
Deep Learning-Based Wrist Vascular Biometric Recognition



Abstract
:1. Introduction
- Extension of the literature survey carried out in our previous study [6].
- Segmentation of wrist vein images using a modified UNet architecture.
- Development of a matching engine that can compare probe image with reference image using Convolutional Neural Network (CNN) followed by Siamese Neural Network [10] for vascular biometrics.
- Development of a Graphical User Interface (GUI) and integration of the subsystems to form a complete end-to-end deep learning-based wrist vein biometric system.
2. Literature Review
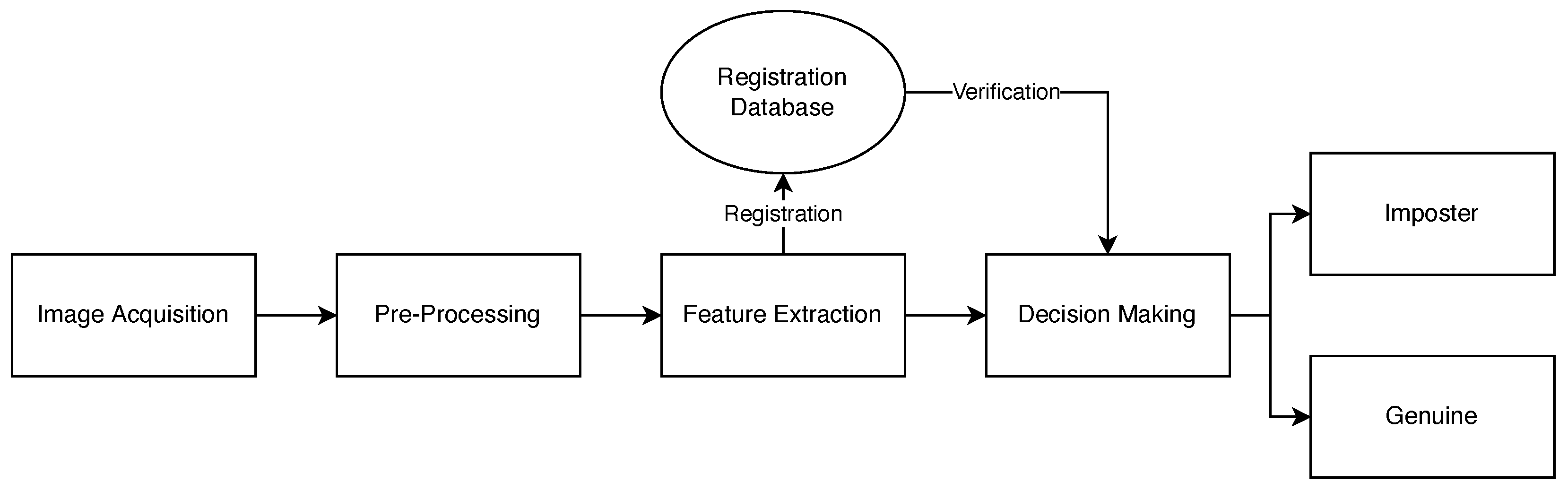
3. Proposed System
3.1. Image Acquisition Subsystem
3.2. Preprocessing Subsystem
3.3. Image Segmentation and Feature Extraction Subsystem
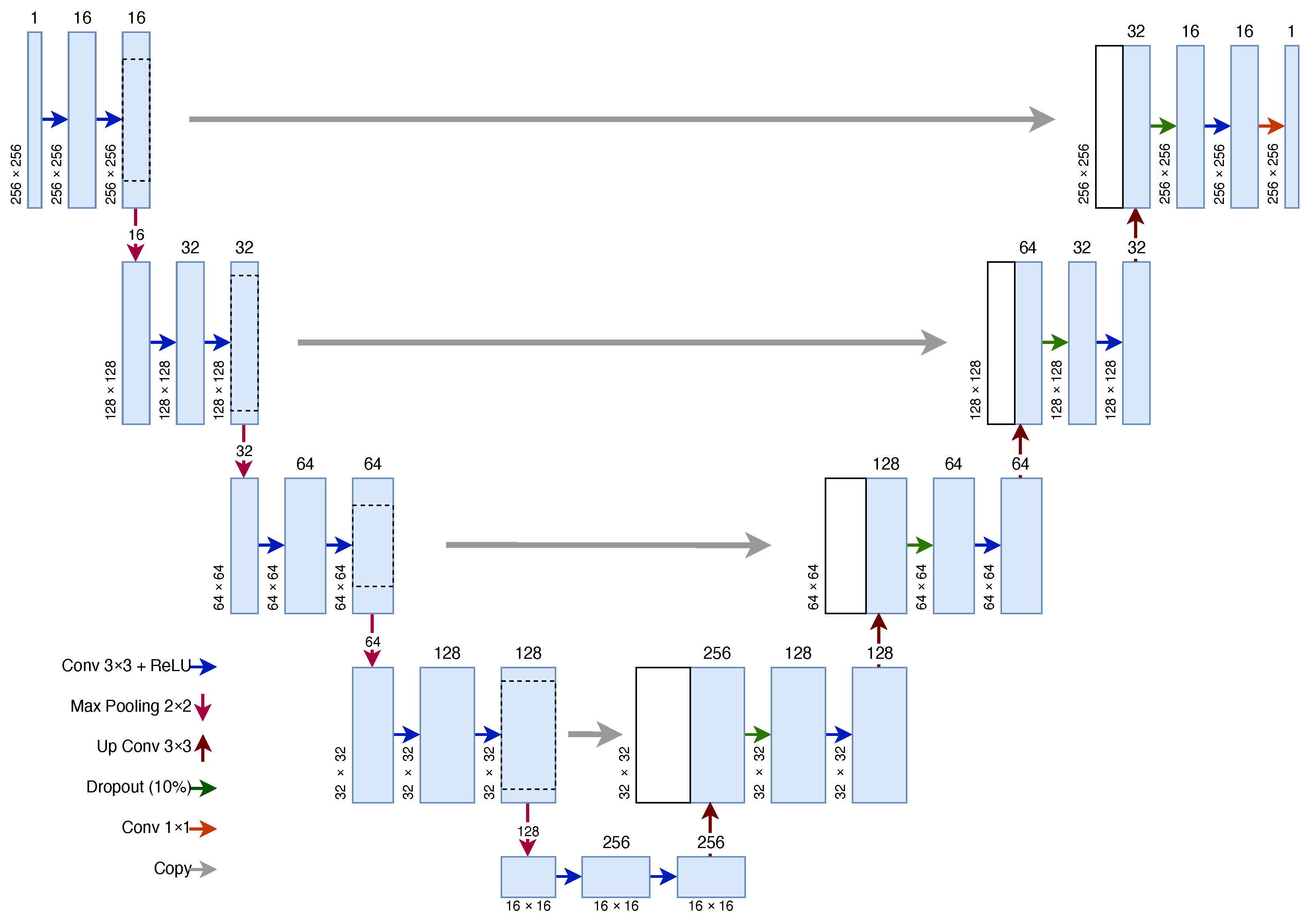
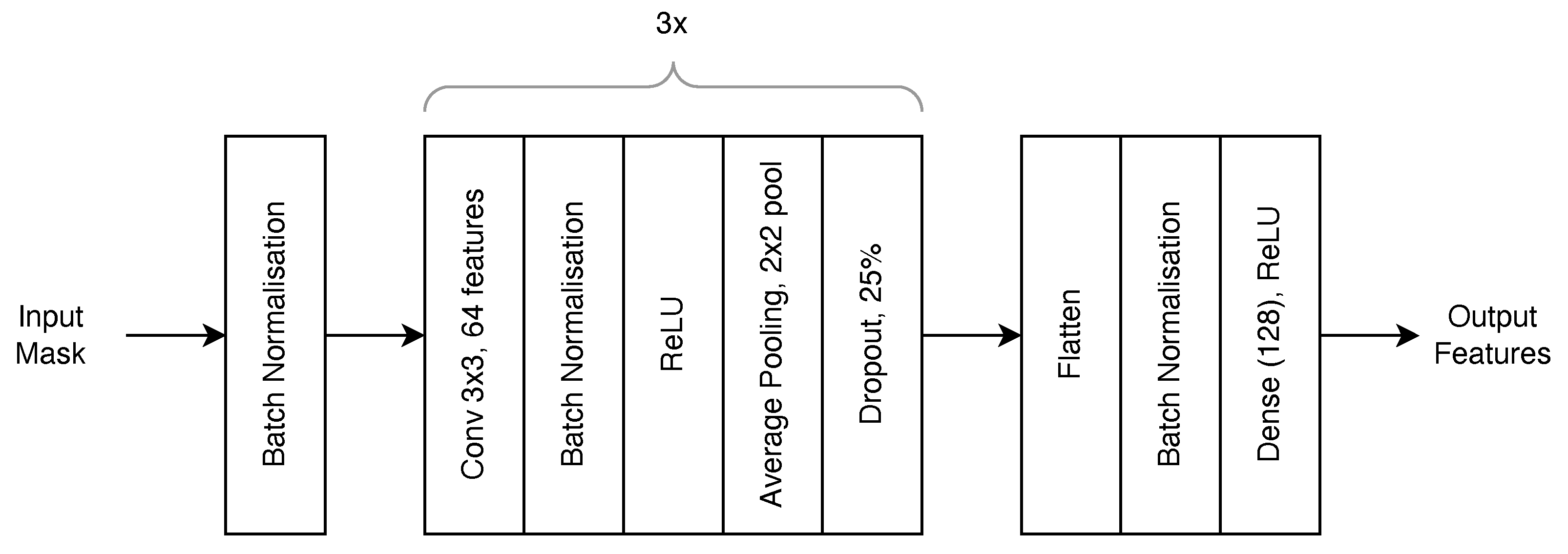
3.3.1. U-Net Architecture for Vein Segmentation
3.3.2. Mask Image Generation Algorithm
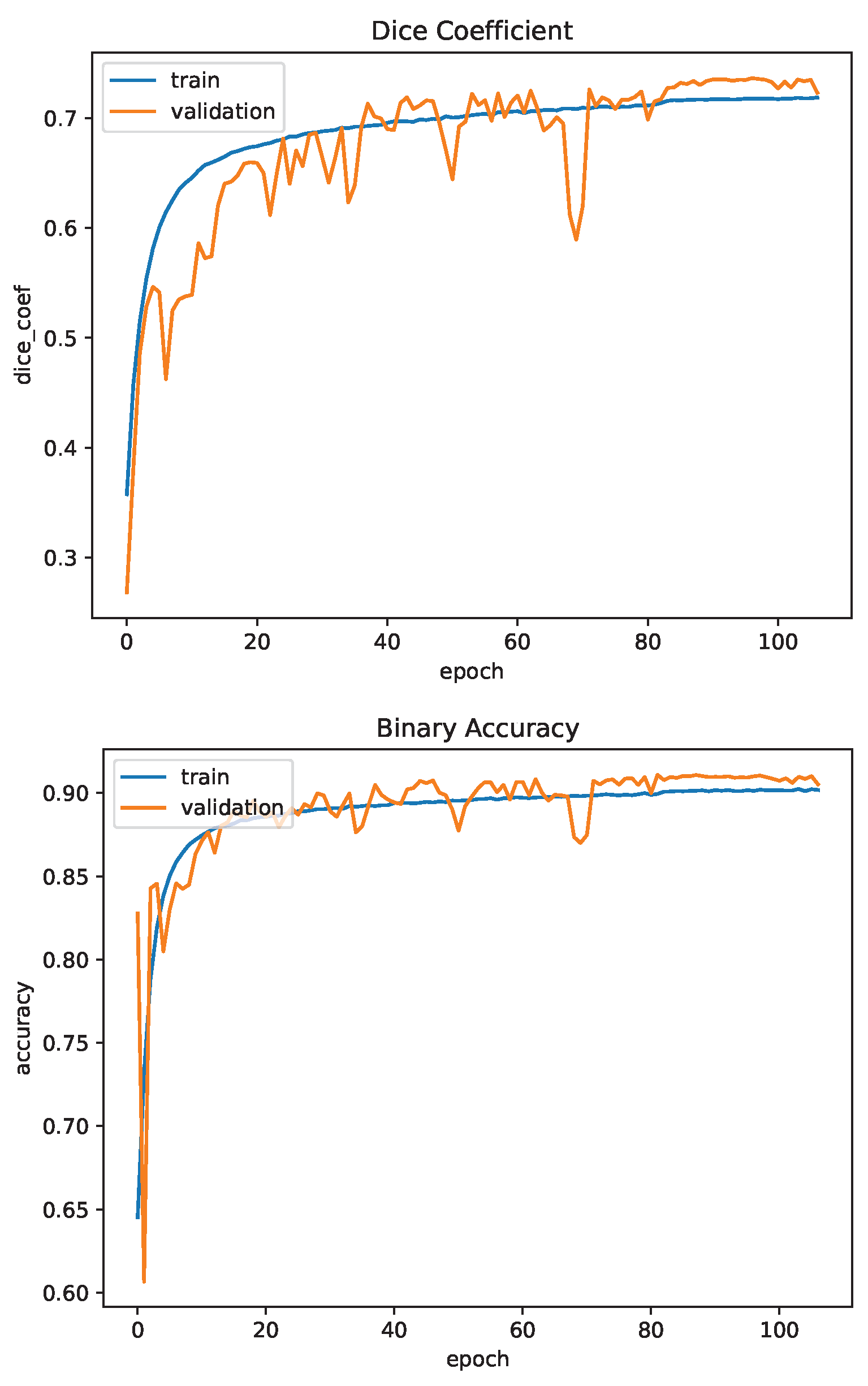
3.3.3. Dice Coefficient
3.3.4. U-Net Training
3.4. Image Matching and Decision Making Subsystem
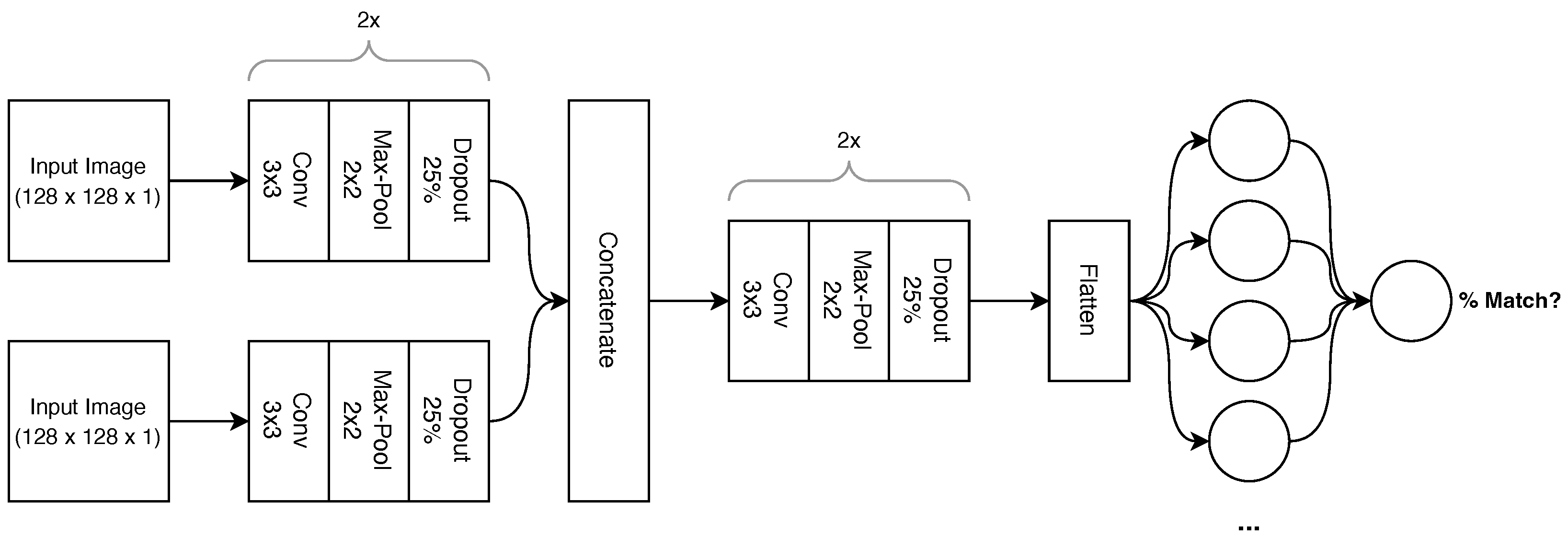
3.4.1. Convolutional Neural Network
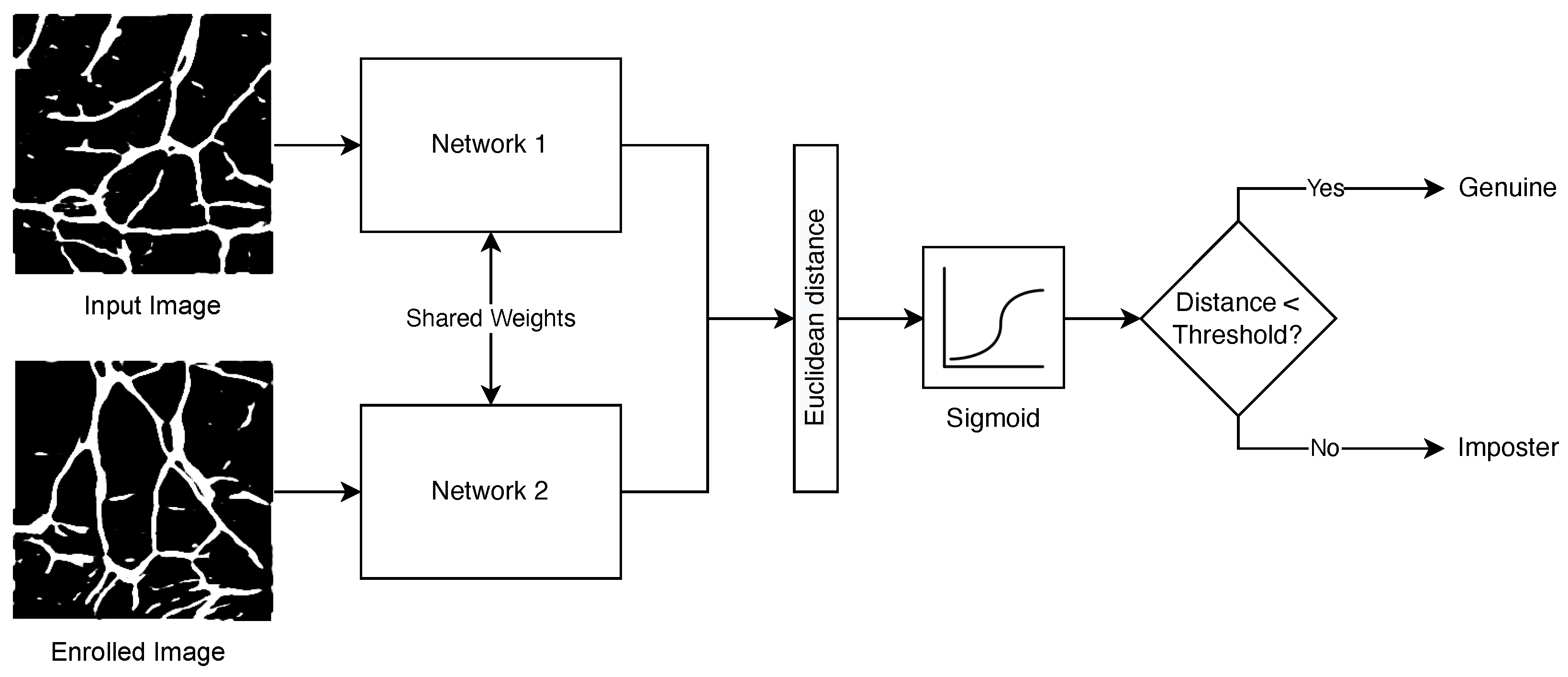
3.4.2. Siamese Neural Network
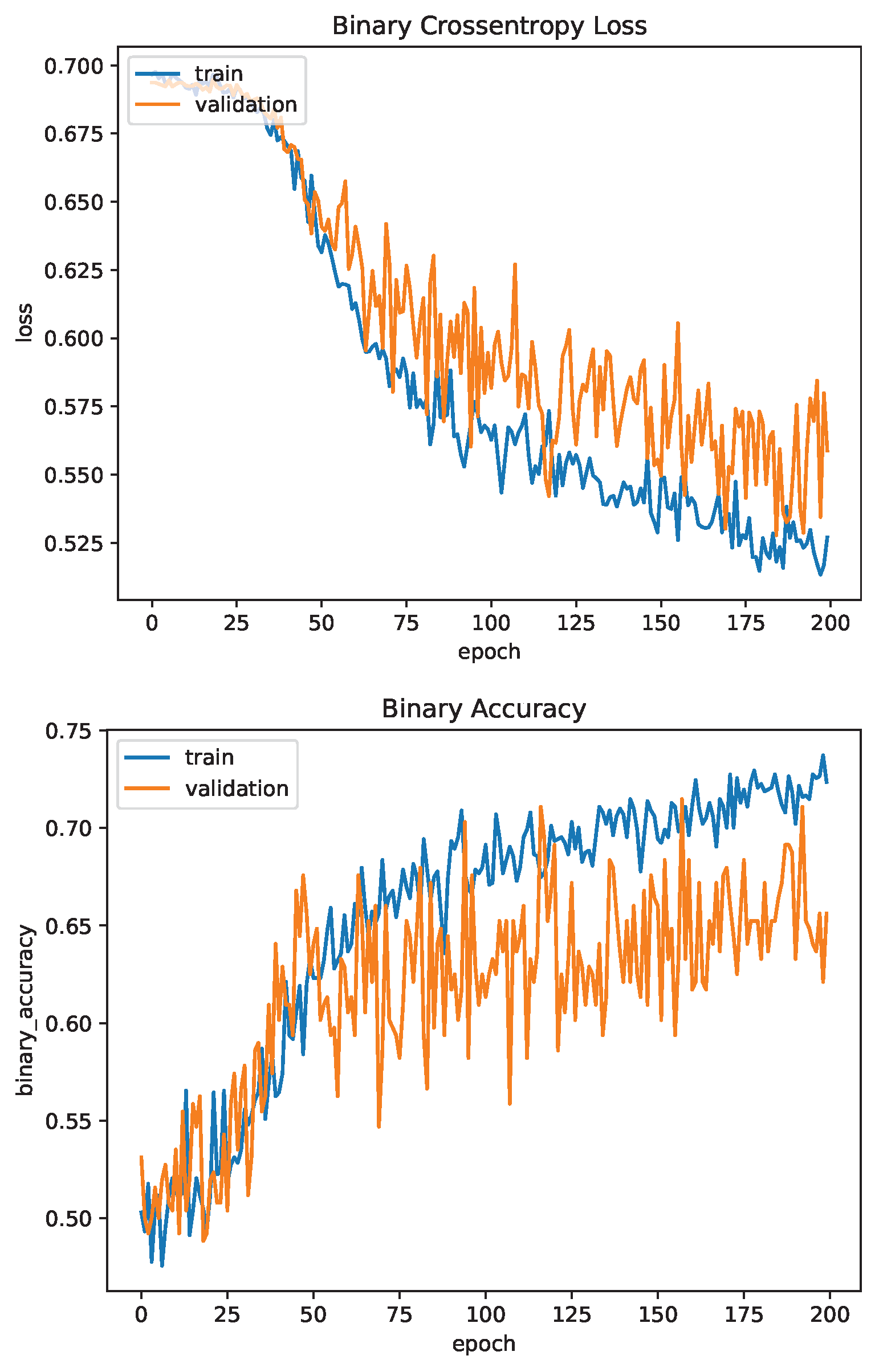
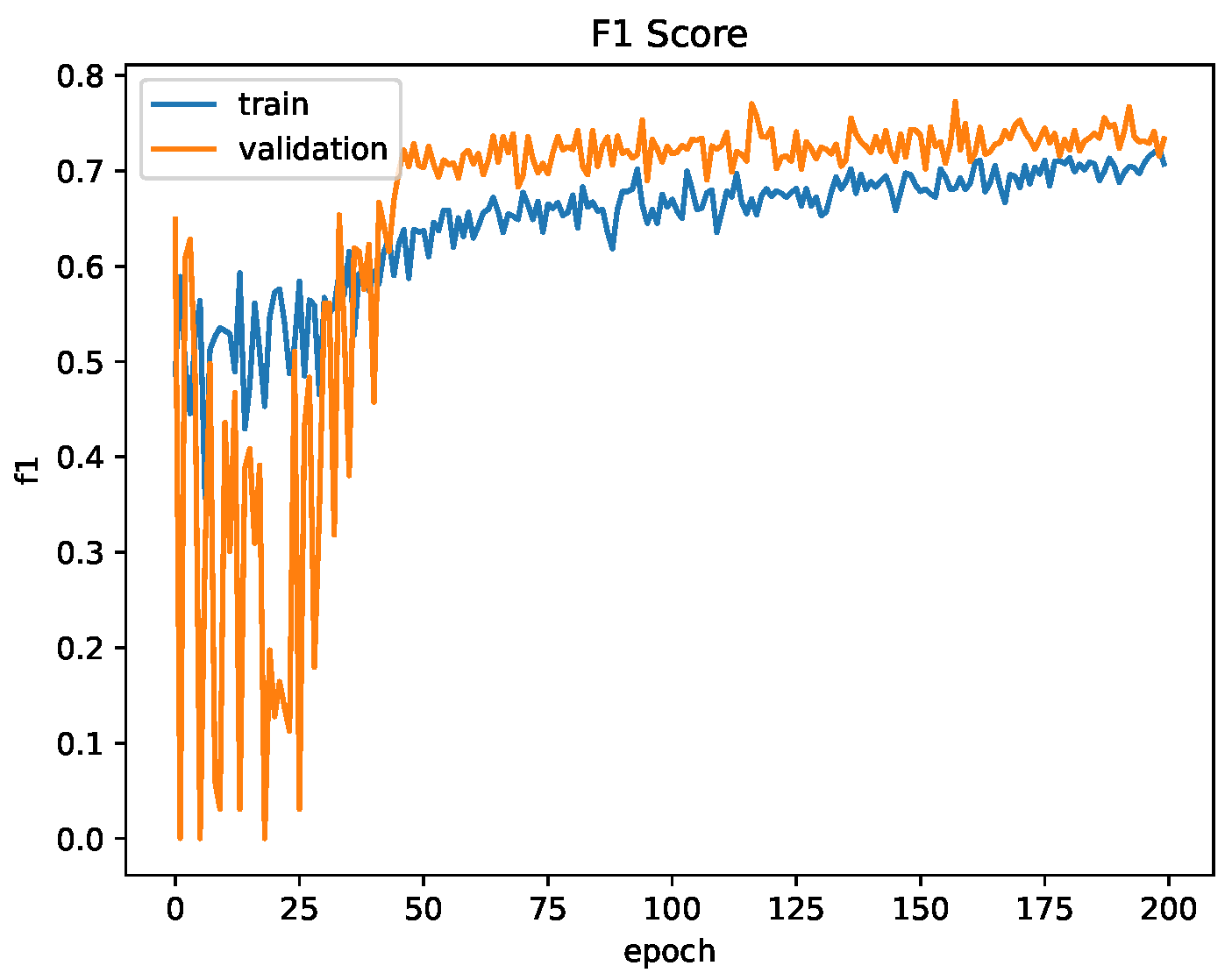
3.4.3. Network Training
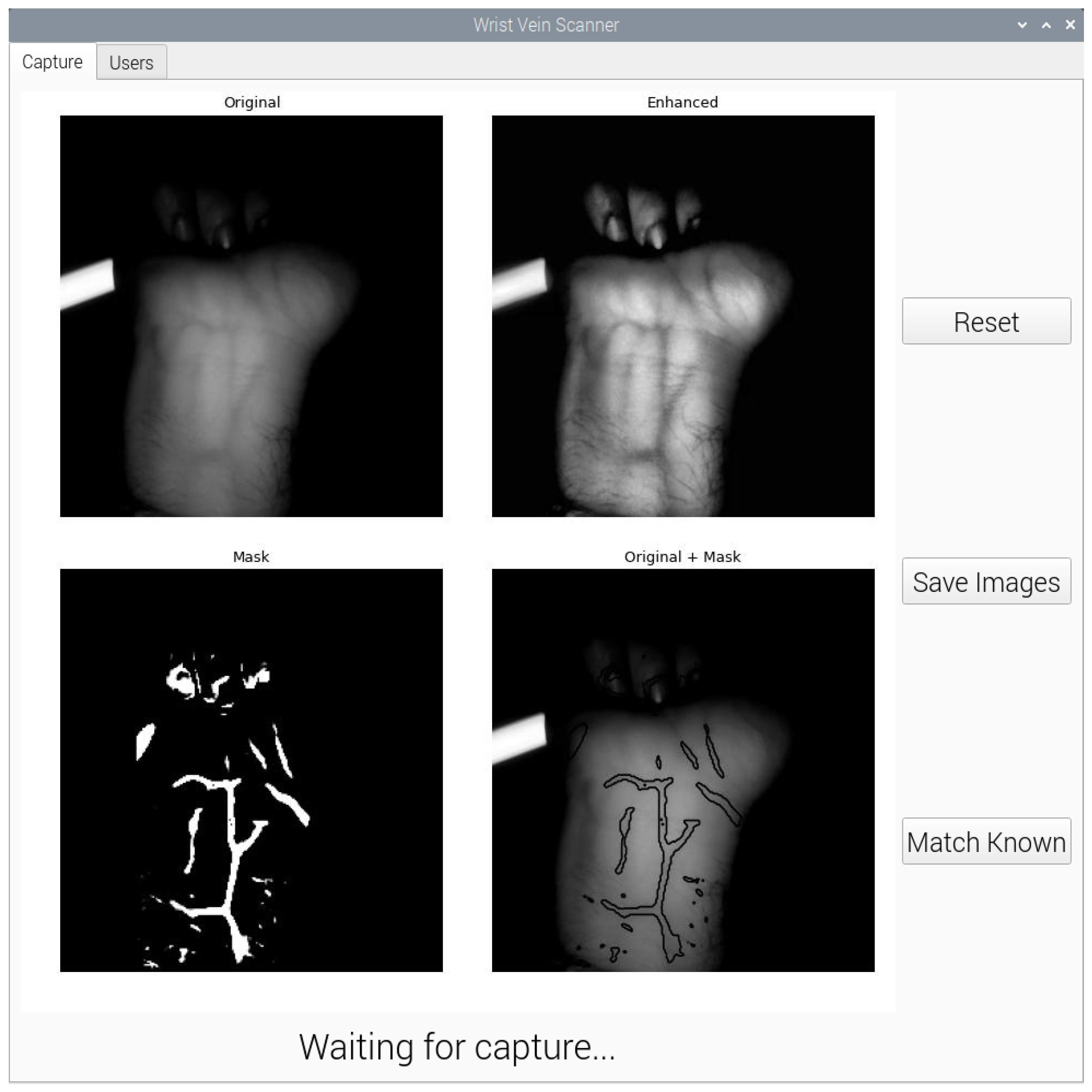
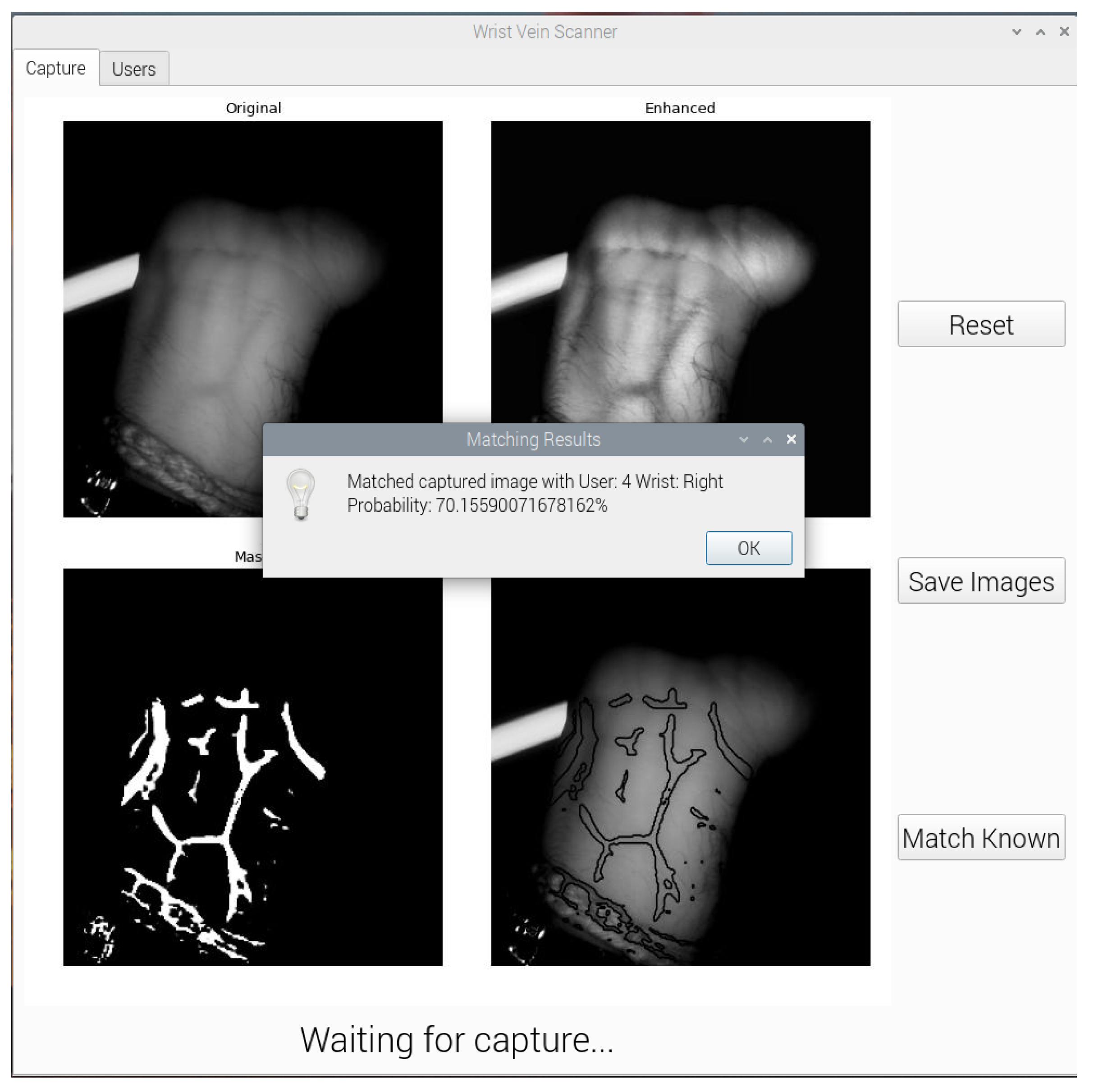
3.5. Graphical User Interface
