1. Introduction
Gait refers to the movement patterns of an individual’s walk. It encompasses the rhythm, speed, and style of movement which require a strong coordination of the upper and lower limbs. The process of gait analysis involves evaluating an individual’s walking pattern to assess their biomechanics and identify any abnormalities or inefficiencies in their movement [
1]. It has been an active research area over the last few years due to its utilization in numerous real-world applications, e.g., clinical assessment and rehabilitation, robotics, gaming, entertainment, etc. [
2,
3]. The quantitative gait analysis has also been explored as a biometric modality to identify a person [
4]. The gait analysis has several advantages over other existing modalities; in particular, it is unobtrusive and difficult to steal or falsify. Gait analysis is a challenging task because it involves the complex coordination of human skeletal, muscular, and nervous systems. Additionally, the gait can be affected by a wide range of factors, such as age, injury, disease, and environmental conditions. This results in intra-personal variations, which are always greater than inter-personal variations.
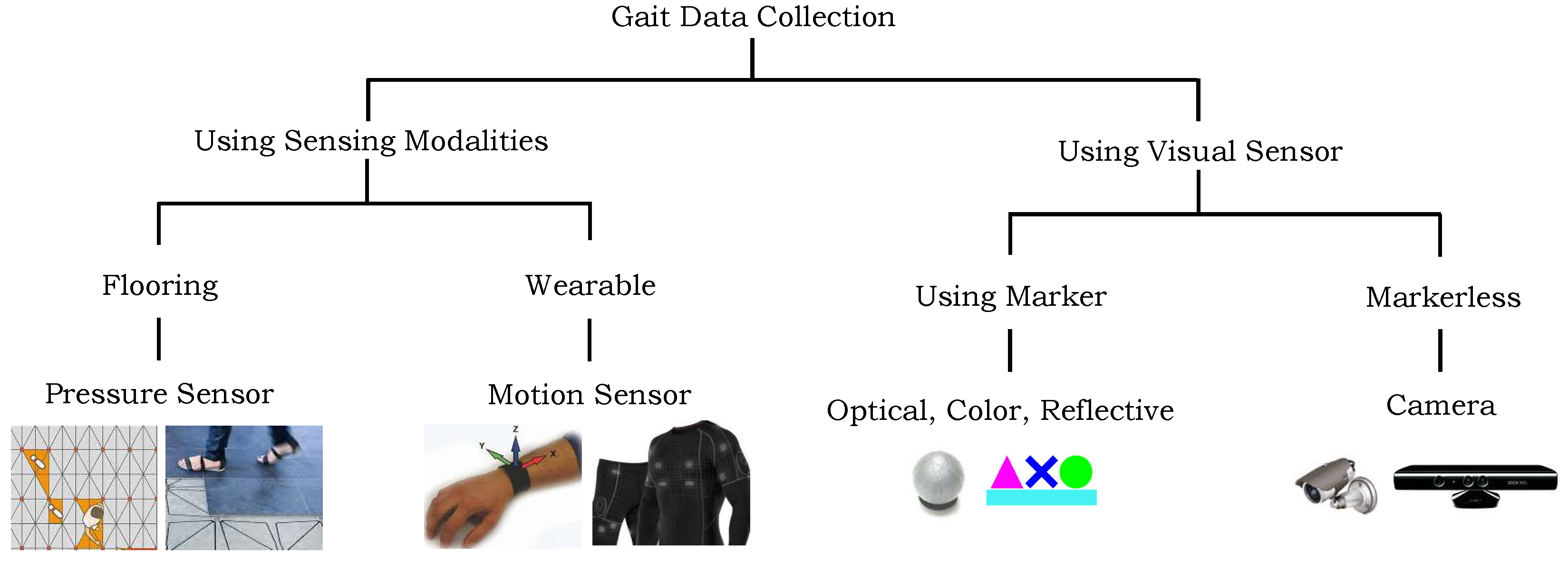
The gait data can be gathered via a variety of sensing modalities that can be broadly divided into two groups: using sensing modalities [
5] and using visual cameras [
3].
