
Sleep Stage Classification in Children Using Self-Attention and Gaussian Noise Data Augmentation
 , , , , and
, , , , and 
Abstract
1. Introduction
2. Related Work
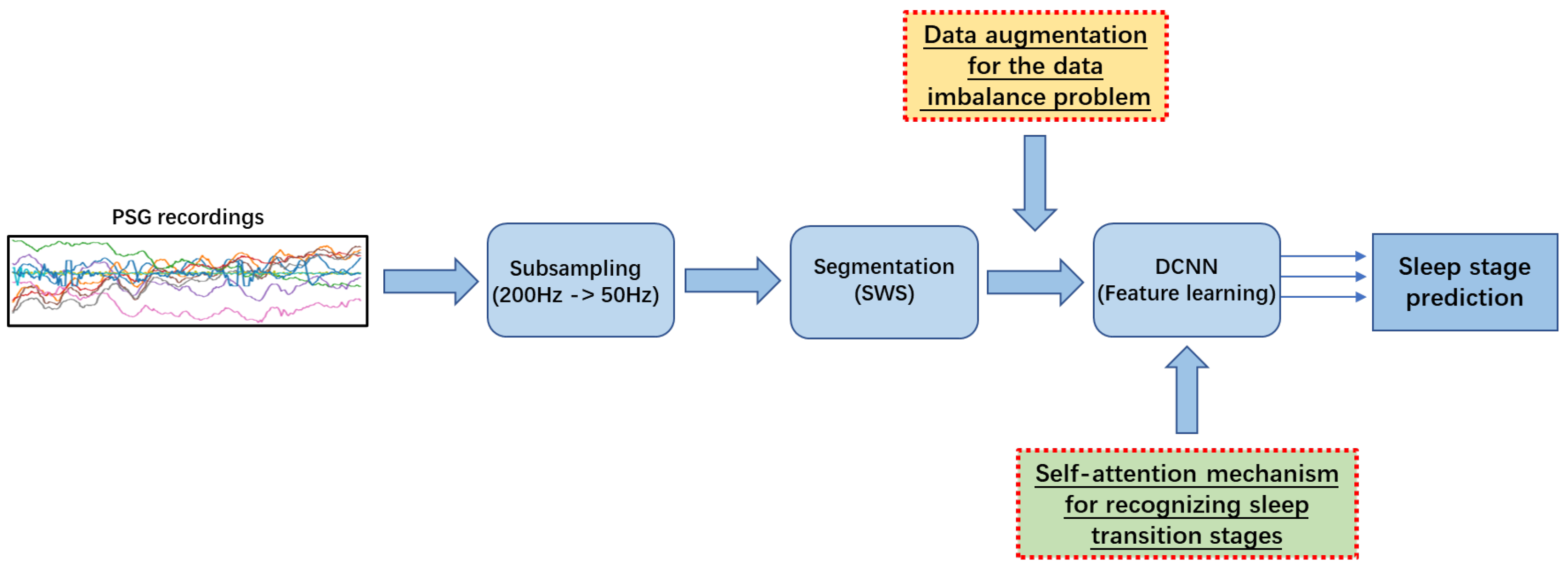
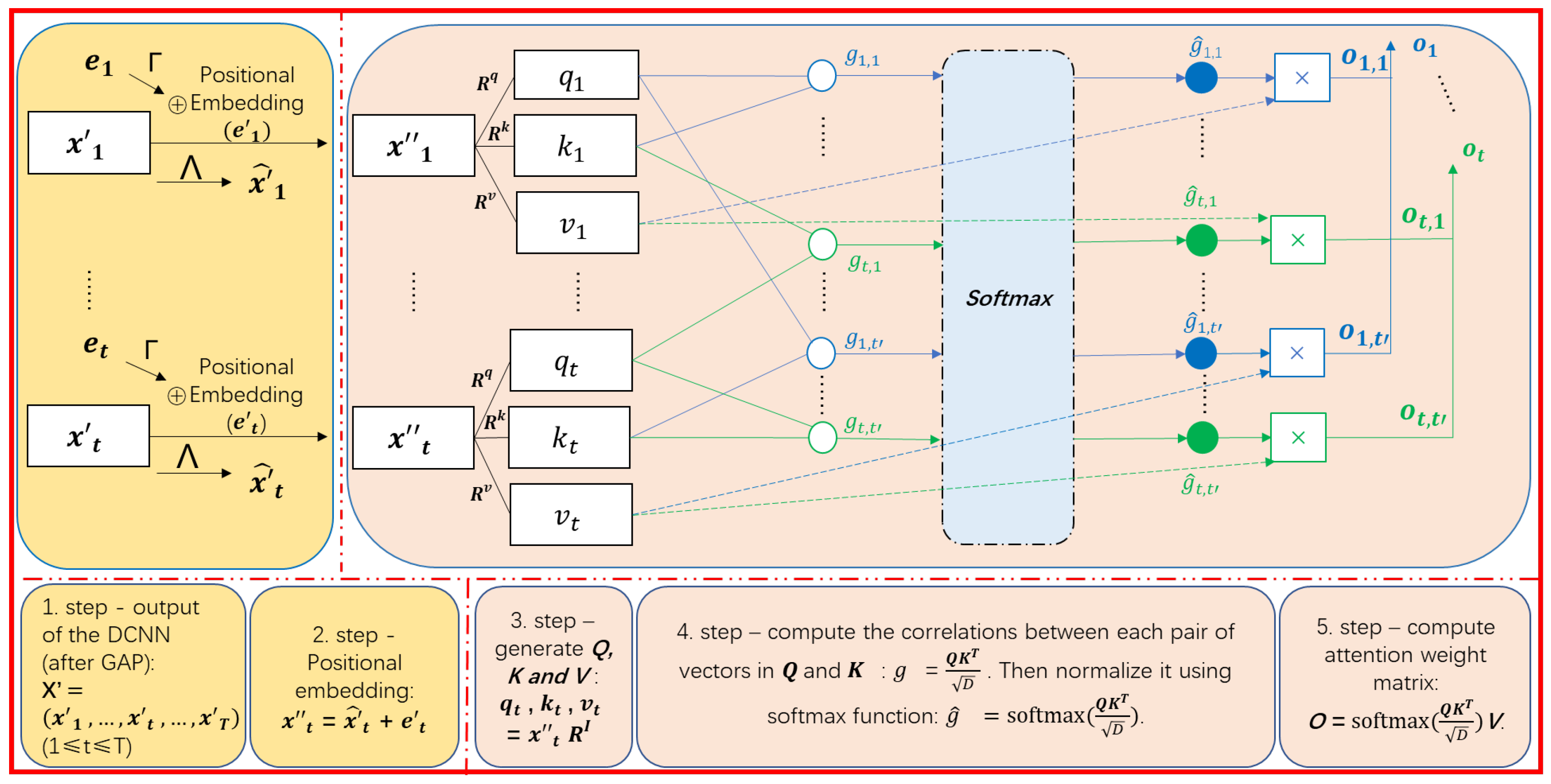
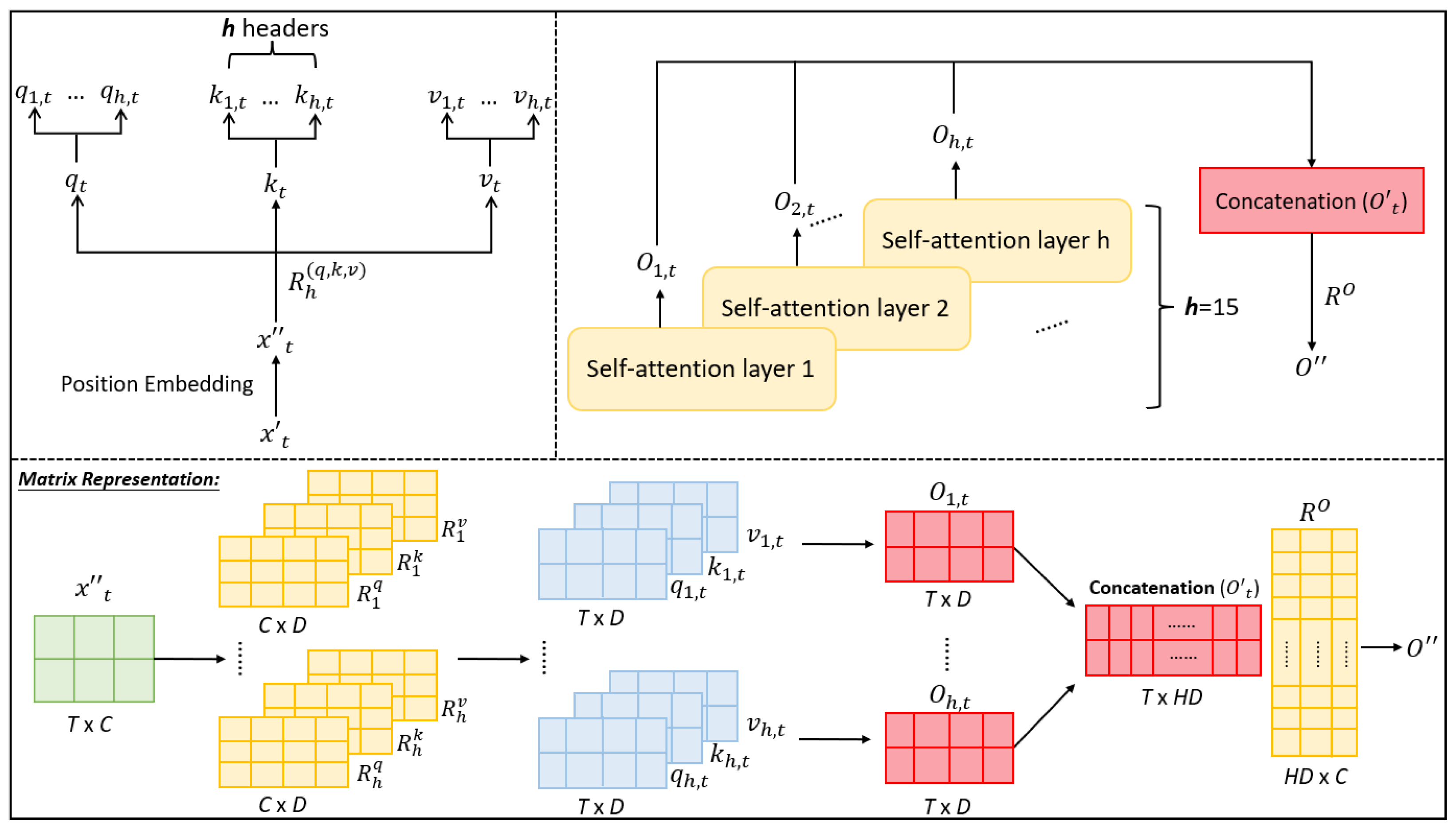
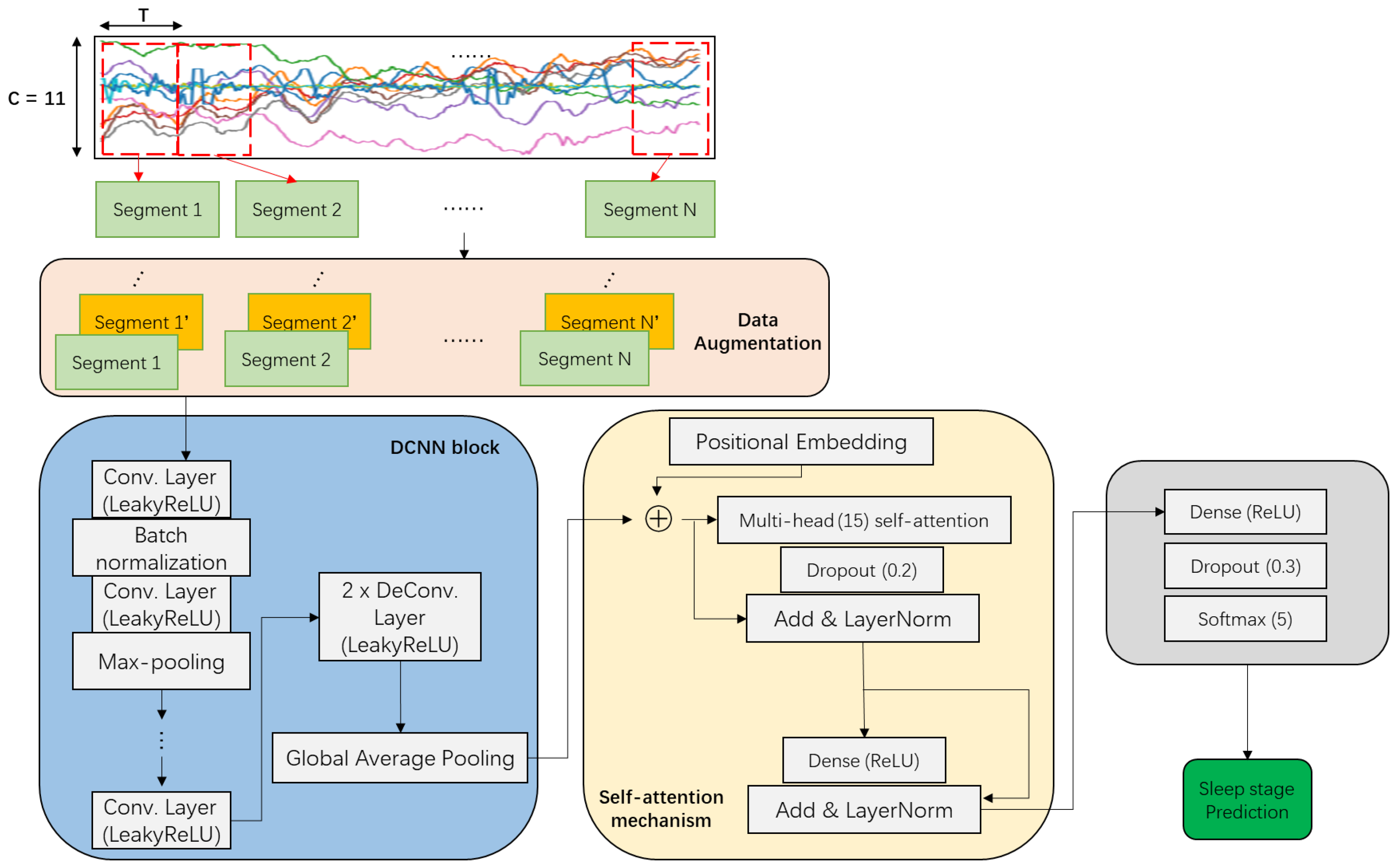
3. Methodology
DeConvolution- and Self-Attention-Based Model
4. Experiments
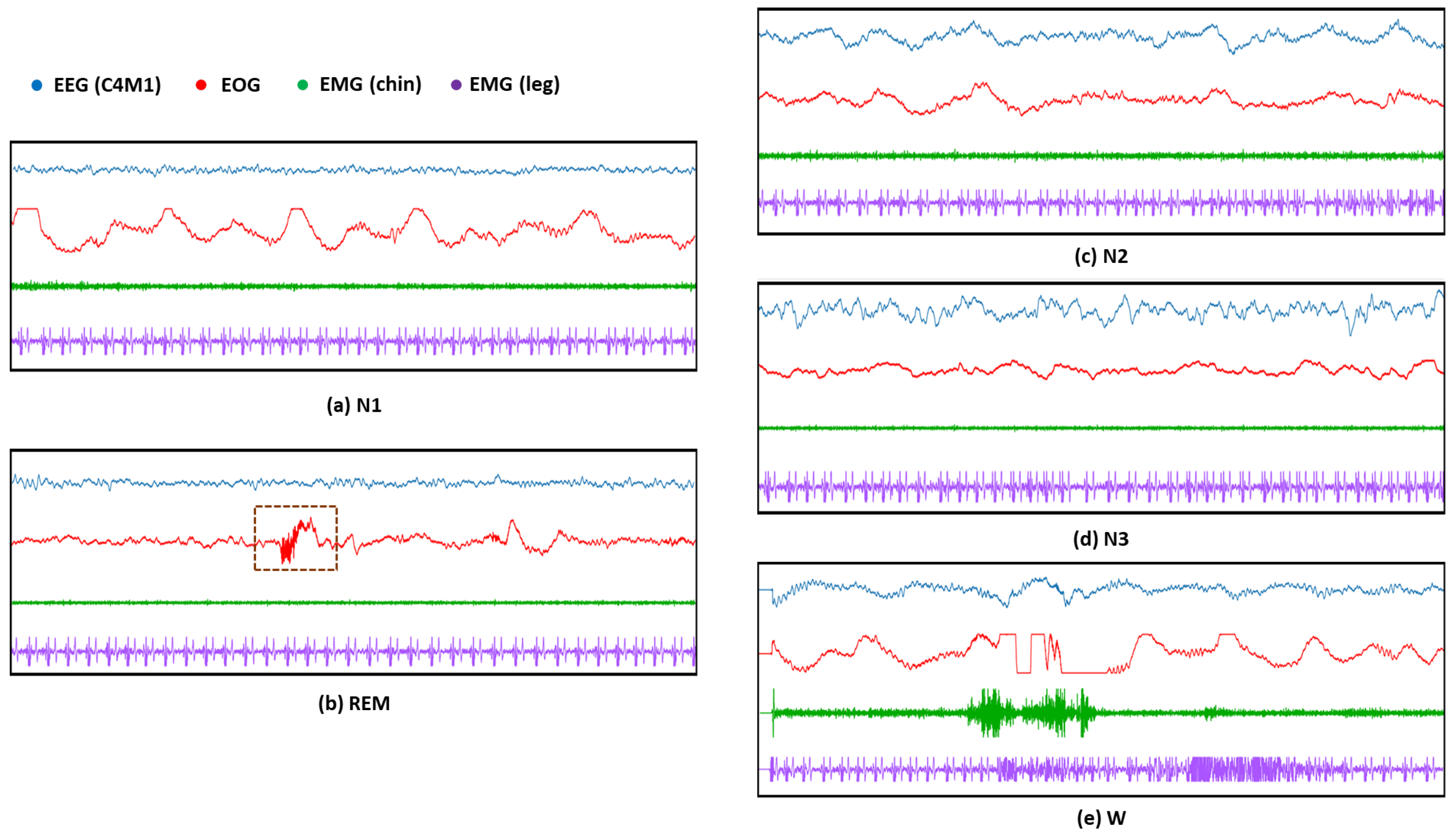
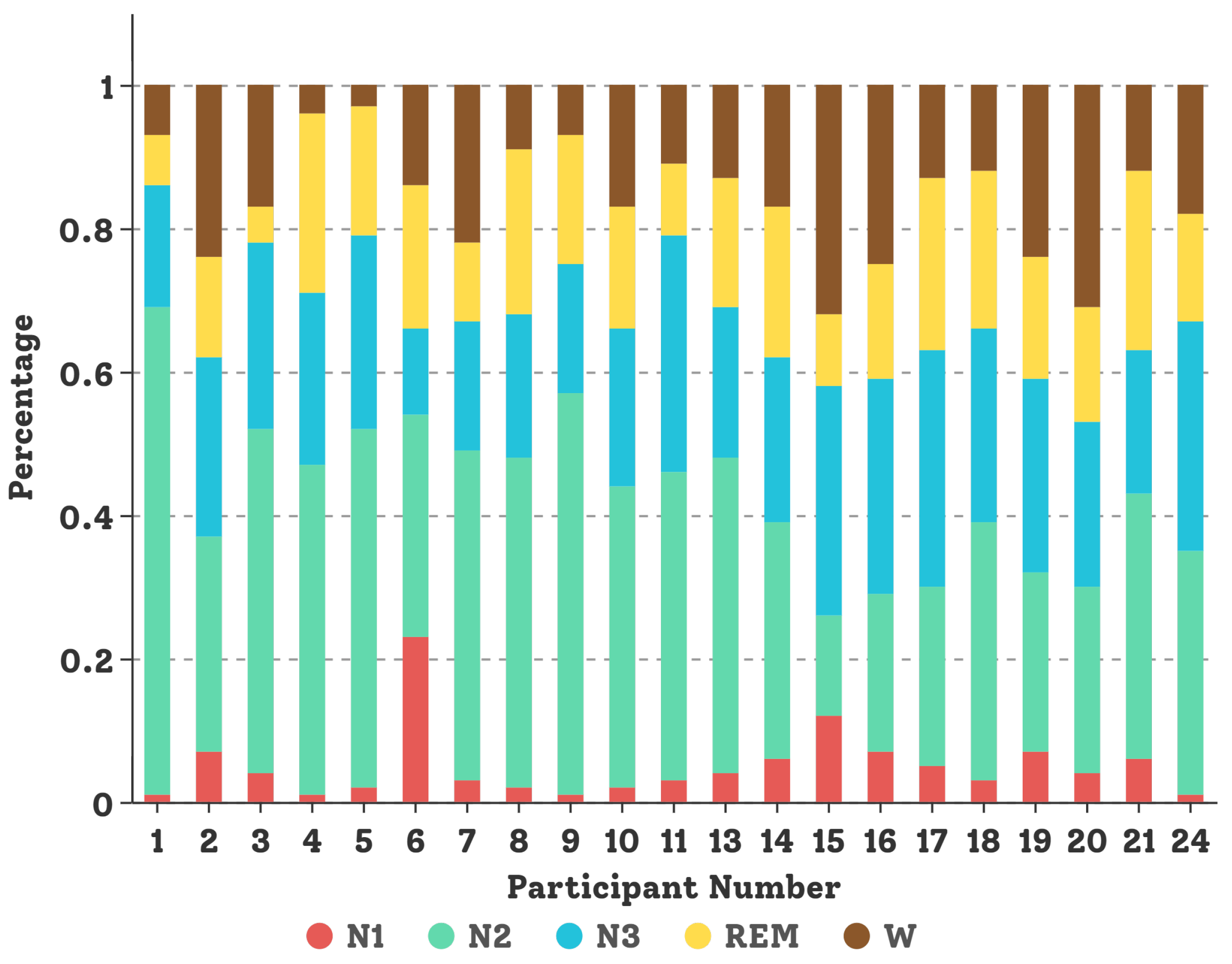
4.1. SDCP Dataset
4.1.1. Dataset Description
4.1.2. Data Preprocessing
4.2. Sleep-EDFX Dataset
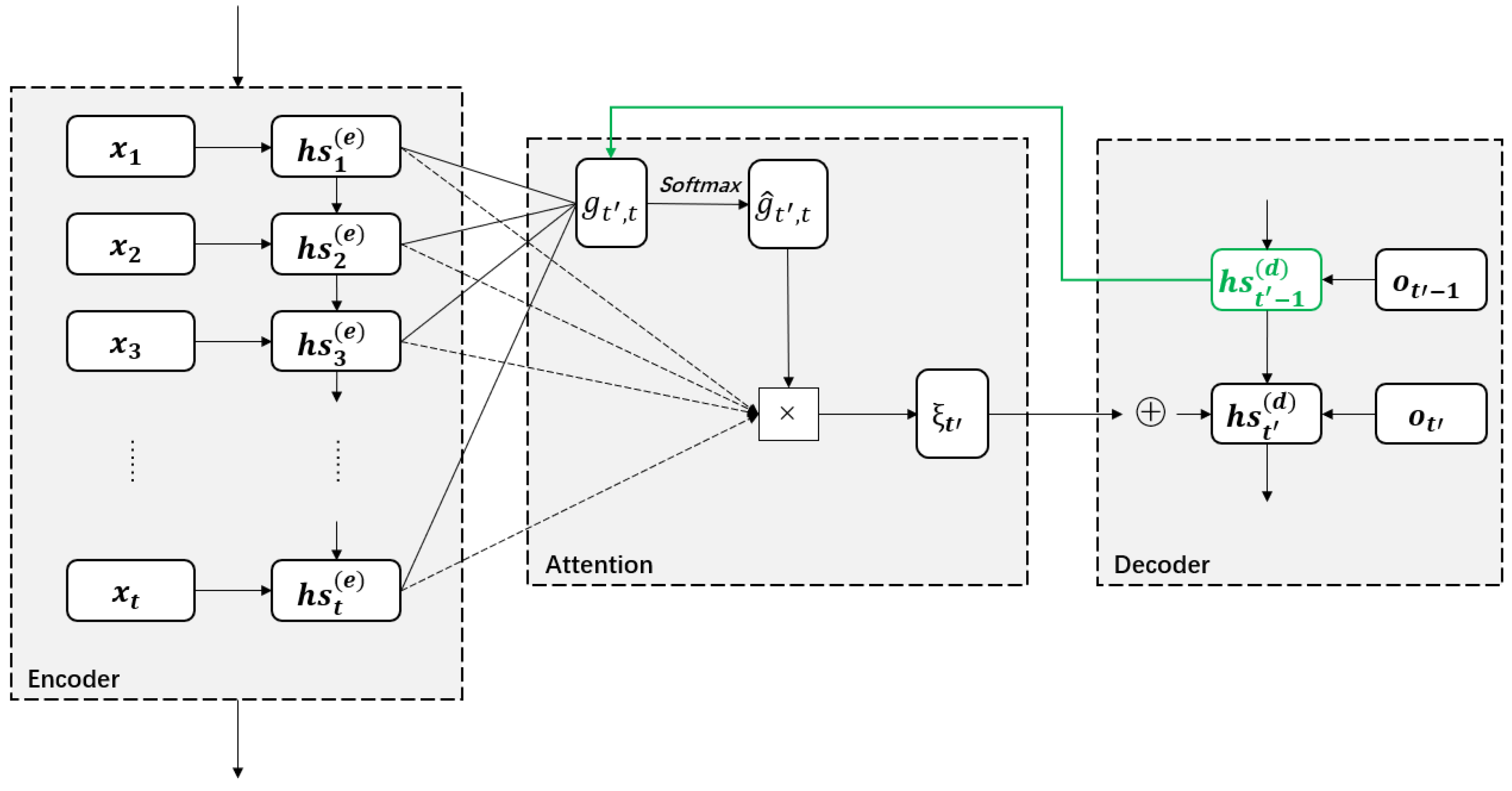
4.3. RNN-Based Attention Model
4.4. Experimental Setup
4.5. Performance Evaluation on the SDCP Dataset
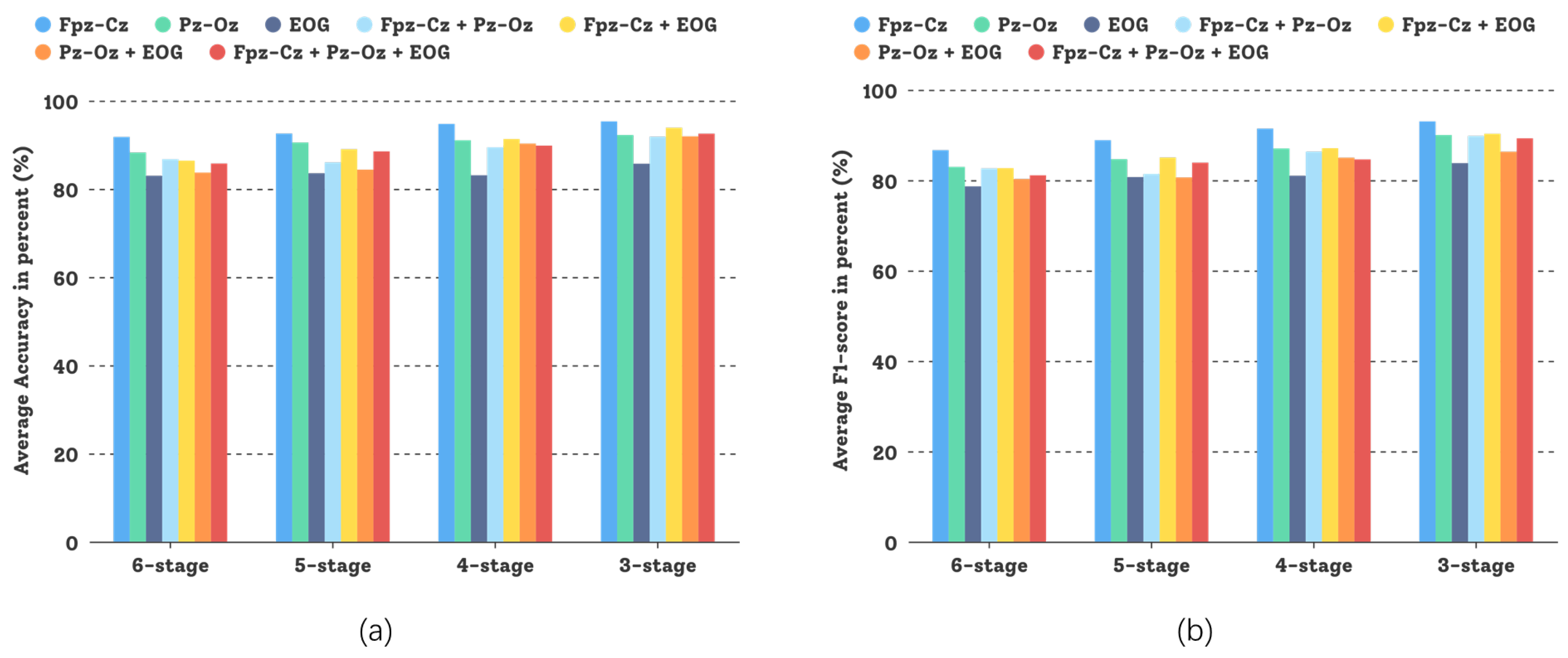
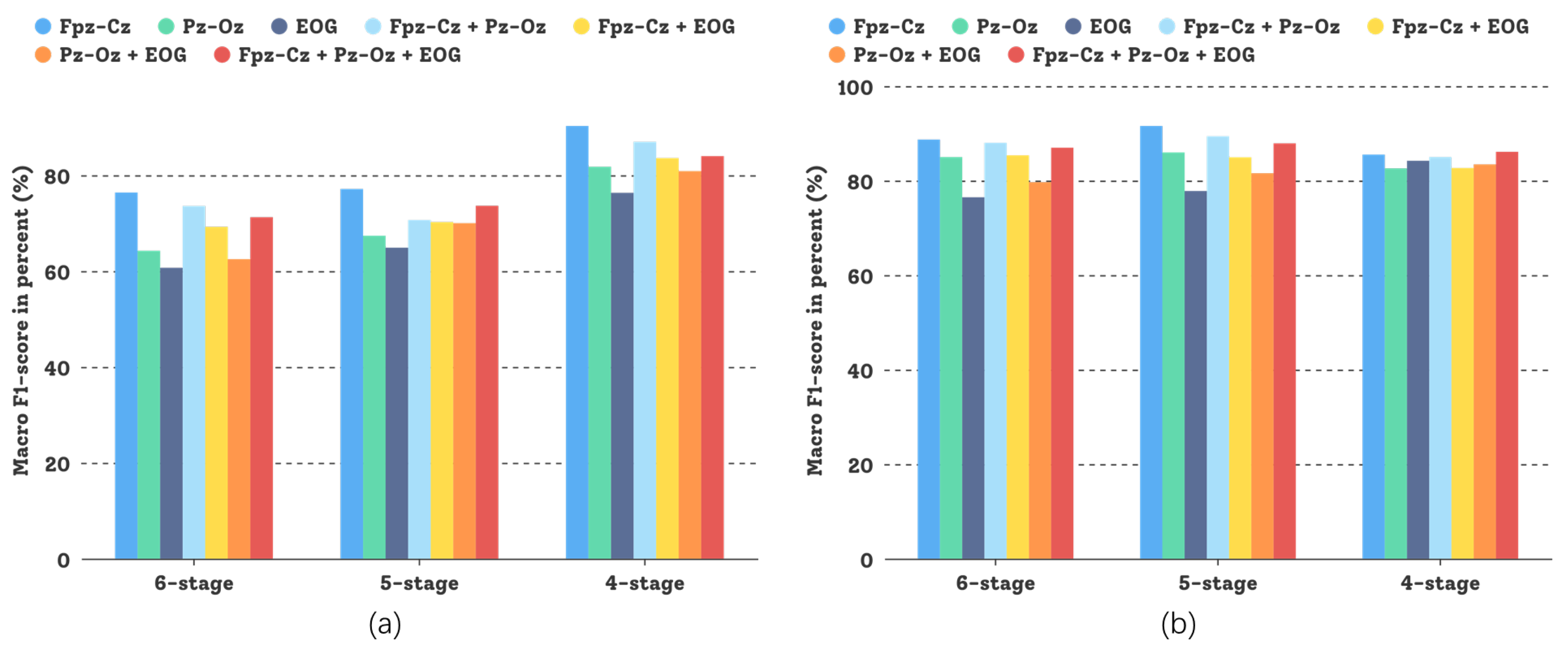
4.6. Comparative Experiment on the Sleep-EDFX Dataset
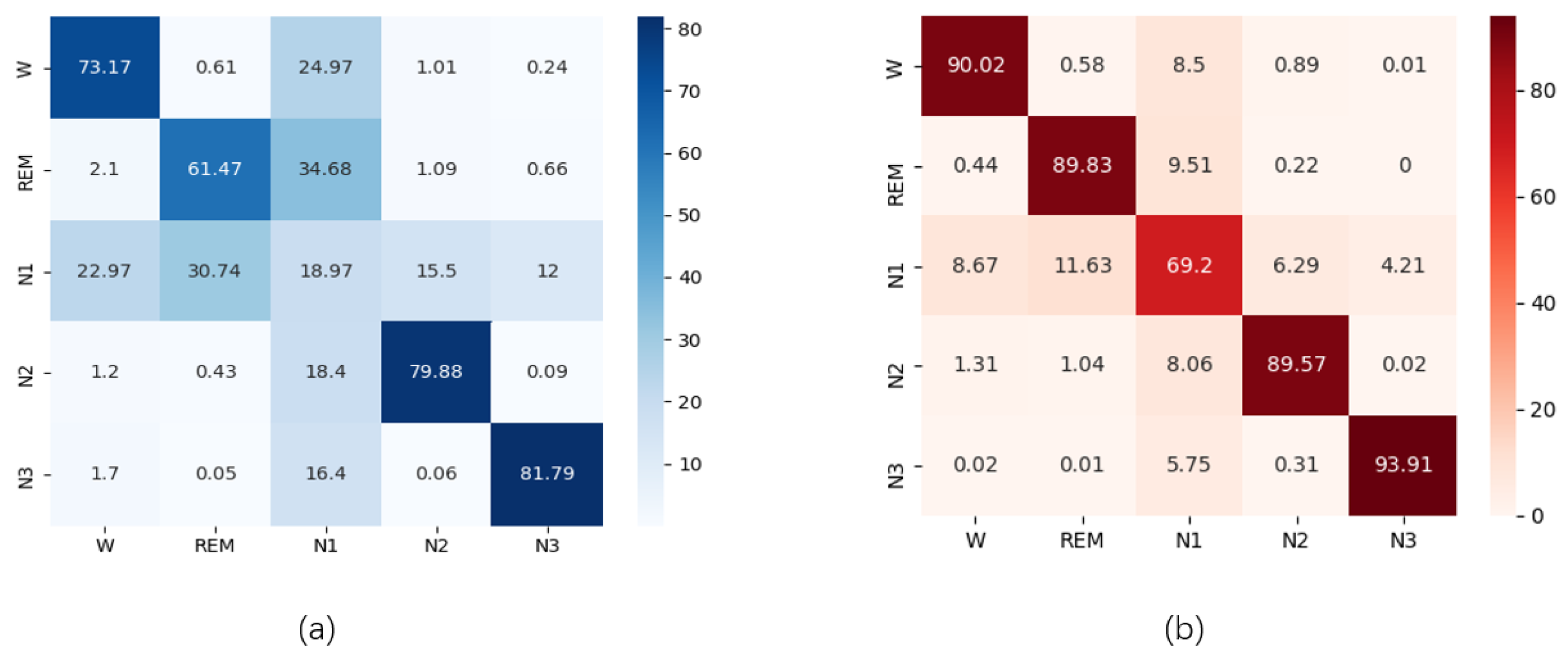
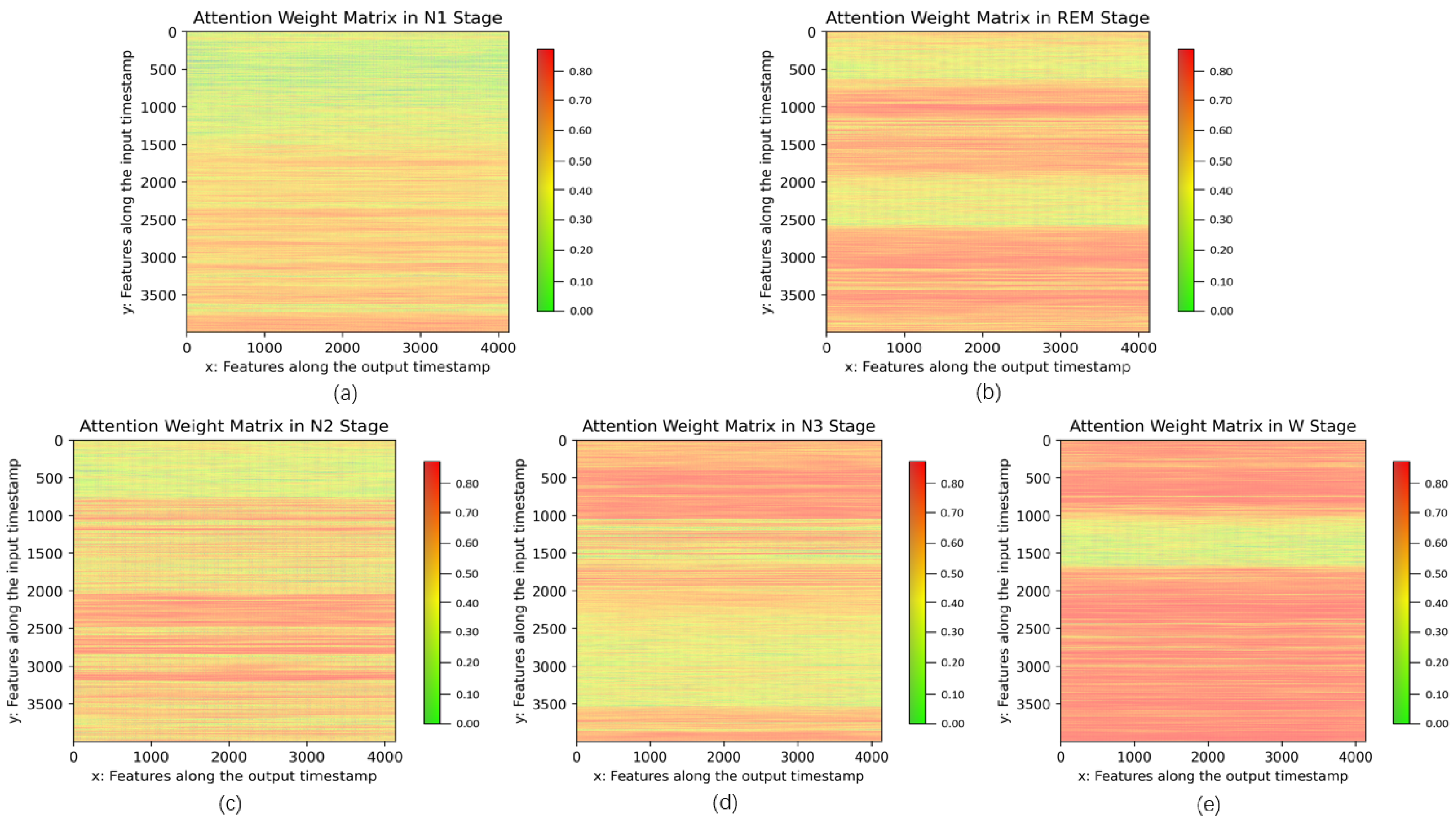
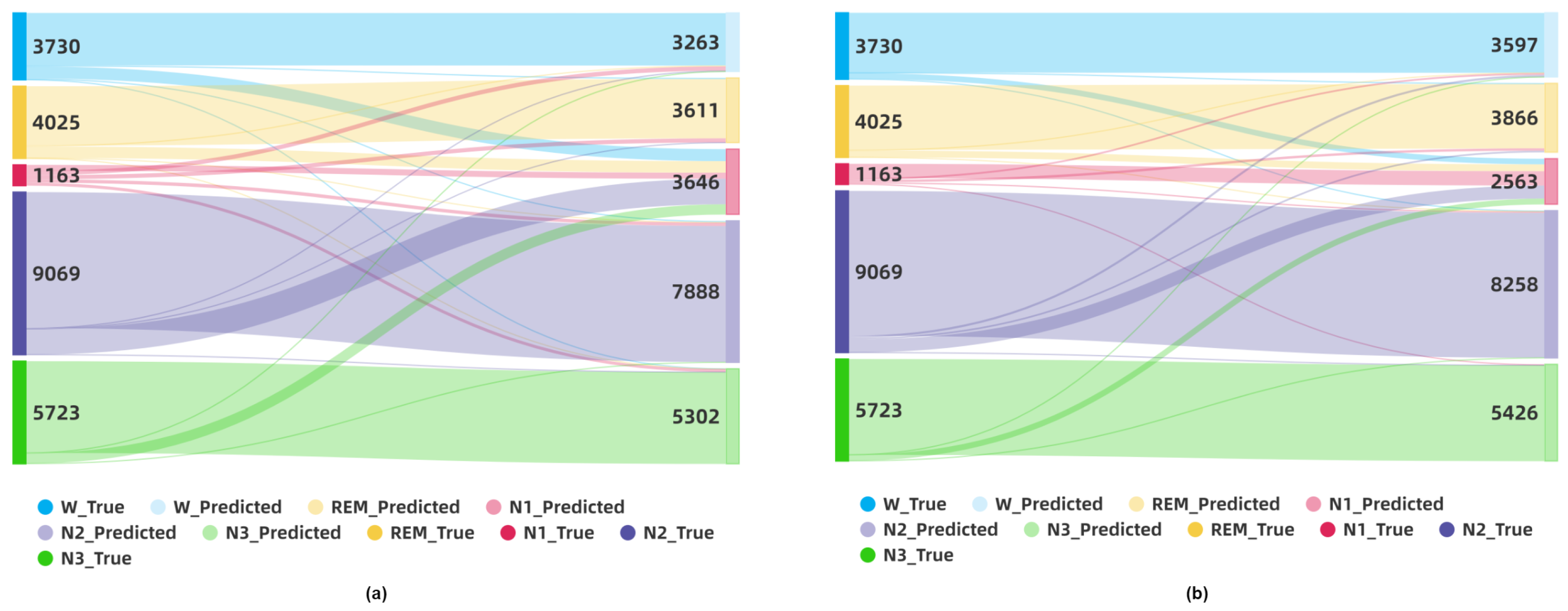
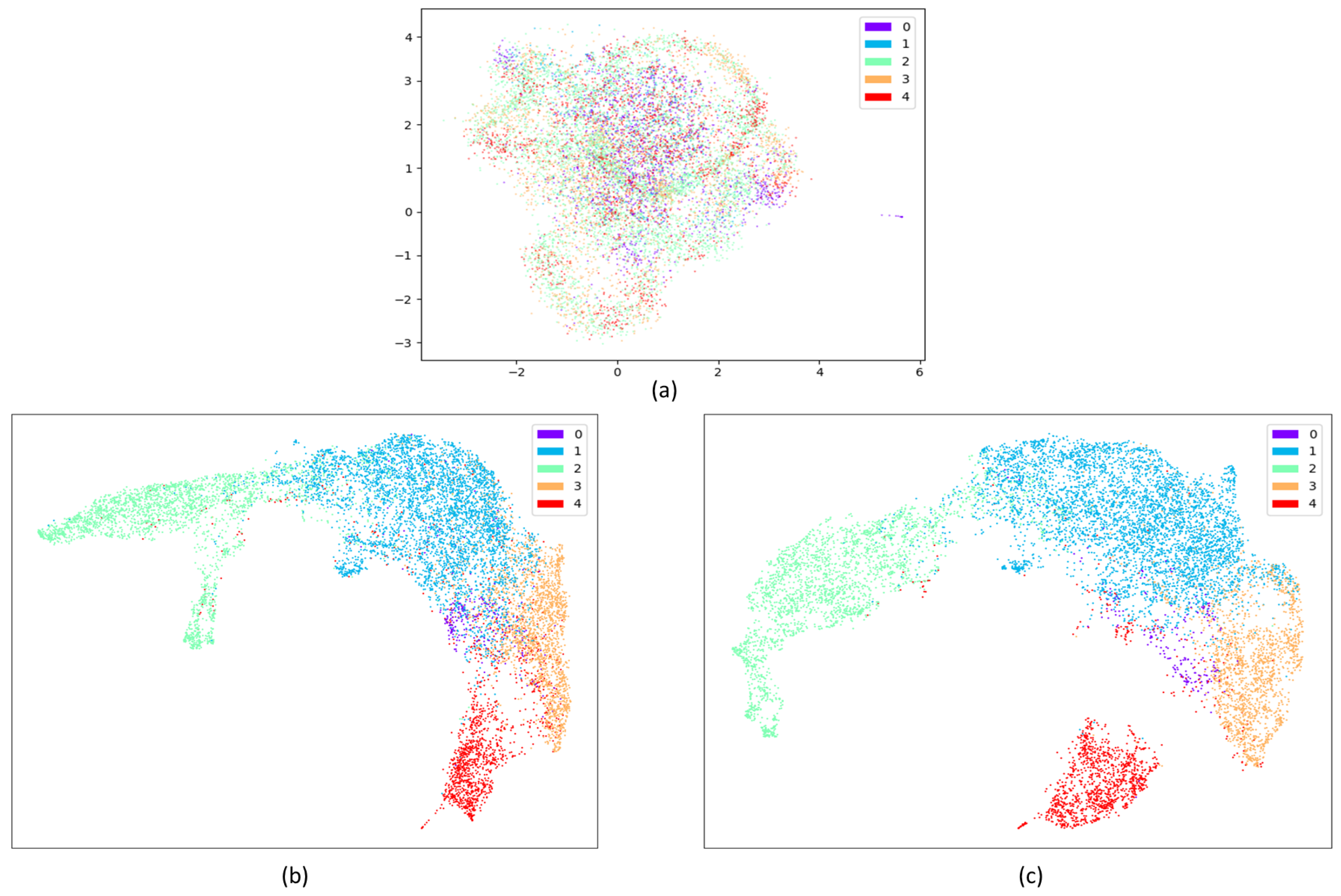
4.7. Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GNDA | Gaussian Noise Data Augmentation |
| DCSAM | DeConvolution- and Self-Attention-based Model |
| PSG | Polysomnography |
| R & K | Rechtschaffen & Kales |
| AASM | American Academy of Sleep Medicine |
| REM | Rapid Eye Movement |
| EEG | Electroencephalography |
| EOG | Electrooculography |
| EMG | Electromyography |
| PPG | Photoplethysmogram |
| NLP | Natural Language Processing |
| CV | Computer Vision |
| TSA | Time Series Analysis |
| DWT | Discrete Wavelet Transform |
