
Performance Analysis of Centralized Cooperative Schemes for Compressed Sensing
Abstract
1. Introduction
- For the HR case, we propose closed-form expressions for the number of active sensors required by an FC to achieve a target performance, assuming SUs with a given performance. Several fusion rules are considered: and-rule, or-rule, and MV-rule. In contrast to existing work, the proposed expressions have both accuracy and low complexity.
- For the HR case, we propose closed-form expressions for the number of compressed samples required by an ED to achieve a target performance, assuming a given PU signal-to-noise ratio (SNR). Again, the proposed expressions have both accuracy and low complexity, thereby enabling low-energy self-computation at the SU side. Previous work in [64,65,66] only includes a limited subset of expressions, mainly for conventional non-cooperative sensing, whereas this paper derives a complete performance analysis valid for cooperative compressed sensing.
- For the SR case, we propose closed-form expressions for the aggregate number of samples required by an FC to achieve a target performance. Also, in this case, the proposed expressions combine accuracy with low complexity.
2. State of the Art
3. System Model
3.1. Overview of Centralized Cooperative Sensing
3.2. Statistical Signal Model
- And-rule, where ;
- Or-rule, where ;
- MV-rule, where , with S being an odd integer.
4. Performance Analysis
4.1. HR Case, FC Performance
4.1.1. And-Rule
4.1.2. Or-Rule
4.1.3. MV-Rule
4.2. HR Case, SU Performance
- Standard GA, where a chi-squared random variable is approximated by a Gaussian random variable using the CLT (see [15] and references therein).
4.2.1. Standard GA
4.2.2. PGA
4.2.3. PA
4.3. SR Case, FC Performance
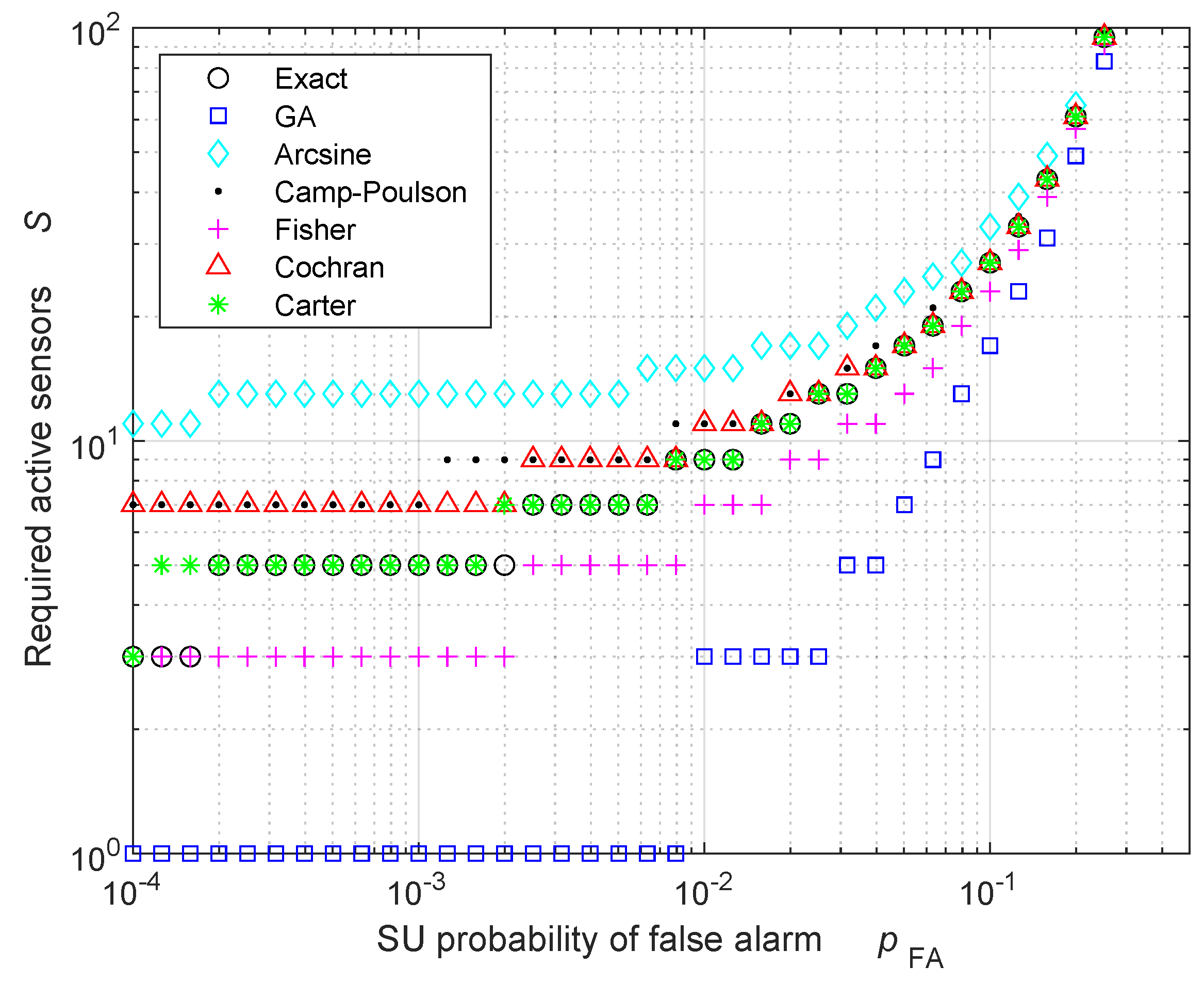
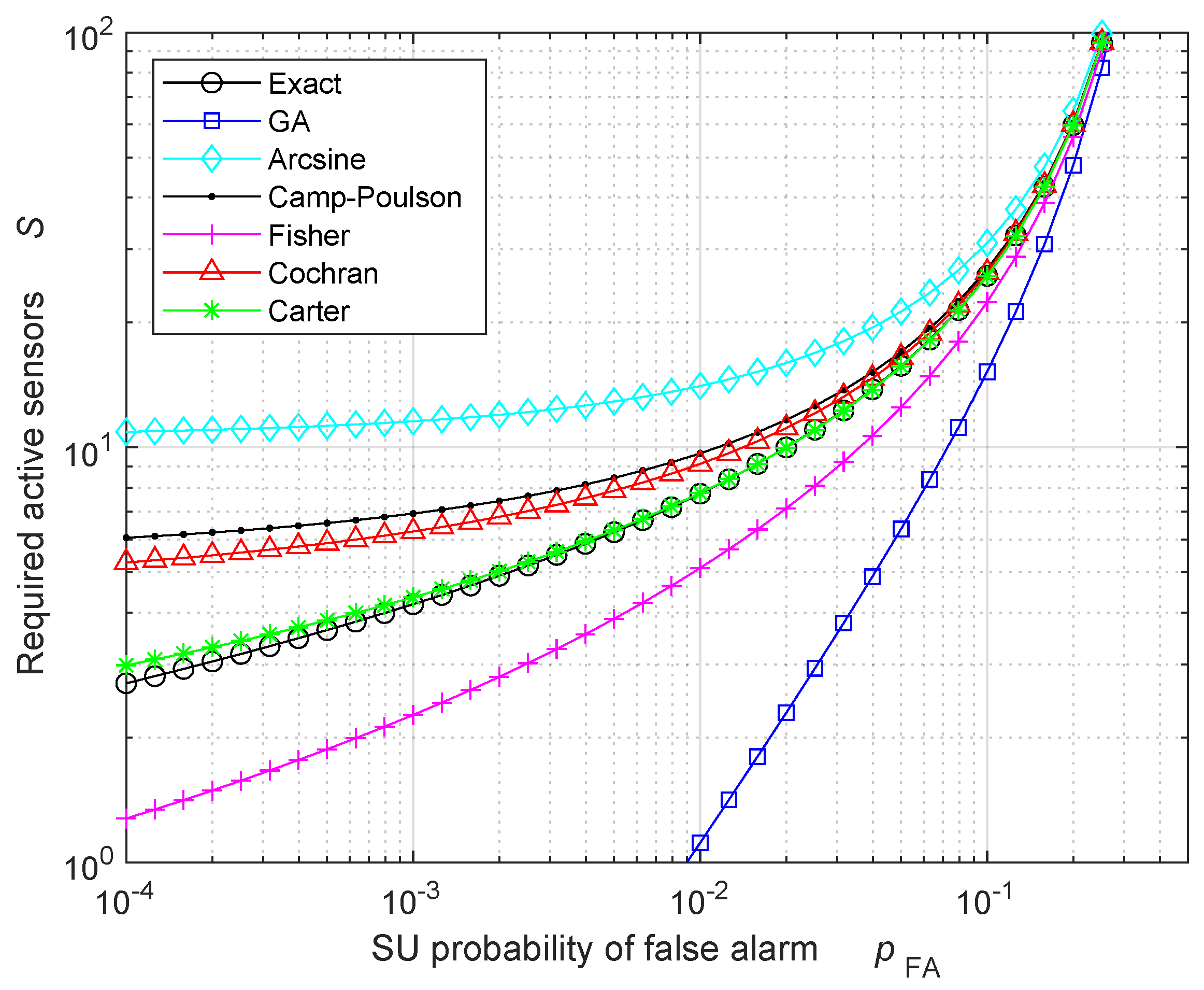
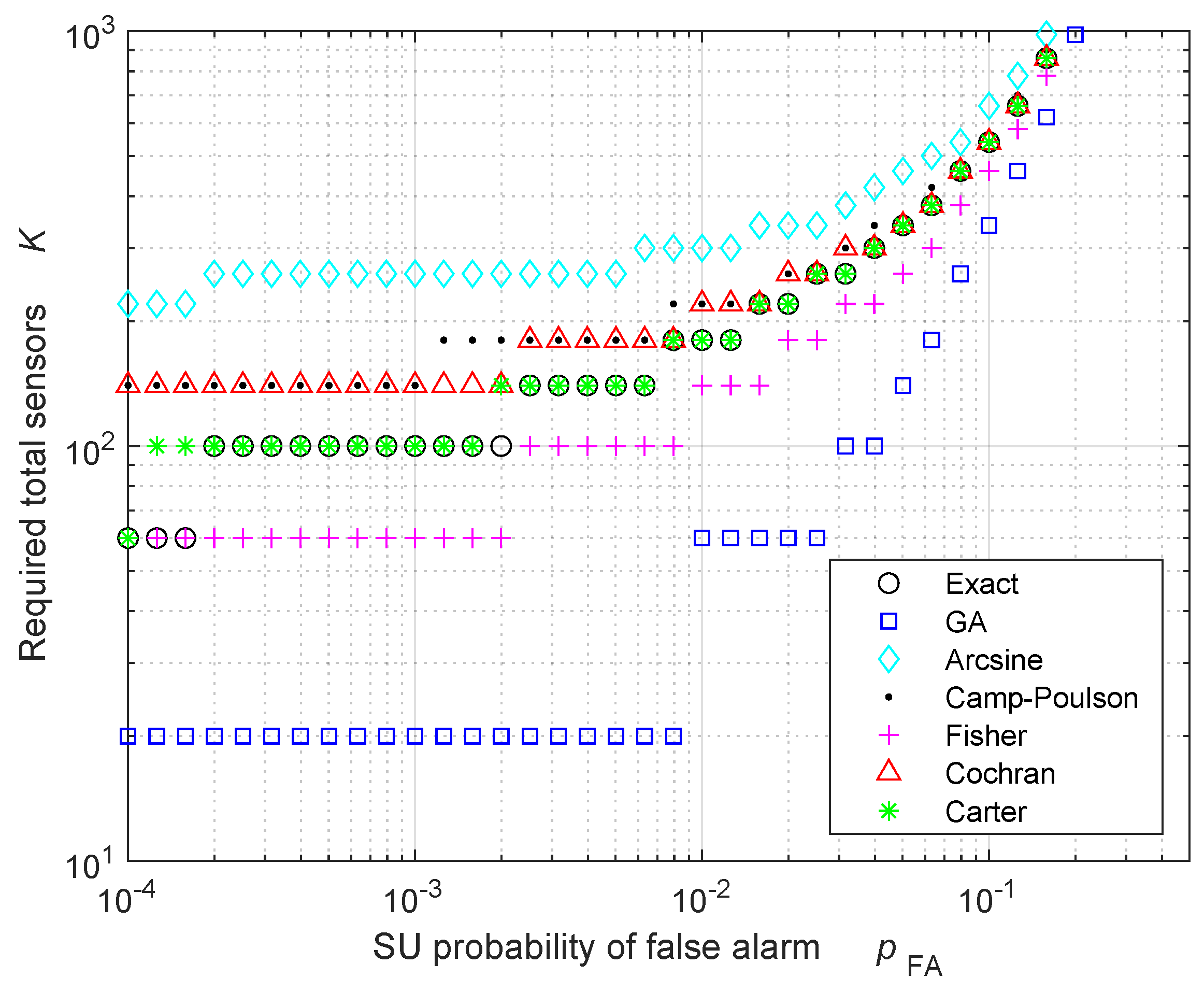
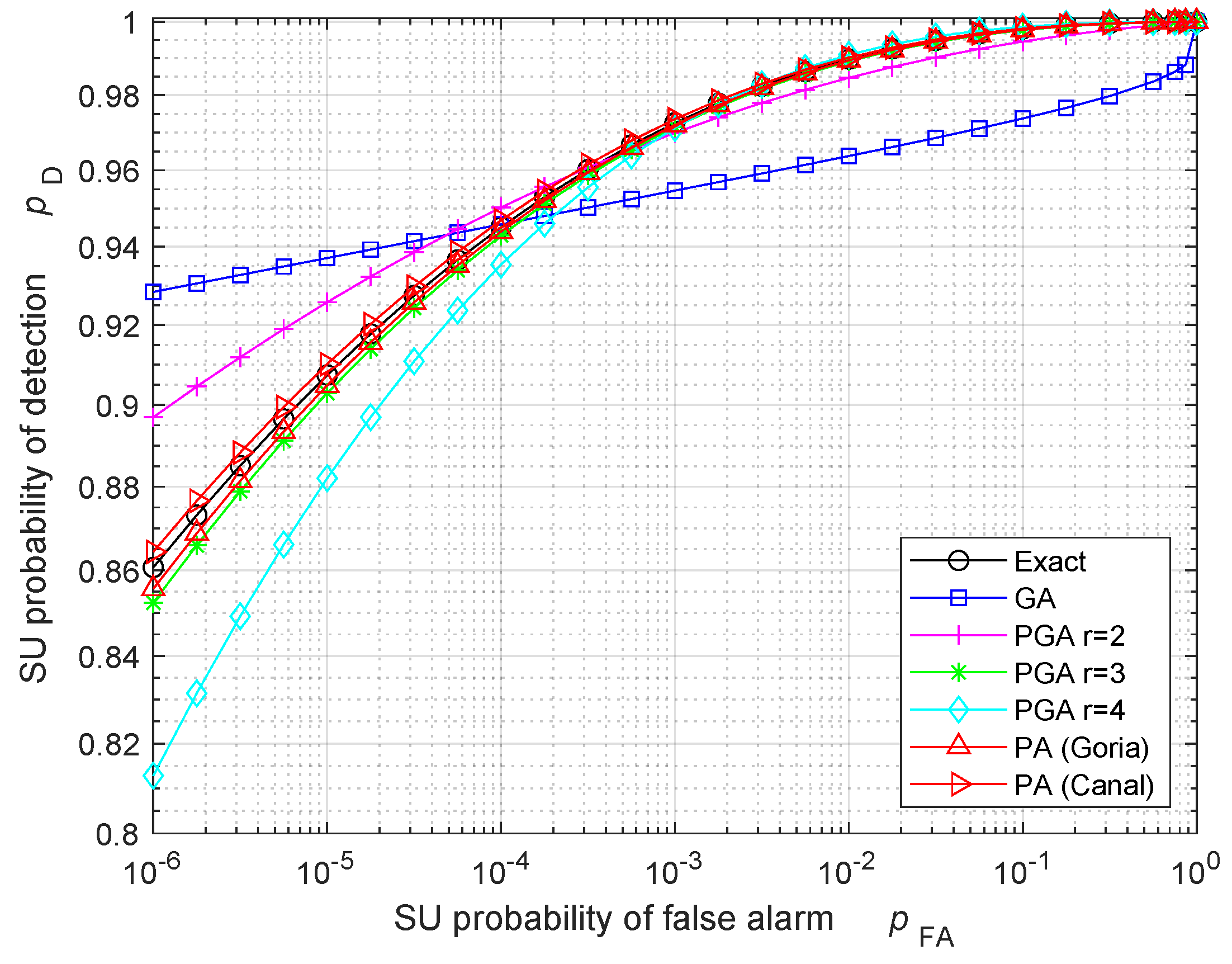
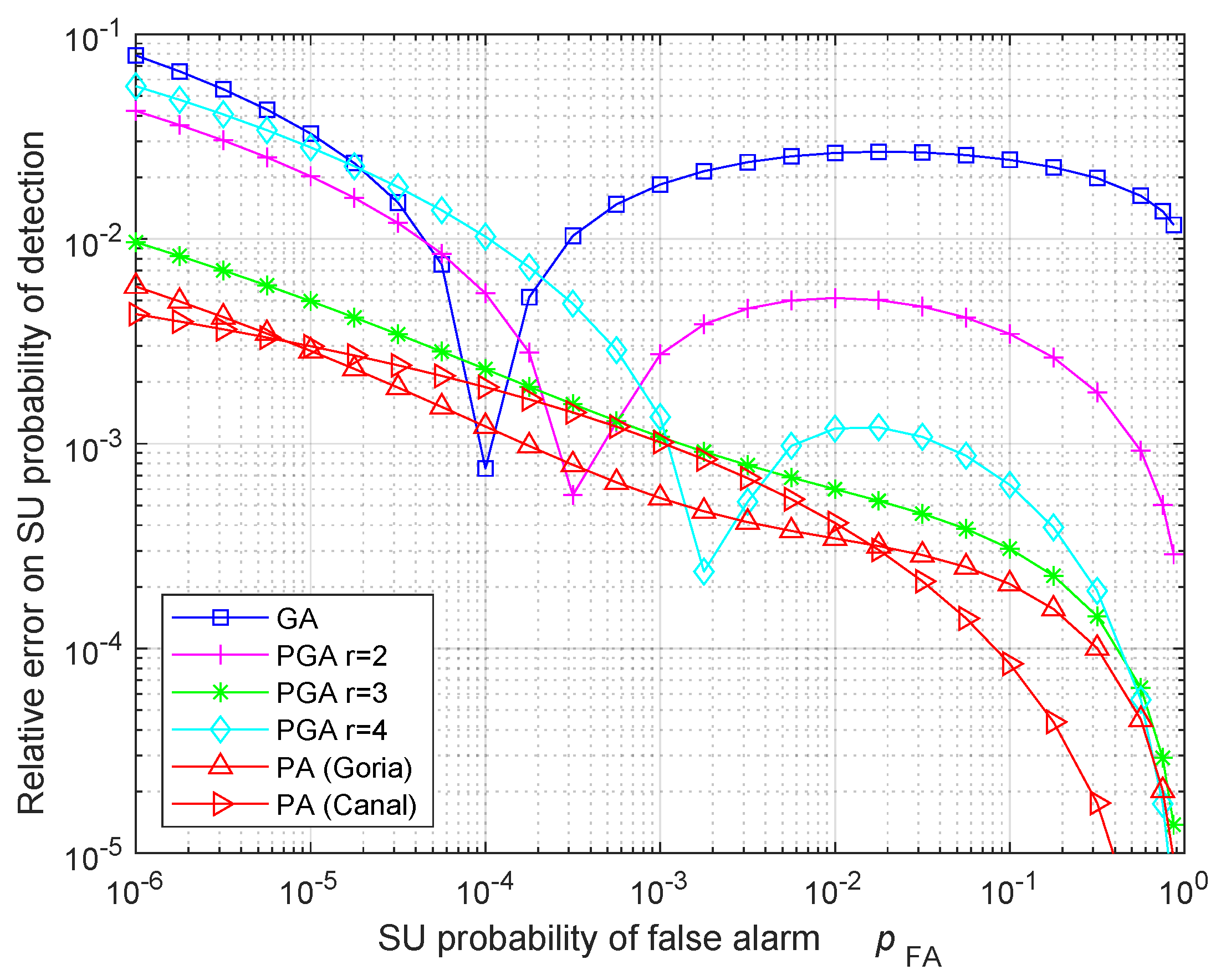
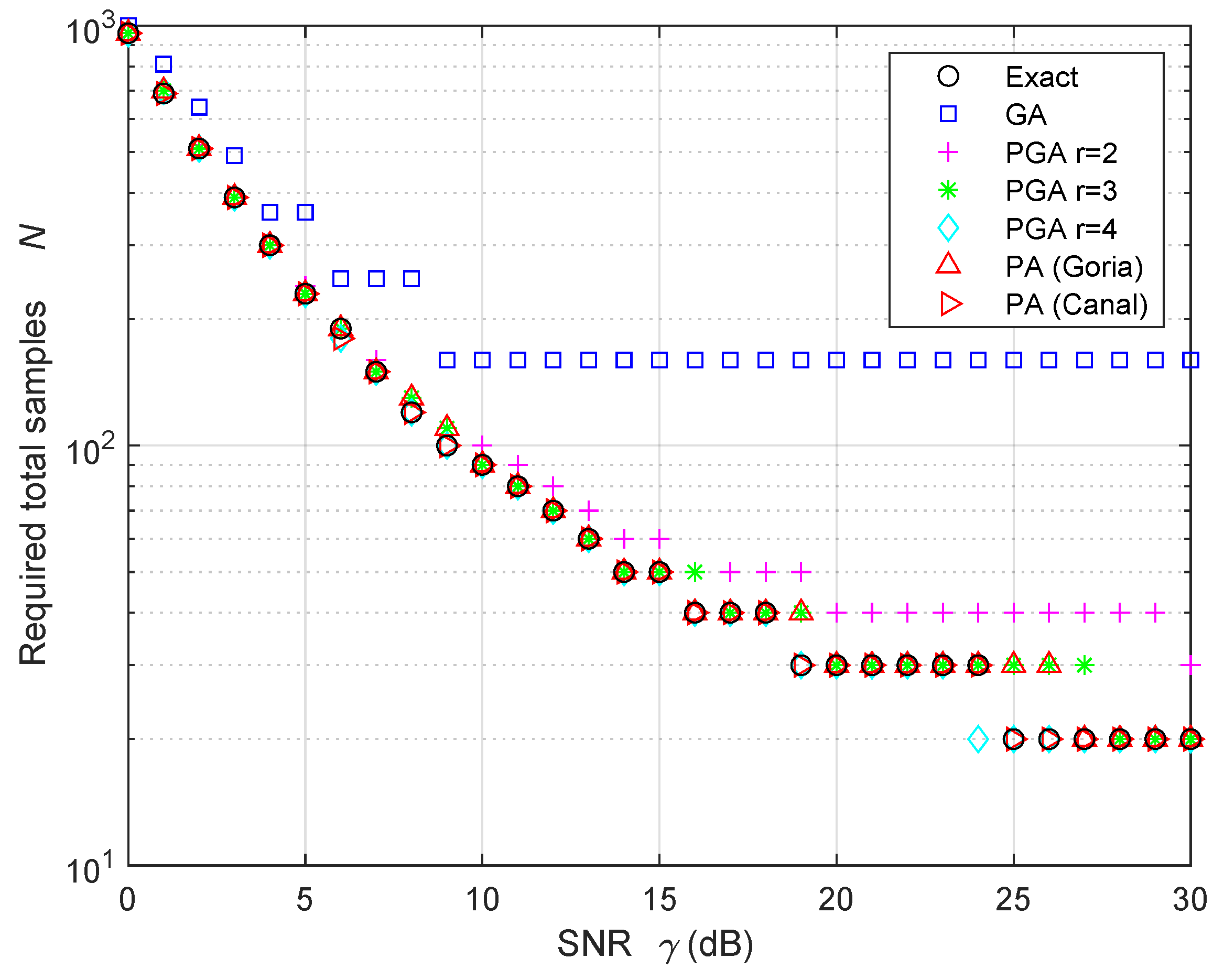
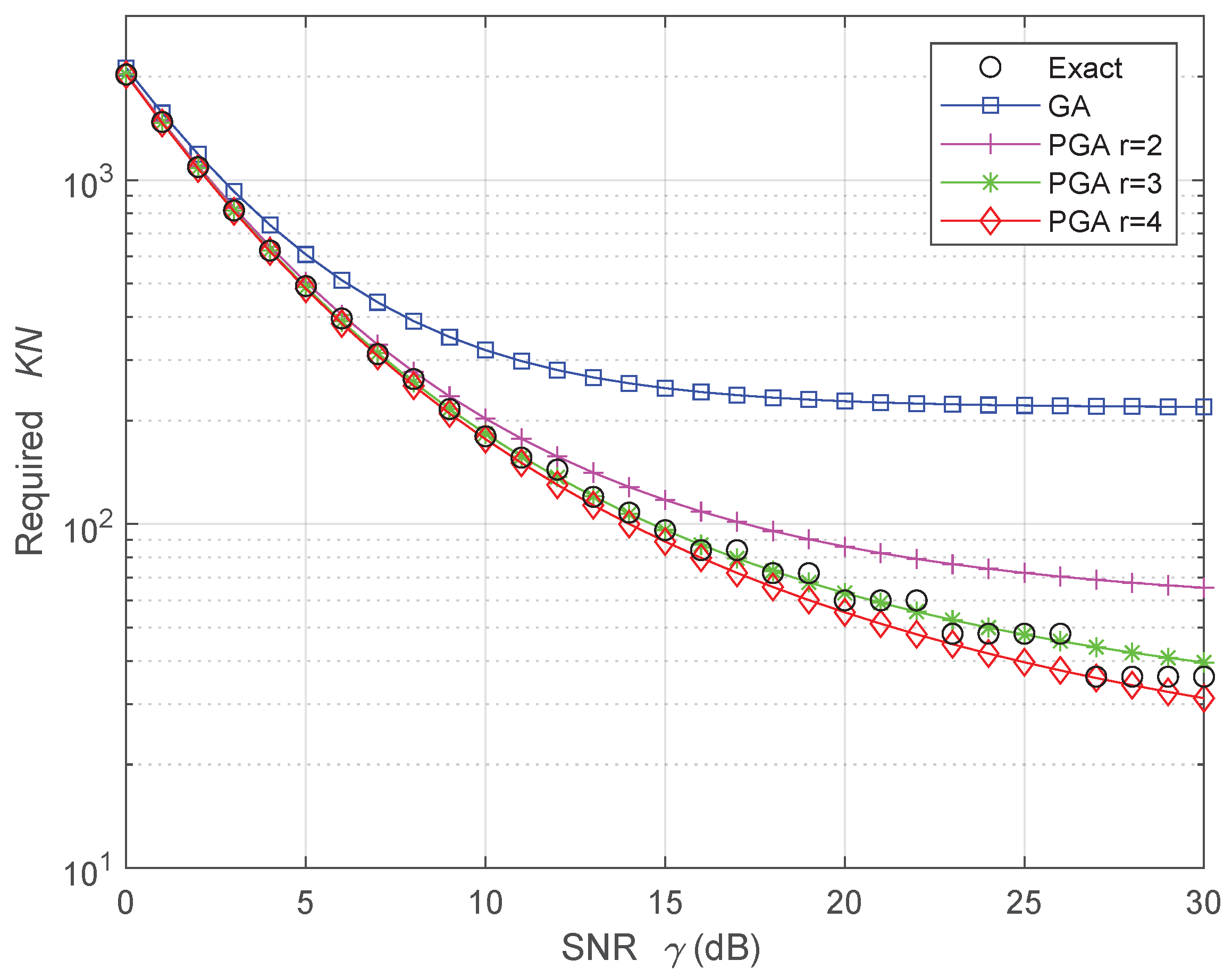
5. Numerical Results: Validation and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CLT | Central limit theorem |
| CR | Cognitive radio |
| CSS | Cooperative spectrum sensing |
