
Indoor Pedestrian Positioning Method Based on Ultra-Wideband with a Graph Convolutional Network and Visual Fusion



Abstract
1. Introduction
- (1)
- UWB positioning module based on a GCN: We propose an indoor pedestrian positioning method utilizing a GCN. By leveraging the powerful feature-extraction capabilities of GCNs, our method integrates features from neighboring positioning points to improve accuracy, advancing beyond traditional algorithms like the Chan–Taylor method.
- (2)
- Visual localization module based on Bi-GRU: We introduce a visual localization method that employs a Bi-GRU network. This model effectively compensates for visual localization errors caused by camera distortions by learning and correcting residual errors in the positioning results.
- (3)
- Data fusion algorithm based on PF: We developed a particle filter-based fusion algorithm that combines data from UWB and visual systems. By considering the uncertainty and noise from both types of sensors, our fusion algorithm improves the accuracy and robustness of positioning.
2. UWB Indoor Positioning
2.1. UWB Indoor Positioning Method Based on TDOA
2.2. UWB Indoor Positioning Method Based on a GCN
- (1)
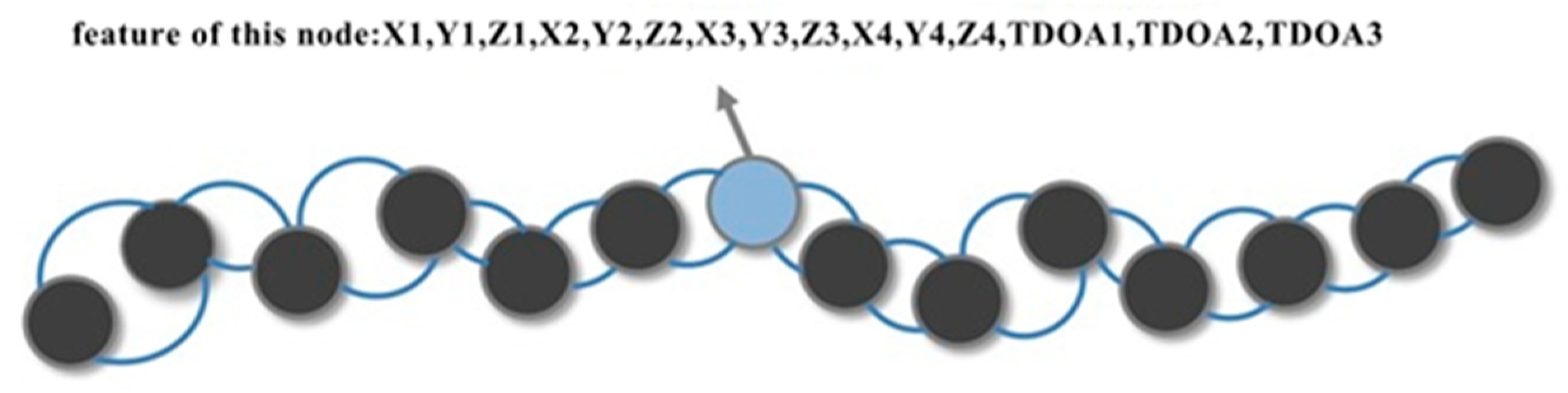
- Input Module. The inputs are the coordinates of the four base stations, and the positioning data consist of three TDOA values. By selecting m localized nodes that are consecutive in the time series, the feature matrix of the input graph convolutional neural network is an m × 15-dimensional matrix. Thus, the input data are defined as follows:where Cv = (Xv, Yv, Zv) (v = 1, 2, 3, 4) denotes the coordinates of the vth UWB base station, and denotes the TDOA value of the mth localized point to the host station and the ith slave base station. We used three slave base stations, so i = 1, 2, 3.For a graph with m nodes, its adjacency matrix A ∈ Rm*m is denoted:
- (2)
- Graph Convolution Module. The positioning data features of neighboring positioning points are extracted using the graph convolution module. The module includes sequentially connected graph convolution layers and fully connected layers. Input the node feature matrix X and the adjacency matrix A of the whole graph through a two-layer GCN to get the node-embedding matrix E:where is the normalized result of , IN is the unit matrix, and D is the degree matrix of the graph. W0 and W1 denote the trainable weight matrices, and ELU is the activation function used in training the graph convolutional neural network. Therefore, the GCN outputs the prediction result , which is represented as follows:where ω denotes the weight of the fully connected layer, and b denotes the bias term of the fully connected layer. They are both trainable parameters in neural networks.
- (3)
- Output Module. Outputs the estimated position of the target.
