1. Introduction
Facial expression is one of the most prevalent and vital signals conveying human emotions and intentions. As one of the fundamental tasks in computer vision, facial expression recognition (FER) has attracted increasing attention in recent years due to its close relevance to human–computer interaction, education, healthcare, and online monitoring applications.
Two types of datasets are primarily used in the facial expression recognition task. The first type is datasets in laboratory environments such as JAFFE [
1], CK+ [
2], etc. The facial expression images in these datasets are pictures of individuals making expressions in a laboratory environment according to instructions and then being captured by a camera. The second type is datasets in real-world scenarios, such as RAF-DB [
3], AffectNet [
4], FERPlus [
5], etc. Most of the images in these datasets are collected from the Internet and obtained by keyword searches. The background environments in each picture vary significantly. In the early studies on facial expression recognition, datasets primarily used were collected in laboratory settings. For these datasets, researchers relied on handcrafted features such as HOG (Histograms of Oriented Gradients) [
6], LBP (Local Binary Patterns) [
7], LDP (Local Directional Patterns) [
8], and SIFT (Local Scale-Invariant Feature Transform) [
9] features to analyze facial expressions, and they achieved good recognition results. However, in practical applications, the environment is complex and dynamic. Using handcrafted features for facial expression recognition faces challenges due to uncontrollable factors such as occlusion, head posture variations, facial deformation, etc., leading to a decrease in recognition effectiveness. With the development of deep learning, CNNs (convolutional neural networks) have been introduced into the field of facial expression recognition due to their efficient computational efficiency and powerful feature extraction capabilities [
10,
11,
12,
13]. Algorithms based on CNNs have achieved outstanding results on datasets in laboratory environments. However, constrained by the limitations of the local receptive fields, the CNNs fail to fully consider the importance of the global information of images. Although the recognition accuracy on datasets in a laboratory environment has already exceeded 99%, the recognition accuracy on datasets in a natural environment still needs to be improved. After the Transformer was applied to computer vision, Xue et al. [
14] designed the first Transformer network, TransFER, for facial expression recognition, which improved Vision Transformer (ViT) by combining global and local information. Since then, ViT has been introduced to facial expression recognition tasks with state-of-the-art (SOTA) results [
15,
16,
17,
18,
19,
20].
Meanwhile, researchers have explored the role of different features in facial expression recognition. LBP features can effectively describe the texture information of an image and are robust to illumination changes, which can be a complement of image features. By combining LBP features with image features and fusing the global and local information, facial expression recognition performance can be effectively improved [
19,
21,
22]. Some studies have investigated the role of facial landmarks in facial expression recognition. Landmarks are a set of crucial points in a face image, which can exclude the interference of factors such as skin color, gender, age, and image background and have a specific generalization ability. They provide a sparse representation of the facial region and can be used as a complement to image information. Landmark features extracted automatically from landmarks can help the model to focus on more important details, which can help to improve the variance value of the inter-class differences [
23,
24]. Zheng et al. [
25] proposed the idea of fusing landmark features and image features. They found that landmark features are the key to solving the inter-class similarity and intra-class differences. The image features are used as supplementary information to assist landmark features in facial expression classification. Although this approach has achieved good results, it still has the following problems. On the one hand, adding scale information solely through upsampling and downsampling may not enrich semantic details as much as introducing other features. On the other hand, the network structure introduces a large number of parameters, leading to increased computational cost.
Despite the outstanding performance of these algorithms, the following problems still exist: (1) Insufficient feature information. Convolutional neural networks can only extract the CNN feature of images, and the input of ViT can only be a single RGB image. Both can only handle single pieces of information, but they fail to make effective use of features that help distinguish subtle differences between images. (2) Inter-class similarity. There is a similarity between pictures of the same person in different expressions, and this similarity makes it difficult to distinguish between different expressions. There are similarities between different expression categories for the same person, posing a challenge in distinguishing between different expressions. (3) Intra-class variability. There may be significant variability between images of the same expression from different individuals, and this variability can easily lead to the misrecognition of expression categories. For example, differences in skin color, gender, image environment, and age among different individuals can contribute to such variations. (4) Model parameters and floating-point operations per second (FLOPs). Many works have only considered accuracy as the model evaluation metric. However, a large number of parameters and slow operation speed cannot meet the needs of practical applications, especially the requirements of real-time expression recognition tasks. Therefore, it is essential to include model parameter size and FLOPs in the evaluation criteria.
