
Efficient Reinforcement Learning for 3D Jumping Monopods

 , , , and
, , , and
Abstract
1. Introduction
Paper Contribution
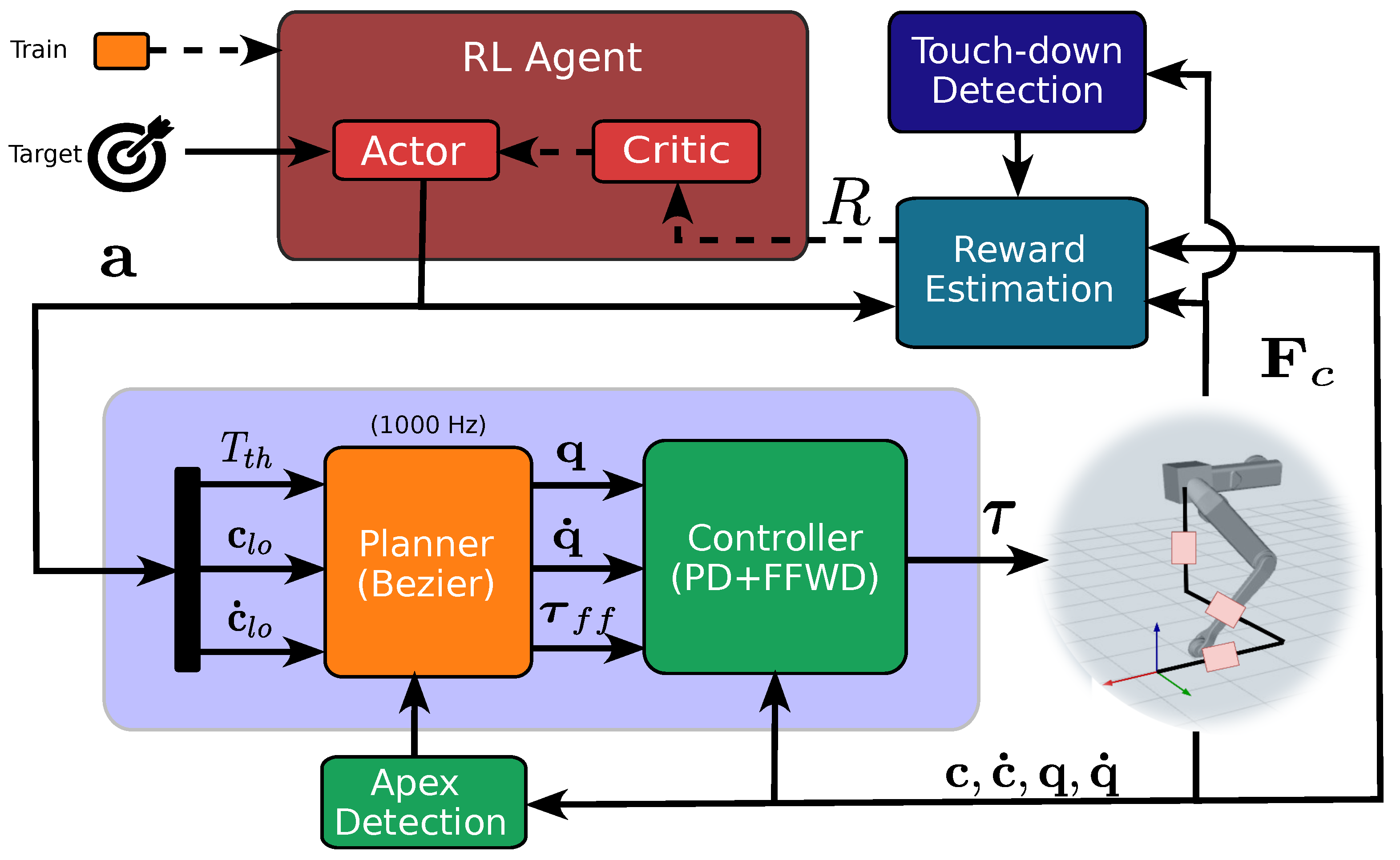
2. Guided Reinforcement Learning for Jumping
2.1. Problem Description
2.2. Overview of the Approach
3. Learning Framework
3.1. The Action Space
Trajectory Parametrization in Cartesian Space
3.2. A Physically Informative Reward Function
3.3. Implementation Details
4. Simulation Results
4.1. Non-Linear Trajectory Optimization
4.2. End-to-End RL
4.3. Policy Performance: The Feasibility Region
4.3.1. Performance Baseline: Trajectory Optimization
4.3.2. Performance of GRL
4.3.3. Performance Baseline: E2E RL
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jenelten, F.; Grandia, R.; Farshidian, F.; Hutter, M. TAMOLS: Terrain-Aware Motion Optimization for Legged Systems. IEEE Trans. Robot. 2022, 38, 3395–3413. [Google Scholar] [CrossRef]
- Roscia, F.; Focchi, M.; Prete, A.D.; Caldwell, D.G.; Semini, C. Reactive Landing Controller for Quadruped Robots. IEEE Robot. Autom. Lett. 2023, 8, 7210–7217. [Google Scholar] [CrossRef]
- Park, H.W.; Wensing, P.M.; Kim, S. High-speed bounding with the MIT Cheetah 2: Control design and experiments. Int. J. Robot. Res. 2017, 36, 167–192. [Google Scholar] [CrossRef]
- Yim, J.K.; Singh, B.R.P.; Wang, E.K.; Featherstone, R.; Fearing, R.S. Precision Robotic Leaping and Landing Using Stance-Phase Balance. IEEE Robot. Autom. Lett. 2020, 5, 3422–3429. [Google Scholar] [CrossRef]
- Nguyen, C.; Nguyen, Q. Contact-timing and Trajectory Optimization for 3D Jumping on Quadruped Robots. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 11994–11999. [Google Scholar] [CrossRef]
- Chignoli, M.; Kim, S. Online Trajectory Optimization for Dynamic Aerial Motions of a Quadruped Robot. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; IEEE: New York, NY, USA, 2021; pp. 7693–7699. [Google Scholar]
- García, G.; Griffin, R.; Pratt, J. Time-Varying Model Predictive Control for Highly Dynamic Motions of Quadrupedal Robots. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xi’an, China, 30 May–5 June 2021; pp. 7344–7349. [Google Scholar] [CrossRef]
- Chignoli, M.; Morozov, S.; Kim, S. Rapid and Reliable Quadruped Motion Planning with Omnidirectional Jumping. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; pp. 6621–6627. [Google Scholar] [CrossRef]