2.3. Positioning Methods and Process Based on a GCN
- (1)
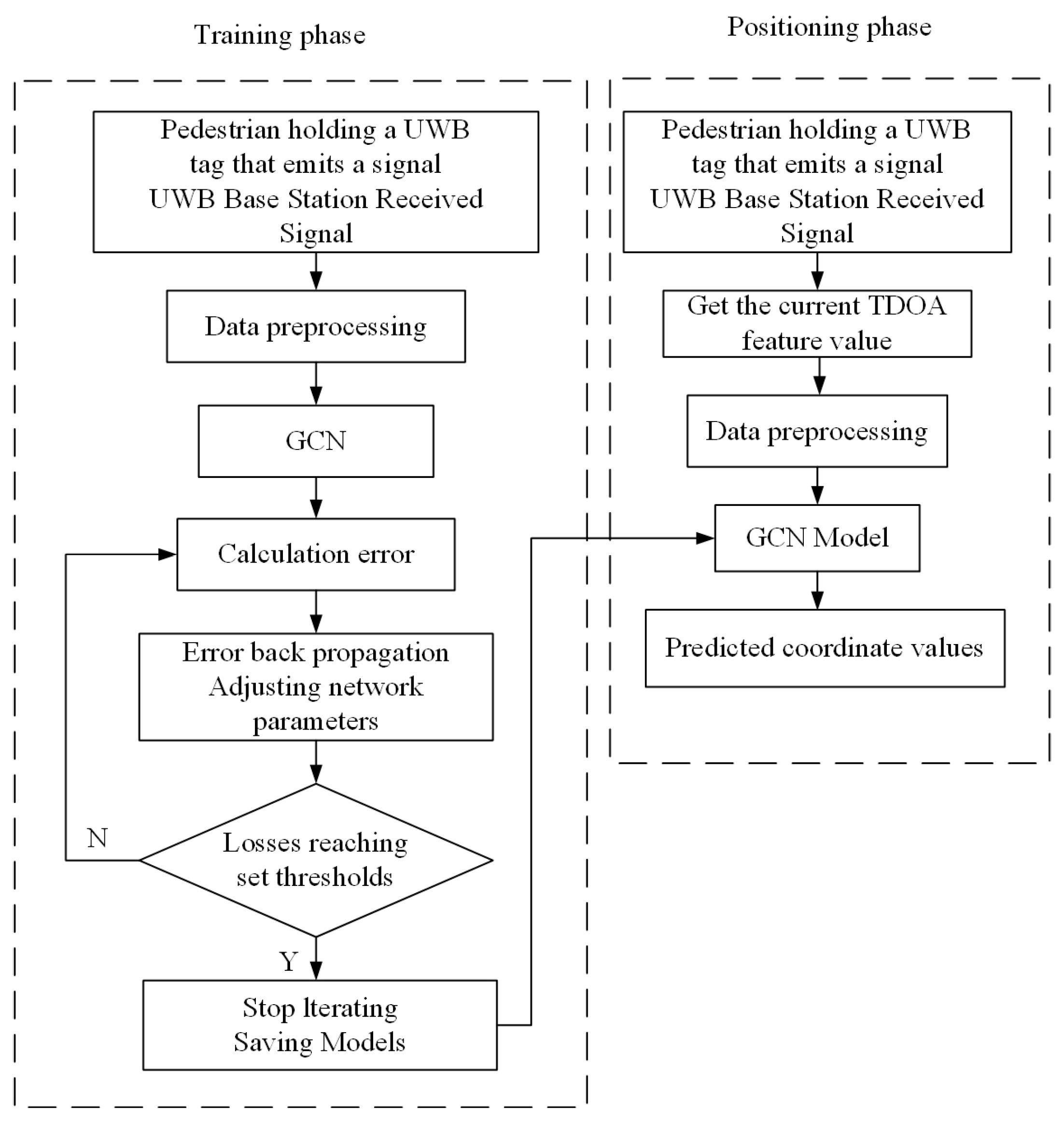
- Data acquisition. In the indoor environment where the UWB positioning system is installed, pedestrians walk around holding UWB tags that emit signals. The UWB base station receives the pulse signals from the tags. Then, it transmits the raw TDOA positioning data to the host computer through a switch, which serves as the a priori data for training the graph convolutional neural network.
- (2)
- Training model. Firstly, we preprocess the base-station coordinates measured by the laser range finder and the raw TDOA positioning data received by the host computer. Secondly, these positioning data are constructed into graph data that conformed to the inputs of the graph convolutional neural network, including the feature matrix and the graph’s adjacency matrix . The difference between the predicted result output by the graph neural network and the actual label is compared. The deviation between them is calculated using the MSE loss function, and the gradient of the weights is calculated based on the loss function. Train the network by stochastic gradient descent and update the weight parameters of the network. The training is stopped until the loss is lower than the expected threshold. Finally, the model parameters are saved to get the optimal graph convolutional neural network model for UWB positioning.
- (3)
