
Information Extraction Network Based on Multi-Granularity Attention and Multi-Scale Self-Learning

Abstract
:1. Introduction
2. Related Work
2.1. Entity and Relation Extraction
2.2. NLP Tasks Based on the MRC Approach
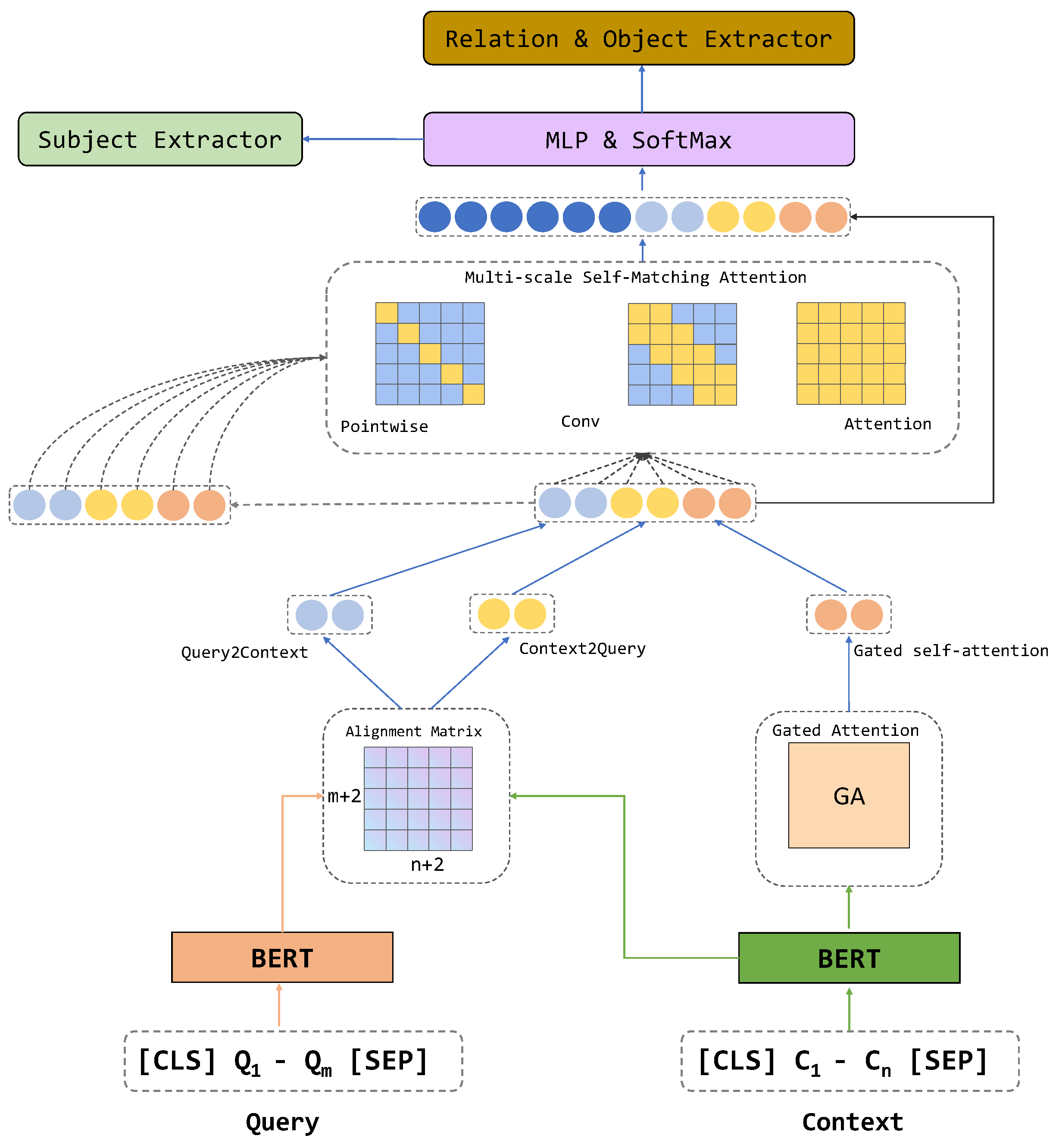
3. Methodology
3.1. Overview
3.2. Formalization of Tasks
3.2.1. Named Entity Recognition
3.2.2. Entity Relation Extraction
3.3. Input Layer
3.4. Multi-Scale Attention
3.4.1. Interactive Attention
3.4.2. Long-Term-Memory-Gated Attention
3.5. Multi-Scale Self-Learning Layer
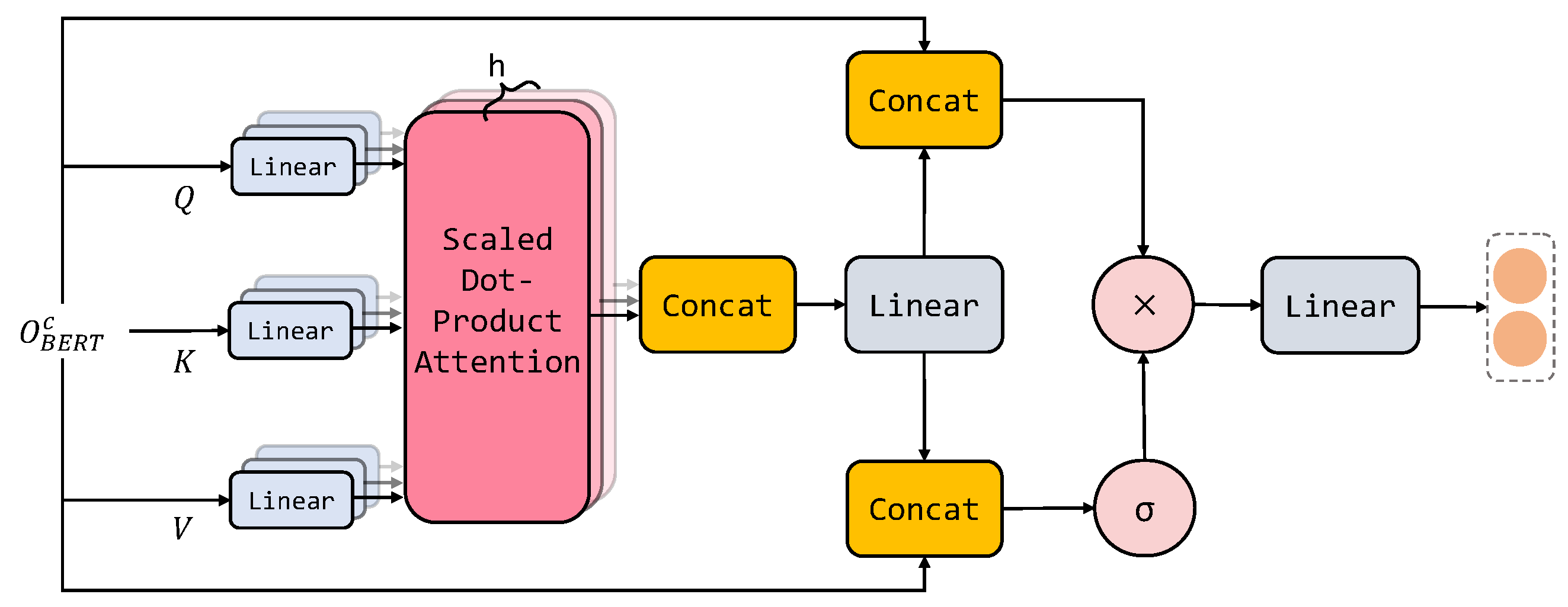
3.5.1. Global-Information-Gated Attention
3.5.2. Local-Features-Focused Attention
3.6. Decoding Layer
4. Experimental Section
4.1. Datasets
4.2. Experimental Setups
4.3. Named Entity Recognition
4.3.1. Baseline Models for Named Entity Recognition
4.3.2. Experimental Results of Named Entity Recognition
4.4. Baseline Models for Relation Extraction
Experimental Results of Relation Extraction
4.5. Ablation Study
4.6. Case Study
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Guo, X.; Zhou, H.; Su, J.; Hao, X.; Tang, Z.; Diao, L.; Li, L. Chinese agricultural diseases and pests named entity recognition with multi-scale local context features and self-attention mechanism. Comput. Electron. Agric. 2020, 179, 105830. [Google Scholar] [CrossRef]
- Chen, X.; Zhang, N.; Li, L.; Yao, Y.; Deng, S.; Tan, C.; Huang, F.; Si, L.; Chen, H. Good visual guidance makes A better extractor: Hierarchical visual prefix for multimodal entity and relation extraction. arXiv 2022, arXiv:2205.03521. [Google Scholar]
- Yuan, L.; Cai, Y.; Wang, J.; Li, Q. Joint multimodal entity-relation extraction based on edge-enhanced graph alignment network and word-pair relation tagging. arXiv 2022, arXiv:2211.15028. [Google Scholar]
- Yang, S.; Tu, K. Bottom-up constituency parsing and nested named entity recognition with pointer networks. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2022; pp. 2403–2416. [Google Scholar]
- Lou, C.; Yang, S.; Tu, K. Nested named entity recognition as latent lexicalized constituency parsing. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2022, Dublin, Ireland, 22–27 May 2022; Muresan, S., Nakov, P., Villavicencio, A., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2022; pp. 6183–6198. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional Transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized BERT pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. arXiv 2019, arXiv:1907.12412. [Google Scholar] [CrossRef]
- Xu, Y.; Li, M.; Cui, L.; Huang, S.; Wei, F.; Zhou, M. Layoutlm: Pre-training of text and layout for document image understanding. In Proceedings of the KDD ’20: The 26th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Virtual Event, CA, USA, 23–27 August 2020; Gupta, R., Liu, Y., Tang, J., Aditya Prakash, B., Eds.; ACM: New York, NY, USA, 2020; pp. 1192–1200. [Google Scholar]
