
Fast Helmet and License Plate Detection Based on Lightweight YOLOv5

Abstract
1. Introduction
- (1)
- Due to the absence of a public electric bikes, helmet, and license plate detection dataset, the RHNP dataset was created. The dataset includes four categories: the whole of the rider and the electric bike, the head of the person without the helmet, the license plate of the electric bike, and the head of the person wearing the helmet.
- (2)
- Since YOLOv5 is difficult to deploy on small mobile embedded devices due to its high computing load and high memory requirements [10], a SG-YOLOv5 model is proposed. Specifically, two lightweight networks, ShuffleNetv2 and GhostNet, were introduced in YOLOv5, and the feature fusion method was changed at the same time. The improved model reduces the number of parameters and computation dramatically, while ensuring the detection accuracy.
- (3)
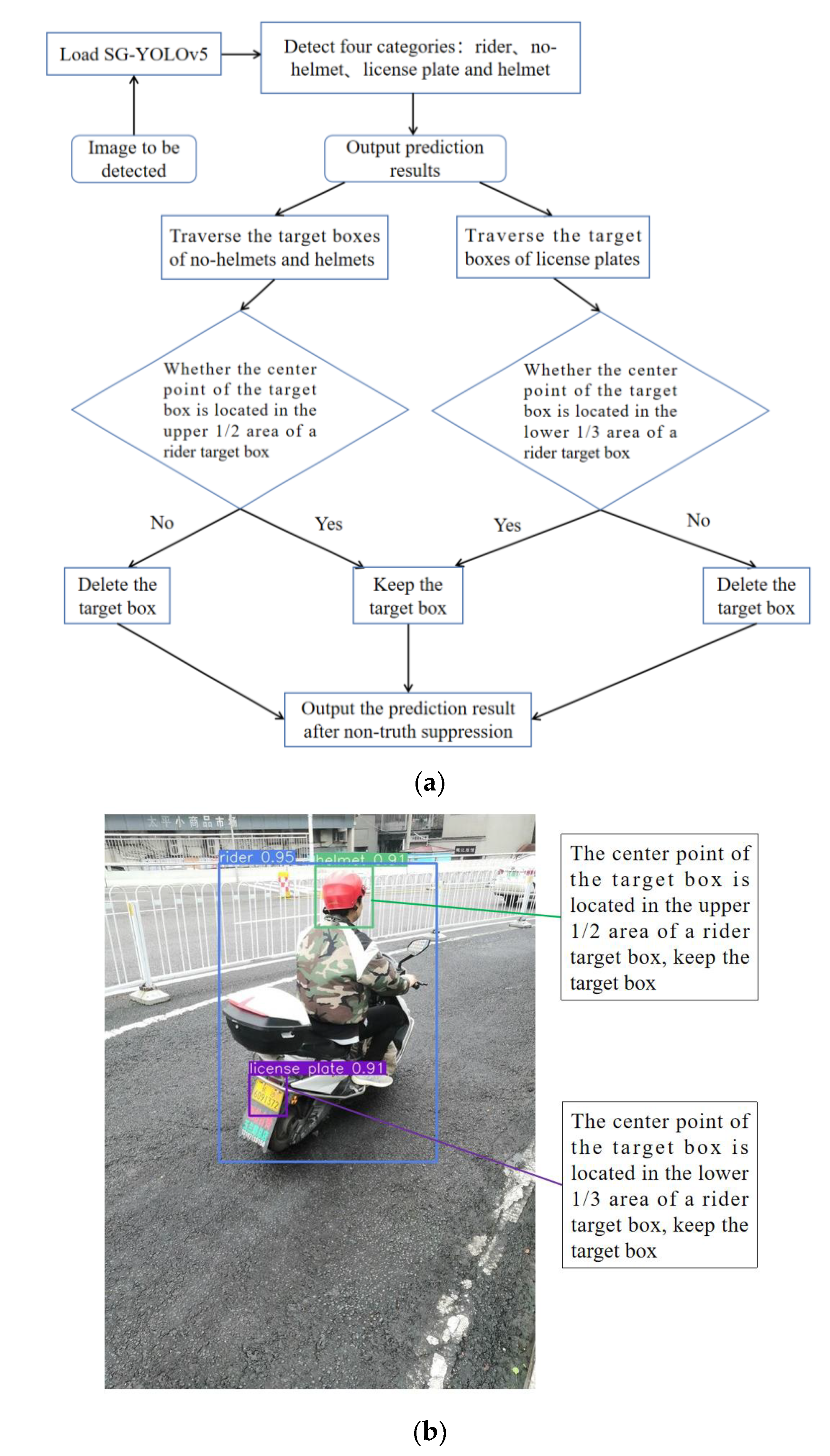
- As for the tedious and time-consuming detection process of violators’ license plates in existing research, this paper draws on and improves the detection method proposed by Allamki L. et al. [9]. Firstly, a scene-based non-truth suppression method is proposed to eliminate the interference of pedestrians’ heads and parked vehicles’ license plates. Then, the violator’s license plate is located through the inclusion relationships of the predicted helmet, rider, and license plate.