- Model application. When pedestrians need location services, the pedestrian TDOA data and the base-station coordinates are input to the trained graph convolutional neural network model.
- (4)
- Coordinate calculation. The graphical convolutional neural network model outputs a prediction of the pedestrian’s coordinates based on the positioning data input.
3. Visual Target Detection and Positioning
3.1. Video Image Pedestrian Detection
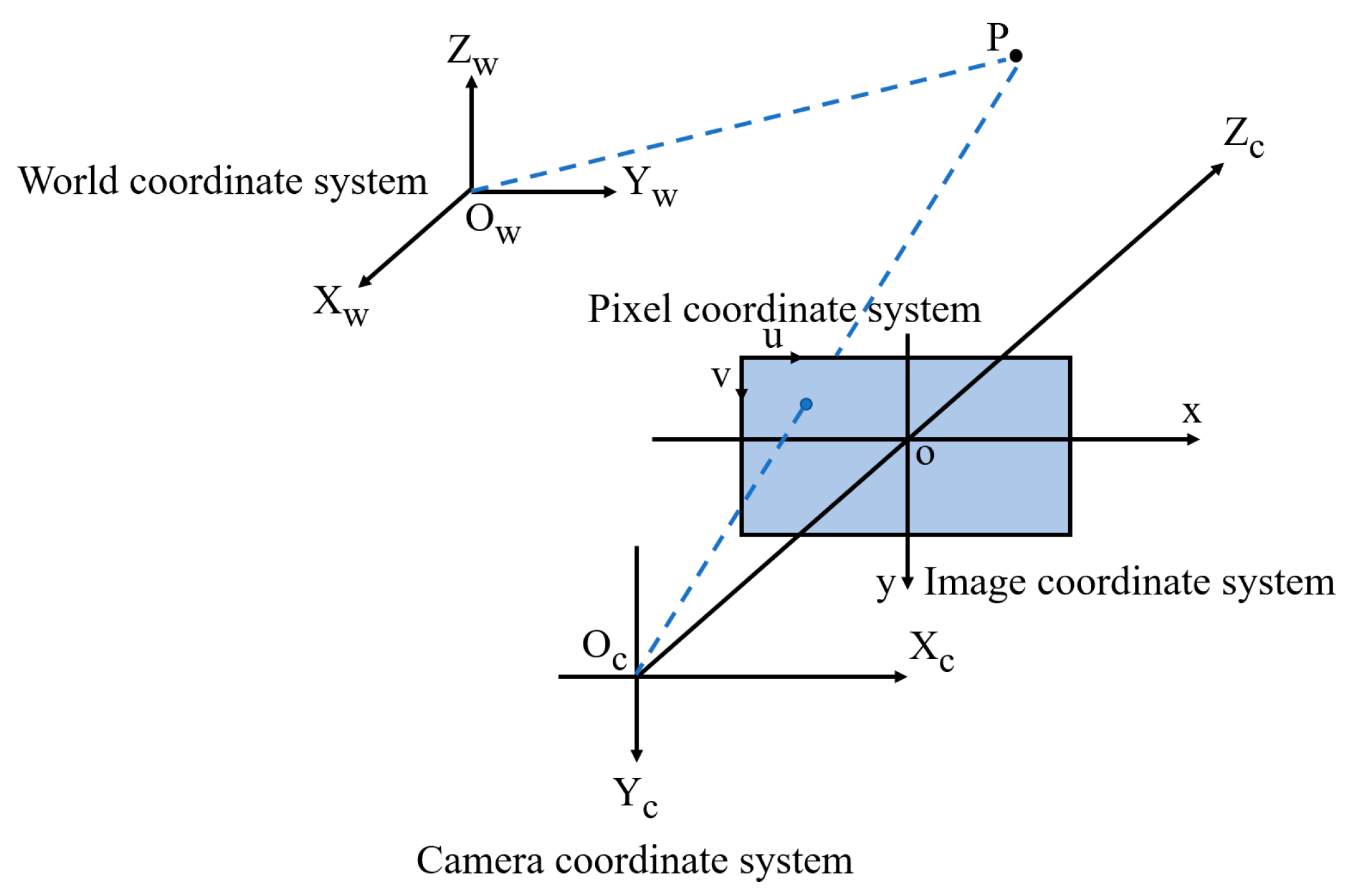
3.2. Principle of Coordinate Frame Transformation
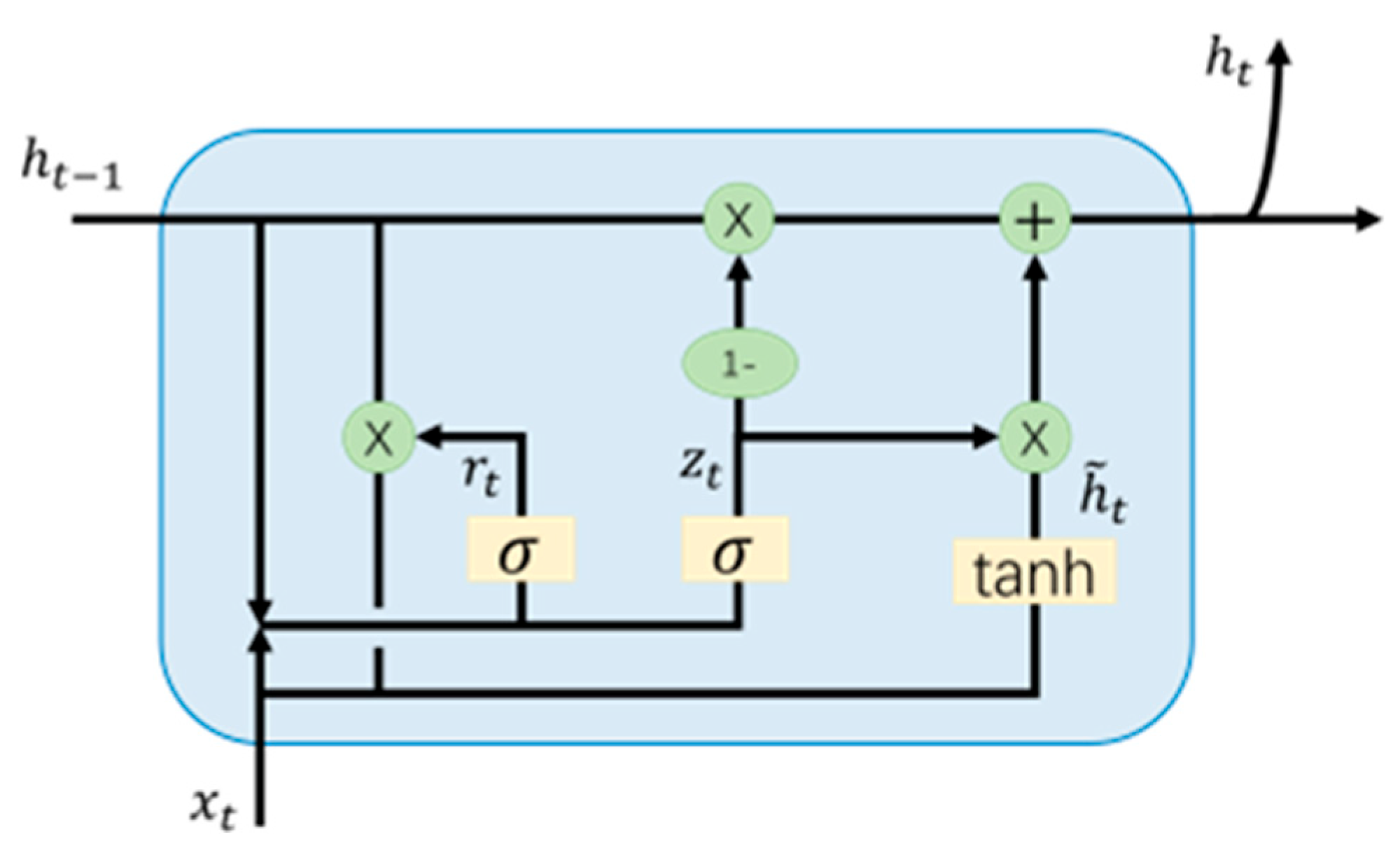
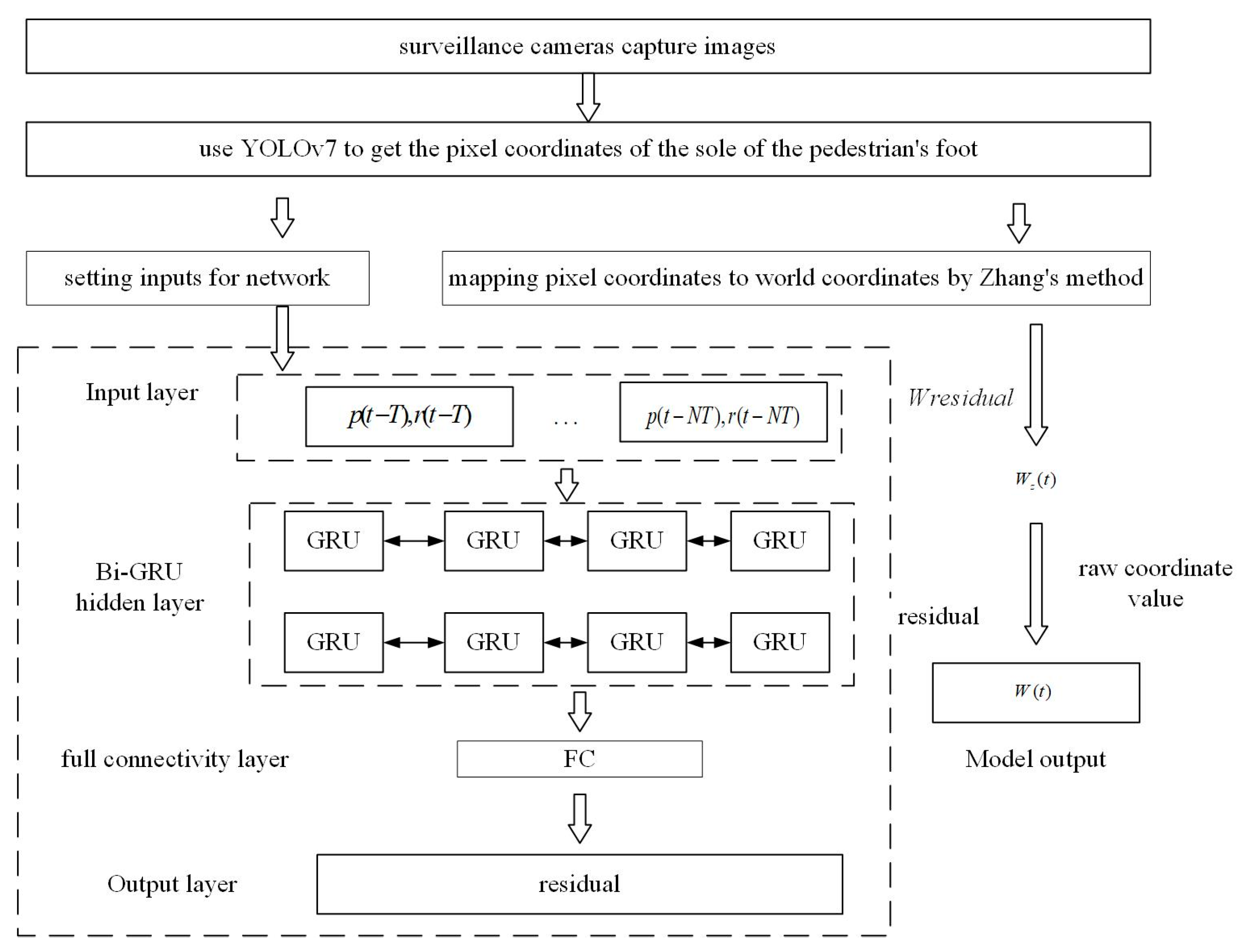
3.3. Indoor Visual Positioning Method Based on Bi-GRU and Residual Fitting
4. Fusion Positioning
4.1. Particle Filter Algorithm
4.2. UWB/Visual Data Fusion Algorithm Based on Particle Filtering
- (1)
- Initialization
- (2)
- Update
- (3)
- Resampling
- (4)
- Output
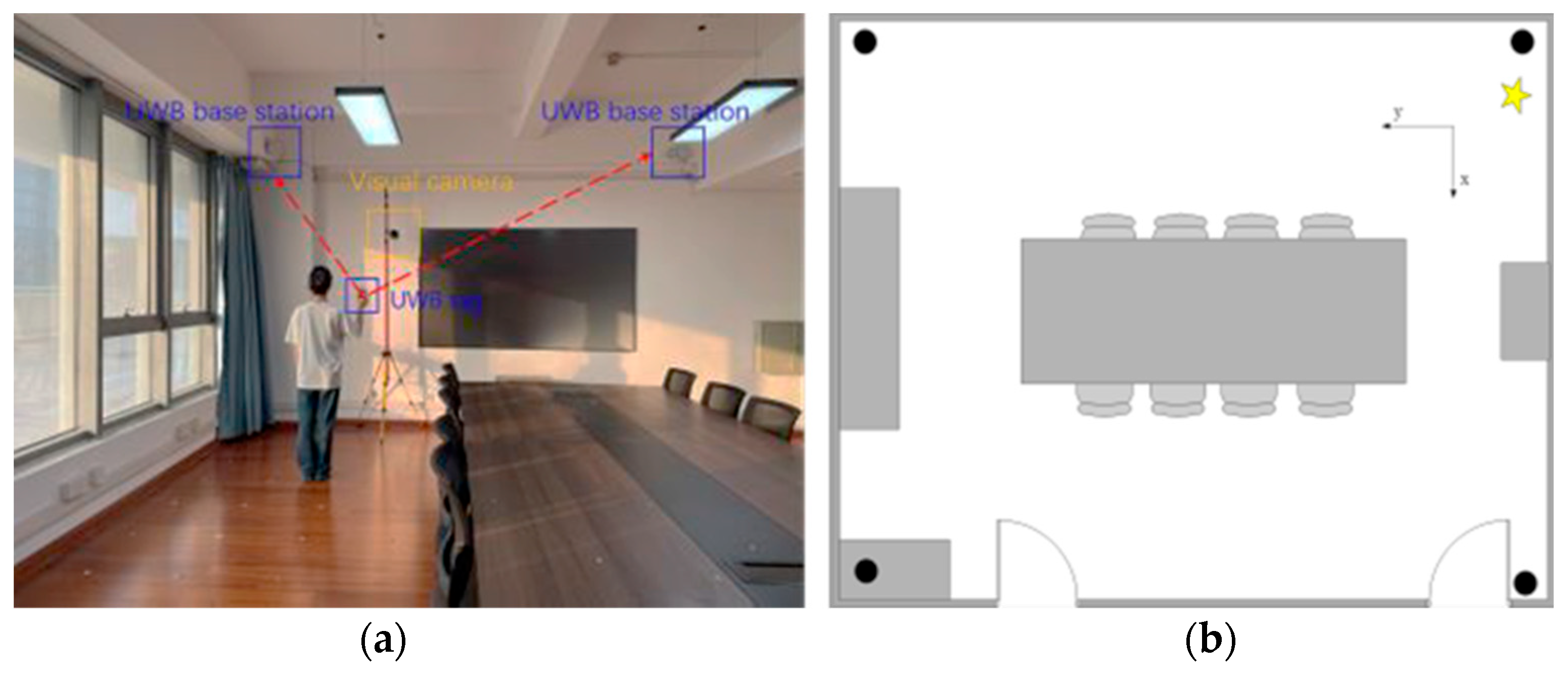
5. Evaluation
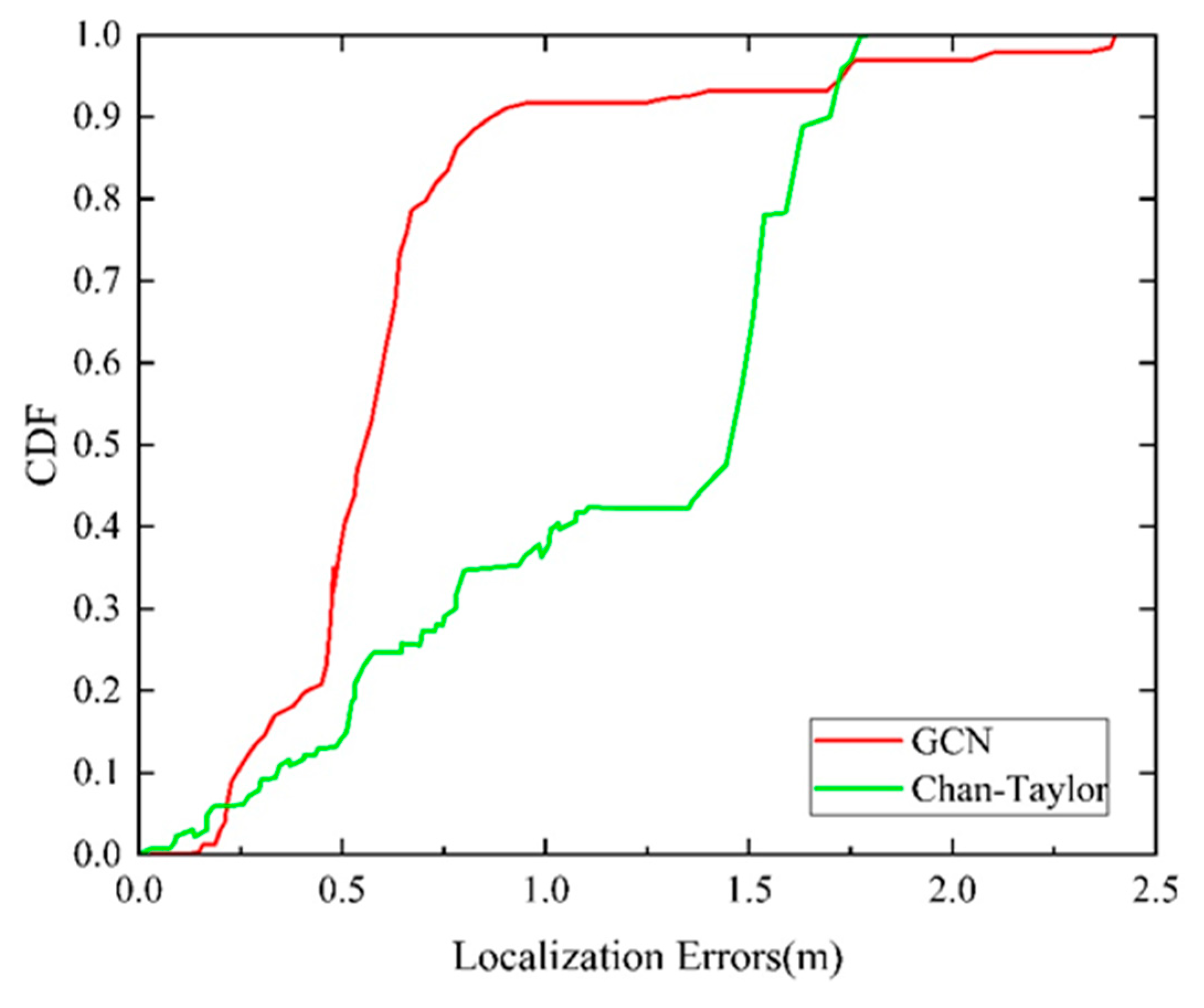
5.1. Experimental Results of the UWB Positioning
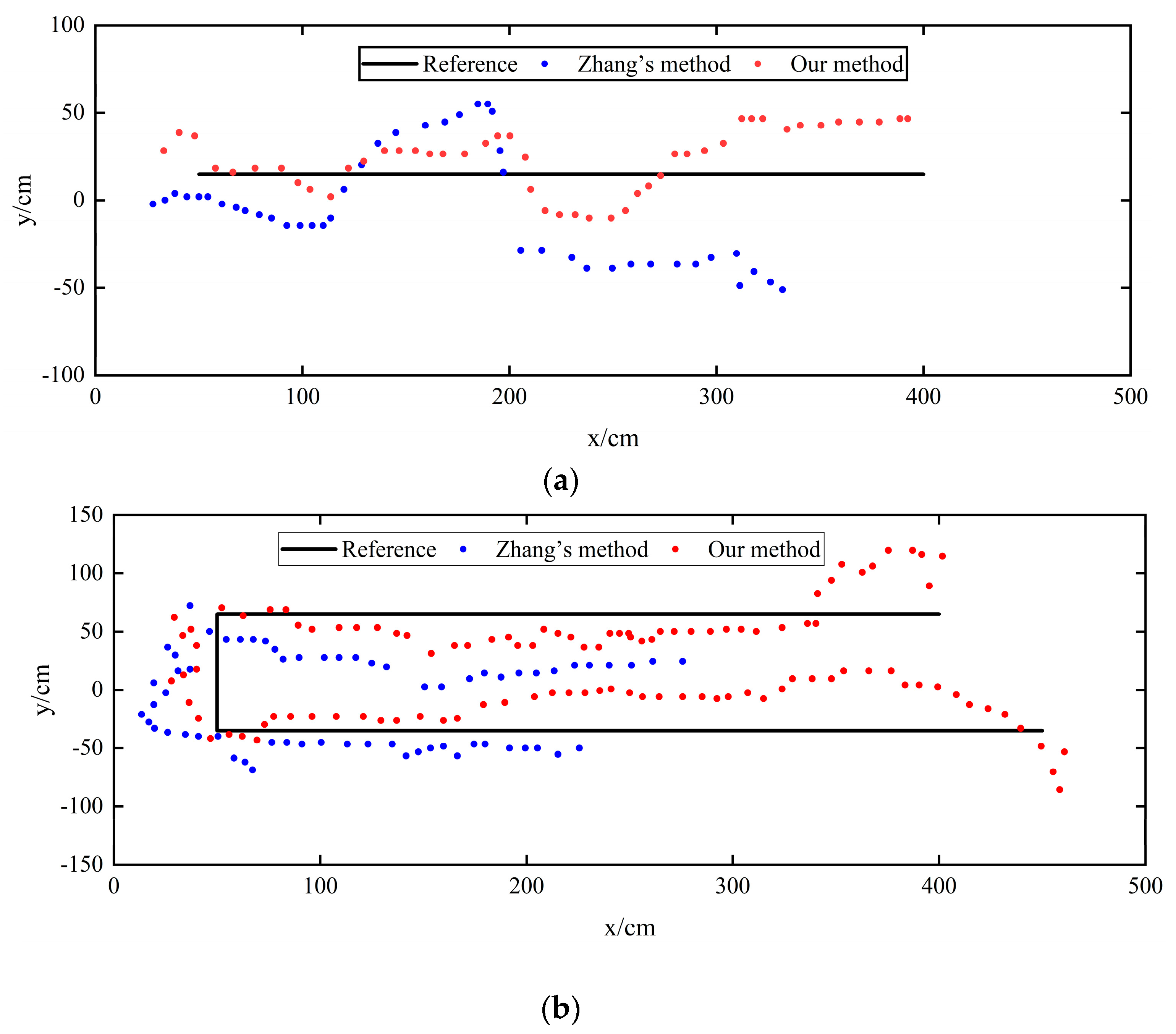
5.2. Experimental Results of the Visual Positioning
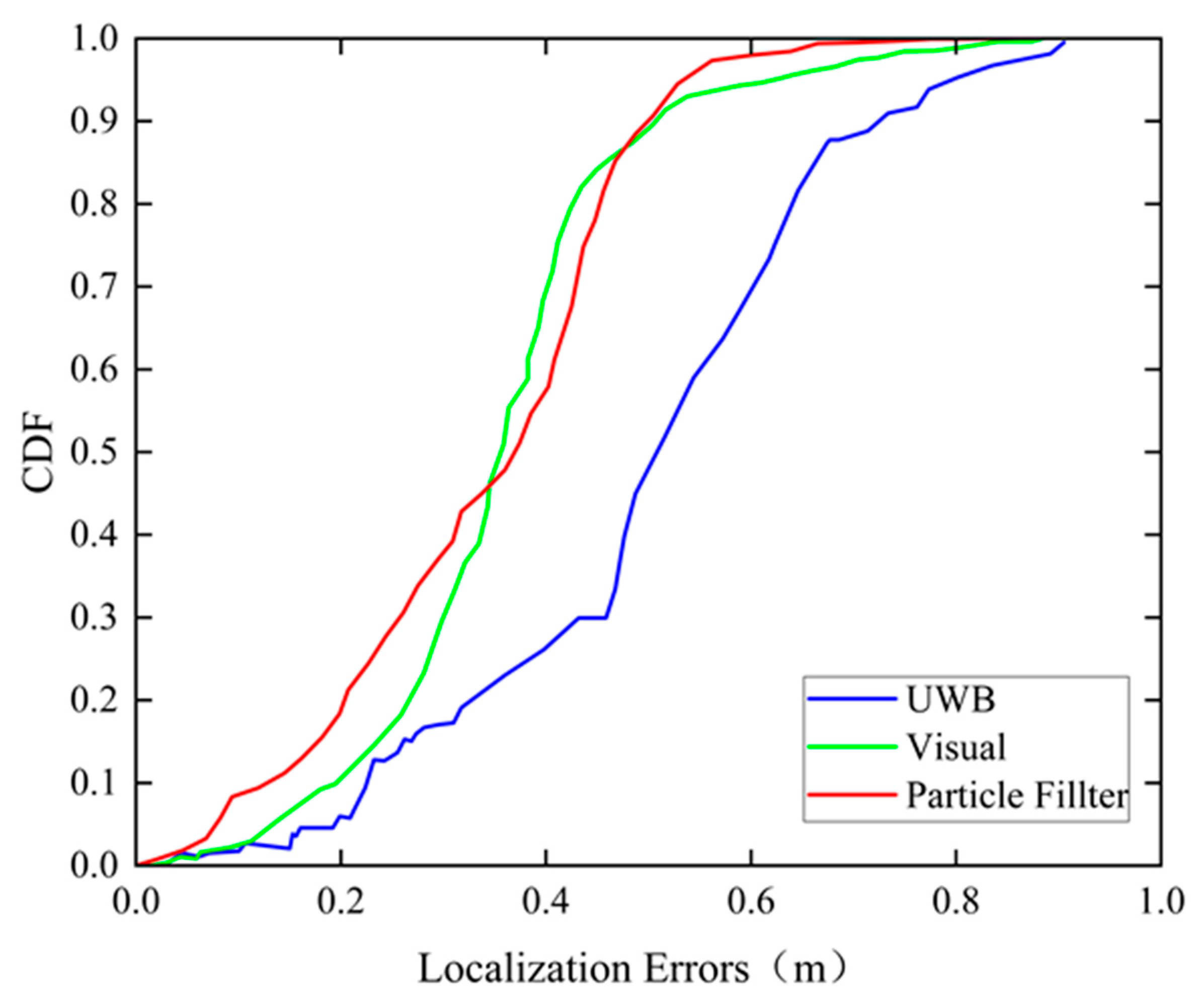
5.3. Experimental Results of the Fusion Positioning
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Krska, J.; Navratil, V. Utilization of Carrier-Frequency Offset Measurements in UWB TDOA Positioning with Receiving Tag. Sensors 2023, 5, 23–45. [Google Scholar]
