
Swin-Transformer-Based YOLOv5 for Small-Object Detection in Remote Sensing Images

Abstract
:1. Introduction
- The improved K-means clustering algorithm makes the algorithm more suitable for the DOTA dataset, improving the recall rate and accelerating the convergence speed of the model.
- An improved CSPDarknet53 network based on the Swin Transformer (C3SW-T) is proposed, which preserves the context information better and improves the accuracy of small-target detection.
- A deeper and highly effective weighted bidirectional feature pyramid network is presented to improve the detection performance of objects of different scales, especially for small objects.
- Coordinate Attention (CA) was introduced into YOLOv5 to allow the network to pay attention to a larger area without unnecessary computational overhead.
2. Materials and Methods
2.1. Object Detection Based on CNN
2.2. Vision Transformer
2.3. Methods
2.3.1. Improved K-Means Clustering Algorithm
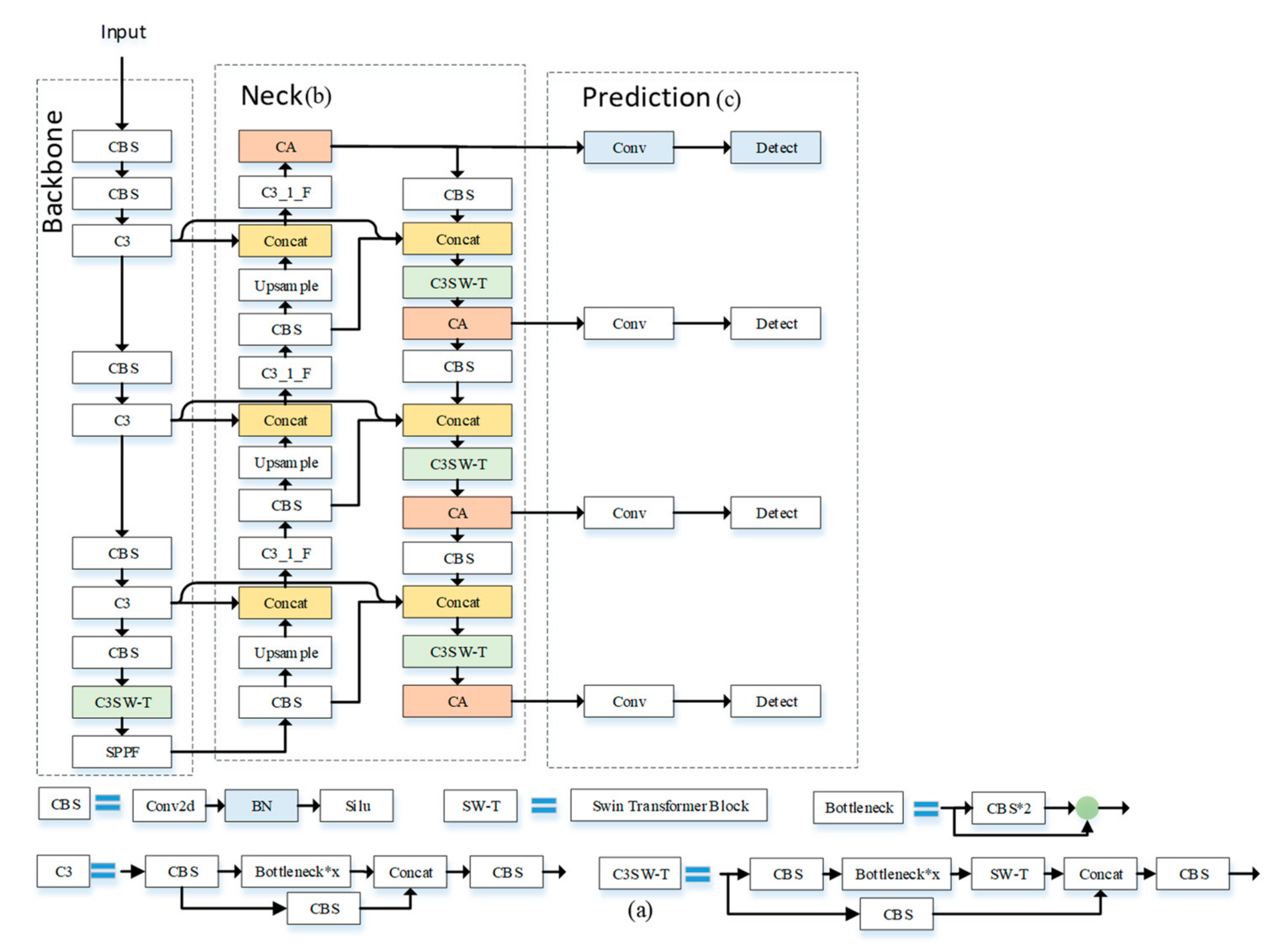
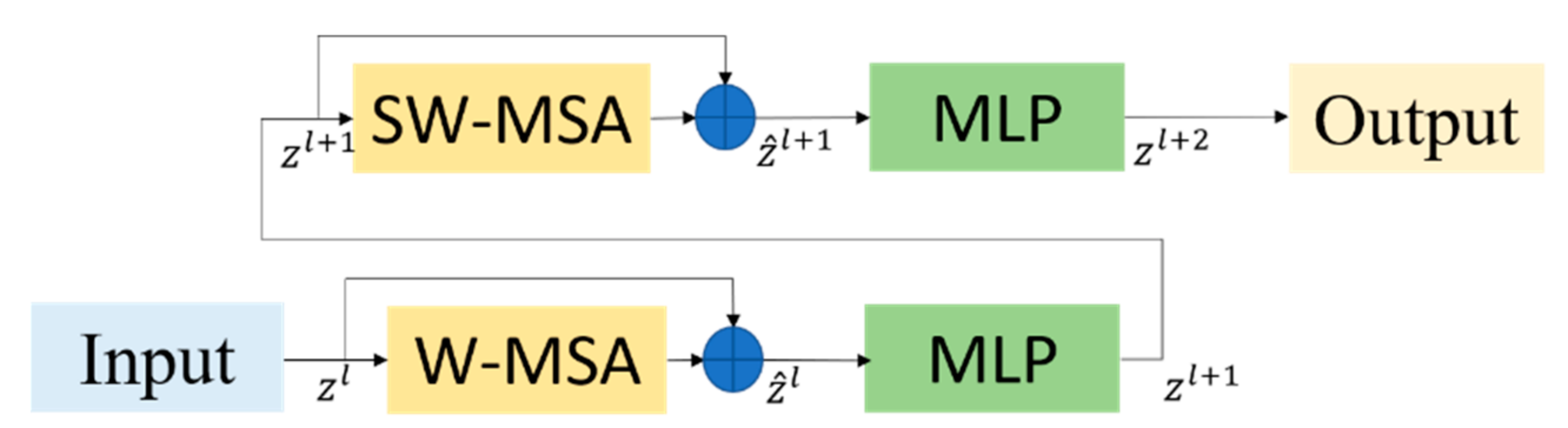
2.3.2. Swin Transformer Block
2.3.3. Coordinate Attention
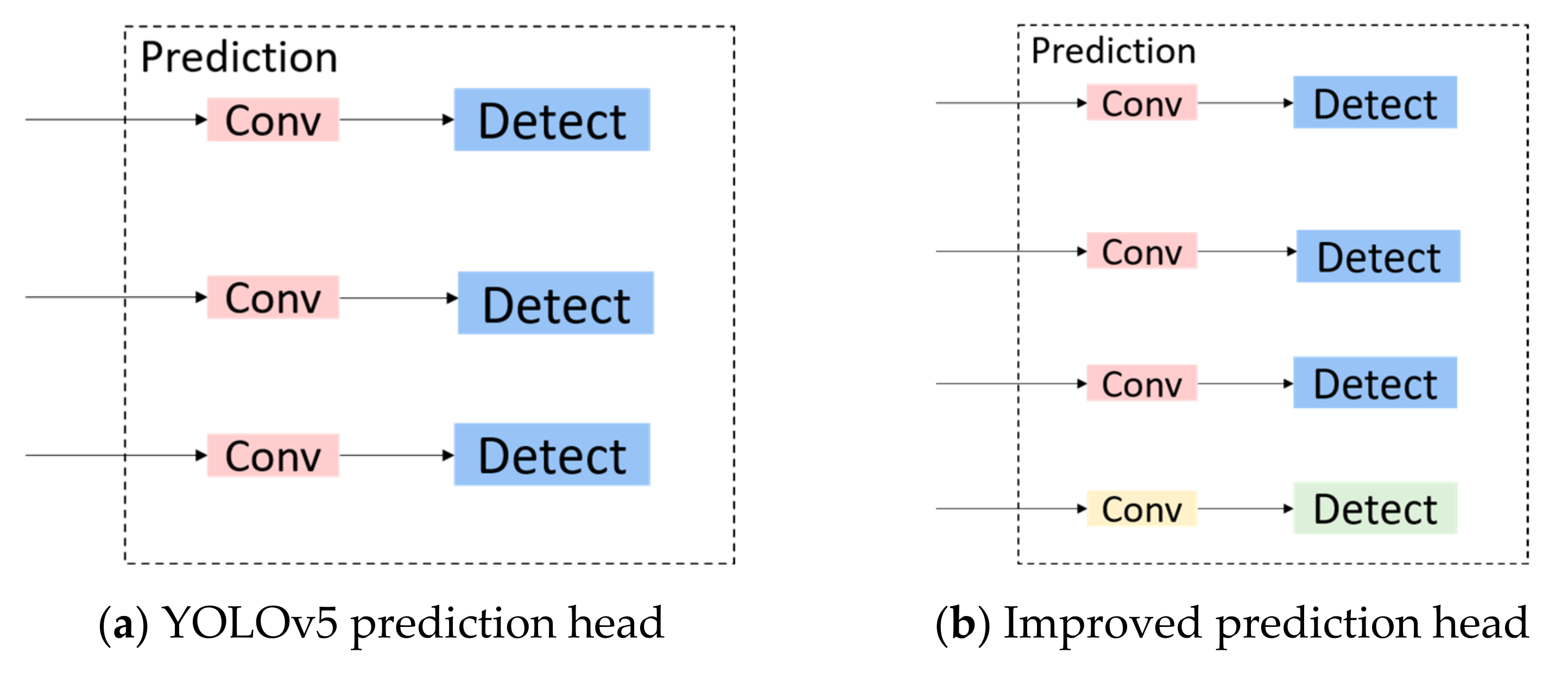
2.3.4. Multi-Scale Feature Detection
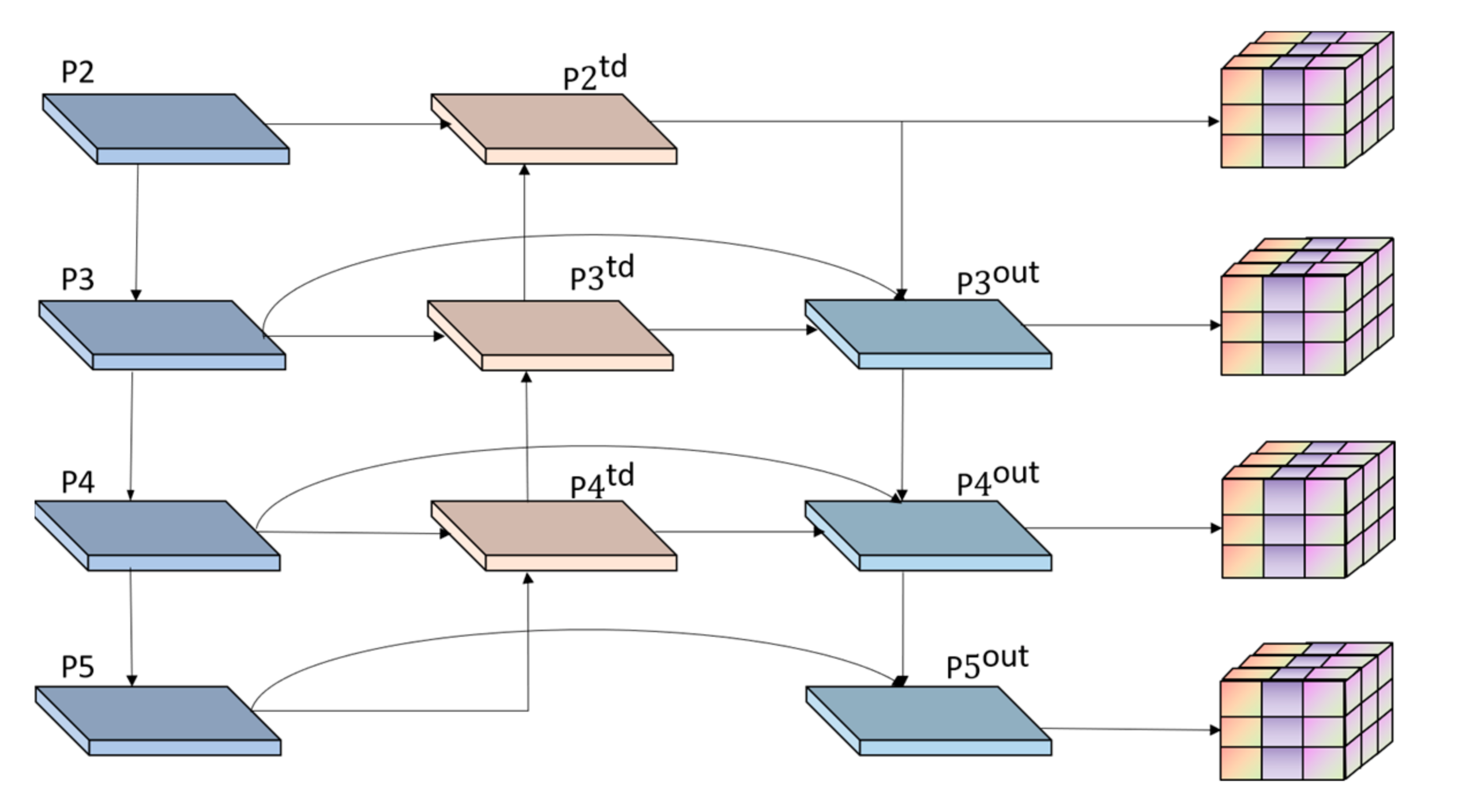
2.3.5. Improvement of Feature Fusion Network
3. Results
3.1. Dataset
3.2. Experimental Environment and Parameter Settings
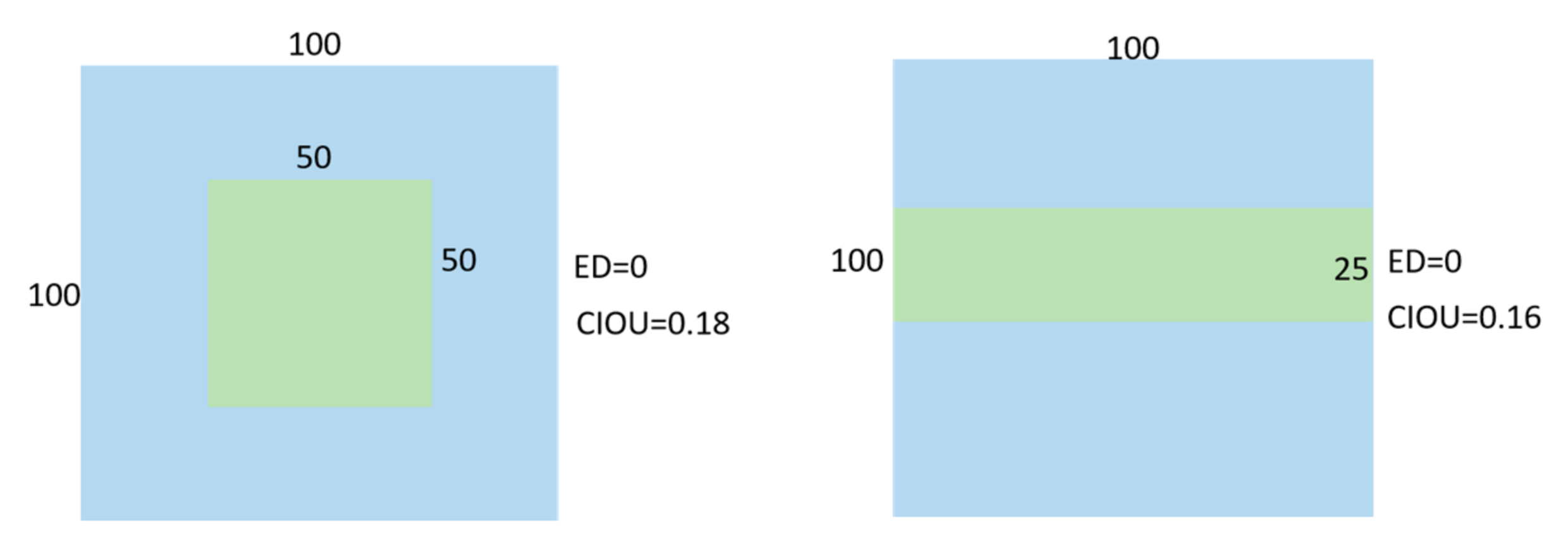
3.3. Evaluation Indicators
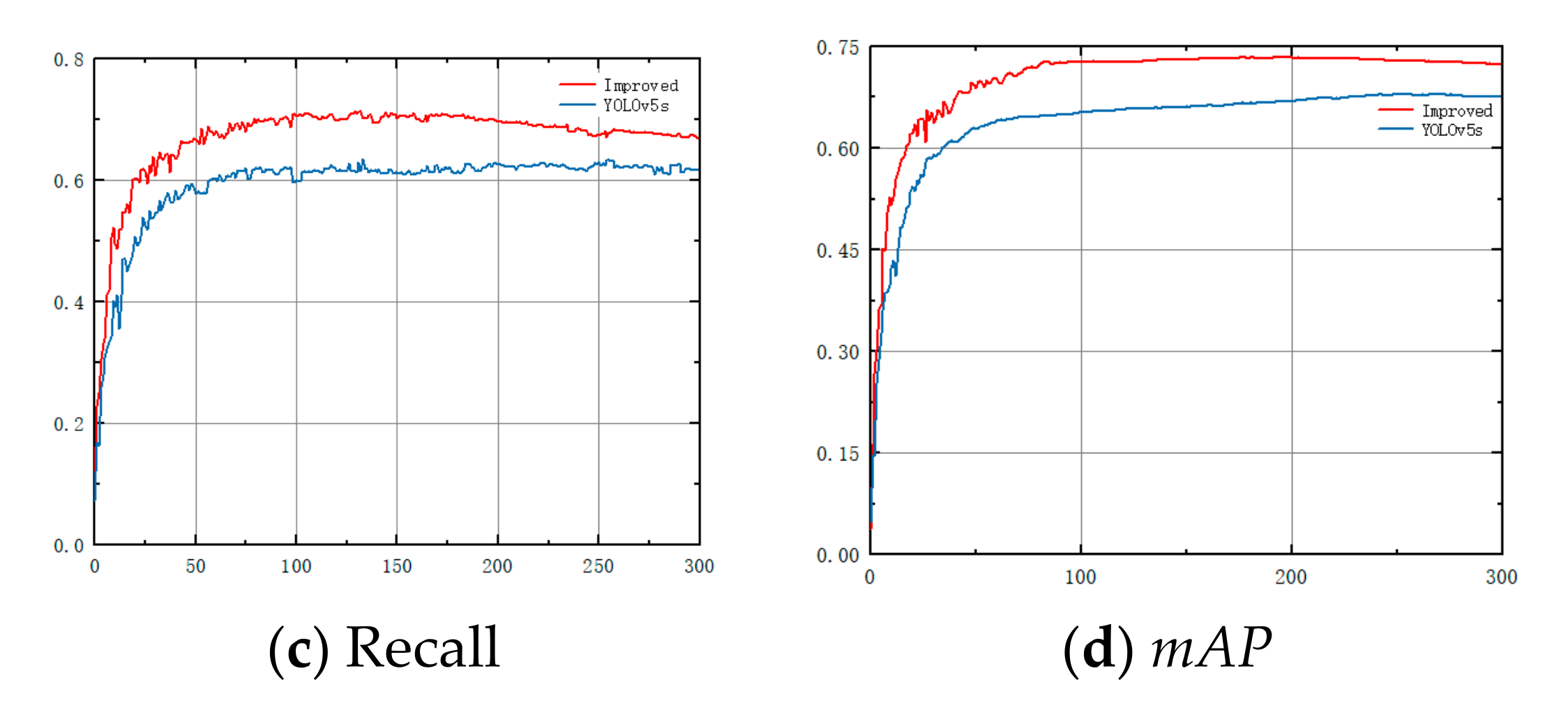
3.4. Training Results
4. Discussions
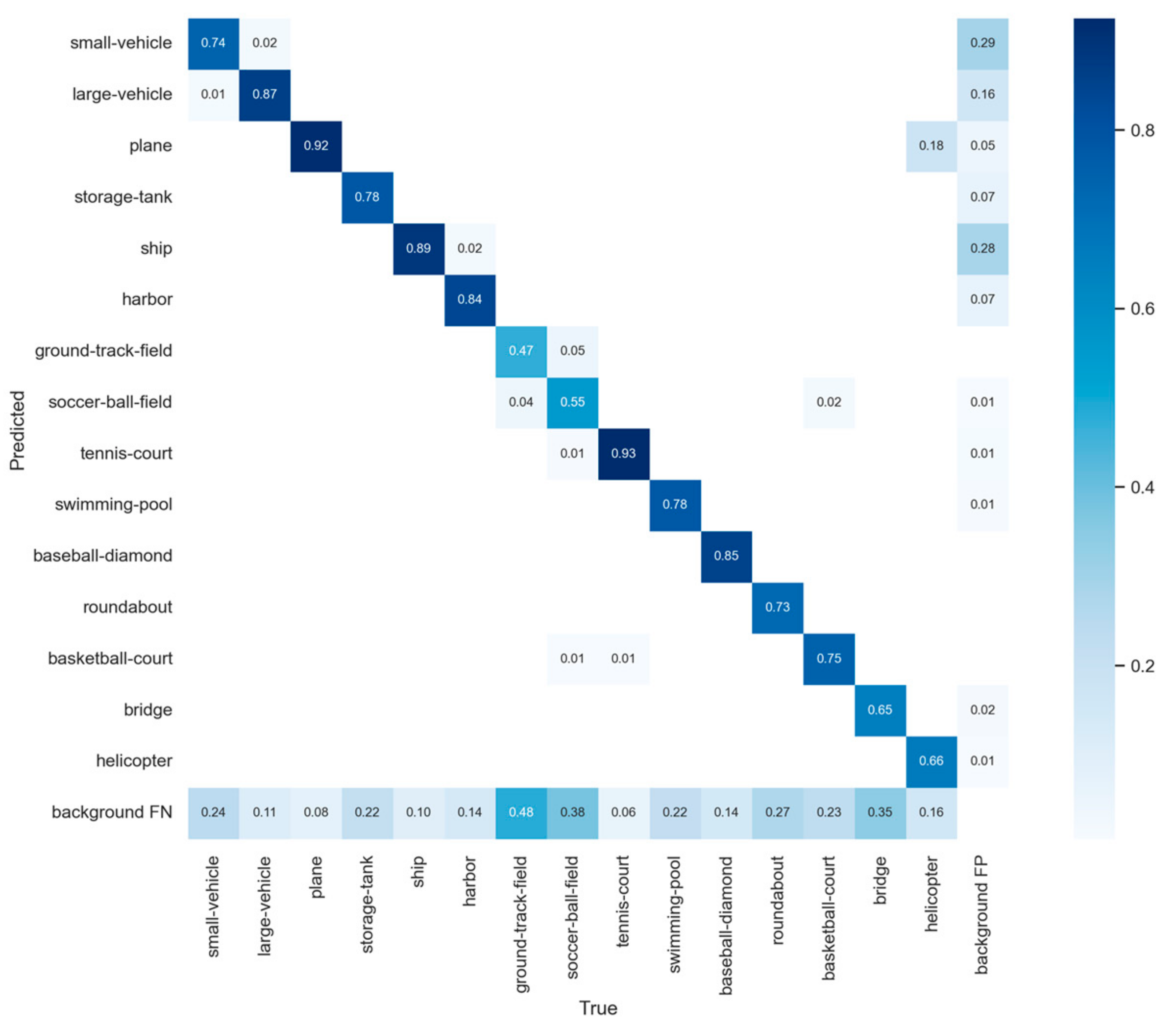
