
Advanced Image Analytics for Mobile Robot-Based Condition Monitoring in Hazardous Environments: A Comprehensive Thermal Defect Processing Framework




Abstract
1. Introduction
- A hybrid model based on the pre-trained VGG16 CNN architecture as a feature extractor and RF and XGBoost as classifiers was introduced to industrial CM to perform semantic segmentation tasks on IR image datasets.
- The employed unsupervised approach using PCA-K-means could help us significantly reduce the dimensions of the unlabeled segmented labels to cluster them based on degree of severity.
- A benchmark of the proposed models in segmentation and classification of thermal defects in BC idlers was created on an industrial dataset, proving the usability of the created data, as well as the model in the other industrial IR image-based CM domains.
2. Literature Review
2.1. Failure Causes in Idler Bearings
2.2. Classical IR Image Processing Methods
2.3. Deep Learning-Based IR Image Processing Methods
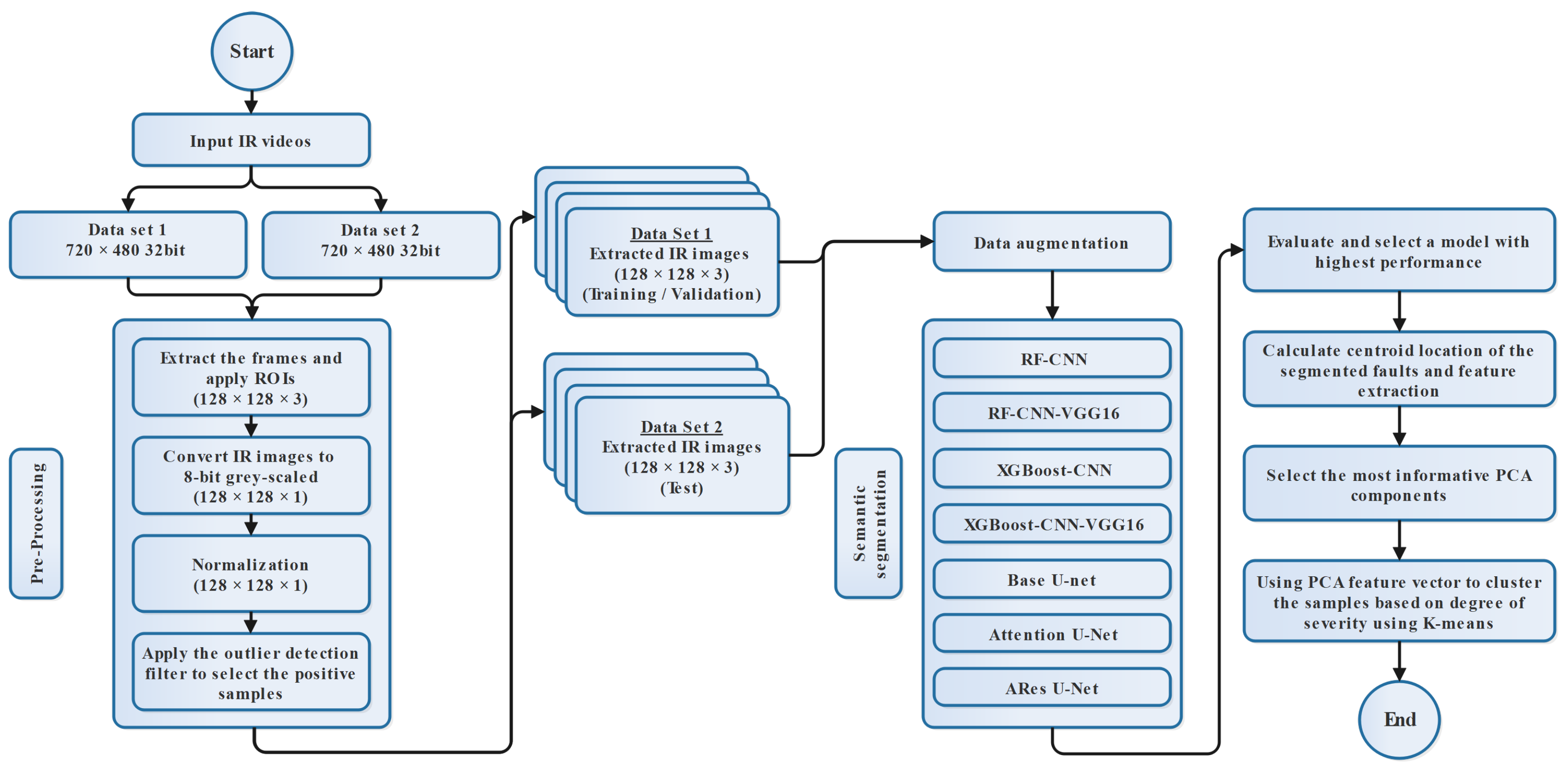
3. Proposed Methodology
3.1. Pre-Processing
3.2. Handling the Class Imbalance Problem Using an Outlier Detection Filter
3.3. Data Augmentation
3.4. Efficient Image Feature Extraction Using CNN and Transfer Learning Approach
- Input layerIn the input layer, the image is entered into the CNN architecture. In examples where the initial model has been trained on samples with different dimensions, to take advantage of the transfer learning approach, the input images need to be reshaped to match the pre-trained CNN architecture input dimensions.In our case, to reshape the dimension of the input images, we first reduce the number of image channels from three (RGB) to one (grayscale). However, to take advantage of the pre-trained VGG16 architecture without the need to transform the 8-bit grayscale images into color ones, we create two new dimensions and repeat the image array. As long as we have the same image over all three channels, the performance of the model should be the same as when it was initially trained on RGB images.
