
Cascaded Feature Fusion Grasping Network for Real-Time Robotic Systems


Abstract
1. Introduction
2. Related Work
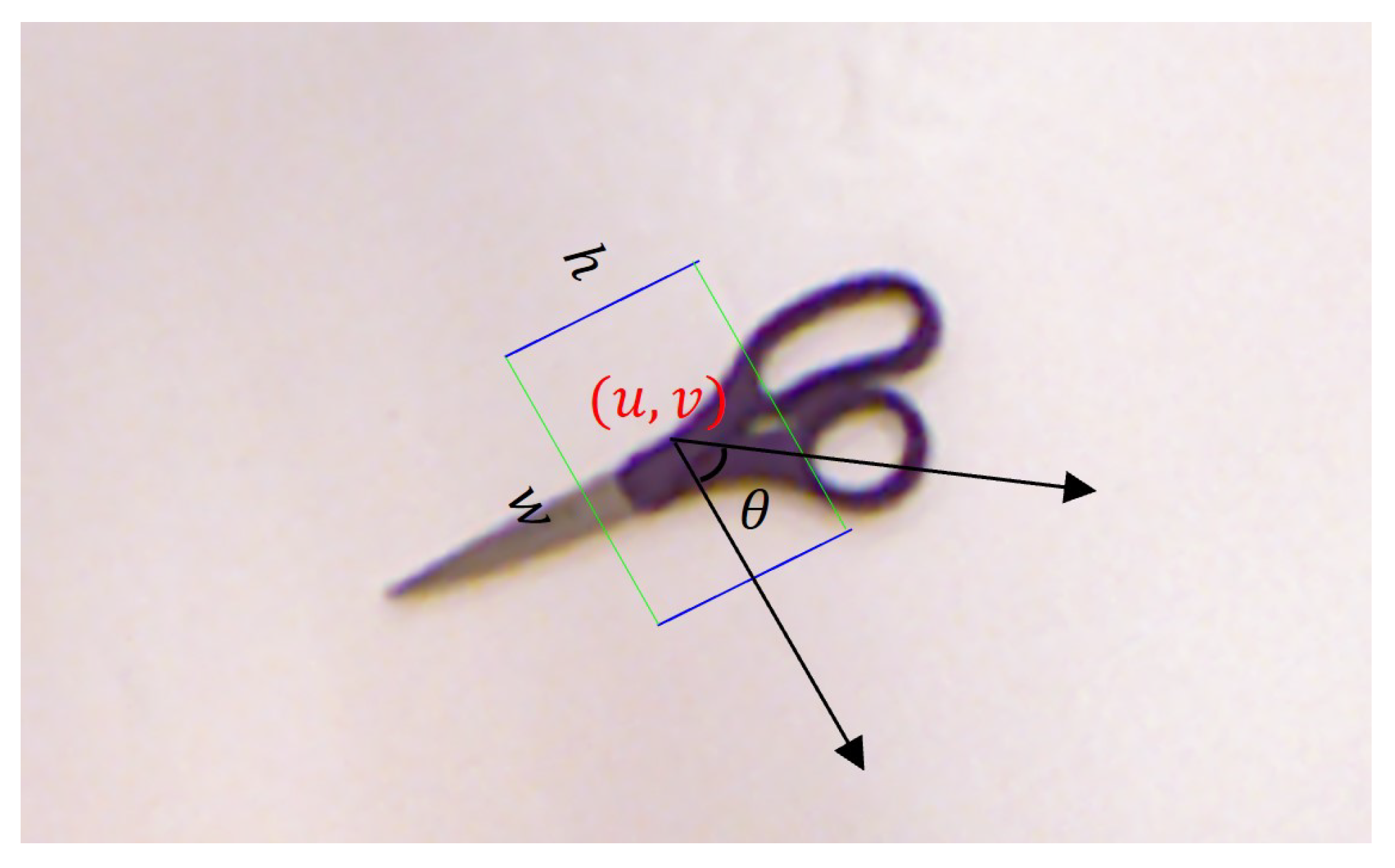
3. Problem Statement
- represents the rotation angle for grasping.