| ED | Energy detector |
| EGC | Equal-gain combining |
| FA | False alarm |
| FC | Fusion center |
| GA | Gaussian approximation |
| HR | Hard reporting |
| MD | Missed detection |
| MV | Majority voting |
| PA | Polynomial approximation |
| Probability density function | |
| PGA | Power-of-Gaussian approximation |
| PU | Primary user |
| RE | Relative error |
| ROC | Receiver operating characteristic |
| SNR | Signal-to-noise ratio |
| SR | Soft reporting |
| SU | Secondary user |
References
- Akyildiz, I.F.; Lo, B.F.; Balakrishnan, R. Cooperative Spectrum Sensing in Cognitive Radio Networks: A Survey. Phys. Commun. 2011, 4, 40–62. [Google Scholar] [CrossRef]
- Joshi, G.; Nam, S.; Kim, S. Cognitive Radio Wireless Sensor Networks: Applications, Challenges and Research Trends. Sensors 2013, 13, 11196–11228. [Google Scholar] [CrossRef] [PubMed]
- Cichoń, K.; Kliks, A.; Bogucka, H. Energy-Efficient Cooperative Spectrum Sensing: A Survey. IEEE Commun. Surv. Tuts. 2016, 18, 1861–1886. [Google Scholar] [CrossRef]
- Davenport, M.A.; Boufounos, P.T.; Wakin, M.B.; Baraniuk, R.G. Signal Processing with Compressive Measurements. IEEE J. Sel. Topics Signal Process. 2010, 4, 445–460. [Google Scholar] [CrossRef]
- Song, Z.; Yang, J.; Zhang, H.; Gao, Y. Approaching Sub-Nyquist Boundary: Optimized Compressed Spectrum Sensing Based on Multicoset Sampler for Multiband Signal. IEEE Trans. Signal Process. 2022, 70, 4225–4238. [Google Scholar] [CrossRef]
- Yucek, T.; Arslan, H. A Survey of Spectrum Sensing Algorithms for Cognitive Radio Applications. IEEE Commun. Surv. Tuts. 2009, 11, 116–130. [Google Scholar] [CrossRef]
- Arjoune, Y.; Kaabouch, N. A Comprehensive Survey on Spectrum Sensing in Cognitive Radio Networks: Recent Advances, New Challenges, and Future Research Directions. Sensors 2019, 19, 126. [Google Scholar] [CrossRef]
- Nasser, A.; Al Haj Hassan, H.; Abou Chaaya, J.; Mansour, A.; Yao, K. Spectrum Sensing for Cognitive Radio: Recent Advances and Future Challenge. Sensors 2021, 21, 2408. [Google Scholar] [CrossRef]
- Lorincz, J.; Ramljak, I.; Begušić, D. A Survey on the Energy Detection of OFDM Signals with Dynamic Threshold Adaptation: Open Issues and Future Challenges. Sensors 2021, 21, 3080. [Google Scholar] [CrossRef]
