1. Introduction
Recently, gait analysis has become an essential tool in healthcare, sports, and fitness. It is especially prevalent in elderly care as the gait and balance deficits increase with age. The gait analysis helps to estimate the risk of falls and screen for frailty [
1]. Gait-related parameters are also commonly used for intrinsic capacity (IC) and functional ability evaluation [
2] as they correspond to the performance of the older adults in the IC locomotion domain.
Besides IC, there are several geriatric assessment tools based on gait speed and dynamic balance. The most renowned tests measure the time it takes to cover a given distance in various conditions. The most straightforward, the 10-meter walk test, assesses walking speed over a short distance [
3]. More complex solutions assume following a defined path, e.g., walking a figure eight shape [
4] or moving along a narrow path between parallel lines [
5]. Others require passing over obstacles or keeping a straight walk while turning the head to the right or left or tipping the head up and down [
6].
As human movement can be accurately measured using inertial sensors, automatization of such evaluation procedures with wearable sensors seems an obvious solution. The application of inertial sensors to geriatric gait assessment is presented in many publications. In the survey [
7], inertial sensor-based frailty and fall risk evaluation methods are compared. They differ in the number of sensors used and their position. Six inertial measurement units (IMUs) were even used in the most extensive test setups. The sensors are typically attached to feet, instep, heels, the chest, the sternum, trunks, or the tibia or combinations of these locations.
Most tests are performed in clinical conditions where numerous sensors on different body parts can be easily placed. Unfortunately, such an experimental setup is hard to recreate in everyday living conditions. In such applications, the sensors should fulfill several requirements: they should be easy to operate and charge and should not cause the user any significant discomfort while putting them on or taking them off. Otherwise, such solutions might not be accepted by the older adults. Despite the problems mentioned above, great hope is being placed in such solutions as monitoring the gait of older adults during everyday activities would provide data better reflecting their overall health state [
8,
9].
Another important area of gait analysis application is related to sports, fitness, and rehabilitation. In these cases, most of the tests described in the literature utilize sensors mounted in the lower limb area. In the comprehensive review [
10] of running gait analysis methods, out of 170 analyzed works, over 100 relied on measurements performed in the lower limb area (tibia, shoe, insoles), whereas a mere 2 works obtained data with a wrist-worn sensor.
Generally, regardless of the domain, most gait evaluation tests with inertial measurement units are performed using shoe or tibia-mounted sensors. Although giving accurate results in laboratory environments, such sensors are unsuitable for daily monitoring. Shoe-based sensors are fragile and require the same pair of shoes to be worn all the time. Tibia-mounted sensors are usually uncomfortable, and their orientation might shift if not tightly attached. A much better solution would be to use inertial measurement units embedded in smartwatches or smart bands worn by the users.
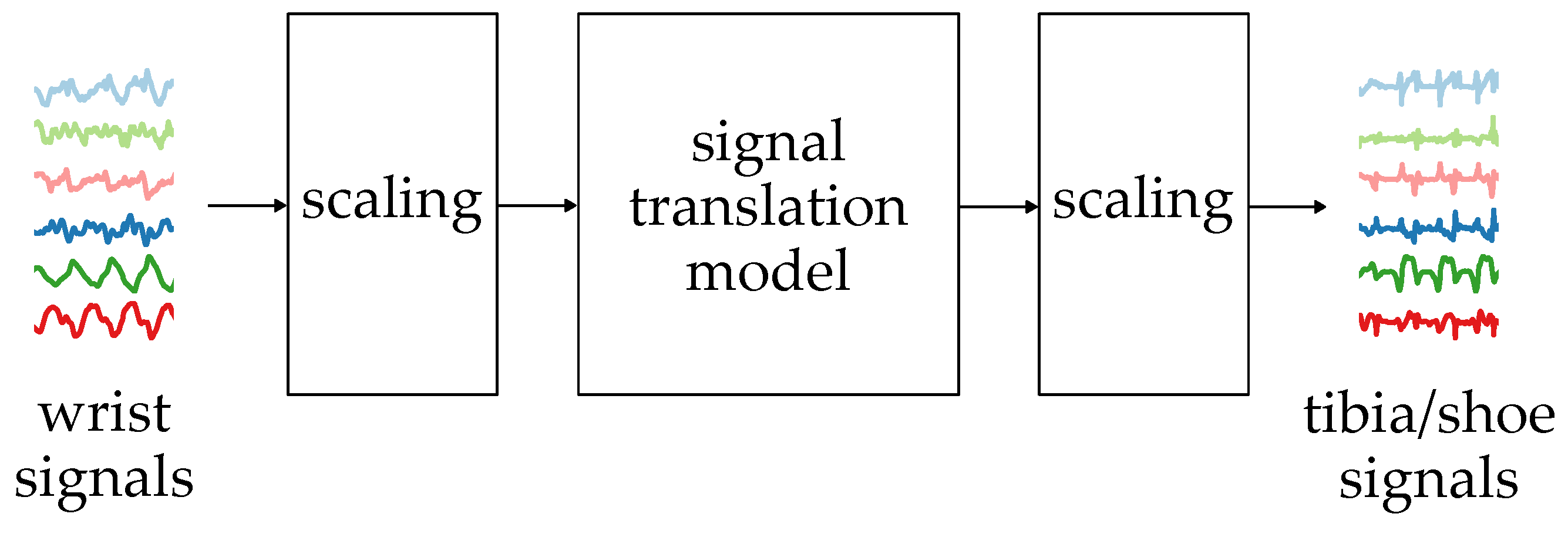
The motivation for the following study is to find a method that would enable the translation of signals recorded by an inertial sensor worn on the wrist to signals that would be recorded by sensors placed in the lower limb area: tibia and foot. The main contributions of this study are the following:
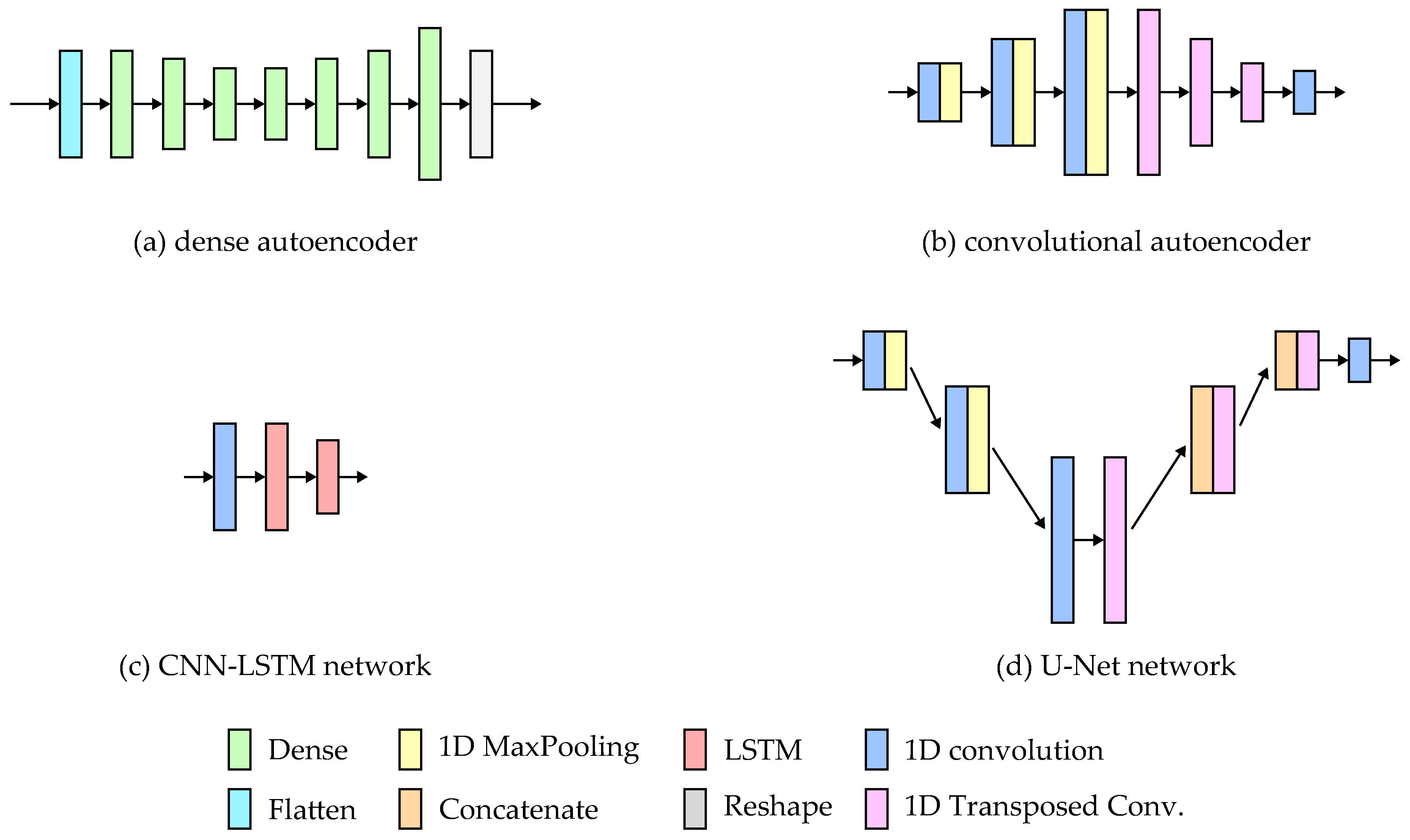
We analyzed four different neural network architectures for wrist-to-tibia and wrist-to-shoe translation of inertial signals (acceleration and angular velocity),
We gathered a dataset comprising inertial measurements registered using the wrist, tibia, and shoe-worn sensors collected over several hours of walking.