- denotes the grasping width.
- represents the grasping quality score for this position.
4. Methodology
4.1. Overall Network Architecture
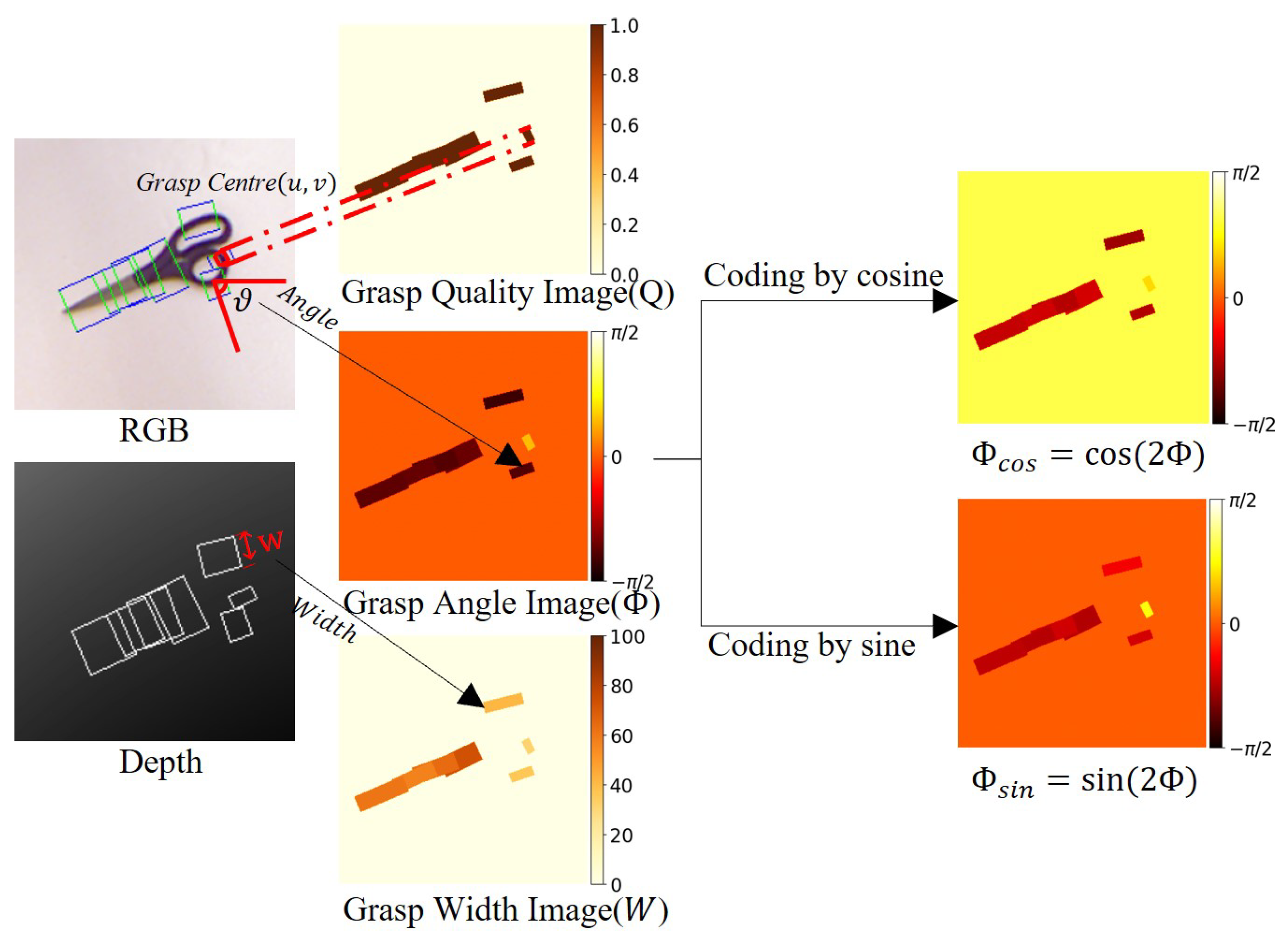
4.2. Grasp Representation
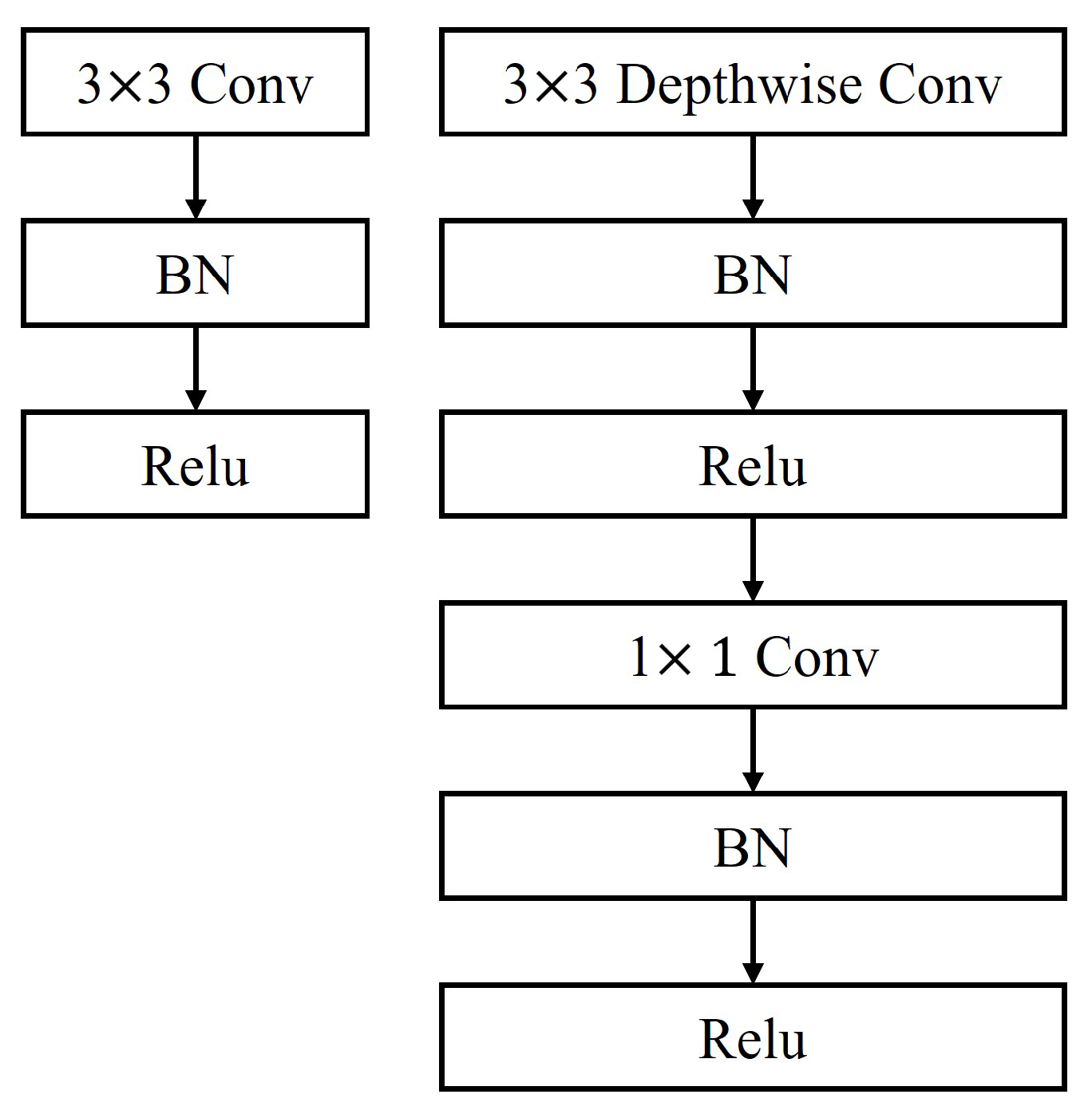
4.3. Depth-Wise Separable Convolution Module
4.4. Multiple Enhanced Feature Extraction and Fusion
4.4.1. Convolutional Block Attention Module (CBAM)
4.4.2. Multi-Scale Dilated Convolution Module (MCDM)
- Three 3 × 3 convolutions with ReLU activation and different dilation rates (1, 2, and 4).
