



Korean Cattle 3D Reconstruction from Multi-View 3D-Camera System in Real Environment

 , , , , , , , , , and
, , , , , , , , , and
Abstract
1. Introduction
- A method of two-step optimization is proposed. In step 1, a global mesh is generated from all cameras, and in step 2, each camera is aligned to the global mesh. This optimization can run well with cameras that have small overlapping and considerable noise.
- Automatic 3D segmenting of cattle parts from 3D data of each camera.
2. Related Work
3. Material and Data Acquisition
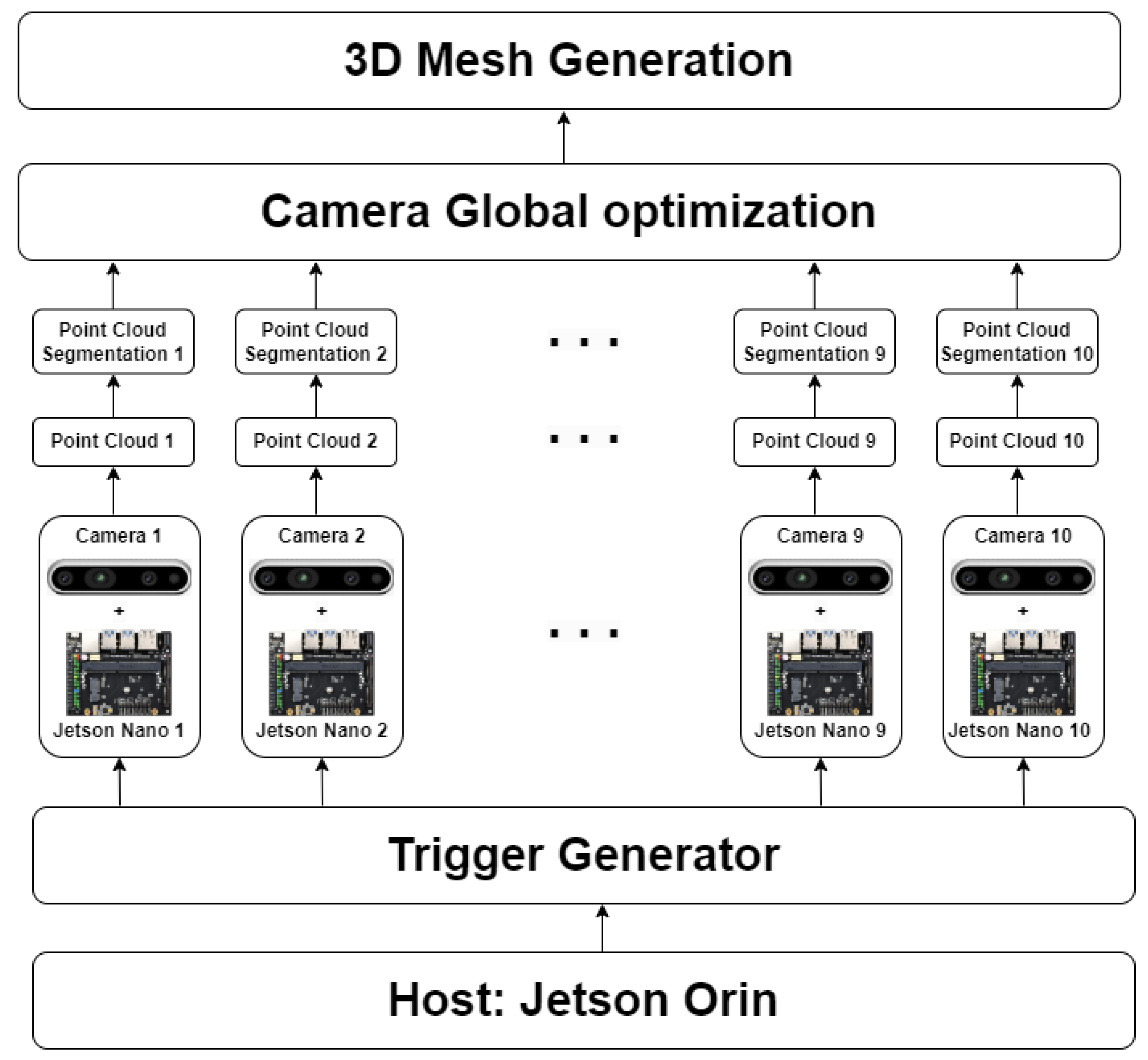
3.1. The 3D Reconstruction Framework
- Camera synchronization and data acquisition.
