
Optical Encryption Using Attention-Inserted Physics-Driven Single-Pixel Imaging


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Principles and Methods
2.1. Optical Image Encryption
2.2. Decryption and Image Reconstruction
2.3. Image Reconstruction Neural Network
3. Numerical Simulation and Analysis
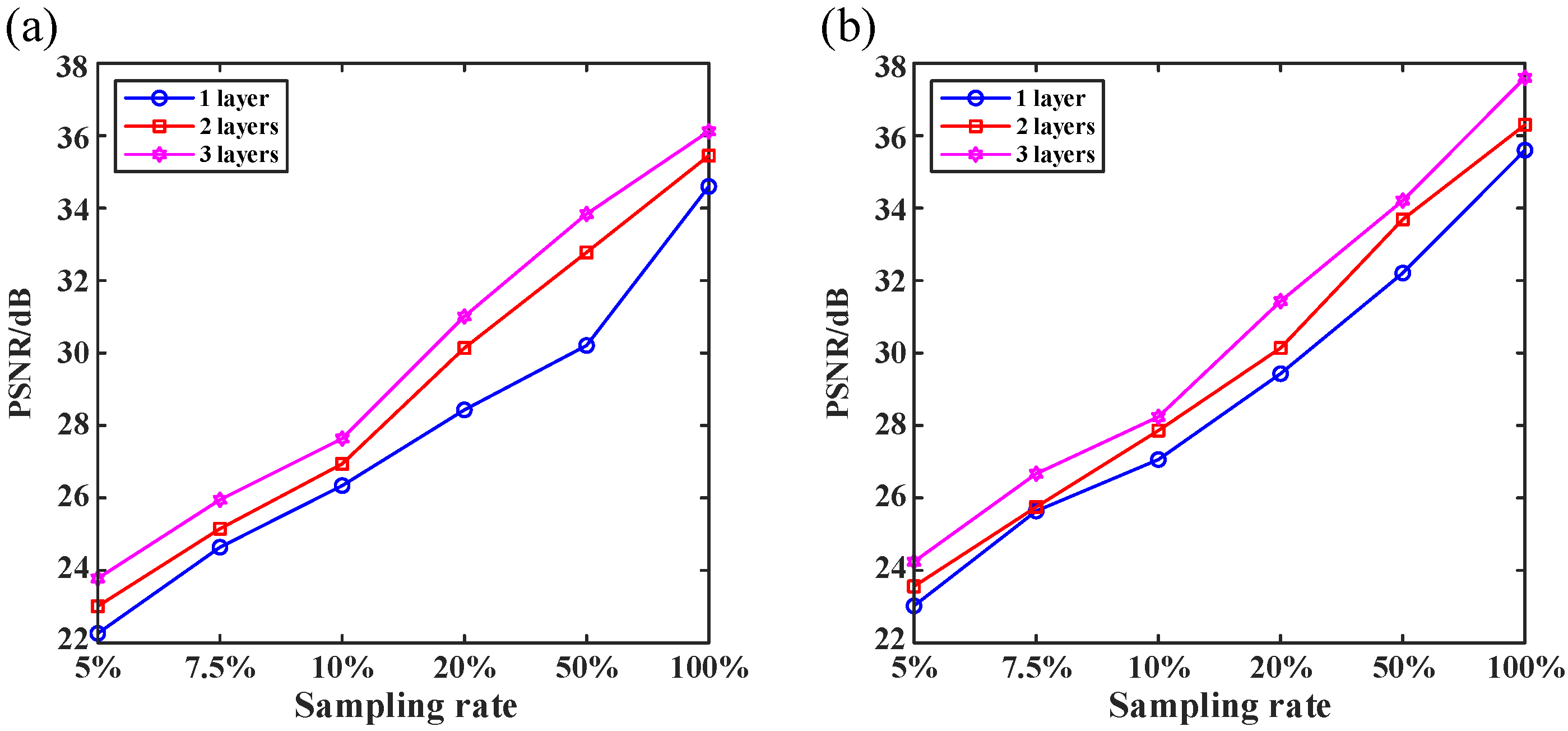
3.1. Effect of Network Parameters on Reconstruction Results
3.2. Effect of the Number of Training Steps on Reconstruction Quality
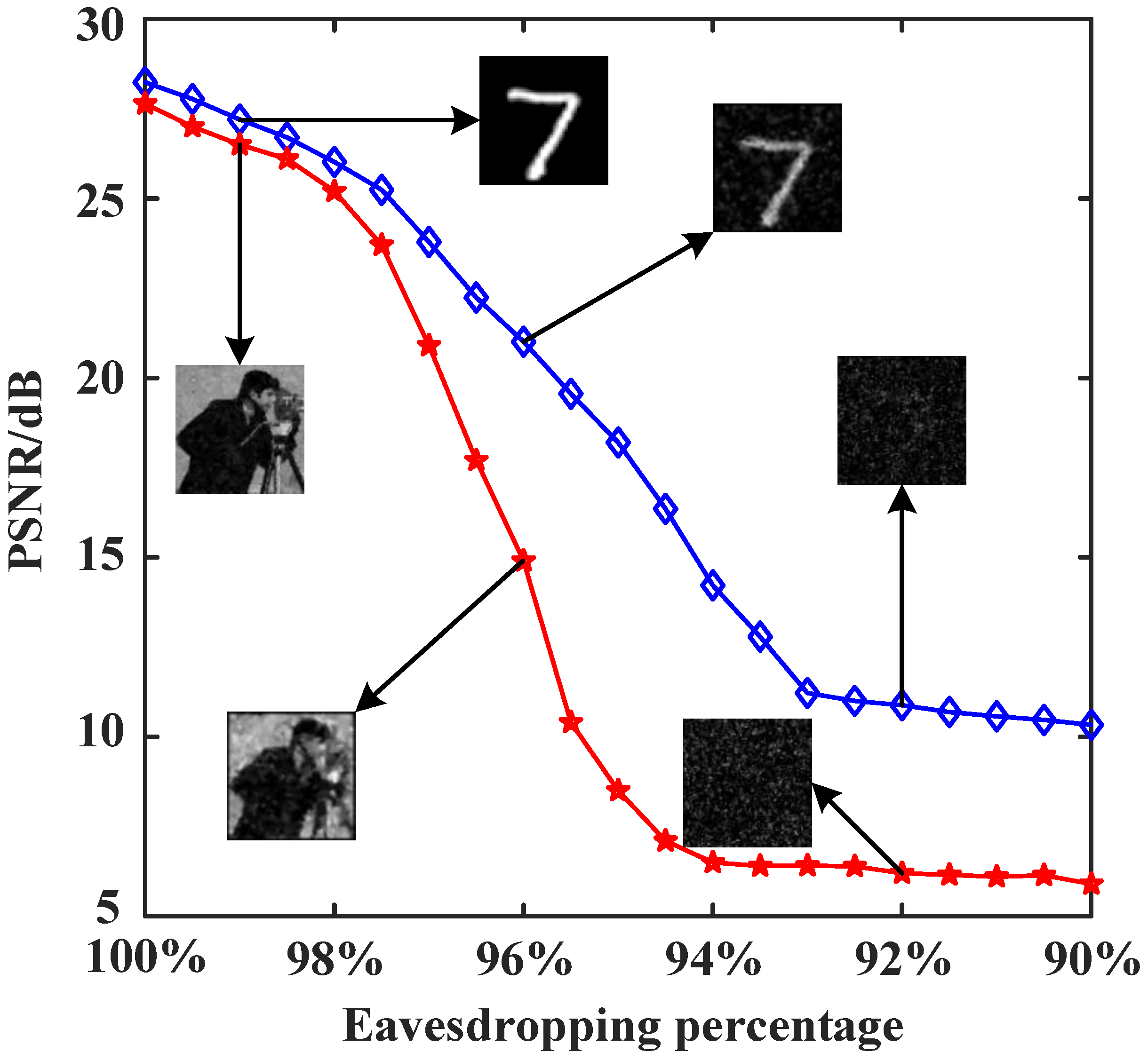
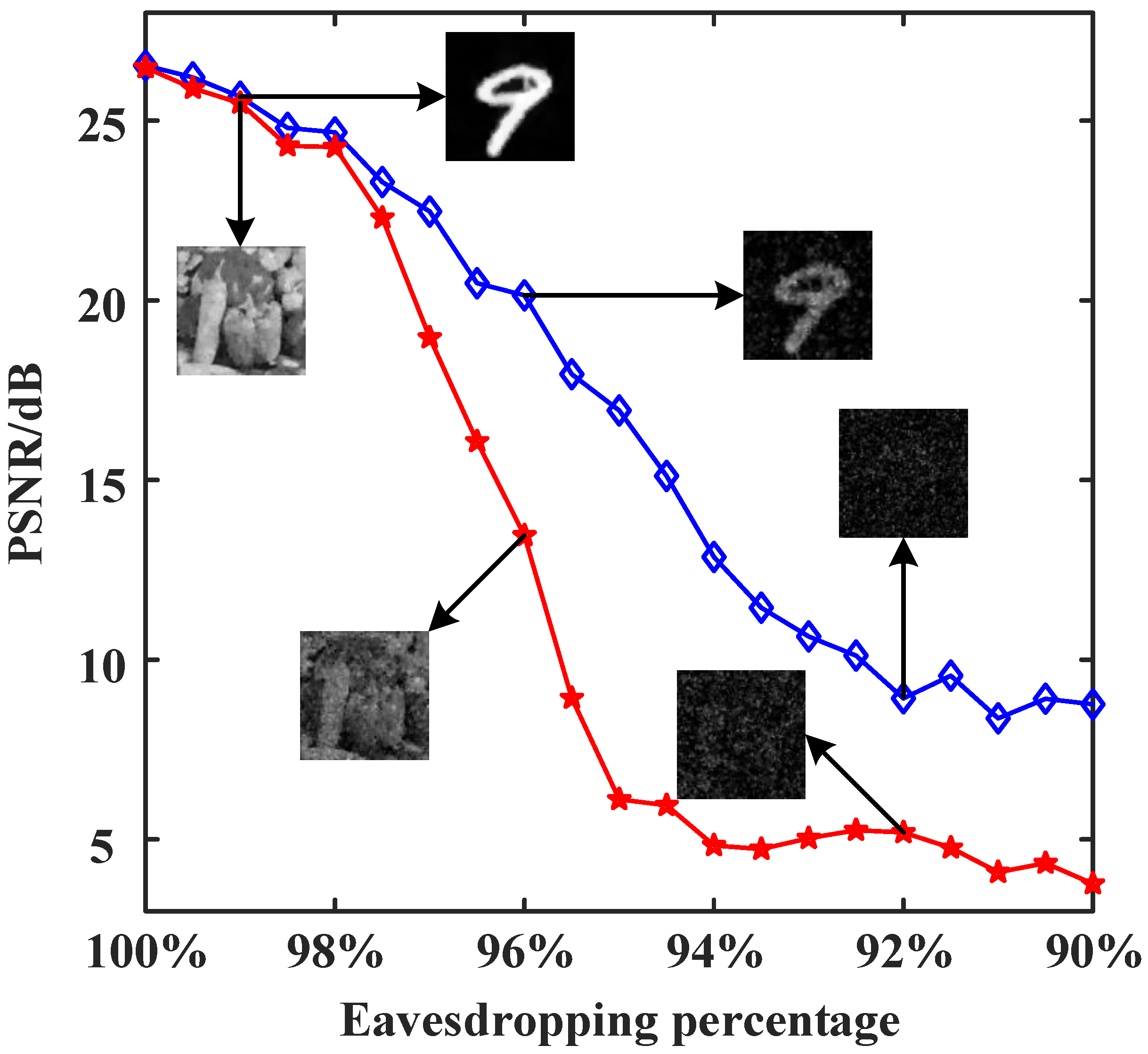
3.3. Effect of the Number of Stolen Bits of the Cryptographic Key Sequence on the Reconstruction Results
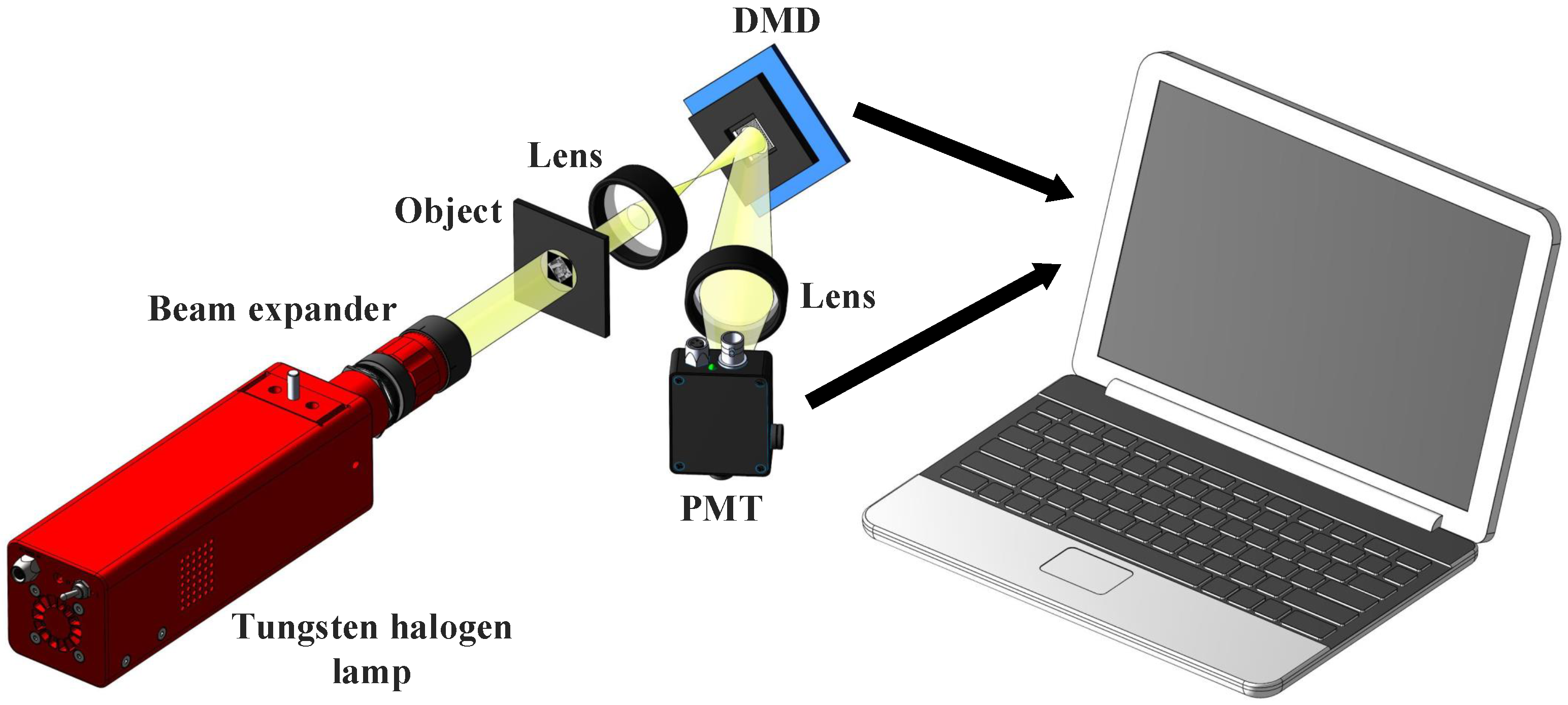
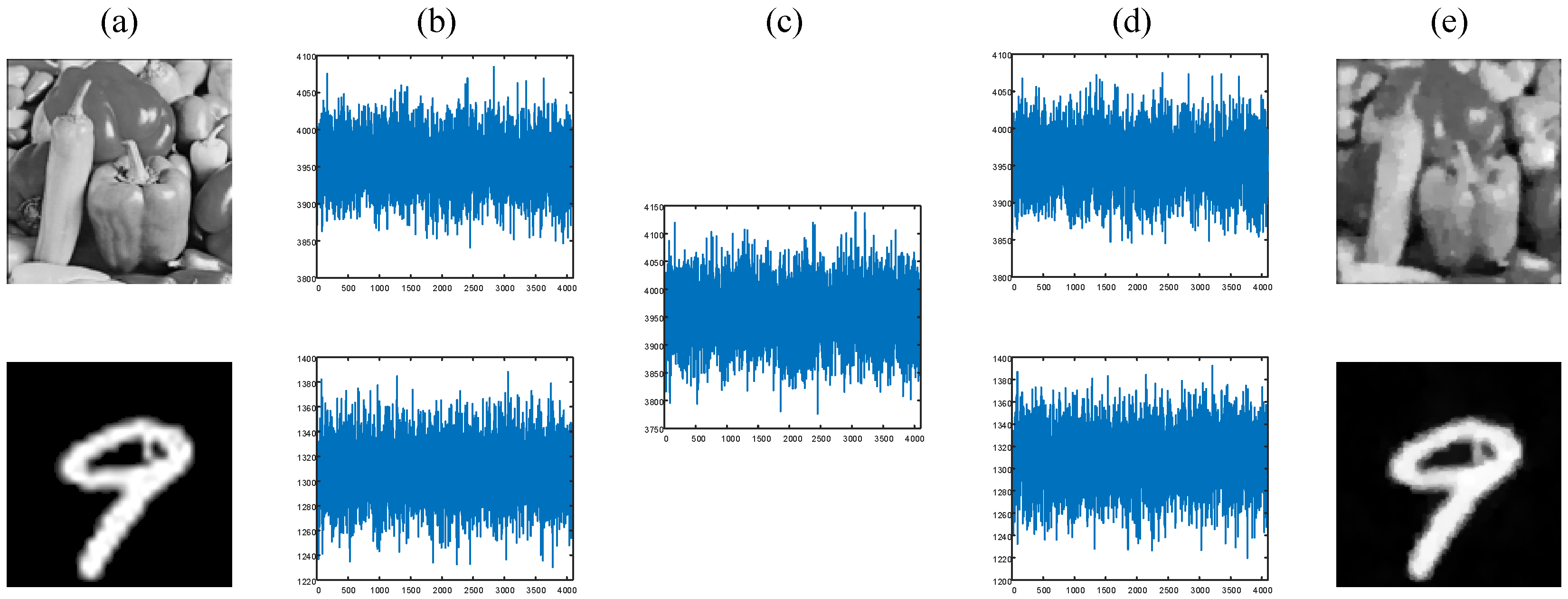
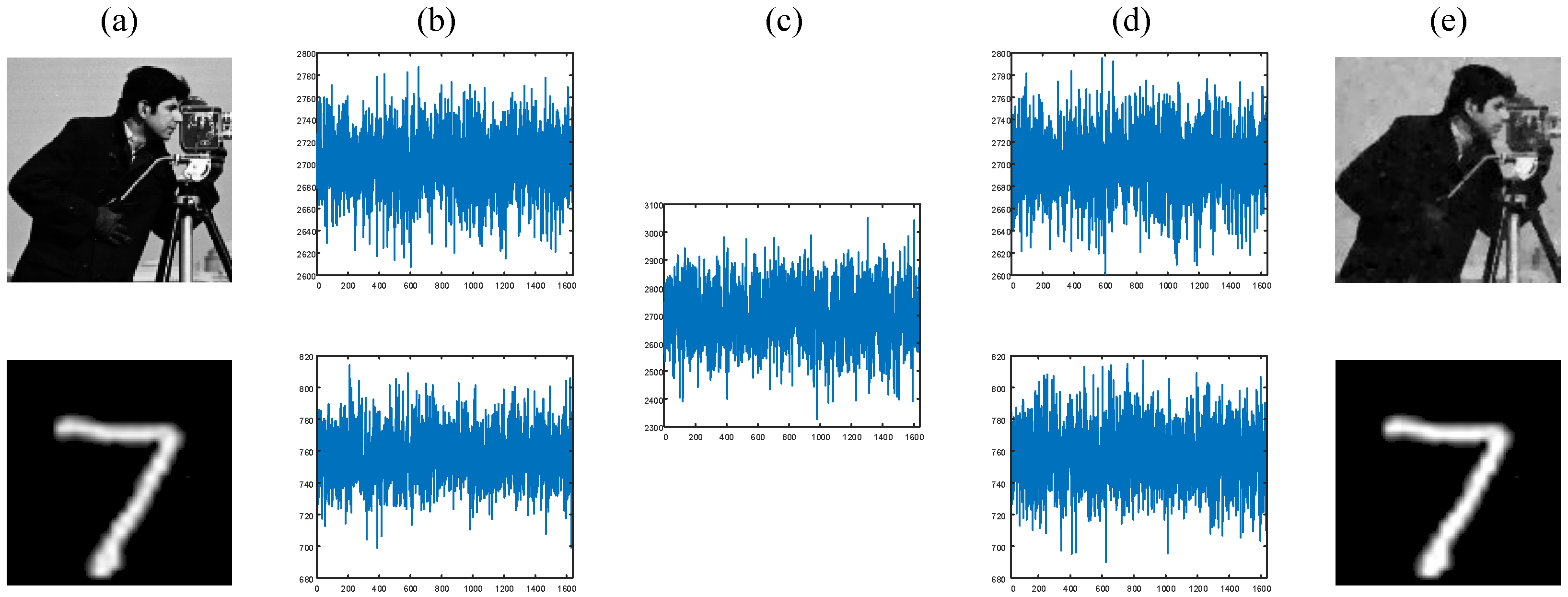
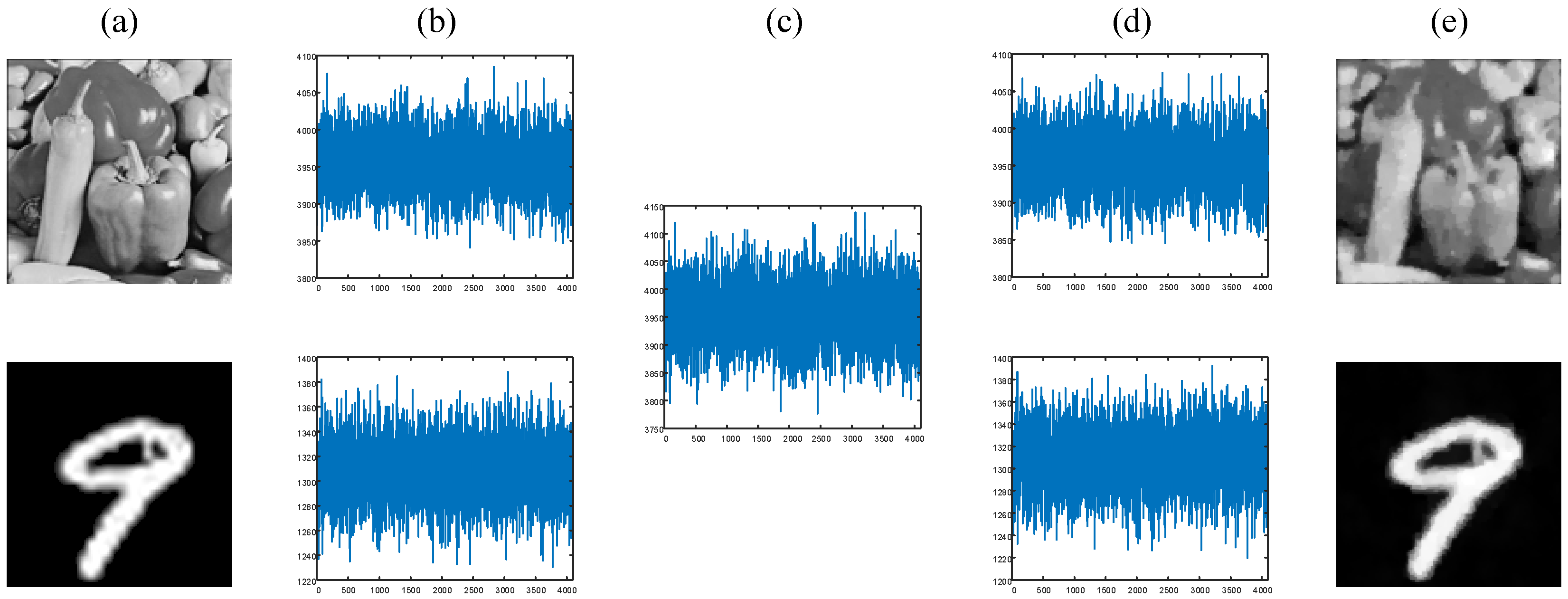
4. Optical Experiment Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, K.T. Hybrid encoding method for hiding information by assembling double-random phase-encoding technique and binary encoding method. Appl. Opt. 2010, 49, 3814–3820. [Google Scholar] [CrossRef] [PubMed]
- Moon, I.; Kim, Y.; Gholami, S.; Jeong, O. Double random phase encoding schemes with perfect forward secrecy for robust image cryptography. OSA Contin. 2021, 4, 2245–2259. [Google Scholar] [CrossRef]
