Abstract
Appropriate cooling of the converter valve in a high-voltage direct current (HVDC) transmission system is highly significant for the safety, stability, and economical operation of a power grid. The proper adjustment of cooling measures is based on the accurate perception of the valve’s future overtemperature state, which is characterized by the valve’s cooling water temperature. However, very few previous studies have focused on this need, and the existing Transformer model, which excels in time-series predictions, cannot be directly applied to forecast the valve overtemperature state. In this study, we modified the Transformer and present a hybrid Transformer–FCM–NN (TransFNN) model to predict the future overtemperature state of the converter valve. The TransFNN model decouples the forecast process into two stages: (i) The modified Transformer is used to obtain the future values of the independent parameters; (ii) the relation between the valve cooling water temperature and the six independent operating parameters is fit, and the output of the Transformer is used to calculate the future values of the cooling water temperature. The results of the quantitative experiments showed that the proposed TransFNN model outperformed other models with which it was compared; with TransFNN being applied to predict the overtemperature state of the converter valves, the forecast accuracy was 91.81%, which was improved by 6.85% compared with that of the original Transformer model. Our work provides a novel approach to predicting the valve overtemperature state and acts as a data-driven tool for operation and maintenance personnel to use to adjust valve cooling measures punctually, effectively, and economically.
1. Introduction
With the increase in global power demand, the security and stability of power systems are more dependent on high-voltage direct current (HVDC) transmission systems [1], in which the converter valve is the core component. If the operating temperature of the converter valve is too high, its internal thyristors and other components will be damaged, thus affecting the normal operation of the converter station and even the regional power grid [2]. The converter valve is equipped with a cooling system. Among its many operating parameters, the cooling water temperature is an important criterion for determining whether the converter valve is in an overtemperature state [3], and different types of cooling systems have diverse overtemperature thresholds. If the temperature of the valve cooling water exceeds the corresponding threshold, the converter valve will operate in the overtemperature state and will be irreversibly damaged if stronger cooling measures are not taken [4].
At present, the operation and maintenance personnel of converter stations mainly judge a valve’s future overtemperature state through manual experience and adopt the following emergency cooling measures [5,6]: (i) increasing the cooling power of the water circulation system; (ii) putting the standby auxiliary cooling equipment into operation; (iii) increasing the water level of the cooling water tank; (iv) distributing the load in the area to other converter stations. However, due to the lack of quantitative perception of overtemperature, operation and maintenance personnel are unable to take timely and appropriate cooling measures, which leads to two negative consequences: On one hand, for the sake of safety, they tend to adopt cooling measures that are stronger than actually needed, but this will cause a waste of energy and water resources and impose dispensable pressure on the operation of the regional power grid [7]; on the other hand, manual experience is not reliable enough to address the occasional overtemperature of a converter valve, so the core equipment cannot be protected to the maximum extent. Therefore, research on methods for predicting the overtemperature state of an HVDC converter valve can improve the perception of operation and maintenance personnel of future overtemperature states, which is of great significance for resource conservation and the stable operation of power grids.
Currently, the research on the overtemperature state of HVDC converter valves is insufficient. Berg et al. [8] and Zhou et al. [9] simulated thermodynamic models of two specific types of converter valves by using 3D simulation and numerical calculation methods so as to obtain a novel valve layout for better heat dissipation efficiency, but converter valves of other types need to be re-simulated before analysis, which is not universally applicable. Liu et al. [10] studied the structure of an internal reactor and other components of a converter valve and proposed a method for reducing the heat generated during the operation of a converter valve by reducing the valve’s power loss, but this method is still incapable of improving the perception of operation and maintenance personnel of the overtemperature of converter valves. Some researchers proposed a new series structure for cooling systems [11], which can reduce power loss and make the temperature of a converter valve more easily perceived and controlled, but it has no guiding significance for a large number of converter stations that are already equipped with the original models of cooling systems. Ma et al. [12] studied the relation between the cooling water temperature of a valve and the DC load, but the approximated relation was vague, and the study lacked further research on the relation between the cooling water temperature and other operating parameters of the converter valve. To sum up, the studies mentioned above lacked adequate predictive research and complete operating parameter analyses for existing converter valves; therefore, they cannot enable operation and maintenance personnel to punctually and appropriately adjust valve cooling measures by analyzing future overtemperature states of converter valves. Therefore, it is necessary to study methods of time-series prediction for the cooling water temperature of converter valves.
In the field of time-series prediction, many AI methods have relatively excellent performance. They can avoid the difficulty of mastering physical mechanisms and excel in building implicit mappings between input and output values. Many algorithms have been developed for time-series prediction, e.g., the back-propagation neural network (BPNN) [13], random forest (RF) [14], support vector regression (SVR) [15], recurrent neural network (RNN) [16], long short-term memory (LSTM) [17], and gated recurrent unit (GRU) [18]. Generally speaking, more recent algorithms have certain improvements in prediction accuracy and training complexity compared with earlier ones. The attention mechanism [19] is the basis of the novel Transformer encoder–decoder architecture [20], which was originally applied in the field of natural language processing (NLP). This Transformer model has powerful sequence–sequence prediction abilities; it can establish the global dependence between the input and output, and it has an excellent prediction effect on time series [21].
To the best of our knowledge, the Transformer model has different performance when processing time series in different scenarios [21]. Under the application background of this study, the valve cooling water temperature is not a typical time series, as it is influenced by multi-source parameters under different operating conditions. Therefore, we need to modify the Transformer model in order to equip it with better competence in valve overtemperature prediction. In this context, we propose a novel TransFNN model that coordinates an improved Transformer model and the F-NN framework (composed of the FCM algorithm and artificial neural networks). On one hand, the Transformer model can forecast future values of the independent parameters of a converter valve. On the other hand, F-NN can accurately fit the relations between several independent parameters and one dependent parameter of the converter valve, and it can calculate the future values of the valve’s cooling water temperature, i.e., the dependent parameter, by using future values of the independent parameters obtained by the Transformer. The major contributions and innovations of this study can be stated from three perspectives:
- (i)
- The proposed TransFNN model is capable of more accurately forecasting the overtemperature state of a converter valve, and it can act as a data-driven tool for operation and maintenance personnel to use to effectively and economically adjust cooling measures.
- (ii)
- We improved the positional encoding method in the Transformer to make it suitable for predictions of time series with strong periodicity in different time dimensions.
- (iii)
- Our research provides an effective framework for time-series predictions with multi-source data, and it has satisfying performance in scenarios in which the investigated object has a variety of complex operating conditions.
