

Simultaneous Determination of Four Catechins in Black Tea via NIR Spectroscopy and Feature Wavelength Selection: A Novel Approach
Abstract
1. Introduction
2. Materials and Methods
2.1. Black Tea Sample Preparation
2.2. NIR Spectra Acquisition
2.3. Determination of Catechins and Caffeine Content by HPLC
2.4. Establishment of Quantitative Prediction Models
2.4.1. Competitive Adaptive Reweighted Sampling
2.4.2. Monte Carlo Uninformative Variable Elimination
2.4.3. Successive Projection Algorithm
2.4.4. Feature Interval Combination Sensitivity Segmentation
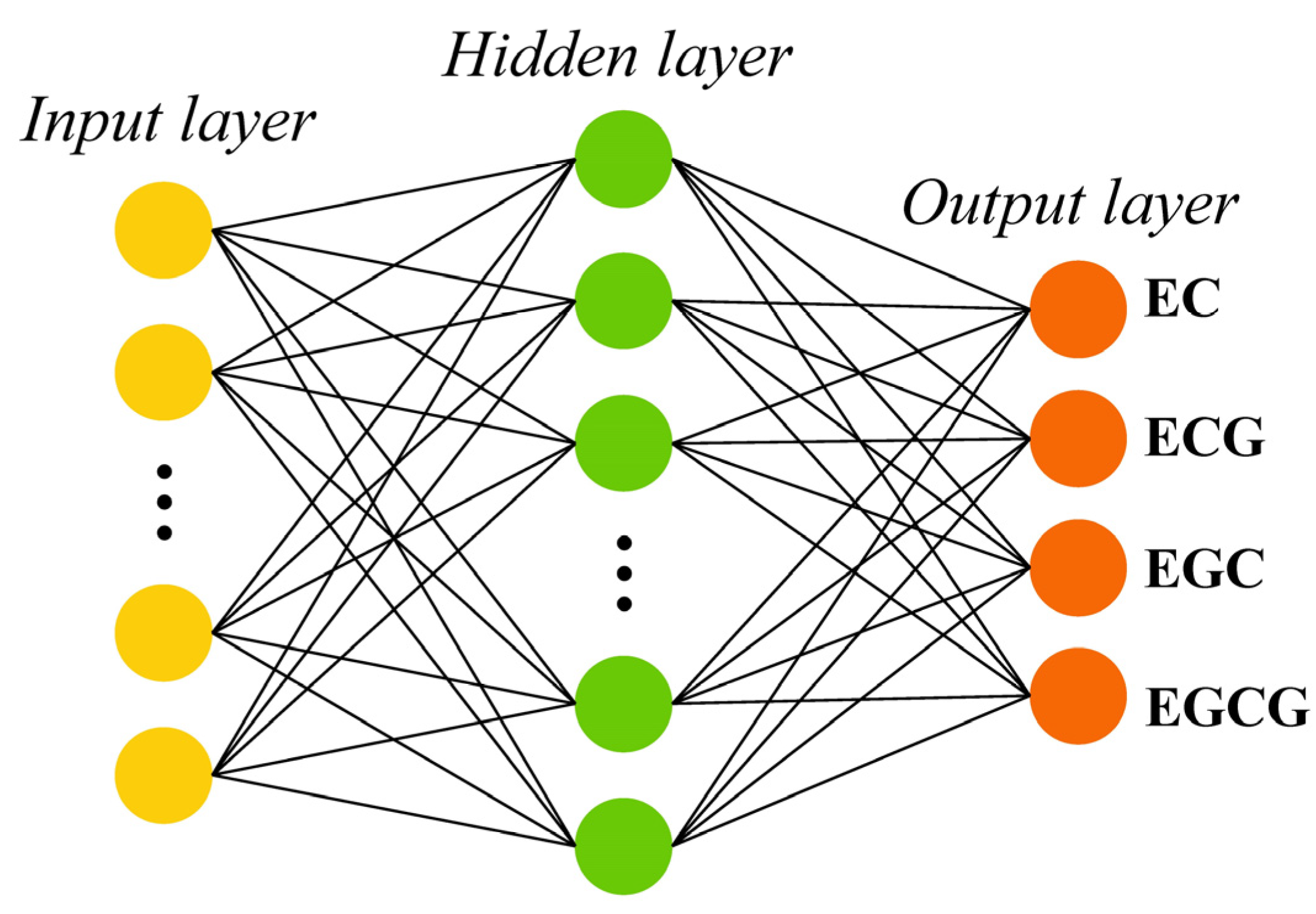
2.4.5. Extreme Learning Machine
2.5. Performance Evaluation
3. Results and Discussion
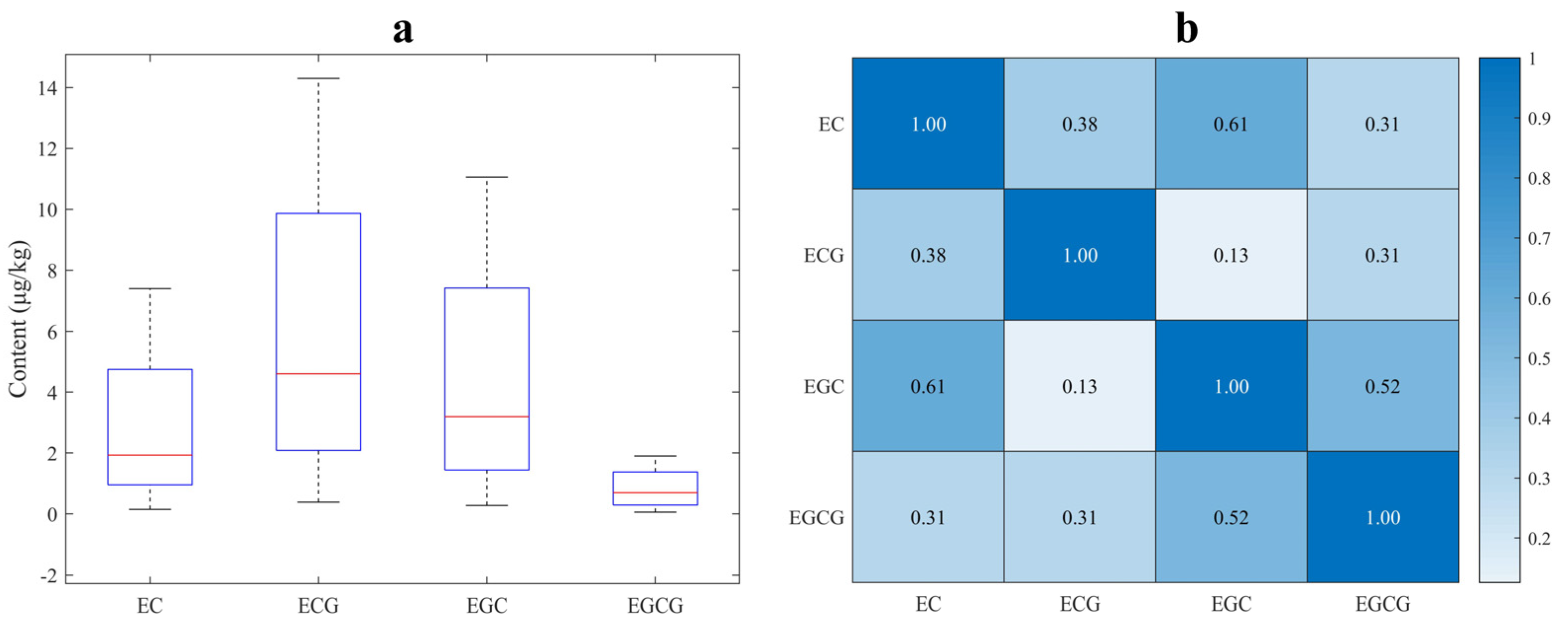
3.1. Descriptive Statistics of Measured Catechins
3.2. NIR Spectroscopy Analysis of Black Tea Samples
3.3. Performance of Prediction Models Based on Full Spectra
3.4. Performance of Prediction Models Based on Feature Wavelengths
3.4.1. FIC-SS-ELM
3.4.2. MC-UVE-ELM
3.4.3. SPA-ELM
3.4.4. CARS-ELM
3.5. Model Comparison and Discussion
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Wang, J.H.; Wang, Y.F.; Cheng, J.J.; Wang, J.; Sun, X.D.; Sun, S.; Zhang, Z.Y. Enhanced cross-category models for predicting the total polyphenols, caffeine and free amino acids contents in Chinese tea using NIR spectroscopy. LWT 2018, 96, 90–97. [Google Scholar] [CrossRef]
- Huang, J.; Ren, G.; Sun, Y.; Jin, S.; Li, L.; Wang, Y.; Ning, J.; Zhang, Z. Qualitative discrimination of Chinese dianhong black tea grades based on a handheld spectroscopy system coupled with chemometrics. Food Sci. Nutr. 2020, 8, 2015–2024. [Google Scholar] [CrossRef] [PubMed]
- Firmani, P.; De Luca, S.; Bucci, R.; Marini, F.; Biancolillo, A. Near infrared (NIR) spectroscopy-based classification for the authentication of Darjeeling black tea. Food Control 2019, 100, 292–299. [Google Scholar] [CrossRef]
- Ignasimuthu, K.; Prakash, R.; Murthy, P.S.; Subban, N. Enhanced bioaccessibility of green tea polyphenols and lipophilic activity of EGCG octaacetate on gram-negative bacteria. LWT 2019, 105, 103–109. [Google Scholar] [CrossRef]
- Jain, S.; Popli, H.; Aggarwal, G.; Gupta, M. Green tea—An antioxidant mystic herb. PharmaTutor 2018, 6, 23–31. [Google Scholar] [CrossRef]