- Wang, Z.; Su, Y.; Wang, X.; Wang, B.; Li, S.; Liu, C.; Li, J.; Cai, Z.; Wan, W. Security-enhanced multiple-image encryption based on quick response codes and modified double random phase encoding in the fractional Fourier transform domain. Appl. Opt. 2022, 61, 7255–7264. [Google Scholar] [CrossRef] [PubMed]
- Tian, P.; Su, R. A novel virtual optical image encryption scheme created by combining chaotic s-box with double random phase encoding. Sensors 2022, 22, 5325. [Google Scholar] [CrossRef] [PubMed]
- Zhou, L.; Xiao, Y.; Chen, W. Machine-learning attacks on interference-based optical encryption: Experimental demonstration. Opt. Express 2019, 27, 26143–26154. [Google Scholar] [CrossRef] [PubMed]
- Zhu, N.; Wang, Y.; Liu, J.; Xie, J.; Zhang, H. Optical image encryption based on interference of polarized light. Opt. Express 2009, 17, 13418–13424. [Google Scholar] [CrossRef]
- Wang, Q.; Guo, Q.; Zhou, J. Multiple-image encryption using polarized light encoding and the optical interference principle in the Fresnel-transform domain. Appl. Opt. 2013, 52, 8854–8863. [Google Scholar] [CrossRef]
- Piao, M.; Liu, Z.; Piao, Y.; Wu, H.; Yu, Z.; Kim, N. Multi-depth three-dimensional image encryption based on the phase retrieval algorithm in the Fresnel and fractional Fourier transform domains. Appl. Opt. 2018, 57, 7609–7617. [Google Scholar] [CrossRef]
