1. Introduction
In order to pursue a higher imaging resolution, both space-based and ground-based telescopes are being developed in the direction of a larger aperture. However, the larger the size of the telescope’s primary mirror, the more difficult to design, process, manufacture, and verify it is. The emergence of segmented mirrors has greatly reduced the quality of primary mirrors, processing costs, manufacturing cycles, and the difficulty of transportation and launch. Based on the position of the reference submirror, other submirrors of the segmented primary mirror have six degrees of freedom: piston aberration along the optical axis (z-axis), tip-tilt along the x and y axes, movement in the x and y planes, and rotation around the optical axis. However, the first three of these factors have the biggest impact on image quality, and they are collectively known as the co-phase error. In order to bring the overall imaging quality of the segmented telescope close to the level of the diffraction limit, it is required that the submirrors have an extremely high co-phase accuracy [
1,
2].
At present, an accurate co-phase of the submirrors mainly includes two steps of submirror co-phase error detection and submirror error correction, where submirror error correction can be achieved with a multi-dimensional precision displacement platform. According to this principle, successfully applied co-phase error detection methods can be divided into pupil surface detection methods based on specific hardware sensors [
3,
4,
5,
6] and methods based on focal plane image information [
7,
8,
9,
10,
11,
12,
13].
Among these methods, methods based on deep learning have been rapidly developed and widely studied in recent years because they only rely on focal plane image information, have a fast processing speed, can extend the detection range through multi-wavelength or wide spectra, and can be applied to point targets and extended targets at the same time. However, in these methods, in order to achieve a high submirror co-phase accuracy, a high registration accuracy is required between the simulation model of the optical system used to generate the training dataset and the actual optical system, if the neural network training dataset is generated by the simulation model. However, this problem is difficult to solve; it is very difficult to obtain an accurate training dataset using real system data. The problem has greatly hindered the practical application of this method.
The deep reinforcement learning algorithm [
14] is composed of deep learning and reinforcement learning, in which deep learning is responsible for the low-dimensional feature extraction of high-dimensional data, like our eyes, and reinforcement learning uses the Markov process to make judgments and decisions, like our brain. This approach combines the higher perceptual capabilities of deep learning and the decision-making capabilities of reinforcement learning. Through a continuous interaction with the external environment, deep reinforcement learning algorithms can learn how to perform correct operations under complex conditions without modeling the external environment in the process. Therefore, in this paper, we placed a mask on the pupil plane of the segmented telescope optical system. Additionally, based on the wide spectrum, point spread function (PSF), and modulation transfer function (MTF) of the optical system and deep reinforcement learning, we implemented an automatic co-phase method for the multiple-submirror piston errors of segmented telescopes. This method does not need to model segmented telescopes and retains the advantages of not requiring iterations and does not depend on custom sensors. It also has the low computing power requirements of the deep learning co-phase error correction method. In reference [
15], the author used the reinforcement learning method to correct the piston error of two submirrors in a three-submirror optical system. Compared with the methods in reference [
15], the optical system used in this method is more complex and the correction efficiency is higher.
2. Method
2.1. Deep Reinforcement Learning
In recent years, with the development of deep learning technology, deep reinforcement learning algorithms have been more widely used, the most famous of which is the AlphaGo system [
16] developed by the DeepMind (USA) team. With this algorithm as the core, it overwhelmingly defeated the Go World Champion Lee Sedol.
Reinforcement learning [
14] is an integral part of machine learning. Its biggest feature is learning through interaction. Its goal is to train an agent to output a series of decisions based on the feedback of the environment, instead of only one result, which is similar to the human brain.
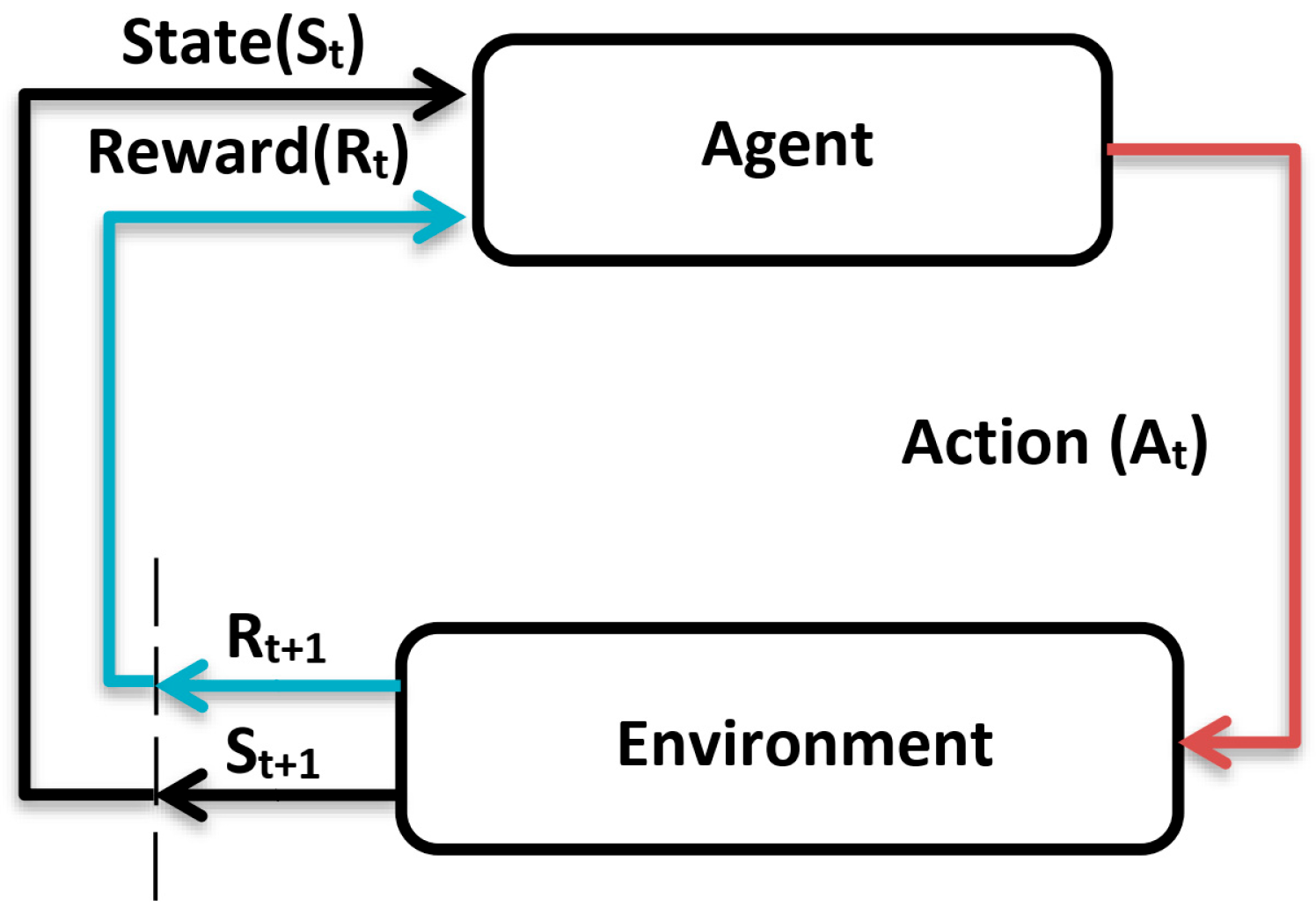
The reinforcement learning algorithm is mainly composed of an agent, an environment, value function , action policy function , and reward function . The agent maximizes the cumulative reward by sensing the state of the environment and learning to choose a series of actions according to the reward function value of the environment’s feedback.