Figure 1 illustrates these sensing modalities that can be used for data gathering. Each of these modalities have their own strengths and limitations, and researchers choose to use single or a combination of several modalities to capture gait data based on their research questions and goals. Vision-based systems have been extensively used in the gait analysis due to their higher precisions however, their use raises confidentiality and privacy concerns [
6]. Conversely, the digital sensors such as inertial measurement units (IMU), and pressure sensors have been also used to collect the gait data. These tiny sensors can easily be embedded in our environment, including walking floor, wearable devices, and clothes. Furthermore, a few of such sensors are already embedded in our daily used digital gadgets, e.g., smart phones, smart watches, and smart glasses [
7]. These devices generate data in the form of pressure signals, velocity, acceleration, and positions which can be used to represent the gait.
Analyzing gait requires the use of sophisticated tools and techniques. Since the gait comprises continuous time series data, we need to extract a set of relevant features from these raw data to represent gait patterns. There are several approaches in the literature to extract features, and they can be categorized into three groups: (1) handcrafted [
8], (2) codebook-based [
9], and (3) automatic deep learning-based [
10] feature extraction approaches. The handcrafted features are usually a few statistical quantities, e.g., mean, variance, skewness, kurtosis, etc., that are extracted from raw data based on the prior knowledge of experts in the application domain. Later, these features are fed to machine learning algorithms for classification. Typically, they are simple to implement and are computationally efficient; however, they are designed to solve a specific problem and are not robust [