- Zhuang, Y.; Zhang, C.; Huai, J.; Li, Y.; Chen, L.; Chen, R. Bluetooth Localization Technology: Principles, Applications, and Future Trends. IEEE Internet Things J. 2022, 9, 23506–23524. [Google Scholar] [CrossRef]
- Wei, S.; Wang, J.; Zhao, Z. Poster Abstract: LocTag: Passive WiFi Tag for Robust Indoor Positioning via Smartphones. In Proceedings of the IEEE INFOCOM 2020—IEEE Conference on Computer Communications Workshops (INFOCOM WKSHPS), Toronto, ON, Canada, 6–9 July 2020; pp. 1342–1343. [Google Scholar] [CrossRef]
- Vena, A.; Illanes, I.; Alidieres, L.; Sorli, B.; Perea, F. RFID based Indoor Positioning System to Analyze Visitor Behavior in a Museum. In Proceedings of the 2021 IEEE International Conference on RFID Technology and Applications (RFID-TA), Delhi, India, 6–8 October 2021; pp. 183–186. [Google Scholar] [CrossRef]
- Yan, D.; Kang, B.; Zhong, H.; Wang, R. Research on positioning system based on Zigbee communication. In Proceedings of the 2018 IEEE 3rd Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chongqing, China, 12–14 October 2018; pp. 1027–1030. [Google Scholar] [CrossRef]
- Liu, C.; Liao, M.; Sun, Y.; Wang, X.; Liang, J.; Hu, X.; Zhang, P.; Yang, G.; Liu, Y.; Wang, J.; et al. Preliminary Assessment of BDS Radio Occultation Retrieval Quality and Coverage Using FY-3E GNOS II Measurements. Remote Sens. 2023, 15, 5011. [Google Scholar] [CrossRef]
- Elsanhoury, M.; Makela, P.; Koljonen, J.; Valisuo, P.; Shamsuzzoha, A.; Mantere, T.; Elmusrati, M.; Kuusniemi, H. Precision Positioning for Smart Logistics Using Ultra-Wideband Technology-Based Indoor Navigation: A Review. IEEE Access 2022, 10, 44413–44445. [Google Scholar] [CrossRef]