The action policy function defines the behavior of the agent in a given state of the external environment and maps from a state to a behavior, it is the core of the reinforcement learning system.
The reward function defines the learning goal of reinforcement learning. In each time step, after the agent makes a corresponding action according to the environment state and action policy function , the reward function will output the corresponding reward value to the agent, which defines the performance of the agent in the environment.
The concept of a long-term reward is commonly used in reinforcement learning and is defined by Equation (1), where
is the discount factor and
is the reward function value obtained at the time step
t of the agent.
The value function represents the value of the environmental state of the agent. More specifically, the state value function describes the reward function expectations of the agent in a given state based on a particular policy function . In addition, an action value function can also be defined. The value function is crucial to reinforcement learning, as it allows the agent to determine the quality of the state of its current environment and the quality of the action policy .
The environmental model is the simulation of environmental state transfer. When the external environment state and the output behavior of the agent are given, we can obtain the environmental state of the next moment according to the environmental model. In this paper, the environment is the segmented optical system. Reinforcement learning does not always require the environment model, it can be divided into two types: model-based and model-free. Model-free reinforcement learning algorithms mainly learn through analysis of the policy function and the value function. The proximal policy optimization algorithm subsequently used in this paper is a model-free method, so there is no need to model the segmented mirror optical system.
On the whole, in reinforcement learning, the agent chooses corresponding actions to perform in different environmental states according to the policy function
, the environment feedbacks the new state and reward value according to the actions of the agent, the agent chooses new actions according to the new state, and the cycle continues until the end of the training. This process is called an episode. In deep reinforcement learning, both the policy function
and the value function
are composed of neural networks, so we hope to maximize the cumulative reward obtained by an episode by adjusting the parameters of policy function and value function; thus, the reinforcement learning algorithm will ultimately translate into the optimization problem of how to design an agent that maximizes long-term reward in the environment. The reward function is only used to update the parameters of the agent during the training process and is no longer needed after the training is completed. The schematic diagram of the reinforcement learning algorithm is shown in
Figure 1.
2.2. Proximal Policy Optimization (PPO)
Proximal policy optimization (PPO) [
17], a reinforcement learning algorithm proposed by OpenAI in 2017, is considered to be the current state-of-the-art method in the field of reinforcement learning, this method is used in the recently popular ChatGPT [
18]. It is a method of an on-policy, online, model-free, policy gradient which used to solve continuous or discrete action spaces. The piston error correction of the segmented mirror in this paper belongs to the continuous action space, so this paper will build the corresponding method based on the PPO algorithm. Compared with other algorithms, PPO’s strategy update is more stable, so the correction operation of submirrors is safer during training. This method has a good scalability for large-scale problems, and it can be used to deal with complex tasks by increasing the scale of the network and using distributed computing methods.
In PPO, the policy is represented by actor policy network , the input of which is the observation quantity of the environment state of the agent. In this paper, the output of the actor network is the piston error correction quantity of the segmented telescope, so it belongs to the continuous action space problem. Therefore, the output of the actor network in the PPO algorithm used in this paper is the mean and standard deviation of the Gaussian probability distribution of taking each continuous action A when in state of the environment. The value function consists of the critic network , whose input is the observation quantity of the environment state in which the agent is located, and whose output is the long-term discount reward that the agent can achieve under the current actor policy network .
The training process of PPO is as follows:
1. Randomly initialize the parameter of the critic network and the parameter of the actor network;
2. Use the current actor policy network
to make the agent interact with the environment many times, so as to obtain multiple pairs of data composed of the environmental state, the action, and the corresponding reward values:
where
is the state observation quantity of the environment at time
t,
is the corresponding action taken by the agent according to the observed environmental state
, the actor policy network
, and the output action probability distribution.
is the observation quantity of the environmental state at the next moment.
is the value of the reward function obtained by the environment moving from
to
, and
is the starting time step of the current set of N experiences.
3. For each episode step
t =
ts + 1,
ts + 2, …,
ts +
N, compute the advantage function
by generalized advantage estimator [
19], which is the discounted sum of temporal difference errors.
Here,
, if
is not a terminal state and
otherwise.
is a smoothing factor.
is the discount factor. Compute the return
.
4. Sample a random mini-batch dataset of size from the current set of experiences. Each element of the mini-batch dataset contains a current experience and the corresponding return and advantage function values.
Update the parameters of the critic net by minimizing the loss
and across all sampled mini-batch data.
Update the parameters of the actor policy net by minimizing the actor loss function
across all sampled mini-batch data,
where
,
,
is the advantage function for the i-th element of the mini-batch, and
is the corresponding return value.
and are the probability of taking action when in state , given the updated policy parameter and given the previous policy parameter from before the current learning epoch, respectively. is the clip factor. is the entropy loss. is the entropy loss weight factor, which promotes the agent to exploration.
5. Repeat Steps 2 through 4 until the training episode reaches a terminal state.
2.3. Piston Error Automatic Correction Technology for Optical Segmented Mirrors via PPO
In the process of the co-phase adjustment of segmented telescopes, the co-phase errors of submirrors are divided into piston errors (along the optical axis) and tip/tilt errors (which rotate around the x/y axis). The research of reference [
20] shows that tip/tilt errors have a lower impact than piston errors in the imaging of segmented primary mirrors. In this paper, we will use the PPO to implement the automatic correction of the piston error of the segmented mirror. Theoretically, this method does not require the optical model and only needs the constructed reward function value and focal plane image. Thus, the method avoids the problem that the simulation model has difficulty in accurately registering with the actual model in the methods based on supervised learning [
21,
22,
23]. In addition, since the algorithm maximizes the value of the reward function obtained by constantly adjusting the position of the submirror, the absolute positioning accuracy of the submirror high-precision adjustment platform is less required, and only its resolution is required; this advantage further reduces the difficulty of the method implementation.
