
Emotion Recognition Using Different Sensors, Emotion Models, Methods and Datasets: A Comprehensive Review


Abstract
1. Introduction
2. Emotion Models
Discrete Emotion Model
3. Sensors for Emotion Recognition
3.1. Visual Sensor
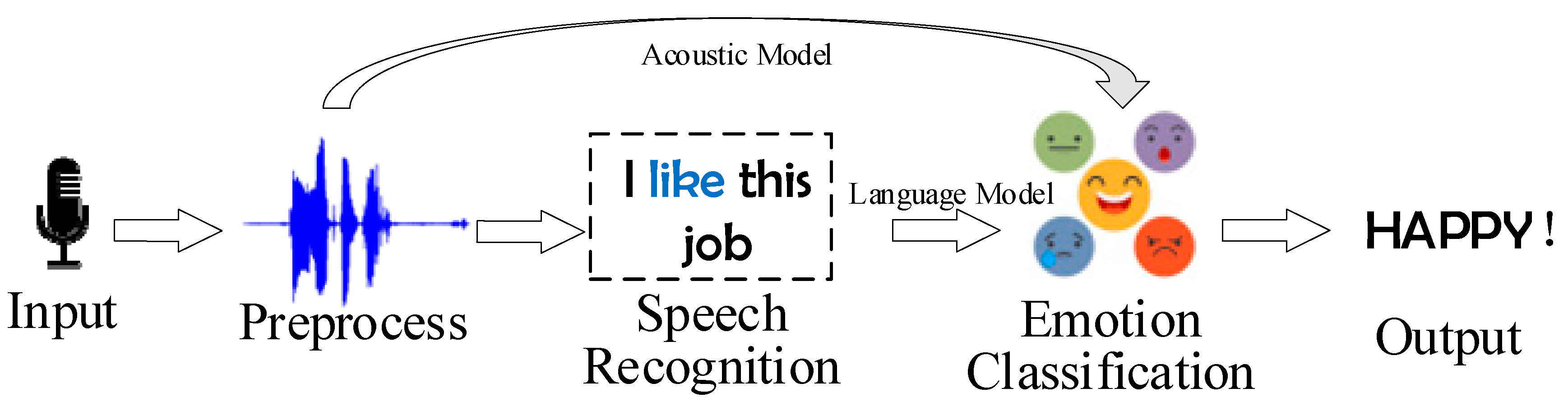
3.2. Audio Sensor
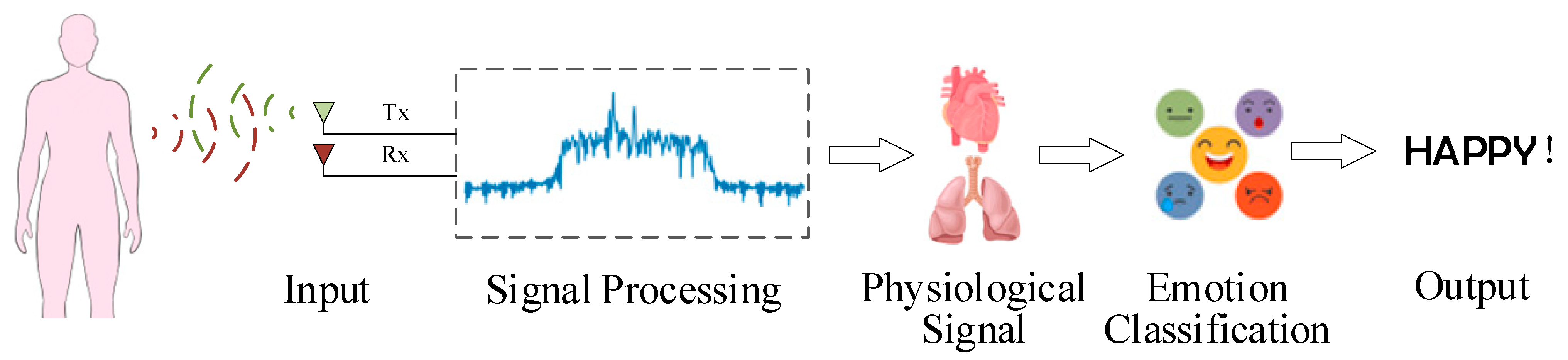
3.3. Radar Sensor
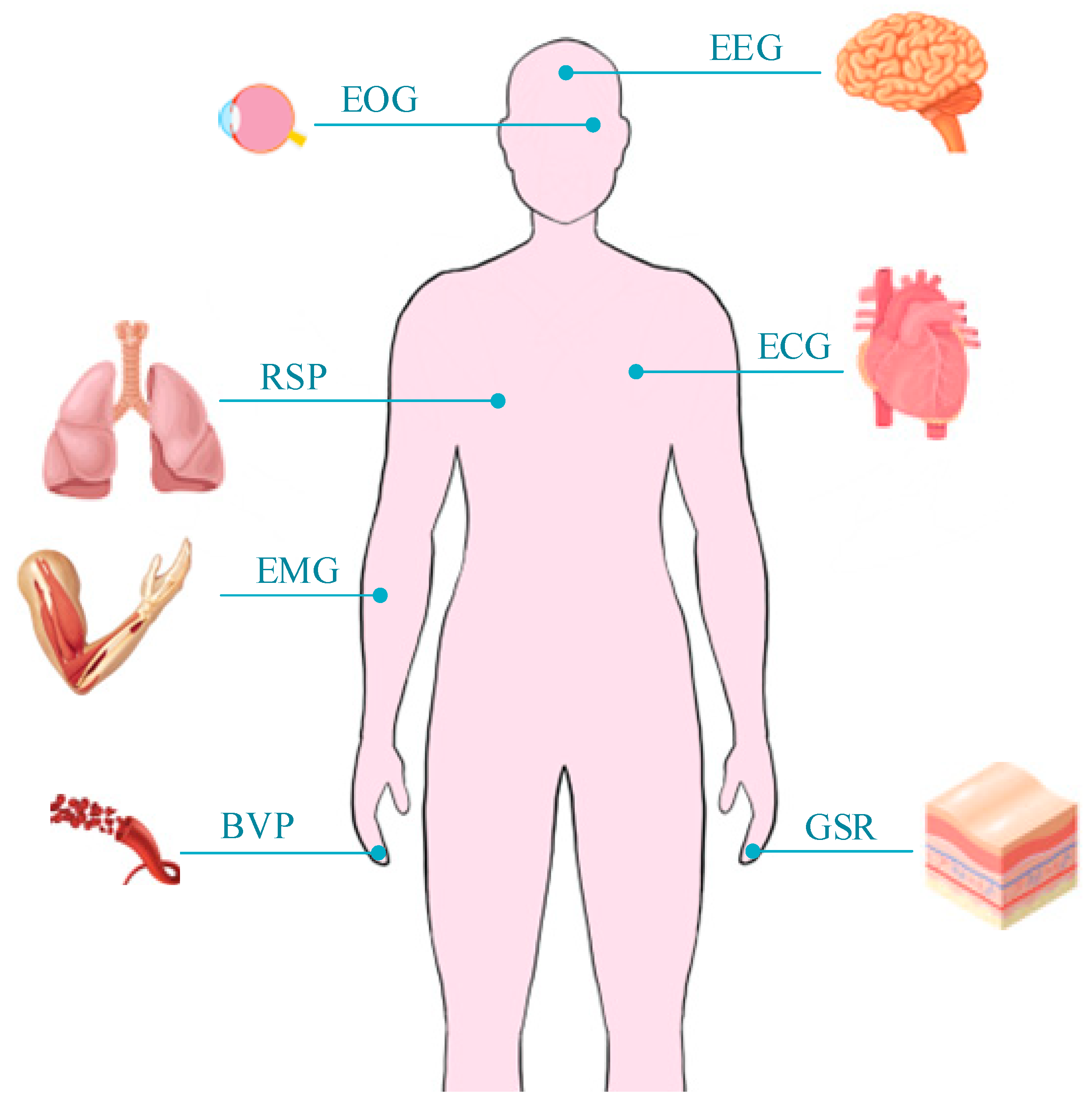
3.4. Other Physiological Sensors
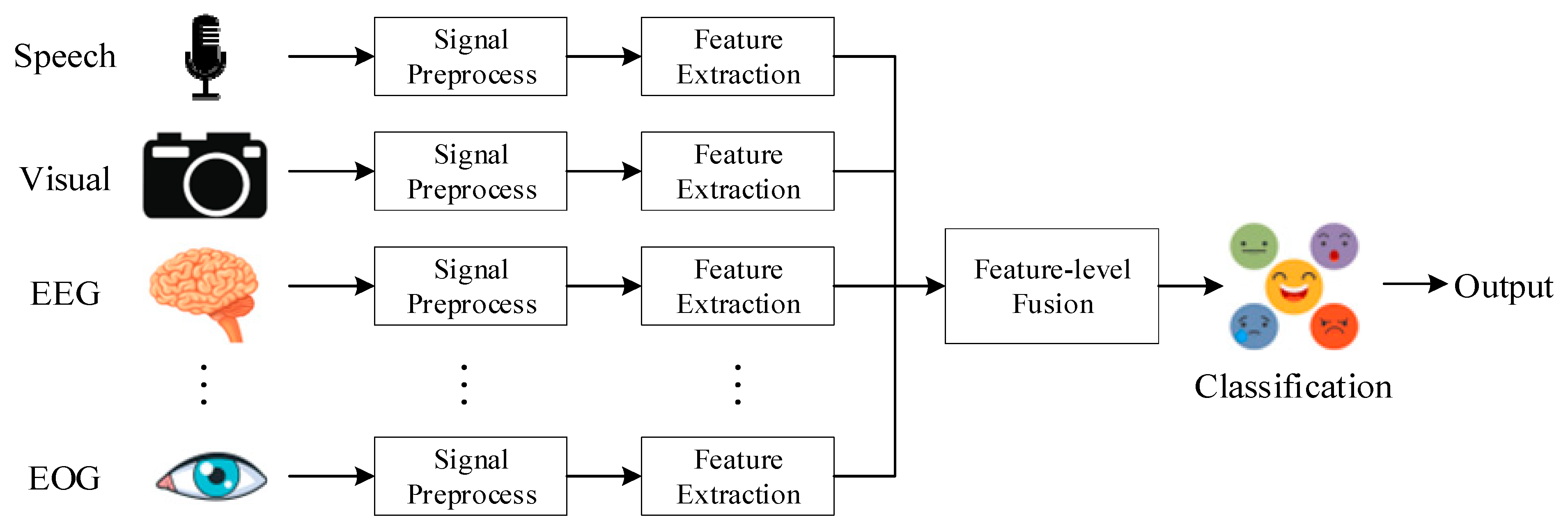
3.5. Multi-Sensor Fusion
4. Emotion Recognition Method
4.1. Signal Preprocessing
- Silent frame removal: Remove frames below the set threshold to reduce calculation consumption [89];
- Pre-emphasis: Compensate for high-frequency components of the signal;
- Regularization: Adjust the signal to a standard level to reduce the influence of different environments on the results;
- Window: Prevent signal edge leakage from affecting feature extraction [90];
- Noise reduction algorithm: Use noise reduction algorithms such as minimum mean square error (MMSE) to reduce background noise.
