

Flood-Related Multimedia Benchmark Evaluation: Challenges, Results and a Novel GNN Approach
 , ,
, ,  ,
,  and
and 
Abstract
1. Introduction
- Present the creation and public release of a flood-related multimedia benchmark dataset, which is in Italian (rather than typically in English) and is annotated by experts
- Describe the Flood-related Multimedia Task 2020 and comment on the challenges faced by the participants
- Propose a novel Graph Neural Network approach for relevance estimation and evaluate it against state-of-the-art methods to show its outperformance
2. Related Work
2.1. Related Dataset & Competitions
2.2. Related Methodologies
3. Methodology
3.1. Feature Extraction
3.2. Sequence-Based Classification
3.3. Neural Structure Learning
4. The Flood-Related Multimedia Dataset & Task
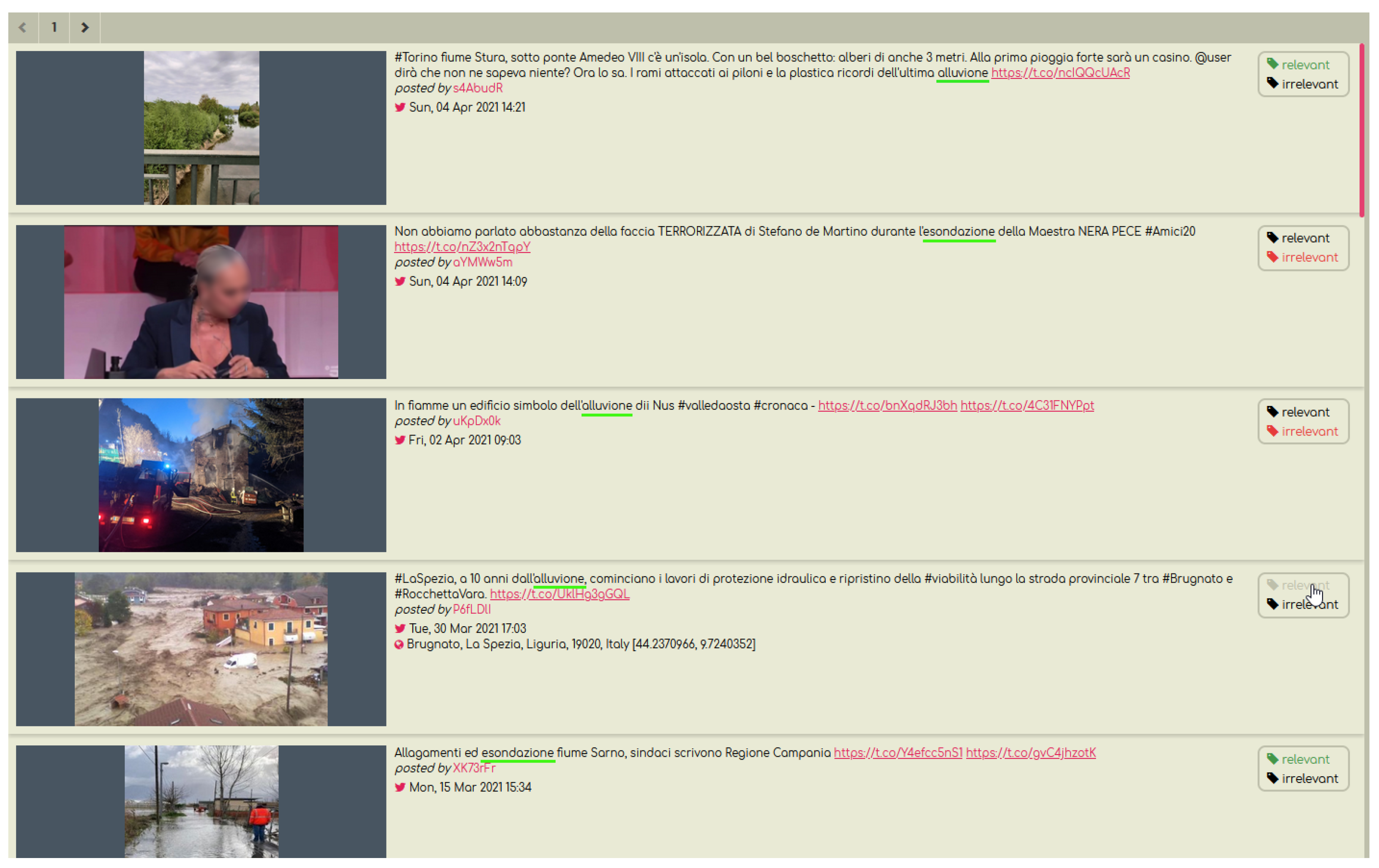
4.1. Dataset Preparation
- All tweets contain both textual (Twitter message) and visual information (attached image), which makes the dataset fitting for evaluating fusion techniques.