- Wu, J.; Wang, J.; Nie, Y.; Hu, L. Multiple-image optical encryption based on phase retrieval algorithm and fractional Talbot effect. Opt. Express 2019, 27, 35096–35107. [Google Scholar] [CrossRef]
- He, X.; Jiang, Z.; Kong, Y.; Wang, S.; Liu, C. Optical multi-image encryption based on focal length multiplexing and multimode phase retrieval. Appl. Opt. 2020, 59, 7801–7812. [Google Scholar] [CrossRef]
- Muniraj, I.; Guo, C.; Malallah, R.; Ryle, J.; Healy, J.; Lee, B.; Sheridan, J. Low photon count based digital holography for quadratic phase cryptography. Opt. Lett. 2017, 42, 2774–2777. [Google Scholar] [CrossRef] [PubMed]
- Matoba, O.; Javidi, B. Optical retrieval of encrypted digital holograms for secure real-time display. Opt. Lett. 2002, 27, 321–323. [Google Scholar] [CrossRef]
- Kim, Y.; Sim, M.; Moon, I. Secure storage and retrieval schemes for multiple encrypted digital holograms with orthogonal phase encoding multiplexing. Opt. Express 2019, 27, 22147–22160. [Google Scholar] [CrossRef] [PubMed]
- Shapiro, J.H. Computational ghost imaging. Phys. Rev. A 2008, 78, 061802(R). [Google Scholar] [CrossRef]
- Katz, O.; Bromberg, Y.; Silberberg, Y. Compressive ghost imaging. Appl. Phys. Lett. 2009, 95, 131110. [Google Scholar] [CrossRef]
- He, Y.; Zhang, A.; Li, M.; Huang, Y.; Quan, B.; Li, D.; Wu, L.; Chen, L. High-resolution sub-sampling incoherent x-ray imaging with a micro-structured scintillator array. Opt. Express 2019, 27, 38109–38119. [Google Scholar]
