Abstract
In this paper, we propose a novel distributed algorithm based on model predictive control and alternating direction multiplier method (DMPC-ADMM) for cooperative trajectory planning of quadrotor swarms. First, a receding horizon trajectory planning optimization problem is constructed, in which the differential flatness property is used to deal with the nonlinear dynamics of quadrotors while we design a relaxed form of the discrete-time control barrier function (DCBF) constraint to balance feasibility and safety. Then, we decompose the original trajectory planning problem by ADMM and solve it in a fully distributed manner with peer-to-peer communication, which induces the quadrotors within the communication range to reach a consensus on their future trajectories to enhance safety. In addition, an event-triggered mechanism is designed to reduce the communication overhead. The simulation results verify that the trajectories generated by our method are real-time, safe, and smooth. A comprehensive comparison with the centralized strategy and several other distributed strategies in terms of real-time, safety, and feasibility verifies that our method is more suitable for the trajectory planning of large-scale quadrotor swarms.
1. Introduction
In recent years, with the rapid development of communication, computing, and automation technologies, intelligent UAV swarm systems inspired by the behavior of biological swarms have received extensive attention from researchers and practitioners [1]. An intelligent UAV swarm system is a holistic system composed of a group of UAVs capable of accomplishing complex tasks through cooperation and information sharing [2]. UAV swarm systems have advantages in terms of timeliness, economy, and functionality [3]. Consequently, they have been widely used in both civil and military fields [4], such as infrastructure inspection [5], logistics transportation [6], and search and rescue [7]. Among them, trajectory planning, as a crucial and challenging component for UAV swarms to perform tasks, needs to ensure the safety of a smooth trajectory from the initial position to the target position under the dynamics constraints, especially in a confined space. Furthermore, coordination among the UAVs is crucial.
There is increasing research that has emerged to address this safety-critical challenging problem, including potential fields [8], velocity obstacles [9,10], dynamic windows [11], and inter-robot prioritization [12]. However, these classical methods do not pay much attention to the interaction among robots, making them ineffective for more complex environments. Recently, learning-based methods [13,14] have been proposed to consider inter-robot interaction to solve trajectory planning. However, they usually require high-quality training data for generalization and lose the interpretability of the internal decision-making process. The above problems can be overcome by constructing an optimization problem using the MPC framework to handle complex objective functions and constraints explicitly, as well as providing sequences of future state and control input information predictively [15,16,17].
The major challenge of implementing MPC for the trajectory planning of quadrotor swarms lies in the difficulties of guaranteeing the real-time feasibility and safety of the system under various practical constraints. In this paper, we present a novel distributed trajectory planning algorithm for quadrotor swarms based on DMPC-ADMM, referring to Figure 1. Our contributions can be summarized as follows:
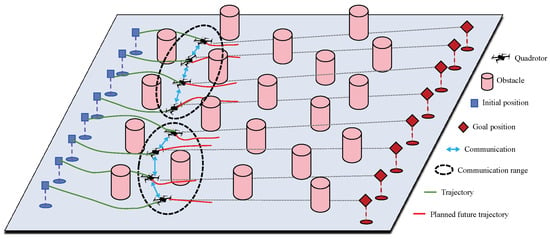
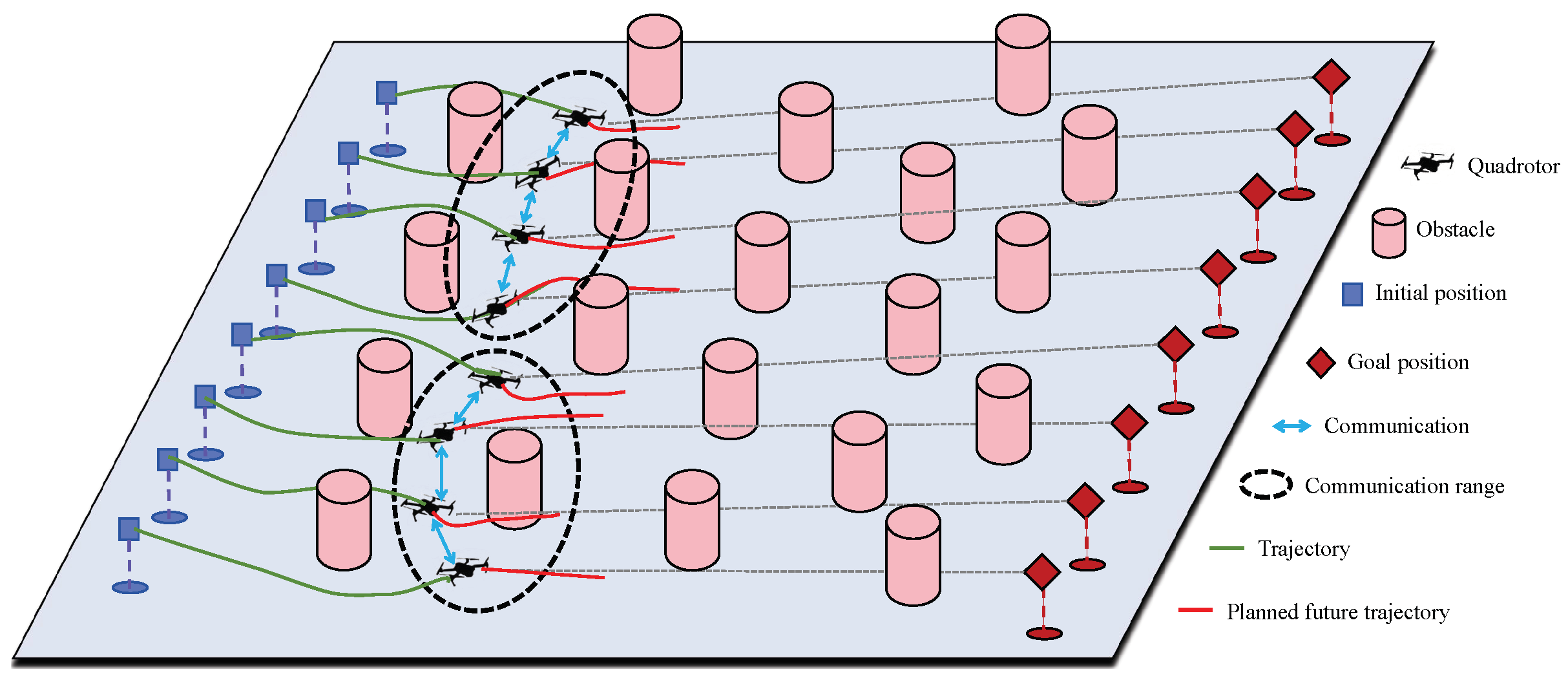
Figure 1.
Illustration of the trajectory planning based on DMPC-ADMM for a quadrotor swarm in a crowded environment.
- A trajectory planning optimization problem for quadrotor swarms is constructed based on MPC, which uses the differential flatness property to handle the nonlinear dynamics of quadrotors. The dimension of the planning space is reduced compared to directly utilizing the nonlinear model. Additionally, we design a relaxed form of DCBF constraint to balance feasibility and safety. Due to the non-convexity of the DCBF, we linearize the DCBF at each time step and use an iterative convex optimization scheme to improve the solution’s efficiency.
- The high-dimensional optimization problem is decomposed to construct a fully distributed trajectory planning algorithm based on ADMM. In this distributed algorithm, the quadrotors within the communication range reach a consensus on future trajectories through cooperation, thus enhancing the safety of trajectories. To further improve communication efficiency, we design an event-triggered mechanism to reduce the communication overhead.
- The simulation results verify that our method can generate safe and smooth trajectories online under limited communication range, collision avoidance, and dynamic constraints. The comparison with the centralized strategy and several other distributed strategies confirms that our method is more suitable for large-scale quadrotor swarms.
The remainder of this paper is organized as follows. In Section 2, we mainly review the literature on the trajectory planning of UAVs. In Section 3, we introduce the differential flatness and DCBF. The quadrotor swarm trajectory planning problem based on MPC and DCBF is formulated in Section 4. In Section 5, we provide the distributed algorithm to solve the optimization problem via ADMM and design an event-triggered mechanism to reduce the communication overhead. We present the simulation experiments and results in Section 6, followed by concluding remarks in Section 7.
2. Related Work
Ensuring the safety of generated trajectories has consistently been a central issue in the field of multi-robotics, as well as a prerequisite for successful execution of tasks. As noted in [18], the existing literature often adopts Euclidean norms to model distance constraints, which are activated only when the reachable set intersects with the obstacles, resulting in the robot taking action only when it is close to them. To overcome this shortcoming, Ref. [18] combined CBF with MPC to avoid obstacles at an early stage and enhance the safety of the trajectory. The MPC-CBF formulation was also investigated on different platforms, including unmanned aerial vehicles [19,20] and autonomous vehicles [21].
The object of interest in this paper is a group of quadrotors whose underactuation and intrinsic instability make generating safe trajectories challenging. An effective solution involves leveraging the differential flatness property of quadrotors, as introduced in [22], to simplify the optimization problem while preserving the nonlinear dynamics of the quadrotors. This approach was successfully applied to UAV trajectory planning in crowded environments [23], as well as avoiding obstacles [24]. Specifically, Ref. [19] used CBF constraints to ensure trajectory safety for multi-quadrotor systems based on differential flatness. In this paper, we propose a distributed algorithm for the trajectory planning of quadrotor swarms with the MPC-CBF formulation.