The remainder of this paper is organized as follows. Section 2 presents the mathematical model for the prediction of a valve’s cooling water temperature. In Section 3, the Transformer-based model is modified to address the problem of independent operating parameter prediction. Section 4 is devoted to introducing the method for the calculation of a valve’s cooling water temperature based on the F-NN algorithm. Section 5 involves quantitative experiments, as well as an evaluation of the result and an analysis. Section 6 summarizes the crucial conclusions and declares the research prospects.
2. Mathematical Model for Valve Cooling Water Temperature Predictions
The prediction of a valve’s cooling water temperature is essentially a combination of time-series prediction and function approximation, and the main stages of model construction are as follows: Firstly, the influencing factors of a valve’s cooling water temperature are identified as the independent parameters; secondly, a time-series prediction model is established to forecast future values of the independent variables; thirdly, the relation between the valve’s cooling water temperature and the independent variables is approximated by using the historical operating data of the converter valve; finally, the two models established in the second and third stages are combined to form the complete model. The model is trained with historical operating data so that it can be used to predict the future values of the valve’s cooling water temperature. A flowchart of the overall scheme is shown in Figure 1.
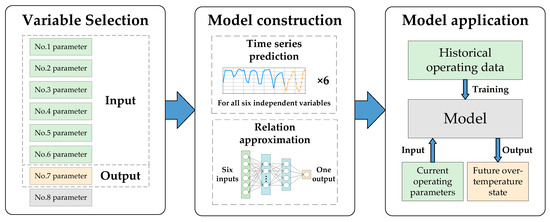
Figure 1.
Flowchart of the overall scheme.
A valve cooling system can be divided into its internal and external parts. The internal cooling water system is a closed cycle and has the functions of heat absorption, water circulation, water treatment, etc. The cooling water in the internal system absorbs the heat generated during the operation of the converter valve and is sent to the external cooling water system. The external cooling water system is an open cycle with the functions of water softening, water purification, water make-up, etc. A cooling tower sprays the internal cooling water pipe for heat dissipation, and the heat of the internal cooling water system is discharged into the atmospheric environment through a fan. The internal and external cooling water systems work together to perform continuous cooling for the converter valve.
Generally, when the operation and maintenance personnel of a converter station patrol the cooling system of a converter valve, eight operating parameters are recorded, and they can be divided into three categories:
- (i)
- Electrical data: DC load;
- (ii)
- Environmental data: external ambient temperature, valve cooling water temperature;
- (iii)
- Water cooling system data: inlet water temperature of the valve’s cooling system, outlet water temperature of the valve’s cooling system.
Both the inlet and outlet water temperatures can be regarded as parameters of the valve’s cooling water temperature, which indicates whether the converter valve is overheated. The inlet water temperature and the cooling measures are two main factors that determine the outlet water temperature. Since the cooling measures of a converter valve are not the main focus of this study and the inlet and outlet water temperatures show a high correlation (the correlation analysis is presented in Section 5), we ignore the parameter of outlet water temperature and use the inlet water temperature to represent the valve’s cooling water temperature, i.e., the dependent parameter. The other six operating parameters are defined as independent variables, and they have a decisive impact on the dependent variable, as shown in Table 1.

Table 1.
Operating parameters of the cooling system of an HVDC converter valve.
For parameter predictions, we can take the DC load () as an example. We denote the historical sequence of at time as , and our target is to predict the future time series at time , where represents the maximum number of prediction steps and is the value of the DC load at time . The prediction model for the time series is expressed by Equation (1):
where represents model’s parameter vector; is the implicit function of the time-series prediction model to be introduced in Section 3; represents the input historical sequence, as shown in Equation (2):
where and represent the length of the historical sequence and the value of the DC load at time , respectively.
The prediction model is trained on the historical dataset. In a given dataset consisting of input–output pairs , the optimal parameter vector of the trained model is obtained by minimizing the loss function as follows:
In addition to the DC power, the above model can also be used to predict the future values of the external ambient temperature and the valve hall temperature. However, some independent parameters, i.e., the water level of the expansion tank, the water level of the spray tank, and the conductivity of the main water circuit, are directly controlled by the operation and maintenance personnel [5], so they do not have typical temporal characteristics. Therefore, when predicting the future values of these three parameters, their future values that were preset by the operation and maintenance personnel are generally accepted, and the other three with typical time-series characteristics can be predicted by using the improved Transformer model, which will be introduced in Section 3.
For this multi-input and single-output prediction problem, we also need a model to approximate the relation between the several inputs and the one output. The value of the dependent variable at time is denoted as , and the vector of independent variables is denoted as , which includes different types of features. Then, the implicit function between the independent and dependent variables can be represented by , as shown in Equation (5):
All independent and dependent parameters are substituted into Equation (5):
where , indicating that there are 6 independent variables; is the implicit function representing the relation between the 6 independent variables and the dependent variable, which is to be introduced in Section 4.
It is worth mentioning that the simple time-series prediction of a valve’s cooling water temperature is of little reference value. It can be seen in Equation (6) that the valve’s cooling water temperature is determined by the six independent variables, but only , and are typical time-series parameters, while , and have few temporal characteristics. Therefore, if the valve’s cooling water temperature is directly predicted in time series, it is the default that all the corresponding independent variables have typical time-series characteristics. This will lead to relatively large errors in the prediction results because this forecasting method runs contrary to the temporal characteristics of the operating parameters; a detailed verification of this will be carried out in Section 5. Hence, we adopt the following prediction strategies:, and , which have obvious time-series characteristics, will participate in the time-series prediction, while , and , which are directly controlled by the operation and maintenance personnel, will be preset before the forecasting process; when the values of the independent variables at time are given, the predicted value of the corresponding valve cooling water temperature can be calculated by using Equation (6). The process of predicting a valve’s cooling water temperature introduced in this section is demonstrated in Figure 2.
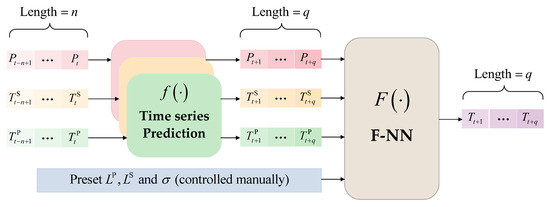
Figure 2.
Schematic diagram of the prediction of a valve’s cooling water temperature.
3. Time-Series Prediction Model Based on the Improved Transformer
The encoder–decoder architecture is based on the attention mechanism, and it was originally used in the field of NLP. The Transformer is a more novel model based on the encoder–decoder architecture, and it has great application prospects in the domain of time-series prediction. In this section, the attention mechanism, the modified Transformer model, and the process of time-series prediction by the Transformer model will be introduced.