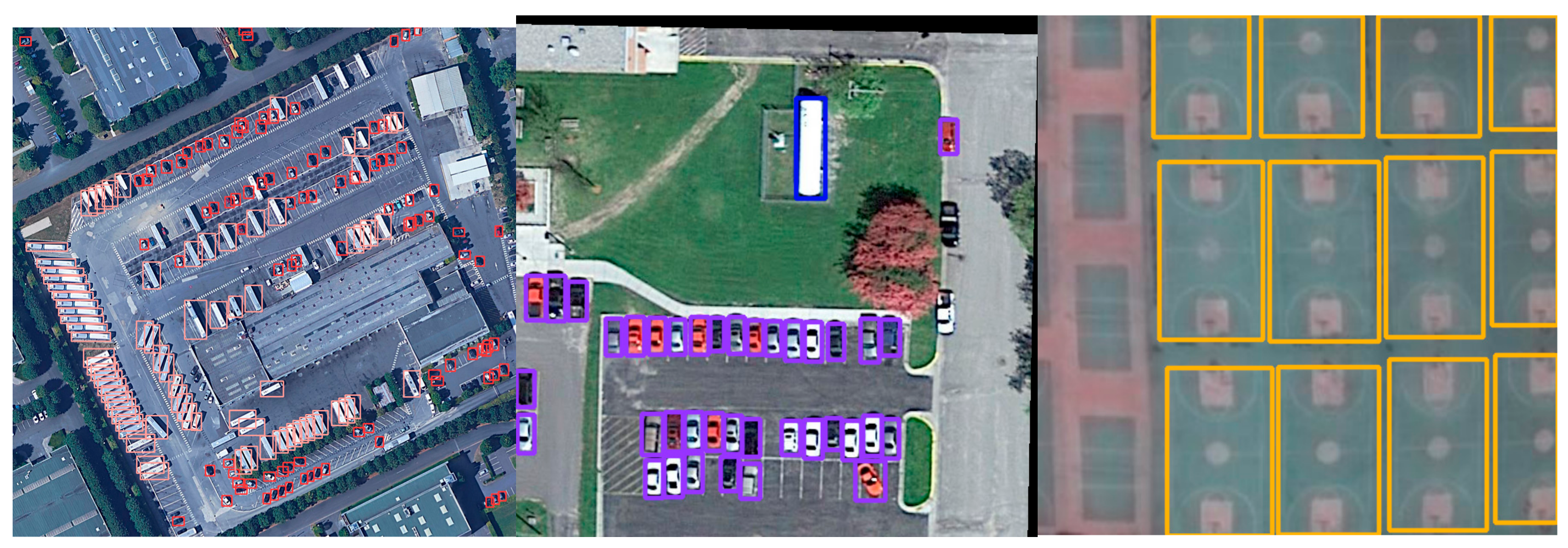
4.1. Compared with YOLOv5
4.2. Ablation Experiment
4.3. Comparison with Other YOLO Models
4.4. Scaled Image Size Exploration
4.5. Comparison with Other Models
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. In TPH-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Ding, Y. Research and Implementation of Small Target Detection Network in Complex Background. Master’s Thesis, Beijing University of Posts and Telecommunications, Beijing, China, 2020. [Google Scholar]
- Albahli, S.; Nawaz, M.; Javed, A.; Irtaza, A. An improved faster-RCNN model for handwritten character recognition. Arab. J. Sci. Eng. 2021, 46, 8509–8523. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. Ssd: Single Shot Multibox Detector, European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Gong, H.; Mu, T.; Li, Q.; Dai, H.; Li, C.; He, Z.; Wang, W.; Han, F.; Tuniyazi, A.; Li, H. Swin-Transformer-Enabled YOLOv5 with Attention Mechanism for Small Object Detection on Satellite Images. Remote Sens. 2022, 14, 2861. [Google Scholar] [CrossRef]
- Cheng, G.; Lang, C.; Wu, M.; Xie, X.; Yao, X.; Han, J. Feature enhancement network for object detection in optical remote sensing images. J. Remote Sens. 2021. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate object localization in remote sensing images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Zhang, Z.; Lu, X.; Cao, G.; Yang, Y.; Jiao, L.; Liu, F. ViT-YOLO: Transformer-Basd YOLO for Object Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 2799–2808. [Google Scholar]