4. Results and Discussion
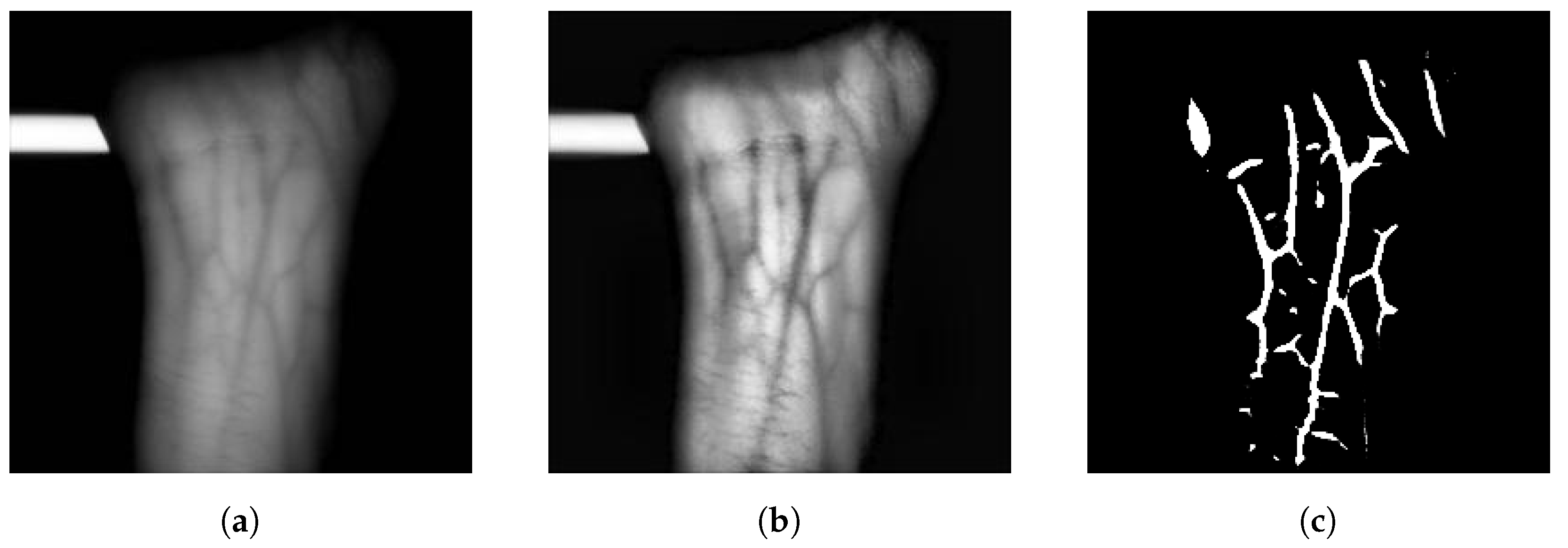
4.1. Image Acquisition
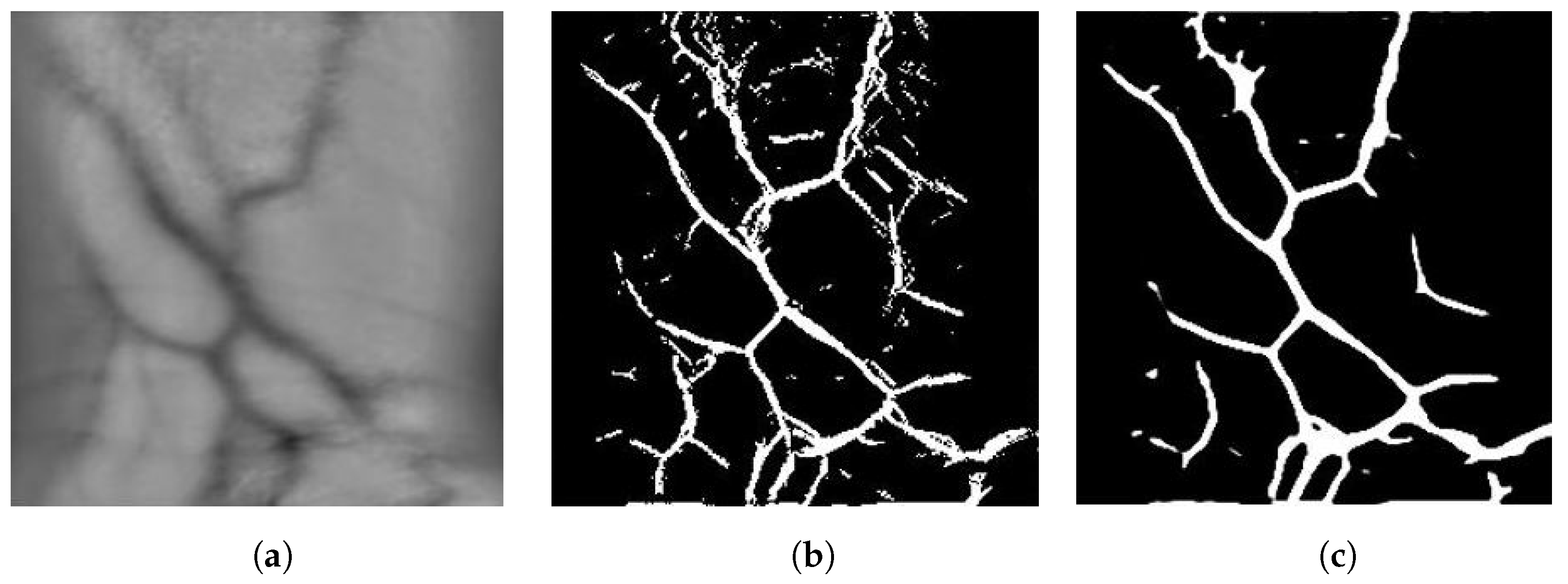
4.2. Image Segmentation
4.3. Image Matching
4.3.1. Convolutional Neural Network
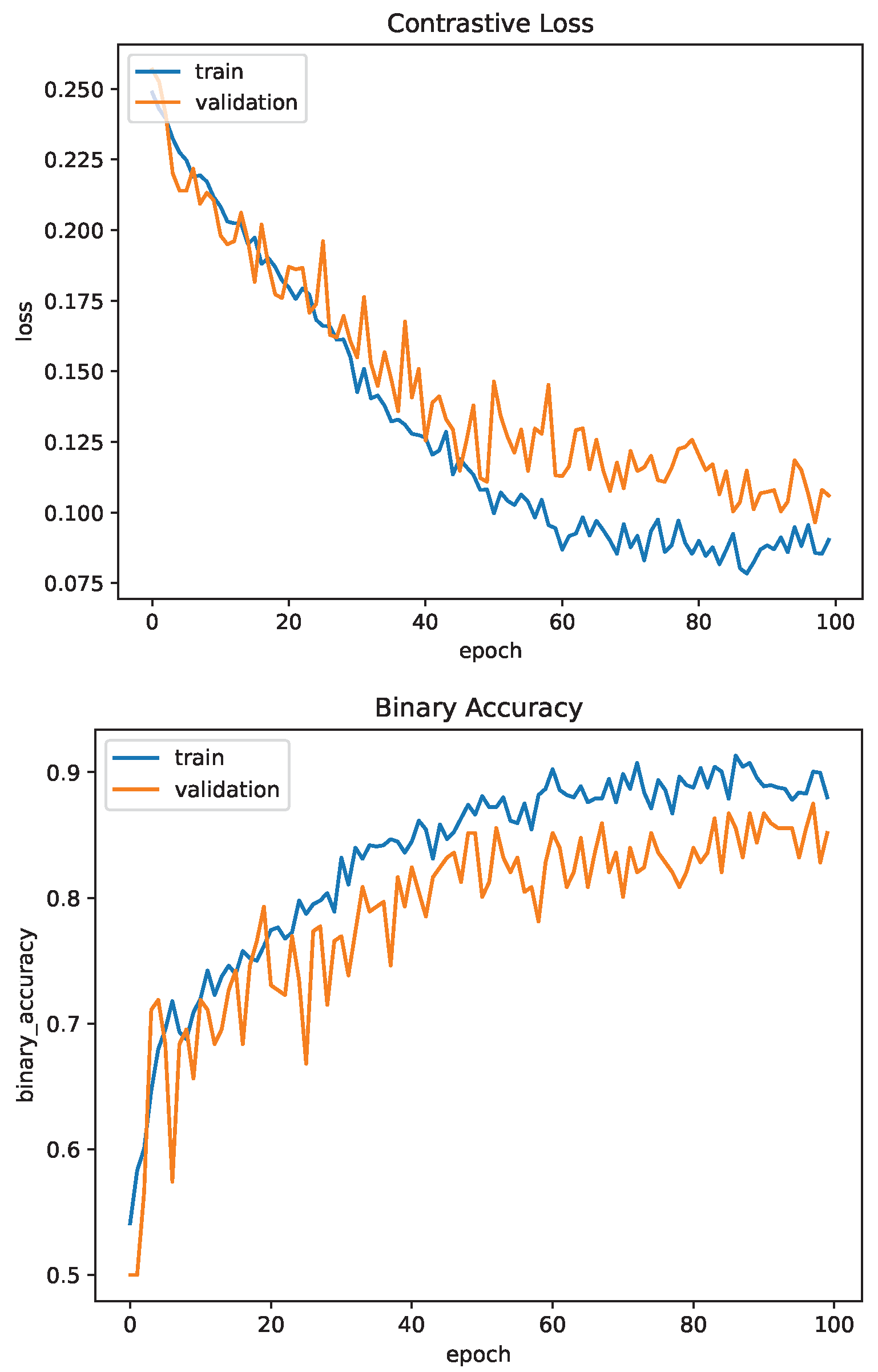
4.3.2. Siamese Neural Network
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Herzog, T.; Uhl, A. Analysing a vein liveness detection scheme. In Proceedings of the 2020 8th International Workshop on Biometrics and Forensics (IWBF), Porto, Portugal, 29–30 April 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Raut, S.; Humbe, V. Review of biometrics: Palm vein recognition system. IBMRDs J. Manag. Res. 2014, 3, 217–223. [Google Scholar]
- Ali, W.; Tian, W.; Din, S.U.; Iradukunda, D.; Khan, A.A. Classical and modern face recognition approaches: A complete review. Multimed. Tools Appl. 2021, 80, 4825–4880. [Google Scholar] [CrossRef]
- Marattukalam, F.; Abdulla, W.H. On palm vein as a contactless identification technology. In Proceedings of the 2019 Australian & New Zealand Control Conference (ANZCC), Auckland, New Zealand, 27–29 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 270–275. [Google Scholar]
- Wagh, D.P.; Fadewar, H.; Shinde, G. Biometric finger vein recognition methods for authentication. In Computing in Engineering and Technology; Springer: Singapore, 2020; pp. 45–53. [Google Scholar]