For the deep reinforcement learning algorithm, the reward function is very important: it should effectively represent the piston error of each submirror. We construct the reward function using the method in references [
24,
25,
26,
27], which is briefly explained below.
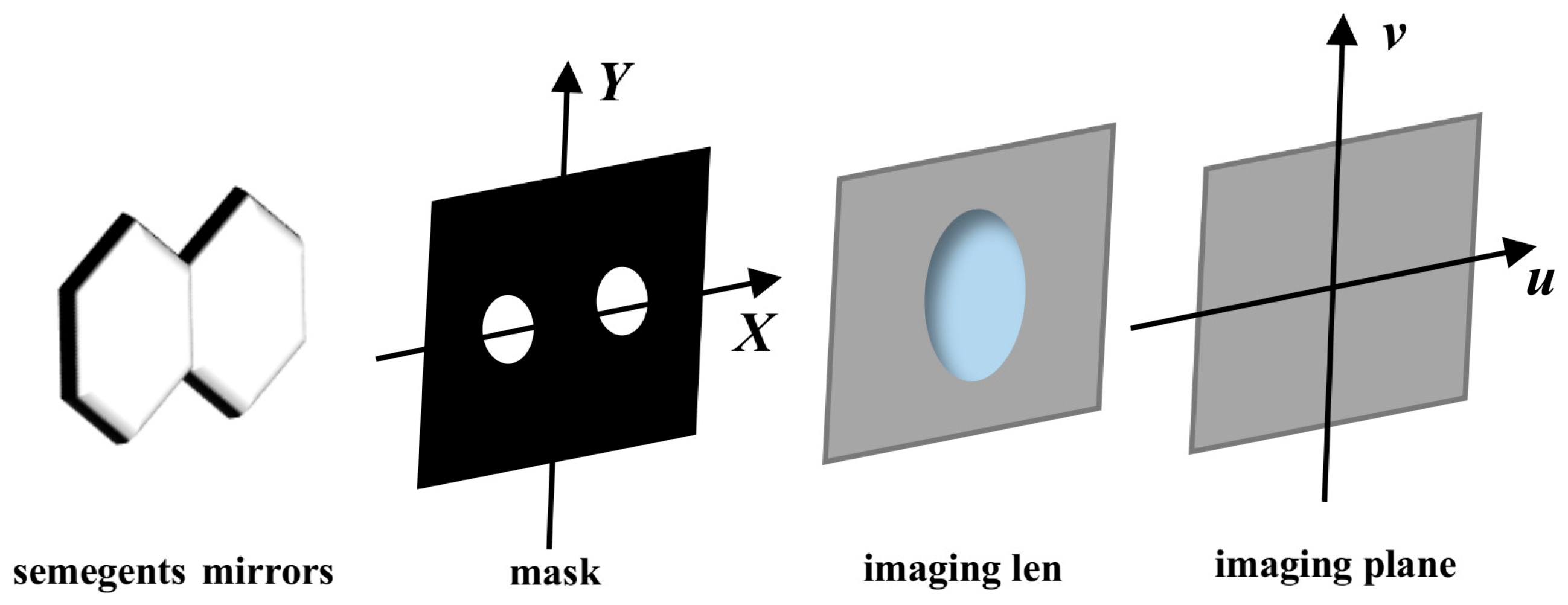
As can be seen in
Figure 2, a double-hole mask is placed on the exit pupil surface of the segmented mirror imaging system, which can pass through the reflected light of the two submirrors. Assuming that the incident light is a wide spectrum,
is the central wavelength, and
is the bandwidth of the wide spectrum, the PSF expression of the optical system can be expressed by Equation (6).
where
is the point spread function in the case of monochromatic light, and its expression is as follows:
where
is the piston error,
is the center distance between two subpupils,
is the diameter of the subpupil,
is the first-order Bessel function, and
is the focal length of the imaging lens. Equation (7) can be approximately expressed as a differential summation, the range is divided into
n intervals equally, and the equation is as follows:
The MTF can be given by Equation (9), where
is the MTF of a single aperture diffraction limited imaging system in which the aperture diameter is
,
,
. If
,
, else
is shown in Equation (10).
According to Equation (9), the MTF is composed of two side-lobes and one center peak. The center normalized amplitude of the MTF side-lobe (
) decreases with the increase of the piston, when the value of the piston reaches half the coherence length,
will be zero. The coherence length
can be given by Equation (11), at the same time, this method can break ambiguity of
and extend the capture range to half of the coherent length
. The relationship between the piston and the
can be given by Equation (12).
