Author Contributions
Conceptualization, R.L., Y.S., and L.Y.; methodology, R.L.; software, Y.S.; validation, R.L.; formal analysis, R.L., Y.S., and L.Y.; writing—original draft, Y.S.; writing—review and editing, Y.S. and L.Y.; visualization, R.L.; supervision, R.S. All authors have read and agreed to the published version of the manuscript.
Figure 1.
Deep learning algorithms can capture huge amounts of vehicle information in a specific region based on remote sensing data.
Figure 1.
Deep learning algorithms can capture huge amounts of vehicle information in a specific region based on remote sensing data.
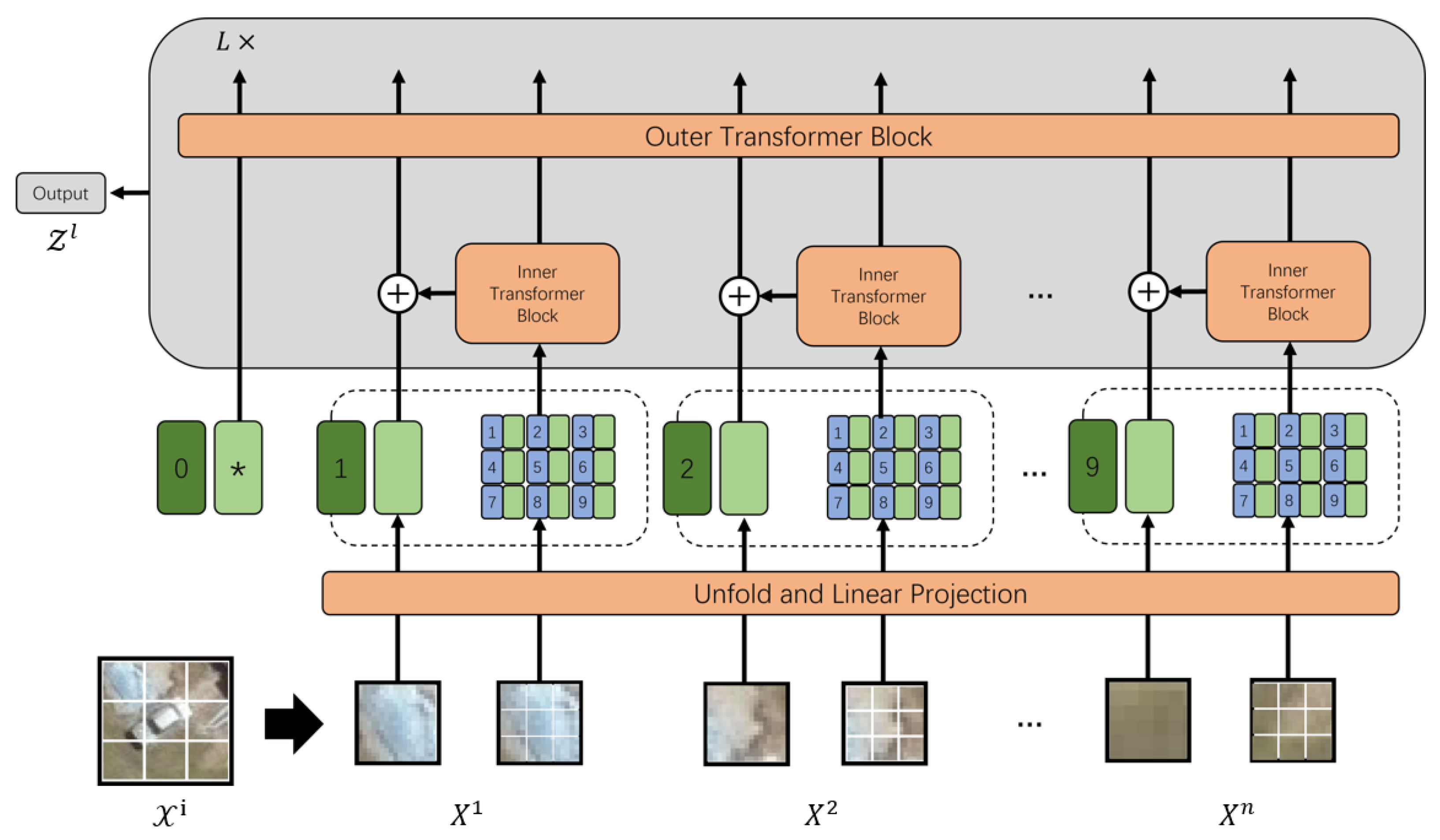
Figure 2.