| SVM | Support Vector Machine |
| DCNN | DeConvolutional Neural Network |
| Bi-LSTM | Bidirectional Long Short-term Memory |
| CNN | Convolutional Neural Network |
| LeakyReLU | Leaky Rectified Linear Unit |
| FT | Fourier Transform |
| SFA | Spectral Features Analysis |
| TA | Time-frequency Analysis |
| LAMF | Low Amplitude Mixed Frequency |
| SWS | Sliding Window Segmentation |
| JS | Jacobian Score |
| GAN | Generative Adversarial Networks |
| IMU | Inertial Measurement Unit |
| Acc | Accuracy |
| MF1 | Macro F1 score |
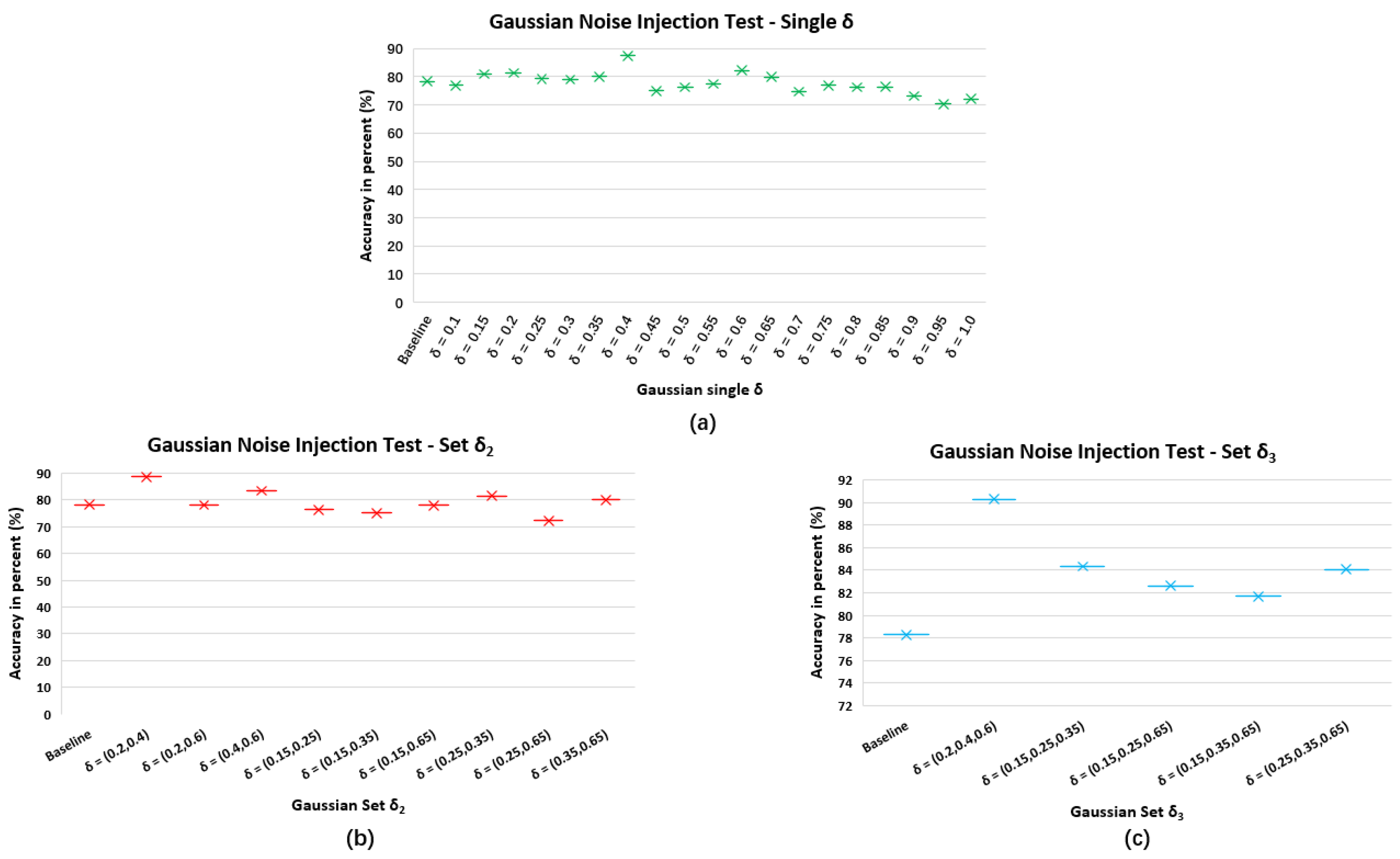
Appendix A. Gaussian Noise Injection Test

Appendix B. Subsampling Frequency Test

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | 5 Hz | 10 Hz | 50 Hz | |||
|---|---|---|---|---|---|---|
| ACC | MF1 | ACC | MF1 | ACC | MF1 | |
| DWT + SVM without GNDA | 52.69 | 45.43 | 56.98 | 48.11 | 67.59 | 55.52 |
| GNDA(0.4) + DWT + SVM | 54.40 | 46.02 | 56.50 | 46.86 | 67.81 | 52.05 |
| GNDA(0.2, 0.4) + DWT + SVM | 58.01 | 49.97 | 60.93 | 51.92 | 71.12 | 56.44 |
| GNDA(0.2, 0.4, 0.6) + DWT + SVM | 60.32 | 52.53 | 64.03 | 54.07 | 71.97 | 59.45 |
| DCNN without GNDA | 74.48 | 61.39 | 76.33 | 62.17 | 77.13 | 63.02 |
| GNDA(0.4) + DCNN | 74.92 | 63.23 | 78.56 | 64.71 | 80.01 | 68.88 |
| GNDA(0.2, 0.4) + DCNN | 76.57 | 62.82 | 78.19 | 65.14 | 80.34 | 67.35 |
| GNDA(0.2, 0.4, 0.6) + DCNN | 77.12 | 63.19 | 78.45 | 64.66 | 79.52 | 66.48 |
| RNN-based attention without GNDA | 69.78 | 63.51 | 70.29 | 63.96 | 71.48 | 65.27 |
| GNDA(0.4) + RNN-based attention | 71.33 | 65.48 | 72.55 | 64.28 | 73.98 | 66.47 |