- Wavelet transform [93]: Using time window and frequency window to characterize the local characteristics of physiological signals;
4.2. Feature Extraction
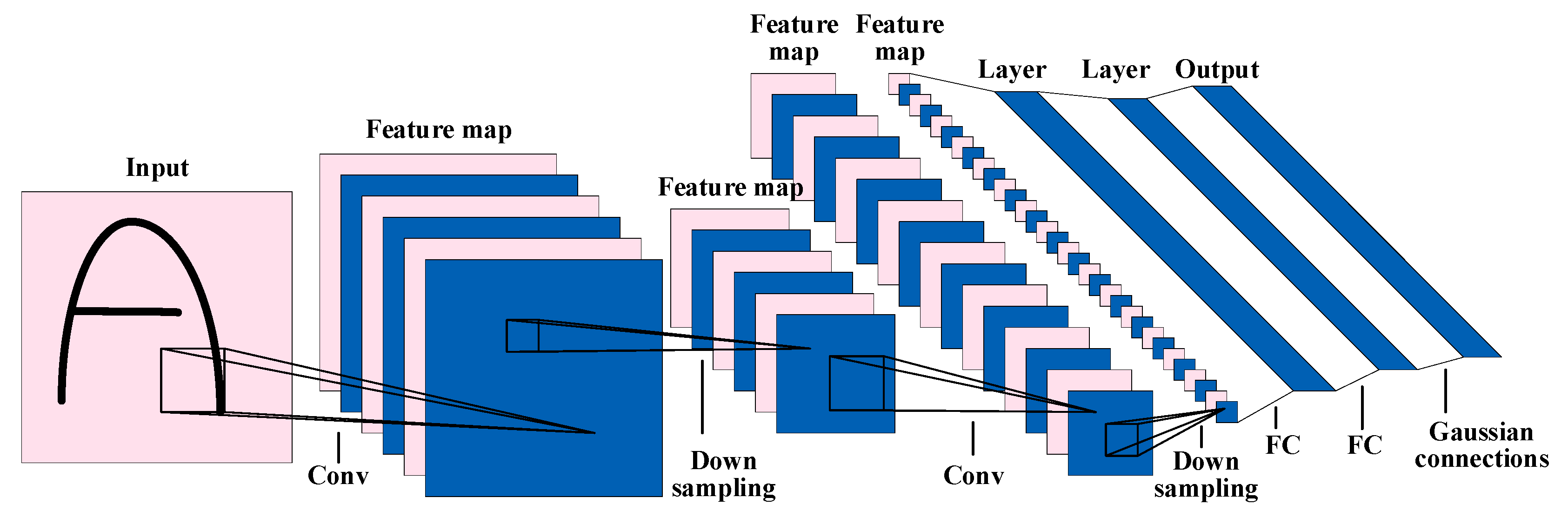
4.2.1. For Visual Signals
4.2.2. For Speech Signals
4.2.3. For Physiological and Radar signals
5. Classification
5.1. Machine Learning Methods
5.1.1. SVM
5.1.2. GMM
- Expectation: Infer optimal latent variables from the training set;
- Maximization: Use maximum likelihood estimation of parameters based on observed variables. It can obtain a mixture model of probabilities of all sub-distribution contained in the overall distribution. In this way, a better classification effect can be achieved without pre-determining the label of the data.
5.1.3. HMM
5.1.4. RF
5.2. Deep Learning Methods
5.2.1. CNN
5.2.2. LSTM
5.2.3. DBN
5.2.4. Other Classification Methods
6. Datasets
7. Conclusions and Discussions
8. Future Trends
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Picard, R.W. Affective Computing; MIT Press: Cambridge, MA, USA, 2000; pp. 4–5. [Google Scholar]
- Nayak, S.; Nagesh, B.; Routray, A.; Sarma, M. A Human-Computer Interaction Framework for Emotion Recognition through Time-Series Thermal Video Sequences. Comput. Electr. Eng. 2021, 93, 107280. [Google Scholar] [CrossRef]
- Colonnello, V.; Mattarozzi, K.; Russo, P.M. Emotion Recognition in Medical Students: Effects of Facial Appearance and Care Schema Activation. Med. Educ. 2019, 53, 195–205. [Google Scholar] [CrossRef] [PubMed]
- Feng, X.; Wei, Y.J.; Pan, X.L.; Qiu, L.H.; Ma, Y.M. Academic Emotion Classification and Recognition Method for Large-Scale Online Learning Environment-Based on a-Cnn and Lstm-Att Deep Learning Pipeline Method. Int. J. Environ. Res. Public Health 2020, 17, 1941. [Google Scholar] [CrossRef] [PubMed]
- Fu, E.; Li, X.; Yao, Z.; Ren, Y.X.; Wu, Y.H.; Fan, Q.Q. Personnel Emotion Recognition Model for Internet of Vehicles Security Monitoring in Community Public Space. Eurasip J. Adv. Signal Process. 2021, 2021, 81. [Google Scholar] [CrossRef]
- Oh, G.; Ryu, J.; Jeong, E.; Yang, J.H.; Hwang, S.; Lee, S.; Lim, S. DRER: Deep Learning-Based Driver’s Real Emotion Recognizer. Sensors 2021, 21, 2166. [Google Scholar] [CrossRef] [PubMed]
- Sun, X.; Song, Y.Z.; Wang, M. Toward Sensing Emotions With Deep Visual Analysis: A Long-Term Psychological Modeling Approach. IEEE Multimed. 2020, 27, 18–27. [Google Scholar] [CrossRef]
- Mandryk, R.L.; Atkins, M.S.; Inkpen, K.M. A continuous and objective evaluation of emotional experience with interactive play environments. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Montréal, QC, Canada, 22–27 April 2006; pp. 1027–1036. [Google Scholar]
- Ogata, T.; Sugano, S. Emotional communication between humans and the autonomous robot which has the emotion model. In Proceedings of the 1999 IEEE International Conference on Robotics and Automation (Cat. No. 99CH36288C), Detroit, MI, USA, 10–15 May 1999; pp. 3177–3182. [Google Scholar]
- Malfaz, M.; Salichs, M.A. A new architecture for autonomous robots based on emotions. IFAC Proc. Vol. 2004, 37, 805–809. [Google Scholar] [CrossRef]
- Rattanyu, K.; Ohkura, M.; Mizukawa, M. Emotion monitoring from physiological signals for service robots in the living space. In Proceedings of the ICCAS 2010, Gyeonggi-do, Republic of Korea, 27–30 October 2010; pp. 580–583. [Google Scholar]
- Hasnul, M.A.; Aziz, N.A.A.; Alelyani, S.; Mohana, M.; Aziz, A.A.J.S. Electrocardiogram-based emotion recognition systems and their applications in healthcare—A review. Sensors 2021, 21, 5015. [Google Scholar] [CrossRef]
- Feidakis, M.; Daradoumis, T.; Caballé, S. Emotion measurement in intelligent tutoring systems: What, when and how to measure. In Proceedings of the 2011 Third International Conference on Intelligent Networking and Collaborative Systems, Fukuoka, Japan, 30 November–2 December 2011; pp. 807–812. [Google Scholar]
- Saste, S.T.; Jagdale, S. Emotion recognition from speech using MFCC and DWT for security system. In Proceedings of the 2017 international Conference of Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 20–22 April 2017; pp. 701–704. [Google Scholar]
- Zepf, S.; Hernandez, J.; Schmitt, A.; Minker, W.; Picard, R. Driver emotion recognition for intelligent vehicles: A survey. ACM Comput. Surv. (CSUR) 2020, 53, 1–30. [Google Scholar] [CrossRef]
- Houben, M.; Van Den Noortgate, W.; Kuppens, P. The relation between short-term emotion dynamics and psychological well-being: A meta-analysis. Psychol. Bull. 2015, 141, 901. [Google Scholar] [CrossRef]
- Bal, E.; Harden, E.; Lamb, D.; Van Hecke, A.V.; Denver, J.W.; Porges, S.W. Emotion recognition in children with autism spectrum disorders: Relations to eye gaze and autonomic state. J. Autism Dev. Disord. 2010, 40, 358–370. [Google Scholar] [CrossRef]
- Martínez, R.; Ipiña, K.; Irigoyen, E.; Asla, N.; Garay, N.; Ezeiza, A.; Fajardo, I. Emotion elicitation oriented to the development of a human emotion management system for people with intellectual disabilities. In Trends in Practical Applications of Agents and Multiagent Systems: 8th International Conference on Practical Applications of Agents and Multiagent Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 689–696. [Google Scholar]
- Ekman, P. Universals and cultural differences in facial expressions of emotion. In Nebraska Symposium on Motivation; University of Nebraska Press: Lincoln, NE, USA, 1971. [Google Scholar]
- Darwin, C.; Prodger, P. The Expression of the Emotions in Man and Animals; Oxford University Press: Oxford, UK, 1998. [Google Scholar]
- Ekman, P.; Sorenson, E.R.; Friesen, W.V.J.S. Pan-cultural elements in facial displays of emotion. Science 1969, 164, 86–88. [Google Scholar] [CrossRef]
- Plutchik, R. Emotions and Life: Perspectives from Psychology, Biology, and Evolution; American Psychological Association: Washington, DC, USA, 2003. [Google Scholar]
- Bakker, I.; Van Der Voordt, T.; Vink, P.; De Boon, J. Pleasure, arousal, dominance: Mehrabian and Russell revisited. Curr. Psychol. 2014, 33, 405–421. [Google Scholar] [CrossRef]
- Mehrabian, A.; Russell, J.A. An Approach to Environmental Psychology; the MIT Press: Cambridge, MA, USA, 1974. [Google Scholar]
- Bain, A. The senses and the intellect; Longman, Green, Longman, Roberts, and Green: London, UK, 1864. [Google Scholar]
- Hassan, M.U.; Rehmani, M.H.; Chen, J.; Computing, D. Differential privacy in blockchain technology: A futuristic approach. J. Parallel Distrib. Comput. 2020, 145, 50–74. [Google Scholar] [CrossRef]
- Ray, T.R.; Choi, J.; Bandodkar, A.J.; Krishnan, S.; Gutruf, P.; Tian, L.; Ghaffari, R.; Rogers, J. Bio-integrated wearable systems: A comprehensive review. Chem. Rev. 2019, 119, 5461–5533. [Google Scholar] [CrossRef]
- Li, S.; Deng, W. Deep facial expression recognition: A survey. IEEE Trans. Affect. Comput. 2020, 13, 1195–1215. [Google Scholar] [CrossRef]
- Schmid, P.C.; Mast, M.S.; Bombari, D.; Mast, F.W.; Lobmaier, J. How mood states affect information processing during facial emotion recognition: An eye tracking study. Swiss J. Psychol. 2011. [Google Scholar] [CrossRef]
- Sandbach, G.; Zafeiriou, S.; Pantic, M.; Yin, L.J.I.; Computing, V. Static and dynamic 3D facial expression recognition: A comprehensive survey. Image Vis. Comput. 2012, 30, 683–697. [Google Scholar] [CrossRef]
- Wang, W.; Den Brinker, A.C.; Stuijk, S.; De Haan, G. Algorithmic principles of remote PPG. IEEE Trans. Biomed. Eng. 2016, 64, 1479–1491. [Google Scholar] [CrossRef] [PubMed]
- Xie, K.; Fu, C.-H.; Liang, H.; Hong, H.; Zhu, X. Non-contact heart rate monitoring for intensive exercise based on singular spectrum analysis. In Proceedings of the 2019 IEEE Conference on Multimedia Information Processing and Retrieval (MIPR), San Jose, CA, USA, 28–30 March 2019; pp. 228–233. [Google Scholar]
- Ghimire, D.; Lee, J. Geometric feature-based facial expression recognition in image sequences using multi-class adaboost and support vector machines. Sensors 2013, 13, 7714–7734. [Google Scholar] [CrossRef] [PubMed]
