
Systematic Review of EEG-Based Imagined Speech Classification Methods


Abstract
1. Introduction
2. Materials and Methods
2.1. Protocol
2.2. Eligibility Criteria
2.2.1. Inclusion Criteria
- (a)
- Focus on EEG-based imagined speech classification:EEG has been proven to be an effective and non-invasive way of recording brain signals. It also has more applications in imagined speech classification, indicating its outstanding contribution to BCIs and neuroprosthetics. This review focuses on EEG for the specificity of better technologies that deal with more relevant technologies in the field.
- (b)
- Utilization of public datasets:This ensures that the results are reproducible from one researcher to another using the same raw data. Public datasets also enable a broader comparison of different studies, thereby improving the validity of systematic reviews.
- (c)
- Investigation of directional word classification:The use of directional words like “up”, “down”, “left”, “right”, “forward”, and “backward” will give an oriented and measurable imagined speech classification. This focus is particularly relevant for applications in assistive technologies where simple commands are crucial.
2.2.2. Exclusion Criteria
- (a)
- Non-English language studies:Limiting this review to English language studies recognizes the reviewers’ language capabilities. In addition, it ensured a uniform interpretation and analysis of the studies.
- (b)
- Studies not using EEG for signal collection:As this is a review specifically on EEG-based classification, other methods such as fMRI or PET scans are not included. This ensures that the review remains focused on related literature without dilution.
- (c)
- Scope not focused on classifying imagined speech:This guarantees that the review will be perfectly tailored to the particular scope of interest (imagined speech classification), excluding broader EEG studies on different applications.
- (d)
- Studies utilizing classifying vowels, phonemes, letters, or syllables:By omitting studies dealing with vowels, phonemes, letters, and syllables, this review restricts its scope to a particular domain—the classification of directional words. This aids in creating a more cohesive and targeted review.
2.3. Information Sources and Search Strategy
- (covert speech EEG) OR (covert speech Electroencephalography)
- (decoding speech EEG) OR (decoding speech Electroencephalography)
- (envisioned speech EEG) OR (envisioned speech Electroencephalography)
- (imagery speech EEG) OR (imagery speech Electroencephalography)
- (imaginary speech EEG) OR (imaginary speech Electroencephalography)
- (imagined words EEG) OR (imagined words Electroencephalography)
- (inner speech EEG) OR (inner speech Electroencephalography)
- (silent speech EEG) OR (silent speech Electroencephalography)
- (unspoken words EEG) OR (unspoken words Electroencephalography)
2.4. Study Selection and Data Management
- (a)
- Initial screening:The titles and abstracts of articles found in the databases were assessed during the initial screening. The goal was to identify studies that met the predefined eligibility criteria.
- (b)
- Application of predefined eligibility criteria:Predetermined eligibility criteria were applied systematically to ensure an unbiased and straightforward study selection process.
- (c)
- Full-text assessment for eligibility:The full text of studies was reviewed to determine their eligibility when titles or abstracts indicated potential relevance or uncertainty. This step ensured comprehensive alignment with the inclusion criteria for the review
- (d)
- Data management using Mendeley software (Version 2.100.0) & EPPI-Reviewer software (Version 6.15.1.0):References and data from the selected studies were organized and managed using specialized software tools, including Mendeley and EPPI-Reviewer.
- Mendeley [14]: A reference manager facilitates the storage, organizing, noting, sharing, and citation of research data and references.
- EPPI-Reviewer [15]: EPPI-Reviewer manages and analyzes literature review data. While its features apply to any literature review, the software was designed to support various forms of systematic reviews (e.g., framework synthesis and thematic synthesis). The software facilitates qualitative and quantitative analyses, including thematic synthesis and reference management. Additionally, it includes “text mining” technology, which can improve the effectiveness of systematic reviewing.
This methodology emphasizes commitment to a thorough, elaborate strategy, which is the core factor in the systematic review’s robustness.
2.5. Data Collection Process
- (a)
- Author(s’) information: The authors of each study were identified to recognize their contributions and understand the diversity of the research community.
