

Deep Reinforcement Learning for Autonomous Driving with an Auxiliary Actor Discriminator


Abstract
1. Introduction
2. Materials and Methods
2.1. Experiment Design and Data Collection
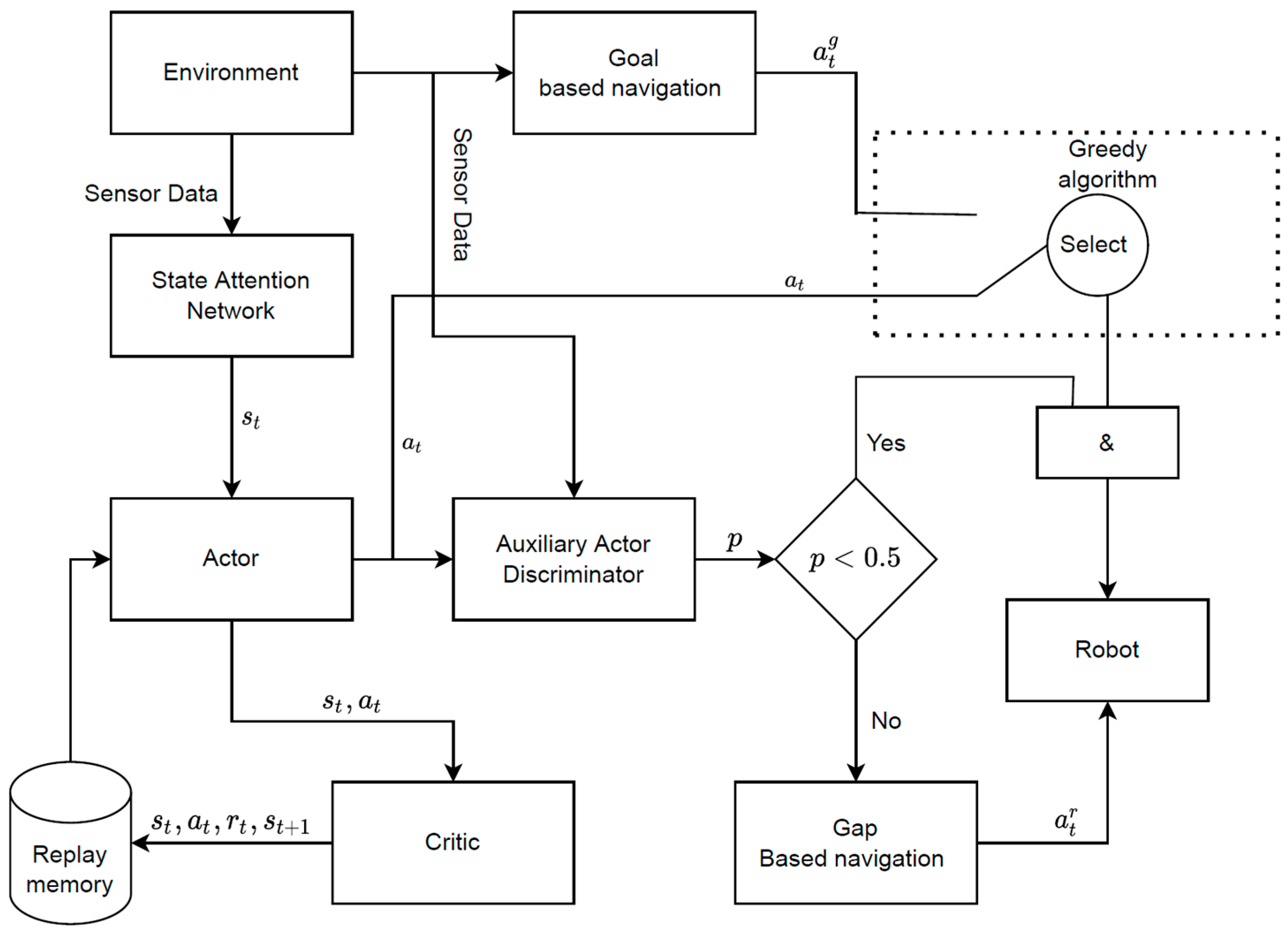
2.2. Model Development
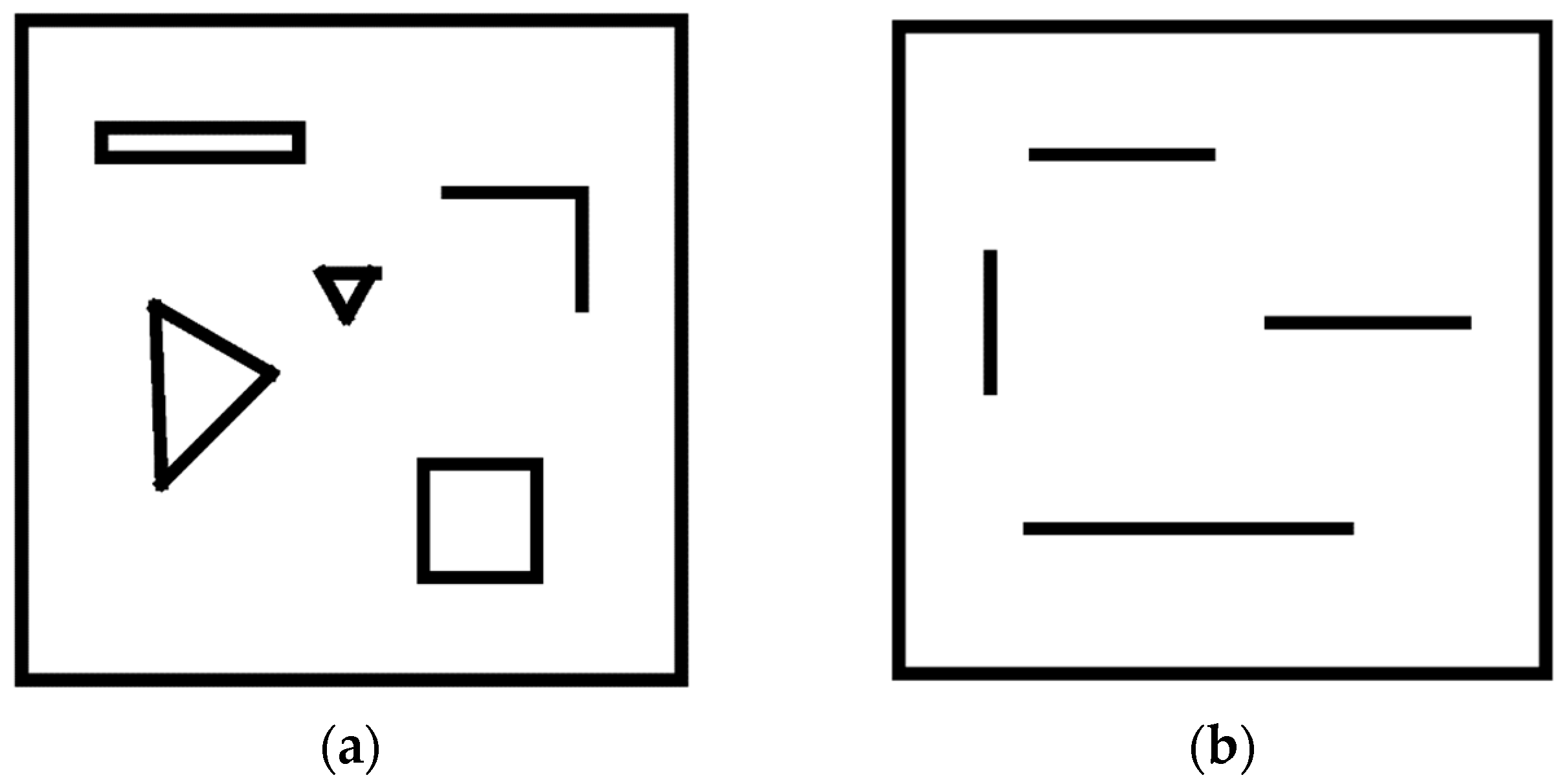
2.3. State Attention Network (SAN)
2.4. Auxiliary Actor Discriminator (AAD)
2.5. Prior Knowledge
| Algorithm 1: Our proposed algorithm |
|
3. Results
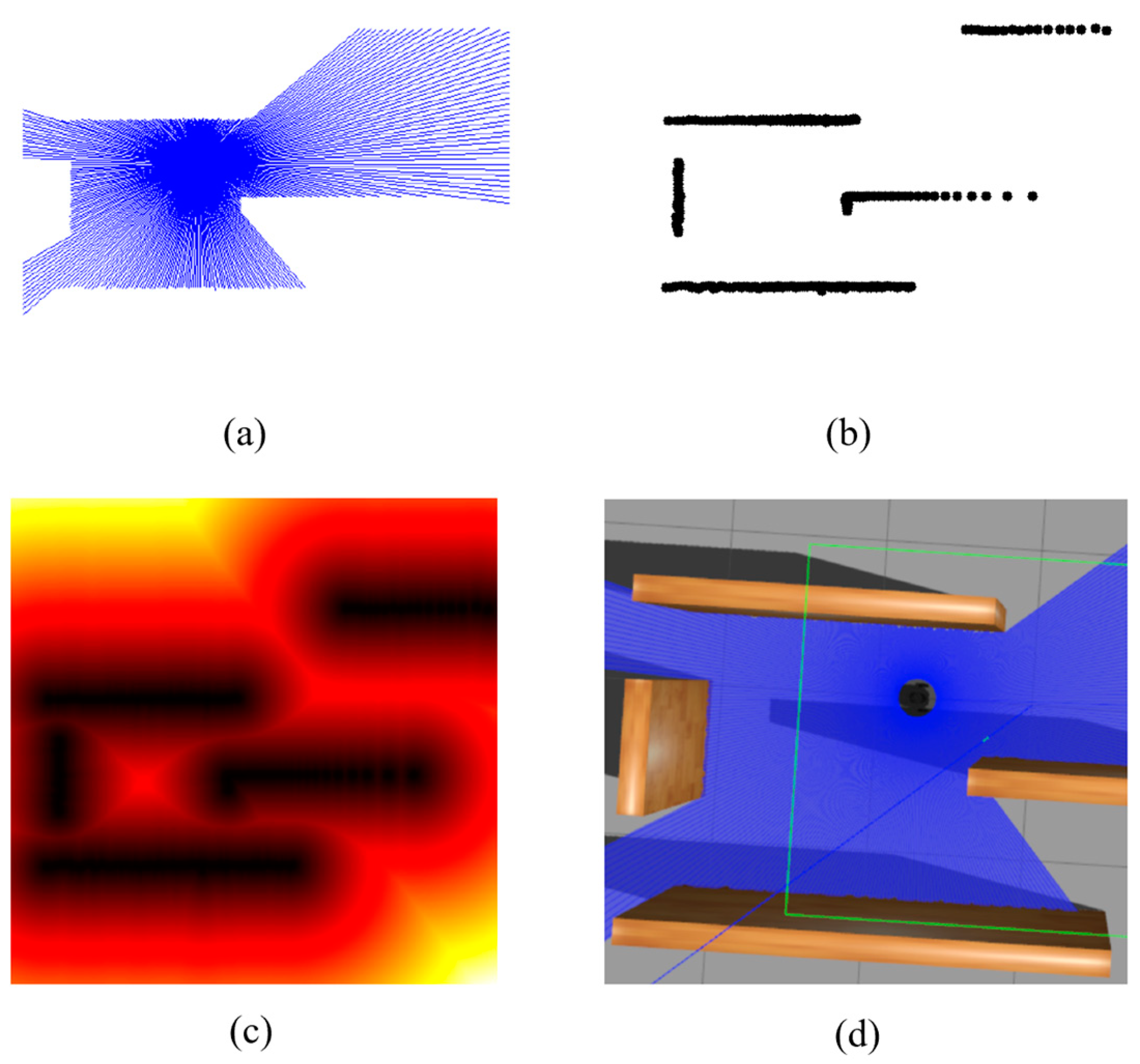
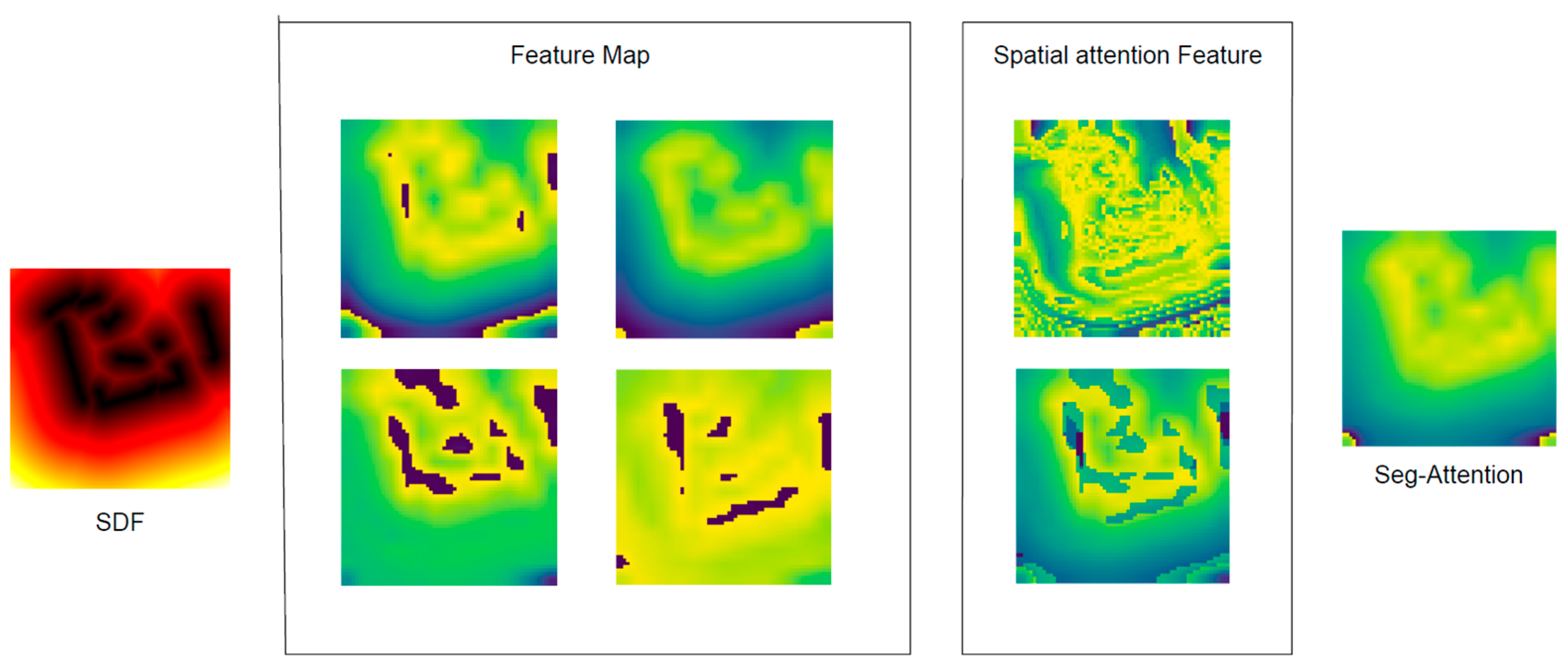
3.1. Radar Data Representation
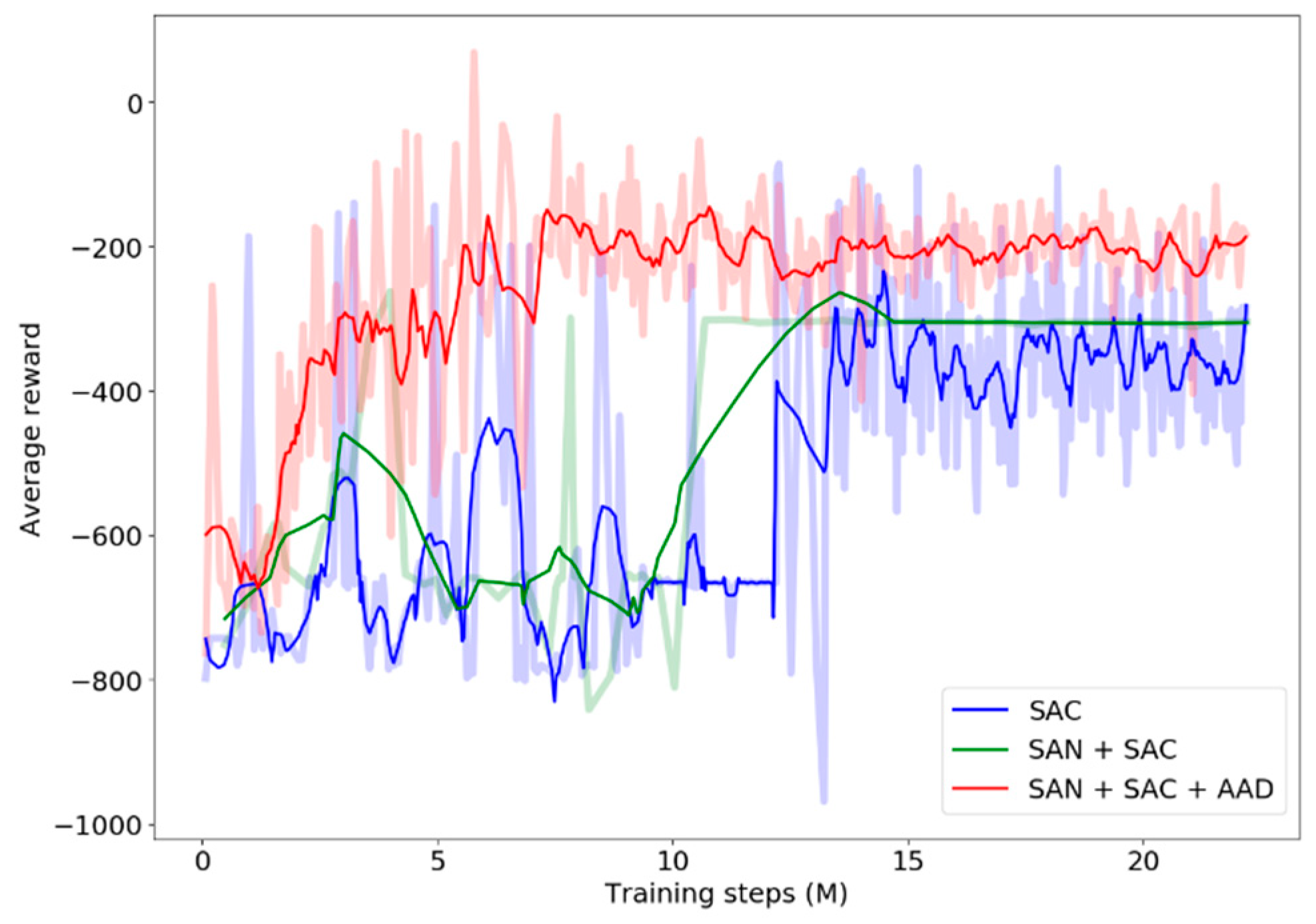
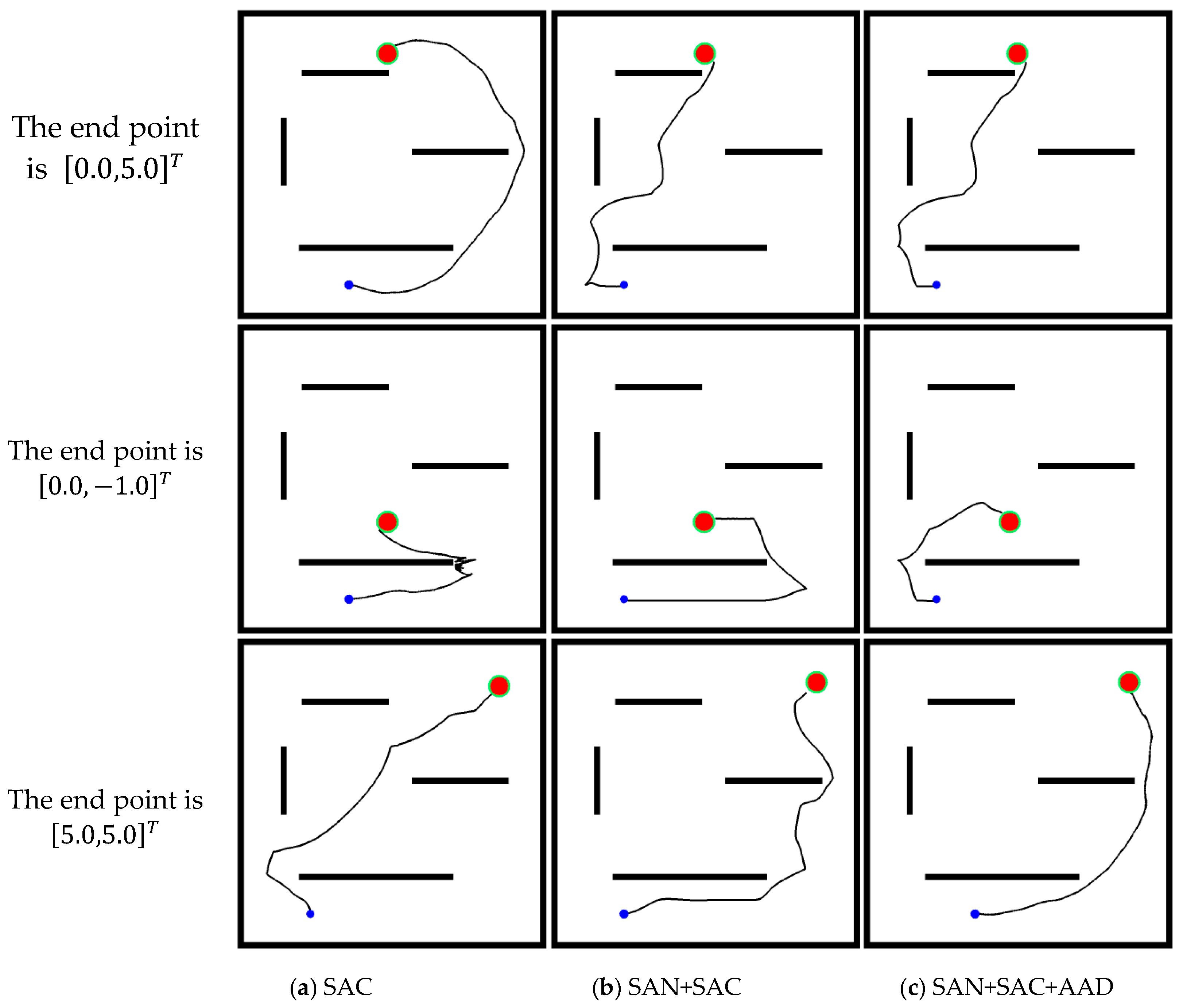
3.2. Model Performance
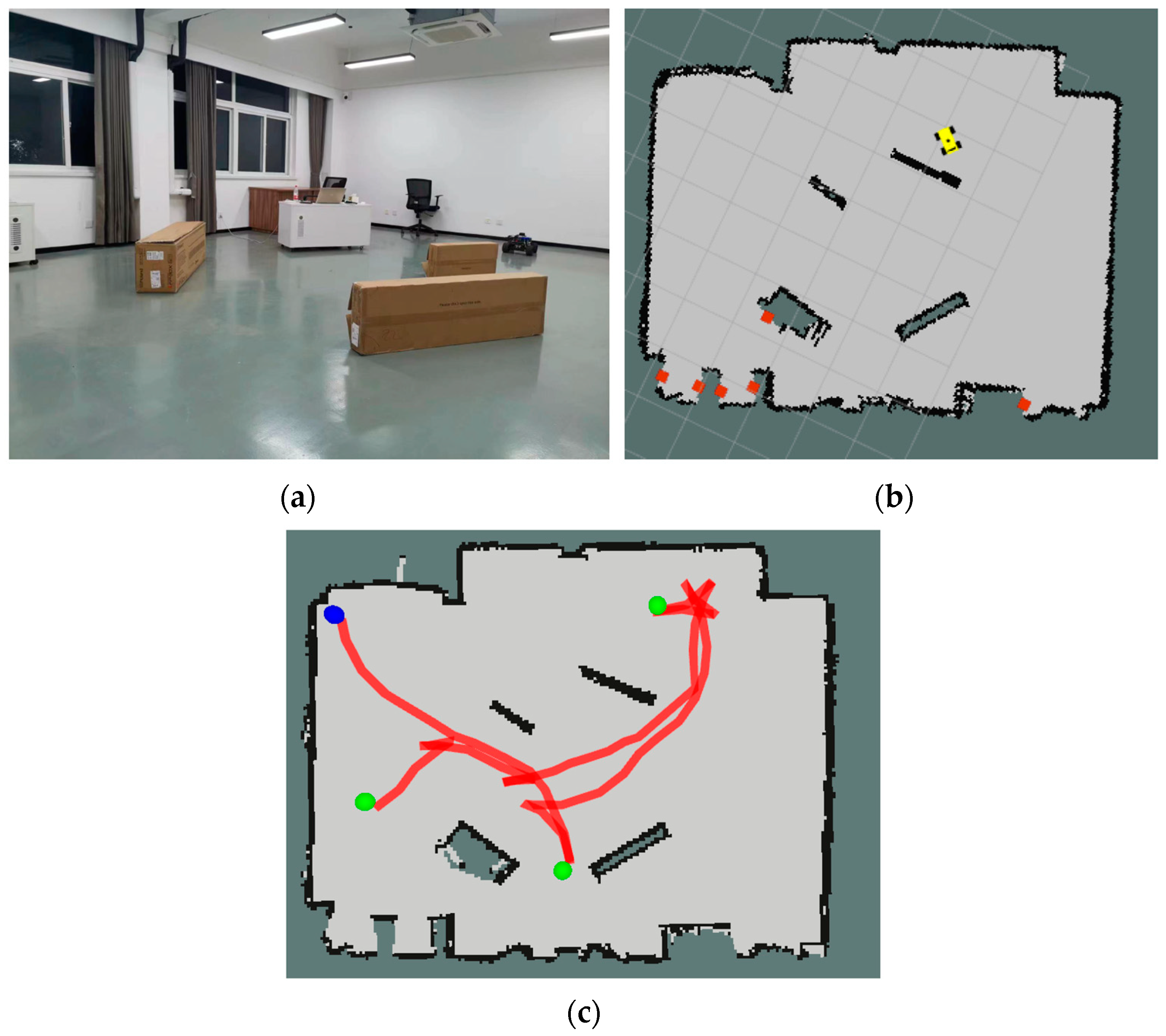
3.3. Real Scenario Validation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Peng, Z.; Wang, D.; Zhang, H.; Sun, G. Distributed neural network control for adaptive synchronization of uncertain dynamical multiagent systems. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 1508–1519. [Google Scholar] [CrossRef] [PubMed]
- Jiang, L.; Huang, H.; Ding, Z. Path planning for intelligent robots based on deep q-learning with experience replay and heuristic knowledge. IEEE/CAA J. Autom. Sin. 2019, 7, 1179–1189. [Google Scholar] [CrossRef]