3.1. Fundamentals of the Attention Mechanism
The attention mechanism fundamentally maps a query to a series of key–value pairs, which are regarded as the constituent elements within a source. There are three steps in computing attention [20]: Firstly, the similarity of the Query and Key is calculated by using a perceptron, dot product, or concat operation; secondly, the similarity calculated above is normalized by a softmax function; finally, the sum of the weights multiplied by the corresponding Value is calculated so that the attention value can be obtained. The three steps can be summarized as follows:
where represents the length of the source.
The scaled dot-product attention model [20], as shown in Figure 3a, provides a more practical attention calculation method. Its input contains a -dimensional , -dimensional and -dimensional , and its output is
where is used to minimize the inner product; , and represent the , and , respectively; is used to evaluate the similarity between the and . In the attention mechanism, is generally identical to , and the normalized similarity can be obtained after is processed with a softmax function. In the scaled dot-product attention mechanism, , and are calculated as follows: , , and , where is the input matrix of the attention calculation, and , and are the weight matrices, which are randomly initialized and updated during the training of the model, so the values of the output of Equation (8) can better reflect the importance of each element within the sequence.
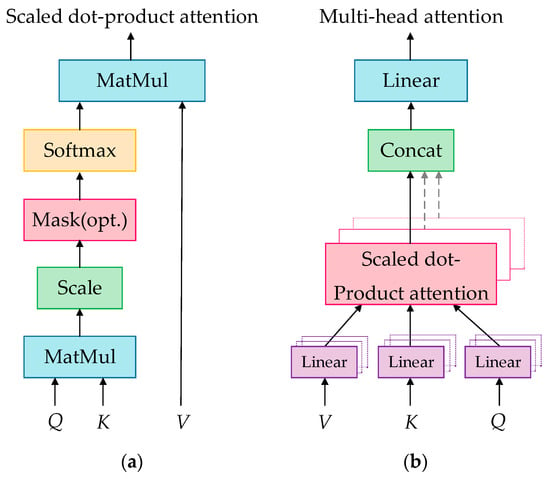
Figure 3.
Two attention models: (a) scaled dot-product attention model; (b) multi-head attention model.
The multi-head attention model [20] is an improvement of the scaled dot-product attention model, as shown in Figure 3b. In this model, , and are mapped through the projection matrices, after which they are used to perform the attention calculation. Then, there are repetitive processes, whose results are finally concatenated, as shown in Equation (9):
where , and are projection matrices that project , and into different dimensions, so different attention models can be trained, leading to an improvement in the accuracy of the attention calculation. Then, the value of attention of heads is concatenated into one, as shown in Equation (10):
where .
3.2. The Transformer Model
The Transformer model is a novel architecture based on the attention mechanism, and it excels in processing sequence-to-sequence problems. It is composed of an encoder and a decoder, and the architecture is shown in Figure 4.
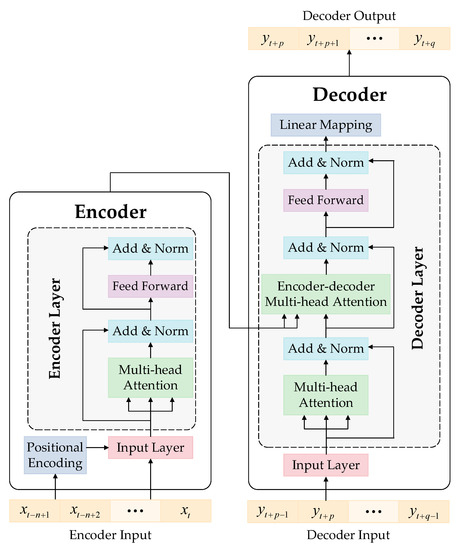
Figure 4.
The Transformer model’s architecture.
The encoder consists of an input layer, a positional encoding layer, and several stacked encoder layers that share the same structure and parameters. Each encoder layer contains a multi-head attention layer and a feed-forward layer, both of which are followed by a normalization layer. The input sequence is mapped to be -dimensional and coded to get the order information in the positional encoding (PE) layer. The PE method of our proposed model is different from the absolute positional encoding method adopted in the original Transformer model [20]. The DC load, external ambient temperature, and valve hall temperature are the three independent parameters to be predicted, and they all have obvious periodicity in the fluctuations in their values over 24 h per day, 30 days per month, and 12 months per year. Therefore, it is necessary to separately perform positional encoding in the three dimensions, and an example of hourly positional encoding is shown in Equations (11) and (12).
where and represent the sine and cosine forms of PE in the first dimension (hourly) of a certain element from the input sequence, respectively; represents the hour of the day corresponding to the time when this element was sampled, and . When positional encoding needs to be performed daily or monthly, and are 30 and 12, respectively. Thus, the input sequence is mapped into 7 dimensions, with the original value in the first dimension, and , , , , , and are the elements of the other six dimensions. By improving the PE, the periodicity of the independent parameters of the converter valve in different time dimensions can be better learned by the Transformer model.
The output sequence of the encoder contains abundant information, and it is fed into the decoder for further processing. In order to use the encoder’s output for the attention mechanism, the decoder layer inserts an encoder–decoder multi-head attention layer between the multi-head layer and the feed-forward layer. After each sublayer in the decoder, there is also a normalization layer, and the linear mapping layer processes the output of the last decoder layer to obtain the decoder’s output.
In Figure 4, the input of the encoder is a sequence , i.e., historical DC load data, where and represent the current time step and the length of the input sequence, respectively. The decoder’s input is , i.e., future DC load data, where is the maximum prediction step. The decoder’s output is , which lags the input sequence of the decoder by one step. The parameters of the Transformer model are obtained through training, e.g., with the weights and biases of the feed-forward layers and the values of , and in the attention layers.
3.3. Process of Parameter Prediction Based on the Transformer
The process of independent parameter predictions with the Transformer model is very similar to that of other time-series prediction models, such as LSTM [22]. The overall prediction process is shown in Figure 5, and all variables to be predicted, including the DC load, ambient temperature, and valve hall temperature, need to go through the same process, but by using three trained Transformer models with different parameter vectors .
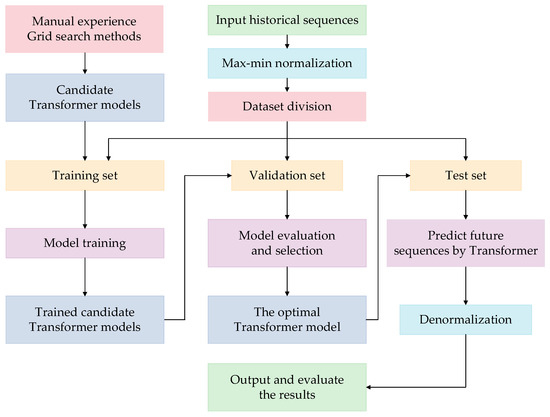
Figure 5.