- Mastalli, C.; Merkt, W.; Xin, G.; Shim, J.; Mistry, M.; Havoutis, I.; Vijayakumar, S. Agile Maneuvers in Legged Robots:a Predictive Control Approach. arXiv 2022, arXiv:2203.07554v2. [Google Scholar]
- Li, H.; Wensing, P.M. Cafe-Mpc: A Cascaded-Fidelity Model Predictive Control Framework with Tuning-Free Whole-Body Control. arXiv 2024, arXiv:2403.03995. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.M.O.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Gehring, C.; Coros, S.; Hutler, M.; Dario Bellicoso, C.; Heijnen, H.; Diethelm, R.; Bloesch, M.; Fankhauser, P.; Hwangbo, J.; Hoepflinger, M.; et al. Practice Makes Perfect: An Optimization-Based Approach to Controlling Agile Motions for a Quadruped Robot. IEEE Robot. Autom. Mag. 2016, 23, 34–43. [Google Scholar] [CrossRef]
- Hwangbo, J.; Lee, J.; Dosovitskiy, A.; Bellicoso, D.; Tsounis, V.; Koltun, V.; Hutter, M. Learning agile and dynamic motor skills for legged robots. Sci. Robot. 2019, 4, eaau5872. [Google Scholar] [CrossRef] [PubMed]
- Peng, X.; Coumans, E.; Zhang, T.; Lee, T.W.; Tan, J.; Levine, S. Learning Agile Robotic Locomotion Skills by Imitating Animals. In Proceedings of the Robotics: Science and Systems 2020, Corvalis, OR, USA, 12–16 July 2020. [Google Scholar] [CrossRef]
- Ji, G.; Mun, J.; Kim, H.; Hwangbo, J. Concurrent Training of a Control Policy and a State Estimator for Dynamic and Robust Legged Locomotion. IEEE Robot. Autom. Lett. 2022, 7, 4630–4637. [Google Scholar] [CrossRef]
- Rudin, N.; Hoeller, D.; Reist, P.; Hutter, M. Learning to walk in minutes using massively parallel deep reinforcement learning. In Proceedings of the Conference on Robot Learning. PMLR, Auckland, New Zealand, 14–18 December 2022; pp. 91–100. [Google Scholar]
- Fankhauser, P.; Hutter, M.; Gehring, C.; Bloesch, M.; Hoepflinger, M.A.; Siegwart, R. Reinforcement learning of single legged locomotion. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 188–193. [Google Scholar] [CrossRef]
- OpenAI. Benchmarks for Spinning Up Implementations. 2022. Available online: https://spinningup.openai.com/en/latest/spinningup/bench.html#benchmarks-for-spinning-up-implementations (accessed on 26 February 2023).