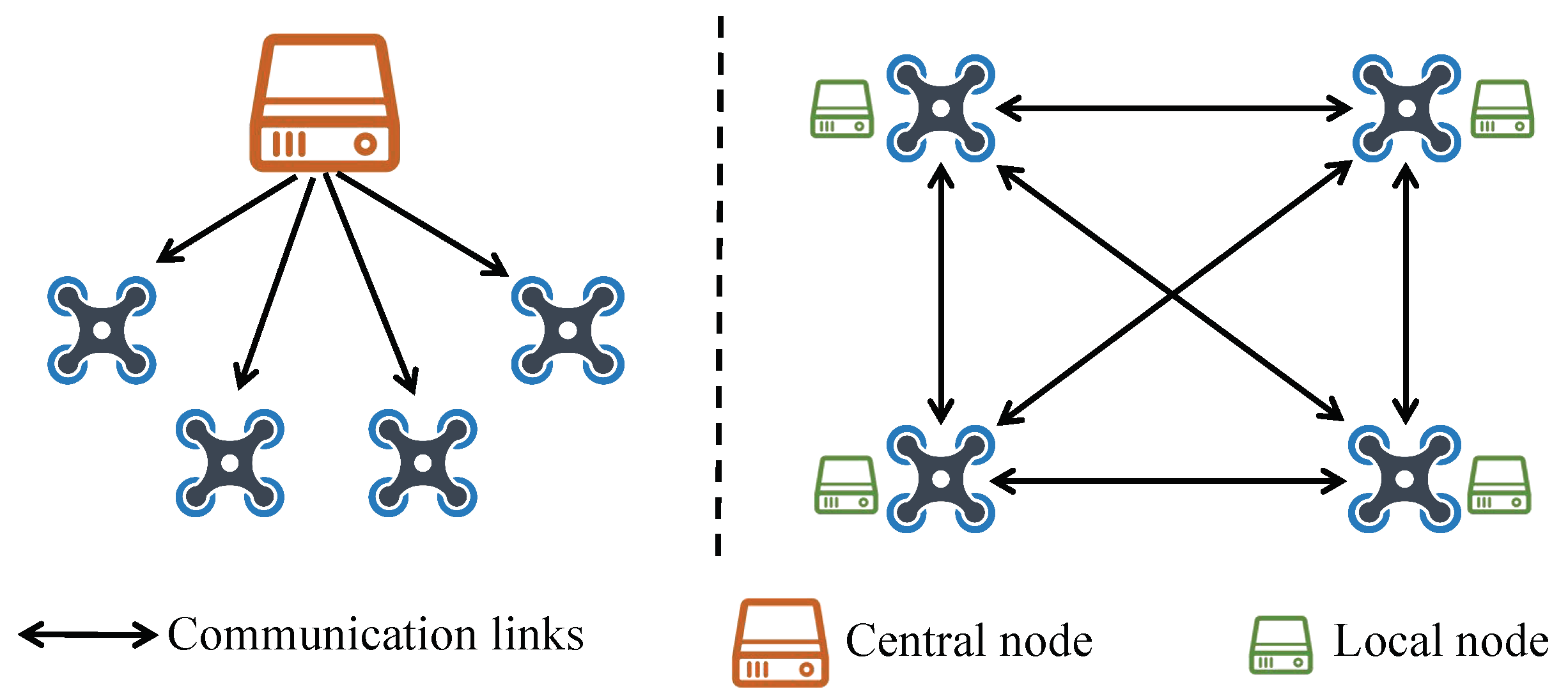
UAV swarm trajectory planning is a complex optimization problem involving multiple constraints, variables, and nonlinear effects. Several existing studies on the trajectory planning of UAVs are summarized in Table 1. Centralized methods [24,25,26] have been proposed for the trajectory planning of UAV swarms. Kumar et al. [24] resolved the heterogeneous UAV formation reconfiguration and trajectory planning based on mixed integer quadratic programming (MIQP). Ref. [25] considered the collision-free trajectory generation for multiple UAVs in 3D space as a nonconvex optimization problem, which can be solved by sequential convex programming (SCP). These centralized approaches require the presence of a central node capable of acquiring the state information of the entire system and transmitting the planning results to each UAV. Nevertheless, one of its disadvantages is the large amount of computation, and once the center node fails, the whole system stops working, resulting in poor real-time and scalability. Therefore, the distributed methods have attracted much research attention in recent years. Compared to the centralized ones, each UAV in the distributed framework uses peer-to-peer communication to compute its trajectory without the need for a central node, referring to Figure 2. Hence, the distributed framework is scalable and robust in the face of unexpected node and link failures.

Figure 2.
Centralized design (left) vs. our distributed design (right) for cooperative trajectory planning of quadrotor swarms.
Distributed Model Predictive Control (DMPC) [27] has found successful applications in various networked systems ranging from electric power networks [28] to multi-robot systems [29,30,31]. It is an appealing option for distributed trajectory planning. Borrelli et al. [29] addressed the UAV formation problem based on a decentralized linear MPC approach that guaranteed collision avoidance under constraints. Luis et al. [31] developed a DMPC algorithm for online point-to-point flight trajectory generation in multi-UAV scenarios, which employed on-demand collision avoidance and event-triggered replanning. However, the second-order dynamics did not take into account the characteristics of quadrotors, and the safe distance constraint was approximated by a first-order Taylor expansion of the Euclidean distance. These limitations made it challenging to ensure trajectory safety in confined environments. To solve the quadrotor navigation problem, an online decentralized obstacle avoidance algorithm based on differential flatness and MPC was proposed in [30], where Optimal Reciprocal Collision Avoidance (ORCA) was employed for obstacle avoidance. However, the quadrotors lack cooperation to reach a consensus on their future trajectories, potentially leading to collisions in dense environments.

Table 1.
Existing studies on the trajectory planning of UAVs.
Table 1.
Existing studies on the trajectory planning of UAVs.
| References | UAV Model | Methods | Collision Avoidance | Evaluation |
|---|---|---|---|---|
| Kumar et al. [24] | Differential flatness | MIQP and downwash effect | Yes | Centralized methods: optimal global planning, poor real-time, high computational complexity, poor scalability |
| Augugliaro et al. [25] | Differential flatness | Discrete planning and continuous refinement | Yes | |
| Preiss et al. [26] | Second-order dynamics | SCP and posteriori vehicle-specific feasibility check | Yes | |
| Borrelli et al. [29] | Second-order dynamics | MILP and inter-vehicle coordination rules | Yes | Distributed methods: good real-time, strong robustness, suitable for large-scale swarms |
| Arul et al. [30] | Linear flat model | ORCA, downwash effect, and flatness-based feedforward linearization | Yes | |
| Luis et al. [31] | Second-order dynamics | On-demand collision avoidance | Yes |
Distributed optimization theory and its applications have gained increasing attention in recent years. The alternating direction multiplier method (ADMM) [32], as one of them, has been proven to show significant advantages in terms of convergence speed and computational efficiency in multi-robot task scenarios [33]. A series of examples combining MPC and ADMM approaches for multiple robots [3,34,35,36] illustrate the effectiveness and scalability of such a distributed framework. For instance, Ref. [34] proposed a distributed MPC method utilizing ADMM decomposition to coordinate the control problem of waterborne AGVs. Chen et al. [35] employed MPC and ADMM to achieve formation navigation of multiple vessels under environmental perturbations. In [3], a flocking control framework based on MPC and ADMM was presented to enable multi-vehicle systems to track desired trajectories while considering limited communication distances, collision avoidance, and bounded speed and control inputs. Compared to the methods above, we address a more complex quadrotor scenario that takes into account the quadrotor’s dynamics. Moreover, we utilize the linearized DCBF instead of the Euclidean norms and incorporate MPC to ensure the real-time generation of safe trajectories.
3. Preliminaries
In this section, we present an overview of differential flatness and DCBF. We highlight the linear flat model of the quadrotor and a relaxed form of the DCBF constraint. In addition, the main symbols used in this paper are defined in Abbreviations.
3.1. Differential Flatness and Quadrotor Dynamics
A nonlinear system is considered differentially flat if it can be described using a set of differentially independent variables called flat output, i.e., the state and input of the system can be expressed as algebraic functions of the flat output and its finite-order derivatives [37]. The definition is as follows:
where , , and are smooth functions. Both and are also called endogenous transformations of the system. Here, p and q are the maximum orders of the derivatives of and required to describe the system. The quadrotor has been shown to have the differential flatness property [22] with a flat output .
Consider a quadrotor with its control input , where T is the commanded thrust, and are the commanded roll and pitch angles, and is the commanded yaw rate. The state includes position, velocity, and roll, pitch, and yaw angles. As in [38], the inner-loop attitude dynamics are written as follows:
where and are the gains and time constants of the roll and pitch angles, respectively. Then the following equation gives the relationship between and flat output .
From (4) and (5), we can then compute in terms of flat output and its derivatives. Hence, we simplify the quadrotor trajectory generation process by seeking a sufficiently smooth flat output trajectory within a reduced planning space dimension.
Hagenmeyer et al. [37] introduced the notion of exact feedforward linearization based on differential flatness. The differential flat system can be transformed into an equivalent linear discrete-time flat model that can provide the benefit of reducing computation overload. The linear flat model of the quadrotor [38] is shown as:
where
and denotes the flat state of the quadrotor, including position, velocity, acceleration, and yaw angle. denotes the flat input, including the third-order derivatives of the position and the yaw rate. In this paper, we consider (6) as the quadrotor dynamics model to generate a smooth collision-free trajectory.
3.2. Discrete-Time CBF
Consider a discrete-time dynamical system as
where denotes the state of the system at time k, is the control input, and f is a continuous dynamics function. Obstacle avoidance requires the invariance of a trajectory with respect to a safe, connected set. Specifically, if the system (7) is safe with respect to a set , then any trajectory starting inside the set will remain inside it. The set is defined to be a superlevel set of the continuously differentiable functions .
Here, is called a safety set. The function h is a discrete-time CBF (DCBF) [18] if the following condition (9) is satisfied.
where , and is a hyperparameter. The constraint (9) implies , i.e., the lower bound of decays exponentially at time k with the rate . Incorporating a valid DCBF constraint (9) into an optimization problem ensures the safety of the generated trajectories. If decreases, the system becomes more capable of avoiding obstacles, but it might lead to an unfeasible problem. On the other hand, if increases, the problem is more likely to be feasible, but the trajectory rapidly approaches the boundary of the safe set , making the system unsafe. Therefore, the fixed is challenging to adapt to complex and changing environments; see [18] for details. To better balance feasibility and safety, we design a relaxed form of the DCBF constraint as follows:
Here, the slack variable will be adaptively optimized along with other variables in the optimization problem. The collision-free trajectory needs to consider both the neighbors and the obstacles in the external environment, so two types of safety constraints are added. One is the constraint between quadrotor i and quadrotor j, and the other is the constraint between quadrotor i and obstacle . The formulation of and are shown in the next section.
4. Problem Formulation
In this section, we present an undirected adjacency graph representing communication among quadrotors and then formulate a trajectory planning optimization problem based on MPC and DCBF.
4.1. Proximity Network
To realize cooperative trajectory planning, quadrotors need to communicate and exchange information with each other. In this paper, we use an undirected proximity graph to represent the communication topology of quadrotors at time k, where is the set of vertices and is the set of edges. In graph , vertex i stands for quadrotor i. The edge stands for a communication link between quadrotor i and quadrotor j at time k, as
where and is the maximum distance that quadrotors can communicate. At time k, the neighbors of quadrotor i are defined as . The graph is time-varying due to the movement of the quadrotors. Therefore, may be ∅, i.e., quadrotor i does not communicate with any other quadrotors at time k.