- Men, S.; Chargé, P.; Fu, Z. Dynamic Robust Spectrum Sensing Based on Goodness-of-Fit Test Using Bilateral Hypotheses. Drones 2023, 7, 18. [Google Scholar] [CrossRef]
- Guimarães, D. Modified Gini Index Detector for Cooperative Spectrum Sensing over Line-of-Sight Channels. Sensors 2023, 23, 5403. [Google Scholar] [CrossRef] [PubMed]
- Fernando, X.; Lăzăroiu, G. Spectrum Sensing, Clustering Algorithms, and Energy-Harvesting Technology for Cognitive-Radio-Based Internet-of-Things Networks. Sensors 2023, 23, 7792. [Google Scholar] [CrossRef] [PubMed]
- Axell, E.; Leus, G.; Larsson, E.G.; Poor, H.V. Spectrum Sensing for Cognitive Radio: State-of-the-art and Recent Advances. IEEE Signal Process. Mag. 2012, 29, 101–116. [Google Scholar] [CrossRef]
- Zhang, W.; Mallik, R.K.; Letaief, K.B. Optimization of Cooperative Spectrum Sensing with Energy Detection in Cognitive Radio Networks. IEEE Trans. Wireless Commun. 2009, 8, 5761–5766. [Google Scholar] [CrossRef]
- Umar, R.; Sheikh, A.U.; Deriche, M. Unveiling the Hidden Assumptions of Energy Detector Based Spectrum Sensing for Cognitive Radios. IEEE Commun. Surv. Tuts. 2013, 16, 713–728. [Google Scholar] [CrossRef]
- Atapattu, S.; Tellambura, C.; Jiang, H. Energy Detection Based Cooperative Spectrum Sensing in Cognitive Radio Networks. IEEE Trans. Wireless Commun. 2011, 10, 1232–1241. [Google Scholar] [CrossRef]
- Banjade, V.R.S.; Tellambura, C.; Jiang, H. Approximations for Performance of Energy Detector and p-norm Detector. IEEE Commun. Lett. 2015, 19, 1678–1681. [Google Scholar] [CrossRef]
- Sobron, I.; Diniz, P.; Martins, W.; Velez, M. Energy Detection Technique for Adaptive Spectrum Sensing. IEEE Trans. Commun. 2015, 63, 617–627. [Google Scholar] [CrossRef]
- Chandrasekaran, G.; Kalyani, S. Performance Analysis of Cooperative Spectrum Sensing Over κ-μ Shadowed Fading. IEEE Wireless Commun. Lett. 2015, 4, 553–556. [Google Scholar] [CrossRef]
- Lesnikov, V.; Naumovich, T.; Chastikov, A.; Dubovcev, D. Approximation of the Central Chi-Squared Distribution for On-Line Computation of the Threshold for Energy Detector. In Proceedings of the 2016 IEEE East–West Design and Test Symposium (EWDTS), Yerevan, Armenia, 14–17 October 2016. [Google Scholar] [CrossRef]