- Gao, Z.; Qin, J.; Wang, S.; Wang, Y. Boundary Gap Based Reactive Navigation in Unknown Environments. IEEE/CAA J. Autom. Sin. 2021, 8, 468–477. [Google Scholar] [CrossRef]
- Bounini, F.; Gingras, D.; Pollart, H.; Gruyer, D. Modified artificial potential field method for online path planning applications. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–17 June 2017; pp. 180–185. [Google Scholar]
- Cao, X.; Ren, L.; Sun, C. Research on Obstacle Detection and Avoidance of Autonomous Underwater Vehicle Based on Forward-Looking Sonar. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 9198–9208. [Google Scholar] [CrossRef] [PubMed]
- Barraquand, J.; Latombe, J.C. Robot motion planning: A distributed representation approach. Int. J. Robot. Res. 1991, 10, 628–649. [Google Scholar] [CrossRef]
- Zeng, J.; Ju, R.; Qin, L.; Hu, Y.; Hu, C. Navigation in unknown dynamic environments based on deep reinforcement learning. Sensors 2019, 19, 3837. [Google Scholar] [CrossRef]
- Berg, J.; Guy, S.J.; Lin, M.; Manocha, D. Reciprocal n-body collision avoidance. In Robotics Research; Springer: Berlin/Heidelberg, Germany, 2011; pp. 3–19. [Google Scholar]
