
Research on the Algorithm of Position Correction for High-Speed Moving Express Packages Based on Traditional Vision and AI Vision


Abstract
1. Introduction
- Development of an enhanced network architecture based on YOLOv5, aimed at augmenting the model’s proficiency in detecting and localizing moving express parcels.
- This study introduces a novel algorithm for positioning moving express parcels, integrating traditional vision techniques based on brightness values with AI-driven vision.
2. Related Work
- The introduction of visual technology into intelligent logistics sorting systems has been the main direction of research in the industry in recent years, serving as a crucial means to enhance the performance of intelligent logistics sorting systems.
- Different visual detection methods exist for various intelligent logistics sorting systems in different industries and scenarios.
3. Proposed Method
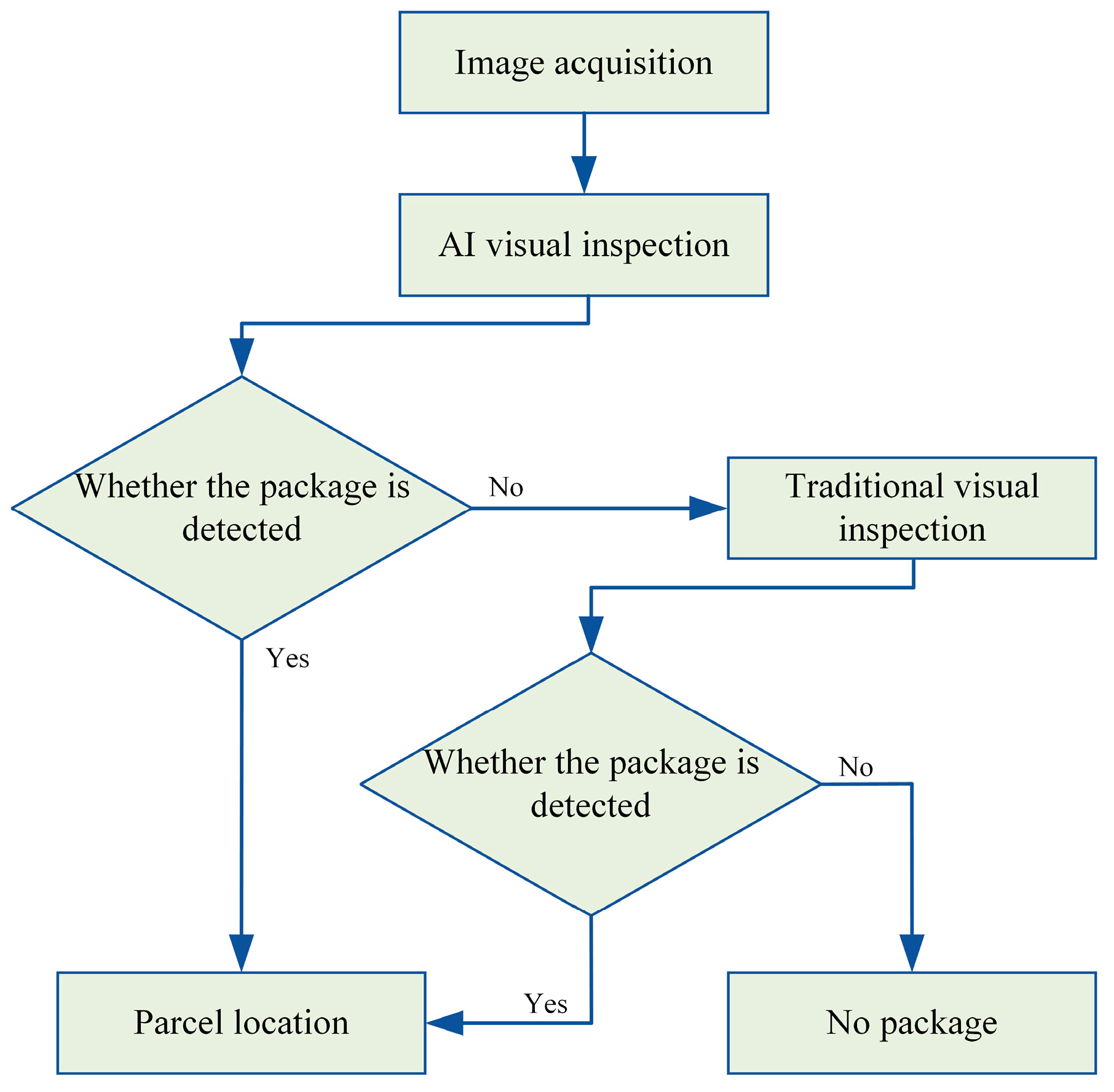
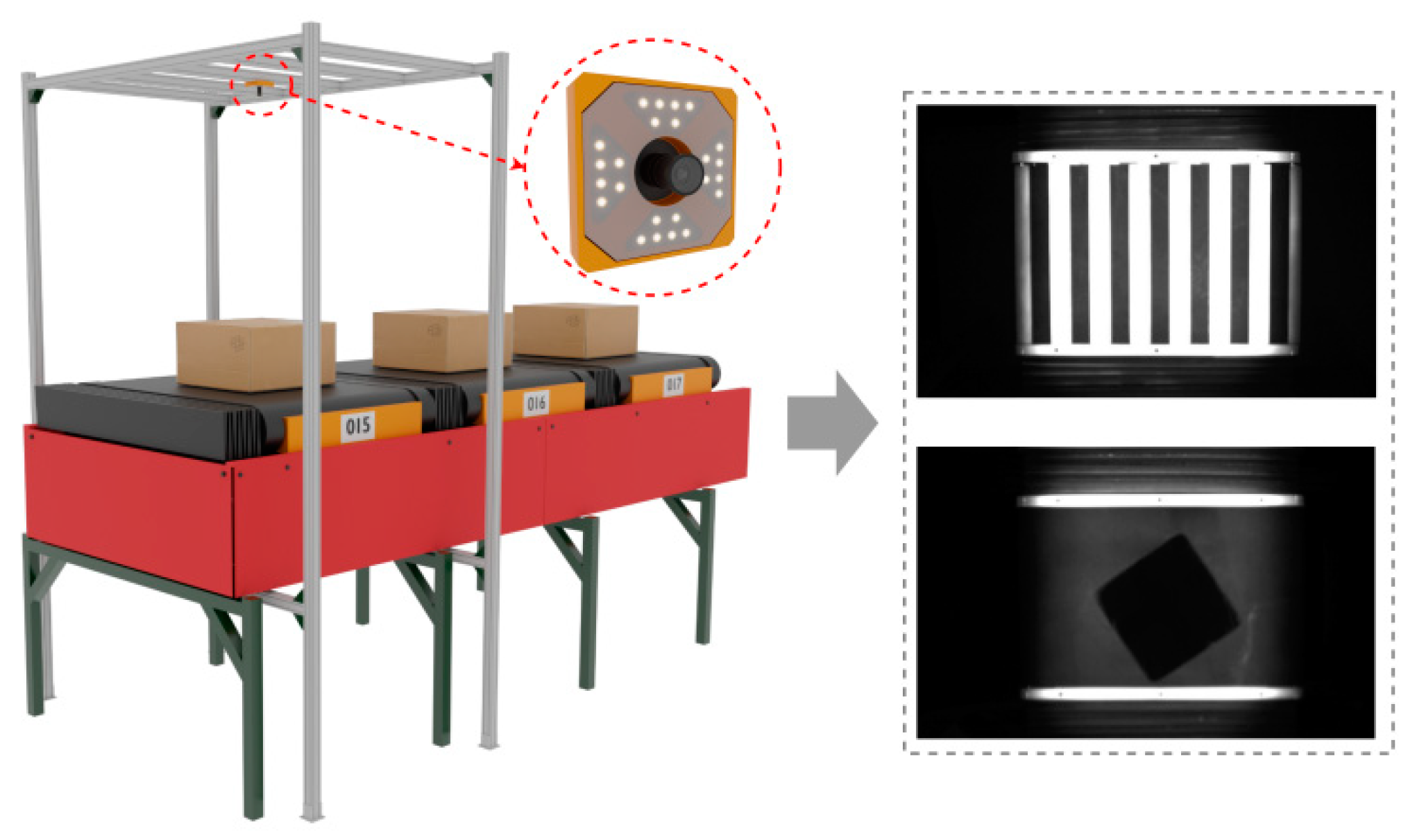
3.1. Overall Structure Design of Image Acquisition
3.2. Design of Traditional Visual Package Positioning Algorithm
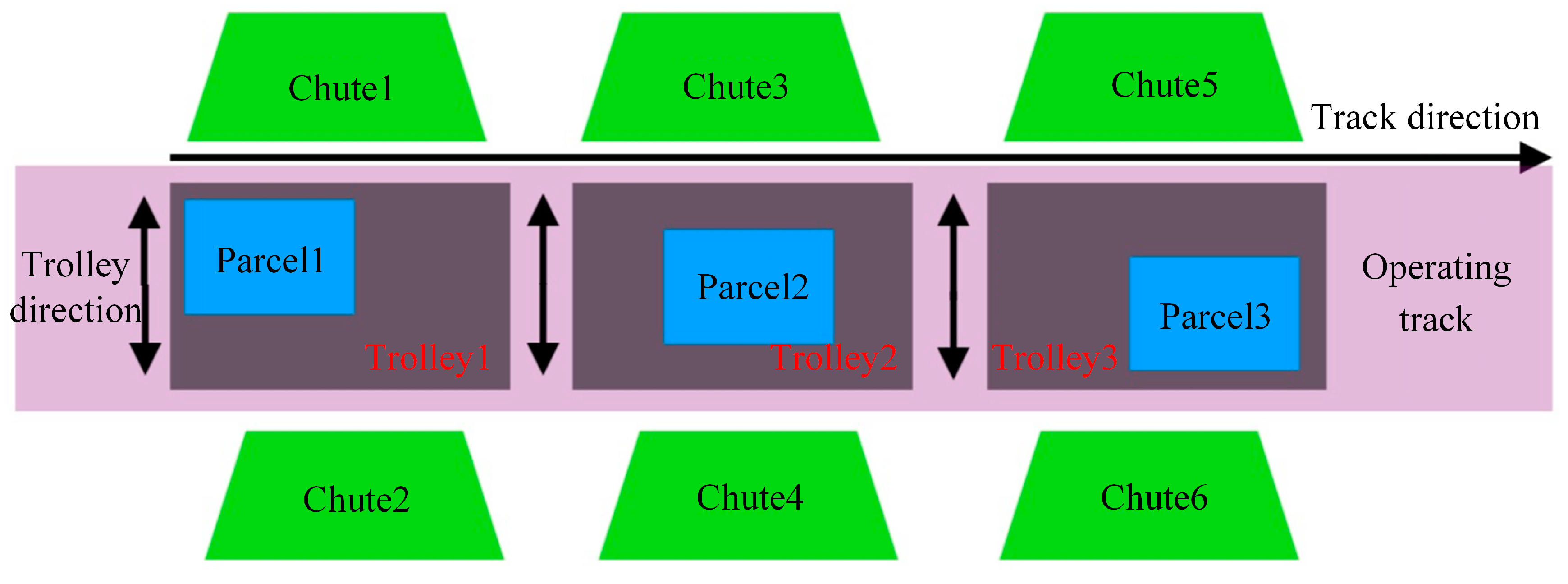
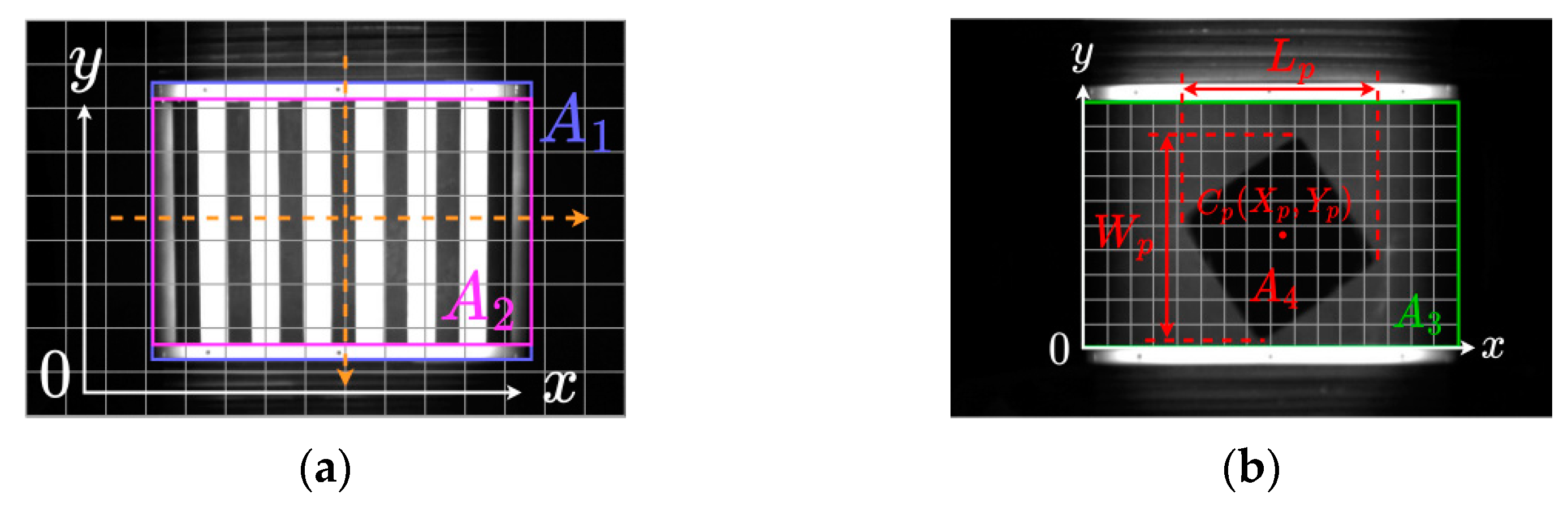
3.2.1. Trolley Detection Area Division
3.2.2. Parcel Location
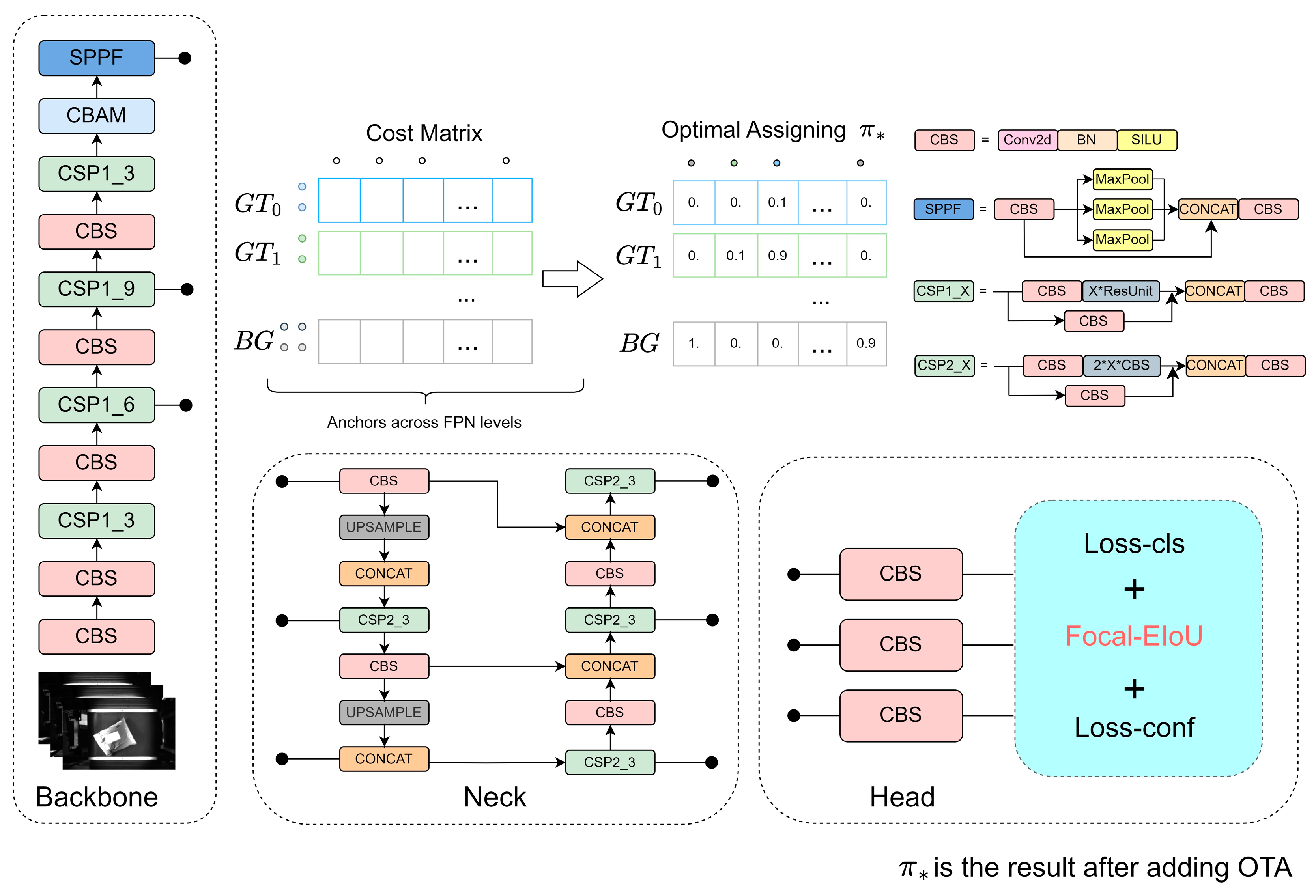
3.3. Parcel Location Algorithm Design of AI Vision
3.3.1. Algorithm Basis
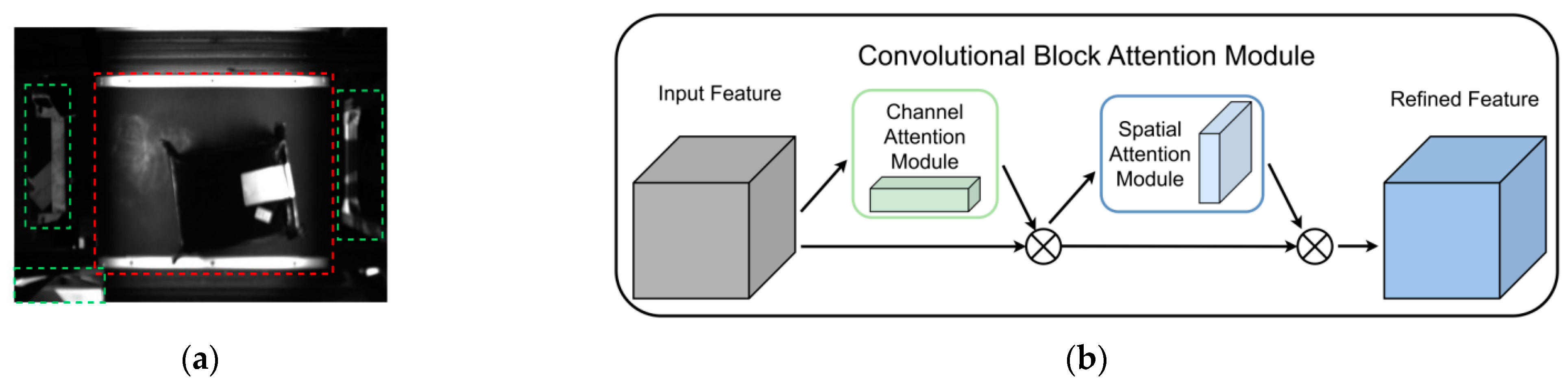
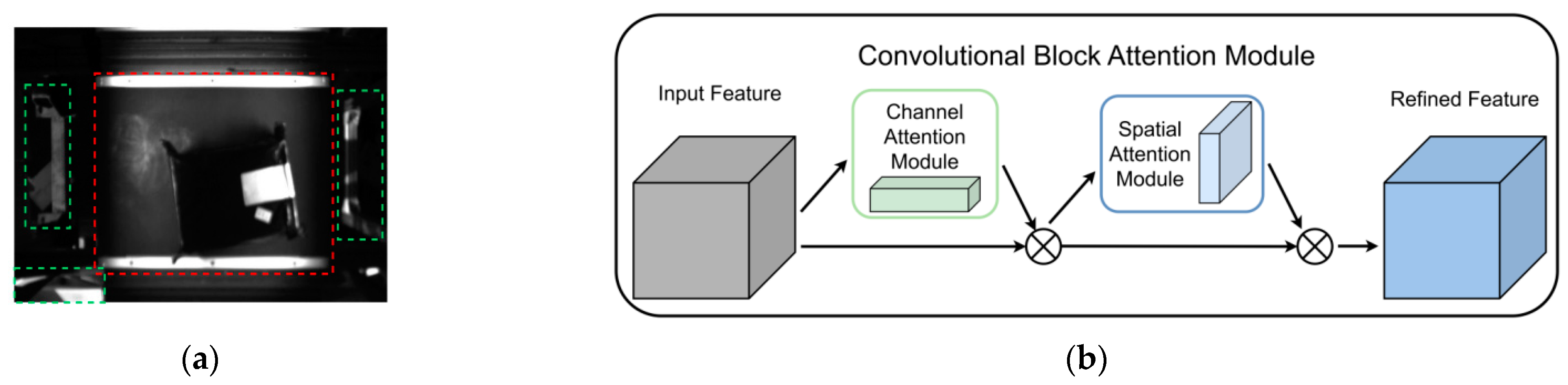
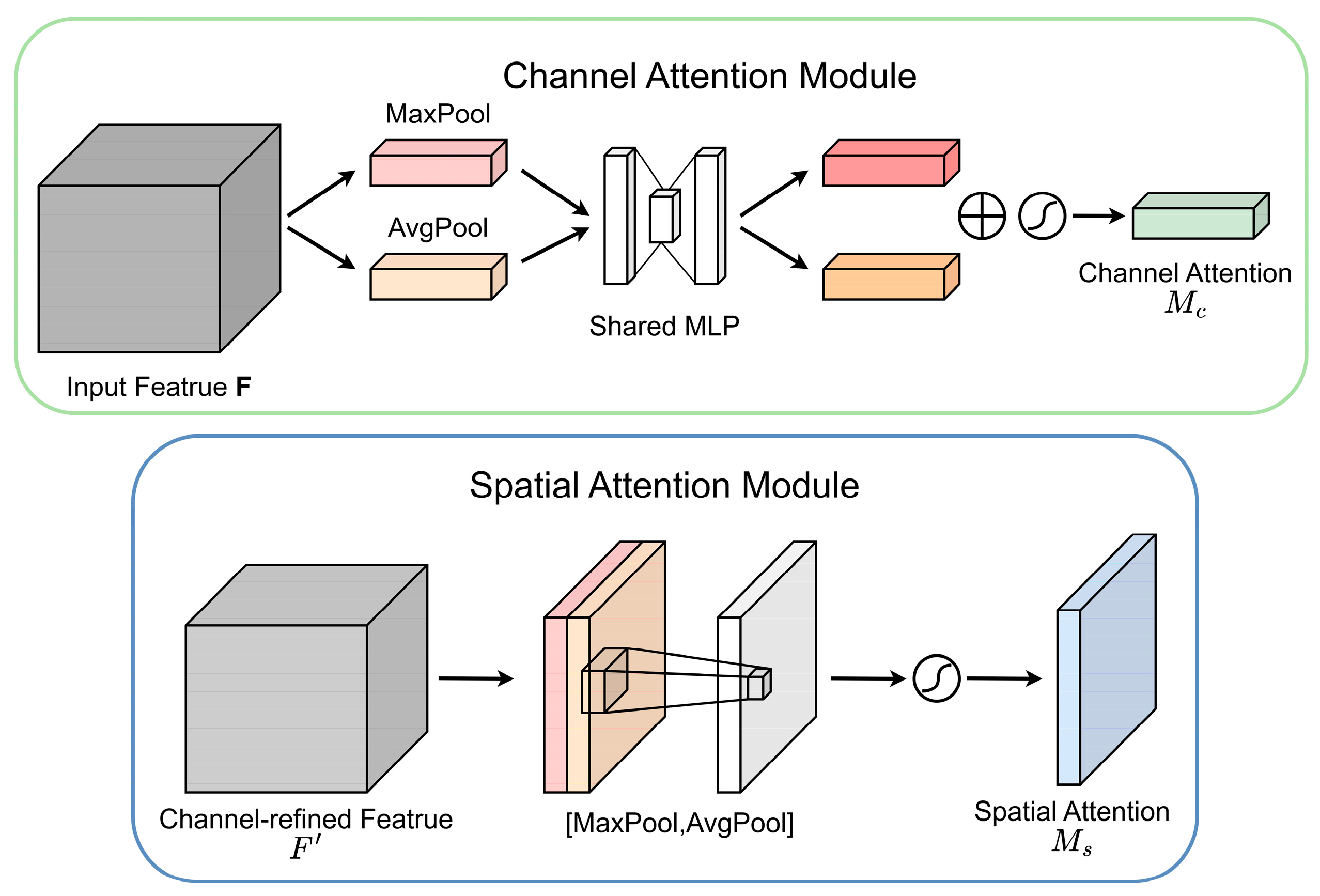
3.3.2. Convolutional Block Attention Module
