1. Introduction
The challenges encountered in the realm of computer vision often present a high degree of complexity. To address these complexities effectively, it is common to employ a range of sensors that work collaboratively to augment the information gathered from the scene and the objects within it. The integration of diverse sensors frequently leads to solutions that not only enhance accuracy but also bolster robustness [
1]. 3D LiDAR (Light Detection and Ranging) sensors and thermal cameras, valued for their accurate point clouds and heat information receptivity, are gaining attention for use in data fusion. Extrinsically calibrating these sensors, each with its own coordinate system, is essential for their accurate data integration.
3D LiDAR sensors have emerged as one of the most popular sensors in fields such as agriculture, autonomous vehicles, and robotics. Some of their applications include odometry and SLAM (Simultaneous Localization and Mapping) [
2] in robotics, semantic scene understanding [
3], and 3D object detection [
4] in self-driving cars, forest attribute estimation [
5], and precision farming [
6].
A LiDAR sensor produces a 3D point cloud where each point is precisely defined by its x, y, and z LIDAR coordinates. Furthermore, this point cloud includes data regarding the strength of the reflected laser pulse at each point. Consequently, a LiDAR sensor does not offer supplementary information for individual points, such as color. However, when we integrate LiDAR data with additional data from other sensors, it becomes feasible to improve performance across a range of tasks. For instance, in the study by Xu et al. [
7], LiDAR data was combined with data from an RGB camera to enhance 3D object detection.
Thermal cameras have gained attention as alternative sensors to fuse with LiDAR data due to their ability to create high-quality images based on temperature differences in objects and their surroundings, even in adverse conditions like darkness, snow, dust, smoke, fog, and rain [
8]. Because thermal cameras can capture spectra that other sensors like visual light cameras cannot, they have numerous applications in agriculture, security, healthcare, the food industry, aerospace, and the defense industry, among others [
9,
10].
Combining data from 3D LiDAR sensors and thermal cameras can yield the benefits of both sensors simultaneously. By leveraging both 3D spatial information and heat signatures, a more comprehensive and accurate representation of the environment is achieved. This integration enhances overall situational awareness, robustness, and accuracy across many tasks, especially when compared with the use of either technology in isolation. For example, in any application involving the heat data of a scene and its objects, it can be augmented with LiDAR data to obtain the 3D location of various elements within the scene. For instance, when measuring the attributes of fruits on a tree or detecting pedestrians in the streets, leveraging the 3D location can provide accurate positioning information to allow the robotic arm to harvest the fruit or enable the control component in an autonomous vehicle pipeline to take necessary actions to avoid colliding with pedestrians. The following are some of the existing applications of combining these two sensors for various purposes. Kragh et al. [
11] instrumented a tractor with multi-modal sensors, including LiDAR and a thermal camera, to detect static and moving obstacles, including humans, to increase safety during operations in the field. Choi et al. [
12] developed a multi-modal dataset including LiDAR and thermal camera data for studying various tasks, including drivable region detection, object detection, localization, and more, in the context of assisted and autonomous driving, both during the day and at night. Shin et al. [
13] used LiDAR and thermal cameras to investigate depth estimation in challenging lighting and weather conditions for autonomous vehicles. In their research, Yin et al. [
14] built a ground robot instrumented with various sensors, including a thermal camera and LiDAR. They argued that visual SLAM with an RGB camera is ineffective in low visibility situations such as darkness and smoke, and using a thermal camera can address some of these challenges. Tsoulias et al. [
15] used a thermal camera and LiDAR to create a 3D thermal point cloud to detect disorders caused by solar radiation on fruit surfaces. Yue et al. [
16] incorporated a thermal camera alongside LiDAR to enhance the robots’ ability to create a map of the environment, both during the day and at night.
A thermal camera and LiDAR have their own coordinate systems. To use data from both modalities, these two sensors should be extrinsically calibrated. Here, extrinsic calibration is the task of finding the rotation matrix and translation vector to express the coordinate of a point in the LiDAR’s coordinate system in the camera’s coordinate system. is an orthogonal matrix that describes rotation in 3D space, and is a 3D vector that represents a shift in 3D space. After obtaining the extrinsic parameters, the point in the thermal camera system corresponding to the LiDAR point in the LiDAR coordinate system can be obtained according to .
In the extrinsic calibration of visible light cameras and LiDAR, various types of targets, including checkerboard targets [
17], are typically employed. Nonetheless, these targets are not visible to a thermal camera. To adapt them for the extrinsic calibration of a thermal camera and LiDAR, these targets can be modified by crafting them from various heat-conductive materials and then either pre-cooling or heating them before use [
18], or by incorporating heat-generating electrical elements such as light bulbs [
15]. Using these adopted targets comes with some drawbacks. Creating them is both challenging and expensive. Using them in situations where the sensor setup frequently changes or sensor drift occurs can be cumbersome. Additionally, over time, heating leaks can occur from the heat-generating elements, or their temperature can become similar to the surrounding environment, rendering them ineffective for use, and getting them operational again can take some time.