- (b)
- Publication year: The year of publication was recorded to evaluate the timeline and progression of research in the field.
- (c)
- Research objectives: The specific objectives of each study were described within the scope of EEG-based imagined speech classification, highlighting the diverse approaches used for classifying directional words.
- (d)
- Reported limitations: The limitations reported by the authors were documented, including methodological challenges, data handling difficulties, issues with generalizing classification models, and other obstacles encountered in this area of research.
- (e)
- Suggested future directions: Future research avenues proposed by each study were captured to highlight potential advancements in algorithm development and EEG signal processing techniques. This information is critical for identifying opportunities in the field and guiding subsequent research efforts.
- (f)
- Utilized dataset details: Details of the datasets used, including the subjects, devices, and protocols, were collected to enhance the understanding of the relevance and applicability of the research findings.
- (g)
- Signal processing techniques: The techniques used for raw data processing were documented to provide insights into the initial steps of data handling.
- (h)
- Data downsampling: Information on whether the data were downsampled to reduce its size was documented.
- (i)
- Feature extraction methods: The methods used to identify and extract relevant features from the data were documented, as they are essential for effective data classification.
- (j)
- Classification methods: The methods used for classifying the data were detailed to facilitate the comparison of results across studies.
- (k)
- Optimization strategies: The techniques implemented to optimize classification performance were documented.
- (l)
- Reported accuracy: The accuracy reported in each study was recorded to measure the effectiveness of the methodologies employed.
- (m)
- Evaluation metrics: Additional metrics used to assess the performance of the classification were documented in detail.
- (n)
- Classification type: The type of classification, whether binary or multiclass, was recorded to evaluate its impact on the complexity and effectiveness of the applied methods.
- (o)
- Subject dependency: The approach was identified as either subject-dependent (tailored to specific individuals) or subject-independent (generalizable across individuals), as this distinction influenced the scope and applicability of the findings.
3. Results
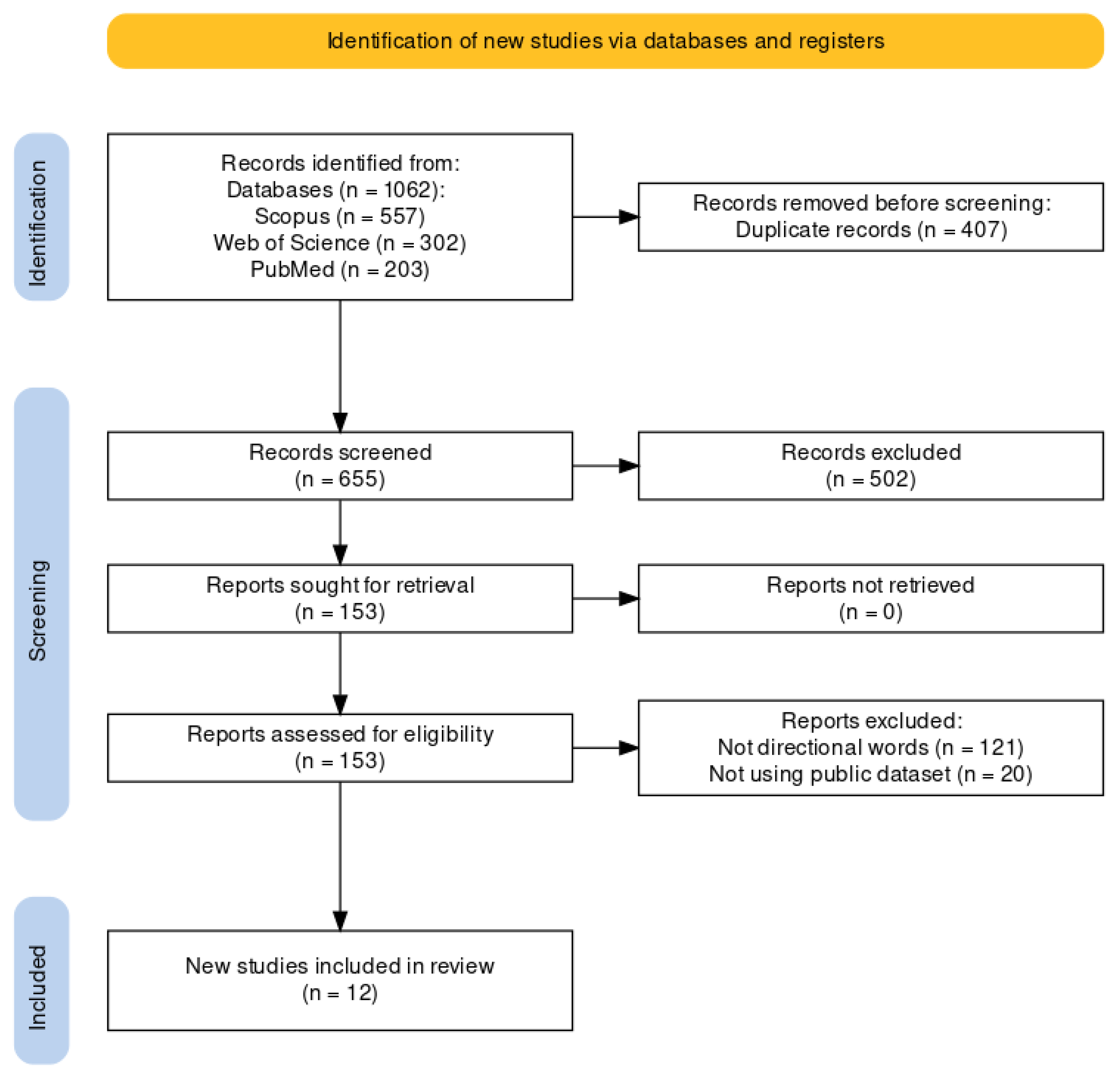
3.1. Study Selection
3.2. Synthesis of Results
3.2.1. Effect of Feature Extraction on Classification Performance
3.2.2. Classification Methods to Enhance Classification Performance
3.2.3. Investigation of Brain Lateralization in Imagined Speech
3.2.4. Generalization and Scalability in EEG-Based Imagined Speech
- (a)
