
Human-Aware Collaborative Robots in the Wild: Coping with Uncertainty in Activity Recognition
 ,
,  ,
,  and
and 
Abstract
1. Introduction
1.1. Importance of Human Activity Recognition for Human-Robot Collaboration
1.2. Research Question and Objectives
- Enhance Long Short-Term Memory (LSTM) networks by incorporating fuzzy logic to model human uncertainty (Fuzzy-LSTM), building upon the work of [20]: the goal is to improve the performance of LSTM networks by incorporating fuzzy logic to model human uncertainty. In this method, features are extracted from sensor data, which may be uncertain due to the ambiguity of human behaviour or noise in the sensors. These features are then fuzzified using Tilt and Motion linguistic variables. This fuzzification step allows the model to handle uncertain data, making it more robust. The fuzzified features are then used as input to the LSTM network during training. The goal of this approach is to improve the accuracy of the LSTM network in handling uncertain sensor data.
- Further extend Fuzzy-LSTM representing the sequence of activities through finite-state machines (FSM), thus leading to the Fuzzy State LSTM (FS-LSTM): the goal of this method is to enhance the predictability of human activity sequences by combining the strengths of FSM and fuzzy logic in an LSTM-based model. In this approach, an LSTM network is trained for each state within the FSM. The output of the LSTM network is then used to determine the possible transitions between states.
