


The Impact of Noise and Brightness on Object Detection Methods

 ,
,
Abstract
1. Introduction
2. Related Works
3. Methodology
3.1. Sensor Noise Model
- Model A simulates an imaging CMOS sensor with a single source of noise, namely Poisson type.
- Model B accounts for additional noise types, including Gaussian, speckle, salt-and-pepper, and uniform noises.
3.2. Synthetic Noise Emulation
3.3. Object Detection Performance Degradation
4. Experimental Results
4.1. Methods
4.2. Dataset
4.3. Parameter Selection
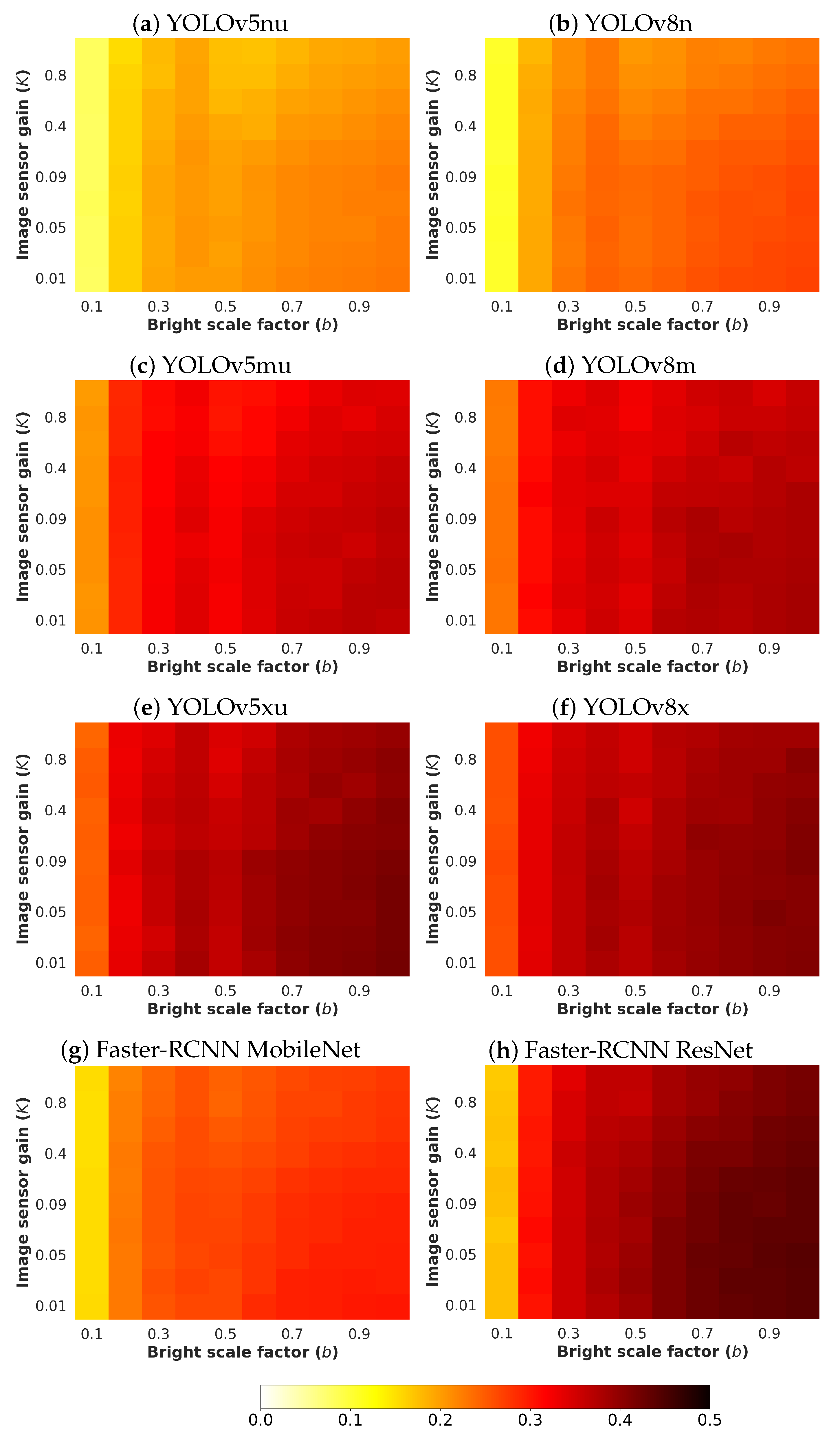
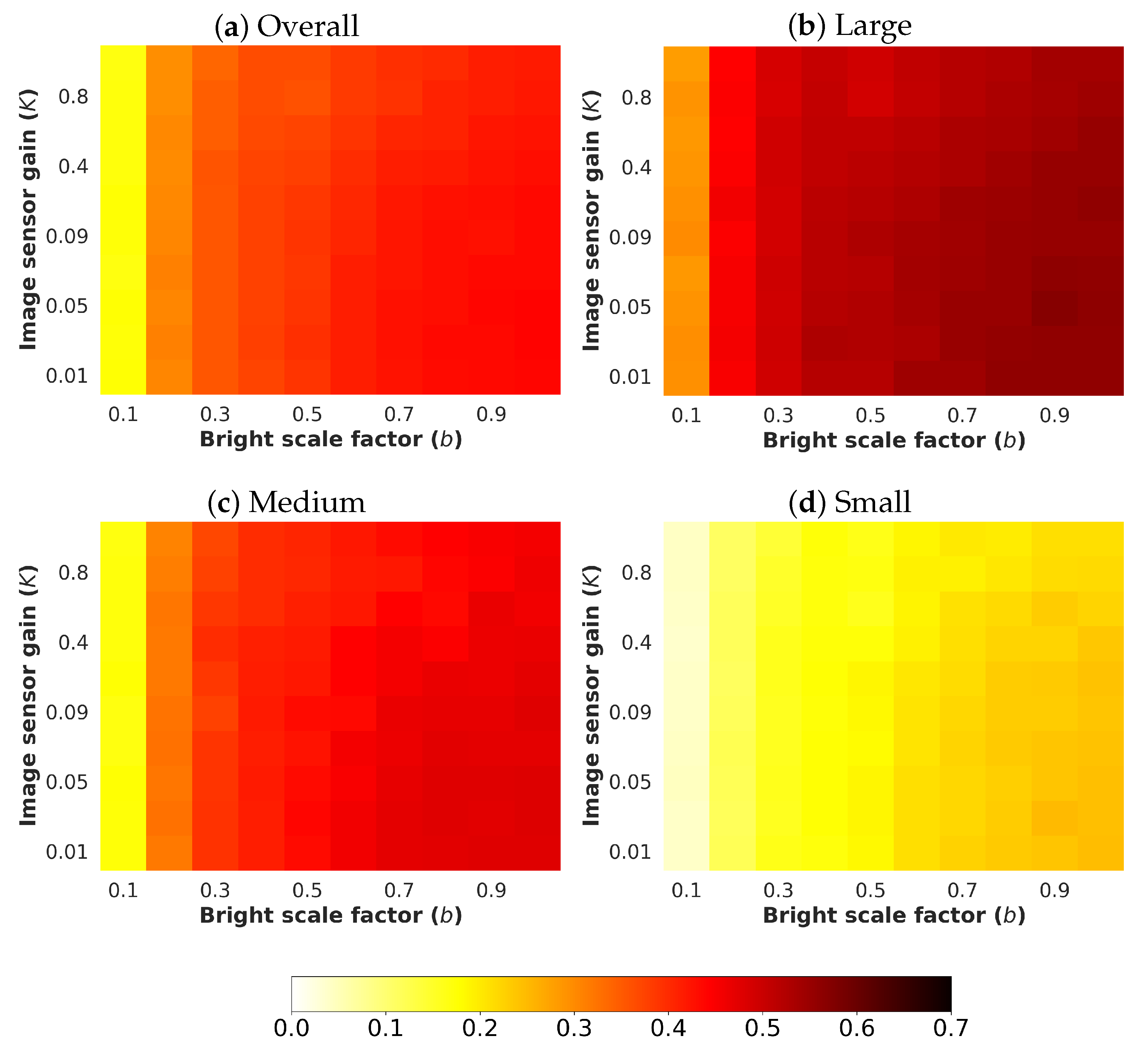
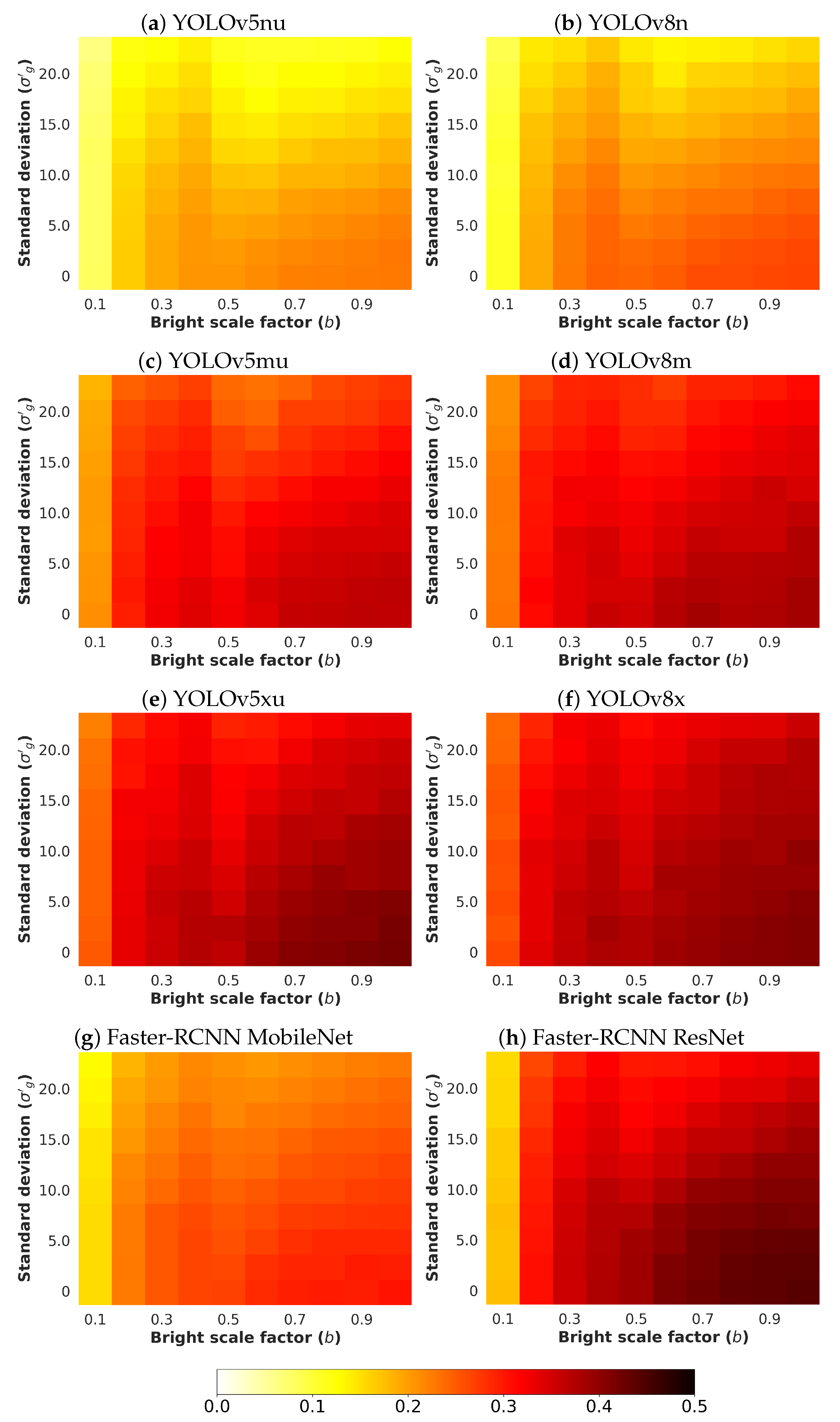
- b: The brightness scale factor emulates illumination conditions by controlling the minimum and maximum values of the image. The tuned values for this parameter b have