
Off-Screen Sound Separation Based on Audio-visual Pre-training Using Binaural Audio


Abstract
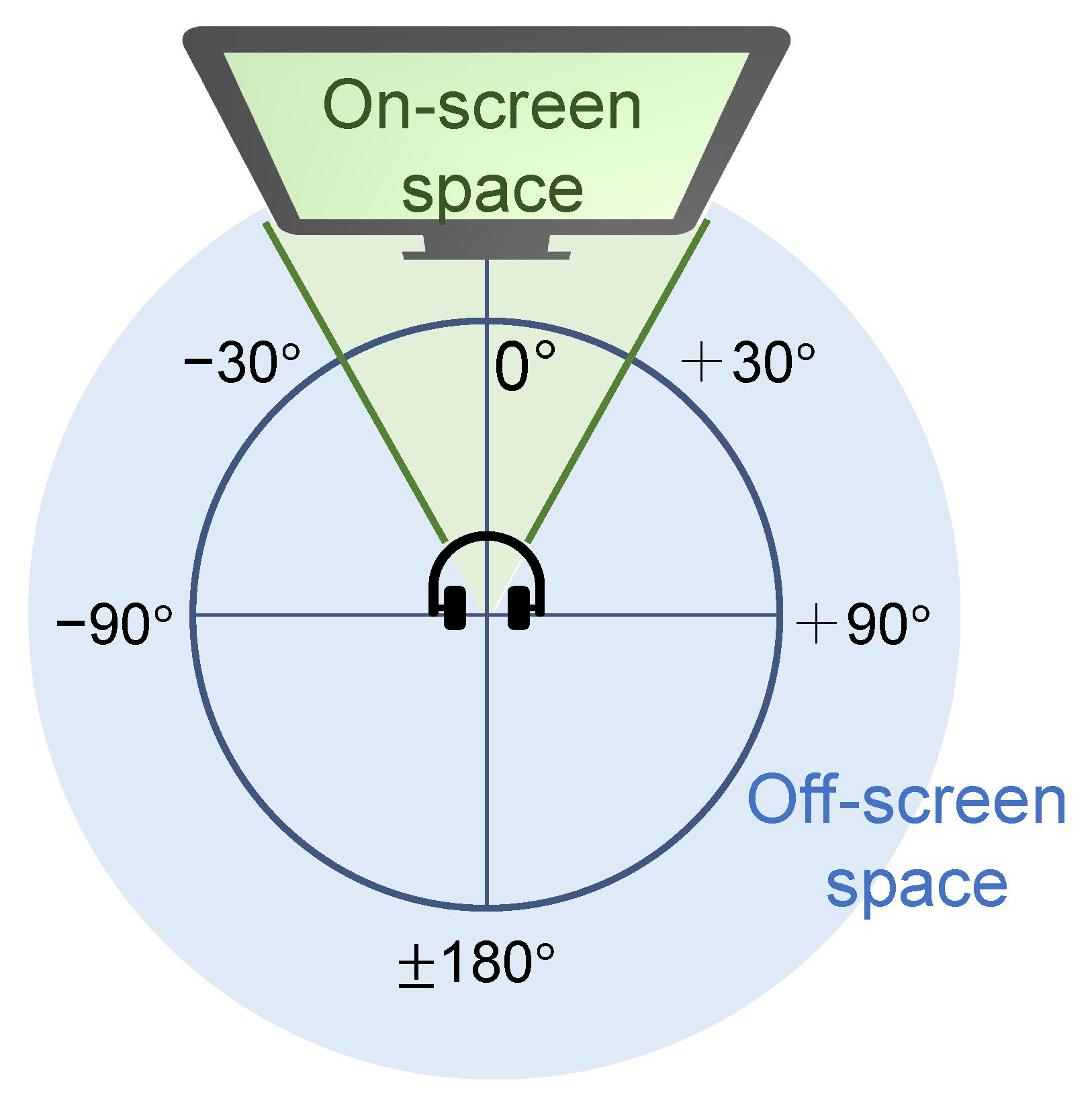
1. Introduction
2. Related Works
2.1. Audio-Visual Source Separation
2.2. Pre-Training in Videos
2.3. Audio-Visual Learning Using Binaural Audio
3. Proposed Method
- Phase (a)
- We generated data for use in subsequent phases. Specifically, we generated labels for Phase (b) and the ground truth for Phase (c). ( Section 3.1)
- Phase (b)
- We conducted pre-training to obtain an effective audio-visual representation for OSS separation. The task was the detection of OSSs. (Section 3.2)
- Phase (c)
- We trained a model for separating OSSs, which is the primary objective of our method. (Section 3.3)
3.1. Synthesizing Off-Screen Sound
3.2. Obtaining a Pre-Trained Audio-Visual Representation
3.3. OSS Separation
4. Experiments
4.1. OSS Detection
4.1.1. Settings
- (1)
- Audio without any OSS.
