
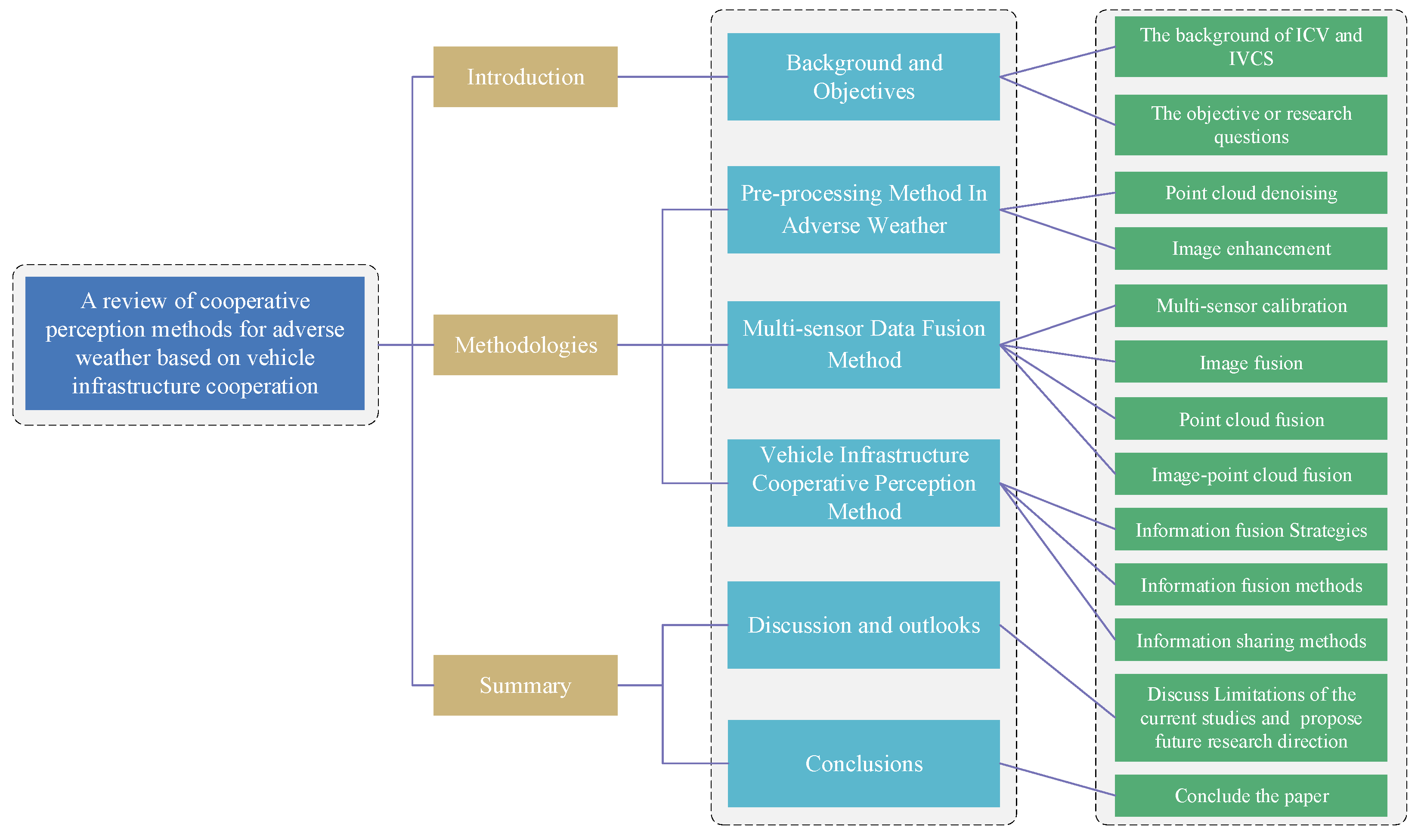
Perception Methods for Adverse Weather Based on Vehicle Infrastructure Cooperation System: A Review




Abstract
1. Introduction
2. The Preprocessing Method in Adverse Weather Conditions
2.1. LiDAR Point Denoising in Adverse Weather Conditions
2.2. Image Enhancement in Adverse Weather Conditions
3. Multi-Sensor Data Fusion Method
3.1. Multi-Sensor Temporal and Spatial Calibration
3.2. Multi-Sensor Image Fusion Method
3.3. Multi-Sensor Point Cloud Fusion Method
3.4. Multi-Sensor Image-Point Cloud Fusion Method
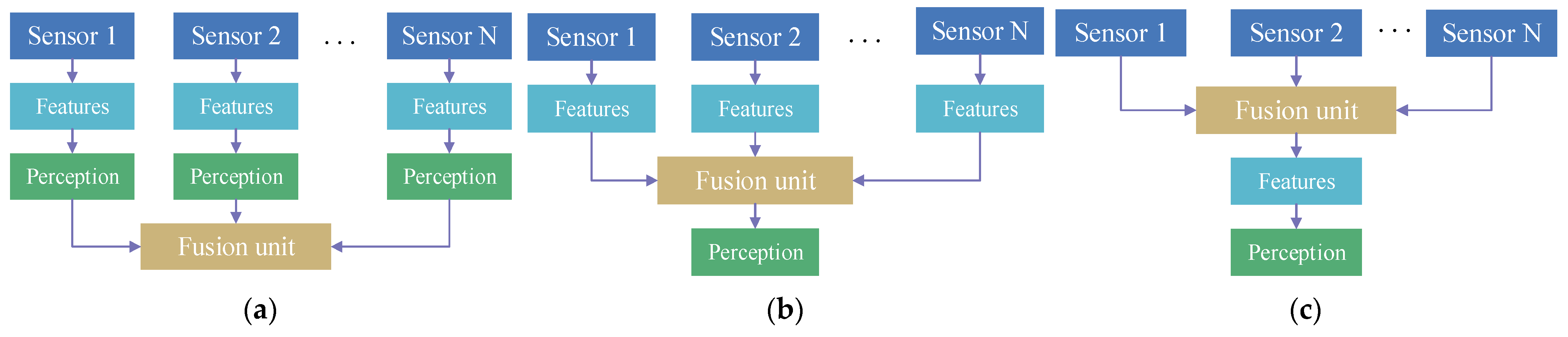
3.5. Multi-Sensor Data Fusion Strategies
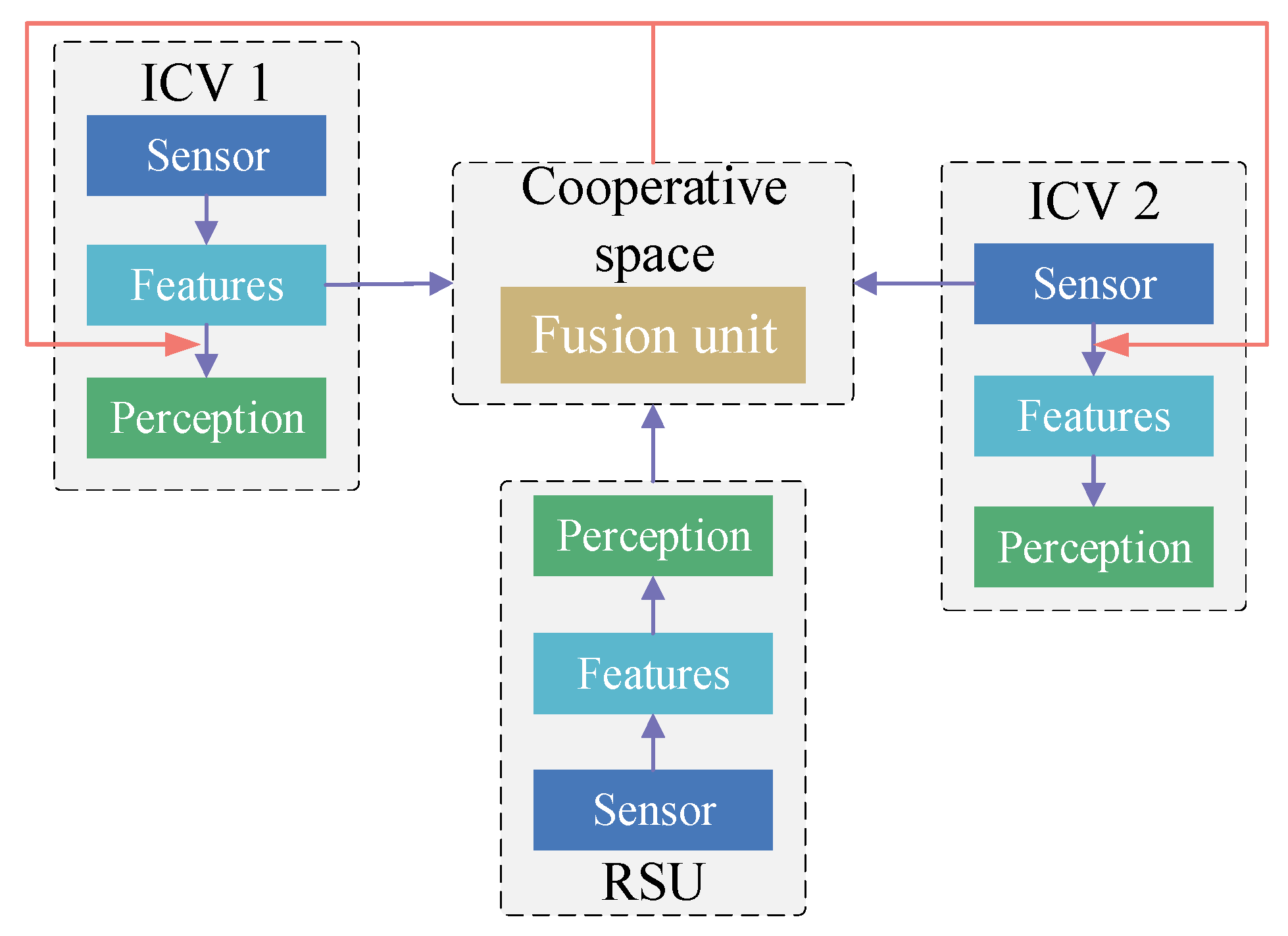
4. Vehicle–Infrastructure Cooperative Perception Method
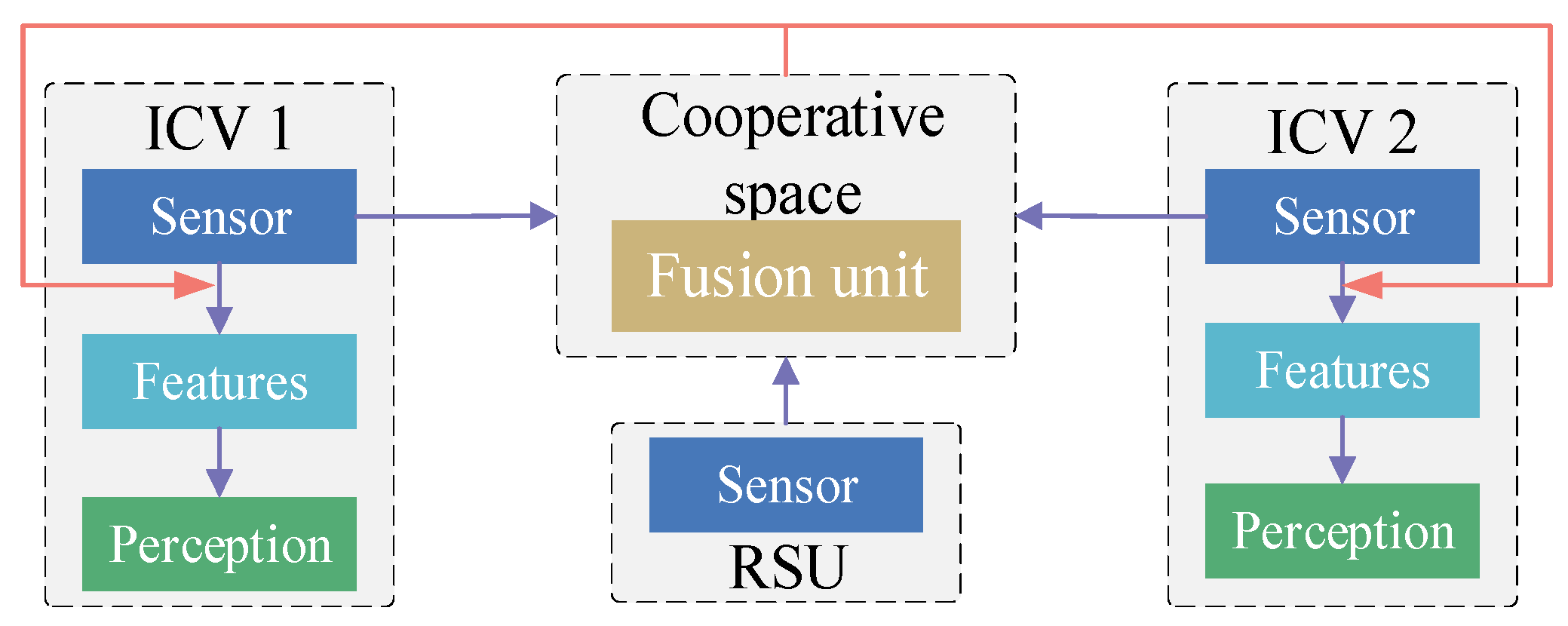
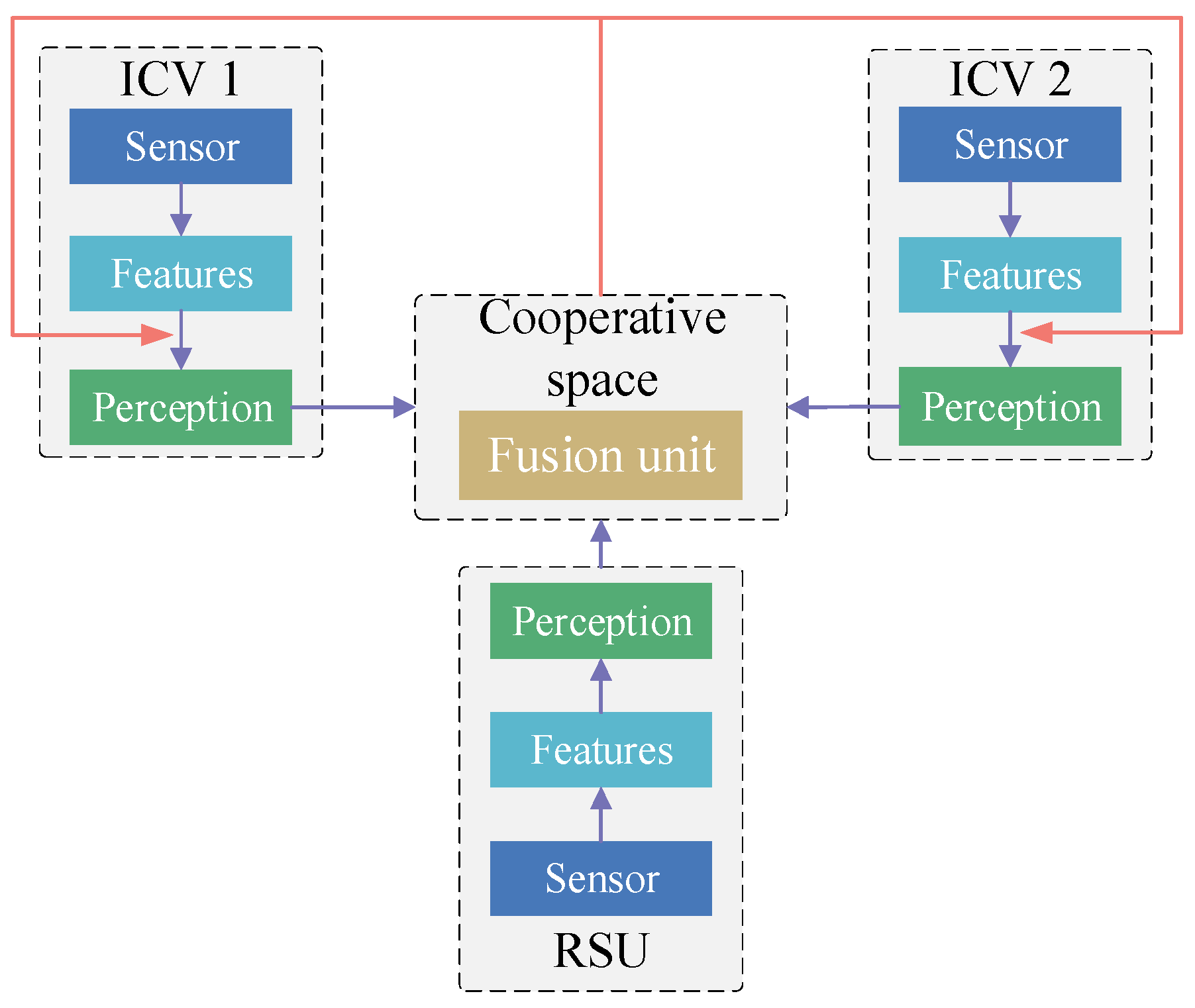
4.1. Information Fusion Strategies in Cooperative Perception
4.2. Information Fusion Methods in Cooperative Perception
4.3. Information Sharing Methods in Cooperative Perception
5. Discussion and Outlooks
- (1)
- Raw data preprocessing in adverse weather conditions is mainly to judge, denoise and repair by identifying obvious features between normal data and noisy data. Future work can focus on using multi-scale information by integrating depth and semantic information to obtain more features of rain and snow, and utilizing the data difference based on early information cooperation strategy to filter the noisy data.
- (2)
- The cooperation perceptive networks only deal with homogeneous data, features and detection results from the same extraction mode or object detection methods. Future work can explore an adaptive calibration method or construct a uniform standard specification to standardize the format of detection results and extracted features obtained from different data types and algorithms in early- or medium-term cooperation.
- (3)