- Convolution layerIn the convolutional layer, the convolutional filter, also called the kernel, is defined as a matrix that passes over the input sample to generate feature maps. The generated feature maps in the convolutional layer accentuate the special features of the input image. Convolution is a linear operation that is used in different domains, such as image processing, statistics, and physics.A mathematical operation called a convolutional can be defined by sliding the kernel matrix over the input sample’s matrix. The element-wise matrix multiplication should be performed at every pixel to sum the result and represent it in a feature map.To perform feature map extraction in RGB images, usually, multiple 2D convolutional filters are employed in CNN architectures. The feature in this process is extracted by computing the 2D convolutional filter from the input sample channels.Considering an RGB sample (three channels), the size of the input image can be defined as , where 2D convolutional kernels of size are available in the first 2D convolutional layer. Therefore, the first 2D convolutional layer can generate the feature maps of size × . Each feature map is calculated based on computation of the dot product between the weight matrix, which is defined by , and the local area position and the neuron value at position in the jth layer, as follows:In Equation (3), defines the activation function of the ith layer, while is an additive bias of the jth feature map at the ith layer. Moreover, variable m indexes the connection between the feature map in the th layer and the current jth feature map. Moreover, and refer to the height and width of the 2D convolutional kernel, respectively. The variable is the weight for input with an offset of in the 2D convolutional kernel [54,55].
