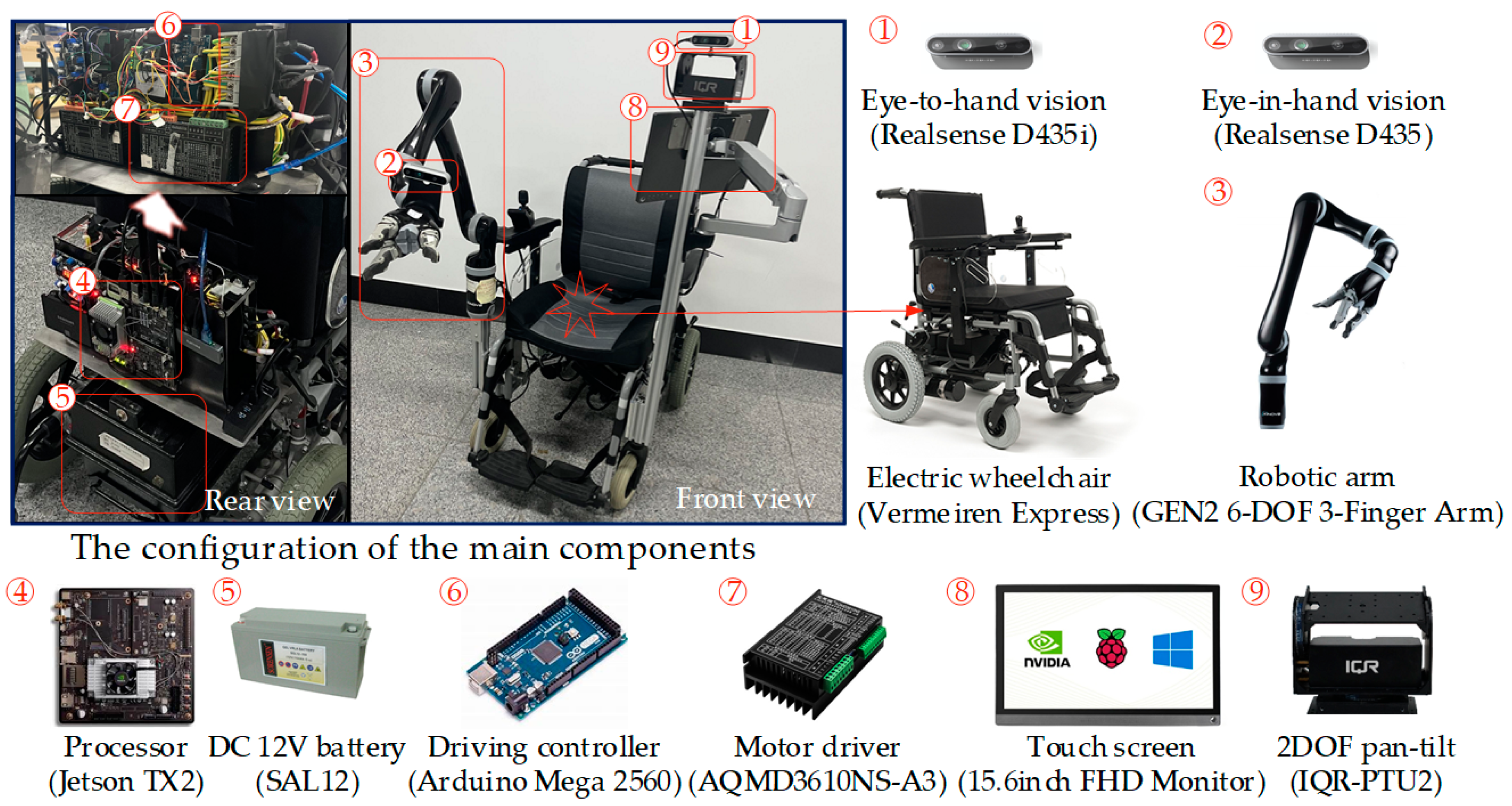
1. Introduction
Nowadays, the world’s population is in the stage of growing [
1]. The increasing number of people challenges the social care services system, and most care workers are facing unprecedented pressure [
2]. The WMRA can help people complete some household tasks independently [
3], which will improve the quality of life and reduce caregiving stress. However, the traditional joystick remote control mode on the WMRA requires frequent limb movements of the user, which brings physical and psychological burdens. The WMRA should be easy to operate and have a sense of control [
4,
5]. Therefore, helping users interact with the WMRA with less limb movements and conveying their intentions with the least operation is the current research focus impacting the performance and user acceptance of the WMRA.
To facilitate the operation of robots for users with different levels of physical ability, many human–robot interactions (HRI) interfaces utilizing residual limb abilities have been studied, such as using chin [
6], shoulder [
7], gesture [
8], and eye movement [
9]. In these studies, the interaction operations mapped the residual limb movement to robot instructions, such as forward, back, left, right, rotation, or other cartesian motions for the robotic arm, and some preset simple household tasks, which could help users perform some structured tasks, but still needing frequent limb movement. In addition, using biological signals remote control robots to perform the tasks would substantially reduce limb movements and physical burden [
10,
11,
12,
13]. However, the time-consuming signal recognition, complex operation, and high cost limit their development.
In recent years, researchers have tried to use the concept of “shared attention [
14]” to reduce the complexity of manipulating robots. The concept refers to “what you see is what you want” so that robots can grasp or place the target objects for a user by capturing the focus of the user’s attention. For instance, screen tapping [
15], eye gaze [
16], laser pointer [
17,
18], and electroencephalogram (EEG) recognition [
19] can share attention with robots. However, compared with laser pointer, gaze, EEG, and a screen would attract too much attention from users, which will make them ignore the surrounding environment and lead to safety risks.
Users could convey simple intentions to the robot through share attention. However, people’s intentions are complex and robots’ tasks are unstructured, which requires a robot to make deeper inferences about intention from a simple interaction. The concept of object affordance refers to actions that match the physical properties of an object [
20,
21], which contribute to reasoning the intention of deeper tasks from the shared attention of users. Therefore, we propose an implicit intention interaction technology using a laser pointer based on the idea of object affordance. A user could point to the objects in the scene using a laser pointer, and the WMRA would reason the action intentions through the selected objects and execute the corresponding action content.
