
Hybrid Recommendation Network Model with a Synthesis of Social Matrix Factorization and Link Probability Functions

 ,
,  ,
,  and
and 
Abstract
1. Introduction
- The existing or old artists are noteworthy, as they are the ones who are well established and have made great contributions in their areas, and there are also the people who have a passionate love for old music. Thus, old artists are recommended based on other users’ preferences. Hence, traditional collaborative filtering methods are the best fit for this criterion.
- New or unheard artists are equally important as old ones. When a new album or new tracks are released, generally music lovers show a keen interest in the latest and new songs just to keep abreast of music in their interest. Therefore, because of new tracks or albums, there is no or very limited information available about user choices, and that makes it challenging for CF methods to make any recommendations. Thus, for recommending new or unheard artists, item content or attributes and item network structure information make major contributions in such cases.
- If a user is inactive or completely new to the system and a very small piece of information is known about their taste or there is no availability of their preferences, then it is possible to make effective use of relations among items as well as relations with other users on the social networks to make recommendations.
- Exploratory variables are significant for online user communities. Based on the content information of artists and the social relations of users, user profiles can be created to establish communities with similar preferences. Moreover, it is also possible to describe which artists are liked by which types of users.
1.1. Motivation
1.2. Problem Statement
1.3. Contribution
- The core contribution of this study is the further extension of RCTR and CTR–SMF models to build a hybrid hierarchical Bayesian RCTR–SMF model that impeccably assimilates rating data, item content, social information of users and relational information of items to mitigate the sparsity issue in RS.
- Another major contribution of RCTR–SMF is to demonstrate the effectiveness of item relational networks and social networks together in enhancing prediction accuracy.
- The RCTR–SMF model can address the cold-start problem in case there is hardly any rating information available. It makes effective use of item content or attributes, relations among items as well as relations with other users on the social networks to generate predictions for new users (who have rated very few items) and new items (with one or two ratings only). This, in turn, enhances the recommendation quality.
- The experiments conducted on a public dataset reveal that the proposed recommendation model can attain higher accuracy in predictions than state-of-the-art algorithms.
2. Related Works
2.1. Matrix Factorization
2.2. Topic Modeling
2.3. CTR and Its Variants
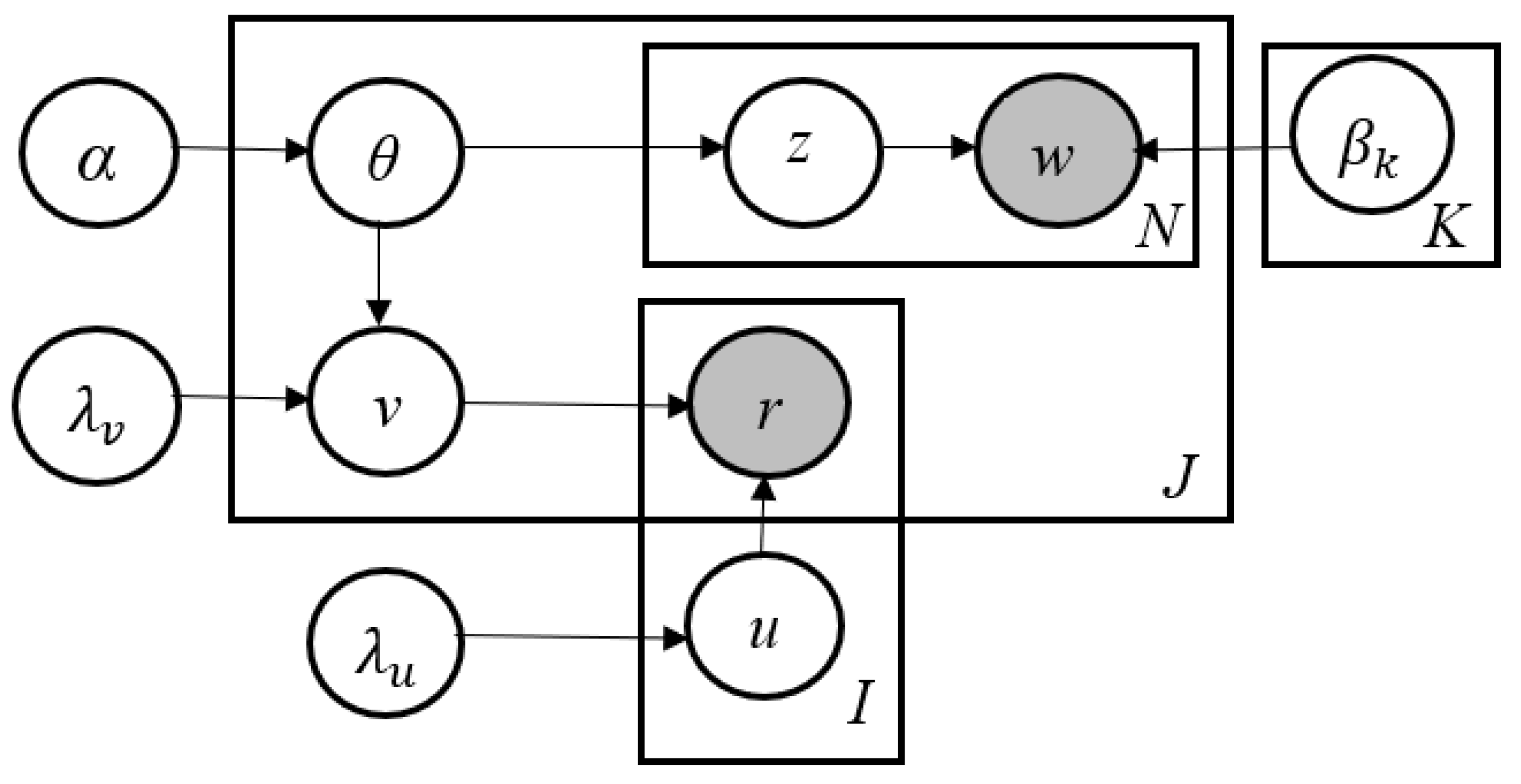
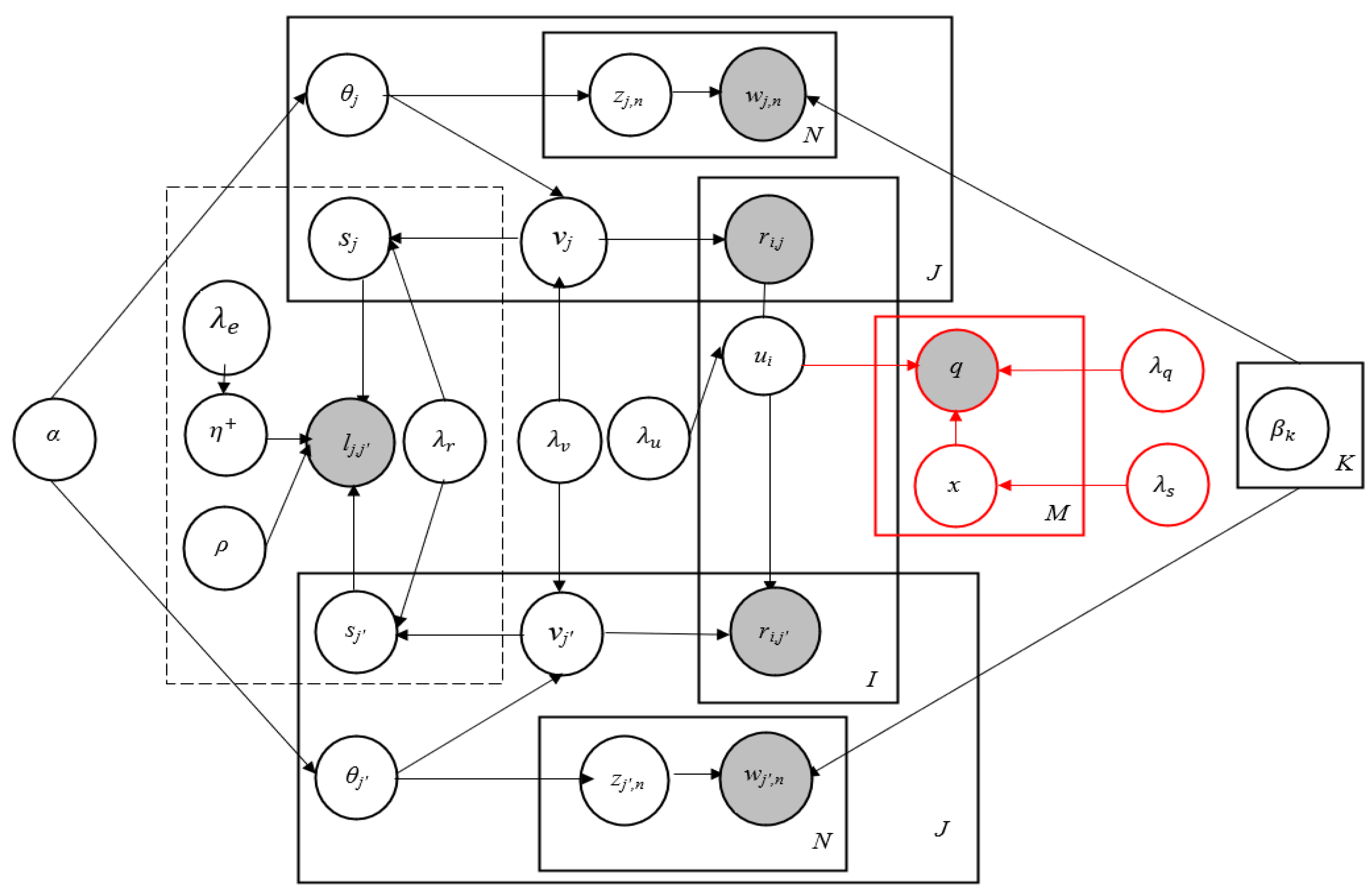
3. Proposed Model
3.1. Model Building
- 1.
- For each user i: draw a user latent vector
- 2.
- For each item j:
- (a)
- Draw topic proportions ~ Dirichlet (α).
- (b)
- Draw item latent offset and set the item latent vector as
- (c)
- Draw item relational offset and set the item relational vector as
- (d)
- For each word :
- (i)
- Draw topic assignment Mult (θj).
- (ii)
- Draw word Mult ().
- 3.
- Draw parameter
- 4.
- Draw a binary link pointer between each pair of items (),
- 5.