2. Related Works
3. Yolov5 Network Structure
4. Improved YOLOv5s Detection Algorithm
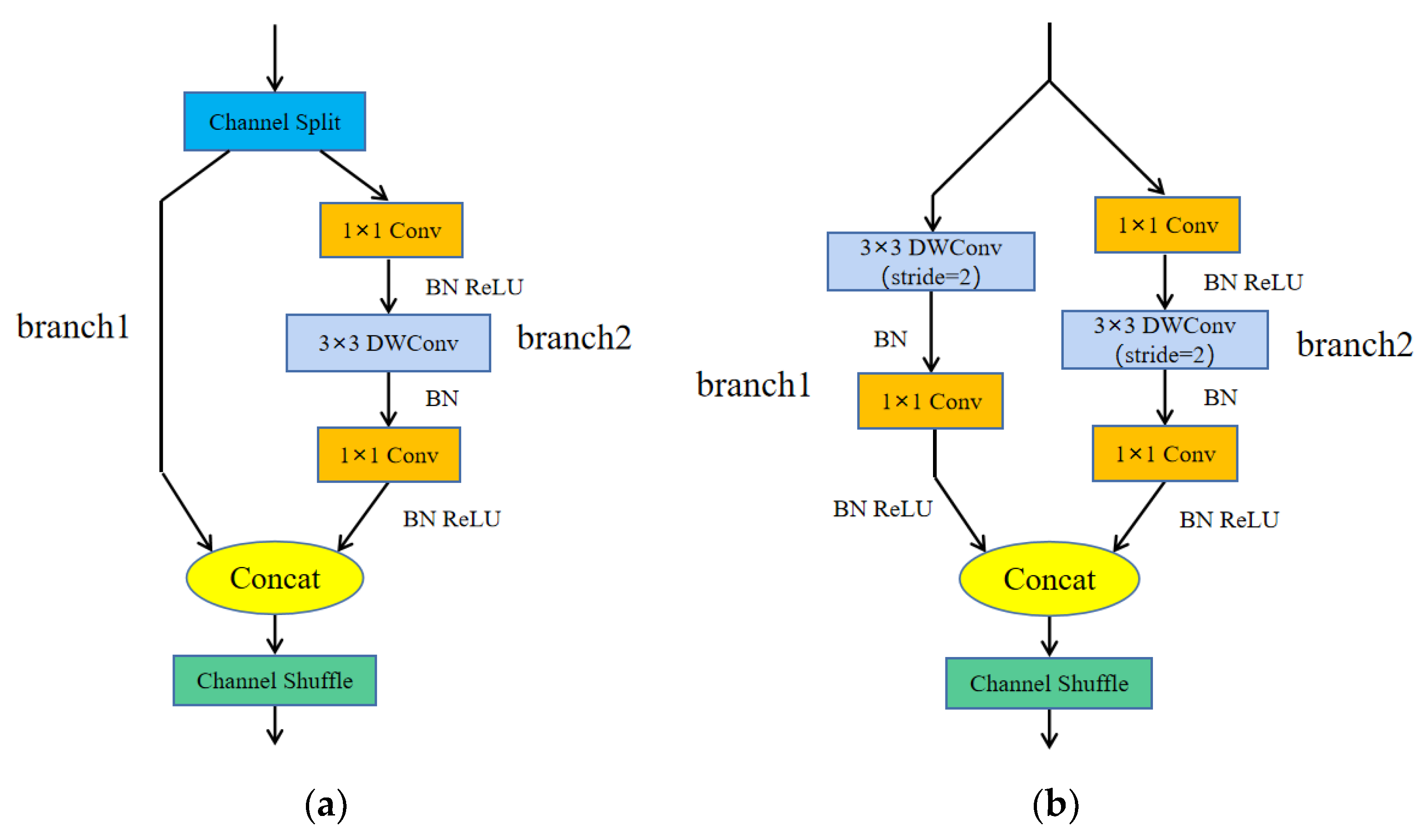
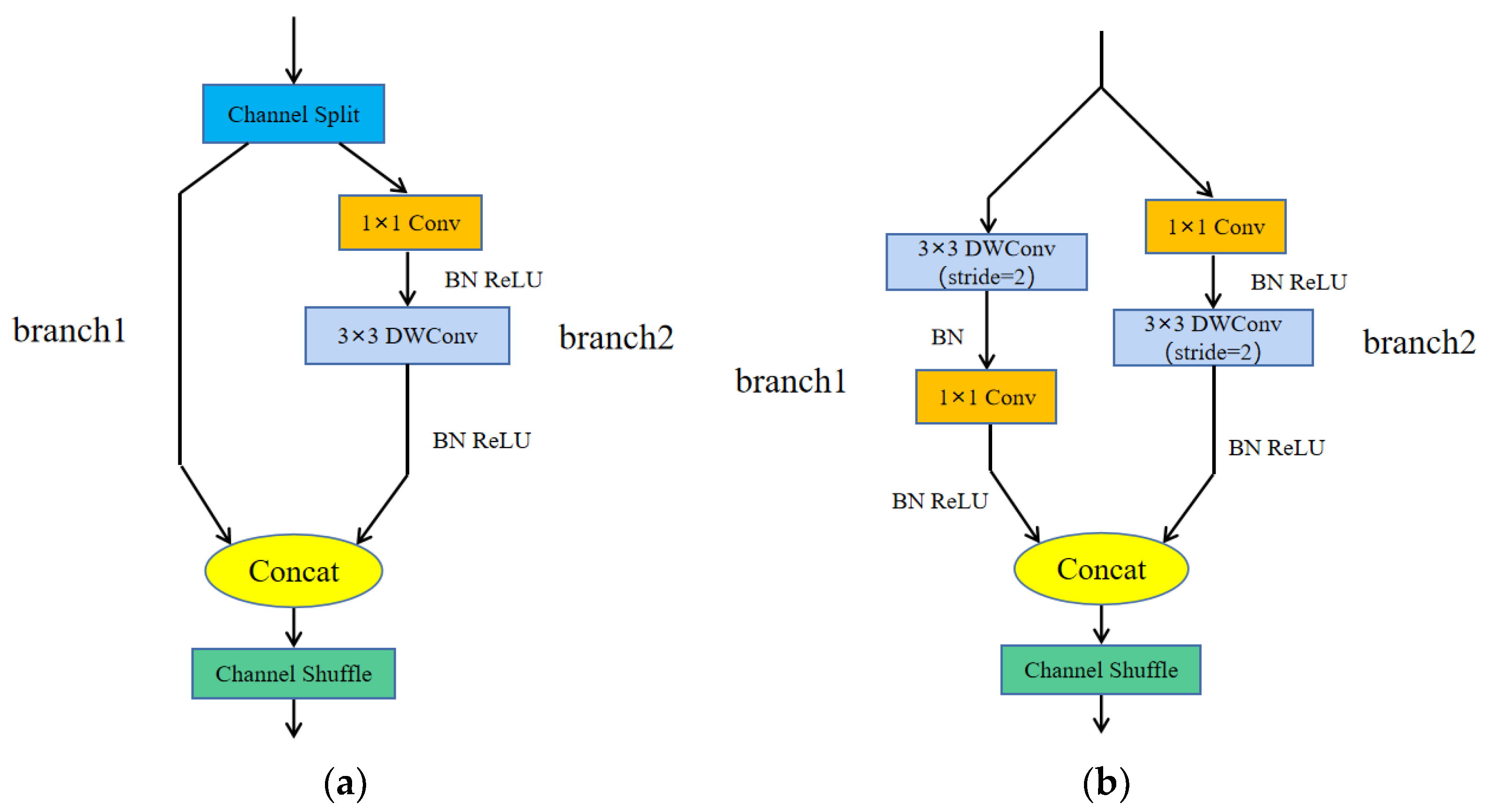
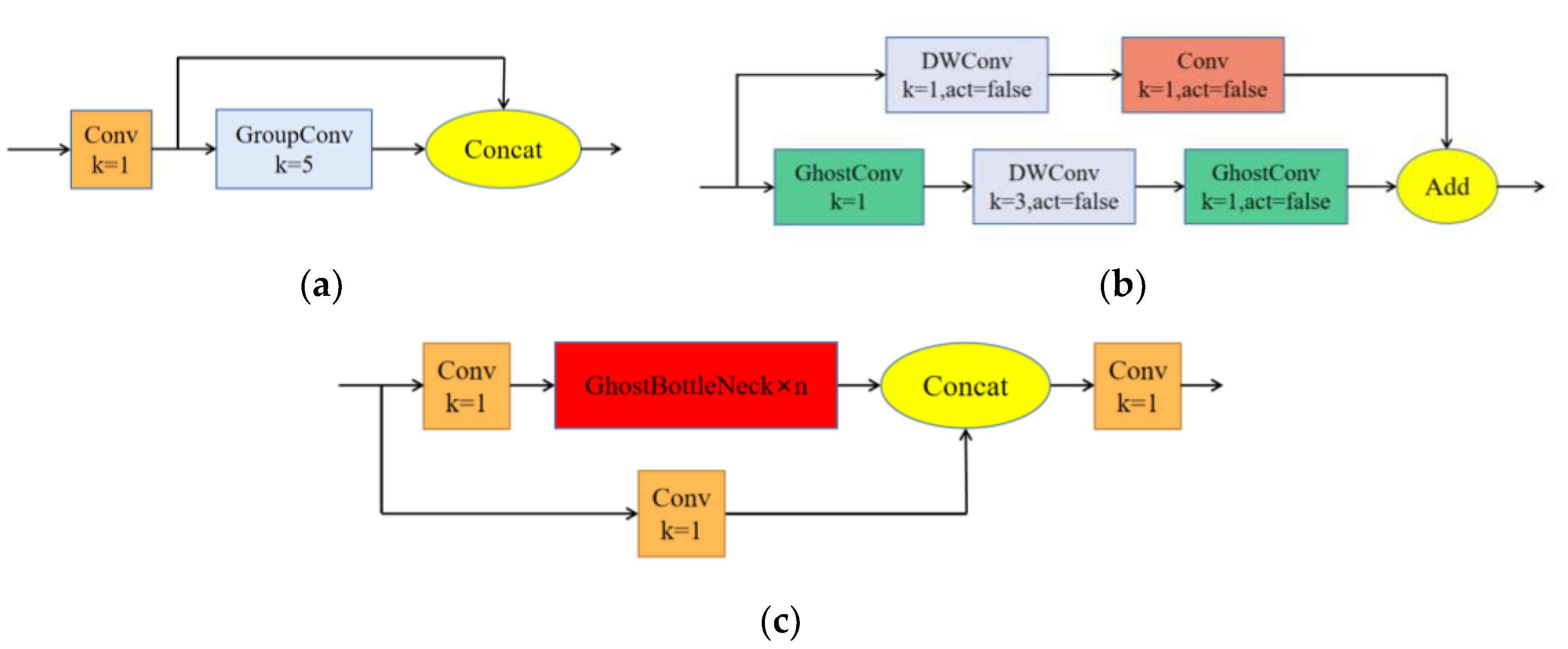
4.1. Introducing Two Lightweight Networks: ShuffleNetv2 and GhostNet
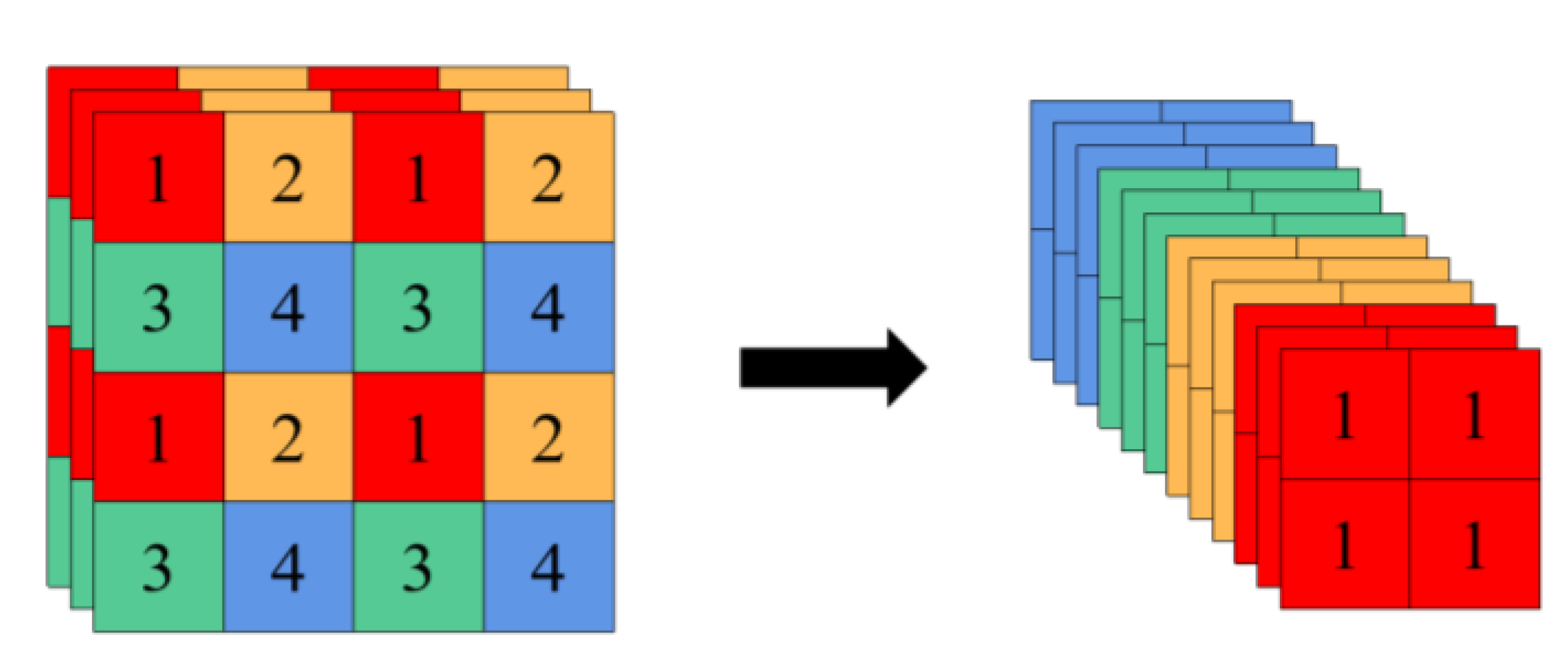
4.1.1. ShuffleNetv2 Lightweight Network
- (1)
- When the number of input and output channels is the same, MAC is the smallest.
- (2)
- Group convolution with too large a number of groups will increase MAC.
- (3)
- Fragmented operations are not conducive to parallel acceleration.
- (4)
- The cost of element-by-element operations (such as ReLU function, Shortcut-add, etc.) cannot be ignored.
