
Attention-Based Lightweight YOLOv8 Underwater Target Recognition Algorithm


Abstract
1. Introduction
2. Model-Related Work
2.1. YOLOv8 Introduction
2.2. Underwater Object Detection
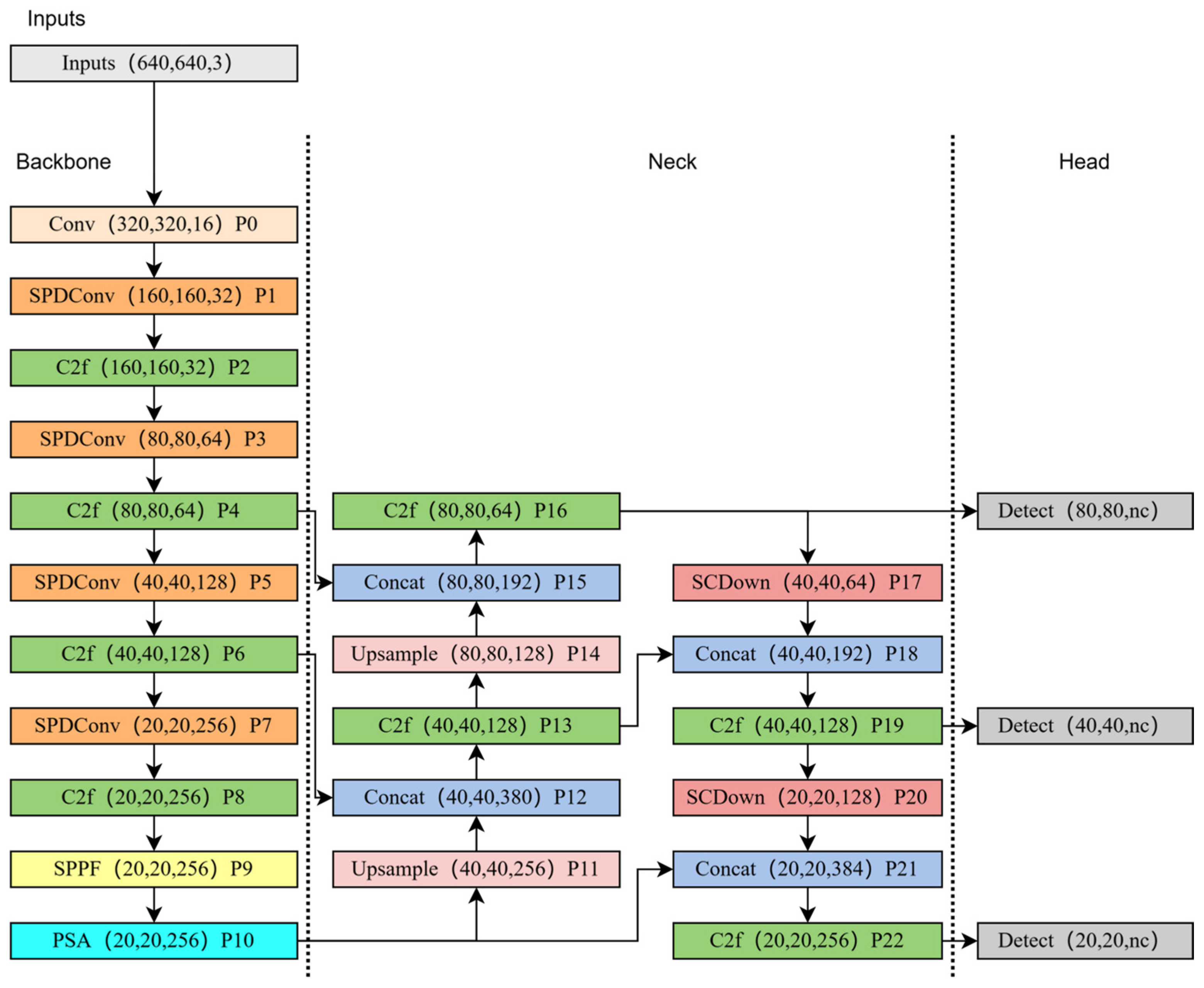
3. Network Architecture
3.1. Space-to-Depth Convolutions (SPDConv)
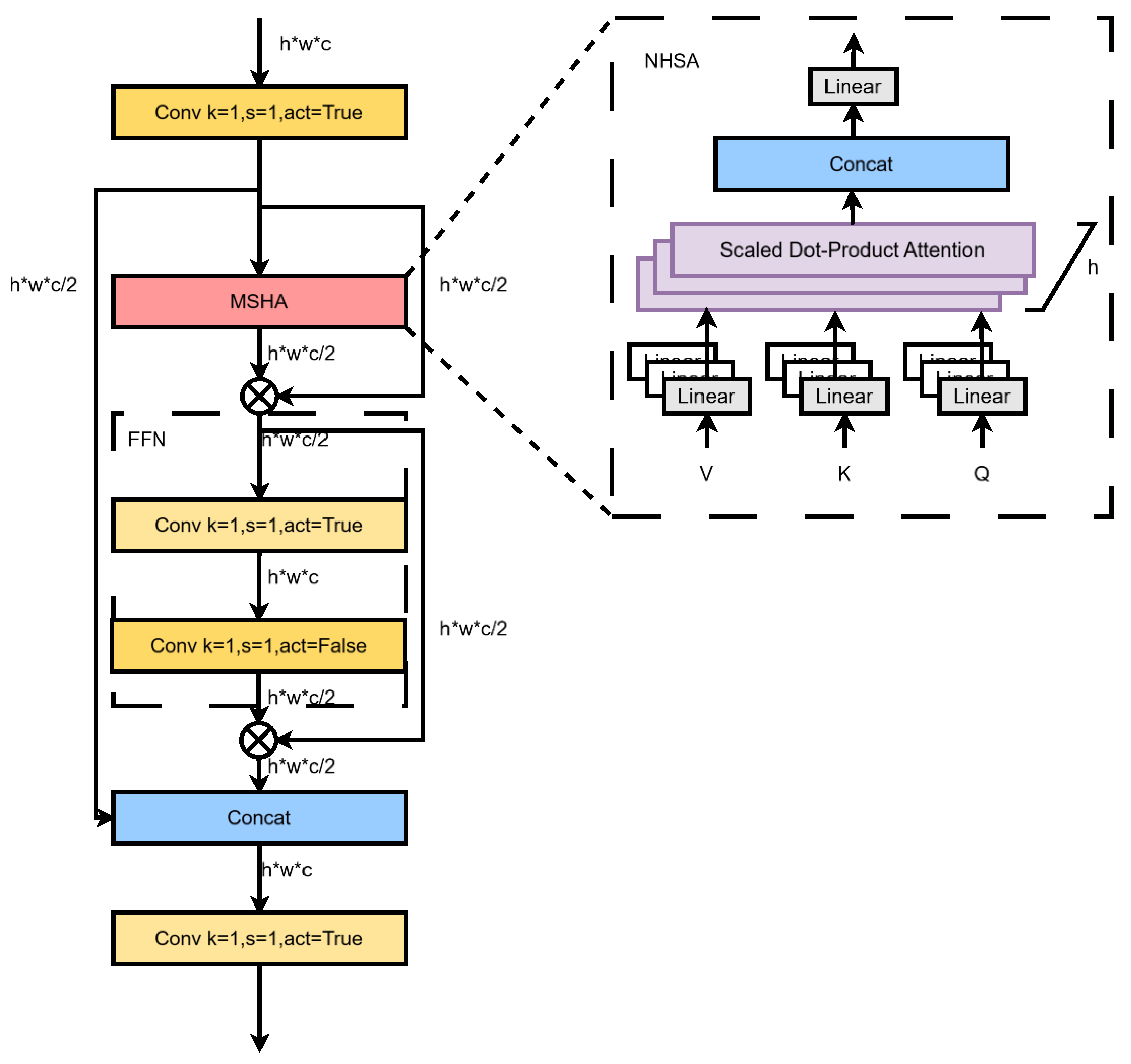
3.2. Partial Self-Attention (PSA)
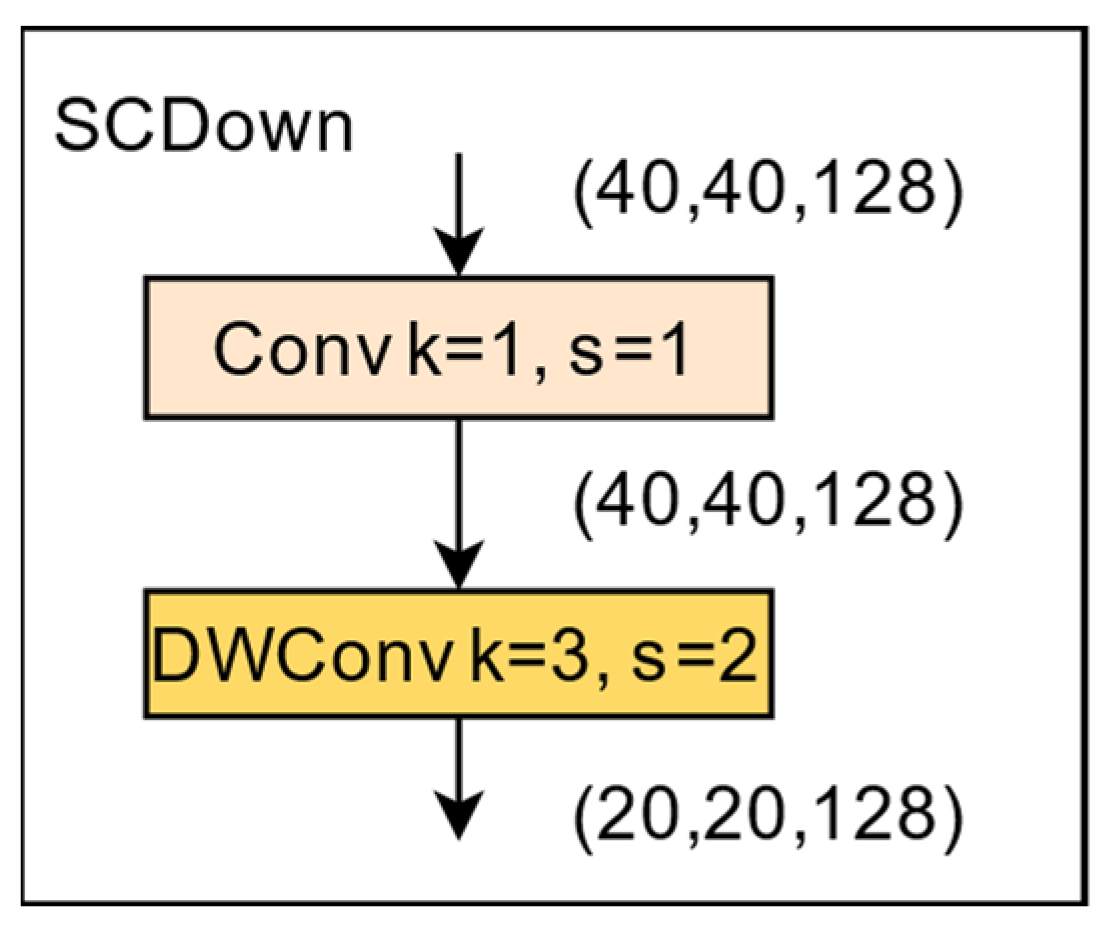
3.3. Spatial–Channel Decoupled Downsampling (SCDown)
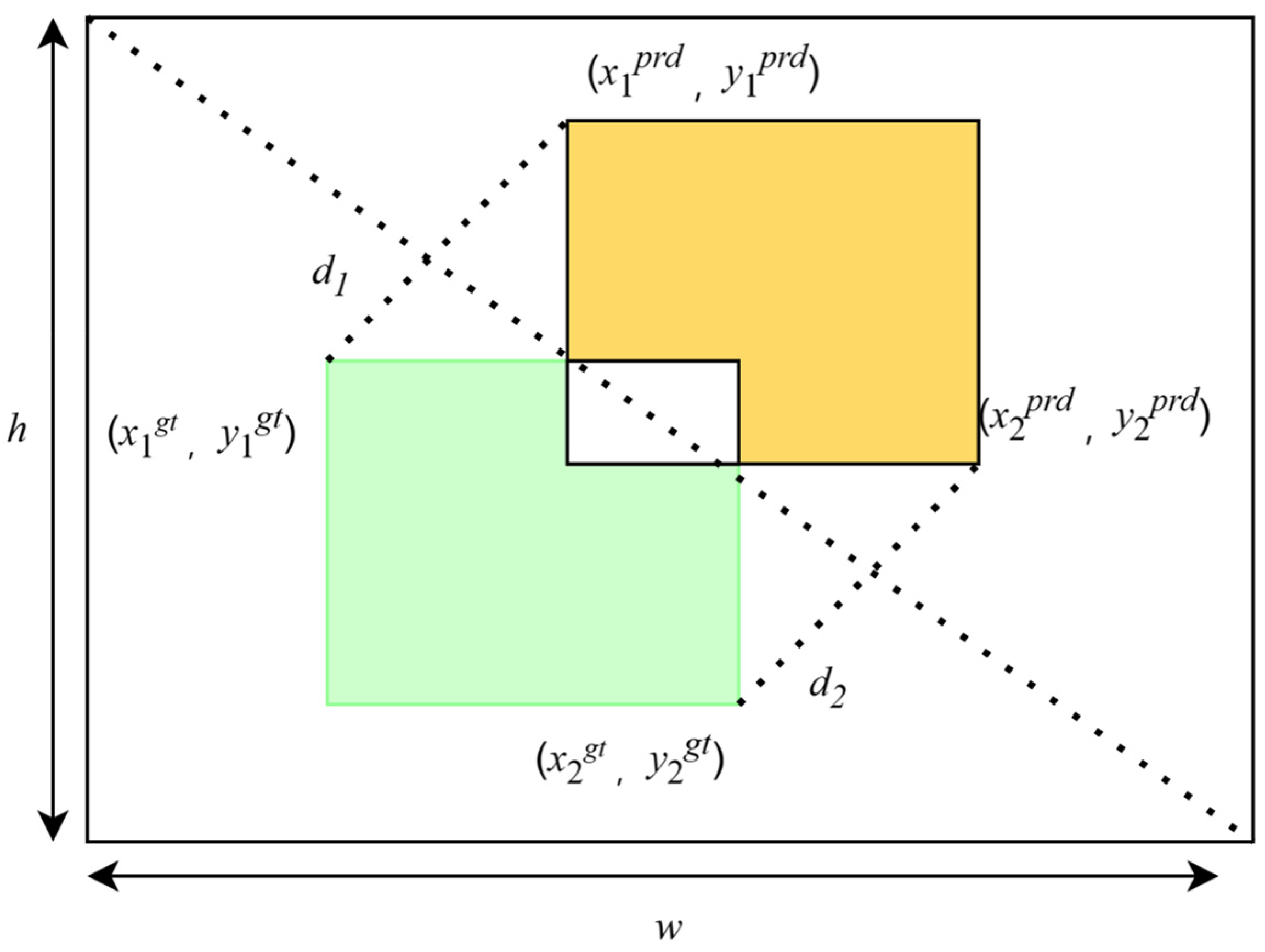
3.4. MPDIoU Loss Function
4. Experiments
4.1. Datasets and Estimated Metrics
4.2. Experimental Equipment and Parameter Configuration
4.3. Comparative Experiments on the RUOD Dataset
4.4. Convergence Analysis
4.5. Improving the Performance of the Backbone Network
4.6. Impact of Different Attention Mechanisms
4.7. Comparison of Loss Functions
4.8. Ablation Experiments
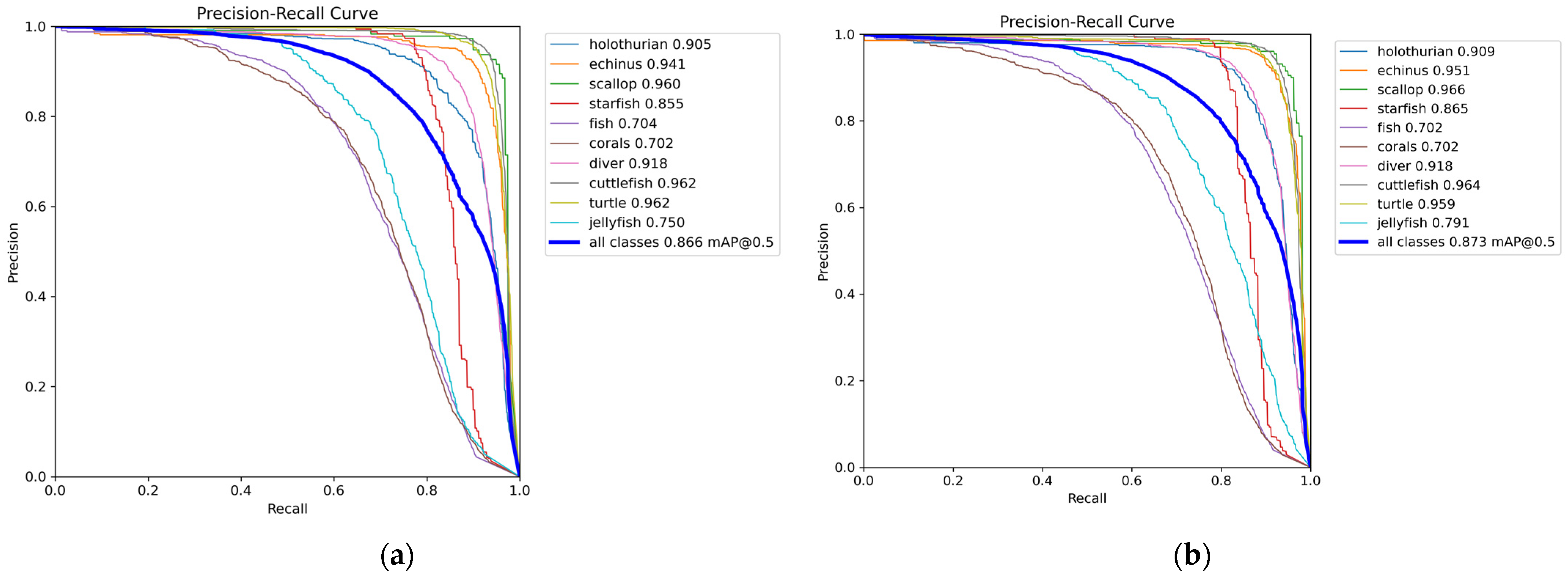
4.9. Experiment Validation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Li, J.; Xu, W.; Deng, L.; Xiao, Y.; Han, Z.; Zheng, H. Deep learning for visual recognition and detection of aquatic animals: A review. Rev. Aquac. 2022, 15, 409–433. [Google Scholar] [CrossRef]
- Zhang, Y. Research on Underwater Image Enhancement and Optical Target Detection Algorithm Based on Deep Learning. Master’s Thesis, Harbin Engineering University, Harbin, China, 2022. [Google Scholar]
- Lv, W.; Xu, S.; Zhao, Y.; Wang, G.; Wei, J.; Cui, C.; Du, Y.; Dang, Q.; Liu, Y. DETRs Beat YOLOs on Real-time Object Detection. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Wang, C.-Y.; Yeh, I.-H.; Liao, H. YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information. arXiv 2024, arXiv:2402.13616. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J.; Ding, G. YOLOv10: Real-Time End-to-End Object Detection. arXiv 2024, arXiv:2405.14458. [Google Scholar]
- Raveendran, S.; Patil, M.D.; Birajdar, G.K. Underwater image enhancement: A comprehensive review, recent trends, challenges and applications. Artif. Intell. Rev. 2021, 54, 5413–5467. [Google Scholar] [CrossRef]
- Ma, S.; Xu, Y. MPDIoU: A Loss for Efficient and Accurate Bounding Box Regression. arXiv 2023, arXiv:2307.07662. [Google Scholar]