- Zu, C.; Yang, C.; Wang, J.; Gao, W.; Wang, F.Y. Simulation and field testing of multiple vehicles collision avoidance algorithms. IEEE/CAA J. Autom. Sin. 2020, 7, 1045–1063. [Google Scholar] [CrossRef]
- Jin, J.; Kim, Y.G.; Wee, S.G.; Gans, N. Decentralized cooperative mean approach to collision avoidance for nonholonomic mobile robots. In Proceedings of the 2015 IEEE International Conference on Robotics and Automation (ICRA), Washington, DC, USA, 26–30 May 2015; pp. 35–41. [Google Scholar]
- Boubertakh, H.; Tadjine, M.; Glorennec, P.Y. A new mobile robot navigation method using fuzzy logic and a modified Q-learning algorithm. J. Intell. Fuzzy Syst. 2010, 21, 113–119. [Google Scholar] [CrossRef]
- Zhang, R.; Tang, P.; Su, Y.; Li, X.; Yang, G.; Shi, C. An adaptive obstacle avoidance algorithm for unmanned surface vehicle in complicated marine environments. IEEE/CAA J. Autom. Sin. 2014, 1, 385–396. [Google Scholar]
- Miao, X.; Lee, J.; Kang, B.Y. Scalable coverage path planning for cleaning robots using rectangular map decomposition on large environments. IEEE Access 2018, 6, 38200–38215. [Google Scholar] [CrossRef]