Flowchart of Transformer-based prediction of independent operation variables.
Taking the prediction of the DC load as an example, the steps are as follows:
- (i)
- The historical DC load data are collected as the input, and they are mapped to . The normalization formula is in shown in (13):where is the original sample data, and is the normalized form; and represent the maximum and minimum values of the sample dataset, respectively.
- (ii)
- The sample dataset is divided into a training set, validation set, and test set.
- (iii)
- Candidate Transformer models with different hyperparameters are obtained by using manual experience and grid search methods [23].
- (iv)
- The candidate models are trained on the training set.
- (v)
- The trained candidate models are evaluated on the validation set and the optimal Transformer model that produces the lowest error is selected.
- (vi)
- The optimal Transformer model is tested on the test set. The output of the optimal Transformer model is denormalized to obtain the predictive values, and they are analyzed with some evaluation indicators [24].
4. Calculation of a Valve’s Cooling Water Temperature Based on F-NN
In Equation (6), the implicit function represents the relation between the valve’s cooling water temperature and the six independent parameters. These seven variables involve complex thermodynamic and electromagnetic relations; therefore, it is difficult to obtain analytical expressions. However, deep learning methods can be used for function approximation so as to fit the relation between the valve’s cooling water temperature and the six independent variables. A converter station operates in different seasons and time periods, and it may be in different operating conditions due to the influence of the external environment and the peaks and valleys of power consumption [1]. Therefore, we put forward the F-NN algorithm, which coordinates the fuzzy C-means clustering (FCM) algorithm and artificial neural networks (ANNs). Firstly, the FCM algorithm is used to cluster the data of the valve’s operating parameters and to form several typical databases belonging to different typical operating conditions of the converter valve. Then, a neural network is applied to fit the relationship between the independent variables and dependent variables under different operating conditions obtained by FCM. By using F-NN, we can approximate the relation represented by the implicit function and then realize the lean calculation of the cooling water temperature of the converter valve.
4.1. Extraction of Typical Operating Conditions Based on FCM
4.1.1. Fundamentals of the FCM Algorithm
FCM is a partition-based clustering algorithm that ensures that the samples clustered in the same class have the highest similarity and that the samples between different classes have the lowest similarity [25]. The FCM algorithm introduces the concept of the membership degree, making it distinct from the K-means clustering algorithm. The membership degree matrix is used to judge the degree of belonging of each sample to each category. The probability of samples belonging to each category is between 0 and 1, so the FCM clustering algorithm is deemed to be soft clustering. The core idea of the FCM algorithm is to constantly update the membership matrix and clustering center matrix until the objective function reaches the minimum, and then the clustering center of the final iteration will be output.
The original operating database of the converter valve can be divided into an input matrix and an output sequence. We denote the historical data matrix of independent parameters in the valve cooling system as the input matrix , as shown in Equation (14):
where is the input sequence of the type of independent parameter, and is the length of the historical data sequence. The diagram of the original operating database of the converter valve is shown in Figure 6.
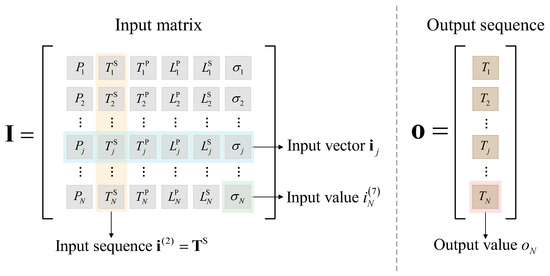
Figure 6.
Original operating database of the converter valve cooling system.
The objective function of the FCM algorithm is:
where represents the total clustering categories that should be set in advance, and it has a great impact on the validity of clustering; is the category order number; is the membership matrix, in which all elements in a column add up to 1, and every element stands for the membership of the sample in the category; is the clustering center matrix, in which any element stands for the clustering center of the category for the variable feature; is the fuzzy index, and the clustering effect is best when [26]; is the Euclidean distance of the input vector of the sample and the clustering center. Both and are randomly initialized.
Lagrange multiplication is used to optimize the objective function to obtain the following formula:
The necessary first-order conditions for optimization are expressed as follows:
According to Equations (17)–(19), the relationship between the membership and Euclidean distance of each element can be obtained, as shown in Equation (20).
Hence, the clustering center can be derived from (19) and (20),
Thus, by Equations (20) and (21), the clustering center matrix and its corresponding membership matrix can be obtained. iterations are performed to update and with Equations (20) and (21) until the value change of the objective function is smaller than the preset iteration accuracy , as shown in (22):
where and represent the membership matrix and the clustering center matrix in the iteration, respectively.
FCM is an unsupervised algorithm, and it is necessary to preset a specific clustering category number so that the sample data will be clustered into categories. Based on the fundamental principle of the clustering algorithm, the smaller the overall distance within a cluster is, and the larger the distances between clusters are, and the more valid the clustering result will be. The clustering category number has a decisive influence on the validity of the clustering results; therefore, a function of is required to characterize the clustering validity, which is named the clustering validity function [26], as shown in Equation (23):
The greater the value of is, the more effective the clustering results are. Before determining the clustering category number, we can let traverse integers: . Then, the FCM calculation process is performed based on different values of so as to obtain the optimal corresponding to the maximum value of , as shown in Equation (24):
The pseudocode of the FCM algorithm is illustrated in Algorithm 1.
| Algorithm 1: Pseudocode of the FCM algorithm |
| Set the fuzzy index , iteration accuracy , and maximum category number for Initialize and randomly while True Update with Equation (20) Update with Equation (21) if [In Equation (22) is satisfied] break while end if end while Calculate the clustering validity function with Equation (23) end for Choose the optimal with Equation (24) return and the corresponding |
4.1.2. Construction of Typical Operating Databases
By using the optimal that was obtained, N samples of historical operating data can be clustered into categories corresponding to typical databases, each of which contains samples consisting of six independent variables and one dependent variable from Table 1. The typical database belongs to the typical operating condition, which is mathematically characterized by the clustering center vector . The data vectors in a typical operating database have the highest similarity with each other and the greatest distinction from those in other typical operating databases. A diagram of the construction of a typical database is shown in Figure 7.
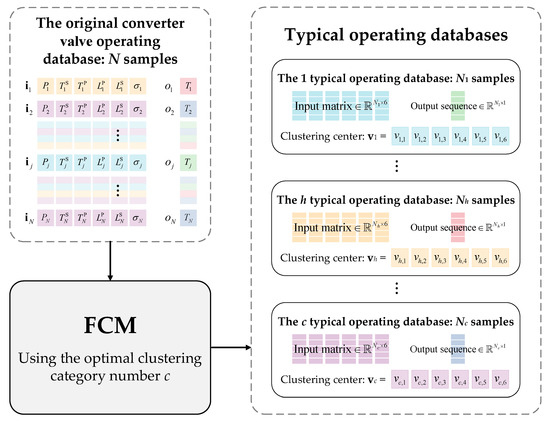
Figure 7.