- Activation functionThe activation function is a component that takes place after the convolutional layer. The generated feature maps in the convolutional filter layer should be processed through the activation function before the layer generates the output feature maps. The rectified linear unit (ReLU) activation function is a common activation function that can be defined as a piecewise linear function that will output the input signal if it is positive; otherwise, it will generate a zero value.
- Pooling layerTo reduce the dimensions of the image, the pooling layer is responsible for combining the neighboring pixels into a single pixel and retrieving the optimal features of the input tensor. Down-sampling might be performed after the activation layer.
3.4.1. CNN Model with Random Weights
3.4.2. VGG-16 Model with Transfer Learning
3.5. CNN Fusion with RF and XGBoost
Classification Methods
3.6. A PCA-K-Means Approach for Clustering the Segmented Thermal Anomalies
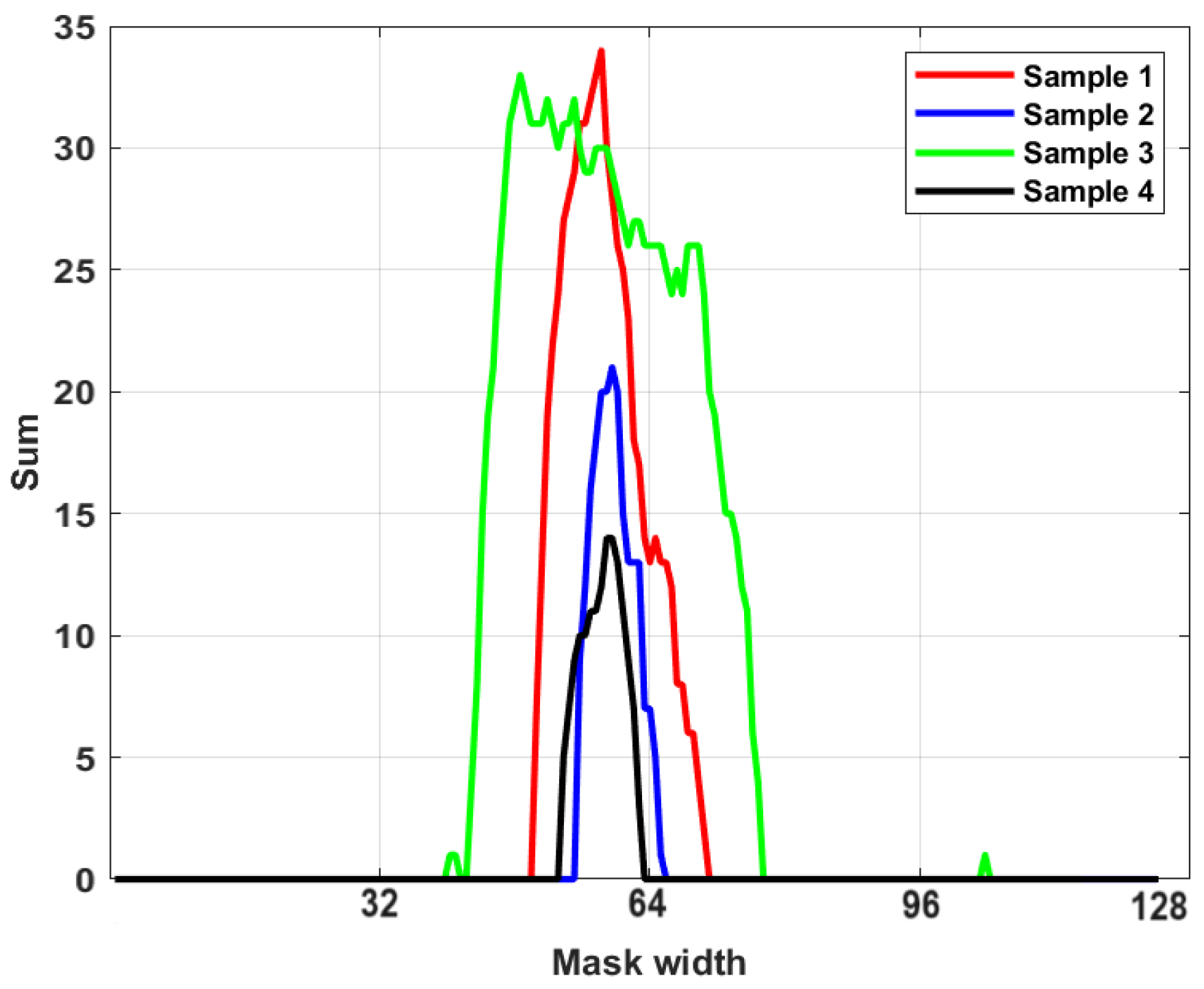
3.6.1. Centroid Calculation of Binary Masks
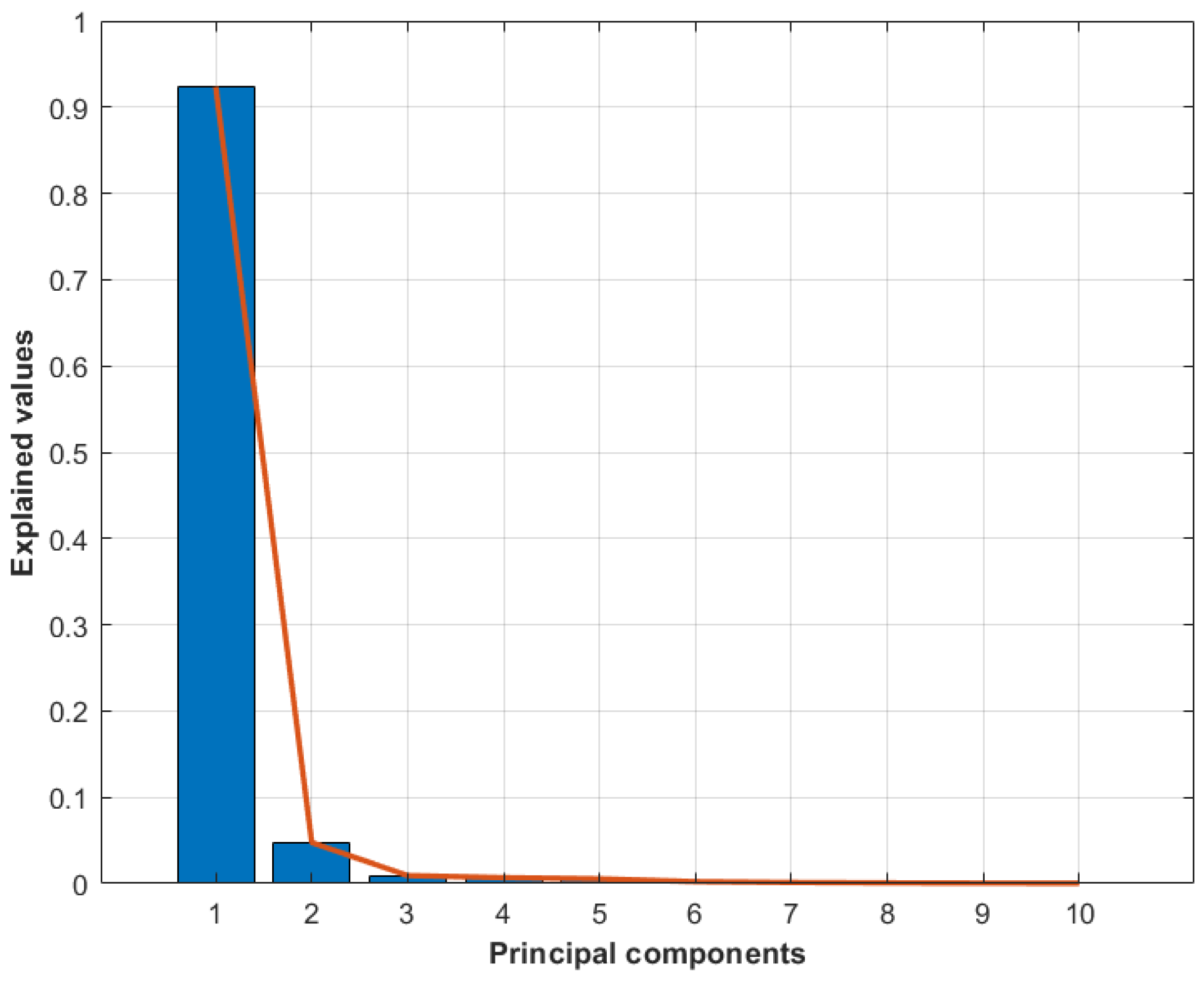
3.6.2. PCA Method
3.6.3. K-Means Method
4. Evaluation Metrics
5. Results and Discussion
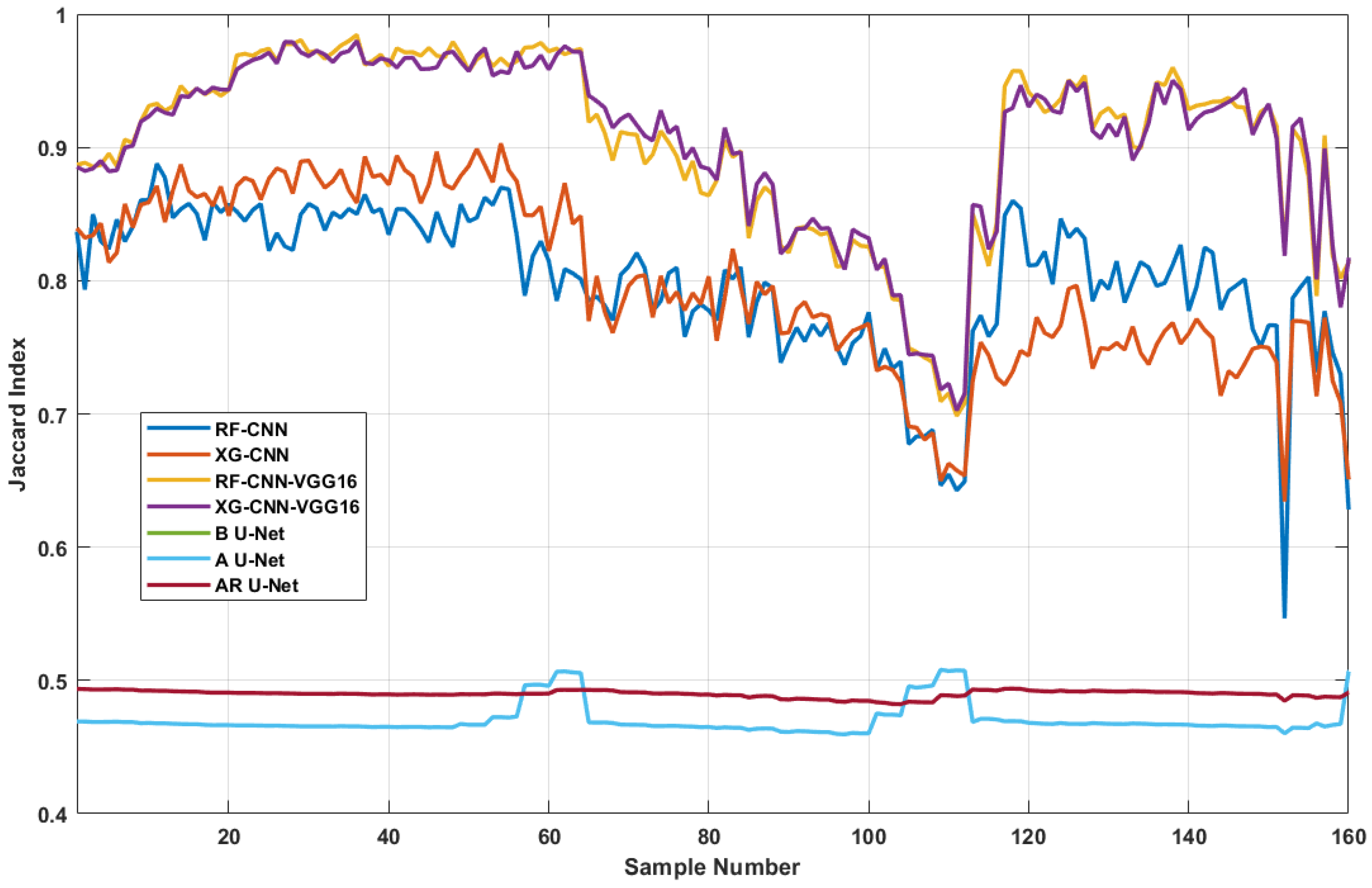
5.1. Semantic Segmentation Models
5.2. Fault Clustering Model
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Dabek, P.; Szrek, J.; Zimroz, R.; Wodecki, J. An Automatic Procedure for Overheated Idler Detection in Belt Conveyors Using Fusion of Infrared and RGB Images Acquired during UGV Robot Inspection. Energies 2022, 15, 601. [Google Scholar] [CrossRef]
- Szrek, J.; Jakubiak, J.; Zimroz, R. A Mobile Robot-Based System for Automatic Inspection of Belt Conveyors in Mining Industry. Energies 2022, 15, 327. [Google Scholar] [CrossRef]
- Topolsky, D.; Topolskaya, I.; Plaksina, I.; Shaburov, P.; Yumagulov, N.; Fedorov, D.; Zvereva, E. Development of a Mobile Robot for Mine Exploration. Processes 2022, 10, 865. [Google Scholar] [CrossRef]
- Rahman, M.; Liu, H.; Masri, M.; Durazo-Cardenas, I.; Starr, A. A railway track reconstruction method using robotic vision on a mobile manipulator: A proposed strategy. Comput. Ind. 2023, 148, 103900. [Google Scholar] [CrossRef]
