
Unmanned-Aerial-Vehicle-Assisted Secure Free Space Optical Transmission in Internet of Things: Intelligent Strategy for Optimal Fairness

Abstract
:1. Introduction
1.1. Previous Work
1.2. Contributions
- We analyzed the decoding outage probability for all sensors, in terms of an UAV-assisted FSO relay communication network, where all closed-form expressions were derived.
- We used a DRL-based approach to tain the optimal scheme, for transmit power allocation, to minimize the maximum decoding outage probability of all sensors. Note that the relationship between input and output can be modeled using a well-trained policy network, approximate analytical expressions for optimal transmit power levels can be obtained. To the best of our knowledge, this is the first work to investigate an optimal transmission scheme for UAV-assisted FSO communication network in the IoT from the perspective of fairness.
- We illustrate some design trade-offs and compare various design approaches through selected numerical examples. These results can greatly facilitate the fairness-aware design of UAV-assisted FSO communication networks in the IoT.
2. System and Channel Model
2.1. System Model
2.2. Channel Model
3. Outage Probability Analysis
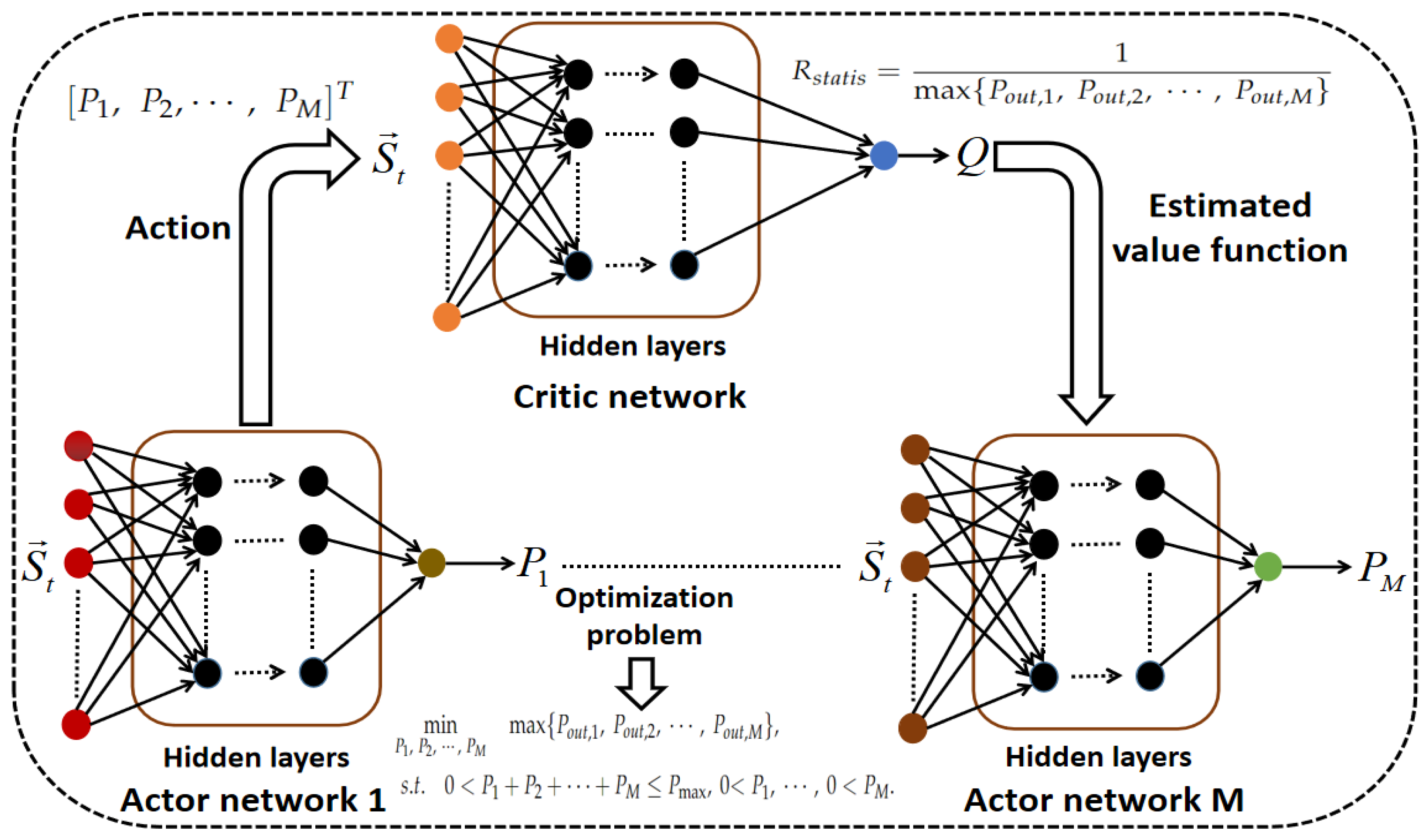
4. Fairness-Aware Optimal Transmission Scheme
4.1. Reward Function
4.2. Deep Actor Networks and Critic Network
4.3. Model Training Process
4.4. Random Exploration
4.5. The Pseudo Code
| Algorithm 1 The pseudo code of training. |
|
5. Numerical Results
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wu, C.; Chen, K.H.J.; Zhao, Z.; Du, R. Toward robust detection of puppet attacks via characterizing fingertip-touch behaviors. IEEE Trans. Dependable Secur. Comput. 2021, 19, 4002–4018. [Google Scholar] [CrossRef]
- Yang, X.; Chen, J.; Bai, K.H.H.; Wu, C.; Du, R. Efficient privacy-preserving inference outsourcing for convolutional neural networks. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4815–4829. [Google Scholar] [CrossRef]
- Wu, C.; Cao, H.; Xu, G.; Zhou, C.; Sun, J.; Yan, R.; Liu, Y.; Jiang, H. It’s all in the touch: Authenticating users with HOST gestures on multi-touch screen devices. IEEE Trans. Mob. Comput. 2024, 23, 10016–10030. [Google Scholar] [CrossRef]
- Wu, C.; Cao, H.; Xu, G.; Zhou, C.; Sun, J.; Yan, R.; Liu, Y.; Jiang, H. CaiAuth: Context-aware implicit authentication when the screen is awake. IEEE Internet Things J. 2020, 7, 11420–11430. [Google Scholar] [CrossRef]