The mentioned difficulties encountered while working with calibration targets motivated our proposed method. We propose a novel method for the extrinsic calibration of a thermal camera and a LiDAR without using a dedicated calibration target based on matching segmented people in both modalities during the movement of the sensor setup in environments such as farm fields or streets that contain humans. The extrinsic parameters are obtained by optimizing a designed loss function that measures the alignment of human masks in both modalities. This is achieved using a novel optimization algorithm based on evolutionary algorithms. We present two versions of our algorithm. The first version disregards input noise, while the second version seeks to mitigate the effects of noisy inputs. This innovative approach minimizes the expenses associated with the creation of calibration targets for thermal cameras and eliminates the often labor-intensive and time-consuming process of collecting diverse poses for calibration targets, particularly in the context of autonomous vehicles where positioning a large target at various angles and heights can be challenging. It also addresses the issue of the repetitive calibration efforts required when sensor drift or setting changes occur, making the process more efficient. Additionally, it enhances the accessibility of 3D LiDAR and thermal camera fusion by eliminating the necessity for specific targets.
The remainder of the paper is structured as follows: In
Section 2, we provide an overview and examination of prior research.
Section 3 outlines the cross-calibration algorithm.
Section 4 showcases our experiments and their outcomes on the FieldSAFE [
11] and
[
13] datasets. Lastly,
Section 5 serves as the conclusion of our paper and outlines potential avenues for future research.
2. Related Work
Some studies have explored the calibration of thermal cameras and LiDAR systems using various target-based approaches. These methods typically involve utilizing the known specifications of the calibration targets and minimizing a cost function to establish the extrinsic parameters that align these specifications across both sensor modalities. Krishnan et al. [
18] used a checkerboard target made of laser-cut black and white melamine with different heat conductivity. They placed it in front of the sun for approximately one hour to enable the detection of checkerboard corners by a thermal camera. A user manually selected the four outer corners of the target inside the thermal image, and to detect the calibration target within the point cloud, they used a region-growing algorithm. They determined the rotation matrix and translation vector by attempting to minimize the distance between the points on the edges of the target in the LiDAR point cloud and their nearest points on the edges of the target in the thermal image. Their algorithm requires a good initial rotation, translation, and several poses. Krishnan et al. [
19] developed a cross-calibration method that involved the creation of a target by cutting a circular hole in white cardboard with a precisely known radius. They utilized a damp black cloth as the background, which improved the circle’s visibility in the thermal camera. The process started by manually selecting a pixel in the circle for a region-growing algorithm to segment it in the image. Likewise, the user picked a point on the cardboard to locate the target in the point cloud. They captured multiple poses for cross-calibration. In each pair, they projected the circle’s edges from the point cloud onto the thermal image. Finally, they solved an optimization problem of aligning the thermal camera’s circle edges with the projected edges, ensuring precise calibration. Borrmann et al. [
20] devised a calibration target visible in thermal cameras by creating a dot pattern on a board using light bulbs. In the calibration process, they collected multiple pairs of images and their corresponding point clouds. For each of these pairs, they precisely determined the locations of the light bulbs in in both modalities. To establish the positions of the light bulbs within the LiDAR coordinate system, they located the calibration target within the point cloud data. Leveraging the well-defined geometry of their calibration target, they computed the positions of the light bulbs in the LiDAR coordinate system. Subsequently, for each image-point cloud pair, they mapped the positions of the light bulbs from the point cloud to the thermal image. Finally, to determine the extrinsic parameters, they solved an optimization problem aimed at minimizing the disparity between the light bulb positions in the thermal image and their projected positions in the point cloud. In the proposed method of Dalirani et al. [
21], an active checkerboard target with embedded resistors for generating heat was used, and extrinsic parameters between both the thermal and LiDAR sensors were obtained from the correspondence of lines and plane equations of the calibration target in the image and point cloud pair. Zhang et al. [
22] created four equally spaced circles on an electric blanket. They identified these circles in both modalities and optimized the extrinsic parameters by minimizing the 2D re-projection error.
In many studies, when using a thermal camera and LiDAR data, instead of directly performing extrinsic calibration between the thermal camera and LiDAR, each of them is extrinsically calibrated with another sensor, such as an RGB camera, for example. Then, the two sets of obtained extrinsic calibration parameters are used to determine
and
between the thermal camera and LiDAR. Azam et al. [
23] employed a thermal camera capable of providing both visual and thermal images, along with extrinsic parameters linking these two types of images. They applied an established RGB camera-LiDAR calibration technique to achieve extrinsic calibration between the visual camera and LiDAR. Subsequently, they utilized this knowledge, in conjunction with extrinsic calibration parameters connecting the visual and thermal cameras, to derive the transformation between the thermal camera and the LiDAR. Similarly, Zhang et al. [
24] divided the calibration process for the thermal camera and LiDAR into two sequential steps. In the FieldSAFE dataset [
11], a similar method [
25] was employed to determine the rotation and translation between sensors. They calculated the extrinsic parameters between the LiDAR and the stereo vision system using the iterative closest point algorithm [
26]. To calibrate the stereo vision system and the thermal camera, they constructed a checkerboard with both copper and non-copper materials and attached 60 resistors to generate heat. Subsequently, through post-processing, they were able to employ a regular cross-calibration tool for two visual light cameras to extrinsically calibrate the RGB and thermal cameras. Finally, by comparing the two solutions, the parameters between the thermal and LiDAR sensors could be obtained. In the
dataset [
13,
27], for their instrumented car, they established extrinsic calibration parameters between all sensors, including the thermal cameras and LiDAR, in conjunction with the NIR camera. The rotation and translation between other sensors can be obtained by using these extrinsic parameters with the NIR camera. To calibrate the NIR and thermal cameras, they used a
AprilTag board with metallic tape attached to it.
