

Embedded Processing for Extended Depth of Field Imaging Systems: From Infinite Impulse Response Wiener Filter to Learned Deconvolution

 , , ,
, , ,
Abstract
:1. Introduction
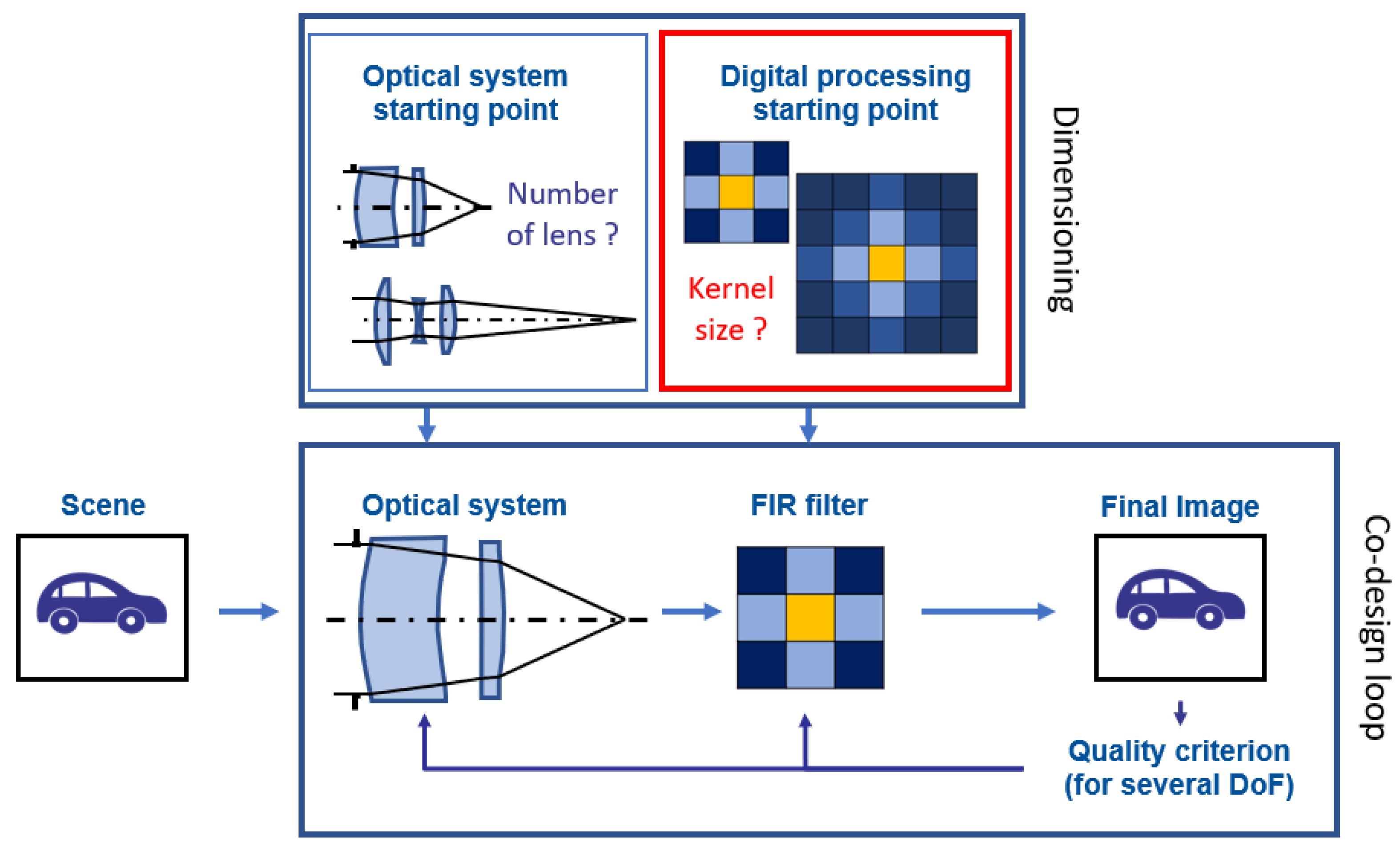
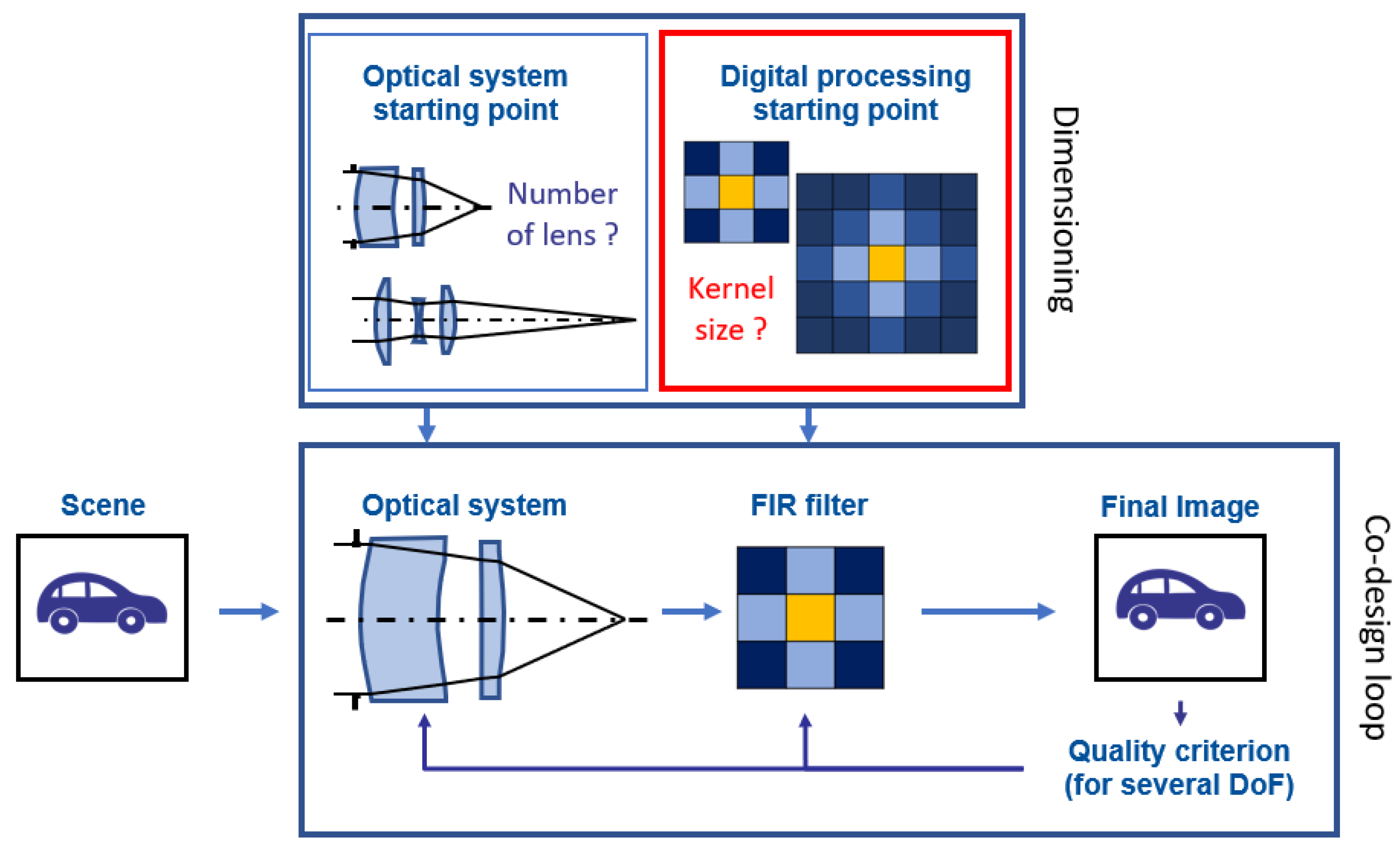
2. Description of the Processing Pipeline
