
Evaluation of Malware Classification Models for Heterogeneous Data


Abstract
1. Introduction
2. Background
2.1. Types of Model Verification
2.2. Types of Malware Classifiers
2.3. Overview of LIME
3. Methods
3.1. Malware Classifier Explanations
3.2. Mitigating the Influence of Adversarial Examples Using Vadam
Example 1: Malware Classification with Neural Networks
4. Results
4.1. Settings
4.2. Model and Time Complexity
4.3. Classifiers
4.4. Datasets
4.5. Model Evaluation
4.6. Results for Dynamic Analyzer
4.7. Results for Static Analyzer
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Saxe, J.; Berlin, K. Deep neural network based malware detection using two dimensional binary program features. In Proceedings of the 2015 10th International Conference on Malicious and Unwanted Software (MALWARE), Fajardo, PR, USA, 20–22 October 2015; pp. 11–20. [Google Scholar]
- Yuan, Z.; Lu, Y.; Wang, Z.; Xue, Y. Droid-sec: Deep learning in android malware detection. In Proceedings of the 2014 ACM Conference on SIGCOMM, Chicago, IL, USA, 17–22 August 2014; Volume 44, pp. 371–372. [Google Scholar]
- Bayer, U.; Comparetti, P.M.; Hlauschek, C.; Kruegel, C.; Kirda, E. Scalable, behavior-based malware clustering. In Proceedings of the 16th Annual Network & Distributed System Security Symposium (NDSS 2009), San Diego, CA, USA, 8–11 February 2009; Volume 9, pp. 8–11. [Google Scholar]
- Jang, J.; Brumley, D.; Venkataraman, S. Bitshred: Feature hashing malware for scalable triage and semantic analysis. In Proceedings of the 18th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 17–21 October 2011; pp. 309–320. [Google Scholar]
- Cova, M.; Kruegel, C.; Vigna, G. Detection and analysis of drive-by-download attacks and malicious JavaScript code. In Proceedings of the 19th International Conference on World Wide Web, Raleigh North, CO, USA, 26–30 April 2010; pp. 281–290. [Google Scholar]
- Rajab, M.A.; Ballard, L.; Lutz, N.; Mavrommatis, P.; Provos, N. CAMP: Content-agnostic malware protection. In Proceedings of the 20th Annual Network and Distributed System Security Symposium (NDSS 2013), San Diego, CA, USA, 24–27 February 2013. [Google Scholar]
- Egele, M.; Stringhini, G.; Kruegel, C.; Vigna, G. Compa: Detecting compromised accounts on social networks. In Proceedings of the 20th Annual Network and Distributed System Security Symposium (NDSS 2013), San Diego, CA, USA, 24–27 February 2013. [Google Scholar]
- Stringhini, G.; Kruegel, C.; Vigna, G. Shady paths: Leveraging surfing crowds to detect malicious web pages. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, Berlin, Germany, 4–8 November 2013; pp. 133–144. [Google Scholar]
- Schlumberger, J.; Kruegel, C.; Vigna, G. Jarhead analysis and detection of malicious Java applets. In Proceedings of the 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 3–7 December 2012; pp. 249–257. [Google Scholar]
- Laskov, P.; Šrndić, N. Static detection of malicious JavaScript-bearing PDF documents. In Proceedings of the 27th Annual Computer Security Applications Conference, Orlando, FL, USA, 5–9 December 2011; pp. 373–382. [Google Scholar]
- Kakavelakis, G.; Young, J. Auto-learning of SMTP TCP Transport-Layer Features for Spam and Abusive Message Detection. In Proceedings of the 25th International Conference on Large Installation System Administration (LISA’25), Boston, MA, USA, 4–9 December 2011; p. 18. [Google Scholar]
- Šrndic, N.; Laskov, P. Detection of malicious pdf files based on hierarchical document structure. In Proceedings of the 20th Annual Network & Distributed System Security Symposium, San Diego, CA, USA, 24–27 February 2013; pp. 1–16. [Google Scholar]
- Smutz, C.; Stavrou, A. Malicious PDF detection using metadata and structural features. In Proceedings of the 28th Annual Computer Security Applications Conference, Orlando, FL, USA, 3–7 December 2012; pp. 239–248. [Google Scholar]
- Smutz, C.; Stavrou, A. When a Tree Falls: Using Diversity in Ensemble Classifiers to Identify Evasion in Malware Detectors. In Proceedings of the The Network and Distributed System Security Symposium 2016, San Diego, CA, USA, 21–24 February 2016. [Google Scholar]
- Šrndić, N.; Laskov, P. Hidost: A static machine-learning-based detector of malicious files. EURASIP J. Inf. Secur. 2016, 2016, 22. [Google Scholar] [CrossRef]
- A Perfect Score’: Sonicwall Capture ATP Aces Latest ICSA Lab Test, Finds More ‘Never-Before-Seen’ Malware than Ever. 2019. Available online: https://www.sonicwall.com/news/sonicwall-capture-atp-aces-icsa-lab-test/ (accessed on 3 November 2023).