| GNDA(0.2, 0.4) + RNN-based attention | 70.40 | 63.03 | 69.89 | 61.57 | 71.57 | 63.99 |
| GNDA(0.2, 0.4, 0.6) + RNN-based attention | 73.01 | 66.79 | 74.52 | 67.24 | 74.68 | 68.24 |
| Self-attention without GNDA | 76.47 | 68.24 | 77.11 | 68.97 | 78.25 | 70.83 |
| GNDA(0.4) + Self-attention | 80.65 | 71.59 | 82.07 | 74.50 | 82.97 | 75.87 |
| GNDA(0.2, 0.4) + Self-attention | 78.98 | 70.24 | 80.86 | 71.34 | 84.45 | 77.75 |
| GNDA(0.2, 0.4, 0.6) + Self-attention | 81.17 | 73.78 | 83.07 | 75.24 | 82.67 | 75.87 |
| GNDA(0.4) + DCNN + Self-Attention | 83.01 | 79.57 | 84.02 | 81.89 | 87.37 | 85.22 |
| GNDA(0.2, 0.4) + DCNN + Self-Attention | 84.77 | 81.78 | 86.99 | 83.05 | 88.55 | 84.69 |
| GNDA(0.2, 0.4, 0.6) + DCNN + Self-Attention | 86.34 | 81.87 | 88.85 | 84.41 | 90.26 | 86.51 |
| Model | 5 Hz | 10 Hz | 50 Hz | |||
|---|---|---|---|---|---|---|
| ACC | MF1 | ACC | MF1 | ACC | MF1 | |
| DWT + SVM without GNDA | 50.87 | 43.39 | 55.21 | 50.09 | 67.01 | 53.79 |
| GNDA(0.4) + DWT + SVM | 53.08 | 44.24 | 55.57 | 50.06 | 68.92 | 52.97 |
| GNDA(0.2, 0.4) + DWT + SVM | 56.60 | 50.01 | 59.89 | 50.85 | 69.92 | 52.99 |
| GNDA(0.2, 0.4, 0.6) + DWT + SVM | 61.02 | 51.59 | 62.89 | 53.00 | 69.94 | 54.18 |
| DCNN without GNDA | 73.54 | 63.08 | 75.26 | 64.27 | 77.90 | 66.11 |
| GNDA(0.4) + DCNN | 75.88 | 64.22 | 79.21 | 66.19 | 80.67 | 71.39 |
| GNDA(0.2, 0.4) + DCNN | 82.69 | 71.57 | 85.08 | 71.59 | 86.02 | 75.88 |
| GNDA(0.2, 0.4, 0.6) + DCNN | 83.34 | 72.01 | 84.61 | 72.03 | 85.81 | 76.11 |