In another approach, targetless extrinsic calibration methods do not use a target but instead employ feature alignment in both modalities. Fu et al. [
28] introduced a targetless extrinsic calibration method that calibrates a stereo visual camera system, a thermal camera, and a LiDAR sensor. In their method, first, the transformation between LiDAR and the stereo system is estimated. Then, the thermal camera is calibrated with the left camera in the stereo system by simultaneously using data from LiDAR and the left stereo camera. By establishing transformations between the thermal camera and the stereo system, as well as between LiDAR and the stereo system, the transformation between LiDAR and the thermal camera can be calculated. Their method optimizes extrinsic parameters by maximizing the alignment of edges in the three modalities. To derive edges from the LiDAR point cloud, they employed the horizontal depth difference and utilized the Canny edge detector [
29] to detect edges in the thermal camera and the left stereo camera. Their method requires sufficient edge features in the modalities and a rough initial guess for optimization. Mharolkar et al. [
30] proposed a targetless cross-calibration method for visual and thermal cameras with LiDAR sensors by utilizing a deep neural network. Instead of employing hand-crafted features, they utilized multi-level features from their network and used these extracted feature maps to regress extrinsic parameters. To train the network for calibrating the visual camera and LiDAR on the KITTI360 dataset [
31], they utilized 44,595 image-point cloud pairs. For training the network for calibrating the thermal camera, they employed pre-trained weights for the visual camera and LiDAR and trained the model on their thermal camera and LiDAR dataset, consisting of 8075 thermal images and LiDAR pairs. Additionally, for a new set of sensors, the network should be re-trained.
Our proposed method does not require a target and optimizes extrinsic parameters during the movement of the sensor setup in an environment with human presence by aligning segmented people in both modalities. Importantly, it does not rely on the presence of rich edge features, making it applicable even in environments like farm fields, which often lack distinct edges. Moreover, it does not demand a precise initial solution, enhancing its versatility and ease of use. To the best of our knowledge, in the literature on the extrinsic calibration of thermal cameras and 3D LiDAR sensors, our proposed method represents a novel approach distinct from any existing methodologies. To date, no other method for these sensors has demonstrated the same innovative techniques employed in our study.
3. Methodology
In this paper, we propose an extrinsic calibration method for determining rotation matrix and translation vector between a thermal camera and a 3D LiDAR sensor without the need for a target. Our method relies on matching segmented humans in both modalities during the movement of the sensor setup. In the following, we will explain the steps of the proposed method, including data collection, formulating the problem, designing a cost function, and the method for optimizing the extrinsic parameters by minimizing the cost function.
3.1. Data Collection
While the thermal camera and LiDAR sensor setup is in motion on a moving vehicle, such as a tractor, robot, or car, in various environments like streets and farm fields, the dataset is created by capturing several frames at different time points, denoted as , , …, , for both modalities. denotes the number of captured frames. At each time , both the LiDAR and thermal camera capture the scene simultaneously, producing the captured image and point cloud, which we denote as and , respectively. Given that our method relies on matching humans in both modalities, it is essential that each image and point cloud pair in the dataset contains human subjects, and the number of humans should be equal, which may vary from one or more individuals. As the number of humans increases, the likelihood of overlapping also rises, introducing more errors in segmenting humans in both data modalities. Therefore, only frames containing between one and a small number, denoted as , of humans are retained.
In the beginning, the dataset
D is empty. During the movement of the sensor setup in the environment at the moment
, a thermal image and a point cloud are captured. Then, an off-the-shelf person segmentation model and a human detector are applied to the captured image and point cloud, respectively. If the number of humans found in both modalities is equal and is greater than zero, the image and point cloud pair are kept; otherwise, it is discarded. In the provided pair,
is generated by assigning a value of one to pixels within the human masks and zero to pixels outside the masks in the thermal image. Similarly,
is produced by retaining the points in the point cloud that correspond to humans and removing all other points. Subsequently, the
and
pair is included in the dataset
D. This process continues until the dataset
D reaches a specific size, denoted as
. Two examples from the FieldSAFE [
11] and
[
13] datasets are shown in
Figure 1.
In collected data pairs, one important consideration is that humans should be positioned at various locations and sizes within the thermal image. Otherwise, the obtained extrinsic parameters will exhibit bias toward specific areas, causing them to deviate from the actual parameters. Furthermore, since the positions of humans in both thermal images and point clouds do not change significantly in consecutive frames, when a thermal image and point cloud are added to the dataset at time , the next three frames will not be considered for inclusion in the dataset.
3.2. Cost Function
To optimize the extrinsic parameters and between a thermal camera and a 3D LiDAR sensor, based on human matching in both modalities, a cost function is required to measure the alignment of humans in both modalities for all thermal image and point cloud pairs (, ) in the dataset , with respect to a set of extrinsic parameters.
When provided with a candidate rotation matrix
and a translation vector
for image and point cloud pairs (
,
), the loss is calculated according to Equation (
1).