- Chen, Y.; Wang, S.; She, D.; Jana, S. On training robust PDF malware classifiers. In Proceedings of the 29th USENIX Security Symposium (USENIX Security 20), Berkeley, CA, USA, 12–14 August 2020; pp. 2343–2360. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial machine learning at scale. arXiv 2016, arXiv:1611.01236. [Google Scholar]
- Alfeld, S.; Zhu, X.; Barford, P. Data Poisoning Attacks against Autoregressive Models. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16), Phoenix, AZ, USA, 12–17 February 2016; pp. 1452–1458. [Google Scholar]
- Huang, S.; Papernot, N.; Goodfellow, I.; Duan, Y.; Abbeel, P. Adversarial attacks on neural network policies. arXiv 2017, arXiv:1702.02284. [Google Scholar]
- Hu, W.; Tan, Y. Generating adversarial malware examples for black-box attacks based on GAN. arXiv 2017, arXiv:1702.05983. [Google Scholar]
- Heiderich, M.; Niemietz, M.; Schuster, F.; Holz, T.; Schwenk, J. Scriptless attacks: Stealing the pie without touching the sill. In Proceedings of the 2012 ACM Conference on Computer and Communications Security, Raleigh North, CO, USA, 16–18 October 2012; pp. 760–771. [Google Scholar]
- Shacham, H. The geometry of innocent flesh on the bone: Return-into-libc without function calls (on the x86). In Proceedings of the ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 31 October–2 November 2007; pp. 552–561. [Google Scholar]
- Šrndić, N.; Laskov, P. Practical evasion of a learning-based classifier: A case study. In Proceedings of the 2014 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 18–21 May 2014; pp. 197–211. [Google Scholar]
- Chen, C.; Li, O.; Tao, D.; Barnett, A.; Rudin, C.; Su, J.K. This looks like that: Deep learning for interpretable image recognition. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8930–8941. [Google Scholar]
- Alvarez Melis, D.; Jaakkola, T. Towards robust interpretability with self-explaining neural networks. Adv. Neural Inf. Process. Syst. 2018, 31, 7775–7784. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Shrikumar, A.; Greenside, P.; Kundaje, A. Learning Important Features Through Propagating Activation Differences. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 3145–3153. [Google Scholar]
- Yin, B.; Tran, L.; Li, H.; Shen, X.; Liu, X. Towards interpretable face recognition. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9348–9357. [Google Scholar]
- Williford, J.R.; May, B.B.; Byrne, J. Explainable Face Recognition. arXiv 2020, arXiv:2008.00916. [Google Scholar]
- Sundararajan, M.; Taly, A.; Yan, Q. Axiomatic attribution for deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 70, pp. 3319–3328. [Google Scholar]
- Lundberg, S.M.; Lee, S.I. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4768–4777. [Google Scholar]
- Vitali Petsiuk, A.D.; Saenko, K. Rise: Randomized input sampling for explanation of black-box models. In Proceedings of the 2018 British Machine Vision Conference, Newcastle, UK, 3–6 September 2018. [Google Scholar]
- Lakkaraju, H.; Kamar, E.; Caruana, R.; Leskovec, J. Faithful and customizable explanations of black box models. In Proceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society, Honolulu, HI, USA, 27–28 January 2019; pp. 131–138. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Model-agnostic interpretability of machine learning. arXiv 2016, arXiv:1606.05386. [Google Scholar]
- Hancox-Li, L. Robustness in machine learning explanations: Does it matter? In Proceedings of the 2020 Conference on Fairness, Accountability, and Transparency, Barcelona, Spain, 27–30 January 2020; pp. 640–647. [Google Scholar]
- FreeDesktop.org. Poppler. 2018. Available online: https://poppler.freedesktop.org/releases.html (accessed on 3 November 2023).