- Xiong, J.; Zhang, Z.-H.; Li, Z.; Zheng, P.; Li, J.; Zhang, X.; Gao, Z.; Wei, Z.; Zheng, G.; Wang, S.-P.; et al. Perovskite single-pixel detector for dual-color metasurface imaging recognition in complex environment. Light-Sci. Appl. 2023, 12, 286. [Google Scholar] [CrossRef]
- Ye, Z.; Zhou, C.; Ding, C.-X.; Zhao, J.; Jiao, S.; Wang, H.-B.; Xiong, J. Ghost diffractive deep neural networks: Optical classifications using light’s second-order coherence. Phys. Rev. Appl. 2023, 20, 054012. [Google Scholar] [CrossRef]
- Liu, J.; Wang, L.; Zhao, S. Secret sharing scheme based on spread spectrum ghost imaging. Appl. Opt. 2022, 61, 7102–7107. [Google Scholar] [CrossRef] [PubMed]
- Lin, S.; Wang, X.; Zhu, A.; Xue, J.; Xu, B. Steganographic optical image encryption based on single-pixel imaging and an untrained neural network. Opt. Express 2022, 30, 36144–36154. [Google Scholar] [CrossRef] [PubMed]
- Jiao, S.; Feng, J.; Gao, Y.; Lei, T.; Yuan, X. Visual cryptography in single-pixel imaging. Opt. Express 2020, 28, 7301–7313. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Li, S. Optical multiple-image compression-encryption via single-pixel Radon transform. Appl. Opt. 2020, 59, 9744–9754. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Lin, S.; Xue, J.; Xu, B.; Chen, J. Information security scheme using deep learning-assisted single-pixel imaging and orthogonal coding. Opt. Express 2023, 31, 2402–2413. [Google Scholar] [CrossRef] [PubMed]