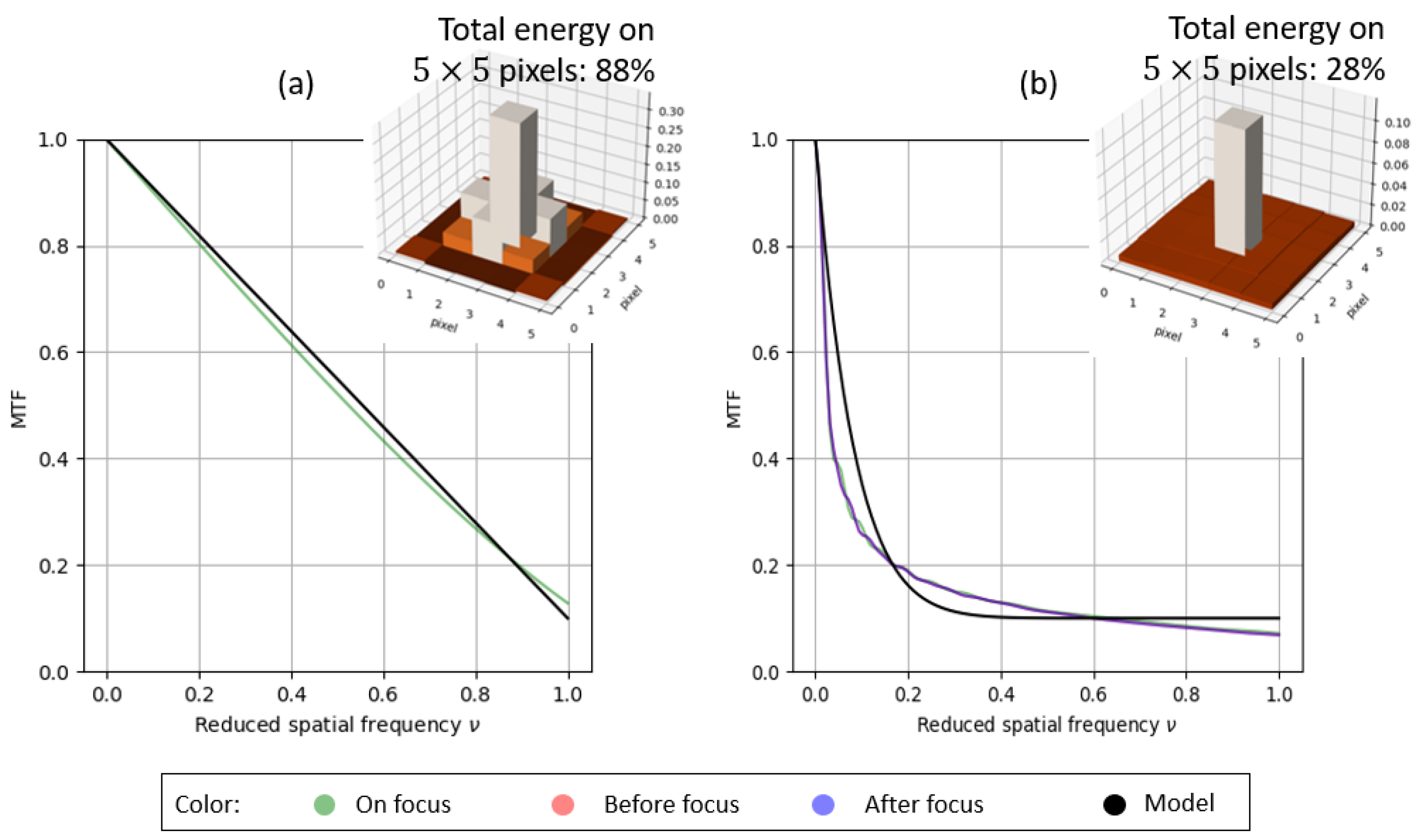
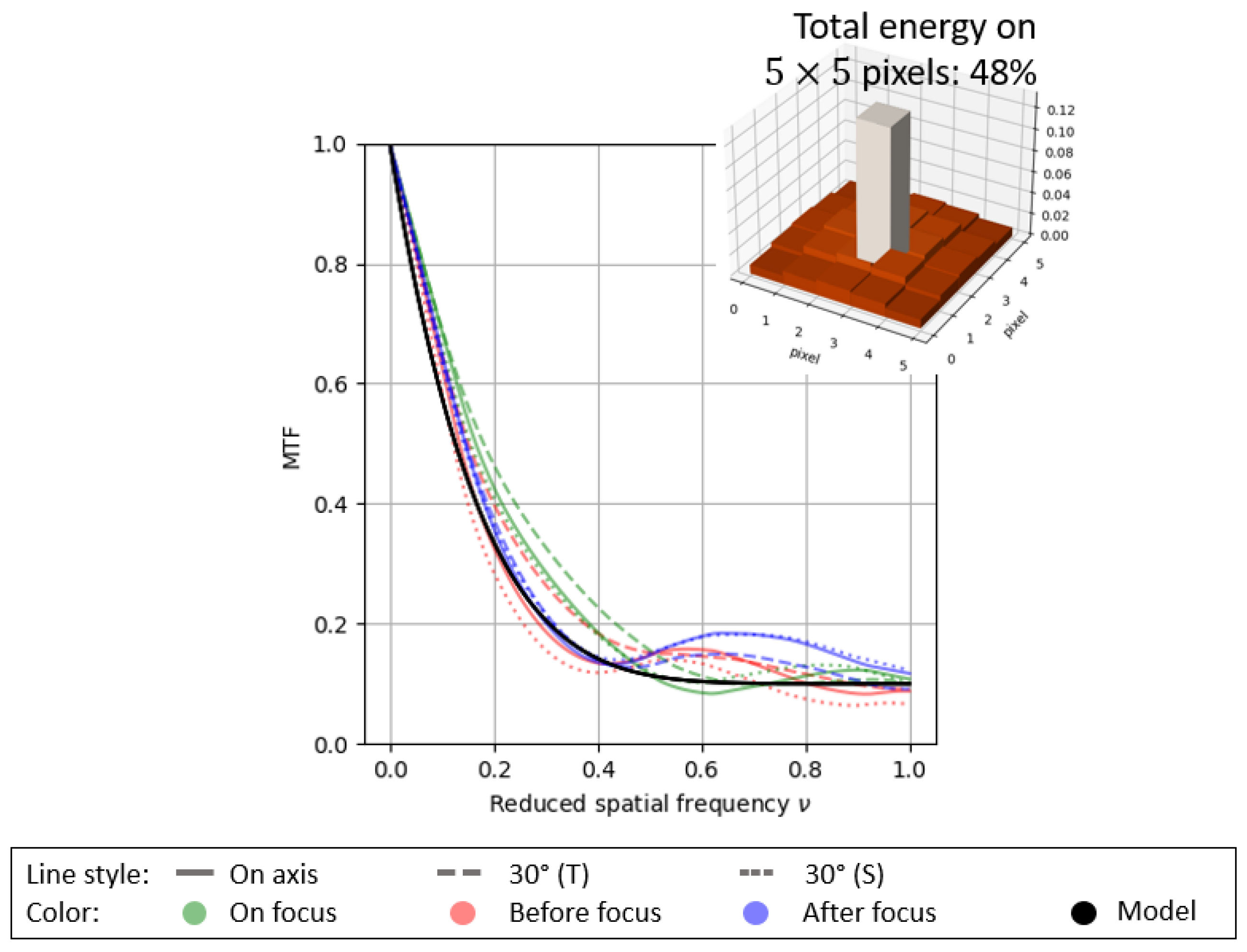
2.1. PSD Model and Image Database
2.2. PSF Model for System with Extended DoF
2.3. The MSE Criterion
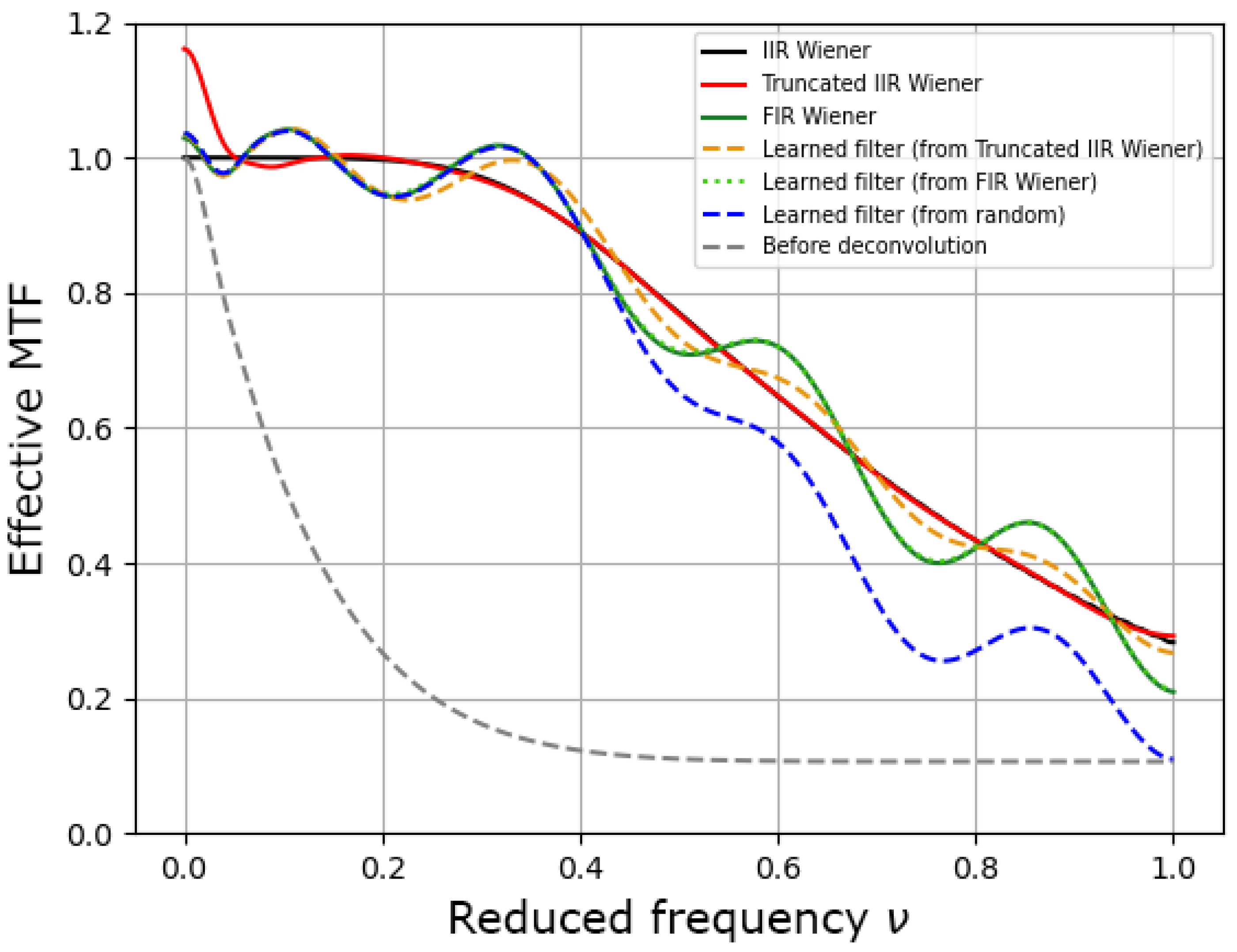
2.4. Different FIR Filters
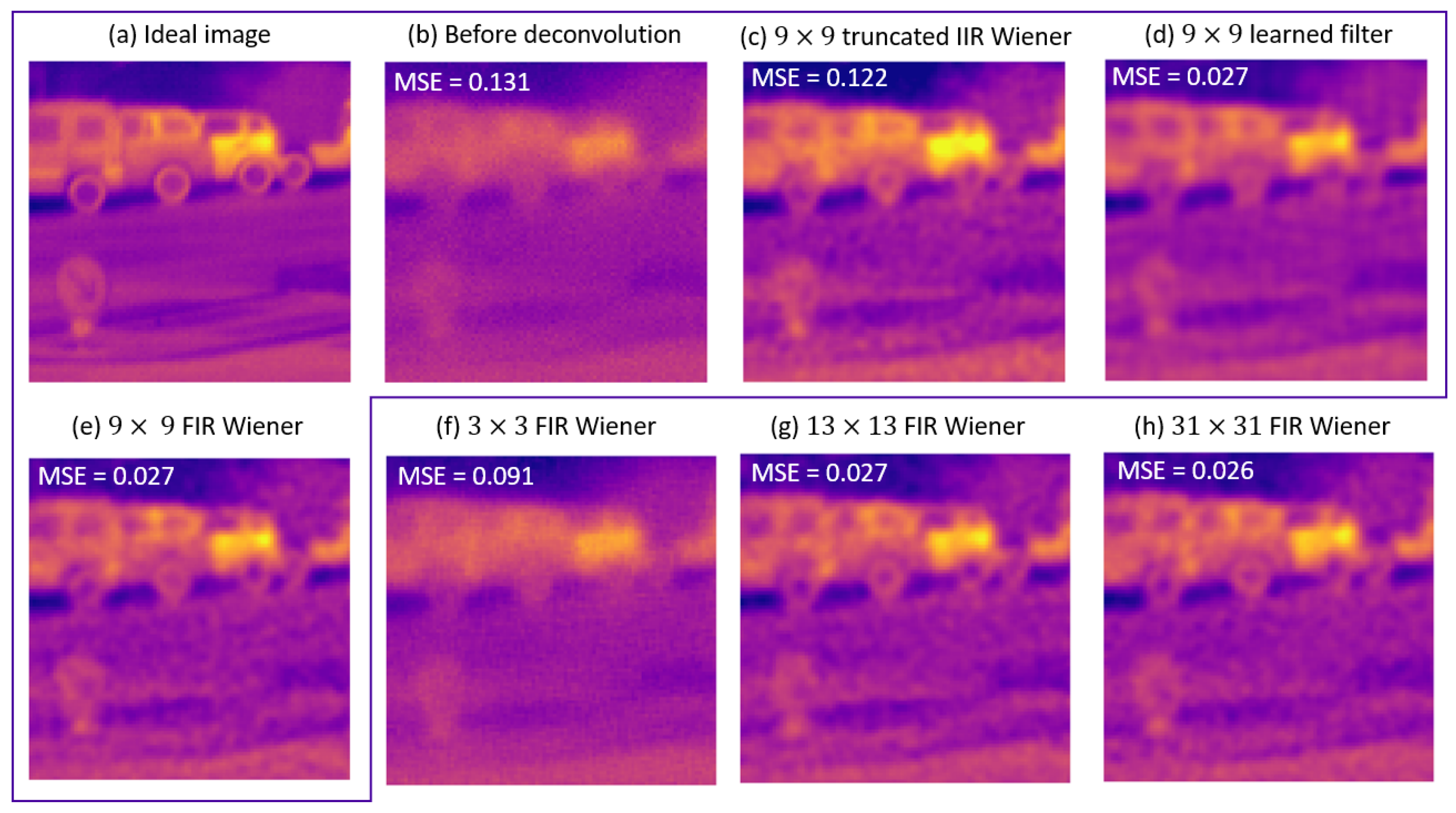
- The simplest approach is to truncate the IIR Wiener filter, in the direct space, to the chosen kernel size . It will be noted as the “Truncated IIR Wiener filter” in the following. Since we consider small kernel sizes, we use a simple rectangular windowing and no apodization, which is in contrast with [26,27,28,29].
