

A Comprehensive Review on Machine Learning in Healthcare Industry: Classification, Restrictions, Opportunities and Challenges


Abstract
1. Introduction
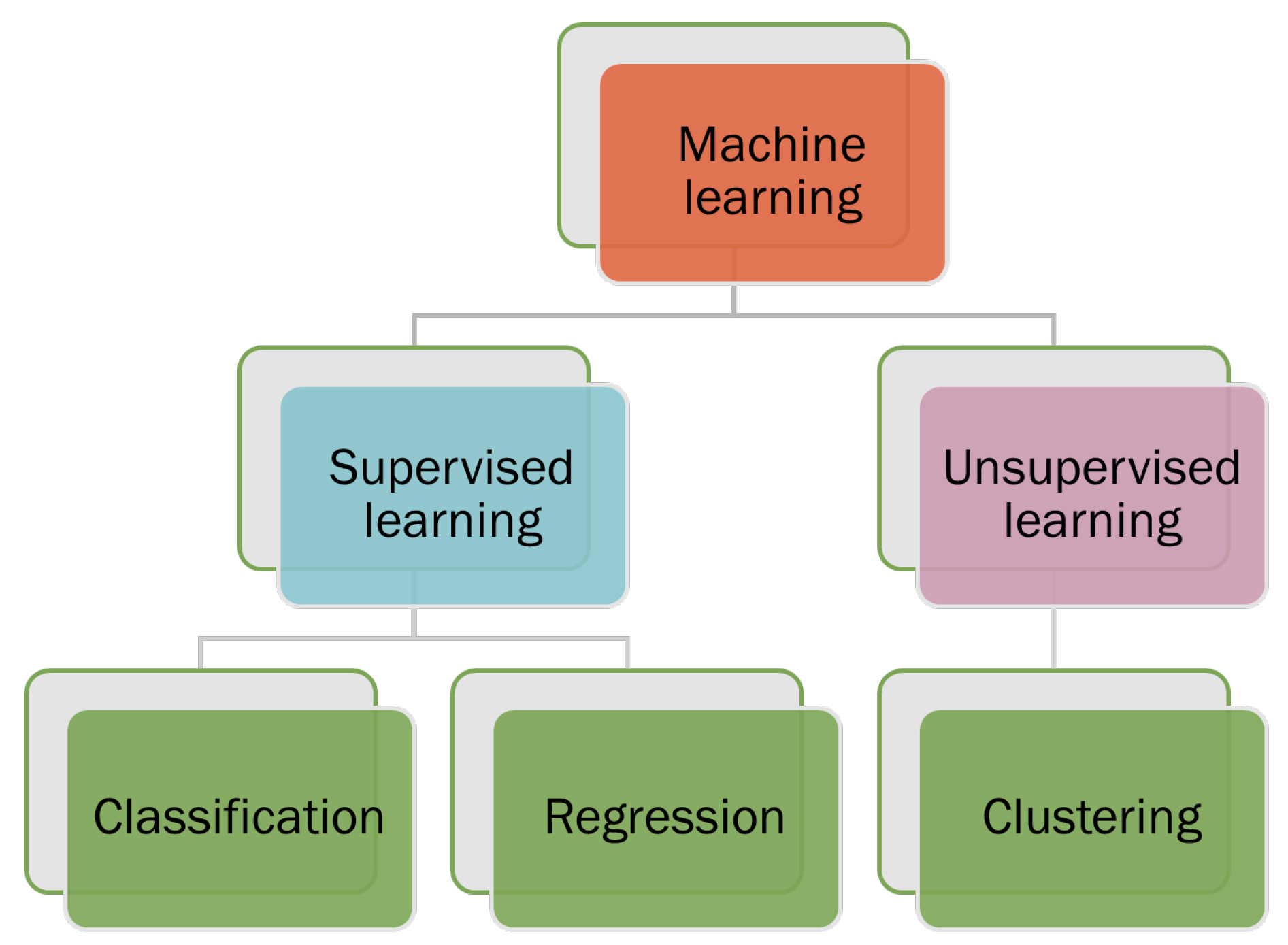
- Supervised machine-learning: the papers in this category cover different machine-learning models’ performance and limitations in the healthcare industry.
- Unsupervised machine learning in the healthcare industry: this category covers the advantage and disadvantages of unsupervised models, where labeled data are unavailable
- Comparative analysis of machine learning model: the papers in this category cover all possible machine learning model used in the healthcare industry and their performance which will provide a future direction for the researcher to think more about machine learning-based solutions in healthcare.
2. Overview of Machine-Learning in Healthcare
- Predictive analytics: Machine learning algorithms can analyze data from electronic health records, claims data and other sources to predict the likelihood of specific health outcomes, such as hospital readmissions or the onset of chronic diseases. This can help healthcare providers identify high-risk patients and take proactive steps to prevent adverse outcomes.
- Diagnosis and treatment: Machine learning algorithms can be trained to analyze medical images, such as CT scans or X-rays, to help diagnose or identify the most appropriate treatment for a patient.
- Personalized medicine: Machine learning can be used to predict which treatments are most likely to be effective for a given patient based on their individual characteristics, such as their genetics and medical history.
- Clinical decision support: Machine learning algorithms can be integrated into clinical decision support systems to help healthcare providers make more informed decisions about patient care.
- Population health management: Machine learning can be used to analyze data from large populations to identify trends and patterns that can inform the development of public health initiatives.
3. Review of Machine Learning
3.1. Some Common Supervised Classification Machine Learning Algorithms
3.1.1. Health Datasets
3.1.2. Feature Extractions
- PCA: PCA is a widely used dimensionality reduction method in data analysis and machine learning. As a linear transformation approach, it aims to discern patterns in high-dimensional data by projecting it onto a lower-dimensional space. The primary objective of PCA is to encapsulate the most important variations in the data while minimizing noise and redundancy [18].
- LDA: Linear discriminant analysis (LDA) is a supervised dimensionality reduction method extensively used in machine learning, pattern recognition, and statistical evaluation. LDA’s main goal is to convert high-dimensional data into a lower-dimensional space while optimizing the distinction between different classes. This property makes LDA especially fitting for classification tasks, as well as for extracting features and visualizing multifaceted, multi-class data [19].
- t-SNE: t-SNE is a non-linear dimensionality reduction method that is especially adept at visualizing high-dimensional data. Laurens van der Maaten and Geoffrey Hinton created t-SNE in 2008. Its primary purpose is to conserve local structures within the data, which entails preserving the distances between adjacent data points during dimensionality reduction. This characteristic renders t-SNE highly effective in unveiling patterns, clusters, and structures within intricate datasets [20].
- Autoencoders: Autoencoders are a form of unsupervised artificial neural network employed for dimensionality reduction, feature extraction, and representation learning. They comprise an encoder and a decoder that collaboratively compress and reconstructs input data while minimizing information loss. Autoencoders are especially valuable for tasks such as denoising, anomaly detection, and unsupervised pre-training for intricate neural networks [21].
- Filter methods: these techniques prioritize features by evaluating them using specific statistical metrics such as correlation, mutual information, or the chi-square test. Subsequently, the most prominent features are chosen. Filter methods are exemplified by approaches like Pearson’s correlation and Information Gain (IG) method [22].
- Wrapper methods: Wrapper methods represent feature selection approaches utilized in machine learning and data analysis. Their main objective is to determine the best subset of features that enhances the performance of a specific machine learning algorithm. By directly evaluating various feature combinations based on the performance of the learning algorithm, wrapper methods are more computationally demanding than filter methods, which are based on the data’s inherent characteristics [23].