- If we just use a kind of information cooperation strategy to achieve cooperation perception, it is hard to balance the accuracy and computing speed of an artificial neural network in any conditions. Future work can innovate a hybrid information cooperation method to adaptively share extracted features or raw perception data based on motion prediction results and importance scores. These scores are determined by predicting the importance of a CPM.
- (4)
- Some cooperation perception networks often integrate various modules into the backbone network to obtain a higher accuracy. These modules make the networks large and complex, which need high computing units. Further research needs to focus on a lightweight deep learning network by utilizing a powerful learning ability of artificial intelligence in data preprocessing, object detection, and cooperative perception.
- (5)
- The current deep learning algorithms mainly rely on the specific features and labeled data for environment perception. Different traffic scenarios require to build different datasets and a large number of labeled data. It severely limits the generality and migration of the deep learning algorithms. Future efforts focus on constructing networks with unsupervised learning, self-supervised learning and autoencoders.
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Gerla, M.; Lee, E.-K.; Pau, G.; Lee, U. Internet of vehicles: From intelligent grid to autonomous cars and vehicular clouds. In Proceedings of the 2014 IEEE World Forum on Internet of Things (WF-IoT), Seoul, Republic of Korea, 6–8 March 2014; pp. 241–246. [Google Scholar]
- Behere, S.; Törngren, M. A functional architecture for autonomous driving. In Proceedings of the First International Workshop on Automotive Software Architecture, Montreal, QC, Canada, 4 May 2015; pp. 3–10. [Google Scholar]
