1. Introduction
In Machine Learning (ML) [
1], the problem of data privacy, i.e., the existence of data private to the owning subject, has become relevant in many application fields in these last years, as well shown in the recent survey in [
2].
In ML, this data privacy issue was explicitly tackled for the first time in 2015 with the introduction of the concept of Federated Learning (FL) [
3,
4]; in the basic form of this approach, a server starts its execution by creating a random solution under the form of a model that is sent to a set of clients, one for each set of data that should be kept private. Learning on any local set of private data only takes place on the local client associated with those specific data, so it is never sent elsewhere. Learning on a node results in the model being modified locally to best adhere to the local data. The locally modified model is sent back to the server at the end of the local learning. Once the latter has received all the modified models, it aggregates them to create a new model that considers all the local learning. After the aggregation phase, this latter model is sent again to the clients, and the process continues until it reaches a termination criterion on the server. A good survey on recent advances in FL can be found in [
5].
Not all the existing ML techniques can be used within FL, because only some can undergo a meaningful aggregation process. For example, there is no such aggregation process available for methods based on Deep Neural Networks (DNNs) [
6], logistic regression [
7] and Radial Basis Functions [
8].
Another important issue relevant to ML is the interpretability of the proposed solutions, as well evidenced in [
9]. This means that a proposed solution should be understandable by any user. This is clearly a problem with the recent and numerically well-performing ML techniques, which DNNs [
10,
11] are. The latter build an internal model that, although capable of excellent numerical performance, is unintelligible to the user, be it a physician or a patient, which is why they are called black boxes.
To somehow get rid of this problem, in 2017, Explainable Artificial Intelligence (XAI) (
https://sites.google.com/view/fl-tutorial/?pli=1 accessed on 8 February 2023) [
12] was introduced, which tries to endow DNNs with mechanisms allowing the creation of an external model that can somehow explain the behavior of the algorithm in making its decisions [
13]. The problem with this is that there cannot be any guarantee that the external model is the same as the internal one over the data domain, which could lead to serious errors that could even be fatal in the medical domain.
This paper proposes a general ML framework that can satisfy the issues related to data privacy and interpretability. Namely, our approach is based on the use of Evolutionary Algorithms (EAs), a widely used class of ML methodologies [
14,
15,
16], and consists of the use of a distributed version of an EA (dEA) [
17,
18].
The proposed methodology is close to the classical FL approach, yet it is simultaneously different from it. It is similar because it allows each client to work on local data only and because global knowledge of the problem is obtained by aggregating the different local knowledge. The difference with the classical FL is that this aggregation is performed implicitly rather than explicitly, as in the typical FL scheme. A thorough explanation of this difference is given later in the paper.
From an architectural viewpoint, the dEA framework we put forward contains both a master acting as the server and, thus, managing the algorithm, and a set of nodes, each of which represents a client and only contains local data to be kept private. Grammatical Evolution (GE) [
19,
20] is used as the specific EA: in it, each proposed solution is a model constituted by an expression linking (some of) the problem variables, so it represents explicit knowledge that users can immediately understand. Given this choice, we make use of a distributed GE scheme.
In our proposed framework, learning takes place locally on each node, on which good local knowledge specific to the local data is gained in terms of a local model. Moreover, at given times, these good local models are sent to the master. This latter evaluates the global quality of each of these models over all the data, thanks to the help of all the nodes, without any need to transmit data from any node; then, it sends to all of the nodes all these models. These arrived solutions enter the local learning process; in this way, the local knowledge in each node can be augmented thanks to that arriving from other nodes. As a consequence of this exchange of information, better global knowledge can be obtained.
This kind of implicit aggregation process ties local models into a global one. Said otherwise, during the execution of our algorithm, global knowledge emerges from the data contained in the various local sets without any need to physically exchange or make them visible. At the end of the execution, the model performing the best globally, i.e., over all the local sets of private data, is obtained as desired. Moreover, as a very interesting byproduct of our framework, apart from the global knowledge of the problem, for each set of private data, personalized knowledge is obtained that is specific to each of them.