Illustration of TNT model details. Apart from positional embeddings, Mark * in the figure refers to other learnable embeddings.
Figure 2.
Illustration of TNT model details. Apart from positional embeddings, Mark * in the figure refers to other learnable embeddings.
Figure 3.
DenseNet model structure showing a four-layer dense block. Each layer takes all preceding feature maps as input. The convolutional layers between two adjacent blocks are used to adjust the size of the feature map.
Figure 3.
DenseNet model structure showing a four-layer dense block. Each layer takes all preceding feature maps as input. The convolutional layers between two adjacent blocks are used to adjust the size of the feature map.
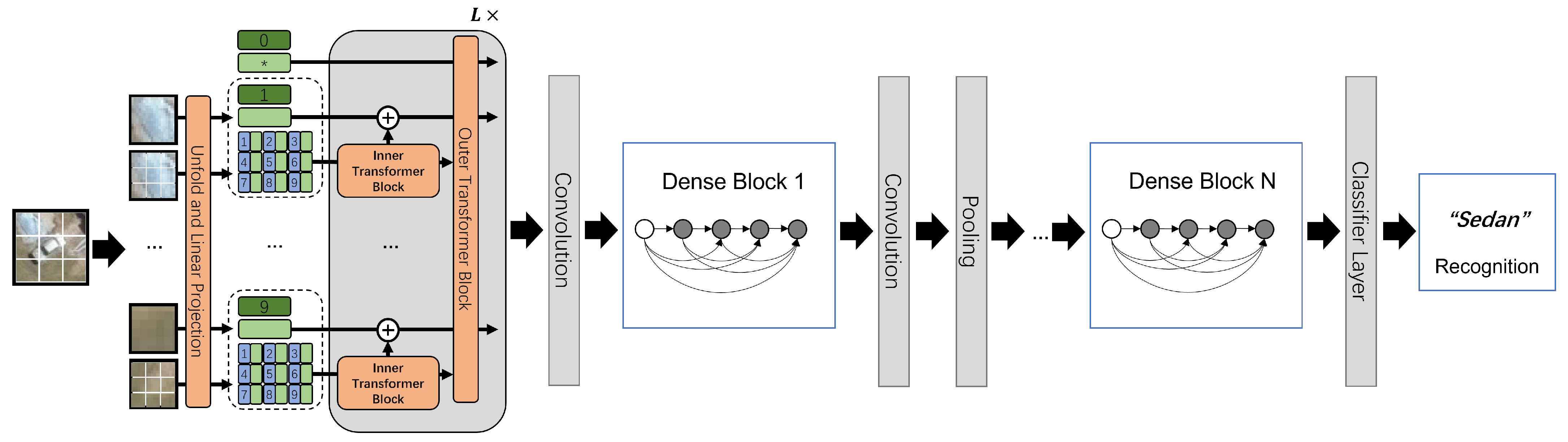
Figure 4.
The architecture of the proposed Dense-TNT neural network, consisting of TNT and DenseNet parts. The classifier layer serves as the recognition layer used to compute the type probability of the input vehicle. Mark * in the figure refers to other learnable embeddings.
Figure 4.
The architecture of the proposed Dense-TNT neural network, consisting of TNT and DenseNet parts. The classifier layer serves as the recognition layer used to compute the type probability of the input vehicle. Mark * in the figure refers to other learnable embeddings.
Figure 5.
Classification results with corresponding probabilities under normal weather conditions.
Figure 5.
Classification results with corresponding probabilities under normal weather conditions.