- The dataset is dedicated to the natural disaster of floods and expands to posts published from 2017 to 2019.
- The tweets are manually annotated as relevant/non-relevant by experts, thus they can be used as a high-quality training dataset for relevance classification.
- The tweets are in Italian, so the dataset overcomes the usual limitation of training data being in English.
4.2. Dataset Release
4.3. Lessons Learnt
5. Experiments
5.1. Baselines
- BERT [31] is based on transformer encoder architectures and has been successfully used on a variety of tasks in NLP (natural language processing). They compute vector-space representations of natural language that are suitable for use in deep learning models. BERT models are usually pre-trained on a large corpus of text, then fine-tuned for specific tasks.
- CNN [58] classify text by working through the 1-dimensional convolving filters which are used as ngram detectors and each filter specializing in a closely-related family of ngrams. Afterwards, max-pooling over time extracts the relevant ngrams for making a decision. The rest of the network classifies the text based on this information.
- BiLSTM proved to be effective with high accuracy in text classification tasks [59] compared to RNN, CNN and LSTM.
- CNN+BiLSTM [44] propose an hybrid model that capitalize on the advantages of LSTM and CNN for text classification.
- CNN+VGG16 [34] propose to use both text and image modalities of social media data to learn a joint representation using state-of-the-art deep learning techniques.
- FIG [53] undersampled the dataset in order to have a more balanced set. Additionally, text features were extracted with CNN and LSTM models and then combined by Multi-Layer Perceptron before the single output unit. Contrary to that, to address the individual weaknesses and leverage the distinct advantages of LSTM and CNN, we used the SBC hybrid RNN model.
- UEHB-ML [54] used Synthetic Minority Oversampling Technique (SMOTE) [60] for the imbalanced problem. In feature extraction, they used pre-trained CNNs for the images and Bag-of-Words for text. Finally, they combined the visual and textual information in a late fusion scheme. Alternatively, we used knowledge graphs whose nodes represent the particular features (i.e., text, image, time).
- QUT [55] early fused the textual and visual features extracted from Bag-of-Words and pre-trained Xception on the ImageNet dataset. We employ BERT and VGG19 for feature extraction.
- Fast-NuDs [56] used Augmentor [61] for the imbalanced dataset, which creates multiple copies of each image. For the training, VGG16 has utilised hybrid weights of Places365 [62] and ImageNet for the visual features and TF-IDF with Multinomial Naïve Bayes for the textual features. Finally, the average of each outcome was used for late fusion. Opposed to that, we used undersampling and focused on textual features, which generally led to better performance.
- HBKU_UNITN_SIMULA [57] used BERT in the text network and ResNet152 for the image network. In parallel, object and scene-level features were extracted through VGGNet16 and were pre-trained on ImageNet and Places Datasets. All these features were early fused during the training. In our model, we consider temporal features as external information to enhance its performance.
