1. Introduction
In recent years, unmanned aerial vehicles (UAVs) have found applications in various military and civilian domains due to their advantages, such as high mobility, accessibility, convenient deployment, and low cost. They have gradually become indispensable in modern society, with roles in civil sectors, such as agriculture [
1,
2], mineral exploration [
3], and forest rescue [
4], as well as in military reconnaissance [
5] and strikes [
6]. Multi-UAV target search problems is a significant issue in autonomous UAV decision-making and has garnered extensive academic attention recently. Multi-UAV target search involves UAVs using on-board detection equipment to reconnoiter designated areas. They share information via a communication network, thereby jointly capturing targets. Currently, three primary methods are used for multi-UAV target search. The first category is pre-planning methods, such as partition search [
7] and formation search [
8]. These methods, essentially, transform the target search problem into a planning problem with area coverage, offering high reliability and easy evaluation of the solution results. However, they require a known mission area model in advance, involve longer planning times, and are not highly adaptive to dynamic environmental changes. The second category is online optimization methods, which approximate the search problem as a real-time objective function optimization problem. These methods typically employ traditional or heuristic algorithms, such as ant colony algorithms [
9] and genetic algorithms [
10]. They are better adapted to environmental dynamics than to pre-planning approaches. However, they depend on a central node for decision-making and exhibit low adaptability in distributed environments. The third category entails Multi-Agent Reinforcement Learning (MARL) methods, which model the problem as a Partially Observable Markov Decision Process (POMDP) and utilize algorithms based on the MARL framework. These methods enable agents to learn and optimize their behavior through interactions with the environment and other agents, allowing them to adapt to dynamic changes and make rapid decisions [
11,
12]. The primary challenge of these methods lies in designing the algorithm training architecture, agent exploration mechanism, and reward function tailored to specific task requirements.
Recently, the design of MARL methods has become a prominent area of research in the field of artificial intelligence. It has found applications in areas such as multi-UAV target search [
13], autonomous vehicle path planning [
14], and other related applications. Within the MARL framework, Shen et al. [
15] proposed the DNQMIX algorithm, which enhances search rate and coverage. Lu et al. [
16] proposed the MUICTSTP algorithm, demonstrating superior performance in terms of anti-interference and collision avoidance. Yu et al. [
