
The Development of a Data Collection and Browser Fingerprinting System



Abstract
:1. Introduction
- Building a website to carry out browser fingerprint data collection which is described in Section 4;
- An in-depth understanding of the key attributes of browser fingerprinting. A total of 15 attributes have been collected and the methods to obtain those attributes are discussed in Section 5;
- The datasets of the collected browser fingerprint will be shared and downloadable via the developed website. This research has been collected for more than 500 fingerprints and the collection is still ongoing; the YTD datasets are accessible via the link presented in Section 4.
2. Justification of Study
3. Background
3.1. Previous Studies
3.1.1. Panopticlick
3.1.2. AmIUnique
3.1.3. Hiding in the Crowd
3.2. Previous Studies vs. the Proposed Research
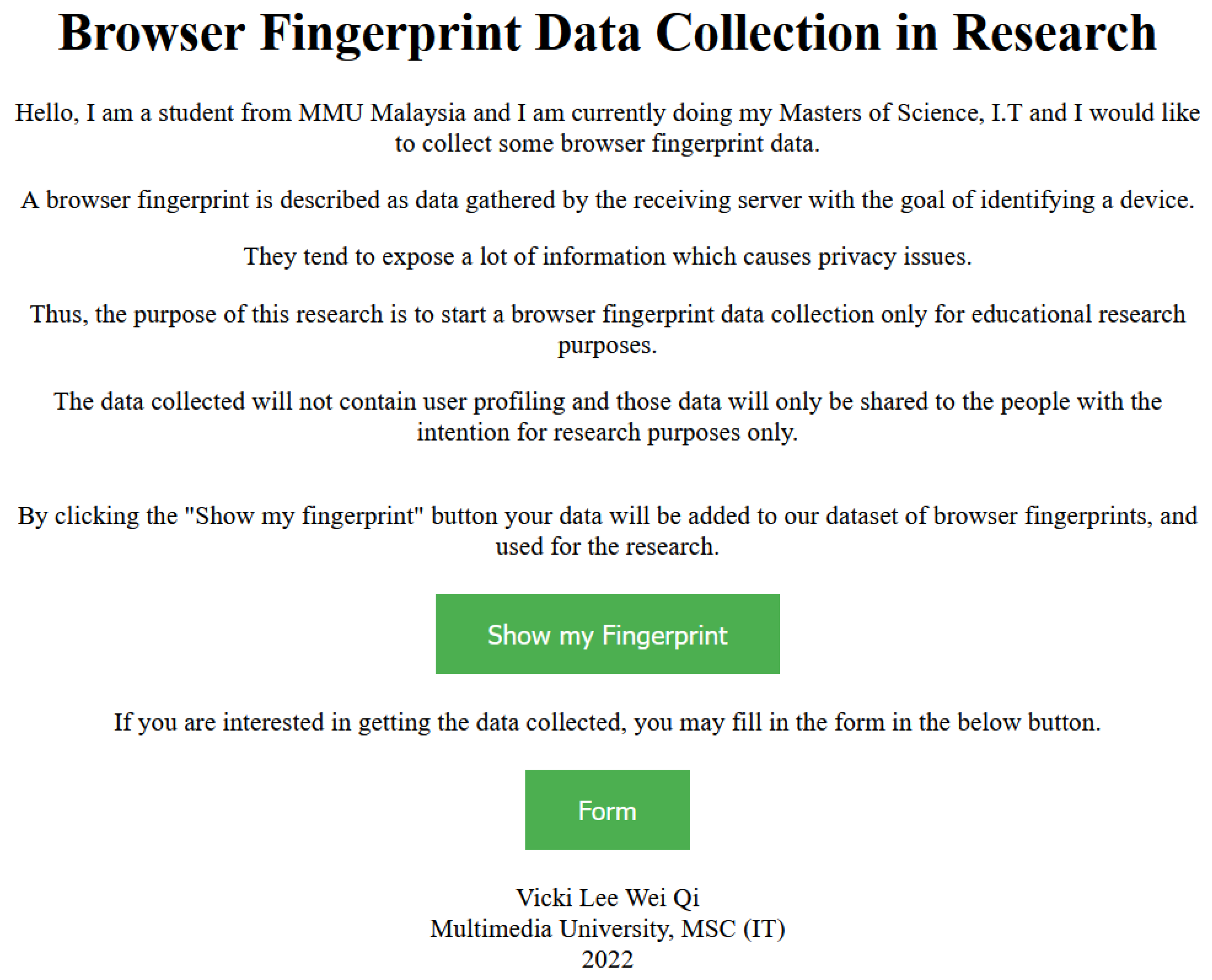
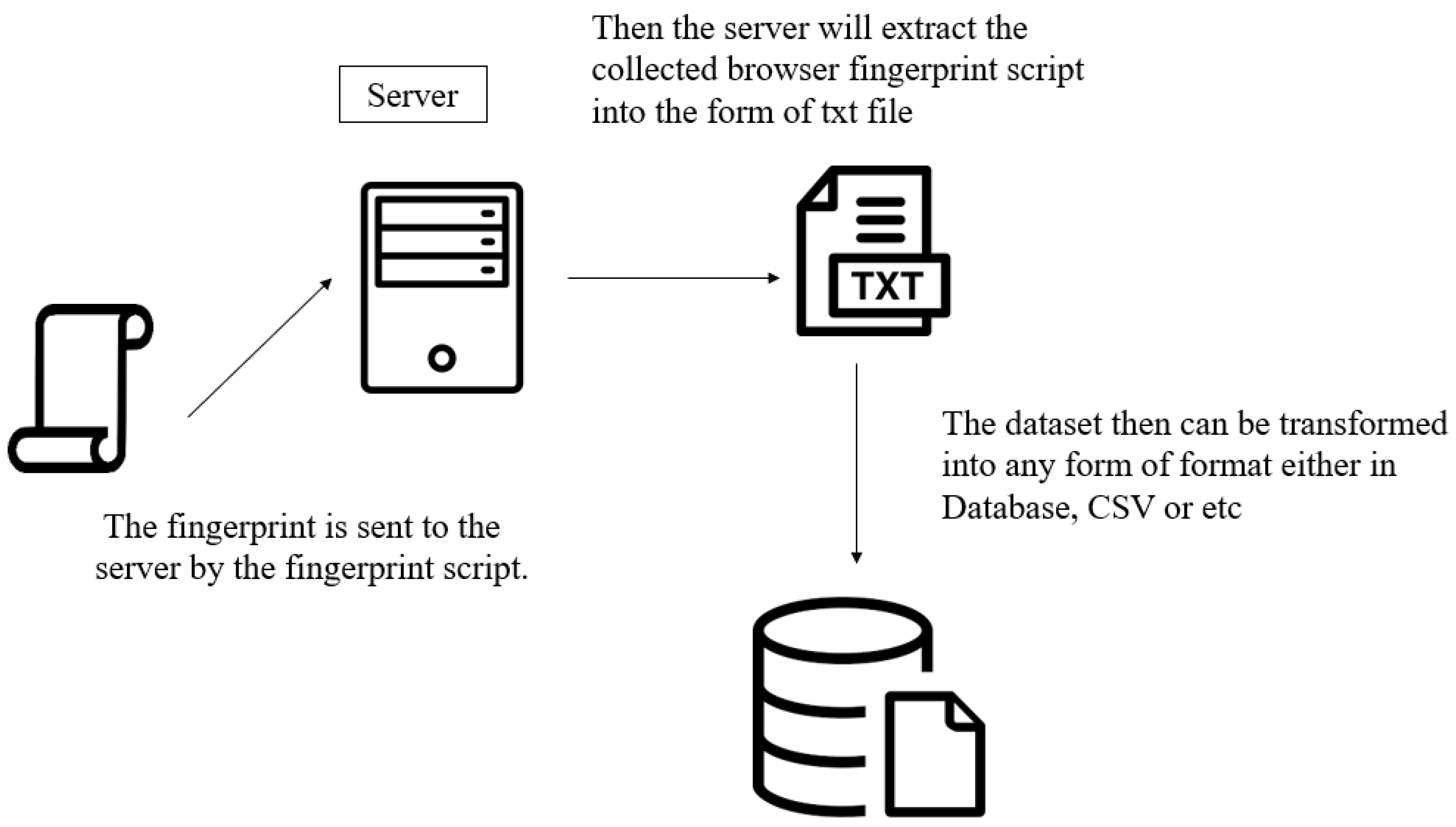