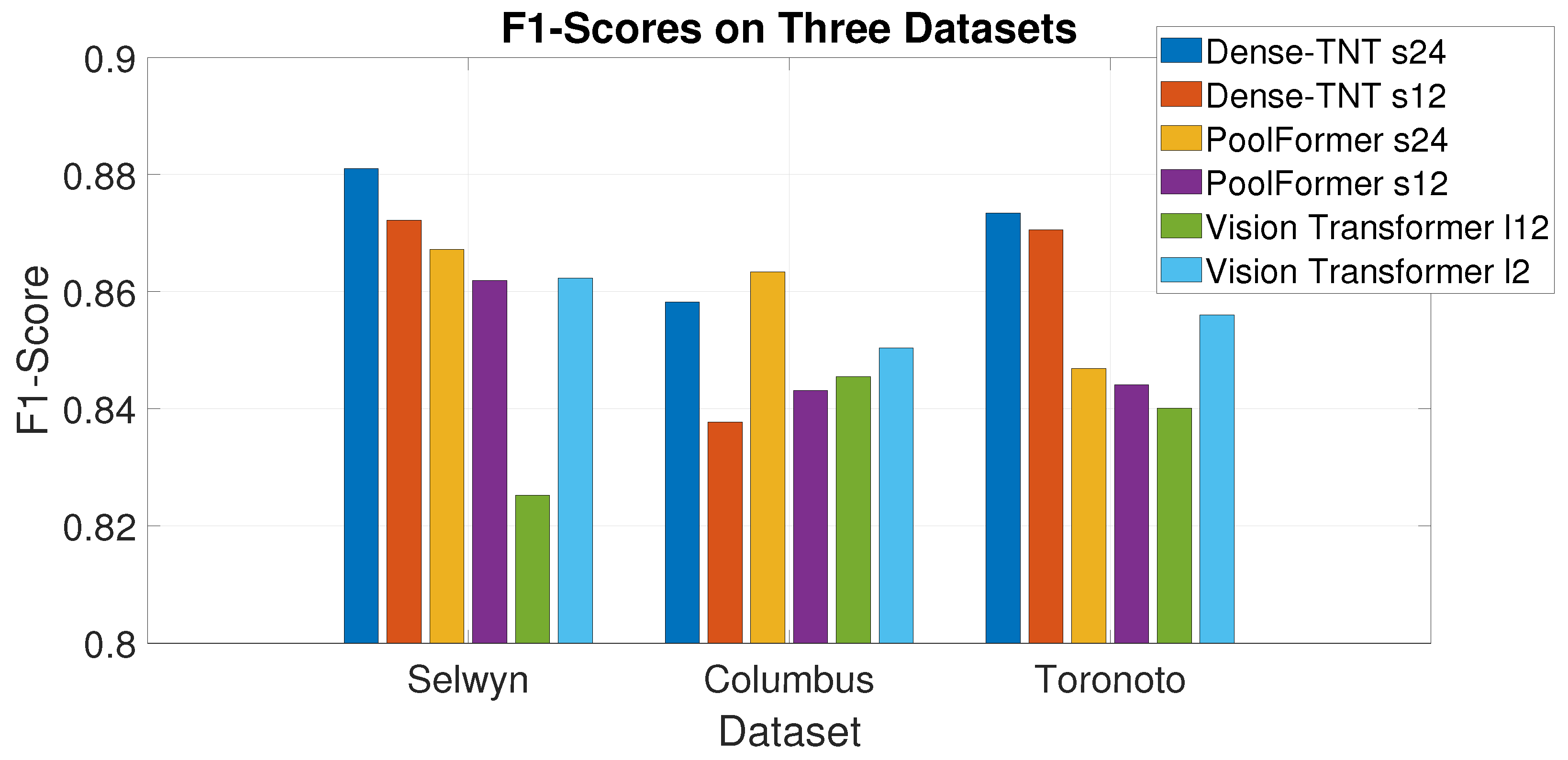
Figure 6.
F1-scores for the three datasets under normal weather conditions.
Figure 6.
F1-scores for the three datasets under normal weather conditions.
Figure 7.
Example images from the VAID dataset; from left to right: sedan, minibus, truck, pickup truck, bus, cement truck, and trailer.
Figure 7.
Example images from the VAID dataset; from left to right: sedan, minibus, truck, pickup truck, bus, cement truck, and trailer.