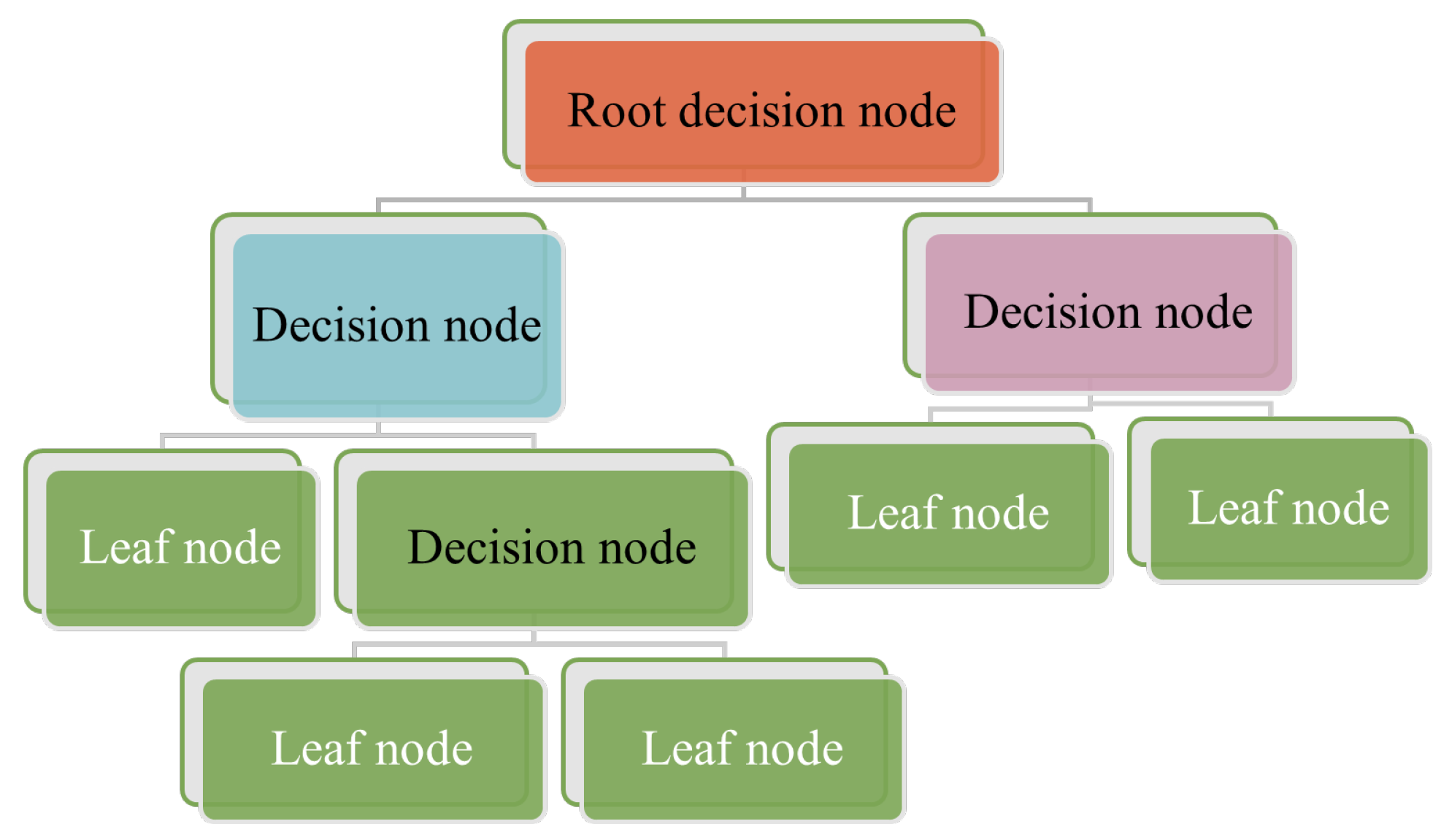
3.1.3. Decision Trees
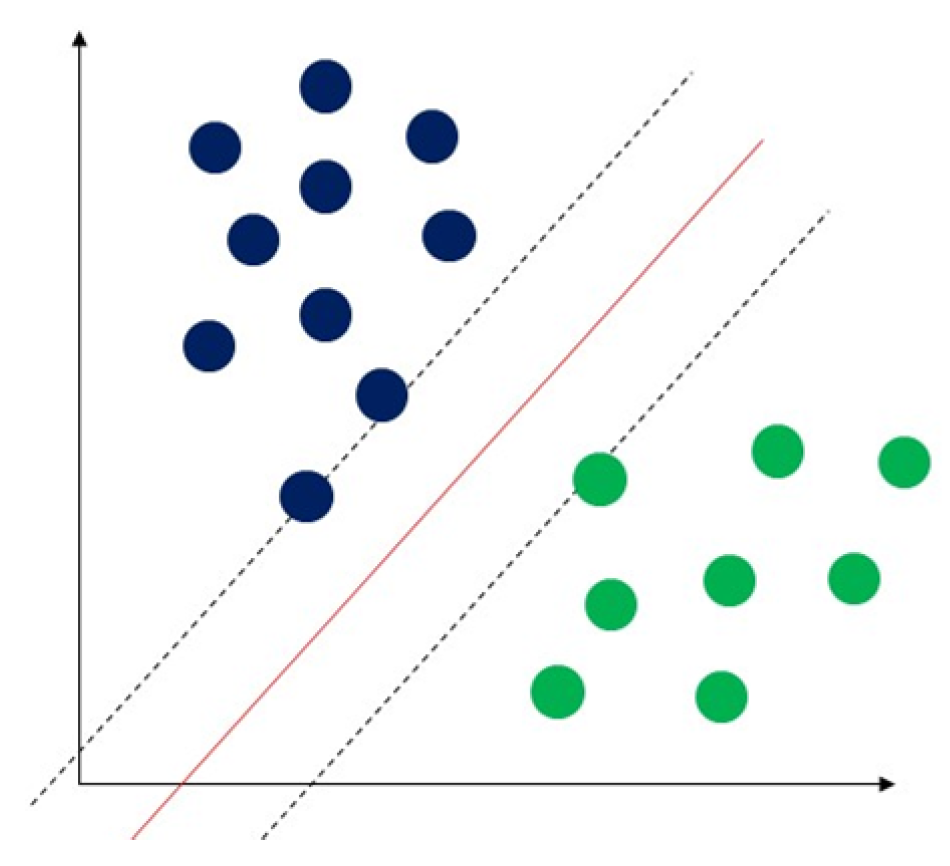
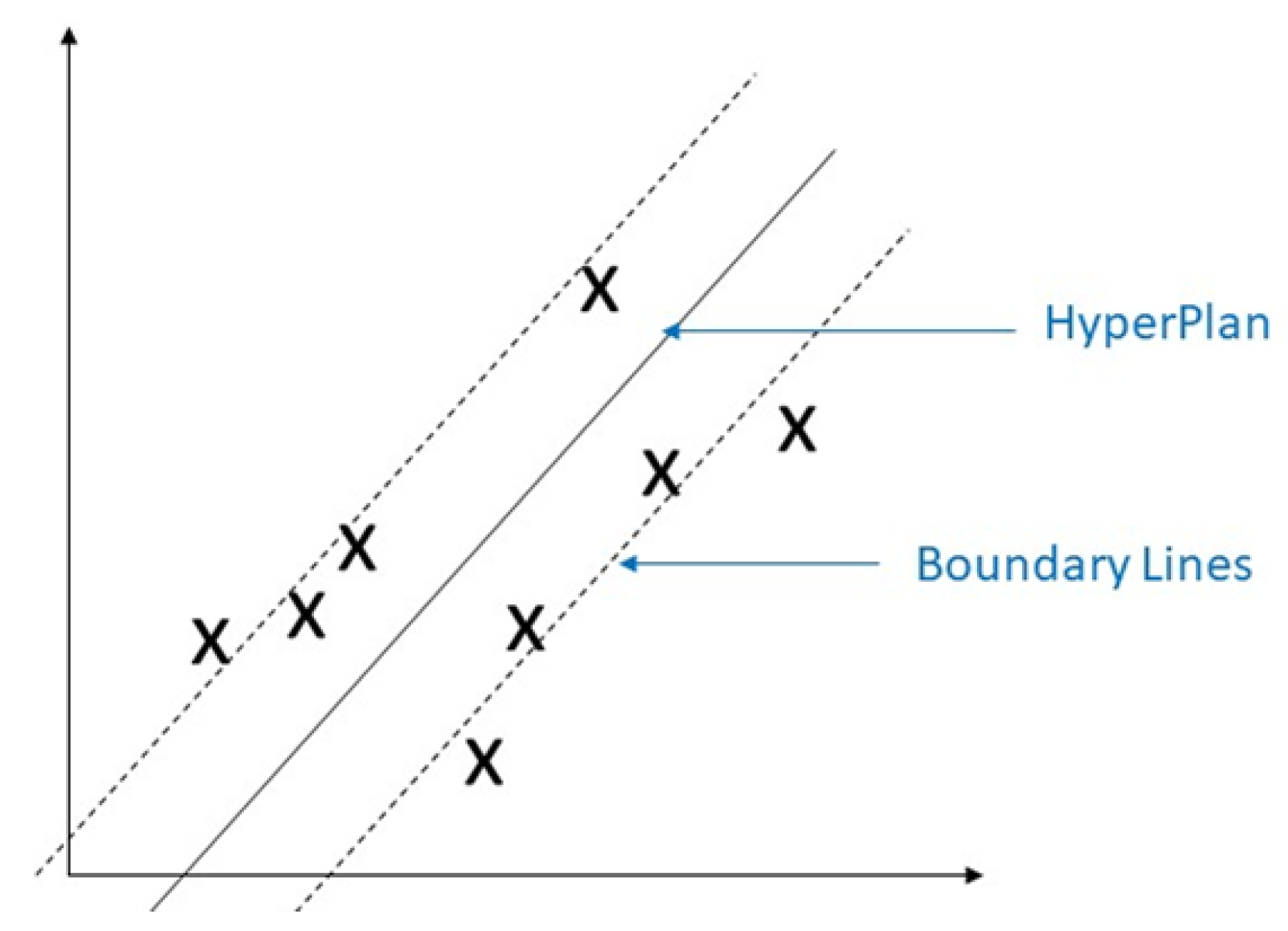
3.1.4. Support Vector Machine (SVM)
3.1.5. Naïve Bayes
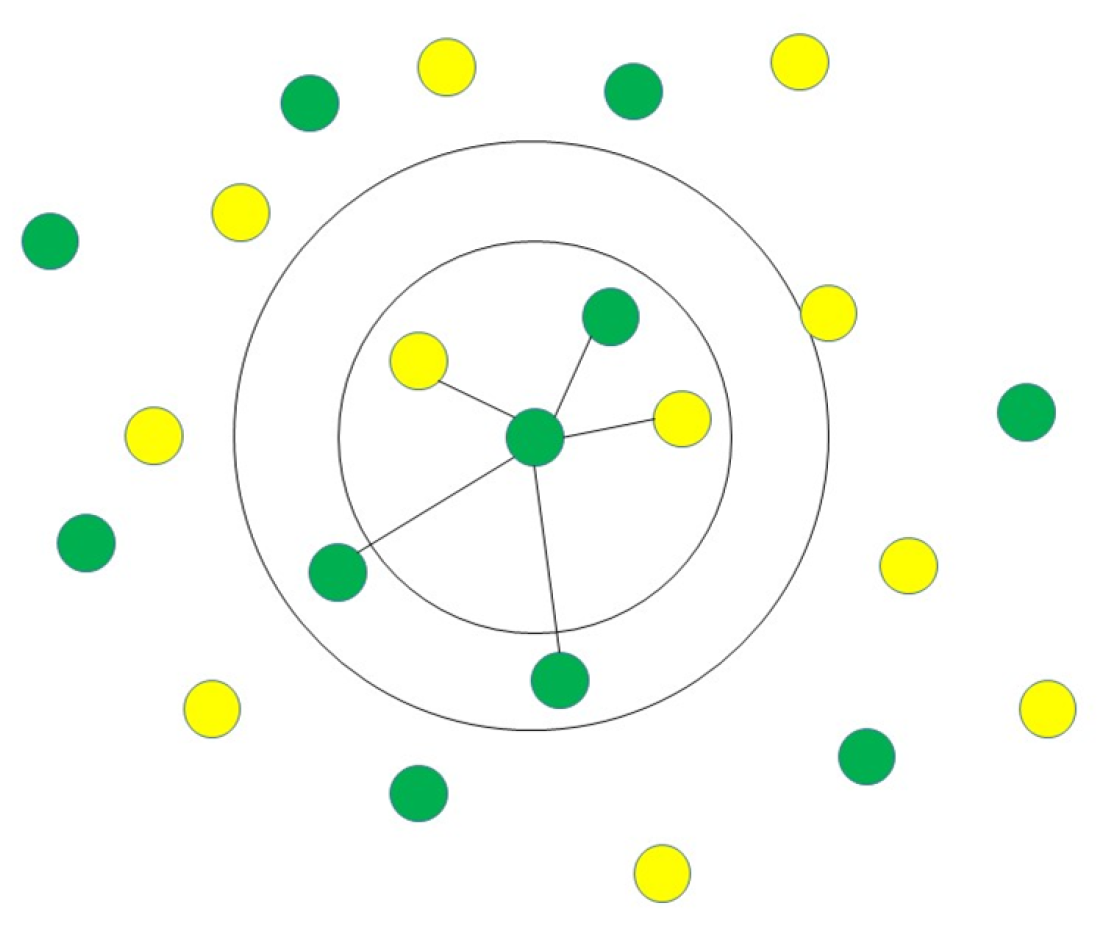
3.1.6. K-Nearest Neighbours (K-NN)
4. Some Popular Supervised Machine Learning Regression Algorithms
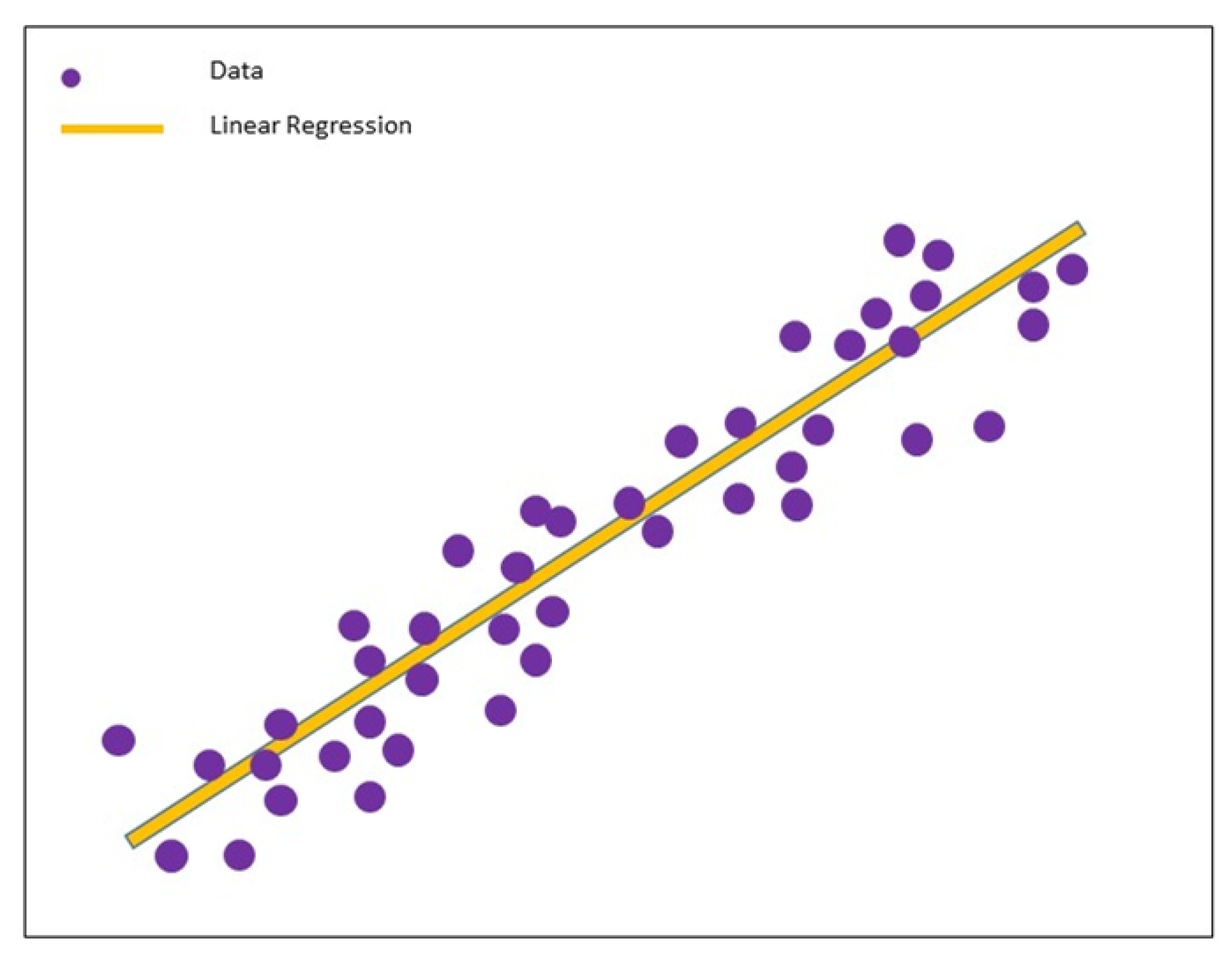
4.1. Linear Regression
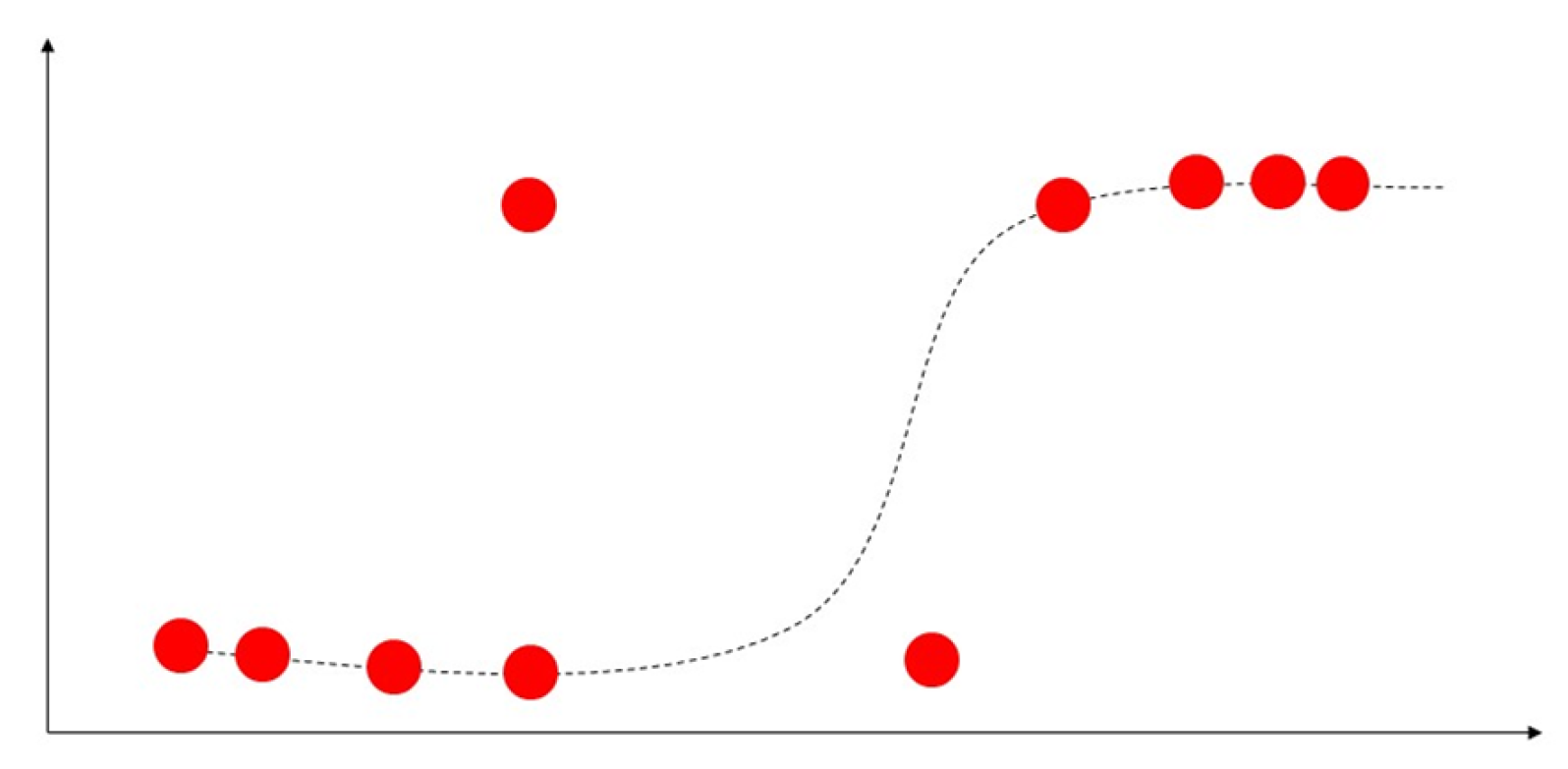
4.2. Logistic Regression
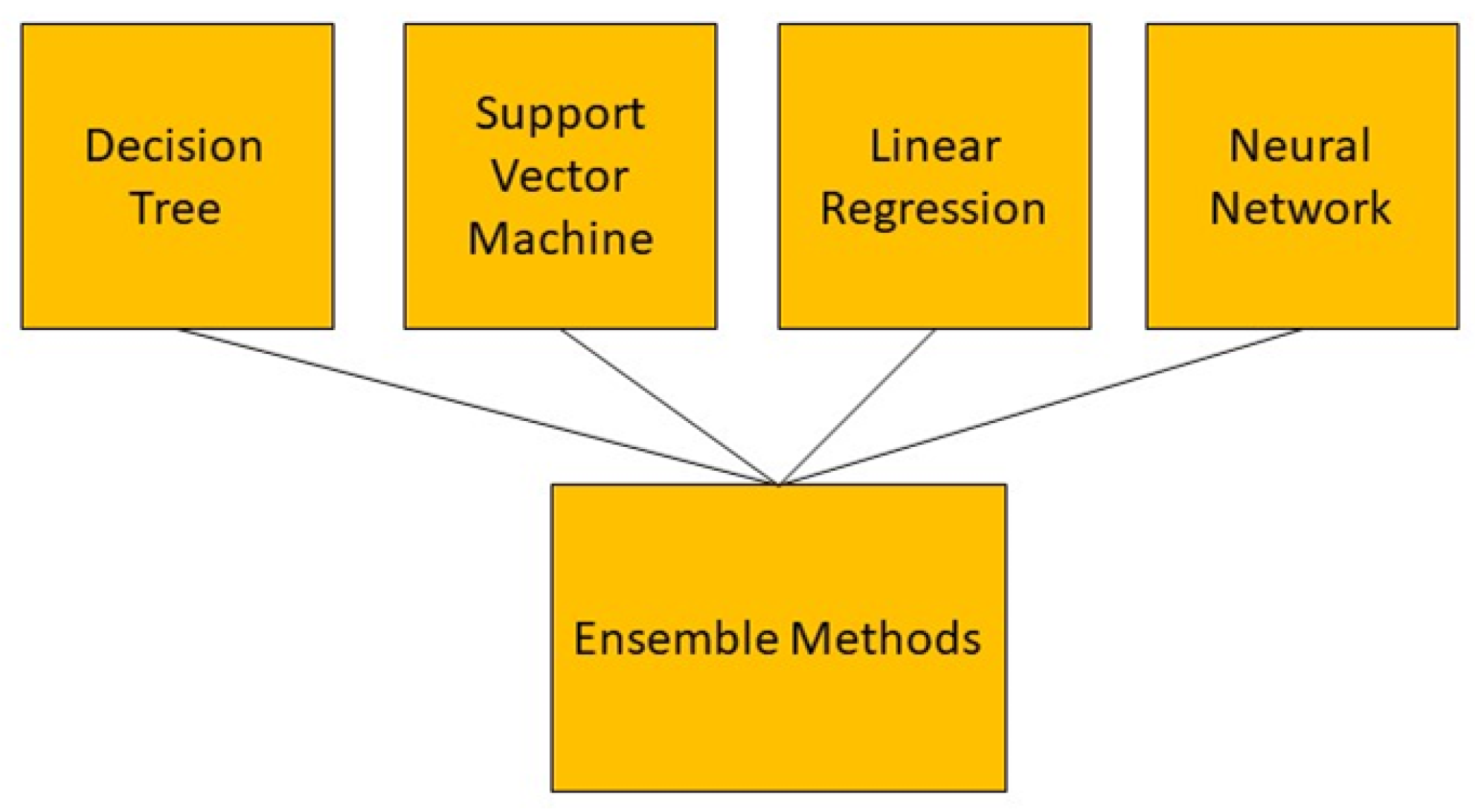
4.3. Ensemble Methods
4.4. Support Vector Regression (SVR)
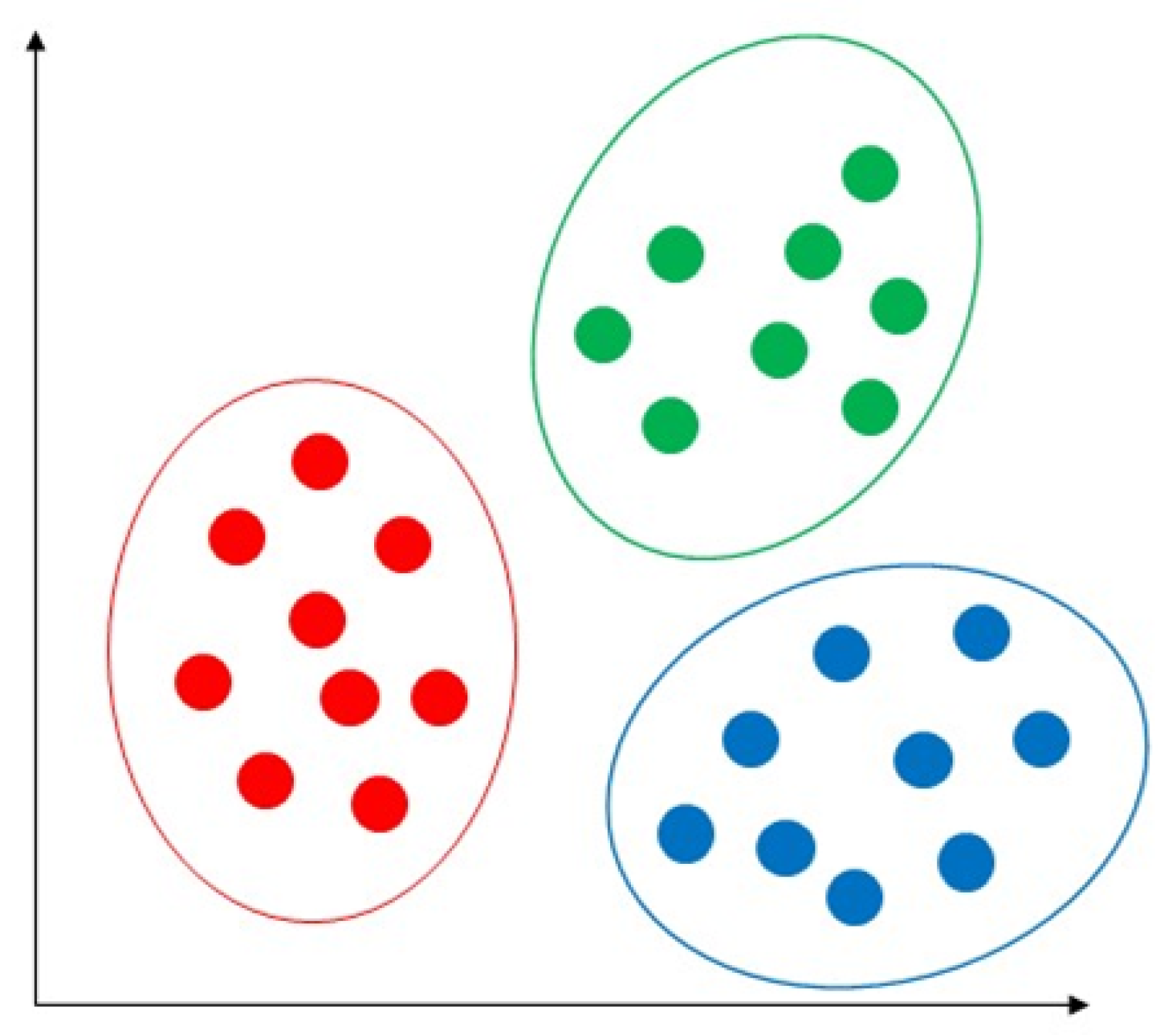
5. Unsupervised Machine Learning
5.1. Common Hard Clustering Algorithms
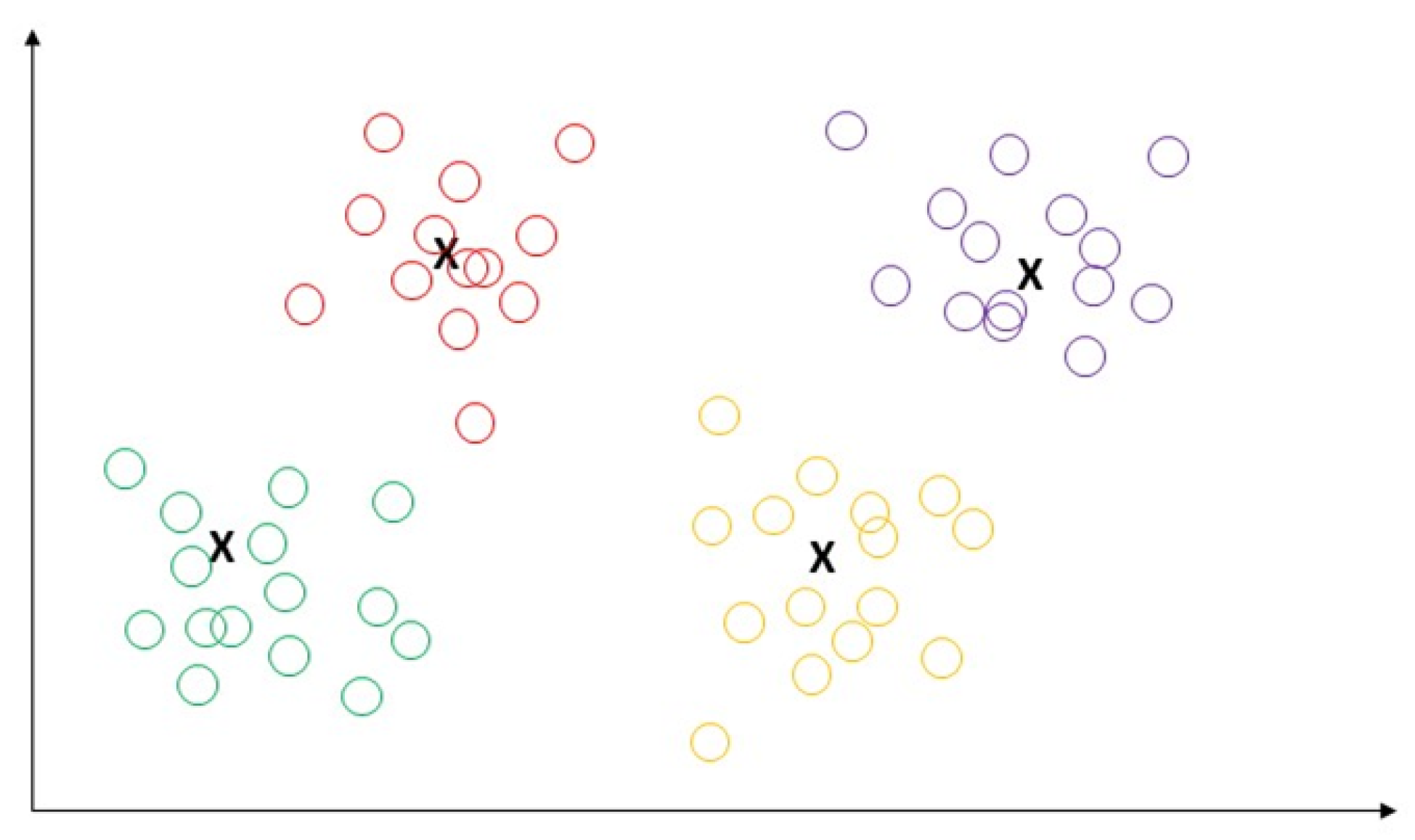
5.1.1. K-Means
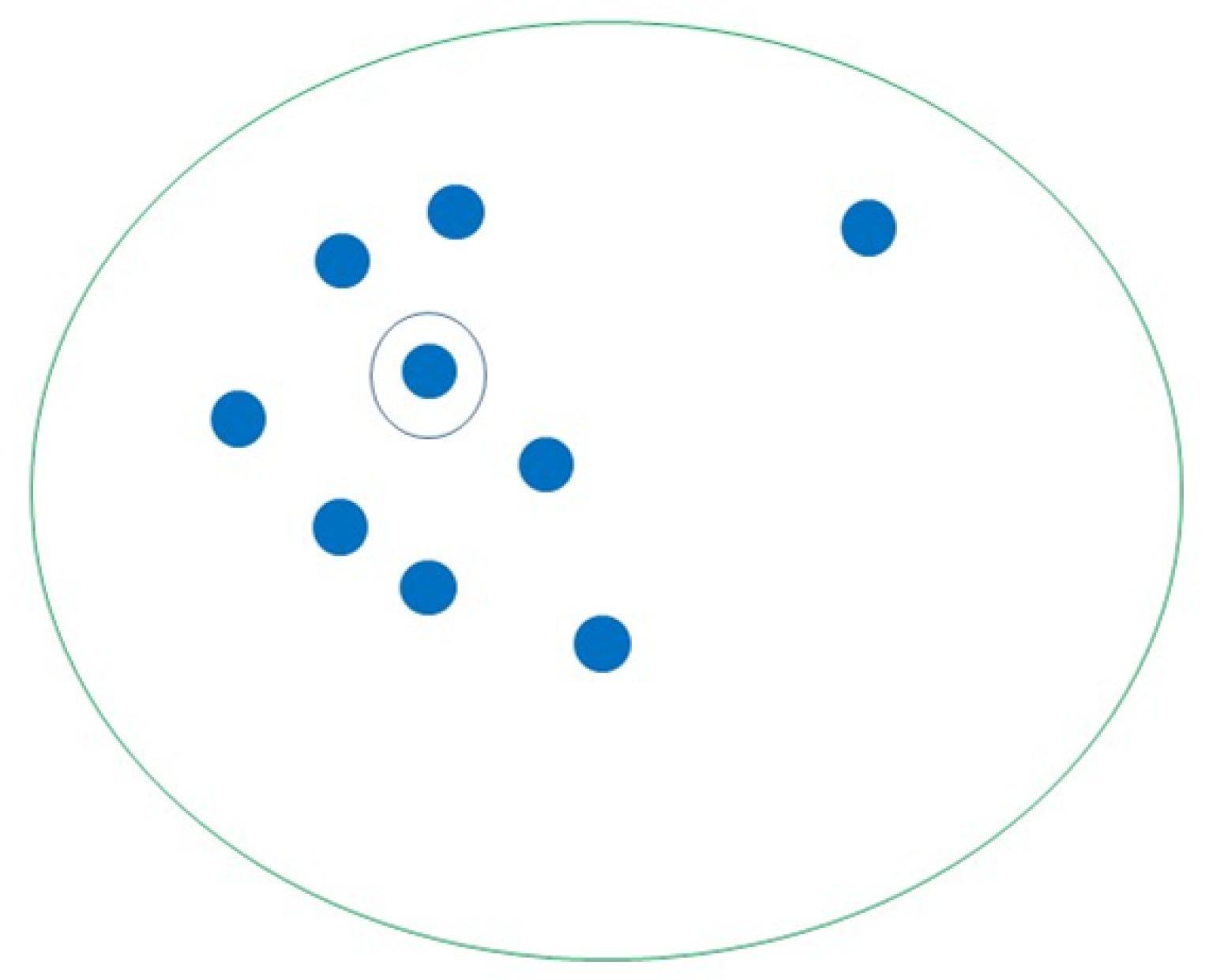
5.1.2. K-Medoids
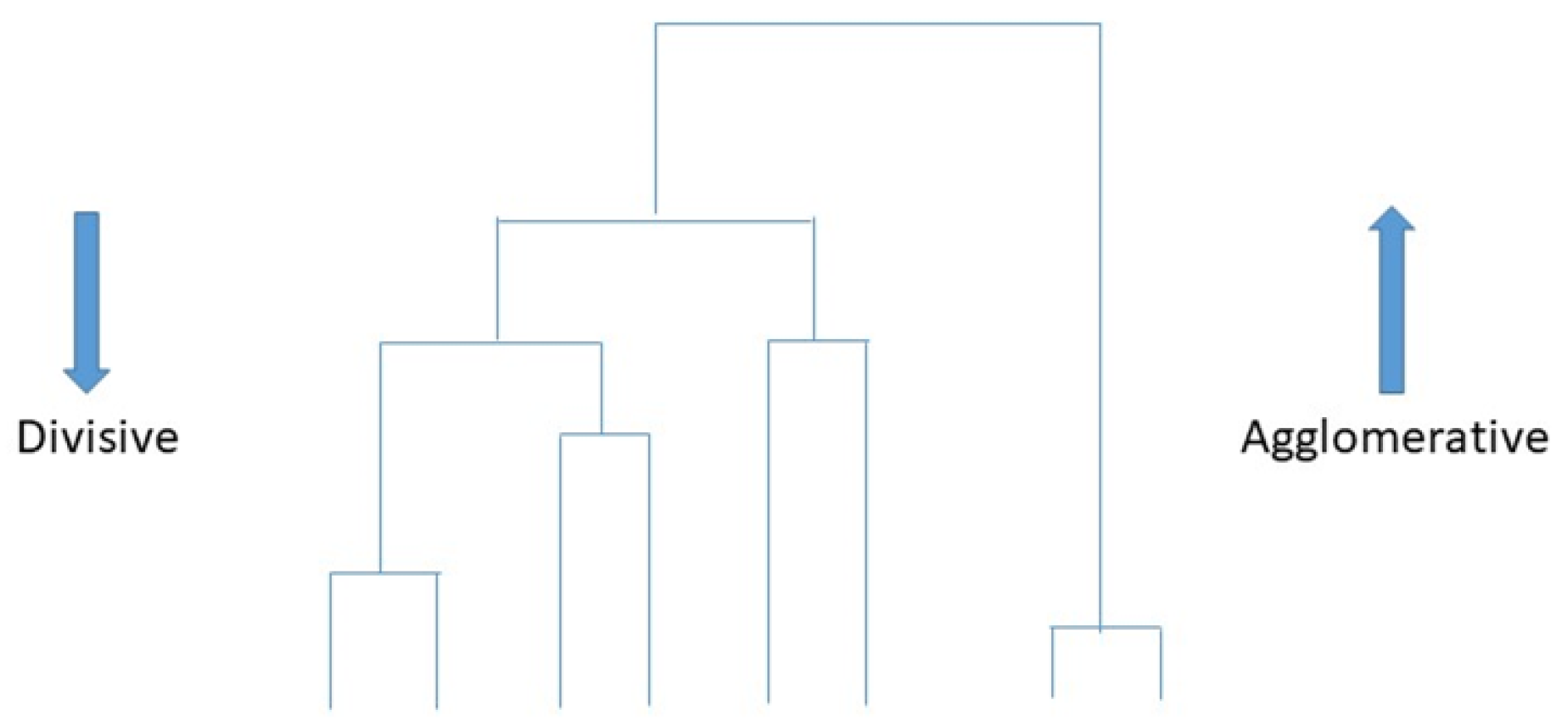
5.1.3. Hierarchical Clustering
5.2. Some Common Soft Clustering Algorithms
5.2.1. Fuzzy c-Means
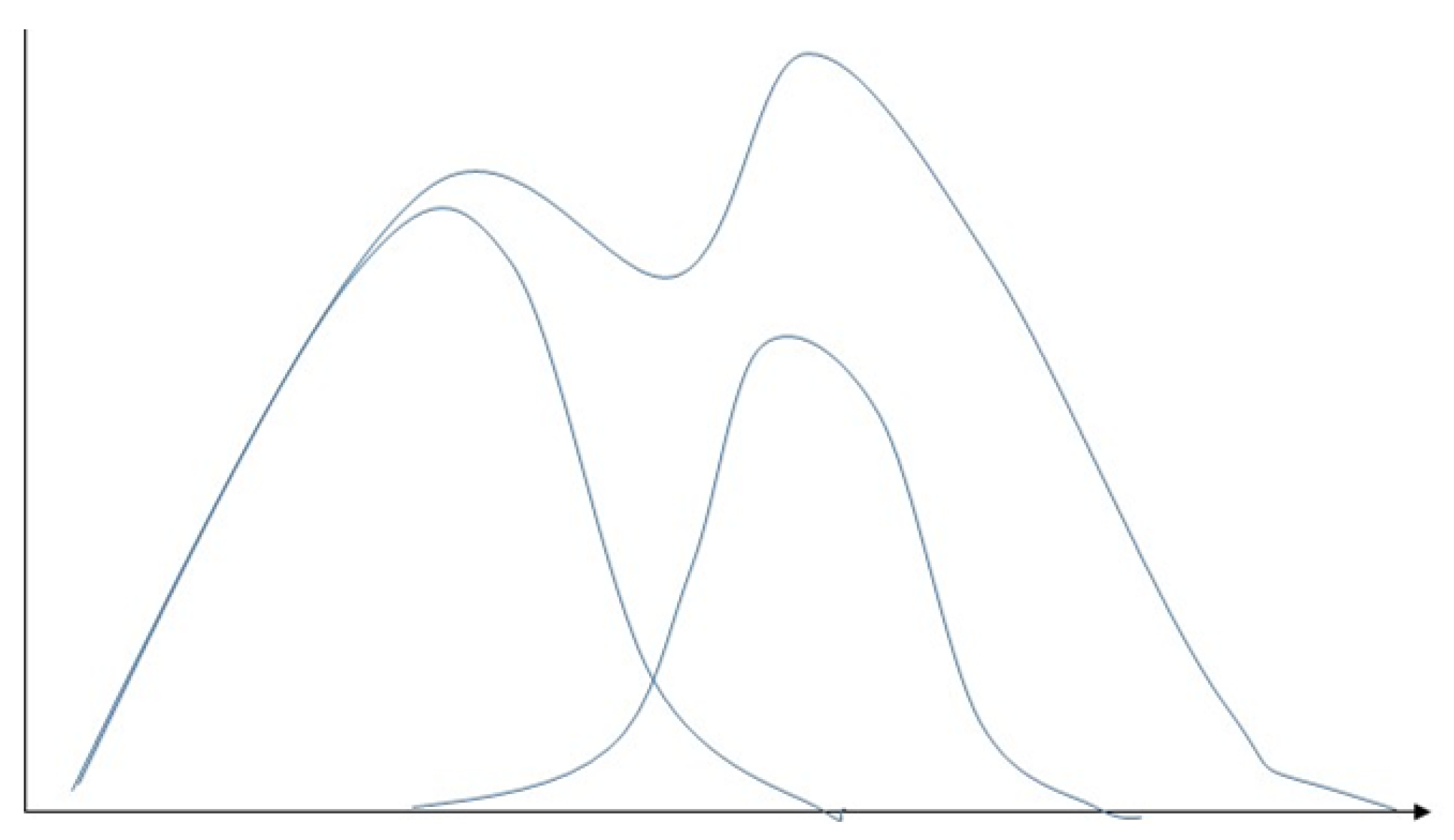
5.2.2. Gaussian Mixture Model
5.2.3. Hidden Markov Model
6. Evaluation of Matrix for Machine Learning
6.1. Evaluation Matrix of Supervised Classification Algorithms
6.2. Evaluation Matrix of Supervised Regression Algorithms
6.3. Evaluation Matrix of Unsupervised Clustering Algorithms
7. Discussion
8. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Dhillon, A.; Singh, A. Machine learning in healthcare data analysis: A survey. J. Biol. Today World 2019, 8, 1–10. [Google Scholar]
- Sinha, U.; Singh, A.; Sharma, D.K. Machine learning in the medical industry. In Handbook of Research on Emerging Trends and Applications of Machine Learning; IGI Global: Hershey, PA, USA, 2020; pp. 403–424. [Google Scholar]
- Wuest, T.; Weimer, D.; Irgens, C.; Thoben, K.D. Machine learning in manufacturing: Advantages, challenges, and applications. Prod. Manuf. Res. 2016, 4, 23–45. [Google Scholar] [CrossRef]
- Chen, M.; Hao, Y.; Hwang, K.; Wang, L.; Wang, L. Disease prediction by machine learning over big data from healthcare communities. IEEE Access 2017, 5, 8869–8879. [Google Scholar] [CrossRef]
- Ngiam, K.Y.; Khor, W. Big data and machine learning algorithms for health-care delivery. Lancet Oncol. 2019, 20, e262–e273. [Google Scholar] [CrossRef]
- Garg, A.; Mago, V. Role of machine learning in medical research: A survey. Comput. Sci. Rev. 2021, 40, 100370. [Google Scholar] [CrossRef]
- Yan, Z.; Zhan, Y.; Peng, Z.; Liao, S.; Shinagawa, Y.; Zhang, S.; Metaxas, D.N.; Zhou, X.S. Multi-instance deep learning: Discover discriminative local anatomies for bodypart recognition. IEEE Trans. Med. Imaging 2016, 35, 1332–1343. [Google Scholar] [CrossRef]
- Anthimopoulos, M.; Christodoulidis, S.; Ebner, L.; Christe, A.; Mougiakakou, S. Lung pattern classification for interstitial lung diseases using a deep convolutional neural network. IEEE Trans. Med. Imaging 2016, 35, 1207–1216. [Google Scholar] [CrossRef] [PubMed]
- Schlemper, J.; Caballero, J.; Hajnal, J.V.; Price, A.; Rueckert, D. A deep cascade of convolutional neural networks for MR image reconstruction. In Proceedings of the Information Processing in Medical Imaging: 25th International Conference, IPMI 2017, Boone, NC, USA, 25–30 June 2017; Springer: Berlin/Heidelberg, Germany; pp. 647–658. [Google Scholar]