- Dong, G.; Li, B.; Chen, Y.; Wang, X. Review of Typical Vehicle Detection Algorithms Based on Deep Learning. J. Eng. Res. Rep. 2022, 23, 165–177. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. In Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Wang, J.; Fu, P.; Gao, R.X. Machine vision intelligence for product defect inspection based on deep learning and Hough transform. J. Manuf. Syst. 2019, 51, 52–60. [Google Scholar] [CrossRef]
- Girdhar, R.; Gkioxari, G.; Torresani, L.; Paluri, M.; Tran, D. Detect-and-track: Efficient pose estimation in videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 350–359. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S. An image is worth 16x16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable detr: Deformable transformers for end-to-end object detection. arXiv 2020, arXiv:2010.04159. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef]
- Wu, H.; Xiao, B.; Codella, N.; Liu, M.; Dai, X.; Yuan, L.; Zhang, L. Cvt: Introducing convolutions to vision transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 22–31. [Google Scholar]
- Wang, L.; Zhou, K.; Chu, A.; Wang, G.; Wang, L. An Improved Light-Weight Traffic Sign Recognition Algorithm Based on YOLOv4-Tiny. IEEE Access 2021, 9, 124963–124971. [Google Scholar] [CrossRef]
- Saleem, M.H.; Potgieter, J.; Arif, K.M. Weed detection by faster RCNN model: An enhanced anchor box approach. Agronomy 2022, 12, 1580. [Google Scholar] [CrossRef]