- Maiorca, D.; Corona, I.; Giacinto, G. Looking at the bag is not enough to find the bomb: An evasion of structural methods for malicious pdf files detection. In Proceedings of the 8th ACM SIGSAC Symposium on Information, Computer and Communications Security, Hangzhou, China, 8–10 May 2013; pp. 119–130. [Google Scholar]
- Xu, W.; Qi, Y.; Evans, D. Automatically evading classifiers. In Proceedings of the 2016 Network and Distributed Systems Symposium, San Diego, CA, USA, 21–24 February 2016; pp. 21–24. [Google Scholar]
- Dang, H.; Huang, Y.; Chang, E.C. Evading classifiers by morphing in the dark. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security, Dallas, TX, USA, 30 October–3 November 2017; pp. 119–133. [Google Scholar]
- Islam, R.; Tian, R.; Batten, L.; Versteeg, S. Classification of malware based on string and function feature selection. In Proceedings of the 2010 Second Cybercrime and Trustworthy Computing Workshop, Ballarat, VIC, Australia, 19–20 July 2010; pp. 9–17. [Google Scholar]
- Islam, R.; Tian, R.; Batten, L.M.; Versteeg, S. Classification of malware based on integrated static and dynamic features. J. Netw. Comput. Appl. 2013, 36, 646–656. [Google Scholar] [CrossRef]
- Fang, Y.; Yu, B.; Tang, Y.; Liu, L.; Lu, Z.; Wang, Y.; Yang, Q. A new malware classification approach based on malware dynamic analysis. In Proceedings of the Australasian Conference on Information Security and Privacy, Auckland, New Zealand, 3–5 July 2017; pp. 173–189. [Google Scholar]
- Agrawal, R.; Stokes, J.W.; Marinescu, M.; Selvaraj, K. Neural sequential malware detection with parameters. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2656–2660. [Google Scholar]