- Draw the rating for each user-item pair (i, j) as
3.2. Social Network Graph
3.3. Learning the Parameters
3.4. Prediction
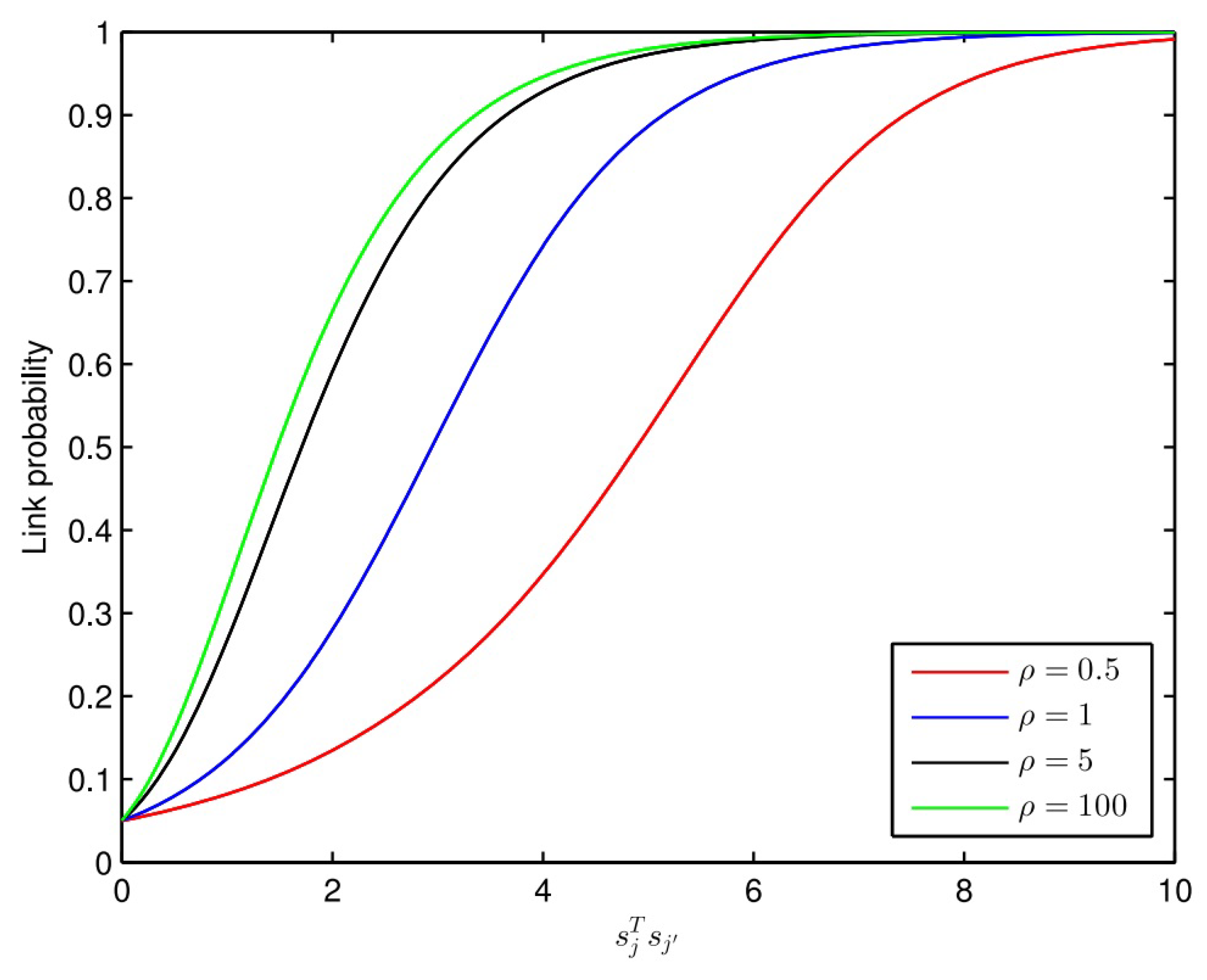
3.5. About the Link Probability Functions
4. Results Analysis and Discussion
4.1. Experimental Analysis
4.1.1. Dataset Used
4.1.2. Experimental Settings
4.1.3. Evaluation Metrics
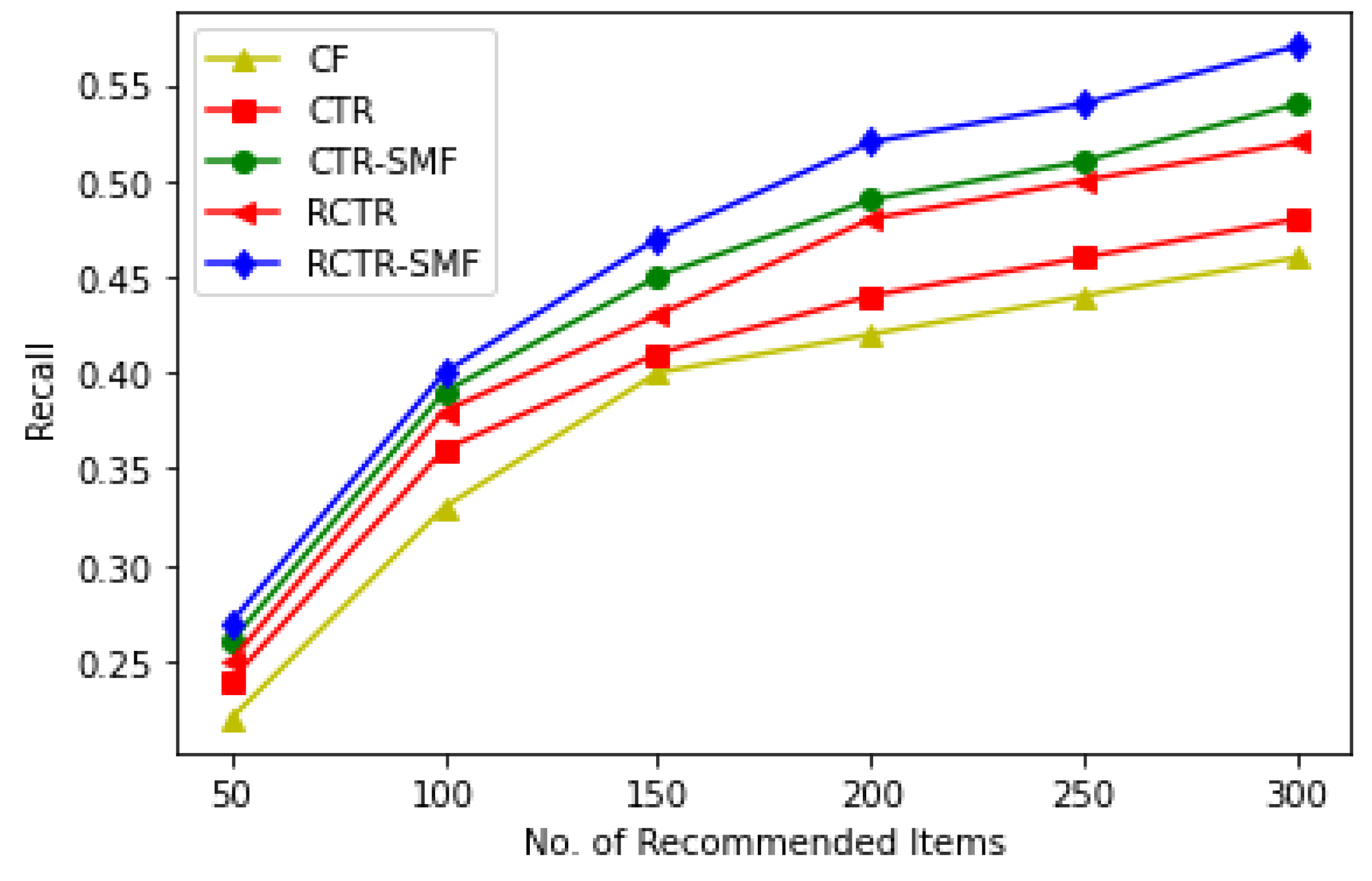
4.2. Generating Top M Recommendations
4.3. Complexity Analysis
5. Comparative Analysis and Discussions
- (a)
- How does the proposed model (i.e., RCTR–SMF) perform in comparison to other existing recommendation approaches?
- (b)
- How does social matrix factorization and the family of LPFs together help improve prediction accuracy?
- (c)
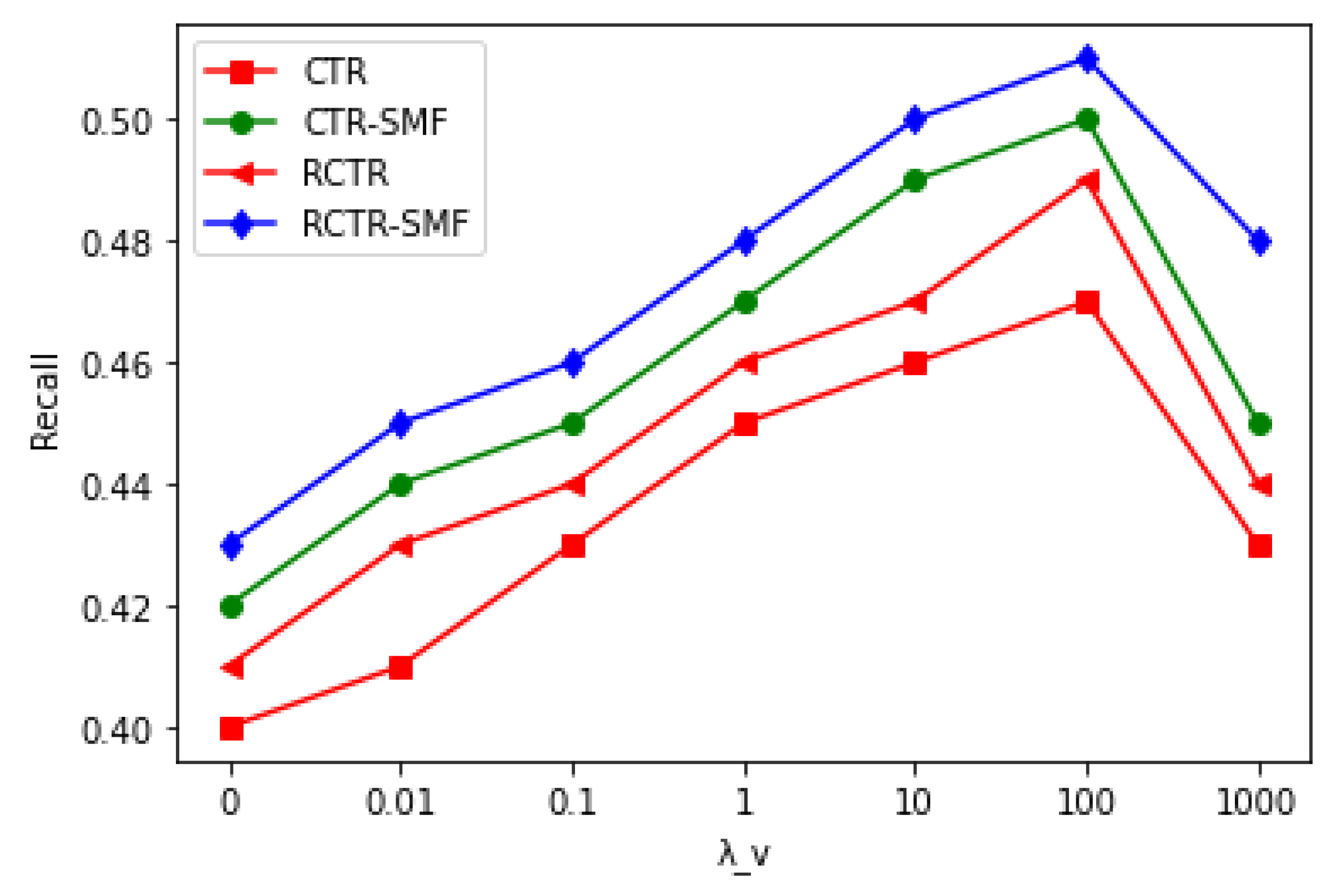
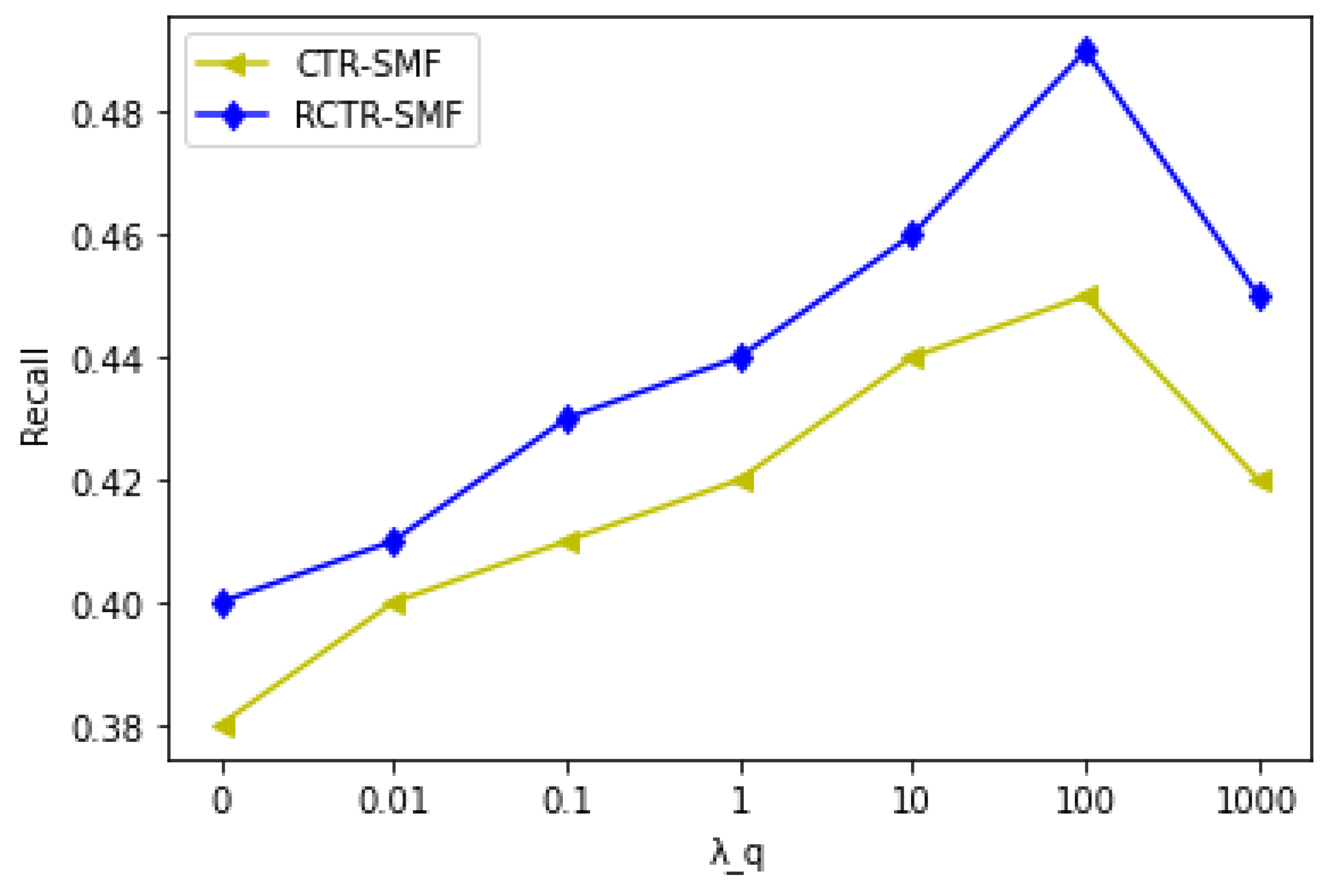
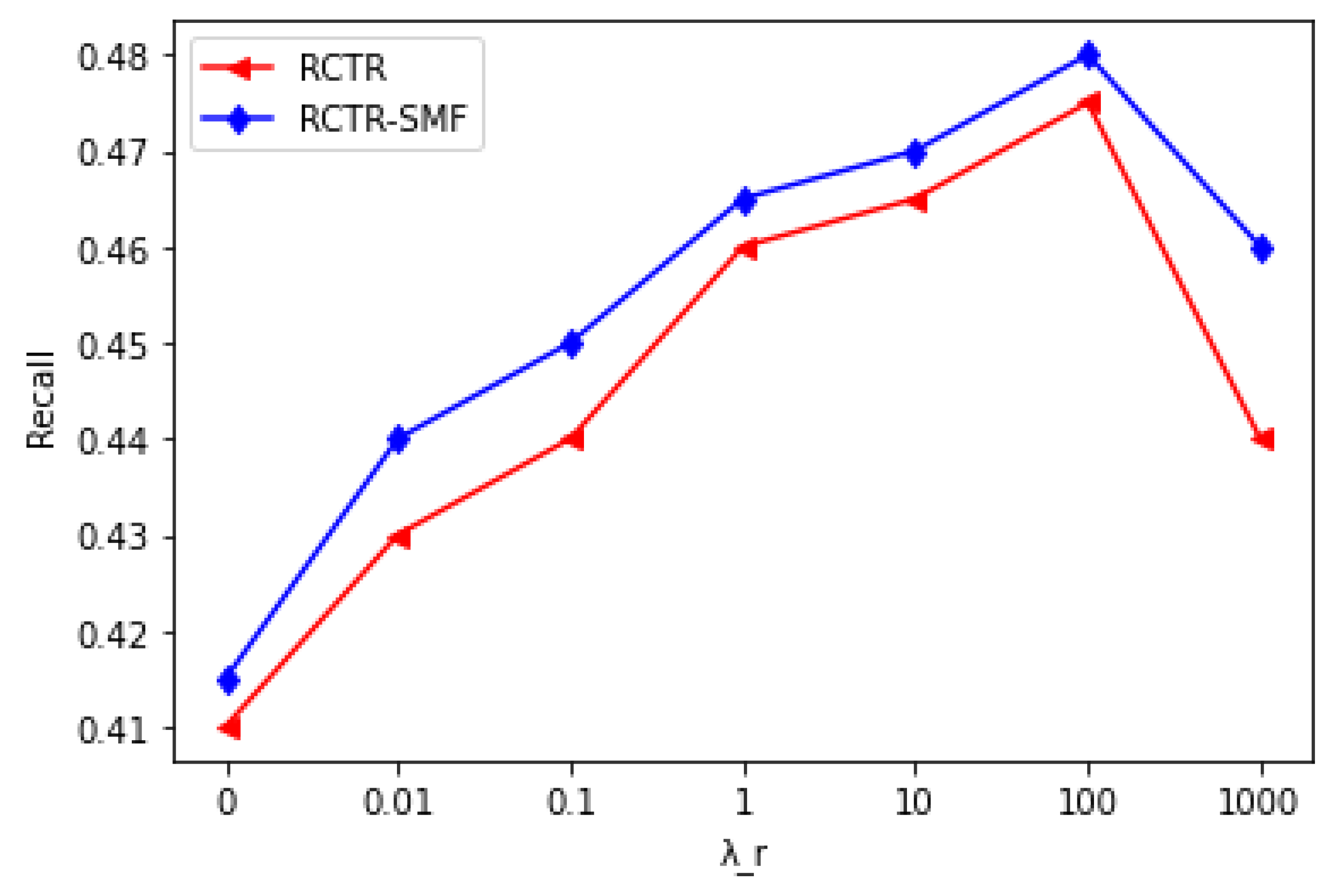
- How do the various parameters affect the prediction performance such as (item content parameter), (item relational parameter) and (social relationship parameter)?
5.1. Performance Comparison
5.2. Influence of the Parameters , and
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Gupta, S.; Mishra, A. Recommendation Engine: Challenges and Scope. In Emerging Technologies in Data Mining and Information Security; Springer: Singapore, 2023; pp. 675–680. [Google Scholar]
- Kumar, B.; Sharma, N. Approaches, Issues and Challenges in Recommender Systems: A Systematic Review. Indian J. Sci. Technol. 2016, 9, 1–12. [Google Scholar] [CrossRef]
- Valcarce, D. Information retrieval models for recommender systems. In ACM SIGIR Forum; ACM: New York, NY, USA, 2021; Volume 53, pp. 44–45. [Google Scholar]
- Liu, H.; Zheng, C.; Li, D.; Zhang, Z.; Lin, K.; Shen, X.; Xiong, N.N.; Wang, J. Multi-perspective social recommendation method with graph representation learning. Neurocomputing 2022, 468, 469–481. [Google Scholar] [CrossRef]
- Kumar, B.; Sharma, N.; Sharma, S. Collaborative Topic Regression-Based Recommendation Systems: A Comparative Study. In Proceedings of the ICRIC 2019, Jammu, India, 8–9 March 2019; Springer: Cham, Switzerland, 2020; pp. 723–737. [Google Scholar]