- One 1 × 1 convolution with ReLU activation.
- A concatenation layer to combine the outputs of all branches.
- A batch normalization (BN) layer.
- A final ReLU activation.
4.4.3. Bidirectional Feature Pyramid Network (BiFPN)
4.4.4. Integration of Multiple Modules in CFFGN
- CBAM (Convolutional Block Attention Module): This module strengthens the network’s focus on the most relevant features. By implementing both channel and spatial attention mechanisms, the CBAM enhances the network’s ability to capture crucial information within the input data.
- MCDM (Multi-scale Dilated Convolution Module): By employing convolutions with various dilation rates, the MCDM enables the network to capture multi-scale information effectively. This approach allows for a comprehensive understanding of features at different spatial scales, contributing to improved feature representation.
- BiFPN (Bidirectional Feature Pyramid Network): This module facilitates the efficient fusion of features across different scales. Through its bidirectional information flow, the BiFPN enables the network to integrate both high-level semantic information and low-level fine-grained details, resulting in a more robust feature representation.
4.5. Experiment Conditions
4.5.1. Training Strategy and Parameter Selection
- Number of epochs: 200 (determined by monitoring validation loss convergence);
- Batch size: 32 (optimized for GPU memory utilization and training stability);
- Optimizer: Adam (chosen for its adaptive learning rate capability and robust performance);
- Initial learning rate: 0.001 (with cosine annealing scheduler);
- Weight decay: 1 × 10−4 (to prevent overfitting);
- Early stopping patience: 20 epochs.
4.5.2. Model Generalization Strategies
- Dropout layers: incorporated with a rate of 0.3 in the fully connected layers to prevent overfitting;
- Batch normalization: applied after convolutional layers to stabilize training and improve generalization;
- Data augmentation: implemented various transformation techniques including random rotation (±30°), random cropping (maintaining 85% of original image), and horizontal flipping (50% probability) to increase data diversity and simulate real-world variations.
4.6. Dataset and Preprocessing
4.7. Assessment Indicators
- A represents the area of the predicted bounding box;
- B represents the area of the ground truth bounding box;
- denotes the intersection area of A and B;
- denotes the union area of A and B;
- represents the area of A;
- represents the area of B.
- The IoU between the predicted bounding box and the ground truth bounding box is greater than 25%.
- The angle error between the predicted grasp and the ground truth grasp is less than 30°.
4.8. Experiments
4.8.1. Performance on Cornell Dataset
- Image-wise split: randomly selecting 80% of the images for training and the remaining 20% for testing.
- Object-wise split: ensuring that objects in the training set do not appear in the test set.
4.8.2. Performance on Jacquard Dataset
4.8.3. Ablation Experiments
- The first two paths each contain a 3 × 3 convolutional layer followed by a bilinear upsampling layer with a scale factor of 2.
- The third path includes a 3 × 3 convolutional layer followed by a bilinear upsampling layer with a scale factor of 3.