- Li, X.; Wang, C.; Ju, H.; Li, Z. Surface defect detection model for aero-engine components based on improved YOLOv5. Appl. Sci. 2022, 12, 7235. [Google Scholar] [CrossRef]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 12993–13000. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Chen, Z.; Zhang, F.; Liu, H.; Wang, L.; Zhang, Q.; Guo, L. Real-time detection algorithm of helmet and reflective vest based on improved YOLOv5. J. Real-Time Image Process. 2023, 20, 4. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Ren, Z.; Yu, Z.; Yang, X.; Liu, M.-Y.; Lee, Y.J.; Schwing, A.G.; Kautz, J. Instance-aware, context-focused, and memory-efficient weakly supervised object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10598–10607. [Google Scholar]
- Yang, F.; Li, X.; Shen, J. MSB-FCN: Multi-scale bidirectional fcn for object skeleton extraction. IEEE Trans. Image Process. 2020, 30, 2301–2312. [Google Scholar] [CrossRef]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 10781–10790. [Google Scholar]
- Hua, F. Improved Surface Defect Detection of YOLOV5 Aluminum Profiles based on CBAM and BiFPN. Int. Core J. Eng. 2022, 8, 264–274. [Google Scholar]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. arXiv 2022, arXiv:2207.02696. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Tian, T.; Yang, J. Remote sensing image target detection based on multi-scale feature fusion network. Laser Optoelectron. Prog. 2022, 59, 427–435. [Google Scholar]
