

A Low-Cost AI-Empowered Stethoscope and a Lightweight Model for Detecting Cardiac and Respiratory Diseases from Lung and Heart Auscultation Sounds

Abstract
1. Introduction
2. Related Work
2.1. Heart Sound Diagnosis
2.2. Lung Sound Diagnosis
3. Materials and Methods
3.1. Dataset
3.2. Data Preprocessing
3.3. Data Augmentation
3.4. Image Generation
3.5. Model Proposition
- The input layer is set to .
- The first 2D convolutional layer takes the bispectrum as the input with 24 filters. The kernel size is set to with a stride of and with ReLU as the activation function.
- The second 2D convolutional layer has 48 filters. The kernel size is set to with a stride of .
- Thirdly, a 2D max-pooling layer is set up with a kernel and a stride.
- Finally, a 2D convolutional is set up with 16 filters. The kernel size is set to with a stride of .
3.6. Model Training and Testing
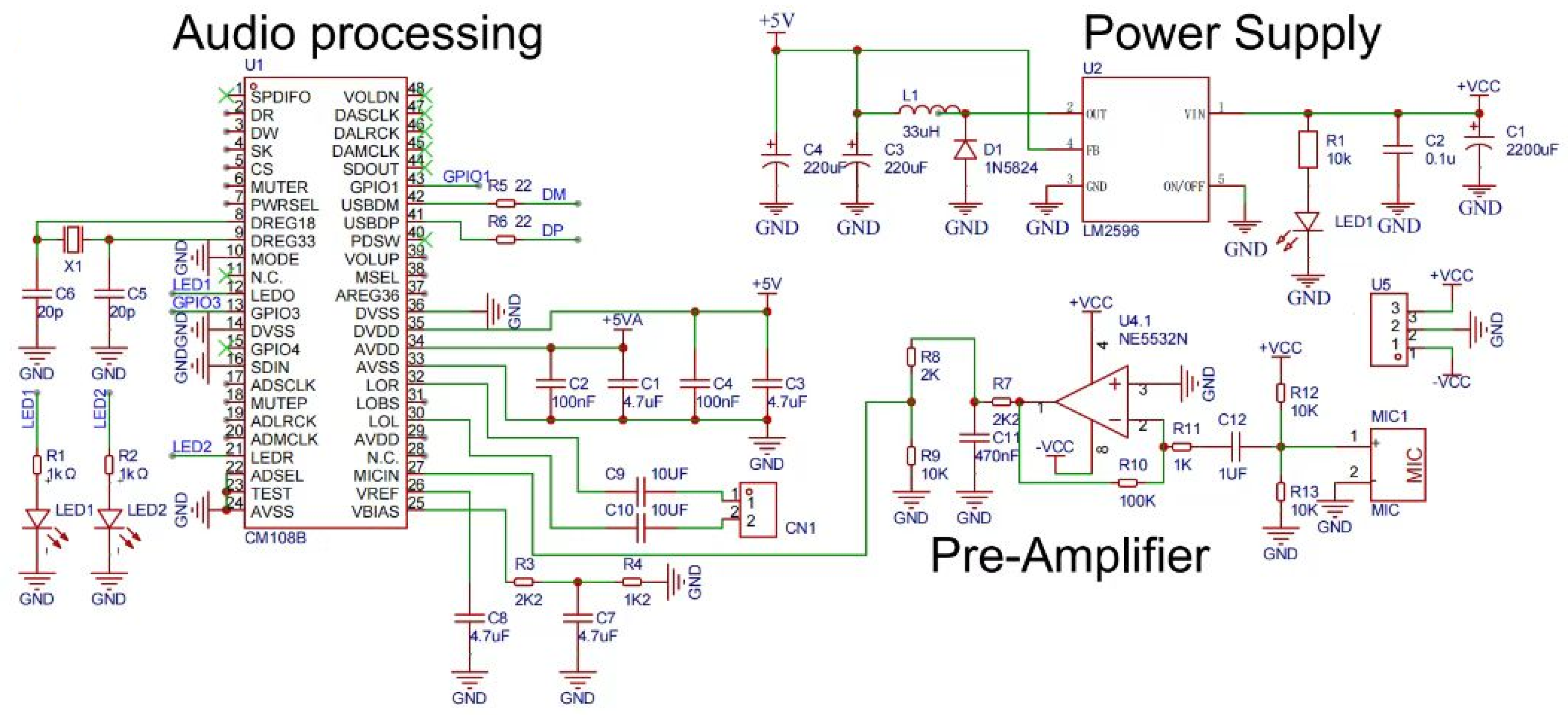
4. Model Deployment with Edge Computing
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- WHO. WHO’s Global Health Estimates: The Top 10 Causes of Death; World Health Organization: Geneva, Switzerland, 2020. [Google Scholar]
- Hu, X.; Ma, X.; Zhao, Q.M.; Yan, W.L.; Ge, X.L.; Jia, B.; Liu, F.; Wu, L.; Ye, M.; Liang, X.; et al. Pulse Oximetry and Auscultation for Congenital Heart Disease Detection. Pediatrics 2017, 140, e20171154. [Google Scholar] [CrossRef] [PubMed]
- Arts, L.; Lim, E.H.; van de Ven, P.M.; Heunks, L.M.A.; Tuinman, P.R. The diagnostic accuracy of lung auscultation in adult patients with acute pulmonary pathologies: A meta-analysis. Sci. Rep. 2020, 10, 7347. [Google Scholar] [CrossRef] [PubMed]
- Mangione, S.; Nieman, L.Z. Pulmonary auscultatory skills during training in internal medicine and family practice. Am. J. Respir. Crit. Care Med. 1999, 159 Pt 1, 1119–1124. [Google Scholar] [CrossRef] [PubMed]
- Weisse, A.B. An Underappreciated Problem with Auscultation. Bayl. Univ. Med. Cent. Proc. 2013, 26, 191–192. [Google Scholar] [CrossRef]
- Hafke-Dys, H.; Bręborowicz, A.; Kleka, P.; Kocinski, J.; Biniakowski, A. The accuracy of lung auscultation in the practice of physicians and medical students. PLoS ONE 2019, 14, e0220606. [Google Scholar] [CrossRef] [PubMed]
- Pasterkamp, H.; Brand, P.L.P.; Everard, M.L.; García-Marcos, L.; Melbye, H.; Priftis, K.N. Towards the standardisation of lung sound nomenclature. Eur. Respir. J. 2015, 47, 724–732. [Google Scholar] [CrossRef]
- Tariq, Z.; Shah, S.K.; Lee, Y. Feature-Based Fusion Using CNN for Lung and Heart Sound Classification. Sensors 2022, 22, 1521. [Google Scholar] [CrossRef]