The proposed framework does not deal with the security issue in the current implementation. For a thorough description of the problems of privacy guarantees for users and detection against possible attacks, interested readers can refer to [
21,
22].
The framework is applicable in different domains [
23,
24]: healthcare, bank loans, advertising, financial fraud, and insurance, among others. In this paper, we focus our attention on the medical field, where there is a high need for data privacy and interpretability of the solutions.
Regarding privacy, medical data are highly sensitive and strictly personal to the patient, so they should not be disclosed to anybody else, meaning both any other patient participating in the study and any person involved in the handling of the data or the learning process. In the European Union, this issue is regulated by the General Data Protection Regulation (GDPR) (2016/679 law) (
https://eur-lex.europa.eu/eli/reg/2016/679/oj accessed on 3 February 2023) [
25] that concerns data protection and privacy within the Union.
For interpretability, in medicine, a solution should be understandable by any subject participating in the study. This holds for a physician wishing to evaluate from a medical viewpoint the soundness and the interest of the knowledge proposed by the ML system, or a patient wishing to receive a diagnosis that is clear and well explains the reasons for that decision. This also follows the GDPR law, specifically Article 12, which states that the data controller gives information to the ‘data subject in a concise, transparent, intelligible and easily accessible form, using clear and plain language’. Moreover, Article 25 recognizes subjects’ right to contest any automated decision making that was solely algorithmic.
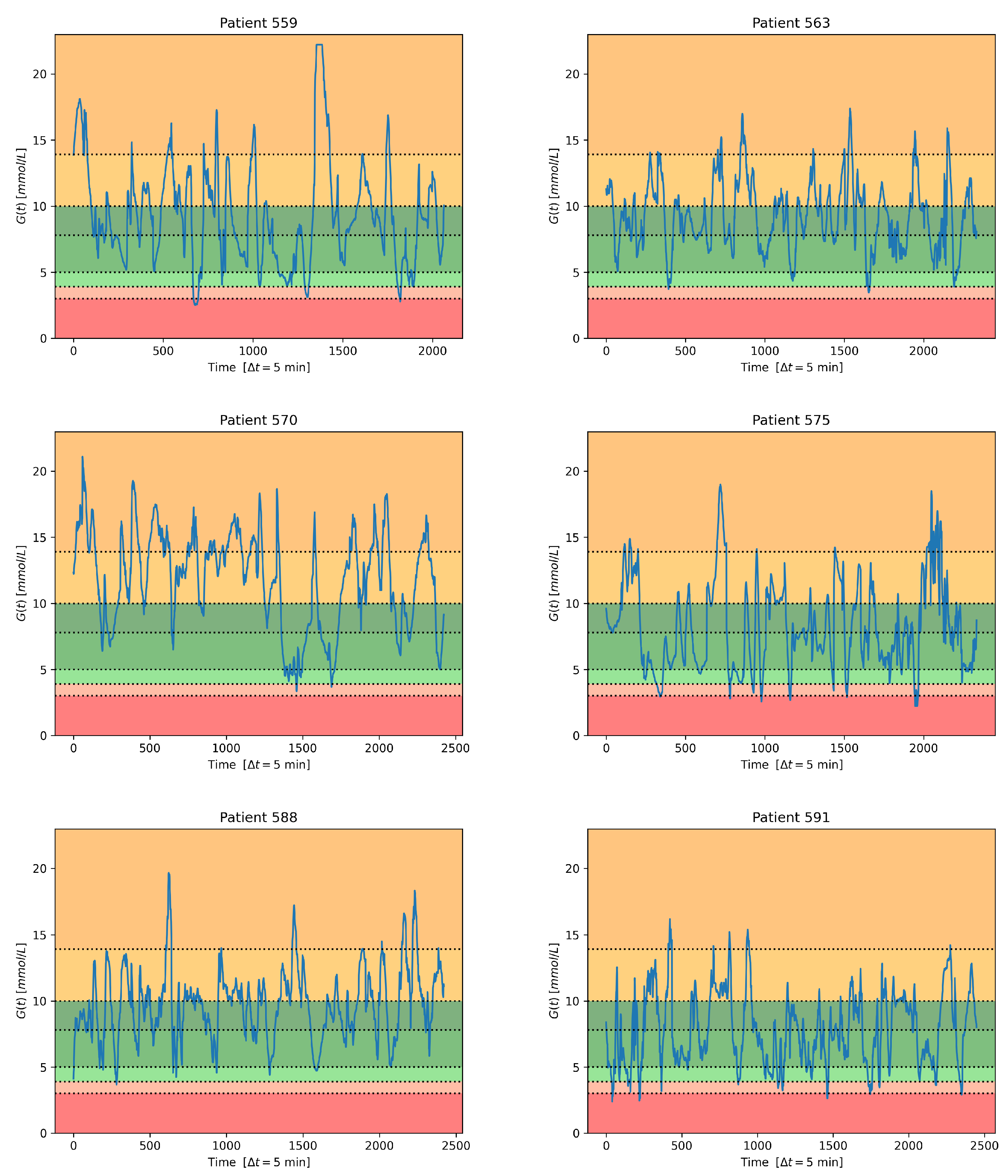
Within the medical field, we chose to take into account diabetes [
26] disease, with specific reference to the prediction of future glucose values for subjects suffering from Type-1 diabetes mellitus (T1DM). Diabetes is a chronic disease, and its T1DM version is characterized by the fact that the subject’s pancreas produces practically no insulin, which calls for a life-lasting treatment consisting in the daily administration of amounts of insulin. In fact, if not treated, diabetes determines hyperglycemia, a condition of increased blood glucose values that with time may yield relevant damage to several parts of the body, among which are the eyes, kidneys, nerves, heart, lower limbs, and blood vessels [