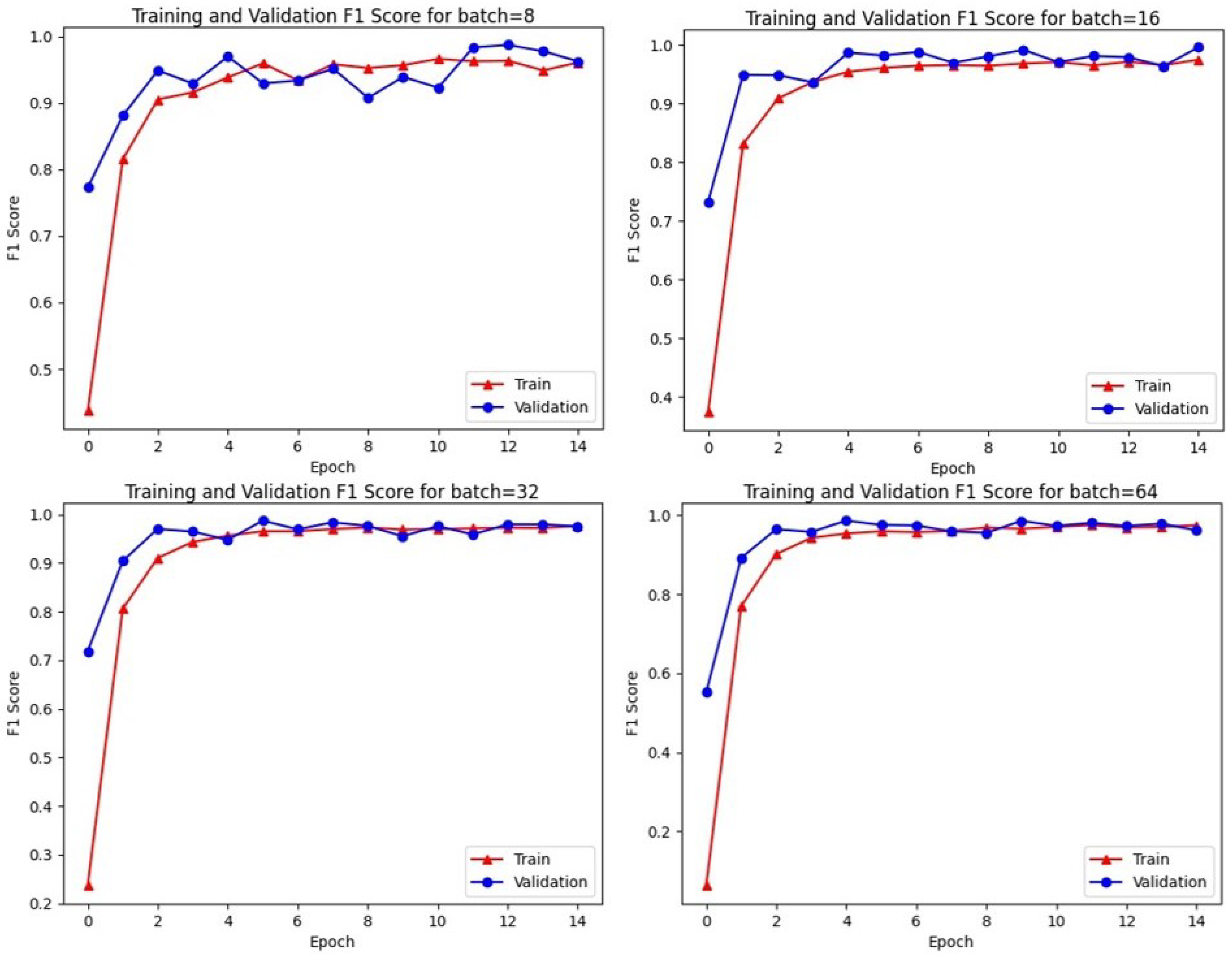
5.2. Settings
5.3. Results
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| KDE | Kernel Density Estimation |
| NGM | Neural Graph Machines |
| SBC | Sequence-Based Classification |
| GNN | Graph Neural Network |
References
- Merchant, R.M.; Elmer, S.; Lurie, N. Integrating social media into emergency-preparedness efforts. N. Engl. J. Med. 2011, 365, 289–291. [Google Scholar] [CrossRef] [PubMed]
- Reuter, C.; Hughes, A.L.; Kaufhold, M.A. Social media in crisis management: An evaluation and analysis of crisis informatics research. Int. J. Hum.-Comput. Interact. 2018, 34, 280–294. [Google Scholar] [CrossRef]
- Panagiotopoulos, P.; Barnett, J.; Bigdeli, A.Z.; Sams, S. Social media in emergency management: Twitter as a tool for communicating risks to the public. Technol. Forecast. Soc. Chang. 2016, 111, 86–96. [Google Scholar] [CrossRef]
- Imran, M.; Castillo, C.; Diaz, F.; Vieweg, S. Processing social media messages in mass emergency: Survey summary. In Proceedings of the The Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 507–511. [Google Scholar]
- Sadri, A.M.; Hasan, S.; Ukkusuri, S.V.; Cebrian, M. Crisis communication patterns in social media during Hurricane Sandy. Transp. Res. Rec. 2018, 2672, 125–137. [Google Scholar] [CrossRef]
- Li, J.; Stephens, K.K.; Zhu, Y.; Murthy, D. Using social media to call for help in Hurricane Harvey: Bonding emotion, culture, and community relationships. Int. J. Disaster Risk Reduct. 2019, 38, 101212. [Google Scholar] [CrossRef]
- Tandoc Jr, E.C.; Lim, Z.W. The use of social media during the 2019–2020 Australian bushfires. Aust. J. Emerg. Manag. 2020, 35, 44–50. [Google Scholar]
- Thomas, T.; Eid, D.; Khayr Yaakoub, H. The Lebanese Revolution on Twitter: Framing, sources, and networked publics. Int. J. Commun. 2021, 15, 18. [Google Scholar]
- Bui, T.D.; Ravi, S.; Ramavajjala, V. Neural graph learning: Training neural networks using graphs. In Proceedings of the Eleventh ACM International Conference on Web Search and Data Mining, Los Angeles, CA, USA, 6–8 February 2018; pp. 64–71. [Google Scholar]
- Awad, G.; Butt, A.; Liu, J.; Drew, W. Disaster Scene Description and Indexing (DSDI). 2020 TREC Video Retrieval Evaluation Notebook Papers and Slides. 2021. Available online: https://tsapps.nist.gov/publication/get_pdf.cfm?pub_id=931766 (accessed on 1 April 2023).
- Ionescu, B.; Müller, H.; Villegas, M.; Arenas, H.; Boato, G.; Dang-Nguyen, D.T.; Cid, Y.D.; Eickhoff, C.; de Herrera, A.G.S.; Gurrin, C.; et al. Overview of ImageCLEF 2017: Information extraction from images. In Proceedings of the International Conference of the Cross-Language Evaluation Forum for European Languages, Dublin, Ireland, 11–14 September 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 315–337. [Google Scholar]