17] proposed the Multi-Agent Proximal Policy Optimization (MAPPO) algorithm, which has exhibited excellent performance in multi-agent testing environments and is regarded as one of the most advanced algorithms available. Wei et al. [
18] combined the MAPPO algorithm with optimal control (OC) and GPU parallelization to propose the OC–MAPPO algorithm, which accelerates UAV learning.
To better describe environmental uncertainty, Bertuccelli et al. [
19] proposed a probabilistic approach. This method divides the task area into units, each associated with the probability of target presence, establishing a target probability graph. The method has achieved good results in target search and is widely recognized. Building on the MARL framework and the target probability graph, Zhang et al. [
20] designed a confidence probability graph using evidence theory and proposed a double critic DDPG algorithm. This approach effectively balances the bias in action–value function estimation and the variance in strategy updates. Hou et al. [
21] converted the probability function into a grid-based goal probability graph and proposed a MADDPG-based search algorithm, improving search speed and avoiding collisions and duplications.
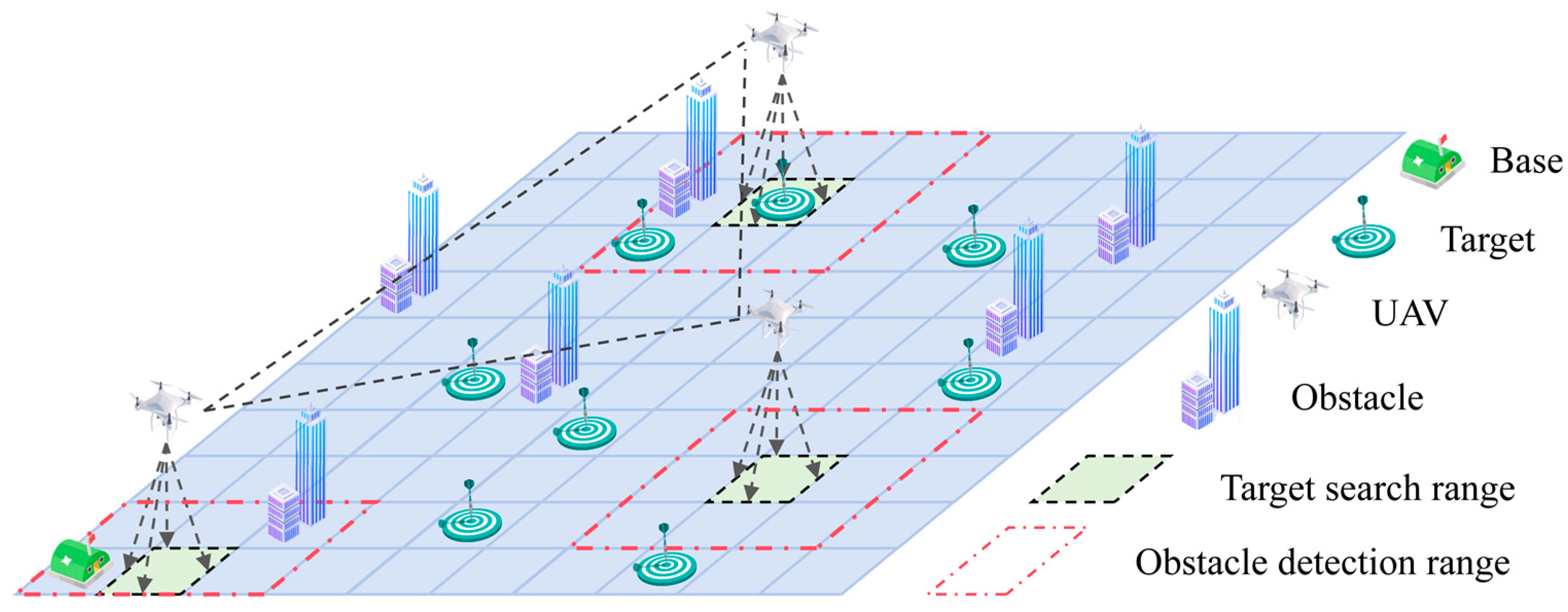
Multi-UAV target search has made some progress over time, but two challenges remain. Firstly, the utilization of sample data remains inefficient, and balancing utilization and exploration presents a challenge. Existing MARL algorithms primarily employ neural networks, such as fully connected networks and convolutional networks. These networks often fail to simultaneously achieve efficient utilization of temporal and spatial information in the sample data, and also lack effective environmental exploration. Secondly, the behavioral modeling of dynamic target is relatively simple. Existing work primarily considers changes in the target’s position over time, often transforming the target search problem into a target tracking problem. In actual non-cooperative target search scenarios, targets may exhibit escape behavior. They actively change their position to evade detection and, potentially, use environmental blind spots to hide, preventing real-time tracking by UAVs. Addressing the challenges identified above, this paper investigates the Multi-UAV Escape Target Search (METS) problem in complex environments. The contributions of this paper are summarized as follows:
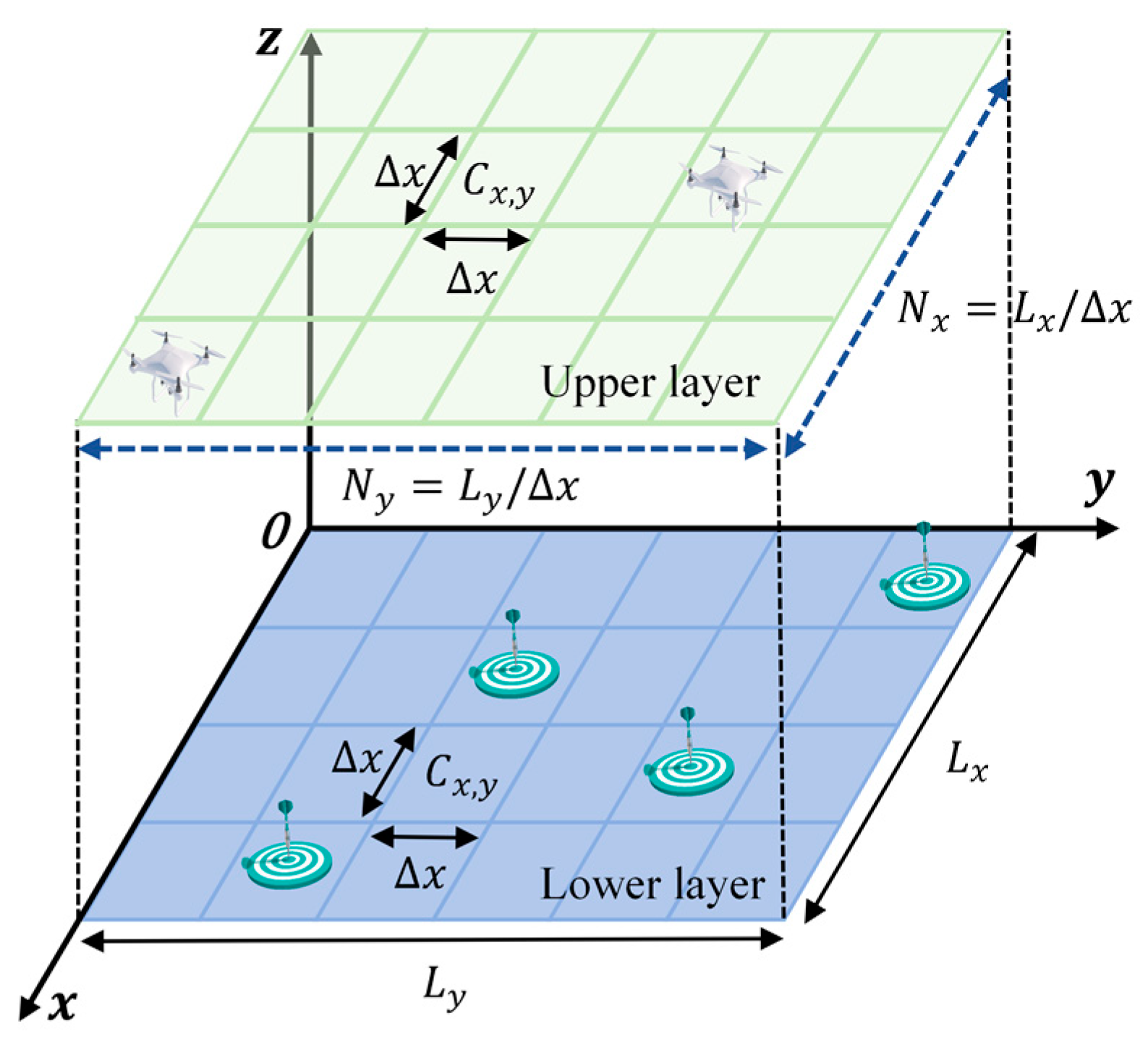
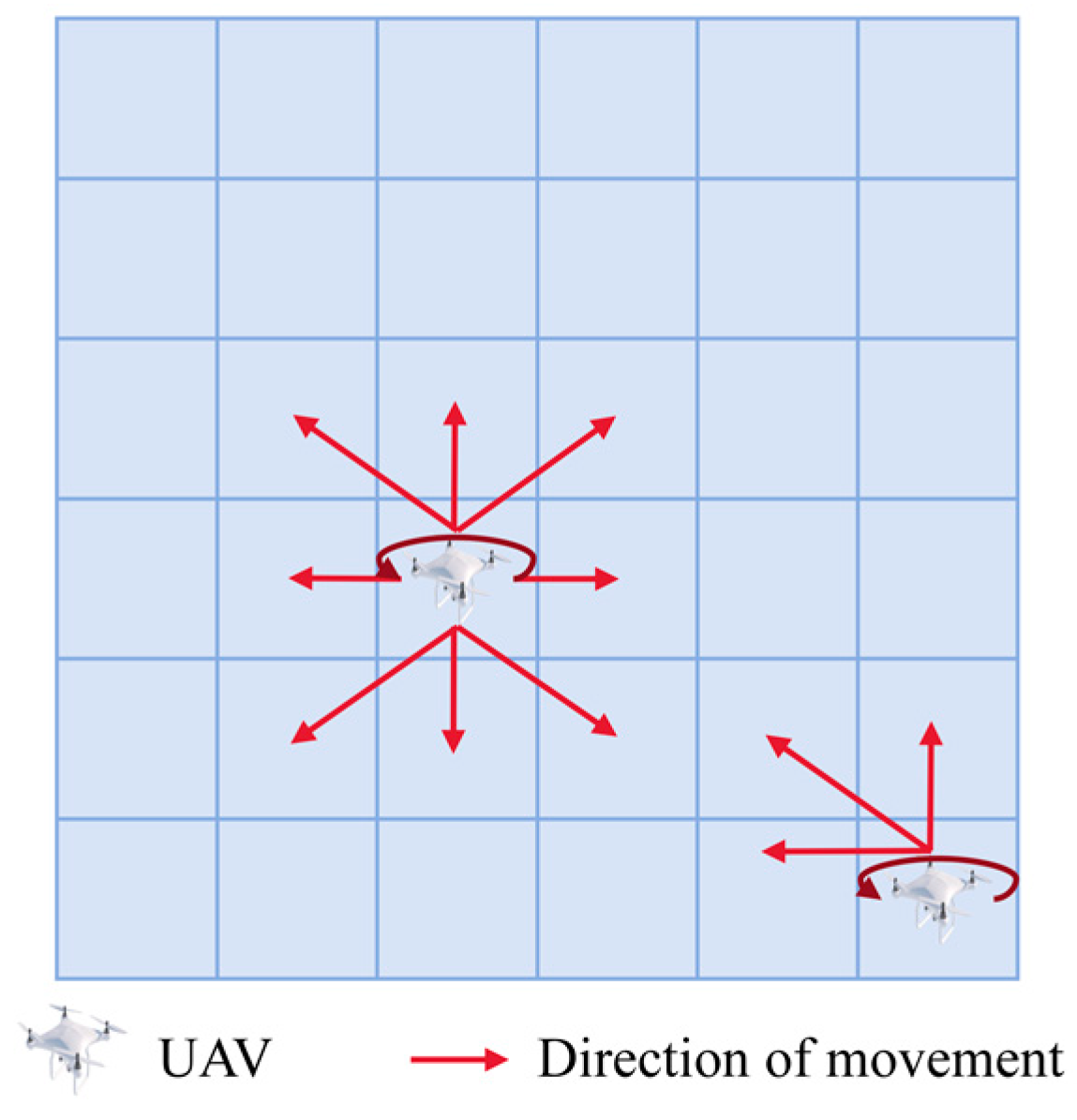
The simulation environment for the METS problem is constructed, introducing a Target Existence Probability Map (TEPM), with an appropriate probability update method employed for the escaping target. Based on the TEPM, a local state field of view is designed, with local state values obtained through entropy calculation. Additionally, a new state space, action space, and reward function are devised within the framework of Decentralized Partially Observable Markov Decision process (DEC-POMDP). Ultimately, a model that addresses the METS problem is established.