4.2. Trajectory Planning Based on MPC and DCBF
Cooperative trajectory planning for quadrotor swarms is a multi-variable and multi-constraint optimization problem. Combining MPC and DCBF, we aim to generate a safe and smooth trajectory under collision avoidance and dynamics constraints. Consider a swarm system with N quadrotors in a shared workspace . This finite-time optimization problem with constraints at time k within a prediction horizon H can be formulated as follows:
where N is the number of quadrotors, and denotes the prediction at time k for the state at time . The cost function (12a) is composed of two parts along the prediction horizon H, i.e., the cost with respect to the variables and , and the additional cost with respect to the slack variables . (12b) and (12c) are the linear flat model of the quadrotor described by (6), while (12d) and (12e) denote the system dynamics constraints and initial state conditions, respectively. To ensure the safety of the trajectory, (12f) and (12g) give two types of DCBF constraints defined by (10). The specific forms of the cost function and constraints in the optimization are described in detail below.
- (1)
- Cost : The cost function consists of three parts, including the terminal cost , the stage cost , and the input change rate cost , as shown below:where P, Q, R, and S denote the weight matrices of the corresponding parts, respectively. is the target state of quadrotor i. From Equations (14)–(16), it can be seen that this cost penalizes the deviation of the predicted state from the target state, the size of the input, and the size of the input variations along the prediction horizon H. Therefore, the objective of the optimization problem is to enable the quadrotors to rapidly approach the target state while minimizing input size and its variation.
- (2)
- Cost : The additional cost function is to drive the slack variables close to 0 to ensure the safety of the generated trajectories as follows:where is a weighting coefficient. It is advisable to set to a large value to prevent excessive relaxation of the DCBF constraints, which is also verified in the simulation experiments. In addition, the cost function can be tuned for different performance.
- (3)
We model each quadrotor i as a closed rigid sphere with radius and each obstacle o as a closed ellipsoid with semi-major axis . Similar to [18], the corresponding h-functions are given by
where represents the position of quadrotor i and is a component of the output . Correspondingly, is the position of obstacle o. (20) implies that the sphere representing quadrotor i does not intersect the sphere representing quadrotor j, see Figure 3 for details. Similarly, (21) can be interpreted as approximating the obstacle o as an enlarged ellipsoid to check whether the position of quadrotor i is inside it [16], and . Since the DCBF is nonconvex, the real-time computation of problem (12) is challenging when it has a large prediction horizon H. Therefore, we linearize the DCBF around the result of the previous iteration at each time step using a first-order Taylor expansion as follows:
where is the result of the previous iteration for quadrotor i. Then, we can solve problem (12) with an iterative convex optimization. The detailed steps of the solution are described in the following section.

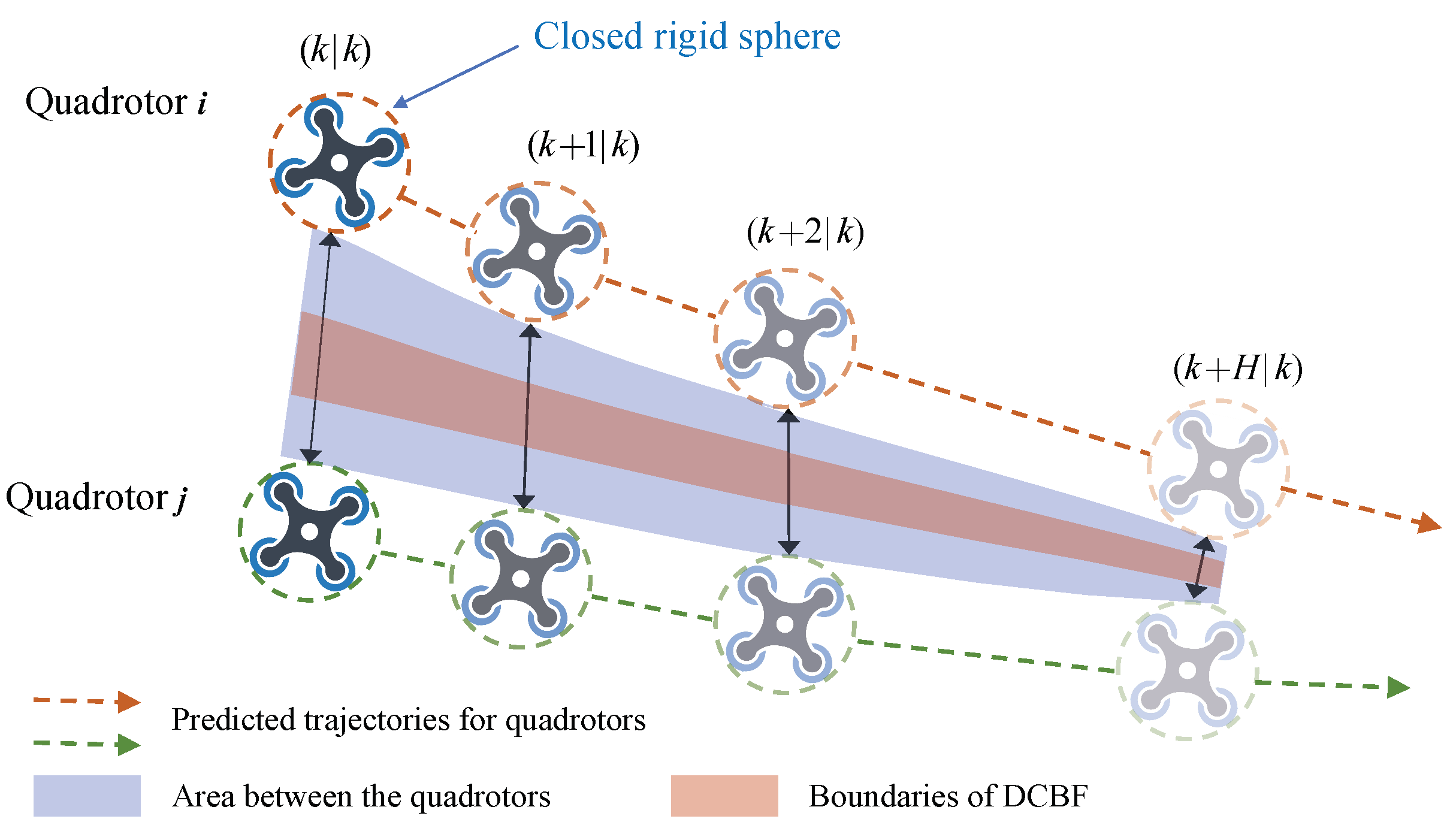
Figure 3.
DCBF-based collision avoidance between quadrotor i and quadrotor j. The black solid arrows indicate the positions at the identical global time. The boundaries of the DCBF are defined by the corresponding constraints to prevent the quadrotors from approaching each other too fast.
Remark 1.
In this paper, we consider that the yaw direction of the quadrotor is fixed as in the desired trajectory, and the focus is on the spatial position of the quadrotor.
The above is the optimization problem for trajectory planning. We will introduce a fully distributed trajectory planning algorithm for efficiently computing future trajectories for all quadrotors in a swarm, as explained in the following section.
5. DMPC-ADMM Based Trajectory Planning
In this section, we reformulate the trajectory planning (12) for quadrotor swarms based on ADMM, converting it into a fully distributed framework. This approach decomposes the original high-dimensional optimization problem into N low-dimensional optimization subproblems, allowing each quadrotor i to compute its optimal trajectory in parallel to speed up the online solution of the problem. The focus lies in determining the communication information and mode to coordinate the quadrotors in order to avoid collision among them.
5.1. General ADMM Formulation
Here, we present a brief overview of ADMM. For more details, the readers can refer to [32]. ADMM is an iterative algorithm for solving distributed optimization problems. It decomposes the original problem into several subproblems and solves them by updating the multipliers and alternating iterations. The standard ADMM considers the following optimization problem with equation constraints.
where and are the original decision variables. , , , , and . ADMM utilizes the augmented Lagrangian function with an additional quadratic penalty term to obtain better convergence. (24) is the augmented Lagrangian function of problem (23). The steps of ADMM iteratively solving (23) are described in Algorithm 1 until the predefined stopping iteration condition is satisfied.
where is the Lagrange multiplier and is the penalty coefficient. Although is independent of the convergence of the optimization problem (23), it affects the convergence rate. And we can obtain a suitable by sufficient experiments. The next subsection describes how to reformulate the trajectory planning problem (12) as an adaptation of the structure of problem (23) to solve it in a distributed manner.
5.2. Problem Decomposition Based on ADMM
For trajectory planning of quadrotor swarms, the only coupling among quadrotors is represented by the collision avoidance constraints (18). The purpose of interactions among quadrotors is to tell the neighbors about their own future trajectories so that they can avoid collision in advance. In such scenarios, quadrotors need to agree on safe trajectories within the confined space. Motivated by [36], each quadrotor maintains communication with its neighbors while computing trajectories by introducing duplicates of its neighbors’ trajectories. Specifically, we use to represent the duplicate of the trajectory , and is the duplicate of quadrotor i for the trajectory of quadrotor j, which can also be interpreted as the desired trajectory proposed by quadrotor i for quadrotor j. Then the control barrier function can be reformulated as
It can be seen that using and , the coupling among quadrotors is successfully decoupled. Here, we use to denote an indicator function, defined as
Compared to the problem (23), we replace the cost function of the optimization problem (12) with as follows:
where the set denotes all the constraints in (12) except for inter-quadrotor collision avoidance. So, the optimization problem (12) can be transformed into the form as follows:
Obviously, (29) is an optimization problem with equation constraints, whose augmented Lagrangian form is given in (30), where and are the corresponding dual variables and is the penalty coefficient. This allows us to solve this optimization problem according to Algorithm 1, iteratively updating , , , and sequentially until the stopping condition is satisfied or the maximum number of iterations is reached. Each quadrotor i computes its trajectory while maintaining communication with its neighbors to exchange future trajectories of the prediction horizon H.
| Algorithm 1 ADMM. |
The last equation in (30) holds because a bi-directional interaction is assumed, i.e., . So, we can flip the indexes i and j. and in (30) are defined as follows:
According to Algorithm 1, we separate the Lagrangian function (30) into two subproblems. We first minimize over the local variables and , and then minimize it over the global variables and . Algorithm 2 describes the steps of the distributed trajectory planning algorithm based on DMPC-ADMM, containing the steps of prediction, coordination, and mediation, as well as two communications, all of which are executed iteratively on the quadrotors in parallel. The prediction step ensures that each quadrotor i computes a trajectory of prediction horizon H under the constraints represented by . The trajectory should be close to the target position while not deviating too much from its collision-free trajectory and the desired trajectories that its neighbors propose. Each quadrotor i then exchanges the updated trajectory with its neighbors in the first round of communication. In the coordination step, each quadrotor i updates . This is done by coordinating with its neighbors to avoid collision while staying as close as possible to the trajectory computed in the prediction step. In the mediation step, the Lagrange multipliers that accumulate the deviation between the trajectories computed in the prediction step and the coordination step are updated, further facilitating the quadrotors to reach a consensus on the trajectories of prediction horizon H. Finally, the desired Lagrange multipliers and trajectories are exchanged with its neighbors in the second round of communication. The iteration is finished when the stopping iteration condition (35) is satisfied or the maximum number of iterations is reached. The first control input is selected from to guide the controller at time . Then, this algorithm repeats in this manner until all the quadrotors have reached the target positions.
| Algorithm 2 Distributed algorithm based on DMPC-ADMM. |
|
In (22), we give a specific formulation of the linearized DCBF such that (29) is a convex problem with constraints. Here, we solve (32) and (33) in an iterative manner to approximate the optimal solution; see Algorithms 3 and 4. In Algorithm 3, the updated output is passed between iterations allowing for the linearization of . The iteration is finished when the convergence criterion (34) is satisfied or the maximum number of iterations is reached. The updated optimal is then exchanged with its neighbors in the first round of communication. Algorithm 4 follows the same principle as Algorithm 3, so it is not explained further here.
where is constant, (34) implies that the iteration of Algorithm 3 is finished when the absolute value of the change in output is less than .
| Algorithm 3 Iterative convex optimization of (32). |
| Algorithm 4 Iterative convex optimization of (33). |
|
Remark 2.