- Marattukalam, F.; Cole, D.; Gulati, P.; Abdulla, W.H. On Wrist Vein Recognition for Human Biometrics. In Proceedings of the 2022 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Chiang Mai, Thailand, 7–10 November 2022; IEEE: Piscataway, NJ, USA, 2022. [Google Scholar]
- Olsen, L.O.; Takiwaki, H.; Serup, J. High-frequency ultrasound characterization of normal skin. Skin thickness and echographic density of 22 anatomical sites. Skin Res. Technol. 1995, 1, 74–80. [Google Scholar] [CrossRef] [PubMed]
- Kauba, C.; Piciucco, E.; Maiorana, E.; Gomez-Barrero, M.; Prommegger, B.; Campisi, P.; Uhl, A. Towards practical cancelable biometrics for finger vein recognition. Inf. Sci. 2022, 585, 395–417. [Google Scholar] [CrossRef]
- Toygar, Ö.; Babalola, F.O.; Bitirim, Y. FYO: A novel multimodal vein database with palmar, dorsal and wrist biometrics. IEEE Access 2020, 8, 82461–82470. [Google Scholar] [CrossRef]
- Marattukalam, F.; Abdulla, W.H.; Swain, A. N-shot Palm Vein Verification Using Siamese Networks. In Proceedings of the 2021 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 15–17 September 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Crisan, S.; Tarnovan, I.G.; Crisan, T.E. Vein pattern recognition. Image enhancement and feature extraction algorithms. In Proceedings of the 15th IMEKO TC4 Symposium, Iaşi, Romania, 19–21 September 2007. [Google Scholar]
- Raghavendra, R.; Busch, C. A low cost wrist vein sensor for biometric authentication. In Proceedings of the 2016 IEEE International Conference on Imaging Systems and Techniques (IST), Chania, Greece, 4–6 October 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 201–205. [Google Scholar]