- Segmenting 3D data.
- Global 3D camera pose optimization and generating mesh.
3.2. Cameras System
- Trigger Generator: This device generates a synchronous signal to ten camera devices.
- Camera devices—Intel Realsense D435i: This device connects and sends stereo images to Jetson Nano.
- Single Board Computer—Jetson Nano: This device receives stereo images from cameras and then transfers them to Jetson Orin.
- Host Computer—Jetson Orin: Center device of capturing system. It generates a signal to the active Trigger Generator. It retrieves stereo images from Jetson Nano devices and reconstructs the final 3D mesh.
3.3. Camera Synchronization System
3.4. Camera Calibration System
- Calibration of each camera to determine its intrinsic parameters.
- Calibration global extrinsic matrix of all ten cameras.
4. Korean Cattle 3D Reconstruction
4.1. Point Cloud Generation and Removing Fence for a Single Camera
Point Cloud Generation and Segmentation
4.2. Camera Pose Optimization
4.2.1. Objective
4.2.2. Optimization
| Algorithm 1 Algorithm of alignment for all cameras |
|
5. Experimental Results
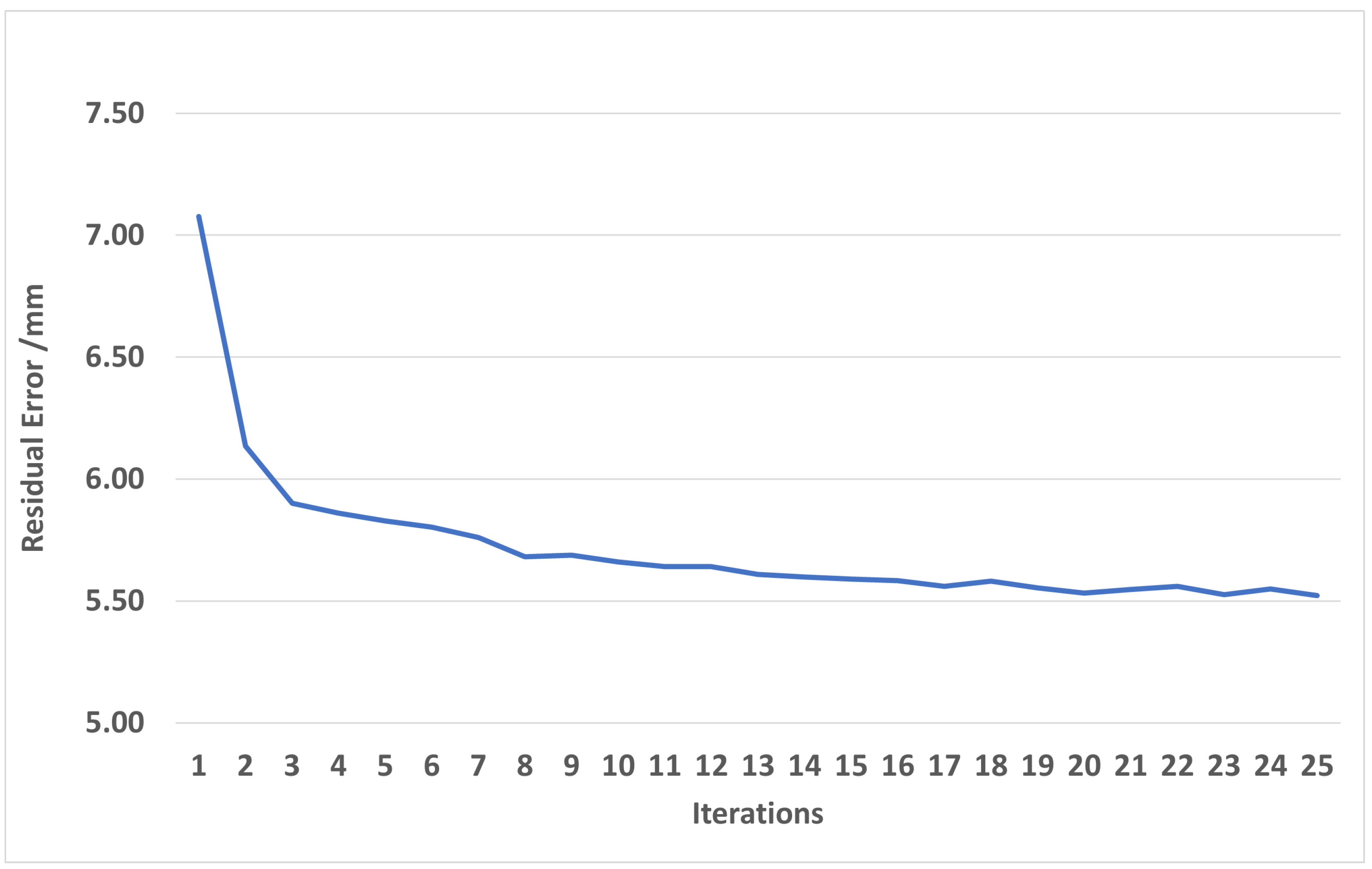
5.1. Evaluation of Synchronization Process
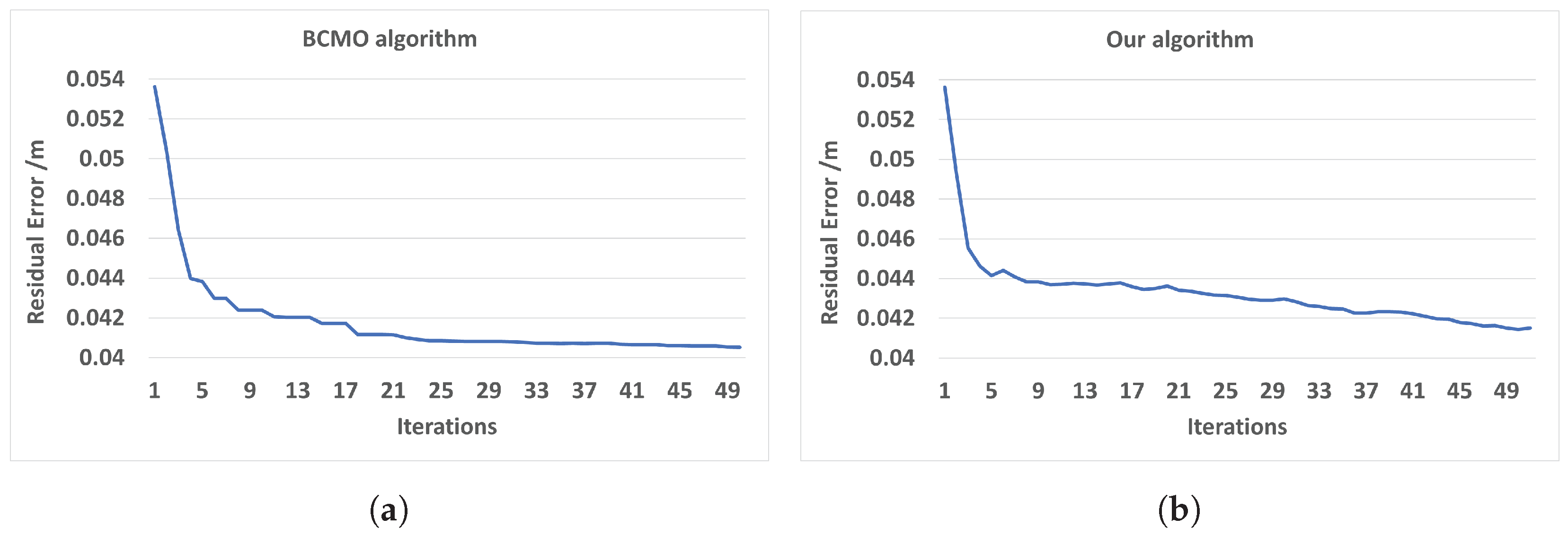
5.2. Evaluation of Optimization Process
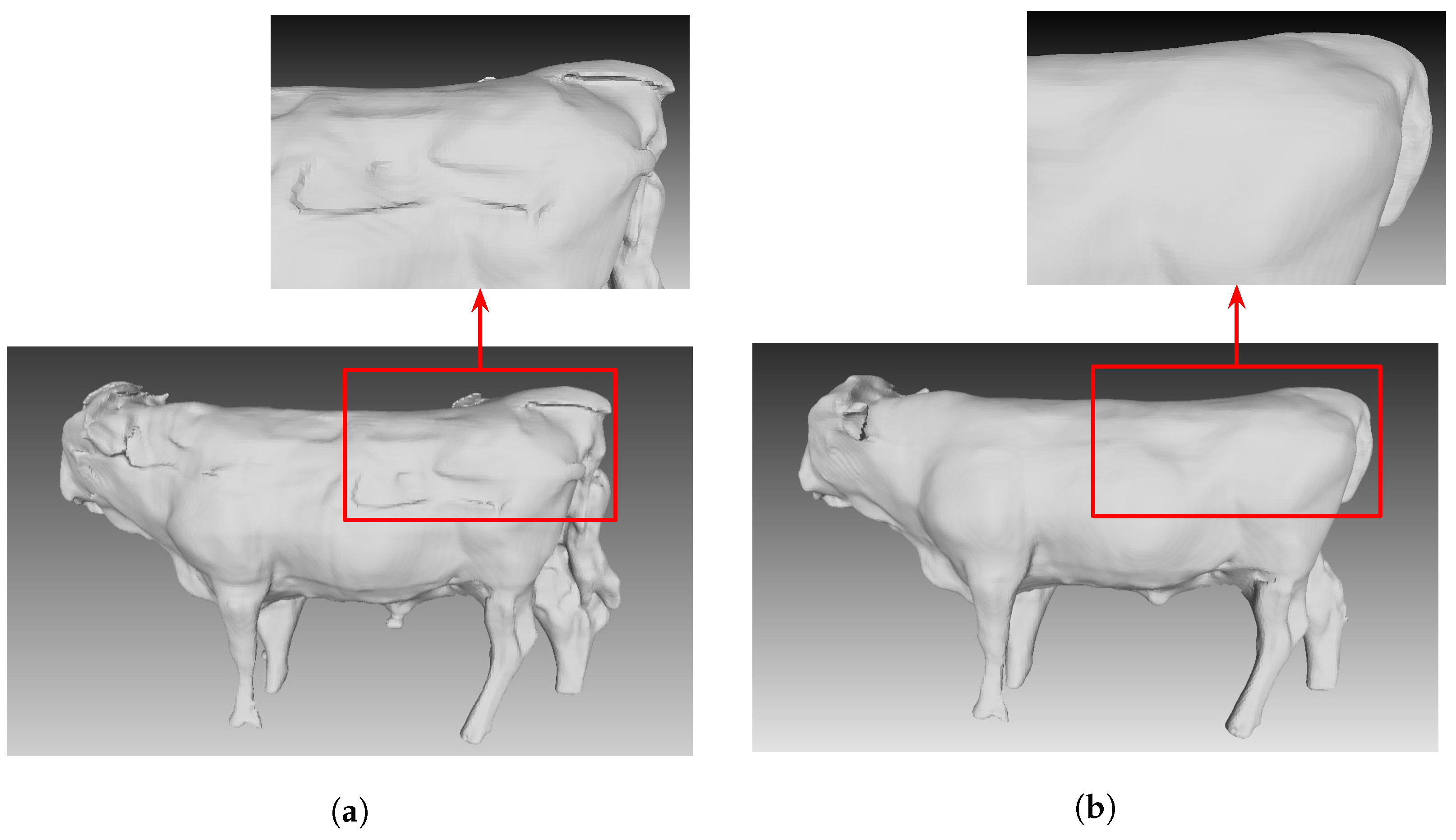
5.3. Cow Reconstruction Result
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3D | Three Dimension |
| A.I | Artificial Intelligence |
| BCMO | Balance Composite Motion Optimization |
| FPFH | Fast-Point Feature Histogram |
| ICP | Iterative Closest Point |
| Kd-tree | K-dimension tree |
| PSR | Poisson Surface Reconstruction |
| M | 3D Mesh generated from points and normals of 10 cameras by PSR algorithm |
| Super4PCS | Super 4-Point Congruent Set |
| T | Transformation matrix |
References