7]. The codebook-based feature learning techniques follow the channel of Bag-of-Visual-Words (BOVWs) approach [
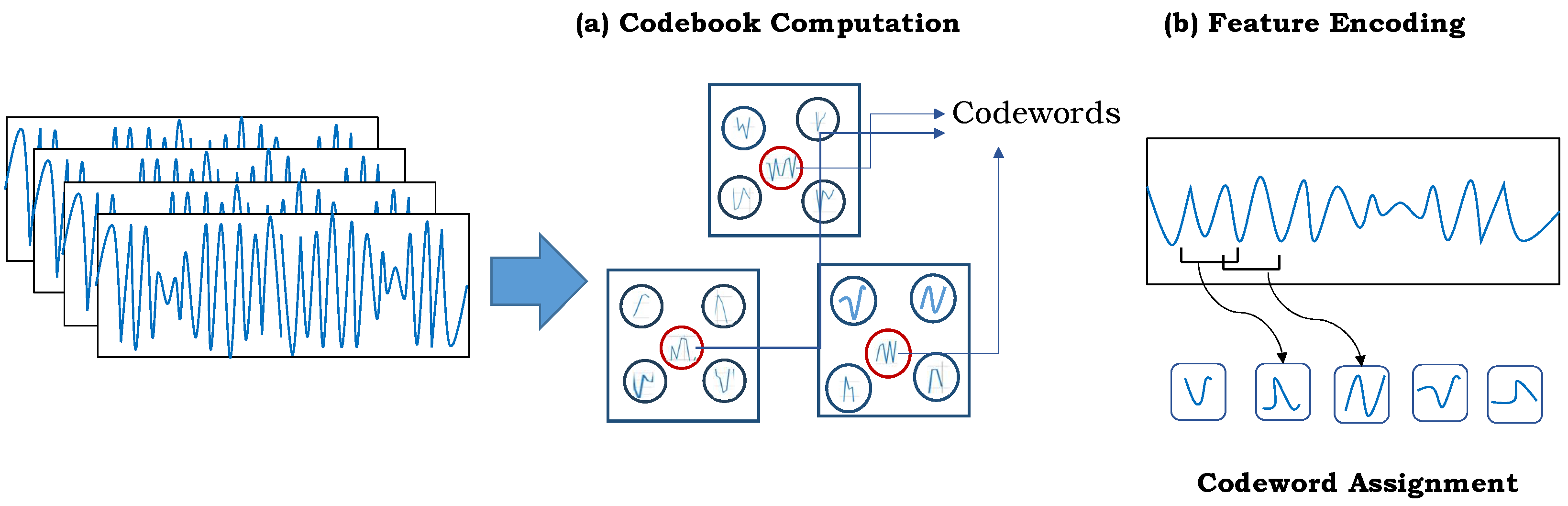
11] to compute gait features. Specifically, they employ clustering algorithms, e.g., k-means, to build a dictionary (also known as codebook) using the gait sub-sequences from raw data. The data are grouped based on their underlying similarities, and the clusters’ centers are known as “codewords”. Later, a histogram-based representation is computed for other sequences by tying them to the closest-related codeword. Codebook-based techniques are proven to be robust as they can capture more complex patterns in the gait data; however, they are computationally expensive [
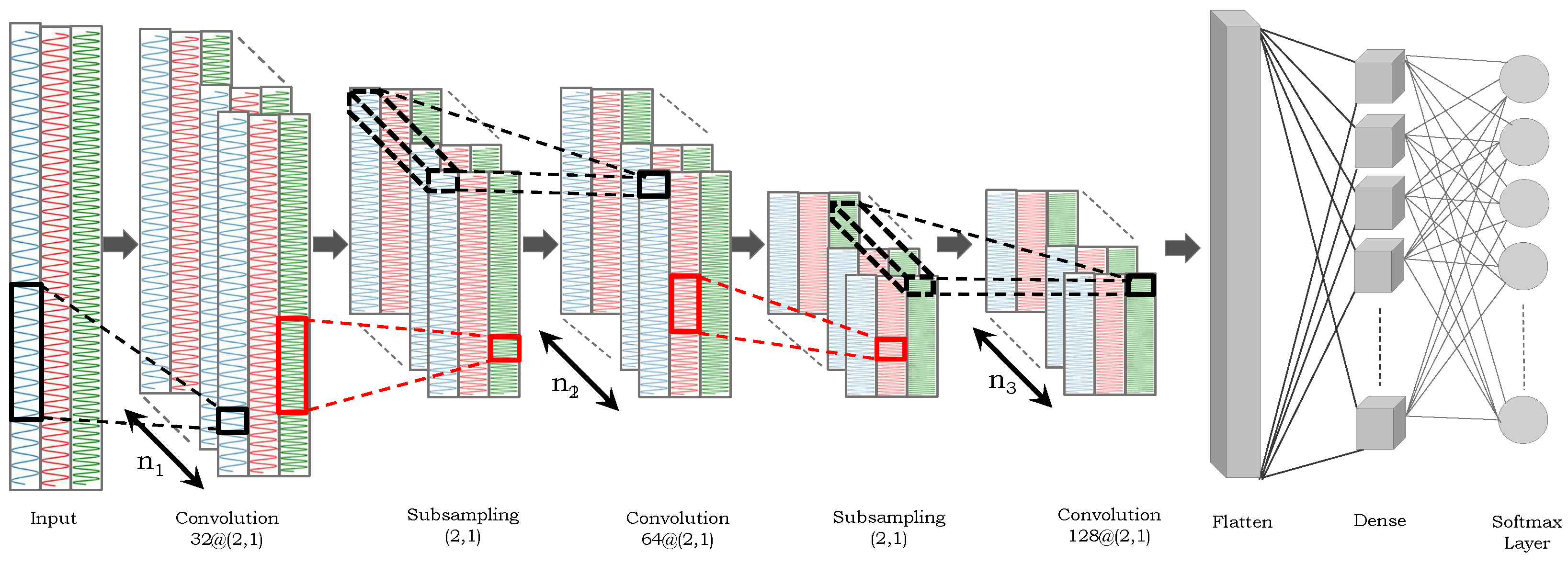
12]. Deep learning-based techniques automatically compute discriminative features directly from the input data using artificial neural networks (ANNs). A deep network usually comprises several layers where each layer consists of artificial neurons. After obtaining input, a specific feature map is computed by the neurons in each layer and then forwarded to the next layer for further processing, and so forth. Finally, the network’s last layers generate highly abstract feature representations of the raw sensory data. A few examples of deep learning approaches for gait analysis are convolutional neural networks (CNNs) [
13], recurrent neural networks (RNNs) [
14], and long short-term memory networks (LSTMs) [
15]. Deep learning-based approaches can automatically learn complex features from raw data and are adaptable to new datasets and scenarios; however, they are computationally much more expensive and require a huge amount of labeled instances to optimally choose the hyperparameters’ values of the deep network. The entire process is greatly hampered by the lack of prior information necessary to encode the appropriate features in the application domain and the choice of the best parameters for the machine learning algorithms [
7].