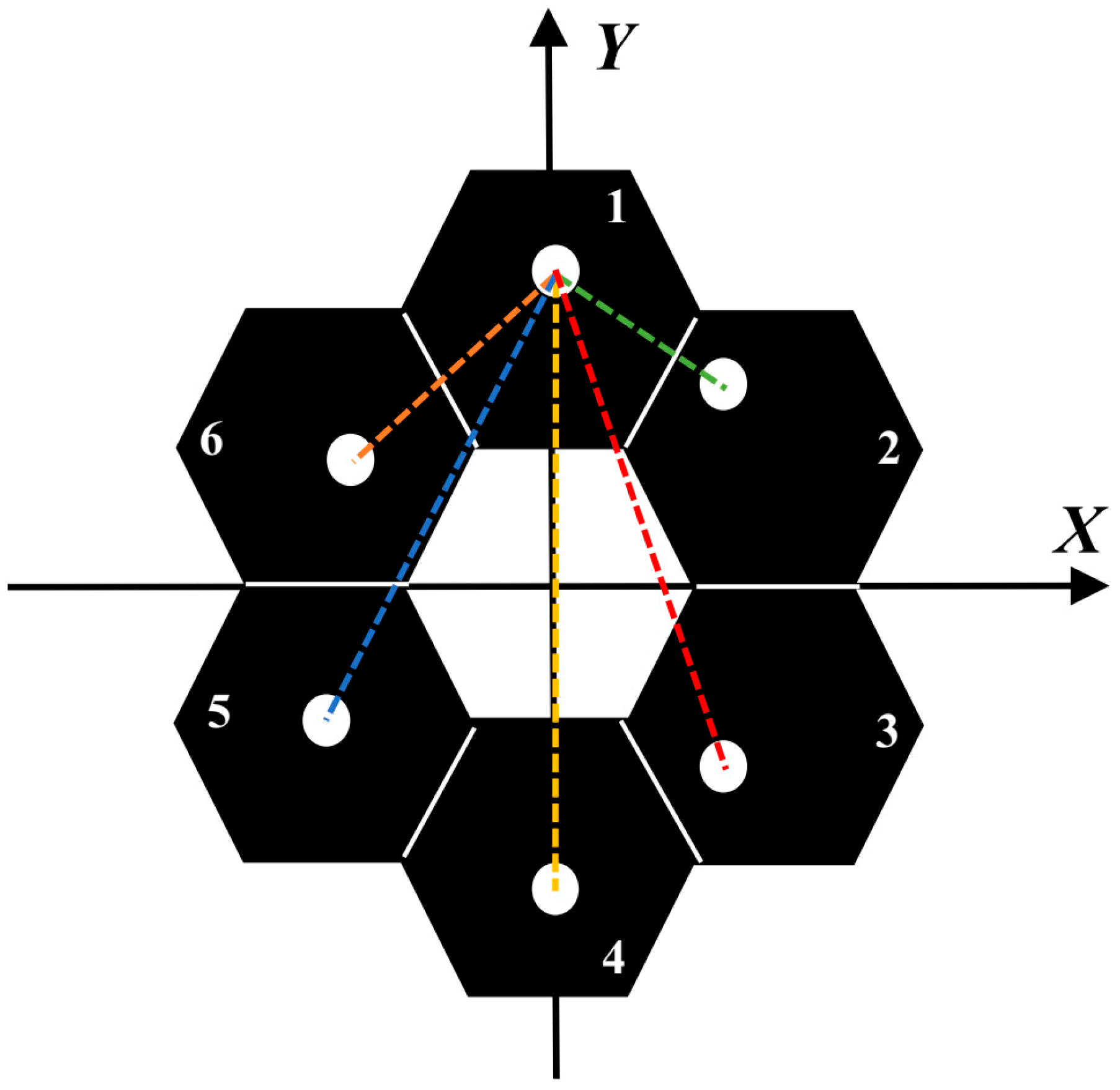
If a multihole mask is placed in a multi-submirror segmented optical system and the position of Submirror 1 is taken as the reference, as long as there is no overlap under each interference baseline, that is, the MTF of the optical system is a non-redundant MTF, Equation (12) is still true. Therefore, the amplitude of each
can effectively represent the piston error of each submirror. Therefore, in this paper, we place the multihole mask at the corresponding position to obtain the
of each submirror and reference submirror, and sum the amplitude of each
as the reward function of the reinforcement learning algorithm. We designed the corresponding mask according to the method in reference [
25]. The shape of the mask is set up as shown in
Figure 3, where the position of Submirror 1 is used as the reference, and the dotted lines of each color are the interference baseline of other numbered submirrors and Submirror 1.
The PSF and MTF of the corresponding optical system are shown in
Figure 4a,b. The yellow star points in
Figure 4b are the
collected to reflect the piston errors of each submirror. In reference [
28], the author proved that the focal plane image in the segmented telescope optical system containing a multihole mask system has a good ability to represent the piston error of the submirrors. Therefore, in this paper, we take the focal plane image as the observation quantity of the external environment.
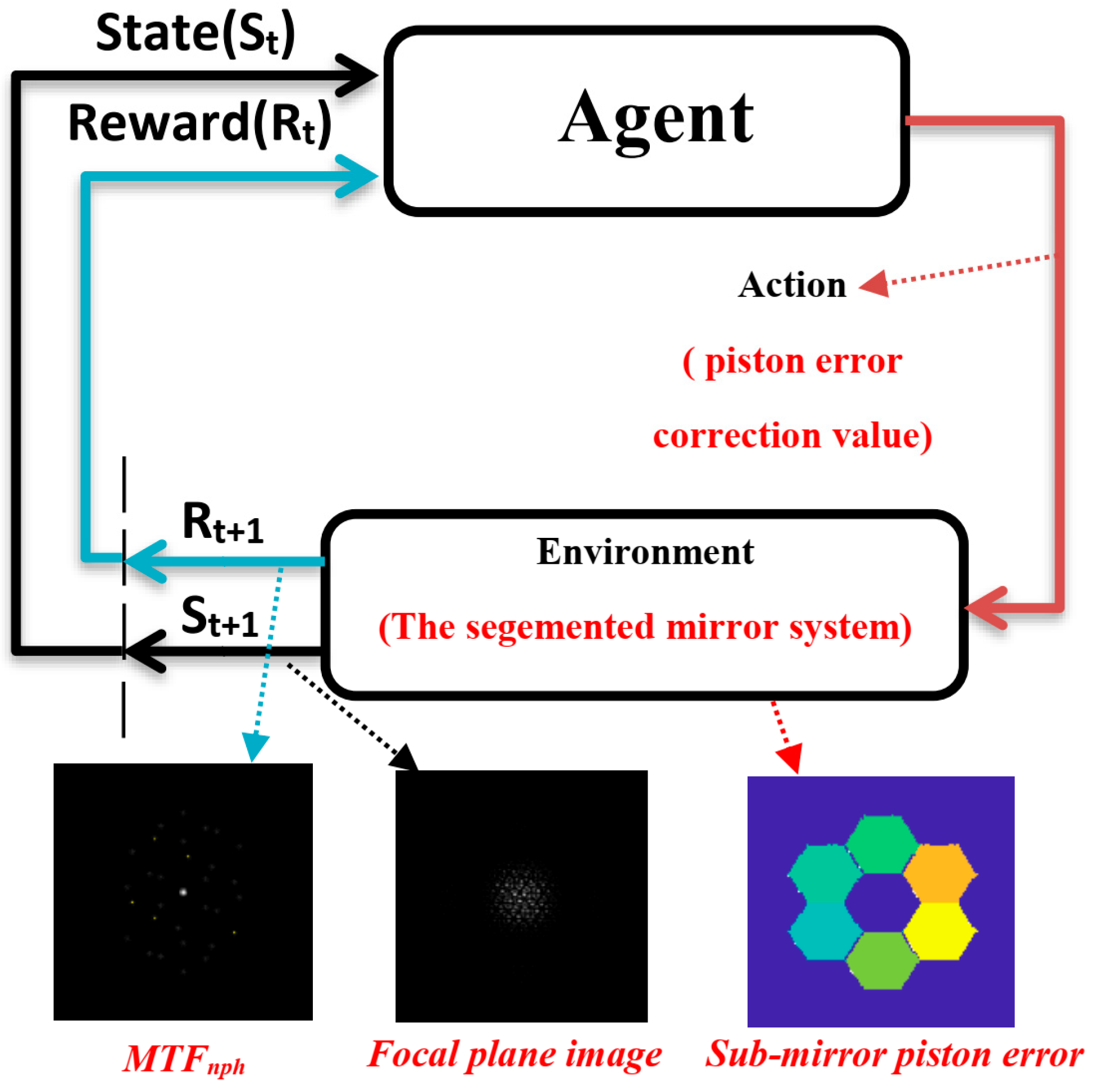
To sum up, in this paper, we implement an automatic piston error correction method of the segmented mirror based on the PPO, as shown in
Figure 5 below, in which the focal plane image of the optical system after adding a multihole mask will be used as the environmental observation quantity, the
sum of each submirror and the reference submirror will be used as the reward function
, and the segmented telescope will be used as the interaction environment with the agent. The agent will directly output the piston error correction quantity of each submirror according to the input focal plane image of the segmented mirror optical system, and it will output the next correction quantity of each submirror according to the re-input focal plane image after the submirror’s correction. In this process, the agent will update the critic network
and actor policy network
according to the reward function, and this process will continue to cycle until the end of training. A well-trained agent will learn an actor policy network
that can precisely correct each submirror piston error under any submirror piston error condition.