- Yan, X.; Xie, Y.; Chen, J.; Yuan, T.; Leng, T.; Chen, Y.; Xie, J.; Yu, Q. NIR Spectrometric Approach for Geographical Origin Identification and Taste Related Compounds Content Prediction of Lushan Yunwu Tea. Foods 2022, 11, 2976. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Li, T.; Li, L.; Ning, J.; Zhang, Z. Evaluating taste-related attributes of black tea by micro-NIRS. J. Food Eng. 2021, 290, 110181. [Google Scholar] [CrossRef]
- Wang, Y.J.; Li, T.H.; Li, L.Q.; Ning, J.M.; Zhang, Z.Z. Micro-NIR spectrometer for quality assessment of tea: Comparison of local and global models. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2020, 237, 118403. [Google Scholar] [CrossRef]
- El-Shahawi, M.S.; Hamza, A.; Bahaffi, S.O.; Al-Sibaai, A.A.; Abduljabbar, T.N. Analysis of some selected catechins and caffeine in green tea by high performance liquid chromatography. Food Chem. 2012, 134, 2268–2275. [Google Scholar] [CrossRef]
- Ning, J.; Li, D.; Luo, X.; Ding, D.; Song, Y.; Zhang, Z.; Wan, X. Stepwise identification of six tea (Camellia sinensis (L.)) categories based on catechins, caffeine, and theanine contents combined with fisher discriminant analysis. Food Anal. Methods 2016, 9, 3242–3250. [Google Scholar] [CrossRef]
- Wang, Y.; Li, M.; Li, L.; Ning, J.; Zhang, Z. Green analytical assay for the quality assessment of tea by using pocket-sized NIR spectrometer. Food Chem. 2021, 345, 128816. [Google Scholar] [CrossRef]
- Jia, J.M.; Zhou, X.F.; Li, Y.; Wang, M.; Liu, Z.Y.; Dong, C.W. Establishment of a rapid detection model for the sensory quality and components of Yuezhou Longjing tea using near-infrared spectroscopy. LWT 2022, 164, 113625. [Google Scholar] [CrossRef]
- Liew, O.W.; Chong, P.C.J.; Li, B.; Asundi, A.K. Signature optical cues: Emerging technologies for monitoring plant health. Sensors 2008, 8, 3205–3239. [Google Scholar] [CrossRef] [PubMed]
- Chen, Q.; Chen, M.; Liu, Y.; Wu, J.; Wang, X.; Ouyang, Q.; Chen, X. Application of FT-NIR spectroscopy for simultaneous estimation of taste quality and taste-related compounds content of black tea. J. Food Sci. Technol. 2018, 55, 4363–4368. [Google Scholar] [CrossRef]