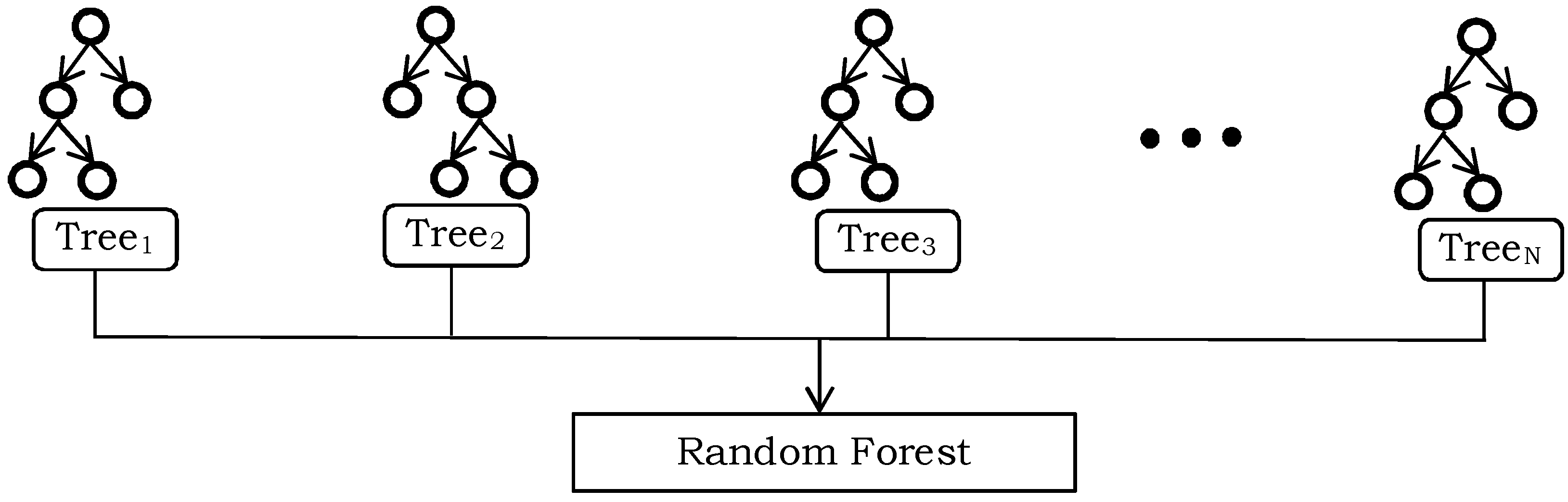
This paper presents a systematic evaluation of numerous feature learning techniques to encode multimodal time series sensory data for gait analysis. Furthermore, the proposed feature encoding techniques also explored to recognize the human daily activities which were recorded using sensory data too.Specifically, we presented three different encoding techniques to recognize the walking styles. In the first technique of handcrafted features, we computed eighteen different statistical quantities from the raw sensory data, and they are fused together in a single feature vector to obtain the high-level representation. In the second feature learning technique, we build a codebook using k-means clustering algorithm, and the high-level feature representation is obtained using Locality-constraint linear encoding (LLC) [
16]. In both of the aforementioned techniques, we explored the effectiveness of Support Vector Machines (SVMs) and Random Forest (RF) as machine learning algorithms to recognize different walking styles. Third, we presented two deep learning models, a CNN and an LSTM, which employed raw sensory data as input to recognize walking sequences. The effectiveness of the proposed features was assessed on four datasets, namely Gait-IMU, MHEALTH [
17], WISDM [
18], and UCI-HAR [
19]. An extensive experimental evaluation of different feature encoding techniques was carried out along with different values of hyperparameters, and the recognition scores were compared with recent state-of-the-art approaches. The proposed framework establishes a solid foundation and generic framework to encode any time series multimodal sensory data. We believe that the raw time series sensory data of other sensing modalities such as SensFloor, skin temperature sensors, and electrocardiograms (ECGs) can also be encoded using the proposed approaches to perform recognition tasks. The proposed framework can be employed in numerous emerging fields and technologies, including healthcare and rehabilitation, sports, assistive living, and others. The major contributions of the proposed manuscript are as follows:
A comparative study of three different feature encoding techniques is presented.