- Özyeşil, O.; Voroninski, V.; Basri, R.; Singer, A. A survey of structure from motion. Acta Numer. 2017, 26, 305–364. [Google Scholar] [CrossRef]
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. Kinectfusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Zhou, Q.Y.; Koltun, V. Simultaneous localization and calibration: Self-calibration of consumer depth cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 454–460. [Google Scholar]
- Besl, P.J.; McKay, N.D. Method for registration of 3-D shapes. In Proceedings of the Sensor Fusion IV: Control Paradigms and Data Structures, Spie, Boston, MA, USA, 1 April 1992; Volume 1611, pp. 586–606. [Google Scholar]
- Segal, A.; Haehnel, D.; Thrun, S. Generalized-icp. In Proceedings of the Robotics: Science and Systems, Seattle, WA, USA, 28 June–1 July 2009; Volume 2, p. 435. [Google Scholar]
- Horn, B.K. Closed-form solution of absolute orientation using unit quaternions. J. Opt. Soc. Am. A 1987, 4, 629–642. [Google Scholar] [CrossRef]
- Zhang, Z. Iterative point matching for registration of free-form curves and surfaces. Int. J. Comput. Vis. 1994, 13, 119–152. [Google Scholar] [CrossRef]
- Aiger, D.; Mitra, N.J.; Cohen-Or, D. 4-points congruent sets for robust pairwise surface registration. In ACM SIGGRAPH 2008 Papers; ACM: New York, NY, USA, 2008; pp. 1–10. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Beetz, M. Fast point feature histograms (FPFH) for 3D registration. In Proceedings of the 2009 IEEE International Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 3212–3217. [Google Scholar]
- Zhang, J.; Singh, S. LOAM: Lidar odometry and mapping in real-time. In Proceedings of the Robotics: Science and Systems, Berkeley, CA, USA, 12–16 July 2014; Volume 2, pp. 1–9. [Google Scholar]
- Wang, S.; Zuo, X.; Du, C.; Wang, R.; Zheng, J.; Yang, R. Dynamic non-rigid objects reconstruction with a single rgb-d sensor. Sensors 2018, 18, 886. [Google Scholar] [CrossRef] [PubMed]