| RNN-based attention without GNDA | 66.74 | 60.20 | 66.92 | 61.57 | 71.03 | 64.51 |
| GNDA(0.4) + RNN-based attention | 67.45 | 61.24 | 68.48 | 61.03 | 70.44 | 63.06 |
| GNDA(0.2, 0.4) + RNN-based attention | 66.24 | 60.07 | 67.51 | 61.11 | 68.76 | 62.28 |
| GNDA(0.2, 0.4, 0.6) + RNN-based attention | 68.30 | 62.31 | 69.87 | 64.22 | 70.56 | 66.47 |
| Self-attention without GNDA | 75.01 | 65.23 | 75.89 | 66.04 | 77.29 | 68.27 |
| GNDA(0.4) + Self-attention | 78.87 | 70.34 | 80.33 | 72.48 | 80.67 | 73.88 |
| GNDA(0.2, 0.4) + Self-attention | 75.21 | 68.55 | 78.99 | 69.30 | 80.05 | 72.97 |
| GNDA(0.2, 0.4, 0.6) + Self-attention | 78.59 | 70.40 | 80.64 | 73.01 | 81.15 | 74.19 |
| GNDA(0.4) + DCNN + Self-Attention | 82.08 | 78.24 | 85.19 | 80.03 | 86.24 | 81.89 |
| GNDA(0.2, 0.4) + DCNN + Self-Attention | 85.57 | 81.78 | 87.69 | 83.56 | 88.06 | 83.18 |
| GNDA(0.2, 0.4, 0.6) + DCNN + Self-Attention | 86.38 | 81.81 | 88.84 | 83.08 | 88.56 | 83.57 |
Appendix C. Sensor Channel Test on the SDCP Dataset
| Sensor Modality | Sensor Channel | Jacobian Score () |
|---|---|---|
| EEG | C4M1 | 0.1827 |
| EEG | C3M2 | 0.1752 |
| EOG | LEOGM2 | 0.1748 |
| EOG | REOGM1 | 0.1600 |
| EEG | O2M1 | 0.1442 |
| EEG | F4M1 | 0.1299 |
| EEG | F3M2 | 0.1225 |
| EEG | O1M2 | 0.1060 |
| EMG | Chin EMG | 0.0244 |
| EMG | Leg (left) | 0.0109 |
| EMG | Leg (right) | 0.0087 |
| Sensor Channel | s, Hz | Sensor Channel | s, Hz | ||
|---|---|---|---|---|---|
| ACC | MF1 | ACC | MF1 | ||
| C3M2 | 82.89 | 76.31 | C3M2 + O2M1 | 80.19 | 72.07 |
| C4M1 | 83.77 | 78.09 | C4M1 + O1M2 | 85.28 | 80.20 |