A comprehensive review of the existing techniques is presented, and their benefits and drawbacks are discussed.
The effectiveness of various machine learning methods is evaluated in order to classify the multimodal sensory data.
The computational analysis of different feature encoding techniques is presented.
The robustness of the proposed technique is assessed on several applications, including walking styles, human activities, etc.
A rigorous evaluation of all the feature encoding techniques is carried out on four large datasets.
A large gait dataset that is collected using IMU sensors is proposed.
2. Related Work
Gait analysis is a fundamental tool in biomechanics that allows for both quantitative and qualitative assessment of human movement. It involves the analysis of the spatiotemporal parameters, kinematics, and kinetics of gait, which are important indicators of the locomotion function [
20,
21,
22]. This paper mainly emphasizes on gait analysis using multimodal time series sensory data. The existing techniques employed either a pressure sensor [
23,
24,
25] or an IMU [
26,
27] to encode walking patterns. In recent years, a large number of algorithms has been presented to investigate the movement of human body parts for clinical and behavioural assessment. They can be broadly divided into three groups, as depicted in
Figure 2. In the following, a brief summary of a few techniques from each group is presented.
2.1. Handcrafted Feature-Based Techniques
These set of techniques either compute several statistical measurements on input data (e.g., average, variance, skewness) or extract more complex gait characteristics, which may include stride length, joint angles, and other related features. In the context of machine learning, handcrafted features refer to manually designed features that are extracted from raw data and used as input to a classifier [
8,
28,
29,
30]. For instance, the technique proposed in [
31] extracted several statistical quantities on input data (e.g., mean, median, mode, standard deviation, skewness, and kurtosis) to show the gait fluctuation in a patient with Parkinson’s. They employed Fisher Discriminant Ratio to determine the most discriminatory statistical feature. A comparative study of different handcrafted features is proposed in [
28] for the early detection of traumatic brain injury. The authors employed the location and accelerometer sensory data of a smartphone to extract nine gait features, including coefficient of variance, step count, cadence, regularity in step, stride, etc. Similarly, the authors of [
32] extracted standard deviation, skewness, kurtosis, and bandwidth frequency features from the accelerometer data of an IMU sensor mounted on the subject’s lower back to distinguish between normal and stroke gait patterns. The study presented in [
33] extracted thirty-eight statistical quantities, including maximum, minimum, average, spectral energy, etc., to monitor and quantify various human physical activities using a smartphone’s IMU sensory data. Similarly, the technique proposed in [
34] employed frequency domain features to assess gait accelerometer signals. The approach proposed in [
35] analyzed the gait sensory data using adaptive one-dimensional time invariant features.
These techniques appear simple in implementation; however, they are highly based on expert knowledge in the application domain. Additionally, they are designed to solve a specific problem and are not robust.