- Xu, Y.; Xu, Y.; Lv, T.; Cui, L.; Wei, F.; Wang, G.; Lu, Y.; Florêncio, D.A.F.; Zhang, C.; Che, W.; et al. Layoutlmv2: Multi-modal pre-training for visually-rich document understanding. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, ACL/IJCNLP 2021, (Volume 1: Long Papers), Virtual Event, 1–6 August 2021; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 2579–2591. [Google Scholar]
- Sun, Y.; Wang, S.; Feng, S.; Ding, S.; Pang, C.; Shang, J.; Liu, J.; Chen, X.; Zhao, Y.; Lu, Y.; et al. Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation. arXiv 2021, arXiv:2107.02137. [Google Scholar]
- Wang, Q.; Dai, S.; Xu, B.; Lyu, Y.; Zhu, Y.; Wu, H.; Wang, H. Building chinese biomedical language models via multi-level text discrimination. arXiv 2021, arXiv:2110.07244. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. arXiv 2022, arXiv:2203.02155. [Google Scholar]
- Chen, Z.; Balan, M.M.; Brown, K. Language models are few-shot learners for prognostic prediction. arXiv 2023, arXiv:2302.12692. [Google Scholar]
- Li, X.; Feng, J.; Meng, Y.; Han, Q.; Wu, F.; Li, J. A unified mrc framework for named entity recognition. arXiv 2019, arXiv:1910.11476. [Google Scholar]
- Li, X.; Yin, F.; Sun, Z.; Li, X.; Yuan, A.; Chai, D.; Zhou, M.; Li, J. Entity-relation extraction as multi-turn question answering. In Proceedings of the Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Chen, N.; Liu, F.; You, C.; Zhou, P.; Zou, Y. Adaptive bidirectional attention: Exploring multi-granularity representations for machine reading comprehension. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2020. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 23–24 June 2014. [Google Scholar]
- Straková, J.; Straka, M.; Hajič, J. Neural architectures for nested ner through linearization. arXiv 2019, arXiv:1908.06926. [Google Scholar]
- Luan, Y.; Wadden, D.; He, L.; Shah, A.; Osten-dorf, M.; Hajishirzi, H. A general framework for information extraction using dynamic span graphs. arXiv 2019, arXiv:1904.03296. [Google Scholar]
- Zelenko, D.; Aone, C.; Richardella, A. Kernel methods for relation extraction. J. Mach. Learn. Res. 2003, 3, 1083–1106. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-end relation extraction using lstms on sequences and tree structures. arXiv 2016, arXiv:1601.00770. [Google Scholar]
- Katiyar, A.; Cardie, C. Going out on a limb: Joint extraction of entity mentions and relations without dependency trees. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017. [Google Scholar]