- Liu, Q.; Huang, W.; Duan, X.; Wei, J.; Hu, T.; Yu, J.; Huang, J. DSW-YOLOv8n: A New Underwater Target Detection Algorithm Based on Improved YOLOv8n. Electronics 2023, 12, 3892. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Song, P.; Li, P.; Dai, L.; Wang, T.; Chen, Z. Boosting R-CNN: Reweighting R-CNN samples by RPN’s error for underwater object detection. Neurocomputing 2023, 530, 150–164. [Google Scholar] [CrossRef]
- Yi, D.; Ahmedov, H.B.; Jiang, S.; Li, Y.; Flinn, S.J.; Fernandes, P.G. Coordinate-Aware Mask R-CNN with Group Normalization: A underwater marine animal instance segmentation framework. Neurocomputing 2024, 583, 127488. [Google Scholar] [CrossRef]
- Wang, Z.; Ruan, Z.; Chen, C. DyFish-DETR: Underwater Fish Image Recognition Based on Detection Transformer. J. Mar. Sci. Eng. 2024, 12, 864. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Keypoint Triplets for Object Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6568–6577. [Google Scholar]
- Wang, S.; Guo, J.; Guo, S.; Fu, Q.; Xu, J. Study on Real-time Recognition of Underwater Live Shrimp by the Spherical Amphibious Robot Based on Deep Learning. In Proceedings of the 2022 IEEE International Conference on Mechatronics and Automation (ICMA), Guilin, China, 7–10 August 2022; pp. 917–922. [Google Scholar]
- Yuan, X.; Fang, S.; Li, N.; Ma, Q.; Wang, Z.; Gao, M.; Tang, P.; Yu, C.; Wang, Y.; Martínez Ortega, J.-F. Performance Comparison of Sea Cucumber Detection by the Yolov5 and DETR Approach. J. Mar. Sci. Eng. 2023, 11, 2043. [Google Scholar] [CrossRef]
- Zhu, J.; Hu, T.; Zheng, L.; Zhou, N.; Ge, H.; Hong, Z. YOLOv8-C2f-Faster-EMA: An Improved Underwater Trash Detection Model Based on YOLOv8. Sensors 2024, 24, 2483. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chen, B.; Wang, W.; Chen, L.C.; Tan, M.; Chu, G.; Vasudevan, V.; Zhu, Y.; Pang, R.; et al. Searching for MobileNetV3. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1314–1324. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. In Proceedings of the Computer Vision—ECCV 2018, Munich, Germany, 8–14 September 2018; pp. 122–138. [Google Scholar]
- Zhao, L.; Wang, L. A new lightweight network based on MobileNetV3. KSII Trans. Internet Inf. Syst. 2022, 16, 1–15. [Google Scholar]
- Cao, M.; Fu, H.; Zhu, J.; Cai, C. Lightweight tea bud recognition network integrating GhostNet and YOLOv5. Math. Biosci. Eng. MBE 2022, 19, 12897–12914. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Jiang, H.; Yang, J.; Ma, X.; Chen, J.; Li, Z.; Tang, X. Lightweight tomato ripeness detection algorithm based on the improved RT-DETR. Front. Plant Sci. 2024, 15, 1415297. [Google Scholar] [CrossRef]