- Bischke, B.; Helber, P.; Schulze, C.; Srinivasan, V.; Dengel, A.; Borth, D. The Multimedia Satellite Task at MediaEval 2017. In Proceedings of the MediaEval, Dublin, Ireland, 13–15 September 2017. [Google Scholar]
- Bischke, B.; Helber, P.; Zhao, Z.; De Bruijn, J.; Borth, D. The Multimedia Satellite Task at MediaEval 2018: Emergency response for flooding events. In Proceedings of the MediaEval, Sophia Antipolies, France, 29–31 October 2018. [Google Scholar]
- Bischke, B.; Helber, P.; Brugman, S.; Basar, E.; Zhao, Z.; Larson, M.; Pogorelov, K. The Multimedia Satellite Task at MediaEval 2019: Estimation of Flood Severity. In Proceedings of the MediaEval 2019 Workshop, Sophia Antipolis, France, 27–30 October 2019. [Google Scholar]
- Andreadis, S.; Gialampoukidis, I.; Karakostas, A.; Vrochidis, S.; Kompatsiaris, I.; Fiorin, R.; Norbiato, D.; Ferri, M. The Flood-related Multimedia Task at MediaEval 2020. In Proceedings of the MediaEval 2020, Online, 14–15 December 2020. [Google Scholar]
- Imran, M.; Mitra, P.; Castillo, C. Twitter as a Lifeline: Human-annotated Twitter Corpora for NLP of Crisis-related Messages. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portoroz, Slovenia, 23–28 May 2016. [Google Scholar]
- Imran, M.; Elbassuoni, S.; Castillo, C.; Diaz, F.; Meier, P. Practical extraction of disaster-relevant information from social media. In Proceedings of the 22nd international Conference on World Wide Web Companion, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1021–1024. [Google Scholar]
- Imran, M.; Elbassuoni, S.M.; Castillo, C.; Diaz, F.; Meier, P. Extracting information nuggets from disaster-related messages in social media. In Proceedings of the ISCRAM, Baden-Baden, Germany, 12–15 May 2013. [Google Scholar]
- Alam, F.; Ofli, F.; Imran, M. CrisisMMD: Multimodal Twitter Datasets from Natural Disasters. In Proceedings of the 12th International AAAI Conference on Web and Social Media (ICWSM), Palo Alto, CA, USA, 25–28 June 2018. [Google Scholar]
- Nguyen, D.T.; Ofli, F.; Imran, M.; Mitra, P. Damage assessment from social media imagery data during disasters. In Proceedings of the 2017 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, Sydney, NSW, Australia, 31 July–3 August 2017; pp. 569–576. [Google Scholar]
- Zahra, K.; Imran, M.; Ostermann, F.O. Automatic identification of eyewitness messages on twitter during disasters. Inf. Process. Manag. 2020, 57, 102107. [Google Scholar] [CrossRef]
- Alam, F.; Joty, S.; Imran, M. Domain Adaptation with Adversarial Training and Graph Embeddings. arXiv 2018, arXiv:1805.05151. [Google Scholar]