- Liu, H.; Kong, X.; Bai, X.; Wang, W.; Bekele, T.M.; Xia, F. Context-based collaborative filtering for citation recommendation. IEEE Access 2015, 3, 1695–1703. [Google Scholar] [CrossRef]
- Wang, R.; Wu, Z.; Lou, J.; Jiang, Y. Attention-based dynamic user modeling and deep collaborative filtering recommendation. Expert Syst. Appl. 2022, 188, 116036. [Google Scholar] [CrossRef]
- Liao, M.; Sundar, S.S. When E-Commerce Personalization Systems Show and Tell: Investigating the Relative Persuasive Appeal of Content-Based versus Collaborative Filtering. J. Advert. 2022, 51, 256–267. [Google Scholar] [CrossRef]
- Walek, B.; Fajmon, P. A hybrid recommender system for an online store using a fuzzy expert system. Expert Syst. Appl. 2023, 212, 118565. [Google Scholar] [CrossRef]
- Duan, R.; Jiang, C.; Jain, H.K. Combining review-based collaborative filtering and matrix factorization: A solution to rating’s sparsity problem. Decis. Support Syst. 2022, 156, 113748. [Google Scholar] [CrossRef]
- Raghavendra, C.K.; Srikantaiah, K.C. Analysis of Prediction Accuracies for Memory Based and Model-Based Collaborative Filtering Models. In Inventive Systems and Control; Springer: Singapore, 2022; pp. 737–747. [Google Scholar]
- Belmessous, K.; Sebbak, F.; Batouche, A. Co-rating Aware Evidential User-Based Collaborative Filtering Recommender System. In Proceedings of the International Conference on Computing Systems and Applications, Algiers, Algeria, 17–18 May 2022; Springer: Cham, Switzerland, 2022; pp. 51–60. [Google Scholar]
- Ngaffo, A.N.; Choukair, Z. A deep neural network-based collaborative filtering using a matrix factorization with a twofold regularization. Neural Comput. Appl. 2022, 34, 6991–7003. [Google Scholar] [CrossRef]
- Feng, Y.; Zhao, G. Implementation of Short Video Click-Through Rate Estimation Model Based on Cross-Media Collaborative Filtering Neural Network. Comput. Intell. Neurosci. 2022, 2022, 4951912. [Google Scholar] [CrossRef]