For the initialization of Algorithm 2, we use the optimal result of the previous loop of DMPC-ADMM. Likewise, we use the optimal result of the previous iteration as the initial guess in Algorithms 3 and 4. This hot-start strategy can speed up the convergence of the algorithm, especially in slowly changing scenarios.
Each quadrotor i plans its trajectory by taking into account its optimal trajectory and the desired trajectories that are proposed by its neighbors. Thus, the stopping iteration condition for each MPC-ADMM loop can be designed in the following form:
where and represent tolerable deviation thresholds, respectively, and is the number of neighbors of quadrotor i. With sufficient iterations, the quadrotor i will agree with its neighbors on the trajectories of prediction horizon H. However, extensive simulations show that the algorithm reaches an accepted result after a certain number of iterations. To reduce the computational burden, we present an empirical value of that allows us to compute a sub-optimal result.
5.3. Event-Triggered Mechanism
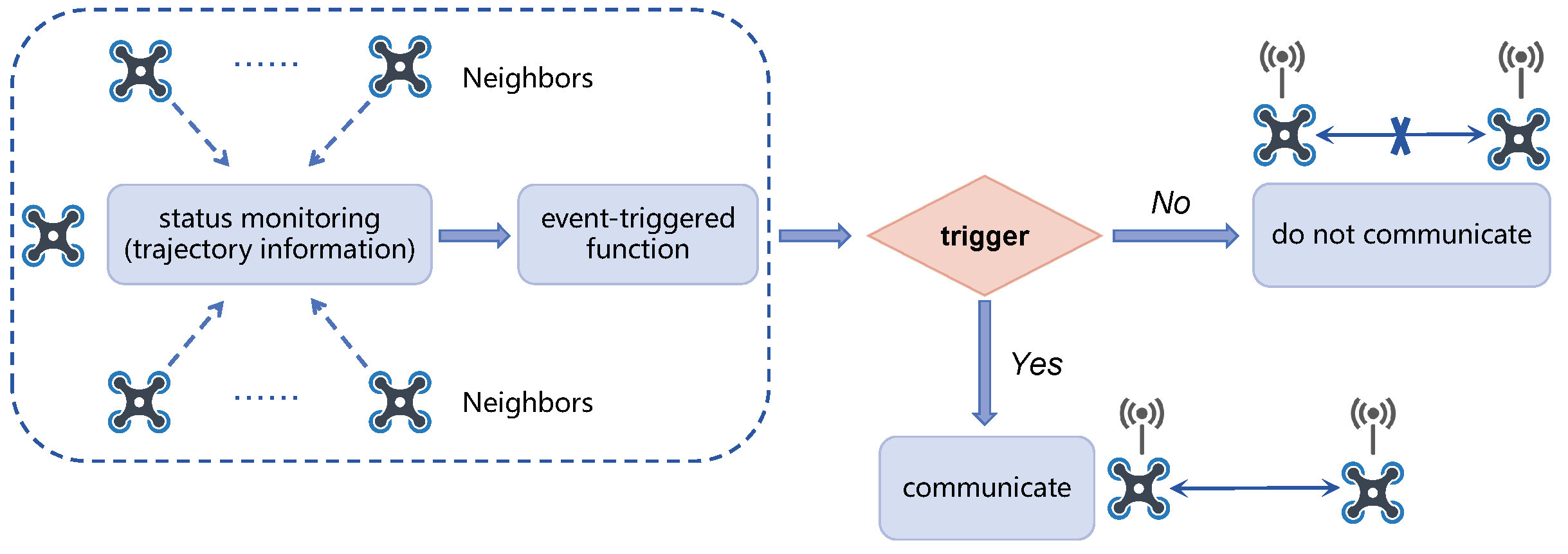
In general, the maximum communicable distance is much greater than the distance that quadrotors can fly within the prediction horizon H. Consequently, Algorithm 2 exhibits substantial redundancy in inter-quadrotor communication, especially in scenarios involving many quadrotors. Inspired by [39,40], we design an event-triggered mechanism that initiates communication only when a specific trigger condition is met. The critical element of the event-triggered mechanism lies in the design of the event detector. The content and operational mode of the event detector determines the functioning of the event-triggered mechanism, subsequently influencing the communication frequency of the system, as shown in Figure 4.

Figure 4.
Structure of the event detector.
Considering a scenario in which two quadrotors are widely separated, there is no risk of collision within the prediction horizon H, so they need not maintain communication while generating trajectories. Within the distributed framework, at time k, quadrotor i listens to the position of its neighbor to determine whether the event is triggered. We design the trigger function of the event detector as follows:
where , are the positions of quadrotor i and its neighbor at time k, is the time step, and is the maximum velocity of the quadrotor. The trigger condition holds when the value of the trigger function (36) is negative. We then incorporate this event-triggered mechanism into Algorithm 2, which reduces communication resources and the number of collision avoidance constraints .
Remark 3.
The optimization problem may become infeasible when the flight space of the quadrotors is highly competitive. In this case, we can slow down the quadrotors quickly, and after a few time steps, the problem becomes feasible again.
6. Simulation Experiments and Results
In this section, we describe and evaluate the implementation of our method in simulation experiments. The simulation results validate the efficiency of our method. And we use the RflySim platform [41] to validate the proposed method. The platform provides quadrotor dynamics that are almost indistinguishable from actual scenario flights. The trajectories of all quadrotors are generated by our method, and the PID controller is used to track the trajectories. A video demonstration on the RflySim platform can be found at https://www.bilibili.com/video/BV11u4y1w7HU (accessed on 15 January 2024).
6.1. Experimental Setup
All the quadrotors have the same dynamics model, and we apply a box constraint set on the flat state as is done in [42] for trajectory generation, as shown in (37). The parameters used in the simulation are shown in Table 2. Here, we define two scenarios, one for obstacle avoidance flight in complex environments (Scenario 1) and one for exchanging positions flight (Scenario 2). We provide a performance comparison of our method with centralized MPC (CMPC), constant velocity MPC (CVMPC, treat the quadrotor as a constant velocity model), and distributed MPC (DMPC, use the future trajectories computed by its neighbors at the previous time as collision avoidance constraints) [16] for trajectory planning. The only difference among these methods is the coordination strategies, where all parameters are identical. All methods are solved using OSQP [43] with the modeling language Yalmip [44]. We use a Windows desktop with Intel Core i7-11700K (CPU 3.6 GHz) running MATLAB for all computations. In the simulation, we assume that the environmental information is known, the communication packets are not lost, and there are no external perturbations.
Table 2.
Parameters setting.