- Mehta, J.; Majumdar, A. Rodeo: Robust de-aliasing autoencoder for real-time medical image reconstruction. Pattern Recognit. 2017, 63, 499–510. [Google Scholar] [CrossRef]
- Qureshi, K.N.; Din, S.; Jeon, G.; Piccialli, F. An accurate and dynamic predictive model for a smart M-Health system using machine learning. Inf. Sci. 2020, 538, 486–502. [Google Scholar] [CrossRef]
- Shailaja, K.; Seetharamulu, B.; Jabbar, M. Machine learning in healthcare: A review. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 910–914. [Google Scholar]
- Kang, J.J. Systematic analysis of security implementation for internet of health things in mobile health networks. In Data Science in Cybersecurity and Cyberthreat Intelligence; Springer: Berlin/Heidelberg, Germany, 2020; pp. 87–113. [Google Scholar]
- Ciaburro, G.; Iannace, G.; Ali, M.; Alabdulkarem, A.; Nuhait, A. An artificial neural network approach to modelling absorbent asphalts acoustic properties. J. King Saud. Univ. Eng. Sci. 2021, 33, 213–220. [Google Scholar] [CrossRef]
- Das, S.; Dey, A.; Pal, A.; Roy, N. Applications of artificial intelligence in machine learning: Review and prospect. Int. J. Comput. Appl. 2015, 115, 31–41. [Google Scholar] [CrossRef]
- Muna, A.H.; Moustafa, N.; Sitnikova, E. Identification of malicious activities in industrial internet of things based on deep learning models. J. Inf. Secur. Appl. 2018, 41, 1–11. [Google Scholar]
- Cai, J.; Luo, J.; Wang, S.; Yang, S. Feature selection in machine learning: A new perspective. Neurocomputing 2018, 300, 70–79. [Google Scholar] [CrossRef]
- Song, F.; Guo, Z.; Mei, D. Feature selection using principal component analysis. In Proceedings of the 2010 International Conference on System Science, Engineering Design and Manufacturing Informatization, Yichang, China, 12–14 November 2010; Volume 1, pp. 27–30. [Google Scholar]
- Wen, J.; Fang, X.; Cui, J.; Fei, L.; Yan, K.; Chen, Y.; Xu, Y. Robust sparse linear discriminant analysis. IEEE Trans. Circuits Syst. Video Technol. 2018, 29, 390–403. [Google Scholar] [CrossRef]
- Li, M.A.; Luo, X.Y.; Yang, J.F. Extracting the nonlinear features of motor imagery EEG using parametric t-SNE. Neurocomputing 2016, 218, 371–381. [Google Scholar] [CrossRef]
- Luo, X.; Li, X.; Wang, Z.; Liang, J. Discriminant autoencoder for feature extraction in fault diagnosis. Chemom. Intell. Lab. Syst. 2019, 192, 103814. [Google Scholar] [CrossRef]
- Nagarajan, S.M.; Muthukumaran, V.; Murugesan, R.; Joseph, R.B.; Meram, M.; Prathik, A. Innovative feature selection and classification model for heart disease prediction. J. Reliab. Intell. Environ. 2022, 8, 333–343. [Google Scholar] [CrossRef]
- Li, B.; Zhang, P.l.; Tian, H.; Mi, S.S.; Liu, D.S.; Ren, G.Q. A new feature extraction and selection scheme for hybrid fault diagnosis of gearbox. Expert Syst. Appl. 2011, 38, 10000–10009. [Google Scholar] [CrossRef]
- Mohamed, W.N.H.W.; Salleh, M.N.M.; Omar, A.H. A comparative study of reduced error pruning method in decision tree algorithms. In Proceedings of the 2012 IEEE International Conference on Control System, Computing and Engineering, Penang, Malaysia, 23–25 November 2012; pp. 392–397. [Google Scholar]
- Kotsiantis, S.B.; Zaharakis, I.; Pintelas, P. Supervised machine learning: A review of classification techniques. Emerg. Artif. Intell. Appl. Comput. Eng. 2007, 160, 3–24. [Google Scholar]