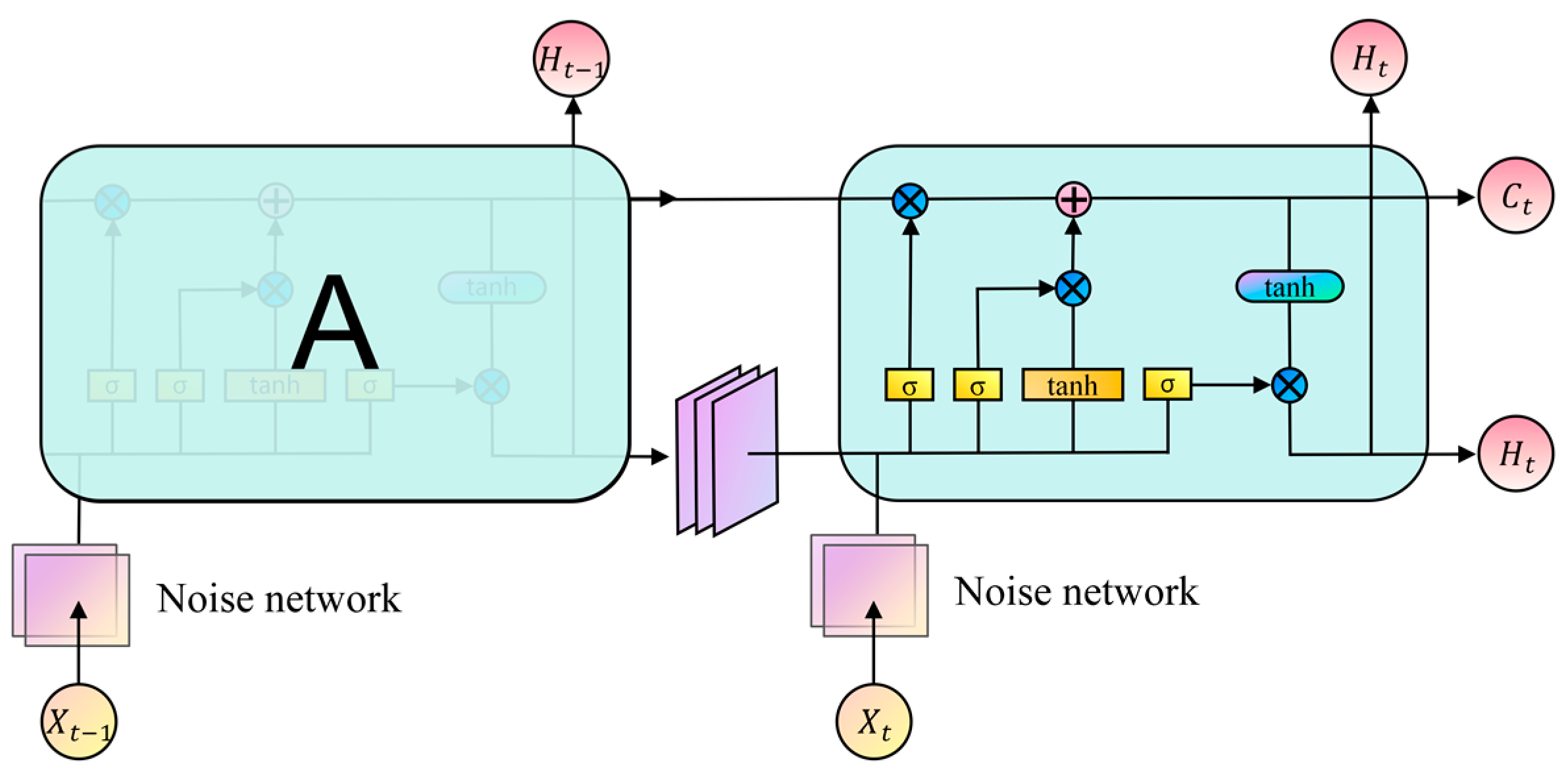
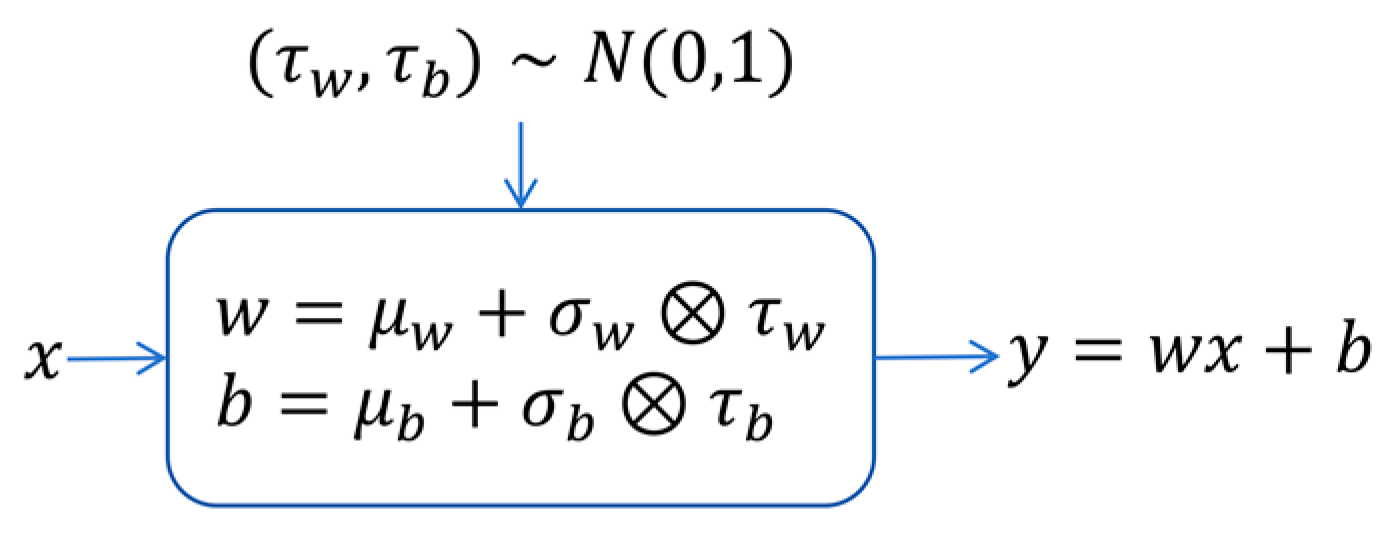
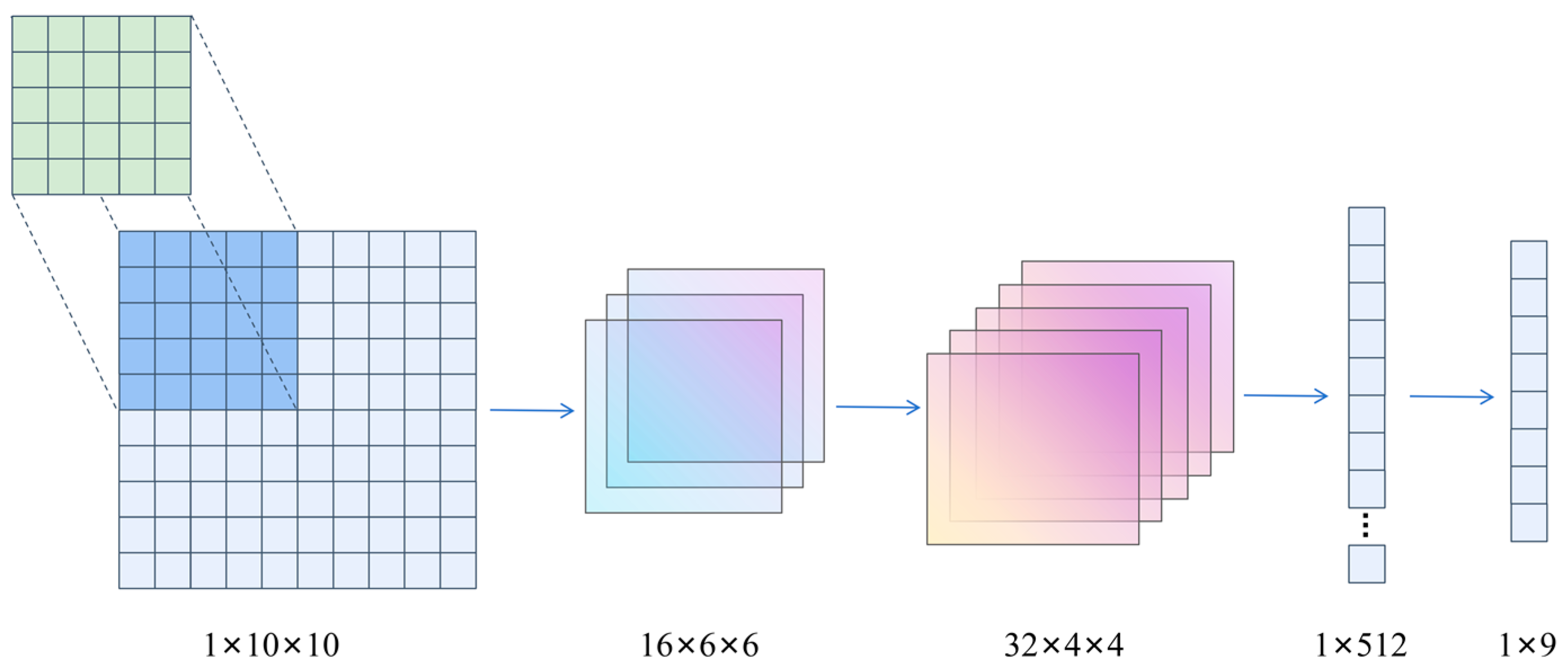
To enhance the MARL algorithm’s ability to process spatio-temporal sequence information and improve environmental exploration, this paper proposes the Spatio-Temporal Efficient Exploration (STEE) network, constructed using a convolutional long short-term memory network and a noise network. This network is integrated into the MAPPO algorithm, and its impact on the overall performance of the MAPPO algorithm is validated.