- Zhao, M.; Adib, F.; Katabi, D. Emotion recognition using wireless signals. In Proceedings of the 22nd Annual International Conference on Mobile Computing and Networking, New York, NY, USA, 3–7 October 2016; pp. 95–108. [Google Scholar]
- Zhang, J.; Yin, Z.; Chen, P.; Nichele, S. Emotion recognition using multi-modal data and machine learning techniques: A tutorial and review. Inf. Fusion 2020, 59, 103–126. [Google Scholar] [CrossRef]
- Lopes, A.T.; De Aguiar, E.; De Souza, A.F.; Oliveira-Santos, T. Facial expression recognition with convolutional neural networks: Coping with few data and the training sample order. Pattern Recognit. 2017, 61, 610–628. [Google Scholar] [CrossRef]
- Kim, D.H.; Baddar, W.J.; Jang, J.; Ro, Y. Multi-objective based spatio-temporal feature representation learning robust to expression intensity variations for facial expression recognition. IEEE Trans. Affect. Comput. 2017, 10, 223–236. [Google Scholar] [CrossRef]
- Zhong, L.; Liu, Q.; Yang, P.; Huang, J.; Metaxas, D. Learning multiscale active facial patches for expression analysis. IEEE Trans. Cybern. 2014, 45, 1499–1510. [Google Scholar] [CrossRef] [PubMed]
- Schroff, F.; Kalenichenko, D.; Philbin, J. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 815–823. [Google Scholar]
- Hertzman, A.B. Photoelectric plethysmography of the fingers and toes in man. Proc. Soc. Exp. Biol. Med. 1937, 37, 529–534. [Google Scholar] [CrossRef]
- Ram, M.R.; Madhav, K.V.; Krishna, E.H.; Komalla, N.R.; Reddy, K.A. A novel approach for motion artifact reduction in PPG signals based on AS-LMS adaptive filter. IEEE Trans. Instrum. Meas. 2011, 61, 1445–1457. [Google Scholar] [CrossRef]
- Temko, A. Accurate heart rate monitoring during physical exercises using PPG. IEEE Trans. Biomed. Eng. 2017, 64, 2016–2024. [Google Scholar] [CrossRef] [PubMed]
- Poh, M.-Z.; McDuff, D.J.; Picard, R.W. Advancements in noncontact, multiparameter physiological measurements using a webcam. IEEE Trans. Biomed. Eng. 2010, 58, 7–11. [Google Scholar] [CrossRef] [PubMed]
- Li, X.; Chen, J.; Zhao, G.; Pietikainen, M. Remote heart rate measurement from face videos under realistic situations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 4264–4271. [Google Scholar]
- Tarassenko, L.; Villarroel, M.; Guazzi, A.; Jorge, J.; Clifton, D.; Pugh, C. Non-contact video-based vital sign monitoring using ambient light and auto-regressive models. Physiol. Meas. 2014, 35, 807. [Google Scholar] [CrossRef] [PubMed]
- Jeong, I.C.; Finkelstein, J. Introducing contactless blood pressure assessment using a high speed video camera. J. Med. Syst. 2016, 40, 1–10. [Google Scholar] [CrossRef]
- Zhang, L.; Fu, C.-H.; Hong, H.; Xue, B.; Gu, X.; Zhu, X.; Li, C. Non-contact Dual-modality emotion recognition system by CW radar and RGB camera. IEEE Sens. J. 2021, 21, 23198–23212. [Google Scholar] [CrossRef]
- Hinton, G.; Deng, L.; Yu, D.; Dahl, G.E.; Mohamed, A.R.; Jaitly, N.; Senior, A.; Vanhoucke, V.; Nguyen, P.; Sainath, T.N.; et al. Deep Neural Networks for Acoustic Modeling in Speech Recognition. IEEE Signal Process. Mag. 2012, 29, 82–97. [Google Scholar] [CrossRef]
- Martin, O.; Kotsia, I.; Macq, B.; Pitas, I. The eNTERFACE’05 audio-visual emotion database. In Proceedings of the 22nd International Conference on Data Engineering Workshops (ICDEW’06), Atlanta, GA, USA, 3–7 April 2016; p. 8. [Google Scholar]
- Li, J.; Deng, L.; Haeb-Umbach, R.; Gong, Y. Robust Automatic Speech Recognition: A Bridge to Practical Applications; Academic Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Williams, C.E.; Stevens, K. Vocal correlates of emotional states. Speech Eval. Psychiatry 1981, 52, 221–240. [Google Scholar]
- Schuller, B.W. Speech emotion recognition: Two decades in a nutshell, benchmarks, and ongoing trends. Commun. ACM 2018, 61, 90–99. [Google Scholar] [CrossRef]
- France, D.J.; Shiavi, R.G.; Silverman, S.; Silverman, M.; Wilkes, M. Acoustical properties of speech as indicators of depression and suicidal risk. IEEE Trans. Biomed. Eng. 2000, 47, 829–837. [Google Scholar] [CrossRef]
- Hansen, J.H.; Cairns, D.A. Icarus: Source generator based real-time recognition of speech in noisy stressful and lombard effect environments. Speech Commun. 1995, 16, 391–422. [Google Scholar] [CrossRef]
- Ang, J.; Dhillon, R.; Krupski, A.; Shriberg, E.; Stolcke, A. Prosody-based automatic detection of annoyance and frustration in human-computer dialog. In Proceedings of the INTERSPEECH, Denver, CO, USA, 16–20 September 2002; pp. 2037–2040. [Google Scholar]
- Cohen, R. A computational theory of the function of clue words in argument understanding. In Proceedings of the 10th International Conference on Computational Linguistics and 22nd Annual Meeting of the Association for Computational Linguistics, Stanford University, Stanford, CA, USA, 2–6 July 1984; pp. 251–258. [Google Scholar]
- Deng, J.; Frühholz, S.; Zhang, Z.; Schuller, B. Recognizing emotions from whispered speech based on acoustic feature transfer learning. IEEE Access 2017, 5, 5235–5246. [Google Scholar] [CrossRef]
- Guo, S.; Feng, L.; Feng, Z.-B.; Li, Y.-H.; Wang, Y.; Liu, S.-L.; Qiao, H. Multi-view laplacian least squares for human emotion recognition. Neurocomputing 2019, 370, 78–87. [Google Scholar] [CrossRef]
- Grosz, B.J.; Sidner, C.L. Attention, intentions, and the structure of discourse. Comput. Linguist. 1986, 12, 175–204. [Google Scholar]
- Dellaert, F.; Polzin, T.; Waibel, A. Recognizing emotion in speech. In Proceedings of the Fourth International Conference on Spoken Language Processing. ICSLP’96, Philadelphia, PA, USA, 3–6 October 1996; pp. 1970–1973. [Google Scholar]
- Burmania, A.; Busso, C. A Stepwise Analysis of Aggregated Crowdsourced Labels Describing Multimodal Emotional Behaviors. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 152–156. [Google Scholar]
- Lee, S.-W. The generalization effect for multilingual speech emotion recognition across heterogeneous languages. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5881–5885. [Google Scholar]
- Ashhad, S.; Kam, K.; Del Negro, C.A.; Feldman, J. Breathing rhythm and pattern and their influence on emotion. Annu. Rev. Neurosci. 2022, 45, 223–247. [Google Scholar] [CrossRef]
- Du, G.; Long, S.; Yuan, H. Non-contact emotion recognition combining heart rate and facial expression for interactive gaming environments. IEEE Access 2020, 8, 11896–11906. [Google Scholar] [CrossRef]
- Verkruysse, W.; Svaasand, L.O.; Nelson, J. Remote plethysmographic imaging using ambient light. Opt. Express 2008, 16, 21434–21445. [Google Scholar] [CrossRef] [PubMed]
- Qing, C.; Qiao, R.; Xu, X.; Cheng, Y. Interpretable emotion recognition using EEG signals. IEEE Access 2019, 7, 94160–94170. [Google Scholar] [CrossRef]
- Theorell, T.; Ahlberg-Hulten, G.; Jodko, M.; Sigala, F.; De La Torre, B. Influence of job strain and emotion on blood pressure in female hospital personnel during workhours. Scand. J. Work Environ. Health 1993, 19, 313–318. [Google Scholar] [CrossRef] [PubMed]
- Nouman, M.; Khoo, S.Y.; Mahmud, M.P.; Kouzani, A. Recent Advances in Contactless Sensing Technologies for Mental Health Monitoring. IEEE Internet Things J. 2021, 9, 274–297. [Google Scholar] [CrossRef]
- Boiten, F. The effects of emotional behaviour on components of the respiratory cycle. Biol. Psychol. 1998, 49, 29–51. [Google Scholar] [CrossRef]
- Yasuma, F.; Hayano, J. Respiratory sinus arrhythmia: Why does the heartbeat synchronize with respiratory rhythm? Chest 2004, 125, 683–690. [Google Scholar] [CrossRef]
- Li, C.; Cummings, J.; Lam, J.; Graves, E.; Wu, W. Radar remote monitoring of vital signs. IEEE Microw. Mag. 2009, 10, 47–56. [Google Scholar] [CrossRef]
- Li, H.; Shrestha, A.; Heidari, H.; Le Kernec, J.; Fioranelli, F. Bi-LSTM network for multimodal continuous human activity recognition and fall detection. IEEE Sens. J. 2019, 20, 1191–1201. [Google Scholar] [CrossRef]
- Ren, L.; Kong, L.; Foroughian, F.; Wang, H.; Theilmann, P.; Fathy, A. Comparison study of noncontact vital signs detection using a Doppler stepped-frequency continuous-wave radar and camera-based imaging photoplethysmography. IEEE Trans. Microw. Theory Technol. 2017, 65, 3519–3529. [Google Scholar] [CrossRef]