- Ray, S. A quick review of machine learning algorithms. In Proceedings of the 2019 International Conference on Machine Learning, Big Data, Cloud and Parallel Computing (COMITCon), Faridabad, India, 14–16 February 2019; pp. 35–39. [Google Scholar]
- Thenmozhi, K.; Deepika, P. Heart disease prediction using classification with different decision tree techniques. Int. J. Eng. Res. Gen. Sci. 2014, 2, 6–11. [Google Scholar]
- Pathak, A.K.; Arul Valan, J. A predictive model for heart disease diagnosis using fuzzy logic and decision tree. In Smart Computing Paradigms: New Progresses and Challenges; Springer: Berlin/Heidelberg, Germany, 2020; pp. 131–140. [Google Scholar]
- Cheung, N. Machine Learning Techniques for Medical Analysis; School of Information Technology and Electrical Engineering: Atlanta, GA, USA, 2001. [Google Scholar]
- Suthaharan, S. Support vector machine. In Machine Learning Models and Algorithms for Big Data Classification; Springer: Berlin/Heidelberg, Germany, 2016; pp. 207–235. [Google Scholar]
- Kazemi, M.; Kazemi, K.; Yaghoobi, M.A.; Bazargan, H. A hybrid method for estimating the process change point using support vector machine and fuzzy statistical clustering. Appl. Soft Comput. 2016, 40, 507–516. [Google Scholar] [CrossRef]
- Yuan, R.; Li, Z.; Guan, X.; Xu, L. An SVM-based machine learning method for accurate internet traffic classification. Inf. Syst. Front. 2010, 12, 149–156. [Google Scholar] [CrossRef]
- Bhavsar, H.; Ganatra, A. A comparative study of training algorithms for supervised machine learning. Int. J. Soft Comput. Eng. (IJSCE) 2012, 2, 2231–2307. [Google Scholar]
- Boero, L.; Marchese, M.; Zappatore, S. Support vector machine meets software defined networking in ids domain. In Proceedings of the 2017 29th International Teletraffic Congress (ITC 29), Genoa, Italy, 4–8 September 2017; Volume 3, pp. 25–30. [Google Scholar]
- Ali, L.; Niamat, A.; Khan, J.A.; Golilarz, N.A.; Xingzhong, X.; Noor, A.; Nour, R.; Bukhari, S.A.C. An optimized stacked support vector machines based expert system for the effective prediction of heart failure. IEEE Access 2019, 7, 54007–54014. [Google Scholar] [CrossRef]
- Nilashi, M.; Ahmadi, H.; Manaf, A.A.; Rashid, T.A.; Samad, S.; Shahmoradi, L.; Aljojo, N.; Akbari, E. Coronary heart disease diagnosis through self-organizing map and fuzzy support vector machine with incremental updates. Int. J. Fuzzy Syst. 2020, 22, 1376–1388. [Google Scholar] [CrossRef]
- Arar, Ö.F.; Ayan, K. A feature dependent Naive Bayes approach and its application to the software defect prediction problem. Appl. Soft Comput. 2017, 59, 197–209. [Google Scholar] [CrossRef]
- Nasteski, V. An overview of the supervised machine learning methods. Horizons. B 2017, 4, 51–62. [Google Scholar] [CrossRef]
- Dulhare, U.N. Prediction system for heart disease using Naive Bayes and particle swarm optimization. Biomed. Res. 2018, 29, 2646–2649. [Google Scholar] [CrossRef]
- Mydyti, H. Data Mining Approach Improving Decision-Making Competency along the Business Digital Transformation Journey: A Case Study–Home Appliances after Sales Service. Seeu Rev. 2021, 16, 45–65. [Google Scholar] [CrossRef]
- Abikoye, O.C.; Omokanye, S.O.; Aro, T.O. Text Classification Using Data Mining Techniques: A Review. Comput. Inf. Syst. J. 2018, 1, 1–8. [Google Scholar]