- A second approach consists of optimizing a “FIR Wiener filter”, i.e., finding the best linear filter under the constraint of a finite kernel size [22]. It needs the autocorrelation of the scene for its construction, which is calculated from the scene PSD using a Fourier transform.
- Finally, the “learned filter” corresponds to the minimization over the filter coefficients of the MSE criterion averaged on an image database (which plays the role of the scene PSD). We use the Adam optimizer for that, with a batch size of 10 and as the learning rate. The choice of starting point will be discussed in Section 3.
3. Results
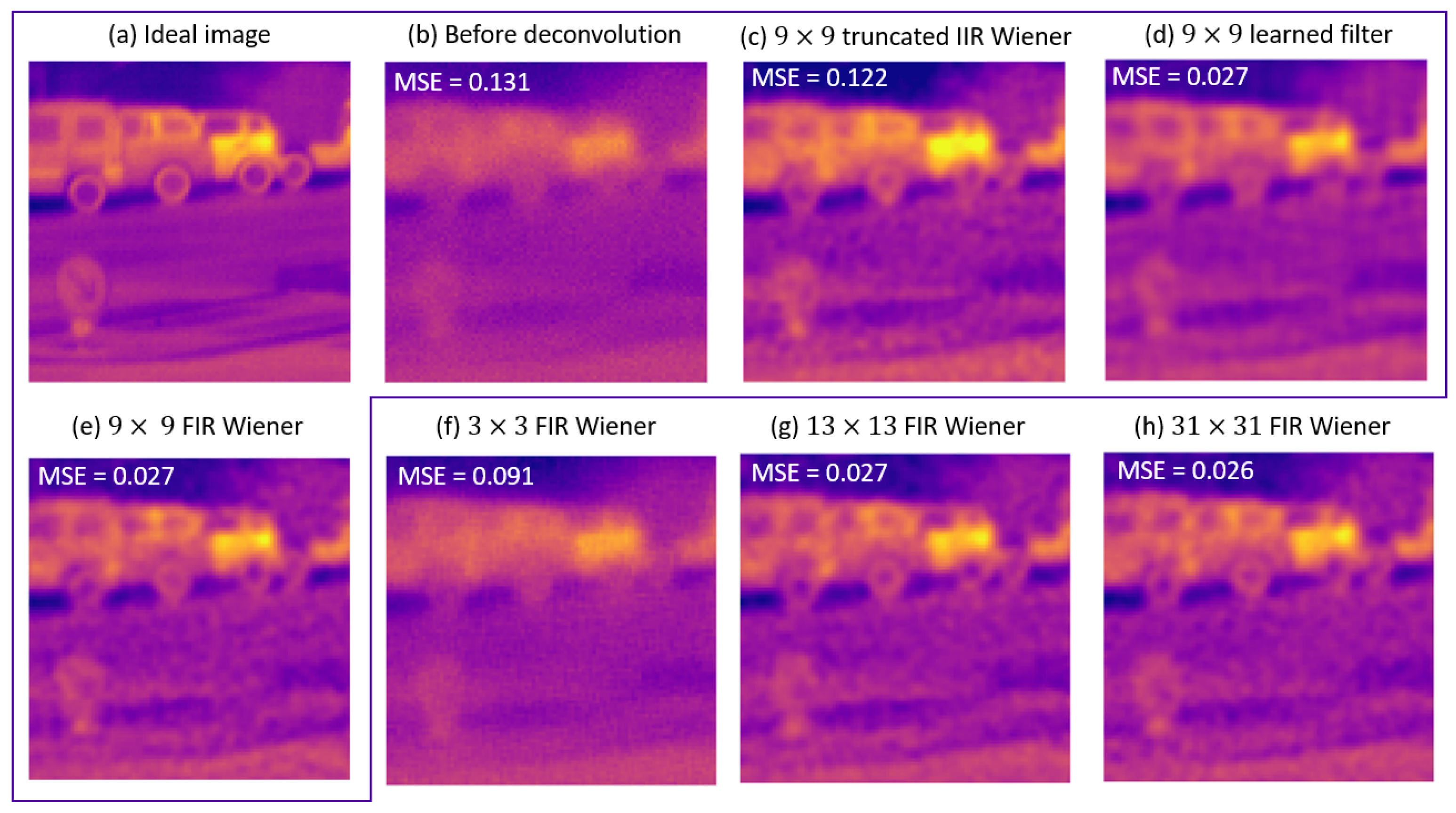
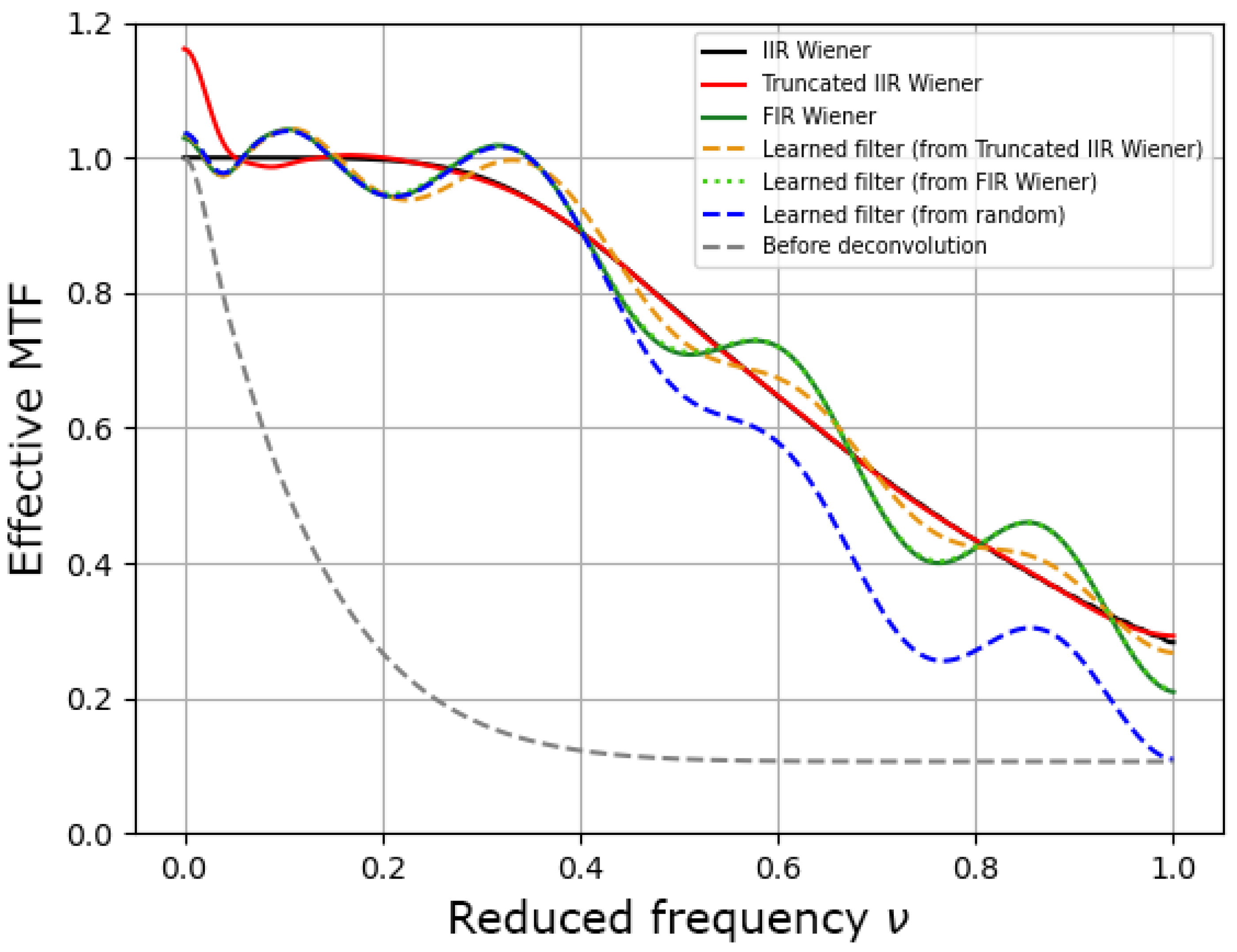
3.1. First Case Study
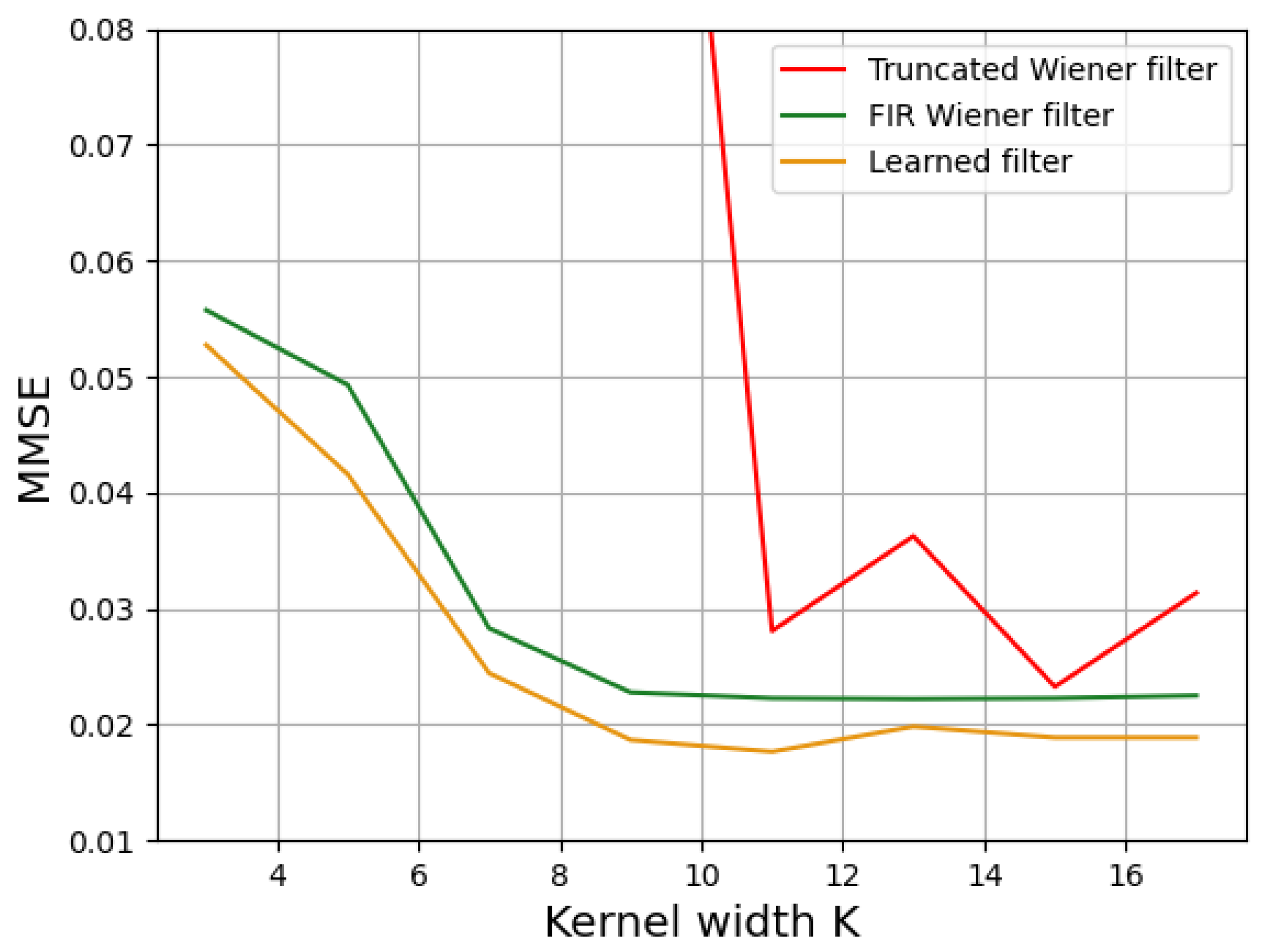
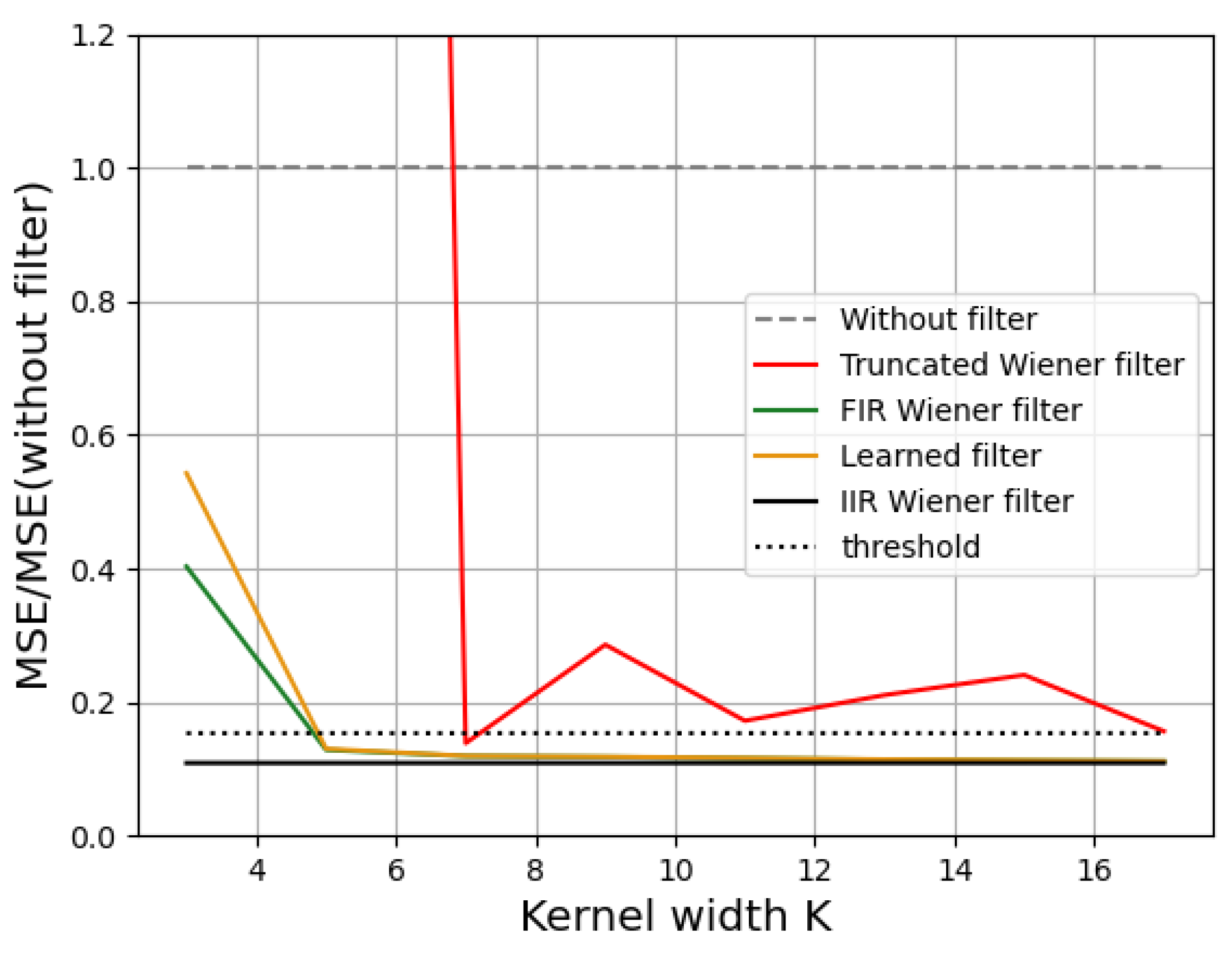