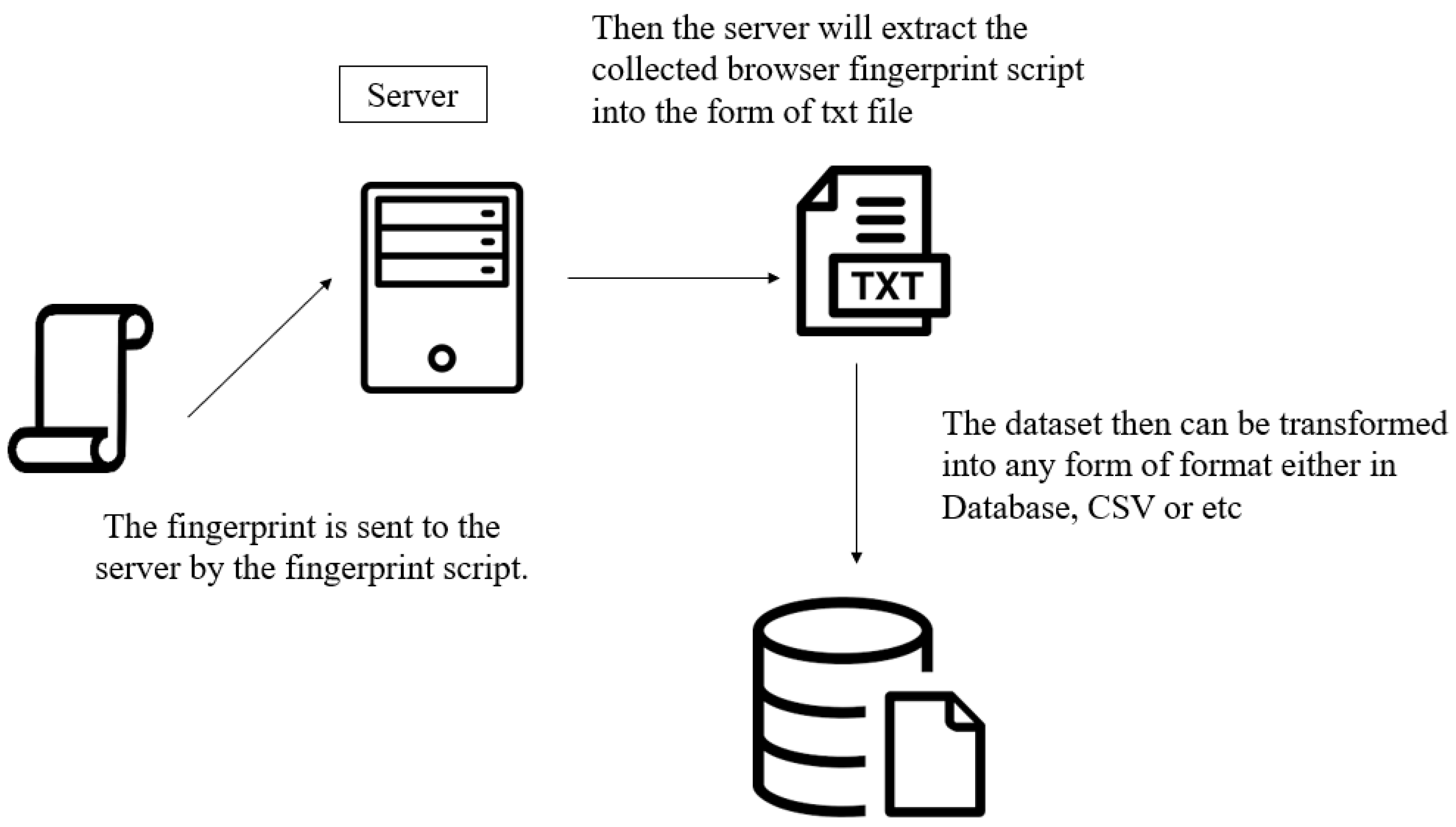
4. Data Collection
5. Attributes
- Uniqueness: The attributes collected in this research are individually unique but the combination of all attributes will turn them into one whole browser fingerprint. The fingerprints need to be unique to differentiate one browser from another. The fact is, if multiple browsers share the same fingerprints, they are invulnerable to browser fingerprinting tracking.