- Barbehenn, M. A note on the complexity of Dijkstra’s algorithm for graphs with weighted vertices. IEEE Trans. Comput. 1998, 47, 263. [Google Scholar] [CrossRef]
- Valtorta, M. A result on the computational complexity of heuristic estimates for the A* algorithm. Inf. Sci. 1984, 34, 47–59. [Google Scholar] [CrossRef]
- Stentz, A. Optimal and efficient path planning for partially known environments. In Intelligent Unmanned Ground Vehicles; Springer: Boston, MA, USA, 1997; pp. 203–220. [Google Scholar]
- LaValle, S.M.; Kuffner, J.J.; Donald, B.R. Rapidly-exploring random trees: Progress and prospects. Algorithmic Comput. Robot. New Dir. 2001, 5, 293–308. [Google Scholar]
- Kavraki, L.E.; Svestka, P.; Latombe, J.C.; Overmars, M.H. Probabilistic roadmaps for path planning in high-dimensional configuration spaces. IEEE Trans. Robot. Autom. 1996, 12, 566–580. [Google Scholar] [CrossRef]
- Khatib, O. Real-time obstacle avoidance for manipulators and mobile robots. In Autonomous Robot Vehicles; Springer: New York, NY, USA, 1986; pp. 396–404. [Google Scholar]
- Alonso-Mora, J.; Breitenmoser, A.; Rufli, M.; Beardsley, P. Optimal reciprocal collision avoidance for multiple non-holonomic robots. In Distributed Autonomous Robotic Systems; Springer: Berlin/Heidelberg, Germany, 2013; pp. 203–216. [Google Scholar]