- Sunkara, R.; Luo, T. No More Strided Convolutions or Pooling: A New CNN Building Block for Low-Resolution Images and Small Objects. In Proceedings of the ECML/PKDD, Grenoble, France, 19–23 September 2022. [Google Scholar]
- Xiong, Y.; Li, Z.; Chen, Y.; Wang, F.; Zhu, X.; Luo, J.; Wang, W.; Lu, T.; Li, H.; Qiao, Y.; et al. Efficient Deformable ConvNets: Rethinking Dynamic and Sparse Operator for Vision Applications. arXiv 2024, arXiv:2401.06197. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Vaswani, A.; Shazeer, N.M.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar] [CrossRef]
- Fu, C.Z.; Liu, R.; Fan, X.; Chen, P.; Fu, H.; Yuan, W.; Zhu, M.; Luo, Z. Rethinking general underwater object detection: Datasets, challenges, and solutions. Neurocomputing 2022, 517, 243–256. [Google Scholar] [CrossRef]
- Liu, C.; Li, H.; Wang, S.; Zhu, M.; Wang, D.; Fan, X.; Wang, Z. A Dataset and Benchmark of Underwater Object Detection for Robot Picking. In Proceedings of the 2021 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), Shenzhen, China, 5–9 July 2021; pp. 1–6. [Google Scholar]
- Ding, J.; Hu, J.; Lin, J.; Zhang, X. Lightweight enhanced YOLOv8n underwater object detection network for low light environments. Sci. Rep. 2024, 14, 27922. [Google Scholar] [CrossRef]
- Wang, A.; Chen, H.; Lin, Z.; Pu, H.; Ding, G. RepViT: Revisiting Mobile CNN From ViT Perspective. arXiv 2023, arXiv:2307.09283. [Google Scholar]
- Chen, H.; Wang, Y.; Guo, J.; Tao, D. VanillaNet: The Power of Minimalism in Deep Learning. arXiv 2023, arXiv:2305.12972. [Google Scholar]
- Qin, D.; Leichner, C.; Delakis, M.; Fornoni, M.; Luo, S.; Yang, F.; Wang, W.; Banbury, C.R.; Ye, C.; Akin, B.; et al. MobileNetV4—Universal Models for the Mobile Ecosystem. arXiv 2024, arXiv:2404.10518. [Google Scholar]
- Ma, L.; Ma, T.; Liu, R.; Fan, X.; Luo, Z. Supplemental Materials: Toward Fast, Flexible, and Robust Low-Light Image Enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–23 June 2022. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 1 June 2016; p. 1. [Google Scholar]
- Mehta, S.; Rastegari, M. Separable Self-attention for Mobile Vision Transformers. arXiv 2022, arXiv:2206.02680. [Google Scholar] [CrossRef]