- Alam, F.; Ofli, F.; Imran, M.; Alam, T.; Qazi, U. Deep Learning Benchmarks and Datasets for Social Media Image Classification for Disaster Response. In Proceedings of the 2020 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (ASONAM), The Hague, The Netherlands, 7–10 December 2020. [Google Scholar]
- Alam, F.; Sajjad, H.; Imran, M.; Ofli, F. CrisisBench: Benchmarking Crisis-related Social Media Datasets for Humanitarian Information Processing. In Proceedings of the 15th International Conference on Web and Social Media (ICWSM), Online, 7–10 June 2021. [Google Scholar]
- Madichetty, S.; Sridevi, M. Detecting informative tweets during disaster using deep neural networks. In Proceedings of the 2019 11th International Conference on Communication Systems & Networks (COMSNETS), Bangalore, India, 7–11 January 2019; pp. 709–713. [Google Scholar]
- Nguyen, D.T.; Mannai, K.A.A.; Joty, S.; Sajjad, H.; Imran, M.; Mitra, P. Rapid classification of crisis-related data on social networks using convolutional neural networks. arXiv 2016, arXiv:1608.03902. [Google Scholar]
- de Bruijn, J.A.; de Moel, H.; Weerts, A.H.; de Ruiter, M.C.; Basar, E.; Eilander, D.; Aerts, J.C. Improving the classification of flood tweets with contextual hydrological information in a multimodal neural network. Comput. Geosci. 2020, 140, 104485. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Conneau, A.; Lample, G.; Ranzato, M.; Denoyer, L.; Jégou, H. Word translation without parallel data. arXiv 2017, arXiv:1710.04087. [Google Scholar]
- Mouzannar, H.; Rizk, Y.; Awad, M. Damage Identification in Social Media Posts using Multimodal Deep Learning. In Proceedings of the ISCRAM, Rochester, NY, USA, 20–23 May 2018. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Gautam, A.K.; Misra, L.; Kumar, A.; Misra, K.; Aggarwal, S.; Shah, R.R. Multimodal analysis of disaster tweets. In Proceedings of the 2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM), Singapore, 11–13 September 2019; pp. 94–103. [Google Scholar]
- Suk, H.I.; Shen, D. Deep learning-based feature representation for AD/MCI classification. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Singapore, 18–22 September 2013; pp. 583–590. [Google Scholar]
- Ofli, F.; Alam, F.; Imran, M. Analysis of social media data using multimodal deep learning for disaster response. arXiv 2020, arXiv:2004.11838. [Google Scholar]
- Khan, Q.; Kalbus, E.; Zaki, N.; Mohamed, M.M. Utilization of social media in floods assessment using data mining techniques. PLoS ONE 2022, 17, e0267079. [Google Scholar] [CrossRef] [PubMed]
- Kanth, A.K.; Chitra, P.; Sowmya, G.G. Deep learning-based assessment of flood severity using social media streams. Stoch. Environ. Res. Risk Assess. 2022, 36, 473–493. [Google Scholar] [CrossRef]