- Yang, X.; Wang, J.; Song, D.; Feng, B.; Ye, H. A Novel NLOS Error Compensation Method Based IMU for UWB Indoor Positioning System. IEEE Sens. J. 2021, 21, 11203–11212. [Google Scholar] [CrossRef]
- Zhang, S.; Benenson, R.; Omran, M.; Hosang, J.; Schiele, B. Towards Reaching Human Performance in Pedestrian Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 973–986. [Google Scholar] [CrossRef] [PubMed]
- Gong, Y.; Li, K. Context-aware Transformer Model for Crowd Positioning. In Proceedings of the 2022 3rd International Conference on Computer Vision, Image and Deep Learning & International Conference on Computer Engineering and Applications (CVIDL & ICCEA), Changchun, China, 20–22 May 2022; pp. 199–202. [Google Scholar] [CrossRef]
- Furfari, F.; Girolami, M.; Barsocchi, P. Integrating Indoor Localization Systems through a Handoff Protocol. IEEE J. Indoor Seamless Position. Navig. 2024, 2, 130–142. [Google Scholar] [CrossRef]
- Furfari, F.; Girolami, M.; Barsocchi, P. Radio-Frequency Handoff Strategies to Seamlessly Integrate Indoor Localization Systems. In Proceedings of the 2023 13th International Conference on Indoor Positioning and Indoor Navigation (IPIN), Nuremberg, Germany, 25–28 September 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Anagnostopoulos, G.G.; Barsocchi, P.; Crivello, A.; Pendao, C.; Silva, I.; Torres-Sospedra, J. Evaluating Open