- Ali, Z.; Qi, G.; Kefalas, P.; Khusro, S.; Khan, I.; Muhammad, K. SPR-SMN: Scientific paper recommendation employing SPECTER with memory network. Scientometrics 2022, 127, 6763–6785. [Google Scholar] [CrossRef]
- Purushotham, S.; Liu, Y.; Kuo, C.C.J. Collaborative topic regression with social matrix factorization for recommendation systems. In Proceedings of the 29th International Conference on Machine Learning, Edinburgh, UK, 26 June–1 July 2012. [Google Scholar]
- Chen, C.; Zheng, X.; Wang, Y.; Hong, F.; Lin, Z. Context-Aware Collaborative Topic Regression with Social Matrix Factorization for Recommender Systems. In Proceedings of the AAAI Conference on Artificial Intelligence, Quebec, QC, Canada, 27–31 July 2014; Volume 28. [Google Scholar]
- Wang, H.; Li, W.J. Online egocentric models for citation networks. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; pp. 2726–2732. [Google Scholar]
- Wang, C.; Blei, D.M. Collaborative topic modeling for recommending scientific articles. In Proceedings of the 17th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Diego, CA, USA, 21–24 August 2011; pp. 448–456. [Google Scholar]
- Wang, H.; Li, W.-J. Relational Collaborative Topic Regression for Recommender Systems. IEEE Trans. Knowl. Data Eng. 2015, 27, 1343–1355. [Google Scholar] [CrossRef]
- Hu, Y.; Koren, Y.; Volinsky, C. Collaborative filtering for implicit feedback datasets. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 263–272. [Google Scholar]
- Hiriyannaiah, S.; Siddesh, G.M.; Srinivasa, K.G. DeepLSGR: Neural collaborative filtering for recommendation systems in smart community. Multimed. Tools Appl. 2023, 82, 8709–8728. [Google Scholar] [CrossRef]
- Mnih, A.; Salakhutdinov, R.R. Probabilistic matrix factorization. Adv. Neural Inf. Process. Syst. 2008, 20, 1257–1264. [Google Scholar]
- Wang, H.; Hong, Z.; Hong, M. Research on product recommendation based on matrix factorization models fusing user reviews. Appl. Soft Comput. 2022, 123, 108971. [Google Scholar] [CrossRef]