- Agrawal, P.; Kapoor, R.; Agrawal, S. A hybrid partial fingerprint matching algorithm for estimation of equal error rate. In Proceedings of the 2014 IEEE International Conference on Advanced Communications, Control and Computing Technologies, Ramanathapuram, India, 8–10 May 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1295–1299. [Google Scholar]
- Pascual, J.E.S.; Uriarte-Antonio, J.; Sanchez-Reillo, R.; Lorenz, M.G. Capturing hand or wrist vein images for biometric authentication using low-cost devices. In Proceedings of the 2010 Sixth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Darmstadt, Germany, 15–17 October 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 318–322. [Google Scholar]
- Garcia-Martin, R.; Sanchez-Reillo, R.; Suarez-Pascual, J.E. Wrist vascular biometric capture using a portable contactless system. In Proceedings of the 2019 International Carnahan Conference on Security Technology (ICCST), Chennai, India, 1–3 October 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–6. [Google Scholar]
- Kurban, O.C.; Nıyaz, Ö.; Yildirim, T. Neural network based wrist vein identification using ordinary camera. In Proceedings of the 2016 International Symposium on INnovations in Intelligent SysTems and Applications (INISTA), Sinaia, Romania, 2–5 August 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1–4. [Google Scholar]
- Garcia-Martin, R.; Sanchez-Reillo, R. Vein biometric recognition on a smartphone. IEEE Access 2020, 8, 104801–104813. [Google Scholar] [CrossRef]
- Lindeberg, T. Scale invariant feature transform. Scholarpedia 2012, 7, 10491. [Google Scholar] [CrossRef]
- Kabaciński, R.; Kowalski, M. Vein pattern database and benchmark results. Electron. Lett. 2011, 47, 1127–1128. [Google Scholar] [CrossRef]
- Wang, L.; Leedham, G.; Cho, S.Y. Infrared imaging of hand vein patterns for biometric purposes. IET Comput. Vis. 2007, 1, 113–122. [Google Scholar] [CrossRef]
- Uriarte-Antonio, J.; Hartung, D.; Pascual, J.E.S.; Sanchez-Reillo, R. Vascular biometrics based on a minutiae extraction approach. In Proceedings of the 2011 Carnahan Conference on Security Technology, Barcelona, Spain, 18–21 October 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1–7. [Google Scholar]
- Fernández Clotet, P.; Findling, R.D. Mobile wrist vein authentication using SIFT features. In Proceedings of the International Conference on Computer Aided Systems Theory, Las Palmas de Gran Canaria, Spain, 19–24 February 2017; Springer: Cham, Switzerland, 2017; pp. 205–213. [Google Scholar]
- Achban, A.; Nugroho, H.A.; Nugroho, P. Wrist hand vein recognition using local line binary pattern (LLBP). In Proceedings of the 2019 5th International Conference on Science and Technology (ICST), Yogyakarta, Indonesia, 30–31 July 2019; IEEE: Piscataway, NJ, USA, 2019; Volume 1, pp. 1–6. [Google Scholar]