- Yan, Z.; Li, P.; Fu, Z.; Xu, S.; Shi, Y.; Chen, X.; Zheng, Y.; Li, Y.; Liu, T.; Li, C.; et al. INT2: Interactive Trajectory Prediction at Intersections. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 8536–8547. [Google Scholar]
- Wu, J.; Chen, X.; Bie, Y.; Zhou, W. A co-evolutionary lane-changing trajectory planning method for automated vehicles based on the instantaneous risk identification. Accid. Anal. Prev. 2023, 180, 106907. [Google Scholar] [CrossRef] [PubMed]
- Tripathi, S.; Singh, V.P.; Kishor, N.; Pandey, A. Load frequency control of power system considering electric Vehicles’ aggregator with communication delay. Int. J. Electr. Power Energy Syst. 2023, 145, 108697. [Google Scholar] [CrossRef]
- Alam, F.; Mehmood, R.; Katib, I.; Altowaijri, S.M.; Albeshri, A. TAAWUN: A decision fusion and feature specific road detection approach for connected autonomous vehicles. Mob. Netw. Appl. 2023, 28, 636–652. [Google Scholar] [CrossRef]
- Krajewski, R.; Bock, J.; Kloeker, L.; Eckstein, L. The highd dataset: A drone dataset of naturalistic vehicle trajectories on german highways for validation of highly automated driving systems. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 2118–2125. [Google Scholar]
- Zhang, Y.; Carballo, A.; Yang, H.; Takeda, K. Perception and sensing for autonomous vehicles under adverse weather conditions: A survey. ISPRS J. Photogramm. Remote Sens. 2023, 196, 146–177. [Google Scholar] [CrossRef]
- Wang, Z.J.; Yu, W.; Niu, Q.Q. Multi-sensor fusion in automated driving: A survey. IEEE Access 2019, 8, 2847–2868. [Google Scholar] [CrossRef]
- SAE. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles. 2018. Available online: https://www.sae.org/standards/content/j3016_201806/ (accessed on 15 November 2022).
- National Standard of the People’s Republic of China. Taxonomy of Driving Automation for Vehicles. 2021. Available online: https://www.chinesestandard.net/PDF.aspx/GBT40429-2021 (accessed on 15 November 2022).