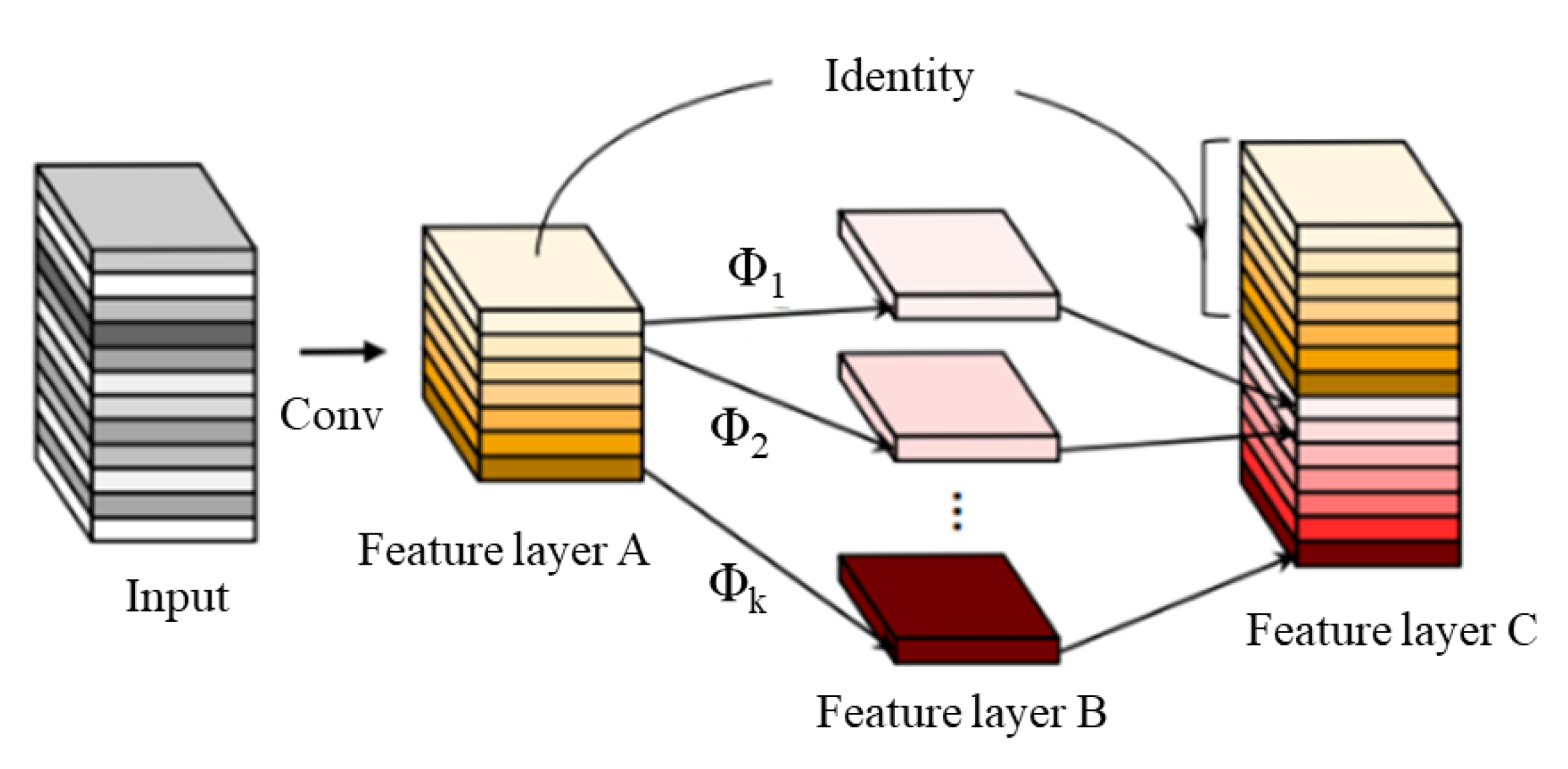
4.1.2. GhostNet Lightweight Network
4.2. Add-Based Feature Fusion Method
4.3. Scene-Based Non-Truth Suppression Method
4.4. SG-YOLOv5 Network Structure
5. Experiments and Result Analysis
5.1. Experiment Preparation and Setup
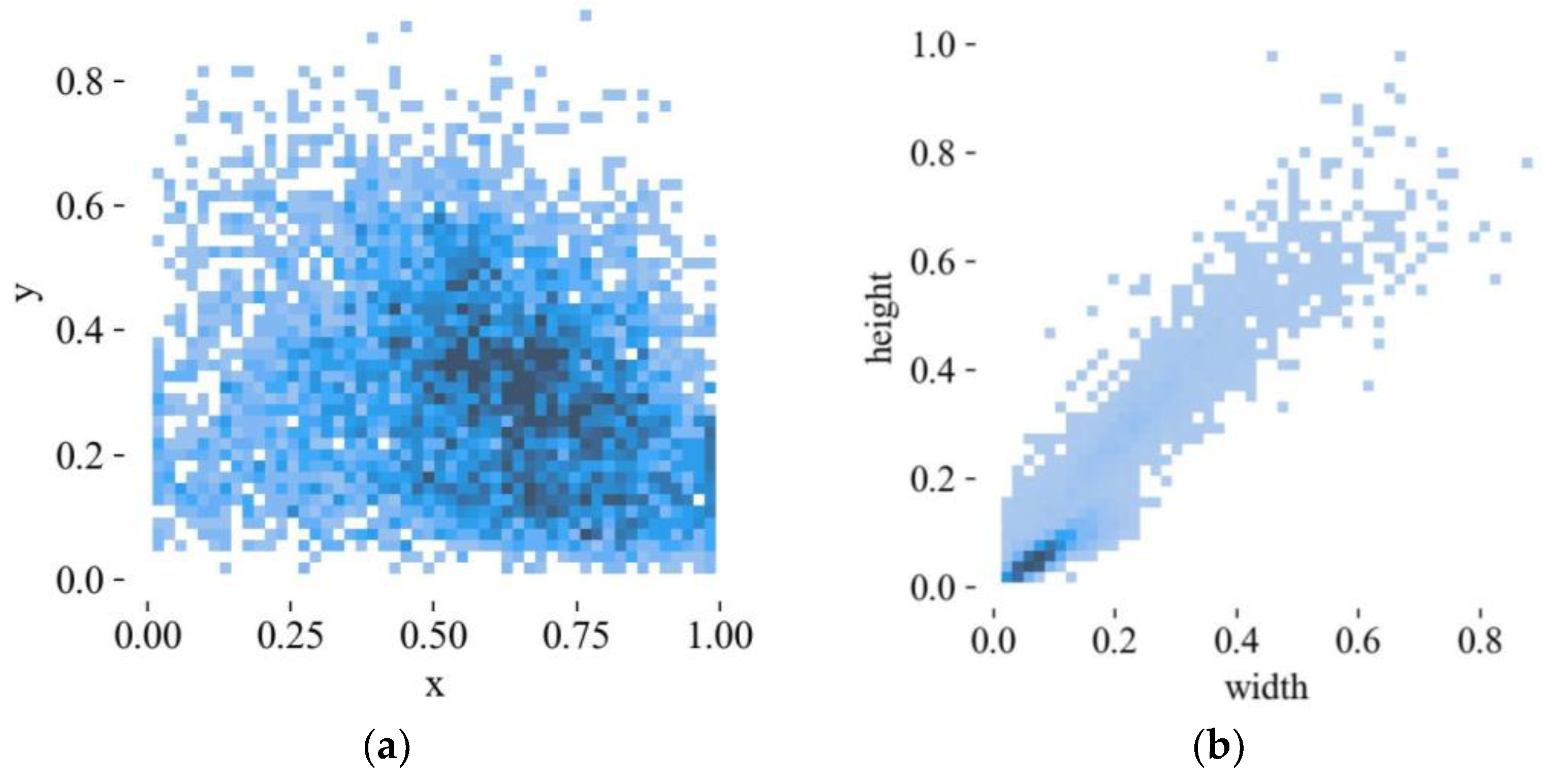
5.1.1. Dataset Collection
5.1.2. Experimental Environment and Parameter Settings
5.1.3. Evaluation Indicators
5.2. Experimental Results
5.2.1. Training Results
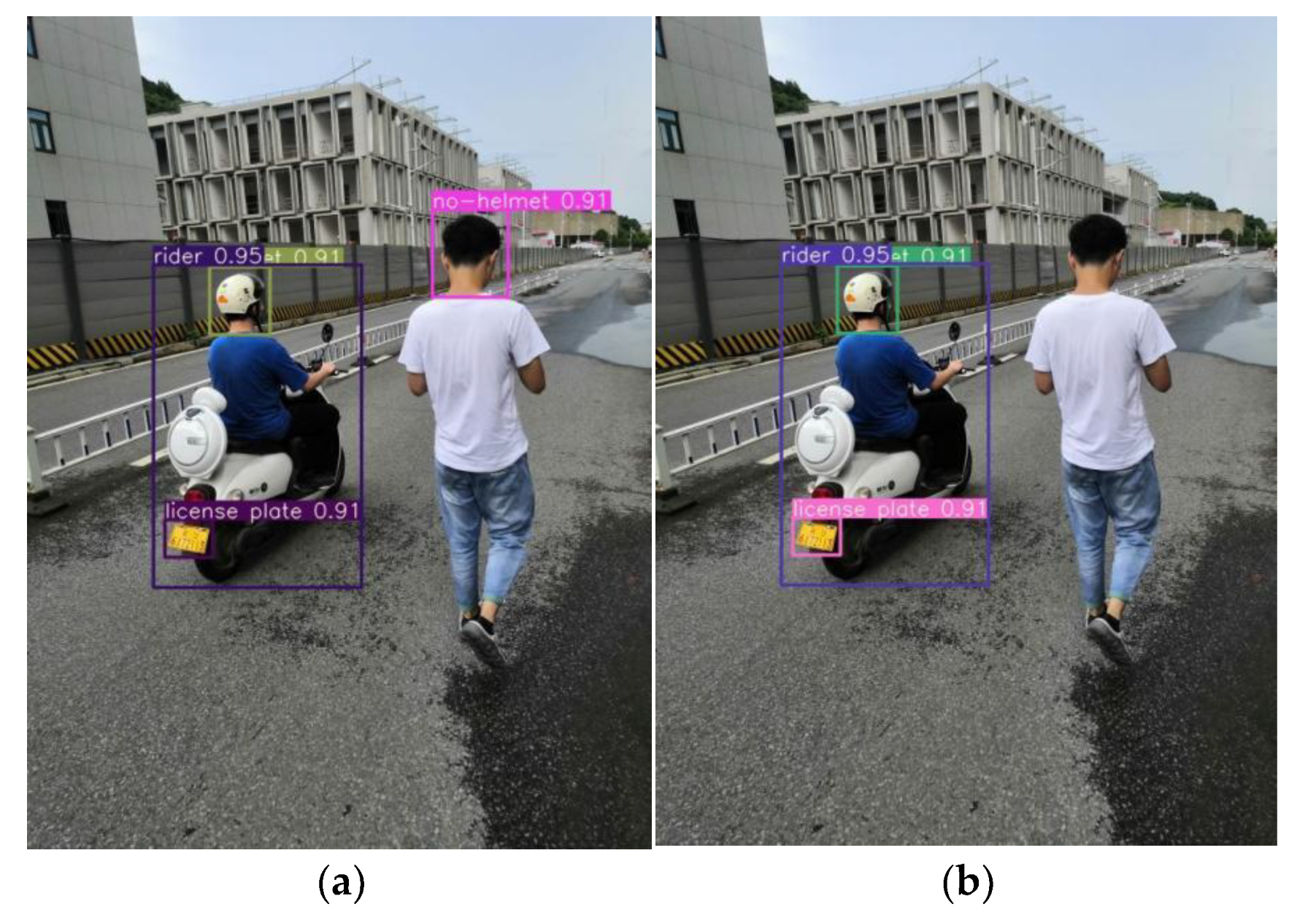
5.2.2. Non-Truth Suppression and License Plate Extraction Experiment
5.2.3. Comparative Experiment
6. Conclusions
- (1)