Our experiments have proved that the U-Net-based model and the CNN autoencoder can be successfully applied to solve IMU signal translation problems.
The structure of the rest of the paper is as follows.
Section 2 describes the current state of the art concerning neural-network-based signal translation methods. The problem and the proposed inertial signal translation model are outlined in
Section 3 and
Section 4, respectively. The experiments and results are presented in
Section 5.
Section 6 concludes the paper.
2. Related Work
Signal translation using neural networks is a vibrant field of research. Most of the articles written on the matter concern image-to-image translation [
11] including style transfer [
12] and generating semantic maps [
13]. The research described in the literature is mainly concerned with the conversion of photos or videos. The works that address translating signals obtained through means other than visual are much less common. In this section, we analyze works that employ machine learning (ML)-based signal translation methods to solve relevant problems, converting the signals to those obtained using different sensors or under different conditions.
There are different reasons to apply signal translation. In most cases, its purpose is to transform a signal into another domain, which enables more efficient data processing, for example, by using ML models trained on data gathered using a different sensor [
14] or to change the signal representation to one which is widely known and easier to interpret by human experts [
15]. Most of the signal translation methods use one of two network architectures: autoencoders [
16] or generative adversarial networks (GANs) [
17]. The employed models range from simple feed-forward networks to sophisticated architectures, including several convolutional and LSTM (long short-term memory) layers.
The method proposed in [
14] translates range-Doppler maps obtained using a newer version of an ultra-wideband (UWB) radar to a domain associated with its older counterpart. The main goal is to enable the use of ML models trained on data gathered using the previous sensor version. The authors propose a novel Sig2Sig architecture that builds upon the well-known Pix2Pix model [
18]. The model consists of a U-Net-shaped generator [
19] with squeeze and excitation blocks used for information compression. The generator is followed by a multi-channel attention selection module, which allows the model to obtain uncertainty maps for calculating losses, in which more important pixels are taken with greater consideration. The experiments have shown that the translated signals can be successfully used with previously trained ML models. The performance classification model was very close to that obtained using the data collected with the older sensor.
Signal translation can solve a similar problem when the results returned by the sensor are harder to interpret by human experts than their standard counterparts. In [
15], an adapted version of the CycleGAN model [
20] is proposed to transform raw ECG (electrocardiography) measurements from a novel 11-channel contactless capacitive sensor into the standard output of 12-channel wet electrode ECG. As the original CycleGAN architecture was intended for 2D image processing, the authors propose a simplified architecture in which the convolution and residual blocks in both generator and discriminator are omitted (the tests performed by the authors have shown that their presence slows the model’s performance without significantly enhancing its performance). The model is compared against three typical architectures: MLP, PIX2PIX, and LSTM. For most leads, the obtained ECG measurements are more accurate. The quality of the resulting ECG measurements enables their use by medical professionals for heart health assessment.
A similar problem is solved in [
21], where the seismocardiogram signals are translated into the domain of ECG distance transform. The authors propose the SeismoNet architecture, which is a modification of the U-Net model [
19]. The U-Net model is prepended with a convoluted ensemble averaging block consisting of several convolutional layers, whose purpose is to reduce the signal jitter. At the U-Net output, a denoising block is appended. The obtained signals’ quality allows for high-accuracy heart rate parameter estimation.
Another blood-flow-related application is presented in [
22], where photoplethysmogram (PPG) signals are converted to blood pressure (BP) waveforms, which are easily interpretable by doctors. The proposed method uses the generalized regression neural network (GRNN) [
23] as a basis. The GRNN consists of four subsequent layers: input, pattern, summation, and output. The pattern layer uses a radial basis activation function. The signal is processed in the following manner: First, a single period of the PPG is encoded into N harmonics. The harmonics are fed into the GRNN model, which converts them into N harmonics of the BP signal, which are then decoded into the BP waveform signal. The network achieved high signal reconstruction accuracy, conforming with restrictive medical device requirements.
Signal translation has been applied in processing medical images. In [
24], a modification of the Cycle-GAN network [
20] called Cycle-MedGAN is used to translate positron emission-computed tomography (PET) to computer tomography (CT). Cycle-MedGAN introduces novel non-adversarial loss functions, which are calculated using a pre-trained feature extractor. The new loss function is supposed to capture the perceptual aspects of the generated image quality, which pixel-wise loss analysis does not cover sufficiently. The experiments showed that the proposed architecture performs better in a PET-CT translation scenario than the original Cycle-GAN network. A similar study, where CT images are converted to magnetic resonance (MR), is presented in [
25]. The authors propose a GAN-based translation model in which an additional U-Net-like segmentation network is used to improve the semantic content consistency between the generated images. The demonstrated results proved the proposed model’s effectiveness.
Signal translation also has uses in brain activity monitoring, where it is used to interpret brain signals. In [
26], a novel MSATNet (Multi-Scale Activity Transition Network) model is proposed to mitigate the translation problems that occur in convolutional neural networks (CNNs). The proposed network consists of several subsequent activity structure blocks (including multiple convolutional layers) followed by pooling layers. The features returned by each block are processed with activity transition blocks (composed of LSTMs) and then are concatenated prior to the final fully connected layer. The proposed model is used for electroencephalogram (EEG) decoding. The results have shown that the proposed solution is superior to the analyzed counterparts.
A different application of brain signal translation is presented in [
27], where 3D continuous hand movement is predicted based on the time-frequency features of electrocorticography signals. For this purpose, the authors consider five network architectures:
CNN-FC (fully connected);
CNN-LSTM, outputting a single sample;
CNN-LSTM, outputting a part of the signal trajectory;
CNN-LSTM-FC, where the outputs of the LSTM layers are subject to an additional time-based convolution prior being fed to the fully connected layer;
CNN-FC, where 3D convolutions are applied to process whole signal sequences at the same time.
The results of the experimental evaluation are not consistent, as some of the models perform better for some axes than others. The best overall performance was achieved using the CNN-LSTM model, translating a part of the signal trajectory.
Signal translation can also be used in other scenarios, e.g., assessing structural damage suffered by large-scale objects. In [
28], a model based on the transformer architecture [
29] is used to translate acceleration measured by sensors mounted on a bridge to live load displacement caused by passing cars. The model consists of two modules: the encoder and the decoder. The layers used in the modules include self-attention followed by fully connected and normalization sub-layers. The decoder layers include an additional encoder–decoder attention sub-layer, which allows the self-attention mechanism to be applied over the encoder output. The tests performed at a highway showed that the displacement estimate obtained with the proposed model is much more accurate than in the case of the alternative free vibration method.
Gait-based user authentication is another area where converting the signals may be required. In such methods, the inertial sensors worn by the user are used to analyze their gait and movement patterns and extract their unique features, which allow for user identification and subsequent authentication, making the wearable systems more secure. One of the main problems of such solutions is the high dependence between the sensor readings and its location. Calibrating the authentication for one sensor location might result in misidentification when the sensor is worn differently.
In [
30], the authors propose to use an ML model, which translates the signals from a device worn in an unusual location to a standard one. The proposed model is an autoencoder including several dense layers and is trained in a supervised setting. The model is finely tuned to the particular users using the transfer-learning approach. The model was tested for different sensor location translation scenarios (chest to waist, head, shin, thigh, and upper arm). The results showed that the translated signals can be successfully used for authentication key generation. The problem of user identification in the case of variable sensor location scenarios is also addressed in [
31], where a method based on a unified autoencoder framework is used. The AE directly extracts discriminative features of the user’s gait and simplifies the whole authentication algorithm. To consider the geometry of the data, the authors propose to use the spectral angle distance instead of the traditional mean squared error (MSE).
Signal translation can also find its application in gait parameter analysis for medical purposes. For example, the gait parameters may be calculated by analyzing a video feed of a walking person. In such algorithms, the subsequent frames are analyzed to obtain the user’s pose and location of limbs. In [
32], a model of stacked progressive autoencoders (SPAEs) is employed to convert the gait energy images (GEIs) registered for people dressed in untypical, complicated clothes, e.g., down jacket or long coat, to images of people in typical clothing. The model consists of two stacked autoencoders that aim to map the GEIs of persons in unconventional clothing to typical conditions while keeping the typical GEIs unchanged.