been selected from the interval 0.1 to 1.0 with a step of 0.1. With this configuration, the lower the value of b, the darker the noisy image.
- K: The image sensor gain that converts electrons into digit values is represented by this parameter, which is exclusively dependent on the sensor performance. With the aim of analysing realistic scenarios, different commercial vision sensor data-sheets have been collected [21,22,23,24], where K goes from 0.01 to 0.1 . Furthermore, in order to study those more complex situations, higher values for K have been considered.
- : The standard deviation modulates the quantity of Gaussian noise. The higher the value of , the noisier the image. While the read-out noise of most commercial vision sensors is less than 1 when 8-bit encoding is used, values from 0 to 22.5 with a step of 2.5 have been considered.
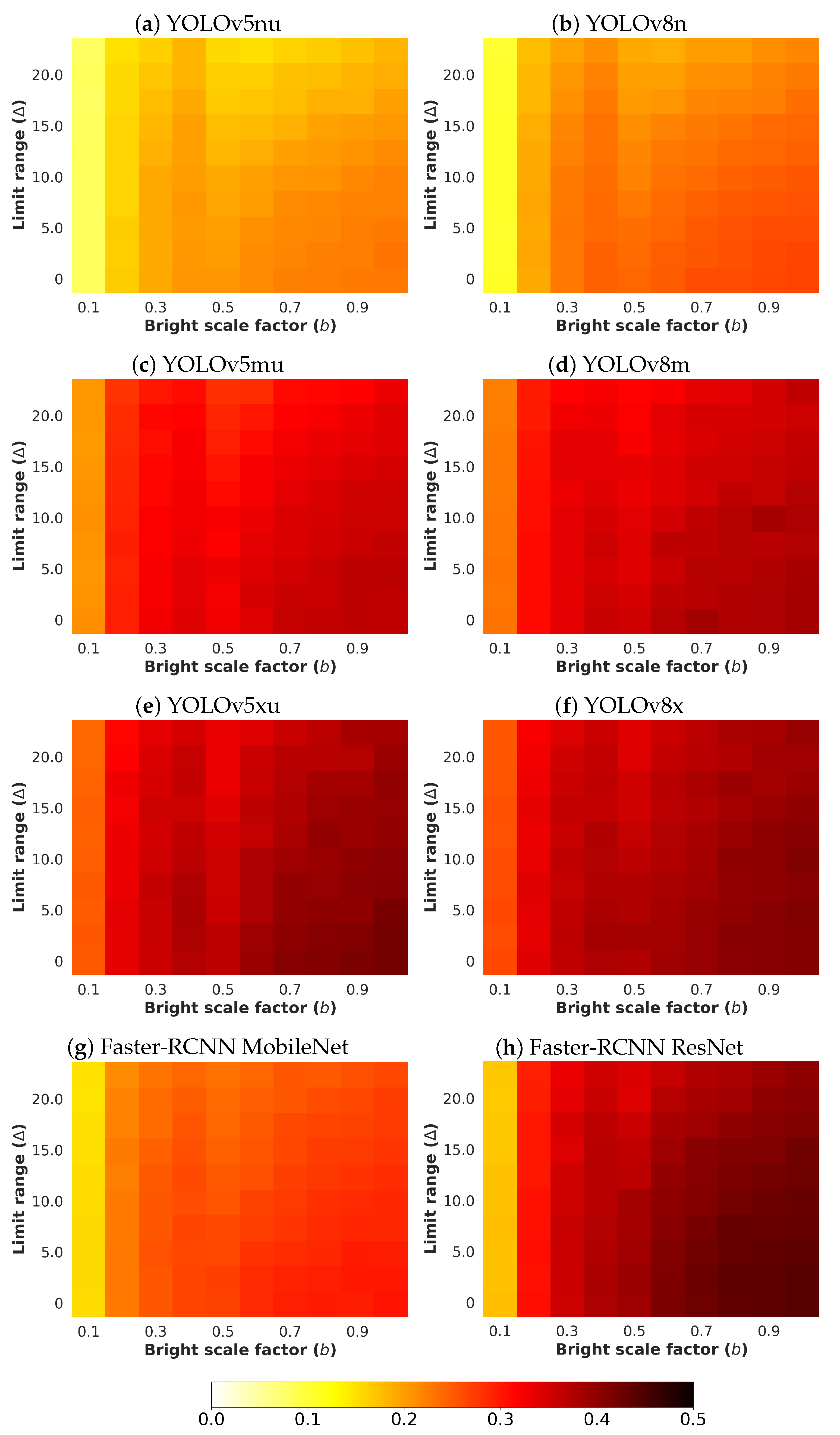
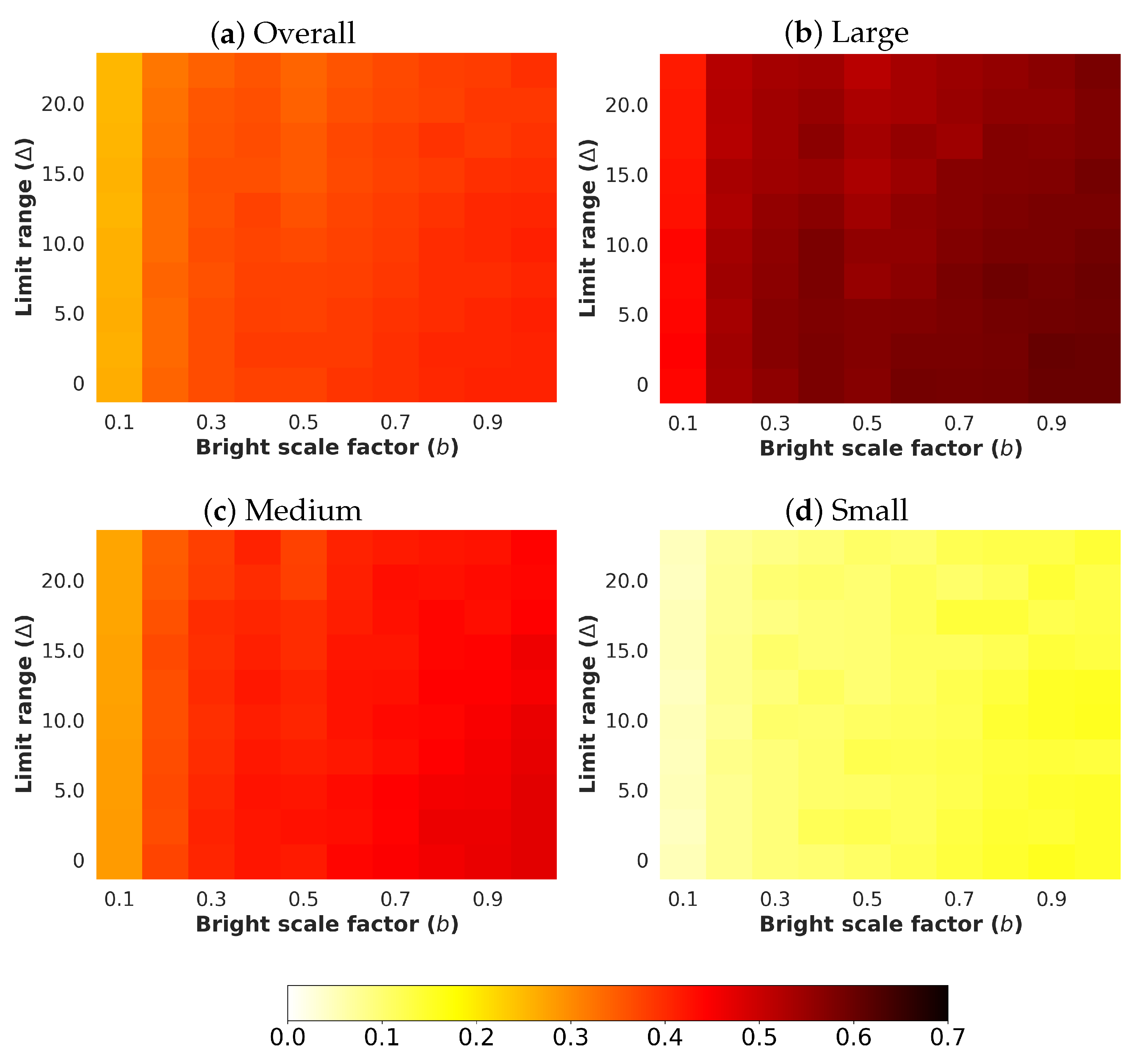
- : The limit range value establishes the minimum and maximum values that define the uniform noise that can be reached. The parameter manages both values by considering the range [,] to introduce additive noise. The chosen values for this parameter are in the interval from 0 to 22.5 with a step of 2.5 .
