1. Introduction
The shoulder is the most mobile joint in the body, allowing rotation across multiple axes, with some capable of full 360° rotation, as well as enabling arm elevation and overhead reaching. This mobility is facilitated by the rotator cuff, a complex group of muscles and tendons. With repetitive movements, the rotator cuff wears out, eventually leading to rotator cuff tears (RCTs). This injury most commonly occurs with aging, but it also affects athletes and individuals in professions that involve frequent shoulder movements, such as manual labor or cleaning, making it one of the most prevalent shoulder injuries. According to [
1], approximately 2 million people in the U.S. consult their physicians each year for this condition. RCTs can advance to more serious conditions over time, reinforcing the relevance of early detection. In [
2], the prevalence of rotator cuff tears in the general population was reported to be
. Magnetic resonance imaging (MRI) is the gold-standard imaging technique. However, its use is restricted to imaging centers, and it does not always provide accurate depictions of the presence and severity of tears [
3]. In [
4], it was reported that the overall accuracy for detecting RCTs of different sizes with the use of MRI is
.
With the occurrence of RTCs, synovial fluid (SF) aspirates locally in the injury area [
5,
6]. This accumulation of SF changes the dielectric properties of the shoulder joint [
7]. This change makes microwave imaging (MWI) a credible alternative to MRI which we need to investigate. The portability and costs of MWI systems make them ideal candidates for fast and early diagnosis. At this stage, the main issue is detecting the presence of RCTs. As discussed with physicians, this would be the first step, and if the detection is positive, then the patient will undergo an advanced imaging modality such as MRI in order to evaluate the size and location of the RCT. In [
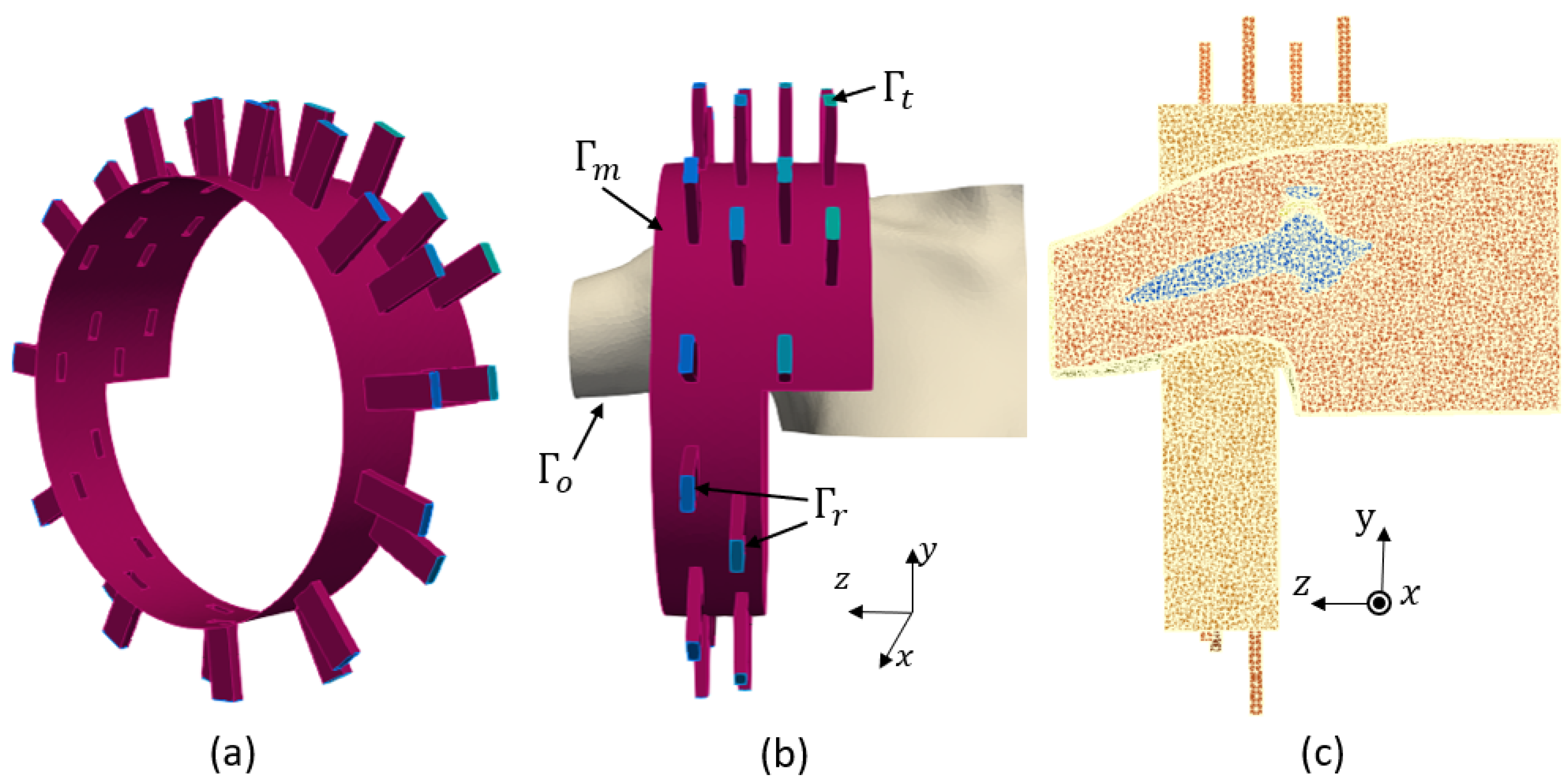
8], we introduced an alternative low-cost, portable and non-invasive electromagnetic imaging (EMI) system for the on-site diagnosis of RCTs. At that time, no EMI system for the shoulder existed, (To the best of our knowledge, this remains true.) and thus we had to start from scratch. To save time and resources during the initial design phase, we developed a virtual model of the shoulder and an imaging system to study and optimize the EMI system, as described in [
8]. This model is the first step toward a microwave digital twin prototype (MDTP).