- Da Silva Santos, K.R.; de Oliveira, W.R.; Villani, E.; Dttmann, A. 3D scanning method for robotized inspection of industrial sealed parts. Comput. Ind. 2023, 147, 103850. [Google Scholar] [CrossRef]
- Wodecki, J.; Shiri, H.; Siami, M.; Zimroz, R. Acoustic-based diagnostics of belt conveyor idlers in real-life mining conditions by mobile inspection robot. In Proceedings of the Conference on Noise and Vibration Engineering, ISMA, Leuven, Belgium, 12–14 September 2022. [Google Scholar]
- Shiri, H.; Wodecki, J.; Ziętek, B.; Zimroz, R. Inspection Robotic UGV Platform and the Procedure for an Acoustic Signal-Based Fault Detection in Belt Conveyor Idler. Energies 2021, 14, 7646. [Google Scholar] [CrossRef]
- Bortnowski, P.; Gondek, H.; Król, R.; Marasova, D.; Ozdoba, M. Detection of Blockages of the Belt Conveyor Transfer Point Using an RGB Camera and CNN Autoencoder. Energies 2023, 16, 1666. [Google Scholar] [CrossRef]
- Dabek, P.; Krot, P.; Wodecki, J.; Zimroz, P.; Szrek, J.; Zimroz, R. Rotation speed assessment for idlers in belt conveyors using image analysis. Proc. IOP Conf. Ser. Earth Environ. Sci. 2023, 1189, 012006. [Google Scholar] [CrossRef]
- Zimroz, R.; Hardygóra, M.; Blazej, R. Maintenance of Belt Conveyor Systems in Poland—An Overview. In Proceedings of the 12th International Symposium Continuous Surface Mining-Aachen 2014; Niemann-Delius, C., Ed.; Springer International Publishing: Cham, Switzerland, 2015; pp. 21–30. [Google Scholar] [CrossRef]
- Bołoz, Ł.; Biały, W. Automation and Robotization of Underground Mining in Poland. Appl. Sci. 2020, 10, 7221. [Google Scholar] [CrossRef]
- Trybała, P.; Blachowski, J.; Błażej, R.; Zimroz, R. Damage detection based on 3d point cloud data processing from laser scanning of conveyor belt surface. Remote Sens. 2021, 13, 55. [Google Scholar] [CrossRef]
- Błażej, R.; Kirjanów, A.; Kozłowski, T. A high resolution system for automatic diagnosing the condition of the core of conveyor belts with steel cords. Diagnostyka 2014, 15, 41–45. [Google Scholar]
- Zimroz, R.; Król, R. Failure analysis of belt conveyor systems for condition monitoring purposes. Min. Sci. 2009, 128, 255–270. [Google Scholar]