- Pham, L.D.; Phan, H.; Palaniappan, R.; Mertins, A.; Mcloughlin, I. CNN-MoE Based Framework for Classification of Respiratory Anomalies and Lung Disease Detection. IEEE J. Biomed. Health Inform. 2021, 25, 2938–2947. [Google Scholar] [CrossRef]
- Singh, M.; Cheema, A. Heart Sounds Classification using Feature Extraction of Phonocardiography Signal. Int. J. Comput. Appl. 2013, 77, 13–17. [Google Scholar] [CrossRef]
- Sun, S.; Wang, H.; Jiang, Z.; Fang, Y.; Tao, T. Segmentation-based heart sound feature extraction combined with classifier models for a VSD diagnosis system. Expert Syst. Appl. 2014, 41, 1769–1780. [Google Scholar] [CrossRef]
- Karar, M.E.; El-Khafif, S.H.; El-Brawany, M.A. Automated Diagnosis of Heart Sounds Using Rule-Based Classification Tree. J. Med. Syst. 2017, 41, 60. [Google Scholar] [CrossRef] [PubMed]
- Kristomo, D.; Hidayat, R.; Soesanti, I.; Kusjani, A. Heart sound feature extraction and classification using autoregressive power spectral density (AR-PSD) and statistics features. In AIP Conference Proceedings; AIP Publishing LLC: Melville, NY, USA, 2016. [Google Scholar]
- Sharma, S.; Dhar, J. Deep Learning Approach for Analysis of Artifacts in Heart Sound. In Proceedings of the International Conference on Advances in Electronics, Electrical & Computational Intelligence (ICAEEC) 2019, Prayagraj, India, 31 May–1 June 2019. [Google Scholar]
- Deperlioglu, O. Classification of phonocardiograms with convolutional neural networks. BRAIN. Broad Res. Artif. Intell. Neurosci. 2018, 9, 22–33. [Google Scholar]
- Yaseen; Son, G.; Kwon, S. Classification of Heart Sound Signal Using Multiple Features. Appl. Sci. 2018, 8, 2344. [Google Scholar] [CrossRef]
- Alqudah, A.M.; Alquran, H.; Qasmieh, I.A. Classification of heart sound short records using bispectrum analysis approach images and deep learning. Netw. Model. Anal. Health Inform. Bioinform. 2020, 9, 66. [Google Scholar] [CrossRef]
- Rocha, B.M.M.; Filos, D.; Mendes, L.; Vogiatzis, I.M.; Perantoni, E.; Kaimakamis, E.; Natsiavas, P.; Oliveira, A.; Jácome, C.; Marques, A.; et al. A Respiratory Sound Database for the Development of Automated Classification. In Proceedings of the BHI 2017, Cambridge, MA, USA, 8–9 May 2017; pp. 33–37. [Google Scholar]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujscie, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Nguyen, T.T.; Pernkopf, F. Lung Sound Classification Using Snapshot Ensemble of Convolutional Neural Networks. In Proceedings of the 2020 42nd Annual International Conference of the IEEE Engineering in Medicine & Biology Society (EMBC) 2020, Montréal, QC, Canada, 20–24 July 2020; pp. 760–763. [Google Scholar]