In Equation (
1),
iterates points in the point cloud
,
is the
intrinsic camera matrix, and
denotes the number of points in a point cloud. In this equation,
maps the point
from the LiDAR coordinate system to camera coordinate (
), and multiplying it by
maps the point to camera image coordinate (
).
is inhomogeneous representation and should be converted to inhomogeneous.
is a function that outputs a penalty score based on distance of the projected point
from LiDAR coordinate system to image coordinate to the nearest human pixel in
. The function
is defined according to Equation (
2).
In Equation (
2),
represents the Manhattan distance, and
and
provide the height and width of
. Additionally,
represents the nearest human pixel in
to
.
is a piecewise function. If a projected point from the LiDAR coordinate system to the camera coordinate system is in front of the camera, the function calculates the distance of the point projection in the thermal image coordinate system to the nearest human pixel. If the projected point from the LiDAR coordinate system to the camera coordinate system is behind the camera, it indicates that the projection is highly invalid. In such cases, we impose a significant penalty by assigning a large value. We determined this penalty to be the maximum value between the image height and width, multiplied by the constant
. Selecting a low value, such as one for
, means that we do not differentiate enough between a mapping that projects a LiDAR point in front of the camera, outside the image, and not too far from the edges of the image, and a mapping that projects the LiDAR point to the back of the camera. A larger value of
, such as five, makes cases like this more distinguishable. In
Figure 2, the loss for two sets of extrinsic parameters for one pair of thermal images and point clouds from the FieldSAFE dataset [
11] is shown. The loss for
Figure 2a is
, which is much smaller than the
loss for
Figure 2b. In the case of
Figure 2b, greater deviations in the extrinsic parameters from the true values caused LiDAR-projected points to be further from humans in the image, resulting in a larger loss.
The total loss for a candidate
and
on dataset
is the average of losses on all image and point cloud pairs in the dataset, as defined in Equation (
3).
3.3. Optimization Method
In the proposed method, the estimate of the extrinsic parameters,
and
, that describes the relationship between a thermal camera and a LiDAR sensor, involves the minimization of Equation (
3). To achieve this, we introduced an optimization approach rooted in evolutionary algorithms for the purpose of parameter calculation between these two sensors. Since errors, such as false positives, false negatives, under-segmentation, and over-segmentation, can occur in the detection and segmentation of humans in both modalities, the proposed algorithm incorporates a mechanism to reduce the effect of outliers. First, we will explain the algorithm that does not consider outlier rejection, Algorithm 1. Afterward, we will provide a comprehensive explanation of the Algorithm 2.
We decided to create the optimization algorithm based on evolutionary algorithms for the following reasons. First, in the case of non-differentiable or noisy objective functions, evolutionary optimization can obtain good solutions. Second, evolutionary optimization is much less likely to be affected by local minima, and it eliminates the need for an initial solution in our calibration method. Third, evolutionary algorithms often exhibit greater robustness in the face of noisy and uncertain observations.
Algorithm 1 presents the proposed algorithm, omitting any outlier rejection. The algorithm creates a population of random individuals and gradually evolves the population in each generation to optimize
and
. Each individual of the population is an instance of Individual structure. As demonstrated in lines 1–6 Algorithm 1, the Individual structure consists of four fields. The first field, denoted as
t, represents the translation vector from a LiDAR sensor to a thermal camera. The second field, labeled as
r, corresponds to Rodrigues’ rotation vector from the LiDAR to the thermal camera. Instead of directly optimizing the rotation matrix
with its 9 elements and managing its orthogonality, we optimize rotation vector
with only 3 parameters and subsequently convert it to rotation matrix
using OpenCV’s Rodrigues function [
32]. The third field comprises the resulting loss on the dataset based on the individual’s
r and
t, which is calculated according to Equation (
3). The fourth field for an individual represents the probability of selection for crossover and mutation, a concept we will elaborate on further.
| Algorithm 1 Proposed algorithm without outlier handling |
Require: D, , , , , , - 1:
Struct Individual { - 2:
vector3D t; - 3:
vector3D r; - 4:
float ; - 5:
float ; - 6:
} - 7:
= initialPopulation(size=, , ) - 8:
for to do - 9:
= - 10:
if then - 11:
= top lowest loss individuals in - 12:
end if - 13:
for in do - 14:
= Loss( D; , ) (Equation ( 3)) - 15:
end for - 16:
for in do - 17:
= selectionProbability(, ) - 18:
end for - 19:
Add the top lowest loss individuals to . - 20:
Randomly select pairs with replacement from based on the probability of each individual. - 21:
Apply the ‘crossOver()’ operation to each selected pair and add the resulting new individuals to the . - 22:
Randomly select individuals with replacement from the based on the probability of each individual. - 23:
Apply the ‘mutation()’ operation to each selected individual and add the resulting new individuals to the . - 24:
- 25:
end for - 26:
return and of in with smallest
|
This algorithm operates on a dataset denoted as
D, which has been generated in accordance with
Section 3.1. It takes parameters like
, signifying the number of individuals in the population, and
and
, representing the rotation and translation intervals used for generating random initial individuals in the population. Furthermore, we have
, a parameter that determines the percentage of the best-performing individuals with the lowest loss to be retained in the next generation. Additionally,
is another parameter that specifies the percentage of the population selected for crossover.