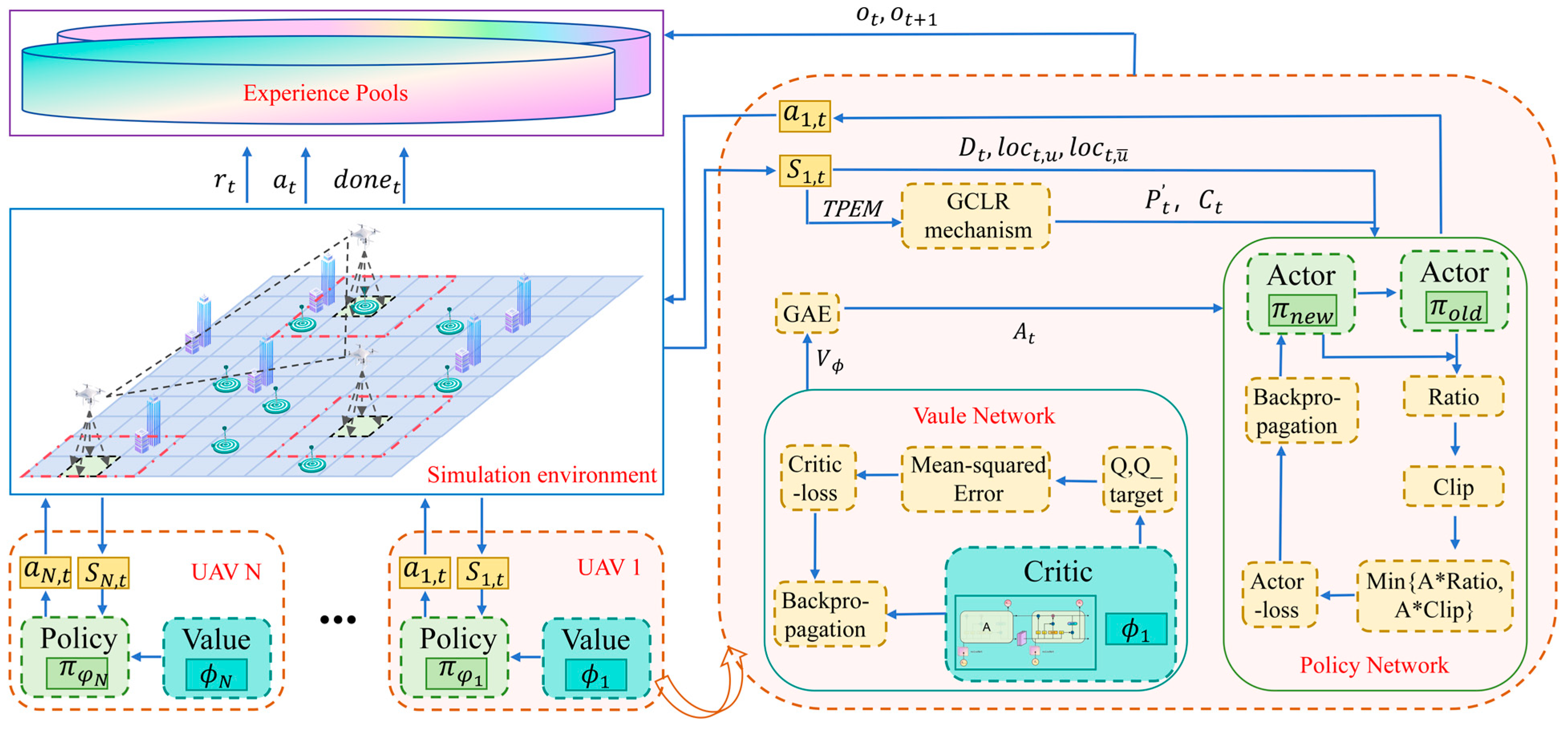
To search the escaping target in the METS problem, the Global Convolutional Local Ascent (GCLA) mechanism is proposed. A Multi-UAV Escape Target Search algorithm based on MAPPO (ETS–MAPPO) is introduced by combining MAPPO with the STEE network. This algorithm effectively addresses the challenges of searching for escape targets. Experimental comparisons with five classic MARL algorithms show significant improvements in the number of target searches, area coverage rate, and other metrics.