- Estimate human uncertainty by aggregating predicted scores of the LSTM into a crisp output through defuzzification: this proposed method aims to estimate the uncertainty of the LSTM classifier’s predictions by converting the classification scores into a crisp value through defuzzification. The classification scores are first converted into a fuzzy set to represent the degree of uncertainty in the predictions. Then, the fuzzy set is transformed into a crisp value to indicate the certainty of the classifier’s predictions. This process allows for quantifying the uncertainty of the predictions, which is not only used within the FS-LSTM method to accept or reject transitions between states, but can also be useful in our future work in HRC, where certainty is important.
1.3. Organization of the Article
2. Literature Review
3. Use Case and Data Collection
3.1. Use Case: The FEROX Project
3.2. Data Collection: FEROX Simulator and Synthetic Data
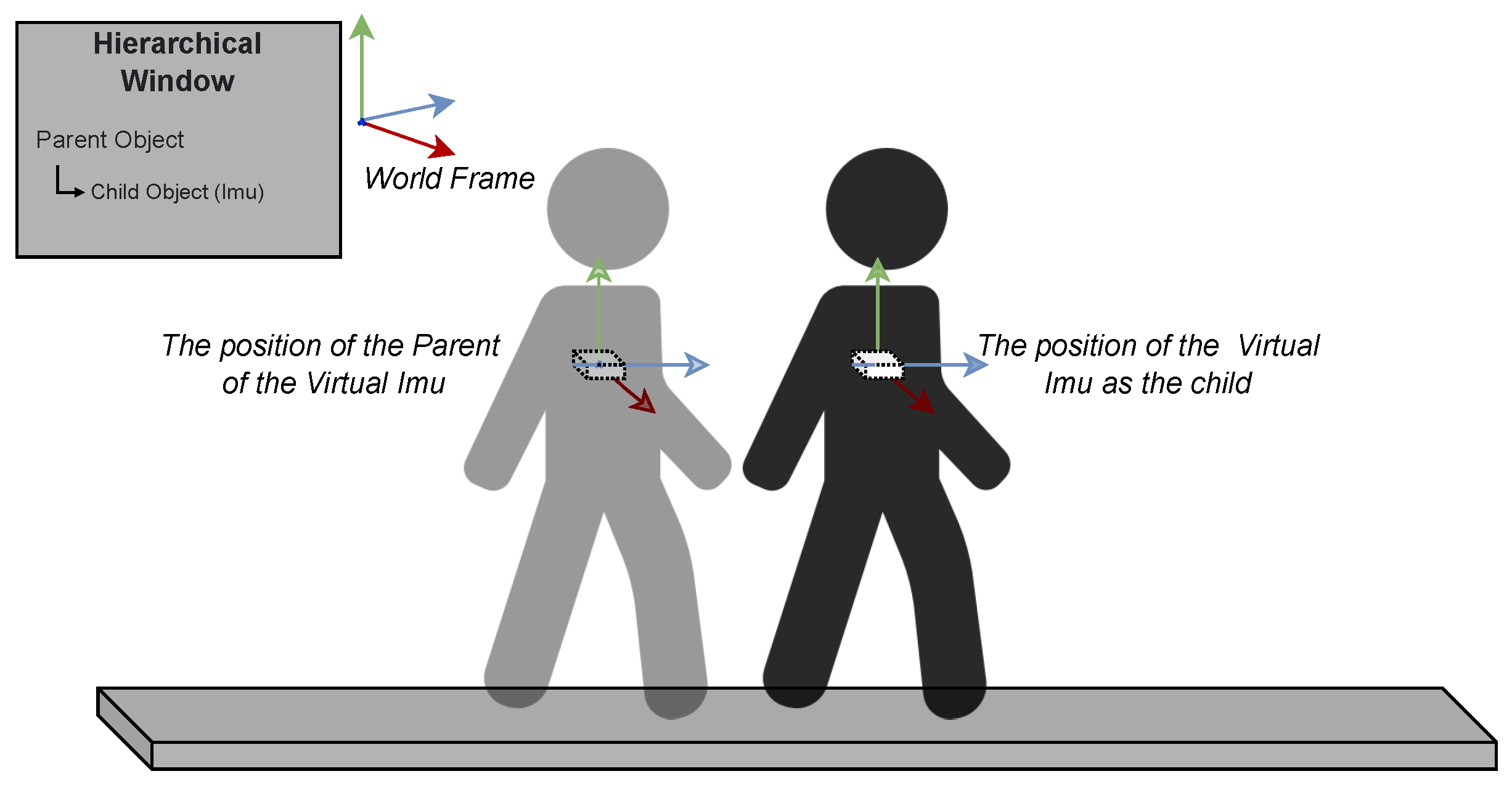
3.2.1. FEROX Simulator Development and Virtual Sensor Modelling
3.2.2. Data Preparation
3.2.3. Synthetic Data Validation
4. Fuzzy State Long-Short Term Memory (FS-LSTM)
4.1. Fuzzification of Features
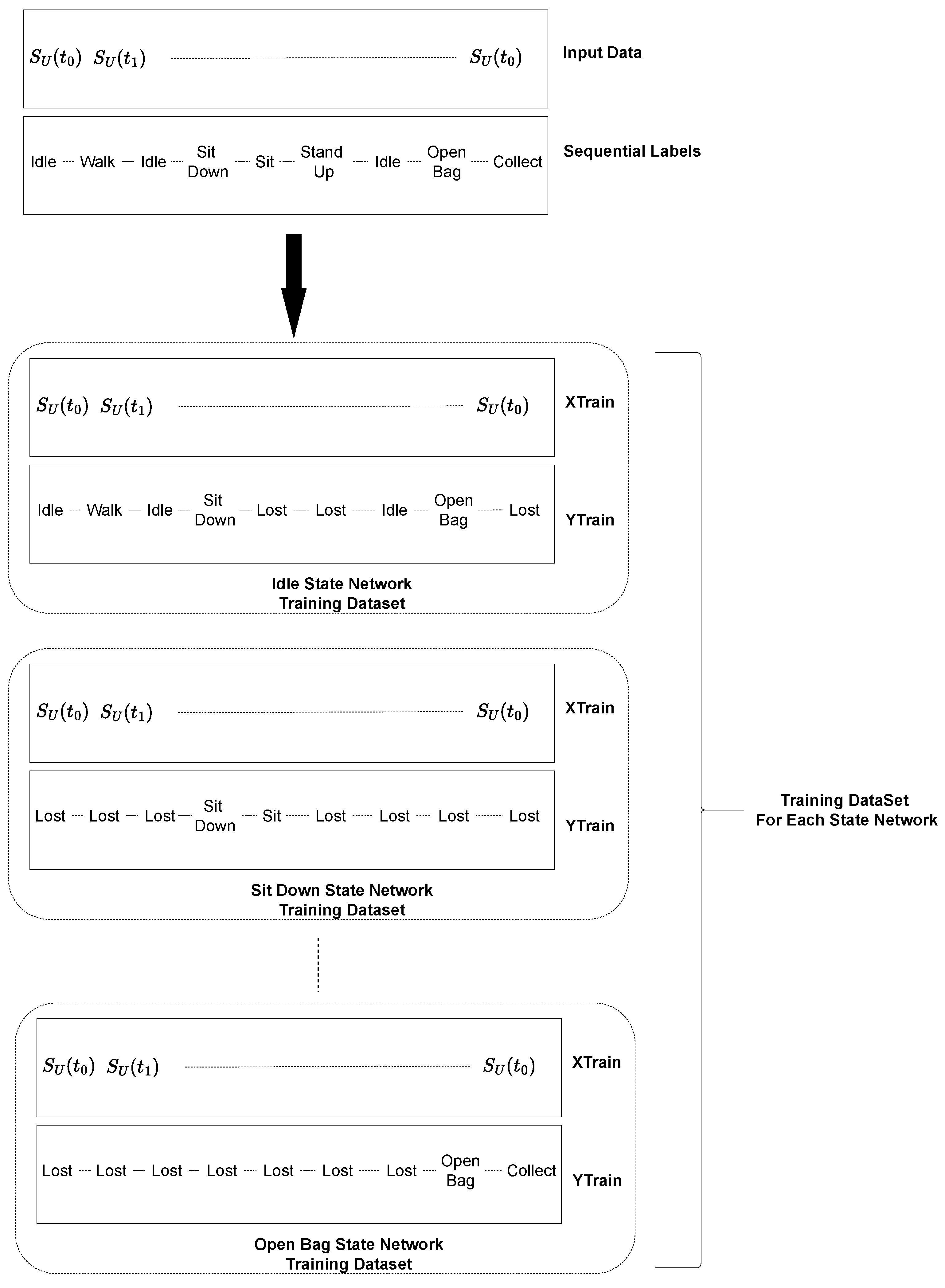
4.2. State Machine Learning
4.3. Coping with the Uncertainty through Defuzzification
- IF Idle is Low and Close Bag is Low and Lost is Low THEN Uncertainty is High
- IF Idle is Medium and Close Bag is Medium and Lost is Medium THEN Uncertainty is High
- IF Idle is High and Close Bag is High and Lost is High THEN Uncertainty is High