- Stability: Because the browser fingerprint is dynamic, tracking requires a certain level of consistency even when the attributes collected are all unique [14]. Browser fingerprint evolves as a result of user setting changes, browser updates, and other occurrences. In this research, an extension randomly chooses the value of the collected canvas attributes with any of the visits; thus, the browser fingerprint will continue to be unique simply because the canvas is unique. However, it becomes difficult to monitor the fingerprint over time because the canvas is constantly shifting. This research does not collect data that do not have stability such as the viewport size, the performance, and the network speed.
5.1. Triggers
- Automatic: This event occurs automatically without the user’s permission. For example, when the user-agent, browser, or OS attribute is collected, there is no need for the user’s setting changes because most of the values are fixed [13].
- Context-dependent: This is happening because of the user’s settings/concept and due to how the user configures their personal devices settings. For example, attributes collected such as the monitor resolution, location, or time zone can easily be modified by the user as the values are not fixed.
- User-triggered: It requires user involvement input on some attributes. For example, the scenario of how the user enables cookies on their browser.
5.2. HTTP Headers Fields
5.3. Java Script Attributes
5.3.1. Navigator Object
5.3.2. Window and Screen
5.3.3. Canvas Fingerprinting
| Algorithm 1 How the canvas fingerprint is being generated. |
| <b>Hash:</b> <span id=‘hash-code’></span><br> <canvas id=‘myCanvas’ width=‘200’ height=‘40’ style=‘border:1px solid #000000;’></canvas> <script> var canvas = document.getElementById(“myCanvas”); var ctx = canvas.getContext(“2d”); ctx.fillStyle = “rgb(255,0,255)”; ctx.beginPath(); ctx.rect(20, 20, 150, 100); ctx.fill(); ctx.stroke(); ctx.closePath(); ctx.beginPath(); ctx.fillStyle = “rgb(0,255,255)”; ctx.arc(50, 50, 50, 0, Math.PI * 2, true); ctx.fill(); ctx.stroke(); ctx.closePath(); txt = ‘abz190#$%^@£éú’; ctx.textBaseline = “top”; ctx.font = ‘17px “Arial 17”‘; ctx.textBaseline = “alphabetic”; ctx.fillStyle = “rgb(255,5,5)”; ctx.rotate(.03); ctx.fillText(txt, 4, 17); //hashing function src = canvas.toDataURL(); hash = 0; for (i = 0; i < src.length; i++) { char = src.charCodeAt(i); hash = ((hash<<5)-hash)+char; hash = hash & hash; } //output this however you want $(‘#hash-code’).html(hash); </script> |
5.3.4. CSS Fingerprinting
5.4. List of Fonts
6. Results and Discussion
Discussion over the Dataset
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Salomatin, A.A.; Iskhakov, A.Y.; Iskhakova, A.O. Web user identification based on browser fingerprints using machine learning methods. IFAC-PapersOnLine 2021, 54, 582–587. [Google Scholar] [CrossRef]
- Upathilake, R.; Li, Y.; Matrawy, A. A classification of web browser fingerprinting techniques. In Proceedings of the 2015 7th International Conference on New Technologies, Mobility and Security—Proceedings of NTMS 2015 Conference and Workshops, Paris, France, 27–29 July 2015. [Google Scholar] [CrossRef]
- Eckersley, P. How Unique Is Your Web Browser? 2010. Available online: https://panopticlick.eff.org (accessed on 1 June 2022).
- Laperdrix, P.; Rudametkin, W.; Baudry, B. Beauty and the Beast: Diverting Modern Web Browsers to Build Unique Browser Fingerprints. In Proceedings of the Proceedings—2016 IEEE Symposium on Security and Privacy (SP), San Jose, CA, USA, 22–26 May 2016; pp. 878–894. [Google Scholar] [CrossRef] [Green Version]
- Karpukhin, E.; Sharmaev, V.; Propp, A. De-Anonymization of the User of Web Resource with Browser Fingerprint Technology. J. Theor. Appl. Inf. Technol. 2022, 31, 14. Available online: www.jatit.org (accessed on 1 July 2022).