- Abdelrazek, A.; Eid, Y.; Gawish, E.; Medhat, W.; Hassan, A. Topic modeling algorithms and applications: A survey. Inf. Syst. 2023, 112, 102131. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Wang, J.; Zhang, X.-L. Deep NMF topic modeling. Neurocomputing 2023, 515, 157–173. [Google Scholar] [CrossRef]
- Ye, X.; Liu, D. An interpretable sequential three-way recommendation based on collaborative topic regression. Expert Syst. Appl. 2021, 168, 114454. [Google Scholar] [CrossRef]
- Kang, J.-H.; Lerman, K. LA-CTR: A Limited Attention Collaborative Topic Regression for Social Media. In Proceedings of the Twenty-Seventh AAAI Conference on Artificial Intelligence, Bellevue, WA, USA, 14–18 July 2013. [Google Scholar]
- Ding, X.; Jin, X.; Li, Y.; Li, L. Celebrity recommendation with collaborative social topic regression. In Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence, Beijing, China, 3–9 August 2013; AAAI Press: Phoenix, AZ, USA, 2013; pp. 2612–2618. [Google Scholar]
- Alzogbi, A. Time-aware collaborative topic regression: Towards higher relevance in textual item recommendation. In Proceedings of the 3rd Joint Workshop on Bibliometric-Enhanced Information Retrieval and Natural Language Processing for Digital Libraries (BIRNDL 2018) Co-Located with the 41st International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2018), Ann Arbor, MI, USA, 12 July 2018. [Google Scholar]
- Hamzehei, A.; Wong, R.K.; Koutra, D.; Chen, F. Collaborative topic regression for predicting topic-based social influence. Mach. Learn. 2019, 108, 1831–1850. [Google Scholar] [CrossRef]
- Wang, J.; Lv, J. Tag-informed collaborative topic modeling for cross domain recommendations. Knowl.-Based Syst. 2020, 203, 106119. [Google Scholar] [CrossRef]
- Sharma, R.; Kukreja, V. Amalgamated convolutional long term network (CLTN) model for Lemon Citrus Canker Disease Multi-classification. In Proceedings of the 2022 International Conference on Decision Aid Sciences and Applications (DASA), Chiangrai, Thailand, 23–25 March 2022; pp. 326–329. [Google Scholar]