- Zhang, M.; Yue, Z.; Fu, G. End-to-end neural relation extraction with global optimization. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 9–11 September 2017. [Google Scholar]
- Sun, C.; Gong, Y.; Wu, Y.; Gong, M.; Duan, N. Joint type inference on entities and relations via graph convolutional networks. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Fu, T.J.; Li, P.H.; Ma, W.Y. Graphrel: Modeling text as relational graphs for joint entity and re-lation extraction. In Proceedings of the Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019. [Google Scholar]
- Shen, Y.; Ma, X.; Tang, Y.; Lu, W. A trigger-sense memory flow framework for joint entity and relation extraction. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 1704–1715. [Google Scholar]
- Zhao, T.; Yan, Z.; Cao, Y.; Li, Z. Asking effective and diverse questions: A machine reading comprehen-sion based framework for joint entity-relation extraction. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 3948–3954. [Google Scholar]
- Levy, O.; Seo, M.; Choi, E.; Zettlemoyer, L. Zero-shot relation extraction via reading comprehension. arXiv 2017, arXiv:1706.04115. [Google Scholar]
- McCann, B.; Keskar, N.S.; Xiong, C.; Socher, R. The natural language decathlon: Multitask learning as question answering. arXiv 2018, arXiv:1806.08730. [Google Scholar]
- Yang, P.; Cong, X.; Sun, Z.; Liu, X. Enhanced language representation with label knowledge for span extrac-tion. arXiv 2021, arXiv:2111.00884. [Google Scholar]
- Du, X.; Cardie, C. Event extraction by answering (almost) natural questions. arXiv 2020, arXiv:2004.13625. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems 30, Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Seo, M.; Kembhavi, A.; Farhadi, A.; Hajishirzi, H. Bidirectional attention flow for machine comprehension. arXiv 2016, arXiv:1611.01603. [Google Scholar]
- Yang, B.; Mitchell, T.M. Joint extraction of events and entities within a document context. arXiv 2016, arXiv:1609.03632. [Google Scholar]
- Chen, Y.; Xu, L.; Kang, L.; Zeng, D.; Zhao, J. Event extraction via dynamic multi-pooling convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics(ACL2015), Beijing, China, 26–31 July 2015. [Google Scholar]
- Katiyar, A.; Cardie, C. Nested named entity recognition revisited. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar]
- Yu, J.; Bohnet, B.; Poesio, M. Named entity recognition as dependency parsing. In Proceedings of the Meeting of the Association for Computational Linguistics, Online, 5–10 July 2020. [Google Scholar]
- Hou, F.; Wang, R.; He, J.; Zhou, Y. Improving entity linking through semantic reinforced entity embeddings. arXiv 2021, arXiv:2106.08495. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Entity Type | Query |
|---|---|