- Jenke, P.; Wand, M.; Bokeloh, M.; Schilling, A.; Straßer, W. Bayesian point cloud reconstruction. Comput. Graph. Forum 2006, 25, 379–388. [Google Scholar] [CrossRef]
- Schall, O.; Belyaev, A.; Seidel, H.-P. Adaptive feature-preserving non-local denoising of static and time-varying range data. Comput. Aided Des. 2008, 40, 701–707. [Google Scholar] [CrossRef]
- Rusu, R.; Cousins, S. 3d is here: Point cloud library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Yang, Y.L. Research on Environment Perception Algorithm of Vehicles in Foggy Weather Based on Machine Vision. Ph.D. Thesis, Sichuan University, Chengdu, China, 2021. [Google Scholar]
- Sim, H.; Ki, S.; Choi, J.S.; Seo, S.; Kim, S.; Kim, M. High-resolution Image Dehazing with respect to Training Losses and Receptive Field Sizes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 912–919. [Google Scholar]
- Shen, J.; Cheung, S. Layer depth denoising and completion for structured-light RGB-D cameras. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 1187–1194. [Google Scholar]
- Tomasi, C.; Manduchi, R. Bilateral filtering for gray and color images. In Proceedings of the 6th International Conference on Computer Vision (IEEE Cat. No.98CH36271), Bombay, India, 7 January 1998; pp. 839–846. [Google Scholar]
- Rönnbäck, S.; Wernersson, A. On filtering of laser range data in snowfall. In Proceedings of the 2008 4th International IEEE Conference Intelligent Systems, Varna, Bulgaria, 6–8 September 2008; Volume 2, pp. 17–33. [Google Scholar]
- Liu, Y.F.; Jaw, D.W.; Huang, S.C.; Hwang, J.N. DesnowNet: Context-aware deep network for snow removal. IEEE Trans. Image Process. 2018, 27, 3064–3073. [Google Scholar] [CrossRef]
- Lv, P.; Li, K.; Xu, J.; Li, T.; Chen, N. Cooperative sensing information transmission load optimization for automated vehicles. Chin. J. Comput. 2021, 44, 1984–1997. [Google Scholar]
- Chen, X.; Ma, H.; Wan, J.; Li, B.; Xia, T. Multiview 3d object detection network for autonomous driving. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1907–1915. [Google Scholar]
- Yang, B.; Guo, R.; Liang, M.; Casas, S.; Urtasun, R. Exploiting radar for robust perception of dynamic objects. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 496–512. [Google Scholar]
- Bai, Y.; Zhang, B.; Xu, N.; Zhou, J.; Shi, J.; Diao, Z. Vision-based navigation and guidance for agricultural autonomous vehicles and robots: A review. Comput. Electron. Agric. 2023, 205, 107584. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, S.; Zhang, Y.; Ji, J.; Duan, Y.; Huang, Y.; Peng, J.; Zahng, Y. Multi-modality fusion perception and computing in autonomous driving. J. Comput. Res. Dev. 2020, 57, 1781–1799. [Google Scholar]
- Yu, G.Z.; Li, H.; Wang, Y.P.; Chen, P.; Zhou, B. A review on cooperative perception and control supported infrastructure-vehicle system. Green Energy Intell. Transp. 2022, 1, 100023. [Google Scholar] [CrossRef]
- PR Newswire. Cooperative Vehicle Infrastructure System (CVIS) and Vehicle to Everything (V2X) Industry Report. 2018. Available online: https://www.prnewswire.com/news-releases/cooperative-vehicle-infrastructure-system-cvis-and-vehicle-to-everything-v2x-industry-report-2018-300755332.html (accessed on 17 November 2022).
- Baskar, L.D.; Schutter, B.D.; Hellendoorn, H. Optimal routing for automated highway systems. Transp. Res. Part C Emerg. Technol. 2013, 30, 1–22. [Google Scholar] [CrossRef]
- Row, S. Intelligent Drive: Safer. Smarter. Greener. Public Roads 2010, 6, 1–11. [Google Scholar]
- Dawkins, J.; Bishop, R.; Powell, B.; Bevly, D. Investigation of Pavement Maintenance Applications of Intellidrive SM (Final Report): Implementation and Deployment Factors for Vehicle Probe-Based Pavement Maintenance (PBPM); Auburn University: Auburn, AL, USA, 2011; pp. 1–35. [Google Scholar]
- Saroj, A.; Roy, S.; Guin, A.; Hunter, M.; Fujimoto, R. Smart city real-time data driven transportation simulation. In Proceedings of the 2018 Winter Simulation Conference (WSC), Gothenburg, Sweden, 9–12 December 2018; pp. 857–868. [Google Scholar]
- Ibrahim, A.; Goswami, D.; Li, H.; Soroa, I.M.; Basten, T. Multi-layer multi-rate model predictive control for vehicle platooning under IEEE 802.11p. Transp. Res. Part C Emerg. Technol. 2021, 124, 102905. [Google Scholar] [CrossRef]
- Luttenberger, A. Legal framework on eSafety communication in road transport. In Faculty of Tourism and Hospitality Management in Opatija. Biennial International Congress. Tourism & Hospitality Industry; University of Rijeka, Faculty of Tourism & Hospitality Management: Ika, Croatia, 2012; p. 126. [Google Scholar]
- Bubel, D.; Szymczyk, K. The smart freight project as a superior way to cope with congestion and environmental negative externalities in urban areas. Transp. Res. Procedia 2016, 16, 25–34. [Google Scholar] [CrossRef]
- Tao, Z.Z. Comparison and analysis of the overall development trend of Intelligent Transportation System (ITS). Zhonghua Technol. 2009, 7, 112–123. [Google Scholar]
- Li, Y.C. Research on Key Technologies of Intelligent Vehicle-Road Collaborative System Based on 4G+ Network and GPS. Master’s Thesis, Nanjing University of Posts and Telecommunications, Nanjing, China, 2020. [Google Scholar]
- Wang, L.; Wang, H.; Zhao, Q.; Yang, H.; Zhao, H.; Huang, B. Development and prospect of intelligent pavement. China Highw. J. 2019, 32, 54–76. [Google Scholar]
- Matsushita, H.; Hayashi, T. Quantification of Abrupt Driving Maneuver Utilizing ETC 2.0 Probe Data: A Case Study in Japan. In Proceedings of the 2018 8th International Conference on Logistics, Informatics and Service Sciences (LISS), Toronto, ON, Canada, 3–6 August 2018; pp. 1–6. [Google Scholar]
- Wang, X.J.; Wang, S.F.; Tu, Y. Overall design of intelligent expressway. Highway 2016, 61, 137–142. [Google Scholar]
- Wang, C.H.; Chen, Q.; Tang, X.; Ye, J. Pedestrian detection based on point cloud and image decision level fusion. J. Guangxi Univ. (Nat. Sci. Ed.) 2021, 46, 1592–1601. [Google Scholar]
- Yu, J.Y.; Li, X.; Yang, M.Y. Pedestrian Short-time Social Conflict Prediction based on YOLOv3 and Kalman filtering. Sens. Microsyst. 2021, 40, 133–137+141. [Google Scholar]
- Wang, S.F. Evolution and Development of Vehicle-Road Coordination. 2020. Available online: https://www.7its.com/index.php?m=home&c=View&a=index&aid=15786 (accessed on 30 October 2023).