A more traditional way to analyze gait parameters is to use inertial sensors. In the literature, many methods and ML models require the sensors to be mounted on shoes or user’s tibias. In order to apply these methods in scenarios where the user wears a smartwatch, the obtained signal must be translated. In [
33], a neural network is used to translate the readings of the wrist-worn accelerometer to readings of accelerometers mounted on each of the ankles. The proposed network model consists of three types of layers: CNN, LSTM, and dense. The model takes a sequence of acceleration samples from a wrist sensor and outputs six samples corresponding to readings in three axes of right and left ankle-worn sensors. The obtained results are superior compared to a simple feed-forward network. Although the model gives satisfactory results, it comes with certain significant limitations. First, as the model outputs samples instead of whole sequences, translating longer signals requires repeatedly calling the model using the sliding window technique. The model also has high computational complexity as the layers have nearly 12 million trainable parameters. Such complexity and the use of slow LSTM lowers its applicability to more powerful units and prevents it from being implemented directly in the wearables. Additionally, the network translates only the acceleration measurements. It does not consider the angular velocity, which allows for accurate evaluation of gait parameters due to exhibiting significant changes even when the movements are less intensive.
3. Inertial Measurements at Different Locations
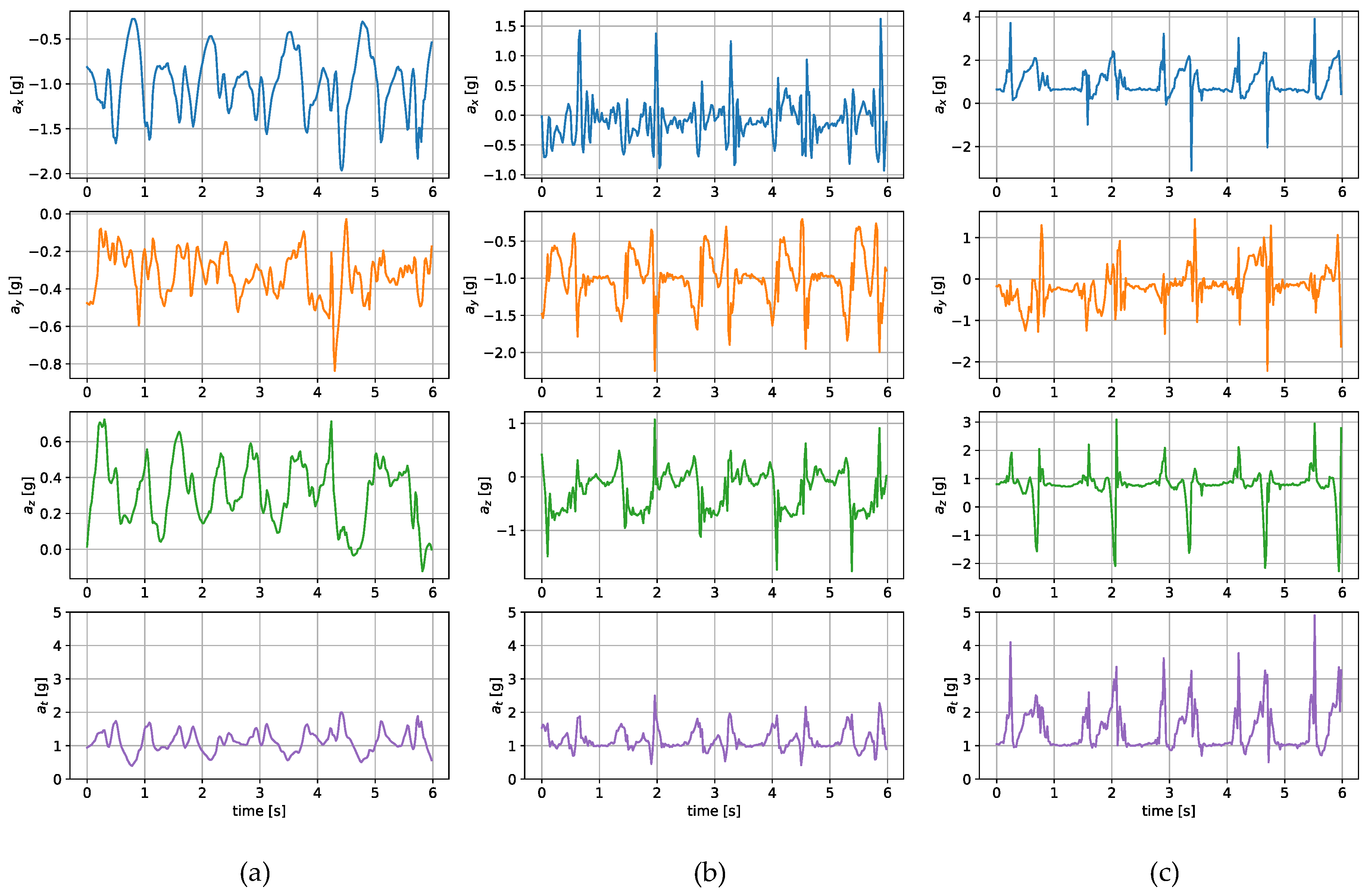
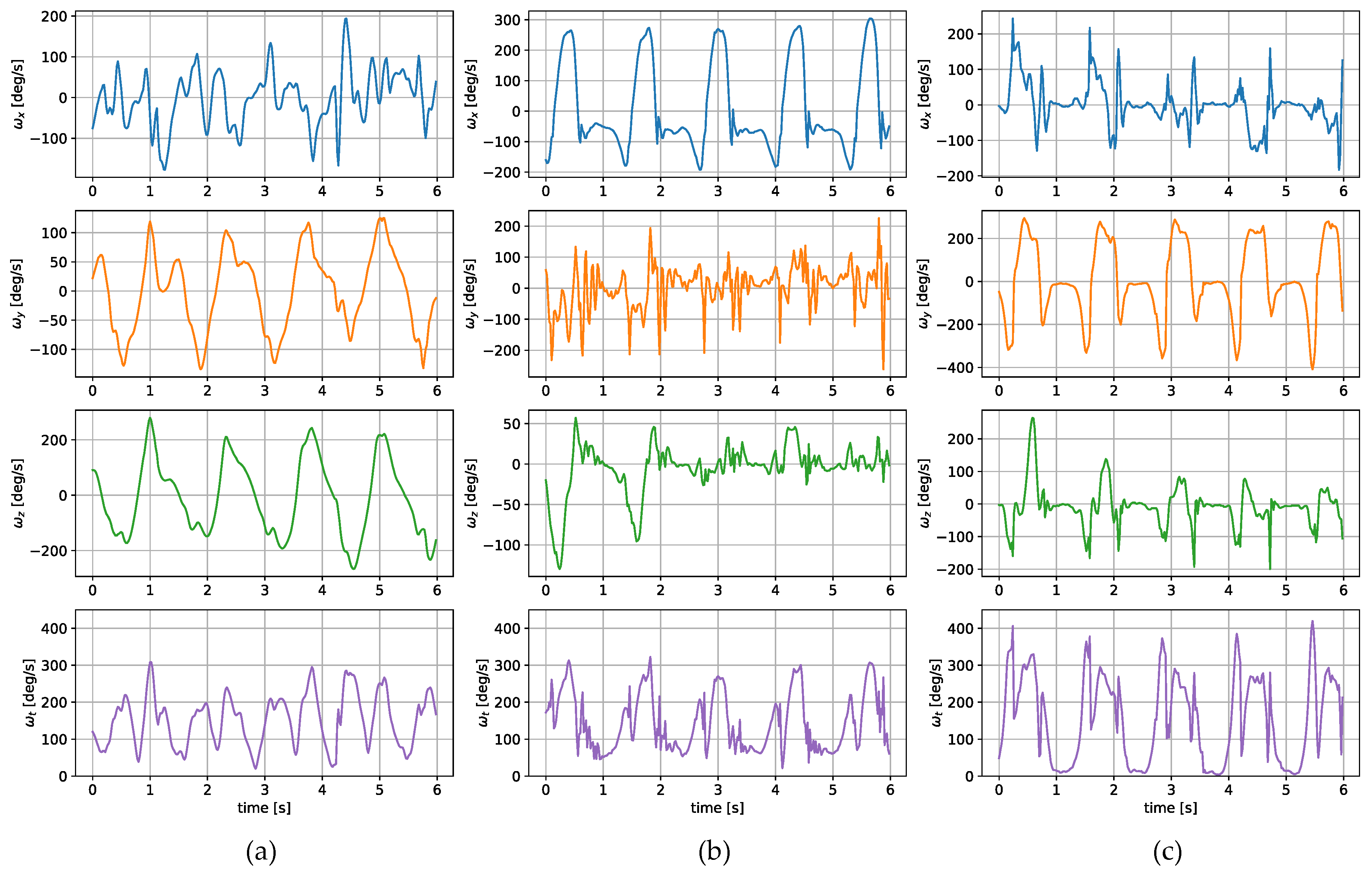
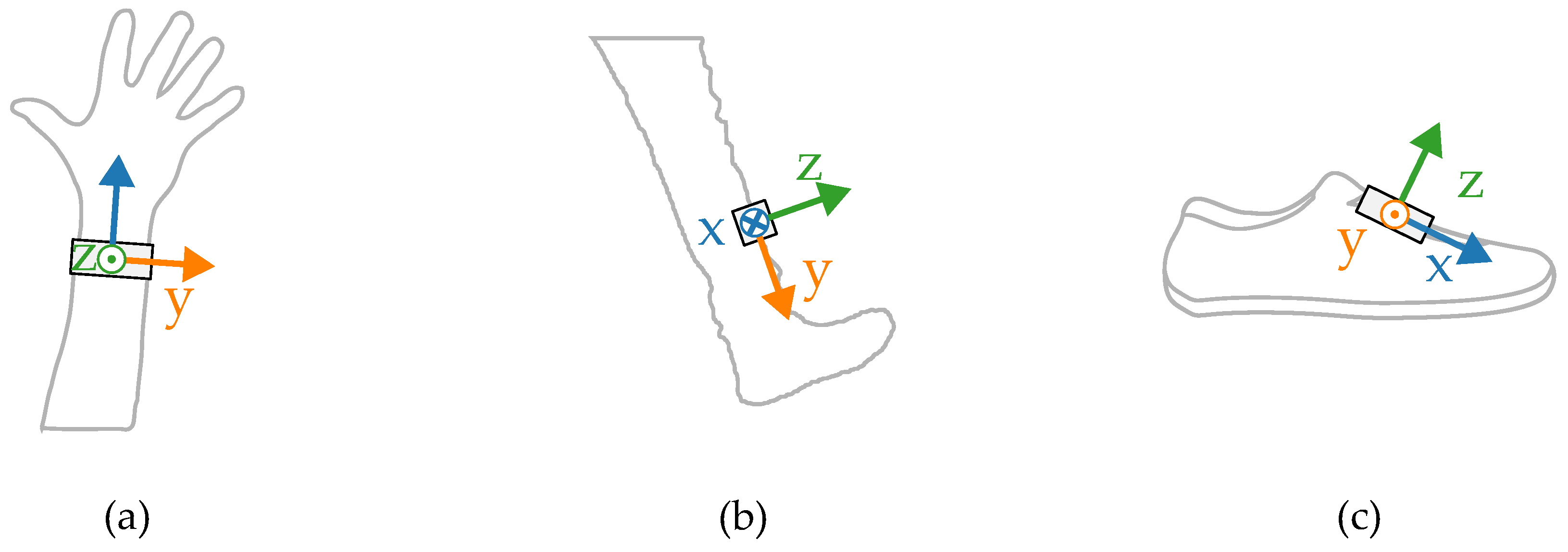
Most wearable gait evaluation systems utilize measurements from IMUs including a tri-axial accelerometer and a tri-axial gyroscope. The amplitudes and shapes of the signals are highly dependent on how and where the sensor is worn. In order to illustrate the differences, a small set of inertial measurements registered concurrently in three locations was gathered. The placements of the sensors during the experiments are presented in
Figure 1.
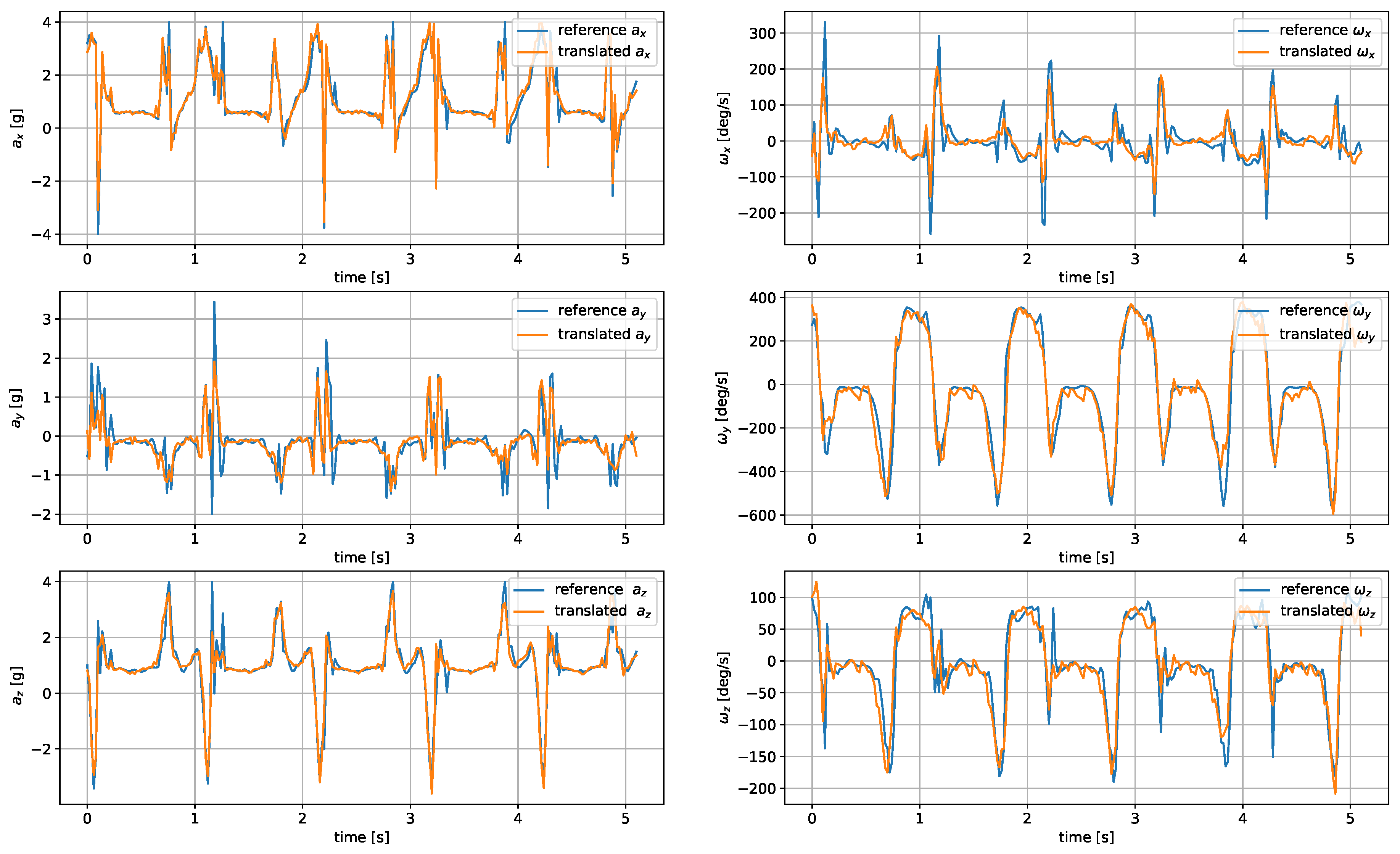
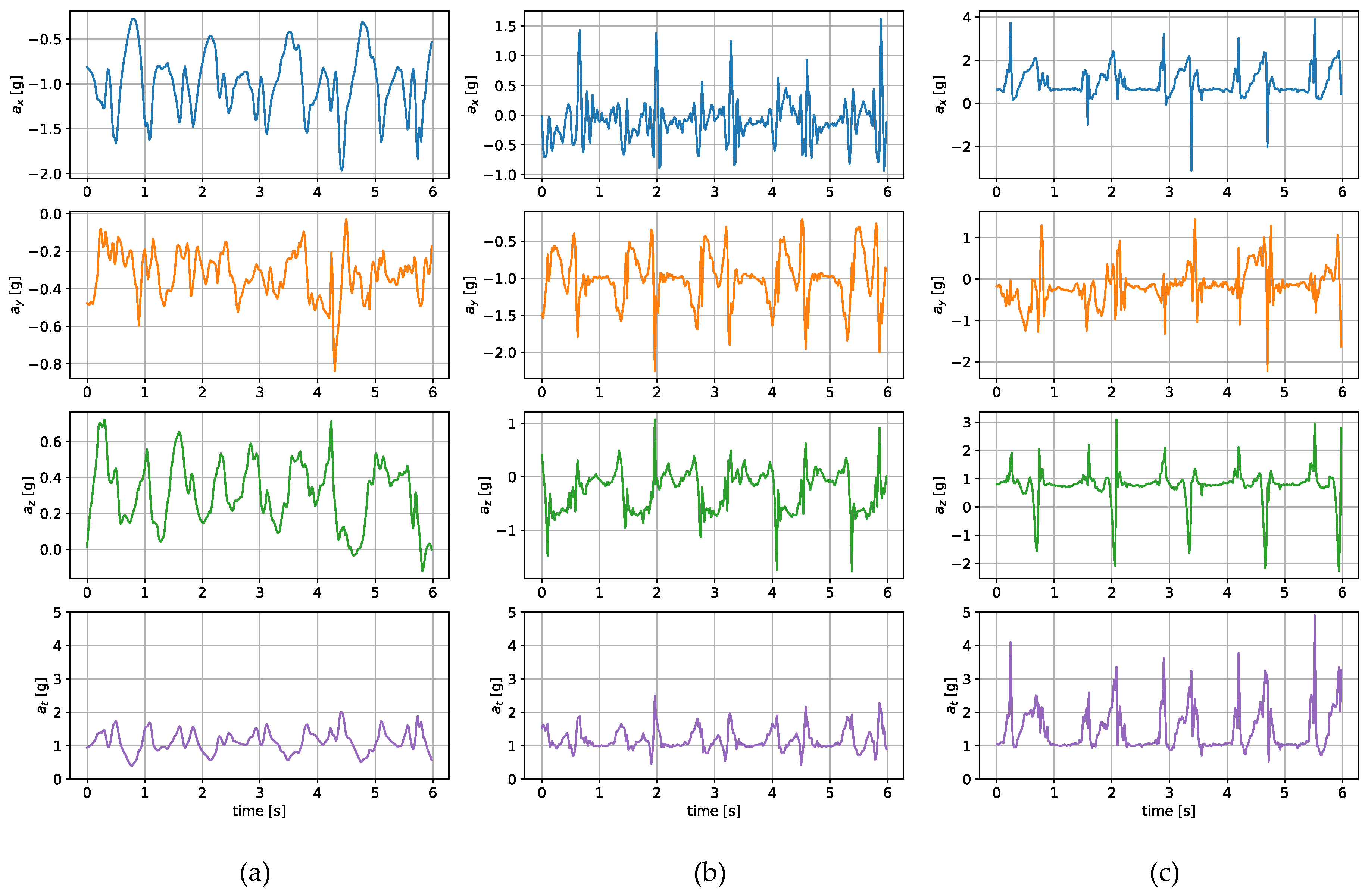
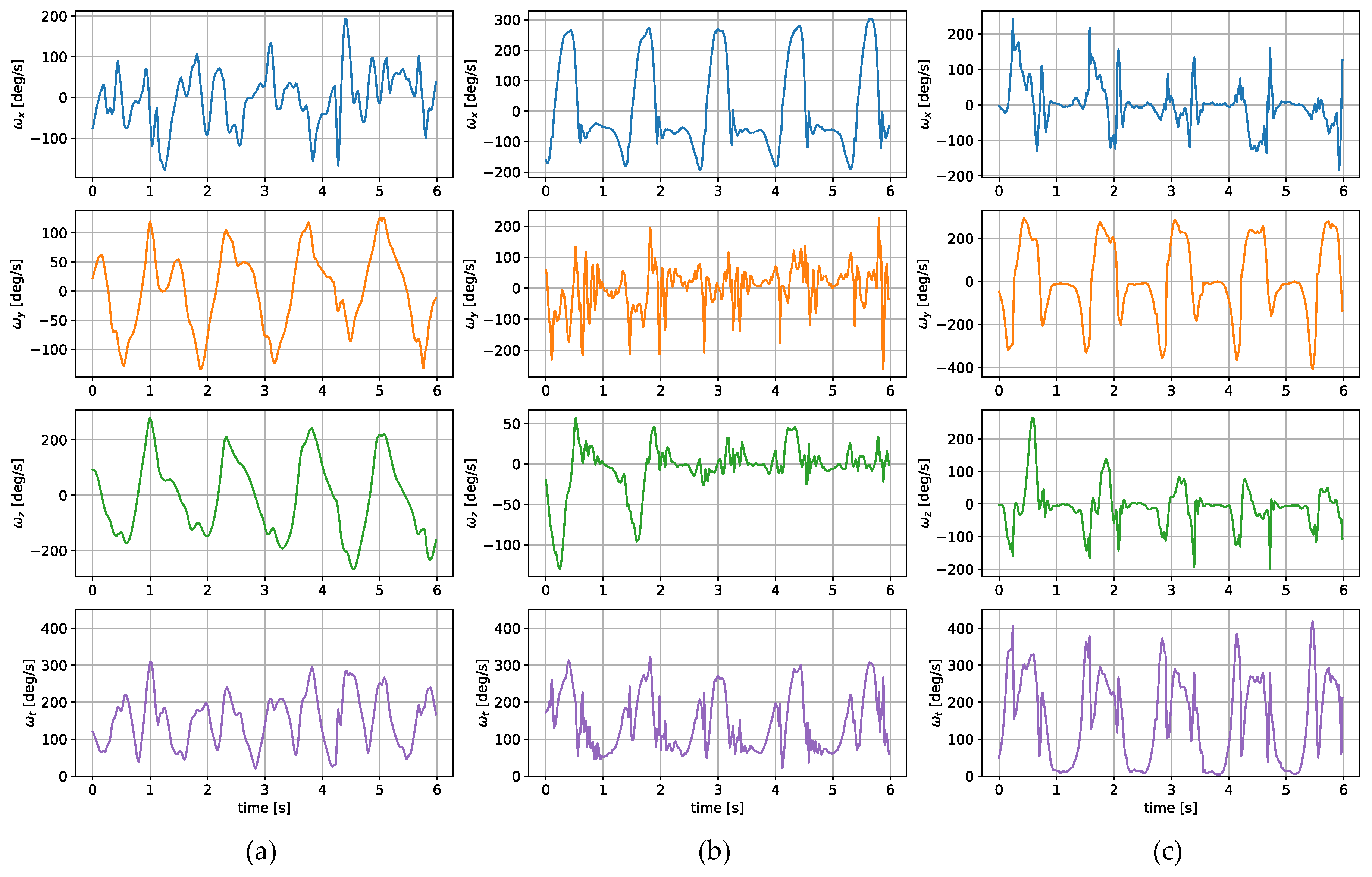