- Bogdanovic, M.; Khadiv, M.; Righetti, L. Model-free reinforcement learning for robust locomotion using demonstrations from trajectory optimization. Front. Robot. AI 2022, 9, 854212. [Google Scholar] [CrossRef] [PubMed]
- Bellegarda, G.; Nguyen, C.; Nguyen, Q. Robust Quadruped Jumping via Deep Reinforcement Learning. arXiv 2023, arXiv:cs.RO/2011.07089. [Google Scholar]
- Grandesso, G.; Alboni, E.; Papini, G.P.; Wensing, P.M.; Prete, A.D. CACTO: Continuous Actor-Critic with Trajectory Optimization-Towards Global Optimality. IEEE Robot. Autom. Lett. 2023, 8, 3318–3325. [Google Scholar] [CrossRef]
- Peng, X.B.; van de Panne, M. Learning Locomotion Skills Using DeepRL: Does the Choice of Action Space Matter? In Proceedings of the ACM SIGGRAPH/Eurographics Symposium on Computer Animation, Los Angeles, CA, USA, 28–30 July 2017. [Google Scholar]
- Bellegarda, G.; Byl, K. Training in Task Space to Speed Up and Guide Reinforcement Learning. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 2693–2699. [Google Scholar] [CrossRef]
- Chen, S.; Zhang, B.; Mueller, M.W.; Rai, A.; Sreenath, K. Learning Torque Control for Quadrupedal Locomotion. arXiv 2022, arXiv:2203.05194. [Google Scholar]
- Aractingi, M.; Léziart, P.A.; Flayols, T.; Perez, J.; Silander, T.; Souères, P. Controlling the Solo12 Quadruped Robot with Deep Reinforcement Learning. Sci. Rep. 2023, 13, 11945. [Google Scholar] [CrossRef] [PubMed]
- Majid, A.Y.; Saaybi, S.; van Rietbergen, T.; François-Lavet, V.; Prasad, R.V.; Verhoeven, C. Deep Reinforcement Learning Versus Evolution Strategies: A Comparative Survey. arXiv 2021, arXiv:2110.01411. [Google Scholar] [CrossRef] [PubMed]
- Atanassov, V.; Ding, J.; Kober, J.; Havoutis, I.; Santina, C.D. Curriculum-Based Reinforcement Learning for Quadrupedal Jumping: A Reference-free Design. arXiv 2024, arXiv:2401.16337. [Google Scholar]
- Yang, Y.; Meng, X.; Yu, W.; Zhang, T.; Tan, J.; Boots, B. Continuous Versatile Jumping Using Learned Action Residuals. In Proceedings of the Machine Learning Research PMLR, Philadelphia, PA, USA, 15–16 June 2023; Volume 211, pp. 770–782. [Google Scholar]
- Vezzi, F.; Ding, J.; Raffin, A.; Kober, J.; Della Santina, C. Two-Stage Learning of Highly Dynamic Motions with Rigid and Articulated Soft Quadrupeds. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Yokohama, Japan, 13–17 May 2024. [Google Scholar]
- Henderson, P.; Hu, J.; Romoff, J.; Brunskill, E.; Jurafsky, D.; Pineau, J. Towards the systematic reporting of the energy and carbon footprints of machine learning. J. Mach. Learn. Res. 2020, 21, 10039–10081. [Google Scholar]
- Mock, J.W.; Muknahallipatna, S.S. A comparison of ppo, td3 and sac reinforcement algorithms for quadruped walking gait generation. J. Intell. Learn. Syst. Appl. 2023, 15, 36–56. [Google Scholar] [CrossRef]
- Shafiee, M.; Bellegarda, G.; Ijspeert, A. ManyQuadrupeds: Learning a Single Locomotion Policy for Diverse Quadruped Robots. arXiv 2024, arXiv:2310.10486. [Google Scholar]
- Zador, A.M. A critique of pure learning and what artificial neural networks can learn from animal brains. Nat. Commun. 2019, 10, 3770. [Google Scholar] [CrossRef] [PubMed]
- Shen, H.; Yosinski, J.; Kormushev, P.; Caldwell, D.G.; Lipson, H. Learning Fast Quadruped Robot Gaits with the RL PoWER Spline Parameterization. Cybern. Inf. Technol. 2013, 12, 66–75. [Google Scholar] [CrossRef]
- Kim, T.; Lee, S.H. Quadruped Locomotion on Non-Rigid Terrain using Reinforcement Learning. arXiv 2021, arXiv:2107.02955. [Google Scholar]