- Han, R.; Chen, S.; Hao, Q. A Distributed Range-Only Collision Avoidance Approach for Low-cost Large-scale Multi-Robot Systems. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 25–29 October 2020; pp. 8020–8026. [Google Scholar]
- Ataka, A.; Lam, H.K.; Althoefer, K. Reactive magnetic-field-inspired navigation for non-holonomic mobile robots in unknown environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 6983–6988. [Google Scholar]
- Tai, L.; Liu, M. Deep-learning in mobile robotics-from perception to control systems: A survey on why and why not. arXiv 2016, arXiv:1612.07139. [Google Scholar]
- Lowe, R.; Wu, Y.I.; Tamar, A.; Harb, J. Multi-agent actor-critic for mixed cooperative-competitive environments. Adv. Neural Inf. Process. Syst. 2017, 30, 6382–6393. [Google Scholar]
- Everett, M.; Chen, Y.F.; How, J.P. Motion planning among dynamic, decision-making agents with deep reinforcement learning. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 3052–3059. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef]
- Wiering, M.A.; Van Otterlo, M. Reinforcement learning. Adapt. Learn. Optim. 2012, 12, 729. [Google Scholar]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905, 2018. [Google Scholar]
- Christodoulou, P. Soft actor-critic for discrete action settings. arXiv 2019, arXiv:1910.07207. [Google Scholar]
- Yarats, D.; Zhang, A.; Kostrikov, I.; Amos, B.; Pineau, J.; Fergus, R. Improving sample efficiency in model-free reinforcement learning from images. arXiv 2019, arXiv:1910.01741. [Google Scholar] [CrossRef]
- Kiumarsi, B.; Vamvoudakis, K.G.; Modares, H.; Lewis, F.L. Optimal and autonomous control using reinforcement learning: A survey. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 2042–2062. [Google Scholar] [CrossRef] [PubMed]
- Choi, J.; Lee, G.; Lee, C. Reinforcement learning-based dynamic obstacle avoidance and integration of path planning. Intell. Serv. Robot. 2021, 14, 663–677. [Google Scholar] [CrossRef] [PubMed]
- Zhelo, O.; Zhang, J.; Tai, L.; Liu, M.; Burgard, W. Curiosity-driven exploration for mapless navigation with deep reinforcement learning. arXiv 2018, arXiv:1804.00456, 2018. [Google Scholar]