- Subject-independent approach:This approach aims to develop general models that can cover different subjects without individual calibration or training, which are very important for practical implementation and wide use in EEG-based imagined speech systems. The models can be easily applied to new users without extensive training sessions and customization, making the systems usable and scalable.In [16], a subject-independent leave-one-out cross-validation (LOO CV) approach was used for the performance evaluation of classifying imagined words. This is crucial, as it is relevant to understand how well generalizing a BCI system across individuals without individual-specific training is possible. The model in the subject-independent LOO CV was learned from all the subjects, but one was held out as a test set. This was repeated so that each subject’s data were taken as the test set exactly once. In this regard, the testing strategy helps judge the model’s generalization capability across new and unfamiliar subjects. The results showed that although classifiers could handle subject variability up to a certain level, the performance metrics simultaneously showed room for improvement in accuracy and reliability across unseen subjects. Thus, while the subject-independent LOO CV approach widens the applicability of BCI systems, high accuracy remains a challenge and an open area for future research.In contrast, the work in [19] provides a rigorous testing framework in which models are trained and tested across different groups of subjects to ensure effective generalization. The importance given to subject-independent generalization indicates that the generalization of BCI systems for recognizing imagined speech can be effective for different subjects without adaptation to the individual subject. Such a development is necessary to generalize and practically deploy BCI technologies in real-life applications. The results obtained from this dataset show that the model is generalizable across subjects with high accuracy. This eliminates the need for detailed recalibration with new users.The paper [20] also presented a subject-independent approach that uses all collected data for training and testing models without dividing the data into subgroups by individual subjects. Therefore, the results discussed in this paper show that a subject-independent approach attains considerably high accuracy rates, thus demonstrating the ability of a BCI system to do so. The performance also outperformed other studies, revealing robust generalization ability and capturing variations across different individuals as needed in a scalable BCI.The reviewed studies underscore the critical trade-offs in subject-independent approaches. While the LOO CV approach in [16] provided foundational insights into generalization, its relatively low accuracy (21.53%) reflects the difficulty in adapting models to diverse EEG patterns. In contrast, the approaches by [19,20] achieved significantly higher accuracies of 60.42% and 72.36%, respectively, demonstrating the benefits of advanced optimization and robust evaluation frameworks. These findings suggest that subject-independent approaches are increasingly viable, with optimization techniques playing a pivotal role in closing the performance gap with subject-dependent models.