- Nikisins, O.; Eglitis, T.; Anjos, A.; Marcel, S. Fast cross-correlation based wrist vein recognition algorithm with rotation and translation compensation. In Proceedings of the 2018 International Workshop on Biometrics and Forensics (IWBF), Sassari, Italy, 7–8 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Mohamed, C.; Akhtar, Z.; Eddine, B.N.; Falk, T.H. Combining left and right wrist vein images for personal verification. In Proceedings of the 2017 Seventh International Conference on Image Processing Theory, Tools and Applications (IPTA), Montreal, QC, Canada, 28 Novembe–1 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Das, A.; Pal, U.; Ballester, M.A.F.; Blumenstein, M. A new wrist vein biometric system. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence in Biometrics and Identity Management (CIBIM), Orlando, FL, USA, 9–12 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 68–75. [Google Scholar]
- Pizer, S.M.; Amburn, E.P.; Austin, J.D.; Cromartie, R.; Geselowitz, A.; Greer, T.; ter Haar Romeny, B.; Zimmerman, J.B.; Zuiderveld, K. Adaptive histogram equalization and its variations. Comput. Vision Graph. Image Process. 1987, 39, 355–368. [Google Scholar] [CrossRef]
- Humeau-Heurtier, A. Texture feature extraction methods: A survey. IEEE Access 2019, 7, 8975–9000. [Google Scholar] [CrossRef]
- Kocer, H.E.; Çevik, K.K. Deep neural networks based wrist print region segmentation and classification. MANAS J. Eng. 2021, 9, 30–36. [Google Scholar] [CrossRef]