27].
As the data set to conduct our experiments, we avail ourselves of the well-known and publicly available Ohio T1DM data set [
28]. In the experiments, rather than attempting to predict the exact future glucose values, as would be the case in multivariable regression, we treat prediction as a classification problem. This is an approach already taken in the scientific literature through various methods [
29]. To follow this way of operating, we divide the glucose range into seven intervals, and for each future value, we aim at predicting the interval it lies within. This is a good way to predict if a future glucose value will lie in high-risk intervals, such as those associated with very low or very high values. In this case, immediate recovery actions can be taken to eliminate or reduce risks to the subject’s health.
In clinical practice, Time-in-Range represents the time spent within a safe glucose-level range [
30]. Within the safe range, the patient may avoid unnecessary actions to correct the blood glucose level, which may accidentally trigger an undesired outcome. In principle, the patient needs to know whether he/she is staying within the safe range or deviating from it. The proposed prediction addresses this need, while relieving the patient from the stress of operating with exact glucose levels, which may lead to diabetes burnout [
31]. As a side effect, the resulting models can be simpler, thus reducing the computational complexity for lower-power devices and for possible cloud processing for thousands of patients. Moreover, the proposed method has the future potential to be applied as a watchdog over an insulin pump’s controller activity. As it is a prediction method, it could detect the controller’s failure to keep glucose levels in the safe range ahead of time.
As the outcome of our experiments, we expect to obtain an explicit global model able to perform generalization. This means that such a model should perform acceptably well on all the subjects involved in this learning process and on others not involved in creating the model. This would be highly important in real-world situations where we have to start monitoring diabetic subjects for which we do not have specific knowledge. We would need a general model to use on them to predict their future glucose values, and we could use the one obtained through our framework.