- Qiu, S.; Zhao, H.; Jiang, N.; Wang, Z.; Liu, L.; An, Y.; Zhao, H.; Miao, X.; Liu, R.; Fortino, G. Multi-sensor information fusion based on machine learning for real applications in human activity recognition: State-of-the-art and research challenges. Inf. Fusion 2022, 80, 241–265. [Google Scholar] [CrossRef]
- Neubeck, A.; Luc, L.G. Efficient non-maximum suppression. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; Volume 3, pp. 850–855. [Google Scholar]
- Liang, L.; Xie, S.; Li, G.Y.; Ding, Z.; Yu, X. Graph-based resource sharing in vehicular communication. IEEE Trans. Wirel. Commun. 2018, 17, 4579–4592. [Google Scholar] [CrossRef]
- Marvasti, E.E.; Raftari, A.; Marvasti, A.E.; Fallah, Y.P. Bandwidth-Adaptive Feature Sharing for Cooperative LIDAR Object Detection. In Proceedings of the 2020 IEEE 3rd Connected and Automated Vehicles Symposium (CAVS), Victoria, BC, Canada, 18 November–16 December 2020; pp. 1–7. [Google Scholar]
- Han, X.F.; Jin, J.S.; Wang, M.J.; Jiang, W.; Gao, L.; Xiao, L. A review of algorithms for filtering the 3D point cloud. Signal Process. Image Commun. 2017, 57, 103–112. [Google Scholar] [CrossRef]
- Schall, O.; Belyaev, A.; Seidel, H.P. Robust filtering of noisy scattered point data. In Proceedings of the Eurographics/IEEE VGTC Symposium Point-Based Graphics, Stony Brook, NY, USA, 21–22 June 2005; pp. 71–144. [Google Scholar]
- Hu, W.; Li, X.; Cheung, G.; Au, O. Depth map denoising using graph-based transform and group sparsity. In Proceedings of the IEEE 15th International Workshop on Multimedia Signal Processing (MMSP), Pula, Italy, 30 September–2 October 2013; pp. 1–6. [Google Scholar]
- Kurup, A.; Bos, J. Dsor: A scalable statistical filter for removing falling snow from lidar point clouds in severe winter weather. arXiv 2021, arXiv:2109.07078. [Google Scholar]
- Luo, S.T.; Hu, W. Score-based point cloud denoising. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 4583–4592. [Google Scholar]
- Paris, S. A gentle introduction to bilateral filtering and its applications. In ACM SIGGRAPH 2007 Courses; Association for Computing Machinery: New York, NY, USA, 2007; pp. 3–es. [Google Scholar]
- Charron, N.; Phillips, S.; Waslander, S.L. De-noising of lidar point clouds corrupted by snowfall. In Proceedings of the 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018; pp. 254–261. [Google Scholar]
- Wang, W.; You, X.; Chen, L.; Tian, J.; Tang, F.; Zhang, L. A scalable and accurate de-snowing algorithm for LiDAR point clouds in winter. Remote Sens. 2022, 14, 1468. [Google Scholar] [CrossRef]
- Roy, G.; Cao, X.; Bernier, R.; Tremblay, G. Physical model of snow precipitation interaction with a 3d lidar scanner. Appl. Opt. 2020, 59, 7660–7669. [Google Scholar] [CrossRef]
- Park, J.; Kim, K. Fast and accurate de-snowing algorithm for lidar point clouds. IEEE Access 2020, 8, 160202–160212. [Google Scholar] [CrossRef]
- Roriz, R.; Campos, A.; Pinto, S.; Gomes, T. DIOR: A Hardware-Assisted Weather Denoising Solution for LiDAR Point Clouds. IEEE Sens. J. 2021, 22, 1621–1628. [Google Scholar] [CrossRef]
- Lipman, Y.; Cohen-Or, D.; Levin, D.; Tal-Ezer, H. Parameterization-free projection for geometry reconstruction. ACM Trans. Graph. (TOG) 2007, 26, 22. [Google Scholar] [CrossRef]
- Huang, H.; Li, D.; Zhang, H.; Ascher, U.; Cohen-Or, D. Consolidation of unorganized point clouds for surface reconstruction. ACM Trans. Graph. (TOG) 2009, 28, 1–7. [Google Scholar] [CrossRef]
- Duan, Y.; Yang, C.; Chen, H.; Yan, W.; Li, H. Low-complexity point cloud filtering for lidar by PCA based dimension reduction. Opt. Commun. 2021, 482, 126567. [Google Scholar] [CrossRef]
- Heinzler, R.; Piewak, F.; Schindler, P.; Stork, W. CNN-based lidar point cloud de-noising in adverse weather. IEEE Robot. Autom. Lett. 2020, 5, 2514–2521. [Google Scholar] [CrossRef]
- Piewak, F.; Pinggera, P.; Schafer, M.; Peter, D.; Schwarz, B.; Schneider, N.; Enzweiler, M.; Pfeiffer, D.; Zollner, M. Boosting lidar-based semantic labeling by cross-modal training data generation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 8–14. [Google Scholar]
- Balta, H.; Velagic, J.; Bosschaerts, W.; De Cubber, G.; Siciliano, B. Fast statistical outlier removal based method for large 3D point clouds of outdoor environments. IFAC Pap. 2018, 51, 348–353. [Google Scholar] [CrossRef]
- Shamsudin, A.U.; Ohno, K.; Westfechtel, T.; Takahiro, S.; Okada, Y.; Tadokoro, S. Fog removal using laser beam penetration, laser intensity, and geometrical features for 3D measurements in fog-filled room. Adv. Robot. 2016, 30, 729–743. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, S.; Chen, C.; Zeng, B. A hierarchical approach for rain or snow removing in a single color image. IEEE Trans. Image Process. 2017, 26, 3936–3950. [Google Scholar] [CrossRef]
- Chen, L.; Lin, H.; Li, S. Depth image enhancement for Kinect using region growing and bilateral filter. In Proceedings of the 21st International Conference on Pattern Recognition (ICPR), Tsukuba, Japan, 11–15 November 2012; pp. 3070–3073. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2341–2353. [Google Scholar]
- Bijelic, M.; Mannan, F.; Gruber, T.; Ritter, W.; Dietmayer, K.; Heide, F. Seeing through fog without seeing fog: Deep sensor fusion in the absence of labeled training data. arXiv 2019, arXiv:1902.08913. [Google Scholar]
- Kang, L.; Lin, C.; Fu, Y. Automatic single-image-based rain streaks removal via image decomposition. IEEE Trans. Image Process. 2011, 21, 1742–1755. [Google Scholar] [CrossRef]
- Rajderkar, D.; Mohod, P. Removing snow from an image via image decomposition. In Proceedings of the 2013 IEEE International Conference ON Emerging Trends in Computing, Communication and Nanotechnology (ICECCN), Tirunelveli, India, 25–26 March 2013; pp. 576–579. [Google Scholar]
- Pei, S.; Tsai, Y.; Lee, C. Removing rain and snow in a single image using saturation and visibility features. In Proceedings of the 2014 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), Chengdu, China, 14–18 July 2014; pp. 1–6. [Google Scholar]
- Chen, D.; Chen, C.; Kang, L. Visual depth guided color image rain streaks removal using sparse coding. IEEE Trans. Circuits Syst. Video Technol. 2014, 24, 1430–1455. [Google Scholar] [CrossRef]
- Luo, Y.; Xu, Y.; Ji, H. Removing rain from a single image via discriminative sparse coding. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3397–3405. [Google Scholar]
- Kim, J.; Sim, J.; Kim, C. Video de-raining and de-snowing using temporal correlation and low-rank matrix completion. IEEE Trans. Image Process. 2015, 24, 2658–2670. [Google Scholar] [CrossRef] [PubMed]
- Li, P.; Yun, M.; Tian, J.; Tang, Y.; Wang, G.; Wu, C. Stacked dense networks for single-image snow removal. Neurocomputing 2019, 367, 152–163. [Google Scholar] [CrossRef]
- Zhang, J. Research on Visual Enhancement and Perception Method Based on Generative Adversarial Network in Complex Environment. Master’s Thesis, Chongqing University, Chongqing, China, 2020. [Google Scholar]