In line 7, the initial population is generated using the ‘initialPopulation’ function. To enhance diversity, the size of the population that it generates is set to be times larger than . However, after the first iteration, the population size is reduced to , as shown in lines 10–12. If the number of individuals in the population is low, setting to a value like five can increase diversity. However, when the population is large, it can be set to one to prevent unnecessary computation. To create a random individual within the population, ‘initialPopulation’ initializes an instance of the Individual structure. The function randomly samples all three elements of vectors t and r from the intervals and , respectively. In all our experiments, we assumed no prior information about the LiDAR and thermal camera position and orientation relative to each other. We selected a wide interval of [−3.5, 3.5] radians and [−1, 1] meters; however, a user can choose smaller intervals if they wish to incorporate prior knowledge about the positions and orientations of sensors. Next, the produced individual becomes part of the population under the condition that, for a pair of and in dataset D, a minimum of of the points in project within the thermal image. This projection is achieved through the utilization of a randomly generated rotation vector r and translation vector t associated with the individual. In case this criterion is not met, the individual is discarded, and a new one is generated in its place.
Between lines 8 and 25, the next generation is formed through a process that combines elitism, crossover, and mutation techniques. In lines 13–15, the loss on dataset
D for each individual is computed as per Equation (
3). In lines 16–18,
is calculated for each
in the population using the ‘selectionProbability’ function as defined in Equations (
4) and (
5). The first one computes a fitness score based on individual loss relative to the population, and the second one calculates the selection probability for an individual, taking their fitness score and the sum of fitness scores for the entire population into account.
In line 19, the top percent of individuals with the lowest loss in the population are directly copied to the next generation. This elitism ensures that the best solutions found so far are not lost and continue to contribute to the population’s overall quality over the next generations.
Between lines 20–23, individuals for crossover and mutation are selected, and the functions ‘crossOver’ and ‘mutation’ are applied. ‘crossOver’ creates a new individual from a pair of individuals according to Equations (
6) and (
7). In these two equations,
and
are two members of the population, and
has a lower loss than the other one. Also,
is a random number between
and 1. The function ‘mutation’ affects an individual by applying noise to its rotation and translation vectors, creating a new individual. The ‘mutation’ operation adds random uniform noise within the range of
to each element of the rotation vector and independently adds noise within the range of
to each element of the translation vector.
Algorithm 2 contains the complete proposed algorithm, which attempts to mitigate the effects of outlier data pairs. The general idea of this algorithm is to handle outliers in a dataset (D) by iteratively fitting a model to a small subset of the data, identifying and removing outliers based on a loss threshold, and then re-fitting the model to the inliers. The algorithm is designed to robustly estimate rotation () and translation () parameters for a given dataset.
Algorithm 2 requires all the inputs of Algorithm 1, with the addition of some extra inputs.
represents the size of a random subset of
D that is chosen to find extrinsic parameters.
denotes the number of fitting attempts to detect outliers.
determines whether a sample should be considered an outlier or not. If the calculated loss for a sample pair, as per Equation (
1), is greater than
, it is considered an outlier. A solution of a fitting attempt on the selected subset of
D is deemed correct if the ratio of samples with a loss smaller than or equal to the value of
is greater than or equal to
. Furthermore,
represents the indicator function. It outputs the value of one when the condition is met and zero otherwise.
| Algorithm 2 Proposed algorithm with outlier handling |
Require: D, , , , , , , , , , - 1:
Create an array, , with a size of and initialize each element with - 2:
for to do - 3:
Create by randomly sampling data pairs from D - 4:
Create using the remaining data pairs from D - 5:
Obtain and by using Algorithm 1 - 6:
= loss of and for each data pairs in using Equation ( 1) - 7:
- 8:
if then - 9:
for in do - 10:
if > then - 11:
False - 12:
end if - 13:
end for - 14:
end if - 15:
end for - 16:
Create by selecting elements in D where the corresponding element in is True - 17:
Obtain and by applying Algorithm 1 to - 18:
return and
|
The proposed algorithms aim to determine a rigid body transform between the coordinate systems of a thermal camera and a LiDAR sensor by estimating the rotation matrix
and translation vector
. It is essential for both sensors to operate with the same scale for accurate results. If the two sensors are not on the same scale, and assuming the factory configurations of sensors are available (which is almost always the case for these two types of sensors), this information can be used to preprocess the data and convert them to the same scale. In Equation (
1),
is utilized to map a LiDAR point in the image coordinate system in a homogeneous format. Subsequently, the homogeneous point is converted to an inhomogeneous coordinate in the thermal image. When using data with different scales, as the cost function minimizes the distance in the thermal image, it can yield a solution that effectively maps LiDAR points to their corresponding thermal image pixels, even when dealing with data of varying scales. However, the obtained translation vector may not accurately represent the real distance between the sensors, as it will be scaled by the difference in scale between the two sensors.
To efficiently calculate the function in Equation (
1), for each
in a collected dataset, an array with a height of
h and a width of
w can be created, where each element represents the distance from that pixel to the nearest pixel belonging to a human. For a dataset of size
, the computational complexity of this operation is
. In Equation (
2), for a given
and
pair, for the number of points in the point cloud
, several fixed matrix multiplications and summations take place. Therefore, for one pair, the computational complexity will be
. According to Equation (
3), its computation complexity is
. Therefore, since Algorithm 1 performs
iterations, and each iteration calculates the loss of individuals on a scale of
, the total computational complexity will be
, where
is the number of points in the point cloud with the most points. The computational complexity of Algorithm 2 remains the same, with the additional step of calculating extrinsic parameters using a subsampled dataset of size
for
times.