- Berrar, D. Bayes’ theorem and naive bayes classifier. In Encyclopedia of Bioinformatics and Computational Biology: ABC of Bioinformatics; Elsevier Science Publisher: Amsterdam, The Netherlands, 2018; Volume 403, p. 412. [Google Scholar]
- Osisanwo, F.; Akinsola, J.; Awodele, O.; Hinmikaiye, J.; Olakanmi, O.; Akinjobi, J. Supervised machine learning algorithms: Classification and comparison. Int. J. Comput. Trends Technol. (IJCTT) 2017, 48, 128–138. [Google Scholar]
- Xu, S. Bayesian Naïve Bayes classifiers to text classification. J. Inf. Sci. 2018, 44, 48–59. [Google Scholar] [CrossRef]
- Balaha, H.M.; Hassan, A.E.S. Skin cancer diagnosis based on deep transfer learning and sparrow search algorithm. Neural Comput. Appl. 2023, 35, 815–853. [Google Scholar] [CrossRef]
- Gupta, A.; Kumar, L.; Jain, R.; Nagrath, P. Heart disease prediction using classification (naive bayes). In Proceedings of the First International Conference on Computing, Communications, and Cyber-Security (IC4S 2019), Chandigarh, India, 12 October 2019; pp. 561–573. [Google Scholar]
- Duneja, A.; Puyalnithi, T. Enhancing classification accuracy of k-nearest neighbours algorithm using gain ratio. Int. Res. J. Eng. Technol 2017, 4, 1385–1388. [Google Scholar]
- Chen, Z.; Zhou, L.J.; Da Li, X.; Zhang, J.N.; Huo, W.J. The Lao text classification method based on KNN. Procedia Comput. Sci. 2020, 166, 523–528. [Google Scholar] [CrossRef]
- Deekshatulu, B.; Chandra, P. Classification of heart disease using k-nearest neighbor and genetic algorithm. Procedia Technol. 2013, 10, 85–94. [Google Scholar]
- Shouman, M.; Turner, T.; Stocker, R. Applying k-nearest neighbour in diagnosing heart disease patients. Int. J. Inf. Educ. Technol. 2012, 2, 220–223. [Google Scholar] [CrossRef]
- Ciaburro, G. MATLAB for Machine Learning; Packt Publishing Ltd.: Birmingham, UK, 2017. [Google Scholar]
- Hope, T.M. Linear regression. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 67–81. [Google Scholar]
- Chen, C.T.; Gu, G.X. Machine learning for composite materials. MRS Commun. 2019, 9, 556–566. [Google Scholar] [CrossRef]
- Petrou, S.; Murray, L.; Cooper, P.; Davidson, L.L. The accuracy of self-reported healthcare resource utilization in health economic studies. Int. J. Technol. Assess. Health Care 2002, 18, 705–710. [Google Scholar] [CrossRef] [PubMed]
- Lemon, S.C.; Roy, J.; Clark, M.A.; Friedmann, P.D.; Rakowski, W. Classification and regression tree analysis in public health: Methodological review and comparison with logistic regression. Ann. Behav. Med. 2003, 26, 172–181. [Google Scholar] [CrossRef] [PubMed]
- Liu, H.; Duan, Z.; Li, Y.; Lu, H. A novel ensemble model of different mother wavelets for wind speed multi-step forecasting. Appl. Energy 2018, 228, 1783–1800. [Google Scholar] [CrossRef]
- Lepping, J. Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery; John Wiley: Hoboken, NJ, USA, 2018. [Google Scholar]
- Kaushik, S.; Choudhury, A.; Sheron, P.K.; Dasgupta, N.; Natarajan, S.; Pickett, L.A.; Dutt, V. AI in healthcare: Time-series forecasting using statistical, neural, and ensemble architectures. Front. Big Data 2020, 3, 4. [Google Scholar] [CrossRef]
- Zhang, F.; O’Donnell, L.J. Support vector regression. In Machine Learning; Elsevier: Amsterdam, The Netherlands, 2020; pp. 123–140. [Google Scholar]