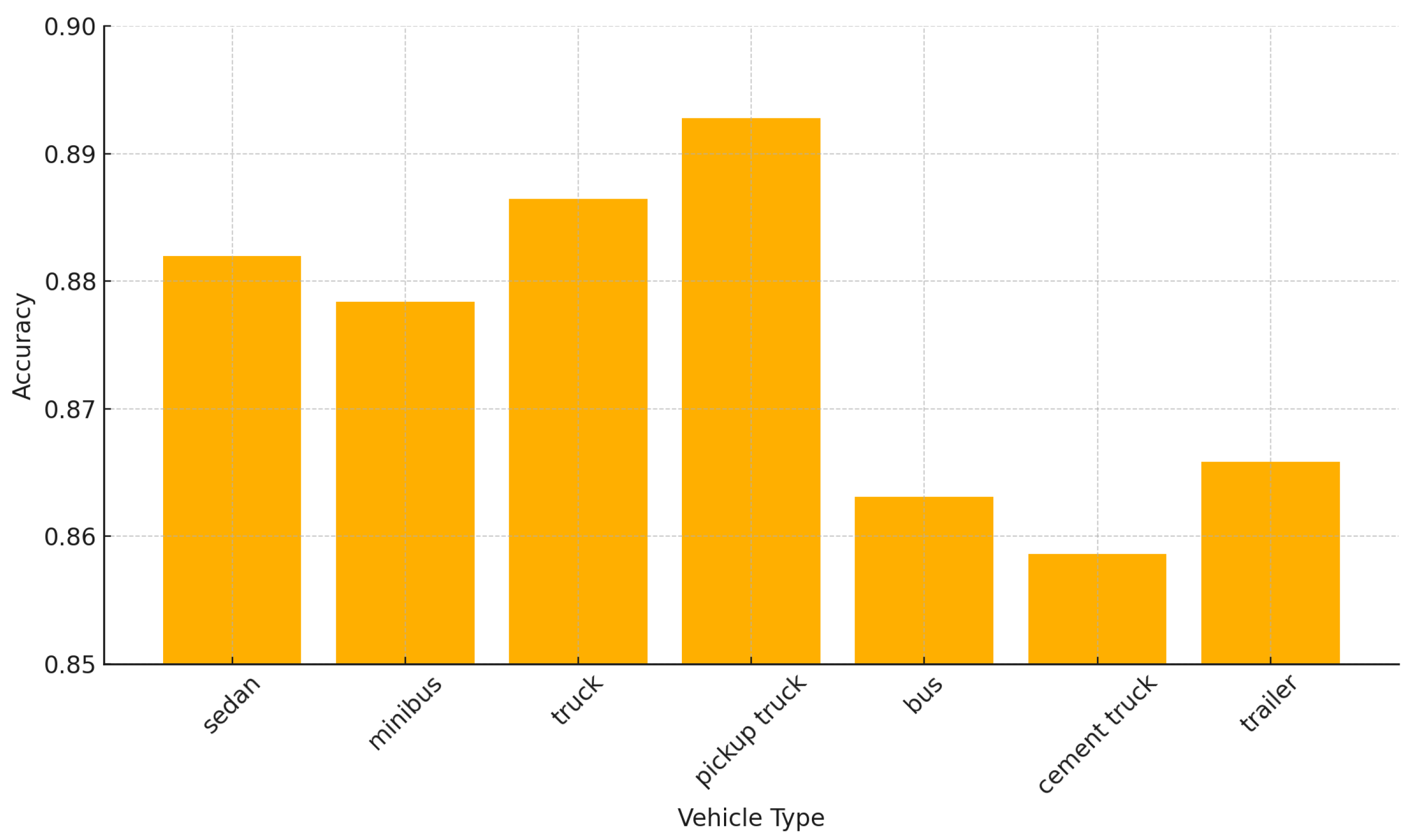
Figure 8.
Classification accuracy for different vehicle types.
Figure 8.
Classification accuracy for different vehicle types.
Figure 9.
Classification results with corresponding probabilities under foggy weather conditions.
Figure 9.
Classification results with corresponding probabilities under foggy weather conditions.