- Gu, C.; Wang, G.; Li, Y.; Inoue, T.; Li, C. A hybrid radar-camera sensing system with phase compensation for random body movement cancellation in Doppler vital sign detection. IEEE Trans. Microw. Theory Technol. 2013, 61, 4678–4688. [Google Scholar] [CrossRef]
- James, W. The Principles of Psychology; Cosimo, Inc.: New York, NY, USA, 2007; Volume 1. [Google Scholar]
- Petrantonakis, P.C.; Hadjileontiadis, L. Emotion recognition from brain signals using hybrid adaptive filtering and higher order crossings analysis. IEEE Trans. Affect. Comput. 2010, 1, 81–97. [Google Scholar] [CrossRef]
- Katsigiannis, S.; Ramzan, N. DREAMER: A database for emotion recognition through EEG and ECG signals from wireless low-cost off-the-shelf devices. IEEE J. Biomed. Health Inform. 2017, 22, 98–107. [Google Scholar] [CrossRef] [PubMed]
- Wen, W.; Liu, G.; Cheng, N.; Wei, J.; Shangguan, P.; Huang, W. Emotion recognition based on multi-variant correlation of physiological signals. IEEE Trans. Affect. Comput. 2014, 5, 126–140. [Google Scholar] [CrossRef]
- Jerritta, S.; Murugappan, M.; Nagarajan, R.; Wan, K. Physiological signals based human emotion recognition: A review. In Proceedings of the 2011 IEEE 7th International Colloquium on Signal Processing and Its Applications, Penang, Malaysia, 4–6 March 2011; pp. 410–415. [Google Scholar]
- Kushki, A.; Fairley, J.; Merja, S.; King, G.; Chau, T. Comparison of blood volume pulse and skin conductance responses to mental and affective stimuli at different anatomical sites. Physiol. Meas. 2011, 32, 1529. [Google Scholar] [CrossRef]
- Lim, J.Z.; Mountstephens, J.; Teo, J. Emotion recognition using eye-tracking: Taxonomy, review and current challenges. Sensors 2020, 20, 2384. [Google Scholar] [CrossRef] [PubMed]
- Ekman, P. The argument and evidence about universals in facial expressions. In Handbook of Social Psychophysiology; John Wiley & Sons: Hoboken, NJ, USA, 1989; Volume 143, p. 164. [Google Scholar]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Cai, H.; Qu, Z.; Li, Z.; Zhang, Y.; Hu, X.; Hu, B. Feature-level fusion approaches based on multimodal EEG data for depression recognition. Inf. Fusion 2020, 59, 127–138. [Google Scholar] [CrossRef]
- Ho, T.K.; Hull, J.J.; Srihari, S. Decision combination in multiple classifier systems. IEEE Trans. Pattern Anal. Mach. Intell. 1994, 16, 66–75. [Google Scholar]
- Aziz, A.M. A new adaptive decentralized soft decision combining rule for distributed sensor systems with data fusion. Inf. Sci. 2014, 256, 197–210. [Google Scholar] [CrossRef]
- Canal, F.Z.; Müller, T.R.; Matias, J.C.; Scotton, G.G.; de Sa Junior, A.R.; Pozzebon, E.; Sobieranski, A. A survey on facial emotion recognition techniques: A state-of-the-art literature review. Inf. Sci. 2022, 582, 593–617. [Google Scholar] [CrossRef]
- Kartali, A.; Roglić, M.; Barjaktarović, M.; Đurić-Jovičić, M.; Janković, M.M. Real-time algorithms for facial emotion recognition: A comparison of different approaches. In Proceedings of the 2018 14th Symposium on Neural Networks and Applications (NEUREL), Belgrade, Serbia, 20–21 November 2018; pp. 1–4. [Google Scholar]
- Nema, B.M.; Abdul-Kareem, A.A. Preprocessing signal for speech emotion recognition. J. Sci. 2018, 28, 157–165. [Google Scholar] [CrossRef]
- Beigi, H. Fundamentals of Speaker Recognition; Springer Science & Business Media: Berlin, Germany, 2011. [Google Scholar]
- Jerritta, S.; Murugappan, M.; Wan, K.; Yaacob, S. Emotion recognition from facial EMG signals using higher order statistics and principal component analysis. J. Chin. Inst. Eng. 2014, 37, 385–394. [Google Scholar] [CrossRef]
- Izard, C.E. Emotion theory and research: Highlights, unanswered questions, and emerging issues. Annu. Rev. Psychol. 2009, 60, 1–25. [Google Scholar] [CrossRef]
- Subasi, A. EEG signal classification using wavelet feature extraction and a mixture of expert model. Expert Syst. Appl. 2007, 32, 1084–1093. [Google Scholar] [CrossRef]
- Pincus, S.M. Approximate entropy as a measure of system complexity. Proc. Natl. Acad. Sci. USA 1991, 88, 2297–2301. [Google Scholar] [CrossRef]
- Richman, J.S.; Moorman, J.; Physiology, C. Physiological time-series analysis using approximate entropy and sample entropy. Am. J. Physiol.-Heart Circ. Physiol. 2000, 278, H2039–H2049. [Google Scholar] [CrossRef]
- Schreiber, T. Measuring information transfer. Phys. Rev. Lett. 2000, 85, 461. [Google Scholar] [CrossRef] [PubMed]
- Zhang, C.; Wang, H.; Fu, R. Automated detection of driver fatigue based on entropy and complexity measures. IEEE Trans. Intell. Transp. Syst. 2013, 15, 168–177. [Google Scholar] [CrossRef]
- Tenenbaum, J.B.; Silva, V.d.; Langford, J. A global geometric framework for nonlinear dimensionality reduction. Science 2000, 290, 2319–2323. [Google Scholar] [CrossRef]
- Abdulrahman, M.; Gwadabe, T.R.; Abdu, F.J.; Eleyan, A. Gabor wavelet transform based facial expression recognition using PCA and LBP. In Proceedings of the 2014 22nd Signal Processing and Communications Applications Conference (SIU), Trabzon, Turkey, 23–25 April 2014; pp. 2265–2268. [Google Scholar]
- Arora, M.; Kumar, M. AutoFER: PCA and PSO based automatic facial emotion recognition. Multimed. Tools Appl. 2021, 80, 3039–3049. [Google Scholar] [CrossRef]
- Yang, J.; Zhang, D.; Frangi, A.F.; Yang, J. Two-dimensional PCA: A new approach to appearance-based face representation and recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 131–137. [Google Scholar] [CrossRef] [PubMed]
- Seng, K.P.; Ang, L.-M.; Ooi, C. A combined rule-based & machine learning audio-visual emotion recognition approach. IEEE Trans. Affect. Comput. 2016, 9, 3–13. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; pp. 886–893. [Google Scholar]
- Dahmane, M.; Meunier, J. Emotion recognition using dynamic grid-based HoG features. In Proceedings of the 2011 IEEE International Conference on Automatic Face & Gesture Recognition (FG), Santa Barbara, CA, USA, 21–25 March 2011; pp. 884–888. [Google Scholar]
- Kumar, P.; Happy, S.; Routray, A. A real-time robust facial expression recognition system using HOG features. In Proceedings of the 2016 International Conference on Computing, Analytics and Security Trends (CAST), Pune, India, 19–21 December 2016; pp. 289–293. [Google Scholar]
- Hussein, H.I.; Dino, H.I.; Mstafa, R.J.; Hassan, M. Person-independent facial expression recognition based on the fusion of HOG descriptor and cuttlefish algorithm. Multimed. Tools Appl. 2022, 81, 11563–11586. [Google Scholar] [CrossRef]
- Ahonen, T.; Hadid, A.; Pietikäinen, M. Face recognition with local binary patterns. In Proceedings of the European conference on Computer Vision, Prague, Czech Republic, 11–14 May 2004; pp. 469–481. [Google Scholar]
- Chintalapati, S.; Raghunadh, M. Automated attendance management system based on face recognition algorithms. In Proceedings of the 2013 IEEE International Conference on Computational Intelligence and Computing Research, Enathi, India, 26–28 December 2013; pp. 1–5. [Google Scholar]
- Swain, M.; Routray, A.; Kabisatpathy, P. Databases, features and classifiers for speech emotion recognition: A review. Int. J. Speech Technol. 2018, 21, 93–120. [Google Scholar] [CrossRef]
- Molau, S.; Pitz, M.; Schluter, R.; Ney, H. Computing mel-frequency cepstral coefficients on the power spectrum. In Proceedings of the 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (cat. No. 01CH37221), Salt Lake City, UT, USA, 7–11 May 2001; pp. 73–76. [Google Scholar]
- Wong, E.; Sridharan, S. Comparison of linear prediction cepstrum coefficients and mel-frequency cepstrum coefficients for language identification. In Proceedings of the 2001 International Symposium on Intelligent Multimedia, Video and Speech Processing. ISIMP 2001 (IEEE Cat. No. 01EX489), Hong Kong, China, 4 May 2001; pp. 95–98. [Google Scholar]