- Lesnikov, V.; Naumovich, T.; Chastikov, A. Computation of the Energy Detector Threshold for Various Approximations of Noise Power Distribution. In Proceedings of the 2017 IEEE East–West Design and Test Symposium (EWDTS), Novi Sad, Serbia, 29 September–2 October 2017. [Google Scholar] [CrossRef]
- Sobron, I.; Eizmendi, I.; Martins, W.; Diniz, P.; Ordiales, J.; Velez, M. Implementation Issues of Adaptive Energy Detection in Heterogeneous Wireless Networks. Sensors 2017, 17, 932. [Google Scholar] [CrossRef]
- Li, J.; Li, B.; Liu, M. Performance Analysis of Cooperative Spectrum Sensing over Large and Small Scale Fading Channels. AEÜ Intl. J. Electron. Commun. 2017, 78, 90–97. [Google Scholar] [CrossRef]
- Bhatt, M.; Soni, S.K. A Unified Performance Analysis of Energy Detector over α-η-μ/Lognormal and α-κ-μ/Lognormal Composite Fading Channels with Diversity and Cooperative Spectrum Sensing. AEÜ Intl. J. Electron. Commun. 2018, 94, 367–376. [Google Scholar] [CrossRef]
- Cao, K.; Qian, P.; An, J.; Wang, L. Accurate and Practical Energy Detection over α-μ Fading Channels. Sensors 2020, 20, 754. [Google Scholar] [CrossRef] [PubMed]
- Lopez-Benitez, M.; Toma, O.H.; Patel, D.K.; Umebayashi, K. Sample Size Analysis of Energy Detection under Fading Channels. In Proceedings of the 2020 IEEE Wireless Communications and Networking Conference Workshops (WCNCW), Seoul, Republic of Korea, 25–28 May 2020. [Google Scholar] [CrossRef]
- Lorincz, J.; Ramljak, I.; Begušić, D. Algorithm for Evaluating Energy Detection Spectrum Sensing Performance of Cognitive Radio MIMO-OFDM Systems. Sensors 2021, 21, 6881. [Google Scholar] [CrossRef] [PubMed]
- Maleki, S.; Leus, G. Censored Truncated Sequential Spectrum Sensing for Cognitive Radio Networks. IEEE J. Sel. Areas Commun. 2013, 31, 364–378. [Google Scholar] [CrossRef]
- Maleki, S.; Chepuri, S.P.; Leus, G. Optimization of Hard Fusion Based Spectrum Sensing for Energy-Constrained Cognitive Radio Networks. Phys. Commun. 2013, 9, 193–198. [Google Scholar] [CrossRef]
- Shakir, M.Z.; Rao, A.; Alouini, M.-S. Generalized Mean Detector for Collaborative Spectrum Sensing. IEEE Trans. Commun. 2013, 61, 1242–1253. [Google Scholar] [CrossRef]