- Mayer, J.R.; Barlow, J.P. ‘Any person… a pamphleteer’ Internet Anonymity in the Age of Web 2.0. Bachelor’s Thesis, Princeton University, Princeton, NJ, USA, 2009. Available online: http://arks.princeton.edu/ark:/88435/dsp01nc580n467 (accessed on 1 June 2022).
- Gómez-Boix, A.; Laperdrix, P.; Baudry, B. Hiding in the Crowd. In Proceedings of the 2018 World Wide Web Conference on World Wide Web—WWW ’18, Lyon, France, 23–27 April 2018; pp. 309–318. [Google Scholar] [CrossRef] [Green Version]
- Acar, G.; Juarez, M.; Nikiforakis, N.; Diaz, C.; Gürses, S.; Piessens, F.; Preneel, B. FPDetective. In Proceedings of the 2013 ACM SIGSAC conference on Computer & communications security—CCS ’13, Berlin, Germany, 4–8 November 2013; pp. 1129–1140. [Google Scholar] [CrossRef] [Green Version]
- Nikiforakis, N.; Kapravelos, A.; Joosen, W.; Kruegel, C.; Piessens, F.; Vigna, G. Cookieless Monster: Exploring the Ecosystem of Web-Based Device Fingerprinting. In Proceedings of the 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 19–22 May 2013; pp. 541–555. [Google Scholar] [CrossRef] [Green Version]
- Laperdrix, P.; Bielova, N.; Baudry, B.; Avoine, G. Browser Fingerprinting. ACM Trans. Web 2020, 14, 1–33. [Google Scholar] [CrossRef] [Green Version]
- ThreatMetrix. ThreatMetrix Announces Cookieless Device Identification to Prevent Online Fraud While Protecting Customer Privacy. 2018. Available online: https://www.retailitinsights.com/doc/threatmetrix-announces-cookieless-0001 (accessed on 1 August 2022).
- Bursztein, E.; Malyshev, A.; Pietraszek, T.; Thomas, K. Picasso. In Proceedings of the 6th Workshop on Security and Privacy in Smartphones and Mobile Devices, Vienna, Austria, 24 October 2016; pp. 93–102. [Google Scholar] [CrossRef] [Green Version]
- Supervisors, A.V.; Rouvoy, R.; Rudametkin, W. Tracking Versus Security: Investigating the Two Facets of Browser Fingerprinting. Ph.D. Thesis, Université de Lille Nord de France, Lille, France, 2019. [Google Scholar]
- Rouvoy, R.; Rudametkin, W. Leveraging Browser Fingerprinting to Strengthen Web Authentication Antonin DUREY. Ph.D. Thesis, Université de Lille, Lille, France, 2020. [Google Scholar]
- Antonio, E.; Fajardo, A.; Medina, R. Browser Fingerprint Standardization Using Rule-Based Algorithm and Multi-Class Entropy A new method of location estimation for fingerprinting localization technique of indoor positioning system View project Browser Fingerprinting View project Browser Fingerprint Standardization Using Rule-Based Algorithm And Multi-Class Entropy. Int. J. Sci. Technol. Res. 2020, 9, 3635–3639. [Google Scholar] [CrossRef]
- Mowery, K.; Shacham, H. Pixel Perfect: Fingerprinting Canvas in HTML5. 2012. Available online: https://hovav.net/ucsd/papers/ms12.html (accessed on 1 June 2022).
- Mowery, K.; Bogenreif, D.; Yilek, S.; Shacham, H. Fingerprinting Information in JavaScript Implementations. In Proceedings of the W2SP 2011, Oakland, CA, USA, 26 May 2011; pp. 1–11. [Google Scholar]
- Takei, N.; Saito, T.; Takasu, K.; Yamada, T. Web Browser Fingerprinting Using only Cascading Style Sheets. In Proceedings of the 2015 10th International Conference on Broadband and Wireless Computing, Communication and Applications, BWCCA, Krakow, Poland, 4–6 November 2015; pp. 57–63. [Google Scholar] [CrossRef]
- Buhov, D.; Rauchberger, J.; Schrittwieser, S. FLASH: Is the 20th Century Hero Really Gone? Large-Scale Evaluation on Flash Usage & Its Security and Privacy Implications. 2018. Available online: http://www.cvedetails.com/product/6761/Adobe-Flash-Player.html?vendor_id=53 (accessed on 1 June 2022).