- Newcombe, R.A.; Fox, D.; Seitz, S.M. Dynamicfusion: Reconstruction and tracking of non-rigid scenes in real-time. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 343–352. [Google Scholar]
- Le-Duc, T.; Nguyen, Q.H.; Nguyen-Xuan, H. Balancing composite motion optimization. Inf. Sci. 2020, 520, 250–270. [Google Scholar] [CrossRef]
- Choi, S.; Zhou, Q.Y.; Koltun, V. Robust reconstruction of indoor scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5556–5565. [Google Scholar]
- Park, J.; Zhou, Q.Y.; Koltun, V. Colored point cloud registration revisited. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 143–152. [Google Scholar]
- Ruchay, A.; Kober, V.; Dorofeev, K.; Kolpakov, V.; Gladkov, A.; Guo, H. Live Weight Prediction of Cattle Based on Deep Regression of RGB-D Images. Agriculture 2022, 12, 1794. [Google Scholar] [CrossRef]
- Li, J.; Ma, W.; Li, Q.; Zhao, C.; Tulpan, D.; Yang, S.; Ding, L.; Gao, R.; Yu, L.; Wang, Z. Multi-view real-time acquisition and 3D reconstruction of point clouds for beef cattle. Comput. Electron. Agric. 2022, 197, 106987. [Google Scholar] [CrossRef]
- Li, S.; Lu, R.; Liu, J.; Guo, L. Super edge 4-points congruent sets-based point cloud global registration. Remote Sens. 2021, 13, 3210. [Google Scholar] [CrossRef]
- Bueno, M.; Bosché, F.; González-Jorge, H.; Martínez-Sánchez, J.; Arias, P. 4-Plane congruent sets for automatic registration of as-is 3D point clouds with 3D BIM models. Autom. Constr. 2018, 89, 120–134. [Google Scholar] [CrossRef]
- Le Cozler, Y.; Allain, C.; Caillot, A.; Delouard, J.; Delattre, L.; Luginbuhl, T.; Faverdin, P. High-precision scanning system for complete 3D cow body shape imaging and analysis of morphological traits. Comput. Electron. Agric. 2019, 157, 447–453. [Google Scholar] [CrossRef]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings of the Third International Conference on 3-D Digital Imaging and Modeling, Quebec City, QC, Canada, 28 May–1 June 2001; pp. 145–152. [Google Scholar]