To evaluate the effectiveness of the mechanism of information exchange among nodes, our algorithm is experimentally compared against a distributed EA differing only in the absence of exchange. This comparison is effected both in terms of numerical performance achieved in the classification and from the statistical analysis perspective.
The rest of this paper is structured as follows.
Section 2 presents a brief state-of-the-art review.
Section 3 describes the proposed collaborative approach and the data set used. The experimental framework and the discussion about findings are reported in
Section 4. In the same section, the results of the statistical analysis test, performed over the twelve subjects of the complete Ohio T1DM data set, are outlined. The last section exposes the conclusions and provides some indications on future work.
2. State of the Art
An important issue when dealing with ML applications is data privacy related to the protection of sensible personal information. This issue is increasing with the usage of online platforms collecting private data to provide services. A privacy-preservation framework must ensure high protection to let individuals share their information. FL represents the most employed technology to accomplish the privacy task [
3,
4,
32]. This federated technique facilitates distributed collaborative learning by multiple clients under the coordination of a server. Data privacy is assured by training a prediction model through decentralized data, locally associated with different clients and not exchanged or transferred. Federated Learning is applied to support privacy-sensitive applications in several fields [
24].
Another important issue of ML lies in its ability to discover underlying explanatory structures. The most performing techniques, i.e., deep learning neural networks, can be regarded as black boxes lacking an explicit knowledge representation. Utilizing black box learning models involves difficulty in understanding what model inputs drive the decisions (explainability) and, above all, prevents specialists from understanding the reason for a prediction (interpretability) [
9,
33]. The demand for transparent decisions pushes towards explainable and interpretable systems [
34]. Explainable systems are black box learning models endowed with external XAI tools, without guarantee that these external tools allow capturing the internal model behavior. Interpretable models are models able to explain themselves by providing explicit models. From now on, the term interpretability is employed with the above meaning.
Both the above issues assume noticeable importance in the medical domain, e.g., diabetes management. Several techniques have been investigated to discover data-driven glucose forecasting models, ranging from approaches based on regression [
35,
36,
37,
38,
39] to those that handle the prediction as a classification problem [
29,
40,
41,
42]. These techniques can be classified as explainable or interpretable based on the techniques employed for discovering the learning model.
Leaving aside the regression-based models, a brief literature survey on the state-of-the-art works on diabetes classification using data-driven ML models is conducted for the explainable and interpretable models described above. The review is related to recent articles that explore different techniques for dealing with glucose prediction formulated as a classification problem.
The first category concerns explainable techniques, most based on neural models, that exhibit outstanding performance at the expense of the difficulty of comprehending the aspects that can explain the decision, even when enriched with external XAI explanation tools [
43,
44,
45,
46,
47,
48,
49,
50,
51,
52,
53,
54,
55]. As already illustrated in the introduction, the lack of explanation could yield the usage of these classification techniques problematic in the medical domain [
56]. In fact, these learning models’ inner workings are too complicated to understand for physicians.
The second category includes interpretable models characterized by explicit prediction models. Most of these models rely on decision trees [
57,
58,
59,
60,
61,
62,
63,
64,
65,
66,
67,
68,
69]. Although the methods based on these trees [
70] could provide explicit knowledge, in many cases, it is challenging to linearize the resulting acyclic decision graphs into simple decision rules. Other attempts have been carried out to make predictions through classification rules based on if–then–else conditions induced by an evolutionary approach [
71,
72].
Independently of the belonging category, none of the above-examined approaches consider the problem of data privacy, which remains a critical concern when handling sensitive information such as diabetic data [
73]. FL technology has been utilized in the medical domain to train a prediction model through decentralized data for dealing with different problems [
74,
75,
76,
77].
Only some recent papers contemplate the problem of implementing privacy-protected diabetes prediction systems relying on FL approaches and encryption with different training processes [
78,
79]. However, instead of employing data related to a single patient, the training concerns data collected in each hospital [
78] or grouped by defining cohorts associated with diabetes-related complications [
79]. Therefore, while ensuring data protection, these approaches do not permit the development of personalized models that are important from the point of view of precision medicine.