The concept of the digital twin (DT) was originally proposed by Michael Grieves at the University of Michigan for monitoring product lifecycle management. This involves creating a virtual model of a physical system, which is continuously updated with real-time data from the existing physical system. DTs are not intended for system design. However, in [
9], the same authors introduced the digital twin prototype (DTP), which exists in virtual space and is to be used in what the authors referred to as the creation phase. Since 2002, DTs have been widely used and developed for Industry 4.0 applications [
10,
11,
12]. In the healthcare sector, a comprehensive review of Digital Twin for Health (DT4H) can be found in [
12]. A wide range of applications was already investigated, including detecting and monitoring cardiac pathologies, diabetes, breast or oropharyngeal cancers and Alzheimer’s diseases. DT4H often incorporates machine learning (ML) in order to enhance the performance of illness detection, as exemplified in [
13] with COVID-19. Quite recently, DTs have been efficiently used for microwave ablation [
14] and imaging purposes [
15]. In this paper, we introduce the concept of a microwave digital twin prototype as a virtual system which mimics the physical one and is capable of predicting the presence of RCTs. The model not only includes the anthropomorphological model of the shoulder (whether it is injured or not) but also the imaging system and uncertainties due to its use, like noise, positioning errors and errors due to RCTs themselves, like the synovial fluid’s variation, which depends on the RCT’s severity.
Compared with our previous work [
8], we aim to improve and systematize the detection of RCTs. Thus far, we have been solving an inverse problem for detecting the presence of RCTs. This process is time-consuming, requires extensive computing resources and is therefore not compatible with a large number of case studies. As an example, the final design consists of 32 ceramic (
) loaded, open-ended waveguides. It requires 11 min and 27 s for image reconstruction of one shoulder model with the use of 480 computing cores. These amounts of resources may not always be available and can limit the practical use of the device in the real world. In this paper, we aim to address this issue through the use of ML algorithms.
The rise of ML has led to the development of valuable tools in various medical applications, such as predicting sports injuries [
16], simplifying medical imaging processes [
17] and advancing stroke medicine [
18]. Further, combining microwave imaging systems with ML algorithms has significantly improved stroke detection, stroke type classification and localizing affected areas [
19,
20,
21].
Dataset gathering is a crucial component of machine learning algorithms, particularly in medical applications, but it presents numerous challenges and limitations [
22]. For example, insufficient or biased data can result in poor generalization, which highly affects the algorithm’s accuracy in making predictions or diagnoses. To enhance generalization, large and diverse training datasets are necessary. Moreover, the effectiveness of ML algorithms heavily relies on the quality and quantity of the data. However, in the real world, obtaining data from patients involves privacy and authorization challenges and is a time-consuming process. Furthermore, the limited available training data significantly impacts the performance of the classifiers. To address this issue, generating synthetic data through numerical simulations or various computer algorithms has emerged as a promising solution in recent years [
23,
24]. In [
25], numerical simulations of a system were performed to investigate how integrating mathematical models with experimental datasets could enhance classification performance. It is important to note that while the use of synthetic data can enhance continual and causal learning, it also carries the risk of introducing biases [
26]. This emphasizes the importance of generating a reliable dataset.