- Hamza, D.; Aissa, S.; Aniba, G. Equal Gain Combining for Cooperative Spectrum Sensing in Cognitive Radio Networks. IEEE Trans. Wireless Commun. 2014, 13, 4334–4345. [Google Scholar] [CrossRef]
- Gupta, K.; Merchant, S.N.; Desai, U.B. A Novel Multistage Decision Fusion for Cognitive Sensor Networks Using AND and OR Rules. Digital Signal Process. 2015, 42, 27–34. [Google Scholar] [CrossRef]
- Alaa, A.M.; Nasr, O.A. Globally Optimal Cooperation in Dense Cognitive Radio Networks. Wireless Pers. Commun. 2015, 84, 885–899. [Google Scholar] [CrossRef]
- Duan, M.; Zeng, Z.; Guo, C.; Liu, F. User Selection for Cooperative Spectrum Sensing in Mobile Cognitive Radios. In Proceedings of the 2015 IEEE/CIC International Conference on Communications in China (ICCC), Shenzhen, China, 2–4 November 2015. [Google Scholar] [CrossRef]
- Do, T.-N.; An, B. A Soft-Hard Combination-Based Cooperative Spectrum Sensing Scheme for Cognitive Radio Networks. Sensors 2015, 15, 4388–4407. [Google Scholar] [CrossRef]
- Pradhan, P.M.; Panda, G. Information Combining Schemes for Cooperative Spectrum Sensing: A Survey and Comparative Performance Analysis. Wireless Pers. Commun. 2017, 94, 685–711. [Google Scholar] [CrossRef]
- Men, S.; Chargé, P.; Pillement, S. Cooperative Spectrum Sensing with Small Sample Size in Cognitive Wireless Sensor Networks. Wireless Pers. Commun. 2017, 96, 1871–1885. [Google Scholar] [CrossRef]
- Aquino, G.; Guimarães, D.; Mendes, L.; Pimenta, T. Combined Pre-Distortion and Censoring for Bandwidth-Efficient and Energy-Efficient Fusion of Spectrum Sensing Information. Sensors 2017, 17, 654. [Google Scholar] [CrossRef] [PubMed]
- Fu, Y.; Yang, F.; He, Z. A Quantization-Based Multibit Data Fusion Scheme for Cooperative Spectrum Sensing in Cognitive Radio Networks. Sensors 2018, 18, 473. [Google Scholar] [CrossRef]
- Qian, X.; Hao, L.; Ni, D.; Tran, Q. Hard Fusion Based Spectrum Sensing over Mobile Fading Channels in Cognitive Vehicular Networks. Sensors 2018, 18, 475. [Google Scholar] [CrossRef]
- Tong, J.; Jin, M.; Guo, Q.; Li, Y. Cooperative Spectrum Sensing: A Blind and Soft Fusion Detector. IEEE Trans. Wireless Commun. 2018, 17, 2726–2737. [Google Scholar] [CrossRef]