3.3.3. Focal-EIoU
3.3.4. Optimal Transport Assignment
3.3.5. CFO-YOLOv5
4. Experimental Test and Result Analysis
4.1. Preparation of Datasets
4.2. Experimental Environment and Training Treatment
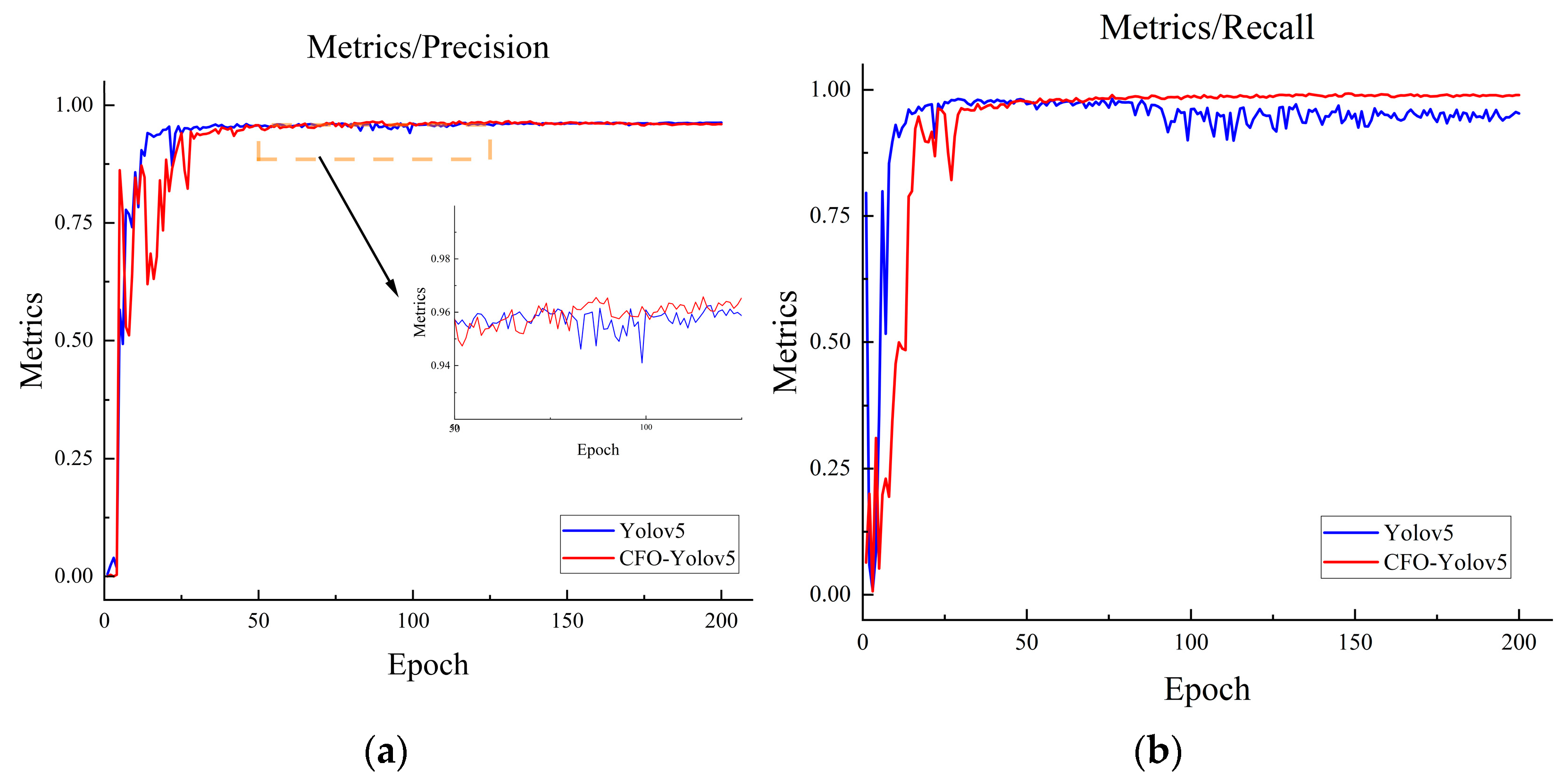
4.3. Model Measure
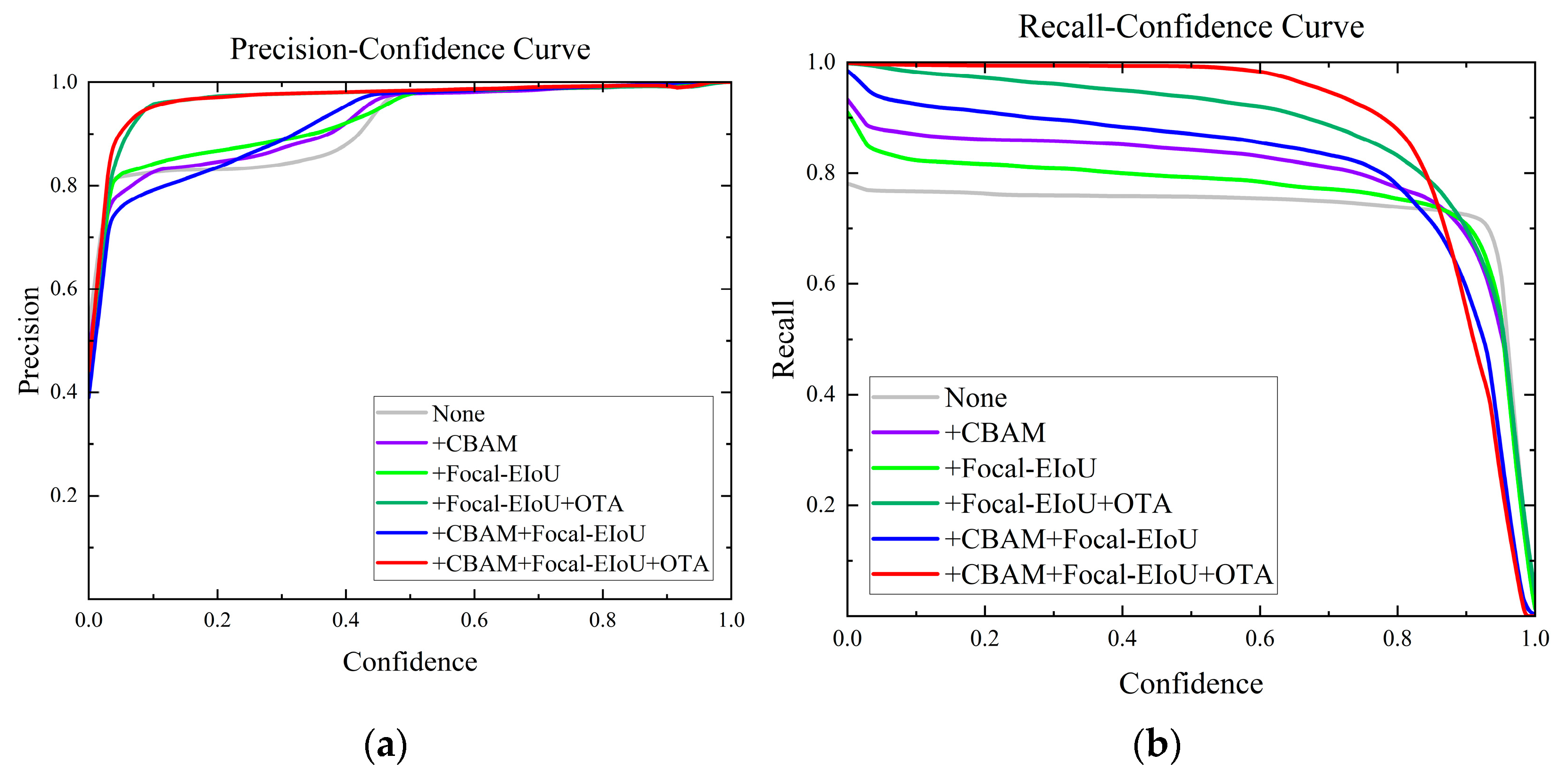
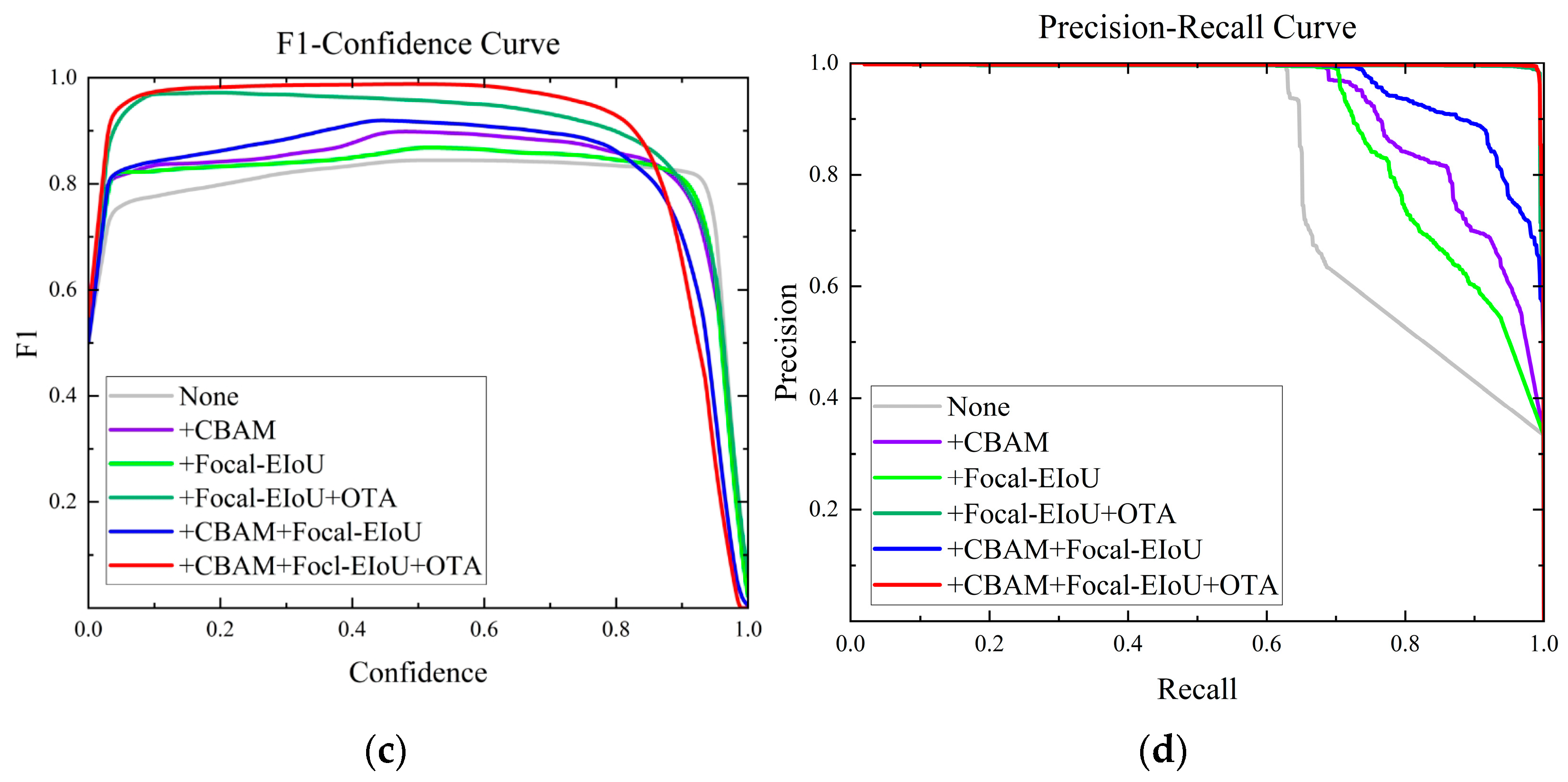
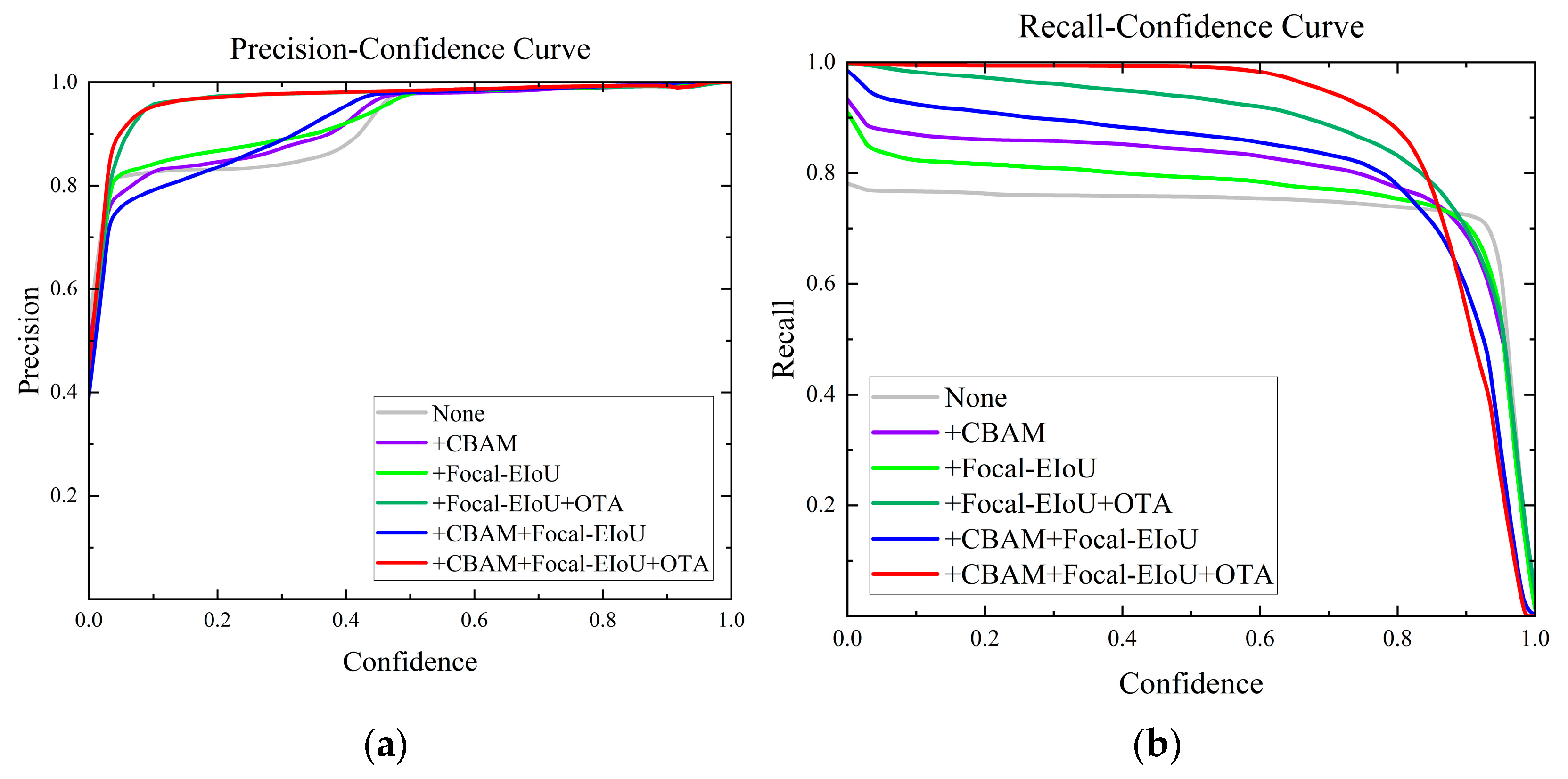
4.4. Ablation Experiment
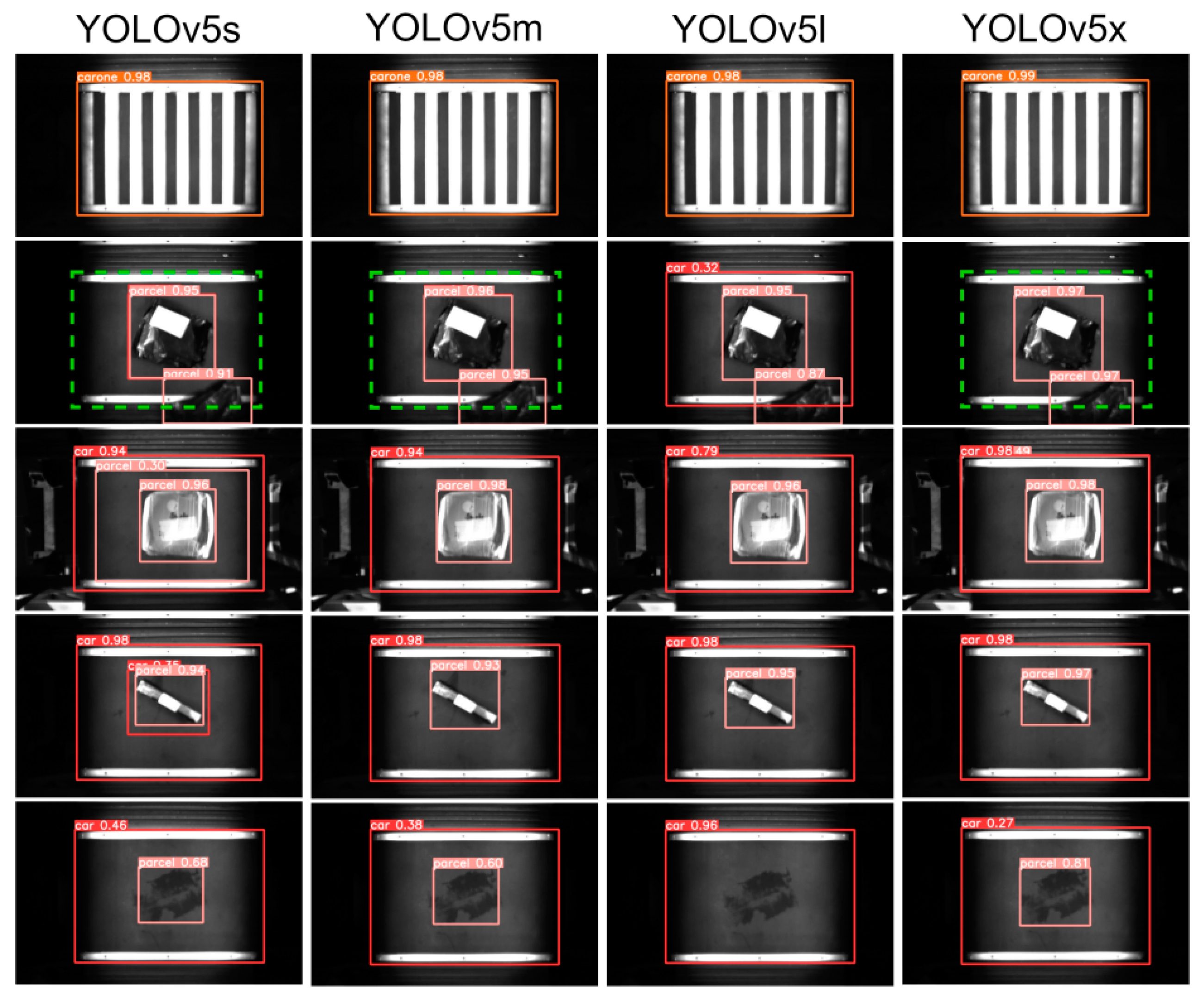
4.5. Comparative Analysis of Model Target Recognition
4.6. Comparison of Model Performance on Public Datasets
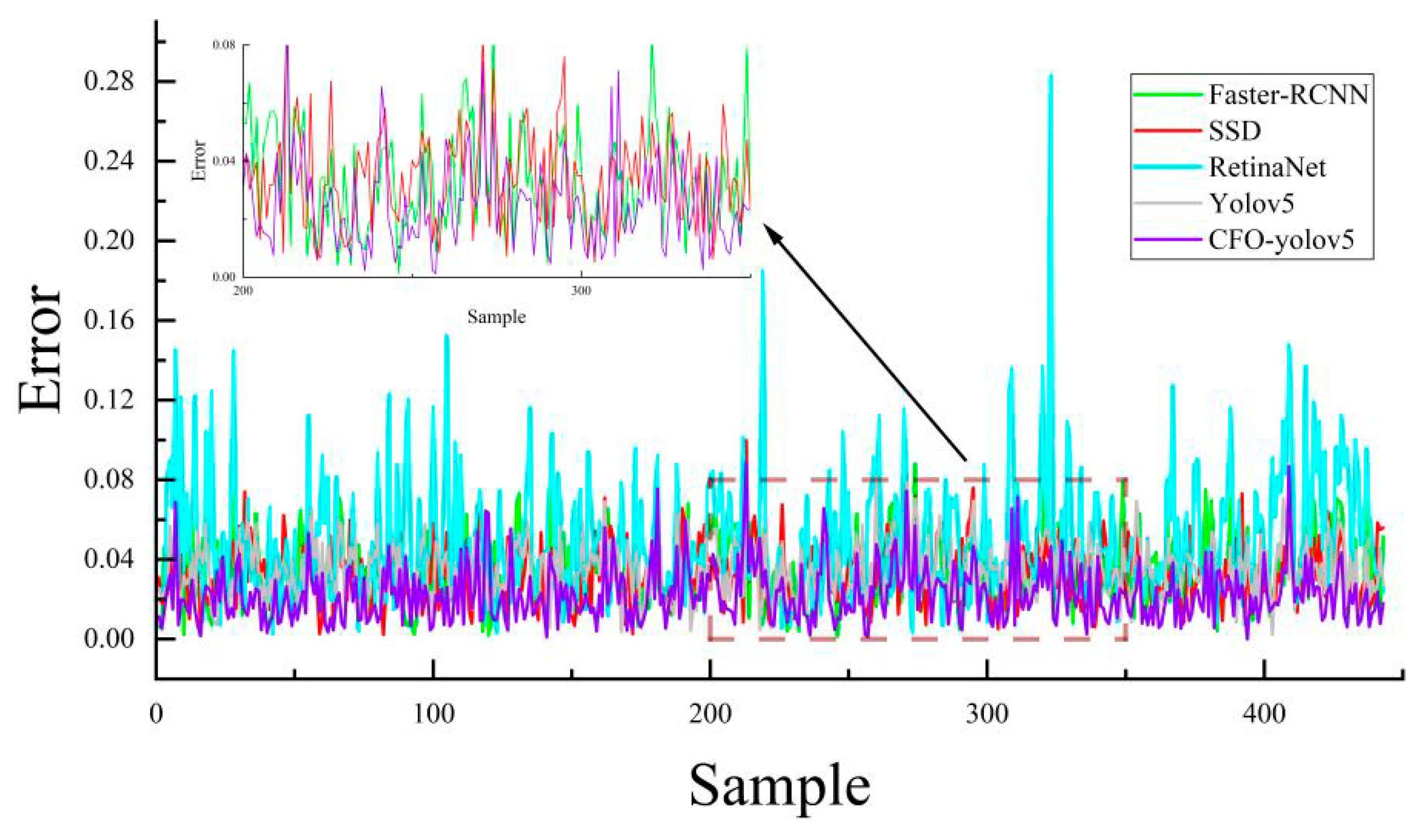
4.7. Comparative Analysis of Model Target Positioning Error
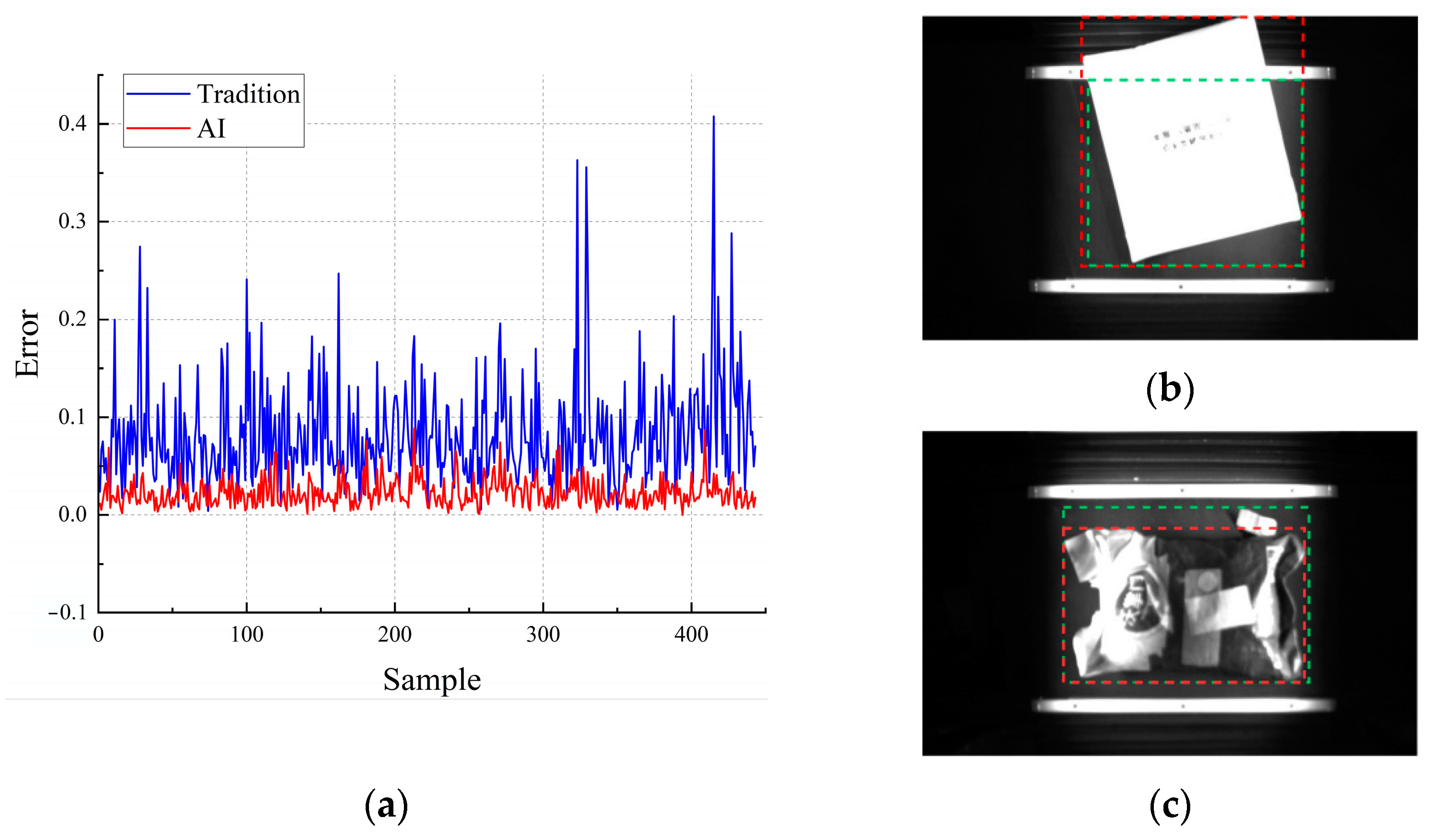
4.8. Supplementary Experiment
5. Conclusions
- (1)
- The introduction of the CFO-YOLOv5 network structure for the localization of moving express packages marks a significant advancement. This enhanced structure, built upon the YOLOv5 framework, incorporates critical improvements in its backbone, head, and training sample allocation. When compared to the original YOLOv5l model, CFO-YOLOv5 registers a notable 23.6% increase in recall rate. Moreover, it surpasses classical object detection networks in both detection accuracy and inference speed.
- (2)
- To counter the limitations of AI vision in missing detections, the paper advocates for the integration of traditional vision, particularly focusing on brightness values, as a complementary approach to express package localization. The effectiveness and practical applicability of traditional vision for this purpose were successfully validated.