| F3M2 | 79.09 | 72.24 | F3M2 + O2M1 | 83.73 | 78.91 |
| F4M1 | 78.52 | 73.19 | F4M1 + O1M2 | 80.54 | 74.85 |
| O1M2 | 69.18 | 63.66 | 6 EEG channels | 87.64 | 82.19 |
| O2M1 | 72.43 | 64.04 | REOGM1 (EOG) | 83.95 | 78.12 |
| C3M2 + C4M1 | 83.58 | 78.10 | LEOGM2 (EOG) | 84.02 | 76.53 |
| F3M2 + F4M1 | 81.50 | 77.00 | 2 EOG channels | 84.98 | 79.50 |
| O1M2 + O2M1 | 68.22 | 61.28 | 6 EEG + 2 EOG | 88.14 | 83.64 |
| C3M2 + F4M1 | 84.69 | 77.59 | 3 EMG channels | 42.21 | 32.34 |
| C4M1 + F3M2 | 82.51 | 75.80 | All 11 sensor channels | 90.26 | 86.51 |
References
- Fricke-Oerkermann, L.; Plück, J.; Schredl, M.; Heinz, K.; Mitschke, A.; Wiater, A.; Lehmkuhl, G. Prevalence and course of sleep problems in childhood. Sleep 2007, 30, 1371–1377. [Google Scholar] [CrossRef] [PubMed]
- Tsukada, E.; Kitamura, S.; Enomoto, M.; Moriwaki, A.; Kamio, Y.; Asada, T.; Arai, T.; Mishima, K. Prevalence of Childhood Obstructive Sleep Apnea Syndrome and Its Role in Daytime Sleepiness. PLoS ONE 2018, 13, e0204409. [Google Scholar] [CrossRef]
- Kales, A.; Rechtschaffen, A. A Manual of Standardized Terminology, Techniques and Scoring System for Sleep Stages of Human Subjects; Rechtschaffen, A., Kales, A., Eds.; NIH Publication, U. S. National Institute of Neurological Diseases and Blindness, Neurological Information Network: Bethesda, MD, USA, 1968. [Google Scholar]
- AASM. The AASM Manual for the Scoring of Sleep and Associated Events in Version 2.6. 2020. Available online: https://aasm.org/clinical-resources/scoring-manual (accessed on 16 February 2023).