- Wang, C.; Wang, J.; Zhang, X.; Zhang, X. Autonomous navigation of UAV in large-scale unknown complex environment with deep reinforcement learning. In Proceedings of the 2017 IEEE Global Conference on Signal and Information Processing (Glob-alSIP), Montreal, QC, Canada, 14–16 November 2017; pp. 858–862. [Google Scholar]
- Yang, X. An overview of the attention mechanisms in computer vision. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2020; Volume 1693, p. 012173. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Li, X.; Liu, Y.; Wang, K.; Wang, F.-Y. A recurrent attention and interaction model for pedestrian trajectory prediction. IEEE/CAA J. Autom. Sin. 2020, 7, 1361–1370. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Learning rate | 0.001 |
| Update frequency | 1 × 104 |
| Replay memory | 1 × 106 |
| Collision threshold | 0.6 |
| Temperature parameter | 0.5 |
| Mini-batch size | 1024 |
| Discount factor | 0.99 |
| Action selection factor | 0.5 |
| Model | Target Point 1 | Target Point 2 | Target Point 3 | |
|---|---|---|---|---|
| Moving step count | SAC | 1805 | 2049 | 2224 |
| SAN+SAC | 1708 | 1921 | 2085 | |
| SAN+SAC+ADD | 1573 | 1351 | 1558 | |
| Average reward | SAC | −415.26 | −524.36 | −583.46 |
| SAN+SAC | −365.28 | −460.87 | −468.23 | |
| SAN+SAC+ADD | −294.57 | −136.86 | −281.39 |