- Zhang, Z.; Qi, P.; Wang, W. Dynamic Malware Analysis with Feature Engineering and Feature Learning. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 1210–1217. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep Inside Convolutional Networks: Visualising Image Classification Models and Saliency Maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Weinberger, K.; Dasgupta, A.; Langford, J.; Smola, A.; Attenberg, J. Feature hashing for large scale multitask learning. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 1113–1120. [Google Scholar]
- Bender, C.; Li, Y.; Shi, Y.; Reiter, M.K.; Oliva, J. Defense Through Diverse Directions. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 756–766. [Google Scholar]
- Khan, M.E.; Lin, W. Conjugate-computation variational inference: Converting variational inference in non-conjugate models to inferences in conjugate models. arXiv 2017, arXiv:1703.04265. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Exploit-Database. 2020. Available online: https://www.exploit-db.com/search (accessed on 3 November 2023).
- Damodaran, A.; Di Troia, F.; Visaggio, C.A.; Austin, T.H.; Stamp, M. A comparison of static, dynamic, and hybrid analysis for malware detection. J. Comput. Virol. Hacking Tech. 2017, 13, 1–12. [Google Scholar] [CrossRef]
- Ahmed, F.; Hameed, H.; Shafiq, M.Z.; Farooq, M. Using spatio-temporal information in API calls with machine learning algorithms for malware detection. In Proceedings of the 2nd ACM Workshop on Security and Artificial Intelligence, Chicago, IL, USA, 9 November 2009; pp. 55–62. [Google Scholar]