- (2)
- Audio converted to mono from the entire audio described in (1).
- (3)
- Audio with OSS.
- (4)
- Audio with OSS. The OSS in this case was created by manipulating the arrival direction of the on-screen sound. Here, because the semantic information about on-screen sounds and OSSs was the same, only the spatial information about the sound was used for detection.
- (5)
- Audio that did not visually appear on the screen but arrived from the on-screen direction.
- (6)
- Audio converted to mono from the entire audio described in (3).
4.1.2. Experimental Results
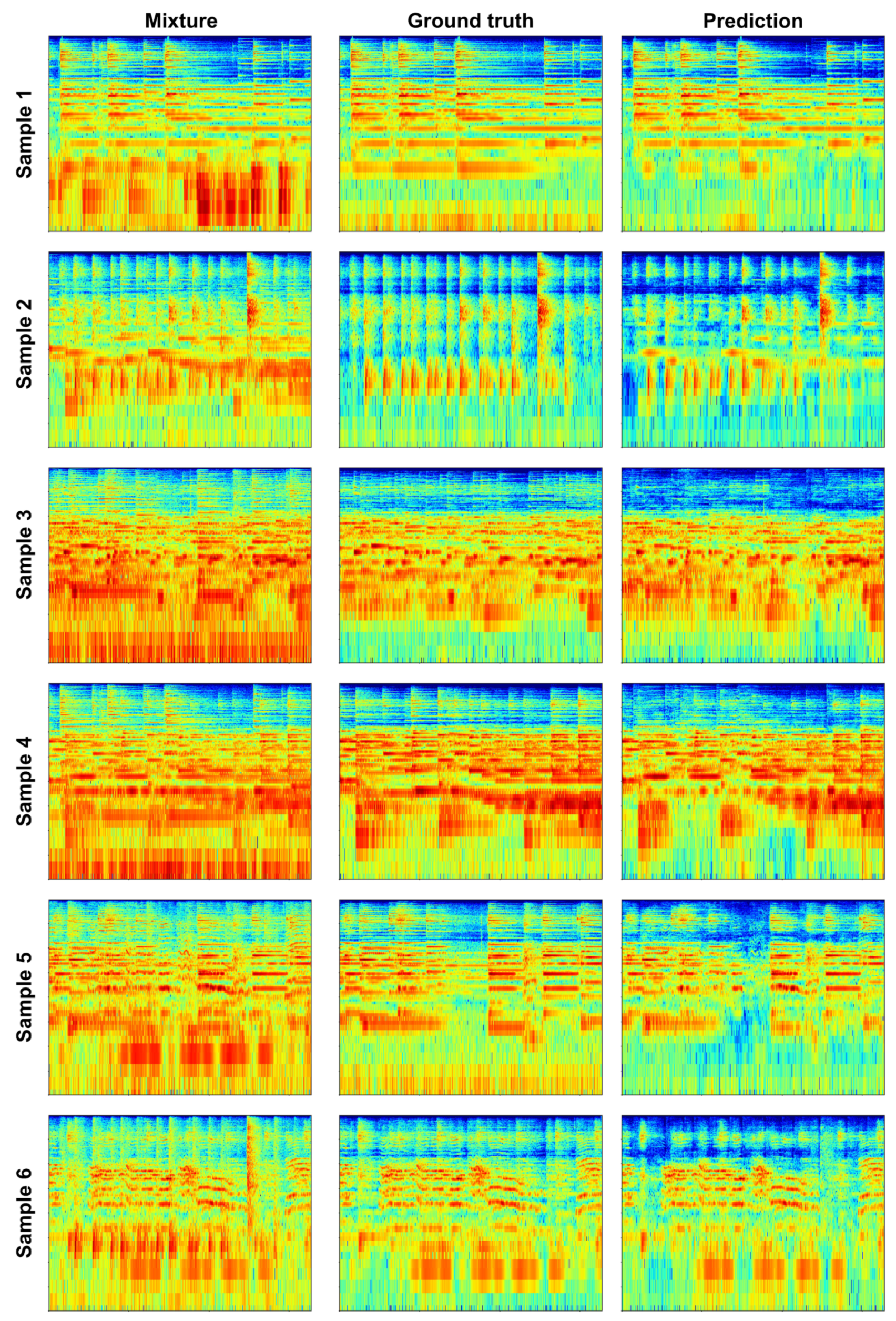
4.2. OSS Separation
4.2.1. Settings
- CM1.