- Zhang, K.; Li, R.; Yu, Y.; Luo, W.; Li, C. Deep dense multi-scale network for snow removal using semantic and depth priors. IEEE Trans. Image Process. 2021, 30, 7419–7431. [Google Scholar] [CrossRef] [PubMed]
- Bossu, J.; Hautiere, N.; Tarel, J. Rain or snow detection in image sequences through use of a histogram of orientation of streaks. Int. J. Comput. Vis. 2011, 93, 348–367. [Google Scholar] [CrossRef]
- Xie, K.Y. Research on Facial Feature Extraction in Video in Rain and Snow Environment. Master’s Thesis, Harbin Engineering University, Harbin, China, 2013. [Google Scholar]
- Tian, J.; Han, Z.; Ren, W.; Chen, X.; Tang, Y. Snowflake removal for videos via global and local low-rank decomposition. IEEE Trans. Multimed. 2018, 20, 2659–2669. [Google Scholar] [CrossRef]
- Verma, S.; Berrio, J.S.; Worrall, S.; Nebot, E. Automatic extrinsic calibration between a camera and a 3D LIDAR using 3D point and plane correspondences. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3906–3912. [Google Scholar]
- Huang, J.; Grizzle, J. Improvements to target-based 3D LIDAR to camera calibration. IEEE Access 2020, 8, 134101–134110. [Google Scholar] [CrossRef]
- Zhang, J.H. Research on Vehicle Detection and Tracking Based on LiDAR and Camera Fusion. Master’s Thesis, Jilin University, Changchun, China, 2022. [Google Scholar]
- Xiao, Z.; Mo, Z.; Jiang, K.; Yang, D. Multimedia fusion at semantic level in vehicle cooperative perception. In Proceedings of the 2018 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Löhdefink, J.; Bär, A.; Schmidt, N.M.; Hüger, F.; Schlicht, P.; Fingscheidt, T. Focussing learned image compression to semantic classes for V2X applications. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1641–1648. [Google Scholar]
- Rippel, O.; Bourdev, L. Real-time adaptive image compression. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, NSW, Australia, 6–11 August 2017; pp. 2922–2930. [Google Scholar]
- Rubino, C.; Crocco, M.; Bue, A.D. 3d object localization from multi-view image detections. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1281–1294. [Google Scholar]
- Cortés, I.; Beltrán, J.; de la Escalera, A.; García, F. siaNMS: Non-Maximum Suppression with Siamese Networks for Multi-Camera 3D Object Detection. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NY, USA, 19 October–13 November 2020; pp. 933–938. [Google Scholar]
- Chen, Q.; Tang, S.; Yang, Q.; Fu, S. Cooper: Cooperative perception for connected autonomous vehicles based on 3D point clouds. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019; pp. 514–524. [Google Scholar]
- Ye, E.; Spiegel, P.; Althoff, M. Cooperative raw sensor data fusion for ground truth generation in autonomous driving. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems (ITSC), Rhodes, Greece, 20–23 September 2020; pp. 1–7. [Google Scholar]
- Chen, Q.; Ma, X.; Tang, S.; Guo, J.; Yang, Q.; Fu, S. F-cooper: Feature based cooperative perception for autonomous vehicle edge computing system using 3D point clouds. In Proceedings of the 4th ACM/IEEE Symposium on Edge Computing, Arlington, VA, USA, 7–9 November 2019; pp. 88–100. [Google Scholar]
- Arnold, E.; Dianati, M.; de Temple, R.; Fallah, S. Cooperative perception for 3D object detection in driving scenarios using infrastructure sensors. IEEE Trans. Intell. Transp. Syst. 2020, 23, 1852–1864. [Google Scholar] [CrossRef]
- Ji, Z.; Prokhorov, D. Radar-vision fusion for object classification. In Proceedings of the 2008 11th International Conference on Information Fusion, Cologne, Germany, 30 June–3 July 2008; pp. 1–7. [Google Scholar]
- Wang, X.; Xu, L.; Sun, H.; Xin, J.; Zheng, N. On-road vehicle detection and tracking using MMW radar and monovision fusion. IEEE Trans. Intell. Transp. Syst. 2016, 17, 2075–2084. [Google Scholar] [CrossRef]
- Vora, S.; Lang, A.H.; Helou, B.; Beijbom, O. Pointpainting: Sequential fusion for 3d object detection. In Proceedings of the 2020 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 4603–4611. [Google Scholar]
- Liang, M.; Yang, B.; Chen, Y.; Hu, R.; Urtasun, R. Multi-task multi-sensor fusion for 3D object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7345–7353. [Google Scholar]
- Shah, M.; Huang, Z.; Laddha, A.; Langford, M.; Barber, B.; Zhang, S.; Vallespi-Gonzalez, C.; Urtasun, R. Liranet: End-to-end trajectory prediction using spatio-temporal radar fusion. arXiv 2020, arXiv:2010.00731. [Google Scholar]
- Saito, M.; Shen, S.; Ito, T. Interpolation method for sparse point cloud at long distance using sensor fusion with LiDAR and camera. In Proceedings of the 2021 IEEE CPMT Symposium Japan (ICSJ), Kyoto, Japan, 10–12 November 2021; pp. 116–117. [Google Scholar]
- Yang, X.Y. Research on Laser Point Cloud and Visual Information Fusion Method for Driving Environment Perception. Master’s Thesis, University of Electronic Science and Technology of China, Chengdu, China, 2022. [Google Scholar]
- Liu, D.; Zhang, Y.; Tian, S.; He, X.; Wang, C. A Design and Experimental Method of Perception Fusion. In Proceedings of the 2020 IEEE 2nd International Conference on Civil Aviation Safety and Information Technology (ICCASIT), Weihai, China, 14–16 October 2020; pp. 893–896. [Google Scholar]
- Chen, S.; Hu, J.; Shi, Y.; Peng, Y.; Fang, J.; Zhao, R.; Zhao, L. Vehicle-to-everything (V2X) services supported by LTE-based systems and 5G. IEEE Commun. Stand. Mag. 2017, 1, 70–76. [Google Scholar] [CrossRef]
- Storck, C.R.; Figueiredo, F.D. A 5G V2X ecosystem providing internet of vehicles. Sensors 2019, 19, 550. [Google Scholar] [CrossRef] [PubMed]
- Qiu, H.; Ahmad, F.; Bai, F.; Gruteser, M.; Govindan, R. Avr: Augmented vehicular reality. In Proceedings of the 16th Annual International Conference on Mobile Systems, Applications, and Services, Munich, Germany, 10–15 June 2018; pp. 81–95. [Google Scholar]
- Aoki, S.; Higuchi, T.; Altintas, O. Cooperative perception with deep reinforcement learning for connected vehicles. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 328–334. [Google Scholar]
- Schiegg, F.A.; Llatser, I.; Bischoff, D.; Volk, G. Collective perception: A safety perspective. Sensors 2021, 21, 159. [Google Scholar] [CrossRef] [PubMed]
- Shan, M.; Narula, K.; Wong, Y.F.; Worrall, S.; Khan, M.; Alexander, P.; Nebot, E. Demonstrations of cooperative perception: Safety and robustness in connected and automated vehicle operations. Sensors 2021, 21, 200. [Google Scholar] [CrossRef] [PubMed]
- Cui, Y.; Xu, H.; Wu, J.; Sun, Y.; Zhao, J. Automatic vehicle tracking with roadside lidar data for the connected-vehicles system. IEEE Intell. Syst. 2019, 34, 44–51. [Google Scholar] [CrossRef]
- Zhao, J.; Xu, H.; Liu, H.; Wu, J.; Zheng, Y.; Wu, D. Detection and tracking of pedestrians and vehicles using roadside lidar sensors. Transp. Res. Part C Emerg. Technol. 2019, 100, 68–87. [Google Scholar] [CrossRef]
- Ma, H.; Li, S.; Zhang, E.; Lv, Z.; Hu, J.; Wei, X. Cooperative autonomous driving oriented MEC-aided 5G-V2X: Prototype system design, field tests and AI-based optimization Tools. IEEE Access 2020, 8, 54288–54302. [Google Scholar] [CrossRef]