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; et al. Searching for MobileNetV3. arXiv 2019, arXiv:1905.02244. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.-T.; Sun, J. ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design. arXiv 2018, arXiv:1807.11164. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. GhostNet: More Features from Cheap Operations. arXiv 2019, arXiv:1911.11907. [Google Scholar] [CrossRef]
- Li, Y.; Hou, Q.; Zheng, Z.; Cheng, M.-M.; Yang, J.; Li, X. Large Selective Kernel Network for Remote Sensing Object Detection. arXiv 2023, arXiv:2303.09030. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. arXiv 2021, arXiv:2103.14030. [Google Scholar] [CrossRef]
- Narayanan, M. SENetV2: Aggregated dense layer for channelwise and global representations. arXiv 2023, arXiv:2311.10807. [Google Scholar] [CrossRef]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 14420–14430. [Google Scholar]
- Chen, J.; Kao, S.-h.; He, H.; Zhuo, W.; Wen, S.; Lee, C.-H.; Chan, S.-H.G. Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks. arXiv 2023, arXiv:2303.03667. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNetV2: Smaller Models and Faster Training. arXiv 2021, arXiv:2104.00298. [Google Scholar] [CrossRef]
- Cai, Y.; Zhou, Y.; Han, Q.; Sun, J.; Kong, X.; Li, J.Y.; Zhang, X. Reversible Column Networks. arXiv 2022, arXiv:2212.11696. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Kweon, I.-S.; Xie, S. ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 16133–16142. [Google Scholar]
- Ding, X.; Zhang, Y.; Ge, Y.; Zhao, S.; Song, L.; Yue, X.; Shan, Y. UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition. arXiv 2023, arXiv:2311.15599. [Google Scholar]
- Zhang, J.; Li, X.; Li, J.; Liu, L.; Xue, Z.; Zhang, B.; Jiang, Z.; Huang, T.; Wang, Y.; Wang, C. Rethinking Mobile Block for Efficient Attention-based Models. In Proceedings of the 2023 IEEE/CVF International Conference on Computer Vision (ICCV), Vancouver, BC, Canada, 17–24 June 2023; pp. 1389–1400. [Google Scholar]
- Azad, R.; Niggemeier, L.; Huttemann, M.; Kazerouni, A.; Khodapanah Aghdam, E.; Velichko, Y.; Bagci, U.; Merhof, D. Beyond Self-Attention: Deformable Large Kernel Attention for Medical Image Segmentation. arXiv 2023, arXiv:2309.00121. [Google Scholar] [CrossRef]