- Vrablecová, P.; Ezzeddine, A.B.; Rozinajová, V.; Šárik, S.; Sangaiah, A.K. Smart grid load forecasting using online support vector regression. Comput. Electr. Eng. 2018, 65, 102–117. [Google Scholar] [CrossRef]
- Awad, M.; Khanna, R. Support vector regression. In Efficient Learning Machines; Springer: Berlin/Heidelberg, Germany, 2015; pp. 67–80. [Google Scholar]
- Sharin, S.N.; Radzali, M.K.; Sani, M.S.A. A network analysis and support vector regression approaches for visualising and predicting the COVID-19 outbreak in Malaysia. Healthc. Anal. 2022, 2, 100080. [Google Scholar] [CrossRef]
- Khanum, M.; Mahboob, T.; Imtiaz, W.; Ghafoor, H.A.; Sehar, R. A survey on unsupervised machine learning algorithms for automation, classification and maintenance. Int. J. Comput. Appl. 2015, 119. [Google Scholar] [CrossRef]
- Yu, C.H. Exploratory data analysis in the context of data mining and resampling. Int. J. Psychol. Res. 2010, 3, 9–22. [Google Scholar] [CrossRef]
- Xu, J.; Lange, K. Power k-means clustering. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6921–6931. [Google Scholar]
- Sinaga, K.P.; Yang, M.S. Unsupervised K-means clustering algorithm. IEEE Access 2020, 8, 80716–80727. [Google Scholar] [CrossRef]
- Fränti, P.; Sieranoja, S. How much can k-means be improved by using better initialization and repeats? Pattern Recognit. 2019, 93, 95–112. [Google Scholar] [CrossRef]
- Tang, J.; Wang, D.; Zhang, Z.; He, L.; Xin, J.; Xu, Y. Weed identification based on K-means feature learning combined with convolutional neural network. Comput. Electron. Agric. 2017, 135, 63–70. [Google Scholar] [CrossRef]
- Capó, M.; Pérez, A.; Lozano, J.A. An efficient approximation to the K-means clustering for massive data. Knowl.-Based Syst. 2017, 117, 56–69. [Google Scholar] [CrossRef]
- Govender, P.; Sivakumar, V. Application of k-means and hierarchical clustering techniques for analysis of air pollution: A review (1980–2019). Atmos. Pollut. Res. 2020, 11, 40–56. [Google Scholar] [CrossRef]
- Ripan, R.C.; Sarker, I.H.; Hossain, S.M.M.; Anwar, M.M.; Nowrozy, R.; Hoque, M.M.; Furhad, M.H. A data-driven heart disease prediction model through K-means clustering-based anomaly detection. SN Comput. Sci. 2021, 2, 1–12. [Google Scholar] [CrossRef]
- Kavitha, M.; Srinivas, P.; Kalyampudi, P.L.; Srinivasulu, S. Machine learning techniques for anomaly detection in smart healthcare. In Proceedings of the 2021 Third International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 2–4 September 2021; pp. 1350–1356. [Google Scholar]
- Zhang, Z.; Murtagh, F.; Van Poucke, S.; Lin, S.; Lan, P. Hierarchical cluster analysis in clinical research with heterogeneous study population: Highlighting its visualization with R. Ann. Transl. Med. 2017, 5, 75. [Google Scholar] [CrossRef] [PubMed]
- Srividya, M.; Mohanavalli, S.; Bhalaji, N. Behavioral modeling for mental health using machine learning algorithms. J. Med. Syst. 2018, 42, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Dana, R.; Dikananda, A.; Sudrajat, D.; Wanto, A.; Fasya, F. Measurement of health service performance through machine learning using clustering techniques. In Proceedings of the Journal of Physics: Conference Series, Ningbo, China, 1–3 July 2019; IOP Publishing: Bristol, UK, 2019; Volume 1360, p. 012017. [Google Scholar]