- Meng, S.-Y.; Shi, W.-W.; Ji, J.; Tao, J.-J.; Fu, Q.; Chen, X.-H.; Wu, L.-A. Super-resolution filtered ghost imaging with compressed sensing. Chin. Phys. B 2020, 29, 128704. [Google Scholar] [CrossRef]
- Zhou, C.; Feng, D.; Wang, G.; Huang, J.; Huang, H.; Liu, X.; Li, X.; Feng, Y.; Sun, H.; Song, L. Double filter iterative ghost imaging for high quality edge and image acquisition. Opt. Express 2023, 31, 25013–25024. [Google Scholar] [CrossRef] [PubMed]
- Gong, W. Disturbance-free single-pixel imaging via complementary detection. Opt. Express 2023, 31, 30505–30513. [Google Scholar] [CrossRef]
- Yu, W.-K. Super sub-Nyquist single-pixel imaging by means of cake-cutting Hadamard basis sort. Sensors 2019, 19, 4122. [Google Scholar] [CrossRef] [PubMed]
- Hou, H.-Y.; Zhao, Y.-N.; Han, J.-C.; Cao, D.-Z.; Zhang, S.-H.; Liu, H.-C.; Liang, B.-L. Complex-amplitude Fourier single-pixel imaging via coherent structured illumination. Chin. Phys. B 2023, 32, 064201. [Google Scholar] [CrossRef]
- Deng, Z.; Qi, S.; Zhang, Z.; Zhong, J. Autofocus Fourier single-pixel microscopy. Opt. Lett. 2023, 48, 6076–6079. [Google Scholar] [CrossRef]