In this paper, we propose a tri-cross-attention transformer with a multi-feature fusion network (TriCAFFNet) to solve further the four problems of insufficient feature information, inter-class similarity, intra-class variability, and the excessive number of model parameters. TriCAFFNet is a model that processes landmark features, CNN features, and LBPHOG (fusion features of Local Binary Pattern and Histogram of Oriented Gradients) features by using the original input image and the fused feature image as model inputs. Based on the excellent performance of the facial expression recognition of LBP and HOG features, they can be used as important information to distinguish different faces, thus decreasing the intra-class variability instead of other handcraft features. The proposed model uses the a convolutional neural network to extract high-level features from the fused image of LBPHOG, enhancing the model’s ability to recognize facial expressions and improving overall robustness. With the advantage of landmark features in automation and robustness in the unexpected surrounding factors of an image, landmark features are used to distinguish the subtle differences and decrease the inter-class similarity. Meanwhile, the CNN features are used as complementary information for the landmark features and LBPHOG features, and the proposed tri-cross-attention mechanism can adaptively fuse these three types of feature information. In addition, our model extracts two different features using the same image backbone, which keeps the total number of parameters of the model at a low level while ensuring recognition accuracy at an advanced level. In summary, the contributions of this paper are as follows:
This paper proposes to introduce LBP, HOG, landmark, and CNN features of an image simultaneously in the facial expression recognition task to alleviate the problem of insufficient feature information in the expression recognition task by fusing and cross-utilizing multiple different features.
A tri-cross-attention mechanism is proposed, which enhances the model’s ability to resolve inter-class similarities and intra-class variability by guiding the three types of features to each other, adaptively fusing the three types of features, and comprehensively exploiting the advantages of each feature.
The effectiveness of TriCAFFNet was verified through extensive experiments, with TriCAFFNet achieving state-of-the-art recognition accuracies on two commonly used datasets (RAF-DB 92.17%, AffectNet (7 cls) 67.40%, AffectNet (8 cls) 63.49%).
4. Experiments
4.1. Datasets
The availability of large-scale datasets in real-world scenarios is essential for facial expression recognition tasks. Large-scale datasets can provide rich samples of facial expressions, which can help networks learn more comprehensive features. These datasets can cover face images of different ages, genders, races, and emotional states, thus making the trained models more robust in real-world scenarios. In this paper, two commonly used facial expression datasets in real-world scenarios are chosen to validate the effectiveness of the proposed TriCAFFNet model.
RAF-DB [
3]: Real-world Affective Faces Database (RAF-DB) is a facial expression recognition dataset containing seven different basic facial expressions (happy, sad, anger, surprise, fear, disgust, and neutral). The dataset includes 29,672 face images from the real world. Among them, 15,339 images are used for facial expression recognition tasks, with 12,271 images for training and 3068 images for testing. Each image is annotated with labelled expression categories and intensity levels. The RAF-DB dataset is widely used in the field of facial expression recognition and is one of the commonly used benchmark datasets for evaluating and comparing different algorithms.
AffectNet [
4]: AffectNet is one of the largest publicly available datasets for facial expression recognition tasks. It is a large-scale dataset in a real-world scenario, containing more than one million facial images collected from the Internet. The photos are labelled into eight emotion categories, including the seven primary expressions and the contempt expression. Comparison of model recognition results can be based on two different uses: accuracy based on seven emotion categories and accuracy based on eight emotion categories. We verify the recognition effect of the proposed model based on these two uses.