- (3)
- While the improved YOLOv5 model facilitates the rapid localization of express packages, there remains potential for further enhancements in detection accuracy and inference speed. Future work is directed towards augmenting the model’s detection capabilities, especially for uniquely shaped or special packages, to attain even higher levels of precision and efficiency.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qu, Y.; Zhao, N.; Zhang, H. A study on digital twin technology of Human-machine integration cross-belt Sorting System. Chin. J. Mech. Eng. 2023. [Google Scholar] [CrossRef]
- Ashraf, M.H.; Chen, Y.; Yalcin, M.G. Minding Braess Paradox amid third-party logistics hub capacity expansion triggered by demand surge. Int. J. Prod. Econ. 2022, 248, 108454. [Google Scholar] [CrossRef]
- Kwon, K.; Jun, S.; Lee, Y.-J.; Choi, S.; Lee, C. Logistics technology forecasting framework using patent analysis for technology roadmap. Sustainability 2022, 14, 5430. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, X. A two-stage robust model for express service network design with surging demand. Eur. J. Oper. Res. 2022, 299, 154–167. [Google Scholar] [CrossRef]
- Li, X. SF EXPRESS Automated Robotic Sorting System Based on Machine Learning. In Proceedings of the 2022 International Conference on Urban Planning and Regional Economy (UPRE 2022), Cyberjaya, Malaysia, 25–27 July 2022; Atlantis Press: Amsterdam, The Netherlands, 2022; pp. 92–98. [Google Scholar]