- In this paper, the license plate detection of the riders without helmets is realized only in a relatively ideal traffic environment. However, in complex traffic environments, such as crowds of pedestrians and riders in the image, there may be overlapping of heads or license plates, resulting in the unclear positioning of violators and corresponding license plates. Therefore, the corresponding research work should be carried out in more complex traffic environment in the future.
- (2)
- This paper only classifies and detects several related categories. Despite the interference of pedestrians and parked electric bikes being excluded, the identification of the license plate information of the violators still needs to be further improved. For example, after locating the license plate of the illegal rider, optical character recognition (OCR) of the license plate should be performed.
- (3)
- Foggy backgrounds and image motion blur are not considered in this paper. In future work, we can deploy a defogging algorithm and a deblurring algorithm to clear the image, and then carry out target detection on the image.
- (4)
- As for future work, we also hope to develop a license plate identification system for illegal riders, with the complete interface and the software and hardware platform to better protect peoples’ safe travels.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Stilo, L.; Segura-Velandia, D.; Lugo, H.; Conway, P.P.; West, A.A. Electric bicycles, next generation low carbon transport systems: A survey. Transp. Res. Interdiscip. Perspect. 2021, 10, 100347. [Google Scholar] [CrossRef]
- WHO. Organisation Mondiale de la Santé: Global Status Report on Road Safety 2018; WHO: Geneva, Switzerland, 2018. [Google Scholar]
- Liu, B.; Ivers, R.; Norton, R.; Blows, S.; Lo, S.K. Helmets for preventing injury in motorcycle riders. Cochrane Database Syst. Rev. 2008, 1. [Google Scholar] [CrossRef] [PubMed]
- Eby, D.W. Naturalistic Observational Field Techniques for Traffic Psychology Research. In Handbook of Traffic Psychology; Academic Press: Cambridge, MA, USA, 2011; pp. 61–72. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ultralytics. YOLOv5. Available online: https://github.com/ultralytics/yolov5 (accessed on 1 November 2020).