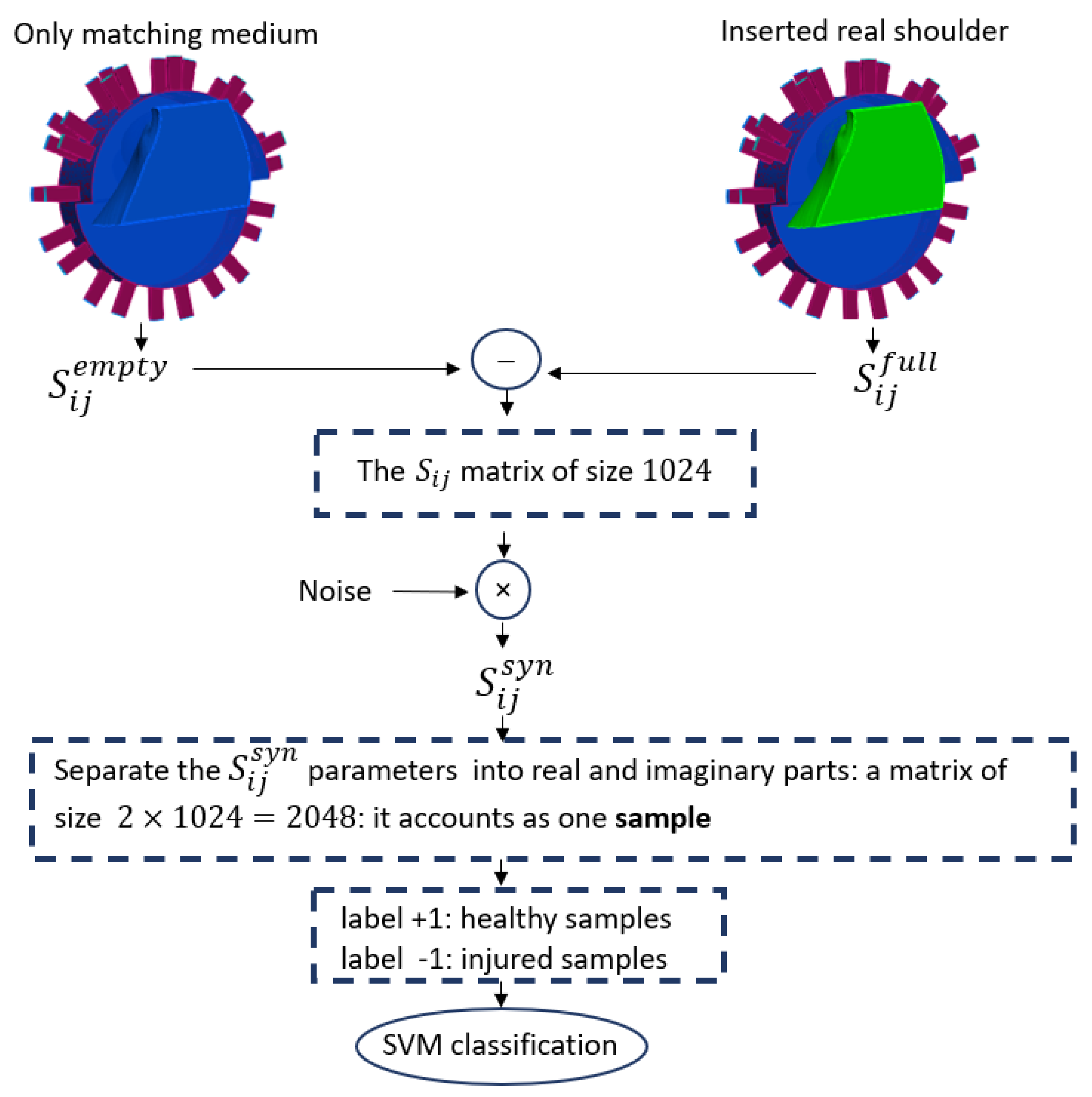
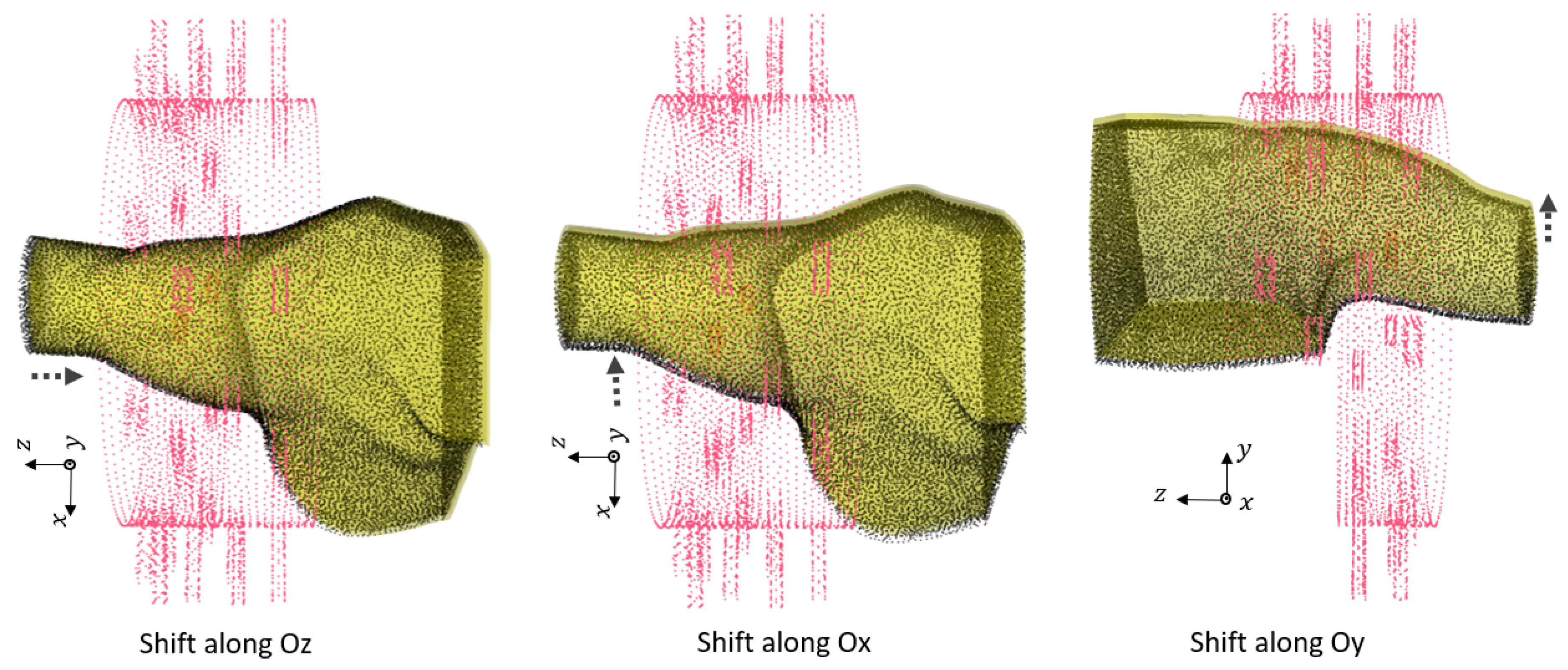
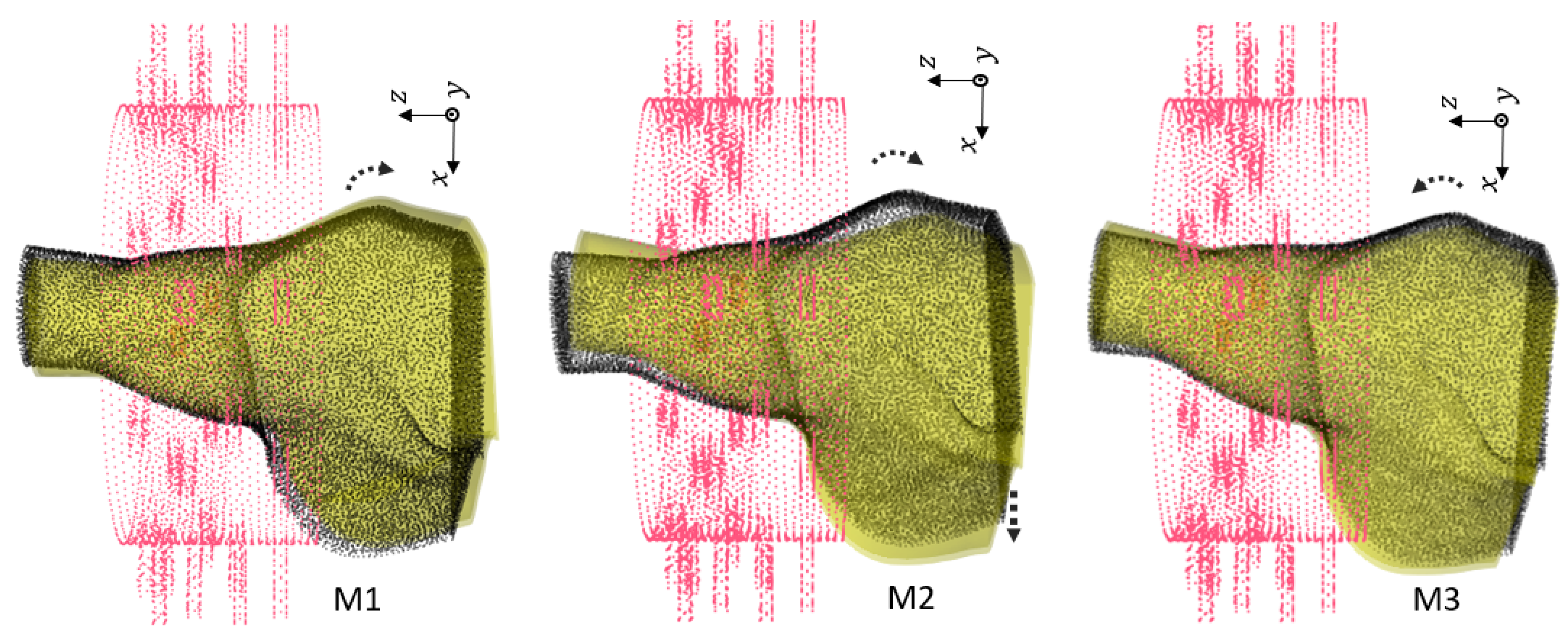
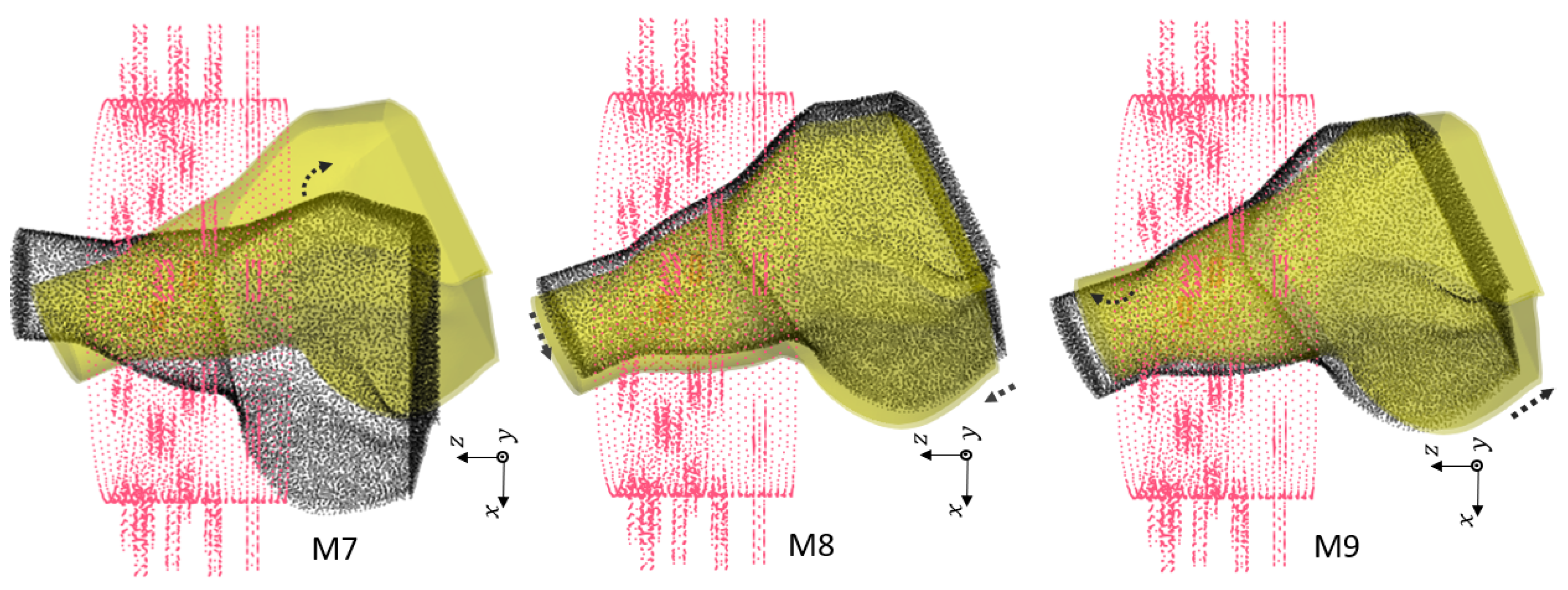
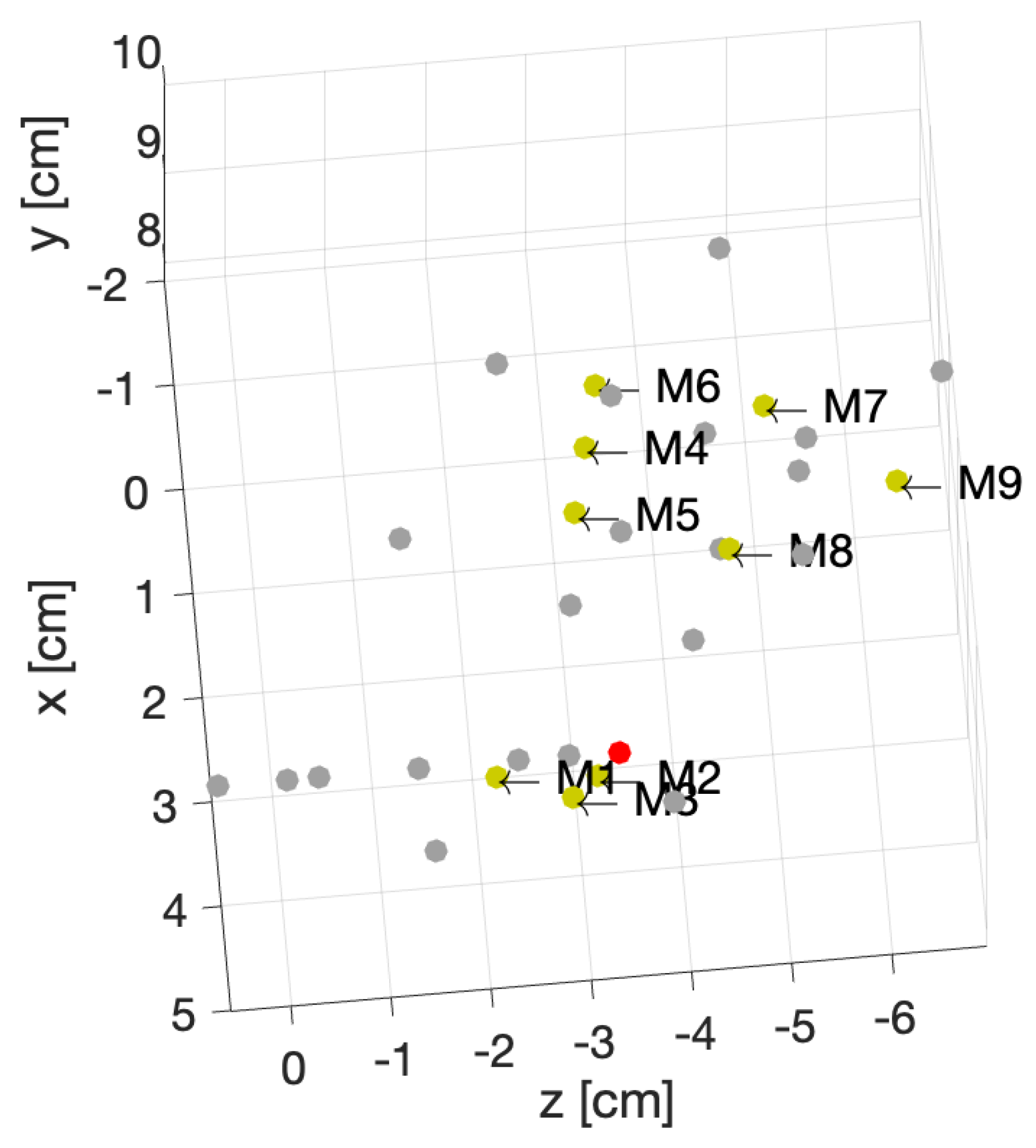
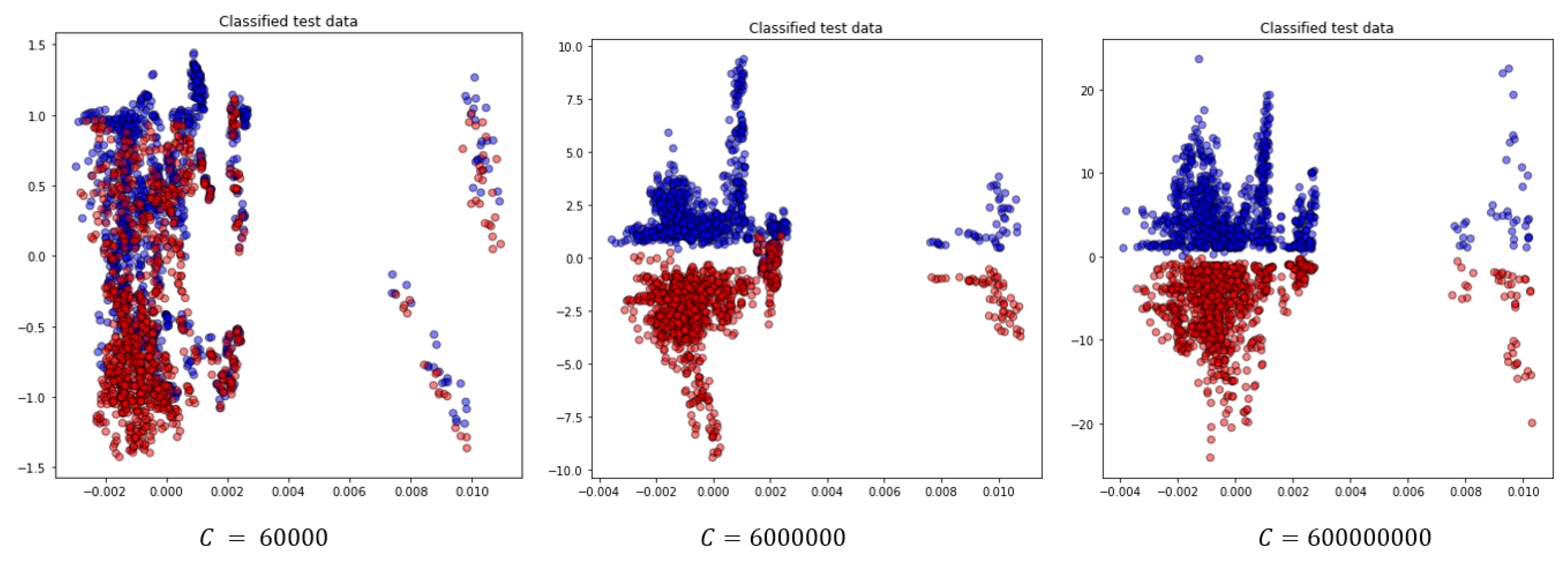