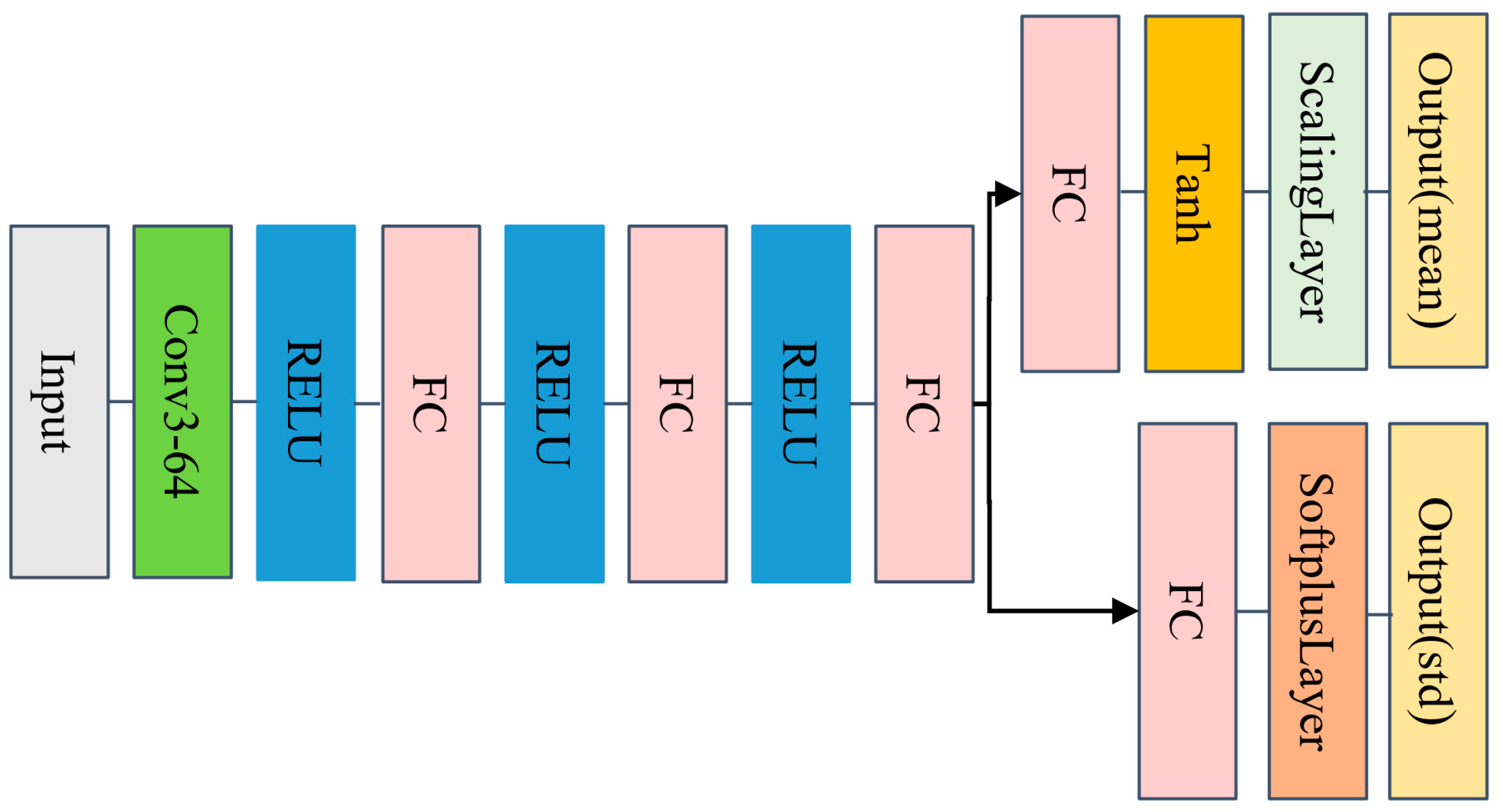
3. Simulation
In the PPO algorithm, we need to build the critic network
and actor policy network
. The network structures of both are shown in
Figure 6 and
Figure 7, respectively. The motivation for adopting a simple architecture is that it is easy to use when prototyping new problems, thereby eliminating the need for simultaneous architectural exploration and hyperparameter optimization. In future research work, we will use more complex network structures to explore whether the corresponding experimental effects can be improved.
The central wavelength of the spectrum is
and the bandwidth
, so the coherence length
can be calculated according to Equation (11). Therefore, the piston error range of the submirror in this paper is set to
. We use MATLAB to model the segmented telescope, which contains 6 hexagonal submirrors, the pixel size of the imaging detector is 2.5 µm, the F# is 10, and the size of the exit pupil plane is 256 pixels. The mask is set according to the method mentioned in the reference [
24,
25,
26]. The diameter of the mask hole is 8 pixels. The outer circle of the submirror is 40 pixels in diameter.
In order to effectively improve the exploration efficiency in state space and reduce the training difficulty, in contrast to the reference [
15], multi-step reinforcement learning is adopted in this paper. The maximum number of steps of each episode is 30 and the discount factor
. Therefore, this method can also be used as a long-term maintenance method for the position of the submirrors.