4.9. Actual Robot Grasping Experiments
5. Conclusions
- Further optimization of the network structure to enhance model robustness in processing complex object shapes and materials;
- Exploration of multi-sensor fusion strategies, incorporating perceptual information beyond RGB-D to address challenges posed by transparent or reflective objects;
- Consideration of applying this network to larger-scale multi-object grasping scenarios and improving adaptability to complex tasks.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| MCDM | Multi-scale Dilated Convolution Module |
| BiFPN | Bidirectional Feature Pyramid Network |
| DSCM | Depth-Separable Convolution Module |
| CBAM | Convolutional Block Attention Module |
| CFFGN | Cascaded Feature Fusion Grasping Network |
| IoU | Intersection over Union |
| CNN | Convolutional Neural Network |
| MLP | Multi-Layer Perceptron |
| ReLU | Rectified Linear Unit |
| BN | Batch Normalization |
References
- Miller, A.T.; Knoop, S.; Christensen, H.I.; Allen, P.K. Automatic grasp planning using shape primitives. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation (Cat. No. 03CH37422), Taipei, Taiwan, 14–19 September 2003; IEEE: Piscataway, NJ, USA, 2003; Volume 2, pp. 1824–1829. [Google Scholar]
- Bicchi, A.; Kumar, V. Robotic grasping and contact: A review. In Proceedings of the 2000 ICRA, Millennium Conference, IEEE International Conference on Robotics and Automation, Symposia Proceedings (Cat. No. 00CH37065), San Francisco, CA, USA, 24–28 April 2000; IEEE: Piscataway, NJ, USA, 2000; Volume 1, pp. 348–353. [Google Scholar]
- Redmon, J.; Angelova, A. Real-time grasp detection using convolutional neural networks. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, DC, USA, 26–30 May 2015; pp. 1316–1322. [Google Scholar] [CrossRef]
- Kumra, S.; Joshi, S.; Sahin, F. Antipodal Robotic Grasping using Generative Residual Convolutional Neural Network. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 9626–9633. [Google Scholar] [CrossRef]
- Levine, S.; Pastor, P.; Krizhevsky, A.; Quillen, D. Learning Hand-Eye Coordination for Robotic Grasping with Large-Scale Data Collection. In Springer Proceedings in Advanced Robotics, Proceedings of the 2016 International Symposium on Experimental Robotics, Nagasaki, Japan, 3–8 October 2016; Kulic, D., Nakamura, Y., Khatib, O., Venture, G., Eds.; Toyota Motor Corp.: Toyota, Japan, 2017; Volume 1, pp. 173–184. [Google Scholar] [CrossRef]
- Xu, Y.; Wang, L.; Yang, A.; Chen, L. GraspCNN: Real-Time Grasp Detection Using a New Oriented Diameter Circle Representation. IEEE Access 2019, 7, 159322–159331. [Google Scholar] [CrossRef]
- Morrison, D.; Corke, P.; Leitner, J. Closing the Loop for Robotic Grasping: A Real-time, Generative Grasp Synthesis Approach. In Robotics: Science and Systems XIV, Proceedings of the 14th Conference on Robotics—Science and Systems, Carnegie Mellon Univ, Pittsburgh, PA, USA, 26–30 June 2018; KressGazit, H., Srinivasa, S., Howard, T., Atanasov, N., Eds.; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Chu, F.J.; Xu, R.; Vela, P.A. Real-World Multiobject, Multigrasp Detection. IEEE Robot. Autom. Lett. 2018, 3, 3355–3362. [Google Scholar] [CrossRef]