- Costa, L.; Guimarães, D.; De Souza, R.; Bomfin, R. Cooperative Spectrum Sensing with Coded and Uncoded Decision Fusion under Correlated Shadowed Fading Report Channels. Sensors 2019, 19, 51. [Google Scholar] [CrossRef]
- Liu, S.; Wang, K.; Liu, K.; Chen, W. Noncoherent Decision Fusion over Fading Hybrid MACs in Wireless Sensor Networks. Sensors 2019, 19, 120. [Google Scholar] [CrossRef]
- Mi, Y.; Lu, G.; Li, Y.; Bao, Z. A Novel Semi-Soft Decision Scheme for Cooperative Spectrum Sensing in Cognitive Radio Networks. Sensors 2019, 19, 2522. [Google Scholar] [CrossRef]
- Luo, X.; Zhao, W.; Li, H.; Jin, M.; Cui, G. Fusion Test Statistics Based Mixture Detector for Spectrum Sensing. IEEE Trans. Veh. Technol. 2022, 71, 3315–3319. [Google Scholar] [CrossRef]
- Wang, Y.; Ma, S.; Chen, Q.; Zhuang, J.; Jiang, D. A Geodesic Projection-Based Data Fusion Scheme for Cooperative Spectrum Sensing. Digital Signal Process. 2023, 137, 104006. [Google Scholar] [CrossRef]
- Zhuang, J.; Wang, Y.; Peng, S.; Zhang, S.; Liu, Y. Siegel Distance-Based Fusion Strategy and Differential Evolution Algorithm for Cooperative Spectrum Sensing. Digital Signal Process. 2023, 142, 104215. [Google Scholar] [CrossRef]
- Liu, X.; Jia, M.; Gu, X.; Tan, X. Optimal Periodic Cooperative Spectrum Sensing Based on Weight Fusion in Cognitive Radio Networks. Sensors 2013, 13, 5251–5272. [Google Scholar] [CrossRef] [PubMed]
- Do, T.-N.; An, B. Cooperative Spectrum Sensing Schemes with the Interference Constraint in Cognitive Radio Networks. Sensors 2014, 14, 8037–8056. [Google Scholar] [CrossRef]
- Guimarães, D.; Aquino, G. Resource-Efficient Fusion over Fading and Non-Fading Reporting Channels for Cooperative Spectrum Sensing. Sensors 2015, 15, 1861–1884. [Google Scholar] [CrossRef] [PubMed]
- Guimarães, D.; Aquino, G.; Cattaneo, M. Resource-Efficient Fusion with Pre-Compensated Transmissions for Cooperative Spectrum Sensing. Sensors 2015, 15, 10891–10908. [Google Scholar] [CrossRef] [PubMed]
- Banavathu, N.R.; Khan, M.Z.A. On Throughput Maximization of Cooperative Spectrum Sensing Using the M-out-of-K Rule. In Proceedings of the IEEE 89th Vehicular Technology Conference (VTC2019-Spring), Kuala Lumpur, Malaysia, 28 April–1 May 2019. [Google Scholar] [CrossRef]