- This method [7] uses the mix-and-separate framework and visual information for separation.
- CM2.
- This method [8] first detects and obtains candidates of sound sources and uses the detected results for separation.
- CM3.
- This method is solely based on semantic representation learning [11].
- CM4.
- This method is solely based on spatial representation learning [13].
- AB1.
- For the ablation studies, this method uses a randomly initialized feature without pre-training.
- AB2.
- For ablation studies, this method uses a feature obtained from mono learning as described in Section 4.1.
- AB3.
- For ablation studies, this method removes the visual subnetwork and uses only audio information. This method uses the feature obtained from the no-visual learning in Section 4.1.
4.2.2. Experimental Results
5. Limitation and Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cherry, E.C. Some experiments on the recognition of speech, with one and with two ears. J. Acoust. Soc. Am. 1953, 25, 975–979. [Google Scholar] [CrossRef]
- Arons, B. A review of the cocktail party effect. J. Am. Voice I/O Soc. 1992, 12, 35–50. [Google Scholar]
- Holmes, N.P.; Spence, C. Multisensory integration: Space, time and superadditivity. Curr. Biol. 2005, 15, 762–764. [Google Scholar] [CrossRef] [PubMed]
- Shimojo, S.; Shams, L. Sensory modalities are not separate modalities: Plasticity and interactions. Curr. Opin. Neurobiol. 2001, 11, 505–509. [Google Scholar] [CrossRef] [PubMed]
- Ephrat, A.; Mosseri, I.; Lang, O.; Dekel, T.; Wilson, K.; Hassidim, A.; Freeman, W.T.; Rubinstein, M. Looking to Listen at the Cocktail Party: A Speaker-Independent Audio-Visual Model for Speech Separation. ACM Trans. Graph. 2018, 37, 1–11. [Google Scholar] [CrossRef]
- Lu, R.; Duan, Z.; Zhang, C. Audio—Visual Deep Clustering for Speech Separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1697–1712. [Google Scholar] [CrossRef]
- Zhao, H.; Gan, C.; Rouditchenko, A.; Vondrick, C.; McDermott, J.; Torralba, A. The sound of pixels. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 570–586. [Google Scholar]
- Gao, R.; Grauman, K. Co-separating sounds of visual objects. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 3879–3888. [Google Scholar]
- Tzinis, E.; Wisdom, S.; Jansen, A.; Hershey, S.; Remez, T.; Ellis, D.; Hershey, J.R. Into the Wild with AudioScope: Unsupervised Audio-Visual Separation of On-Screen Sounds. In Proceedings of the International Conference on Learning Representations (ICLR), Virtual Event, Austria, 3–7 May 2021. [Google Scholar]
- Tzinis, E.; Wisdom, S.; Remez, T.; Hershey, J.R. Improving On-Screen Sound Separation for Open-Domain Videos with Audio-Visual Self-Attention. arXiv 2021, arXiv:2106.09669. [Google Scholar]
- Arandjelovic, R.; Zisserman, A. Look, listen and learn. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 609–617. [Google Scholar]
- Owens, A.; Efros, A.A. Audio-visual scene analysis with self-supervised multisensory features. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 631–648. [Google Scholar]
- Yang, K.; Russell, B.; Salamon, J. Telling left from right: Learning spatial correspondence of sight and sound. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 9932–9941. [Google Scholar]