- Rizvi, S.; Cao, J.; Hao, Q. Deep learning based projector defocus compensation in single-pixel imaging. Opt. Express 2020, 28, 25134–25148. [Google Scholar] [CrossRef]
- Hu, H.-K.; Sun, S.; Lin, H.-Z.; Jiang, L.; Liu, W.-T. Denoising ghost imaging under a small sampling rate via deep learning for tracking and imaging moving objects. Opt. Express 2020, 28, 37284–37293. [Google Scholar] [CrossRef]
- Liu, X.; Han, T.; Zhou, C.; Huang, J.; Ju, M.; Xu, B.; Song, L. Low sampling high quality image reconstruction and segmentation based on array network ghost imaging. Opt. Express 2023, 31, 9945–9960. [Google Scholar] [CrossRef]
- Peng, L.; Xie, S.; Qin, T.; Cao, L.; Bian, L. Image-free single-pixel object detection. Opt. Lett. 2023, 48, 2527–2530. [Google Scholar] [CrossRef]
- Peng, Y.; Chen, W. Learning-based correction with Gaussian constraints for ghost imaging through dynamic scattering media. Opt. Lett. 2023, 48, 4480–4483. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Wang, C.; Chen, M.; Gong, W.; Zhang, Y.; Han, S.; Situ, G. Far-field super-resolution ghost imaging with a deep neural network constraint. Light-Sci. Appl. 2022, 11, 1. [Google Scholar] [CrossRef] [PubMed]
- Wei, Z.; Wu, X.; Tong, W.; Zhang, S.; Yang, X.; Tian, J.; Hui, H. Elimination of stripe artifacts in light sheet fluorescence microscopy using an attention-based residual neural network. Biomed. Opt. Express 2022, 13, 1292–1311. [Google Scholar] [CrossRef]