- Li, J.; Wang, P.; Xiong, P.; Cai, T.; Yan, Z.; Yang, L.; Liu, J.; Fan, H.; Liu, S. Practical stereo matching via cascaded recurrent network with adaptive correlation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16263–16272. [Google Scholar]
- Dang, C.; Choi, T.; Lee, S.; Lee, S.; Alam, M.; Lee, S.; Han, S.; Hoang, D.T.; Lee, J.; Nguyen, D.T. Case Study: Improving the Quality of Dairy Cow Reconstruction with a Deep Learning-Based Framework. Sensors 2022, 22, 9325. [Google Scholar] [CrossRef] [PubMed]
- Staranowicz, A.N.; Brown, G.R.; Morbidi, F.; Mariottini, G.L. Practical and accurate calibration of RGB-D cameras using spheres. Comput. Vis. Image Underst. 2015, 137, 102–114. [Google Scholar] [CrossRef]
- Kazhdan, M.; Bolitho, M.; Hoppe, H. Poisson surface reconstruction. In Proceedings of the Fourth Eurographics Symposium on Geometry Processing, Sardinia, Italy, 26–28 June 2006; Volume 7. [Google Scholar]
- Kazhdan, M.; Hoppe, H. Screened poisson surface reconstruction. ACM Trans. Graph. (ToG) 2013, 32, 29. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Device | Specification |
|---|---|
| Depth Camera (Intel Realsense D435i) | - Use environment: Indoor/Outdoor - Baseline [mm]: 50 - Resolution: 1920 × 1080 px - Frame rate: 30 fps - Sensor FOV (H × V × D): 69.40 × 42.5 × 77 (±3) - Dimensions: 90 × 25 × 25 mm - Connection: USB-C 3.1 Gen1 |
| Single Board Computer (Jetson Nano) | - GPU: 128-Core Maxwell - CPU: Quad-core ARM Cortex-A57 CPU - RAM: 4 GB 64-bit LPDDR4 25.6 GB/s - Storage: microSD card slot for storage (256 GB) - USB: 4× USB 3.0 ports, USB 2.0 Micro-B - Networking: Gigabit Ethernet - Wireless: Optional Wi-Fi/Bluetooth module - Operating System: Supports NVIDIA’s Linux-based operating system - Power: 5 V/4 A power supply |