6.2. Performance Comparison of Different Methods
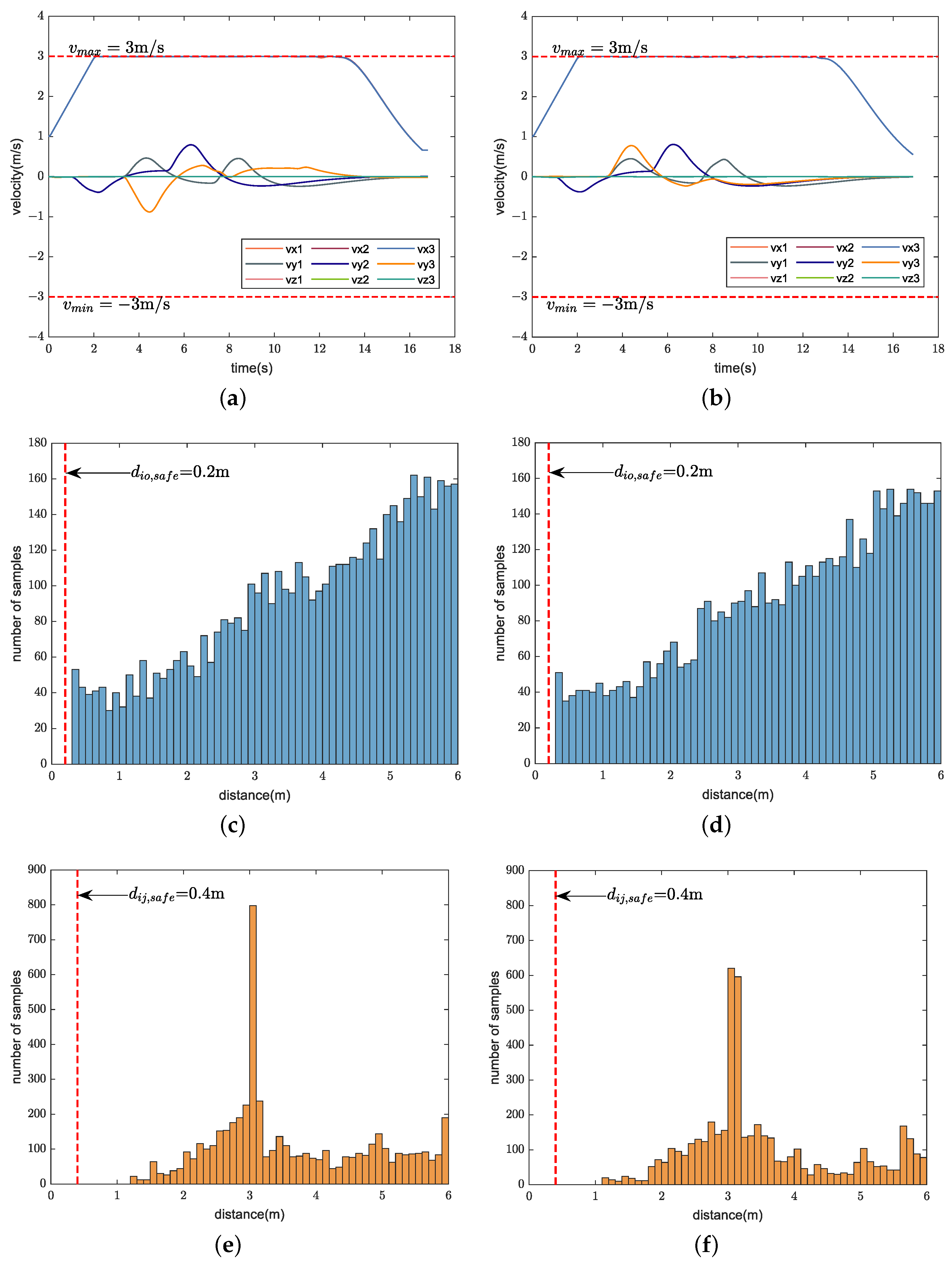
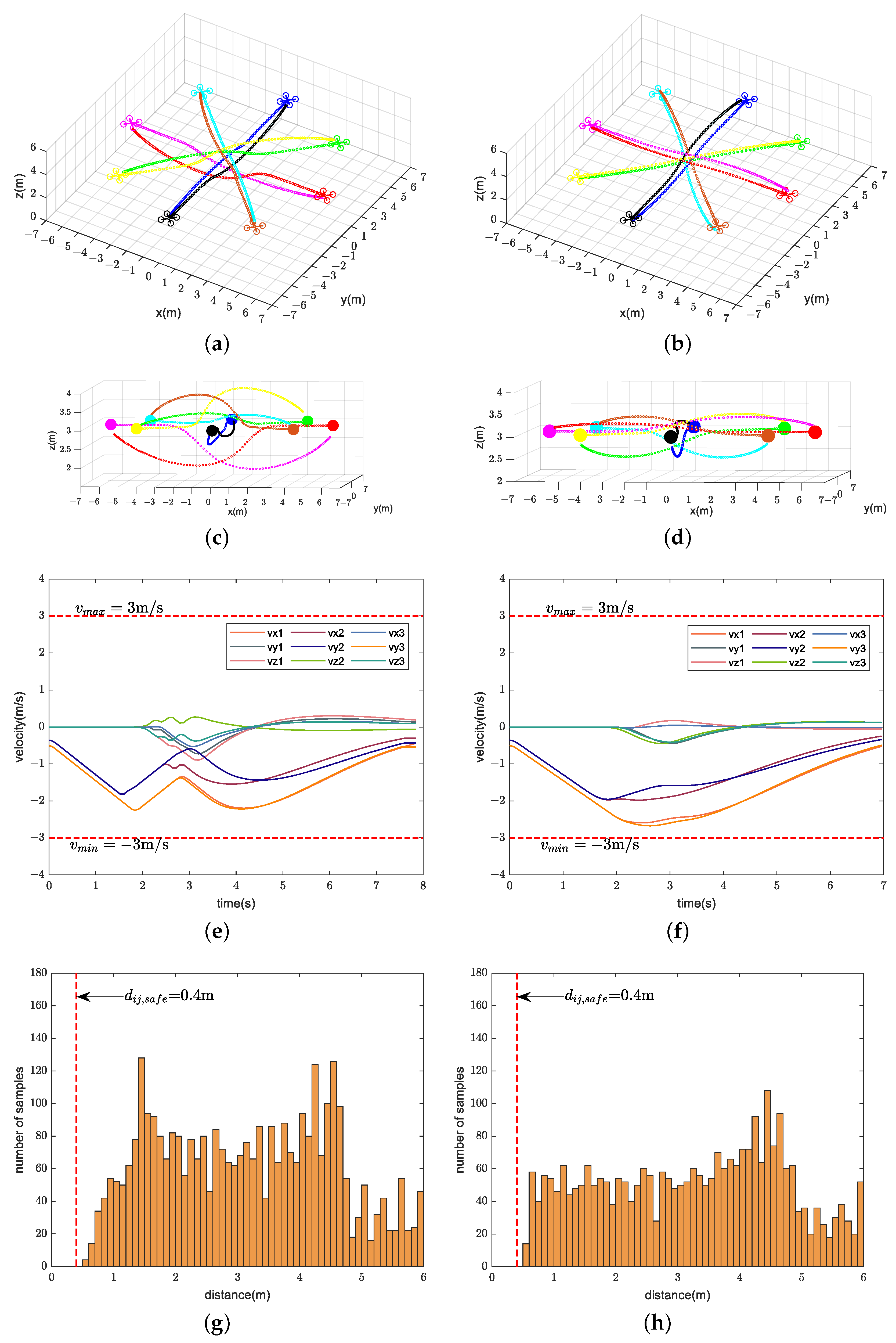
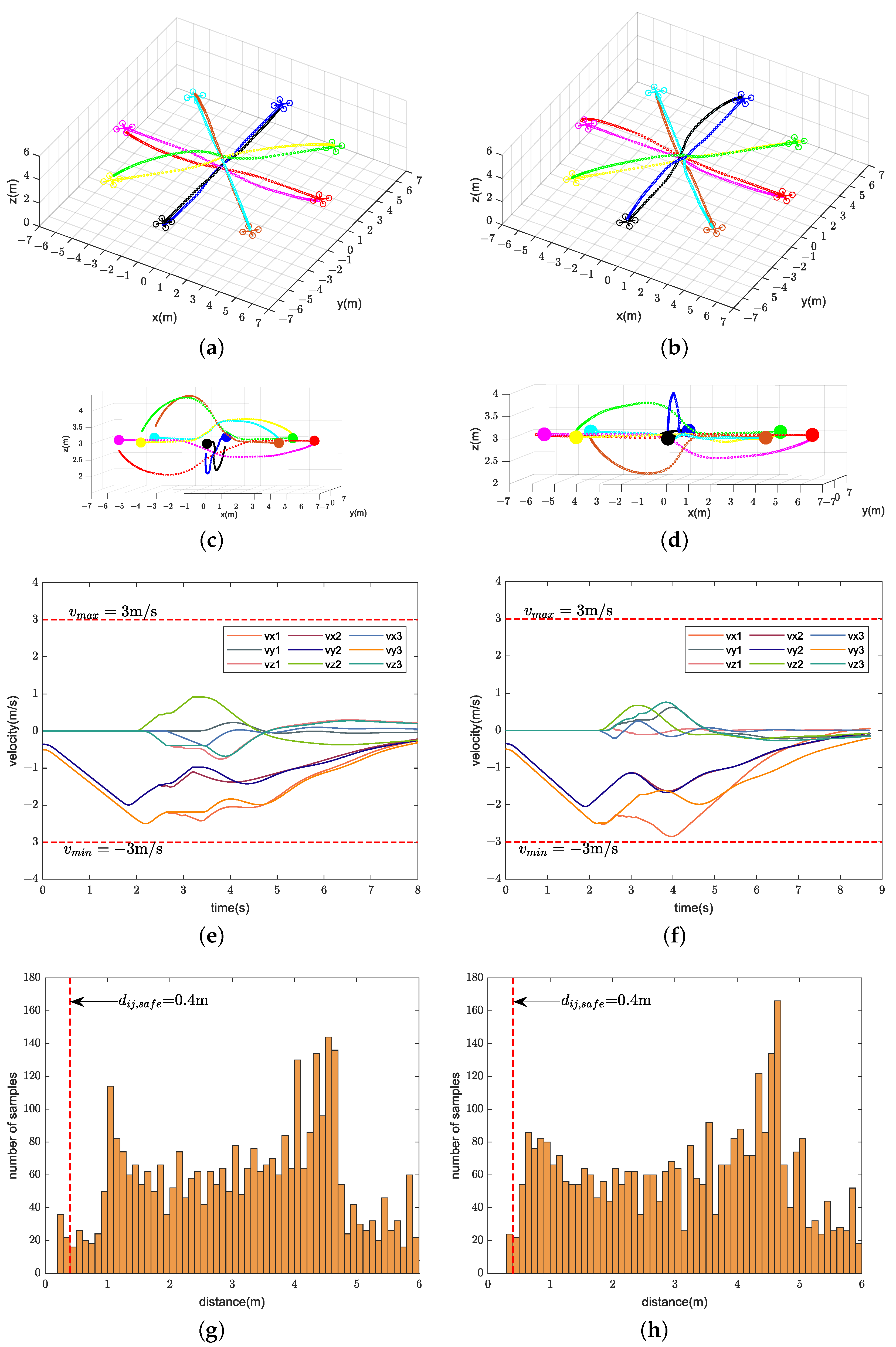
We compare the performance of our method with CMPC, CVMPC, and DMPC in two scenarios. For Scenario 1 with ten quadrotors, Figure 5, Figure 6 and Figure 7 show the simulation results using our method and CMPC, respectively. Figure 8 and Figure 9 show the simulation results of the eight quadrotors in Scenario 2 using the four methods. From the velocity variations of three of the quadrotors, we observe that our method generates smoother trajectories compared to CVMPC and DMPC, and the statistics of the distance among quadrotors show that our method is safer. Moreover, the performance of the trajectories generated by our method is not much different from that of CMPC.
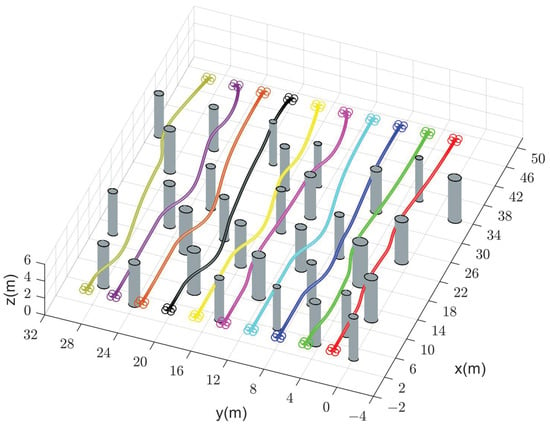
Figure 5.
Generated trajectories of ten quadrotors (solid dots in different colors) cross a finite space with obstacles using our method (DMPC-ADMM).

Figure 6.
Generated trajectories of ten quadrotors (solid dots in different colors) cross a finite space with obstacles using CMPC.

Figure 7.
Simulation results of ten quadrotors cross a finite space with obstacles using our method (left) and CMPC (right). (a,b) Velocity variations. (c,d) Distance between quadrotors and obstacles (Only distance statistics within 6 m are shown). (e,f) Distance among quadrotors (Only distance statistics within 6 m are shown). The red dashed lines represent the maximum velocity , the minimum velocity , the safe distance between quadrotors and obstacles , and the safe distance among quadrotors , respectively.

Figure 8.