The proposed technology is composed of two major parts. One is the laser semantics identification model based on the SVM and YOLOv4 fusion algorithm, which mainly identifies the corresponding semantics by detecting the flicker frequency of the laser spot. The other is the household task intentions reasoning model based on the conditional random field (CRF) and Q-learning algorithm. We formalize the concept of object affordance based on the CRF algorithm and reason the user’s intention through the object information in the scene. In addition, through the Q-learning algorithm, the proposed reasoning model can learn user preferences in the long-term historical intention prediction, in which people may have different operation intentions for the same object on different occasions. Based on the above models, our implicit interaction technology can use the laser pointer to achieve “share attention” with the WMRA and reason the user’s intention. In the end, to execute the household tasks and verify the practicability of the proposed method, we embed the DMP algorithm into the laser interaction technology to generalize the action trajectories of the tasks and achieve the logical state transformation of different actions through the finite state machine.
The contributions of this paper are summarized below:
The WMRA with laser interaction is designed, and it can identify the laser semantics correctly even if users point to the wrong position due to hand tremors.
The model of intention reasoning and execution based on object affordance is proposed so that the WMRA can identify the desired intention faster and perform tasks with less limb involvement from the user.
The rest of this paper is as follows.
Section 2 presents related works.
Section 3 describes our system and laser semantic identification.
Section 4 describes the technology of reasoning intentions and executing tasks.
Section 5 reports the experiments and results. Lastly, the paper is concluded and discussed in
Section 6.
4. Intention Reasoning and Task Execution
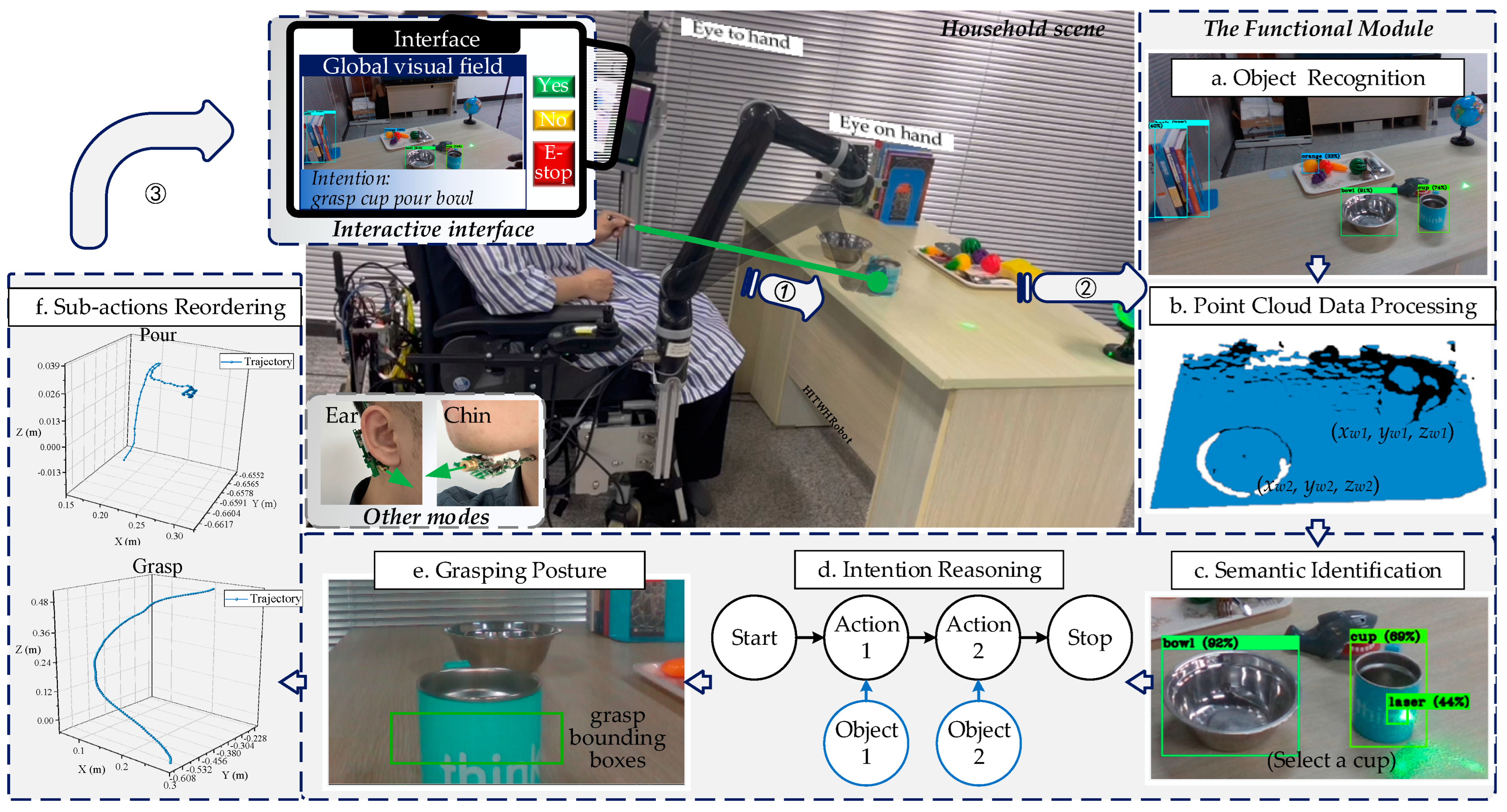
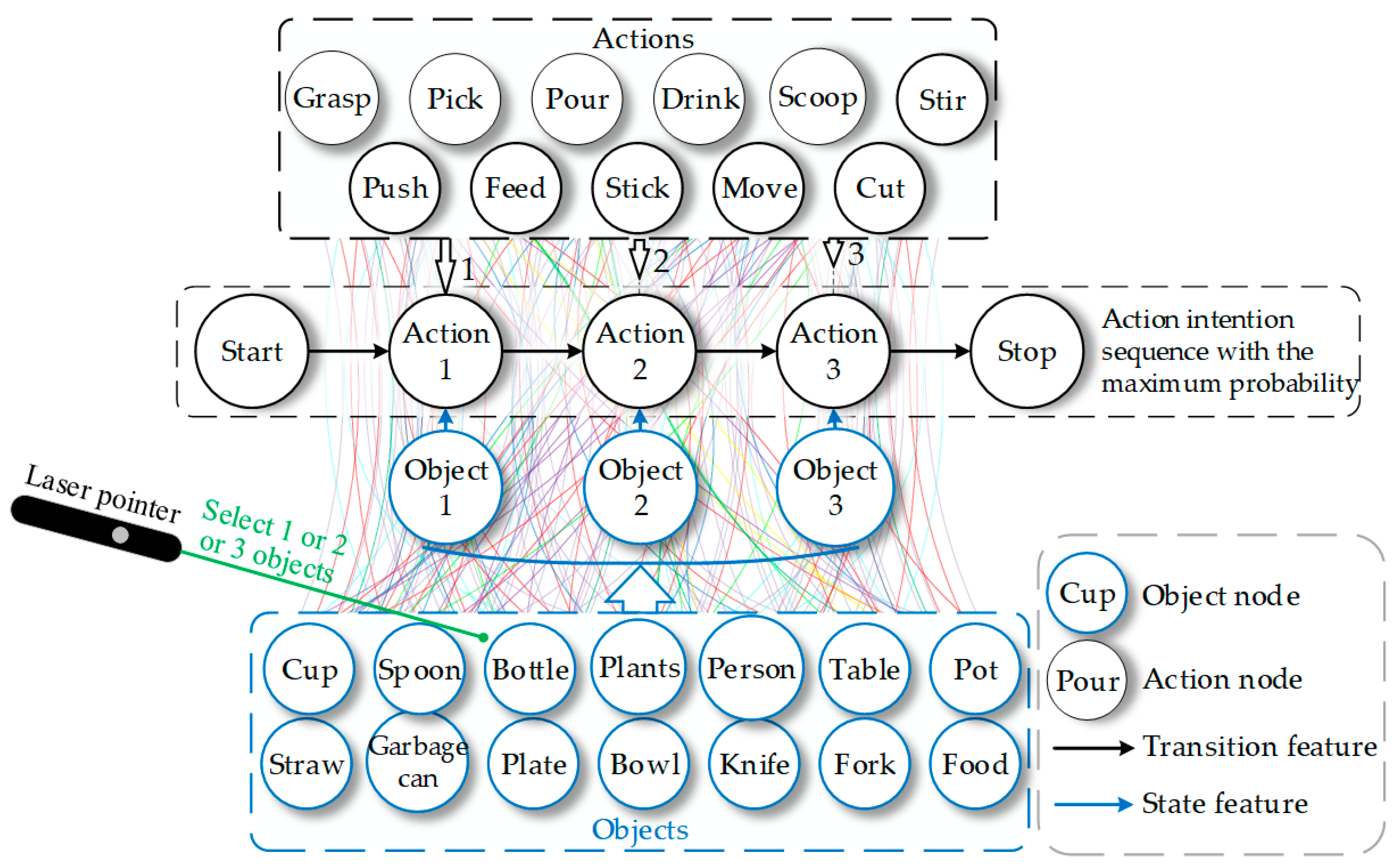
The semantic identification module transmits the category information of selected objects to the intention reasoning module, as shown in
Figure 2d. To infer the user’s intention, we explore the implicit action of objects and construct an object–action intention network (OAIN) based on the concept of object affordance.
Figure 4 illustrates the workflow of the reasoning module. First, OAIN gets semantic information and outputs some intentions with a different probability. Users next express their decision, which will be used to learn user preferences. When the user confirms the intention, the final intention will be output to the next module and logically assembled to execute.