- Li, B.; Li, Z.; Xu, Y.; Tao, Y.; An, J. Design of weak current control system for express sorting. Int. Core J. Eng. 2020, 6, 153–159. [Google Scholar]
- Li, Z.; Xu, Y.; Li, B.; Tao, Y.; An, J. Intelligent sorting machine design applied to express industry. Int. Core J. Eng. 2020, 6, 37–41. [Google Scholar]
- Zou, B.; De Koster, R.; Gong, Y.; Xu, X.; Shen, G. Robotic sorting systems: Performance estimation and operating policies analysis. Transp. Sci. 2021, 55, 1430–1455. [Google Scholar] [CrossRef]
- Khir, R.; Erera, A.; Toriello, A. Robust planning of sorting operations in express delivery systems. Eur. J. Oper. Res. 2023, 306, 615–631. [Google Scholar] [CrossRef]
- Li, Y. A Design of Robot System for Rapidly Sorting Express Carton with Mechanical Arm Based on Computer Vision Technology. Highlights Sci. Eng. Technol. 2023, 52, 168–177. [Google Scholar] [CrossRef]
- Kim, M.; Kim, Y. Parcel Classification and Positioning of Intelligent Parcel Storage System Based on YOLOv5. Appl. Sci. 2023, 13, 437. [Google Scholar] [CrossRef]
- Xu, X.; Xue, Z.; Zhao, Y. Research on an Algorithm of Express Parcel Sorting Based on Deeper Learning and Multi-Information Recognition. Sensors 2022, 22, 6705. [Google Scholar] [CrossRef]
- Han, S.; Liu, X.; Han, X.; Wang, G.; Wu, S. Visual Sorting of Express Parcels Based on Multi-Task Deep Learning. Sensors 2020, 20, 6785. [Google Scholar] [CrossRef]