- Lella, K.K.; Alphonse, P.J.A. Automatic COVID-19 disease diagnosis using 1D convolutional neural network and augmentation with human respiratory sound based on parameters: Cough, breath, and voice. AIMS Public Health 2021, 8, 240–264. [Google Scholar] [CrossRef] [PubMed]
- Bardou, D.; Zhang, K.; Ahmad, S.M. Lung sounds classification using convolutional neural networks. Artif. Intell. Med. 2018, 88, 58–69. [Google Scholar] [CrossRef] [PubMed]
- Demir, F.; Şengür, A.; Bajaj, V. Convolutional neural networks based efficient approach for classification of lung diseases. Health Inf. Sci. Syst. 2020, 8, 4. [Google Scholar] [CrossRef]
- Shuvo, S.B.; Ali, S.N.; Swapnil, S.I.; Hasan, T.; Bhuiyan, M.I.H. A Lightweight CNN Model for Detecting Respiratory Diseases From Lung Auscultation Sounds Using EMD-CWT-Based Hybrid Scalogram. IEEE J. Biomed. Health Inform. 2021, 25, 2595–2603. [Google Scholar] [CrossRef]
- Ward, J.J. Rale lung Sounds 3.1 Professional Edition. Respir. Care 2005, 50, 1385–1388. [Google Scholar]
- Fraiwan, L.; Hassanin, O.; Fraiwan, M.; Khassawneh, B.Y.; Ibnian, A.M.; Alkhodari, M. Automatic identification of respiratory diseases from stethoscopic lung sound signals using ensemble classifiers. Biocybern. Biomed. Eng. 2021, 41, 1–14. [Google Scholar] [CrossRef]
- Fraiwan, M.; Fraiwan, L.; Alkhodari, M.; Hassanin, O. Recognition of pulmonary diseases from lung sounds using convolutional neural networks and long short-term memory. J. Ambient. Intell. Humaniz. Comput. 2021, 13, 4759–4771. [Google Scholar] [CrossRef]
- Rocha, B.M.M.; Filos, D.; Mendes, L.; Serbes, G.; Ulukaya, S.; Kahya, Y.P.; Jakovljević, N.; Turukalo, T.L.; Vogiatzis, I.M.; Perantoni, E.; et al. An open access database for the evaluation of respiratory sound classification algorithms. Physiol. Meas. 2019, 40, 035001. [Google Scholar] [CrossRef] [PubMed]
- Alqudah, A.M. AOCT-NET: A convolutional network automated classification of multiclass retinal diseases using spectral-domain optical coherence tomography images. Med. Biol. Eng. Comput. 2019, 58, 41–53. [Google Scholar] [CrossRef] [PubMed]
- Alqudah, A.M.; Qazan, S.; Masad, I.S. Artificial Intelligence Framework for Efficient Detection and Classification of Pneumonia Using Chest Radiography Images. J. Med. Biol. Eng. 2021, 41, 599–609. [Google Scholar] [CrossRef]