- IF Idle is High and Close Bag is Low and Lost is Low THEN Uncertainty is Low
- IF Idle is Low and Close Bag is High and Lost is Low THEN Uncertainty is Low
- IF Idle is Low and Close Bag is Low and Lost is High THEN Uncertainty is Low
- IF Idle is High and Close Bag is not Low and Lost is not Low THEN Uncertainty is High
- IF Idle is not Low and Close Bag is High and Lost is not Low THEN Uncertainty is High
- IF Idle is not Low and Close Bag is not Low and Lost is High THEN Uncertainty is High
5. Results and Discussion
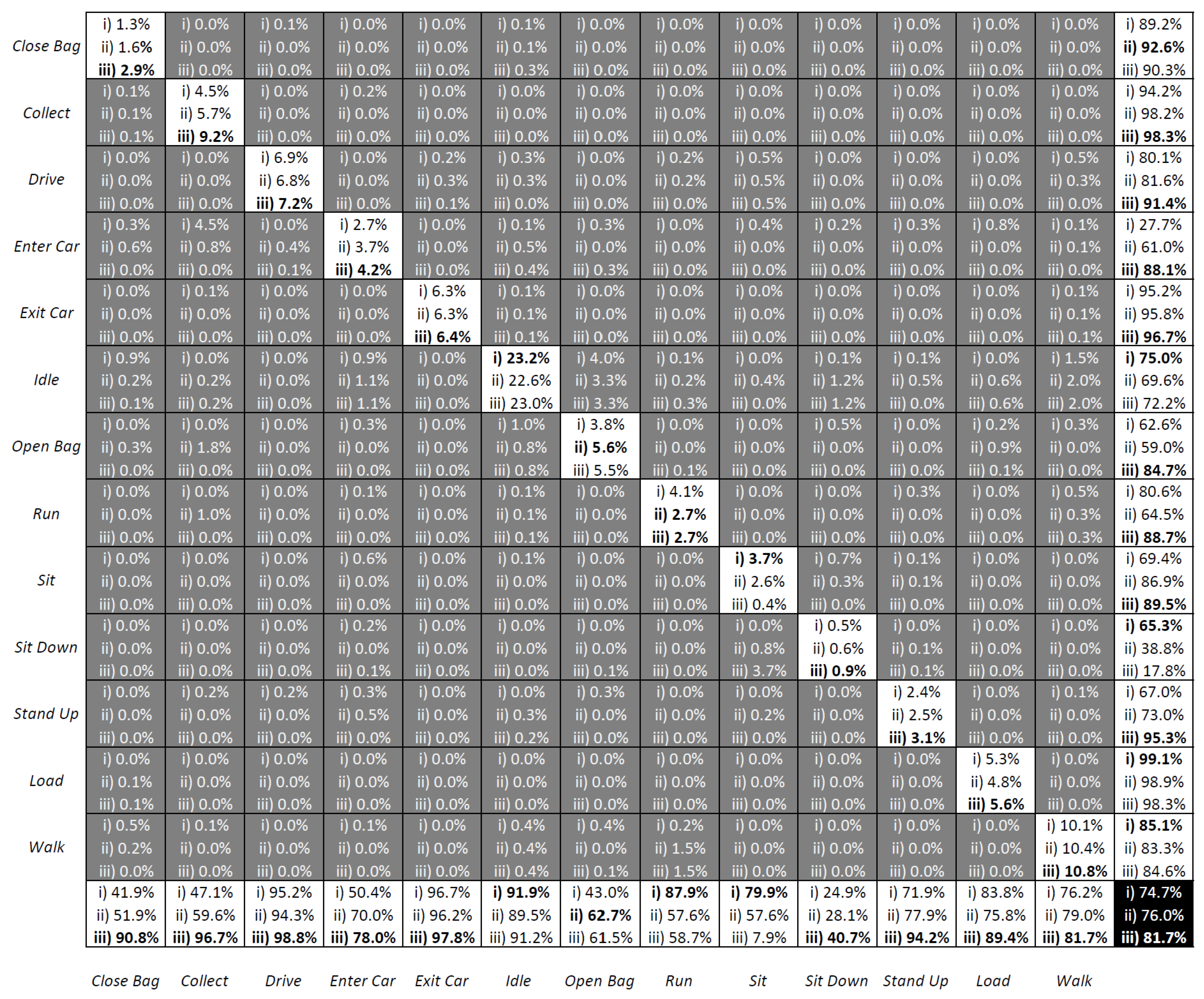
5.1. Benchmark of Activity Recognition Performance
5.2. Benchmark of Efficiency
5.3. Discussion
- Enhance Long Short-Term Memory (LSTM) networks by incorporating fuzzy logic to model human uncertainty (Fuzzy-LSTM): the objective of this research was to enhance the accuracy of LSTM networks by incorporating fuzzy logic to model human uncertainty. Even though the preliminary results, as shown in Figure 5, depicted an accuracy of 84.9% for recognizing four activities, such accuracy dropped to 23.3% when trying to recognize 13 different activities. By utilizing fuzzified Motion and Tilt features, the Fuzzy-LSTM model was capable to effectively handle uncertain data. The initial results of the study showed that Fuzzy-LSTM improved the accuracy of activity recognition by a significant margin, achieving 93.2% accuracy compared to the traditional LSTM model using raw sensor data.
