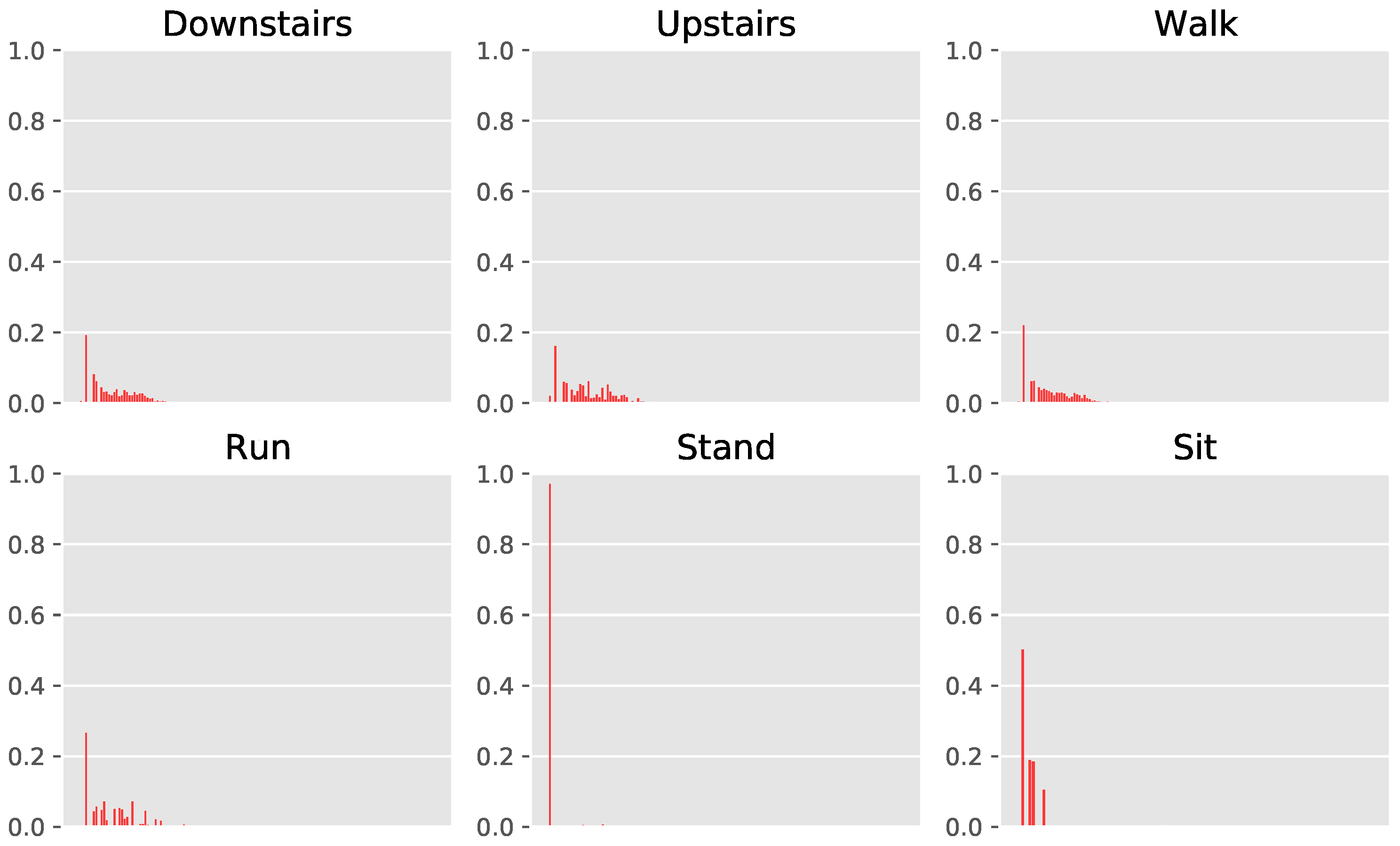
In
Figure 5 and
Figure A2, we present the histograms of the discrete representations per activity. The
y-axis comprises the fraction of the total sum of representations held by each discrete symbol. First, we note that the discrete representations exhibit long-tailed distributions, with a significant portion of representations being used very sparsely (more clearly visible in
Figure A2). The impact of such a distribution is challenging to predict, on one hand, the rarely occuring symbols can increase the complexity of the classifiers (and embeddings) due to their numerosity, while on the other, it is likely they capture more niche movements as they may be performed by participants. Such niche movements can potentially help with the classification of less frequent activities. In addition, we also note that the distributions for sitting and standing contain limited variability, as the underlying movements themselves exhibit less motion. This somewhat verifies that the learned discrete representations correspond to the movements themselves, given that a lack of movement is captured in the distribution of representations per activity. Interestingly, the histograms for going up and down the stairs look very similar, while walking also retains similarities to them. Running looks slightly different, with more spreading out across the symbolic representations, therefore indicating that higher variability of underlying movements involving running, which makes sense intuitively. Therefore, the distributions of the discrete representations provide practitioners with an additional tool for understanding human activities as well as the underlying movements. This is a point in favor of discrete representations, as the analysis is possible in conjunction with comparable if not better performance for activity recognition.