| Facility (FAC) | find all facility entities in the context. |
| Geopolitical (GPE) | find all geopolitical entities in the context. |
| Location (LOC) | find all location entities in the context. |
| Organization (ORG) | find all organization entities in the context. |
| Person (PER) | find all person entities in the context. |
| Vehicle (VEH) | find all vehicle entities in the context. |
| Weapon (WEA) | find all weapon entities in the context. |
| Relation Type | Head Type | Tail Type | Query |
|---|---|---|---|
| ART | GPE | FAC | find all facility entities in the context that have an artifact relationship with geopolitical entity . |
| ART | GPE | WEH | find all vehicle entities in the context that have an artifact relationship with geopolitical entity . |
| PHYS | FAC | FAC | find all facility entities in the context that have a physical relationship with facility entity . |
| PART–WHOLE | GPE | GPE | find all geopolitical entities in the context that have a part–whole relationship with geopolitical entity . |
| PART–WHOLE | GPE | LOC | find all location entities in the context that have a part–whole relationship with geopolitical entity . |
| ACE2004 | |||
| Model | P | R | F1 |
| Straková et al. [19] | - | - | 84.40 |
| Luan et al. [20] | - | - | 84.70 |
| Yu et al. [40] † | 85.42 | 85.92 | 85.67 |
| Li et al. [15] † | 86.38 | 85.07 | 85.72 |
| MAML-NET | 86.82 | 84.88 | 85.84 |
| ACE2005 | |||
| Model | P | R | F1 |
| Straková et al. [19] | - | - | 84.33 |
| Li et al. [15] † | 85.48 | 84.36 | 84.92 |
| Yu et al. [40] † | 84.50 | 84.72 | 84.61 |
| Hou et al. [41] | 83.95 | 85.39 | 84.66 |
| MAML-NET | 85.26 | 84.95 | 85.10 |
| GENIA | |||
| Model | P | R | F1 |
| Straková et al. [19] | - | - | 76.44 |
| Li et al. [15] † | 79.62 | 76.8 | 78.19 |
| Yu et al. [40] † | 79.43 | 78.32 | 78.87 |
| Hou et al. [41] | 79.45 | 78.94 | 79.19 |
| MAML-NET (ours) | 79.65 | 79.37 | 79.51 |
| Dataset | Model | Entity | Relation | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| ACE2004 | Miwa et al. [22] | 80.8 | 82.9 | 81.8 | 48.7 | 48.1 | 48.4 |
| Straková et al. [23] | 81.2 | 78.1 | 79.6 | 46.4 | 45.3 | 45.7 | |
| Li et al. [16] † | 84.4 | 82.9 | 83.6 | 50.1 | 48.7 | 49.4 | |
| MAML-NET | 87.9 | 88.8 | 87.9 | 57.9 | 60.2 | 59.2 | |
| ACE2005 | Miwa et al. [22] | 82.9 | 83.9 | 83.4 | 57.2 | 54.0 | 55.6 |
| Straková et al. [23] | 84.0 | 81.3 | 82.6 | 55.5 | 51.8 | 53.6 | |
| Zhang et al. [24] | - | - | 83.5 | - | - | 57.5 | |
| Sun et al. [25] | 83.9 | 83.2 | 83.6 | 64.9 | 55.1 | 59.6 | |
| Li et al. [16] † | 84.7 | 84.9 | 84.8 | 64.8 | 56.2 | 60.2 | |
| Zhao et al. [28] † | 85.1 | 84.2 | 84.6 | 57.8 | 61.9 | 59.8 | |
| Zhao et al. [28] †† | 85.9 | 85.2 | 85.5 | 62.0 | 62.2 | 62.1 | |