4.1. Implicit Action Intention Recognition
The international classification of functioning, disability, and health (ICF) guideline describes the necessary tasks to maintain the lives of people in a home environment. Therefore, we construct a knowledge base dataset about household tasks by extracting the executed object and action labels from the ICF, as shown in
Table 1. The dataset contains three types of task descriptions, which consist of a different number of object–action pairs. Objects represent the target that the WMRA will execute, and actions reflect the function affordance of adjacent objects.
In order to formalize affordance between objects, we propose an intention reasoning method based on the conditional random field (CRF). The CRF is a machine learning algorithm that can predict implicit random variables based on the visible random variable by solving the maximum conditional probability . The way of reasoning action intention with object category information as a context clue can be regarded as a process of solving the maximum probability implicit variable “action intention” with the visible variable “object”.
The CRF algorithm consists of nodes and edges. As depicted in
Figure 5, nodes represent the variable, and edges represent the transition features. The edge between object nodes and action nodes represents the state transition feature, which is defined as
, and the edge between the action nodes represents the action transition feature, which is defined as
.
The object and action sets are represented as
and
, respectively. Under the condition that the value of
is
and the value of
is
. The conditional probability model
is expressed as:
where
where
and
represent the weights of the action transition feature and state transition feature in the model.
and
represent the sequence number of the different transition features.
represents the normalization coefficient, which is the weighted sum of all actions and the given objects.
To solve the weight parameter, we use the log-likelihood equation and the improved iterative scaling method. The log-likelihood equation is expressed as:
where
where
where
represents the empirical probability distribution.
represents the frequency of a sample
in the training dataset.
is the total number of samples.
The prediction of OAIN is the Viterbi algorithm, which can quickly traverse all probability distributions based on the known input sequence and select the maximum probability. The predicted action with the maximum probability can be expressed as:
where
represents the optimal action intention sequence.