The remaining chapters of this paper are organized as follows:
Section 2 defines the system model and provides a mathematical formulation of the METS problem.
Section 3 introduces the ETS–MAPPO algorithm within the MARL framework and describes it in detail. In
Section 4, experiment results are presented to validate the effectiveness of ETS–MAPPO.
Section 5 concludes the paper and discusses future research.
4. Experiments
To verify the effectiveness of the proposed ETS–MAPPO algorithm, it was compared against five classic MARL algorithms: MAPPO [
17], MADDPG [
31], MATD3 [
32], QMIX [
33], and IQL [
34]. Ablation experiments were also conducted to demonstrate the contributions of the STEE network and the GCLA mechanism.
4.1. Simulation Environment and Parameter Settings
In the multi-UAV escape target search simulation scenario established, the environment was divided into two layers with a size of 2000 m × 2000 m. There were three UAVs, with a detection range for targets of 200 m and a detection range for stationary obstacles of 400 m. There were 10 escape targets, with a detection range for UAVs of 200 m, an escape range of 400 m, and a single escape attempt. The initial position of the target was taken to be randomly generated. The number of obstacles was 15. The simulation environment and network parameters are detailed in
Table 1.
The simulation experiments were conducted using the following computer hardware and software: an Intel i5-12400F CPU manufactured by Intel Corporation and sourced from Hefei, China, 32 GB RAM, an NVIDIA GeForce RTX 4060Ti GPU manufactured by PC Partner and sourced from Dongguan, China, Python 3.11.5, and Pytorch 2.1.0.
4.2. Model Performance Analysis
The analysis of model performance began with the evaluation of the training results of each model, focusing on the convergence and performance metrics of six algorithm models: ETS–MAPPO, MAPPO, MADDPG, MATD3, QMIX, and IQL. Subsequently, the test results were analyzed to assess the generalization performance and real-time performance of the ETS–MAPPO algorithm model. Finally, the operational state of the ETS–MAPPO algorithm in the simulation environment at different time step was obtained. To ensure the reliability of the experiments, the number of network layers and neurons in each algorithm was kept consistent, and the algorithm parameters were appropriately tuned. All experiments were conducted three times under random seeds of 1, 2, and 3, and the average value of the three experiments was taken as the final experimental result.
4.2.1. Analysis of Model Training Results
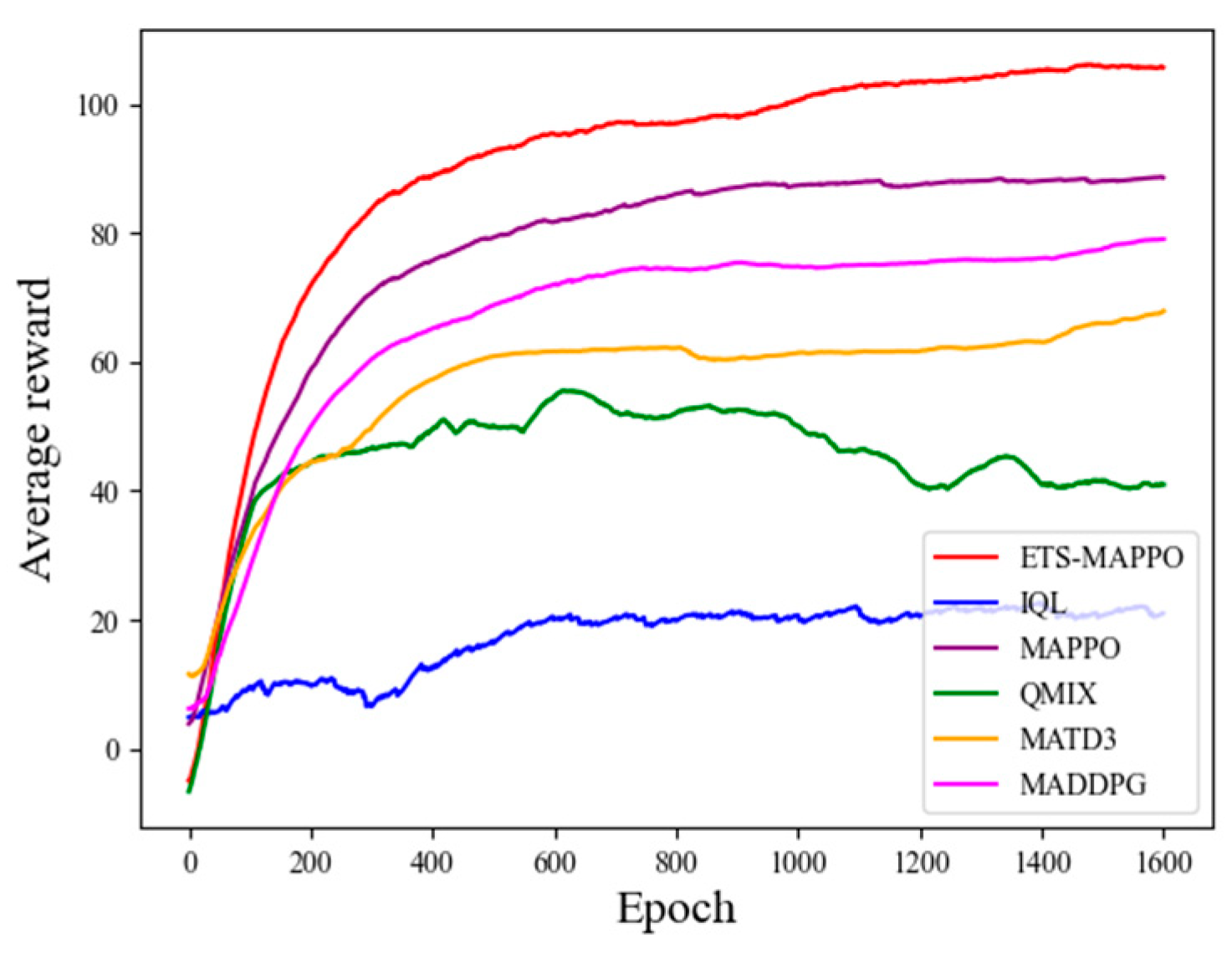
Model training was conducted according to the experimental setup described above, with the convergence curves of the six algorithms—ETS–MAPPO, MAPPO, MAD-DPG, MATD3, QMIX, and IQL—presented in
Figure 8. As the number of training rounds increased, the UAV average reward value gradually increased and converged. The average reward value curve of the ETS–MAPPO algorithm demonstrates a significant advantage over the other five classic algorithms.