- Srilakshmi, M.; Chandrika, K.; Sivakumar, K. Helmet Detection. Int. J. Res. Publ. Rev. 2021, 2, 155–158. [Google Scholar]
- Mistry, J.; Misraa, A.K.; Agarwal, M.; Vyas, A.; Chudasama, V.M.; Upla, K.P. An automatic detection of helmeted and non-helmeted motorcyclist with license plate extraction using convolutional neural network. In Proceedings of the 2017 Seventh International Conference on Image Processing Theory, Tools and Applications (IPTA), Montreal, QC, Canada, 28 November–1 December 2017; pp. 1–6. [Google Scholar]
- Allamki, L.; Panchakshari, M.; Sateesha, A.; Pratheek, K.S. Helmet detection using machine learning and automatic License Plate Recognition. Int. Res. J. Eng. Technol. (IRJET) 2019, 6, 80–84. [Google Scholar]
- Dong, X.; Yan, S.; Duan, C. A lightweight vehicles detection network model based on YOLOv5. Eng. Appl. Artif. Intell. 2022, 113, 104914. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2001, Kauai, HI, USA, 8–14 December 2001; Volume 1. [Google Scholar]
- Viola, P.; Jones, M.J. Robust real-time face detection. Int. J. Comput. Vis. 2004, 57, 137–154. [Google Scholar] [CrossRef]
- Lienhart, R.; Maydt, J. An extended set of haar-like features for rapid object detection. In Proceedings of the International Conference on Image Processing, Rochester, NY, USA, 22–25 September 2002; Volume 1. [Google Scholar]
- Felzenszwalb, P.; McAllester, D.; Ramanan, D. A discriminatively trained, multiscale, deformable part model. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, UK, 2016; Volume 1, pp. 326–366. [Google Scholar]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, L.; Wang, G.; et al. Recent advances in convolutional neural networks. arXiv 2015, arXiv:1512.07108. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.; Henderson, D.; Howard, R.; Hubbard, W.; Jackel, L. Handwritten digit recognition with a back-propagation network. Adv. Neural Inf. Process. Syst. 1989, 2, 396–404. [Google Scholar]
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Du, L.; Zhang, R.; Wang, X. Overview of two-stage object detection algorithms. J. Phys. Conf. Ser. 2020, 1544, 012033. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [PubMed]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision (ECCV 2016), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unifified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2017), Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Chen, S.; Lan, J.; Liu, H.; Chen, C.; Wang, X. Helmet Wearing Detection of Motorcycle Drivers Using Deep Learning Network with Residual Transformer-Spatial Attention. Drones 2022, 6, 415. [Google Scholar] [CrossRef]
- Vasanthakumar, G.U.; Kumar, D. HDRT: Helmet Detection System using Convolutional Neural Network in Real Time. In Proceedings of the 2022 IEEE 2nd Mysore Sub Section International Conference (MysuruCon), Mysuru, India, 16–17 October 2022; pp. 1–5. [Google Scholar]
- Jamtsho, Y.; Riyamongkol, P.; Waranusast, R. Real-time license plate detection for non-helmeted motorcyclist using YOLO. Ict Express 2021, 7, 104–109. [Google Scholar] [CrossRef]
- Anitha Moses, V.; Brightlin Selvamary, A.; Sreelekha, M. Automatic detection of license plate number of motorcyclists without helmet. In Proceedings of the 2013 XXXIX Latin American Computing Conference (CLEI), Caracas, Venezuela, 7–11 October 2013. [Google Scholar]
- Jin, Z.; Qu, P.; Sun, C.; Luo, M.; Gui, Y.; Zhang, J.; Liu, H. DWCA-YOLOv5: An improve single shot detector for safety helmet detection. J. Sens. 2021, 2021, 4746516. [Google Scholar] [CrossRef]
- Hou, Y.; Shi, G.; Zhao, Y.; Wang, F.; Jiang, X.; Zhuang, R.; Mei, Y.; Ma, X. R-YOLO: A YOLO-Based Method for Arbitrary-Oriented Target Detection in High-Resolution Remote Sensing Images. Sensors 2022, 22, 5716. [Google Scholar] [CrossRef] [PubMed]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6023–6032. [Google Scholar]