4.2. Learning Mechanism
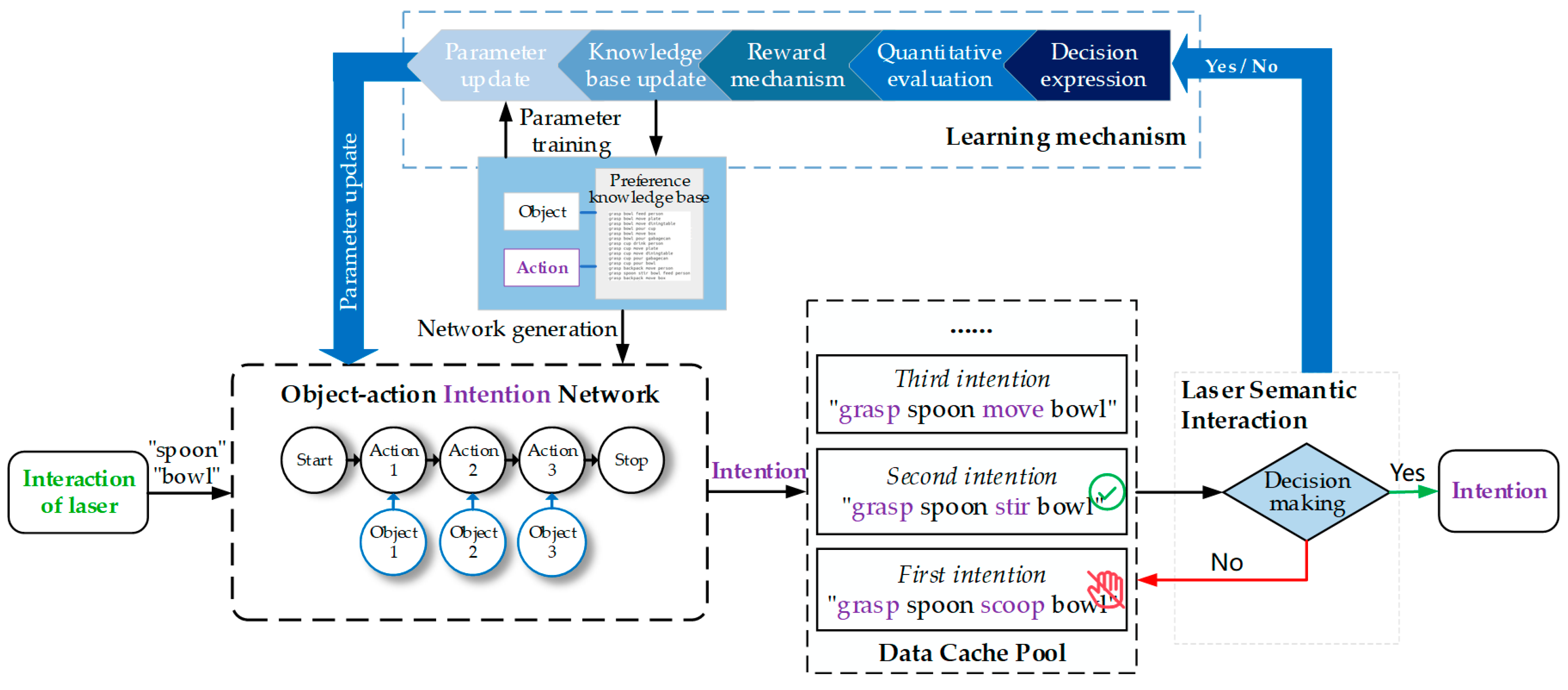
Although we have trained the OAIN using the CRF algorithm, the OAIN may not correctly output the user’s intention when the user’s preference changes. As shown in
Figure 4, in order to adapt to the user preference, we embed the Q-learning algorithm into the intention reasoning module so that the OAIN can automatically update weight parameters after the user makes a decision about action intention.
Q-learning algorithm is a value iteration algorithm based on the Markov decision process in the field of reinforcement learning. The core of Q-learning is making decisions by evaluating the change in Q value. Q value refers to the reward or penalty value after the agent selects the action, and the action triggers a state change for the agent. The Q value will be iterated based on the Bellman equation and stored in the Q table, which consists of state and action.
The low-probability intention reasoning results in the traversal process of the Viterbi algorithm being put into the data cache pool so that the user expresses a decision about the intention through laser interaction, as depicted in
Figure 4. After the user locks an intention, the learning mechanism will quantify the interaction process and transmit quantization results to the reward mechanism, which is the Bellman equation in Q-learning:
where
is the previous state (previous intention),
is action (the process of interaction),
is the current state (current intention),
is a transition function,
is the reward function, and
is the discount coefficient.
In our scene, the intention of the user may change over time, which means optimal strategy will not exist. Therefore, we adjust the Bellman equation and embed it into our framework. The iterated equation is expressed as:
where
represents the Q value of the previous state;
is reward function, the value is equal to 0 and 1 when the user chooses “no” and “yes”. respectively;
is discount coefficient and set as 1.
4.3. Intention Execution
To perform actions intention sequence continuously, the finite state machine (FSM) is used to logically assemble actions. The FSM is a state transition mechanism, which has the characteristics of state storage and logic coordination.
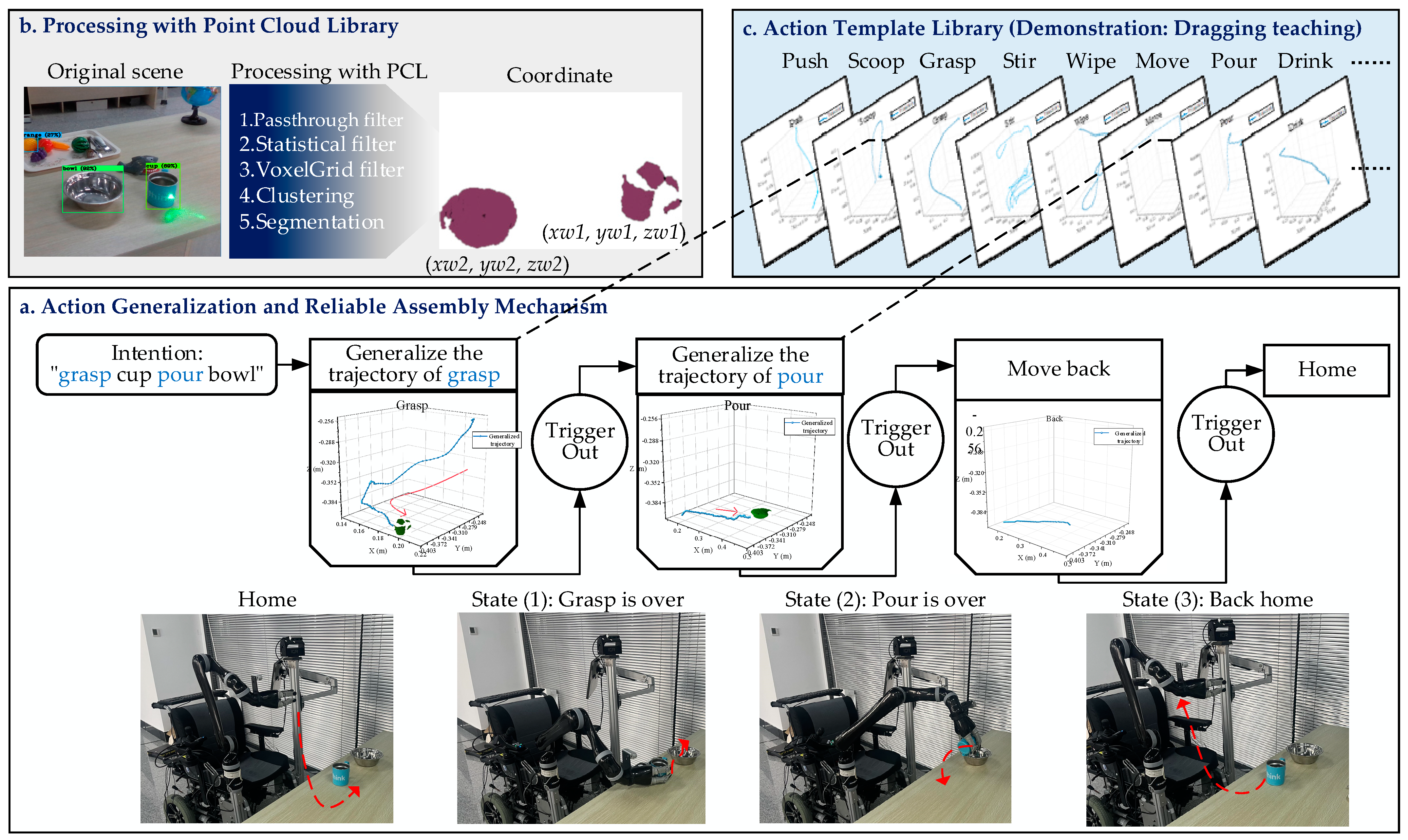