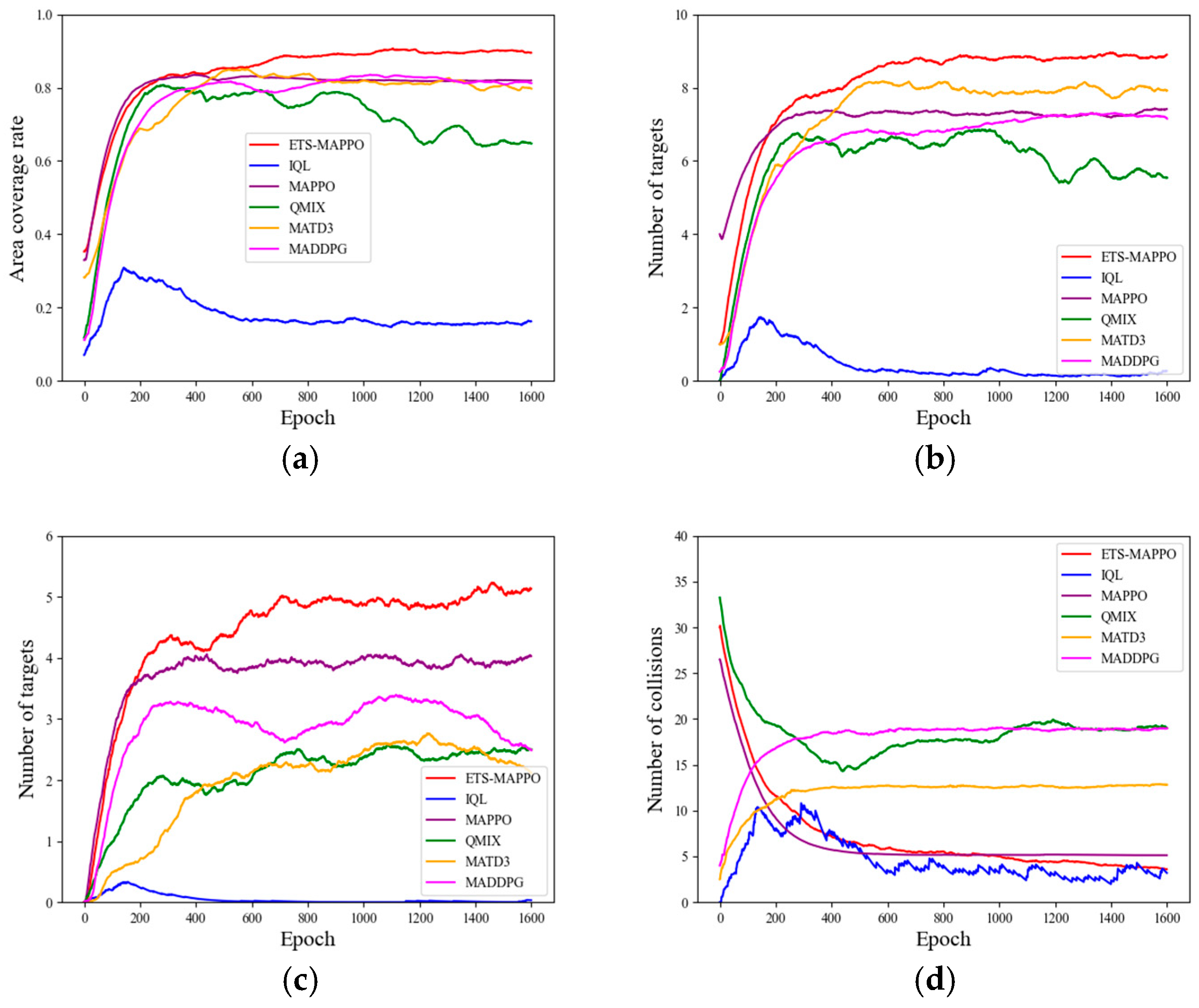
Besides the average reward results representing the combined effect of multiple metrics, the specific parameter metrics that measure the actual performance in the METS problem include the area coverage rate, the number of collisions, the number of initial target searches, and the number of target re-searches. As shown in
Figure 9a–c, the ETS–MAPPO algorithm was compared with the other five algorithms in terms of area coverage, the number of initial target searches, and the number of target re-searches. Although the convergence curves are intertwined in the early stages, the results after convergence display clear advantages.
With regard to the indicator of the number of collisions shown in
Figure 9d, the convergence trend of MADDPG and MATD3 differed from the downward convergence observed in the ETS–MAPPO, MAPPO, QMIX, and IQL algorithms by exhibiting upward convergence, leading to poorer results. Additionally, the results of the ETS–MAPPO, MAPPO, and IQL algorithms were similar.
The observed results can be attributed to the adoption of the STEE network and the GCLA mechanism within the ETS–MAPPO algorithm. These components enhance the processing of spatio-temporal sequence data and environmental exploration, strengthen the network state parameters, improve the algorithm’s learning efficiency, accelerate network convergence, and optimize the search for the escape target, ultimately yielding higher reward values, as reflected in the specific parameter metrics.
4.2.2. Analysis of Model Testing Results
In order to further validate the experimental results, six algorithms, ETS–MAPPO, MAPPO, MADDPG, MATD3, QMIX and IQL, were tested. The model with the random seed of 1 was chosen for model testing, and each algorithm was tested over 20 rounds so as to take the average value as the test result; other environmental parameters were consistent with the model training above. Then, the number of targets and time steps were changed to verify the generalization performance of the ETS–MAPPO algorithm.
The model test results are shown in
Table 2, which compares the performance of the six algorithms across five metrics. The ETS–MAPPO algorithm outperformed the others on four of these metrics: the average reward, the area coverage rate, the number of initial target searches, and the number of target re-searches. In terms of obstacle collisions, comparison of the training curves and other indicators revealed that the IQL algorithm experienced fewer obstacle collisions, likely due to its limited UAV exploration of the environment, rendering it less comparable. Therefore, excluding the IQL algorithm, the ETS–MAPPO algorithm surpassed the remaining four algorithms in this metric. To summarize, the ETS–MAPPO algorithm outperformed the other five classic algorithms across all five performance metrics and demonstrated superior performance overall.