- García-Ordás, M.T.; Benítez-Andrades, J.A.; García-Rodríguez, I.; Benavides, C.; Alaiz-Moretón, H. Detecting Respiratory Pathologies Using Convolutional Neural Networks and Variational Autoencoders for Unbalancing Data. Sensors 2020, 20, 1214. [Google Scholar] [CrossRef]
- Alqudah, A.M.; Qazan, S.; Al-Ebbini, L.M.; Alquran, H.; Qasmieh, I.A. ECG heartbeat arrhythmias classification: A comparison study between different types of spectrum representation and convolutional neural networks architectures. J. Ambient. Intell. Humaniz. Comput. 2021, 13, 4877–4907. [Google Scholar] [CrossRef]
- Malik, S.I.; Siddiqi, I.; Akram, M.U. Localization and classification of heart beats in phonocardiography signals—A comprehensive review. EURASIP J. Adv. Signal Process. 2018, 2018, 26. [Google Scholar]
- Kumar, D.K.; Jadeja, R.N.; Pande, S. Wavelet bispectrum-based nonlinear features for cardiac murmur identification. Cogent Eng. 2018, 5, 1502906. [Google Scholar] [CrossRef]
- Tariq, Z.; Shah, S.K.; Lee, Y. Lung Disease Classification using Deep Convolutional Neural Network. In Proceedings of the 2019 IEEE International Conference on Bioinformatics and Biomedicine (BIBM) 2019, San Diego, CA, USA, 18–21 November 2019; pp. 732–735. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2004, 45, 5–32. [Google Scholar] [CrossRef]
- Guo, L.; Liu, J.; Lu, R. Subsampling bias and the best-discrepancy systematic cross validation. Sci. China Math. 2019, 64, 197–210. [Google Scholar] [CrossRef]
- Ghosh, S.K.; Ponnalagu, R.; Tripathy, R.; Acharya, U.R. Automated detection of heart valve diseases using chirplet transform and multiclass composite classifier with PCG signals. Comput. Biol. Med. 2020, 118, 103632. [Google Scholar] [CrossRef] [PubMed]
- Knauer, U.; von Rekowski, C.S.; Stecklina, M.; Krokotsch, T.; Minh, T.P.; Hauffe, V.; Kilias, D.; Ehrhardt, I.; Sagischewski, H.; Chmara, S.; et al. Tree Species Classification Based on Hybrid Ensembles of a Convolutional Neural Network (CNN) and Random Forest Classifiers. Remote Sens. 2019, 11, 2788. [Google Scholar] [CrossRef]
- Li, S.; Han, Y.; Yao, X.; Yingchen, S.; Wang, J.; Zhao, Q. Electricity Theft Detection in Power Grids with Deep Learning and Random Forests. J. Electr. Comput. Eng. 2019, 2019, 4136874. [Google Scholar] [CrossRef]
- Yang, S.; Gu, L.; Li, X.; Jiang, T.; Ren, R. Crop Classification Method Based on Optimal Feature Selection and Hybrid CNN-RF Networks for Multi-Temporal Remote Sensing Imagery. Remote. Sens. 2020, 12, 3119. [Google Scholar] [CrossRef]