- Huang, X.; Shirahama, K.; Li, F.; Grzegorzek, M. Sleep stage classification for child patients using DeConvolutional Neural Network. Artif. Intell. Med. 2020, 110, 101981. [Google Scholar] [CrossRef] [PubMed]
- Danker-Hopfe, H.; Anderer, P.; Zeitlhofer, J.; Boeck, M.; Dorn, H.; Gruber, G.; Heller, E.; Loretz, E.; Moser, D.; Parapatics, S.; et al. Interrater reliability for sleep scoring according to the Rechtschaffen & Kales and the new AASM standard. J. Sleep Res. 2009, 18, 74–84. [Google Scholar]
- Berthomier, C.; Muto, V.; Schmidt, C.; Vandewalle, G.; Jaspar, M.; Devillers, J.; Gaggioni, G.; Chellappa, S.L.; Meyer, C.; Phillips, C.; et al. Exploring Scoring Methods for Research Studies: Accuracy and Variability of Visual and Automated Sleep Scoring. J. Sleep Res. 2020, 29. [Google Scholar] [CrossRef]
- Xie, J.; Hu, K.; Zhu, M.; Guo, Y. Bioacoustic signal classification in continuous recordings: Syllable-segmentation vs sliding-window. Expert Syst. Appl. 2020, 152, 113390. [Google Scholar] [CrossRef]
- Dumoulin, V.; Visin, F. A Guide to Convolution Arithmetic for Deep Learning. arXiv 2016, arXiv:stat.ML/1603.07285. [Google Scholar]
- Zheng, X.; Yin, X.; Shao, X.; Li, Y.; Yu, X. Collaborative Sleep Electroencephalogram Data Analysis Based on Improved Empirical Mode Decomposition and Clustering Algorithm. Complexity 2020, 2020, 1496973. [Google Scholar] [CrossRef]
- Abdulla, S.; Diykh, M.; Laft, R.L.; Saleh, K.; Deo, R.C. Sleep EEG signal analysis based on correlation graph similarity coupled with an ensemble extreme machine learning algorithm. Expert Syst. Appl. 2019, 138, 112790. [Google Scholar] [CrossRef]
- Yildirim, O.; Baloglu, U.; Acharya, U.R. A Deep Learning Model for Automated Sleep Stages Classification Using PSG Signals. Int. J. Environ. Res. Public Health 2019, 16, 599. [Google Scholar] [CrossRef]
- Duan, L.; Li, M.; Wang, C.; Qiao, Y.; Wang, Z.; Sha, S.; Li, M. A Novel Sleep Staging Network Based on Data Adaptation and Multimodal Fusion. Front. Hum. Neurosci. 2021, 15, 727139. [Google Scholar] [CrossRef]
- Phan, H.; Chén, O.Y.; Koch, P.; Lu, Z.; McLoughlin, I.; Mertins, A.; De Vos, M. Towards More Accurate Automatic Sleep Staging via Deep Transfer Learning. IEEE Trans. Biomed. Eng. 2021, 68, 1787–1798. [Google Scholar] [CrossRef] [PubMed]
- Lan, K.; Chang, D.; Kuo, C.; Wei, M.; Li, Y.; Shaw, F.; Liang, S. Using Off-the-Shelf Lossy Compression for Wireless Home Sleep Staging. J. Neurosci. Methods 2015, 246, 142–152. [Google Scholar] [CrossRef] [PubMed]
- Wong, S.C.; Gatt, A.; Stamatescu, V.; McDonnell, M.D. Understanding Data Augmentation for Classification: When to Warp? In Proceedings of the 2016 International Conference on Digital Image Computing: Techniques and Applications (DICTA), Gold Coast, QLD, Australia, 30 November–2 December 2016; pp. 1–6. [Google Scholar]
- Krithikadatta, J. Normal Distribution. J. Conserv. Dent. JCD 2014, 17, 96–97. [Google Scholar] [CrossRef] [PubMed]
- Arslan, M.; Guzel, M.; Demirci, M.; Ozdemir, S. SMOTE and Gaussian Noise Based Sensor Data Augmentation. In Proceedings of the 2019 4th International Conference on Computer Science and Engineering (UBMK), Samsun, Turkey, 11–15 September 2019; pp. 1–5. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Luong, M.; Pham, H.; Manning, C. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Kemp, B.; Zwinderman, A.H.; Tuk, B.; Kamphuisen, H.A.C.; Oberye, J.J.L. Analysis of a sleep-dependent neuronal feedback loop: The slow-wave microcontinuity of the EEG. IEEE Trans. Biomed. Eng. 2000, 47, 1185–1194. [Google Scholar] [CrossRef]
- Goldberger, A.; Amaral, L.; Glass, L.; Hausdorff, J.; Ivanov, P.; Mark, R.; Mietus, J.; Moody, G.; Peng, C.; Stanley, H. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the ICLR ’15, 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Zhou, M.; Duan, N.; Liu, S.; Shum, H. Progress in Neural NLP: Modeling, Learning, and Reasoning. Engineering 2020, 6, 275–290. [Google Scholar] [CrossRef]
- Chen, H.; Li, C.; Li, X.; Rahaman, M.M.; Hu, W.; Li, Y.; Liu, W.; Sun, C.; Sun, H.; Huang, X.; et al. IL-MCAM: An interactive learning and multi-channel attention mechanism-based weakly supervised colorectal histopathology image classification approach. Comput. Biol. Med. 2022, 143, 105265. [Google Scholar] [CrossRef]
- Hu, W.; Chen, H.; Liu, W.; Li, X.; Sun, H.; Huang, X.; Grzegorzek, M.; Li, C. A comparative study of gastric histopathology sub-size image classification: From linear regression to visual transformer. Front. Med. 2022, 9. [Google Scholar] [CrossRef] [PubMed]
- Augustinov, G.; Nisar, M.A.; Li, F.; Tabatabaei, A.; Grzegorzek, M.; Sohrabi, K.; Fudickar, S. Transformer-Based Recognition of Activities of Daily Living from Wearable Sensor Data. In Proceedings of the iWOAR ’22, 7th International Workshop on Sensor-based Activity Recognition and Artificial Intelligence, Rostock, Germany, 19–20 September 2022. [Google Scholar] [CrossRef]
- Zhang, M.; Qiu, L.; Chen, Y.; Yang, S.; Zhang, Z.; Wang, L. A Conv -Transformer network for heart rate estimation using ballistocardiographic signals. Biomed. Signal Process. Control 2023, 80, 104302. [Google Scholar] [CrossRef]
- Geethanjali1, N.; Prasannakumari, G.T.; Usha Rani, M. Evaluating Adaboost and Bagging Methods for Time Series Forecasting EEG Dataset. Int. J. Recent Technol. Eng. IJRTE 2019, 8, 965–968. [Google Scholar]
- Nisar, M.A.; Shirahama, K.; Li, F.; Huang, X.; Grzegorzek, M. Rank Pooling Approach for Wearable Sensor-Based ADLs Recognition. Sensors 2020, 20, 3463. [Google Scholar] [CrossRef]
- Wang, J.; Tang, S. Time series classification based on arima and adaboost. MATEC Web Conf. 2020, 309, 03024. [Google Scholar] [CrossRef]
- Mousavi, S.; Afghah, F.; Acharya, U.R. HAN-ECG: An interpretable atrial fibrillation detection model using hierarchical attention networks. Comput. Biol. Med. 2020, 127, 104057. [Google Scholar] [CrossRef] [PubMed]
- Song, H.; Rajan, D.; Thiagarajan, J.J.; Spanias, A. Attend and diagnose: Clinical time series analysis using attention models. In Proceedings of the 32nd AAAI Conference on Artificial Intelligence, AAAI 2018, New Orleans, LA, USA, 2–7 February 2018; pp. 4091–4098. [Google Scholar]
- Du, S.; Li, T.; Yang, Y.; Horng, S. Multivariate time series forecasting via attention-based encoder–decoder framework. Neurocomputing 2020, 388, 269–279. [Google Scholar] [CrossRef]
- Zhang, X.; Liang, X.; Zhiyuli, A.; Zhang, S.; Xu, R.; Wu, B. AT-LSTM: An Attention-based LSTM Model for Financial Time Series Prediction. IOP Conf. Ser. Mater. Sci. Eng. 2019, 569, 052037. [Google Scholar] [CrossRef]
- Rahman, M.M.; Bhuiyan, M.I.H.; Hassan, A.R. Sleep stage classification using single-channel EOG. Comput. Biol. Med. 2018, 102, 211–220. [Google Scholar] [CrossRef]
- Hassan, A.R.; Subasi, A. A decision support system for automated identification of sleep stages from single-channel EEG signals. Knowl.-Based Syst. 2017, 128, 115–124. [Google Scholar] [CrossRef]
- Hassan, A.R.; Bhuiyan, M.I.H. Automatic sleep scoring using statistical features in the EMD domain and ensemble methods. Biocybern. Biomed. Eng. 2016, 36, 248–255. [Google Scholar] [CrossRef]
- Hassan, A.R.; Bhuiyan, M.I.H. An automated method for sleep staging from EEG signals using normal inverse Gaussian parameters and adaptive boosting. Neurocomputing 2017, 219, 76–87. [Google Scholar] [CrossRef]
- Alickovic, E.; Subasi, A. Ensemble SVM Method for Automatic Sleep Stage Classification. IEEE Trans. Instrum. Meas. 2018, 67, 1258–1265. [Google Scholar] [CrossRef]
- Jiang, D.; Lu, Y.; Ma, Y.; Wang, Y. Robust sleep stage classification with single-channel EEG signals using multimodal decomposition and HMM-based refinement. Expert Syst. Appl. 2019, 121, 188–203. [Google Scholar] [CrossRef]
- Lu, G.; Chen, G.; Shang, W.; Xie, Z. Automated detection of dynamical change in EEG signals based on a new rhythm measure. Artif. Intell. Med. 2020, 107, 101920. [Google Scholar] [CrossRef]
- Santaji, S.; Desai, V. Analysis of EEG Signal to Classify Sleep Stages Using Machine Learning. Sleep Vigil. 2020, 4, 145–152. [Google Scholar] [CrossRef]
- Zhou, J.; Wang, G.; Liu, J.; Wu, D.; Xu, W.; Wang, Z.; Ye, J.; Xia, M.; Hu, Y.; Tian, Y. Automatic Sleep Stage Classification With Single Channel EEG Signal Based on Two-Layer Stacked Ensemble Model. IEEE Access 2020, 8, 57283–57297. [Google Scholar] [CrossRef]
- Taran, S.; Sharma, P.C.; Bajaj, V. Automatic sleep stages classification using optimize flexible analytic wavelet transform. Knowl.-Based Syst. 2020, 192, 105367. [Google Scholar] [CrossRef]
- Irshad, M.T.; Nisar, M.A.; Huang, X.; Hartz, J.; Flak, O.; Li, F.; Gouverneur, P.; Piet, A.; Oltmanns, K.M.; Grzegorzek, M. SenseHunger: Machine Learning Approach to Hunger Detection Using Wearable Sensors. Sensors 2022, 22, 7711. [Google Scholar] [CrossRef]
- Sharma, M.; Patel, V.; Acharya, U.R. Automated identification of insomnia using optimal bi-orthogonal wavelet transform technique with single-channel EEG signals. Knowl.-Based Syst. 2021, 224, 107078. [Google Scholar] [CrossRef]
- Li, D.; Ruan, Y.; Zheng, F.; Su, Y.; Lin, Q. Fast Sleep Stage Classification Using Cascaded Support Vector Machines with Single-Channel EEG Signals. Sensors 2022, 22, 9914. [Google Scholar] [CrossRef]
- Li, C.; Qi, Y.; Ding, X.; Zhao, J.; Sang, T.; Lee, M. A Deep Learning Method Approach for Sleep Stage Classification with EEG Spectrogram. Int. J. Environ. Res. Public Health 2022, 19, 6322. [Google Scholar] [CrossRef] [PubMed]
- ElMoaqet, H.; Eid, M.; Ryalat, M.; Penzel, T. A Deep Transfer Learning Framework for Sleep Stage Classification with Single-Channel EEG Signals. Sensors 2022, 22, 8826. [Google Scholar] [CrossRef]
- Barroso-García, V.; Gutiérrez-Tobal, G.C.; Gozal, D.; Vaquerizo-Villar, F.; Álvarez, D.; del Campo, F.; Kheirandish-Gozal, L.; Hornero, R. Wavelet Analysis of Overnight Airflow to Detect Obstructive Sleep Apnea in Children. Sensors 2021, 21, 1491. [Google Scholar] [CrossRef] [PubMed]
- Supratak, A.; Dong, H.; Wu, C.; Guo, Y. DeepSleepNet: A Model for Automatic Sleep Stage Scoring Based on Raw Single-Channel EEG. IEEE Trans. Neural Syst. Rehabil. Eng. 2017, 25, 1998–2008. [Google Scholar] [CrossRef]
- Phan, H.; Andreotti, F.; Cooray, N.; Chén, O.Y.; De Vos, M. SeqSleepNet: End-to-End Hierarchical Recurrent Neural Network for Sequence-to-Sequence Automatic Sleep Staging. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 400–410. [Google Scholar] [CrossRef]
- Zhu, T.; Luo, W.; Yu, F. Convolution-and Attention-Based Neural Network for Automated Sleep Stage Classification. Int. J. Environ. Res. Public Health 2020, 17, 4152. [Google Scholar] [CrossRef] [PubMed]
- Längkvist, M.; Loutfi, A. A Deep Learning Approach with an Attention Mechanism for Automatic Sleep Stage Classification. arXiv 2018, arXiv:abs/1805.05036. [Google Scholar]
- Yuan, Y.; Jia, K.; Ma, F.; Xun, G.; Wang, Y.; Su, L.; Zhang, A. A hybrid self-attention deep learning framework for multivariate sleep stage classification. BMC Bioinform. 2019, 20, 586. [Google Scholar] [CrossRef]
- Nasiri, S.; Clifford, G. Attentive Adversarial Network for Large-Scale Sleep Staging. Mach. Learn. Healthc. 2020, 126, 1–21. [Google Scholar]
- Casal, R.; Di Persia, L.E.; Schlotthauer, G. Temporal convolutional networks and transformers for classifying the sleep stage in awake or asleep using pulse oximetry signals. J. Comput. Sci. 2022, 59, 101544. [Google Scholar] [CrossRef]
- Dehkordi, P.; Garde, A.; Karlen, W.; Wensley, D.; Ansermino, J.M.; Dumont, G.A. Sleep Stage Classification in Children Using Photoplethysmogram Pulse Rate Variability. Comput. Cardiol. 2014, 2014, 297–300. [Google Scholar]
- Awais, M.; Long, X.; Yin, B.; Abbasi, S.; Akbarzadeh, S.; Lu, C.; Wang, X.; Wang, L.; Zhang, J.; Dudink, J.; et al. A Hybrid DCNN-SVM Model for Classifying Neonatal Sleep and Wake States Based on Facial Expressions in Video. IEEE J. Biomed. Health Inform. 2021, 25, 1441–1449. [Google Scholar] [CrossRef] [PubMed]
- Lee, W.H.; Kim, S.H.; Na, J.Y.; Lim, Y.H.; Cho, S.H.; Cho, S.H.; Park, H.K. Non-contact Sleep/Wake Monitoring Using Impulse-Radio Ultrawideband Radar in Neonates. Front. Pediatr. 2021, 9, 782623. [Google Scholar] [CrossRef]
- de Goederen, R.; Pu, S.; Silos Viu, M.; Doan, D.; Overeem, S.; Serdijn, W.; Joosten, K.; Long, X.; Dudink, J. Radar-based Sleep Stage Classification in Children Undergoing Polysomnography: A Pilot-study. Sleep Med. 2021, 82, 1–8. [Google Scholar] [CrossRef]
- Jeon, Y.; Kim, S.; Choi, H.S.; Chung, Y.G.; Choi, S.A.; Kim, H.; Yoon, S.; Hwang, H.; Kim, K.J. Pediatric Sleep Stage Classification Using Multi-Domain Hybrid Neural Networks. IEEE Access 2019, 7, 96495–96505. [Google Scholar] [CrossRef]
- Zhang, J.; Li, C.; Kosov, S.; Grzegorzek, M.; Shirahama, K.; Jiang, T.; Sun, C.; Li, Z.; Li, H. LCU-Net: A Novel Low-cost U-Net for Environmental Microorganism Image Segmentation. Pattern Recognit. 2021, 115, 107885. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Krishnan, D.; Taylor, G.W.; Fergus, R. Deconvolutional networks. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 2528–2535. [Google Scholar]
- Likhomanenko, T.; Xu, Q.; Collobert, R.; Synnaeve, G.; Rogozhnikov, A. CAPE: Encoding Relative Positions with Continuous Augmented Positional Embeddings. arXiv 2021, arXiv:cs.LG/2106.03143. [Google Scholar]
- Liu, F.; Ren, X.; Zhang, Z.; Sun, X.; Zou, Y. Rethinking Residual Connection with Layer Normalization. In Proceedings of the 28th International Conference on Computational Linguistics, Barcelona, Spain (Online), 8–13 December 2020; pp. 3586–3598. [Google Scholar]
- Ambu. Ambu Neuroline Sensors. 2020. Available online: https://www.ambu.de/neurologie (accessed on 18 February 2023).