- Wu, C.; Duan, X.; Ning, T. Express parcel detection based on improved faster regions with CNN features. J. Intell. Fuzzy Syst. (Prepr.) 2023, 45, 4223–4238. [Google Scholar] [CrossRef]
- Zhao, K.; Wang, Y.; Zhu, Q.; Zuo, Y. Intelligent Detection of Parcels Based on Improved Faster R-CNN. Appl. Sci. 2022, 12, 7158. [Google Scholar] [CrossRef]
- Ladplee, N.; Pimpin, A.; Srituravanich, W.; Damrongplasit, N. Volumetric Measurement of Rectangular Parcel Box Using LiDAR Depth Camera for Dimensioning and 3D Bin Packing Applications. In Proceedings of the 2022 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Yeosu, Republic of Korea, 26–28 October 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Duan, X.; Wu, C.; Ning, T. Study of Express Package Data Processing under Specific Scenario. In Proceedings of the 2022 IEEE 10th International Conference on Computer Science and Network Technology (ICCSNT), Dalian, China, 22–23 October 2022; pp. 44–48. [Google Scholar] [CrossRef]
- Vismanis, O.; Arents, J.; Freivalds, K.; Ahluwalia, V.; Ozols, K. Robotic System for Post Office Package Handling. Appl. Sci. 2023, 13, 7643. [Google Scholar] [CrossRef]
- Zhang, Y.; Cheng, W. Vision-based robot sorting system. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Beijing, China, 21–22 November 2019; IOP Publishing: Beijing, China, 2019; Volume 592, p. 012154. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference On Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Zhang, Y.-F.; Ren, W.; Zhang, Z.; Jia, Z.; Wang, L.; Tan, T. Focal and efficient IOU loss for accurate bounding box regression. Neurocomputing 2022, 506, 146–157. [Google Scholar] [CrossRef]