4.2. Implement Details
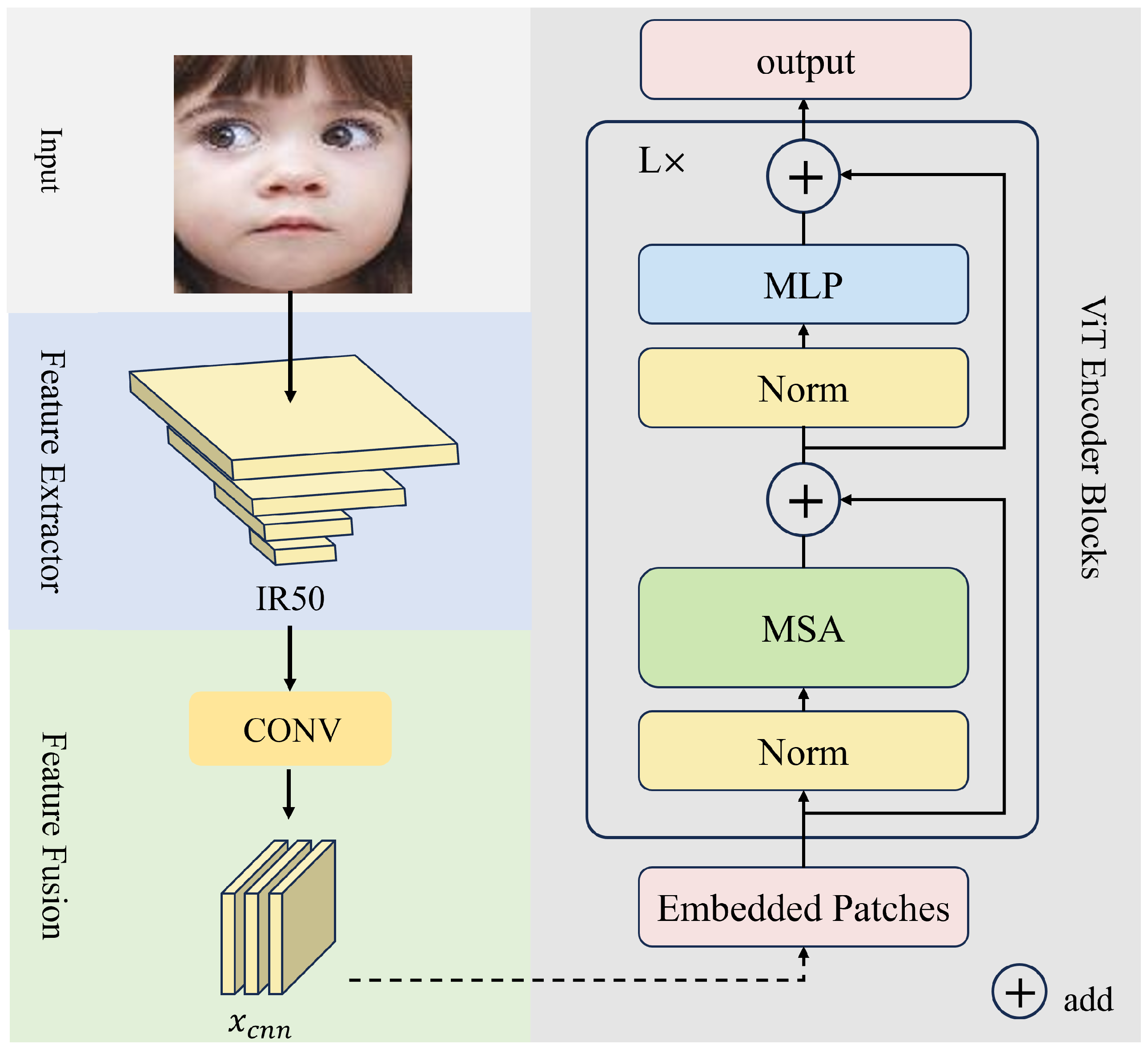
In the experiments, a standardized preprocessing is applied to all input images, including resizing to a uniform size of 224 × 224, random horizontal flipping, random vertical flipping, random addition of Gaussian noise, and random erasure of specific regions in the images. The feature extraction model utilizes the IR50 model pre-trained on the Ms-Celeb-1M dataset as the image backbone. The MobileFaceNet, with the same frozen training parameters, is employed to extract facial landmarks and high-level LBPHOG features. The learning rate is initialized to 0.0004. Adam optimizer is utilized. The batch size is set to 200. The mlp ratio and drop path rate are set to 2.0 and 0.01, respectively. The cross-entropy loss function is used as the loss function. We implemented all the experiments on an NVIDIA RTX 3090 GPU based on the Pytorch framework.