| Host Computer (Jetson Orin) | - GPU: 2048-core NVIDIA Ampere architecture GPU with 64 Tensor Cores - CPU: 12-core Arm® Cortex®-A78AE v8.2 64-bit, CPU - RAM: 64 GB 256-bit LPDDR5, 204.8 GB/s - Storage: 64 GB eMMC 5.1 storage - USB: Up to 2 × 8, 1 × 4, 2 × 1 (PCIe Gen4, Root Port and Endpoint), 3 × USB 3.2 - Networking: 1 × GbE, 1 × 10 GbE - Operating System: Supports various Linux distributions - Power: 15 W–60 W |
| Number of Iteration | 1 Iteration Computation Time | Total Time | |
|---|---|---|---|
| BCMO Algorithm | 50 iterations | 280 s | 14,000 s |
| Our algorithm | 50 iterations | 11 s | 550 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dang, C.G.; Lee, S.S.; Alam, M.; Lee, S.M.; Park, M.N.; Seong, H.-S.; Han, S.; Nguyen, H.-P.; Baek, M.K.; Lee, J.G.; et al. Korean Cattle 3D Reconstruction from Multi-View 3D-Camera System in Real Environment. Sensors 2024, 24, 427. https://doi.org/10.3390/s24020427
Dang CG, Lee SS, Alam M, Lee SM, Park MN, Seong H-S, Han S, Nguyen H-P, Baek MK, Lee JG, et al. Korean Cattle 3D Reconstruction from Multi-View 3D-Camera System in Real Environment. Sensors. 2024; 24(2):427. https://doi.org/10.3390/s24020427
Chicago/Turabian StyleDang, Chang Gwon, Seung Soo Lee, Mahboob Alam, Sang Min Lee, Mi Na Park, Ha-Seung Seong, Seungkyu Han, Hoang-Phong Nguyen, Min Ki Baek, Jae Gu Lee, and et al. 2024. "Korean Cattle 3D Reconstruction from Multi-View 3D-Camera System in Real Environment" Sensors 24, no. 2: 427. https://doi.org/10.3390/s24020427
APA StyleDang, C. G., Lee, S. S., Alam, M., Lee, S. M., Park, M. N., Seong, H.-S., Han, S., Nguyen, H.-P., Baek, M. K., Lee, J. G., & Pham, V. T. (2024). Korean Cattle 3D Reconstruction from Multi-View 3D-Camera System in Real Environment. Sensors, 24(2), 427. https://doi.org/10.3390/s24020427