- Badotra, S.; Panda, S.N. Software-defined networking: A novel approach to networks. In Handbook of Computer Networks and Cyber Security; Springer: Cham, Switzerland, 2020; pp. 313–339. [Google Scholar]
- Bozorgzadeh, N.; Bathurst, R.J. Hierarchical Bayesian approaches to statistical modelling of geotechnical data. Georisk Assess. Manag. Risk Eng. Syst. Geohazards 2022, 16, 452–469. [Google Scholar] [CrossRef]
- Chang, J.; Blei, D. Relational topic models for document networks. Artif. Intell. Stat. 2009, 5, 81–88. [Google Scholar]
- Cantador, I.; Brusilovsky, P.; Kuflik, T. Second workshop on information heterogeneity and fusion in recommender systems (HetRec2011). In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attributes | Total Count | Average(s) with Description |
|---|---|---|
| # Users | 1892 | |
| # Items | 17,632 | |
| # Tags | 11,946 | |
| # User-user relations | 25,434 | Average: 13,443 Social relations/user |
| # User—tags—items | 186,479 | Average: 98,562 tags/user |
| Average: 14,891 tags/artist | ||
| Average: 8764 different tags used for each artist | ||
| Each user used an average of 18,930 different tags | ||
| # User-item relations | 92,834 | Each user listened to an average of 49,067 artists the most |
| Each artist was listened to by an average of 5265 users |
| Row | User ID | Artist ID | Artist Name | Prediction |
|---|---|---|---|---|
| 0 | 45 | 1376 | White Lies | 0.884021 |
| 1 | 45 | 3739 | Hole | 0.860969 |
| 2 | 45 | 183 | Jamiroquai | 0.859264 |
| 3 | 45 | 1131 | Tool | 0.850992 |
| 4 | 45 | 3110 | Fiona Apple | 0.837827 |
| 5 | 45 | 3767 | The Horrors | 0.832549 |
| 6 | 45 | 428 | The Libertines | 0.832283 |
| 7 | 45 | 432 | Klaxons | 0.828805 |
| 8 | 45 | 1639 | Jimi Hendrix | 0.825787 |
| 9 | 45 | 324 | Cobra Starship | 0.813631 |
| Number of Recommendations | CF | CTR | CTR–SMF | RCTR | RCTR–SMF |
|---|---|---|---|---|---|