This review makes us confident that, at least in the recent scientific literature, data privacy has not been considered for tuning interpretable glucose forecasting models for diabetic patients. Indeed, most reviewed predictive models rely on centralized training data, or refer to decentralized training clients associated with data not referred to single patients, and thus are unable to allow personal disease treatment and prevention strategies.
Table 1 summarizes the results of the review. As evinced from this table, the limitation of the current FL approaches is related to solution interpretability.
We aim to overcome this limitation by dealing with a data-privacy paradigm able to discover interpretable Machine Learning models for glucose prediction. This paradigm is based on some collaborative concepts inspired by FL. Specifically, this collaboration is pursued by training a Federated Learning-inspired global model, relying on a dEA that evolves multiple decentralized clients, each representing a single patient, holding local data samples without exchanging them. The collaborative training consists in sharing the model discovered by each local patient to be aggregated in a global model. The personalized models emerged at the end of evolution can be exploited for personal diabetes treatment or aggregated and used as global models.
Regarding interpretability, we concentrated on a grammar-based Evolutionary Algorithm to discover explicit classification models.
The following section illustrates the devised framework and its specific application to the glucose forecasting problem.
4. Experimental Results
4.1. Experimental Framework Setting
Our approach was implemented by exploiting PonyGE2, a freely downloadable and patent-free GE implementation in Python [
82]. PonyGE2 has a number of GE-specific parameters to set, the meaning of which can be found in [
82]. After a preliminary tuning, the parameters used for all the experiments were set as follows: population size and maximum generations equal to 200 and 500, respectively; codon size equal to 100,000, tournament selection with size 4, mutation probability equal to 10%, one-point crossover probability equal to 90%, int flip per codon mutation with one mutation event, and Position Independent Grow method for the individual initialization. For the slaves, a single local stopping conditionwas considered and set to the fulfillment of the maximum number of generations.
We set the communication between the master and the slaves to take place every 100 generations. This value was chosen because of two motivations.
The first reason comes from the field of dEAs: it is known that any subpopulation should not receive immigrating individuals too frequently, because this would perturb the local evolution at each communication time. The local search must be given sufficient time to suitably integrate the arrived individuals into the local subpopulation, so as to exploit their good features.
The second reason is related to the FL principles themselves in terms of security: an FL algorithm should involve the least possible amount of information being transmitted, because any possible communication could be attacked, possibly resulting in a subject’s relevant information being disclosed or in an injection of fake data by attackers, which could lead to totally wrong learning.
Hence, based on our experience, we feel the value of 100 implies the lowest amount of communication that allows improvement in the learning process while, at the same time, not excessively exposing the process to external attacks. In fact, this value of 100, together with the number of generations being set to 500, means that, during the whole execution, only five communication phases between the master and the slaves take place.
The forecasting horizon is
min, because the forecasting accuracy becomes worse and less reliable as the prediction horizon augments [
91,
92]. A horizon longer than 30 min, e.g., 2 or 4 h, is only practical for time spans that refer to almost steady-state situations as nocturnal predictions when sleeping. Any external event can cause a substantial and unpredictable glucose-level variation during these long intervals. The considered past time window is
min for the historical samples leveraged for the forecasting. The time span for the historical data is chosen considering that 30-min data in the past are enough to perform an effective prediction [
93]. Given that the values are taken at 5-min intervals, the values for
k and
h are equal to 12 and 6, respectively. This implies that both in the grammar and in Equation (
5), at each time t, we consider twelve glucose values in the past and six insulin and carbohydrate values in the future.