- Bono, C.A.; Mülâyim, M.O.; Pernici, B. Learning early detection of emergencies from word usage patterns on social media. Inf. Technol. Disaster Risk Reduct. 2022, 2022, 1–16. [Google Scholar]
- Bischke, B.; Bhardwaj, P.; Gautam, A.; Helber, P.; Borth, D.; Dengel, A. Detection of Flooding Events in Social Multimedia and Satellite Imagery using Deep Neural Networks. In Proceedings of the MediaEval, Dublin, Ireland, 13–15 September 2017. [Google Scholar]
- Abavisani, M.; Wu, L.; Hu, S.; Tetreault, J.; Jaimes, A. Multimodal categorization of crisis events in social media. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 14679–14689. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Ogie, R.; James, S.; Moore, A.; Dilworth, T.; Amirghasemi, M.; Whittaker, J. Social media use in disaster recovery: A systematic literature review. Int. J. Disaster Risk Reduct. 2022, 70, 102783. [Google Scholar] [CrossRef]
- Zhou, J.; Cui, G.; Zhang, Z.; Yang, C.; Liu, Z.; Wang, L.; Li, C.; Sun, M. Graph neural networks: A review of methods and applications. arXiv 2018, arXiv:1812.08434. [Google Scholar] [CrossRef]
- Wu, L.; Li, S.; Hsieh, C.J.; Sharpnack, J. Stochastic shared embeddings: Data-driven regularization of embedding layers. arXiv 2019, arXiv:1905.10630. [Google Scholar]
- Jang, B.; Kim, M.; Harerimana, G.; Kang, S.u.; Kim, J.W. Bi-LSTM model to increase accuracy in text classification: Combining Word2vec CNN and attention mechanism. Appl. Sci. 2020, 10, 5841. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Sammut, C.; Webb, G.I. Tf–idf. In Encyclopedia of Machine Learning; Springer: Boston, MA, USA, 2010; pp. 986–987. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity mappings in deep residual networks. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 630–645. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Efron, M.; Lin, J.; He, J.; De Vries, A. Temporal feedback for tweet search with non-parametric density estimation. In Proceedings of the 37th International ACM SIGIR Conference on Research & Development in Information Retrieval, Gold Coast, Australia, 6–11 July 2014; pp. 33–42. [Google Scholar]
- Sheather, S.J.; Jones, M.C. A reliable data-based bandwidth selection method for kernel density estimation. J. R. Stat. Soc. Ser. (Methodol.) 1991, 53, 683–690. [Google Scholar] [CrossRef]
- Nikoletopoulos, T.; Wolff, C. A tweet text binary Artificial Neural Network classifier. In Proceedings of the MediaEval 2020, Online, 14–15 December 2020. [Google Scholar]
- Said, N.; Ahmad, K.; Gul, A.; Ahmad, N.; Al-Fuqaha, A. Floods Detection in Twitter Text and Images. arXiv 2020, arXiv:2011.14943. [Google Scholar]
- Jony, R.I.; Woodley, A. Flood Detection in Twitter Using a Novel Learning Method for Neural Networks. In Proceedings of the MediaEval 2020, Online, 14–15 December 2020. [Google Scholar]