- Xi, X.; Meng, X.; Qin, Z.; Nie, X.; Yin, Y.; Chen, X. IA-net: Informative attention convolutional neural network for choroidal neovascularization segmentation in OCT images. Biomed. Opt. Express 2020, 11, 6122–6136. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Zhang, Y.; Cheng, Z.; Zhai, J.; Hu, H. Attention-based neural network for polarimetric image denoising. Opt. Lett. 2022, 47, 2726–2729. [Google Scholar] [CrossRef]
- Li, Q.; Meng, X.; Yin, Y.; Wu, H. A multi-image encryption based on sinusoidal coding frequency multiplexing and deep learning. Sensors 2021, 21, 6178. [Google Scholar] [CrossRef] [PubMed]
- Perez, R.A.; Vilardy, J.M.; Pérez-Cabré, E.; Millán, M.S.; Torres, C.O. Nonlinear encryption for multiple images based on a joint transform correlator and the gyrator transform. Sensors 2023, 23, 1679. [Google Scholar] [CrossRef]
- Feng, W.; Wang, Q.; Liu, H.; Ren, Y.; Zhang, J.; Zhang, S.; Qian, K.; Wen, H. Exploiting newly designed fractional-order 3D Lorenz chaotic system and 2D discrete polynomial hyper-chaotic map for high-performance multi-image encryption. Fractal Fract. 2023, 7, 887. [Google Scholar] [CrossRef]