Figure 6 illustrates an example of a “grasp cup pour bowl” task. Firstly, the WMRA will process the point cloud data of the target objects to calculate their positions. The WMRA will choose the template trajectory based on the action intention from our action template library and generate new trajectories to adapt to the positions of target objects in the scene. Lastly, trajectories would be reordered by the FSM, and the WMRA follows FSM-defined rules to execute action intention automatically.
Given the demonstrated trajectories in the template library cannot adapt to the change of object position in the scene, the dynamic movement primitives (DMP) algorithm [
48,
49] is used to post-process the trajectories. DMP is a known trajectory generalization algorithm [
50], which would further generalize the trajectory of similar actions by solving the optimal curve characteristic solution of the teaching trajectory. The generalization of one-dimensional motion is generated by the following differential equations.
where
where
is the position of the trajectory.
is the speed of the trajectory points.
is the starting point of the trajectory.
is the goal of the trajectory.
is the time scaling factor.
and
are the gain coefficients of the system, which are used to adjust the convergence trajectory of the system.
is the nonlinear function of the demonstrated trajectory.
5. Experiment and Results
In this section, the feasibility of the proposed implicit interaction technology is verified on a WMRA platform. We test the ability of the laser interaction, the intention reasoning model, the learning mechanism, and task execution. Compared with some previous works [
41,
44], our model achieves some better results.
5.1. Laser Interaction Evaluation
We have deployed YOLOv4 and SVM-based laser interaction on the embedded board, Jetson TX2. Compared to other visual algorithms, such as Transformer [
51], the YOLOv4 algorithm requires fewer computational resources, has faster recognition speed, and is more compatible with hardware environments. Therefore, the YOLOv4 is selected as our visual detection algorithm.
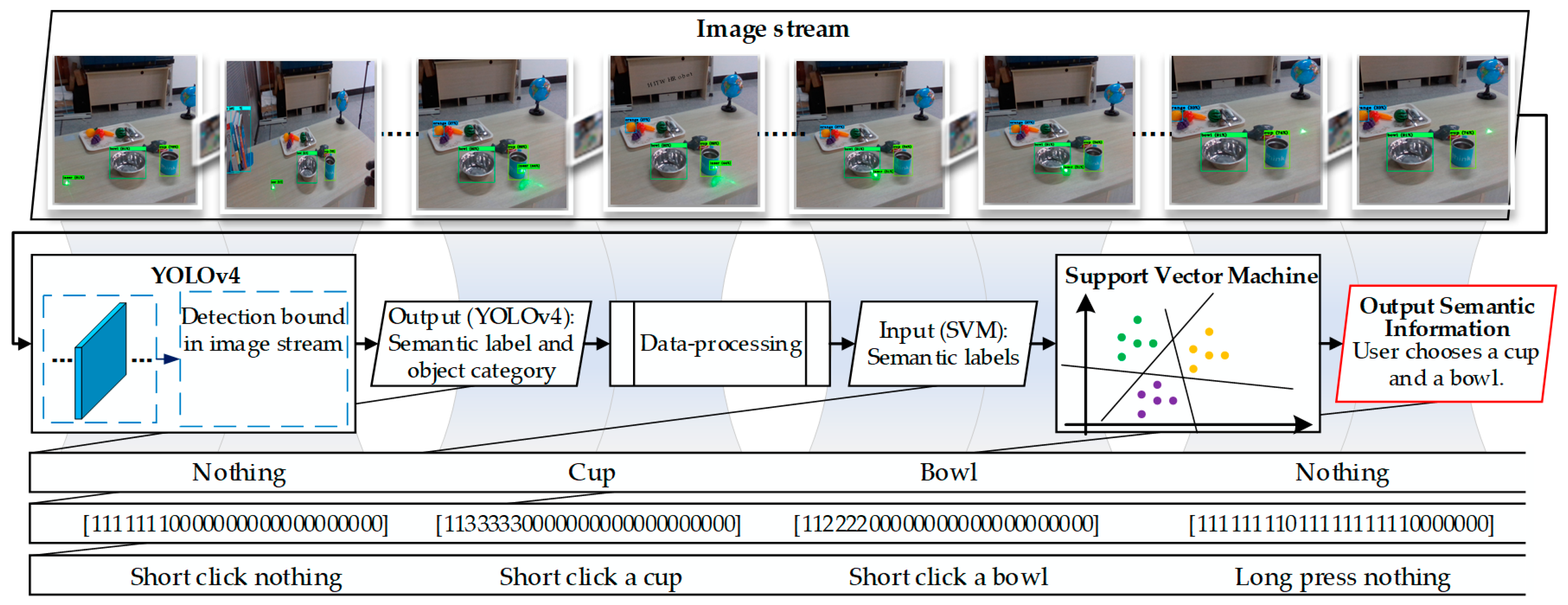
As shown in
Figure 7, researchers conduct 50 clicking tests on different objects respectively and observe whether the output results match the target objects. The success rate is shown in
Table 2. The results represent that the minimum success rate can reach over 92%, with the accuracy of the table even reaching 100%. We analyze that the high success rate is due to their larger clickable space, more uniform surface curvature, and less laser reflection, while the objects with lower success rate do not possess these characteristics.