- Dąbek, P.; Krot, P.; Wodecki, J.; Zimroz, P.; Szrek, J.; Zimroz, R. Measurement of idlers rotation speed in belt conveyors based on image data analysis for diagnostic purposes. Measurement 2022, 202, 111869. [Google Scholar] [CrossRef]
- Bortnowski, P.; Król, R.; Nowak-Szpak, A.; Ozdoba, M. A Preliminary Studies of the Impact of a Conveyor Belt on the Noise Emission. Sustainability 2022, 14, 2785. [Google Scholar] [CrossRef]
- Siami, M.; Barszcz, T.; Wodecki, J.; Zimroz, R. Semantic segmentation of thermal defects in belt conveyor idlers using thermal image augmentation and U-Net-based convolutional neural networks. Sci. Rep. 2024, 14, 5748. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention—MICCAI 2015, Munich, Germany, 5–9 October 2015; Navab, N., Hornegger, J., Wells, W.M., Frangi, A.F., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Scheding, S.; Dissanayake, G.; Nebot, E.M.; Durrant-Whyte, H. An experiment in autonomous navigation of an underground mining vehicle. IEEE Trans. Robot. Autom. 1999, 15, 85–95. [Google Scholar] [CrossRef]
- Grehl, S.; Donner, M.; Ferber, M.; Dietze, A.; Mischo, H.; Jung, B. Mining-rox—Mobile robots in underground mining. In Proceedings of the Third International Future Mining Conference, Sydney, Australia, 4–6 November 2015; pp. 4–6. [Google Scholar]
- Król, R.; Kisielewski, W. Research of loading carrying idlers used in belt conveyor-practical applications. Diagnostyka 2014, 15, 67–74. [Google Scholar]
- Peruń, G.; Opasiak, T. Assessment of technical state of the belt conveyor rollers with use vibroacoustics methods—Preliminary studies. Diagnostyka 2016, 17, 75–81. [Google Scholar]
- Gładysiewicz, L.; Król, R.; Kisielewski, W. Measurements of loads on belt conveyor idlers operated in real conditions. Meas. J. Int. Meas. Confed. 2019, 134, 336–344. [Google Scholar] [CrossRef]
- ISO 15243; Rolling Bearings—Damage and Failures—Terms, Characteristics and Causes. International Organization for Standardization: Geneva, Switzerland, 2017.