4.3. Comparison with State-of-the-Art Results
In this section, we compare the recognition results of the method proposed in this paper with some SOTA methods on RAF-DB and AffectNet datasets.
Results on RAF-DB: We compare the results with the FER algorithms that have achieved SOTA performance on the RAF-DB dataset in recent years. The results are shown in
Table 1. The experimental results indicate that our TriCAFFNet achieved SOTA performance on the RAF-DB dataset with an accuracy of 92.17%. It outperforms MVT (88.62%) [
17], PSR (88.98%) [
28], QOT (89.97%) [
42], TransFER (90.91%) [
14], APViT (91.98%) [
29], and LCFC(89.23%) [
30] by 3.55%, 3.19%, 2.2%, 1.26%, 0.19%, and 2.94%, respectively. It surpasses our Baseline(91.88%) by 0.29%, and also surpasses the second-highest method, POSTER (92.05%) [
25], by 0.12%.
Results on AffectNet (7 cls): The results of TriCAFFNet on AffectNet (7 cls) dataset in comparison with the previous methods are presented in
Table 2. TriCAFFNet (67.40%) outperforms MVT (64.57%) [
17], EAC (65.32%) [
43], TransFER (66.23%) [
14], APViT (66.91%) [
29], and POSTER (67.31%) [
25] on AffectNet (7 cls) by 2.83%, 2.08%, 1.17%, 0.43%, and 0.09%, respectively. It surpasses our Baseline(66.34%) by 1.06%, and also surpasses the second-highest method, QOT (67.37%) [
42], by 0.03%.
Results on AffectNet (8 cls).
Table 3 shows the results of TriCAFFNet on the AffectNet (8 cls) dataset in comparison with the previous methods. TriCAFFNet (63.49%) is 2.81%, 2.16%, 2.09% 1.32% higher than PSR (60.68%) [
28], ARM (61.33%) [
44], MVT (61.40%) [
17] and LCFC (62.17%) [
30], respectively. It surpasses our Baseline(63.14%) by 0.35% and is 0.15% higher than the second highest POSTER (63.34%) [
25] method.