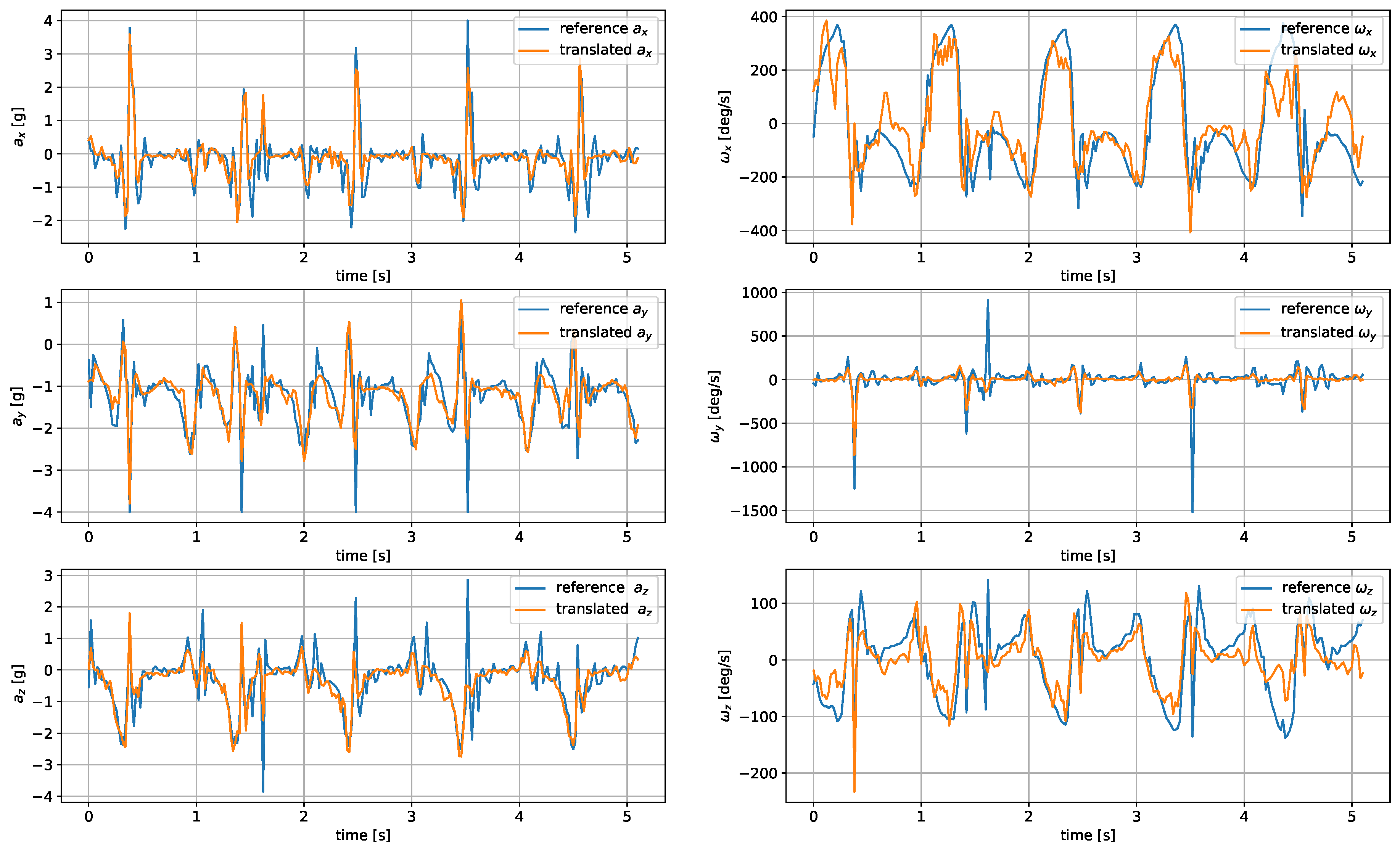
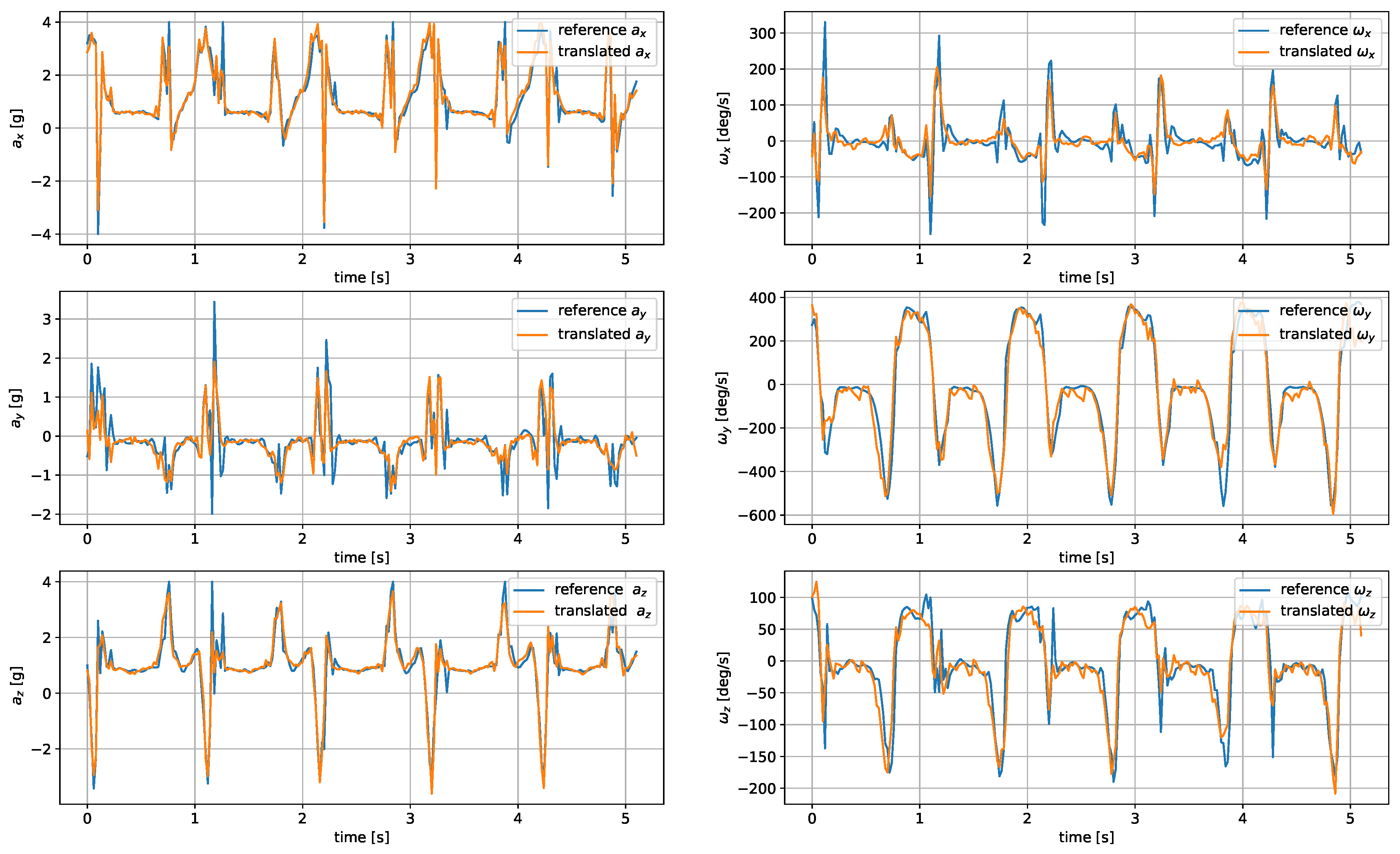
The measurements were taken with the sensors attached in three places: to a wrist, to a tibia, and mounted on a shoe. The direction of the axes differ between the sensor placements. Therefore, the measurements registered with those sensors are not easily interchangeable. Exemplary six-second acceleration and angular velocity sequences recorded for a walking person are presented in
Figure 2 and
Figure 3, respectively.
In the case of both acceleration and angular velocity, the signals differ significantly. The results gathered in the same sensor axes differ due to different sensor orientations. In the case of acceleration measurements, both the tibia and shoe-mounted sensor return signals with higher amplitudes. The waveforms are also sharper and include distinct short peaks, making it easier to perform gait timing measurements. The most evident peaks are in the shoe-sensor signals due to the high acceleration measured during the heel strike.
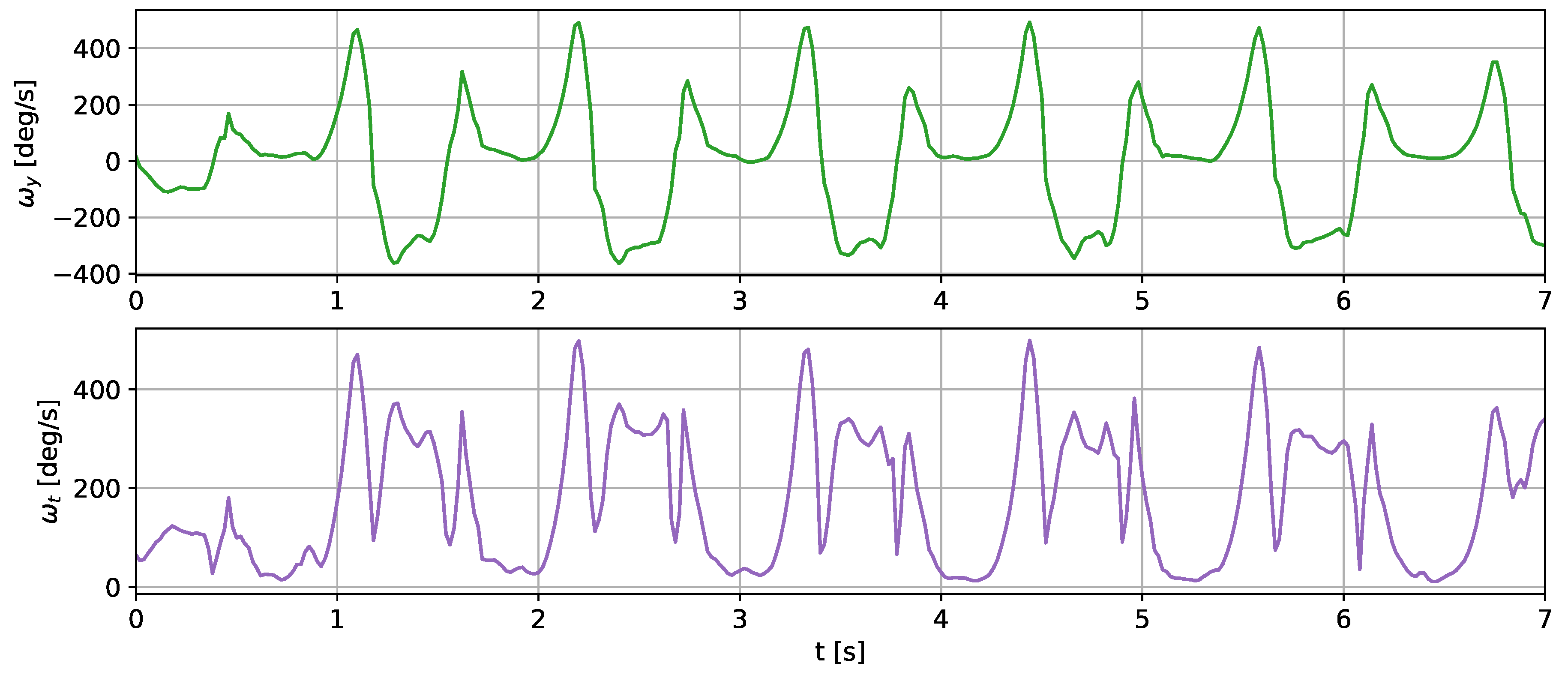
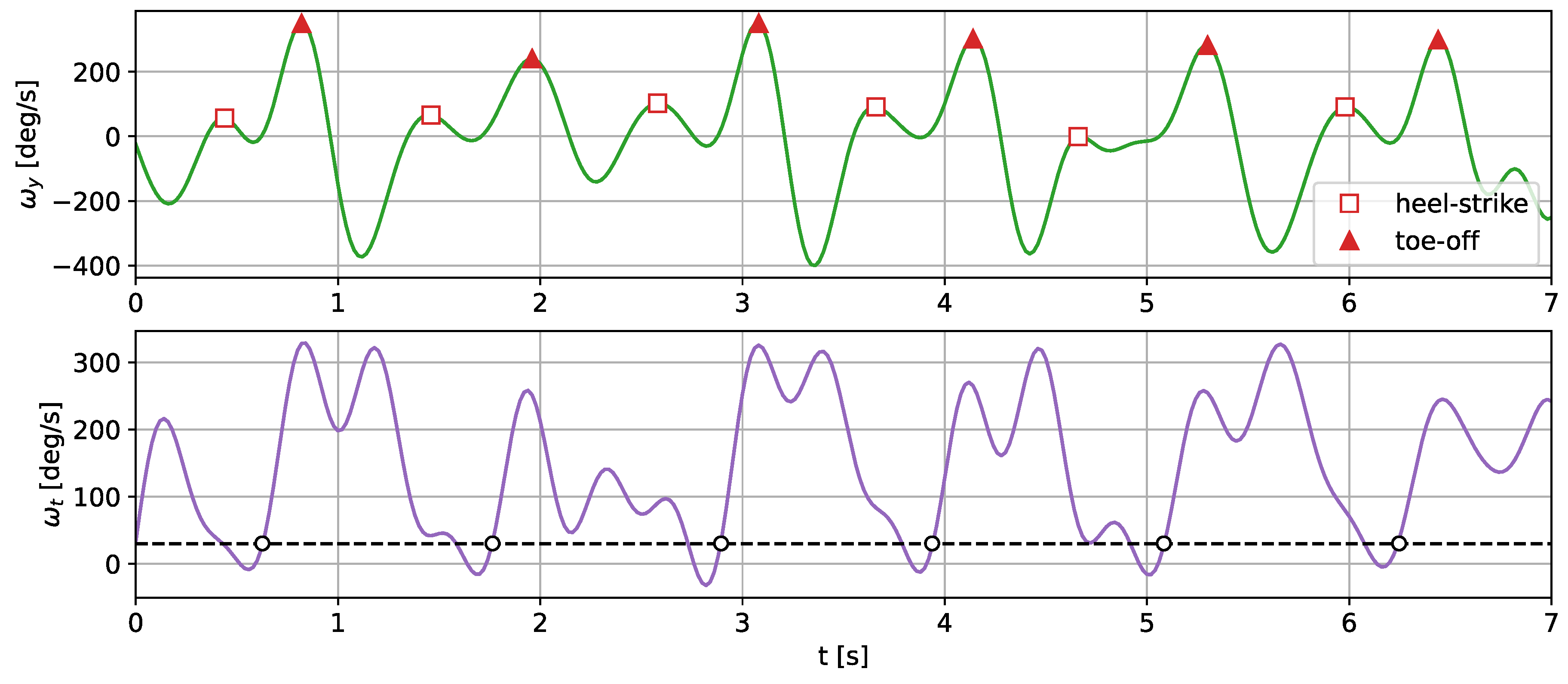