- Wang, P.; Sun, X.; Diao, W.; Fu, K. FMSSD: Feature-merged single-shot detection for multiscale objects in large-scale remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2019, 58, 3377–3390. [Google Scholar] [CrossRef]
- Ding, J.; Xue, N.; Long, Y.; Xia, G.-S.; Lu, Q. Learning roi transformer for oriented object detection in aerial images. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 2849–2858. [Google Scholar]
- Azimi, S.M.; Vig, E.; Bahmanyar, R.; Körner, M.; Reinartz, P. Towards Multi-Class Object Detection in Unconstrained Remote Sensing Imagery, Asian Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2018; pp. 150–165. [Google Scholar]
- Acatay, O.; Sommer, L.; Schumann, A.; Beyerer, J. Comprehensive evaluation of deep learning based detection methods for vehicle detection in aerial imagery. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Cheng, X.; Yu, J. RetinaNet with difference channel attention and adaptively spatial feature fusion for steel surface defect detection. IEEE Trans. Instrum. Meas. 2020, 70, 1–11. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5s | 89.9 | 73.2 | 44.2 | 47.2 | 62.2 | 82.3 | 87.0 | 93.1 | 64.1 | 69.4 | 46.0 | 56.8 | 75.6 | 60.2 | 67.1 | 67.9 |
| Proposed work | 93.4 | 84.5 | 53.6 | 54.9 | 67.0 | 87.0 | 89.7 | 94.5 | 71.2 | 80.8 | 59.5 | 69.5 | 82.4 | 65.5 | 66.6 | 74.7 |
| Method | Size | Precision (%) | Recall (%) | mAP (%) | Inference Time (ms) |
|---|---|---|---|---|---|
| YOLOv5s | 640 × 640 | 75.95 | 60.27 | 67.9 | 16 |
| YOLOv5m | 640 × 640 | 79.29 | 61.67 | 68.5 | 34 |