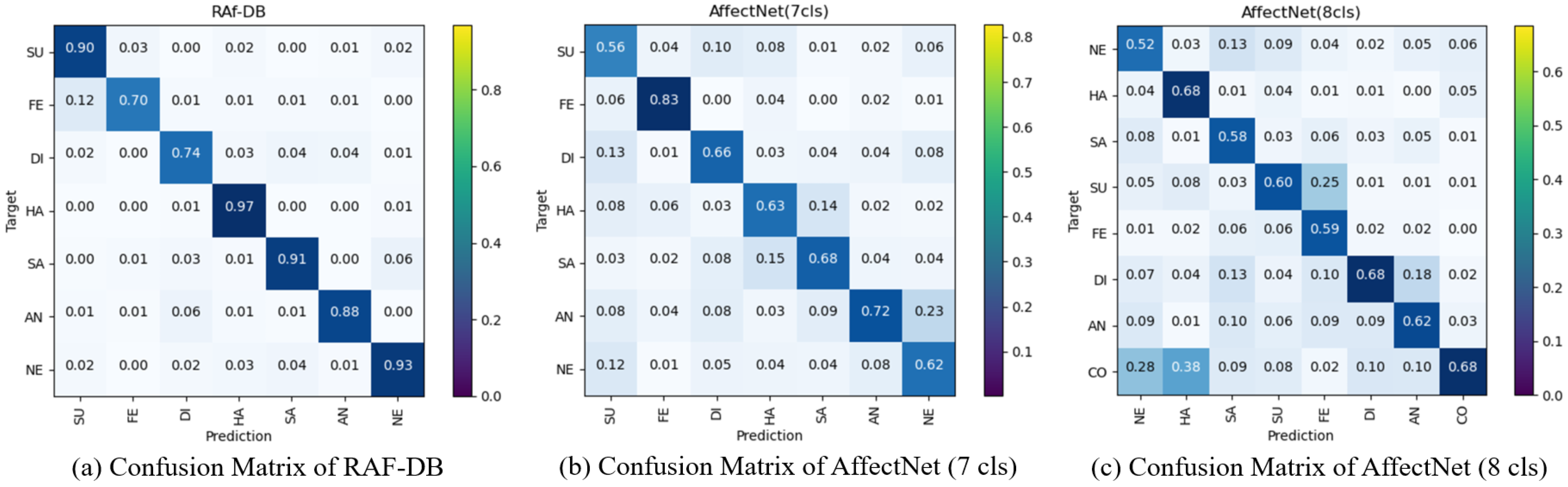
As shown in
Figure 4, we display the confusion matrices of the proposed model on these datasets. The darker colors of the diagonal positions in the confusion matrix represent the higher recognition accuracy of the class. Lighter colors in other positions indicate lower misidentification rates. It can be seen that TriCAFFNet performs well on the RAF-DB dataset and is weaker than the different classes, only in Fear and Disgust, which have fewer training samples. It also reaches a good level on AffectNet.
Model size and FLOPs: In model evaluation, the number of parameters and FLOPs are also crucial metrics.
Table 4 compares the number of parameters and FLOPs of our TriCAFFNet model with MVT [
17], VTFF [
19], Transfer [
14], POSTER [
25] and APViT [
29]. The proposed model keeps the number of parameters at a lower level by using the same image backbone to extract different features and also improves performance.
4.4. Result Analysis
In order to better understand TriCAFFNet’s efficient use of multiple features and the effectiveness of the architecture, we compared TriCAFFNet with other SOTA methods in terms of facial expression recognition accuracy as well as average accuracy on the seven classes of expressions in the RAF-DB dataset. The results are shown in
Table 5.
Among the seven expression categories, TriCAFFNet achieves the highest facial expression recognition accuracy in neutral and sad compared to all other models listed in the table. Neutral expressions are easily misidentified as other expressions because they have no apparent emotional coloring. TriCAFFNet outperformed the second-ranked model TransFER [
14] on neutral by 2.79%, which indicates that TriCAFFNet is capable of utilizing multiple features to distinguish subtle differences between various expressions, enhancing its ability to address inter-class similarity issues. The feature differences between sad and other expressions are pretty obvious. TriCAFFNet enhances this distinctiveness by introducing landmark features and LBPHOG features, thereby improving the model’s ability to address inter-class differences. Additionally, all models perform the worst in the fear category, which is because, in the training set of RAF-DB, the number of images in the fear category accounts for only 2.2% of the total number of images. It is nearly 20 times lower than the happy (38.9%) category, which has the most significant proportion. Therefore, the model lacks a sufficient number of training samples for the fear category. TriCAFFNet performs well in this category as well, which indicates that even with a limited number of training samples, TriCAFFNet is able to capture various features that provide valuable information for recognition.