To assess the effectiveness of the proposed approach, we conducted two experiments:
In the first experiment, we used a non-FL approach consisting of FLEA with no communication between the master and the slave nodes during the evolution. In other words, we executed a separate optimization for all the patients, thus obtaining for each of them a personalized model. At the end of the executions, we collected all the models and selected among all of them the model with the best average performance on all the patients;
In the second experiment, we used FLEA. The average outcomes for each run were evaluated at the end of the evolution by considering all the best local models received by the master node from all the slaves and measuring their performance on all the patients to evaluate how they perform on average when adopted as global models.
For each patient, indicated with the identifier ID, twenty runs were carried out to reduce the randomness in the GE algorithm initialization. The evaluation is performed on all instances for which a glucose measurement is available over the prediction period.
4.2. Findings and Discussion
Table 5 and
Table 6 report the
score of the best models on each slave of both experiments, and the last row and column show their averages and standard deviations. By looking at
Table 5, it can be evidenced that, when adopted as a global model, each personalized model exhibits
score values that are quite different on a specific patient (rows), and the same is true also when the performance of the models is measured on a specific patient (columns). On the contrary, inspecting the results of
Table 6 related to our approach, the scenario changes. Independently of the adopted global model, the average
score of the evolved models is always better than the previous case, except for subject 570, and very close to each other (rows). A similar consideration also holds for all the models on a specific patient (columns), thus evidencing that the proposed approach can evolve generalized models exhibiting better performance. Moreover, if we look at the best models evolved on local data (diagonals in the tables), it is evident that communication helps improve the performance on local nodes too.
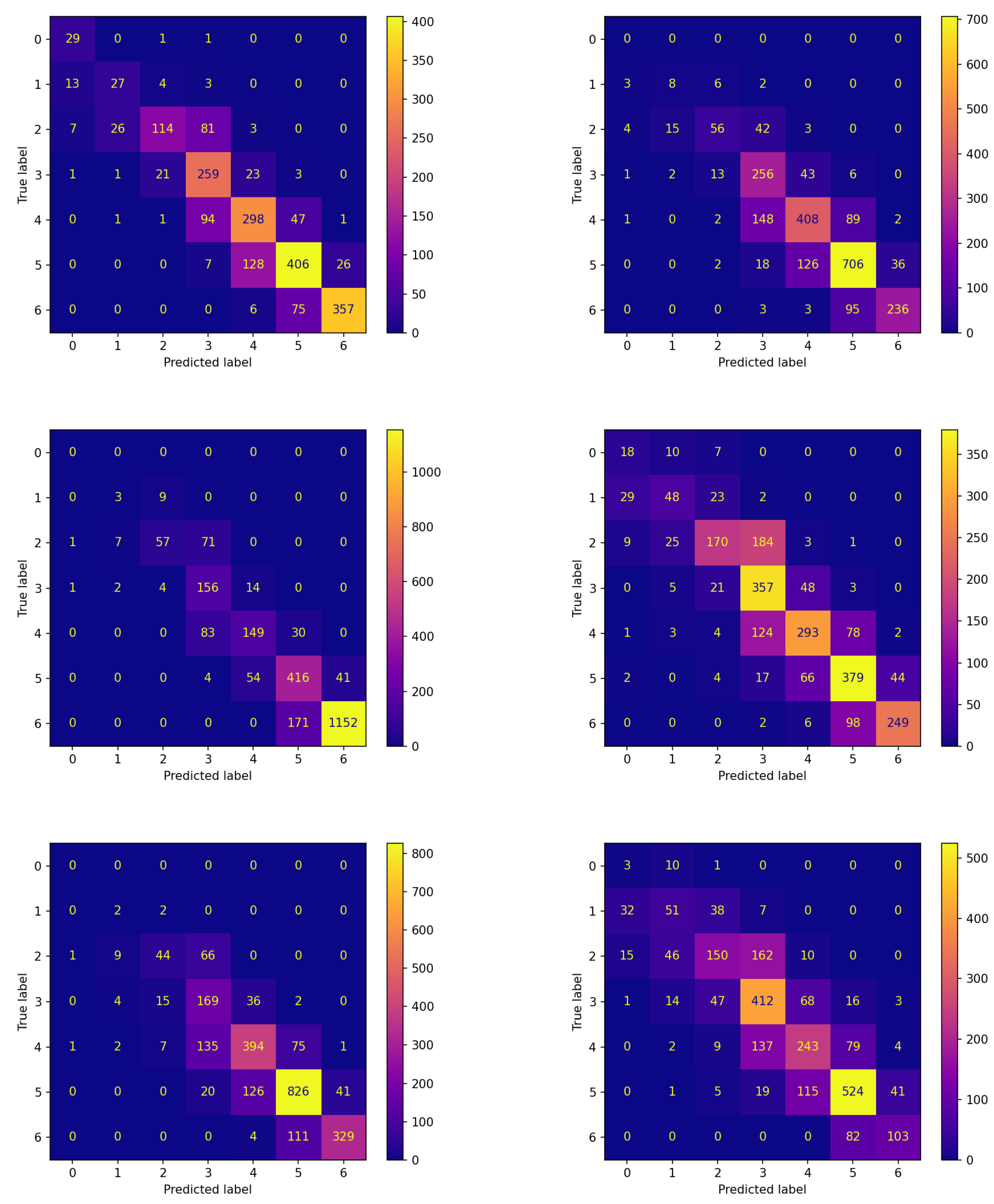
Analogous reflections can be made by comparing the corresponding panes of
Figure 4 and
Figure 5 reporting the confusion matrices on the testing set for both experiments. This comparison documents that FLEA frequently increases the number of items correctly assigned to the classes. This can be verified by looking at the cells along the diagonals, which in most cases contain higher values.
Once we found the two global models proposed by the two different approaches, we wished to investigate their generalization capability to ascertain whether or not they have similar performance for this issue. To this aim, we executed them on six more patients in the Ohio data set.