- Zhang, J.; Yan, J.; Infield, D.; Liu, Y.; Lien, F.S. Short-term forecasting and uncertainty analysis of wind turbine power based on long short-term memory network and Gaussian mixture model. Appl. Energy 2019, 241, 229–244. [Google Scholar] [CrossRef]
- Reddy, A.; Ordway-West, M.; Lee, M.; Dugan, M.; Whitney, J.; Kahana, R.; Ford, B.; Muedsam, J.; Henslee, A.; Rao, M. Using gaussian mixture models to detect outliers in seasonal univariate network traffic. In Proceedings of the 2017 IEEE Security and Privacy Workshops (SPW), San Jose, CA, USA, 25 May 2017; pp. 229–234. [Google Scholar]
- Fan, Y.; Huang, W.; Huang, G.; Li, Y.; Huang, K.; Li, Z. Hydrologic risk analysis in the Yangtze River basin through coupling Gaussian mixtures into copulas. Adv. Water Resour. 2016, 88, 170–185. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, J.; Ma, Z.; Zhang, Y. Clustering analysis in the wireless propagation channel with a variational Gaussian mixture model. IEEE Trans. Big Data 2018, 6, 223–232. [Google Scholar] [CrossRef]
- Su, C.; Deng, W.; Sun, H.; Wu, J.; Sun, B.; Yang, S. Forward collision avoidance systems considering driver’s driving behavior recognized by Gaussian Mixture Model. In Proceedings of the 2017 IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 535–540. [Google Scholar]
- Chefira, R.; Rakrak, S. A Knowledge Extraction Pipeline between Supervised and Unsupervised Machine Learning Using Gaussian Mixture Models for Anomaly Detection. J. Comput. Sci. Eng. 2021, 15, 1–17. [Google Scholar] [CrossRef]
- Peng, Y.T.; Lin, C.Y.; Sun, M.T.; Tsai, K.C. Healthcare audio event classification using hidden Markov models and hierarchical hidden Markov models. In Proceedings of the 2009 IEEE International Conference on Multimedia and Expo, New York, NY, USA, 28 June–2 July 2009; pp. 1218–1221. [Google Scholar]
- Sidey-Gibbons, J.A.; Sidey-Gibbons, C.J. Machine learning in medicine: A practical introduction. BMC Med. Res. Methodol. 2019, 19, 1–18. [Google Scholar] [CrossRef]
- Palacio-Niño, J.O.; Berzal, F. Evaluation metrics for unsupervised learning algorithms. arXiv 2019, arXiv:1905.05667. [Google Scholar]
- El Mrabet, M.A.; El Makkaoui, K.; Faize, A. Supervised machine learning: A survey. In Proceedings of the 2021 4th International Conference on Advanced Communication Technologies and Networking (CommNet), Rabat, Morocco, 3–5 December 2021; pp. 1–10. [Google Scholar]
- Muhammad, L.; Algehyne, E.A.; Usman, S.S.; Ahmad, A.; Chakraborty, C.; Mohammed, I.A. Supervised machine learning models for prediction of COVID-19 infection using epidemiology dataset. SN Comput. Sci. 2021, 2, 1–13. [Google Scholar] [CrossRef] [PubMed]
- Mythili, T.; Mukherji, D.; Padalia, N.; Naidu, A. A heart disease prediction model using SVM-decision trees-logistic regression (SDL). Int. J. Comput. Appl. 2013, 68, 11–15. [Google Scholar]
- Sohn, K.; Berthelot, D.; Carlini, N.; Zhang, Z.; Zhang, H.; Raffel, C.A.; Cubuk, E.D.; Kurakin, A.; Li, C.L. Fixmatch: Simplifying semi-supervised learning with consistency and confidence. Adv. Neural Inf. Process. Syst. 2020, 33, 596–608. [Google Scholar]