- Chen, Y.Y.; Hsia, C.H.; Chen, P.H. Contactless Multispectral Palm-Vein Recognition With Lightweight Convolutional Neural Network. IEEE Access 2021, 9, 149796–149806. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Marattukalam, F.; Abdulla, W.H. Segmentation of palm vein images using U-Net. In Proceedings of the 2020 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Auckland, New Zealand, 7–10 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 64–70. [Google Scholar]
- Santurkar, S.; Tsipras, D.; Ilyas, A.; Madry, A. How does batch normalization help optimization? Adv. Neural Inf. Process. Syst. 2018, 31, 1–11. [Google Scholar]
- Wang, F.; Liu, H. Understanding the behaviour of contrastive loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 2495–2504. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Participants | Wrist | Samples | Sessions | Total | Camera | NIR |
|---|---|---|---|---|---|---|---|
| PUT [19] | 50 | 2 | 4 | 3 | 1200 | Unknown | Unknown |
| Singapore [20] | 150 | 2 | 3 | Unknown | 900 | Hitachi KP-F2A | 850 nm |
| FYO [9] | 160 | 2 | 2 | 1 1 | 640 | 1/3 inch infrared CMOS | Unknown |
| UC3M [21] | 121 | 1 | 5 | Unknown | 605 | DM 21BU054 | 880 nm |
| UC3M-CV1 [15] | 50 | 2 | 6 | 2 | 1200 | Logitech HD Webcam C525 | 850 nm |
| UC3M-CV2 [17] | 50 | 2 | 6 | 2 | 1200 per device | Xiaomi Pocophone F1, Xiaomi Mi 8 | 960 nm |
| Kurban et al. [16] | 17 | 2 | 3 | Unknown | 102 | 5MP mobile phone | No NIR |