- Chen, Y.; Deng, J.; Wang, Y.; Liu, B.; Ding, J.; Mao, X.; Zhang, J.; Hu, H.; Li, J. Study on discrimination of white tea and albino tea based on near-infrared spectroscopy and chemometrics. J. Sci. Food Agric. 2014, 94, 1026–1033. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Yan, Y.; Li, J.; Chen, X.; Jiang, H. Classification of tea quality levels using near-infrared spectroscopy based on CLPSO-SVM. Foods 2022, 11, 1658. [Google Scholar] [CrossRef]
- Luo, W.; Tian, P.; Fan, G.; Dong, W.; Zhang, H.; Liu, X. Non-destructive determination of four tea polyphenols in fresh tea using visible and near-infrared spectroscopy. Infrared Phys. Technol. 2022, 123, 104037. [Google Scholar] [CrossRef]
- Li, L.; Sheng, X.; Zan, J.; Yuan, H.; Zong, X.; Jiang, Y. Monitoring the dynamic change of catechins in black tea drying by using near-infrared spectroscopy and chemometrics. J. Food Compos. Anal. 2023, 119, 105266. [Google Scholar] [CrossRef]
- Zou, H.; Shen, S.; Lan, T.; Sheng, X.; Zan, J.; Jiang, Y.; Du, Q.; Yuan, H. Prediction Method of the Moisture Content of Black Tea during Processing Based on the Miniaturized Near-Infrared Spectrometer. Horticulturae 2022, 8, 1170. [Google Scholar] [CrossRef]
- Chen, S.; Wang, C.Y.; Tsai, C.Y.; Yang, I.C.; Luo, S.J.; Chuang, Y.K. Fermentation quality evaluation of tea by estimating total catechins and theanine using near-infrared spectroscopy. Vib. Spectrosc. 2021, 115, 103278. [Google Scholar] [CrossRef]
- Liu, Z.; Xie, H.-l.; Chen, L.; Huang, J.-h. An Improved Weighted Partial Least Squares Method Coupled with Near Infrared Spectroscopy for Rapid Determination of Multiple Components and Anti-Oxidant Activity of Pu-Erh Tea. Molecules 2018, 23, 1058. [Google Scholar] [CrossRef] [PubMed]
- Ong, P.; Jian, J.; Li, X.; Yin, J.; Ma, G. Visible and near-infrared spectroscopic determination of sugarcane chlorophyll content using a modified wavelength selection method for multivariate calibration. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2024, 305, 123477. [Google Scholar] [CrossRef] [PubMed]
- Ren, G.; Ning, J.; Zhang, Z. Multi-variable selection strategy based on near-infrared spectra for the rapid description of dianhong black tea quality. Spectrochim. Acta A Mol. Biomol. Spectrosc. 2021, 245, 118918. [Google Scholar] [CrossRef] [PubMed]