Simulation results of eight quadrotors (solid dots in different colors) exchanging positions flight using our method (left) and CMPC (right). (a,b) Overall view of the trajectories. (c,d) Side view of the trajectories. (e,f) Velocity variations. (g,h) Distance among quadrotors (Only distance statistics within 6 m are shown). The red dashed lines represent the maximum velocity , the minimum velocity , and the safe distance among quadrotors , respectively.

Figure 9.
Simulation results of eight quadrotors (solid dots in different colors) exchanging positions flight using CVMPC (left) and DMPC (right). (a,b) Overall view of the trajectories. (c,d) Side view of the trajectories. (e,f) Velocity variations. (g,h) Distance among quadrotors (Only distance statistics within 6 m are shown). The red dashed lines represent the maximum velocity , the minimum velocity , and the safe distance among quadrotors , respectively.
For further comparison, we report the trajectory length (minimum, maximum, mean value, and standard deviation to compare cooperativeness), the minimum distance among quadrotors, the minimum distance between quadrotors and obstacles, as well as the average computation time of the four methods in Table 3 and Table 4. It can be observed that CVMPC and DMPC have a minimum distance lower than the safe distance due to the lack of coordination and take more time than our method due to the need for a greater number of iterations. Instead, our method and CMPC can achieve safe navigation, and the computation time of our method is much less than that of CMPC.
Table 3.
Comparison of the simulation results of the four methods for ten quadrotors cross a finite space with obstacles. The safe distance among quadrotors is and the safe distance between quadrotors and obstacles is .
Table 4.
Comparison of the simulation results of the four methods for eight quadrotors exchanging positions flight. The safe distance among quadrotors is .
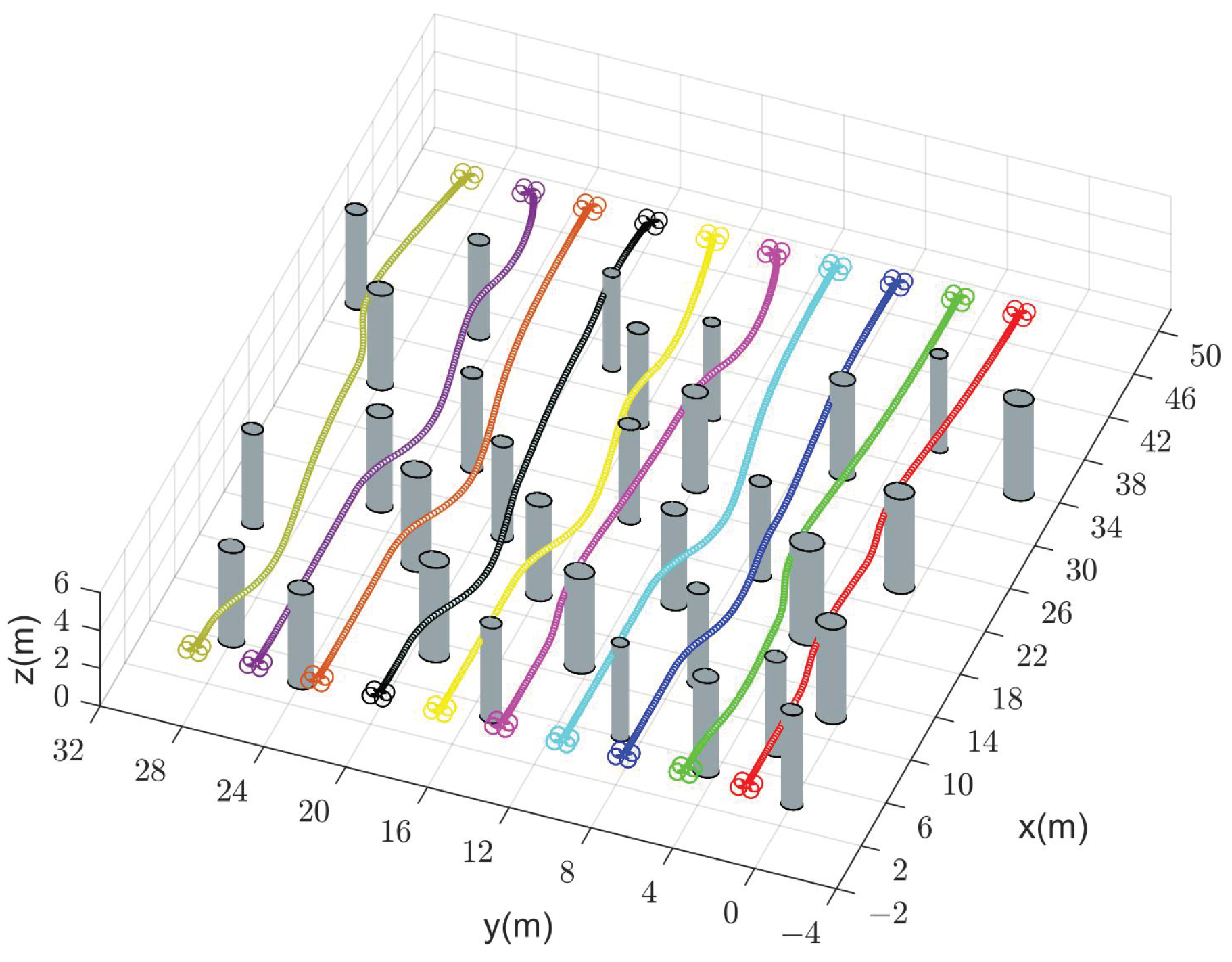
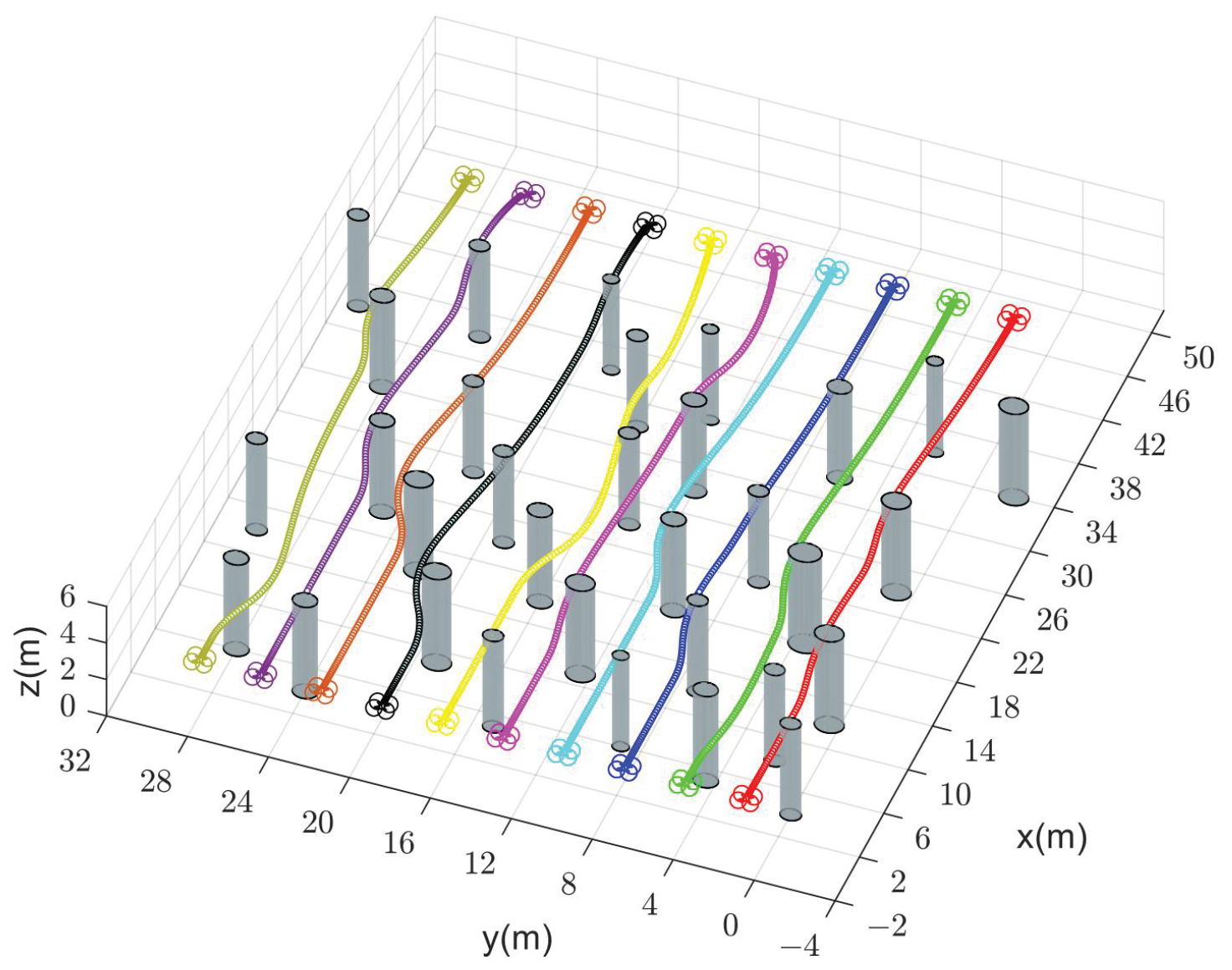
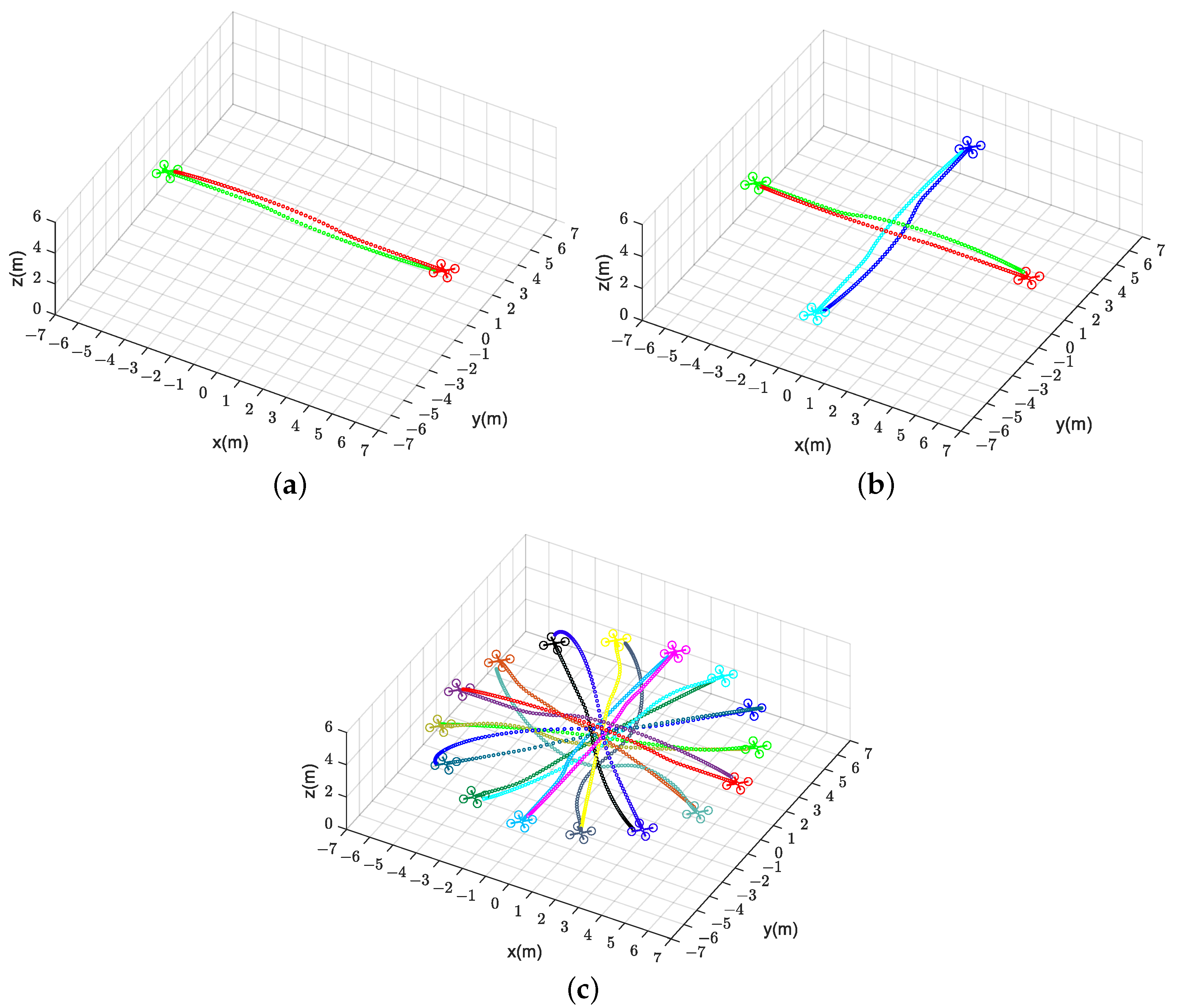
In addition, Table 5 shows the comparison of the four methods in terms of average computation time, collision probability, and feasibility in Scenario 2. For each method, we generate trajectories of the quadrotors under 50 random initial and target states. We define the method as infeasible when the collision probability is greater than . We observe that CMPC suffers from a large computational burden, while our method performs well at a much lower computational cost. The collision probability of our method and CMPC stays below as the number of quadrotors increases. Instead, due to the deviation of trajectory information, CVMPC and DMPC become infeasible with a significant increase in collision probability, especially for CVMPC. Therefore, our method scales well with the number of quadrotors. Figure 10 illustrates the trajectories of two, four, and sixteen quadrotors for exchanging positions in flight.