- Ge, Z.; Liu, S.; Li, Z.; Yoshie, O.; Sun, J. Ota: Optimal transport assignment for object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 303–312. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Cuturi, M. Sinkhorn distances: Lightspeed computation of optimal transport. Adv. Neural Inf. Process. Syst. 2013, 26, 2292–2300. [Google Scholar] [CrossRef]
- Yu, J.; Jiang, Y.; Wang, Z.; Cao, Z.; Huang, T. Unitbox: An advanced object detection network. In Proceedings of the 24th ACM International Conference on Multimedia, Amsterdam, The Netherlands, 15–19 October 2016; pp. 516–520. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Lecture Notes in Computer Science, Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Moosmann, J.; Bonazzi, P.; Li, Y.; Bian, S.; Mayer, P.; Benini, L.; Magno, M. Ultra-efficient on-device object detection on ai-integrated smart glasses with tinyissimoyolo. arXiv 2023, arXiv:2311.01057. [Google Scholar]
- Tu, P.; Xie, X.; Ling, M.; Yang, M.; Al, G.; Huang, Y.; Zheng, Y. FemtoDet: An Object Detection Baseline for Energy Versus Performance Tradeoffs. arXiv 2023, arXiv:2301.06719. [Google Scholar]
- Kim, K.; Ji, B.; Yoon, D.; Hwang, S. Self-knowledge distillation with progressive refinement of targets. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6567–6576. [Google Scholar]