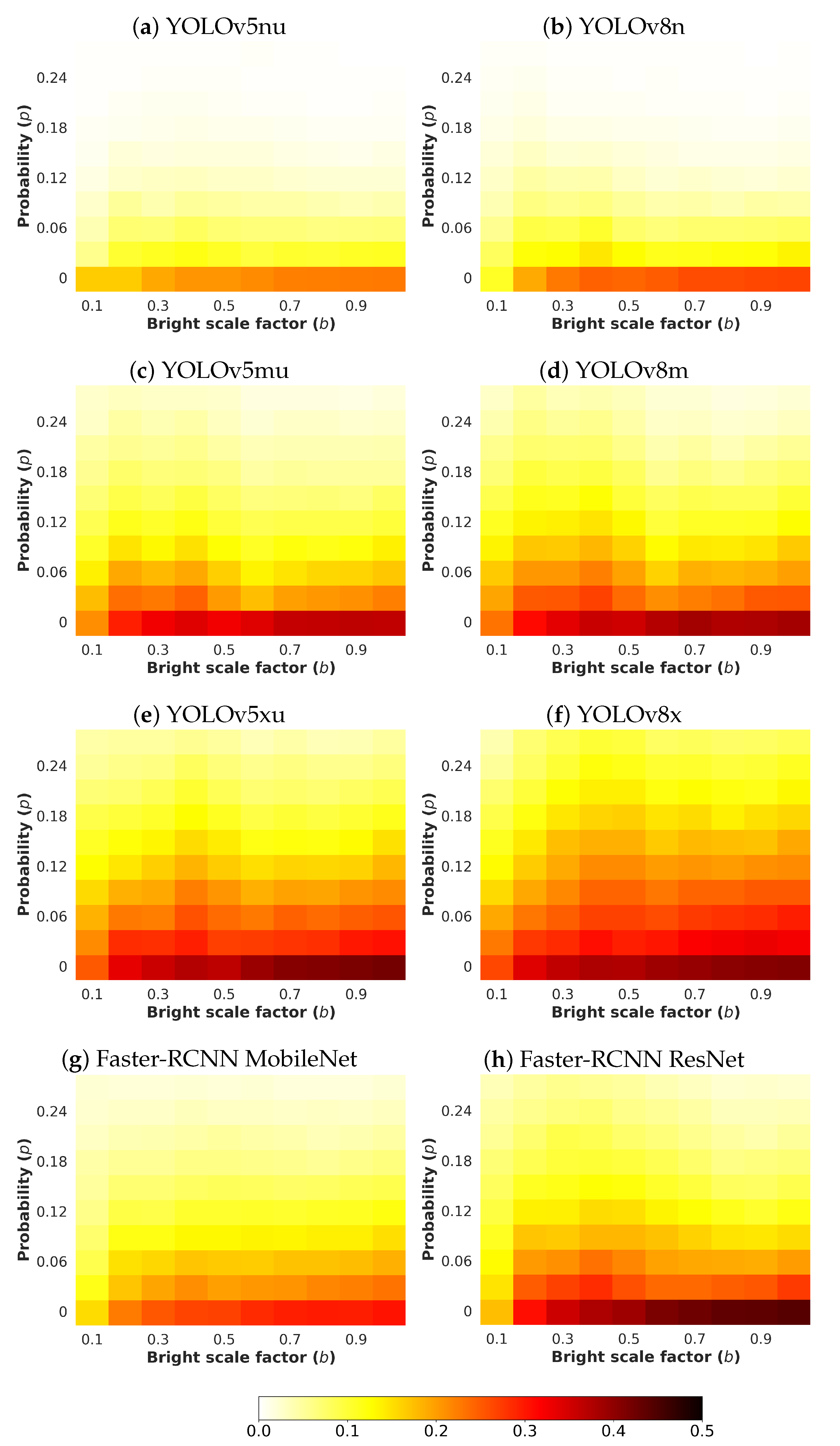
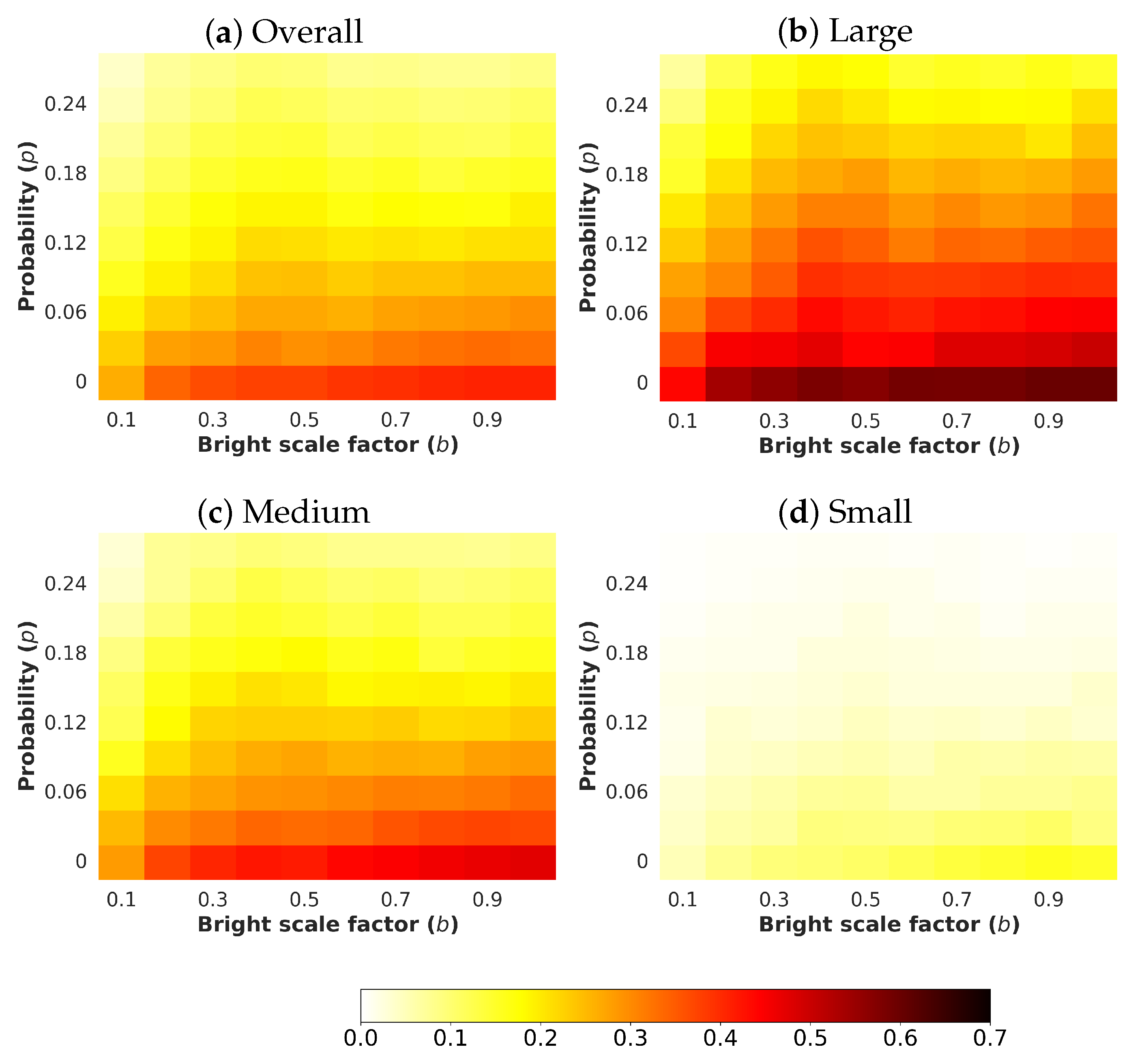
- p: This parameter represents the probability of having a pixel affected by salt-and-pepper noise. It has been considered that the likelihood for salt is precisely the same for pepper, so that, (see Section 3.2). The selected values for this parameter go from 0.00 to 0.27 with a step of 0.03.