- Abramowitz, M.; Stegun, I.A. Handbook of Mathematical Functions with Formulas, Graphs, and Mathematical Tables; Dover: New York, NY, USA, 1972. [Google Scholar]
- Raff, M.S. On Approximating the Point Binomial. J. Am. Stat. Assoc. 1956, 51, 293–303. [Google Scholar] [CrossRef]
- Gebhardt, F. Some Numerical Comparisons of Several Approximations to the Binomial Distribution. J. Am. Stat. Assoc. 1969, 64, 1638–1646. [Google Scholar] [CrossRef]
- Cochran, W.G. Note on an Approximate Formula for the Significance Levels of z. Ann. Math. Stat. 1940, 11, 93–95. [Google Scholar] [CrossRef]
- Thompson, C.M.; Pearson, E.S.; Comrie, L.J.; Hartley, H.O. Tables of Percentage Points of the Incomplete Beta-Function. Biometrika 1941, 32, 151–181. [Google Scholar] [CrossRef]
- Carter, A.H. Approximation to Percentage Points of the z-Distribution. Biometrika 1947, 34, 352–358. [Google Scholar] [CrossRef] [PubMed]
- Aroian, L.A. On the Levels of Significance of the Incomplete Beta Function and the F-Distributions. Biometrika 1950, 37, 219–223. [Google Scholar] [CrossRef] [PubMed]
- Wilson, E.B.; Hilferty, M.M. The Distribution of Chi-Square. Proc. Natl. Acad. Sci. USA 1931, 17, 684–688. [Google Scholar] [CrossRef] [PubMed]
- Hawkins, D.M.; Wixley, R.A.J. A Note on the Transformation of Chi-Squared Variables to Normality. Amer. Stat. 1986, 40, 296–298. [Google Scholar] [CrossRef]
- Goria, M.N. On the Fourth Root Transformation of Chi-Square. Austral. J. Stat. 1992, 34, 55–64. [Google Scholar] [CrossRef]
- Canal, L. A Normal Approximation for the Chi-Square Distribution. Computat. Stat. Data Analysis 2005, 48, 803–808. [Google Scholar] [CrossRef]
- Rugini, L.; Banelli, P.; Leus, G. Small Sample Size Performance of the Energy Detector. IEEE Commun. Lett. 2013, 17, 1814–1817. [Google Scholar] [CrossRef]
- Rugini, L.; Banelli, P.; Leus, G. Spectrum Sensing Using Energy Detectors with Performance Computation Capabilities. In Proceedings of the 24th European Signal Processing Conference (EUSIPCO), Budapest, Hungary, 28 August–2 September 2016; pp. 1608–1612. [Google Scholar] [CrossRef]