The training learning rate is set to 0.0001, the maximum number of episodes is set to 100,000, and the cumulative reward value of each episode will be recorded; if the average of the cumulative reward value of the 20 most recently trained episodes exceeds 29, the training will stop and the agent will be saved.
In the process of algorithm training, we separately add up the piston error correction amount of each submirror output by the actor policy network after each episode starts, so as to judge whether the piston error of each submirror after correction is still within the correction range. When this accumulation amount is beyond the correction range boundary, even if episode does not reach the maximum number of steps this time, the episode will also end in advance and be judged as an error correction failure (Done = 1), and the reward function will be −1 (this method can still be used for the actual segmented telescope, without affecting the authenticity of the simulation system); otherwise, the reward function will be the sum of each normalized amplitude of .
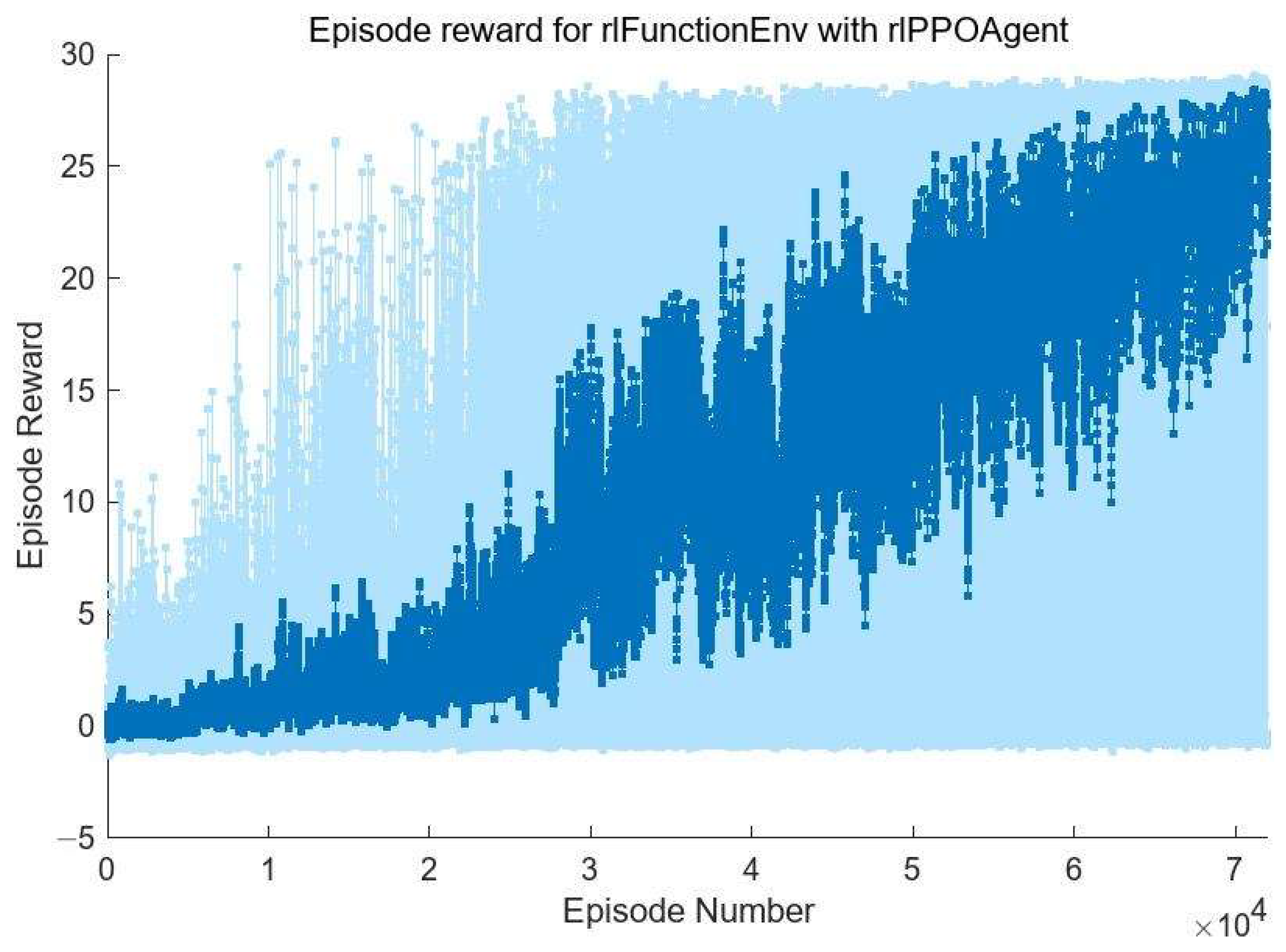
The training process is shown in
Figure 8. The horizontal axis is the number of episodes, and the vertical axis is the cumulative reward function value obtained by the agent in each episode. As can be seen from
Figure 8, in the initial training of the agent, due to the poor output of the action strategy network, the piston errors of each submirror often exceed the correction range after several corrections, so the episode is forced to terminate even though the maximum number of steps is not reached. In this case, the value of the reward function will be assigned as −1; that is, the agent will be punished accordingly. In this case, the agent will update the value network and the action strategy network to reduce the probability of this situation occurring in the subsequent training process. With the progress of training, the agent has gradually begun to learn how to automatically correct the piston errors of each submirror. In the later stage of training, the situation in which the piston errors of submirror are outside the correction range due to the error of correction quantity output is basically eliminated. Meanwhile, the cumulative reward value of each episode is also increasing. This means that in the process of correcting 30 times each episode, each submirror piston error is corrected faster and more accurately. However, in order to improve the efficiency of the agent’s exploration of the environment, entropy loss weights promote agent exploration by imposing penalties for being too certain of the actions to take (doing so helps to agents move away from local optima), so there are large fluctuations in the value of the reward function in
Figure 8.