- (b)
- Multiclass scalability:One of the most significant hurdles in advancing BCI systems for imagined speech is the ability to scale to new classes. Typically, adding a new class to a pre-existing classifier requires collecting a substantial amount of new data for all classes to retrain the system. This process is time-consuming and impractical for dynamic and real-world applications.The study by [18] innovatively employed deep metric learning to facilitate this scalability, allowing a system to be trained on a set number of classes to accommodate additional classes without requiring comprehensive retraining. This approach utilizes incremental learning, where a classifier that is already proficient in distinguishing between established classes is fine-tuned to recognize new classes by adjusting only its fully connected layers. Crucially, this method preserves the classifier’s performance on the original classes, effectively broadening the system’s capabilities without compromising the existing knowledge base. The success of this approach in maintaining accuracy while adding new classes suggests a path forward in which BCI systems can evolve and grow significantly.
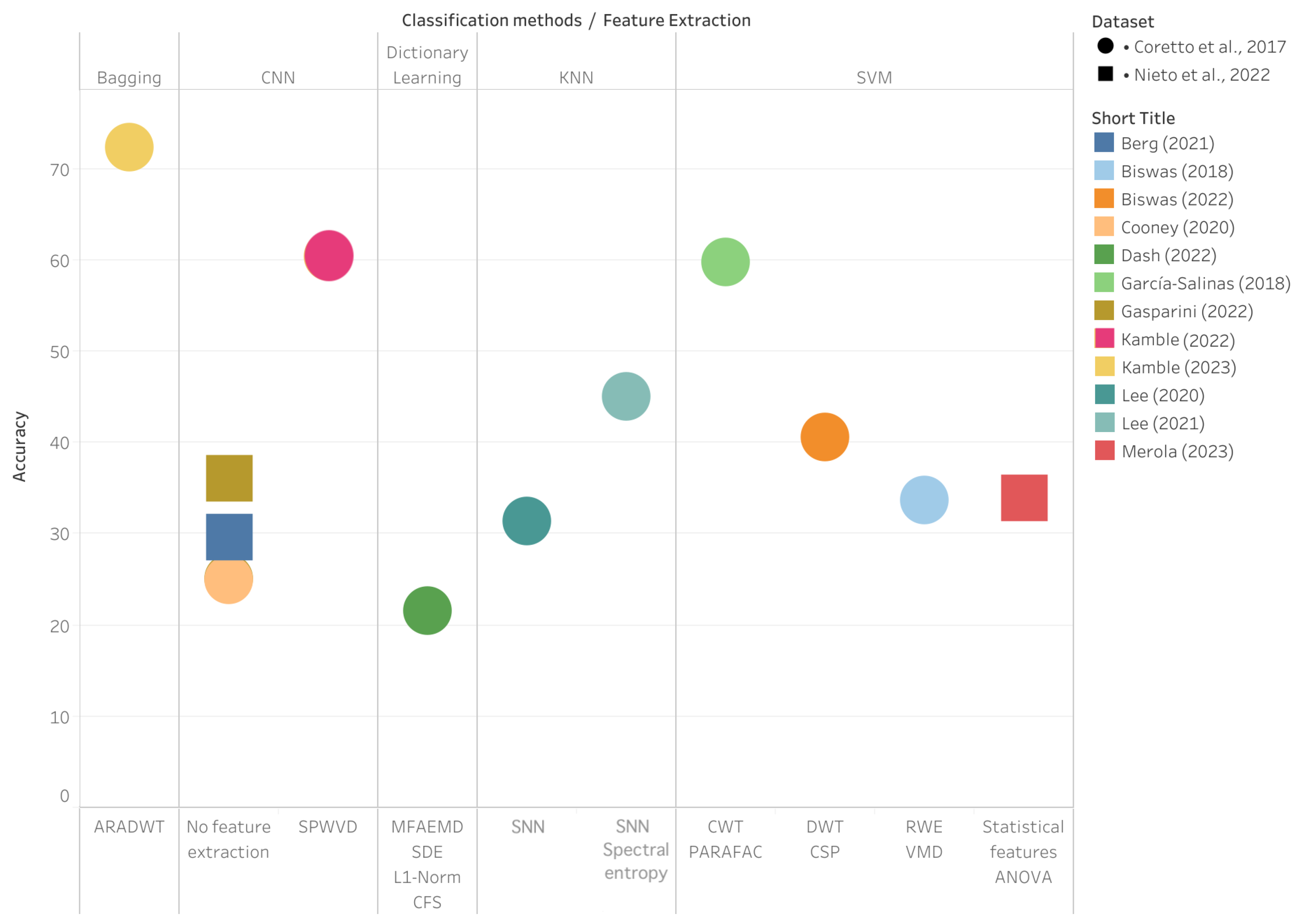
3.2.5. Performance Benchmarking

{kind=link}
{kind=link}
{kind=link}
| Paper | Dataset | Downsampling | Preprocessing | Feature Extraction | Classification Methods | Classification Type (Number of Classes) | Optimization | Evaluation | Accuracy | Subject Dependency |
|---|---|---|---|---|---|---|---|---|---|---|
| Berg et al. (2021) [25] | Nieto et al. (2022) [29] | Downsampled to 254 Hz | Bandpass filter (0.5–100 Hz), Notch filter (50 Hz), ICA | No feature extraction | CNN EEGNet | Multiclass classification (4 classes) | Not mentioned | Accuracy, F1-score, Recall, Precision, K-fold cross-validation | 29.67% | Subject-dependent |
| Biswas et al. (2018) [27] | Coretto et al. (2017) [28] | Downsampled to 128 Hz | No preprocessing | RWE, VMD | SVM-rbf | Multiclass classification (6 classes) | Tuning parameter Y for SVM-rbf | Accuracy K-fold cross-validation | 33.63% | Subject-dependent |
| Biswas et al. (2022) [21] | Coretto et al. (2017) [28] | Not mentioned | No preprocessing | DWT, CSP | SVM-rbf | Multiclass classification (6 classes) | Not mentioned | Accuracy, K-fold cross-validation | 40.59% | Subject-dependent |