| Shen et al. [27] | 86.7 | 87.5 | 87.6 | 62.2 | 63.4 | 62.8 | |
| MAML-NET | 89.5 | 88.9 | 89.6 | 69.4 | 58.8 | 63.7 | |
| Dataset | Model | Entity | Relation | ||||
|---|---|---|---|---|---|---|---|
| P | R | F | P | R | F | ||
| ACE2005 | MAML-NET | 89.5 | 89.8 | 89.6 | 69.4 | 58.8 | 63.7 |
| -MSL | 89.0 | 88.1 | 88.5 | 66.2 | 57.7 | 61.7 | |
| -LTMGA | 88.9 | 89.1 | 89.0 | 66.0 | 58.6 | 62.0 | |
| -MSM<MGA | 87.4 | 88.6 | 88.0 | 64.9 | 57.2 | 60.8 | |
| -IA&MSM<MGA | 84.7 | 84.9 | 84.8 | 64.8 | 56.2 | 60.2 | |
| Sentence 1 | … US officials say some intelligence indicates a red line may have been drawn around the capital with republican guard units ordered to use chemical weapons once US and allied troops cross it. … |
| Multi-QA | ((PER, units), ART, (WEA, weapons)); ((PER, troops), ORG–AFF, (GPE, US)). |
| MAML-NET | ((PER, units), ART, (WEA, weapons)); ((PER, troops), ORG–AFF, (GPE, US)); ((PER, units), ORG–AFF, (ORG, republican guard)); ((PER, units), PHYS, (GPE, capital)). |
| Sentence 2 | … The deadlock, and subsequent lack of any films, has been threatening to de-rail the debut of easy Cinema s first outlet in Milton Keynes, just north of London, which is due to open its doors on May 23. … |
| Multi-QA | ((GPE, Milton Keynes), PHYS, (GPE, London)). |
| MAML-NET | ((GPE, Milton Keynes), PHYS, (GPE, London)); ((ORG, outlet), GEN–AFF, (GPE, Milton Keynes); ((ORG, outlet), PART–WHOLE, (ORG, easy)). |
| Sentence 3 | …And as part of that effort, US special forces today raided the home of the Iraqi microbiologist known as Dr. Germ. … |
| Multi-QA | ((PER, forces), ORG–AFF, (GPE, US)); ((PER, microbiologist), GEN–AFF, (GPE, Iraqi)). |
| MAML-NET | ((PER, forces), ORG–AFF, (GPE, US)); ((PER, microbiologist), GEN–AFF, (GPE, Iraqi)); ((PER, forces), PHYS, (FAC, home)); ((PER, microbiologist), ART, (FAC, home)). |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, W.; Liu, S.; Liu, Y.; Kong, L.; Jian, Z. Information Extraction Network Based on Multi-Granularity Attention and Multi-Scale Self-Learning. Sensors 2023, 23, 4250. https://doi.org/10.3390/s23094250
Sun W, Liu S, Liu Y, Kong L, Jian Z. Information Extraction Network Based on Multi-Granularity Attention and Multi-Scale Self-Learning. Sensors. 2023; 23(9):4250. https://doi.org/10.3390/s23094250
Chicago/Turabian StyleSun, Weiwei, Shengquan Liu, Yan Liu, Lingqi Kong, and Zhaorui Jian. 2023. "Information Extraction Network Based on Multi-Granularity Attention and Multi-Scale Self-Learning" Sensors 23, no. 9: 4250. https://doi.org/10.3390/s23094250
APA StyleSun, W., Liu, S., Liu, Y., Kong, L., & Jian, Z. (2023). Information Extraction Network Based on Multi-Granularity Attention and Multi-Scale Self-Learning. Sensors, 23(9), 4250. https://doi.org/10.3390/s23094250