- Upadhyay, R.; Kumaraswamidhas, L.; Azam, M. Rolling element bearing failure analysis: A case study. Case Stud. Eng. Fail. Anal. 2013, 1, 15–17. [Google Scholar] [CrossRef]
- Vencl, A.; Gašić, V.; Stojanović, B. Fault tree analysis of most common rolling bearing tribological failures. Proc. IOP Conf. Ser. Mater. Sci. Eng. 2017, 174, 012048. [Google Scholar] [CrossRef]
- Tanasijevi, S. Basic Tribology of Machine Elements; Scientific Book: Belgrade, Serbia, 1989. [Google Scholar]
- Vasić, M.; Stojanović, B.; Blagojević, M. Failure analysis of idler roller bearings in belt conveyors. Eng. Fail. Anal. 2020, 117, 104898. [Google Scholar] [CrossRef]
- Hurley, T.J. Infrared qualitative and quantitative inspections for electric utilities. In Proceedings of the Thermosense XII: An International Conference on Thermal Sensing and Imaging Diagnostic Applications, Orlando, FL, USA, 18–20 April 1990; Semanovich, S.A., Ed.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 1990; Volume 1313, pp. 6–24. [Google Scholar] [CrossRef]
- Griffith, B.; Türler, D.; Goudey, H. IR Thermographic Systems: A Review of IR Imagers and Their Use; Lawrence Berkeley National Laboratory: Berkeley, CA, USA, 2001.
- Wurzbach, R.N.; Hammaker, R.G. Role of comparative and qualitative thermography in predictive maintenance. In Proceedings of the Thermosense XIV: An International Conference on Thermal Sensing and Imaging Diagnostic Applications, Orlando, FL, USA, 22–24 April 1992; SPIE: Bellingham, WA, USA, 1992; Volume 1682, pp. 3–11. [Google Scholar]
- Jadin, M.S.; Taib, S.; Kabir, S.; Yusof, M.A.B. Image processing methods for evaluating infrared thermographic image of electrical equipments. In Proceedings of the Progress in Electromagnetics Research Symposium, Marrakesh, Morocco, 20–23 March 2011. [Google Scholar]
- Farrar, C.R.; Worden, K. An introduction to structural health monitoring. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2007, 365, 303–315. [Google Scholar] [CrossRef] [PubMed]
- Szrek, J.; Wodecki, J.; Błazej, R.; Zimroz, R. An inspection robot for belt conveyor maintenance in underground mine-infrared thermography for overheated idlers detection. Appl. Sci. 2020, 10, 4984. [Google Scholar] [CrossRef]
- Siami, M.; Barszcz, T.; Wodecki, J.; Zimroz, R. Design of an Infrared Image Processing Pipeline for Robotic Inspection of Conveyor Systems in Opencast Mining Sites. Energies 2022, 15, 6771. [Google Scholar] [CrossRef]
- Tsanakas, J.A.; Botsaris, P.N. An infrared thermographic approach as a hot-spot detection tool for photovoltaic modules using image histogram and line profile analysis. Int. J. Cond. Monit. 2012, 2, 22–30. [Google Scholar] [CrossRef]
- Ahmad, J.; Farman, H.; Jan, Z. Deep Learning Methods and Applications. In Deep Learning: Convergence to Big Data Analytics; Springer: Singapore, 2019; pp. 31–42. [Google Scholar] [CrossRef]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A.S. A survey of the recent architectures of deep convolutional neural networks. Artif. Intell. Rev. 2020, 53, 5455–5516. [Google Scholar]
- Rao, A.S.; Nguyen, T.; Palaniswami, M.; Ngo, T. Vision-based automated crack detection using convolutional neural networks for condition assessment of infrastructure. Struct. Health Monit. 2021, 20, 2124–2142. [Google Scholar] [CrossRef]
- Siami, M.; Barszcz, T.; Wodecki, J.; Zimroz, R. Automated Identification of Overheated Belt Conveyor Idlers in Thermal Images with Complex Backgrounds Using Binary Classification with CNN. Sensors 2022, 22, 10004. [Google Scholar] [CrossRef]
- Herraiz, H.Á.; Pliego Marugán, A.; García Márquez, F.P. Photovoltaic plant condition monitoring using thermal images analysis by convolutional neural network-based structure. Renew. Energy 2020, 153, 334–348. [Google Scholar] [CrossRef]
- Rahman, M.; Cao, Y.; Sun, X.; Li, B.; Hao, Y. Deep pre-trained networks as a feature extractor with XGBoost to detect tuberculosis from chest X-ray. Comput. Electr. Eng. 2021, 93, 107252. [Google Scholar] [CrossRef]
- Pedrayes, O.D.; Lema, D.G.; Usamentiaga, R.; Venegas, P.; García, D.F. Semantic segmentation for non-destructive testing with step-heating thermography for composite laminates. Measurement 2022, 200, 111653. [Google Scholar] [CrossRef]