4.4. Qualitative Results
4.5. Quantitative Results
- Detection accuracy: This component evaluates how many of the detected objects are actually relevant. It is essential to determine the model’s ability to identify objects of interest under varying conditions, such as noise and brightness.
- Location accuracy: Accuracy in the location and size of detected objects is another essential element of the AP calculation. This is crucial to evaluate the ability of the model to not only detect objects but also to accurately localize them.
- Calculation of AP by class: First, the AP value is calculated for each class of object being detected. This involves measuring the detection and localization accuracy specifically for that category.
- Average AP: Once the AP has been calculated for each class, these values are averaged to obtain the mAP. This average takes into account the detection and localization efficiency across all object categories, providing an overall assessment of the model.
4.5.1. Poisson Noise
4.5.2. Gaussian Noise
4.5.3. Salt & Pepper Noise
4.5.4. Uniform Noise
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Martin-Gonthier, P.; Magnan, P. RTS noise impact in CMOS image sensors readout circuit. In Proceedings of the 2009 16th IEEE International Conference on Electronics, Circuits and Systems-(ICECS 2009), Yasmine Hammamet, Tunisia, 13–16 December 2009; pp. 928–931. [Google Scholar]
- Hemanth, D.J.; Estrela, V.V. Deep Learning for Image Processing Applications; IOS Press: Amsterdam, The Netherlands, 2017; Volume 31. [Google Scholar]
- Górriz, J.M.; Ramírez, J.; Ortíz, A.; Martinez-Murcia, F.J.; Segovia, F.; Suckling, J.; Leming, M.; Zhang, Y.D.; Álvarez-Sánchez, J.R.; Bologna, G.; et al. Artificial intelligence within the interplay between natural and artificial computation: Advances in data science, trends and applications. Neurocomputing 2020, 410, 237–270. [Google Scholar] [CrossRef]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Liu, B.; Zhao, W.; Sun, Q. Study of object detection based on Faster R-CNN. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 6233–6236. [Google Scholar]
- Mohammed Abd-Alsalam Selami, A.; Freidoon Fadhil, A. A study of the effects of gaussian noise on image features. Kirkuk Univ. J.-Sci. Stud. 2016, 11, 152–169. [Google Scholar] [CrossRef]
- Rodríguez-Rodríguez, J.A.; Molina-Cabello, M.A.; Benítez-Rochel, R.; López-Rubio, E. The effect of noise and brightness on convolutional deep neural networks. In Proceedings of the International Conference on Pattern Recognition, Virtual, 10–11 January 2021; Springer: Cham, Switzerland, 2021; pp. 639–654. [Google Scholar]
- Wu, Z.; Moemeni, A.; Castle-Green, S.; Caleb-Solly, P. Robustness of Deep Learning Methods for Occluded Object Detection—A Study Introducing a Novel Occlusion Dataset. In Proceedings of the 2023 International Joint Conference on Neural Networks (IJCNN), Gold Coast, Australia, 18–23 June 2023; pp. 1–10. [Google Scholar]
- Zhang, L.; Zuo, W. Image Restoration: From Sparse and Low-Rank Priors to Deep Priors [Lecture Notes]. IEEE Signal Process. Mag. 2017, 34, 172–179. [Google Scholar] [CrossRef]
- Zha, Z.; Yuan, X.; Wen, B.; Zhou, J.; Zhang, J.; Zhu, C. From rank estimation to rank approximation: Rank residual constraint for image restoration. IEEE Trans. Image Process. 2019, 29, 3254–3269. [Google Scholar] [CrossRef] [PubMed]
- Xu, J.; Zhang, L.; Zhang, D. External Prior Guided Internal Prior Learning for Real-World Noisy Image Denoising. IEEE Trans. Image Process. 2018, 27, 2996–3010. [Google Scholar] [CrossRef] [PubMed]
- López-Rubio, F.J.; Lopez-Rubio, E.; Molina-Cabello, M.A.; Luque-Baena, R.M.; Palomo, E.J.; Dominguez, E. The effect of noise on foreground detection algorithms. Artif. Intell. Rev. 2018, 49, 407–438. [Google Scholar] [CrossRef]
- Rodríguez-Rodríguez, J.A.; Molina-Cabello, M.A.; Benítez-Rochel, R.; López-Rubio, E. The impact of linear motion blur on the object recognition efficiency of deep convolutional neural networks. In Proceedings of the International Conference on Pattern Recognition, Virtual, 10–11 January 2021; Springer: Cham, Switzerland, 2021; pp. 611–622. [Google Scholar]
- EMVA Standard 1288; Standard for Characterization of Image Sensors and Cameras. European Machine Vision Association: Barcelona, Spain, 2010. Available online: https://www.emva.org/standards-technology/emva-1288/ (accessed on 11 December 2023).