| Cooney et al. (2020) [24] | Coretto et al. (2017) [28] | Downsampled to 128 Hz | Bandpass filter (2–40 Hz), ICA with Hessian approximation preconditioning | No feature extraction | CNN EEGNet | Multiclass classification (6 classes) | nCV, Hyperparameter Selection (activation function, learning rate, epochs number, loss function) | Accuracy, Precision, ANOVA, nCV, Tukey Honest Significant Difference (HSD) Test | 24.97% | Subject-dependent |
| Dash et al. (2022) [16] | Coretto et al. (2017) [28] | Not mentioned | Not mentioned | MFAEMD, SDE, L1-Norm, Correlation-based feature selection (CFS) | Dictionary Learning | Multiclass classification (6 classes) | Grid search optimization | Accuracy, F-score, LOO CV | 21.53% | Subject-independent |
| García-Salinas et al. (2018) [22] | Coretto et al. (2017) [28] | Downsampled to 128 Hz | Not mentioned | CWT, PARAFAC, K-means clustering, Histogram generation | SVM-linear | Multiclass classification (6 classes) | Not mentioned | Accuracy, K-fold cross-validation, ANOVA | 59.7% (For the first three subjects only) | Subject-dependent |
| Gasparini et al. (2022) [26] | Coretto et al. (2017) [28] | Not mentioned | Bandpass filter (2–40 Hz) | No feature extraction | CNN BiLSTM | Multiclass classification (6 classes) | Stochastic gradient descent (SGD), nCV | Accuracy | 25.1% | Subject-dependent |
| Gasparini et al. (2022) [26] | Nieto et al. (2022) [29] | Downsampled to 254 Hz | Bandpass filter (0.5–100 Hz), Notch filter (50 Hz) | No feature extraction | CNN BiLSTM | Multiclass classification (4 classes) | Stochastic gradient descent (SGD), nCV | Accuracy, F1-score, Recall, Precision | 36.10% | Subject-dependent |
| Kamble et al. (2022) [19] | Coretto et al. (2017) [28] | Not mentioned | Not mentioned | SPWVD | CNN | Multiclass classification (6 classes) | Hyperparameter optimization (KerasTuner library) | Accuracy | 60.42% | Subject-independent |
| Kamble et al. (2023) [20] | Coretto et al. (2017) [28] | Not mentioned | Not mentioned | ARADWT, Statistical features, ANOVA | Bagging | Multiclass classification (6 classes) | nCV, PSO | Accuracy | 72.36% | Subject-independent |
| Lee et al. (2020) [17] | Coretto et al. (2017) [28] | Downsampled to 128 Hz | No preprocessing | SNN | KNN | Multiclass classification (6 classes) | ADAM optimizer | Accuracy, F1-score, Recall, Precision, K-fold cross-validation, ANOVA, Paired t-test | 31.4% | Subject-dependent |
| Lee et al. (2021) [18] | Coretto et al. (2017) [28] | Not mentioned | No preprocessing | SNN, Spectral entropy, Instantaneous frequency | KNN | Multiclass classification (6 classes) | ADAM optimizer | Accuracy, K-fold cross-validation, ANOVA analysis, t-test | 45% | Subject-dependent |