- Zhu, L.; Wang, X.; Ke, Z.; Zhang, W.; Lau, R.W.H. BiFormer: Vision Transformer with Bi-Level Routing Attention. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 10323–10333. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. arXiv 2018, arXiv:1807.06521. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate Attention for Efficient Mobile Network Design. arXiv 2021, arXiv:2103.02907. [Google Scholar] [CrossRef]
- Jiao, J.; Tang, Y.-M.; Lin, K.-Y.; Gao, Y.; Ma, J.; Wang, Y.; Zheng, W.-S. DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition. arXiv 2023, arXiv:2302.01791. [Google Scholar] [CrossRef]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. arXiv 2019, arXiv:1910.03151. [Google Scholar] [CrossRef]
- Ouyang, D.; He, S.; Zhang, G.; Luo, M.; Guo, H.; Zhan, J.; Huang, Z. Efficient Multi-Scale Attention Module with Cross-Spatial Learning. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; pp. 1–5. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Lau, K.W.; Po, L.-M.; Rehman, Y.A.U. Large Separable Kernel Attention: Rethinking the Large Kernel Attention Design in CNN. arXiv 2023, arXiv:2309.01439. [Google Scholar] [CrossRef]
- Wan, D.; Lu, R.; Shen, S.; Xu, T.; Lang, X.; Ren, Z. Mixed local channel attention for object detection. Eng. Appl. Artif. Intell. 2023, 123, 106442. [Google Scholar] [CrossRef]
- Pan, X.; Ge, C.; Lu, R.; Song, S.; Chen, G.; Huang, Z.; Huang, G. On the Integration of Self-Attention and Convolution. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–23 June 2021; pp. 805–815. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to Attend: Convolutional Triplet Attention Module. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 3138–3147. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision Transformer with Deformable Attention. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–23 June 2022; pp. 4784–4793. [Google Scholar]
- Chen, W.; Huang, H.; Peng, S.; Zhou, C.; Zhang, C. YOLO-face: A real-time face detector. Vis. Comput. 2020, 37, 805–813. [Google Scholar] [CrossRef]
- Chen, X.; Wang, X.; Zhou, J.; Dong, C. Activating More Pixels in Image Super-Resolution Transformer. In Proceedings of the 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; pp. 22367–22377. [Google Scholar]