- Bandela, S.R.; Kumar, T.K. Emotion recognition of stressed speech using teager energy and linear prediction features. In Proceedings of the 2018 IEEE 18th International Conference on Advanced Learning Technologies (ICALT), Mumbai, India, 9–13 July 2018; pp. 422–425. [Google Scholar]
- Idris, I.; Salam, M.S. Improved speech emotion classification from spectral coefficient optimization. In Proceedings of the Advances in Machine Learning and Signal Processing: Proceedings of MALSIP 2015, Ho Chi Minh City, Vietnam, 15–17 December 2015; pp. 247–257. [Google Scholar]
- Feraru, S.M.; Zbancioc, M.D. Emotion recognition in Romanian language using LPC features. In Proceedings of the 2013 E-Health and Bioengineering Conference (EHB), Iasi, Romania, 21–23 November 2013; pp. 1–4. [Google Scholar]
- Dey, A.; Chattopadhyay, S.; Singh, P.K.; Ahmadian, A.; Ferrara, M.; Sarkar, R. A hybrid meta-heuristic feature selection method using golden ratio and equilibrium optimization algorithms for speech emotion recognition. IEEE Access 2020, 8, 200953–200970. [Google Scholar] [CrossRef]
- Bahoura, M.; Rouat, J. Wavelet speech enhancement based on the teager energy operator. IEEE Signal Process. Lett. 2001, 8, 10–12. [Google Scholar] [CrossRef]
- Aouani, H.; Ayed, Y. Speech emotion recognition with deep learning. Procedia Comput. Sci. 2020, 176, 251–260. [Google Scholar] [CrossRef]
- Li, X.; Li, X.; Zheng, X.; Zhang, D. EMD-TEO based speech emotion recognition. In Proceedings of the Life System Modeling and Intelligent Computing: International Conference on Life System Modeling and Simulation, LSMS 2010, and International Conference on Intelligent Computing for Sustainable Energy and Environment, ICSEE 2010, Wuxi, China, 17–20 September 2010; pp. 180–189. [Google Scholar]
- Bandela, S.R.; Kumar, T.K. Stressed speech emotion recognition using feature fusion of teager energy operator and MFCC. In Proceedings of the 2017 8th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Delhi, India, 3–5 July 2017; pp. 1–5. [Google Scholar]
- You, M.; Chen, C.; Bu, J.; Liu, J.; Tao, J. Emotion recognition from noisy speech. In Proceedings of the 2006 IEEE International Conference on Multimedia and Expo, Toronto, ON, Canada, 9–12 July 2006; pp. 1653–1656. [Google Scholar]
- Schafer, R.W.; Rabiner, L. Digital representations of speech signals. Proc. IEEE 1975, 63, 662–677. [Google Scholar] [CrossRef]
- Cochran, W.T.; Cooley, J.W.; Favin, D.L.; Helms, H.D.; Kaenel, R.A.; Lang, W.W.; Maling, G.C.; Nelson, D.E.; Rader, C.M.; Welch, P. What is the fast Fourier transform? Proc. IEEE 1967, 55, 1664–1674. [Google Scholar] [CrossRef]
- Murugappan, M.; Murugappan, S. Human emotion recognition through short time Electroencephalogram (EEG) signals using Fast Fourier Transform (FFT). In Proceedings of the 2013 IEEE 9th International Colloquium on Signal Processing and Its Applications, Kuala Lumpur, Malaysia, 8–10 March 2013; pp. 289–294. [Google Scholar]
- Acharya, D.; Billimoria, A.; Srivastava, N.; Goel, S.; Bhardwaj, A. Emotion recognition using fourier transform and genetic programming. Appl. Acoust. 2020, 164, 107260. [Google Scholar] [CrossRef]
- Khare, S.K.; Bajaj, V. Time–frequency representation and convolutional neural network-based emotion recognition. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2901–2909. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Long, F.; Ding, C. Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1226–1238. [Google Scholar] [CrossRef] [PubMed]
- Zheng, W.-L.; Zhu, J.-Y.; Lu, B. Identifying stable patterns over time for emotion recognition from EEG. IEEE Trans. Affect. Comput. 2017, 10, 417–429. [Google Scholar] [CrossRef]
- Atkinson, J.; Campos, D. Improving BCI-based emotion recognition by combining EEG feature selection and kernel classifiers. Expert Syst. Appl. 2016, 47, 35–41. [Google Scholar] [CrossRef]
- Alazrai, R.; Homoud, R.; Alwanni, H.; Daoud, M. EEG-based emotion recognition using quadratic time-frequency distribution. Sensors 2018, 18, 2739. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.-T.; Xie, Q.; Wu, M.; Cao, W.-H.; Mei, Y.; Mao, J.-W. Speech emotion recognition based on an improved brain emotion learning model. Neurocomputing 2018, 309, 145–156. [Google Scholar] [CrossRef]
- He, X.; Niyogi, P. Locality preserving projections. Adv. Neural Inf. Process. Syst. 2003, 16, 2. [Google Scholar]
- Kira, K.; Rendell, L.A. A practical approach to feature selection. In Machine Learning Proceedings 1992; Elsevier: Amsterdam, The Netherlands, 1992; pp. 249–256. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Soentpiet, R. Advances in Kernel Methods: Support Vector Learning; MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Chen, D.-R.; Wu, Q.; Ying, Y.; Zhou, D.-X. Support vector machine soft margin classifiers: Error analysis. J. Mach. Learn. Res. 2004, 5, 1143–1175. [Google Scholar]
- Pan, Y.; Shen, P.; Shen, L. Speech Emotion Recognition Using Support Vector Machine. Int. J. Smart Home 2012, 6, 101–108. [Google Scholar]
- Bitouk, D.; Verma, R.; Nenkova, A. Class-level spectral features for emotion recognition. Speech Commun. 2010, 52, 613–625. [Google Scholar] [CrossRef]
- Ghimire, D.; Jeong, S.; Lee, J.; Park, S. Facial expression recognition based on local region specific features and support vector machines. Multimed. Tools Appl. 2017, 76, 7803–7821. [Google Scholar] [CrossRef]
- Desmet, B.; Hoste, V. Emotion detection in suicide notes. Expert Syst. Appl. 2013, 40, 6351–6358. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D. Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B 1977, 39, 1–22. [Google Scholar]
- Hu, H.; Xu, M.-X.; Wu, W. GMM supervector based SVM with spectral features for speech emotion recognition. In Proceedings of the 2007 IEEE International Conference on Acoustics, Speech and Signal Processing-ICASSP’07, Honolulu, HI, USA, 15–20 April 2007; pp. IV-413–IV-416. [Google Scholar]
- Shahin, I.; Nassif, A.B.; Hamsa, S. Emotion recognition using hybrid Gaussian mixture model and deep neural network. IEEE Access 2019, 7, 26777–26787. [Google Scholar] [CrossRef]
- Zhang, C.; Li, M.; Wu, D. Federated Multidomain Learning With Graph Ensemble Autoencoder GMM for Emotion Recognition. IEEE Trans. Intell. Transp. Syst. 2022; Early Access. [Google Scholar] [CrossRef]
- Cohen, I.; Garg, A.; Huang, T.S. Emotion recognition from facial expressions using multilevel HMM. In Proceedings of the Neural Information PROCESSING systems, Breckenridge, CO, USA, 1–2 December 2000. [Google Scholar]
- Schuller, B.; Rigoll, G.; Lang, M. Hidden Markov model-based speech emotion recognition. In Proceedings of the 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP ‘03), Hong Kong, China, 6–10 April 2003. [Google Scholar]
- Wu, C.-H.; Lin, J.-C.; Wei, W. Two-level hierarchical alignment for semi-coupled HMM-based audiovisual emotion recognition with temporal course. IEEE Trans. Multimed. 2013, 15, 1880–1895. [Google Scholar] [CrossRef]
- Tang, D.; Zhang, Z.; He, Y.; Lin, C.; Zhou, D. Hidden topic–emotion transition model for multi-level social emotion detection. Knowl.-Based Syst. 2019, 164, 426–435. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Chen, L.; Su, W.; Feng, Y.; Wu, M.; She, J.; Hirota, K. Two-layer fuzzy multiple random forest for speech emotion recognition in human-robot interaction. Inf. Sci. 2020, 509, 150–163. [Google Scholar] [CrossRef]
- Katsis, C.D.; Katertsidis, N.S.; Fotiadis, D. An integrated system based on physiological signals for the assessment of affective states in patients with anxiety disorders. Biomed. Signal Process. Control 2011, 6, 261–268. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Kwon, S. Att-Net: Enhanced emotion recognition system using lightweight self-attention module. Proc. IEEE Haffner 2021, 102, 107101. [Google Scholar]
- Kollias, D.; Zafeiriou, S. Exploiting multi-cnn features in cnn-rnn based dimensional emotion recognition on the omg in-the-wild dataset. IEEE Trans. Affect. Comput. 2020, 12, 595–606. [Google Scholar] [CrossRef]