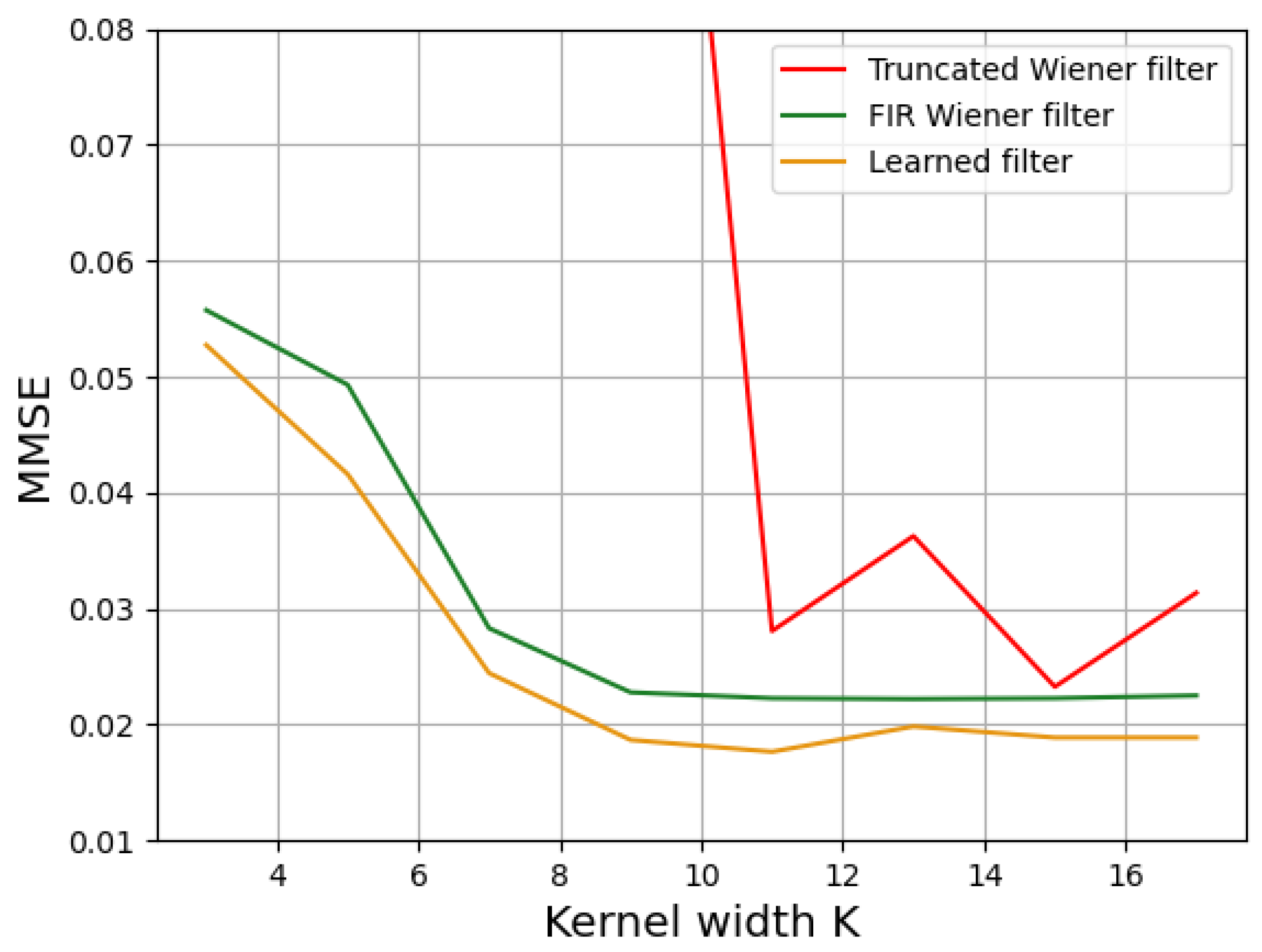
3.2. Impact of Deconvolution Kernel Size on Image Quality
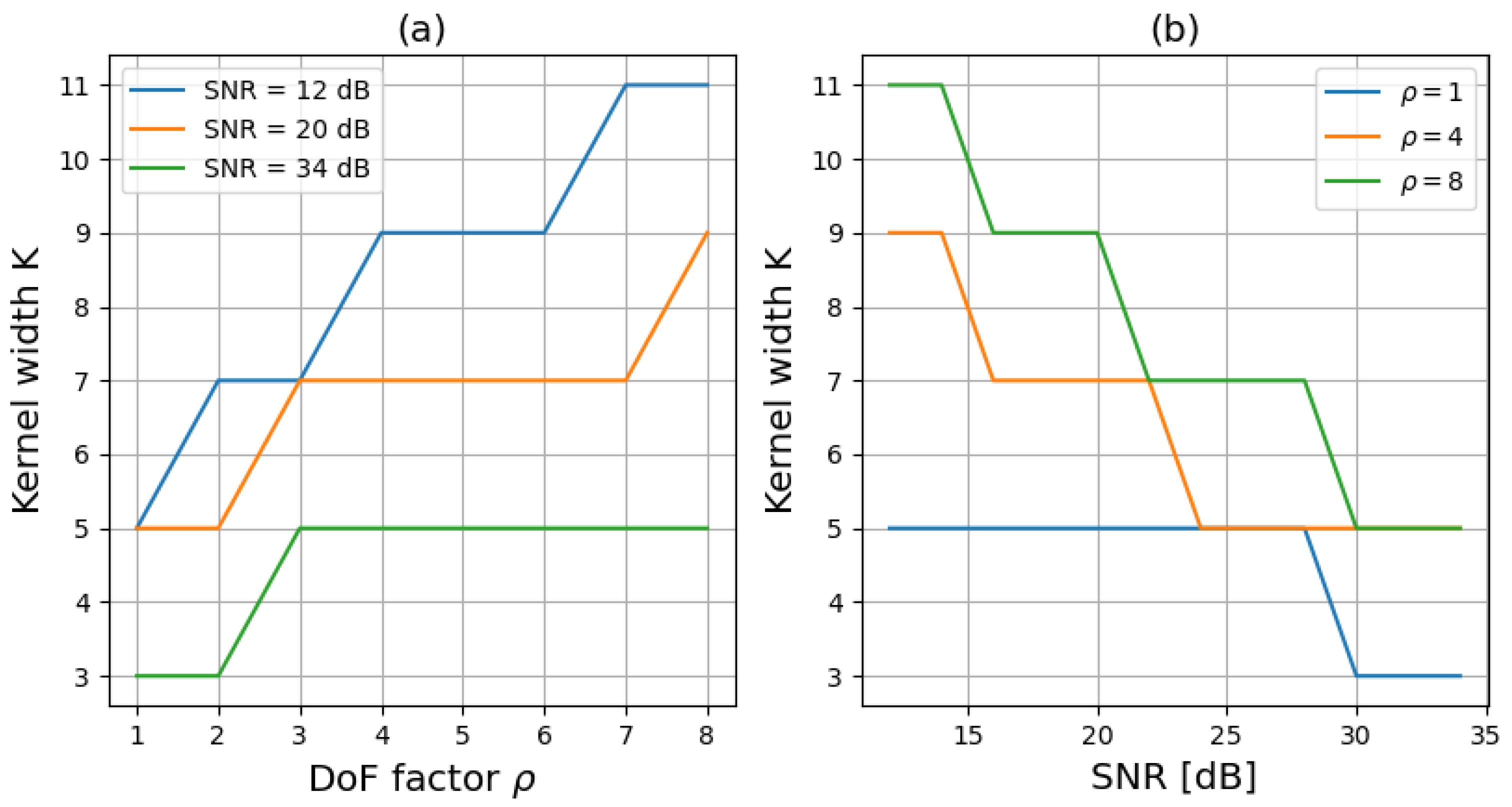
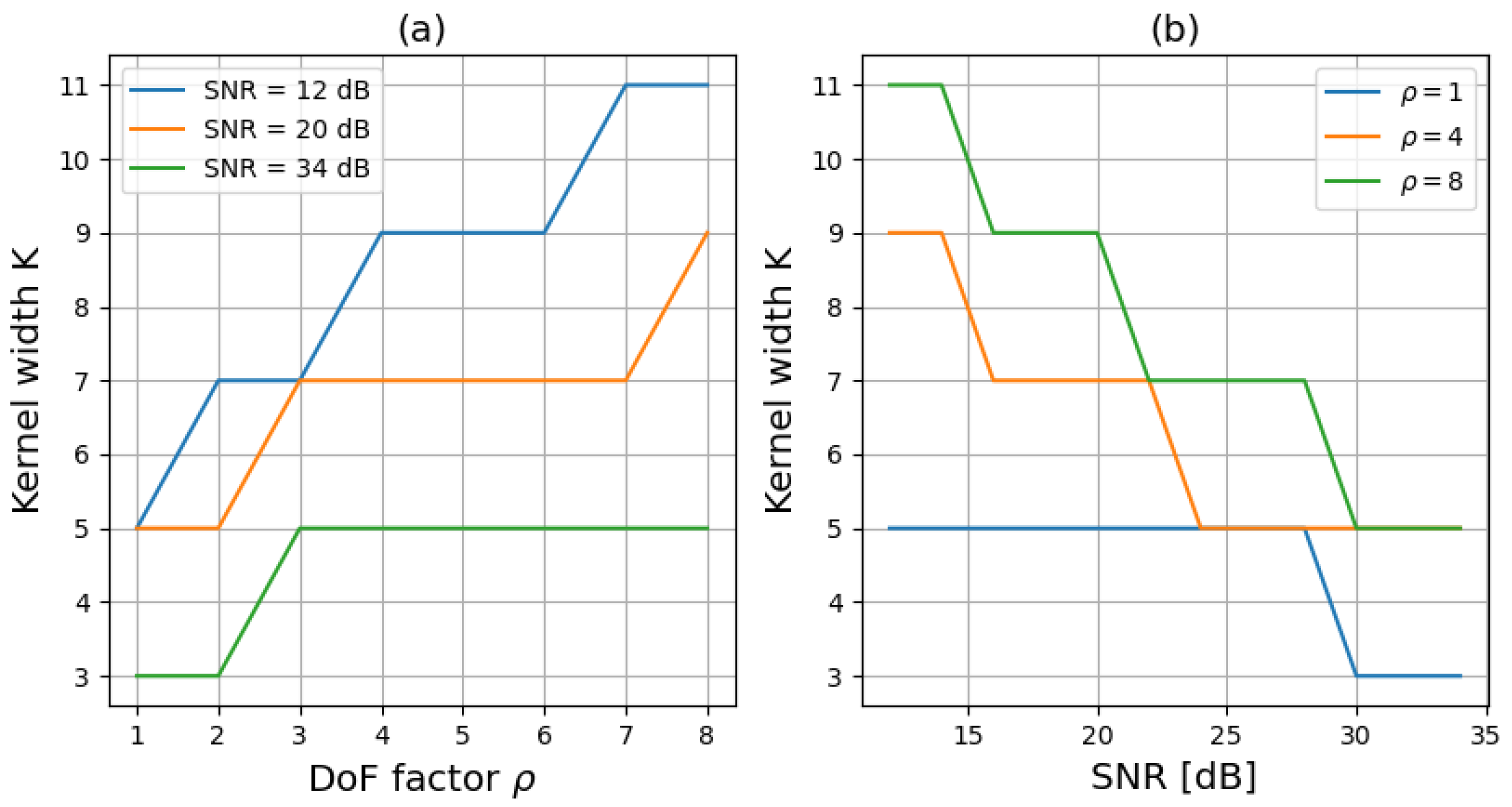
3.3. Method for Choosing the Kernel Size
3.4. Robustness on Real Images
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| DoF | Depth of Field |
| PSF | Point Spread Function |
| IIR | Infinite Impulse Response |
| FIR | Finite Impulse Response |
| SNR | Signal-to-Noise Ratio |
| MTF | Modulation Transfer Function |
| MSE | Mean Square Error |
| PSD | Power Spectral Density |
References
- Dowski, E.R.; Cathey, W.T. Extended depth of field through wave-front coding. Appl. Opt. 1995, 34, 1859. [Google Scholar] [CrossRef] [PubMed]