Table 7 reports the corresponding results in terms of
score for the two models over the testing sets of these six additional patients. The last column in the table reports the average and the standard deviation of these
values.
The table reports that, over all six subjects, the model obtained by FLEA always performs better than that achieved by the non-FL approach. This is very important, because it allows concluding that the model provided by our FLEA framework is more general; therefore, it can be used for new subjects not participating in the learning process.
The confusion matrices corresponding to these experiments are reported in
Figure 6 and
Figure 7 for the two algorithms without and with communication, respectively.
The comparison between the corresponding panes of the two figures evidences that the items are more frequently assigned correctly when FLEA is considered: the cells along the diagonals contain higher values when communication takes place. This is of crucial importance for the two classes corresponding to hypoglycemic events. In fact, the latter are high-risk situations, therefore correctly predicting them well in advance is a major issue for subjects’ health. Moreover, in this case, the results confirm that the model produced by the FLEA algorithm is more general and can be useful when new subjects are to be monitored from scratch.
Table 8 reports a comprehensive view of the six subjects’ numerical scores. This table further confirms that the model achieved by FLEA, on average, performs better than that obtained by the non-FL approach. Specifically, the former shows an improvement of about 3.03% for precision, 1.56% for recall, 3.17% for
, and 1.56% for accuracy.
4.3. Statistical Analysis
A statistical analysis test was executed to assess whether or not the best model proposed by the FLEA algorithm performs better than that obtained by the non-FL one over the complete set of the twelve subjects making up the Ohio T1DM data set. This analysis was carried out on the online web platform ‘Statistical Tests for Algorithms Comparison’ [
94] (STAC) (
https://tec.citius.usc.es/stac/ accessed on 15 January 2023). From among the several statistical tests available, the Quade test was chosen because it considers the higher difficulty of some problems and the larger differences that may be shown by the various algorithms over them; hence, the Quade test is different from the Friedman and Aligned Friedman ones, in which all the problems are considered to be of equal importance. For more details on the statistical analysis shown here in general, and on the Quade test in particular, interested readers can refer to the widely cited paper by [
95].