- Liang, R.; Chen, J.; He, K.; Wu, Y.; Deng, G.; Du, R.; Wu, C. Ponziguard: Detecting ponzi schemes on ethereum with contract runtime behavior graph (crbg). In Proceedings of the 46th IEEE/ACM International Conference on Software Engineering, Lisbon, Portugal, 14–20 April 2024; pp. 1–12. [Google Scholar]
- Li, R.; Chen, T.; Fan, L.; Dang, A. Performance analysis of a multiuser dual-hop amplify and forward relay system with FSO/RF links. J. Opt. Commun. Netw. 2019, 11, 362–370. [Google Scholar] [CrossRef]
- Bag, B.; Das, A.; Ansari, I.S.; Proke, A.; Bose, C.; Chandra, A. Performance analysis of hybrid FSO systems using FSO/RF-FSO link adaptation. IEEE Photonics J. 2018, 10, 33465–33473. [Google Scholar] [CrossRef]
- Hu, Z.; Chen, C.; Zhang, Z. Secure cooperative transmission for mixed RF/FSO spectrum sharing networks. IEEE Trans. Commun. 2020, 68, 3010–3023. [Google Scholar] [CrossRef]
- Nasab, E.S.; Uysal, M. Generalized performance analysis of mixed RF/FSO cooperative systems. IEEE Trans. Wireless Commun. 2016, 15, 714–727. [Google Scholar] [CrossRef]
- Lei, H.; Luo, H.; Park, K.H.; Ansari, I.S.; Lei, W.; Pan, G.; Alouini, M.S. On Secure Mixed RF-FSO Systems with TAS and Imperfect CSI. IEEE Wireless Commun. Lett. 2020, 68, 4461–4475. [Google Scholar]
- Najafi, M.; Jamali, V.; Schober, R. Two-way relay selection in multiple relayed FSO networks. IEEE Trans. Commun. 2017, 65, 2794–2810. [Google Scholar] [CrossRef]
- Erdogan, E.; Altunbas, I.; Kurt, G.K.; Yanikomeroglu, H. The Secrecy Comparison of RF and FSO Eavesdropping Attacks in Mixed RF-FSO Relay Networks. IEEE Photonics J. 2012, 14, 7901508. [Google Scholar] [CrossRef]
- Rjeily, C.A.; Kaddoum, G. Free Space Optical Cooperative Communications via an Energy Harvesting Harvest-Store-Use Relay. IEEE Trans. Wireless Commun. 2020, 19, 6564–6577. [Google Scholar] [CrossRef]
- Saxena, V.N.; Gupta, J.; Dwivedi, V.K. Secured End-to-End FSO-VLC-Based IoT Network With Randomly Positioned VLC: Known and Unknown CSI. IEEE Internet Things J. 2023, 10, 1347–1357. [Google Scholar] [CrossRef]
- Zhang, Y.; Gao, X.; Yuan, H.; Yang, K.; Kang, J.; Wang, P.; Niyato, D. Joint UAV Trajectory and Power Allocation with Hybrid FSO/RF for Secure Space–Air–Ground Communications. IEEE Internet Things J. 2024, 11, 31407–31421. [Google Scholar] [CrossRef]