- Li, C.; Zhao, T.; Li, C.; Mei, L.; Yu, E.; Dong, Y.; Zhu, S. Determination of gossypol content in cottonseeds by near infrared spectroscopy based on Monte Carlo uninformative variable elimination and nonlinear calibration methods. Food Chem. 2017, 221, 990–996. [Google Scholar] [CrossRef] [PubMed]
- Wang, S.; Feng, L.; Liu, P.; Gui, A.; Teng, J.; Ye, F.; Wang, X.; Xue, J.; Gao, S.; Zheng, P. Digital Prediction of the Purchase Price of Fresh Tea Leaves of Enshi Yulu Based on Near-Infrared Spectroscopy Combined with Multivariate Analysis. Foods 2023, 12, 3592. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Barimah, A.O.; Shujat, A.; Zhang, Z.; Ouyang, Q.; Shi, J.; Chen, Q. Simultaneous quantification of active constituents and antioxidant capability of green tea using NIR spectroscopy coupled with swarm intelligence algorithm. LWT 2020, 129, 109510. [Google Scholar] [CrossRef]
- Ur Rehman, N.; Al-Harrasi, A.; Boqué, R.; Mabood, F.; Al-Broumi, M.; Hussain, J.; Alameri, S. FT-NIRS Coupled with PLS Regression as a Complement to HPLC Routine Analysis of Caffeine in Tea Samples. Foods 2020, 9, 827. [Google Scholar] [CrossRef]
- Huang, G.B.; Zhu, Q.Y.; Siew, C.K. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Ren, G.; Zhang, X.; Wu, R.; Yin, L.; Hu, W.; Zhang, Z. Rapid Characterization of Black Tea Taste Quality Using Miniature NIR Spectroscopy and Electronic Tongue Sensors. Biosensors 2023, 13, 92. [Google Scholar] [CrossRef]
- Liu, P.; Zhu, X.; Hu, X.; Xiong, A.; Wen, J.; Li, H.; Wu, R. Local tangent space alignment and relevance vector machine as nonlinear methods for estimating sensory quality of tea using NIR spectroscopy. Vib. Spectrosc. 2019, 103, 102923. [Google Scholar] [CrossRef]
- Yun, Y.H.; Li, H.D.; Wood, L.R.; Fan, W.; Wang, J.J.; Cao, D.S.; Liang, Y.Z. An efficient method of wavelength interval selection based on random frog for multivariate spectral calibration. Spectrochim. Acta Part A Mol. Biomol. Spectrosc. 2013, 111, 31–36. [Google Scholar] [CrossRef] [PubMed]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | Catechin | Calibration Set | Prediction Set | |||
|---|---|---|---|---|---|---|
| RMSEC | RMSEP | RPD | ||||
| PLS | EC | 0.033 | 0.75 | 0.037 | 0.72 | 1.89 |
| ECG | 0.25 | 0.79 | 0.26 | 0.76 | 2.04 | |
| EGC | 0.32 | 0.84 | 0.34 | 0.83 | 2.43 | |
| EGCG | 0.76 | 0.78 | 0.82 | 0.77 | 2.09 | |