| YOLOv5l | 640 × 640 | 78.80 | 63.13 | 69.7 | 49 |
| YOLOv5x | 640 × 640 | 77.86 | 64.45 | 70.1 | 57 |
| Proposed work | 640 × 640 | 80.07 | 71.3 | 74.7 | 32 |
| Improvement Strategy | Experiment | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | ||
| Improved K-means | √ | √ | √ | √ | √ | √ | ||
| C3SW-T (with LN) | √ | |||||||
| C3SW-T (without LN) | √ | √ | √ | √ | ||||
| P2 | √ | √ | √ | |||||
| Coordinate Attention | √ | √ | ||||||
| BiFPN | √ | |||||||
| Evaluationindicator | mAP (%) | 67.9 | 69.3 (+1.4) | 70.6 (+1.3) | 71.5 (+2.2) | 72.1 (+0.6) | 72.3 (+0.2) | 74.7 (+2.4) |
| Precision (%) | 75.9 | 76.2 (+0.3) | 77.8 (+1.6) | 78.6 (+2.4) | 79.1 (+0.5) | 79.7 (+0.6) | 80 (+0.3) | |
| Recall (%) | 63.4 | 67.8 (+4.4) | 68.3 (+0.5) | 68.8 (+1) | 69.2 (+0.4) | 70.9 (+1.7) | 71.3 (+0.4) | |
| Inference Time (ms) | 16 | 16 | 23 | 21 | 27 | 29 | 32 | |
| Method | Image Size | Precision (%) | Recall (%) | mAP (%) | Inference Time (ms) |
|---|---|---|---|---|---|
| YOLOv5s6 | 640 × 640 | 78.7 | 66.9 | 71.0 | 29 |
| YOLOv5m6 | 640 × 640 | 75.7 | 74.2 | 76.4 | 44 |
| YOLOv6s | 640 × 640 | 51.9 | 59.4 | 57.2 | 10.5 |
| YOLOv6l | 640 × 640 | 75.3 | 74.6 | 72.8 | 24.3 |
| YOLOv7 | 640 × 640 | 81.2 | 74.7 | 78.4 | 18 |
| YOLOv7-tiny | 640 × 640 | 74.9 | 68 | 69.4 | 11 |
| YOLOX-s | 640 × 640 | 80.2 | 70 | 74.5 | 24 |
| YOLOR-p6 | 640 × 640 | 79.7 | 61.2 | 64.7 | 20.7 |
| Proposed work-m | 640 × 640 | 79.4 | 74.1 | 77.3 | 47 |
| Proposed work | 640 × 640 | 80 | 71.3 | 74.7 | 32 |