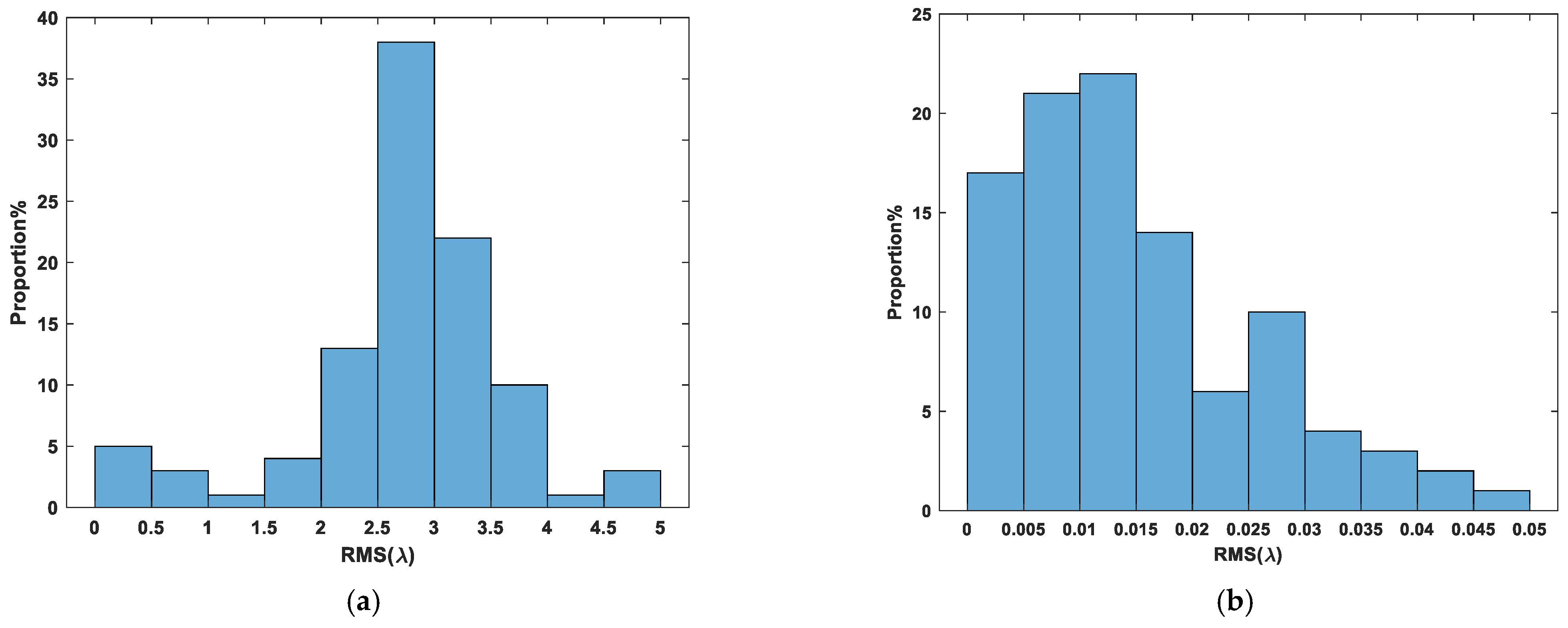
We saved the trained deep reinforcement learning network model and used the model to correct the randomly initialized 100 groups’ submirror piston errors in the range of
and recorded the relevant experimental results, as shown in
Figure 9. It can be seen from
Figure 9 that the maximum RMS of the corrected co-phase error is less than 0.05
, the average RMS is 0.0146
, and the RMS value is less than 0.025
for 81 out of 100 corrections, among which the minimum value is 0.0001889
. Thus, all of the segmented mirror systems which were corrected are known to have a Strehl ratio greater than 0.8 [
29].
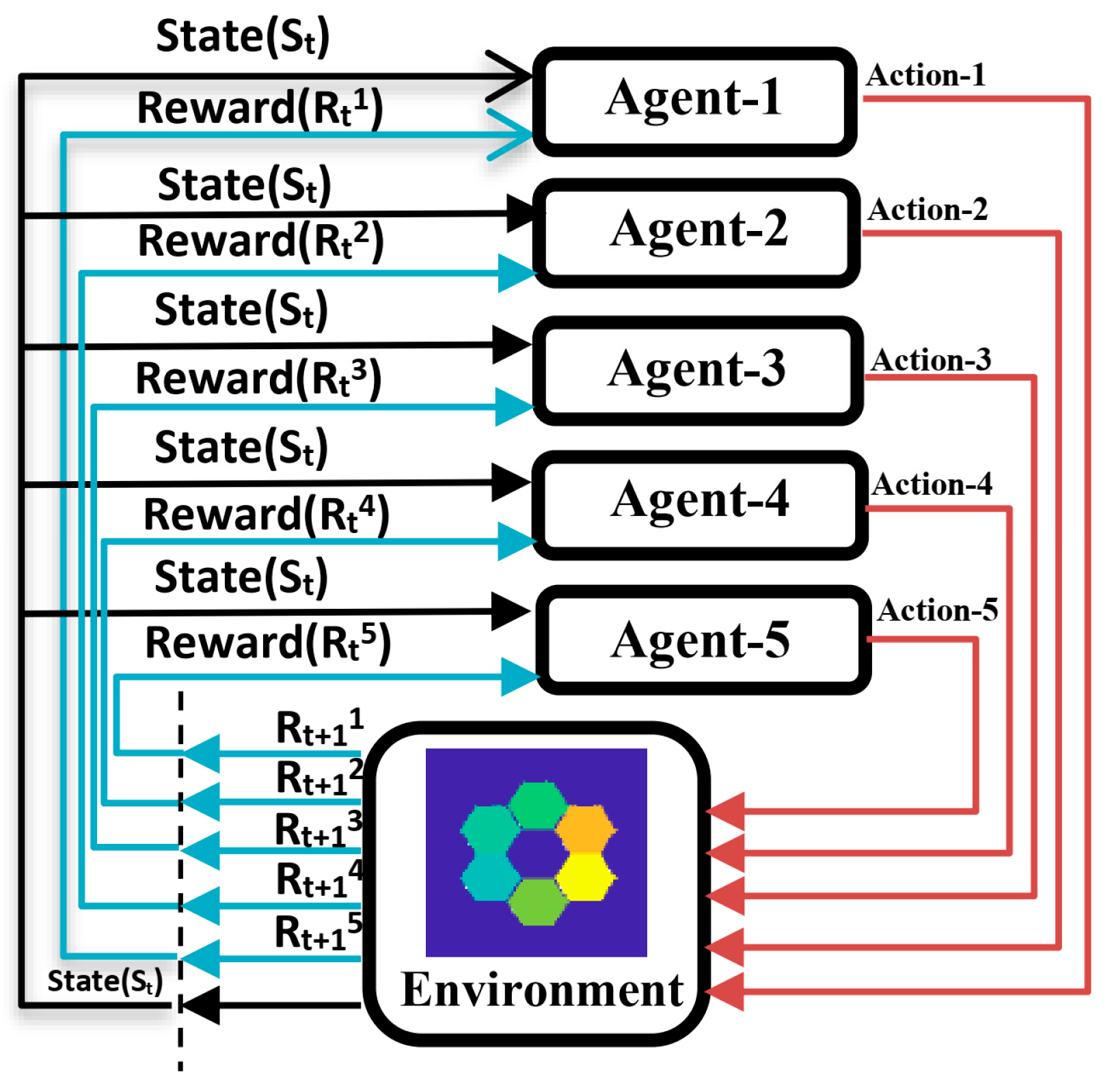
In order to further reduce the implementation difficulty of this method in the actual system, reducing the number of the training times and applying the method to a system with more submirrors, we adopt the multi-agent reinforcement learning [
30] method to train five agents at the same time, and each agent carries out the piston error correction for each submirror, respectively. Although this method seems to require more network parameters to be trained, because each single agent is trained separately, the training difficulty is much lower.