| Pascual et al. [14] | 30 | 2 | 6 | Unknown | 360 | DM 21BU054 | 880 nm |
| Fernández et al. [22] | 30 | Right | 4 | 1 | 120 | CCD Camera | 880 nm |
| Wavelength | Reasoning | Model | Forward Voltage | Forward Current | Radiant Intensity |
|---|---|---|---|---|---|
| 740 nm | Successfully used in wrist vein literature | OIS 330 740 X T | 1.7 V | 30 mA | 6 mW/sr |
| 770 nm | Absorbed best by deoxygenated hemoglobin | OIS 330 770 | 1.65 V | 50 mA | 6 mW/sr |
| 860 nm | Successfully used in wrist vein literature | SFH 4715AS | 2.9 V | 1 A | 1120 mW/sr |
| 880 nm | Successfully used in wrist vein literature | APT1608SF4C-PRV | 1.3 V | 20 mA | 0.8 mW/sr |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marattukalam, F.; Abdulla, W.; Cole, D.; Gulati, P. Deep Learning-Based Wrist Vascular Biometric Recognition. Sensors 2023, 23, 3132. https://doi.org/10.3390/s23063132
Marattukalam F, Abdulla W, Cole D, Gulati P. Deep Learning-Based Wrist Vascular Biometric Recognition. Sensors. 2023; 23(6):3132. https://doi.org/10.3390/s23063132
Chicago/Turabian StyleMarattukalam, Felix, Waleed Abdulla, David Cole, and Pranav Gulati. 2023. "Deep Learning-Based Wrist Vascular Biometric Recognition" Sensors 23, no. 6: 3132. https://doi.org/10.3390/s23063132
APA StyleMarattukalam, F., Abdulla, W., Cole, D., & Gulati, P. (2023). Deep Learning-Based Wrist Vascular Biometric Recognition. Sensors, 23(6), 3132. https://doi.org/10.3390/s23063132