- Pattanayak, D.R.; Dwivedi, V.K.; Karwal, V.; Upadhya, A.; Lei, H. Secure Transmission for Energy Efficient Parallel Mixed FSO/RF System in Presence of Independent Eavesdroppers. IEEE Photonics J. 2022, 14, 7307714. [Google Scholar] [CrossRef]
- Zhu, B.; Cheng, J.; Wu, L. A Distance-Dependent Free-Space Optical Cooperative Communication System. IEEE Commun. Lett. 2015, 19, 969–972. [Google Scholar] [CrossRef]
- Aljohani, A.J.; Mirza, J.; Ghafoor, S. A novel regeneration technique for free space optical communication systems. IEEE Commun. Lett. 2021, 25, 196–199. [Google Scholar] [CrossRef]
- Li, R.; Zhang, J.; Dang, A. Cooperative system in free-space optical communications for simultaneous multiuser transmission. IEEE Commun. Lett. 2018, 22, 2036–2039. [Google Scholar] [CrossRef]
- Ghazy, A.S.; Selmy, H.A.I.; Shalaby, H.M.H. Fair resource allocation schemes for cooperative dynamic free-space optical networks. J. Opt. Commun. Netw. 2016, 8, 822–834. [Google Scholar] [CrossRef]
- Chatzidiamantis, N.D.; Michalopoulos, D.S.; Kriezis, E.E.; Karagiannidis, G.K.; Schober, R. Relay selection protocols for relay-assisted free-space optical systems. J. Opt. Commun. Netw. 2013, 5, 92–103. [Google Scholar] [CrossRef]
- Rjeily, C.A.; Haddad, S. Inter-relay cooperation: A new paradigm for enhanced relay-assisted FSO communications. IEEE Trans. Wireless Commun. 2014, 62, 1970–1982. [Google Scholar] [CrossRef]
- Rjeily, C.A. Performance analysis of FSO communications with diversity methods: Add more relays or more apertures? IEEE J. Sel. Areas Commun. 2015, 33, 1890–1902. [Google Scholar] [CrossRef]
- Fawaz, W.; Rjeily, C.A.; Assi, C. UAV-aided cooperation for FSO communication systems. IEEE Commun. Mag. 2018, 56, 70–75. [Google Scholar] [CrossRef]
- Wang, J.Y.; Ma, Y.; Lu, R.R.; Wang, J.B.; Lin, M.; Cheng, J. Hovering UAV-based FSO communications: Channel modelling, performance analysis, and parameter optimization. IEEE J. Sel. Areas Commun. 2021, 39, 2946–2959. [Google Scholar] [CrossRef]
- Dabiri, M.T.; Sadough, S.M.S.; Khalighi, M.A. Channel modeling and parameter optimization for hovering UAV-based free-space optical links. IEEE J. Sel. Areas Commun. 2018, 36, 2104–2113. [Google Scholar] [CrossRef]
- Lee, J.H.; Park, K.H.; Ko, Y.C.; Alouini, M.S. Throughput maximization of mixed FSO/RF UAV-aided mobile relaying with a buffer. IEEE Trans. Wireless Commun. 2021, 20, 683–694. [Google Scholar] [CrossRef]