Then, we test the accuracy of SVM for semantic recognition and construct a neural network (NN) for comparison, which includes three fully connected layers, and the activation function is Rectified Linear Unit (ReLU). Before the test, we created a guide that describes some target semantics to be implemented (Each semantic is repeated 20 times in a random order in the guide). Researchers click on the laser pointer to output the semantics and judge whether the result is consistent with the content of the guide. The recognition accuracy is shown in
Table 3.
A timing-based method is used as a baseline, which recognizes the laser semantics by calculating the time the laser spot appears. The results show that the SVM and NN methods are much better than the baseline. However, compared to the black-box feature of NN, SVM has a rigorous mathematical theory and is a more transparent classification algorithm. Therefore, we combine the YOLOv4 and SVM algorithms to recognize the laser semantics.
5.2. Intention Reasoning Evaluation
In order to compare the ability of intention reasoning with the previous work [
41], which combines the Markov network and Bayesian incremental learning, we select the same objects and actions to reasoning intention as shown in
Table 4.
Under the same conditions of quantity and type of objects and actions, our work can output 36 single-object intentions and 19 multi-objects intentions. In the other work, the reasoning model could only output the intention with an object and an action, which is low relative to our model. Compared to their work, we can output intentions for several objects and actions. In our opinion, more intentions reflect that the robots have a better comprehension of users and afford users an increased range of options.
5.3. Learning Ability Evaluation
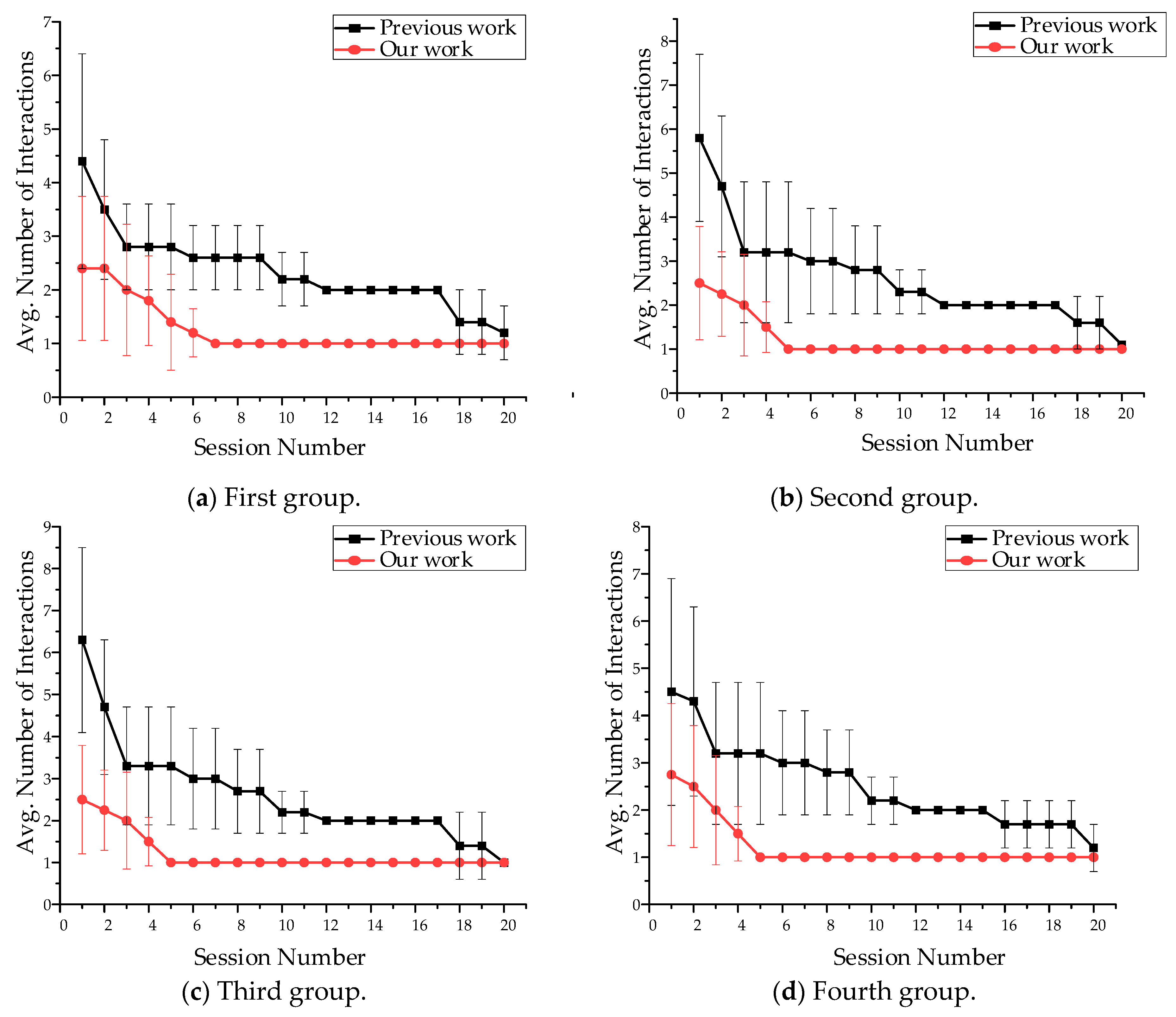
The main metric for evaluating performance is the number of human-computer interactions in each session. The object in the scene selected by the user for the first time is defined as entering the first session, and the laser semantic “yes” or “no” of the user output decision is defined as human–computer interaction. In the process, the user may judge the target intention and find the desired intention in the first session through multiple human-computer interactions. When the user selects the same objects for the second time, it is defined as the second session, and the user may only need less human-computer interaction time to determine the target intention in the second session. The ideal situation will appear when the number of interactions is one, and it is indicating that the first query to users is their expected intention.