Diagram of the construction of a typical database for a converter valve.
4.2. Relation Approximation on Different Operating Conditions Based on an ANN
For each database representing a typical operating condition, we need to fit the relation between the independent parameters and the dependent parameter so that when the input vector is given under a certain operating condition, we can accurately calculate its corresponding output value, i.e., the valve’s cooling water temperature. In this context, of the many types of artificial neural networks, the back-propagation neural network (BPNN) algorithm is of high applicability.
Since each operating condition indicates a distinct relation between the dependent and independent parameters, neural networks should be separately trained to approximate the relations. They share the same network structure and hyperparameters, e.g., the number of hidden layers and the number of neurons in each hidden layer, and they all have 6 inputs and 1 output, but the weight and bias parameters of each neural network are different. When the hyperparameters and network parameters of neural networks are determined, we can use the FCM-based division of typical operating conditions and the ANN-based relation approximation of different operating conditions to calculate the valve’s cooling water temperature if a set of independent parameters are given.
When we need to calculate the value of a valve’s cooling water temperature corresponding to a new input vector , we should first determine the type of typical operating condition to which belongs by calculating the optimal . The Euclidean distance between and the clustering center is minimized, as shown in Equation (25):
is fed into an NN trained on the typical database, and the output of the NN is the valve’s cooling water temperature that is to be predicted. So far, the implicit function in Equation (6) has been realized with F-NN, and we can use TransFNN, which coordinates the improved Transformer model and F-NN, to predict future values of the valve’s cooling water temperature.
5. Experiments
In this section, we use the proposed TransFNN model to predict a valve’s cooling water temperature. The dataset division, correlation analysis, model hyperparameter settings, quantitative experiments, and result analysis are involved.
5.1. Dataset Division
This experiment used the 2012–2014 operating data from 12 converter valves of three HVDC converter stations in different regions of China. The historical operating data included eight types of feature quantities, which were introduced in Section 2, and the sampling interval of the data was 4 h. The 12 converter valves were denoted as No. 1–12. For each converter valve, the dataset produced by the operation and maintenance personnel contained 6576 records (from 1 January 2012 at 00:00 a.m. to 31 December 2014 at 20:00 p.m.). In the case of failure or maintenance, the converter valve was shut down, so the data of each converter valve within 3 years had several breakpoints in time, and the data of 3 years were, thereby, cut into several continuous data sequences.
There were 12 prediction tasks corresponding to 12 converter valves. Taking the time breakpoints of the dataset of each converter valve as the dividing points, each dataset was divided into a training set, a validation set, and a test set, with a ratio of approximately 3:1:1. All training sets were used for model training, the validation sets were devoted to selecting the candidate models with the optimal hyperparameters, and the test sets were used to evaluate the prediction results.
5.2. Correlation Analysis of Independent Variables
In Section 2, we introduced eight operating parameters that are generally recorded by the operation and maintenance personnel of converter stations, i.e., the DC load, external ambient temperature, valve hall temperature, water level of the expansion tank, water level of the spray tank, main water circuit conductivity, valve inlet water temperature, and valve outlet water temperature. However, there can be some correlations between one parameter and another. If there are parameters that are highly correlated, the complexity of the model will be pointlessly magnified, and the training speed of the model will, thus, be reduced. Therefore, we used the Pearson correlation coefficient [27] to perform a correlation analysis of the operating parameters, and the parameters with high correlation coefficients with others were eliminated.
The results of Pearson’s correlation analysis are shown in Figure 8. It was apparent that the inlet water temperature and the outlet water temperature were highly correlated, with the correlation coefficient being as high as 0.96. Therefore, the output water temperature of the converter valve was eliminated from the list of operating parameters that we studied, and the inlet water temperature was used to represent the valve’s cooling water temperature. In addition, all independent parameters appeared competent in acting as the input variables of the proposed prediction method; on one hand, the Pearson correlation coefficient between any two of the independent parameters was less than 0.5 or greater than −0.5, which meant that all six independent parameters mentioned in Table 1 were not highly relevant; on the other hand, each of the independent parameters showed a strong link with the inlet water temperature, as their Pearson correlation coefficients were all greater than 0.5 or smaller than −0.5. Therefore, the six independent parameters were used to predict the valve’s cooling water temperature.
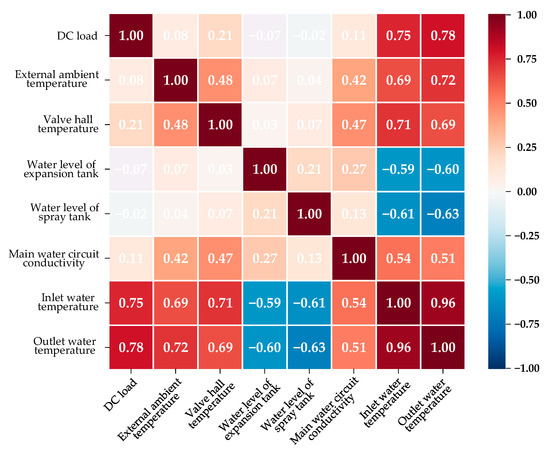
Figure 8.
Pearson’s correlation coefficient analysis of eight operating parameters.
5.3. Model Hyperparameter Settings
In the proposed TransFNN model, there are three types of hyperparameters to be set: (i) the clustering category number of the FCM algorithm, (ii) the length of the historical data sequence and the maximum prediction step , (iii) and the number of hidden layers, the number of neurons in each hidden layer of the BPNN, and the structural and learning parameters of the improved Transformer model.
We first used the 12 training sets of the 12 converter valves to calculate the value of the clustering validity function according to Equation (25). We let the category number traverse from 1 to 10, and the results for each converter valve are shown in Figure 9. For valves No. 6 and No. 12, the values of the clustering validity function corresponding to were marginally greater than those for , and for the other converter valves, the validity of the clustering results was the highest when . Therefore, the optimal clustering number was set to 3 for this case.
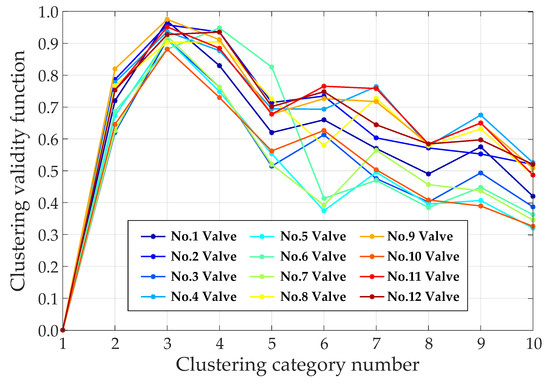
Figure 9.