Table 5.
Comparison of the four methods in terms of average computation time (Av), collision probability (Cp), and feasibility (Fea) in Scenario 2.

Figure 10.
Generated trajectories of multiple quadrotors (solid dots in different colors) exchanging positions flight using our method (DMPC-ADMM). (a) Two quadrotors. (b) Four quadrotors. (c) Sixteen quadrotors.
6.3. Evaluation of Event-Triggered Mechanism
To verify the effectiveness of the event-triggered mechanism, we compare the performance of the algorithm before and after adding the event-triggered mechanism under a uniform spatial distribution of different numbers of quadrotors in Scenario 1. Define a metric as the communication cost and the communication ratio as the ratio of the communication cost after adding the event-triggered mechanism to the original communication cost, as shown in (38). Figure 11 shows a significant reduction in communication ratio and computation time after adding the event-triggered mechanism. Therefore, the event-triggered mechanism greatly improves the performance of the distributed algorithm.

Figure 11.
Comparison of communication ratio and computation time before and after adding the event-triggered mechanism.
6.4. Evaluation of Algorithm Robustness
We compare the sensitivity of our algorithm for different hyperparameters , maximum velocity , and maximum acceleration of the quadrotors in Table 6. It can be seen that the length of the trajectories does not vary much, and the minimum distance among quadrotors is always greater than the safe distance. Please note that as increases, gets closer to the safe distance, and the computation time gets shorter, which is consistent with the explanation in Section 3. In addition, the computation time of our algorithm is kept short. Therefore, our method has good robustness and can be applied to different scenarios.
Table 6.
Performance comparison of our algorithm for eight quadrotors exchanging positions flight at different hyperparameter , maximum velocity (m/s) and maximum acceleration . The safe distance among quadrotors is .
7. Conclusions
In this paper, we propose a fully distributed algorithm for cooperative trajectory planning of quadrotor swarms based on DMPC-ADMM, which employs differential flatness property to handle the complex dynamics of the quadrotor. Additionally, we design a relaxed form of DCBF constraint to balance feasibility and safety. Due to the non-convexity of the DCBF, we linearize the DCBF at each time step and use an iterative convex optimization scheme to solve it. Simulation results show that our method can generate safe and smooth trajectories while satisfying dynamics constraints. Compared with the centralized strategy and several other distributed strategies in terms of computation time, safety, and feasibility, our method is more suitable for the trajectory planning of large-scale quadrotor swarms. Furthermore, the effect of the designed event-triggered mechanism for reducing the communication overhead is also verified.
In future work, we will improve the event-triggered mechanism to enhance inter-quadrotor communication efficiency. It is also worth exploring how to improve the robustness of the algorithm considering the presence of uncertainties in practice, such as perceptual uncertainty, communication packet loss, and external perturbations. Additionally, considering that the trajectory planning framework presented in this paper is currently implemented synchronously, limiting its flexibility, we will develop an asynchronous implementation.
Author Contributions
Conceptualization, Y.Z. and P.Y.; methodology, Y.Z.; software, Y.Z.; validation, Y.Z., P.Y. and Y.H.; formal analysis, Y.Z.; investigation, Y.Z.; resources, Y.Z.; data curation, Y.Z.; writing—original draft preparation, Y.Z.; writing—review and editing, Y.Z., P.Y. and Y.H.; visualization, Y.Z.; supervision, P.Y. and Y.H.; project administration, P.Y.; funding acquisition, P.Y. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| UAV | Unmanned Aerial Vehicle |
| MPC | Model Predictive Control |
| ADMM | Alternating Direction Multiplier Method |
| DCBF | Discrete-time CBF |
| MILP | Mixed Integer Linear Programming |
| MIQP | Mixed Integer Quadratic Programming |
| SCP | Sequential Convex Programming |
| ORCA | Optimal Reciprocal Collision Avoidance |
| AGV | Autonomous Guided Vessel |
| CMPC | Centralized MPC |
| CVMPC | Constant Velocity MPC |
| DMPC | Distributed MPC |
| Symbols | Definitions |
| Flat state of the quadrotor, including position, velocity, acceleration, and yaw angle. | |
| Flat output of the quadrotor, including position and yaw angle. | |
| Flat input of the quadrotor, including the third-order derivatives of the position and yaw rate. | |
| Maximum distance that quadrotors can communicate. | |
| Set of neighbors of quadrotor i. | |
| Set of obstacles. | |
| Dynamics constraint of the quadrotor. | |
| H | Prediction horizon of the optimization problem. |
| Duplicate of the trajectory . | |
| Duplicate of quadrotor i for the trajectory of quadrotor j. | |
| All the constraints in (12) except for inter-quadrotor collision avoidance. | |
| Safety constraints between quadrotor i and quadrotor j. | |
| Safety constraints between quadrotor i and obstacle o. |
References
- Ryan, A.; Zennaro, M.; Howell, A.; Sengupta, R.; Hedrick, J.K. An overview of emerging results in cooperative UAV control. In Proceedings of the 2004 43rd IEEE Conference on Decision and Control (CDC), Nassau, Bahamas, 14–17 December 2004; Volume 1, pp. 602–607. [Google Scholar]
- Chen, W.; Liu, J.; Guo, H.; Kato, N. Toward robust and intelligent drone swarm: Challenges and future directions. IEEE Netw. 2020, 34, 278–283. [Google Scholar] [CrossRef]
- Lyu, Y.; Hu, J.; Chen, B.M.; Zhao, C.; Pan, Q. Multivehicle flocking with collision avoidance via distributed model predictive control. IEEE Trans. Cybern. 2019, 51, 2651–2662. [Google Scholar] [CrossRef] [PubMed]
- Aggarwal, S.; Kumar, N. Path planning techniques for unmanned aerial vehicles: A review, solutions, and challenges. Comput. Commun. 2020, 149, 270–299. [Google Scholar] [CrossRef]
- Bircher, A.; Kamel, M.; Alexis, K.; Oleynikova, H.; Siegwart, R. Receding horizon path planning for 3D exploration and surface inspection. Auton. Robot. 2018, 42, 291–306. [Google Scholar] [CrossRef]
- Tang, S.; Wüest, V.; Kumar, V. Aggressive flight with suspended payloads using vision-based control. IEEE Robot. Autom. Lett. 2018, 3, 1152–1159. [Google Scholar] [CrossRef]
- Madridano, Á.; Al-Kaff, A.; Martín, D.; de la Escalera, A. 3d trajectory planning method for uavs swarm in building emergencies. Sensors 2020, 20, 642. [Google Scholar] [CrossRef]
- Tanner, H.G.; Kumar, A. Towards decentralization of multi-robot navigation functions. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation (ICRA), Barcelona, Spain, 18–22 April 2005; pp. 4132–4137. [Google Scholar]
- Fiorini, P.; Shiller, Z. Motion planning in dynamic environments using velocity obstacles. Int. J. Robot. Res. 1998, 17, 760–772. [Google Scholar] [CrossRef]