- Fontbonne, A.; Sauer, H.; Goudail, F. End-to-end optimization of optical systems with extended depth of field under wide spectrum illumination. Appl. Opt. 2022, 61, 5358. [Google Scholar] [CrossRef] [PubMed]
- Elmalem, S.; Giryes, R.; Marom, E. Learned phase coded aperture for the benefit of depth of field extension. Opt. Express 2018, 26, 15316. [Google Scholar] [CrossRef] [PubMed]
- Sun, Q.; Wang, C.; Fu, Q.; Dun, X.; Heidrich, W. End-to-end complex lens design with differentiate ray tracing. ACM Trans. Graph. 2021, 40, 1–13. [Google Scholar] [CrossRef]
- Tseng, E.; Mosleh, A.; Mannan, F.; St-Arnaud, K.; Sharma, A.; Peng, Y.; Braun, A.; Nowrouzezahrai, D.; Lalonde, J.F.; Heide, F. Differentiable Compound Optics and Processing Pipeline Optimization for End-to-end Camera Design. ACM Trans. Graph. 2021, 40, 1–19. [Google Scholar] [CrossRef]
- Halé, A.; Trouvé-Peloux, P.; Volatier, J.B. End-to-end sensor and neural network design using differential ray tracing. Opt. Express 2021, 29, 34748. [Google Scholar] [CrossRef]
- Li, Y.; Wang, J.; Zhang, X.; Hu, K.; Ye, L.; Gao, M.; Cao, Y.; Xu, M. Extended depth-of-field infrared imaging with deeply learned wavefront coding. Opt. Express 2022, 30, 40018. [Google Scholar] [CrossRef]
- Zhang, R.; Tan, F.; Hou, Q.; Li, Z.; Sun, Z.; Yang, C.; Gao, X. End-to-end learned single lens design using improved Wiener deconvolution. Opt. Lett. 2023, 48, 522. [Google Scholar] [CrossRef]
- Yang, X.; Fu, Q.; Heidrich, W. Curriculum Learning for ab initio Deep Learned Refractive Optics. arXiv 2023, arXiv:2302.01089. Available online: http://xxx.lanl.gov/abs/2302.01089 (accessed on 13 September 2023).