- Extend the Fuzzy-LSTM approach by incorporating finite-state machines (FSM) to model activity sequences, resulting in the Fuzzy State LSTM (FS-LSTM) model: the primary objective of this research was to improve the predictability of human activity sequences by identifying possible transitions between states. While Fuzzy-LSTM achieved 93.2% accuracy under unconstrained GPU resources, approximately 3% more than FS-LSTM, it often resulted in infeasible transitions. However, when using constrained resources such as embedded systems or limited GPU resources, the FS-LSTM showed superior performance compared to Fuzzy-LSTM. As shown in Figure 14, FS-LSTM has a trade-off between accuracy and computational resources, but it offers significant benefits for long-term real-time outdoor applications.
- Develop a defuzzification-based method to estimate human uncertainty by aggregating predicted scores of the LSTM model: this proposed approach aimed to estimate the uncertainty associated with the LSTM classifier’s predictions through defuzzification. By waiting until the prediction became certain, the system could achieve an accuracy of 90.0%. This development is crucial to prevent the system from making wrong transitions between states before the model becomes certain, thereby improving the overall performance of the system. Although this study did not show the direct impact of this issue, it could significantly affect the high-level decision-making process for robots, where the system needs to consider the current human state. Any infeasible transitions could compromise the performance of the system, causing trust and safety issues.