- Zhang, S.; Zhang, S.; Huang, T.; Gao, W. Speech emotion recognition using deep convolutional neural network and discriminant temporal pyramid matching. IEEE Trans. Multimed. 2017, 20, 1576–1590. [Google Scholar] [CrossRef]
- Song, T.; Zheng, W.; Song, P.; Cui, Z. EEG emotion recognition using dynamical graph convolutional neural networks. IEEE Trans. Affect. Comput. 2018, 11, 532–541. [Google Scholar] [CrossRef]
- Salama, E.S.; El-Khoribi, R.A.; Shoman, M.E.; Shalaby, M. A 3D-convolutional neural network framework with ensemble learning techniques for multi-modal emotion recognition. Egypt. Inform. J. 2021, 22, 167–176. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Araño, K.A.; Gloor, P.; Orsenigo, C.; Vercellis, C. When old meets new: Emotion recognition from speech signals. Cogn. Comput. 2021, 13, 771–783. [Google Scholar] [CrossRef]
- Zhang, Y.; Chen, J.; Tan, J.H.; Chen, Y.; Chen, Y.; Li, D.; Yang, L.; Su, J.; Huang, X.; Che, W. An investigation of deep learning models for EEG-based emotion recognition. Front. Neurosci. 2020, 14, 622759. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Liu, J.; Yang, Z.; Sun, L.; Wang, Z. Speech emotion recognition using recurrent neural networks with directional self-attention. Expert Syst. Appl. 2021, 173, 114683. [Google Scholar] [CrossRef]
- Kim, Y.; Lee, H.; Provost, E.M. Deep learning for robust feature generation in audiovisual emotion recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 21 October 2013; pp. 3687–3691. [Google Scholar]
- Hassan, M.M.; Alam, M.G.R.; Uddin, M.Z.; Huda, S.; Almogren, A.; Fortino, G. Human emotion recognition using deep belief network architecture. Inf. Fusion 2019, 51, 10–18. [Google Scholar] [CrossRef]
- Liu, D.; Chen, L.; Wang, Z.; Diao, G. Speech expression multimodal emotion recognition based on deep belief network. J. Grid Comput. 2021, 19, 1–13. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Hassan, M.M.; Almogren, A.; Alamri, A.; Alrubaian, M.; Fortino, G. Facial expression recognition utilizing local direction-based robust features and deep belief network. IEEE Access 2017, 5, 4525–4536. [Google Scholar] [CrossRef]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 5485–5551. [Google Scholar]
- Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Zhao, T. SMART: Robust and Efficient Fine-Tuning for Pre-trained Natural Language Models through Principled Regularized Optimization. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Washington, DC, USA, 5–10 July 2020; pp. 2177–2190. [Google Scholar]
- Shukla, A.; Vougioukas, K.; Ma, P.; Petridis, S.; Pantic, M. Visually guided self supervised learning of speech representations. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 6299–6303. [Google Scholar]
- Ryumina, E.; Dresvyanskiy, D.; Karpov, A. In search of a robust facial expressions recognition model: A large-scale visual cross-corpus study. Neurocomputing 2022, 514, 435–450. [Google Scholar] [CrossRef]
- Chudasama, V.; Kar, P.; Gudmalwar, A.; Shah, N.; Wasnik, P.; Onoe, N. M2FNet: Multi-modal fusion network for emotion recognition in conversation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 21–24 June 2022; pp. 4652–4661. [Google Scholar]
- Majumder, N.; Hazarika, D.; Gelbukh, A.; Cambria, E.; Poria, S. Multimodal sentiment analysis using hierarchical fusion with context modeling. Knowl.-Based Syst. 2018, 161, 124–133. [Google Scholar] [CrossRef]
- Song, X.; Zang, L.; Zhang, R.; Hu, S.; Huang, L. Emotionflow: Capture the dialogue level emotion transitions. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, Singapore, 23–27 May 2022; pp. 8542–8546. [Google Scholar]
- Ding, H.; Zhou, S.K.; Chellappa, R. Facenet2expnet: Regularizing a deep face recognition net for expression recognition. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 118–126. [Google Scholar]
- Savchenko, A.V.; Savchenko, L.V.; Makarov, I. Classifying emotions and engagement in online learning based on a single facial expression recognition neural network. IEEE Trans. Affect. Comput. 2022, 13, 2132–2143. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, C.; Ling, X.; Deng, W. Learn from all: Erasing attention consistency for noisy label facial expression recognition. In Proceedings of the Computer Vision–ECCV 2022: 17th European Conference, Tel Aviv, Israel, 23–27 October 2022; pp. 418–434. [Google Scholar]
- Li, Y.; Wang, L.; Zheng, W.; Zong, Y.; Qi, L.; Cui, Z.; Zhang, T.; Song, T.; Systems, D. A novel bi-hemispheric discrepancy model for EEG emotion recognition. IEEE Trans. Cogn. Dev. Syst. 2020, 13, 354–367. [Google Scholar] [CrossRef]
- Paraskevopoulos, G.; Georgiou, E.; Potamianos, A. Mmlatch: Bottom-up top-down fusion for multimodal sentiment analysis. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, Singapore, 23–27 May 2020; pp. 4573–4577. [Google Scholar]
- Shin, H.-C.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R. Deep convolutional neural networks for computer-aided detection: CNN architectures, dataset characteristics and transfer learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef]
- El Ayadi, M.; Kamel, M.S.; Karray, F. Survey on speech emotion recognition: Features, classification schemes, and databases. Pattern Recognit. 2011, 44, 572–587. [Google Scholar] [CrossRef]
- Ringeval, F.; Sonderegger, A.; Sauer, J.; Lalanne, D. Introducing the RECOLA multimodal corpus of remote collaborative and affective interactions. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–8. [Google Scholar]
- Coan, J.A.; Allen, J.J. Handbook of Emotion Elicitation and Assessment; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Douglas-Cowie, E.; Cowie, R.; Schröder, M. A new emotion database: Considerations, sources and scope. In Proceedings of the ISCA Tutorial and Research Workshop (ITRW) on Speech and Emotion, Newcastle, Northern Ireland, UK, 5–7 September 2000. [Google Scholar]
- Grimm, M.; Kroschel, K.; Narayanan, S. The Vera am Mittag German audio-visual emotional speech database. In Proceedings of the 2008 IEEE International Conference on Multimedia and Expo, Hannover, Germany, 26 August 2008; pp. 865–868. [Google Scholar]
- Lee, C.M.; Narayanan, S.S. Toward detecting emotions in spoken dialogs. IEEE Trans. Speech Audio Process. 2005, 13, 293–303. [Google Scholar]
- Dredze, M.; Crammer, K.; Pereira, F. Confidence-weighted linear classification. In Proceedings of the 25th International Conference on Machine Learning, New York, NY, USA, 5–9 July 2008; pp. 264–271. [Google Scholar]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.D.; Ng, A.Y.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language processing, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Maas, A.; Daly, R.E.; Pham, P.T.; Huang, D.; Ng, A.Y.; Potts, C. Learning word vectors for sentiment analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 142–150. [Google Scholar]
- Burkhardt, F.; Paeschke, A.; Rolfes, M.; Sendlmeier, W.F.; Weiss, B. A database of German emotional speech. In Proceedings of the Interspeech, Lisbon, Portugal, 4–8 September 2005; pp. 1517–1520. [Google Scholar]
- Jackson, P. Surrey Audio-Visual Expressed Emotion (Savee) Database; University of Surrey: Guildford, UK, 2014. [Google Scholar]
- Cao, H.; Cooper, D.G.; Keutmann, M.K.; Gur, R.C.; Nenkova, A.; Verma, R. Crema-d: Crowd-sourced emotional multimodal actors dataset. IEEE Trans. Affect. Comput. 2014, 5, 377–390. [Google Scholar] [CrossRef]
- Busso, C.; Bulut, M.; Lee, C.-C.; Kazemzadeh, A.; Mower, E.; Kim, S.; Chang, J.N.; Lee, S.; Narayanan, S. IEMOCAP: Interactive emotional dyadic motion capture database. Lang. Resour. Eval. 2008, 42, 335–359. [Google Scholar] [CrossRef]
- Tao, J.; Kang, Y.; Li, A. Prosody conversion from neutral speech to emotional speech. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1145–1154. [Google Scholar]
- Poria, S.; Hazarika, D.; Majumder, N.; Naik, G.; Cambria, E.; Mihalcea, R. MELD: A Multimodal Multi-Party Dataset for Emotion Recognition in Conversations. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 527–536. [Google Scholar]