The angular velocity measured does not significantly differ in terms of the signal amplitude. However, the difference in waveform shapes is significant. For the wrist sensor, the waveforms for y z axes and the resultant values are sine-like, which makes it hard to distinguish the stride phases, and only steps can be efficiently counted. In the case of the tibia and shoe sensors, the shapes are more distinct, and we can observe positive and negative peaks in the signal, which correspond to the boundaries between the stance and swing phases.
The different shapes of the waveforms make it impossible to find an analytical solution, allowing for a straightforward translation between them. In this case, the most viable option is to train an ML algorithm to establish their relationships and dependencies.
6. Conclusions
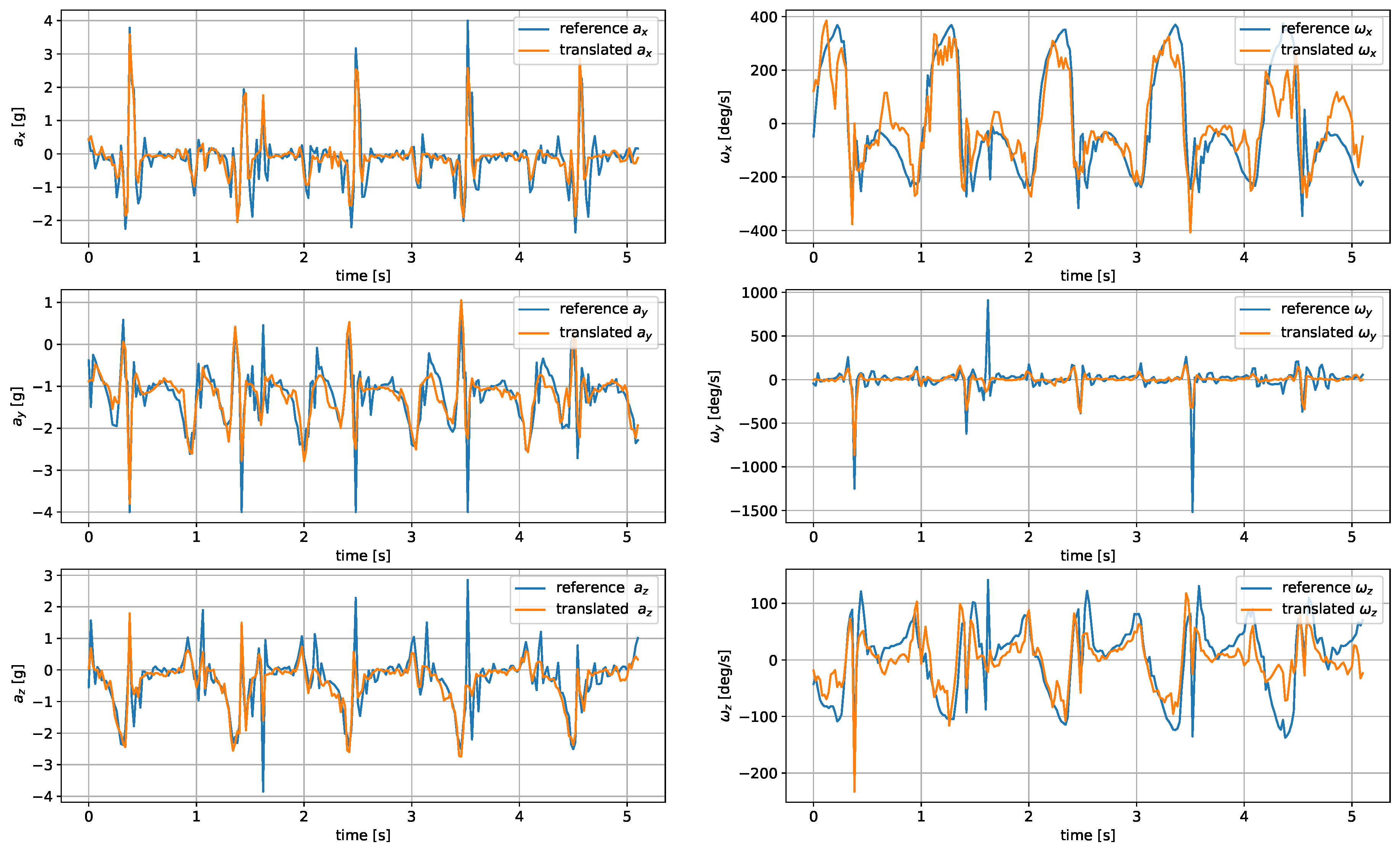
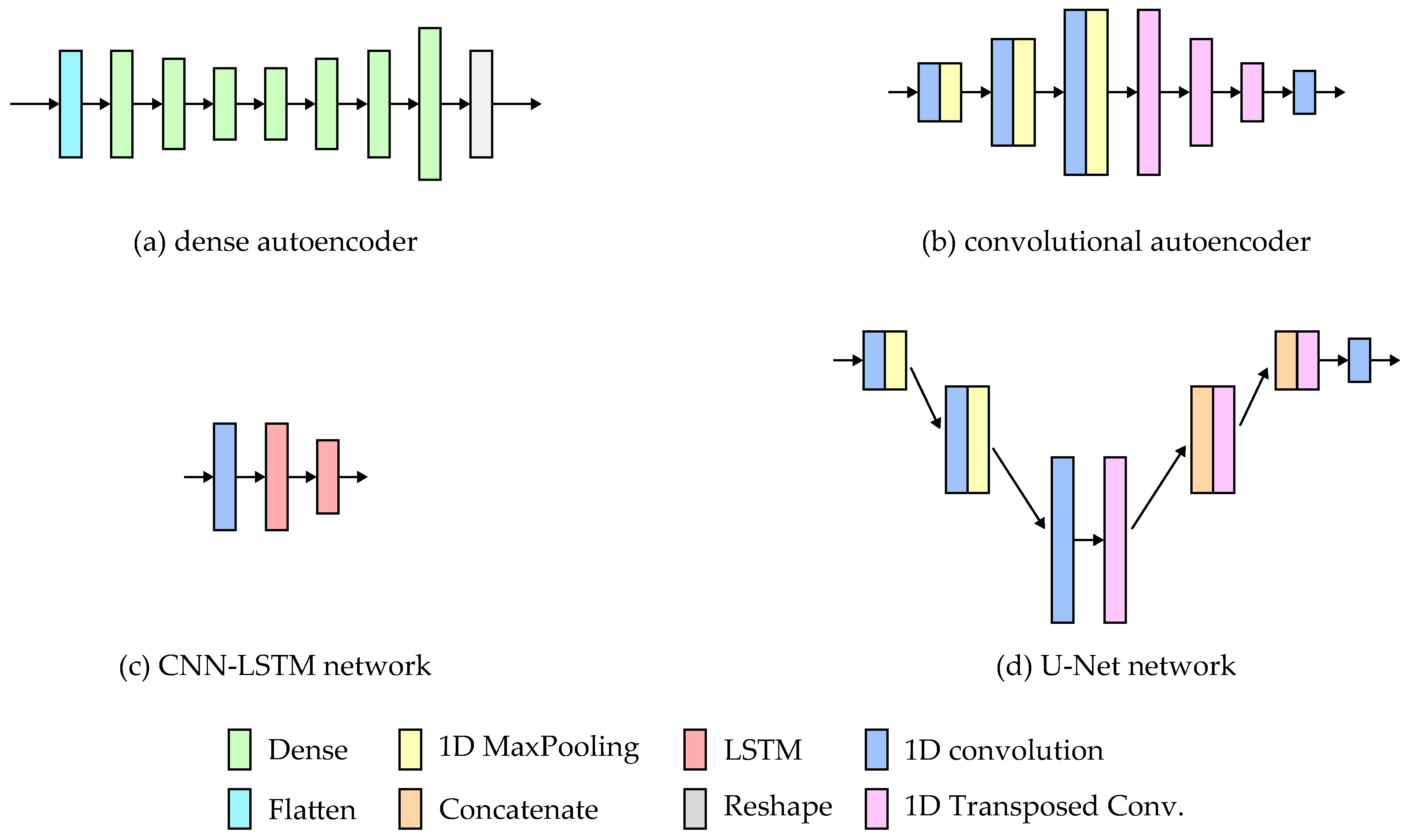
The paper presents and evaluates the concept of inertial measurement translation between different sensor locations. For this purpose, four different neural network architectures were implemented and tested on a custom dataset. The analyzed architectures included FC and CNN autoencoders, a CNN-LSTM