2.2. Codebook-Based Approaches
These techniques follow the work-flow of the BOVWs approach to encode the raw sensory input data into its compact but high-level representation. In particular, the input data are clustered based on similar patterns using a clustering algorithm (e.g., k-means) to create a dictionary. The cluster centers in the dictionary are known as codewords which describe the underlying variability in the gait data. Later, a final representation of the raw gait input data is achieved by estimating the distribution of these codewords in the gait sequence. This results in histogram-like features (where a histogram bin represents the occurrences of a specific codeword) which are fed to a classification algorithm for further analysis. For instance, the authors of [
7,
36] employed sensory information from commonly used wearable devices to identify human activities. They built a codebook using a k-means clustering algorithm, and the final gait representation is achieved using a simple histogram-binning approach. Similarly, the technique proposed in [
37] employed IMU sensory data from smartphones and smartwatches to recognize Parkinson’s tremor using a codebook-based approach. In [
38], research was carried out to recognize the human gait phase using two sensors: an accelerometer and a gyroscope. A codebook-based approach was explored to extract gait features from the raw sensory data. Similarly, the authors of [
39] presented an approach to determine the best working positions for various movement phases and to guide the performer on how to keep them while performing physical activities. They explored a k-means clustering codebook to encode the different working postures for each phase of movement. In [
40], a separate codebook is constructed to each sensor modality, including accelerometer, gyroscope, and magnetometer. The resulting features were concatenated to form a compact and high-level feature vector to classify human daily activities using SVM with a radial basis function (RBF) kernel. The technique in [
41] presented a visual inertial system to recognize daily activities using two RGB-D (red, green, blue, and depth) detectors with a wearable inertial movement unit. They employed codebook-based technique on different sensing modalities to compute the desired features. In [
12], a detailed comparison of different codebook-based feature encoding approaches is presented to recognize gait.
These techniques are proven to be robust, to some extent, as they can capture more complex patterns in the gait data; however, they are computationally expensive [
12]. Additionally, this process of codebook computation may need to be performed again if new classes are added in the dataset [
42].
2.3. Deep Learning-Based Approaches
Lately, automatic deep learning-based feature extraction approaches have been largely explored in different classification tasks due to their robustness in automatic feature extraction, generalization capabilities, and convincing recognition results. A deep network is typically an end-to-end architecture that can learn complicated patterns and relationships in input data using a fully automated feature extraction process. In particular, it comprises many layers of interconnected neurons. The network’s intricate and iterative structure allows for the learning of high-level features from input data as it passes it through (i.e., the weight adjustments of neurons and back-propagation of errors [
43]). Numerous automatic feature learning-based techniques on gait analysis have been proposed in the past; convolutional neural networks (CNNs) [
44] and long short-term memory (LSTM) [
45] are a few examples to quote. For instance, the authors of [
44] presented an IMU-based spectrogram technique to categorize the gait characteristics using a deep CNN. The authors of [
46] explored a CNN to extract the appropriate high-level feature representation from pre-processed time series input data. They turned the input data into two-dimensional (2D) images where the y-axis represents various features and the x-axis represents the time.
Since a CNN is typically designed to process imagery data, a few other networks have also been explored to analyze gait [
47,
48,
49]. For instance, the authors of [
45] employed window-based data segmentation to classify gait sequences using a multi-model long short-term memory (MM-LSTM) network. To compute features from each window, the MM-LSTM network accepts input gait data that have been segmented into several overlapping windows of equal length. The authors of [
50] employed recurrent neural networks (RNNs) for gait analysis. The method for calculating gait mechanics using an artificial neural network (ANN) with measured and simulated inertial measurement unit (IMU) data is suggested in [
51]. The authors concluded that more precise estimations of gait mechanics can be obtained by combining the ANN with both simulated and actual data. In [
52], a comprehensive overview of different deep learning models is presented to monitor the human gait.
The studies show that deep learning-based feature encoding techniques are effective tools for analyzing gait and have the potential to explore the underlying mechanics of gait. They provide automatic end-to-end learning; however, they also require complex computational resources and a huge amount of training data.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}