- Qian, K.; Xiao, Y.; Wei, Y.; Liu, D.; Wang, Q.; Feng, W. A robust memristor-enhanced polynomial hyper-chaotic map and its multi-channel image encryption application. Micromachines 2023, 14, 2090. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.-F.; Yu, W.-K.; Li, Y.-X. Multi-wavelet residual dense convolutional neural network for image denoising. IEEE Access 2020, 8, 214413–214424. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Li, H.; Yu, S.; Feng, W.; Chen, Y.; Zhang, J.; Qin, Z.; Zhu, Z.; Marcin, W. Exploiting dynamic vector-level operations and a 2D-enhanced logistic modular map for efficient chaotic image encryption. Entropy 2023, 25, 1147. [Google Scholar] [CrossRef]






Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, W.-K.; Wang, S.-F.; Shang, K.-Q. Optical Encryption Using Attention-Inserted Physics-Driven Single-Pixel Imaging. Sensors 2024, 24, 1012. https://doi.org/10.3390/s24031012
Yu W-K, Wang S-F, Shang K-Q. Optical Encryption Using Attention-Inserted Physics-Driven Single-Pixel Imaging. Sensors. 2024; 24(3):1012. https://doi.org/10.3390/s24031012
Chicago/Turabian StyleYu, Wen-Kai, Shuo-Fei Wang, and Ke-Qian Shang. 2024. "Optical Encryption Using Attention-Inserted Physics-Driven Single-Pixel Imaging" Sensors 24, no. 3: 1012. https://doi.org/10.3390/s24031012
APA StyleYu, W.-K., Wang, S.-F., & Shang, K.-Q. (2024). Optical Encryption Using Attention-Inserted Physics-Driven Single-Pixel Imaging. Sensors, 24(3), 1012. https://doi.org/10.3390/s24031012