network, and a U-Net network. The most accurate signal translation was achieved using the U-Net and CNN encoder networks. In the case of the DNN, the results were less accurate but still usable for wrist-to-shoe translation. The CNN-LSTM architecture proved to be unsuitable for such a task due to severe problems with proper signal spike reproduction. The translation to the tibia-worn sensor signals proved more challenging for all tested architectures. This might be caused by less consistent tibia sensor placement and orientation. An efficient translation to the tibia sensor signals might require using more advanced ML models or expanding the training dataset with additional examples.
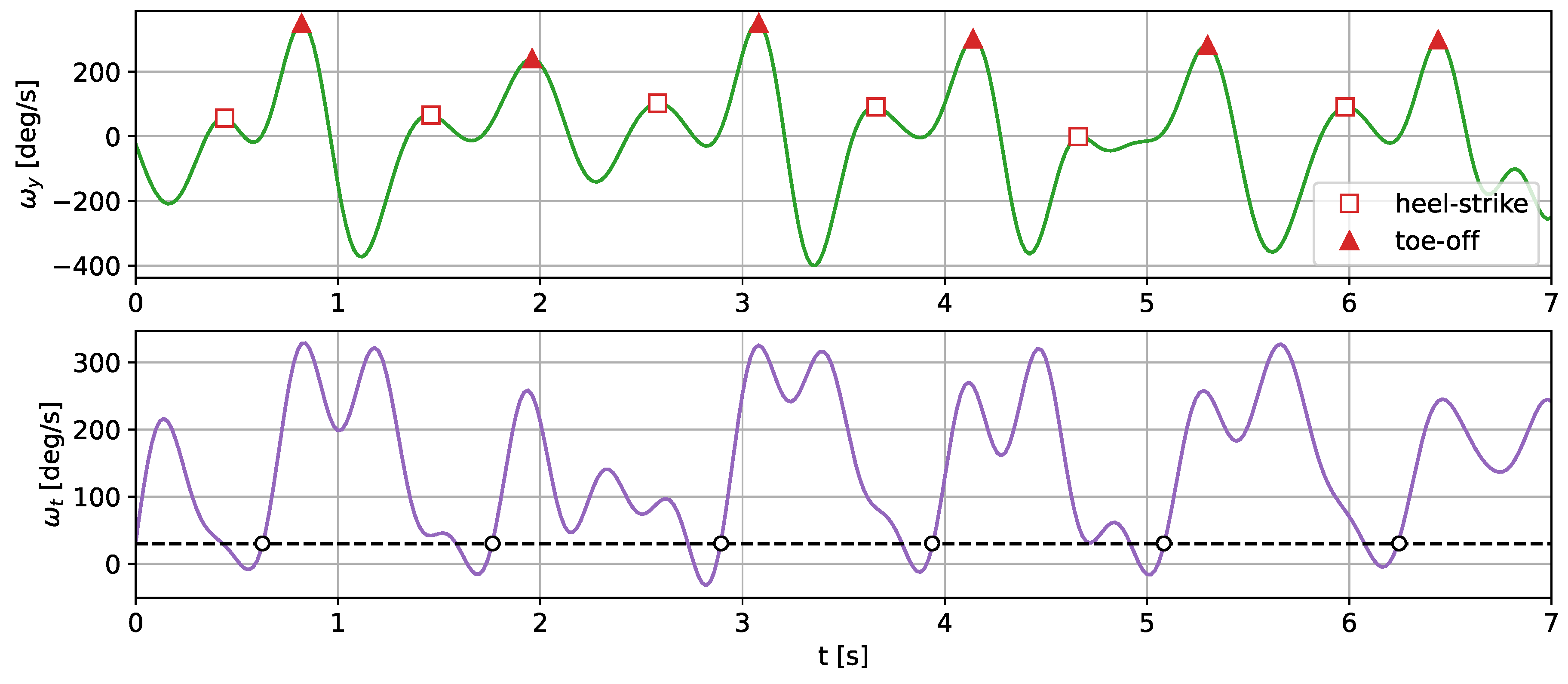
The results of the performed experiments are promising. The translated results were successfully used to assess the gait parameters of a person walking a 10 m straight path. The differences between the obtained gait and stride durations based on the translated and shoe-worn sensor registered signals were small. The proposed translation algorithm opens an opportunity to use much more common and comfortable wrist-worn sensors (smartwatches or smart bands) and still apply the proven, high-accuracy methods relying on lower limb measurements.
The proposed translation algorithm is a simple one and was used mainly to prove signal translation’s efficiency in gait estimation. There are several areas in which the proposed solution could be improved. First, the translation could be made more accurate by employing other more advanced neural network architectures processing some additional data, e.g., atmospheric pressure. The models could also be modified to output only the selected signals needed by the particular methods instead of all of the components. Additionally, the training efficiency might be improved by using custom loss functions more targeted at the problem. For example, when the method requires signal peaks to be reconstructed with high accuracy, the loss function should focus on that while relaxing the requirements for idle moments. The introduced improvements, however, should be carried out with the algorithm complexity in mind, as excessive complexity might prevent its deployment to wearable devices.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}