It can be seen from the previous text that the
amplitude of each submirror and reference mirror is inversely proportional to its own piston error, and it has nothing to do with the piston error of other submirrors. Therefore, in the multi-agent reinforcement learning algorithm in this paper, the reward function of each agent is constructed by the
of each submirror itself. Each agent has the same environmental observation which is the focal plane image of the optical system. The structure of the action strategy network and value network of each agent is the same as in the previous section. The output of the action policy network of each agent is the quantity of piston error correction for each submirror, and the output of each action policy network is only one dimension. The schematic diagram of the automatic correction of submirrors’ piston error based on multi-agents is shown in
Figure 10.
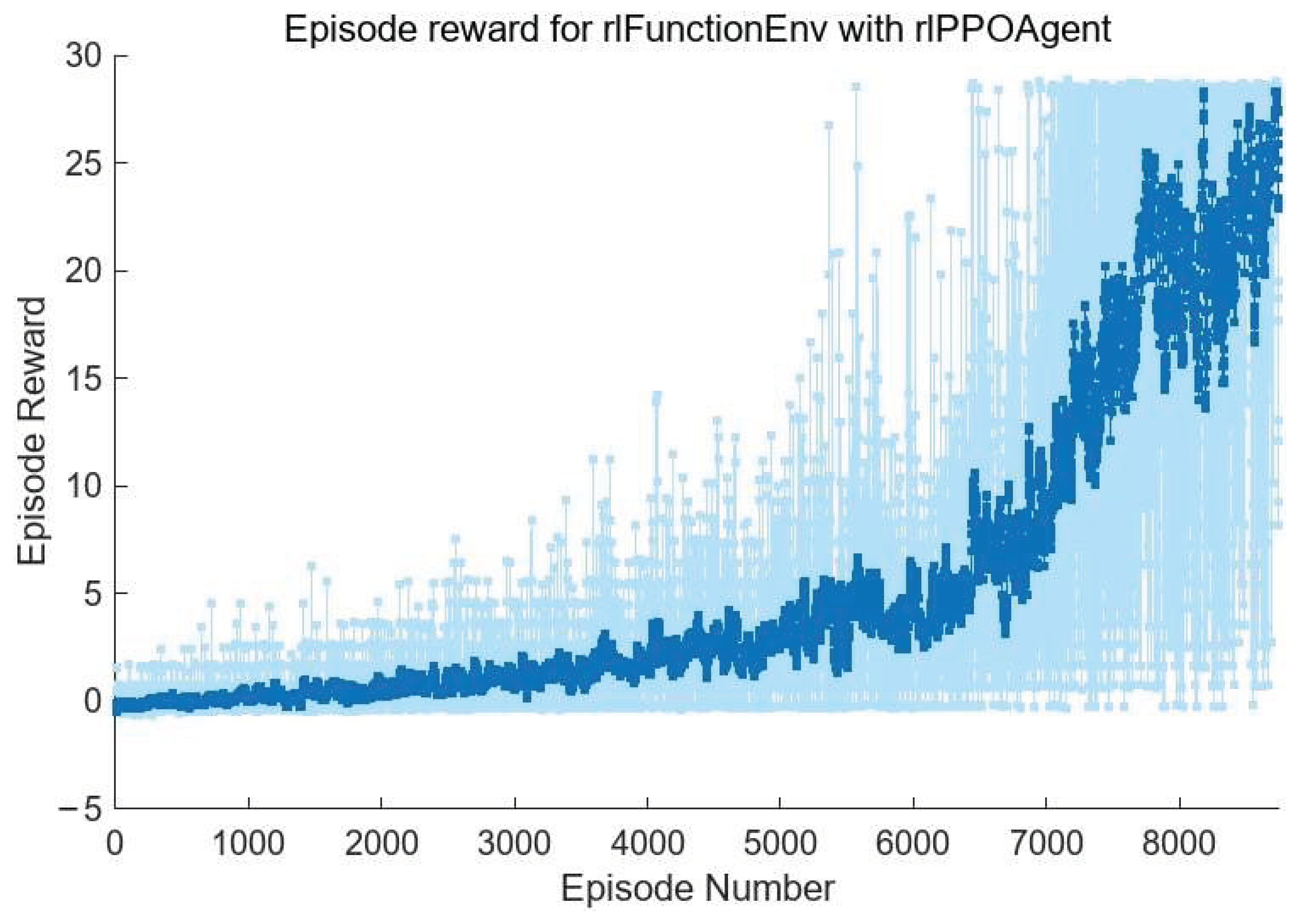
Here, we only show the training process of the agent used to correct submirror 2, as shown in
Figure 11 below. The training process of other agents is similar. As can be seen from
Figure 11, the number of training is significantly reduced. As before, we also saved multi-agent reinforcement learning and used the models to correct the randomly initialized 100 groups submirror piston errors in the range of
and recorded the relevant experimental results, as shown in
Figure 12. It can be seen that the maximum RMS of the corrected co-phase error is less than 0.05
, the average RMS is 0.0152
, and the RMS value is less than 0.025
for 80 out of 100 corrections, among which the minimum value is 0.0002691
. Therefore, the results of the two methods are similar, but in the multi-agent reinforcement learning training process, the interaction between the agent and the environment is less, and the training difficulty is lower.
Of course, we can also not use the multi-agent method but simply train five agents in turn; this method is also effective. But in this multi-agent method, during each experience in the training process, the five sub-agents interact with the agent by correcting the corresponding submirror, these experiences will be collected, and the parameters of the five sub-networks will be updated simultaneously. Thus, the interaction times between the agent and the environment is reduced, and the sample utilization and training efficiency are improved.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}