- Ramachandram, D.; Taylor, G.W. Deep multimodal learning: A survey on recent advances and trends. IEEE Signal Process. Mag. 2017, 34, 96–108. [Google Scholar] [CrossRef]
- Barakabitze, A.A.; Barman, N.; Ahmad, A.; Zadtootaghaj, S.; Sun, L.; Martini, M.G.; Atzori, L. QoE management of multimedia streaming services in future networks: A tutorial and survey. IEEE Commun. Surv. Tutor. 2019, 22, 526–565. [Google Scholar] [CrossRef]
- Zhou, H.; Liu, Y.; Liu, Z.; Luo, P.; Wang, X. Talking face generation by adversarially disentangled audio-visual representation. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019. [Google Scholar]
- Gao, R.; Grauman, K. 2.5D visual sound. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–17 June 2019; pp. 324–333. [Google Scholar]
- Dávila-Chacón, J.; Liu, J.; Wermter, S. Enhanced robot speech recognition using biomimetic binaural sound source localization. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 138–150. [Google Scholar] [CrossRef] [PubMed]
- Tian, Y.; Hu, D.; Xu, C. Cyclic co-learning of sounding object visual grounding and sound separation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 2745–2754. [Google Scholar]
- Owens, A.; Wu, J.; McDermott, J.H.; Freeman, W.T.; Torralba, A. Ambient sound provides supervision for visual learning. In Proceedings of the IEEE European Conference Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 801–816. [Google Scholar]
- Rayleigh, L. On Our Perception of the Direction of a Source of Sound. Proc. Music. Assoc. 1875, 2, 75–84. [Google Scholar] [CrossRef]
- Wightman, F.L.; Kistler, D.J. The dominant role of low-frequency interaural time differences in sound localization. J. Acoust. Soc. Am. 1992, 91, 1648–1661. [Google Scholar] [CrossRef] [PubMed]
- Yin, T.C. Neural mechanisms of encoding binaural localization cues in the auditory brainstem. In Integrative Functions in the Mammalian Auditory Pathway; Springer: Berlin/Heidelberg, Germany, 2002; pp. 99–159. [Google Scholar]
- Lyon, R. A computational model of binaural localization and separation. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Boston, MA, USA, 14–16 April 1983; Volume 8, pp. 1148–1151. [Google Scholar]
- Morgado, P.; Li, Y.; Nvasconcelos, N. Learning Representations from Audio-Visual Spatial Alignment. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Volume 33, pp. 4733–4744. [Google Scholar]
- Wu, X.; Wu, Z.; Ju, L.; Wang, S. Binaural Audio-Visual Localization. In Proceedings of the Conference AAAI Artificial Intelligence, Virtually, 2–9 February 2021; Volume 35, pp. 2961–2968. [Google Scholar]
- Xu, X.; Zhou, H.; Liu, Z.; Dai, B.; Wang, X.; Lin, D. Visually informed binaural audio generation without binaural audios. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 15485–15494. [Google Scholar]
- Vasudevan, A.B.; Dai, D.; Van Gool, L. Semantic object prediction and spatial sound super-resolution with binaural sounds. In Proceedings of the IEEE European Conference Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 638–655. [Google Scholar]