- Batliner, A.; Steidl, S.; Nöth, E. Releasing a Thoroughly Annotated and Processed Spontaneous Emotional Database: The FAU Aibo Emotion Corpus. In Proceedings of the Satellite Workshop of LREC 2008 on Corpora for Research on Emotion and Affect, Marrakech, Morocco, 26–27&31 May–1 June 2008; pp. 28–31. [Google Scholar]
- McKeown, G.; Valstar, M.; Cowie, R.; Pantic, M.; Schroder, M. The semaine database: Annotated multimodal records of emotionally colored conversations between a person and a limited agent. IEEE Trans. Affect. Comput. 2011, 3, 5–17. [Google Scholar] [CrossRef]
- Li, Y.; Tao, J.; Chao, L.; Bao, W.; Liu, Y. CHEAVD: A Chinese natural emotional audio–visual database. J. Ambient Intell. Humaniz. Comput. 2017, 8, 913–924. [Google Scholar] [CrossRef]
- Pantic, M.; Valstar, M.; Rademaker, R.; Maat, L. Web-based database for facial expression analysis. In Proceedings of the 2005 IEEE international conference on multimedia and Expo, Amsterdam, The Netherlands, 6 July 2005. [Google Scholar]
- Zhang, X.; Yin, L.; Cohn, J.F.; Canavan, S.; Reale, M.; Horowitz, A.; Liu, P.; Girard, J.M.J.I.; Computing, V. Bp4d-spontaneous: A high-resolution spontaneous 3d dynamic facial expression database. Image Vis. Comput. 2014, 32, 692–706. [Google Scholar] [CrossRef]
- Lucey, P.; Cohn, J.F.; Kanade, T.; Saragih, J.; Ambadar, Z.; Matthews, I. The extended cohn-kanade dataset (ck+): A complete dataset for action unit and emotion-specified expression. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 94–101. [Google Scholar]
- Zhang, X.; Yin, L.; Cohn, J.F.; Canavan, S.; Reale, M.; Horowitz, A.; Liu, P. A high-resolution spontaneous 3d dynamic facial expression database. In Proceedings of the 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), Shanghai, China, 22–26 April 2013; pp. 1–6. [Google Scholar]
- Kossaifi, J.; Walecki, R.; Panagakis, Y.; Shen, J.; Schmitt, M.; Ringeval, F.; Han, J.; Pandit, V.; Toisoul, A.; Schuller, B.; et al. Sewa db: A rich database for audio-visual emotion and sentiment research in the wild. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 1022–1040. [Google Scholar] [CrossRef] [PubMed]
- Valstar, M.; Pantic, M. Induced disgust, happiness and surprise: An addition to the mmi facial expression database. In Proceedings of the 3rd International Workshop on EMOTION (Satellite of LREC): Corpora for Research on Emotion and Affect, Valletta, Malta, 23 May 2010; p. 65. [Google Scholar]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with gabor wavelets. In Proceedings of the Proceedings Third IEEE international Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar]
- Yin, L.; Wei, X.; Sun, Y.; Wang, J.; Rosato, M.J. A 3D facial expression database for facial behavior research. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 211–216. [Google Scholar]
- Mollahosseini, A.; Hasani, B.; Mahoor, M. Affectnet: A database for facial expression, valence, and arousal computing in the wild. IEEE Trans. Affect. Comput. 2017, 10, 18–31. [Google Scholar] [CrossRef]
- Li, S.; Deng, W.; Du, J. Reliable crowdsourcing and deep locality-preserving learning for expression recognition in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 22–25 July 2017; pp. 2852–2861. [Google Scholar]
- Fabian Benitez-Quiroz, C.; Srinivasan, R.; Martinez, A.M. Emotionet: An accurate, real-time algorithm for the automatic annotation of a million facial expressions in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5562–5570. [Google Scholar]
- Koelstra, S.; Muhl, C.; Soleymani, M.; Lee, J.-S.; Yazdani, A.; Ebrahimi, T.; Pun, T.; Nijholt, A.; Patras, I. Deap: A database for emotion analysis; using physiological signals. IEEE Trans. Affect. Comput. 2011, 3, 18–31. [Google Scholar] [CrossRef]
- Abadi, M.K.; Subramanian, R.; Kia, S.M.; Avesani, P.; Patras, I.; Sebe, N. DECAF: MEG-based multimodal database for decoding affective physiological responses. IEEE Trans. Affect. Comput. 2015, 6, 209–222. [Google Scholar] [CrossRef]
- Miranda-Correa, J.A.; Abadi, M.K.; Sebe, N.; Patras, I. Amigos: A dataset for affect, personality and mood research on individuals and groups. IEEE Trans. Affect. Comput. 2018, 12, 479–493. [Google Scholar] [CrossRef]
- Zheng, W.-L.; Lu, B.-L. A multimodal approach to estimating vigilance using EEG and forehead EOG. J. Neural Eng. 2017, 14, 026017. [Google Scholar] [CrossRef]
- Gouveia, C.; Tomé, A.; Barros, F.; Soares, S.C.; Vieira, J.; Pinho, P. Study on the usage feasibility of continuous-wave radar for emotion recognition. Biomed. Signal Process. Control 2020, 58, 101835. [Google Scholar] [CrossRef]
- Mercuri, M.; Lorato, I.R.; Liu, Y.-H.; Wieringa, F.; Hoof, C.V.; Torfs, T. Vital-sign monitoring and spatial tracking of multiple people using a contactless radar-based sensor. Nat. Electron. 2019, 2, 252–262. [Google Scholar] [CrossRef]
- Dang, X.; Chen, Z.; Hao, Z. Emotion recognition method using millimetre wave radar based on deep learning. IET Radar Sonar Navig. 2022, 16, 1796–1808. [Google Scholar] [CrossRef]
- Zadeh, A.B.; Liang, P.P.; Poria, S.; Cambria, E.; Morency, L.-P. Multimodal language analysis in the wild: Cmu-mosei dataset and interpretable dynamic fusion graph. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; pp. 2236–2246. [Google Scholar]
- Soleymani, M.; Lichtenauer, J.; Pun, T.; Pantic, M. A multimodal database for affect recognition and implicit tagging. IEEE Trans. Affect. Comput. 2011, 3, 42–55. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sensors | Advantages | Disadvantages |
|---|---|---|
| Visual sensor | Simple data collection; high scalability | Restricted by light; easy to cause privacy leakage [26] |
| Audio sensor | Low cost; wide range of applications | Lack of robustness for complex sentiment analysis |
| Radar sensor | Remote monitoring of physiological signals | Radial movement may cause disturbance |
| Other physiological sensors | Ability to monitor physiological signals representing real emotion | Invasive, requires wearing close to the skin surface [27] |
| Multi-sensor fusion | Richer collected information; higher robustness | Multi-channel information needs to be synchronized; the follow-up calculation is relatively large |
| Model Name | Dataset Used | Classification Method | Details |
|---|---|---|---|
| T5-3B [165] | SST (NLP) | Transformer and self-attention | The authors used transfer learning and self-attention to convert all text-based language problems into a text-to-text format. The authors compared the pre-training objectives, architectures, unlabeled datasets, and transfer methods of NLP. The classification accuracy on the SST dataset is 97.4%. |
| MT-DNN-SMART [166] | SST (NLP) | Transformer and smoothness inducing regularization | The authors proposed smoothness-induced regularization based on transfer learning to manage the complexity of the model. At the same time, a new optimization method was proposed to prevent over-updating. The classification accuracy on the SST dataset is 97.5%. |
| GRU [167] | CREMA-D (SER) | Self-supervised representation learning | The authors proposed a framework for learning audio representations guided by the visual modality in the context of audiovisual speech. The authors demonstrated the potential of visual supervision for learning audio representations; and achieved 55.01% SER accuracy on the CREMA-D dataset. |
| EmoAffectNet [168] | CREMA-D and AffectNet (FER) | CNN-LSTM | The authors proposed a flexible FER system using CNN and LSTM. This system consists of a backbone model and several temporal models. Every component of the system can be replaced by other models. The backbone model achieved an accuracy of 66.4% on the AffectNet dataset. The overall model achieved an accuracy of 79% on the CERMA-D dataset. |
| M2FNet [169] | IEMOCAP and MELD (multimodal) | Multi-task CNN and multi-head attention-based fusion | The multimodal fusion network proposed by the authors can extract emotional features from visual, audio, and textual modalities. The feature extractor was trained by an adaptive margin-based triplet loss function. The model achieved 67.85% accuracy and a 66.71 weighted average F1 score on the MELD dataset. Meanwhile, it achieved 69.69% accuracy and a 69.86 weighted average F1 score on the MELD dataset. |