- Mishra, S.; Shah, A.; Bansal, A.; Anjaria, J.; Choi, J.; Shrivastava, A.; Jacobs, D. Learning visual representations for transfer learning by suppressing texture. arXiv 2020, arXiv:2011.01901. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | F1 (%) | Precision (%) | Recall (%) | Inference Time (ms) | mAP50 (%) |
|---|---|---|---|---|---|
| Yolov5s | 85.32 | 98.6 | 75.2 | 10 | 81.9 |
| Yolox5m | 85.05 | 98.2 | 75 | 14 | 81.6 |
| Yolov5l | 85.57 | 98.4 | 75.7 | 19 | 82.3 |
| Yolov5x | 85.43 | 98.7 | 75.3 | 23 | 81.5 |
| No. | Improvement Strategy | P (%) | R (%) | F1 (%) | mAP50 (%) | mAP50:95 (%) |
|---|---|---|---|---|---|---|
| 1 | None | 98.4 | 75.7 | 85.57 | 82.3 | 80.1 |
| 2 | +CBAM | 98 | 78.3 | 87.04 | 88.5 | 85.5 |
| 3 | +Focal-EIoU | 98.3 | 77.1 | 86.41 | 87 | 83.5 |
| 4 | +Focal-EIoU + OTA | 97.2 | 97.3 | 97.24 | 99.1 | 95 |
| 5 | +CBAM + Focal-EIoU | 98.1 | 82.2 | 89.45 | 94 | 89.9 |
| 6 | +CBAM + Focal-EIoU + OTA | 98.4 | 99.3 | 98.84 | 99.2 | 94.8 |
| Model | F1 (%) | P (%) | R (%) | FPS |
|---|---|---|---|---|
| Faster RCNN | 96.25 | 93.17 | 99.53 | 24 |
| SSD | 97.48 | 95.62 | 99.41 | 60 |
| RetinaNet | 64.73 | 88.59 | 51 | 28 |
| Yolov5l | 85.57 | 98.4 | 75.7 | 50 |
| Ours | 98.74 | 98.4 | 99.3 | 45 |
| Model | mAP (%) | mAP@50 (%) | mAP@50:95 (%) |
|---|---|---|---|
| TinyissimoYOLO-v8 [31] | 42.3% | - | - |
| FemtoDet [32] | 22.90% | - | - |
| YOLOv7 + Inner-IoU | - | 64.44% | 38.52% |
| PS-KD [33] | 79.7% | - | - |
| Perona Malik [34] | 74.37% | - | - |
| Ours | 69.25% | 68.7% | 43.8% |
| Model | Standard Deviation | Average | Median |