Clustering validity for different category numbers.
The length of the historical data sequence is of great significance in the Transformer model. To determine , we should take both the completeness of the temporal information and the training complexity into consideration. If is determined to be too large, the training time will be exceedingly long; if it is too small, the input data sequence will not contain sufficient temporal information, which will cause a reduction in prediction accuracy. Therefore, the principle of determining is that the training complexity should be reduced as much as possible on the premise of ensuring the sufficiency of temporal information in the input historical data sequence. Trappenberg et al. [28] proposed a method for calculating the correlation of the mutual information between and , where and represent a time series and its corresponding delay sequence, respectively, and is the length of the lag. In the case that we studied, the mutual information correlation between and showed a downward trend overall, indicating that the two sequences contained more different temporal information as increased. When was between 40 and 112, the value of was almost constant. For the Transformer, the value of was determined by the preset threshold of . When was set to approximately 8, the corresponding was between 40 and 112, and the setting of the threshold was based on manual experience [23]. Given that will cause the input historical data sequence to have the same degree of temporal information sufficiency, and considering the training complexity, should be as small as possible, so we set to 40. In addition, the larger is, the longer the overtemperature state of the converter valve can be monitored, but the predicted values have decreasing reference value as the time step increases. In practical engineering applications, 2 days are adequate for the operation and maintenance personnel of a converter station to adjust the future cooling measures, and there were six samples within a day in this case, so we set to 12.
In the BPNN and the Transformer model, there are eight main hyperparameters to be determined. Using manual experience and grid search methods, the eight structural and learning parameters were set as follows: (i) The number of hidden layers in the BPNN was 2; (ii) the numbers of neurons in each hidden layer were 10 and 5, respectively; (iii) the number of encoding/decoding layers was 3; (iv) the number of neurons in each hidden layer of the feed-forward layer was 32; (v) the learning rate was 0.01; (vi) the size of the epochs was 32; (vii) the batch size was 16; (viii) the dropout was 0.5.
5.4. Quantitative Analysis of TransFNN: Evaluating the Impacts of Individual Modules
In this experiment, historical data sequences of 40 time steps were used to predict future sequences of 12 time steps. It should be noted that DC power, external ambient temperature, and valve hall temperature have obvious time-series characteristics, so their future values were given by the output of the Transformer model; the water level of the expansion tank, water level of the spray tank, and main water circuit conductivity were directly controlled by the operation and maintenance personnel, so their future values in the experiment were obtained by adding Gaussian white noise with an average of 0 to the actual values, where the Gaussian white noise was used to simulate the error of reading the indications of the equipment.
The quantitative experiments were performed with the following models:
- (i)
- The proposed TransFNN;
- (ii)
- : the TransFNN model without the FCM module;
- (iii)
- : the TransFNN model in which the ANN module was substituted with a simpler one, e.g., a multiple linear regression model;
- (iv)
- : the TransFNN model without the improved positional encoding method;
- (v)
- The Transformer model only: equivalent to the TransFNN model without the FCM and ANN modules. The valve’s cooling water temperature was directly predicted with the Transformer.
Each converter valve required a single prediction task. We evaluated the five models on all test sets of every converter valve with statistical measures, i.e., RMSE, MAE, sMAPE, and . The results are shown in Table 2, which indicates that the rankings in every prediction task were not identical, but the TransFNN model always performed the best among the five models in the 12 prediction tasks.
Table 2.
Performance comparison of the five models.
For the sake of clarity, converter valve No. 7 was chosen to display the illustrative results, as shown in Figure 10, and we also present a scatterplot of the measured and predicted values of the valves’ cooling water temperatures in Figure 11.
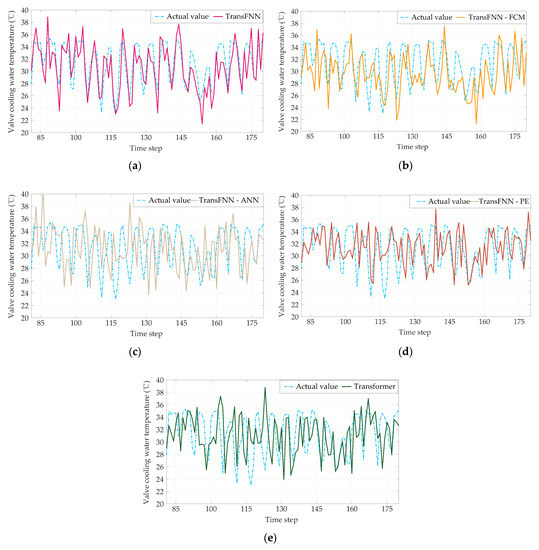
Figure 10.
Prediction results of the five models: (a) ; (b) ; (c) ; (d) ; (e) Transformer only.
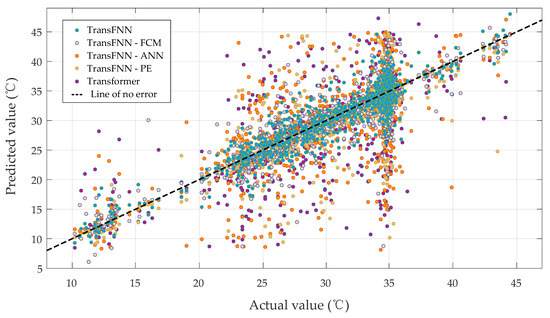
Figure 11.
Scatterplot of the actual and predicted values.
It was indicated after comparing the deviation between the actual values and the predicted values that the proposed TransFNN was the best model for predicting the future values of valves’ cooling water temperatures among the five models. The reasons for the reductions in prediction accuracy of the other four models were as follows:
- (i)
- : A single neural network needed to process the data of all operating conditions because the valve operating conditions were not clustered into several typical operating conditions due to the absence of the FCM module. The learning and fitting abilities of the single NN were insufficient.
- (ii)
- : The complex nonlinear relation between the six independent variable parameters and the valves’ cooling water temperatures was too complicated for simpler models to approximate.
- (iii)
- : Without the improved positional encoding method, the model was incapable of effectively learning the periodicity of the predicted variables in the dimensions of hours, days, and months.
- (iv)
- Only Transformer: Not all impact factors of the valves’ cooling water temperature had temporal characteristics because some factors were directly controlled by the valve operation and maintenance personnel. Therefore, the data sequence of valves’ cooling water temperatures cannot be regarded as a fully typical time series; otherwise, there would be a relatively large error in the predicted values. This also confirmed the discussion of the temporal characteristics of valves’ cooling water temperatures in Section 2.