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| HRC | Human Robot Collaboration |
| HAR | Human Activity Recognition |
| FS-LSTM | Fuzzy State-Long Short-Term Memory |
| Bi-LSTM | Bidirectional Long Short-Term Memory |
| SVM | Support Vector Machines |
| HMM | Hidden Markov Models |
| FSM | Finite State Machines |
| RNN | Recurrent Neural Networks |
| CNN | Convolutional Neural Networks |
| DNN | Deep Neural Networks |
| ANN | Artificial Neural Networks |
| DBMM | Dynamic Bayesian Mixture Model |
| IMU | Inertial Measurement Units |
| ROS | Robot Operating System |
| GPU | Graphics Processing Unit |
References
- Villani, V.; Pini, F.; Leali, F.; Secchi, C. Survey on human–robot collaboration in industrial settings: Safety, intuitive interfaces and applications. Mechatronics 2018, 55, 248–266. [Google Scholar] [CrossRef]
- Ajoudani, A.; Zanchettin, A.M.; Ivaldi, S.; Albu-Schäffer, A.; Kosuge, K.; Khatib, O. Progress and prospects of the human–robot collaboration. Auton. Robot. 2018, 42, 957–975. [Google Scholar] [CrossRef]
- Chueshev, A.; Melekhova, O.; Meshcheryakov, R. Cloud Robotic Platform on Basis of Fog Computing Approach. In Interactive Collaborative Robotics, Proceedings of the Interactive Collaborative Robotics, Leipzig, Germany, 18–22 September 2018; Ronzhin, A., Rigoll, G., Meshcheryakov, R., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 34–43. [Google Scholar]
- Rodriguez-Losada, D.; Matia, F.; Jimenez, A.; Galan, R.; Lacey, G. Implementing Map Based Navigation in Guido, the Robotic SmartWalker. In Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain, 18–22 April 2005; pp. 3390–3395. [Google Scholar] [CrossRef]
- Jia, P.; Hu, H. Head gesture based control of an intelligent wheelchair. In Proceedings of the 11th Annual Conference of the Chinese Automation and Computing Society in the UK [CACSUK05], Sheffield, UK, 10 September 2005; pp. 85–90. [Google Scholar]
- Montemerlo, M.; Pineau, J.; Roy, N.; Thrun, S.; Verma, V. Experiences with a mobile robotic guide for the elderly. AAAI/IAAI 2002, 2002, 587–592. [Google Scholar]
- Bauer, A.; Wollherr, D.; Buss, M. Human–robot collaboration: A survey. Int. J. Humanoid Robot. 2008, 5, 47–66. [Google Scholar] [CrossRef]
- Albu-Schäffer, A.; Haddadin, S.; Ott, C.; Stemmer, A.; Wimböck, T.; Hirzinger, G. The DLR lightweight robot: Design and control concepts for robots in human environments. Ind. Robot. Int. J. 2007, 34, 376–385. [Google Scholar] [CrossRef]
- Nweke, H.F.; Teh, Y.W.; Mujtaba, G.; Al-garadi, M.A. Data fusion and multiple classifier systems for human activity detection and health monitoring: Review and open research directions. Inf. Fusion 2019, 46, 147–170. [Google Scholar] [CrossRef]
- Xiao, Q.; Song, R. Action recognition based on hierarchical dynamic Bayesian network. Multimed. Tools Appl. 2018, 77, 6955–6968. [Google Scholar] [CrossRef]
- Hu, C.; Chen, Y.; Hu, L.; Peng, X. A novel random forests based class incremental learning method for activity recognition. Pattern Recognit. 2018, 78, 277–290. [Google Scholar] [CrossRef]
- Abidine, B.; Fergani, L.; Fergani, B.; Oussalah, M. The joint use of sequence features combination and modified weighted SVM for improving daily activity recognition. Pattern Anal. Appl. 2018, 21, 119–138. [Google Scholar] [CrossRef]
- Ronao, C.A.; Cho, S.B. Human activity recognition using smartphone sensors with two-stage continuous hidden Markov models. In Proceedings of the 2014 10th International Conference on Natural Computation (ICNC), Xiamen, China, 19–21 August 2014; IEEE: New York, NY, USA, 2014; pp. 681–686. [Google Scholar]
- Mohmed, G.; Lotfi, A.; Pourabdollah, A. Enhanced fuzzy finite state machine for human activity modelling and recognition. J. Ambient. Intell. Humaniz. Comput. 2020, 11, 6077–6091. [Google Scholar] [CrossRef]
- Tan, T.H.; Gochoo, M.; Huang, S.C.; Liu, Y.H.; Liu, S.H.; Huang, Y.F. Multi-resident activity recognition in a smart home using RGB activity image and DCNN. IEEE Sens. J. 2018, 18, 9718–9727. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent trends in deep learning based natural language processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Lee, S.M.; Yoon, S.M.; Cho, H. Human activity recognition from accelerometer data using Convolutional Neural Network. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (Bigcomp), Jeju, Republic of Korea, 13–16 February 2017; IEEE: New York, NY, USA, 2017; pp. 131–134. [Google Scholar]
- Inoue, M.; Inoue, S.; Nishida, T. Deep recurrent neural network for mobile human activity recognition with high throughput. Artif. Life Robot. 2018, 23, 173–185. [Google Scholar] [CrossRef]
- Devitt, S. Trustworthiness of autonomous systems. Foundations of Trusted Autonomy (Studies in Systems, Decision and Control, Volume 117); Springer: Berlin/Heidelberg, Germany, 2018; pp. 161–184. [Google Scholar]
- Karthigasri, R.; Sornam, M. Evolutionary Model and Fuzzy Finite State Machine for Human Activity Recognition. Available online: http://www.ijcnes.com/documents/%20V8-I1-P7.pdf (accessed on 1 March 2023).