4. Experiments
To evaluate our method, we used the FieldSAFE dataset [
11] and the first sequence of the
dataset [
13]. The selection of this sequence was random, as it is assumed to be representative of the dataset, given that the sensor setup is identical across all sequences. The FieldSAFE dataset [
11] contains data from a tractor equipped with various sensors, including a thermal camera and a LiDAR sensor, captured during a grass-mowing scenario in Denmark. The
dataset comprises data collected by an instrumented car with different sensor types, such as a thermal camera and LiDAR sensor, in various environments, including city, residential, road, campus, and suburban areas. The thermal camera in the FieldSAFE dataset is a FLIR A65 with a maximum frame rate of 30 frames per second (FPS) and a resolution of 640 × 512 pixels. It obtained LiDAR data from the Velodyne HDL-32E, which is a 32-beam LiDAR sensor with a 10 FPS data rate and 2 cm accuracy. The thermal camera in the
dataset is the same as in FieldSAFE, and the LiDAR is a Velodyne VLP-16, which has sixteen LiDAR beams, a maximum frame rate of 20 FPS, and 3 cm accuracy. In the
dataset, the provided thermal images have a resolution of 640 by 256 pixels. Moreover, in both datasets, the positions and orientations of the sensors with respect to each other are highly different. Our proposed algorithm produces accurate results on both setups, including sparse 16-beam and dense 32-beam LiDARs, demonstrating its effectiveness. Also, in both datasets, the intrinsic camera matrices (
) of thermal cameras are available.
We created two datasets from FieldSAFE and
following the guidelines in
Section 3.1. Additionally, we generated two other datasets for evaluation purposes by manually selecting and annotating the data. For human segmentation in thermal camera images, we utilized Faster R-CNN [
33] trained on a FLIR thermal dataset [
34] and subsequently fed the bounding boxes into the Segment Anything Model (SAM) [
35]. To extract humans from the LiDAR point cloud, we employed MMDetection3D [
36]. The dataset created from FieldSAFE consists of 63 training examples and 20 test samples, while the dataset extracted from
comprises 55 training examples and 19 test samples. For simplicity, we denote them as
,
,
, and
. Since there are often only one to three persons in the sequences used from both the FieldSAFE and
datasets, we selected
to be equal to three. In
, the mean spatial location of all humans in thermal images is (305.82, 103.49), with standard deviations of 155.9 and 43.3 along the x and y axes, respectively. Additionally, the average number of persons per image is 1.16. For
, the corresponding values are (330.2, 140.2) for the mean spatial location, with standard deviations of 166.3 and 11.95 along the x and y axes, respectively. The average number of persons per image is 1.03. In the following, we compare the loss values obtained via Equation (
3) on both the training and test datasets for our proposed methods in Algorithms 1 and 2 across different settings. Since the used data were collected in the past, we compare the proposed method with the extrinsic parameters provided by FieldSAFE and
using target-based calibration methods. For simplicity, we refer to them as
and
.
In all our experiments, we used the hyper-parameters in
Table 1 by default, unless another configuration was specified. We determined the hyper-parameters for the proposed algorithms through a process of testing various candidates and relying on intuition.
To compare Algorithms 1 and 2 with each other as well as with
and
, in
Table 2, we reported the Equation (
3) loss values obtained by their corresponding
and
on the test datasets
and
. As can be seen in the table, Algorithm 2, which uses outlier handling, obtains better results than Algorithm 1. Additionally, Algorithm 2 outperforms
and
, which are obtained using calibration methods based on the target.
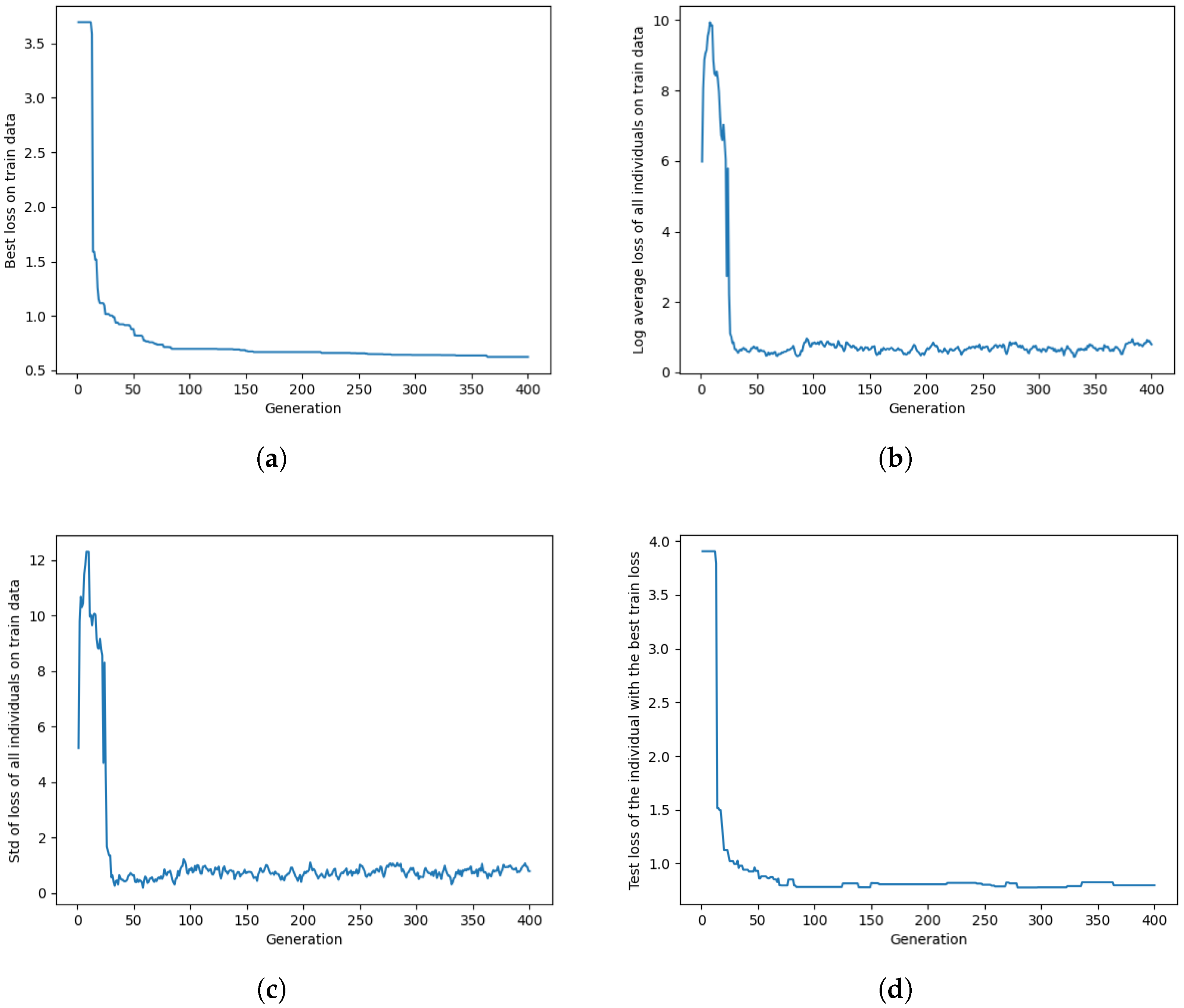
Figure 3 presents some performance metrics for Algorithm 2 optimized on
.