A converter valve will be in an overtemperature state if the valve’s cooling water temperature exceeds a threshold. In order to evaluate the accuracy of the five models in predicting the overtemperature state of a converter valve, we preset the threshold of the cooling water temperature to 38 °C. When the converter valve was actually in the overtemperature state but the cooling water temperature of the valve did not exceed 38 °C or when the converter valve was not in the overtemperature state but the predicted value indicated an overtemperature state, the predicted result was considered to be wrong. We counted the error rate of overtemperature prediction of each model on the test sets of the 12 converter valves, as shown in Figure 12. We can see that removing any module from the proposed TransFNN model led to an increase in the error rate of overtemperature prediction, and the proposed TransFNN model improved the prediction accuracy by 6.58% compared with the original Transformer model.
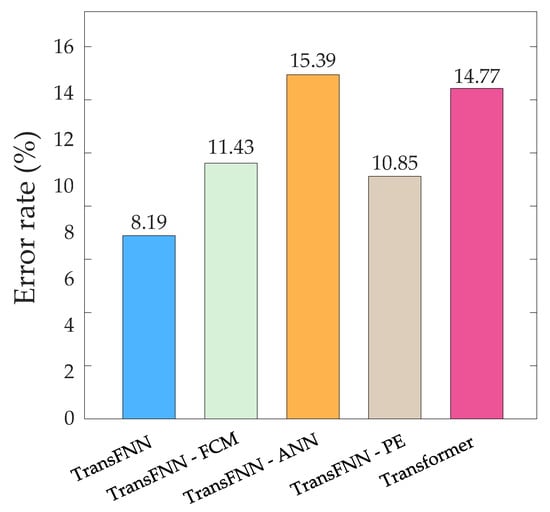
Figure 12.
Bar chart of the error rates of the five models.
5.5. Comparative Analysis of TransFNN: Assessing the Performance against Other Time-Series Prediction Algorithms
The Transformer model has demonstrated excellent performance in time-series prediction, but there are other traditional machine learning algorithms and deep learning models that offer certain advantages in this task, such as faster computing speeds or higher prediction accuracy. Compared to traditional time-series prediction models, such as random forest (RF), RNN, LSTM, and GRU, the Transformer model has two main advantages. Firstly, it uses a unique self-attention mechanism that balances the importance of different time positions in the sequence, thereby better capturing long-term dependencies in the data. This is particularly useful in time-series forecasting, as past values strongly influence future values. Secondly, the Transformer model is fully parallelizable, enabling it to process all elements of an input sequence simultaneously, making it much faster than a model that processes data sequentially.
Based on these advantages, we used the Transformer model as the module for implementing time-series prediction in our proposed TransFNN model. To evaluate the performance of TransFNN, we compared it with other time-series models, including RF, RNN, LSTM, and GRU, which represent a comprehensive range of hybrid models.
We conducted the experiment with the same dataset and experimental setup as in the previous section. For the evaluation index of RMSE, we calculated the average RMSE of the cooling water temperatures of all converter valves in the prediction test set for each model. For the evaluation index of the prediction time, we calculated the average time taken by each model to predict the valves’ cooling water temperatures at a single time point. We then calculated the RMSE reduction for each model compared to RF and the prediction time reduction for each model compared to the RNN, as shown in Table 3. We added the percentage of RMSE reduction and the percentage of prediction time reduction for the different models to obtain the total optimization percentage for these models. It should be noted that the weight given to RMSE reduction and prediction time reduction in evaluating time-series prediction models can depend on the specific application and requirements. In some cases, such as in real-time systems or applications in which speed is critical, the prediction time may be more important than the RMSE. In other cases, such as in scientific research or financial forecasting, the RMSE may be more important than the prediction time.
Table 3.
Performance when using different time-series prediction models.
Table 3 summarizes the performance of the different time-series prediction models. As shown, when the weights given to RMSE reduction and prediction time reduction were the same, the Transformer model outperformed the other models in our proposed framework for predicting the cooling water temperature of a converter valve. However, since the real-time prediction of the overtemperature state of the converter valve was not required in this scenario, we gave a greater weight to RMSE reduction. This further decreased the overall performance ranking of the prediction model that used RF. Nevertheless, the Transformer model remained the best-performing module in this hybrid model. Therefore, the comprehensive performance of the TransFNN model proposed in this paper achieved satisfactory results.
6. Conclusions
This study proposed a novel approach to predicting the overtemperature state of converter valves, which was achieved by implementing the TransFNN model. The model combined an F-NN module, which coordinated the FCM algorithm and an ANN, with an improved Transformer model. This approach overcame the issue of low prediction accuracy in the original Transformer model when processing the cooling water temperature of a converter valve. The TransFNN model was able to accurately predict the overtemperature state of converter valves, which is essential for the effective maintenance and operation of converter stations.
The experimental results showed that the proposed TransFNN model outperformed four other models in terms of prediction accuracy. By removing some modules from TransFNN and applying it to predict the overtemperature state of 12 converter valves, the accuracy was 91.81%, which was 6.85% higher than that of the original Transformer model. The improved accuracy of the TransFNN model provides valuable information to the operation and maintenance personnel of converter stations, enabling them to punctually and appropriately adjust power dispatching and cooling measures, thereby avoiding equipment damage and resource waste. Additionally, the study enhanced the positional encoding method in the Transformer, making it suitable for predicting time series with strong periodicity in different time dimensions. This study also provided a new framework for predicting the time series of multi-source data, with data clustering as one of the pre-processing steps for improving the similarity of the data in the same operating conditions. This resulted in a deep learning model with improved learning abilities, leading to an overall improvement in prediction accuracy.