Science Practices in Indoor Positioning and Indoor Navigation Research. In Proceedings of the 14th International Conference on Indoor Positioning and Indoor Navigation, Hong Kong, China, 14–18 October 2024; pp. 14–17. [Google Scholar]
- Barsocchi, P.; Calabrò, A.; Crivello, A.; Daoudagh, S.; Furfari, F.; Girolami, M.; Marchetti, E. COVID-19 & privacy: Enhancing of indoor localization architectures towards effective social distancing. Array 2021, 9, 100051. [Google Scholar]
- Girolami, M.; Mavilia, F.; Furfari, F.; Barsocchi, P. An Experimental Evaluation Based on Direction Finding Specification for Indoor Localization and Proximity Detection. IEEE J. Indoor Seamless Position. Navig. 2023, 2, 36–50. [Google Scholar] [CrossRef]
- Furfari, F.; Crivello, A.; Baronti, P.; Barsocchi, P.; Girolami, M.; Palumbo, F.; Torres-Sospedra, J. Discovering location based services: A unified approach for heterogeneous indoor localization systems. Internet Things 2021, 13, 100334. [Google Scholar] [CrossRef]
- Hu, W.L.; Zhou, Y.F.; Song, Q.J. Research on indoor positioning algorithm based on UWB and IMU information fusion. Manuf. Autom. 2023, 45, 193–197, 213. [Google Scholar]
- Zhang, X.; Liu, T.; Sun, L.; Li, Q.; Fang, Z. A visual-inertial collaborative indoor positioning method for multiple moving pedestrian targets. Geomat. Inf. Sci. Wuhan Univ. 2021, 46, 672–680. [Google Scholar] [CrossRef]