6.2. Analyzing the VQ-CPC Discretization Framework
Here, we examine specific components of the framework, in order to understand their impact on both discrete representation learning, as well as on downstream activity recognition. To this end, we consider the following components: (i) the Encoder network, where the architecture determines the duration of time covered by each symbol; and (ii) the self-supervised pretext task, which acts as the base for the discrete representation learning. In what follows, we study the activity recognition performance for the same target datasets, albeit replacing the aforementioned components of the framework with suitable alternatives, and examine the performance.
6.2.1. Impact of the Encoder Architecture
Our Encoder architecture is based on the Enhanced CPC framework [
30]. As detailed in
Section 3.1, it contains four convolutional blocks, with a kernel size of (4,1,1,1), and stride of (2,1,1,1), respectively. Therefore, the resulting
z-vectors are obtained approximately once every second timestep (we obtain 49
z-vectors from an input window of 100 timesteps due to the striding). From
Table 5, we see that decreasing the encoder output frequency to 11.5 Hz is detrimental to performance. We now conduct a deeper analysis of the design of suitable encoders by considering the following configurations:
(i) increasing the kernel size of the first layer to (8, 16), while keeping the architecture otherwise identical to the base setup; and
(ii) utilizing an encoder identical to the convolutional encoders of multi-task self-supervision [
15] and SimCLR [
70]. The learning rate and L2 regularization are identical to the base setup, and we also tune the number of aggregator layers across (2,4,6) layers, as described in
Section 4.
In the base setup, movement across four timesteps (0.08 s at 50 Hz) contributes to each symbol. This is increased to (8, 16) timesteps depending on the filter size of the first layer. From
Table 7, we see that this is detrimental to HAR. Clearly, it becomes difficult to learn the mapping between eight timesteps (and greater, i.e., ≥0.16 s) to symbols, as the underlying movements cover much longer durations and thus become too coarse for symbolic representations. We extend this analysis by applying the encoder from multi-task self-supervision. Ref. [
15] instead of the base encoder, for pre-training. As the encoder contains three blocks with filter sizes of (24, 16, 8), a total of 46 timesteps (i.e., 0.92 s of movements) contribute to each symbol. We observe a significant drop in performance as a result, with around 15% reduction for HHAR and approx. 30% decrease for Mobiact. While it is preferable to learn symbols that represent short spans of time, clearly, accurately mapping longer durations to symbols is a difficult proposition. From our exploration, a filter size of 4 (for the first layer) seems ideal, covering sufficient motion as well as resulting in accurate HAR. This also motivates the architecture of our encoder, where all layers apart from the first one have a filter size of 1. Having multiple layers (after the first) with filter size >1 would result in
z-vectors corresponding to longer durations, thereby resulting in reduced performance.
6.2.2. Effect of the Base Self-Supervised Method on Recognition Performance
Next, we evaluate the applicability and utility of various self-supervised methods to serve as the basis for the discrete representation learning setup. Such analysis enables us to determine which self-supervised method can be utilized, allowing us to provide suggestions for specific scenarios. For example, as discussed in [
16], simpler methods such as Autoencoders may be preferable—even though the performance is slightly lower—as they are easier and quicker to train. Furthermore, K-means-based vector quantization (VQ) was also originally introduced in an Autoencoder setup [
29]. Therefore, we not only study Autoencoders, but also other baselines such as multi-task self-supervision and SimCLR, for their effectiveness toward functioning as the base for deriving discrete representations. For this analysis we also perform brief hyperparameter tuning for the baseline methods, using the best parameters detailed in [
16] and over the number of convolutional aggregator layers
(similar to VQ-CPC). The results from this analysis are given in
Table 8.
First, we compare the performance of VQ-CPC against adding the VQ module to the Autoencoder setup (“VQ-Autoencoder” in
Table 8). For target datasets such as HHAR, Motionsense, and PAMAP2, the drop in performance while utilizing the Convolutional Autoencoder as the base is around 10%. In the remaining target scenarios, the reduction is lower at around 4%, save for Myogym where the performance is comparable. The established multi-task self-sup. Ref. [
15] framework is ill-suited for discrete representation learning, with significant reductions in performance throughout, consistently performing worse by approx. 10% for most datasets and peaking at around 29% for Mobiact. A similar analysis of SimCLR shows an even more substantial reduction in performance, dropping by over 35% consistently. As analyzed in
Section 6.2.1, the low performance of SimCLR and multi-task self-sup. is likely due to the encoder architecture itself, which has a large receptive field (see below).