- Dong, L.; Du, H.; Liu, M.; Zhao, Y.; Li, X.; Feng, S.; Liu, X.; Hui, M.; Kong, L.; Hao, Q. Extended-depth-of-field object detection with wavefront coding imaging system. Pattern Recognit. Lett. 2019, 125, 597–603. [Google Scholar] [CrossRef]
- Makarkin, M.; Bratashov, D. State-of-the-Art Approaches for Image Deconvolution Problems, including Modern Deep Learning Architectures. Micromachines 2021, 12, 1558. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Ren, W.; Luo, W.; Lai, W.S.; Stenger, B.; Yang, M.H.; Li, H. Deep Image Deblurring: A Survey. Int. J. Comput. Vis. 2022, 130, 2103–2130. [Google Scholar] [CrossRef]
- Robinson, M.D.; Stork, D.G. Joint design of lens systems and digital image processing. In Proceedings of the International Optical Design Conference 2006, Vancouver, BC, Canada, 4–8 June 2006; Gregory, G.G., Howard, J.M., Koshel, R.J., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2006; Volume 6342, p. 63421G. [Google Scholar] [CrossRef]
- Bryant, K.; Edwards, W.D.; Rogers, R.K. Low-cost computational imaging infrared sensor. In Proceedings of the Infrared Imaging Systems: Design, Analysis, Modeling, and Testing XXV, Baltimore, MD, USA, 6–8 May 2014; Holst, G.C., Krapels, K.A., Ballard, G.H., Buford, J.A., Jr., Lee Murrer, R., Jr., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2014; Volume 9071, p. 90710H. [Google Scholar] [CrossRef]
- Burcklen, M.A.; Diaz, F.; Lepretre, F.; Rollin, J.; Delboulbe, A.; Lee, M.S.L.; Loiseaux, B.; Koudoli, A.; Denel, S.; Millet, P.; et al. Experimental demonstration of extended depth-of-field f/1.2 visible High Definition camera with jointly optimized phase mask and real-time digital processing. J. Eur. Opt. Soc. Rapid Publ. 2015, 10, 15046. [Google Scholar] [CrossRef]
- Chou, C.J.; Mohanakrishnan, S.; Evans, J.B. FPGA implementation of digital filters. Proc. Icspat. Citeseer 1993, 93, 1. [Google Scholar]
- Nayak, S.; Nayak, M.; Matri, S.; Sharma, K.P. Synthesis and Analysis of Digital IIR Filters for Denoising ECG Signal on FPGA. In Evolving Networking Technologies; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2023; Chapter 12; pp. 189–210. [Google Scholar] [CrossRef]
- Rajalakshmi, R.; Vishnupriya, G.; Sudharsanan, R.; Navaneethan, S.; Vijayakumari, P.; Karthikeyan, M.V. Digital Filter Design on High speed Communication with Low Power Criteria. In Proceedings of the 2023 International Conference on Computer Communication and Informatics (ICCCI), Coimbatore, India, 23–25 January 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Pinilla, S.; Miri Rostami, S.R.; Shevkunov, I.; Katkovnik, V.; Egiazarian, K. Hybrid diffractive optics design via hardware-in-the-loop methodology for achromatic extended-depth-of-field imaging. Opt. Express 2022, 30, 32633. [Google Scholar] [CrossRef] [PubMed]
- Pant, L.; Singh, M.; Chandra, K.; Mishra, V.; Pandey, N.; Pant, K.; Khan, G.S.; Sakher, C. Development of cubic freeform optical surface for wavefront coding application for extended depth of field Infrared camera. Infrared Phys. Technol. 2022, 127, 104377. [Google Scholar] [CrossRef]
- Lopez-Ramirez, M.; Ledesma-Carrillo, L.; Cabal-Yepez, E.; Botella, G.; Rodriguez-Donate, C.; Ledesma, S. FPGA-based methodology for depth-of-field extension in a single image. Digit. Signal Process. 2017, 70, 14–23. [Google Scholar] [CrossRef]
- Reichenbach, S.; Park, S. Small convolution kernels for high-fidelity image restoration. IEEE Trans. Signal Process. 1991, 39, 2263–2274. [Google Scholar] [CrossRef]
- Balit, E.; Chadli, A. GMFNet: Gated Multimodal Fusion Network for Visible-Thermal Semantic Segmentation. 2020, pp. 1–4. Available online: https://neovision.fr/wp-content/uploads/2021/02/Papier-ECCV.pdf (accessed on 7 February 2023).
- Sheng, J.; Cai, H.; Wang, Y.; Chen, X.; Xu, Y. Improved Exponential Phase Mask for Generating Defocus Invariance of Wavefront Coding Systems. Appl. Sci. 2022, 12, 5290. [Google Scholar] [CrossRef]
- Fontbonne, A.; Sauer, H.; Goudail, F. Comparison of methods for end-to-end co-optimization of optical systems and image processing with commercial lens design software. Opt. Express 2022, 30, 13556. [Google Scholar] [CrossRef]
- Harris, F. On the use of windows for harmonic analysis with the discrete Fourier transform. Proc. IEEE 1978, 66, 51–83. [Google Scholar] [CrossRef]
- Saramaki, T. Finite Impulse Response Filter Design. In Handbook for Digital Signal Processing; Wiley-Interscience: Hoboken, NJ, USA, 1993. [Google Scholar]
- Vollmerhausen, R. Design of finite impulse response deconvolution filters. Appl. Opt. 2010, 49, 5814. [Google Scholar] [CrossRef] [PubMed]
- Uzo, H.N.; Nonyelu, H.U.; Eneh, J.N.; Ozue, T.I.; Anoliefo, E.C.; Chijindu, V.C.; Oparaku, O.U. FIR Filter Design using Raised Semi-ellipse Window Function. Indones. J. Electr. Eng. Inform. 2022, 10, 592–603. [Google Scholar] [CrossRef]
- Cimpoi, M.; Maji, S.; Kokkinos, I.; Mohamed, S.; Vedaldi, A. Describing Textures in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image Quality Assessment: From Error Visibility to Structural Similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IIR Wiener | Truncated IIR Wiener | FIR Wiener | Random | |
|---|---|---|---|---|
| Before learning | - | |||
| After learning | - |
| No Filter | Truncated IIR Wiener | FIR Wiener | Learned Filter | |
|---|---|---|---|---|
| MMSE | ||||
| SSIM |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fontbonne, A.; Trouvé-Peloux, P.; Champagnat, F.; Jobert, G.; Druart, G. Embedded Processing for Extended Depth of Field Imaging Systems: From Infinite Impulse Response Wiener Filter to Learned Deconvolution. Sensors 2023, 23, 9462. https://doi.org/10.3390/s23239462
Fontbonne A, Trouvé-Peloux P, Champagnat F, Jobert G, Druart G. Embedded Processing for Extended Depth of Field Imaging Systems: From Infinite Impulse Response Wiener Filter to Learned Deconvolution. Sensors. 2023; 23(23):9462. https://doi.org/10.3390/s23239462
Chicago/Turabian StyleFontbonne, Alice, Pauline Trouvé-Peloux, Frédéric Champagnat, Gabriel Jobert, and Guillaume Druart. 2023. "Embedded Processing for Extended Depth of Field Imaging Systems: From Infinite Impulse Response Wiener Filter to Learned Deconvolution" Sensors 23, no. 23: 9462. https://doi.org/10.3390/s23239462
APA StyleFontbonne, A., Trouvé-Peloux, P., Champagnat, F., Jobert, G., & Druart, G. (2023). Embedded Processing for Extended Depth of Field Imaging Systems: From Infinite Impulse Response Wiener Filter to Learned Deconvolution. Sensors, 23(23), 9462. https://doi.org/10.3390/s23239462