Figure 3 includes four plots, each displaying different aspects of the optimization process in each generation. All the loss values for the figure are computed using Equation (
3). We just reported the plots for
as the representative of both the
and
datasets.
Figure 3a shows the training loss value of the individual with the lowest training loss. Because of elitism, mutation, and crossover, the training loss value for the individual with the lowest training loss always remains non-increasing across generations.
Figure 3b,c illustrate the log-average training loss of all individuals and the standard deviation of the loss among all individuals in the population. As individuals with lower training loss have a higher probability of being selected for crossover and mutation, increasing the number of generations results in a decrease in the log-average and standard deviation of train loss. However, due to randomness in mutation and crossover, these values eventually converge to a certain point and fluctuate around it. Finally,
Figure 3d demonstrates the test loss of the individual with the lowest training loss. As depicted in the figure, both the training and test losses exhibit an initial exponential decrease, followed by a gradual convergence to a small value.
To assess the influence of the training dataset size on Algorithms 1 and 2, we performed the sub-sampling of
and
, resulting in new training datasets ranging in size from 5 to the full dataset size, with a step size of 5. Since Algorithm 2 requires a minimum of 15 samples to determine a set of extrinsic parameters and subsequently test other samples for inlier status, we opted not to execute Algorithm 2 for configurations with 15 samples or fewer. As shown in
Table 3 and its equivalent bar charts in
Figure 4, increasing the number of data pairs for the training set from a small number decreases the test loss values significantly. Also, Algorithm 1 exhibits fluctuation in test loss values as the number of thermal images and point cloud pairs in the training set increases. In contrast, Algorithm 2 experiences fewer fluctuations. Additionally, in almost all cases, Algorithm 2 demonstrates superior performance compared with Algorithm 1 with the same training dataset size. In the case of 30 pairs in the dataset
and 20 pairs in the dataset
, Algorithm 2 obtained a slightly worse result, which could be attributed to randomness, especially in the selection of a subsampled set from the dataset to assess the inlier or outlier status of non-subsampled data pairs. As the results in
Table 3 suggest, not having a sufficient number of samples prevents us from executing the algorithms or obtaining good results.
To assess the robustness of Algorithms 1 and 2 under more extreme conditions, we generated
by swapping the thermal mask (
) for two random samples with another two random samples in
. It caused four pairs of thermal images and LiDAR point clouds to lack matching masks in both modalities. Similarly, we created
using the same method. Furthermore, to investigate under different levels of mismatch, we generated comparable datasets by interchanging 4, 6, and 8 pairs, resulting in 8, 12, and 16 mismatched samples, respectively. As shown in
Table 4 and its equivalent bar charts in
Figure 5, Algorithm 2 achieved significantly better test loss and demonstrated greater robustness. In this experiment,
and
were set to three and five for new datasets derived from
, and the variable
was set to 0.3 for
and
. By increasing the number of mismatched pairs, the performance of both algorithms dropped; however, this effect was more significant for Algorithm 1. As the results suggest, it is critical to have good object detection in both modalities; otherwise, large amounts of false positives and false negatives from object detectors can degrade the quality of extrinsic parameters. Another interpretation could be that the presence of many people in a thermal image-point cloud pair may result in more mistakes in segmenting humans in both modalities due to a higher chance of overlapping. Therefore, selecting a large value for
may consequently lead to poorer results.