- Wani, S.U.D.; Khan, N.A.; Thakur, G.; Gautam, S.P.; Ali, M.; Alam, P.; Alshehri, S.; Ghoneim, M.M.; Shakeel, F. Utilization of artificial intelligence in disease prevention: Diagnosis, treatment, and implications for the healthcare workforce. Healthcare 2022, 10, 608. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | Class | Original | After |
|---|---|---|---|
| Heart Sound | AS | 200 | 800 |
| MS | 200 | 800 | |
| MVP | 200 | 800 | |
| MR | 200 | 800 | |
| N | 200 | 800 | |
| Lung Sound | COPD | 793 | 793 |
| P | 37 | 667 | |
| H | 35 | 665 | |
| URTI | 23 | 653 | |
| BA | 16 | 646 | |
| BO | 13 | 643 |
| No. | Layer | Information | Param | |
|---|---|---|---|---|
| 1 | Input layer | Size | 256 × 256 | |
| 2 | Conv2D | Number of filters | 24 | 624 |
| Kernel size | 5 × 5 | |||
| Stride | 4 × 2 | |||
| Activation | RELU | |||
| 3 | Conv2D | Number of filters | 48 | 28,848 |
| Kernel size | 5 × 5 | |||
| Stride | 1 × 1 | |||
| 4 | MaxPooling2D | Kernel size | 4 × 2 | |
| Stride | 4 × 2 | |||
| 5 | Conv2D | Number of filters | 16 | 6928 |
| Kernel size | 3 × 3 | |||
| Stride | 1 × 1 | |||
| Activation | RELU | |||
| Model | Accuracy | F1 Score | Precision | Specificity | Sensitivity | |
|---|---|---|---|---|---|---|
| 8:2 Hold-Out | CNN+BDF | 99.97% | 99.89% | 99.90% | 99.99% | 99.88% |
| CNN | 99.81% | 99.01% | 99.13% | 99.89% | 98.92% | |
| 10-Fold CV | CNN+BDF | 99.94% | 99.72% | 99.84% | 99.89% | 99.66% |
| CNN | 99.53% | 97.46% | 97.68% | 99.74% | 97.33% | |
| Pr. Studies Heart | Yaseen et al. [16] | 97.90% | 94.50% | |||
| Glosh et al. [38] | 98.33% | 98.33% | ||||
| Alqudah et al. [29] | 98.70% | 98.70% | ||||
| Pr. Studies Lung | Fraiwan et al. [26] | 97.62% | 98.56% | |||
| Pham et al. [9] | 98.2% | 84.0% | ||||
| Shuvo et al. [24] | 98.7% | 98.6% |
| BA | BO | COPD | H | P | URTI | AS | MR | MS | MVP | N | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| BA | 121/120 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 |
| BO | 0/0 | 125/125 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 |
| COPD | 0/1 | 0/0 | 179/179 | 1/5 | 1/4 | 0/2 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 |
| H | 0/0 | 0/0 | 0/0 | 144/140 | 0/1 | 0/1 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 |
| P | 0/0 | 0/0 | 0/0 | 0/0 | 148/144 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 |
| URTI | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 133/130 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 |
| AS | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 155/154 | 0/0 | 0/1 | 0/1 | 0/0 |
| MR | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 158/158 | 0/0 | 0/0 | 0/0 |