- Philips. Philips Sleepware G3. 2017. Available online: https://www.philips.com.au/healthcare/product/HC1082462/sleepware-g3-sleep-diagnostic-software (accessed on 18 February 2023).
- Shekar, B.H.; Dagnew, G. Grid Search-Based Hyperparameter Tuning and Classification of Microarray Cancer Data. In Proceedings of the 2019 Second International Conference on Advanced Computational and Communication Paradigms (ICACCP), Gangtok, India, 25–28 February 2019; pp. 1–8. [Google Scholar]
- Al-Qerem, A.; Kharbat, F.; Nashwan, S.; Ashraf, S.; Blaou, K. General Model for Best Feature Extraction of EEG Using Discrete Wavelet Transform Wavelet Family and Differential Evolution. Int. J. Distrib. Sens. Netw. 2020, 16, 1550147720911009. [Google Scholar] [CrossRef]
- Aboalayon, K.A.I.; Faezipour, M.; Almuhammadi, W.S.; Moslehpour, S. Sleep Stage Classification Using EEG Signal Analysis: A Comprehensive Survey and New Investigation. Entropy 2016, 18, 272. [Google Scholar] [CrossRef]
- Eldele, E.; Chen, Z.; Liu, C.; Wu, M.; Kwoh, C.; Li, X.; Guan, C. An Attention-Based Deep Learning Approach for Sleep Stage Classification With Single-Channel EEG. IEEE Trans. Neural Syst. Rehabil. Eng. 2021, 29, 809–818. [Google Scholar] [CrossRef] [PubMed]
- McInnes, L.; Healy, J.; Saul, N.; Großberger, L. UMAP: Uniform Manifold Approximation and Projection. J. Open Source Softw. 2018, 3, 861. [Google Scholar] [CrossRef]
- Michielli, N.; Acharya, U.R.; Molinari, F. Cascaded LSTM Recurrent Neural Network for Automated Sleep Stage Classification Using Single-channel EEG Signals. Comput. Biol. Med. 2019, 106, 71–81. [Google Scholar] [CrossRef] [PubMed]
- Tsinalis, O.; Matthews, P.M.; Guo, Y. Automatic Sleep Stage Scoring Using Time-Frequency Analysis and Stacked Sparse Autoencoders. Ann. Biomed. Eng. 2015, 44, 1587–1597. [Google Scholar] [CrossRef] [PubMed]
- Phan, H.; Andreotti, F.; Cooray, N.; Chén, O.Y.; De Vos, M. Joint Classification and Prediction CNN Framework for Automatic Sleep Stage Classification. IEEE Trans. Biomed. Eng. 2019, 66, 1285–1296. [Google Scholar] [CrossRef] [PubMed]
- Zhu, T.; Luo, W.; Yu, F. Multi-Branch Convolutional Neural Network for Automatic Sleep Stage Classification with Embedded Stage Refinement and Residual Attention Channel Fusion. Sensors 2020, 20, 6592. [Google Scholar] [CrossRef] [PubMed]
- Wang, H.; Lu, C.; Zhang, Q.; Hu, Z.; Yuan, X.; Zhang, P.; Liu, W. Sleep Staging Based on Multi Scale Dual Attention Network. arXiv 2021, arXiv:cs.LG/2107.08442. [Google Scholar] [CrossRef]
- An, P.; Yuan, Z.; Zhao, J.; Jiang, X.; Du, B. An Effective Multi-model Fusion Method for EEG-based Sleep Stage Classification. Knowl.-Based Syst. 2021, 219, 106890. [Google Scholar] [CrossRef]
- Chrysos, G.; Kossaifi, J.; Zafeiriou, S. RoCGAN: Robust Conditional GAN. Int. J. Comput. Vis. 2020, 128, 2665–2683. [Google Scholar] [CrossRef]
- Zheng, Y.; Li, C.; Zhou, X.; Chen, H.; Xu, H.; Li, Y.; Zhang, H.; Li, X.; Sun, H.; Huang, X.; et al. Application of transfer learning and ensemble learning in image-level classification for breast histopathology. Intell. Med. 2022. [Google Scholar] [CrossRef]
- Li, F.; Shirahama, K.; Nisar, M.A.; Huang, X.; Grzegorzek, M. Deep Transfer Learning for Time Series Data Based on Sensor Modality Classification. Sensors 2020, 20, 4271. [Google Scholar] [CrossRef]
- Dai, Y.; Zhang, J.; Yuan, S.; Xu, Z. A Two-Stage Multi-task Learning-Based Method for Selective Unsupervised Domain Adaptation. In Proceedings of the International Conference on Data Mining Workshops (ICDMW), Beijing, China, 8–11 November 2019; pp. 863–868. [Google Scholar]
- Irshad, M.T.; Nisar, M.A.; Gouverneur, P.; Rapp, M.; Grzegorzek, M. AI Approaches towards Prechtl’s Assessment of General Movements: A systematic literature review. Sensors 2020, 20, 5321. [Google Scholar] [CrossRef]













| Layer Number | Layer Type | Parameter | Activation Function | Value |
|---|---|---|---|---|
| 1 | conv. | # kernels Sliding stride size Kernel size | LeakyRuLU same-padding - | 16 (1, 1) (4, 1) |
| 2 | BatchNormalization | - | LeakyReLU | - |
| 3 | conv. | # kernels Sliding stride size Kernel size | LeakyRuLU same-padding - | 16 (1, 1) (3, 1) |
| 4 | max-pooling | pooling size pooling stride size | - - | (3, 3) (1, 1) |
| 5 | conv. | # kernels Sliding stride size Kernel size | LeakyRuLU same-padding - | 32 (1, 1) (2, 1) |
| 6 | max-pooling | pooling size pooling stride size | - - | (3, 3) (2, 1) |
| 7 | conv. | # kernels Sliding stride size Kernel size | LeakyRuLU same-padding - | 64 (1, 1) (4, 1) |
| 8 | max-pooling | pooling size pooling stride size | - - | (3, 3) (2, 1) |
| 9 | conv. | # kernels Sliding stride size Kernel size | LeakyRuLU same-padding - | 128 (1, 1) (5, 1) |
| 10, 11 | deconv. | # kernels Sliding stride size Kernel size | LeakyRuLU valid-padding - | 16, 44 (1, 1), (1, 1) (1, 1), (3, 1) |
| 12 | GAP | - | - | - |
| 13 | positional embedding | - | - | - |
| 14 | attention mechanism | num-head dropout rate attention-axes Q,K,V | - - - - | H = 15 0.5 None T x HD |
| 15 | add & normalization | - | - | - |
| 16 | fully-connected | # neurons | ReLU | 440 |
| 17 | add & normalization | - | - | - |
| 18 | fully-connected | # neurons | ReLU | 800 |
| 19 | Dropout | drop rate | - | 0.3 |
| 20 | softmax | # neurons | logistic | 5 |
| Subject | Age | Sex | Night (Lights Off) | Subject | Age | Sex | Night (Lights Off) |
|---|---|---|---|---|---|---|---|
| P 1 | 6 years old | female | 20:43:27 | P 13 | 4 years old | male | 19:53:15 |
| P 2 | 5 years old | female | 20:54:01 | P 14 | 10 years old | female | 22:13:41 |
| P 3 | 6 years old | male | 22:07:31 | P 15 | 8 years old | male | 21:52:36 |
| P 4 | 7 years old | male | 21:07:10 | P 16 | 5 years old | female | 19:36:53 |
| P 5 | 10 years old | female | 22:29:08 | P 17 | 10 years old | female | 21:32:44 |
| P 6 | 8 years old | female | 21:42:40 | P 18 | 6 years old | male | 20:30:44 |
| P 7 | 9 years old | female | 20:51:50 | P 19 | 5 years old | female | 20:12:13 |
| P 8 | 7 years old | male | 21:34:06 | P 20 | 6 years old | female | 21:36:07 |
| P 9 | 5 years old | male | 21:01:43 | P 21 | 7 years old | female | 20:42:59 |
| P 10 | 4 years old | female | 20:55:15 | P 24 | 7 years old | female | 20:48:00 |
| P 11 | 5 years old | female | 22:19:57 |
| N1 | N2 | N3 | REM | W | |
|---|---|---|---|---|---|
| Original | 1113 (5.76) | 6805 (35.24) | 4743 (24.56) | 3288 (17.03) | 3361 (17.41) |
| = 0, = 0.4 | 2226 (10.90) | 6805 (33.32) | 4743 (23.22) | 3288 (16.10) | 3361 (16.46) |
| = 0, = 0.2, 0.4 | 3339 (15.50) | 6805 (31.60) | 4743 (22.02) | 3288 (15.27) | 3361 (15.61) |
| = 0, = 0.2, 0.4, 0.6 | 4452 (19.65) | 6805 (30.05) | 4743 (20.94) | 3288 (14.52) | 3361 (14.84) |
| Study/Subject | Age | Sex | Placebo Night (Lights Off) | Temazepam Night (Lights Off) |
|---|---|---|---|---|
| SC 1 | 33 years old | female | 22:44 | 22:15 |
| SC 5 | 28 years old | female | 1:22 | 0:35 |
| SC 7 | 30 years old | female | 0:36 | 0:41 |
| SC 10 | 26 years old | male | 22:59 | 23:07 |
| SC 20 | 51 years old | female | 23:10 | 23:15 |
| SC 21 | 51 years old | female | 23:28 | 23:59 |
| SC 26 | 51 years old | female | 23:39 | 0:20 |
| SC 27 | 54 years old | female | 23:41 | 22:58 |
| SC 31 | 54 years old | male | 23:44 | 23:14 |
| SC 51 | 70 years old | male | 23:10 | 0:03 |
| - | - | - | Placebo Night (Lights Off) | Temazepam Night (Lights Off) |
| ST 4 | 18 years old | female | 23:53 | 22:37 |
| ST 5 | 32 years old | female | 23:23 | 23:34 |
| ST 10 | 20 years old | female | 23:21 | 23:28 |
| ST 12 | 21 years old | male | 23:46 | 23:56 |
| ST 15 | 66 years old | female | 23:42 | 23:33 |
| ST 16 | 79 years old | female | 23:21 | 23:18 |
| ST 18 | 53 years old | female | 23:38 | 23:24 |
| ST 19 | 28 years old | female | 23:22 | 23:44 |
| ST 20 | 24 years old | male | 23:47 | 0:01 |
| ST 21 | 34 years old | female | 23:44 | 23:10 |
| S1 | S2 | S3 | S4 | R | WA | |
|---|---|---|---|---|---|---|
| Original | 3203 (5.58) | 13,499 (23.52) | 2444 (4.26) | 2201 (3.83) | 5551 (9.67) | 30,498 (53.14) |
| = 0, = 0.4 | 6406 (10.57) | 13,499 (22.28) | 2444 (4.03) | 2201 (3.63) | 5551 (9.16) | 30,498 (50.33) |
| Layer Number | Layer Type | Parameter | Activation Function | Value |
|---|---|---|---|---|
| 1 | positional embedding | - | - | - |
| 2 | LSTM cell | # units dropout recurrent_dropout | tanh - - | 110 0.5 0.3 |
| 3 | attention mechanism | - | - | - |