- Hanif, M.; Joozer, H.; Tahir, M.A.; Rafi, M. Ensemble based method for the classification of flooding event using social media data. In Proceedings of the MediaEval 2020, Online, 14–15 December 2020. [Google Scholar]
- Alam, F.; Hassan, Z.; Ahmad, K.; Gul, A.; Reiglar, M.; Conci, N.; Al-Fuqaha, A. Flood Detection via Twitter Streams using Textual and Visual Features. arXiv 2020, arXiv:2011.14944. [Google Scholar]
- Jacovi, A.; Shalom, O.S.; Goldberg, Y. Understanding convolutional neural networks for text classification. arXiv 2018, arXiv:1809.08037. [Google Scholar]
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment Analysis of Comment Texts Based on BiLSTM. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Bloice, M.D.; Stocker, C.; Holzinger, A. Augmentor: An image augmentation library for machine learning. arXiv 2017, arXiv:1708.04680. [Google Scholar] [CrossRef]
- Lagerstrom, R.; Arzhaeva, Y.; Szul, P.; Obst, O.; Power, R.; Robinson, B.; Bednarz, T. Image classification to support emergency situation awareness. Front. Robot. AI 2016, 3, 54. [Google Scholar] [CrossRef]
- Prusa, J.; Khoshgoftaar, T.M.; Dittman, D.J.; Napolitano, A. Using Random Undersampling to Alleviate Class Imbalance on Tweet Sentiment Data. In Proceedings of the 2015 IEEE International Conference on Information Reuse and Integration, San Francisco, CA, USA, 13–15 August 2015; pp. 197–202. [Google Scholar] [CrossRef]
- Alam, F.; Joty, S.; Imran, M. Graph based semi-supervised learning with convolution neural networks to classify crisis related tweets. In Proceedings of the International AAAI Conference on Web and Social Media, Palo Alto, CA, USA, 25–28 June 2018; Volume 12. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Research | Data Type | ML Algorithms | Multimodal Fusion |
|---|---|---|---|
| de Bruijn et al. (2020) [27] | Text, Hydro-logical | fastText [28], MUSE [29] | Late Fusion |
| Mouzannar et al. (2018) [30] | Text, Image, Video | Inception, CNN | Late Fusion |
| Gautam et al. (2019) [32] | Text, Image | BiLSTM, Inception-v3, Logistic Regression Decision | Late Fusion |
| F. Ofli, et al. (2020) [34] | Text, Image | VGG16, CNN | Early Fusion |
| M. Abavisani, et al. (2020) [39] | Text, Image | DenseNet [40], BERT [31] | SSE-GRAPH [43] |
| The proposed method | Text, Image, Time | BERT [31], CNN, BiLSTM, VGG19 | NGM [42] |
| Italian Keywords | English Translation |
|---|---|
| allagamento | flooding |
| allerta meteo | weather alert |
| allerta meteo vicenza | weather alert Vicenza |
| alluvione | flood |
| alluvione vicenza | flood Vicenza |
| bacchiglione | Bacchiglione (river) |
| esondazione | flood |
| fiume piena | full river |
| livello fiume | river level |
| sottopasso allagato | flooded underpass |