- Du, J. Understanding of object detection based on CNN family and YOLO. J. Phys. Conf. Ser. 2018, 1004, 012029. [Google Scholar] [CrossRef]
- Abbas, S.M.; Singh, S.N. Region-based object detection and classification using faster R-CNN. In Proceedings of the 2018 4th International Conference on Computational Intelligence & Communication Technology (CICT), Ghaziabad, India, 9–10 February 2018; pp. 1–6. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D.; et al. Ultralytics/yolov5: v7. 0-yolov5 sota realtime instance segmentation. Zenodo 2022. [Google Scholar] [CrossRef]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLOv8 by Ultralytics. 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 11 December 2023).
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Proceedings of the Advances in Neural Information Processing Systems 28: Annual Conference on Neural Information Processing Systems 2015, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Proceedings, Part V 13. Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- High Accuracy Star Tracker CMOS Active Pixel Image Sensor; NOIH25SM1000S Datasheet; ONSemiconductor: Phoenix, AZ, USA, 2009.
- 4” Color CMOS QSXGA (5 Megapixel) Image Sensorwith OmniBSI Technology; OV5640 Datasheet; OmniVision: Santa Clara, CA, USA, 2010.
- ams-OSRAM AG Miniature CMOS Image Sensor. NanEye Datasheet. 2018. Available online: https://ams.com/naneye (accessed on 11 December 2023).
- ams-OSRAM AG CMOS Machine Vision Image Sensor. CMV50000 Datasheet. 2019. Available online: https://ams.com/cmv50000 (accessed on 11 December 2023).
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niterói, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]

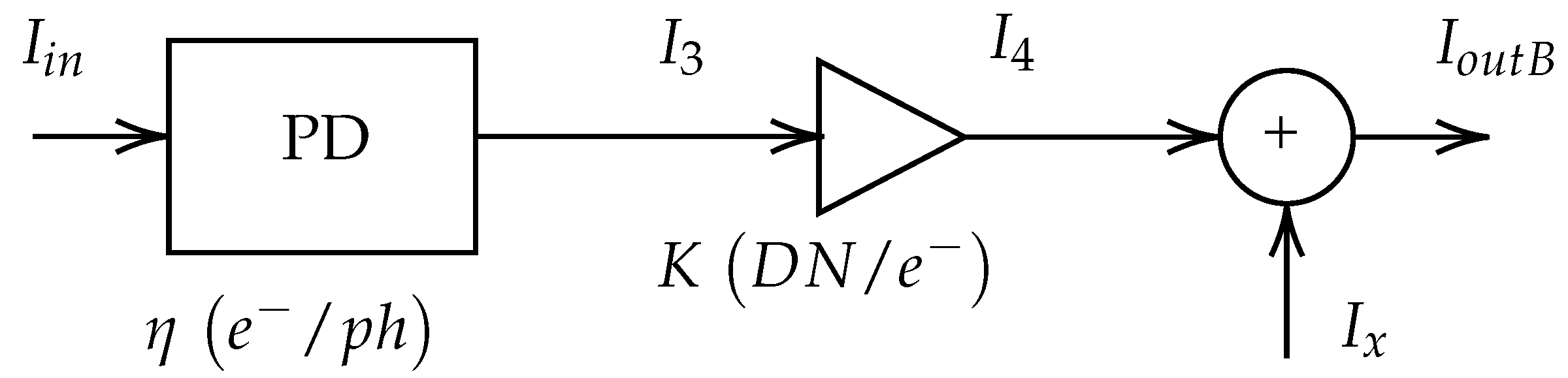





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value | |
|---|---|---|
| Bright scale factor, b | = | {} |
| Image sensor gain, Poisson noise, K | = | {} |
| Standard deviation, Gaussian noise, | = | {} |
| Probability salt and pepper noise, p | = | {} |
| Limit range, uniform noise, | = | {} |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodríguez-Rodríguez, J.A.; López-Rubio, E.; Ángel-Ruiz, J.A.; Molina-Cabello, M.A. The Impact of Noise and Brightness on Object Detection Methods. Sensors 2024, 24, 821. https://doi.org/10.3390/s24030821
Rodríguez-Rodríguez JA, López-Rubio E, Ángel-Ruiz JA, Molina-Cabello MA. The Impact of Noise and Brightness on Object Detection Methods. Sensors. 2024; 24(3):821. https://doi.org/10.3390/s24030821
Chicago/Turabian StyleRodríguez-Rodríguez, José A., Ezequiel López-Rubio, Juan A. Ángel-Ruiz, and Miguel A. Molina-Cabello. 2024. "The Impact of Noise and Brightness on Object Detection Methods" Sensors 24, no. 3: 821. https://doi.org/10.3390/s24030821
APA StyleRodríguez-Rodríguez, J. A., López-Rubio, E., Ángel-Ruiz, J. A., & Molina-Cabello, M. A. (2024). The Impact of Noise and Brightness on Object Detection Methods. Sensors, 24(3), 821. https://doi.org/10.3390/s24030821