- SEYA, Y.; WATANABE, K. Objective and Subjective Sizes of the Effective Visual Field during Game Playing Measured by the Gaze-contingent Window Method. Int. J. Affect. Eng. 2013, 12, 11–19. [Google Scholar] [CrossRef]
- Courant, R.; Hilbert, D. Methods of Mathematical Physics: Partial Differential Equations; John Wiley & Sons: Hoboken, NJ, USA, 2008. [Google Scholar]
- Begault, D.R. 3-D Sound for Virtual Reality and Multimedia; Academic Press: Cambridge, UK, 1994. [Google Scholar]
- Algazi, V.R.; Duda, R.O.; Thompson, D.M.; Avendano, C. The cipic hrtf database. In Proceedings of the IEEE Workshop Applications Signal Processing Audio Acoustics (WASPAA), New Paltz, NY, USA, 17–20 October 2001; pp. 99–102. [Google Scholar]
- Noisternig, M.; Sontacchi, A.; Musil, T.; Holdrich, R. A 3D ambisonic based binaural sound reproduction system. J. Audio Eng. Soc. 2003. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Zhao, H.; Gallo, O.; Frosio, I.; Kautz, J. Loss functions for image restoration with neural networks. IEEE Trans. Comput. Imaging 2016, 3, 47–57. [Google Scholar] [CrossRef]
- Weinrich, S. The problem of front-back localization in binaural hearing. Scand. Audiol. Suppl. 1982, 15, 135–145. [Google Scholar] [PubMed]
- Middlebrooks, J.C.; Green, D.M. Sound localization by human listeners. Annu. Rev. Psychol. 1991, 42, 135–159. [Google Scholar] [CrossRef] [PubMed]
- Scheibler, R.; Bezzam, E.; Dokmanić, I. Pyroomacoustics: A python package for audio room simulation and array processing algorithms. In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 351–355. [Google Scholar]
- Le Roux, J.; Wisdom, S.; Erdogan, H.; Hershey, J.R. SDR–Half-baked or well done? In Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 626–630. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Chen, C.; Jain, U.; Schissler, C.; Gari, S.V.A.; Al-Halah, Z.; Ithapu, V.K.; Robinson, P.; Grauman, K. Soundspaces: Audio-visual navigation in 3D environments. In Proceedings of the IEEE European Conference Computer Vision (ECCV), Glasgow, UK, 23–28 August 2020; pp. 17–36. [Google Scholar]
- Savva, M.; Kadian, A.; Maksymets, O.; Zhao, Y.; Wijmans, E.; Jain, B.; Straub, J.; Liu, J.; Koltun, V.; Malik, J.; et al. Habitat: A platform for embodied ai research. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9339–9347. [Google Scholar]
- Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Niessner, M.; Savva, M.; Song, S.; Zeng, A.; Zhang, Y. Matterport3D: Learning from RGB-D Data in Indoor Environments. In Proceedings of the International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2019; pp. 9339–9347. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| w/o OSS | w/ OSS | w/ Pseudo-OSS | AUC | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Case | (1) | (2) | (3) | (4) | (5) | (6) | ||||
| Ours | 0.96 | 0.95 | 0.88 | 0.76 | 0.96 | 0.97 | 0.94 | |||
| Mono learning | 0.25 | 0.24 | 0.92 | 0.79 | 0.05 | 0.05 | 0.53 | |||
| No visuals | 0.11 | 0.08 | 0.94 | 0.89 | 0.09 | 0.01 | 0.60 | |||
| Method | Ave | ||||||
|---|---|---|---|---|---|---|---|
| CM1 [7] | 1.043 | 1.045 | 1.066 | 1.076 | 1.086 | 1.064 | 1.063 |
| CM2 [8] | 0.942 | 0.929 | 0.930 | 0.940 | 0.946 | 0.960 | 0.941 |
| CM3 [11] | 0.231 | 0.176 | 0.149 | 0.144 | 0.143 | 0.136 | 0.163 |