- Pozzer, S.; Azar, E.R.; Rosa, F.D.; Pravia, Z.M.C. Semantic Segmentation of Defects in Infrared Thermographic Images of Highly Damaged Concrete Structures. J. Perform. Constr. Facil. 2021, 35, 04020131. [Google Scholar] [CrossRef]
- Geng, L.; Zhang, S.; Tong, J.; Xiao, Z. Lung segmentation method with dilated convolution based on VGG-16 network. Comput. Assist. Surg. 2019, 24, 27–33. [Google Scholar] [CrossRef] [PubMed]
- Gonzalez, R.C.; Woods, R.E. Digital Image Processing, 3rd ed.; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2006. [Google Scholar]
- Leevy, J.L.; Khoshgoftaar, T.M.; Bauder, R.A.; Seliya, N. A survey on addressing high-class imbalance in big data. J. Big Data 2018, 5, 42. [Google Scholar] [CrossRef]
- Masko, D.; Hensman, P. The Impact of Imbalanced Training Data for Convolutional Neural Networks. In Proceedings of the International Conference on Hybrid Artificial Intelligence Systems, Bilbao, Spain, 22–24 June 2015. [Google Scholar]
- Lee, H.; Park, M.; Kim, J. Plankton classification on imbalanced large scale database via convolutional neural networks with transfer learning. In Proceedings of the 2016 IEEE International Conference on Image Processing (ICIP), Phoenix, AZ, USA, 25–28 September 2016; pp. 3713–3717. [Google Scholar] [CrossRef]
- Jumaboev, S.; Jurakuziev, D.; Lee, M. Photovoltaics Plant Fault Detection Using Deep Learning Techniques. Remote Sens. 2022, 14, 3728. [Google Scholar] [CrossRef]
- Moutik, O.; Sekkat, H.; Tigani, S.; Chehri, A.; Saadane, R.; Tchakoucht, T.A.; Paul, A. Convolutional Neural Networks or Vision Transformers: Who Will Win the Race for Action Recognitions in Visual Data? Sensors 2023, 23, 734. [Google Scholar] [CrossRef] [PubMed]
- Mazzini, D.; Napoletano, P.; Piccoli, F.; Schettini, R. A Novel Approach to Data Augmentation for Pavement Distress Segmentation. Comput. Ind. 2020, 121, 103225. [Google Scholar] [CrossRef]
- Ma, J.; Sun, D.W.; Pu, H. Model improvement for predicting moisture content (MC) in pork longissimus dorsi muscles under diverse processing conditions by hyperspectral imaging. J. Food Eng. 2017, 196, 65–72. [Google Scholar] [CrossRef]
- Liu, Y.; Pu, H.; Sun, D.W. Efficient extraction of deep image features using convolutional neural network (CNN) for applications in detecting and analysing complex food matrices. Trends Food Sci. Technol. 2021, 113, 193–204. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Dong, L.; Du, H.; Mao, F.; Han, N.; Li, X.; Zhou, G.; Zhu, D.; Zheng, J.; Zhang, M.; Xing, L.; et al. Very High Resolution Remote Sensing Imagery Classification Using a Fusion of Random Forest and Deep Learning Technique—Subtropical Area for Example. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 113–128. [Google Scholar] [CrossRef]
- Khozeimeh, F.; Sharifrazi, D.; Izadi, N.H.; Joloudari, J.H.; Shoeibi, A.; Alizadehsani, R.; Tartibi, M.; Hussain, S.; Sani, Z.A.; Khodatars, M.; et al. RF-CNN-F: Random forest with convolutional neural network features for coronary artery disease diagnosis based on cardiac magnetic resonance. Sci. Rep. 2022, 12, 11178. [Google Scholar] [CrossRef] [PubMed]
- Ranjbarzadeh, R.; Bagherian Kasgari, A.; Jafarzadeh Ghoushchi, S.; Anari, S.; Naseri, M.; Bendechache, M. Brain tumor segmentation based on deep learning and an attention mechanism using MRI multi-modalities brain images. Sci. Rep. 2021, 11, 10930. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Yang, B. Big Data Dimension Reduction Using PCA. In Proceedings of the 2016 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 18–20 November 2016; pp. 152–157. [Google Scholar] [CrossRef]
- Yang, W.; Zhao, Y.; Wang, D.; Wu, H.; Lin, A.; He, L. Using principal components analysis and IDW interpolation to determine spatial and temporal changes of surface water quality of Xin’anjiang river in Huangshan, China. Int. J. Environ. Res. Public Health 2020, 17, 2942. [Google Scholar] [CrossRef] [PubMed]
- Belkhiri, L.; Narany, T.S. Using multivariate statistical analysis, geostatistical techniques and structural equation modeling to identify spatial variability of groundwater quality. Water Resour. Manag. 2015, 29, 2073–2089. [Google Scholar] [CrossRef]
- Chen, J.; Lu, L.; Lu, J.; Luo, Y. An early-warning system for shipping market crisis using climate index. J. Coast. Res. 2015, 73, 620–627. [Google Scholar] [CrossRef]