| 50 | 0.22 | 0.24 | 0.26 | 0.25 | 0.27 |
| 100 | 0.33 | 0.36 | 0.39 | 0.38 | 0.4 |
| 150 | 0.40 | 0.41 | 0.45 | 0.43 | 0.47 |
| 200 | 0.42 | 0.44 | 0.49 | 0.48 | 0.52 |
| 250 | 0.44 | 0.46 | 0.51 | 0.5 | 0.54 |
| 300 | 0.46 | 0.48 | 0.54 | 0.52 | 0.57 |
| CTR | CTR–SMF | RCTR | RCTR–SMF | |
|---|---|---|---|---|
| 0 | 0.4 | 0.42 | 0.41 | 0.43 |
| 0.01 | 0.41 | 0.44 | 0.43 | 0.45 |
| 0.1 | 0.43 | 0.45 | 0.44 | 0.46 |
| 1 | 0.45 | 0.47 | 0.46 | 0.48 |
| 10 | 0.46 | 0.49 | 0.47 | 0.5 |
| 100 | 0.47 | 0.50 | 0.49 | 0.51 |
| 1000 | 0.43 | 0.45 | 0.44 | 0.48 |
| CTR–SMF | RCTR–SMF | |
|---|---|---|
| 0 | 0.38 | 0.40 |
| 0.01 | 0.40 | 0.41 |
| 0.1 | 0.41 | 0.43 |
| 1 | 0.42 | 0.44 |
| 10 | 0.44 | 0.46 |
| 100 | 0.45 | 0.49 |
| 1000 | 0.42 | 0.45 |
| RCTR | RCTR–SMF | |
|---|---|---|
| 0 | 0.41 | 0.415 |
| 0.01 | 0.43 | 0.44 |
| 0.1 | 0.44 | 0.45 |
| 1 | 0.46 | 0.465 |
| 10 | 0.465 | 0.47 |
| 100 | 0.475 | 0.48 |
| 1000 | 0.44 | 0.46 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, B.; Sharma, N.; Sharma, B.; Herencsar, N.; Srivastava, G. Hybrid Recommendation Network Model with a Synthesis of Social Matrix Factorization and Link Probability Functions. Sensors 2023, 23, 2495. https://doi.org/10.3390/s23052495
Kumar B, Sharma N, Sharma B, Herencsar N, Srivastava G. Hybrid Recommendation Network Model with a Synthesis of Social Matrix Factorization and Link Probability Functions. Sensors. 2023; 23(5):2495. https://doi.org/10.3390/s23052495
Chicago/Turabian StyleKumar, Balraj, Neeraj Sharma, Bhisham Sharma, Norbert Herencsar, and Gautam Srivastava. 2023. "Hybrid Recommendation Network Model with a Synthesis of Social Matrix Factorization and Link Probability Functions" Sensors 23, no. 5: 2495. https://doi.org/10.3390/s23052495
APA StyleKumar, B., Sharma, N., Sharma, B., Herencsar, N., & Srivastava, G. (2023). Hybrid Recommendation Network Model with a Synthesis of Social Matrix Factorization and Link Probability Functions. Sensors, 23(5), 2495. https://doi.org/10.3390/s23052495