As mentioned earlier, it is important to collect a dataset with thermal images depicting humans in different locations and sizes. In order to assess the robustness of Algorithms 1 and 2 when dealing with highly unbalanced human locations in a collected dataset, we generated
from
by removing samples where the human masks are located in the left one-third section of the image.
comprises 27 samples. Similarly, we created
by removing samples where the human masks are located in the right one-third of the image.
consists of 36 samples. We generated these two imbalanced pose datasets from various imbalanced datasets that can be created to serve as a representative sample of this issue. As
Table 5 shows, the mentioned unbalanced condition decreases performance when compared with the performance on a balanced dataset of a similar size in
Table 3. However, Algorithm 2 is less affected by this in comparison with Algorithm 1. Therefore, it is important to have humans in diverse locations in the thermal camera’s field of view; otherwise, the pose imbalance can negatively affect the extrinsic calibration.
To assess the importance of each component in Algorithms 1 and 2, we systematically removed one component at a time and reported the results by calculating the Equation (
3) loss using the test dataset
, as shown in
Table 6. The table reveals that removing elitism results in divergence and has the most significant impact. Subsequently, both the crossover and mutation exhibit notable importance, albeit to varying degrees. Removing the condition that projects
of the point cloud into the thermal image during the creation of the initial population has the least impact on test loss.
To observe the impact of the changes in certain hyper-parameters of Algorithms 1 and 2 and explain our intuition for selecting default values of hyper-parameters, we modified one parameter at a time while keeping all other parameters constant, as specified in
Table 1. The corresponding results are presented in
Table 7. In most cases, selecting values near the default showed no significant degradation in the performance of both algorithms. To demonstrate a more pronounced effect, we opted for more extreme values in comparison with the defaults. However, even in this scenario, in many cases, the results were not substantially different from the results of the default hyper-parameters.
As depicted in
Table 7, a small population size (
) results in poorer outcomes than the default value due to insufficient diversity. Conversely, a large population size slows down convergence and adds unnecessary computational overhead, approaching results similar to the default value. A low value of
implies that many of the found good solutions do not directly transition to the next generation, diminishing their contribution to the overall population quality. Conversely, a large value of
restricts the introduction of new individuals. In both cases, the results are inferior compared with the default value. A smaller value of
implies that fewer individuals in the next generation are produced by crossover, and more individuals are created by mutation. In the proposed algorithms, crossover covers a large area in the optimization space, and, as shown, a small value of
resulted in significantly poorer performance compared with the default value. In these algorithms, the mutation operation allows for the discovery of better solutions in the proximity of an existing solution. On the contrary, a large value of
means less mutation, leading to lower performance compared with the default values. Finding a balance between the crossover and mutation is crucial for achieving good results.
and
represent the noise levels for the mutation operator, determining how much change in a found solution is applied to generate a new individual. A very small amount does not alter parameters in the optimization space enough to produce a meaningful change in the outcome, while a large amount results in an individual that is very different from the original solution and does not retain its attributes. As shown, in both cases, the results are worse than the default values.
A low value of
imposes a stringent criterion for considering a sample in the dataset as an inlier, potentially causing issues by incorrectly classifying many good pairs in the data as outliers and rejecting them from the calculation of extrinsic parameters. Conversely, a high-value results in the ineffective detection of outlier samples in data. In both cases, the performance is weaker compared with the default value. As depicted in
Table 3, augmenting the pairs for optimizing extrinsic parameters generally leads to improved performance. A small value of
results in the identification of suboptimal extrinsic parameters, leading to poor outlier detection performance. Conversely, when the value of
is large, there is a higher likelihood of including a significant amount of outliers. The algorithm may face challenges in identifying a robust model amidst the abundance of irrelevant data. As indicated in
Table 7, in both scenarios, the performance is diminished compared with the default value. We selected the default value for
, as represented in
Table 1, based on the performance of Algorithm 1 in
Table 3. As shown in
Table 7, a low value for
can result in obtaining a poor initial estimate for extrinsic calibration parameters, thereby impacting the performance of determining inliers. Additionally, a large value can lead to the exclusion of a significant number of samples from the determination of whether they are outliers or not, resulting in poorer results. As can be interpreted from
Table 7, a small value for
can cause many samples not to be examined for being outliers, resulting in a decrease in performance. On the other hand, a large value does not contribute to finding more outliers, and the performance remains similar to a balanced
while only increasing computation. As indicated by the values in
Table 7, a low value of
does not alter the performance in the specific experiment of
. However, a high value of
led to poor performance, as the proportion of inliers in each iteration of Algorithm 2 was smaller than the
, and, consequently, the detected outliers were rejected.
In
Figure 6, the dots represent projected points in the LiDAR point cloud onto a thermal image using a set of
and
. This figure presents a qualitative comparison of Algorithm 2 (blue dots) with
and
(red dots) on two frames from
and
. As can be observed, both the red and blue dots are closely aligned, demonstrating that our proposed algorithm and
and
are in close agreement. However, as depicted in the zoomed-in patches in
Figure 6b,d, the blue projected points that correspond to humans in the point cloud are more closely aligned with the humans in the thermal images. Additionally, in
Figure 6d, the blue points are more centered on the streetlight.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}