| MS | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 148/147 | 0/0 | 0/0 |
| MVP | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/1 | 0/0 | 0/0 | 156/155 | 0/0 |
| N | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 0/0 | 145/145 |
| No. | Quantity | Comment | Designator | Footprint |
|---|---|---|---|---|
| 1 | 4 | 4.7 uF | C1, C3, C7, C8 | C0603 |
| 2 | 1 | 2200 uF | C1 | CP_16X25MM |
| 3 | 2 | 100 nF | C2, C4 | C0603 |
| 4 | 1 | 0.1 u | C2 | C0805 |
| 5 | 2 | 220 uF | C3, C4 | CAP-TH_BD8.0-P3.50-D1.0-FD |
| 6 | 2 | 20 p | C5, C6 | C0603 |
| 7 | 2 | 10 UF | C9, C10 | C0603 |
| 8 | 1 | 470 nF | C11 | C0603 |
| 9 | 1 | 1 UF | C12 | C0603 |
| 10 | 1 | XH2.54*2P | CN1 | CONN-TH_2P-P2.50-XH2.54-2P |
| 11 | 1 | 1N5824 | D1 | SMA/DO-214AC |
| 12 | 1 | 33 uH | L1 | IND-SMD_L7.7-W7.3 |
| 13 | 2 | 0805G (green) | LED1, LED2 | led0805 |
| 14 | 1 | LED-0805_R | LED1 | LED0805_RED |
| 15 | 1 | MIC | MIC1 | MIC-TH_BD6.0-P2.00 |
| 16 | 2 | 1 kΩ | R1, R2 | R0603 |
| 17 | 1 | 10 k | R1 | R0805 |
| 18 | 2 | 2K2 | R3, R7 | R0603 |
| 19 | 1 | 1K2 | R4 | R0603 |
| 20 | 2 | 22 | R5, R6 | R0603 |
| 21 | 1 | 2 K | R8 | R0603 |
| 22 | 3 | 10 K | R9, R12, R13 | R0603 |
| 23 | 1 | 100 K | R10 | R0603 |
| 24 | 1 | 1 K | R11 | R0603 |
| 25 | 1 | CM108B | U1 | LQFP-48_L7.0-W7.0-P0.50-LS9.0-BL |
| 26 | 1 | LM2596 | U2 | TO-263-5_L10.6-W9.6-P1.70-LS15.9-BR |
| 27 | 1 | NE5532N | U4 | DIP-8_L9.3-W6.4-P2.54-LS7.6-BL |
| 28 | 1 | XH2.54-WI-3P | U5 | CONN-TH_XH2.54-WI-3P |
| 29 | 1 | 8 MHZ 20 PF 10 PPM | X1 | OSC-SMD_L5.0-W3.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Li, M.; Guo, L.; Liu, J. A Low-Cost AI-Empowered Stethoscope and a Lightweight Model for Detecting Cardiac and Respiratory Diseases from Lung and Heart Auscultation Sounds. Sensors 2023, 23, 2591. https://doi.org/10.3390/s23052591
Zhang M, Li M, Guo L, Liu J. A Low-Cost AI-Empowered Stethoscope and a Lightweight Model for Detecting Cardiac and Respiratory Diseases from Lung and Heart Auscultation Sounds. Sensors. 2023; 23(5):2591. https://doi.org/10.3390/s23052591
Chicago/Turabian StyleZhang, Miao, Min Li, Liang Guo, and Jianya Liu. 2023. "A Low-Cost AI-Empowered Stethoscope and a Lightweight Model for Detecting Cardiac and Respiratory Diseases from Lung and Heart Auscultation Sounds" Sensors 23, no. 5: 2591. https://doi.org/10.3390/s23052591
APA StyleZhang, M., Li, M., Guo, L., & Liu, J. (2023). A Low-Cost AI-Empowered Stethoscope and a Lightweight Model for Detecting Cardiac and Respiratory Diseases from Lung and Heart Auscultation Sounds. Sensors, 23(5), 2591. https://doi.org/10.3390/s23052591