Table 5 further lists the various groupings of intentions that are tested in the evaluation.
As shown in
Figure 8, it requires four interactions when our method outputs the user’s expected intention for the first time. In the span of twenty sessions, the average number of interactions required by our framework decreases monotonically. Finally, the average value of all groups will be equal to one. After twenty sessions, the average reduction in interaction is 70%. Because we set the same scene and intention as the previous work and the number of sessions to the desired intention is a 75% reduction, we believe that our method could learn user preferences and be superior.
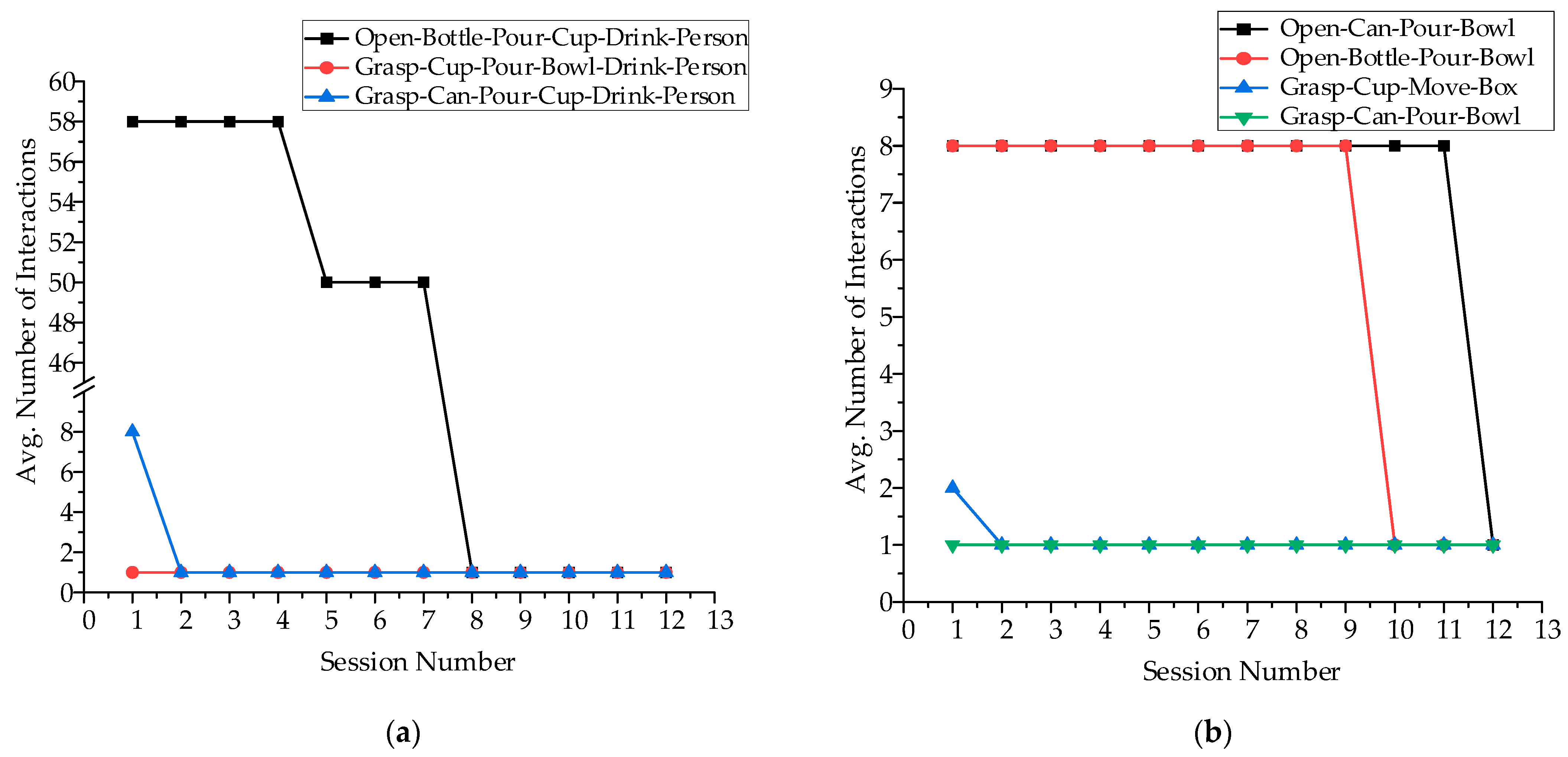
Besides, we also evaluate our method through the intention composed of multiple objects, and to our knowledge, the previous work has not achieved this. As shown in
Table 6, we set two evaluation groups in which task intentions are composed of two objects and three objects, respectively. The metric and process of evaluation are similar to the above.
As shown in
Figure 9, the desired intention in the first session required more interactions compared with the single object intentions. Moreover, it can be seen that the desired intention of three objects required more time interaction than the two objects in the first session. We analyze that the intention prediction of the Viterbi algorithm is to calculate the probability layer by layer, and each layer has many invalid intentions. However, by constantly learning the right intentions, the number of interactions reduces and reaches the ideal situation. Therefore, in general, our method can identify the user’s intention and adapt to user preferences successfully.
Furthermore, we record the time spent on intention reasoning. As we can see from
Table 7, the average intention recognition time of a single object is about 0.12 s, and the average intention recognition time of multiple objects is about 0.19 s, which is less than 0.3 s and meets the requirements of real-time recognition.
5.4. Household Task Execution Evaluation
To evaluate the execution ability of laser implicit intention interaction technology on the WMRA platform, we record and analyze the process of performing tasks, and compare our method with joystick operation.