- Wang, Z.; Sokliep, P.; Xu, C.; Huang, J.; Lu, L.; Shi, Z. Indoor Position Algorithm Based on the Fusion of Wifi and Image. In Proceedings of the 2019 Eleventh International Conference on Advanced Computational Intelligence (ICACI), Guilin, China, 7–9 June 2019; pp. 212–216. [Google Scholar] [CrossRef]
- Zhang, R.; Fu, D.; Chen, G.; Dong, L.; Wang, X.; Tian, M. Research on UWB-Based Data Fusion Positioning Method. In Proceedings of the 2022 28th International Conference on Mechatronics and Machine Vision in Practice (M2VIP), Nanjing, China, 16–18 November 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, Q.; Li, Y. Indoor positioning method of multi-sensor fusion in NLOS environment. Comput. Eng. Des. 2023, 44, 732–738. [Google Scholar] [CrossRef]
- Kim, J. TDOA-Based Target Tracking Filter While Reducing NLOS Errors in Cluttered Environments. Sensors 2023, 23, 4566. [Google Scholar] [CrossRef] [PubMed]
- Kocur, D.; Švecová, M.; Kažimír, P. Taylor Series Based Positioning Method of Moving Persons in 3D Space by UWB Sensors. In Proceedings of the 2019 IEEE 23rd International Conference on Intelligent Engineering Systems (INES), Gödöllő, Hungary, 25–27 April 2019; pp. 000017–000022. [Google Scholar] [CrossRef]
- Sun, Y.; Xiao, Z.; Li, X.B.; Xiang, X. Neural network based TDOA calculation algorithm in a UWB system. Aeronaut. Comput. Tech. 2019, 49, 6–10. [Google Scholar]
- Zhang, Z. Flexible camera calibration by viewing a plane from unknown orientations. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter Types | Symbol | Value |