| Merola et al. (2023) [23] | Nieto et al. (2022) [29] | Not mentioned | Bandpass filter (0.5–100 Hz), Notch filter (50 Hz) | Statistical features, ANOVA | SVM-quadratic | Multiclass classification (4 classes) | Grid search optimization | Accuracy | 33.9% | Subject-dependent |
3.2.6. Limitations
4. Discussion
4.1. Feature Extraction and Classification Performance
4.2. Generalization Challenges and Subject Independence
4.3. Insights from Brain Lateralization
4.4. Standardization of Data Quality and Preprocessing
4.5. Directions for Future Research
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| BCI | Brain–Computer Interface |
| ARADWT | Adaptive Rational Dilation Wavelet Transform |
| BiLSTM | Bidirectional Long Short-Term Memory |
| CFS | Correlation-based Feature Selection |
| CNN | Convolutional Neural Network |
| CSP | Common Spatial Patterns |
| CWT | Continuous Wavelet Transform |
| DWT | Discrete Wavelet Transform |
| EEG | Electroencephalography |
| EMD | Empirical Mode Decomposition |
| FIR | Finite Impulse Response |
| ICA | Independent Component Analysis |
| KNN | K-Nearest Neighbors |
| LDA | Linear Discriminant Analysis |
| LOO CV | Leave-One-Out Cross-Validation |
| ML | Machine Learning |
| MFAEMD | Multivariate Fast and Adaptive Empirical Mode Decomposition |
| nCV | Nested Cross-Validation |
| PARAFAC | Parallel Factor Analysis |
| PSO | Particle Swarm Optimization |
| RBF | Radial Basis Function |
| RNN | Recurrent Neural Network |
| SDE | Slope Domain Entropy |
| SGD | Stochastic Gradient Descent |
| SNN | Siamese Neural Network |
| SPWVD | Smoothed Pseudo-Wigner–Ville Distribution |
| SVM | Support Vector Machine |
| TCN | Temporal Convolutional Network |
| VMD | Variational Mode Decomposition |
References
- Lopez-Bernal, D.; Balderas, D.; Ponce, P.; Molina, A. A state-of-the-art review of EEG-based imagined speech decoding. Front. Hum. Neurosci. 2022, 16, 867281. [Google Scholar] [CrossRef]
- Keiper, A. The age of neuroelectronics. New Atlantis 2006, 11, 4–41. [Google Scholar] [PubMed]
- Vorontsova, D.; Menshikov, I.; Zubov, A.; Orlov, K.; Rikunov, P.; Zvereva, E.; Flitman, L.; Lanikin, A.; Sokolova, A.; Markov, S.; et al. Silent EEG-Speech Recognition Using Convolutional and Recurrent Neural Network with 85% Accuracy of 9 Words Classification. Sensors 2021, 21, 6744. [Google Scholar] [CrossRef] [PubMed]