| CM4 [13] | 0.203 | 0.177 | 0.160 | 0.150 | 0.158 | 0.139 | 0.165 |
| AB1 | 0.286 | 0.185 | 0.161 | 0.156 | 0.140 | 0.132 | 0.177 |
| AB2 | 0.234 | 0.178 | 0.158 | 0.147 | 0.140 | 0.134 | 0.165 |
| AB3 | 0.258 | 0.208 | 0.164 | 0.152 | 0.146 | 0.132 | 0.176 |
| BF1 | 0.491 | 1.727 | 0.494 | 1.727 | 0.491 | 0.604 | 0.922 |
| BF2 | 0.354 | 0.583 | 0.306 | 0.583 | 0.354 | 0.606 | 0.464 |
| PM | 0.201 | 0.176 | 0.144 | 0.140 | 0.136 | 0.130 | 0.155 |
| Method | Ave | ||||||
|---|---|---|---|---|---|---|---|
| CM1 [7] | −2.9 | −2.5 | −2.6 | −2.7 | −2.8 | −3.7 | −2.9 |
| CM2 [8] | −2.7 | −2.5 | −2.5 | −2.5 | −2.5 | −2.5 | −2.5 |
| CM3 [11] | 4.0 | 5.3 | 5.8 | 5.8 | 5.7 | 5.7 | 5.4 |
| CM4 [13] | 4.8 | 5.3 | 5.5 | 5.6 | 5.1 | 5.6 | 5.3 |
| AB1 | 3.0 | 5.2 | 5.5 | 5.5 | 5.7 | 5.8 | 5.1 |
| AB2 | 3.9 | 5.1 | 5.5 | 5.6 | 5.6 | 5.7 | 5.2 |
| AB3 | 3.6 | 4.5 | 5.4 | 5.6 | 5.4 | 5.7 | 5.0 |
| MIX | −0.1 | −0.5 | −1.0 | −1.2 | −1.5 | −1.8 | −1.0 |
| BF1 | 0.1 | −20.2 | 0.1 | −20.2 | 0.1 | −1.6 | −7.0 |
| BF2 | 2.5 | −1.3 | 3.6 | −1.3 | 2.5 | −1.6 | 0.7 |
| PM | 4.8 | 5.4 | 6.0 | 6.0 | 6.0 | 6.0 | 5.7 |
| Method | Ave | ||||||
|---|---|---|---|---|---|---|---|
| CM1 [7] | 17.6 | 18.3 | 16.7 | 17.2 | 17.1 | 16.9 | 17.3 |
| CM2 [8] | 16.8 | 16.9 | 16.6 | 16.6 | 16.4 | 16.4 | 16.6 |
| CM3 [11] | 22.1 | 31.8 | 34.0 | 33.3 | 32.4 | 32.2 | 31.0 |
| CM4 [13] | 28.5 | 32.6 | 31.4 | 31.6 | 27.2 | 29.1 | 30.1 |
| AB1 | 25.8 | 31.0 | 31.8 | 32.1 | 31.3 | 28.8 | 30.1 |
| AB2 | 22.3 | 32.0 | 32.9 | 32.3 | 29.9 | 29.4 | 29.8 |
| AB3 | 28.6 | 31.1 | 29.6 | 30.9 | 31.6 | 30.4 | 30.4 |
| BF1 | 1.9 | 2.6 | 3.5 | 2.6 | 1.9 | 0.2 | 2.1 |
| BF2 | 22.2 | 24.8 | 25.8 | 24.8 | 22.2 | −0.3 | 19.9 |
| PM | 27.9 | 31.7 | 33.2 | 32.8 | 31.2 | 30.8 | 31.3 |
| Method | Ave | ||||||
|---|---|---|---|---|---|---|---|
| CM1 [7] | −0.1 | 0.0 | 0.1 | 0.1 | 0.2 | 0.3 | 0.1 |
| CM2 [8] | 0.3 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 | 0.2 |
| CM3 [11] | 5.4 | 6.6 | 7.4 | 7.5 | 7.6 | 7.8 | 7.0 |
| CM4 [13] | 5.9 | 6.5 | 7.0 | 7.3 | 7.1 | 7.6 | 6.9 |
| AB1 | 4.7 | 6.3 | 7.0 | 7.2 | 7.6 | 7.9 | 6.8 |
| AB2 | 5.3 | 6.5 | 7.0 | 7.4 | 7.6 | 7.8 | 6.9 |
| AB3 | 4.9 | 5.8 | 6.9 | 7.2 | 7.4 | 7.8 | 6.7 |
| BF1 | 2.0 | −3.5 | 1.9 | −3.5 | 2.0 | 1.0 | 0.0 |
| BF2 | 3.6 | 2.0 | 4.4 | 2.0 | 3.6 | 1.0 | 2.8 |
| PM | 6.0 | 6.5 | 7.5 | 7.6 | 7.8 | 8.0 | 7.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yoshida, M.; Togo, R.; Ogawa, T.; Haseyama, M. Off-Screen Sound Separation Based on Audio-visual Pre-training Using Binaural Audio. Sensors 2023, 23, 4540. https://doi.org/10.3390/s23094540
Yoshida M, Togo R, Ogawa T, Haseyama M. Off-Screen Sound Separation Based on Audio-visual Pre-training Using Binaural Audio. Sensors. 2023; 23(9):4540. https://doi.org/10.3390/s23094540
Chicago/Turabian StyleYoshida, Masaki, Ren Togo, Takahiro Ogawa, and Miki Haseyama. 2023. "Off-Screen Sound Separation Based on Audio-visual Pre-training Using Binaural Audio" Sensors 23, no. 9: 4540. https://doi.org/10.3390/s23094540
APA StyleYoshida, M., Togo, R., Ogawa, T., & Haseyama, M. (2023). Off-Screen Sound Separation Based on Audio-visual Pre-training Using Binaural Audio. Sensors, 23(9), 4540. https://doi.org/10.3390/s23094540