- Shang, D.; Zhang, J.; Zhou, K.; Wang, T.; Qi, J. Research on the Application of Visual Recognition in the Engine Room of Intelligent Ships. Sensors 2022, 22, 7261. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.Y.; Liao HY, M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE Press: Washington, DC, USA, 2020; pp. 1571–1580. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 8759–8768. [Google Scholar]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number | From | Params | Module | Arguments |
|---|---|---|---|---|
| 0 | −1 | 3520 | Focus | [3, 32, 3] |
| 1 | −1 | 2880 | Shuffle_Block | [32, 64, 2] |
| 2 | −1 | 9656 | C3Ghost | [64, 64] |
| 3 | −1 | 5280 | Shuffle_Block | [64, 64, 2] |
| 4 | −1 | 28,968 | C3Ghost | [64, 64] |
| 5 | −1 | 9856 | Shuffle_Block | [64, 128, 2] |
| 6 | −1 | 110,160 | C3Ghost | [128, 128] |
| 7 | −1 | 36,096 | Shuffle_Block | [128, 256, 2] |
| 8 | −1 | 143,072 | C3Ghost | [256, 256] |
| 9 | −1 | 18,240 | GhostConv | [256, 128, 1, 1] |
| 10 | −1 | 0 | Upsample | [None, 2, ‘nearest’] |
| 11 | [−1, 6] | 0 | ADD | [1] |
| 12 | −1 | 33,280 | C3Ghost | [128, 128] |
| 13 | −1 | 5024 | GhostConv | [128, 64, 1, 1] |
| 14 | −1 | 0 | Upsample | [None, 2, ‘nearest’] |
| 15 | [−1, 4] | 0 | ADD | [1] |
| 16 | −1 | 8448 | C3Ghost | [64, 64] |
| 17 | −1 | 19,360 | GhostConv | [64, 64, 3, 2] |
| 18 | [−1, 13] | 0 | ADD | [1] |
| 19 | −1 | 25,088 | C3Ghost | [64, 128] |
| 20 | −1 | 75,584 | GhostConv | [128, 128, 3, 2] |
| 21 | [−1, 9] | 0 | ADD | [1] |
| 22 | −1 | 99,328 | C3Ghost | [128, 256] |
| 23 | [16, 19, 22] | 12,177 | Detect | - |
| Parameter | Configuration |
|---|---|
| CPU | AMD Ryzen 9 5950X 16-Core Processor |
| GPU | NVIDIA GeForce RTX 3080 Ti |
| System environment | Windows 10 |
| Acceleration environment | CUDA11.0 |
| Language | Python3.8 |
| Epochs | 300~349 | 350~399 | 400~449 | 450~499 | |
|---|---|---|---|---|---|
| mAP0.5 | YOLOv5s | 96.4% | 96.4% | 96.7% | 96.4% |
| SG-YOLOv5 | 96.8% | 97.0% | 97.3% | 97.2% | |
| mAP0.5:0.95 | YOLOv5s | 67.4% | 67.5% | 67.6% | 67.5% |
| SG-YOLOv5 | 66.3% | 66.6% | 66.7% | 66.9% | |
| precision | YOLOv5s | 95.4% | 95.6% | 95.9% | 95.7% |
| SG-YOLOv5 | 95.3% | 94.4% | 95.4% | 95.0% | |
| recall | YOLOv5s | 93.3% | 93.0% | 93.4% | 92.7% |
| SG-YOLOv5 | 91.7% | 93.1% | 92.7% | 92.9% | |
| Model | AP | mAP0.5 | FPS | Parameters/106 | GFLOPs | Model Size/MB | |||
|---|---|---|---|---|---|---|---|---|---|
| Rider | No-Helmet | License Plate | Helmet | ||||||
| YOLOv3 | 95.8% | 86.6% | 95.6% | 92.6% | 92.6% | 4.2 | 61.54 | 155.1 | 117 |
| YOLOv3-tiny | 94% | 81.1% | 94.3% | 89.6% | 89.8% | 39.5 | 8.68 | 13.0 | 16.6 |
| YOLOv3-spp | 96.2% | 88.2% | 96.2% | 92.9% | 93.4% | 4.1 | 62.59 | 156.0 | 119 |
| YOLOv4 | 97.4% | 83.8% | 96.8% | 90.1% | 92.0% | 20.9 | 63.95 | 59.78 | 244 |
| SSD | 95.2% | 74.4% | 87.8% | 83.1% | 85.1% | 36.1 | 24.01 | 61.11 | 92.1 |
| YOLOv5s | 96.2% | 89.7% | 97% | 93.3% | 94.0% | 24.9 | 7.07 | 16.4 | 13.7 |
| YOLOv5s-MobileNetv3 | 94.5% | 82.2% | 96% | 88.3% | 90.3% | 44.2 | 3.37 | 5.9 | 6.67 |
| YOLOv5s-ShuffleNetv2 | 97.1% | 86.3% | 97.3% | 91.6% | 93.1% | 72.5 | 0.85 | 1.8 | 1.82 |
| YOLOv5s-GhostNet | 96.5% | 88% | 96.1% | 92.9% | 93.4% | 37.6 | 3.92 | 9.7 | 7.79 |
| YOLOv7 | 97.7% | 94.3% | 96.3% | 97.5% | 94.7% | 2.6 | 36.50 | 103.2 | 71.3 |
| SG-YOLOv5 | 97.8% | 89.6% | 97% | 92.6% | 94.2% | 66.7 | 0.65 | 3.2 | 1.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, C.; Tan, Z.; Qing, Q.; Zeng, R.; Wen, G. Fast Helmet and License Plate Detection Based on Lightweight YOLOv5. Sensors 2023, 23, 4335. https://doi.org/10.3390/s23094335
Wei C, Tan Z, Qing Q, Zeng R, Wen G. Fast Helmet and License Plate Detection Based on Lightweight YOLOv5. Sensors. 2023; 23(9):4335. https://doi.org/10.3390/s23094335
Chicago/Turabian StyleWei, Chenyang, Zhao Tan, Qixiang Qing, Rong Zeng, and Guilin Wen. 2023. "Fast Helmet and License Plate Detection Based on Lightweight YOLOv5" Sensors 23, no. 9: 4335. https://doi.org/10.3390/s23094335
APA StyleWei, C., Tan, Z., Qing, Q., Zeng, R., & Wen, G. (2023). Fast Helmet and License Plate Detection Based on Lightweight YOLOv5. Sensors, 23(9), 4335. https://doi.org/10.3390/s23094335