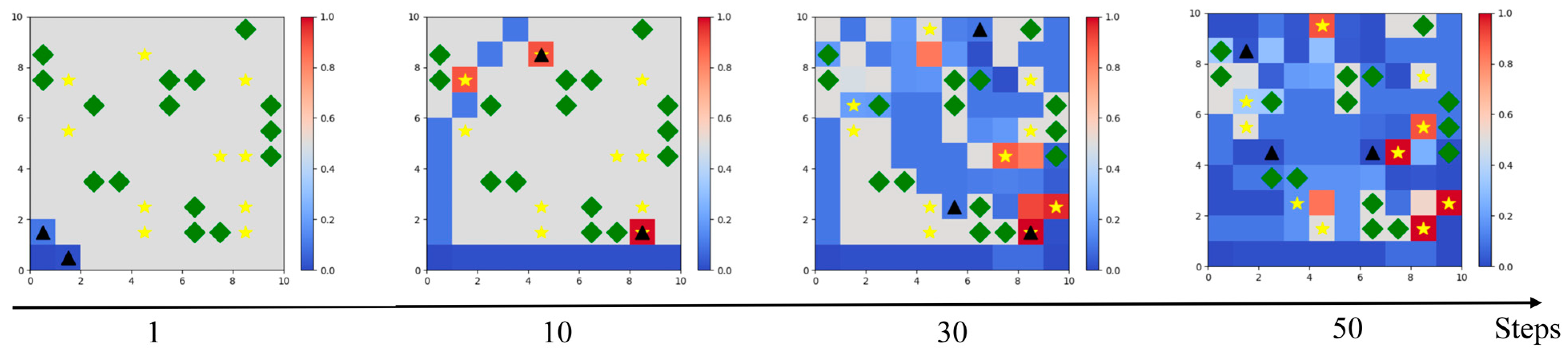
Figure 10 gives the results of the environmental operation under 50 consecutive time steps in the test phase, at time step 1, time step 10, time step 30, and time step 50. At the beginning of the simulation, the UAV departed from the base and followed two paths for searching. From time step 1 to time step 10, it can be found that the UAV was trying to avoid collision with obstacles. From time step 10 to time step 30, it can be observed that the UAVs undertook a decentralized search and started searching for targets in full range, with many targets successfully searched for the first time. It can also be observed that some of the escaped targets had already escaped and there was a change in their position. From the 30th to the 50th time step, some targets were successfully searched for again. It can be observed that the UAV covered and searched most of the mission area. The above test results show that the ETS–MAPPO algorithm can reasonably and efficiently complete the area reconnaissance and escape target search.
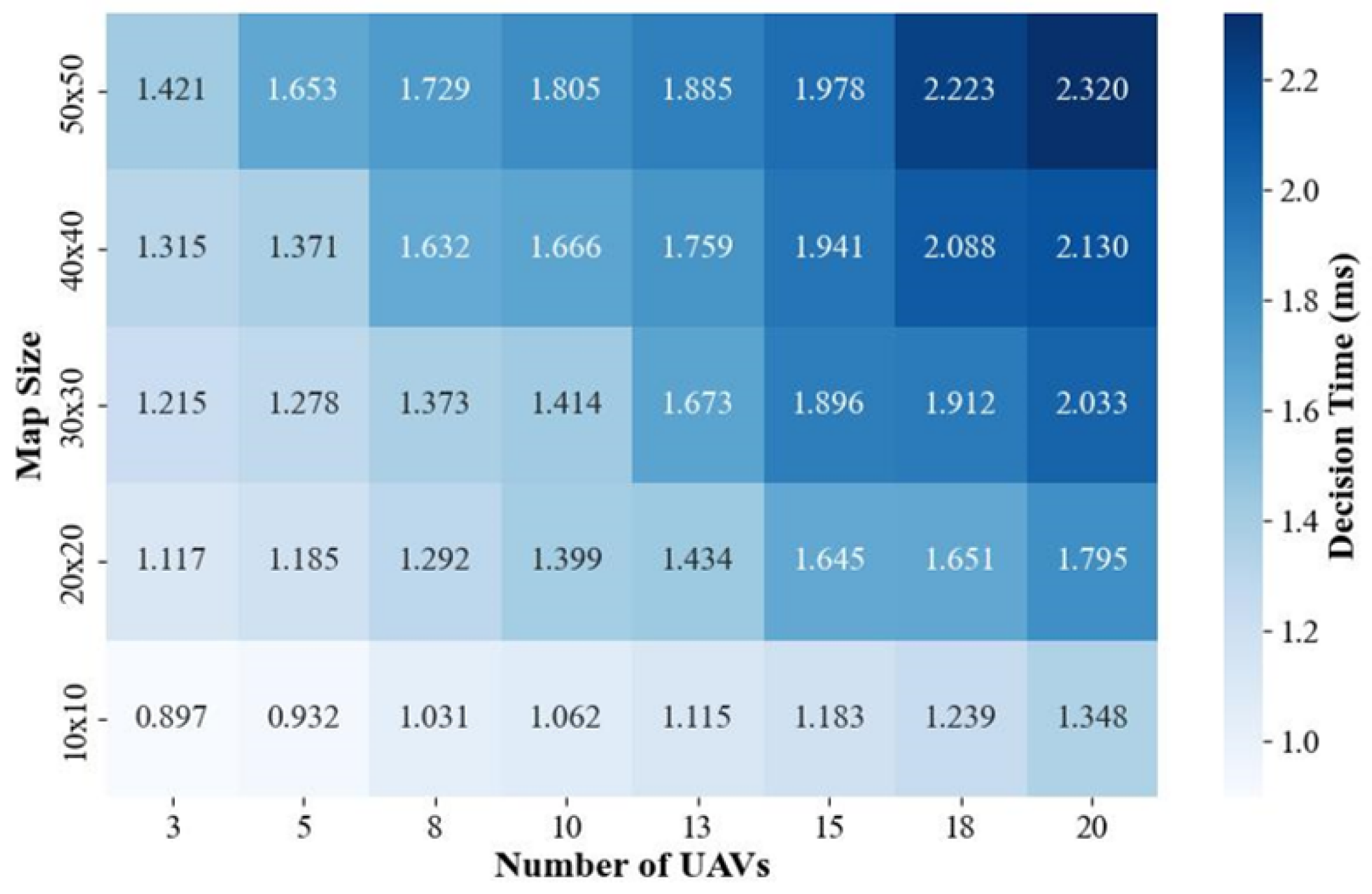
Figure 11 presents the results of the algorithm’s real-time performance test. From the results it can be seen that, as the number of UAVs increased and the range of the explored area expanded, the average decision time per UAV also increased. The variation in average decision time per UAV remained within the millisecond range (0.8–2.4 ms). In practice, this variation did not noticeably affect UAV operation.