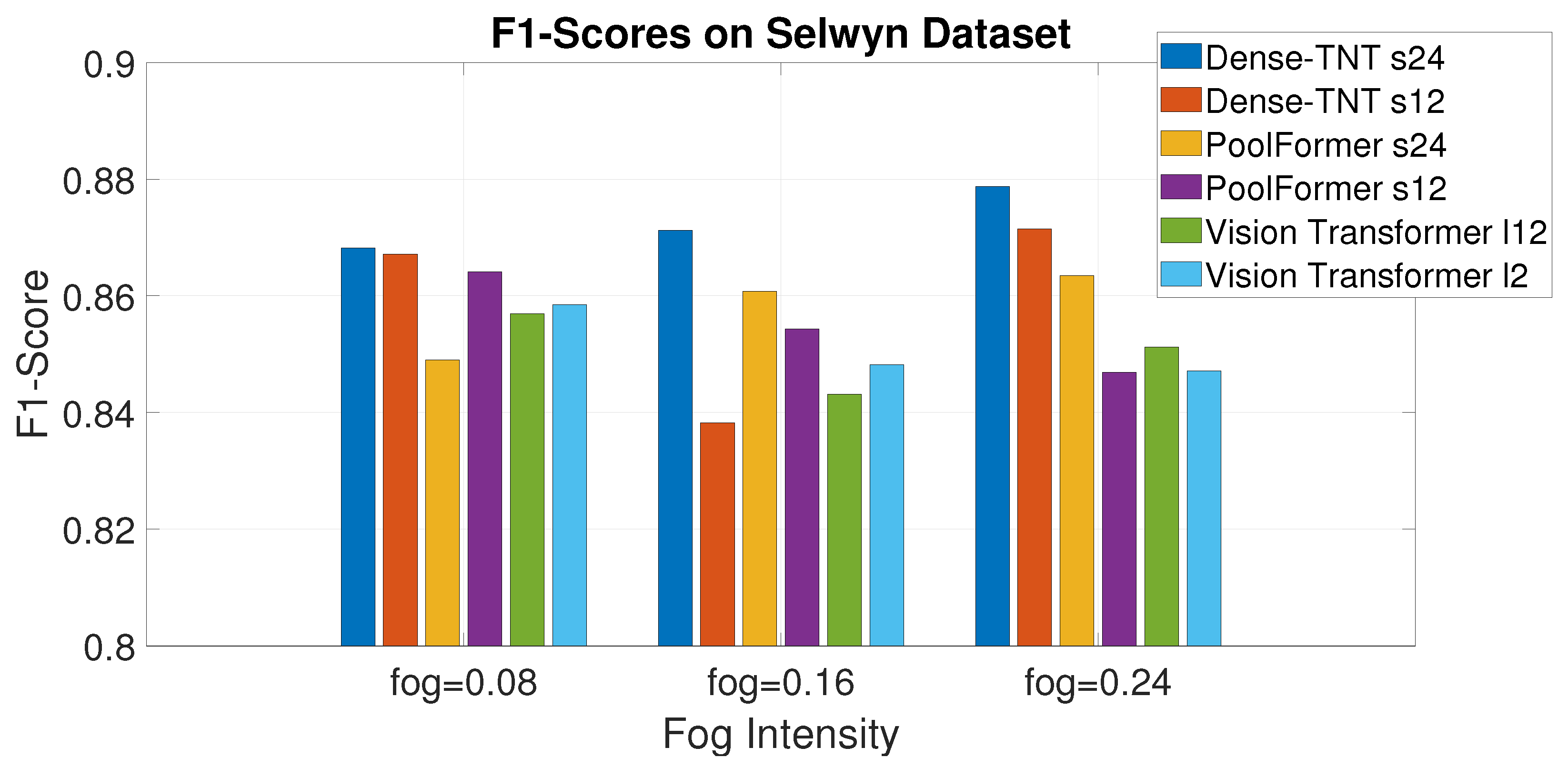
Figure 10.
F1-scores on the Selwyn, New Zealand dataset under different levels of fog.
Figure 10.
F1-scores on the Selwyn, New Zealand dataset under different levels of fog.
Figure 11.
F1-scores on the Selwyn, New Zealand dataset under different darkness condition.
Figure 11.
F1-scores on the Selwyn, New Zealand dataset under different darkness condition.
Table 1.
Model parameter settings.
Table 1.
Model parameter settings.
| Model | Number of Layers (L) | Hidden Size (D) | Attention Heads (H) | MLP Size |
|---|
| Dense-TNT s12 | 12 | 384 | 8 | - |
| Dense-TNT s24 | 24 | 512 | 8 | - |
| PoolFormer s12 | 12 | 384 | - | - |
| PoolFormer s24 | 24 | 512 | - | - |
| Vision Transformer (ViT-L/12) | 12 | 1024 | 16 | 4096 |
| Vision Transformer (ViT-L/2) | 2 | 1024 | 16 | 4096 |
Table 2.