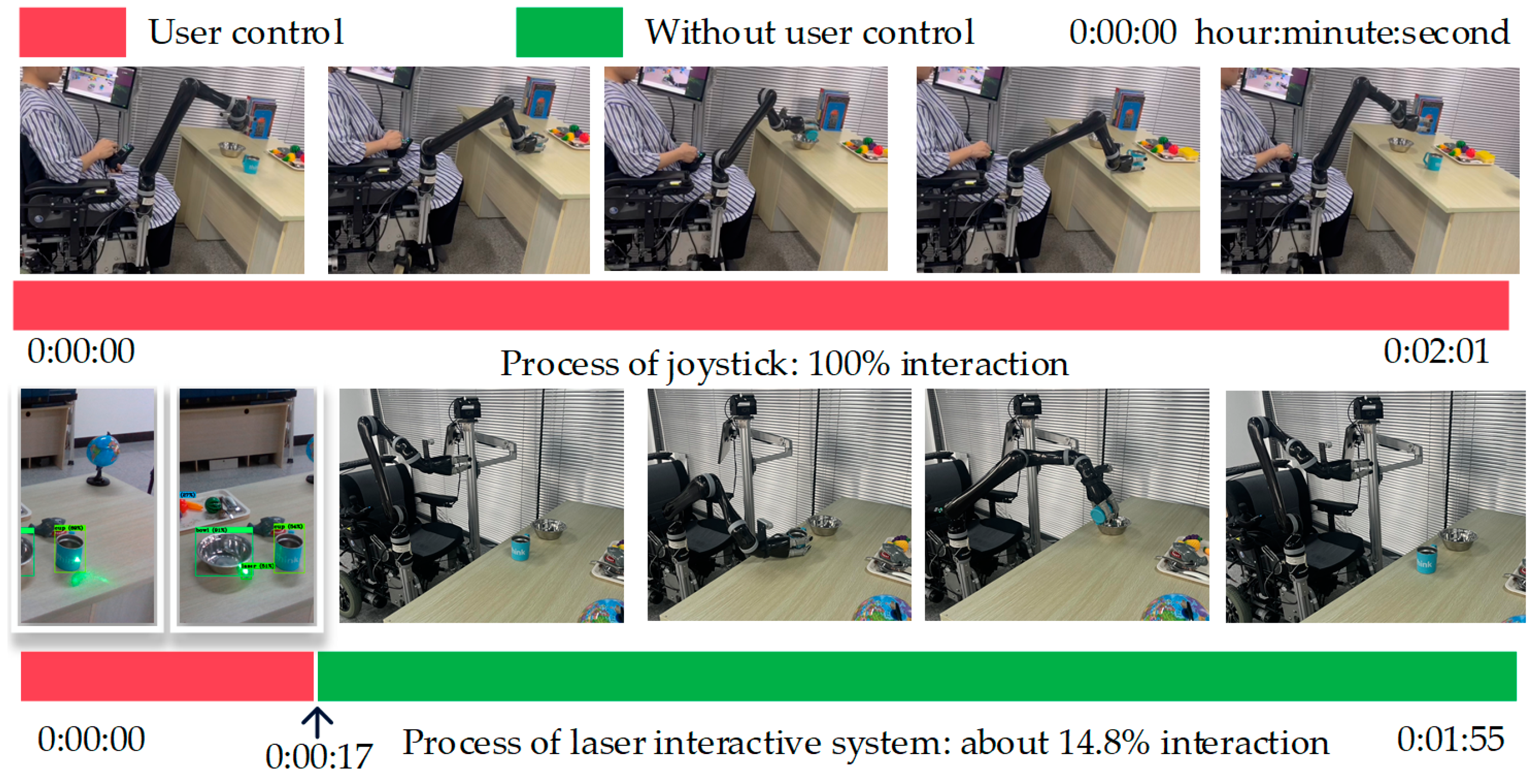
As illustrated in
Figure 10, we take the task “grasp cup pour bowl” as an example and calculate the proportion of human–computer interaction in the video stream. The interaction time required by our method is about 17 s, accounting for 14.78% of the total time. However, in manual mode, the user needs to continuously control the joystick when performing household tasks. Although we only list the interaction time required for the task “grasp cup pour bowl”, the time required for other tasks will not change greatly unless the amount of objects change. Therefore, compared with the joystick operation, the proposed technology could not only save time for task execution but also significantly reduce the user’s limb involvement time (about 85%), which effectively alleviates the user’s physical burden.
6. Conclusions and Discussion
To improve the control sense, usability, and adaptability of the WMRA, we propose an object affordance-based implicit interaction technology using a laser pointer. A laser pointer could lock the target objects, similar to the human gaze. Therefore, a YOLOv4 and SVM-based laser semantic identification algorithm is proposed to convey user intention intuitively. Moreover, the robustness of the algorithm contributes to the automatic correction of the wrong semantics when the user points to a wrong position because of hand tremors. Next, we were inspired by the cognitive psychology of human interaction processes and designed an object affordance-based intention reasoning algorithm, which is based on CRF and Q-learning. The WMRA realized the implicit action intention identification of target objects and learned user preference through the decision of user interaction. Lastly, in order to execute the action sequence in the scene, trajectories of actions were generalized by the DMP and transmitted to the FSM to logically reorder.
We selected many objects and conducted the click test of laser interaction. The results show that the lowest success rate of correctly selecting a desired object is 92%, and the highest is 99%. We inferred that the impacts on the success rate are the surface curvature and material, which is consistent with the discussion in [
24]. However, compared to previous works on laser interaction [
22,
23,
24], we designed more forms of laser clicking and achieved more laser semantics through intention recognition.
Based on the experiments and results, we believe that our research could reduce the burden of interaction between disabled users and assistive robots. Users only need to sequentially click on the target objects, and then they can wait for the robot to execute automatically. Due to security considerations, the research did not include human-related tests. However, in our opinion, the less participation during the task execution, the fewer the users’ interaction burden. Overall, this paper realizes the conveyance of complex task intention through simple interactive operation and executes it, which lays a technical foundation for the rapid practical application of the WMRA.
7. Limitations and Future Work
This paper explores an implicit interaction system that can assist users in completing household self-care tasks, which can reduce the interaction burden in the operation of the robot. However, some limitations that affect our research should be noted. For safety reasons, we have not conducted tests on older adults or other individuals, which limits the diversity of experimental samples. To achieve interactive experiments between robots and older adults, the reliability of the proposed system and the psychological pressure that robots bring to users, such as the trusted testing between users and robots [
52], need further research.
Based on the above limitations, we should not only focus on the execution ability of the robots but also consider the cognitive and decision-making burden of users during the robot operation process. These provide ideas for future research. As reviewed by [
53], Ergonomics & Human Factors (E&HF) should be taken into account in the design process of robots. E&HF contributes to understanding users’ capabilities and limitations and uses this information to minimize the cognitive burden on humans in the process of operating robots [
54]. Therefore, we will further study the reliability and ergonomics of our laser interaction systems and test their ability to interact with older adults in future work.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}