- Zhang, H.; Zhang, S. Shape-IoU: More Accurate Metric considering Bounding Box Shape and Scale. arXiv 2023, arXiv:2312.17663. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Precision | Recall | mAP50 (%) | Parameters (M) | Model Size (MB) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|
| Faster-RCNN | 81.4 | 82.0 | 81.7 | 13.72 | 27.8 | 18.12 | 75.6 |
| CenterNet | 96.2 | 52.6 | 74.4 | 31.6 | 32.7 | 14.6 | 38.2 |
| EfficientDet | 84.2 | 53.4 | 63.7 | 5.9 | 6.6 | 6.1 | 183 |
| YOLOv3-tiny | 87.6 | 76.8 | 83.5 | 8.6 | 17.5 | 12.9 | 214 |
| YOLOv3 | 90.4 | 84.1 | 88.6 | 61.5 | 123.6 | 154.7 | 54 |
| YOLOv3 | 90.4 | 84.1 | 88.6 | 61.5 | 123.6 | 154.7 | 54 |
| YOLOv5n | 87.3 | 79.6 | 86.4 | 1.7 | 3.9 | 4.2 | 306 |
| YOLOv5s | 88.9 | 81.8 | 87.6 | 7.03 | 14.4 | 15.8 | 203 |
| YOLOv5m | 90.2 | 85.0 | 89.1 | 20.88 | 42.2 | 48.0 | 126 |
| YOLOv5l | 90.0 | 84.4 | 89.0 | 46.15 | 92.9 | 107.8 | 88 |
| YOLOv6 | 82.9 | 71.0 | 78.7 | 4.23 | 8.7 | 11.8 | 276 |
| YOLOv7-tiny | 86.7 | 79.7 | 86.2 | 6.03 | 12.3 | 13.3 | 199 |
| YOLOv7 | 88.4 | 85.3 | 89.6 | 37.24 | 74.9 | 105.3 | 77 |
| YOLOv8n | 88.0 | 79.1 | 86.6 | 3.00 | 6.2 | 8.1 | 260 |
| YOLOv8s | 88.7 | 83.7 | 89.0 | 11.12 | 22.5 | 28.5 | 208 |
| YOLOv8m | 89.4 | 84.9 | 89.6 | 25.84 | 52.0 | 78.7 | 109 |
| YOLOv8l | 89.8 | 85.1 | 89.4 | 43.61 | 87.7 | 164.9 | 53 |
| YOLOv9c [4] | 88.7 | 86.2 | 90.3 | 25.32 | 51.6 | 102.4 | 67 |
| RT-DETR [3] | 89.1 | 83.8 | 88.3 | 15.5 | 31.5 | 37.6 | 197 |
| YOLOv10 [5] | 86.2 | 80.2 | 86.4 | 2.69 | 5.8 | 8.2 | 246 |
| PDSC-YOLOv8n [30] | 85.5 | 81.2 | 86.1 | 5.62 | 11.4 | 8.96 | 297 |
| SPSM-YOLOv8 [ours] | 88.6 | 80.1 | 87.3 | 2.87 | 6.0 | 7.7 | 189 |
| Model | Backbone | mAP50 (%) | Parameters (M) | Model Size (MB) | GFLOPs | FPS |
|---|---|---|---|---|---|---|
| Baseline | CSP | 86.6 | 3.00 | 6.2 | 8.1 | 260 |
| ResNet18 [35] | 83.4 | 2.11 | 4.4 | 6.2 | 269 | |
| ResNet34 | 83.9 | 2.18 | 4.6 | 6.4 | 258 | |
| ResNet50 | 83.9 | 2.18 | 4.6 | 6.4 | 247 | |
| ResNet101 | 84.4 | 2.63 | 5.5 | 7.9 | 193 | |
| MobileViTv2 [36] | 86.7 | 3.28 | 6.9 | 11.3 | 125 | |
| MobileNetV3 [37] | 87.2 | 5.65 | 11.7 | 9.4 | 158 | |
| MobileNetV4 [33] | 83.7 | 4.30 | 8.9 | 8.0 | 201 | |
| ShuffleNetV2 [38] | 85.6 | 2.79 | 5.9 | 7.4 | 153 | |
| GhostNet [39] | 84.9 | 5.35 | 11.2 | 8.2 | 104 | |
| LSKNet [40] | 83.5 | 12.31 | 24.9 | 36.6 | 87 | |
| SCINet [34] | 86.5 | 3.00 | 6.3 | 9.1 | 218 | |