In order to study whether smaller filters are more suitable for other self-supervised methods as well, we replace their encoders with the encoder network from VQ-CPC, and study the impact on the recognition accuracy. For the Autoencoder, the effect is mixed, with the performance increasing slightly for datasets such as HHAR, Myogym, and PAMAP2, whilst reducing for Motionsense and MHEALTH. In the case of multi-task self-sup., we observe that matching the encoder network (to VQ-CPC) has a significant impact on performance, resulting in improvements of approx. 8% for PAMAP2, 13% for HHAR, 24% for Mobiact, and more modest 4–5% for Motionsense and MHEALTH. This clearly shows that large receptive fields such as the one resulting from the original Multi-task encoder are detrimental to discrete representation learning. Furthermore, utilizing a filter size of 4 is also a better option for other methods, including SimCLR. Overall, we observe that the Autoencoder or multi-task self-sup. with the replaced encoder can function as viable alternatives, albeit there is generally a reduction in performance relative to VQ-CPC. This can be useful in some situations as simpler methods may be preferable due to computational constraints.
6.3. Potential Impact beyond Standard Activity Recognition, and Next Steps
This work presents a proof of concept in favor of learning discrete representations for sensor-based human activity recognition. We present an alternative data processing and feature extraction pipeline to the HAR community, to be utilized for further application scenarios but also to (once again) jumpstart research into developing discrete learning methods. In what follows, we describe future potential application scenarios where discrete representations can be especially useful.
NLP-Based Pre-training: We observe in
Table 6 that adding pre-trained RoBERTa embeddings results in clear improvements over utilizing randomly initialized learnable embeddings for all target datasets. For the locomotion-style and daily living datasets in particular, this results in state-of-the-art performance, which is highly encouraging, as it opens the possibility of adopting more powerful recent advancements from natural language processing for improved recognition of activities. Replacing RoBERTa, larger models such as GPT-2 [
95] or GPT-3 [
96] or modifications to existing methods (e.g., masking spans of data [
27]) can be utilized on larger scale datasets such as UK Biobank [
94], leading to potential classification performance improvements. This is promising as advancements in NLP can also result in tandem improvements in sensor-based HAR. In resource-constrained situations, however, works miniaturizing and pruning language models [
90,
91,
92] can be employed to reduce size while maintaining similar performance.
Activity Summarization: The discrete representations also enable us to utilize established methods from NLP for unsupervised text summarization. They typically involve extracting key information/sentences from texts via methods like graphs [
97,
98] and clustering [
99,
100]—i.e., they are extractive rather than generative, as they do not have access to paired summaries for training. Therefore, we can utilize such summarization techniques in order to extract the most
informative sensor data, allowing us to, e.g., reduce noise (by removing unnecessary data), or summarize the important movements during the hour/day, etc., for understanding routines.
Sensor Data Compression: The discretization results in symbolic representations, which are essentially the ‘strings of human movements’, effectively compressing the original data requiring substantially less memory for storing relative to multi-dimensional floating point numbers. This can be helpful in situations where data needs to be transmitted from the wearable to a mobile phone or server, leading to a reduction in transfer costs. Furthermore, it also enables more efficient processing of extremely large-scale wearables datasets (such as the UK Biobank with 700k person days of data [
94]), where the size is a crutch for analysis and model development.
Activity and Routine Discovery: As mentioned in [
24], the process of discovering activities from unlabeled data is (in many ways) the opposite of building classifiers to recognize known activities using labeled data. An important application includes health monitoring where typical healthy behavior can be characterized by such discovery algorithms, whereas they may be difficult for humans (incl. experts) to fully specify [
24]. One approach involves deriving ‘characteristic actions’ via motif discovery, as such sequences are statistically unlikely to occur across activities and therefore correspond to important actions within the activity [
24]. Discovering motifs is easier in the discrete space (rather than raw sensor data space), especially for multi-channel data, as the simplification to a smaller alphabet aids with the identification of recurring patterns. Such a setup can be vital for understanding and analyzing human behaviors.
7. Conclusions
The primary aim of this work was to serve as a proof of concept to demonstrate how discrete representations can be learned from wearable sensor data, and that the performance of activity recognition systems based on such learned discretized representations is comparable to, if not better than, when using dense, i.e., continuous representations derived through state-of-the-art representation learning methods. In particular, we showed how automatically deriving the mapping between sensor data and a codebook of vectors in an unsupervised manner can solve some of the existing concerns with HAR applications based on discrete representations, including low activity recognition performance and difficulty with multi-channel data.
A deeper dive into the workings of discretization showed that explicitly controlling the maximum dictionary size can result in better representations. Further, the addition of powerful NLP-based pre-training techniques such as RoBERTa resulted in improved activity recognition for all target datasets. Therefore, this paper casts the multi-channel time-series classification problem as a discrete sequence analysis problem (similar to natural language processing), thereby facilitating the adoption of recent advancements in discrete representation learning for the field of sensor-based human activity recognition. In summary, our work offers an alternative feature extraction pipeline in sensor-based HAR, allowing for discretized abstractions of human movements and therefore enabling improved analysis of movements.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}