- Peng, M.; Meng, W. Cooperative obstacle avoidance for multiple UAVs using spline_VO method. Sensors 2022, 22, 1947. [Google Scholar] [CrossRef]
- Fox, D.; Burgard, W.; Thrun, S. The dynamic window approach to collision avoidance. IEEE Robot. Autom. Mag. 1997, 4, 23–33. [Google Scholar] [CrossRef]
- Čáp, M.; Novák, P.; Kleiner, A.; Seleckỳ, M. Prioritized planning algorithms for trajectory coordination of multiple mobile robots. IEEE Trans. Autom. Sci. Eng. 2015, 12, 835–849. [Google Scholar] [CrossRef]
- Busoniu, L.; Babuska, R.; De Schutter, B. A comprehensive survey of multiagent reinforcement learning. IEEE Trans. Syst. Man Cybern. Part C (Appl. Rev.) 2008, 38, 156–172. [Google Scholar] [CrossRef]
- Chen, Y.F.; Liu, M.; Everett, M.; How, J.P. Decentralized non-communicating multiagent collision avoidance with deep reinforcement learning. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 285–292. [Google Scholar]
- Mayne, D.Q. Model predictive control: Recent developments and future promise. Automatica 2014, 50, 2967–2986. [Google Scholar] [CrossRef]
- Zhu, H.; Alonso-Mora, J. Chance-constrained collision avoidance for mavs in dynamic environments. IEEE Robot. Autom. Lett. 2019, 4, 776–783. [Google Scholar] [CrossRef]
- Lindqvist, B.; Mansouri, S.S.; Agha-mohammadi, A.a.; Nikolakopoulos, G. Nonlinear MPC for collision avoidance and control of UAVs with dynamic obstacles. IEEE Robot. Autom. Lett. 2020, 5, 6001–6008. [Google Scholar] [CrossRef]
- Zeng, J.; Zhang, B.; Sreenath, K. Safety-critical model predictive control with discrete-time control barrier function. In Proceedings of the 2021 American Control Conference (ACC), New Orleans, LA, USA, 25–28 May 2021; pp. 3882–3889. [Google Scholar]
- Wang, L.; Ames, A.D.; Egerstedt, M. Safe certificate-based maneuvers for teams of quadrotors using differential flatness. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3293–3298. [Google Scholar]
- Endo, M.; Ibuki, T.; Sampei, M. Collision-free formation control for quadrotor networks based on distributed quadratic programs. In Proceedings of the 2019 American Control Conference (ACC), Philadelphia, PA, USA, 10–12 July 2019; pp. 3335–3340. [Google Scholar]
- Ma, H.; Chen, J.; Eben, S.; Lin, Z.; Guan, Y.; Ren, Y.; Zheng, S. Model-based constrained reinforcement learning using generalized control barrier function. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 4552–4559. [Google Scholar]
- Mellinger, D.; Kumar, V. Minimum snap trajectory generation and control for quadrotors. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011; pp. 2520–2525. [Google Scholar]
- Zhou, D.; Schwager, M. Vector field following for quadrotors using differential flatness. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 6567–6572. [Google Scholar]
- Mellinger, D.; Kushleyev, A.; Kumar, V. Mixed-integer quadratic program trajectory generation for heterogeneous quadrotor teams. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation (ICRA), Saint Paul, MN, USA, 14–18 May 2012; pp. 477–483. [Google Scholar]
- Augugliaro, F.; Schoellig, A.P.; D’Andrea, R. Generation of collision-free trajectories for a quadrocopter fleet: A sequential convex programming approach. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 1917–1922. [Google Scholar]
- Preiss, J.A.; Hönig, W.; Ayanian, N.; Sukhatme, G.S. Downwash-aware trajectory planning for large quadrotor teams. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 250–257. [Google Scholar]
- Christofides, P.D.; Scattolini, R.; de la Pena, D.M.; Liu, J. Distributed model predictive control: A tutorial review and future research directions. Comput. Chem. Eng. 2013, 51, 21–41. [Google Scholar] [CrossRef]
- Negenborn, R.R.; De Schutter, B.; Hellendoorn, J. Multi-agent model predictive control for transportation networks: Serial versus parallel schemes. Eng. Appl. Artif. Intell. 2008, 21, 353–366. [Google Scholar] [CrossRef]
- Borrelli, F.; Keviczky, T.; Balas, G.J. Collision-free UAV formation flight using decentralized optimization and invariant sets. In Proceedings of the 2004 43rd IEEE Conference on Decision and Control (CDC), Nassau, Bahamas, 14–17 December 2004; Volume 1, pp. 1099–1104. [Google Scholar]
- Arul, S.H.; Manocha, D. Dcad: Decentralized collision avoidance with dynamics constraints for agile quadrotor swarms. IEEE Robot. Autom. Lett. 2020, 5, 1191–1198. [Google Scholar] [CrossRef]
- Luis, C.E.; Vukosavljev, M.; Schoellig, A.P. Online trajectory generation with distributed model predictive control for multi-robot motion planning. IEEE Robot. Autom. Lett. 2020, 5, 604–611. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar] [CrossRef]
- Halsted, T.; Shorinwa, O.; Yu, J.; Schwager, M. A survey of distributed optimization methods for multi-robot systems. arXiv 2021, arXiv:2103.12840. [Google Scholar]
- Zheng, H.; Negenborn, R.R.; Lodewijks, G. Robust distributed predictive control of waterborne AGVs—A cooperative and cost-effective approach. IEEE Trans. Cybern. 2017, 48, 2449–2461. [Google Scholar] [CrossRef]
- Chen, L.; Hopman, H.; Negenborn, R.R. Distributed model predictive control for vessel train formations of cooperative multi-vessel systems. Transp. Res. Part C Emerg. Technol. 2018, 92, 101–118. [Google Scholar] [CrossRef]
- Rey, F.; Pan, Z.; Hauswirth, A.; Lygeros, J. Fully decentralized admm for coordination and collision avoidance. In Proceedings of the 2018 European Control Conference (ECC), Limassol, Cyprus, 12–15 June 2018; pp. 825–830. [Google Scholar]
- Hagenmeyer, V.; Delaleau, E. Exact feedforward linearization based on differential flatness. Int. J. Control 2003, 76, 537–556. [Google Scholar] [CrossRef]
- Greeff, M.; Schoellig, A.P. Flatness-based model predictive control for quadrotor trajectory tracking. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 6740–6745. [Google Scholar]
- Zhang, Z.; Yang, S.; Xu, W. Decentralized ADMM with compressed and event-triggered communication. Neural Netw. 2023, 165, 472–482. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Xu, W.; Wu, G.; Tian, Z.; Ling, Q. Communication-censored ADMM for decentralized consensus optimization. IEEE Trans. Signal Process. 2019, 67, 2565–2579. [Google Scholar] [CrossRef]
- Dai, X.; Ke, C.; Quan, Q.; Cai, K.Y. RFlySim: Automatic test platform for UAV autopilot systems with FPGA-based hardware-in-the-loop simulations. Aerosp. Sci. Technol. 2021, 114, 106727. [Google Scholar] [CrossRef]
- Mueller, M.W.; D’Andrea, R. A model predictive controller for quadrocopter state interception. In Proceedings of the 2013 European Control Conference (ECC), Zurich, Switzerland, 17–19 July 2013; pp. 1383–1389. [Google Scholar]
- Stellato, B.; Banjac, G.; Goulart, P.; Bemporad, A.; Boyd, S. OSQP: An operator splitting solver for quadratic programs. Math. Program. Comput. 2020, 12, 637–672. [Google Scholar] [CrossRef]
- Lofberg, J. YALMIP: A toolbox for modeling and optimization in MATLAB. In Proceedings of the 2004 IEEE International Conference on Robotics and Automation (ICRA), Taipei, Taiwan, 2–4 September 2004; pp. 284–289. [Google Scholar]
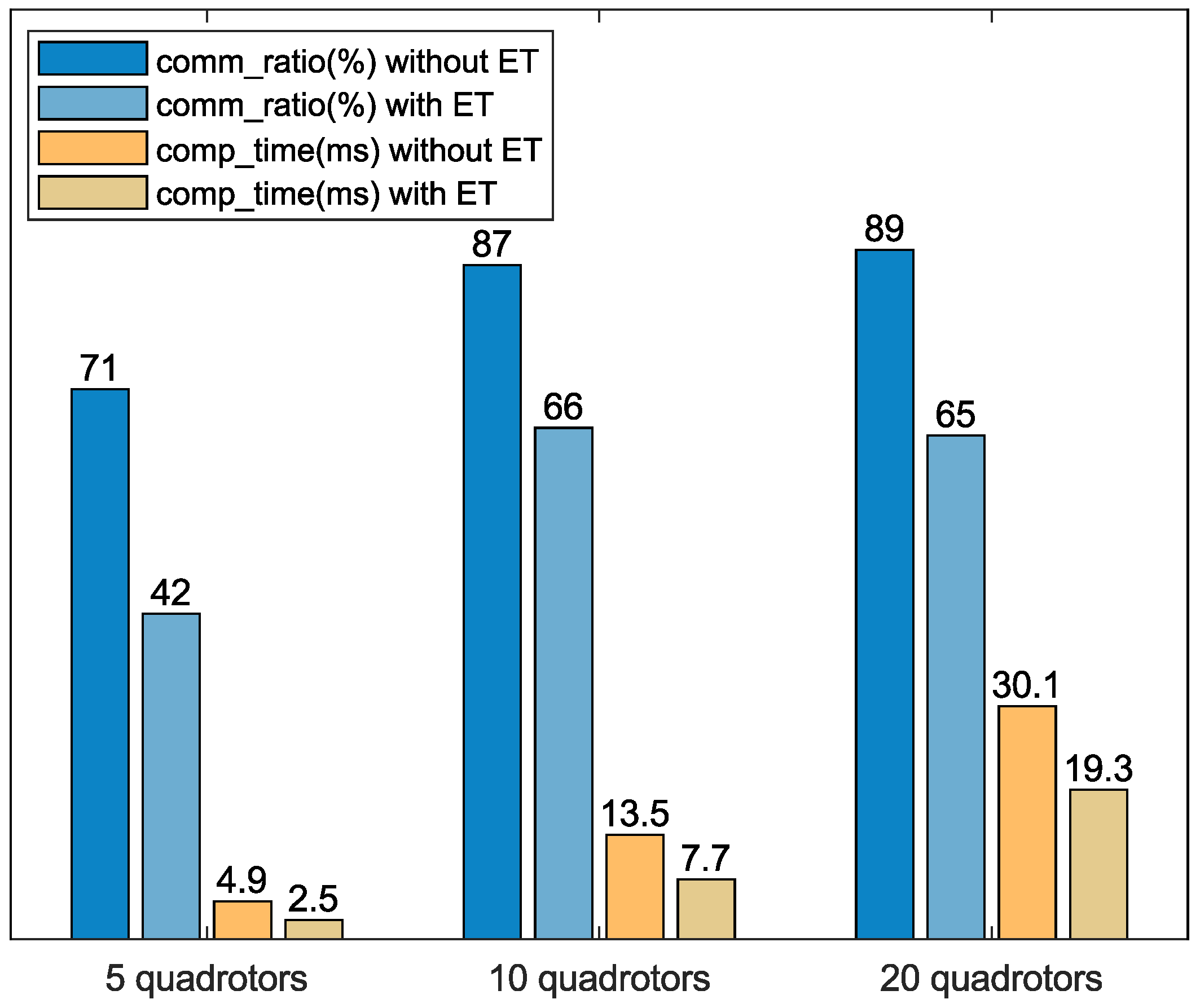
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).