- Kong, Y.; Fu, Y. Human action recognition and prediction: A survey. Int. J. Comput. Vis. 2022, 130, 1366–1401. [Google Scholar] [CrossRef]
- Kostavelis, I.; Vasileiadis, M.; Skartados, E.; Kargakos, A.; Giakoumis, D.; Bouganis, C.S.; Tzovaras, D. Understanding of human behavior with a robotic agent through daily activity analysis. Int. J. Soc. Robot. 2019, 11, 437–462. [Google Scholar] [CrossRef]
- Osman, M. Controlling uncertainty: A review of human behavior in complex dynamic environments. Psychol. Bull. 2010, 136, 65. [Google Scholar] [CrossRef]
- Golan, M.; Cohen, Y.; Singer, G. A framework for operator–workstation interaction in Industry 4.0. Int. J. Prod. Res. 2020, 58, 2421–2432. [Google Scholar] [CrossRef]
- Vuckovic, A.; Kwantes, P.J.; Neal, A. Adaptive decision making in a dynamic environment: A test of a sequential sampling model of relative judgment. J. Exp. Psychol. Appl. 2013, 19, 266. [Google Scholar] [CrossRef]
- Law, T.; Scheutz, M. Trust: Recent Concepts and Evaluations in Human-Robot Interaction; Academic Press: NewYork, NY, USA, 2021; pp. 27–57. [Google Scholar] [CrossRef]
- Kwon, W.Y.; Suh, I.H. Planning of proactive behaviors for human–robot cooperative tasks under uncertainty. Knowl.-Based Syst. 2014, 72, 81–95. [Google Scholar] [CrossRef]
- Ramasamy Ramamurthy, S.; Roy, N. Recent trends in machine learning for human activity recognition—A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1254. [Google Scholar] [CrossRef]
- Dua, N.; Singh, S.N.; Semwal, V.B. Multi-input CNN-GRU based human activity recognition using wearable sensors. Computing 2021, 103, 1461–1478. [Google Scholar] [CrossRef]
- Narayanan, M.R.; Scalzi, M.E.; Redmond, S.J.; Lord, S.R.; Celler, B.G.; Lovell, N.H. A wearable triaxial accelerometry system for longitudinal assessment of falls risk. In Proceedings of the 2008 30th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Vancouver, BC, Canada, 20–25 August 2008; pp. 2840–2843. [Google Scholar] [CrossRef]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine. In Proceedings of the International Workshop on Ambient Assisted Living; Springer: Berlin/Heidelberg, Germany, 2012; pp. 216–223. [Google Scholar]
- Kolekar, M.H.; Dash, D.P. Hidden markov model based human activity recognition using shape and optical flow based features. In Proceedings of the 2016 IEEE Region 10 Conference (TENCON), Singapore, 22–25 November 2016; IEEE: New York, NY, USA, 2016; pp. 393–397. [Google Scholar]
- Abdul-Azim, H.A.; Hemayed, E.E. Human action recognition using trajectory-based representation. Egypt. Inform. J. 2015, 16, 187–198. [Google Scholar] [CrossRef]
- Kellokumpu, V.; Pietikäinen, M.; Heikkilä, J. Human activity recognition using sequences of postures. In Proceedings of the MVA, Tsukuba Science City, Japan, 16–18 May 2005; pp. 570–573. [Google Scholar]
- Yamato, J.; Ohya, J.; Ishii, K. Recognizing human action in time-sequential images using hidden Markov model. In Proceedings of the Proceedings 1992 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Champaign, IL, USA, 15–18 June 1992; pp. 379–385. [Google Scholar] [CrossRef]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. Acm Comput. Surv. 2021, 54, 77. [Google Scholar] [CrossRef]
- Parmar, A.; Katariya, R.; Patel, V. A review on random forest: An ensemble classifier. In International Conference on Intelligent Data Communication Technologies and Internet of Things; Springer: Berlin/Heidelberg, Germany, 2018; pp. 758–763. [Google Scholar]