| Set | Relevant | Not Relevant | Total |
|---|---|---|---|
| Development-set | 1140 (21%) | 4279 (79%) | 5419 |
| Test-set | 492 (22%) | 1787 (78%) | 2279 |
| Complete set | 1632 (21%) | 6066 (79%) | 7698 |
| Hyperparameter | Value |
|---|---|
| classes | 2 |
| max sequence length | 50 |
| distance type | L2 |
| graph regularization multiplier | |
| neighbors | 3 |
| CNN filters | 100 |
| CNN kernel size | 5 |
| CNN activation | tanh |
| CNN kernel regularizer | |
| BiLSTM units | 64 |
| BiLSTM droput | 0.2 |
| Optimizer | adam |
| loss | binarycrossentropy |
| train epochs | 15 |
| batch size | 64 |
| callback | early stop |
| Method | Features | Fusion | F1 |
|---|---|---|---|
| FIG [53] | Text | - | 0.5405 |
| UEHB-ML [54] | Text | - | 0.4376 |
| UT [55] | Text | - | 0.4158 |
| fastNuDs [56] | Text | - | 0.3631 |
| HBKU_UNITN_SIMULA [57] | Text | - | 0.2120 |
| CNN+BiLSTM [44] | Text | - | 0.5425 |
| CNN | Text | - | 0.2178 |
| BiLSTM | Text | - | 0.2002 |
| BERT [31] | Text | - | 0.1514 |
| (OURS) SBC + NGMBERT | Text | NGM | 0.5480 |
| fastNuDs [56] | Text + Image | Late Fusion | 0.2786 |
| QUT [55] | Text + Image | Early Fusion | 0.1478 |
| UEHB-ML [54] | Text + Image | Late Fusion | 0.0936 |
| HBKU_UNITN_SIMULA [57] | Text + Image | Early Fusion | 0.0462 |
| CNN+VGG16 [34] | Text + Image | Early Fusion | 0.2442 |
| CNN+BiLSTM+VGG19 | Text + Image | Early Fusion | 0.2267 |
| (OURS) SBC + NGMVGG19+BERT | Text + Image | NGM | 0.5158 |
| (OURS) SBC | Text + Time | Early Fusion | 0.4932 |
| (OURS) SBC | Text + Image + Time | Early Fusion | 0.1735 |
| (OURS) SBC + NGMVGG19+KDE | Text + Image + Time | NGM | 0.5270 |
| OURS) SBC + NGMBERT+VGG19+KDE | Text + Image + Time | NGM | 0.5379 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadimos, T.; Andreadis, S.; Gialampoukidis, I.; Vrochidis, S.; Kompatsiaris, I. Flood-Related Multimedia Benchmark Evaluation: Challenges, Results and a Novel GNN Approach. Sensors 2023, 23, 3767. https://doi.org/10.3390/s23073767
Papadimos T, Andreadis S, Gialampoukidis I, Vrochidis S, Kompatsiaris I. Flood-Related Multimedia Benchmark Evaluation: Challenges, Results and a Novel GNN Approach. Sensors. 2023; 23(7):3767. https://doi.org/10.3390/s23073767
Chicago/Turabian StylePapadimos, Thomas, Stelios Andreadis, Ilias Gialampoukidis, Stefanos Vrochidis, and Ioannis Kompatsiaris. 2023. "Flood-Related Multimedia Benchmark Evaluation: Challenges, Results and a Novel GNN Approach" Sensors 23, no. 7: 3767. https://doi.org/10.3390/s23073767
APA StylePapadimos, T., Andreadis, S., Gialampoukidis, I., Vrochidis, S., & Kompatsiaris, I. (2023). Flood-Related Multimedia Benchmark Evaluation: Challenges, Results and a Novel GNN Approach. Sensors, 23(7), 3767. https://doi.org/10.3390/s23073767