| SwinTransformer [41] | 86.6 | 29.98 | 60.5 | 402.1 | 56 | |
| SENetV2 [42] | 86.7 | 3.09 | 6.4 | 8.2 | 232 | |
| VanillaNet [32] | 86.3 | 29.76 | 59.8 | 151.3 | 55 | |
| RepViT [31] | 87.2 | 4.12 | 8.6 | 11.7 | 96 | |
| PP-HGNetV2 [3] | 85.6 | 2.29 | 4.8 | 6.6 | 250 | |
| EfficientViT [43] | 86.1 | 4.01 | 8.7 | 9.4 | 55 | |
| FasterNeT [44] | 87.7 | 15.18 | 30.7 | 37.0 | 179 | |
| EfficientNetV2 [45] | 88.9 | 21.75 | 44.3 | 52.1 | 69 | |
| RevColV1 [46] | 83.0 | 32.09 | 64.6 | 79.3 | 51 | |
| ConvNeXtV2 [47] | 84.2 | 5.66 | 11.6 | 14.1 | 102 | |
| UniRepLknet [48] | 85.2 | 6.28 | 13.0 | 16.5 | 81 | |
| EMO [49] | 86.8 | 6.28 | 13.0 | 31.6 | 71 | |
| CSP (SPDConv) | 86.5 | 2.68 | 5.6 | 7.5 | 230 |
| Model | Method | Precision | Recall | mAP50 (%) | Parameters (M) | Model Size (MB) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|
| Baseline | Origin | 88.0 | 79.1 | 86.6 | 3.00 | 6.2 | 8.1 | 260 |
| PSA [5] | 88.6 | 81.4 | 87.5 | 3.12 | 6.5 | 8.1 | 226 | |
| CA [53] | 87.2 | 79.0 | 86.3 | 3.01 | 6.3 | 8.1 | 236 | |
| CBAM [52] | 87.5 | 79.7 | 86.1 | 3.07 | 6.4 | 8.1 | 268 | |
| LSKA [58] | 88.7 | 80.2 | 87.1 | 3.07 | 6.4 | 8.2 | 250 | |
| MSDA [54] | 88.7 | 79.7 | 87.0 | 3.27 | 6.8 | 8.3 | 193 | |
| HAttention [64] | 87.8 | 79.7 | 86.7 | 7.93 | 16.5 | 8.1 | 259 | |
| MLCA [59] | 87.9 | 80.3 | 87.3 | 3.00 | 6.3 | 8.2 | 203 | |
| CGA [43] | 86.6 | 78.8 | 86.1 | 3.05 | 6.7 | 8.3 | 74 | |
| SEAM [63] | 88.6 | 79.4 | 87.0 | 3.11 | 6.5 | 8.3 | 199 | |
| GAM [57] | 87.5 | 80.0 | 86.8 | 4.64 | 9.5 | 9.4 | 253 | |
| ACmix [60] | 88.9 | 79.8 | 87.1 | 3.30 | 6.9 | 8.7 | 117 | |
| DLKA [50] | 87.8 | 77.7 | 85.9 | 4.62 | 9.5 | 13.4 | 52 | |
| DAT [62] | 87.4 | 80.3 | 86.8 | 3.08 | 6.4 | 8.3 | 186 | |
| BiFormer [51] | 83.3 | 73.7 | 81.1 | 3.90 | 8.1 | 43.1 | 139 | |
| TripletAttention [61] | 88.2 | 78.6 | 86.5 | 3.00 | 8.1 | 6.3 | 169 | |
| iRMB [49] | 87.3 | 80.2 | 86.9 | 3.35 | 7.0 | 8.8 | 172 | |
| EMA [56] | 87.0 | 80.3 | 86.7 | 3.00 | 6.3 | 8.2 | 208 | |
| ECA [55] | 87.2 | 79.9 | 86.6 | 3.00 | 6.3 | 8.1 | 271 |
| Model | Method | Precision | Recall | mAP50 (%) | mAP50-90 (%) | AP (%) | |||
|---|---|---|---|---|---|---|---|---|---|
| Echinus | Starfish | Holothurian | Scallop | ||||||
| Baseline | MPDIoU [7] | 79.6 | 69.2 | 76.7 | 40.5 | 71.8 | 90.3 | 81.1 | 63.3 |
| CIoU | 79.3 | 69.8 | 76.5 | 39.9 | 69.7 | 90.6 | 82.4 | 63.4 | |