- Song, Q.; Liu, X.; Yang, L. The random forest classifier applied in droplet fingerprint recognition. In Proceedings of the 2015 12th International Conference on Fuzzy Systems and Knowledge Discovery (FSKD), Zhangjiajie, China, 15–17 August 2015; IEEE: New York, NY, USA, 2015; pp. 722–726. [Google Scholar]
- Wan, S.; Qi, L.; Xu, X.; Tong, C.; Gu, Z. Deep learning models for real-time human activity recognition with smartphones. Mob. Netw. Appl. 2020, 25, 743–755. [Google Scholar] [CrossRef]
- Hammerla, N.Y.; Halloran, S.; Plötz, T. Deep, convolutional, and recurrent models for human activity recognition using wearables. arXiv 2016, arXiv:1604.08880. [Google Scholar]
- Vepakomma, P.; De, D.; Das, S.K.; Bhansali, S. A-Wristocracy: Deep learning on wrist-worn sensing for recognition of user complex activities. In Proceedings of the 2015 IEEE 12th International conference on wearable and implantable body sensor networks (BSN), Cambridge, UK, 9–12 June 2015; IEEE: New York, NY, USA, 2015; pp. 1–6. [Google Scholar]
- Bai, L.; Yao, L.; Wang, X.; Kanhere, S.P.S.; Xiao, Y. Prototype similarity learning for activity recognition. In Proceedings of the Pacific-Asia Conference on Knowledge Discovery and Data Mining, Zhangjiajie, China, 15–17 August 2015; Springer: Berlin/Heidelberg, Germany, 2020; pp. 649–661. [Google Scholar]
- Duffner, S.; Berlemont, S.; Lefebvre, G.; Garcia, C. 3D gesture classification with convolutional neural networks. In Proceedings of the 2014 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: New York, NY, USA, 2014; pp. 5432–5436. [Google Scholar]
- Ishimaru, S.; Hoshika, K.; Kunze, K.; Kise, K.; Dengel, A. Towards reading trackers in the wild: Detecting reading activities by EOG glasses and deep neural networks. In UbiComp ’17: Proceedings of the 2017 ACM International Joint Conference on Pervasive and Ubiquitous Computing and Proceedings of the 2017 ACM International Symposium on Wearable Computers; Association for Computing Machinery: New York, NY, USA, 2017; pp. 704–711. [Google Scholar]
- Guan, Y.; Plötz, T. Ensembles of deep lstm learners for activity recognition using wearables. Proc. ACM Interact. Mob. Wearable Ubiquitous Technol. 2017, 1, 11. [Google Scholar] [CrossRef]
- Ordóñez, F.J.; Roggen, D. Deep convolutional and lstm recurrent neural networks for multimodal wearable activity recognition. Sensors 2016, 16, 115. [Google Scholar] [CrossRef]
- Hossain Shuvo, M.M.; Ahmed, N.; Nouduri, K.; Palaniappan, K. A Hybrid Approach for Human Activity Recognition with Support Vector Machine and 1D Convolutional Neural Network. In Proceedings of the 2020 IEEE Applied Imagery Pattern Recognition Workshop (AIPR), Washington, DC, USA, 13–15 October 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Faria, D.R.; Premebida, C.; Nunes, U. A probabilistic approach for human everyday activities recognition using body motion from RGB-D images. In Proceedings of the 23rd IEEE International Symposium on Robot and Human Interactive Communication, Edinburgh, UK, 25–29 August 2014; IEEE: New York, NY, USA, 2014; pp. 732–737. [Google Scholar]
- Nunes Rodrigues, A.C.; Santos Pereira, A.; Sousa Mendes, R.M.; Araújo, A.G.; Santos Couceiro, M.; Figueiredo, A.J. Using artificial intelligence for pattern recognition in a sports context. Sensors 2020, 20, 3040. [Google Scholar] [CrossRef]