- Ji, Y.; Li, Z.; Sun, Y.; Peng, X.B.; Levine, S.; Berseth, G.; Sreenath, K. Hierarchical Reinforcement Learning for Precise Soccer Shooting Skills using a Quadrupedal Robot. In Proceedings of the 2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Kyoto, Japan, 23–27 October 2022; pp. 1479–1486. [Google Scholar] [CrossRef]
- Grzes, M. Reward Shaping in Episodic Reinforcement Learning; ACM: New York, NY, USA, 2017. [Google Scholar]
- Focchi, M.; Roscia, F.; Semini, C. Locosim: An Open-Source Cross-PlatformRobotics Framework. In Synergetic Cooperation between Robots and Humans, Proceedings of the CLAWAR 2023, Florianopolis, Brazil, 2–4 October 2023; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2024; pp. 395–406. [Google Scholar] [CrossRef]
- Budhiraja, R.; Carpentier, J.; Mastalli, C.; Mansard, N. Differential Dynamic Programming for Multi-Phase Rigid Contact Dynamics. In Proceedings of the IEEE International Conference on Humanoid Robots, Beijing, China, 6–9 November 2018. [Google Scholar]
- Mastalli, C.; Budhiraja, R.; Merkt, W.; Saurel, G.; Hammoud, B.; Naveau, M.; Carpentier, J.; Righetti, L.; Vijayakumar, S.; Mansard, N. Crocoddyl: An Efficient and Versatile Framework for Multi-Contact Optimal Control. In Proceedings of the IEEE International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020; pp. 2536–2542. [Google Scholar] [CrossRef]
- Carpentier, J.; Saurel, G.; Buondonno, G.; Mirabel, J.; Lamiraux, F.; Stasse, O.; Mansard, N. The Pinocchio C++ library—A fast and flexible implementation of rigid body dynamics algorithms and their analytical derivatives. In Proceedings of the IEEE International Symposium on System Integrations (SII), Paris, France, 14–16 January 2019. [Google Scholar]
- Gangapurwala, S.; Campanaro, L.; Havoutis, I. Learning Low-Frequency Motion Control for Robust and Dynamic Robot Locomotion. arXiv 2022, arXiv:2209.14887. [Google Scholar]
- Zhao, T.Z.; Kumar, V.; Levine, S.; Finn, C. Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware. arXiv 2023, arXiv:2304.13705. [Google Scholar]
- Jeon, S.H.; Heim, S.; Khazoom, C.; Kim, S. Benchmarking Potential Based Rewards for Learning Humanoid Locomotion. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 9204–9210. [Google Scholar] [CrossRef]
- Bengio, Y.; Louradour, J.; Collobert, R.; Weston, J. Curriculum learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; Volume 382, pp. 41–48. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Name | Range |
|---|---|---|
| m | Robot mass [kg] | 1.5 |
| P | Proportional gain | 10 |
| D | Derivative gain | 0.2 |
| Nominal configuration | [rad] | |
| Simulator time step [s] | 0.001 | |
| Max torque [Nm] | 8 | |
| Touch-down force th. [N] | 1 | |
| Num. of expl. steps | 1280 (GRL), 10 × 104 (E2E) | |
| Batch size | 256 (GRL), 512 (E2E) | |
| Expl. noise | 0.4 (GRL), 0.3 (E2E) | |
| Landing target repetition | 5 (GRL), 20 (E2E) | |
| Training step interval | 1 (GRL), 100 (E2E) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bussola, R.; Focchi, M.; Del Prete, A.; Fontanelli, D.; Palopoli, L. Efficient Reinforcement Learning for 3D Jumping Monopods. Sensors 2024, 24, 4981. https://doi.org/10.3390/s24154981
Bussola R, Focchi M, Del Prete A, Fontanelli D, Palopoli L. Efficient Reinforcement Learning for 3D Jumping Monopods. Sensors. 2024; 24(15):4981. https://doi.org/10.3390/s24154981
Chicago/Turabian StyleBussola, Riccardo, Michele Focchi, Andrea Del Prete, Daniele Fontanelli, and Luigi Palopoli. 2024. "Efficient Reinforcement Learning for 3D Jumping Monopods" Sensors 24, no. 15: 4981. https://doi.org/10.3390/s24154981
APA StyleBussola, R., Focchi, M., Del Prete, A., Fontanelli, D., & Palopoli, L. (2024). Efficient Reinforcement Learning for 3D Jumping Monopods. Sensors, 24(15), 4981. https://doi.org/10.3390/s24154981