| Method | Image Size | Precision (%) | Recall (%) | mAP (%) | Inference Time (ms) |
|---|---|---|---|---|---|
| YOLOv5m6 | 1280 × 1280 | 79.4 | 77.3 | 77.2 | 58 |
| YOLOv6s | 1280 × 1280 | 58.5 | 62.6 | 63.1 | 34.1 |
| YOLOv6l | 1280 × 1280 | 75.3 | 77.8 | 71.9 | 33 |
| YOLOv7 | 1280 × 1280 | 81.2 | 74.5 | 80.4 | 39.7 |
| YOLOv7-tiny | 1280 × 1280 | 74.6 | 68.5 | 70.1 | 19 |
| Proposed work | 1280 × 1280 | 81.94 | 72.4 | 78.1 | 51 |
| Method | PL | BD | BR | GTF | SV | LV | SH | TC | BC | ST | SBF | RA | HA | SP | HC | mAP |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv4 [32] | 93.8 | 77.1 | 42.3 | 42.9 | 71.2 | 70.9 | 88.3 | 94.5 | 55.8 | 68.7 | 42.6 | 39.4 | 77.3 | 81.9 | 74 | 68.4 |
| YOLOv3 [33] | 79.00 | 77.1 | 33.90 | 68.10 | 52.80 | 52.20 | 49.80 | 89.90 | 74.80 | 59.20 | 55.50 | 49.00 | 61.50 | 55.90 | 41.70 | 60.00 |
| TPH-YOLOv5 [1] | 91.8 | 77.7 | 49.5 | 68.1 | 66.6 | 84.7 | 87.2 | 93.7 | 64.7 | 69.7 | 53.1 | 62.7 | 84.1 | 63.3 | 53.9 | 71.4 |
| ViT-YOLO [8] | 94.7 | 79.2 | 48.8 | 60.7 | 68.4 | 72.7 | 89.1 | 94.8 | 58.8 | 70.2 | 53.1 | 57.9 | 84.0 | 77.8 | 85.8 | 73.1 |
| SSD [4] | 79.42 | 77.13 | 17.7 | 64.05 | 35.3 | 38.02 | 37.16 | 89.41 | 69.64 | 59.28 | 50.3 | 52.91 | 47.89 | 47.4 | 46.3 | 54.13 |
| MDCF2Det [34] | 89.68 | 84.39 | 52.12 | 72.71 | 64.49 | 67.07 | 77.45 | 90.11 | 83.98 | 86.01 | 55.03 | 63.33 | 74.45 | 67.74 | 62.87 | 72.86 |
| FMSSD [35] | 89.11 | 81.51 | 48.22 | 67.94 | 69.23 | 73.56 | 76.87 | 90.71 | 82.67 | 73.33 | 52.65 | 67.52 | 72.37 | 80.57 | 60.15 | 72.43 |