- García, A.A.T.; García, C.A.R.; Villaseñor-Pineda, L.; García, G. Implementing a fuzzy inference system in a multi-objective EEG channel selection model for imagined speech classification. Expert Syst. Appl. 2016, 59, 1–12. [Google Scholar] [CrossRef]
- Panachakel, J.T.; Ramakrishnan, A.G. Decoding covert speech from EEG-a comprehensive review. Front. Neurosci. 2021, 15, 392. [Google Scholar] [CrossRef] [PubMed]
- DaSalla, C.S.; Kambara, H.; Sato, M.; Koike, Y. Single-trial classification of vowel speech imagery using common spatial patterns. Neural Netw. Off. J. Int. Neural Netw. Soc. 2009, 22, 1334–1339. [Google Scholar] [CrossRef] [PubMed]
- Sun, P.; Qin, J. Neural networks based EEG-Speech Models. arXiv 2016, arXiv:1612.05369. [Google Scholar]
- Pawar, D.; Dhage, S.N. Multiclass covert speech classification using extreme learning machine. Biomed. Eng. Lett. 2020, 10, 217–226. [Google Scholar] [CrossRef] [PubMed]
- Min, B.; Kim, J.; Park, H.J.; Lee, B. Vowel Imagery Decoding toward Silent Speech BCI Using Extreme Learning Machine with Electroencephalogram. BioMed Res. Int. 2016, 2016, 2618265. [Google Scholar] [CrossRef]
- Mahapatra, N.C.; Bhuyan, P. Multiclass Classification of Imagined Speech Vowels and Words of Electroencephalography Signals Using Deep Learning. Adv. Hum.-Comput. Interact. 2022, 2022, 1374880. [Google Scholar] [CrossRef]
- Rahman, N.; Khan, D.M.; Masroor, K.; Arshad, M.; Rafiq, A.; Fahim, S.M. Advances in brain-computer interface for decoding speech imagery from EEG signals: A systematic review. Cogn. Neurodyn. 2024, 18, 3565–3583. [Google Scholar] [CrossRef]
- Bakhshali, M.A.; Khademi, M.; Ebrahimi-Moghadam, A. Investigating the neural correlates of imagined speech: An EEG-based connectivity analysis. Digit. Signal Process. 2022, 123, 103435. [Google Scholar] [CrossRef]
- Agarwal, P.; Kumar, S. EEG-based imagined words classification using Hilbert transform and deep networks. Multimed. Tools Appl. 2023, 83, 2725–2748. [Google Scholar] [CrossRef]
- Mendeley Ltd. Mendeley Reference Manager (Version 2.100.0) [Computer Software]. Available online: https://www.mendeley.com (accessed on 14 November 2023).
- Thomas, J.; Graziosi, S.; Brunton, J.; Ghouze, Z.; O’Driscoll, P.; Bond, M.; Koryakina, A. EPPI-Reviewer: Advanced Software for Systematic Reviews, Maps, and Evidence Synthesis, Version 6.15.1.0 [Online software]. EPPI Centre, UCL Social Research Institute, University College London. Available online: https://eppi.ioe.ac.uk/ (accessed on 16 April 2024).