- Zhu, C.; Idemudia, C.U.; Feng, W. Improved logistic regression model for diabetes prediction by integrating PCA and K-means techniques. Inform. Med. Unlocked 2019, 17, 100179. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2015; pp. 3431–3440. [Google Scholar]
- Hurtado, J.V.; Valada, A. Chapter 12—Semantic scene segmentation for robotics. In Deep Learning for Robot Perception and Cognition; Iosifidis, A., Tefas, A., Eds.; Academic Press: Cambridge, MA, USA, 2022; pp. 279–311. [Google Scholar]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Jin, Q.; Meng, Z.; Sun, C.; Cui, H.; Su, R. RA-UNet: A hybrid deep attention-aware network to extract liver and tumor in CT scans. Front. Bioeng. Biotechnol. 2020, 8, 605132. [Google Scholar] [CrossRef] [PubMed]
- Abraham, J.B. Malaria parasite segmentation using U-Net: Comparative study of loss functions. Commun. Sci. Technol. 2019, 4, 57–62. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset 1 | Dataset 2 | |
|---|---|---|
| Total number of extracted frames | 6135 | 6135 |
| Number of inspected idlers | 130 | 130 |
| Percentage of positive cases | 5.21% | 6.67% |
| Percentage of negative cases | 94.78% | 93.32% |
| Model | Hyperparameters | Meaning | Values |
|---|---|---|---|
| RF | Number of trees used in the forest | 50 | |
| Number of random variables used in each tree | 42 | ||
| XGBoost | Learning rate | Shrinkage coefficient of each tree | 0.3 |
| Maximum tree depth | Maximum depth of a tree | 6 | |
| Subsample ratio | Subsample ratio of training samples | 1 | |
| Column subsample ratio | Subsample ratio of columns for tree construction | 1 | |
| Maximum delta step | Maximum depth of a tree | 0 | |
| Gamma | Minimum loss reduction required to make a further partition | 0 |
| Model | Epochs | Trainable Parameters | Training Time | Mean Jaccard Index | |
|---|---|---|---|---|---|
| Validation-BC 1 (FW) | Test Set-BC 1 (BW) | ||||
| RF-CNN | - | - | 429 s | 0.8025 | 0.7974 |
| XGBoost-CNN | - | - | 10 s | 0.8026 | 0.7953 |
| RF-CNN-VGG16 | - | - | 270 s | 0.9439 | 0.9054 |
| XGBoost-CNN-VGG16 | - | - | 13 s | 0.9364 | 0.9052 |
| Base U-Net | 20 | 31 M | 80 s | 0.4615 | 0.4899 |
| Attention U-Net | 20 | 37 M | 102 s | 0.4764 | 0.4708 |
| ARes U-Net | 20 | 39 M | 118 s | 0.5002 | 0.4899 |
| Model | Mean | Median | Minimum | Standard Deviation |
|---|---|---|---|---|
| RF-CNN | 0.7975 | 0.8079 | 0.5466 | 0.0577 |
| XGBoost-CNN | 0.7954 | 0.7833 | 0.6343 | 0.0667 |
| RF-CNN-VGG16 | 0.9054 | 0.9263 | 0.6985 | 0.0668 |
| XGBoost-CNN-VGG16 | 0.9053 | 0.9232 | 0.7026 | 0.0639 |
| Base U-Net | 0.4899 | 0.4901 | 0.4822 | 0.0026 |
| Attention U-Net | 0.4709 | 0.4667 | 0.4596 | 0.0123 |
| ARes U-Net | 0.4899 | 0.4901 | 0.4822 | 0.0026 |
| Studied Case | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | Accuracy |
|---|---|---|---|---|---|---|
| Faulty Idler 1 | 0% | 21.27% | 77.65% | 0% | 0% | 77.65% |
| Faulty Idler 2 | 0% | 87.87% | 0% | 14.12% | 0% | 87.87% |
| Faulty Idler 3 | 0% | 29.63% | 0% | 70.37% | 0% | 70.37% |
| Faulty Idler 4 | 0% | 0% | 0% | 0% | 100% | 100% |
| Healthy Idlers | 100% | 0% | 0% | 0% | 0% | 100% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Siami, M.; Barszcz, T.; Zimroz, R. Advanced Image Analytics for Mobile Robot-Based Condition Monitoring in Hazardous Environments: A Comprehensive Thermal Defect Processing Framework. Sensors 2024, 24, 3421. https://doi.org/10.3390/s24113421
Siami M, Barszcz T, Zimroz R. Advanced Image Analytics for Mobile Robot-Based Condition Monitoring in Hazardous Environments: A Comprehensive Thermal Defect Processing Framework. Sensors. 2024; 24(11):3421. https://doi.org/10.3390/s24113421
Chicago/Turabian StyleSiami, Mohammad, Tomasz Barszcz, and Radoslaw Zimroz. 2024. "Advanced Image Analytics for Mobile Robot-Based Condition Monitoring in Hazardous Environments: A Comprehensive Thermal Defect Processing Framework" Sensors 24, no. 11: 3421. https://doi.org/10.3390/s24113421
APA StyleSiami, M., Barszcz, T., & Zimroz, R. (2024). Advanced Image Analytics for Mobile Robot-Based Condition Monitoring in Hazardous Environments: A Comprehensive Thermal Defect Processing Framework. Sensors, 24(11), 3421. https://doi.org/10.3390/s24113421