| RoI-Transformer [36] | 88.64 | 78.52 | 43.44 | 75.92 | 68.81 | 73.68 | 83.59 | 90.74 | 77.27 | 81.46 | 58.39 | 53.54 | 62.83 | 58.93 | 47.67 | 69.56 |
| ICN [37] | 90.00 | 77.70 | 53.40 | 73.30 | 73.50 | 65.00 | 78.20 | 90.80 | 79.10 | 84.80 | 57.20 | 62.11 | 73.45 | 70.22 | 58.08 | 72.45 |
| DYOLO [38] | 86.60 | 71.40 | 54.60 | 52.50 | 79.20 | 80.60 | 87.80 | 82.20 | 54.10 | 75.00 | 51.00 | 69.20 | 66.40 | 59.20 | 51.30 | 68.10 |
| RetinaNet [39] | 78.22 | 53.41 | 26.38 | 42.27 | 63.64 | 52.63 | 73.19 | 87.17 | 44.64 | 57.99 | 18.03 | 51.00 | 43.39 | 56.56 | 74.4 | 50.39 |
| Proposed work | 93.4 | 84.5 | 53.6 | 54.9 | 67.0 | 87.0 | 89.7 | 94.5 | 71.2 | 80.8 | 59.5 | 69.5 | 82.4 | 65.5 | 66.6 | 74.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, X.; Zhang, Y.; Lang, S.; Gong, Y. Swin-Transformer-Based YOLOv5 for Small-Object Detection in Remote Sensing Images. Sensors 2023, 23, 3634. https://doi.org/10.3390/s23073634
Cao X, Zhang Y, Lang S, Gong Y. Swin-Transformer-Based YOLOv5 for Small-Object Detection in Remote Sensing Images. Sensors. 2023; 23(7):3634. https://doi.org/10.3390/s23073634
Chicago/Turabian StyleCao, Xuan, Yanwei Zhang, Song Lang, and Yan Gong. 2023. "Swin-Transformer-Based YOLOv5 for Small-Object Detection in Remote Sensing Images" Sensors 23, no. 7: 3634. https://doi.org/10.3390/s23073634
APA StyleCao, X., Zhang, Y., Lang, S., & Gong, Y. (2023). Swin-Transformer-Based YOLOv5 for Small-Object Detection in Remote Sensing Images. Sensors, 23(7), 3634. https://doi.org/10.3390/s23073634