- Jiang, Y.; Moseson, S.; Saxena, A. Efficient grasping from rgbd images: Learning using a new rectangle representation. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 3304–3311. [Google Scholar]
- Fang, H.S.; Wang, C.; Gou, M.; Lu, C. GraspNet-1Billion: A Large-Scale Benchmark for General Object Grasping. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 11441–11450. [Google Scholar] [CrossRef]
- Mahler, J.; Liang, J.; Niyaz, S.; Laskey, M.; Doan, R.; Liu, X.; Ojea, J.A.; Goldberg, K. Dex-Net 2.0: Deep Learning to Plan Robust Grasps with Synthetic Point Clouds and Analytic Grasp Metrics. In Robotics: Science and Systems XIII, Proceedings of the 13th Conference on Robotics—Science and Systems, Massachusetts Inst Technol, Cambridge, MA, USA, 12–16 July 2017; Amato, N., Srinivasa, S., Ayanian, N., Kuindersma, S., Eds.; MIT Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Li, L.; Li, N.; Nan, R.; He, Y.; Li, C.; Zhang, W.; Fan, P. Robotic Grasping Technology Integrating Large Kernel Convolution and Residual Connections. Machines 2024, 12, 786. [Google Scholar] [CrossRef]
- Zhong, X.; Chen, Y.; Luo, J.; Shi, C.; Hu, H. A Novel Grasp Detection Algorithm with Multi-Target Semantic Segmentation for a Robot to Manipulate Cluttered Objects. Machines 2024, 12, 506. [Google Scholar] [CrossRef]
- Yu, S.; Zhai, D.H.; Xia, Y.; Wu, H.; Liao, J. SE-ResUNet: A Novel Robotic Grasp Detection Method. IEEE Robot. Autom. Lett. 2022, 7, 5238–5245. [Google Scholar] [CrossRef]
- Fang, H.; Wang, C.; Chen, Y. Robot Grasp Detection with Loss-Guided Collaborative Attention Mechanism and Multi-Scale Feature Fusion. Appl. Sci. 2024, 14, 5193. [Google Scholar] [CrossRef]
- Zhong, X.; Liu, X.; Gong, T.; Sun, Y.; Hu, H.; Liu, Q. FAGD-Net: Feature-Augmented Grasp Detection Network Based on Efficient Multi-Scale Attention and Fusion Mechanisms. Appl. Sci. 2024, 14, 5097. [Google Scholar] [CrossRef]
- Kuang, X.; Tao, B. ODGNet: Robotic Grasp Detection Network Based on Omni-Dimensional Dynamic Convolution. Appl. Sci. 2024, 14, 4653. [Google Scholar] [CrossRef]
- Lenz, I.; Lee, H.; Saxena, A. Deep learning for detecting robotic grasps. Int. J. Robot. Res. 2015, 34, 705–724. [Google Scholar] [CrossRef]
- Wang, S.; Zhou, Z.; Kan, Z. When Transformer Meets Robotic Grasping: Exploits Context for Efficient Grasp Detection. IEEE Robot. Autom. Lett. 2022, 7, 8170–8177. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:abs/1704.04861. [Google Scholar]
- Li, M.; Yuan, J.; Ren, Q.; Luo, Q.; Fu, J.; Li, Z. CNN-Transformer hybrid network for concrete dam crack patrol inspection. Autom. Constr. 2024, 163, 105440. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Computer Vision—ECCV 2018, PT VII, Proceedings of the 15th European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; Springer: Cham, Switzerland, 2018; Lecture Notes in Computer Science; Volume 11211, pp. 3–19. [Google Scholar] [CrossRef]
- Yu, F. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Tan, M.; Pang, R.; Le, V.Q. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2020), Seattle, WA, USA, 14–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 10778–10787. [Google Scholar] [CrossRef]
- Depierre, A.; Dellandréa, E.; Chen, L. Jacquard: A Large Scale Dataset for Robotic Grasp Detection. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3511–3516. [Google Scholar] [CrossRef]