In this work, we use numerical modeling to generate a generalizable dataset of scattering parameters. A parametric study is conducted considering four main categories, which are outlined in
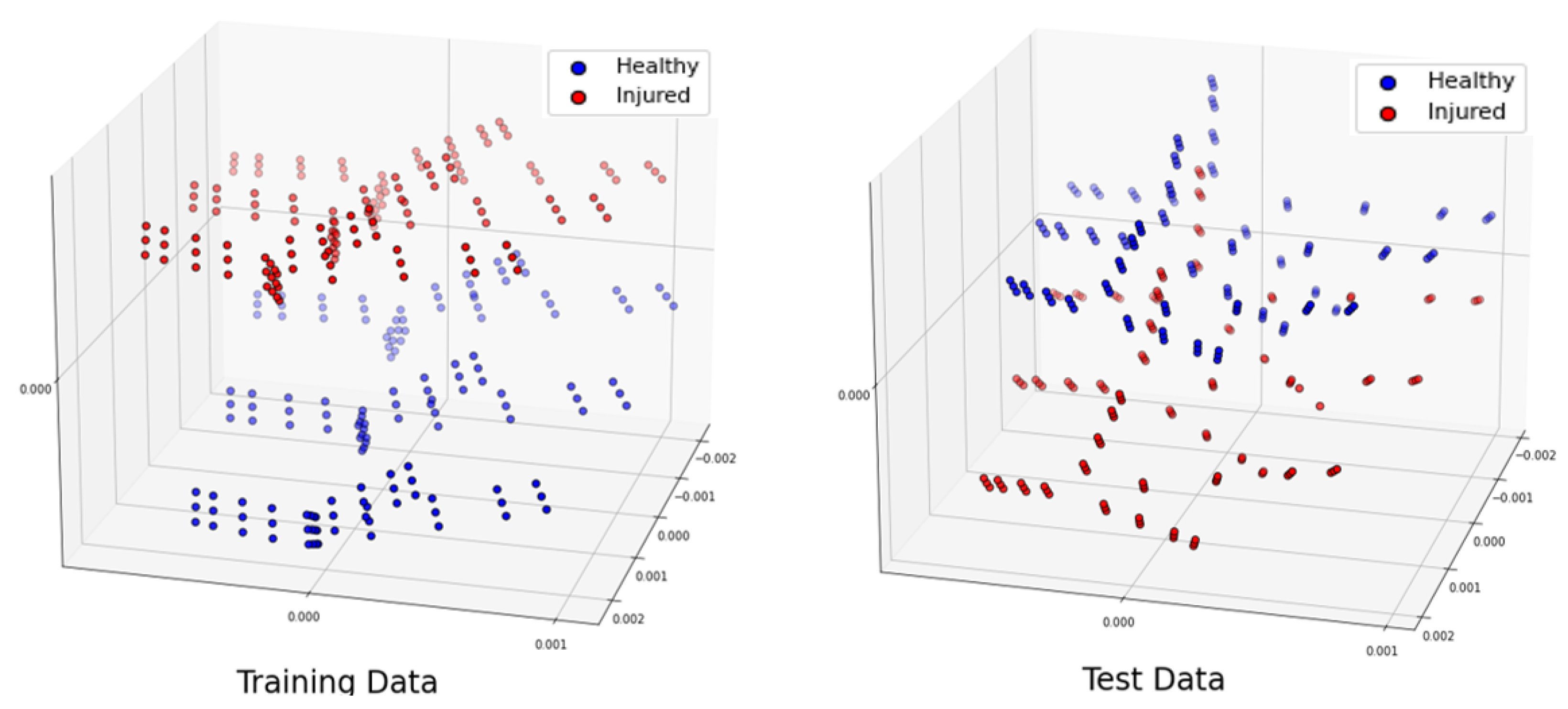
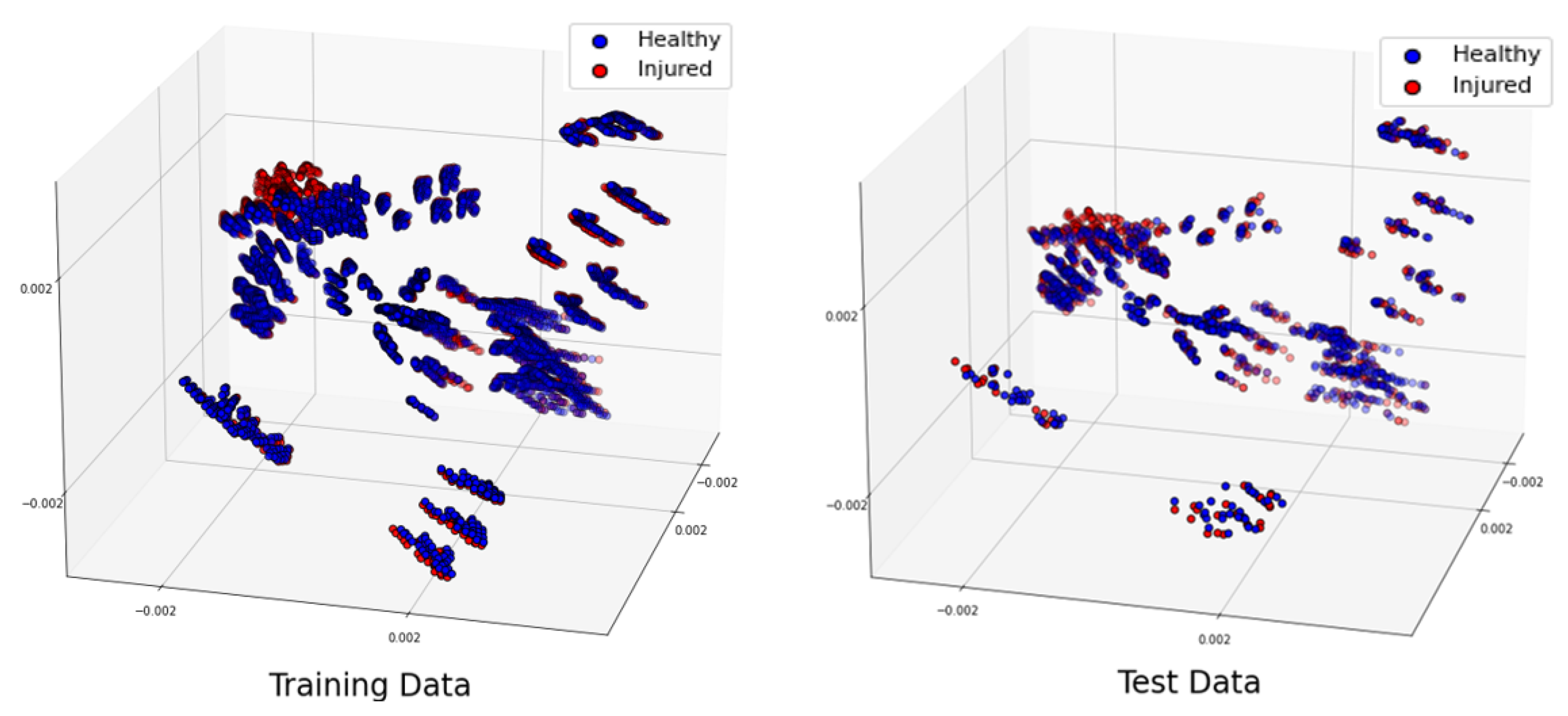
Table 1. For the classification of injured and healthy models, we utilize a supervised machine learning support vector machine (SVM).
Note that the key indicator in differentiating healthy and injured shoulder joints is the presence of RCTs, because this is the most challenging case. The mean aspirate volume of SF is reported to correlate with the size of the tear. This volume for the small tears is
mL, while that for medium tears is
mL and that for large tears is
m [
6]. In this study, we will consider the presence of a small tear in an injured shoulder model, as it is the most difficult tear to detect. This paper is structured as follows.
Section 2 presents the numerical modeling framework, including the numerical modeling of the system, its properties and our methods for data generation and classification analysis using an SVM.
Section 3 discusses the numerical results for various scenarios, and the conclusions are provided in
Section 4.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}