|---|---|---|
| Internal Parameters | fx | 747.3596 |
| Fy | 747.4950 | |
| u0 | 637.8703 | |
| v0 | 360.3958 | |
| External Parameters | R | |
| T |
| Parameter Type Attributes | Attributes |
|---|---|
| Input Vector Dimension | 40 |
| Output Vector Dimension | 2 |
| The Number of Hidden Layer Nodes | 256 |
| The Number of Hidden Layers | 2 |
| Loss Function | MSE |
| Learning Rate | 0.00001 |
| Optimizer | Adam |
| Training Batches | 50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mu, H.; Yu, C.; Jiang, S.; Luo, Y.; Zhao, K.; Chen, W. Indoor Pedestrian Positioning Method Based on Ultra-Wideband with a Graph Convolutional Network and Visual Fusion. Sensors 2024, 24, 6732. https://doi.org/10.3390/s24206732
Mu H, Yu C, Jiang S, Luo Y, Zhao K, Chen W. Indoor Pedestrian Positioning Method Based on Ultra-Wideband with a Graph Convolutional Network and Visual Fusion. Sensors. 2024; 24(20):6732. https://doi.org/10.3390/s24206732
Chicago/Turabian StyleMu, Huizhen, Chao Yu, Shuna Jiang, Yujing Luo, Kun Zhao, and Wen Chen. 2024. "Indoor Pedestrian Positioning Method Based on Ultra-Wideband with a Graph Convolutional Network and Visual Fusion" Sensors 24, no. 20: 6732. https://doi.org/10.3390/s24206732
APA StyleMu, H., Yu, C., Jiang, S., Luo, Y., Zhao, K., & Chen, W. (2024). Indoor Pedestrian Positioning Method Based on Ultra-Wideband with a Graph Convolutional Network and Visual Fusion. Sensors, 24(20), 6732. https://doi.org/10.3390/s24206732