| CH Fusion [170] | IEMOCAP (multimodal) | RNN and feature fusion strategy | The authors used RNN to extract the unimodal features of the three modalities of audio, video, and text. These unimodal features were then fused through a fully connected layer to form trimodal features. Finally, feature vectors for sentiment classification were obtained. The model achieved an F1 score of 0.768 and an accuracy rate of 0.765 on the IEMOCAP dataset. |
| EmotionFlow-large [171] | MELD (multimodal) | BERT model and Conditional random field (CRF) | The authors researched the propagation of emotions in dialogue emotion recognition. The authors utilized an encoder-decoder structure to learn user-specific features. Conditional random fields (CRF) were then applied to capture sequence information at the sentiment level. The weighted F1 score on the MELD dataset was 66.50. |
| FN2EN [172] | CK+ (FER) | DCNN | The authors proposed a two-stage training algorithm. In the first stage, high-level neuronal responses were modeled using probability distribution functions based on the fine-tuned face network. In the second stage, the authors conducted label supervision to improve the discriminative ability. The model achieved 96.8% (eight emotions) and 98.6% (six emotions) accuracy on the CK+ dataset. |
| Multi-task EfficientNet-B2 [173] | AffectNet (FER) | MTCNN and Adam optimization | In the article, the authors analyzed the behavior of students in the e-learning environment. The facial features obtained by the model could be used to quickly predict student engagement, individual emotions, and group-level influence. The model could even be used for real-time video processing on each student’s mobile device without sending the video to a remote server or the teacher’s PC. The model achieved 63.03% (eight emotions) and 66.29% (seven emotions) accuracy on the AffectNet dataset. |
| EAC [174] | RAF-DB (FER) | CNN and Class Activation Mapping (CAM) | The authors approached noisy label FER from the perspective of feature learning, and proposed Erase Attention Consistency (EAC). EAC does not require noise rate or label integration. It can generalize better to noisy label classification tasks with a large number of classes. The overall accuracy on the RAF-DB dataset was 90.35%. |
| BiHDM [175] | SEED (EEG signal) | RNNs | The authors proposed a model to learn the differential information of the left and right hemispheres of the human brain to improve EEG emotion recognition. The authors employed four directed recurrent neural networks based on two orientations to traverse electrode signals on two separate brain regions. This preserved its inherent spatial dependence. The accuracy on the SEED dataset reached 74.35%. |
| MMLatch [176] | CMU-MOSEI (multimodal) | LSTM, RNNs and Transformers | The neural architecture proposed by the authors could capture top-down cross-modal interactions. A forward propagation feedback mechanism was used during model training. The accuracy rate on the CMU-MOSEI dataset reached 82.4. |
| Name | Type | Details | Number of Emotion Categories | Number of Samples |
|---|---|---|---|---|
| MDS [184] | Textual | Product reviews from the Amazon shopping site; consisting of different words, sentences, and documents | 2 or 5 | 100,000 |
| SST [185] | Textual | Semantic emotion recognition database established by Stanford University | 2 or 5 | 11,855 |
| IMDB [186] | Textual | Contains a large number of movie reviews | 2 | 25,000 |
| EMODB [187] | Performer-based | The dataset consists of ten German voices spoken by ten speakers (five males and five females) | 7 | 800 |
| SAVEE [188] | Performer-based | Performed by four female speakers; spoken in English | 7 | 480 |
| CREAM-D [189] | Performer-based | Spoken in English | 6 | 7442 |
| IEMOCAP * [190] | Performer-based | Conversation between two people (one male and one female); spoken in English | 4 | - |
| Chinese Emotion Speech Dataset [191] | Induced | Spoken in Chinese | 5 | 3649 |
| MELD * [192] | Induced | Data from TC-series Friends | 3 | 13,000 |
| RECOLA Speech Database [179] | Natural | Spoken by 46 speakers (19 male and 27 female); spoken in French | 5 | 7 h |
| FAU Aibo emotion corpus [193] | Natural | Communications between 51 children and a robot dog; spoken in German | 11 | 9 h |
| Semaine Database [194] | Natural | Spoken by 150 speakers; spoken in English, Greek, and Hebrew | 5 | 959 conversations |
| CHEAVD [195] | Natural | Spoken by 238 speakers (from children to the elderly); spoken in Chinese | 26 | 2322 |
| Name | Type | Details | Number of Emotion Categories | Number of Samples |
|---|---|---|---|---|
| BP4D [197] | Induced | 41participants; 4 ethnicities; 18–29 years old | 8 | 368,036 |
| CK+ [198] | Induced | 123 participants; 23 facial displays; 21–53 years old | 7 | 593 sequences |
| BU-4DEF [199] | Induced | 101 participants; 5 ethnicities | 6 | 606 sequences |
| SEWA [200] | Induced | 96 participants; 6 ethnicities; 18–65 years old | 7 | 1990 sequences |
| MMI-V [201] | Performer-based | 25 participants; 3 ethnicities; 19–62 years old | 6 | 1.5 h |
| JAFFE [202] | Performer-based | 10 participants | 6 | 213 |
| BU-3DEF [203] | Performer-based | 100 participants 18–70 years old | 6 | 2500 |
| AffectNet [204] | Natural | Average age is 33.01 years old; downloaded from the Internet | 6 | 450,000 |
| RAF-DB [205] | Natural | Collected from Flickr | compound | 29,672 |
| EmotioNet [206] | Natural | Downloaded from the Internet | compound | 1,000,000 |
| Name | Type | Details | Number of Emotion Categories | Physiological Signals |
|---|---|---|---|---|
| DEAP * [207] | Induced | 32 participants; average age is 26.9 years old | Dimensional emotion (arousal-valence-dominance) | EEG; EMG; RSP; GSR; EOG; plethysmograph; skin temperature |
| DECAF * [208] | Induced | 30 participants | Dimensional emotion (arousal-valence) | EMG; NIR; hEOG; ECG; tEMG |
| AMIGOS * [209] | Induced | Individual participant and group participants | Dimensional emotion (arousal-valance) | EEG; GSR; ECG |
| SEED * [210] | Induced | 15 participants; average age is 23.3 | 3 | EEG; EOG |
| DREAMER * [77] | Induced | 23 participants; collected by wireless low-cost off-the-self devices | Dimensional emotion (arousal-valance-dominance) | EEG; ECG |
| Name | Type | Details | Number of Emotion Categories | Types of Signals |
|---|---|---|---|---|
| eNTERFACE [49] | Induced | 42 participants; 14 different nationalities | 6 | Visual signals; audio signals; |
| RECOLA [179] | Natural | 46 participants; 9.5 h | Dimensional emotion (arousal-valence) | Visual signals; audio signals; ECG signals; EDA signals |
| CMU-MOSEI [214] | Natural | 23,453 annotated video segments; 1000 speaker; 250 topics | 6 | Textual signals visual signals; audio signals; |
| MAHNOB-HCI [215] | Induced | 27 participants | Dimensional emotion (arousal-valence-dominance) | Textual signals visual signals; audio signals; EEG signals; RSP signals; GSR signals; ECG signals; skin temperature signals |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cai, Y.; Li, X.; Li, J. Emotion Recognition Using Different Sensors, Emotion Models, Methods and Datasets: A Comprehensive Review. Sensors 2023, 23, 2455. https://doi.org/10.3390/s23052455
Cai Y, Li X, Li J. Emotion Recognition Using Different Sensors, Emotion Models, Methods and Datasets: A Comprehensive Review. Sensors. 2023; 23(5):2455. https://doi.org/10.3390/s23052455
Chicago/Turabian StyleCai, Yujian, Xingguang Li, and Jinsong Li. 2023. "Emotion Recognition Using Different Sensors, Emotion Models, Methods and Datasets: A Comprehensive Review" Sensors 23, no. 5: 2455. https://doi.org/10.3390/s23052455
APA StyleCai, Y., Li, X., & Li, J. (2023). Emotion Recognition Using Different Sensors, Emotion Models, Methods and Datasets: A Comprehensive Review. Sensors, 23(5), 2455. https://doi.org/10.3390/s23052455