- Yu, H.; Luo, Y.; Shu, M.; Huo, Y.; Yang, Z.; Shi, Y.; Guo, Z.; Li, H.; Hu, X.; Yuan, J.; et al. DAIR-V2X: A Large-Scale Dataset for Vehicle-Infrastructure Cooperative 3D Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 21361–21370. [Google Scholar]
- Xiang, C.; Zhang, L.; Xie, X.; Zhao, L.; Ke, X.; Niu, Z.; Wang, F. Multi-sensor fusion algorithm in cooperative vehicle-infrastructure system for blind spot warning. Int. J. Distrib. Sens. Netw. 2022, 18, 15501329221100412. [Google Scholar] [CrossRef]
- Li, Y.; Ren, S.; Wu, P.; Chen, S.; Feng, C.; Zhang, W. Learning distilled collaboration graph for multi-agent perception. Adv. Neural Inf. Process. Syst. 2021, 34, 29541–29552. [Google Scholar]
- Zhao, X.; Mu, K.; Hui, F.; Prehofer, C. A cooperative vehicle-infrastructure based urban driving environment perception method using a DS theory-based credibility map. Optik 2017, 138, 407–415. [Google Scholar] [CrossRef]
- Shangguan, W.; Du, Y.; Chai, L. Interactive perception-based multiple object tracking via CVIS and AV. IEEE Access 2019, 7, 121907–121921. [Google Scholar] [CrossRef]
- Asvadi, A.; Girao, P.; Peixoto, P.; Nunes, U. 3D object tracking using RGB and LIDAR data. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 1255–1260. [Google Scholar]
- Vadivelu, N.; Ren, M.; Tu, J.; Wang, J.; Urtasun, R. Learning to communicate and correct pose errors. In Proceedings of the Conference on Robot Learning, London, UK, 8–11 November 2021; pp. 1195–1210. [Google Scholar]
- Mo, Y.; Zhang, P.; Chen, Z.; Ran, B. A method of vehicle-infrastructure cooperative perception based vehicle state information fusion using improved kalman filter. Multimed. Tools Appl. 2022, 81, 4603–4620. [Google Scholar] [CrossRef]
- Xu, R.; Xiang, H.; Xia, X.; Han, X.; Li, J.; Ma, J. OPV2V: An open benchmark dataset and fusion pipeline for perception with vehicle-to-vehicle communication. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 2583–2589. [Google Scholar]
- Xu, R.; Xiang, H.; Tu, Z.; Xia, X.; Yang, M.H.; Ma, J. V2X-ViT: Vehicle-to-everything cooperative perception with vision transformer. arXiv 2022, arXiv:2203.10638. [Google Scholar]
- Marvasti, E.E.; Raftari, A.; Marvasti, A.E.; Fallah, Y.P.; Guo, R.; Lu, H. Cooperative lidar object detection via feature sharing in deep networks. In Proceedings of the 2020 IEEE 92nd Vehicular Technology Conference (VTC2020-Fall), Virtual, 18 November–16 December 2020; pp. 1–7. [Google Scholar]
- Sridhar, S.; Eskandarian, A. Cooperative perception in autonomous ground vehicles using a mobile-robot testbed. IET Intell. Transp. Syst. 2019, 13, 1545–1556. [Google Scholar] [CrossRef]
- Wang, T.H.; Manivasagam, S.; Liang, M.; Yang, B.; Zeng, W.; Urtasun, R. V2vnet: Vehicle-to-vehicle communication for joint perception and prediction. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 605–621. [Google Scholar]
- Liu, W.; Ma, Y.; Gao, M.; Duan, S.; Wei, L. Cooperative Visual Augmentation Algorithm of Intelligent Vehicle Based on Inter-Vehicle Image Fusion. Appl. Sci. 2021, 11, 11917. [Google Scholar] [CrossRef]
- Glaser, N.; Liu, Y.C.; Tian, J.; Kira, Z. Overcoming Obstructions via Bandwidth-Limited Multi-Agent Spatial Handshaking. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 2406–2413. [Google Scholar]
- Cui, J.; Qiu, H.; Chen, D.; Stone, P.; Zhu, Y. COOPERNAUT: End-to-End Driving with Cooperative Perception for Networked Vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 17252–17262. [Google Scholar]
- Sukhbaatar, S.; Szlam, A.; Fergus, R. Learning multiagent communication with backpropagation. Adv. Neural Inf. Process. Syst. 2016, 29, 2252–2260. [Google Scholar]
- Hoshen, Y. Vain: Attentional multi-agent predictive modeling. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Jiang, J.; Lu, Z. Learning attentional communication for multi-agent cooperation. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Liu, Y.C.; Tian, J.; Glaser, N.; Kira, Z. When2com: Multi-agent perception via communication graph grouping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 4106–4115. [Google Scholar]
- Liu, Y.C.; Tian, J.; Ma, C.Y.; Glaser, N.; Kuo, C.W.; Kira, Z. Who2com: Collaborative perception via learnable handshake communication. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 6876–6883. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Dong, X.; Bao, J.; Chen, D.; Zhang, W.; Yu, N.; Yuan, L.; Chen, D.; Guo, B. Cswin transformer: A general vision transformer backbone with cross-shaped windows. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12124–12134. [Google Scholar]
- Chu, X.; Tian, Z.; Wang, Y.; Zhang, B.; Ren, H.; Wei, X.; Xia, H.; Shen, C. Twins: Revisiting the design of spatial attention in vision transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 9355–9366. [Google Scholar]
- Noh, S.; An, K.; Han, W. Toward highly automated driving by vehicle-to-infrastructure communications. In Proceedings of the 2015 15th International Conference on Control, Automation and Systems (ICCAS), Busan, Republic of Korea, 13–16 October 2015; pp. 2016–2021. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Xu, R.; Tu, Z.; Xiang, H.; Shao, W.; Zhou, B.; Ma, J. CoBEVT: Cooperative bird’s eye view semantic segmentation with sparse transformers. arXiv 2022, arXiv:2207.02202. [Google Scholar]
- Liu, Z.; Tang, H.; Amini, A.; Yang, X.; Mao, H.; Rus, D.L.; Han, S. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. arXiv 2022, arXiv:2205.13542. [Google Scholar]
- He, Z.; Wang, L.; Ye, H.; Li, G.Y.; Juang, B.-H.F. Resource allocation based on graph neural networks in vehicular communications. In Proceedings of the GLOBECOM 2020–2020 IEEE Global Communications Conference, Taipei, Taiwan, 7–11 December 2020; pp. 1–5. [Google Scholar]
- Allig, C.; Wanielik, G. Alignment of perception information for cooperative perception. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1849–1854. [Google Scholar]
- Higuchi, T.; Giordani, M.; Zanella, A.; Zorzi, M.; Altintas, O. Value-anticipating V2V communications for cooperative perception. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 1947–1952. [Google Scholar]
- Talak, R.; Karaman, S.; Modiano, E. Optimizing information freshness in wireless networks under general interference constraints. In Proceedings of the Eighteenth ACM International Symposium on Mobile Ad Hoc Networking and Computing, Los Angeles, CA, USA, 26–29 June 2018; pp. 61–70. [Google Scholar]
- Xu, R.; Chen, W.; Xiang, H.; Xia, X.; Liu, L.; Ma, J. Model-Agnostic Multi-Agent Perception Framework. arXiv 2022, arXiv:2203.13168. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Level | Name | Lateral and Longitudinal Vehicle Motion Control | Object and Event Detection and Response | Dynamic Driving Fallback | Working Conditions |
|---|---|---|---|---|---|
| Level 0 vehicle (L0) | Fully manual driving vehicle | Driver | Driver | Driver | All circumstances |