Before running a statistical test, a null hypothesis must be chosen; we set it as the fact that the two models proposed by the two algorithms are statistically equivalent. Moreover, a significance level must be chosen; we set its value as 0.05, which means that, if the null hypothesis is rejected by the test, there is a probability of incorrectly rejecting it.
Table 9 reports the results of this test: the first column contains the algorithms compared, and the second the corresponding rank value; better algorithms are characterized by lower ranking values.
The table shows that FLEA performs better than non-FL on this test. Yet, as the computed p-value is 0.16680, which is higher than 0.05, this test cannot exclude the statistical equivalence between the two algorithms.
To further investigate this issue, we must make reference to post hoc procedures, also described in [
95].
Table 10 reports the results, in terms of adjusted
p-values, for the complete set of post hoc procedures available in STAC, i.e., Bonferroni–Dunn, Holm, Hochberg, Finner, and Li. The FLEA algorithm was chosen as the control method because it is the algorithm with the lowest ranking value in the Quade test.
To understand the results in the table, each post hoc procedure returns an adjusted p-value for non-FL. For all the procedures, this value is lower than the significance level 0.05. This means that the null hypothesis of equivalence is rejected by all of them. Hence, FLEA is statistically better than non-FL.
5. Conclusions and Future Work
To suitably deal with the issues of data privacy and interpretability, in this paper, we proposed a distributed framework that constitutes an innovative approach to Federated Learning. The framework consists in a master process and a set of slaves: On each of the latter, a Grammatical Evolution algorithm is run that only learns from local private data and generates explicit models that humans can interpret. At given times, a migration process occurs between the slaves through the master, the result of which is that each slave receives the local best models found by the other slaves. This results in an exchange of knowledge between the different nodes merging locally gained knowledge. This process of knowledge exchange allows obtaining local models that can work effectively over all the local sets of private data, i.e., they can be used as global models.
As data privacy and interpretability are highly relevant to the medical field, we applied this framework to a medical problem, i.e., that of the prediction of future glucose values for T1DM patients. This problem is transformed into a seven-class classification task. To assess the importance of this process of knowledge exchange, the framework was experimentally compared with another that only differs in the fact that knowledge exchange does not take place between the slaves.
The results show the importance of this exchange process to create a set of personalized models, each of which can be used as the global model. Moreover, the model obtained by our federated approach showed higher generalization capability than that achieved by the non-FL approach when the two were applied to the data of subjects who did not participate in the learning process. A statistical analysis evidenced the superiority of the FLEA algorithm.
In our future work, the results and behavior shown by our framework on this specific problem must be further investigated on other data sets from the medical domain in which data privacy and interpretable solutions are hard constraints.
Another important step to take in our future work is to perform an experimental investigation to evaluate if an optimal frequency for information exchange exists that allows improving the results without causing too many risks in terms of security for the whole framework. This analysis can be crucial considering that it is well in the field of dEAs that the numerical quality of the results may depend, even more highly, on communication frequency. This could lead to improvement in the results provided by our approach, which could, in this way, perform much better than the model without communication.
Regarding security, it should be evidenced that, currently, the framework we proposed does not deal with the data security problem during the phases of information exchange. As we exploit a distributed approach to evolve a global model, it is highly appropriate to discuss data transmission security. The proposed approach does not propagate patient data (e.g., his/her measured glucose) but rather a compression of his/her metabolic responses in the form of a best-suited model at the given time. Solely, this does not raise a concern; nonetheless, in connection with the known treatment setup, it may give an opportunity to use such representation to build a targeted attack. To avoid an eavesdropping attack, an encrypted communication link between the master and slave nodes has to be established.
Data transmission security is not a concern of this paper and will be a subject of future work. In our future work, we will have to suitably address this problem to define a complete Federated Learning framework that could help in real-world medical trials where data privacy must be guaranteed.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}