Details of the three datasets. The first column refers to the three different areas where images were taken, the second column refers to the total number of images in the area, and the other two columns refer to the number of sedans and pickups in the dataset, respectively.
Table 2.
Details of the three datasets. The first column refers to the three different areas where images were taken, the second column refers to the total number of images in the area, and the other two columns refer to the number of sedans and pickups in the dataset, respectively.
| Locations | Total Number | Number of Sedans | Number of Pickups |
|---|
| Columbus Ohio | 7465 | 6917 | 548 |
| Selwyn | 4525 | 3548 | 1067 |
| Toronto | 45,994 | 44,208 | 1789 |
Table 3.
Example pictures of sedans and pickups. The first column shows four example pictures of sedans and the second column shows four example pictures of sedans.
Table 3.
Example pictures of sedans and pickups. The first column shows four example pictures of sedans and the second column shows four example pictures of sedans.
| Sedan | Pickup |
|---|
![Sensors 24 07662 i002]() | ![Sensors 24 07662 i003]() |
Table 4.
Experimental results showing the classification accuracy of the models on the three datasets.
Table 4.
Experimental results showing the classification accuracy of the models on the three datasets.
| Criteria | Selwyn | Columbus Ohio | Toronto |
|---|
| Models | | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score |
|---|
| Dense-TNT s24 | 0.8065 | 0.8211 | 0.9558 | 0.8810 | 0.7685 | 0.7876 | 0.9516 | 0.8582 | 0.8009 | 0.8205 | 0.9365 | 0.8734 |
| Dense-TNT s12 | 0.7971 | 0.8183 | 0.9399 | 0.8722 | 0.7459 | 0.7855 | 0.9109 | 0.8377 | 0.7968 | 0.8389 | 0.9062 | 0.8706 |
| PoolFormer s24 | 0.7819 | 0.7956 | 0.9559 | 0.8672 | 0.7675 | 0.7835 | 0.9691 | 0.8634 | 0.7584 | 0.7871 | 0.9183 | 0.8469 |
| PoolFormer s12 | 0.7724 | 0.7977 | 0.9424 | 0.8619 | 0.7507 | 0.7812 | 0.9661 | 0.8431 | 0.7456 | 0.7509 | 0.9254 | 0.8441 |
| ViT l12 | 0.7462 | 0.7462 | 0.9256 | 0.8252 | 0.7392 | 0.7421 | 0.9543 | 0.8455 | 0.7300 | 0.7349 | 0.9326 | 0.8401 |
| ViT l2 | 0.7624 | 0.7659 | 0.9435 | 0.8623 | 0.7460 | 0.7486 | 0.9339 | 0.8504 | 0.7510 | 0.7559 | 0.9273 | 0.8560 |
Table 5.
Multiclass classification results, showing the classification performance of the six models on the VAID dataset in terms of accuracy, precision, recall, and F1-score.
Table 5.
Multiclass classification results, showing the classification performance of the six models on the VAID dataset in terms of accuracy, precision, recall, and F1-score.
| Criteria | Accuracy | Precision | Recall | F1-Score |
|---|
| Models | |
|---|
| Dense-TNT s24 | 0.8753 | 0.8764 | 0.9621 | 0.9173 |
| Dense-TNT s12 | 0.8579 | 0.8657 | 0.9591 | 0.9100 |
| PoolFormer s24 | 0.8619 | 0.8636 | 0.9679 | 0.9083 |
| PoolFormer s12 | 0.8376 | 0.8401 | 0.9484 | 0.8910 |
| ViT l12 | 0.8229 | 0.8377 | 0.9580 | 0.8938 |
| ViT l2 | 0.8304 | 0.8459 | 0.9441 | 0.8923 |
Table 6.
Experimental images under different weather conditions. The four columns respectively refer to images taken under normal weather conditions, light fog conditions, medium fog conditions, and heavy fog conditions.
Table 6.
Experimental images under different weather conditions. The four columns respectively refer to images taken under normal weather conditions, light fog conditions, medium fog conditions, and heavy fog conditions.
Table 7.