- Iaroslavskiĭ Gosudarstvennyĭ Universitet; Institute of Electrical and Electronics Engineers—Russia Section CAS Chapter; Moscow Technical University of Communications and Informatics; Institute of Electrical and Electronics Engineers. Proceedings of the 2019 Systems of Signal Synchronization, Generating and Processing in Telecommunications (SYNCHROINFO), Yaroslavl, Russia, 1–3 July 2019; P.G. Demidov Yaroslavl State University: Yaroslavl, Russia, 2019.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Source | Value Examples |
|---|---|---|
| Accept | HTTP header | Text/html, application/xhtml + xml, application/xml; q = 0.9, image/webp, */*; q = 0.8 |
| Connection | HTTP header | Close |
| User-agent | HTTP header | Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, such as Gecko) Chrome/102.0.5005.63 Safari/537.36 |
| Canvas | JavaScript |  |
| Cookies | JavaScript | Yes |
| Local storage | JavaScript | Yes |
| Time zone | JavaScript | −180 |
| Lists of fonts | Flash or JavaScript | Abyssinica SIL, Aharoni CLM, AR PL UMing CN, AR PL UMing HK, AR PL UMing TW… |
| Attribute | Triggers | Value |
|---|---|---|
| Browser | Automatic | Chrome 74 |
| OS | Automatic | Windows NT 4.0|32 bits |
| User-agent | Automatic | Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, such as Gecko) Chrome/102.0.5005.63 Safari/537.36 |
| Display font | Context | 24|1536|864|1536|824 |
| Time zone | Context | −7 |
| Plugins | Automatic/user | N/A |
| Cookie | User | true |
| Browser | Automatic | Chrome 74 |
| User-Agent Header Value | Source |
|---|---|
| Mozilla/5.0 (iPhone; CPU iPhone OS 16_0 such as Mac OS X) AppleWebKit/605.1.15 (KHTML, such as Gecko) Version/16.0 Mobile/15E148 Safari/604.1 | Safari on the iPhone |
| Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0 | Firefox on Windows 10 |
| Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, such as Gecko) Chrome/102.0.5005.63 Safari/537.36 | Chrome 73 on Windows 10 |
| Example of Platforms | Source |
|---|---|
| Linux x86_64, Linux armv7l, Linux armv8l, Linux i686, Linux aarch64 | Browsers running on the Linux |
| iPad, iPhone | Browsers running on iOS. |
| Win64, Win32 | Browsers running on the windows |
| Attribute | Possible Values | Description |
|---|---|---|
| screen.width | 1280 | Pixel width of the screen area that is exposed to the web. If there are several screens, it ought to return the value of the screen on which the browser window is now visible. The browser window’s size has no bearing on the value. |
| screen.avail | 1024 | Amount of horizontal and vertical space in pixels available to the browser window. |
| screen.colorDepth | 24 | Colour depth of the screen. |
| screen.dpi | 120 | Dots per inch is to describe the resolution of the image on the screen. |
| window.inner | 1536 | The browser’s width and height in pixels including the scrollbar’s size. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pau, K.N.; Lee, V.W.Q.; Ooi, S.Y.; Pang, Y.H. The Development of a Data Collection and Browser Fingerprinting System. Sensors 2023, 23, 3087. https://doi.org/10.3390/s23063087
Pau KN, Lee VWQ, Ooi SY, Pang YH. The Development of a Data Collection and Browser Fingerprinting System. Sensors. 2023; 23(6):3087. https://doi.org/10.3390/s23063087
Chicago/Turabian StylePau, Kiu Nai, Vicki Wei Qi Lee, Shih Yin Ooi, and Ying Han Pang. 2023. "The Development of a Data Collection and Browser Fingerprinting System" Sensors 23, no. 6: 3087. https://doi.org/10.3390/s23063087
APA StylePau, K. N., Lee, V. W. Q., Ooi, S. Y., & Pang, Y. H. (2023). The Development of a Data Collection and Browser Fingerprinting System. Sensors, 23(6), 3087. https://doi.org/10.3390/s23063087