|---|---|---|---|
| Faster RCNN | 0.0476 | 0.0333 | 0.0315 |
| SSD | 0.0463 | 0.033 | 0.0314 |
| RetinaNet | 0.08 | 0.05 | 0.0422 |
| Yolov5l | 0.0476 | 0.0346 | 0.034 |
| Ours | 0.0370 | 0.0226 | 0.0201 |
| Confidence Threshold | F1 (%) | P (%) | R (%) | mAP50 (%) |
|---|---|---|---|---|
| 0.4 | 99.4 | 99.4 | 99.4 | 99.1 |
| 0.5 | 99.3 | 99.4 | 99.2 | 99.1 |
| 0.6 | 98.9 | 99.5 | 98.3 | 98.6 |
| 0.7 | 97.2 | 99.6 | 94.9 | 96.9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, N.; Lu, Z.; Chen, J.; Xu, K.; Hu, X.; Yuan, Y. Research on the Algorithm of Position Correction for High-Speed Moving Express Packages Based on Traditional Vision and AI Vision. Sensors 2024, 24, 892. https://doi.org/10.3390/s24030892
Dai N, Lu Z, Chen J, Xu K, Hu X, Yuan Y. Research on the Algorithm of Position Correction for High-Speed Moving Express Packages Based on Traditional Vision and AI Vision. Sensors. 2024; 24(3):892. https://doi.org/10.3390/s24030892
Chicago/Turabian StyleDai, Ning, Zhehao Lu, Jingchao Chen, Kaixin Xu, Xudong Hu, and Yanhong Yuan. 2024. "Research on the Algorithm of Position Correction for High-Speed Moving Express Packages Based on Traditional Vision and AI Vision" Sensors 24, no. 3: 892. https://doi.org/10.3390/s24030892
APA StyleDai, N., Lu, Z., Chen, J., Xu, K., Hu, X., & Yuan, Y. (2024). Research on the Algorithm of Position Correction for High-Speed Moving Express Packages Based on Traditional Vision and AI Vision. Sensors, 24(3), 892. https://doi.org/10.3390/s24030892