| ELM | EC | 0.027 | 0.82 | 0.024 | 0.81 | 2.29 |
| ECG | 0.18 | 0.88 | 0.21 | 0.85 | 2.58 | |
| EGC | 0.27 | 0.87 | 0.31 | 0.84 | 2.50 | |
| EGCG | 0.69 | 0.85 | 0.73 | 0.80 | 2.24 | |
| Catechins | Models | NFW | NWI | AWIW | RMSEP | RPD | |
|---|---|---|---|---|---|---|---|
| EC | FIC-SS-ELM | 212 | 13 | 16.31 | 0.91 | 0.019 | 3.33 |
| MC-UVE-ELM | 69 | 19 | 3.63 | 0.84 | 0.025 | 2.50 | |
| SPA-ELM | 325 | 6 | 54.17 | 0.85 | 0.023 | 2.58 | |
| CARS-ELM | 81 | 11 | 7.36 | 0.85 | 0.023 | 2.58 | |
| ECG | FIC-SS-ELM | 212 | 13 | 16.31 | 0.96 | 0.11 | 5.00 |
| MC-UVE-ELM | 69 | 19 | 3.63 | 0.93 | 0.14 | 3.78 | |
| SPA-ELM | 325 | 6 | 54.17 | 0.94 | 0.15 | 4.08 | |
| CARS-ELM | 81 | 11 | 7.36 | 0.94 | 0.15 | 4.08 | |
| EGC | FIC-SS-ELM | 212 | 13 | 16.31 | 0.97 | 0.15 | 5.77 |
| MC-UVE-ELM | 69 | 19 | 3.63 | 0.94 | 0.21 | 4.08 | |
| SPA-ELM | 325 | 6 | 54.17 | 0.93 | 0.21 | 3.78 | |
| CARS-ELM | 81 | 11 | 7.36 | 0.93 | 0.21 | 3.78 | |
| EGCG | FIC-SS-ELM | 212 | 13 | 16.31 | 0.97 | 0.35 | 5.77 |
| MC-UVE-ELM | 69 | 19 | 3.63 | 0.94 | 0.45 | 4.08 | |
| SPA-ELM | 325 | 6 | 54.17 | 0.92 | 0.53 | 3.54 | |
| CARS-ELM | 81 | 11 | 7.36 | 0.97 | 0.35 | 5.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, Y.; Pan, K.; Liu, Z.; Dai, Y.; Duan, X.; Wang, M.; Shen, Q. Simultaneous Determination of Four Catechins in Black Tea via NIR Spectroscopy and Feature Wavelength Selection: A Novel Approach. Sensors 2024, 24, 3362. https://doi.org/10.3390/s24113362
Liu Y, Pan K, Liu Z, Dai Y, Duan X, Wang M, Shen Q. Simultaneous Determination of Four Catechins in Black Tea via NIR Spectroscopy and Feature Wavelength Selection: A Novel Approach. Sensors. 2024; 24(11):3362. https://doi.org/10.3390/s24113362
Chicago/Turabian StyleLiu, Yabing, Ke Pan, Zhongyin Liu, Yuqiao Dai, Xueyi Duan, Min Wang, and Qiang Shen. 2024. "Simultaneous Determination of Four Catechins in Black Tea via NIR Spectroscopy and Feature Wavelength Selection: A Novel Approach" Sensors 24, no. 11: 3362. https://doi.org/10.3390/s24113362
APA StyleLiu, Y., Pan, K., Liu, Z., Dai, Y., Duan, X., Wang, M., & Shen, Q. (2024). Simultaneous Determination of Four Catechins in Black Tea via NIR Spectroscopy and Feature Wavelength Selection: A Novel Approach. Sensors, 24(11), 3362. https://doi.org/10.3390/s24113362