- Lagunas, E.; Rugini, L. Performance of Compressive Sensing Based Energy Detection. In Proceedings of the IEEE 28th Annual International Symposium on Personal, Indoor, and Mobile Radio Communications (PIMRC), Montreal, QC, Canada, 8–13 October 2017. [Google Scholar] [CrossRef]
- Maleki, S.; Chepuri, S.P.; Leus, G. Energy and Throughput Efficient Strategies for Cooperative Spectrum Sensing in Cognitive Radios. In Proceedings of the IEEE 12th International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), San Francisco, CA, USA, 26–29 June 2011; pp. 71–75. [Google Scholar] [CrossRef]
- Chatterjee, S.; Maity, S.P.; Acharya, T. Energy-Spectrum Efficiency Trade-Off in Energy Harvesting Cooperative Cognitive Radio Networks. IEEE Trans. Cognitive Commun. Netw. 2019, 5, 295–303. [Google Scholar] [CrossRef]
- Chatterjee, S.; De, S. QoE-Aware Cross-Layer Adaptation for D2D Video Communication in Cooperative Cognitive Radio Networks. IEEE Syst. J. 2022, 16, 2078–2089. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Exact | 60 | 100 | 180 | 540 |
| GA | 20 | 20 | 60 | 340 |
| Arcsine | 220 | 260 | 300 | 660 |
| Camp–Poulson | 140 | 140 | 220 | 540 |
| Fisher | 60 | 60 | 140 | 460 |
| Cochran | 140 | 140 | 220 | 540 |
| Carter | 60 | 100 | 180 | 540 |
| SNR = 0 dB | SNR = 10 dB | SNR = 20 dB | SNR = 30 dB | |
|---|---|---|---|---|
| Exact | 960 | 90 | 30 | 20 |
| GA | 1000 | 160 | 160 | 160 |
| PGA, | 960 | 100 | 40 | 30 |
| PGA, | 960 | 90 | 30 | 20 |
| PGA, | 960 | 90 | 30 | 20 |
| PA (Goria) | 960 | 90 | 30 | 20 |
| PA (Canal) | 960 | 90 | 30 | 20 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rugini, L.; Banelli, P. Performance Analysis of Centralized Cooperative Schemes for Compressed Sensing. Sensors 2024, 24, 661. https://doi.org/10.3390/s24020661
Rugini L, Banelli P. Performance Analysis of Centralized Cooperative Schemes for Compressed Sensing. Sensors. 2024; 24(2):661. https://doi.org/10.3390/s24020661
Chicago/Turabian StyleRugini, Luca, and Paolo Banelli. 2024. "Performance Analysis of Centralized Cooperative Schemes for Compressed Sensing" Sensors 24, no. 2: 661. https://doi.org/10.3390/s24020661
APA StyleRugini, L., & Banelli, P. (2024). Performance Analysis of Centralized Cooperative Schemes for Compressed Sensing. Sensors, 24(2), 661. https://doi.org/10.3390/s24020661