- Ongsulee, P. Artificial intelligence, machine learning and deep learning. In Proceedings of the 2017 15th International Conference on ICT and Knowledge Engineering (ICT&KE), Bangkok, Thailand, 22–24 November 2017; pp. 1–6. [Google Scholar]
- Pereira, J.; Silveira, M. Learning representations from healthcare time series data for unsupervised anomaly detection. In Proceedings of the 2019 IEEE International Conference on Big Data and Smart Computing (BigComp), Kyoto, Japan, 27 February–2 March 2019; pp. 1–7. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Algorithms | Reference | Year | Task | Accuracy |
|---|---|---|---|---|
| Decision trees | [28] | 2020 | Heart disease prediction | 88% |
| [24] | 2012 | Data volume reduction | 80/32% | |
| [29] | 2001 | Hear disease prediction | 81.11% | |
| Support vector machine (SVM) | [35] | 2019 | Facial recognition, illness detection and prevention, speech recognition, image recognition, and facial detection | 57.85–91.3% |
| Naïve Bayes | [45] | 2020 | Skin disease detection | 91.2–94.3% |
| [46] | 2020 | Heart disease detection | 88.16% | |
| [29] | 2001 | Hear disease prediction | 81.48% | |
| K-nearest neighbours (K-NN) | [49] | 2013 | Heart disease diagnosis | 75.8–100% |
| [50] | 2012 | Heart disease diagnosing | 94–97.1% |
| Regression Algorithms | Reference | Year | Task | Accuracy |
|---|---|---|---|---|
| Linear regression | [54] | 2019 | Healthcare resource utilization | 95% |
| Logistic regression | [55] | 2003 | Predict health-related behavior | 87.7% |
| Ensemble methods | [58] | 2020 | Predict patients’ weekly average expenditures on certain pain medications | 78–98% |
| Support vector regression (SVR) | [62] | 2022 | Visualizing and predicting the COVID-19 outbreak | 94% |
| Common Hard Clustering Algorithms | Reference | Year | Task | Accuracy |
|---|---|---|---|---|
| K-means | [71] | 2021 | Heart disease prediction | 88% |
| K-medoids | [72] | 2021 | Anomaly detection in smart healthcare | 75.89% |
| Hierarchical clustering | [74] | 2018 | Mental health prediction | 90% |
| Some Common Soft Clustering Algorithms | Reference | Year | Task | Accuracy |
| Fuzzy c-means | [75] | 2019 | Analysis of patient satisfaction perception | 76% |
| Gaussian Mixture Model | [81] | 2021 | Anomaly Detection | 95.5% |
| Hidden Markov Model | [82] | 2020 | Healthcare audio event classification | 70% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
An, Q.; Rahman, S.; Zhou, J.; Kang, J.J. A Comprehensive Review on Machine Learning in Healthcare Industry: Classification, Restrictions, Opportunities and Challenges. Sensors 2023, 23, 4178. https://doi.org/10.3390/s23094178
An Q, Rahman S, Zhou J, Kang JJ. A Comprehensive Review on Machine Learning in Healthcare Industry: Classification, Restrictions, Opportunities and Challenges. Sensors. 2023; 23(9):4178. https://doi.org/10.3390/s23094178
Chicago/Turabian StyleAn, Qi, Saifur Rahman, Jingwen Zhou, and James Jin Kang. 2023. "A Comprehensive Review on Machine Learning in Healthcare Industry: Classification, Restrictions, Opportunities and Challenges" Sensors 23, no. 9: 4178. https://doi.org/10.3390/s23094178
APA StyleAn, Q., Rahman, S., Zhou, J., & Kang, J. J. (2023). A Comprehensive Review on Machine Learning in Healthcare Industry: Classification, Restrictions, Opportunities and Challenges. Sensors, 23(9), 4178. https://doi.org/10.3390/s23094178