Results of experiment with image data affected by fog. The first column of the table refers to the different models, while the other columns show the accuracy of the six models in normal weather, light fog, medium fog, and heavy fog, respectively.
Table 7.
Results of experiment with image data affected by fog. The first column of the table refers to the different models, while the other columns show the accuracy of the six models in normal weather, light fog, medium fog, and heavy fog, respectively.
| Criteria | Light-Foggy (fog = 0.08) | Medium-Foggy (fog = 0.16) | Heavy-Foggy (fog = 0.24) |
|---|
| Models | | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score |
|---|
| Dense-TNT s24 | 0.7941 | 0.8240 | 0.9215 | 0.8682 | 0.7961 | 0.7934 | 0.9352 | 0.8712 | 0.7692 | 0.7660 | 0.9440 | 0.8787 |
| Dense-TNT s12 | 0.7907 | 0.8244 | 0.9178 | 0.8671 | 0.7839 | 0.7815 | 0.9510 | 0.8382 | 0.7648 | 0.7748 | 0.9497 | 0.8715 |
| PoolFormer s24 | 0.7665 | 0.7912 | 0.9243 | 0.8490 | 0.7590 | 0.7630 | 0.9594 | 0.8608 | 0.7535 | 0.7663 | 0.9543 | 0.8635 |
| PoolFormer s12 | 0.7631 | 0.7630 | 0.9289 | 0.8641 | 0.7500 | 0.7469 | 0.9624 | 0.8543 | 0.7371 | 0.7370 | 0.9601 | 0.8469 |
| ViT l12 | 0.7533 | 0.7539 | 0.9310 | 0.8569 | 0.7456 | 0.7369 | 0.9449 | 0.8431 | 0.7428 | 0.7400 | 0.9627 | 0.8512 |
| ViT l2 | 0.7566 | 0.7495 | 0.7297 | 0.8585 | 0.7394 | 0.7402 | 0.9573 | 0.8482 | 0.7383 | 0.7369 | 0.9659 | 0.8471 |
Table 8.
Experimentalimages showing different darkness conditions. The four columns respectively refer to images under normal conditions and under light, medium, and heavy darkness conditions.
Table 8.
Experimentalimages showing different darkness conditions. The four columns respectively refer to images under normal conditions and under light, medium, and heavy darkness conditions.
Table 9.
Results of experiments with data affected by darkness. The first column of the table refers to the six models, while the other columns show the accuracy of the models under normal conditions and light, medium, and heavy darkness conditions.
Table 9.
Results of experiments with data affected by darkness. The first column of the table refers to the six models, while the other columns show the accuracy of the models under normal conditions and light, medium, and heavy darkness conditions.
| Criteria | Light-Darkness () | Medium-Darkness () | Heavy-Darkness () |
|---|
| Models | | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score | Accuracy | Precision | Recall | F1-Score |
|---|
| Dense-TNT s24 | 0.8105 | 0.8122 | 0.8981 | 0.8912 | 0.8044 | 0.8137 | 0.9152 | 0.9048 | 0.7797 | 0.7561 | 0.9259 | 0.8761 |
| Dense-TNT s12 | 0.7852 | 0.8341 | 0.9062 | 0.8783 | 0.7618 | 0.7795 | 0.9150 | 0.8283 | 0.7486 | 0.7847 | 0.9053 | 0.8517 |
| PoolFormer s24 | 0.7432 | 0.7902 | 0.9142 | 0.8370 | 0.7590 | 0.7541 | 0.9495 | 0.8267 | 0.7535 | 0.7569 | 0.9435 | 0.8295 |
| PoolFormer s12 | 0.7631 | 0.7750 | 0.9156 | 0.8566 | 0.7500 | 0.7291 | 0.9604 | 0.8534 | 0.7199 | 0.7257 | 0.9534 | 0.8225 |
| ViT112 | 0.7533 | 0.7129 | 0.9317 | 0.8776 | 0.7528 | 0.7274 | 0.9449 | 0.8264 | 0.7244 | 0.7390 | 0.9567 | 0.8591 |
| ViT12 | 0.7566 | 0.7481 | 0.7957 | 0.8585 | 0.7394 | 0.7337 | 0.9601 | 0.8385 | 0.7223 | 0.7469 | 0.9660 | 0.8351 |












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}