- Liu, W.; Ren, P.; Liu, K.; Duan, H.x. Behavior-based malware analysis and detection. In Proceedings of the 2011 First International Workshop on Complexity and Data Mining, Nanjing, China, 24–28 September 2011; pp. 39–42. [Google Scholar]
- Lee, H.; Bae, H.; Yoon, S. Gradient Masking of Label Smoothing in Adversarial Robustness. IEEE Access 2020, 9, 6453–6464. [Google Scholar] [CrossRef]
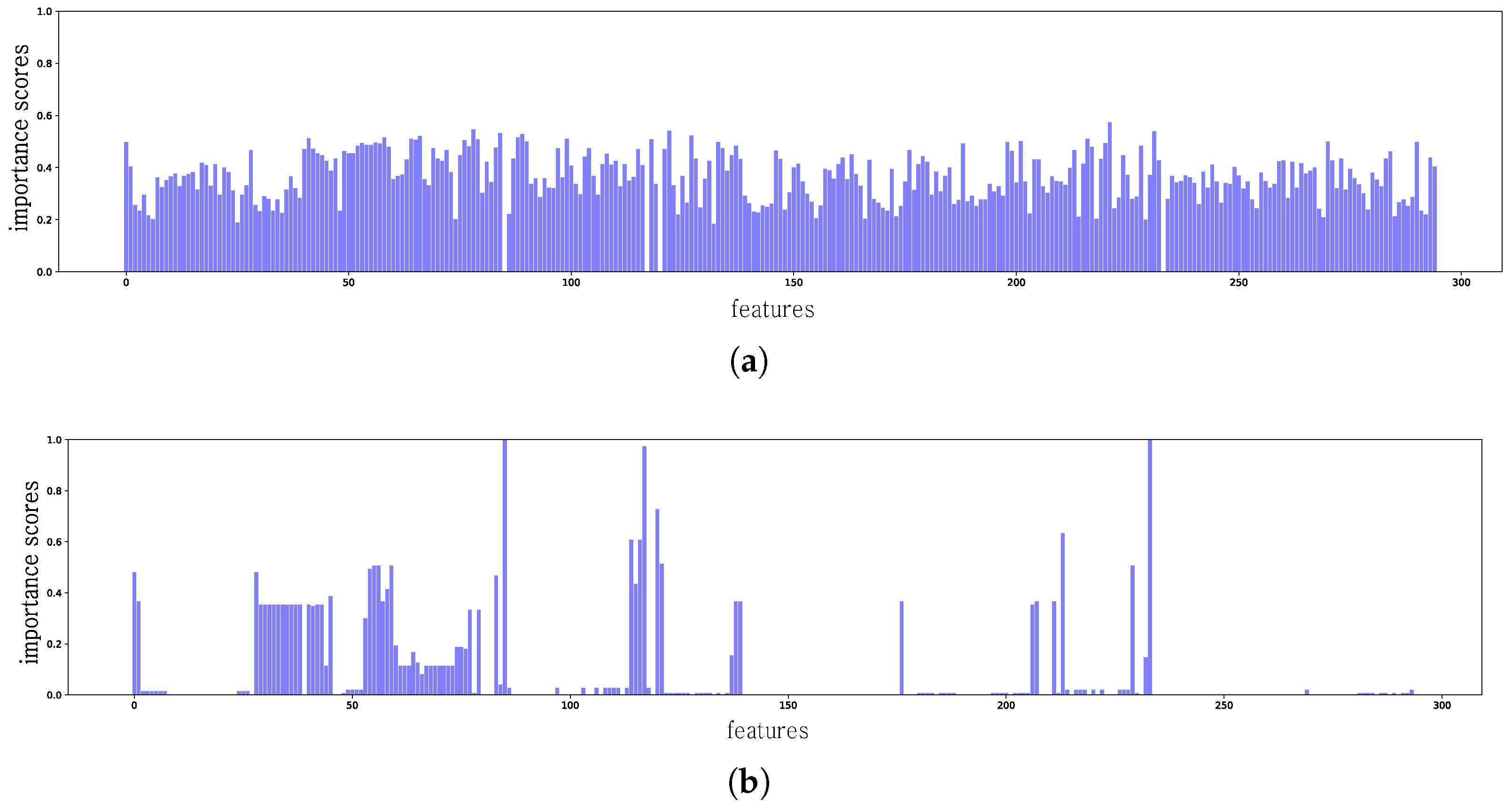

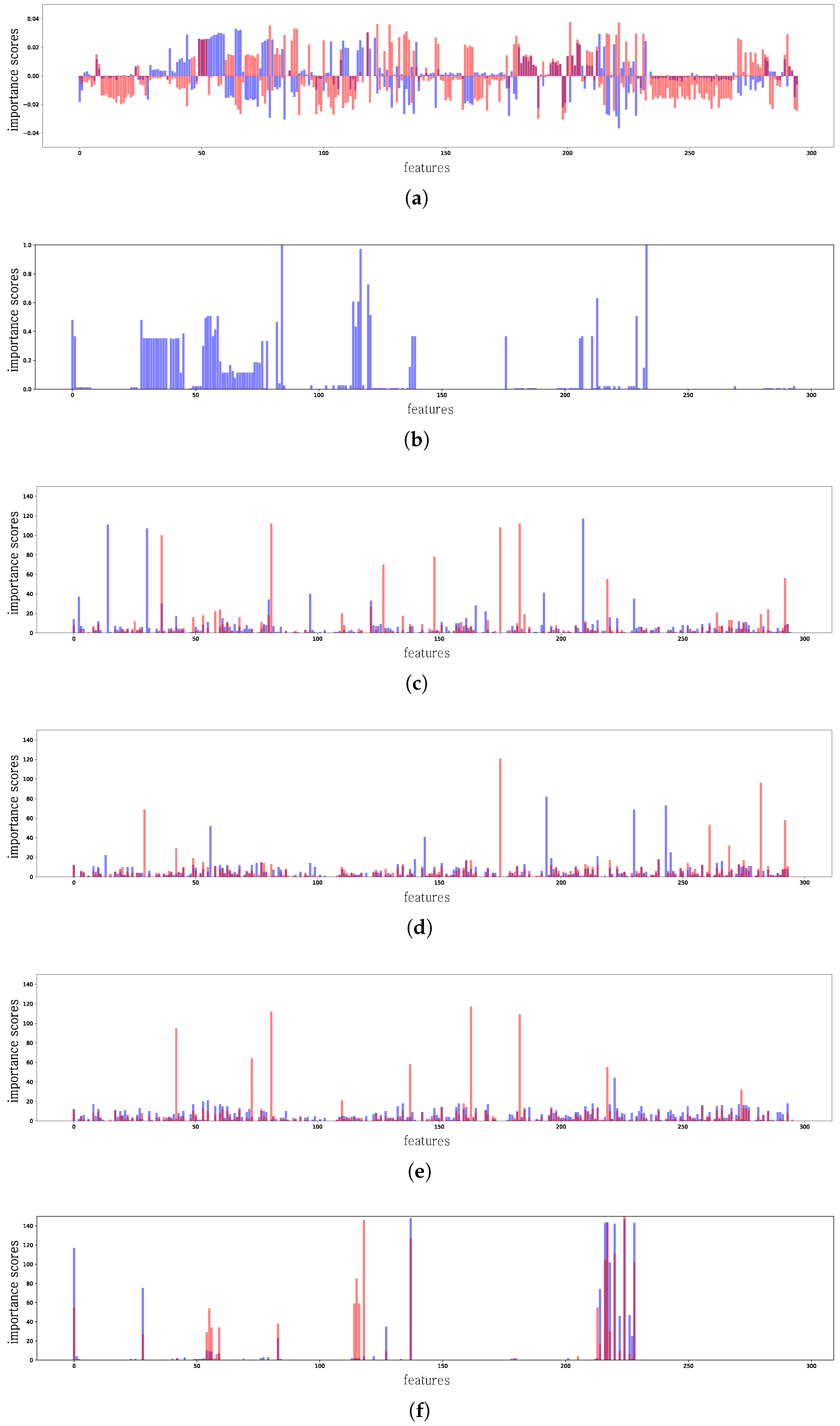

{kind=link}
{kind=link}
{kind=link}
| Feature Name | Types | Dimension |
|---|---|---|
| API name | Strings | 8 |
| API category | Strings | 4 |
| API arguments | ||
| Integer | Integers | 16 |
| Paths | Strings | 16 |
| DLLs | Strings | 8 |
| RegistryKeys | Strings | 12 |
| URLs | Strings | 16 |
| IPs | Strings | 12 |
| String stats | Strings | 10 |
| Classifiers | Accuracy | AUC |
|---|---|---|
| SVM (Hidost 13’) | 96.46% | 0.9886 |
| RF (Hidost 16’) | 96.45% | 0.9880 |
| Ensemble (PDFrate-v2) | 99.37% | 0.9932 |
| Neural nets (PE-based) | 99.93% | 0.9999 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bae, H. Evaluation of Malware Classification Models for Heterogeneous Data. Sensors 2024, 24, 288. https://doi.org/10.3390/s24010288
Bae H. Evaluation of Malware Classification Models for Heterogeneous Data. Sensors. 2024; 24(1):288. https://doi.org/10.3390/s24010288
Chicago/Turabian StyleBae, Ho. 2024. "Evaluation of Malware Classification Models for Heterogeneous Data" Sensors 24, no. 1: 288. https://doi.org/10.3390/s24010288
APA StyleBae, H. (2024). Evaluation of Malware Classification Models for Heterogeneous Data. Sensors, 24(1), 288. https://doi.org/10.3390/s24010288