We further analyze the misrecognition rates of the model on the neutral, fear, and sad expression categories and compare them with POSTER [
25]. The results, as shown in
Table 6, illustrate the ability of TriCAFFNet to address both inter-class similarity and intra-class variability issues. In recognition of the neutral category, the probability of TriCAFFNet misidentifying it as fear or anger is 0, and the likelihood of misidentifying it as other expression categories is also maintained at a low level. Compared to POSTER [
25], TriCAFFNet can further reduce the probability of misidentifying neutral as happy, surprise, and disgust. In the category of fear, which has the smallest sample size, the number of misidentifications as surprise and sad is relatively high due to the dataset itself. However, TriCAFFNet is still able to keep the number of misidentifications of fear as other categories, excluding surprise and sad, at a low level.
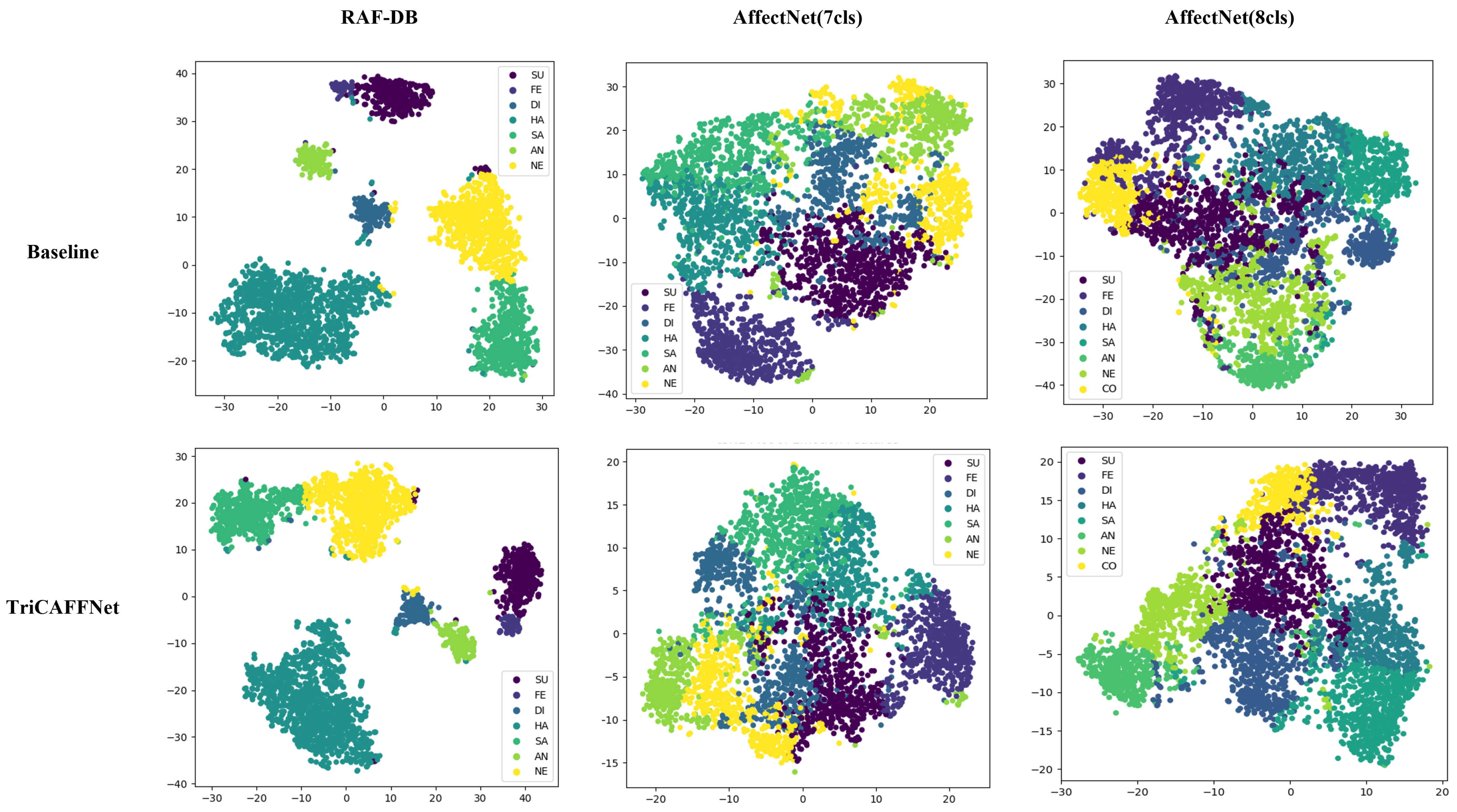
As shown in
Figure 5, the high-dimensional features of TriCAFFNet are visualized using the t-SNE [
45] method. t-SNE visualization plots of the RAF-DB dataset present apparent clustering effects and obvious separability, where the points of different colors are far away from each other. In contrast with our Baseline model, the points of the same color are tightly clustered in the low-dimensional space, which suggests that they have similar features in the high-dimensional space, thus further illustrating the SOTA capability of TriCAFFNet in performing the expression classification task. The AffectNet dataset, because of its massive number of samples and the unbalanced distribution among the samples, has closer distances between the points of individual colors. TriCAFFNet also presents a competitive performance.
4.5. Ablation Study
We conducted ablation experiments on RAF-DB and AffectNet datasets to validate the effectiveness of our proposed architecture, and the results are shown in
Table 7.
Landmark. We verify the importance of landmark features by removing landmark features in the three-stream attention mechanism. After removing landmark features, the recognition accuracy of TriCAFFNet on the RAF-DB dataset and AffectNet dataset decreases from 92.17% and 67.40% to 91.40% and 67.10%, and its recognition effect is greatly reduced. Therefore, we introduce landmark features to enhance the ability of the model to distinguish the subtle differences between images, which can effectively enhance the recognition ability of the model.