- Dash, S.; Tripathy, R.K.; Panda, G.; Pachori, R.B. Automated recognition of imagined commands from EEG signals using multivariate fast and adaptive empirical mode decomposition based method. IEEE Sens. Lett. 2022, 6, 1–4. [Google Scholar] [CrossRef]
- Lee, D.Y.; Lee, M.; Lee, S.W. Classification of imagined speech using Siamese neural network. In Proceedings of the 2020 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Toronto, ON, Canada, 11–14 October 2020; pp. 2979–2984. [Google Scholar]
- Lee, D.Y.; Lee, M.; Lee, S.W. Decoding imagined speech based on deep metric learning for intuitive BCI communication. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 1363–1374. [Google Scholar] [CrossRef]
- Kamble, A.; Ghare, P.H.; Kumar, V. Deep-learning-based BCI for automatic imagined speech recognition using SPWVD. IEEE Trans. Instrum. Meas. 2022, 72, 1–10. [Google Scholar] [CrossRef]
- Kamble, A.; Ghare, P.H.; Kumar, V. Optimized Rational Dilation Wavelet Transform for Automatic Imagined Speech Recognition. IEEE Trans. Instrum. Meas. 2023, 72, 1–10. [Google Scholar] [CrossRef]
- Biswas, S.; Sinha, R. Wavelet filterbank-based EEG rhythm-specific spatial features for covert speech classification. IET Signal Process. 2022, 16, 92–105. [Google Scholar] [CrossRef]
- García-Salinas, J.S.; Villaseñor-Pineda, L.; Reyes-García, C.A.; Torres-García, A. Tensor decomposition for imagined speech discrimination in EEG. In Proceedings of the Advances in Computational Intelligence: 17th Mexican International Conference on Artificial Intelligence, MICAI 2018, Guadalajara, Mexico, 22–27 October 2018; pp. 239–249. [Google Scholar]
- Merola, N.R.; Venkataswamy, N.G.; Imtiaz, M.H. Can Machine Learning Algorithms Classify Inner Speech from EEG Brain Signals? In Proceedings of the 2023 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 7–10 June 2023; pp. 466–470. [Google Scholar]
- Cooney, C.; Korik, A.; Folli, R.; Coyle, D. Evaluation of hyperparameter optimization in machine and deep learning methods for decoding imagined speech EEG. Sensors 2020, 20, 4629. [Google Scholar] [CrossRef] [PubMed]
- van den Berg, B.; van Donkelaar, S.; Alimardani, M. Inner speech classification using EEG signals: A deep learning approach. In Proceedings of the 2021 IEEE 2nd International Conference on Human-Machine Systems (ICHMS), Magdeburg, Germany, 8–10 September 2021; pp. 1–4. [Google Scholar]
- Gasparini, F.; Cazzaniga, E.; Saibene, A. Inner speech recognition through electroencephalographic signals. arXiv 2022, arXiv:2210.06472. [Google Scholar]
- Biswas, S.; Sinha, R. Lateralization of brain during EEG based covert speech classification. In Proceedings of the 2018 15th IEEE India Council International Conference (INDICON), Coimbatore, India, 16–18 December 2018; pp. 1–5. [Google Scholar]
- Coretto, G.A.P.; Gareis, I.E.; Rufiner, H.L. Open access database of EEG signals recorded during imagined speech. In Proceedings of the 12th International Symposium on Medical Information Processing and Analysis, Park City, UT, USA, 23–26 August 2017; Volume 10160, p. 1016002. [Google Scholar]
- Nieto, N.; Peterson, V.; Rufiner, H.L.; Kamienkowski, J.E.; Spies, R. Thinking out loud, an open-access EEG-based BCI dataset for inner speech recognition. Sci. Data 2022, 9, 52. [Google Scholar] [CrossRef] [PubMed]

Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzahrani, S.; Banjar, H.; Mirza, R. Systematic Review of EEG-Based Imagined Speech Classification Methods. Sensors 2024, 24, 8168. https://doi.org/10.3390/s24248168
Alzahrani S, Banjar H, Mirza R. Systematic Review of EEG-Based Imagined Speech Classification Methods. Sensors. 2024; 24(24):8168. https://doi.org/10.3390/s24248168
Chicago/Turabian StyleAlzahrani, Salwa, Haneen Banjar, and Rsha Mirza. 2024. "Systematic Review of EEG-Based Imagined Speech Classification Methods" Sensors 24, no. 24: 8168. https://doi.org/10.3390/s24248168
APA StyleAlzahrani, S., Banjar, H., & Mirza, R. (2024). Systematic Review of EEG-Based Imagined Speech Classification Methods. Sensors, 24(24), 8168. https://doi.org/10.3390/s24248168