| 4 | fully-connected | # neurons | ReLU | 380 |
| 5 | dropout | drop rate | - | 0.2 |
| 6 | softmax | # neurons | logistic | 5 |
| 50 Hz | MF1 for Each Class | ||||||
|---|---|---|---|---|---|---|---|
| ACC | MF1 | N1 | N2 | N3 | REM | W | |
| DWT + SVM without GNDA | 67.59 | 55.52 | 31.59 | 64.20 | 66.92 | 57.14 | 57.75 |
| GNDA(0.4) + DWT + SVM | 67.81 | 52.05 | 29.97 | 62.54 | 64.69 | 55.49 | 47.56 |
| GNDA(0.2, 0.4) + DWT + SVM | 71.12 | 56.44 | 37.19 | 67.54 | 60.22 | 58.75 | 58.50 |
| GNDA(0.2, 0.4, 0.6) + DWT + SVM | 71.97 | 59.45 | 44.48 | 69.36 | 72.11 | 60.98 | 50.32 |
| DCNN without GNDA | 77.13 | 63.02 | 18.79 | 79.88 | 81.79 | 61.47 | 73.17 |
| GNDA(0.4) + DCNN | 80.01 | 66.88 | 25.47 | 82.09 | 82.19 | 69.56 | 75.09 |
| GNDA(0.2, 0.4) + DCNN | 80.34 | 67.35 | 26.43 | 81.84 | 82.29 | 72.63 | 73.53 |
| GNDA(0.2, 0.4, 0.6) + DCNN | 79.52 | 66.48 | 23.92 | 80.23 | 83.66 | 71.62 | 72.96 |
| RNN-based attention without GNDA | 71.48 | 65.27 | 29.97 | 77.67 | 80.09 | 69.68 | 68.94 |
| GNDA(0.4) + RNN-based attention | 73.98 | 66.47 | 32.58 | 78.39 | 81.80 | 71.59 | 67.99 |
| GNDA(0.2, 0.4) + RNN-based attention | 71.57 | 63.99 | 31.69 | 77.98 | 79.77 | 67.43 | 63.08 |
| GNDA(0.2, 0.4, 0.6) + RNN-based attention | 74.68 | 68.24 | 33.34 | 80.17 | 81.62 | 71.87 | 74.20 |
| Self-attention without GNDA | 78.25 | 70.83 | 41.25 | 82.00 | 84.27 | 75.89 | 70.74 |
| GNDA(0.4) + Self-attention | 82.97 | 75.87 | 46.84 | 84.08 | 86.95 | 81.24 | 80.24 |
| GNDA(0.2, 0.4) + Self-attention | 84.45 | 77.75 | 47.88 | 85.97 | 88.05 | 83.00 | 83.85 |
| GNDA(0.2, 0.4, 0.6) + Self-attention | 82.67 | 75.87 | 46.14 | 85.00 | 86.29 | 79.40 | 82.52 |
| GNDA(0.4) + DCNN + Self-Attention | 87.37 | 85.22 | 67.15 | 87.00 | 90.87 | 89.26 | 91.82 |
| GNDA(0.2, 0.4) + DCNN + Self-Attention | 88.55 | 84.69 | 66.72 | 86.17 | 91.89 | 90.44 | 88.23 |
| GNDA(0.2, 0.4, 0.6) + DCNN + Self-Attention | 90.26 | 86.51 | 69.20 | 89.57 | 93.91 | 89.83 | 90.02 |
| Model | 50 Hz | MF1 for Each Class | |||||
|---|---|---|---|---|---|---|---|
| ACC | MF1 | N1 | N2 | N3 | REM | W | |
| DWT + SVM without GNDA | 67.01 | 53.79 | 26.75 | 60.20 | 62.00 | 50.07 | 69.93 |
| GNDA(0.4) + DWT + SVM | 68.92 | 52.97 | 27.15 | 61.13 | 60.49 | 48.04 | 68.04 |
| GNDA(0.2, 0.4) + DWT + SVM | 69.92 | 52.99 | 29.13 | 60.89 | 62.05 | 49.91 | 62.97 |
| GNDA(0.2, 0.4, 0.6) + DWT + SVM | 69.94 | 54.18 | 29.99 | 62.05 | 61.79 | 51.52 | 65.55 |
| DCNN without GNDA | 77.90 | 66.11 | 26.93 | 84.77 | 86.18 | 63.79 | 68.88 |
| GNDA(0.4) + DCNN | 80.67 | 71.39 | 32.78 | 85.12 | 88.26 | 70.68 | 83.08 |
| GNDA(0.2, 0.4) + DCNN | 86.02 | 75.88 | 36.03 | 86.17 | 89.21 | 80.57 | 87.42 |
| GNDA(0.2, 0.4, 0.6) + DCNN | 85.81 | 76.11 | 35.07 | 86.11 | 89.00 | 82.83 | 87.54 |
| RNN-based attention without GNDA | 71.03 | 64.51 | 28.57 | 76.18 | 80.91 | 68.23 | 68.04 |
| GNDA(0.4) + RNN-based attention | 70.44 | 63.06 | 29.67 | 77.26 | 78.66 | 65.76 | 63.95 |
| GNDA(0.2, 0.4) + RNN-based attention | 68.76 | 62.28 | 27.99 | 75.98 | 76.00 | 66.90 | 64.53 |
| GNDA(0.2, 0.4, 0.6) + RNN-based attention | 70.56 | 66.47 | 30.71 | 79.98 | 81.22 | 71.00 | 69.44 |
| Self-attention without GNDA | 77.29 | 68.27 | 39.69 | 80.01 | 83.25 | 74.20 | 67.20 |
| GNDA(0.4) + Self-attention | 80.67 | 73.88 | 43.57 | 83.55 | 86.29 | 77.41 | 78.58 |
| GNDA(0.2, 0.4) + Self-attention | 80.05 | 72.97 | 44.30 | 80.95 | 83.98 | 76.62 | 79.00 |
| GNDA(0.2, 0.4, 0.6) + Self-attention | 81.15 | 74.19 | 44.08 | 81.54 | 85.36 | 78.18 | 81.79 |
| GNDA(0.4) + DCNN + Self-Attention | 86.24 | 81.89 | 61.78 | 86.24 | 88.89 | 86.97 | 85.57 |
| GNDA(0.2, 0.4) + DCNN + Self-Attention | 88.06 | 83.18 | 65.34 | 84.77 | 89.09 | 90.16 | 86.54 |
| GNDA(0.2, 0.4, 0.6) + DCNN + Self-Attention | 88.56 | 83.57 | 66.05 | 85.42 | 90.71 | 87.45 | 88.22 |
| 50 Hz | MF1 for Each Class | ||||||
|---|---|---|---|---|---|---|---|
| ACC | MF1 | N1 | N2 | N3 | REM | W | |
| DWT + SVM without GNDA | 65.00 | 50.03 | 26.10 | 61.75 | 63.49 | 53.02 | 45.79 |
| GNDA(0.4) + DWT + SVM | 63.37 | 46.67 | 24.89 | 57.86 | 60.05 | 50.49 | 40.06 |
| GNDA(0.2, 0.4) + DWT + SVM | 66.62 | 50.28 | 30.49 | 60.57 | 63.25 | 51.70 | 45.39 |
| GNDA(0.2, 0.4, 0.6) + DWT + SVM | 68.07 | 52.88 | 35.34 | 62.19 | 64.86 | 55.57 | 46.44 |
| DCNN without GNDA | 74.73 | 59.49 | 16.30 | 77.54 | 80.69 | 56.30 | 66.62 |
| GNDA(0.4) + DCNN | 77.34 | 63.99 | 22.90 | 80.06 | 80.94 | 61.98 | 74.07 |
| GNDA(0.2, 0.4) + DCNN | 78.65 | 64.02 | 24.04 | 82.53 | 80.47 | 60.37 | 72.69 |
| GNDA(0.2, 0.4, 0.6) + DCNN | 76.54 | 62.70 | 21.94 | 80.50 | 80.40 | 63.01 | 67.65 |
| RNN-based attention without GNDA | 69.60 | 64.03 | 27.00 | 78.63 | 79.40 | 67.23 | 67.89 |
| GNDA(0.4) + RNN-based attention | 70.45 | 64.87 | 30.59 | 79.03 | 80.33 | 69.99 | 64.41 |
| GNDA(0.2, 0.4) + RNN-based attention | 69.03 | 60.51 | 28.43 | 76.35 | 78.00 | 64.33 | 55.44 |
| GNDA(0.2, 0.4, 0.6) + RNN-based attention | 71.28 | 66.36 | 29.58 | 80.04 | 79.21 | 70.46 | 72.51 |
| Self-attention without GNDA | 77.62 | 69.40 | 38.97 | 81.91 | 82.67 | 73.90 | 69.55 |
| GNDA(0.4) + Self-attention | 79.45 | 73.60 | 43.82 | 83.98 | 84.06 | 79.28 | 76.86 |
| GNDA(0.2, 0.4) + Self-attention | 83.06 | 75.24 | 45.00 | 83.97 | 86.59 | 81.29 | 79.35 |
| GNDA(0.2, 0.4, 0.6) + Self-attention | 82.00 | 74.32 | 44.66 | 82.69 | 84.37 | 77.14 | 82.74 |
| GNDA(0.4) + DCNN + Self-Attention | 85.07 | 83.24 | 65.83 | 85.26 | 88.40 | 88.14 | 88.57 |
| GNDA(0.2, 0.4) + DCNN + Self-Attention | 85.86 | 83.09 | 64.70 | 85.09 | 89.26 | 90.00 | 86.40 |
| GNDA(0.2, 0.4, 0.6) + DCNN + Self-Attention | 86.91 | 84.00 | 66.48 | 86.44 | 90.39 | 87.69 | 89.00 |
| AF1 | AACC | Average F1-Score of Each Sleep Stage | ||||||
|---|---|---|---|---|---|---|---|---|
| WA | S1 | S2 | S3 | S4 | R | |||
| 6-stage | 86.64 | 91.77 | 92.79 | 76.40 | 87.94 | 82.07 | 91.94 | 88.69 |
| 5-stage | 88.85 | 92.54 | 92.99 | 77.14 | 89.39 | (S3/S4: 93.16) | 91.57 | |
| 4-stage | 91.41 | 94.73 | 94.01 | (S1/S2: 90.29) | (S3/S4: 95.83) | 85.51 | ||
| 3-stage | 93.01 | 95.30 | 94.05 | (S1/S2/S3/S4: 98.47) | 86.51 | |||
| Study | Dataset & Subjects | Channel | Performance | |||
|---|---|---|---|---|---|---|
| Overall Accuracy (%) | ||||||
| 6-Stage | 5-Stage | 4-Stage | 3-Stage | |||
| TFA+SSAE [76] | Sleep-EDFX | Fpz-Cz | - | 82.00 | - | - |
| CNN+BiLSTM [52] | Sleep-EDFX | Fpz-Cz | - | 82.00 | - | - |
| DWT+MSPCA+RotSVM [40] | Sleep-EDFX | Pz-Oz | - | 91.10 | - | - |
| 1D-CNN [12] | Sleep-EDFX | Fpz-Cz +EOG | 89.54 | 90.98 | 92.33 | 94.34 |
| MT-CNN [77] | Sleep-EDFX | Fpz-Oz + EOG | - | 82.30 | - | - |
| CNN-Att [54] | Sleep-EDFX | Fpz-Cz | - | 93.7 | - | - |
| MB-CNN [78] | Sleep-EDFX | Fpz-Cz + Pz-Oz + EOG | - | 85.80 | - | - |
| MS-DAN [79] | Sleep-EDFX | Fpz-Cz | - | 90.35 | - | - |
| SVM+ OC-SVM [80] | Sleep-EDFX | Fpz-Cz + Pz-Oz | 93.00 | 93.40 | - | - |
| MRCNN+AFR+TCE [73] | Sleep-EDFX | Fpz-Cz | - | 85.6 | - | - |
| CNN+LSTM [13] | Sleep-EDFX | Fpz-Cz + Pz-Oz + EOG | - | 87.50 | - | - |
| Proposed method | Sleep-EDFX | Fpz-Cz + Pz-Oz + EOG | 85.75 | 88.50 | 89.81 | 92.52 |
| Proposed method | Sleep-EDFX | Pz-Oz | 88.24 | 90.51 | 91.02 | 92.22 |
| Proposed method | Sleep-EDFX | Fpz-Cz + Pz-Oz | 86.73 | 86.00 | 89.42 | 91.83 |
| Proposed method | Sleep-EDFX | Fpz-Cz + EOG | 86.40 | 88.99 | 91.30 | 93.86 |
| Proposed method | Sleep-EDFX | Fpz-Cz | 91.77 | 92.54 | 94.73 | 95.30 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, X.; Shirahama, K.; Irshad, M.T.; Nisar, M.A.; Piet, A.; Grzegorzek, M. Sleep Stage Classification in Children Using Self-Attention and Gaussian Noise Data Augmentation. Sensors 2023, 23, 3446. https://doi.org/10.3390/s23073446
Huang X, Shirahama K, Irshad MT, Nisar MA, Piet A, Grzegorzek M. Sleep Stage Classification in Children Using Self-Attention and Gaussian Noise Data Augmentation. Sensors. 2023; 23(7):3446. https://doi.org/10.3390/s23073446
Chicago/Turabian StyleHuang, Xinyu, Kimiaki Shirahama, Muhammad Tausif Irshad, Muhammad Adeel Nisar, Artur Piet, and Marcin Grzegorzek. 2023. "Sleep Stage Classification in Children Using Self-Attention and Gaussian Noise Data Augmentation" Sensors 23, no. 7: 3446. https://doi.org/10.3390/s23073446
APA StyleHuang, X., Shirahama, K., Irshad, M. T., Nisar, M. A., Piet, A., & Grzegorzek, M. (2023). Sleep Stage Classification in Children Using Self-Attention and Gaussian Noise Data Augmentation. Sensors, 23(7), 3446. https://doi.org/10.3390/s23073446