- McManamon, P.F.; Dorschner, T.A.; Corkum, D.L.; Friedman, L.J.; Hobbs, D.S.; Holz, M.; Liberman, S.; Nguyen, H.Q.; Resler, D.P.; Sharp, R.C.; et al. Optical phased array technology. Proc. IEEE 1996, 84, 268–298. [Google Scholar] [CrossRef]
- Gao, J.; Dang, J.; Zhang, Z.; Wu, L. Rate Analysis of Intensity Modulated Broadcast Optical Mobile Communication System with User Mobility. IEEE Photonics J. 2020, 12, 7905312. [Google Scholar] [CrossRef]
- Sharma, M.; Chadha, D.; Chandra, V. High-altitude platform for free-space optical communication: Performance evaluation and reliability analysis. J. Opt. Commun. Netw. 2016, 8, 600–609. [Google Scholar] [CrossRef]
- Shuai, H.; Guo, K.; An, K.; Zhu, S. NOMA-based integrated satellite terrestrial networks with relay selection and imperfect SIC. IEEE Access 2021, 9, 111346–111357. [Google Scholar] [CrossRef]
- Adamchik, V.S.; Marichev, O.I. The algorithm for calculating integrals of hypergeometric type functions and its realization in REDUCE system. In Proceedings of the International Symposium on Symbolic and Algebraic Computation, Tokyo, Japan, 20–24 August 1990; pp. 212–224. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notations | Meaning | Values |
|---|---|---|
| Average noise power | Watt | |
| B | Channel bandwidth | 200 KHz |
| The peak power | 1 Watt | |
| v | Exploration variance | 14 |
| Updation factor | 0.99 | |
| SINR threshold | 0.2 | |
| security outage probability | 0.05 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, F.; Dong, M. Unmanned-Aerial-Vehicle-Assisted Secure Free Space Optical Transmission in Internet of Things: Intelligent Strategy for Optimal Fairness. Sensors 2024, 24, 8070. https://doi.org/10.3390/s24248070
Xu F, Dong M. Unmanned-Aerial-Vehicle-Assisted Secure Free Space Optical Transmission in Internet of Things: Intelligent Strategy for Optimal Fairness. Sensors. 2024; 24(24):8070. https://doi.org/10.3390/s24248070
Chicago/Turabian StyleXu, Fang, and Mingda Dong. 2024. "Unmanned-Aerial-Vehicle-Assisted Secure Free Space Optical Transmission in Internet of Things: Intelligent Strategy for Optimal Fairness" Sensors 24, no. 24: 8070. https://doi.org/10.3390/s24248070
APA StyleXu, F., & Dong, M. (2024). Unmanned-Aerial-Vehicle-Assisted Secure Free Space Optical Transmission in Internet of Things: Intelligent Strategy for Optimal Fairness. Sensors, 24(24), 8070. https://doi.org/10.3390/s24248070