| Model | Environment I | Environment II | |
|---|---|---|---|
| Moving steps | SAC | 3190 | 2594 |
| SAN+SAC | 2714 | 1793 | |
| SAN+SAC+AAD | 2106 | 1394 | |
| Average train steps (M) | SAC | 15.24 | 9.27 |
| SAN+SAC | 12.68 | 8.26 | |
| SAN+SAC+AAD | 8.72 | 5.48 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, Q.; Chang, F.; Yang, J.; Tao, Y.; Ma, L.; Su, H. Deep Reinforcement Learning for Autonomous Driving with an Auxiliary Actor Discriminator. Sensors 2024, 24, 700. https://doi.org/10.3390/s24020700
Gao Q, Chang F, Yang J, Tao Y, Ma L, Su H. Deep Reinforcement Learning for Autonomous Driving with an Auxiliary Actor Discriminator. Sensors. 2024; 24(2):700. https://doi.org/10.3390/s24020700
Chicago/Turabian StyleGao, Qiming, Fangle Chang, Jiahong Yang, Yu Tao, Longhua Ma, and Hongye Su. 2024. "Deep Reinforcement Learning for Autonomous Driving with an Auxiliary Actor Discriminator" Sensors 24, no. 2: 700. https://doi.org/10.3390/s24020700
APA StyleGao, Q., Chang, F., Yang, J., Tao, Y., Ma, L., & Su, H. (2024). Deep Reinforcement Learning for Autonomous Driving with an Auxiliary Actor Discriminator. Sensors, 24(2), 700. https://doi.org/10.3390/s24020700