| Level 1 vehicle (L1) | Partial driver assistance vehicle | Driver and autonomous driving system | Driver | Driver | Partial circumstances |
| Level 2 vehicle (L2) | Combined driver assistance vehicle | Autonomous driving system | Driver | Driver | Partial circumstances |
| Level 3 vehicle (L3) | Conditionally automated driving vehicle | Autonomous driving system | Autonomous driving system | Driver | Partial circumstances |
| Level 4 vehicle (L4) | Highly automated vehicle | Autonomous driving system | Autonomous driving system | Autonomous driving system | Partial circumstances |
| Level 5 vehicle (L5) | Fully automated vehicle | Autonomous driving system | Autonomous driving system | Autonomous driving system | All circumstances |
| Name | Major Technology | Construction Content | Service Subject |
|---|---|---|---|
| VICS1.0 | Physical information and optical technology | Setting up signs and linear guidance facilities on the road. And reflectors are mainly used to solve the blind area problem for drivers in the curve segment of roads and intersections. | Ordinary vehicles |
| VICS2.0 | Road variable speed control and information broadcast technology | Implementing variable speed limit signs and speed control system to instruct drivers, achieving uniform speed changes and avoiding tail-end collision accidents. | Ordinary vehicles |
| VICS3.0 | Active safety warning technology | Installing coil detectors, microwave detectors, video cameras, geomagnetic detectors and LED screens to solve the problem of blind areas on curve roads and adverse weather conditions. | Ordinary vehicles |
| VICS4.0 | Internet of things technology | Setting up electronic toll collection system, active luminous traffic signs, and using millimeter wave radar or machine vision to establish danger warning system, etc. | ICVs |
| VICS5.0 | C-V2X communication technology (DSRC, LTE-V2X, 5G-V2X) | Constructing intelligent signal controllers, high-definition maps, cloud platforms, edge computing units to promote the innovation and application of autonomous driving technology, and using LiDAR sensors to obtain more information. | ICVs |
| Fusion Strategy | Merit | Limitation | Methods |
|---|---|---|---|
| Target-level fusion | Applied to a variety of sensors, low computation, high reliability and fault-tolerant | Low detection accuracy, high false positive rate, high preprocessing difficulty, maximum information loss | Artificial neural network, Bayes estimation, Dempster/Shafer (D-S) evidential reasoning, |
| Feature-level fusion | Data compression for real-time processing, the balance between detection accuracy and information loss | Heterogenous data preprocessing before fusion | Cluster analysis, artificial neural network, probability statistics and fuzzy logic reasoning |
| Data-level fusion | Abundant data, low preprocessing difficulty and best classification performance | Poor real-time performance, huge volume of data, long processing time, high processing cost | Weighted mean, Kalman filter, wavelet transform and principal component analysis (PCA) transform. |
| References | Fusion Scheme | Key Research Points | Findings | Merit | Limitation |
|---|---|---|---|---|---|
| Arnold et al. [92] | Early cooperative fusion | Combining different point clouds from multiple spatially diverse sensing points and using the fusion data to perform 3D object detection. | The result shows more than 95% of the ground-truth objects are detected with precision above 95%. | Detection accuracy is high. | The communication bandwidth is cost highly due to a lot of raw data need to be transferred. |
| Li et al. [112] | Early cooperative fusion | Constructing a teacher–student framework with a novel distilled collaboration graph and a matrix-valued edge weight. | The average precisions are 60.3% at IoU = 0.5 and 53.9% at IoU = 0.7 separately, compared with 56.8% and 50.7% in the V2Vnet. | Achieving a better performance–bandwidth trade-off and detecting more objects. | |
| Shangguan et al. [114] | Late cooperative fusion | The fusion status of surroundings obtained by a Lidar-only multiple-object tracking method is used to generate the trajectories of target vehicles with the preliminary tracking result. | The method has a better performance especially when the Lidar is limited or the V2V communication is failed. | Improving the accuracy of object tracking and expanding the vehicle perception range. | Different real external environment is not considered, such as the partial equipment failure, the mixed traffic conditions, and poor cooperative information has a negative effect on the perceptual accuracy. |
| Mo et al. [117] | Late cooperative fusion | The traditional Kalman Filter is used to obtain position information when the roadside fails, and the state information helps target vehicles improve the average positioning accuracy. | The average positioning accuracy from vehicle infrastructure cooperative perception is 18% higher than vehicle-only perception. | The fusion framework provides CADS methods and systems for coordinating. | |
| Emad et al. [31,120] | Medium-term cooperative fusion | Grids of down-sampled feature data are distributed to increase detective performance, and an encoder/decoder bank is deployed to disentangle the communication bandwidth limitation. | The detective accuracy of pedestrians is 6% higher than translation MOD-Alignment method. | Average precision outperforms feature sharing cooperative object detection method. | If the method fails to compress feature data well or extract distributed features accurately, the perceptive precision and the use of communication bandwidth will be poor. |
| Wang et al. [122] | Medium-term cooperative fusion | A variational image compression algorithm is used to compress intermediate representations, and a convolutional network is used to learn the representations with the help of a learned hyperprior. | The result is 88.6% of average detection precision at IoU = 0.7, 0.79 m error at 3.0 s prediction, and 2.63 trajectory collision rate. | Achieving the best balance between accuracy improvements and bandwidth requirements. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Wu, Z.; Liang, Y.; Tang, J.; Chen, H. Perception Methods for Adverse Weather Based on Vehicle Infrastructure Cooperation System: A Review. Sensors 2024, 24, 374. https://doi.org/10.3390/s24020374
Wang J, Wu Z, Liang Y, Tang J, Chen H. Perception Methods for Adverse Weather Based on Vehicle Infrastructure Cooperation System: A Review. Sensors. 2024; 24(2):374. https://doi.org/10.3390/s24020374
Chicago/Turabian StyleWang, Jizhao, Zhizhou Wu, Yunyi Liang, Jinjun Tang, and Huimiao Chen. 2024. "Perception Methods for Adverse Weather Based on Vehicle Infrastructure Cooperation System: A Review" Sensors 24, no. 2: 374. https://doi.org/10.3390/s24020374
APA StyleWang, J., Wu, Z., Liang, Y., Tang, J., & Chen, H. (2024). Perception Methods for Adverse Weather Based on Vehicle Infrastructure Cooperation System: A Review. Sensors, 24(2), 374. https://doi.org/10.3390/s24020374