- Vital, J.P.; Faria, D.R.; Dias, G.; Couceiro, M.S.; Coutinho, F.; Ferreira, N.M. Combining discriminative spatiotemporal features for daily life activity recognition using wearable motion sensing suit. Pattern Anal. Appl. 2017, 20, 1179–1194. [Google Scholar] [CrossRef]
- Martinez-Gonzalez, P.; Oprea, S.; Garcia-Garcia, A.; Jover-Alvarez, A.; Orts-Escolano, S.; Garcia-Rodriguez, J. Unrealrox: An extremely photorealistic virtual reality environment for robotics simulations and synthetic data generation. Virtual Real. 2020, 24, 271–288. [Google Scholar] [CrossRef]
- Puig, X.; Ra, K.; Boben, M.; Li, J.; Wang, T.; Fidler, S.; Torralba, A. VirtualHome: Simulating Household Activities via Programs. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Quigley, M.; Gerkey, B.; Conley, K.; Faust, J.; Foote, T.; Leibs, J.; Berger, E.; Wheeler, R.; Ng, A.Y. ROS: An open-source Robot Operating System. In Proceedings of the ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, p. 5. [Google Scholar]
- Zangenehnejad, F.; Gao, Y. GNSS smartphones positioning: Advances, challenges, opportunities, and future perspectives. Satell. Navig. 2021, 2, 24. [Google Scholar] [CrossRef] [PubMed]
- Kim, A.; Golnaraghi, M. A quaternion-based orientation estimation algorithm using an inertial measurement unit. In Proceedings of the PLANS 2004. Position Location and Navigation Symposium (IEEE Cat. No.04CH37556), Monterey, CA, USA, 26–29 April 2004; pp. 268–272. [Google Scholar] [CrossRef]
- Haq, I.U.; Ullah, A.; Khan, S.U.; Khan, N.; Lee, M.Y.; Rho, S.; Baik, S.W. Sequential learning-based energy consumption prediction model for residential and commercial sectors. Mathematics 2021, 9, 605. [Google Scholar] [CrossRef]
- Khan, I.U.; Afzal, S.; Lee, J.W. Human activity recognition via hybrid deep learning based model. Sensors 2022, 22, 323. [Google Scholar] [CrossRef] [PubMed]
- Han, S.; Kang, J.; Mao, H.; Hu, Y.; Li, X.; Li, Y.; Xie, D.; Luo, H.; Yao, S.; Wang, Y.; et al. Ese: Efficient speech recognition engine with sparse lstm on fpga. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Washington, DC, USA, 14–18 August 2017; pp. 75–84. [Google Scholar]
- Berrar, D. Bayes’ theorem and naive Bayes classifier. Encycl. Bioinform. Comput. Biol. ABC Bioinform. 2018, 403, 412. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mean ± SD | Fuzzy-LSTM | FS-LSTM | Fuzzy-LSTM * | FS-LSTM * | FS-LSTM ** |
|---|---|---|---|---|---|
| GPU Utilization | 44.55 ± 9.85 | 35.21 ± 9.57 | 28.05 ± 9.56 | 25.58 ± 9.46 | 27.54 ± 10.16 |
| Power Consumption | 29.25 ± 2.04 | 28.14 ± 1.91 | 24.66 ± 0.89 | 24.25 ± 0.89 | 24.70 ± 1.34 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yalçinkaya, B.; Couceiro, M.S.; Soares, S.P.; Valente, A. Human-Aware Collaborative Robots in the Wild: Coping with Uncertainty in Activity Recognition. Sensors 2023, 23, 3388. https://doi.org/10.3390/s23073388
Yalçinkaya B, Couceiro MS, Soares SP, Valente A. Human-Aware Collaborative Robots in the Wild: Coping with Uncertainty in Activity Recognition. Sensors. 2023; 23(7):3388. https://doi.org/10.3390/s23073388
Chicago/Turabian StyleYalçinkaya, Beril, Micael S. Couceiro, Salviano Pinto Soares, and Antonio Valente. 2023. "Human-Aware Collaborative Robots in the Wild: Coping with Uncertainty in Activity Recognition" Sensors 23, no. 7: 3388. https://doi.org/10.3390/s23073388
APA StyleYalçinkaya, B., Couceiro, M. S., Soares, S. P., & Valente, A. (2023). Human-Aware Collaborative Robots in the Wild: Coping with Uncertainty in Activity Recognition. Sensors, 23(7), 3388. https://doi.org/10.3390/s23073388