LBPHOG. We investigated the effect of the introduction of LBPHOG features on the recognition effect. It can be found that the recognition rate of the model on both datasets decreases when the LBPHOG features are removed (RAF-DB decreases by 0.43% and AffectNet decreases by 0.10%). Therefore, the ability of the model to distinguish subtle differences between images can be further enhanced by introducing LBPHOG features, thus improving the accuracy of facial expression recognition.
Tri-Cross-Attention. We explore the effect of the tri-cross-attention mechanism on the model recognition results by removing it. After removing the tri-cross-attention module, the accuracy decreases by 0.78% on RAF-DB and 0.26% on AffectNet. The recognition performance was the poorest in the three ablation experiments, which indicates that the proposed tri-cross-attention mechanism is crucial for the model. For three different features, the tri-cross-attention mechanism enables mutual fusion and guidance. Compared with the common fusion method, it is more helpful in improving the recognition accuracy of the model.
5. Conclusions
In this paper, we propose the tri-cross-attention Transformer with a multi-feature fusion network (TriCAFFNet) for facial expression recognition. We propose to improve the model’s ability to solve the inter-class similarity and the intra-class variability problems by introducing landmark features, LBPHOG features, and CNN features of the image to enable the model to acquire sufficient information related to recognition. The proposed tri-cross-attention mechanism is used to make the three features fuse and guide each other. A large number of FER experiments show that TriCAFFNet achieves SOTA performance while keeping the number of parameters as well as FLOPs at a low level, which makes TriCAFFNet a better choice for FER as it strikes a good balance between accuracy and computational complexity.
We enhanced the model’s recognition capability by selectively leveraging distinct features. However, this approach also increased the complexity of our model inputs, necessitating additional preprocessing steps. Furthermore, during feature extraction, we employed a single parameter-frozen backbone to extract advanced features from two different types of features, significantly reducing the number of trainable parameters and simplifying the model’s complexity. Nonetheless, the inclusion of two backbones and a tri-cross-attention ViT means there is still room for improvement in optimizing the overall parameter count despite maintaining it at a relatively low level.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}