| DIoU | 78.9 | 68.9 | 76.1 | 42.6 | 70.5 | 89.1 | 81.7 | 63.2 | |
| EIoU | 79.3 | 68.2 | 75.5 | 42.6 | 68.5 | 89.0 | 81.2 | 63.4 | |
| SIoU | 79.1 | 67.4 | 75.3 | 42.0 | 68.4 | 89.0 | 81.2 | 62.5 | |
| WIoU | 76.3 | 69.3 | 71.9 | 36.2 | 65.1 | 87.3 | 76.0 | 59.2 | |
| Shape-IoU [65] | 77.9 | 69.5 | 75.5 | 42.1 | 68.9 | 89.7 | 80.5 | 63.1 | |
| Model | Method | SPDConv | PSA | SCDown | MPDIoU | mAP50 (%) | mAP50-95 (%) | Parameters (M) | Model Size (MB) | GFLOPs | FPS |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Baseline | a | 86.6 | 63.2 | 3.00 | 6.2 | 8.1 | 260 | ||||
| b | √ | 86.5 | 62.7 | 2.68 | 5.6 | 7.5 | 230 | ||||
| c | √ | 87.5 | 64.0 | 3.12 | 6.5 | 8.1 | 226 | ||||
| d | √ | 86.4 | 63.1 | 2.84 | 5.9 | 8.0 | 244 | ||||
| e | √ | 87.4 | 64.2 | 3.00 | 6.2 | 8.1 | 262 | ||||
| f | √ | √ | 86.5 | 63.2 | 3.04 | 6.3 | 7.8 | 217 | |||
| g | √ | √ | 86.0 | 62.3 | 2.62 | 5.5 | 7.5 | 208 | |||
| h | √ | √ | 85.7 | 61.3 | 2.79 | 5.8 | 7.6 | 219 | |||
| i | √ | √ | √ | 87.0 | 63.6 | 2.87 | 6.0 | 7.7 | 197 | ||
| j | √ | √ | √ | 87.3 | 63.9 | 3.04 | 6.3 | 7.8 | 226 | ||
| k | √ | √ | √ | 87.0 | 63.8 | 2.62 | 5.5 | 7.5 | 247 | ||
| l | √ | √ | 87.5 | 64.3 | 3.09 | 6.5 | 8.2 | 221 | |||
| m | √ | √ | 87.9 | 65.0 | 3.25 | 6.8 | 8.3 | 242 | |||
| n | √ | √ | √ | 87.9 | 65.1 | 3.09 | 6.5 | 8.2 | 234 | ||
| o | √ | √ | 87.1 | 63.9 | 2.84 | 5.9 | 8.0 | 275 | |||
| p [ours] | √ | √ | √ | √ | 87.3 | 63.6 | 2.87 | 6.0 | 7.7 | 210 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, S.; Wang, Z.; Liu, S.; Han, Y.; Sun, P.; Li, J. Attention-Based Lightweight YOLOv8 Underwater Target Recognition Algorithm. Sensors 2024, 24, 7640. https://doi.org/10.3390/s24237640
Cheng S, Wang Z, Liu S, Han Y, Sun P, Li J. Attention-Based Lightweight YOLOv8 Underwater Target Recognition Algorithm. Sensors. 2024; 24(23):7640. https://doi.org/10.3390/s24237640
Chicago/Turabian StyleCheng, Shun, Zhiqian Wang, Shaojin Liu, Yan Han, Pengtao Sun, and Jianrong Li. 2024. "Attention-Based Lightweight YOLOv8 Underwater Target Recognition Algorithm" Sensors 24, no. 23: 7640. https://doi.org/10.3390/s24237640
APA StyleCheng, S., Wang, Z., Liu, S., Han, Y., Sun, P., & Li, J. (2024). Attention-Based Lightweight YOLOv8 Underwater Target Recognition Algorithm. Sensors, 24(23), 7640. https://doi.org/10.3390/s24237640