Author Contributions
Conceptualization, S.Z. and J.W.; methodology, S.Z. and L.Q.; software, H.S.; validation, H.S., B.P. and X.T.; formal analysis, X.W.; investigation, K.L.; resources, J.W.; data curation, L.Q.; writing—original draft preparation, S.Z.; writing—review and editing, S.Z.; visualization, J.W.; supervision, J.R. and L.Q.; project administration, H.S.; funding acquisition, B.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Acknowledgments
The research, experiments, and writing of this paper were all made possible by the support of the science and technology projects of State Grid Anhui Electric Power Co. Ltd. (52120520005L).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Barnes, M.; Van Hertem, D.; Teeuwsen, S.P.; Callavik, M. HVDC Systems in Smart Grids. Proc. IEEE 2017, 105, 2082–2098. [Google Scholar] [CrossRef]
- Lescale, V.F.; IEEE. Modern HVDC: State of the art and development trends. In Proceedings of the 1998 International Conference on Power System Technology (POWERCON 98), Beijing, China, 18–21 August 1998; pp. 446–450. [Google Scholar]
- Chen, W.Y.; Wang, M.; Yu, T.; Destech Publicat, I. Reliability Evaluation of the Converter Valve Cooling System in HVDC Transmission System Based on Fault Tree Analysis. In Proceedings of the 4th International Conference on Mechanical Automation and Materials Engineering (ICMAME), Wuhan, China, 23–24 May 2015; pp. 614–619. [Google Scholar]
- Ekstrom, A.; Eklund, L. HVDC Thyristor Valve Development. IEEE Trans. Power Electron. 1987, 2, 177–185. [Google Scholar] [CrossRef]
- Kwak, J.S.; Kim, C.K.; Koh, B.E. Cooling system of Haenam-Jeju HVDC system. In Proceedings of the IEEE International Symposium on Industrial Electronics (ISIE), Pusan, Republic of Korea, 12–16 June 2001; pp. 1000–1005. [Google Scholar]
- Holweg, J.; Lips, H.P.; Tu, B.Q.; Uder, M.; Peng, B.S.; Zhang, Y.G. Modem HVDC thyristor valves for China's electric power system. In Proceedings of the International Conference on Power System Technology, Kunming, China, 13–17 October 2002; pp. 520–527. [Google Scholar]
- Ji, Z.; Kang, C.Q.; Chen, Q.X.; Xia, Q.; Jiang, C.M.; Chen, Z.X.; Xin, J.B. Low-Carbon Power System Dispatch Incorporating Carbon Capture Power Plants. IEEE Trans. Power Syst. 2013, 28, 4615–4623. [Google Scholar] [CrossRef]
- Berg, J.R.; Soliman, H.M.; Ormiston, S.J. Effective cooling of stacked heat-generating bodies in a large room: Comparison between floor and side-wall air injection. Int. J. Therm. Sci. 2008, 47, 787–799. [Google Scholar] [CrossRef]
- Zhou, B.D.; Le, Y.J.; Fang, Y.L.; Yang, F.; Dai, T.; Sun, L.; Liu, J.P.; Zou, L.K. Temperature field simulation and ampacity optimisation of 500 kV HVDC cable. J. Eng.-JOE 2019, 2019, 2448–2453. [Google Scholar] [CrossRef]
- Liu, K.; Li, K.; Chang, Z.T.; Fan, C.Y.; Hu, S.Q. Research on Losses and Heat Dissipation of Saturable Reactor Used in Converter Valve. IEEE Access 2022, 10, 17796–17802. [Google Scholar] [CrossRef]
- Ma, J.Z.; Li, C.; Liu, F.Y.; Wang, Y.F.; Liu, T.C.; Feng, X. Optimization of circulating cooling water networks considering the constraint of return water temperature. J. Clean Prod. 2018, 199, 916–922. [Google Scholar] [CrossRef]
- Ma, K.Y.; Liu, M.S.; Zhang, J.L. An improved particle swarm optimization algorithm for the optimization and group control of water-side free cooling using cooling towers. Build. Environ. 2020, 182, 13. [Google Scholar] [CrossRef]
- Hill, T.; Oconnor, M.; Remus, W. Neural network models for time series forecasts. Manag. Sci. 1996, 42, 1082–1092. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Wu, C.H.; Wei, C.C.; Su, D.C.; Chang, M.H.; Ho, J.M. Travel time prediction with support vector regression. In Proceedings of the 6th IEEE International Conference on Intelligent Transportation Systems, Shanghai, China, 12–15 October 2003; pp. 1438–1442. [Google Scholar]
- Husken, M.; Stagge, P. Recurrent neural networks for time series classification. Neurocomputing 2003, 50, 223–235. [Google Scholar] [CrossRef]
- Soutner, D.; Muller, L. Application of LSTM Neural Networks in Language Modelling. In Proceedings of the 16th International Conference on Text, Speech, and Dialogue (TSD), Pilsen, Czech Republic, 1–5 September 2013; pp. 105–112. [Google Scholar]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:arXiv:1406.1078. [Google Scholar]
- Maunsell, J.H.R. Neuronal Mechanisms of Visual Attention. In Annual Review of Vision Science; Movshon, J.A., Wandell, B.A., Eds.; Annual Review of Vision Science; Annual Reviews; Palo Alto: Seoul, Republic of Korea, 2015; Volume 1, pp. 373–391. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Wen, Q.S.; Zhou, T.; Zhang, C.L.; Chen, W.Q.; Ma, Z.Q.; Yan, J.C.; Liang, S. Transformers in Time Series: A Survey. arXiv 2022, arXiv:2022.07125. [Google Scholar]
- Zhu, R.J.; Liao, W.L.; Wang, Y.S. Short-term prediction for wind power based on temporal convolutional network. Energy Rep. 2020, 6, 424–429. [Google Scholar] [CrossRef]
- Wang, L.; He, Y.G.; Li, L.; Liu, X.Y.; Zhao, Y.Y. A novel approach to ultra-short-term multi-step wind power predictions based on encoder-decoder architecture in natural language processing. J. Clean Prod. 2022, 354, 14. [Google Scholar] [CrossRef]
- Yuan, X.H.; Tan, Q.X.; Lei, X.H.; Yuan, Y.B.; Wu, X.T. Wind power prediction using hybrid autoregressive fractionally integrated moving average and least square support vector machine. Energy 2017, 129, 122–137. [Google Scholar] [CrossRef]
- Graves, D.; Pedrycz, W. Fuzzy C-means, Gustafson-Kessel FCM, and kernel-based FCM: A comparative study. In Proceedings of the IFSA 2007 World Congress, Cancun, Mexico, 18–21 June 2007; p. 140. [Google Scholar]
- Kiki, M.J.M.; Zhang, J.B.; Kouassi, A.B. Improved Iteration FCM Algorithm for MapReduce Research. In Proceedings of the 2nd International Conference on Telecommunications and Communication Engineering (ICTCE), Beijing, China, 28–30 November 2018; pp. 379–383. [Google Scholar]
- Dou, J.; Yunus, A.P.; Merghadi, A.; Shirzadi, A.; Nguyen, H.; Hussain, Y.; Avtar, R.; Chen, Y.; Pham, B.T.; Yamagishi, H. Different sampling strategies for predicting landslide susceptibilities are deemed less consequential with deep learning. Sci. Total Environ. 2020, 720, 16. [Google Scholar] [CrossRef] [PubMed]
- Trappenberg, T.; Ouyang, J.; Back, A. Input variable selection: Mutual information and linear mixing measures. IEEE Trans. Knowl. Data Eng. 2006, 18, 37–46. [Google Scholar] [CrossRef]












Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).