- Cao, H.; Chen, G.; Li, Z.; Feng, Q.; Lin, J.; Knoll, A. Efficient Grasp Detection Network With Gaussian-Based Grasp Representation for Robotic Manipulation. IEEE/ASME Trans. Mechatronics 2023, 28, 1384–1394. [Google Scholar] [CrossRef]
- Fu, K.; Dang, X. Light-Weight Convolutional Neural Networks for Generative Robotic Grasping. IEEE Trans. Ind. Inform. 2024, 20, 6696–6707. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Accuracy (%) | Parameter 1 | Detection 2 | |
|---|---|---|---|---|
| Model | Image-Wise | Object-Wise | Count (M) | Speed (ms) |
| [9] | 60.5 | 58.3 | - | 5000 |
| [3] | 80.1 | 87.1 | - | 76 |
| [4] | 89.2 | 88.9 | ⩾32 | 102.9 |
| [7] | 73.0 | 69.0 | 0.062 | 19 |
| [11] | 93 | - | 18 | 800 |
| [5] | 80 | - | 1 | 200 |
| [8] | 96.0 | 96.1 | 28.18 | 120 |
| [10] | 92.4 | 90.7 | 3.71 | 24 |
| [12] | 97.0 | 96.5 | 0.6 | 15 |
| [13] | 97.8 | - | - | 40 |
| [14] | 98.2 | 97.1 | 17.23 | 25 |
| [16] | 96.5 | - | - | 23 |
| CFFGN (Ours) | 98.6 | 96.9 | 0.104 | 15 |
| Network | Accuracy (%) | Parameter Count (M) | Detection Speed (ms) |
|---|---|---|---|
| [15] | 94.4 | - | 17 |
| [7] | 84 | 0.072 | 19 |
| [25] | 93.6 | - | - |
| [12] | 95 | - | 15 |
| [26] | 95.6 | - | - |
| [27] | 95.0 | 0.238 | - |
| CFFGN (Ours) | 96.5 | 0.104 | 14 |
| Network | Accuracy (%) | Detection | |
|---|---|---|---|
| Architecture | Image-Wise | Object-Wise | Speed (ms) |
| Baseline | 87.56 | 84.11 | 30 |
| +DSCM | 87.92 (+0.36) | 85.23 (+1.12) | 11 |
| +CBAM | 90.34 (+2.78) | 89.65 (+5.54) | 36 |
| +MCDM | 91.28 (+3.72) | 90.54 (+6.43) | 33 |
| +BiFPN | 92.15 (+4.59) | 91.36 (+7.25) | 35 |
| CFFGN(Ours) | 98.62 | 96.91 | 15 |
| Network | Accuracy (%) | Detection | |
|---|---|---|---|
| Architecture | Image-Wise | Object-Wise | Speed (ms) |
| Baseline | 87.56 | 84.11 | 30 |
| +CBAM + MCDM | 93.74 (+6.18) | 92.59 (+8.48) | 39 |
| +CBAM + BiFPN | 94.26 (+6.70) | 93.15 (+9.04) | 41 |
| +MCDN + BiFPN | 93.92 (+6.36) | 92.87 (+8.76) | 38 |
| +CBAM + MCDN + BiFPN | 96.16 (+8.6) | 95.29 (+11.18) | 44 |
| CFFGN(Ours) | 98.62 | 96.91 | 15 |
| Object | Grasping Performance | |
|---|---|---|
| Success Rate (%) | Successful Grasps | |
| Thermos | 92 | 23/25 |
| Watch | 88 | 22/25 |
| Stapler | 100 | 25/25 |
| Small express box | 100 | 25/25 |
| Apple | 96 | 24/25 |
| Pencil case | 96 | 24/25 |
| Milk carton | 100 | 25/25 |
| Sunglasses | 92 | 23/25 |
| Wireless mouse | 92 | 23/25 |
| Battery | 100 | 25/25 |
| Average | 95.6 | 23/25 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Zheng, L. Cascaded Feature Fusion Grasping Network for Real-Time Robotic Systems. Sensors 2024, 24, 7958. https://doi.org/10.3390/s24247958
Li H, Zheng L. Cascaded Feature Fusion Grasping Network for Real-Time Robotic Systems. Sensors. 2024; 24(24):7958. https://doi.org/10.3390/s24247958
Chicago/Turabian StyleLi, Hao, and Lixin Zheng. 2024. "Cascaded Feature Fusion Grasping Network for Real-Time Robotic Systems" Sensors 24, no. 24: 7958. https://doi.org/10.3390/s24247958
APA StyleLi, H., & Zheng, L. (2024). Cascaded Feature Fusion Grasping Network for Real-Time Robotic Systems. Sensors, 24(24), 7958. https://doi.org/10.3390/s24247958