To verify the generalization performance of the ETS–MAPPO algorithm, we varied the number of time steps and targets during testing. From
Table 3 and
Table 4, it can be seen that the average reward, the number of initial target searches, and the number of target re-searches increased with the increase in time steps and target count. The area coverage ratio remained near 0.9, and the percentage of initial repeat target searches ratio stayed around 0.5. This demonstrates that the ETS–MAPPO algorithm remained effective across different number of time steps and targets.
4.3. Ablation Experiment
To investigate the impact of the STEE network and the GCLA mechanism on the ETS–MAPPO algorithm’s performance, two variants were constructed: the GCLA–MAPPO, by removing the STEE network, and the STEE–MAPPO, by removing the GCLA mechanism. The test results for these algorithms across five performance metrics were analyzed. The specific configurations of the four algorithms in the ablation experiments are presented in
Table 5, where “√” indicates inclusion and “×” indicates exclusion.
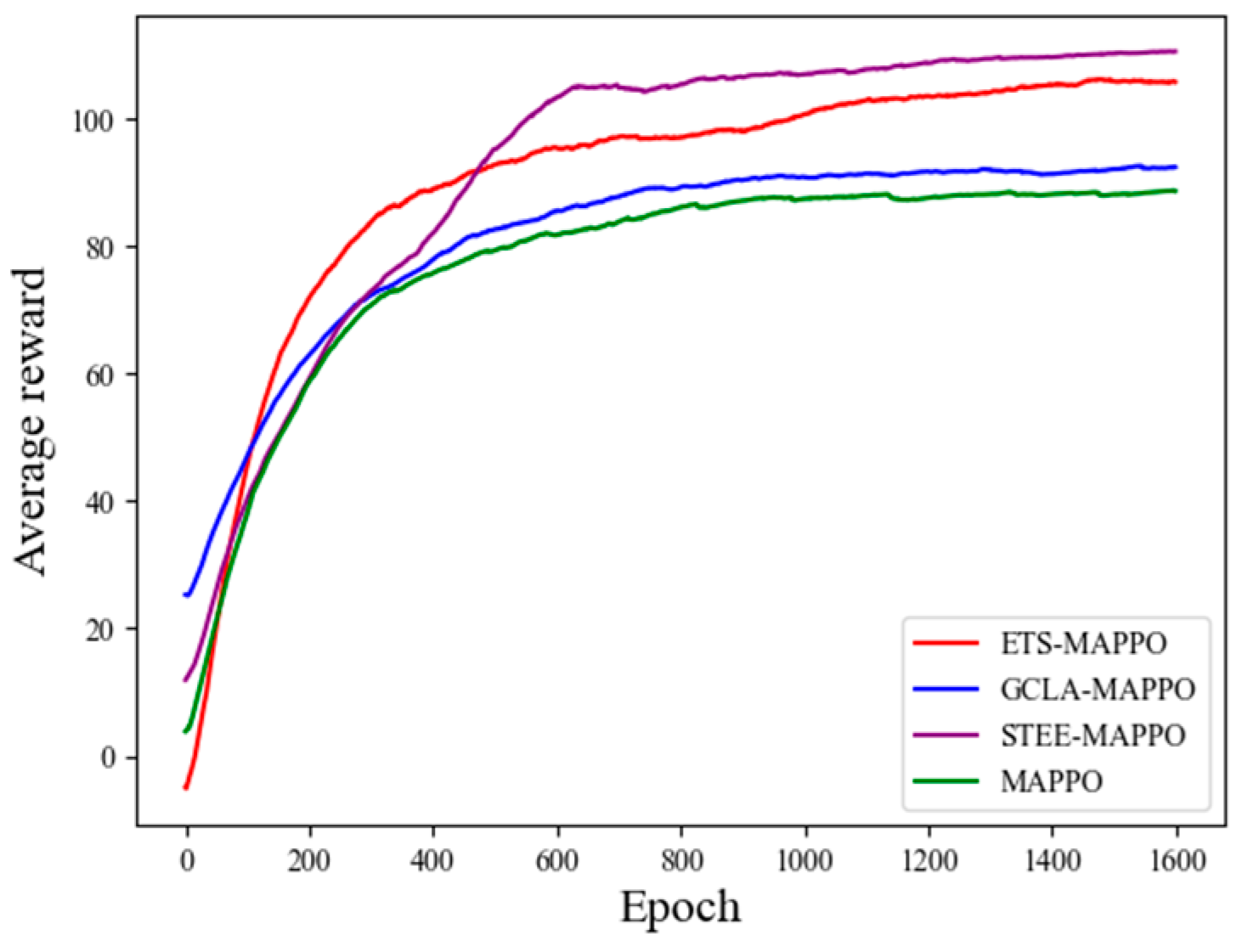
Figure 12 presents the training results of each ablation experiment algorithm in terms of average reward. From these results, it can be seen that the GCLA–MAPPO and MAPPO algorithms had similar reward values, while the ETS–MAPPO and STEE–MAPPO algorithms demonstrated higher reward values, with the ETS–MAPPO algorithm being slightly lower than the STEE–MAPPO algorithm.
Table 6 shows the test results of the four ablation experimental algorithms across five performance metrics. The results demonstrate that the ETS–MAPPO, STEE–MAPPO, and GCLA–MAPPO algorithms showed improvements over the MAPPO algorithm in four metrics: the average reward, the number of collisions, the number of initial target searches, and the number of target re-searches. However, on the area coverage rate metric, the GCLA–MAPPO algorithm was associated with a slightly lower value than that associated with the MAPPO algorithm.
These results can be attributed to the STEE network’s ability to efficiently process spatio-temporal sequence data and enhance environmental exploration, thereby improving the overall performance of the algorithms. Consequently, algorithms utilizing the STEE network achieved higher reward values. The GCLA mechanism caused the UAV to focus its search near the initial target discovery area, which often includes regions that have already been explored. Given the limited number of time steps, the UAV lacked sufficient time to search unexplored areas after repeatedly scanning near the initial target area. This led to a decrease in the area coverage rate and an increase in the number of target re-searches. These findings suggest that the STEE network and the GCLA mechanism effectively enhance the performance of the ETS–MAPPO algorithm in the METS problem.
5. Conclusions
With regard to the multi-UAV escape target search task, this paper addresses the challenges associated with enabling escape target search and efficiently utilizing the sample data from the MARL algorithm, particularly in relation to maintaining a balance between utilization and exploration. This paper proposes a multi-UAV escape target search algorithm that combines the STEE network with the GCLA mechanism, built upon the MAPPO algorithm and applied to the multi-UAV escape target search task. Experimental results demonstrate that the ETS–MAPPO algorithm excels in addressing the METS problem, outperforming the other five MARL algorithms across all metrics. Ablation experiments confirm that the STEE network enhances the utilization of spatio-temporal sequence data while effectively balancing environmental exploration, thereby improving the algorithm’s overall performance. Additionally, the GCLA mechanism significantly improves performance in the escape target search problem.
Future work will investigate the performance of our proposed ETS–MAPPO algorithm in larger-scale scenarios involving more UAVs, while continually optimizing the training efficiency of the network model.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}